Здравствуйте, коллеги!

Обратился как-то раз к нам в компанию заказчик, для которого мы разрабатывали довольно крупное решение с большим количеством интегрированных модулей, с таким простым вопросом: «Вы сейчас разрабатываете, код пишете, даже на прод все это дело периодически подгружается. У нас летом вырастет нагрузка. Оно не упадет?»
Мы такие: «Да не, не должно».
Он: «Точно? А можете убедиться и посмотреть? Вы уверены, что оно выдержит? Что все будет хорошо?»
Мы, конечно, головой покивали, что все будет нормально. Но заказчик был настойчивый и включил нам в договор пункт про то, что система должна вменяемо работать с определенным количеством пользователей.
Каким образом убедиться, что продукт выдержит планируемую нагрузку?
Провести нагрузочное тестирование. Именно про него и про то, как его делать, мы сегодня и поговорим.
Тестирование серверной и клиентской нагрузки

Когда думают про нагрузку на базах, обычно ее разделяют на два типа – это, условно, бэкэнд и фронтэнд.
-
Код, который изначально серверный – регламентные задания, проведение документов, сложные обработки.
-
И код, который начинает свою жизнь на клиенте – формы, обработчики кнопок, динамические списки и т.д.

Есть такой термин – «технопорно». Кто-нибудь знает, что это такое? Это фотографии серверных стоек с красиво уложенными кабелями – сетевыми, питания. Примерно то, что на картинке.
Когда код изначально пишется как серверный, на него приятно смотреть – так же приятно смотреть, как на красивую серверную стойку. И радоваться от того, насколько он красивый и прекрасный. Он стройный, линейный и, если повезет, даже производительный.

А с фронтэндом ситуация иная. Он может выглядеть очень красиво, очень мило, «держать пончик», а на обратной стороне – это мешанина из клиент-серверных вызовов, сложных запросов и всего того, что работает медленно и написано тоже очень и очень плохо.
Тестировать обычно нужно именно те места, в которых вы не уверены, которые плохо работают и, скорее всего, именно там будут основные проблемы.
Как раз нагрузочное тестирование пользовательского интерфейса может помочь найти эти сложные запутанные места и их впоследствии поправить.
Нагрузочное тестирование GUI
При включении в сценарий нагрузочного тестирования работы с UI мы можем получить достаточно реалистичную картину того, что у нас будет происходить в базе на продуктиве.
Мы можем заложить в сценарий полный цикл работы пользователей – какие конкретно кнопки они нажимают и какие документы проводят. Как именно они будут работать через месяц, через два, когда все это окажется на продуктиве.
Мы можем снять реальные счетчики производительности с железа.
Замеры времени по ключевым операциям, по APDEX тоже будут максимально приближены к тому, что мы увидим впоследствии на продуктиве.
Инструменты тестирования
Тест-центр

Для проведения нагрузочного тестирования нам понадобятся инструменты. Один из инструментов, предлагаемый вендором, компанией «1С» – Тест-центр. Он входит в состав «Корпоративного инструментального пакета» – там, где ЦУП, ЦКК и несколько других компонентов. С точки зрения своей реализации он выглядит как подсистема, которая встраивается к вам в конфигурацию и содержит несколько справочников, регистров, общих модулей, которые помогают проводить нагрузочное тестирование.

Для проведения нагрузочного теста нужно настроить три главных справочника, грубо говоря, три компонента, которые есть в Тест-центре.
-
Первый компонент – это обработки. Это либо внешние обработки, либо обработки, встроенные в конфигурацию, содержащие код, который действительно нагружает вашу систему, создает документы, формирует отчеты и т.д.
-
Второй компонент – это роли. Роль состоит из самой обработки и ее настроек. В качестве настроек обычно используются реквизиты обработки, которые сохраняются в хранилище значений. И при прогоне нагрузочного тестирования в параметры передается именно эта настроенная роль.
-
И третий компонент – это клиент. Клиент состоит из компьютера, на котором прогоняется нагрузочный тест, и каких-то его дополнительных параметров запуска – режима запуска приложения, аргументов командной строки и т.д.
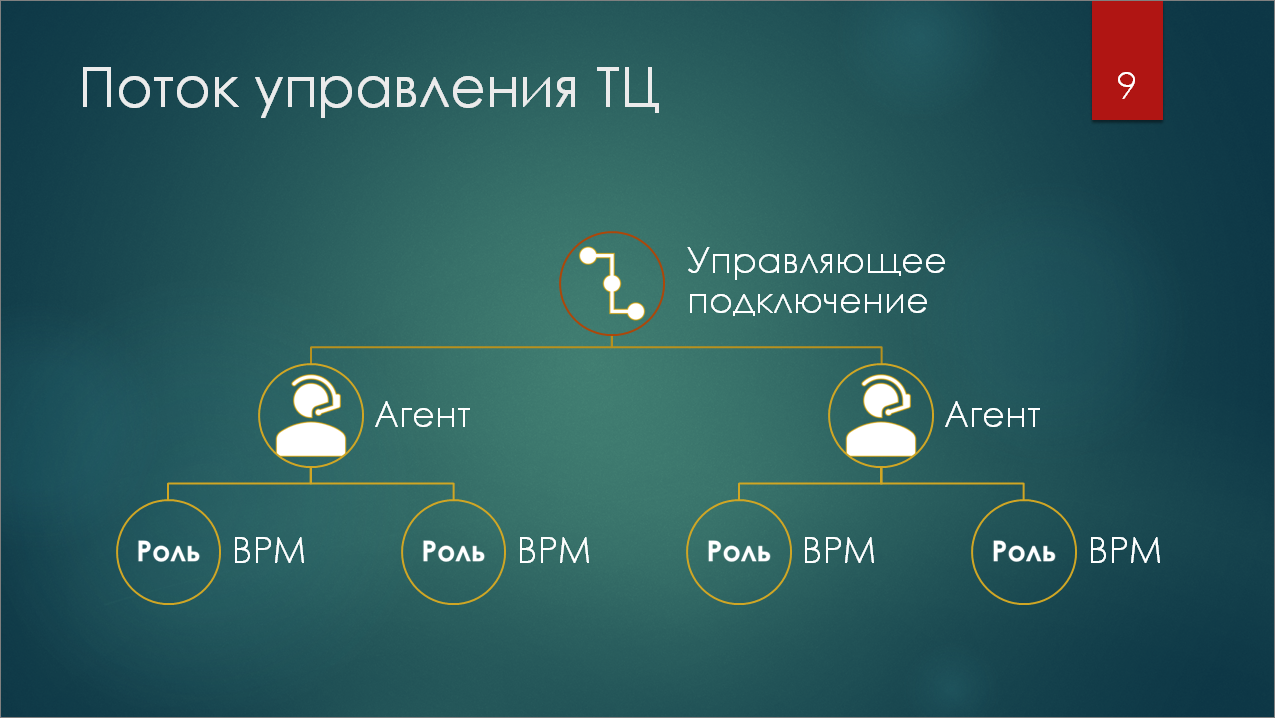
Запуск сценария тестирования производится таким образом:
-
на компьютерах, на которых будут запускаться тесты, нулевым шагом поднимается такая штука как агент. Это – специальный режим запуска 1С:Предприятие с обработкой из состава Тест-центра.
-
На самом верху у нас есть управляющее подключение, которое сообщает агентам информацию о том, какие роли в терминах Тест-центра и в каком количестве нужно запускать на этих агентах.
-
Агенты уже запускают нужное количество так называемых ВРМ (виртуальное рабочее место) – это тоже отдельный сеанс 1С, запущенный с отдельной обработкой. И именно ВРМ уже будет исполнять ту роль, которую ему назначит агент.
Писать тесты интерфейса для самого Тест-центра, на мой взгляд, неудобно. Интерфейс обработок для этого не очень предназначен. И, можно сказать, он больше заточен как раз-таки под серверную нагрузку, под тестирование бэкенда. Да, у нас есть обработка с ИТС, которая позволит преобразовать XML-файл журнала действий пользователя для обработки Тест-центра, но поддерживать все это дело довольно тяжело и сложно. Хочется иметь более простой и понятный инструмент.
Vanessa Automation
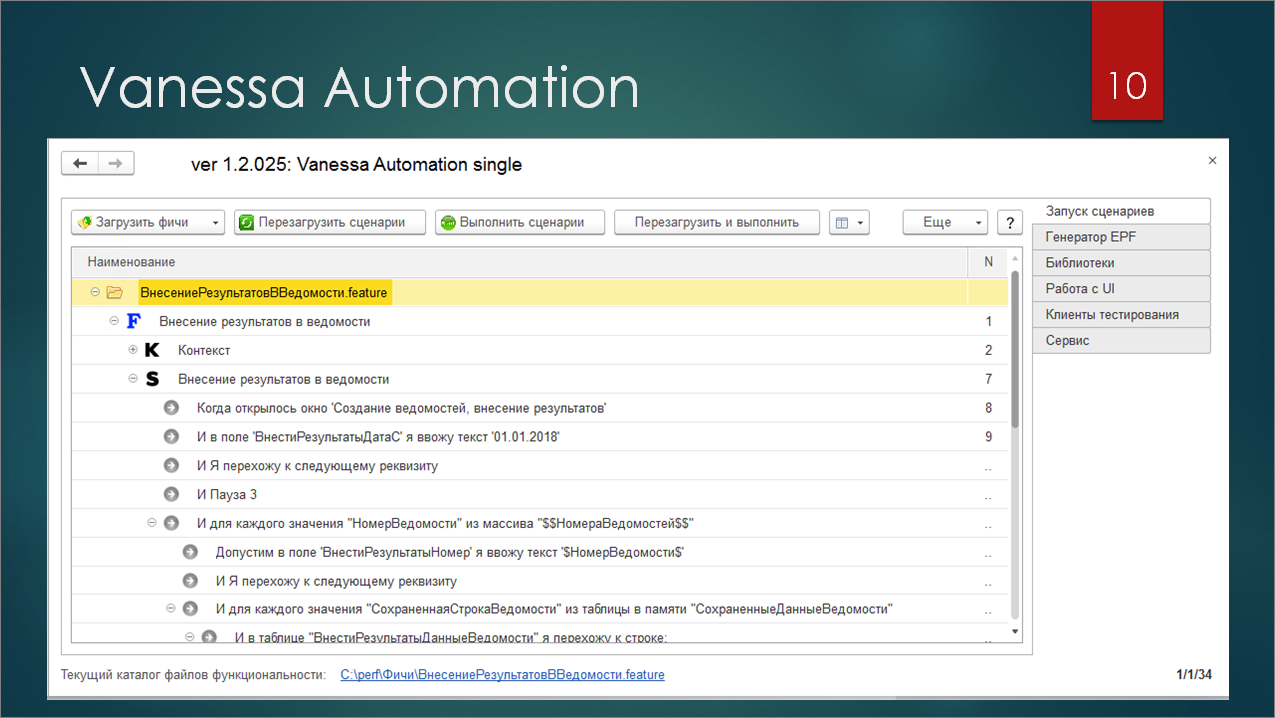
Ок. Кто знает, что изображено на слайде? За 6 лет никто ни разу не слышал про Vanessa Automation, Vanessa Behavior, Vanessa ADD и т.д.?
Vanessa Automation – это фреймворк для BDD. Это – аббревиатура, которая переводится, как «Разработка через поведение». На вход этой обработке мы подаем сценарий на специальном языке Gherkin, и она каждый шаг этого сценария выполняет. Это не придумка чисто для 1С, это порт технологии из другого мира, но, как обычно, с особенностями.
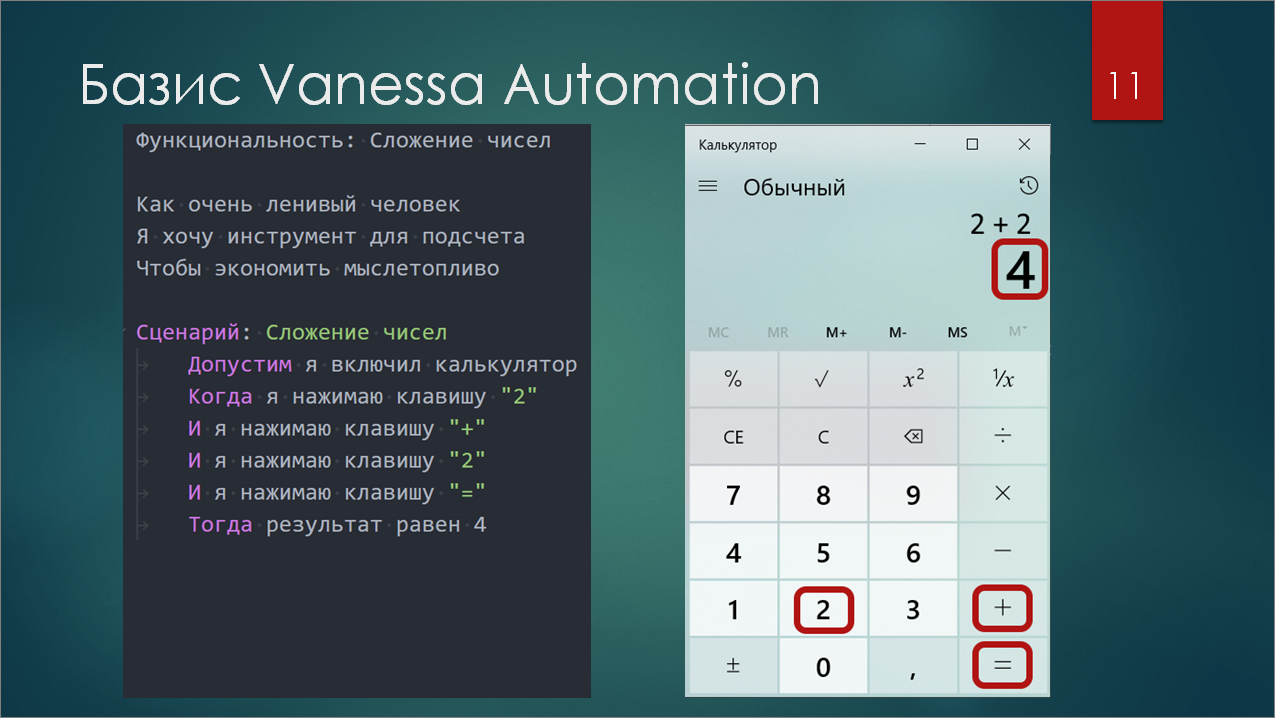
Фреймворк Vanessa Automation базируется на двух составляющих.
-
Первая – это язык Gherkin, формализованный язык описания требований, где каждая строчка, в принципе, что-то значит. Сам язык очень простой. Когда мы складываем 2+2, тогда результат равен 4. Это уже сценарий на Gherkin. Просто нужно грамотно разделить по строчкам то, что вы делаете, и то, что хотите проверить, вставив ключевые слова. И все, сценарий готов.
-
Вторая составляющая, на которой базируется Vanessa Automation в 1С – это «кнопконажималка». Вообще, по классике, авторы BDD говорят о том, что не надо тестировать интерфейс. Но мы 1С-ники, у нас все не с той стороны. «Кнопконажималка» – это механизм, который базируется на процессе автоматизированного тестирования, появившемся в платформе 8.3, он предоставляет простые библиотечные шаги для того, чтобы нажимать на кнопки и получать значения полей.
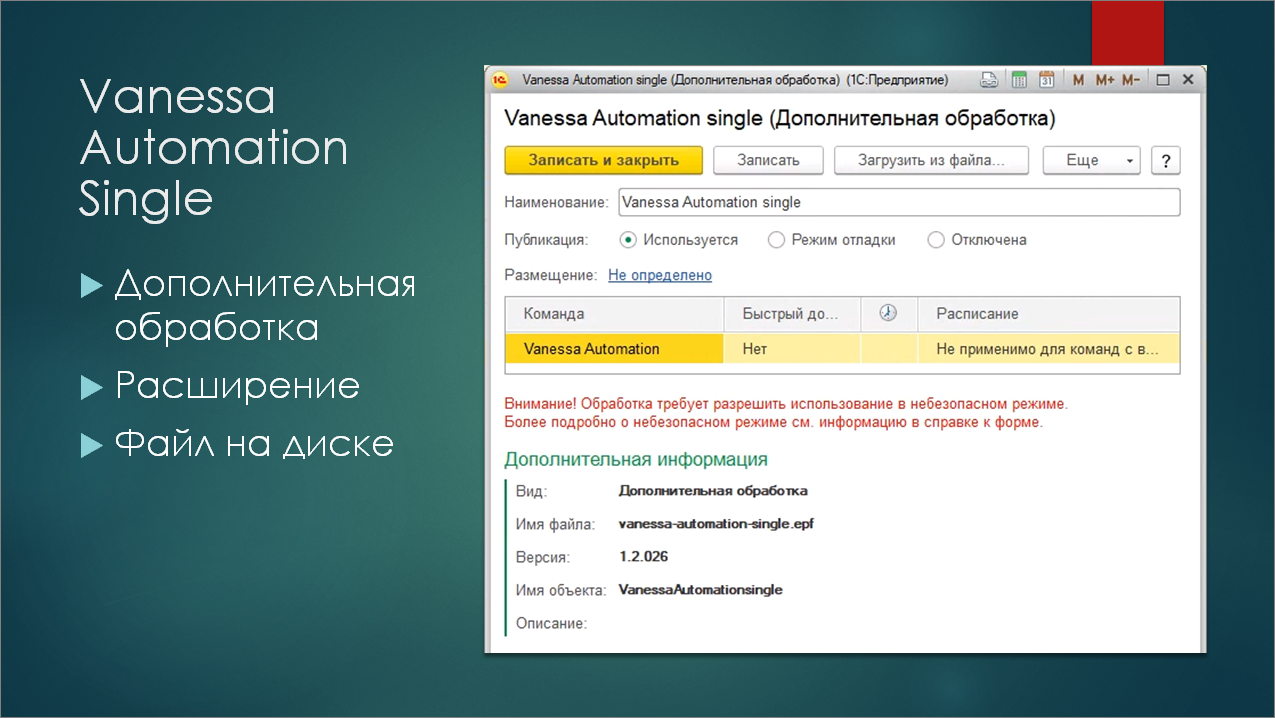
У Vanessa Automation есть два режима поставки.
-
В виде россыпи файлов, где есть сама обработка, библиотеки, и служебные конфигурационные файлы.
-
И в виде единой скомпилированной обработки (так называемая Single-поставка)
Для целей тестирования вариант поставки в виде единой обработки оказался особенно удобен.
Саму эту обработку можно использовать несколькими способами. Мне наиболее удобным показалось помещение этой обработки в справочник дополнительных обработок. Чуть позже покажу, почему.
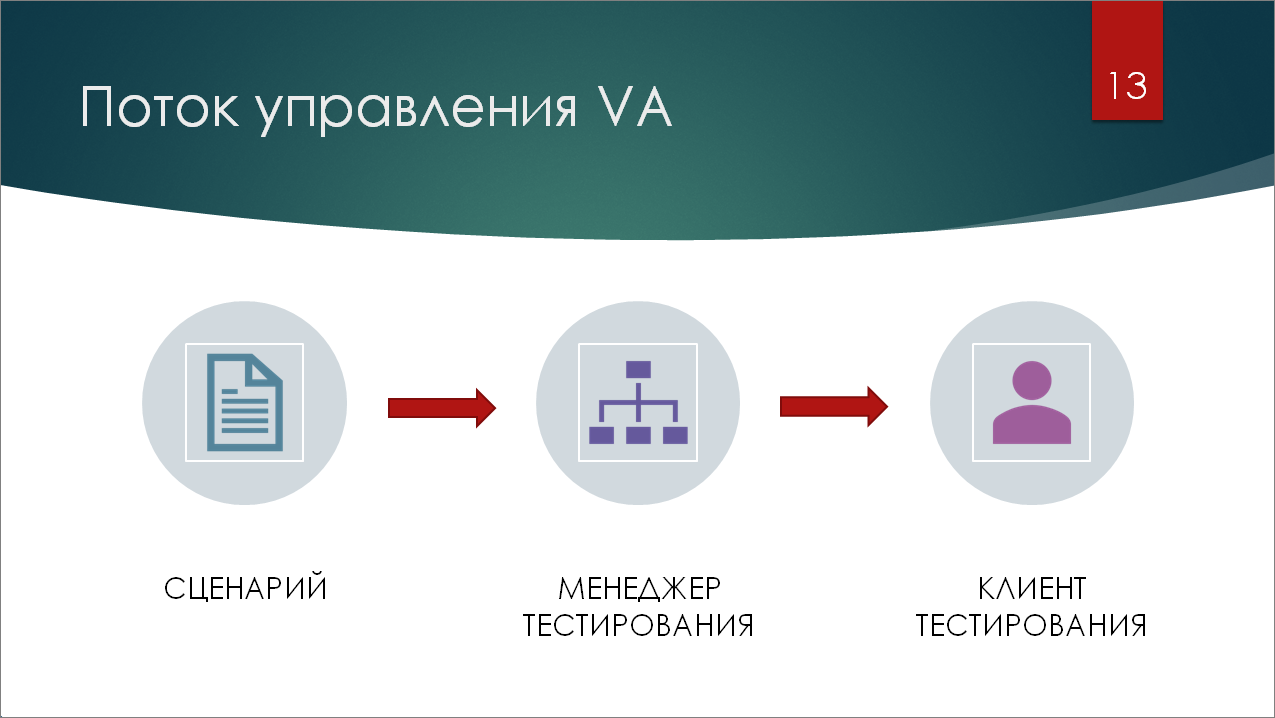
Работа с Vanessa Automation осуществляется более линейно, чем в Тест-центре. У нас есть сценарий в виде файла с расширением feature, написанный на языке Gherkin (так называемый Feature-файл). Он загружается в менеджер тестирования, в котором открыта Vanessa Automation – она запускает клиент тестирования и передает ему команды по нажатию кнопок.
Как научить Тест-центр запускать Vanessa Automation?

Ок. Тест-центр – это хороший инструмент. И Vanessa Automation тоже хороший инструмент. Каким же образом нам заставить их работать вместе? Как же нам научить Тест-центр запускать Vanessa Automation?

Вернемся к структуре Тест-центра. В нагрузочном тесте мы работаем на уровне ВРМ, на самом низком уровне. А значит, именно там мы можем попытаться вмешаться, вставить какую-то логику и запустить Vanessa Automation.
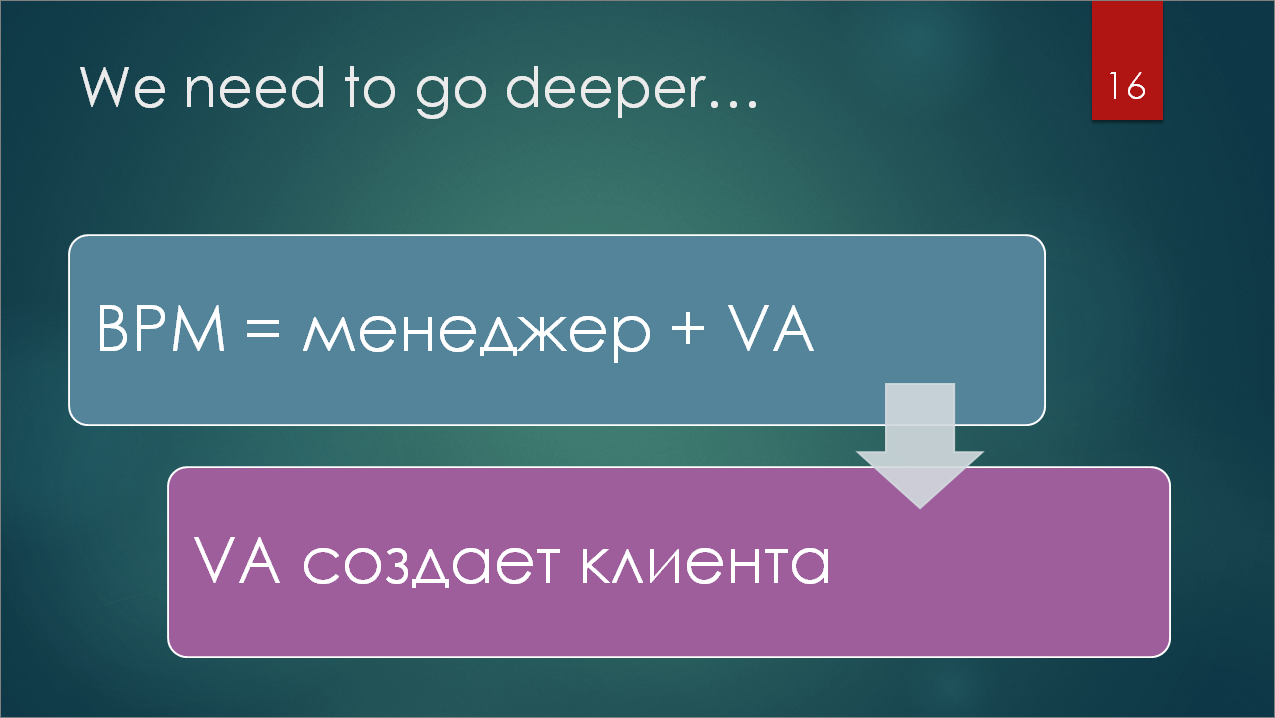
Получается, что нам на уровне ВРМ (виртуального рабочего места) нужно запустить Vanessa Automation, которая запустит еще один клиент тестирования и наше трехуровневое дерево с потоком управления превратится в четырехуровневое – появится еще один клиент.
Как это сделать?
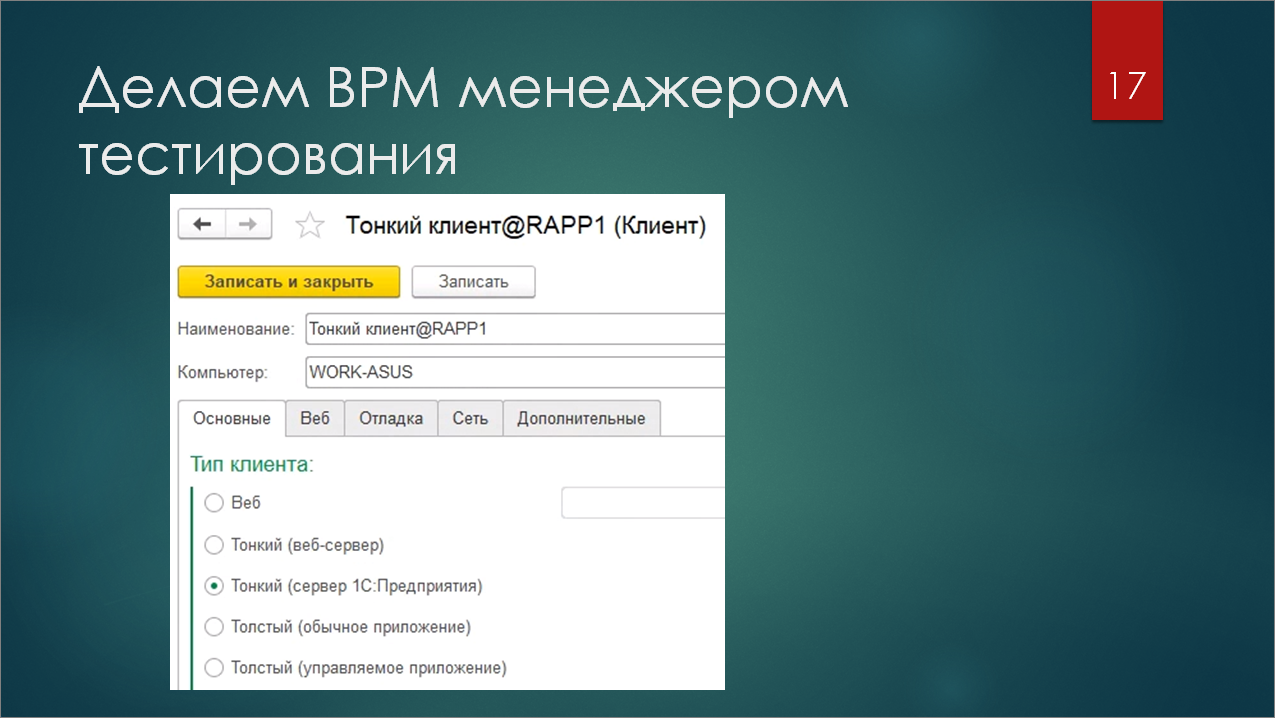
Во-первых, нам нужно запустить ВРМ в режиме тест-менеджера. У запускаемого из Тест-центра клиента есть много разных настроек. Самая главная – это тип клиента (тонкий, толстый, серверная база, файловая).
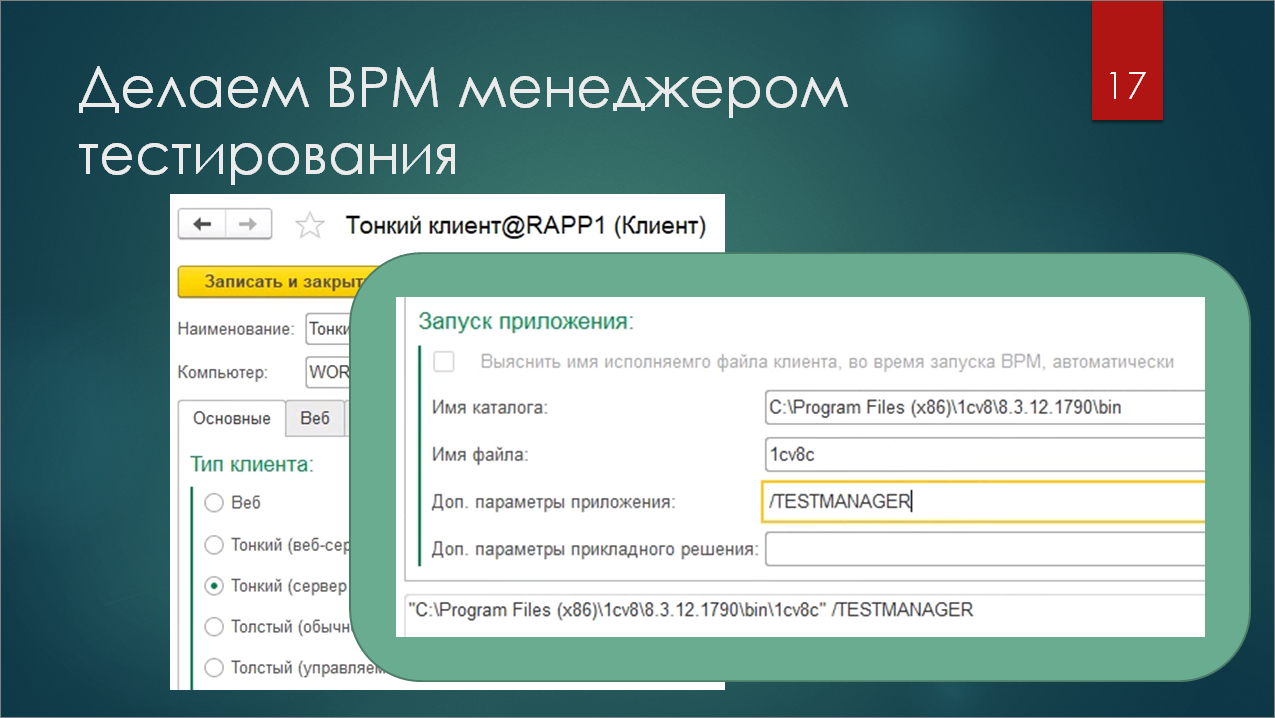
Но, помимо этого, есть секция дополнительных настроек, куда можно передать параметры запуска исполняемого файла 1С. Добавляем параметр /TESTMANAGER – все, мы получили ВРМ, работающее в режиме тест-менеджера.
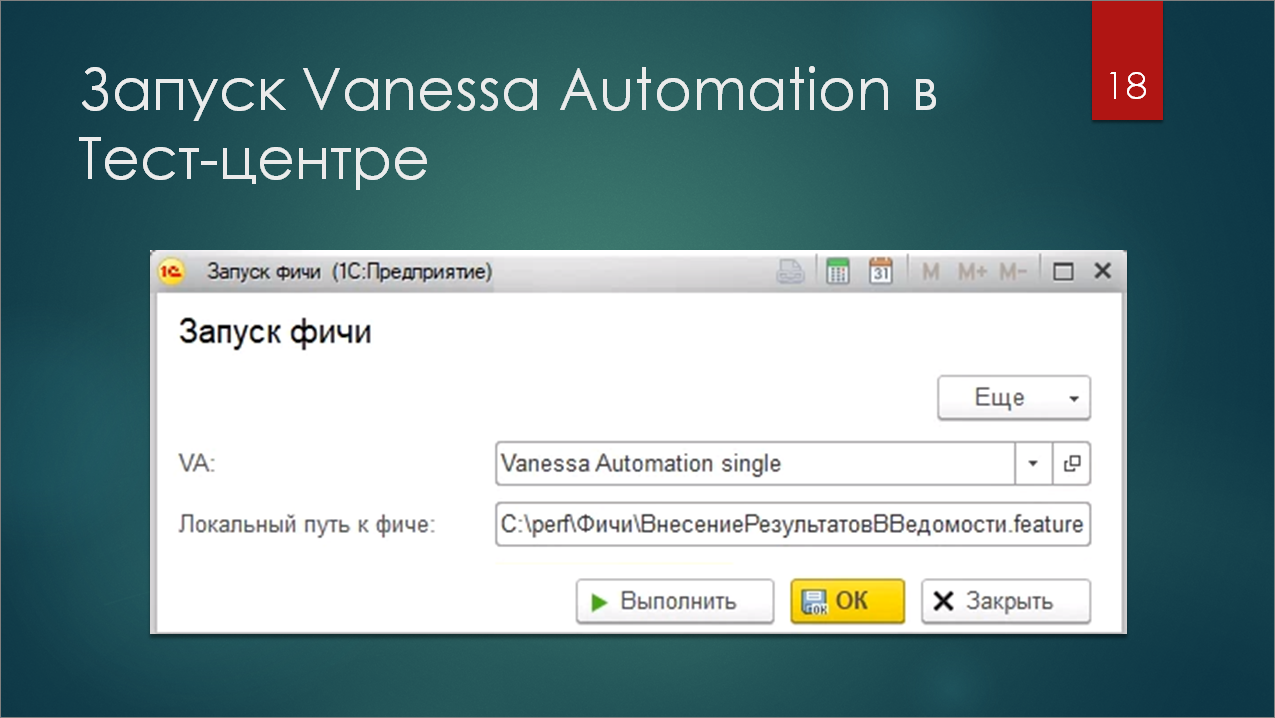
ВРМ теперь может запуститься в режиме менеджера тестирования и управлять клиентами. Но как оно об этом узнает? ВРМ запускает роль – обработку с настройками. На скриншоте есть первая версия обработки, которую я подготовил для нагрузочного тестирования буквально с двумя реквизитами.
Первый реквизит – это ссылка на обработку Vanessa Automation Single, помещенную в справочник.
А второй реквизит – это путь к Feature-файлу, к тому сценарию, который будет запускаться именно в Vanessa Automation. Здесь он указан, как абсолютный, но при желании можно доработать и хранить его в базе. Так затрудняется отладка и доработка, но на финальном этапе разработки сценариев их уже можно поместить в базу. В любом случае допилить все это несложно.
Как написать нагрузочный тест?
С инфраструктурой вроде все понятно – кто, кого, в какой момент должен запускать. Но как писать нагрузочный тест?
Обычный линейный Gherkin здесь не справится. Многие, работавшие с Vanessa Automation либо с Vanesa ADD, знают, что там поддерживаются такие штуки, как группировки шагов, вызов экспортных сценариев, передача параметров в сценарии и прочие штуки, которые к ванильному Gherkin вообще никакого отношения не имеют. Это все по части Turbo-Gherkin – такого расширения языка Gherkin, которое применяется в данном фреймворке тестирования.
Помимо перечисленных особенностей в нем есть еще и такие совсем неканоничные вещи, вроде циклов, условий и переменных контекста. Именно такие нестандартные возможности и становятся лучшими помощниками в написании нагрузочного теста.
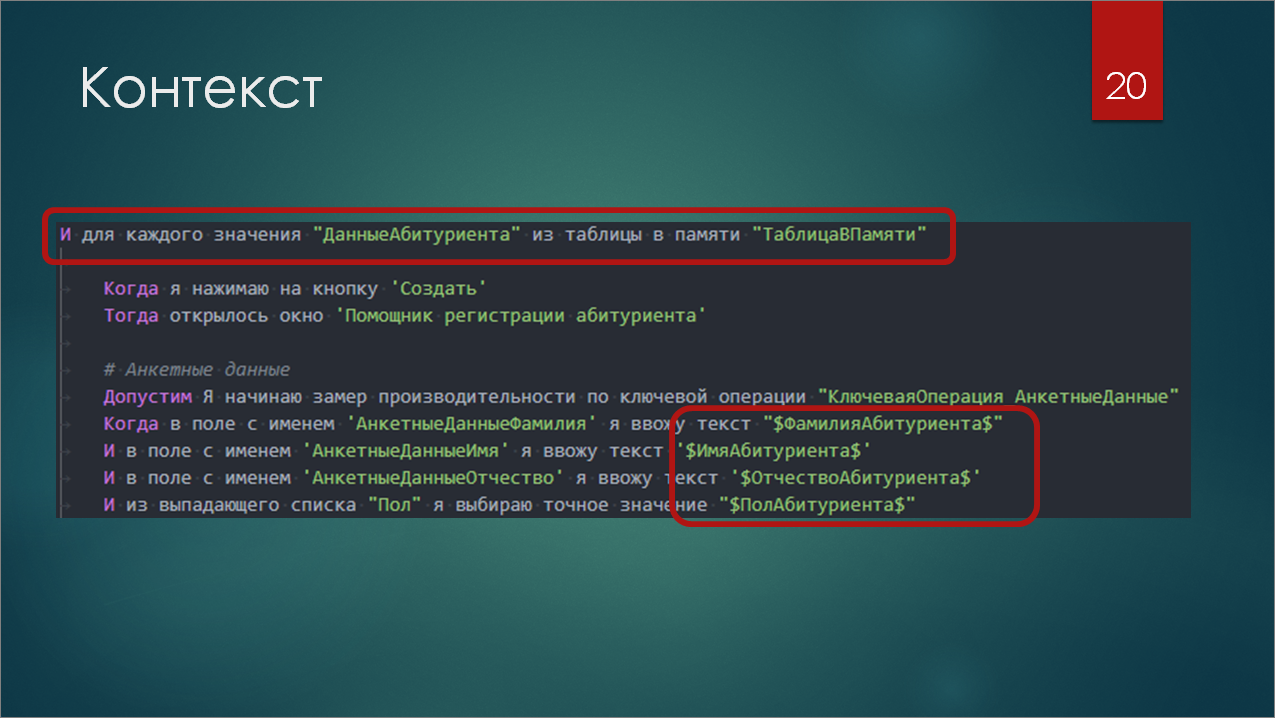
На данном слайде отмечены красным две возможности Turbo-Gherkin – это циклы и переменные контекста.
Первая строчка, обведенная красным, как раз и представляет собой запуск такого цикла «Для каждого». То есть, у нас в контексте есть некая таблица, и для каждой строки этой таблицы будут выполняться шаги, отбитые табуляцией. Причем, значения колонок строки из этой таблицы будут добавлены в отдельные переменные в контексте, которые мы тоже можем использовать в фиче.
И второй, обведенный красным, прямоугольник показывает, что мы можем взять фамилию и пол абитуриента, и поместить их в поле ввода на форме, используя переменные.
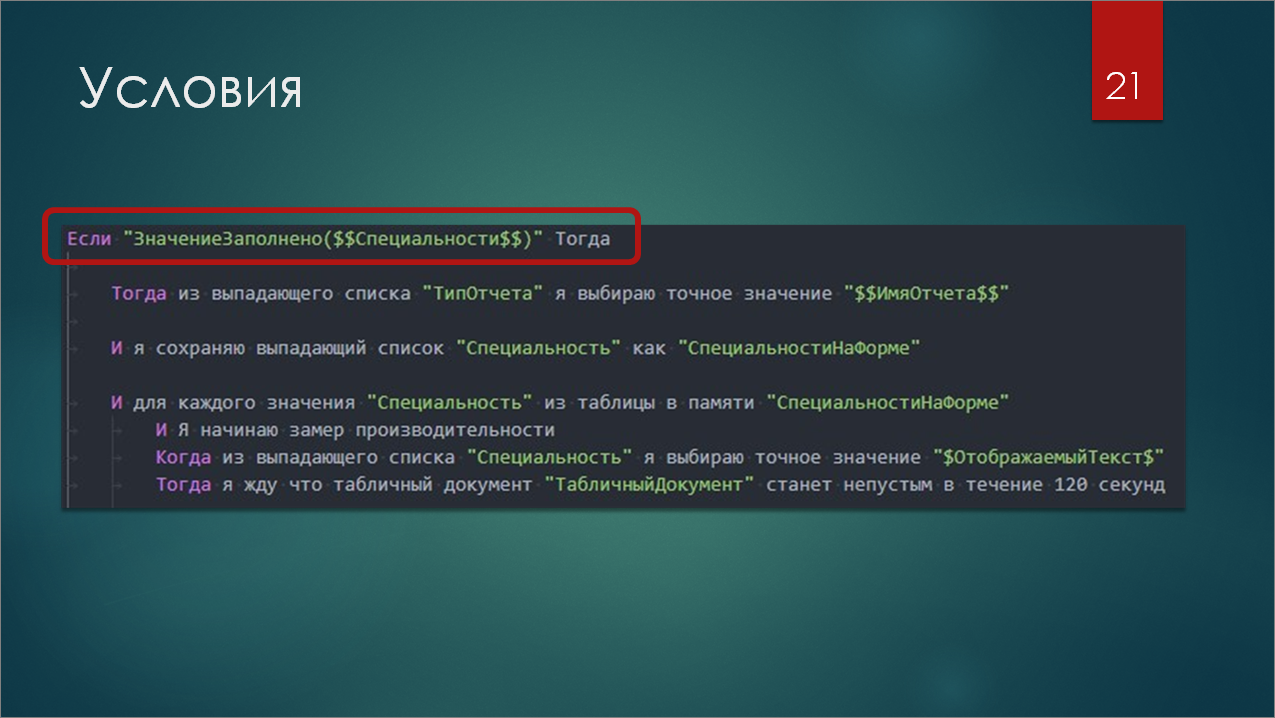
Также есть условия. Они позволяют добавить в ваши фичи вариативности , т.е. вы можете использовать одну фичу с разными настройками для разных ролей, которые у вас будут проводить нагрузочное тестирование.
Здесь применяется шаг условия с выполнением произвольного кода прямо на языке 1С – ЗначениеЗаполнено($$Специальности$$), где $$Специальности$$ – это обозначение переменной из сохраняемого контекста.
То есть, если значение специальности у нас заполнено, тогда выполняются шаги, отбитые внутри табуляцией.
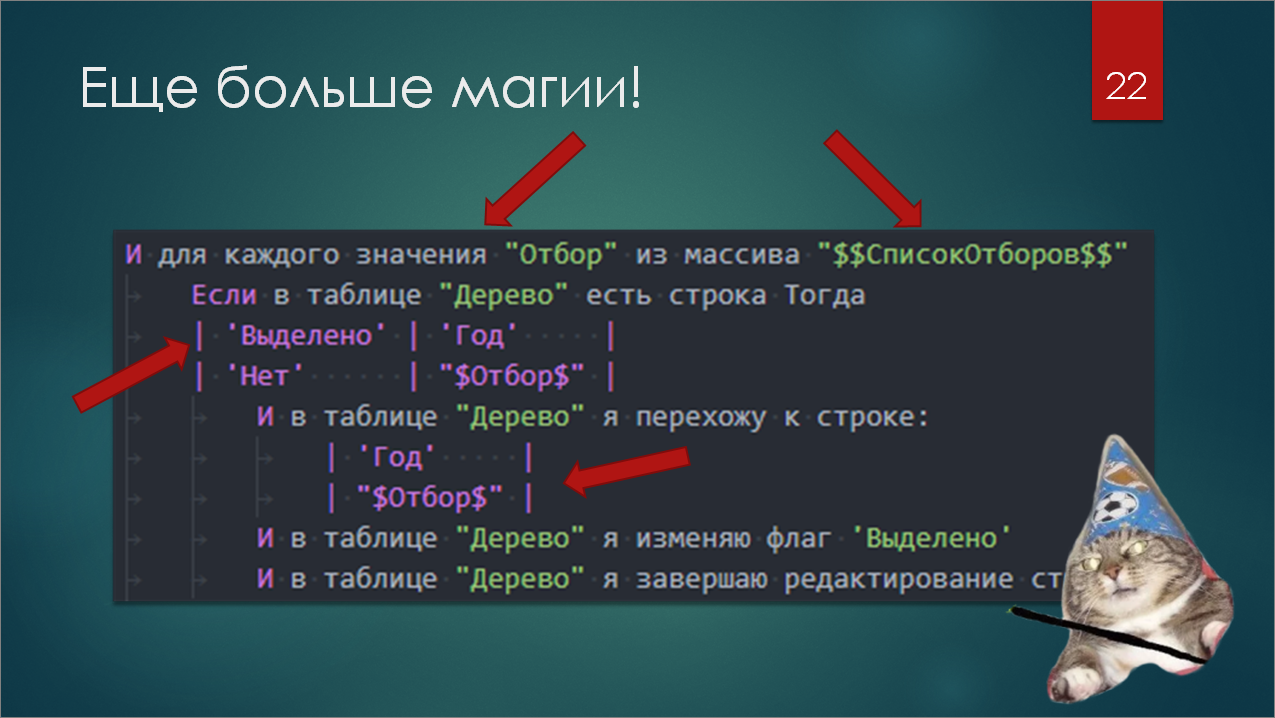
Если все это соединить, то мы можем получить универсальную и гибкую фичу, которую можно один раз написать и впоследствии легко параметризировать на уровне роли – уже ничего не программируя и не открывая Visual Studio Code.
И можно обходить всякие неудобные интерфейсные моменты, типа деревьев значений, которые нужно открывать рекурсивно. Можно использовать какие-то заранее заданные отборы и условиями, циклами все это дело на форме устанавливать. Формы бывают сложные, вы знаете. И в линейном Gherkin не все вещи можно стандартным образом «накликать».
Шаблон тестовой обработки
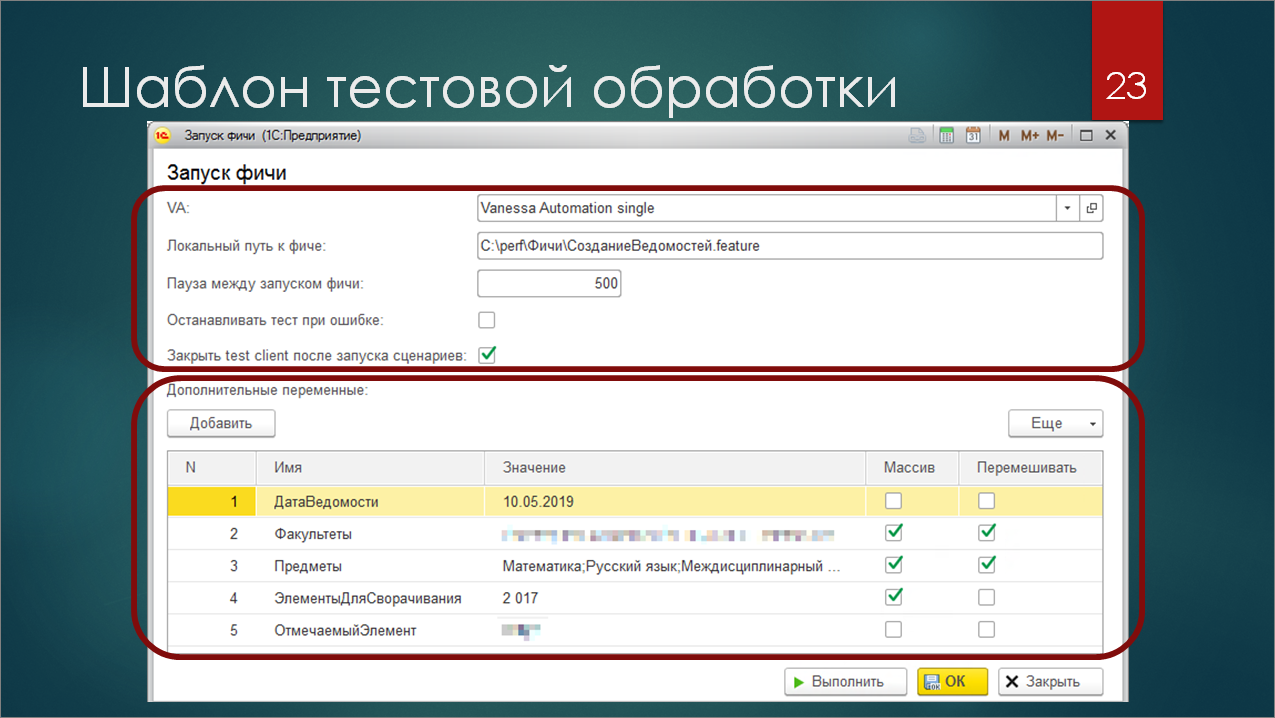
А что там по поводу задания параметров? Как их задавать извне? Где хранить? Как передавать?
На скриншоте представлена подготовленная мной обработка для проведения нагрузочного тестирования. Это – развитие той обработки с двумя реквизитами, то, во что она превратилась после окончания разработки сценариев для нагрузочного тестирования.
На скриншоте я выделил две области:
-
Наверху показаны настройки работы с Vanessa Automation – по цикличному запуску сценариев, по паузам, по работе с тест-клиентом. В целом все это берет на себя ядро обработки, вам все это дополнительно кодить не нужно. Если вы возьмете этот шаблон, добавите в него любой файл сценария, он просто возьмет и заработает.
-
И второе – это секция дополнительных переменных внизу. Это табличная часть, каждая строка которой попадает в контекст, который использует Vanessa Automation для хранения переменных. Из коробки все значения тут строковые, но, используя в качестве разделителя «;», вы можете сделать представленную строку массивом, сохранить массив в контексте и даже его перемешать. То есть, это тоже поможет вам добавить случайности в ваши сценарии.
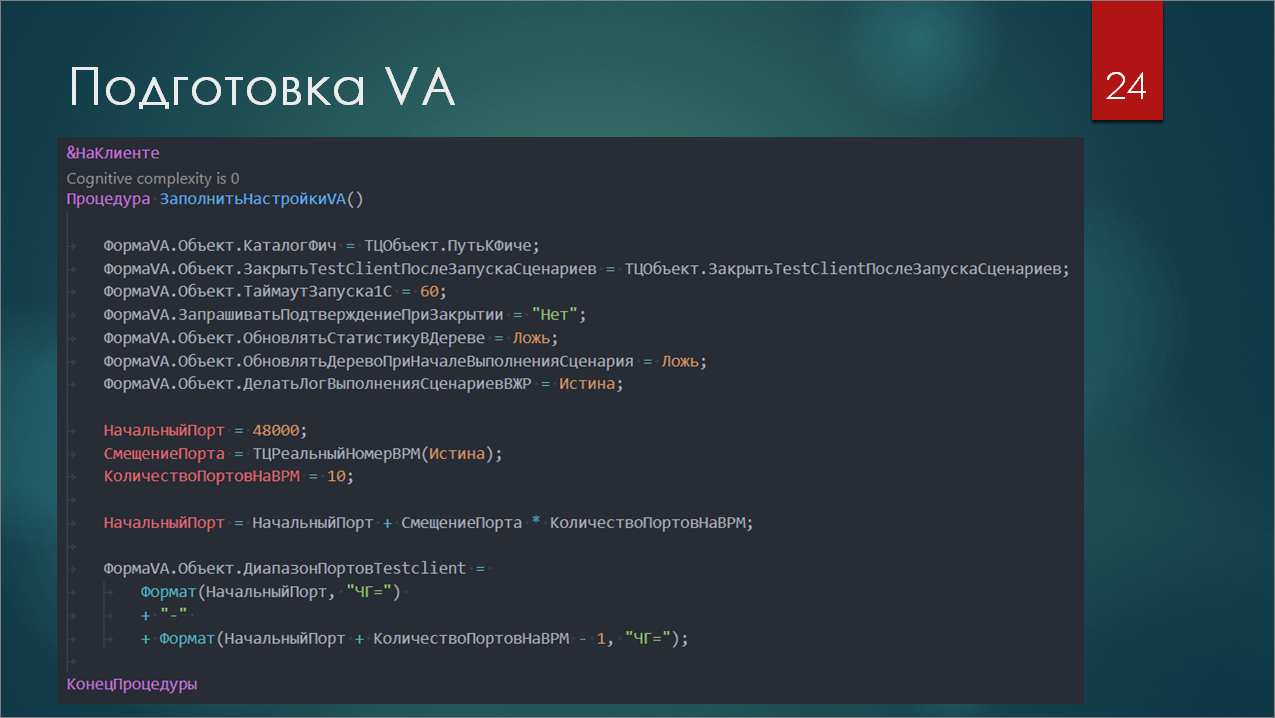
Также обработка содержит полезные методы по работе с Тест-центром в модуле формы. Это несколько точек расширения, в которые может «врезаться» разработчик нагрузочного теста и что-то дополнительно сконфигурировать. На скриншоте изображен шаг подготовки Vanessa Automation. Как вы видите, тут код простой. Мы просто настраиваем форму – объект, который лежит в этой форме. И если вдруг в новых релизах Vanessa Automation появятся какие-то новые особенности, которые стоит дополнительно переконфигурировать, то после добавления пары строк все заработает.
Как решить проблему запуска нескольких менеджеров тестирования на одном компьютере?
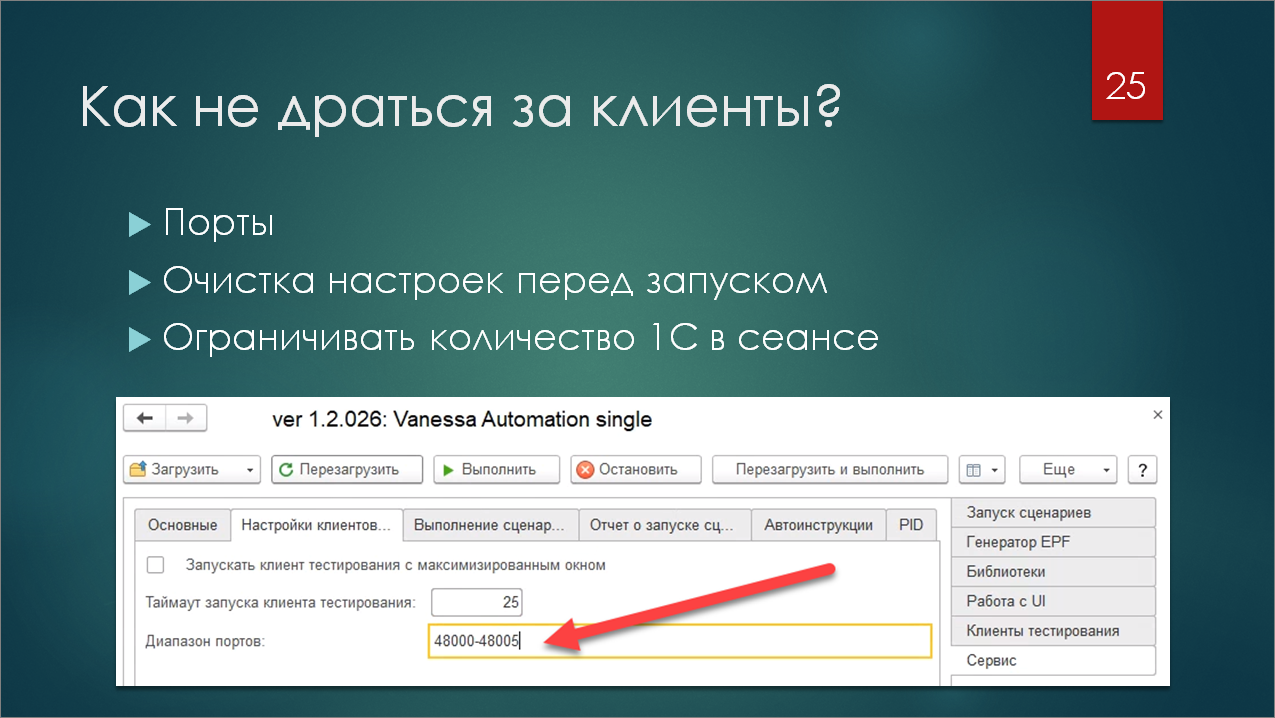
Но не забываем о таком довольно сложном моменте – на одном компьютере будет работать несколько менеджеров тестирования.
Кто-нибудь пробовал запускать несколько экземпляров VA на одном компьютере? Думаю, вы сталкивались с проблемой, что тест-менеджеры начинают драться друг с другом за тест-клиентов: тест-менеджер начинает управлять чужим тест-клиентом, открываются не те формы, что требуются в сценариях. Сценарии начинают падать или зависать. И вообще все очень грустно.
Решается все просто. Есть в Vanessa Automation такая штука, как настройка диапазона портов. Это – те порты, на которых будут запускаться тест-клиенты. По умолчанию, они все запускаются на порту 48000. Поэтому и происходит вот этот перехлест, что все тест-менеджеры начинают ломиться на один порт и друг другу мешать.
Шаблон тестовой обработки берет на себя задачу расчета нужного диапазона портов для каждого отдельного ВРМ. Вы можете запустить нагрузочный тест на 10-50 сеансах на одной машине, и для каждого сеанса эта настройка будет отличаться. Таким образом, у вас будет достаточно стабильная работа. И, по крайней мере, тест-менеджеры с тест-клиентами драться не будут.
У меня сценарии были относительно простые. В рамках одной фичи на Gherkin запускался один тест-клиент. И диапазона в пять портов для первичного запуска тест-клиента мне хватало. Правда, у тест-менеджера не всегда получалось установить соединение с первого раза, но это уже особенности платформы.
Сам тест-клиент в процессе фичи тоже может перезапускаться, тоже что-то может отваливаться. Но за время работы сценария вам должно хватить этих пяти портов, которые будут заниматься и высвобождаться.
Если вы будете запускать в рамках фичи несколько разных тест-клиентов, например, тестировать под разными ролями, то просто в шаблоне поменяйте 5 на 10, например. И диапазоны портов пересчитаются.
Также, если говорить про Vanessa Automation, важным моментом является очистка настроек перед запуском. Потому что Vanessa Automation много вещей хранит в кэше. В том числе она хранит в кэше настройки подключения к тест-клиентам. Их для корректной работы нужно сбрасывать, и это тоже берет на себя обработка.
И третий момент, который помогает не драться за клиентов – это ограничение количества клиентов 1С, которое вы запускаете в рамках одного сеанса операционной системы. Если вы в одном сеансе операционной системы запускаете 50 клиентов 1С, то это будет работать хуже и менее производительно, чем если вы запустите 10 сеансов операционной системы, и в каждом из них по 5 клиентов 1С. Тут уже играет роль взаимодействие 1С с самой операционной системой, Vanessa Automation здесь не при чем. Но такая особенность тоже есть, про нее надо помнить. Поэтому лучше разносить агенты по разным машинам или по разным RDP-сессиям на вашем терминальном сервере.
С чем пришлось столкнуться

При написании нагрузочного теста я столкнулся с определенными трудностями. Классик говорил: «Все врут». Особенно врет документация.
Оба продукта постоянно дорабатываются. И иногда можно много времени потратить на очень простых вещах. На Тест-центре, на котором я работал (версия 2.1.3) можно наткнуться на не совсем верную работу Тест-центра с регистром «Замер времени». В регистр ложатся данные в UTC±0, а Тест-центр читает их со смещением. Поэтому вы запускаете тест, получаете отчет, но в этом отчете ничего не отображается, потому что банально, диапазон времени запуска и окончания прогона сценария не попал в диапазон из регистра.
Также функция НомерВРМ() – ты находишь эту функцию в конфигураторе, у тебя открыта 1С в режиме предприятия, на ней написано ВРМ №13. И ты ожидаешь, что вызовешь функцию НомерВРМ() и получишь 13. Ты ее вызываешь, получаешь 2. Читаешь описание к функции, на ней написано: «Она возвращает уникальный номер ВРМ». Запускаешь другую ВРМ – она возвращает 3. Ок, ладно. А потом запускаешь ее еще раз, но под другой ролью в терминах Тест-центра, и она снова возвращает 2. Два разных ВРМ с одинаковым номером ВРМ? Что происходит?
Встречаются моменты, когда документация иногда может подвирать. Конкретно с функцией НомерВРМ() оказалось, что она возвращает уникальный номер в рамках строки в сценарии тестирования, в рамках той роли, на том клиенте, на котором все это дело запускается.
В шаблоне обработки есть функция, которая возвращает действительно уникальный номер ВРМ, который у вас повторяться не будет.
Процесс написания нагрузочного теста

Каким образом выглядит процесс написания нагрузочного тестирования?
Три шага.
-
Первый шаг не отличается от привычного сценария работы с Vanessa Automation. Мы подключаем клиент тестирования, кликаем кнопки и на выходе получаем текст фичи.
-
Далее этот текст нам нужно превратить в нагрузочный сценарий – нужно разнообразить его условиями, циклами, добавить работу с переменными. Сделать так, чтобы он был независим от тех данных, которые были у вас на форме, когда вы этот сценарий кликали. Например, если вы будете создавать там расходную накладную, выбирать там конкретные товары, то, скорее всего, рано или поздно ваша расходная накладная при проведении ругнется, что такого остатка нет. Потому что тот конкретный товар, который вы будете списывать, у вас будет изначально зашит в тексте фичи. И его бы хорошо параметризировать для того, чтобы по нему кодом остатки создавать, еще что-то. В общем, нужна подготовительная работа по унификации, чтобы сделать фичу универсальной.
-
И третий шаг – настройки, которые мы выделили для подстановки в текст сценария на Gherkin, нужно перенести в роль, которая у нас в Тест-центре.
Как анализировать результаты
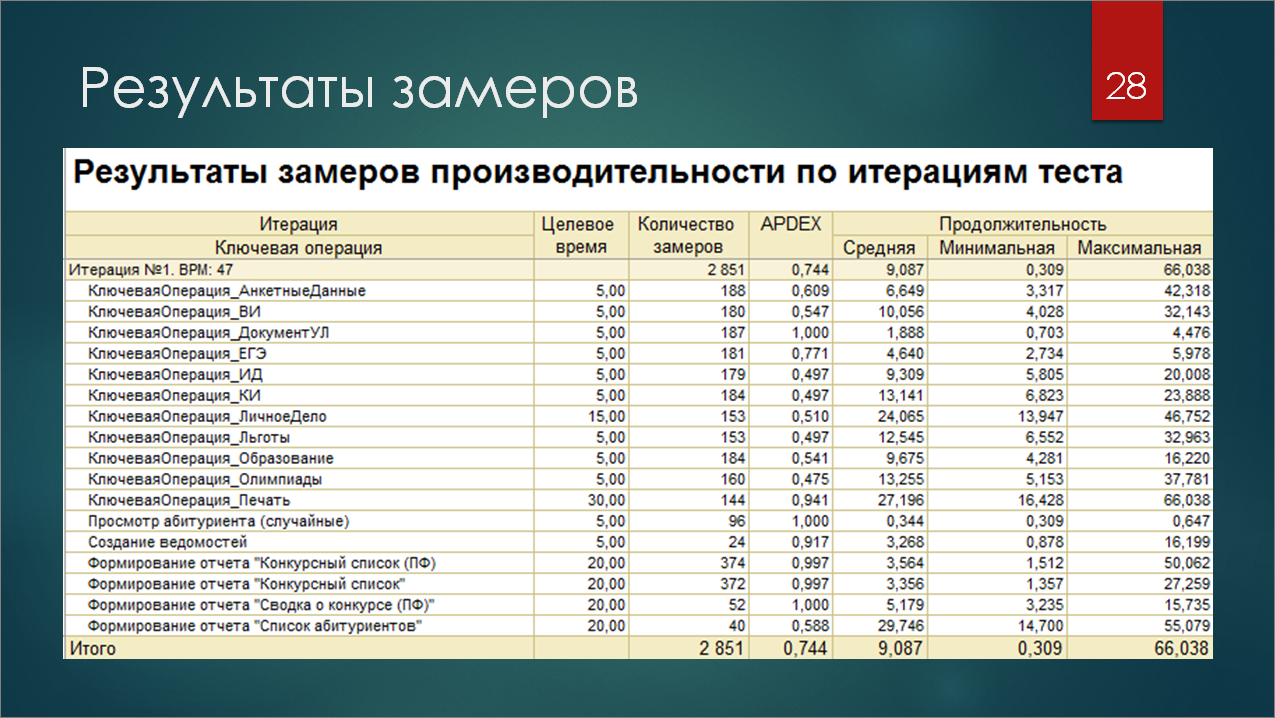
Запустили, оно все прогналось. И на первый раз, мы, скорее всего, ничего не получили, кроме разогретого процессора. Дело в том, что, по крайней мере, на старых версиях БСП при работе документов и формировании отчетов никаких ключевых операций вообще не показывалось, а тест-менеджер на первой вкладке в результатах замеров показывает именно замеры по ключевым операциям.
Но вы в фиче можете ставить шаги по включению и отключению замеров по нужным ключевым операциям и таким образом уже получить в результате вашего нагрузочного теста табличку, в которой будет довольно много полезных данных: сколько раз запускалась данная ключевая операция, ее продолжительность, минимальное, максимальное время. Там справа есть еще ряд колонок – дисперсия, отклонение и пр.
Но для детального анализа и расследования того, где у вас есть проблемы производительности, этого отчета может не хватить.
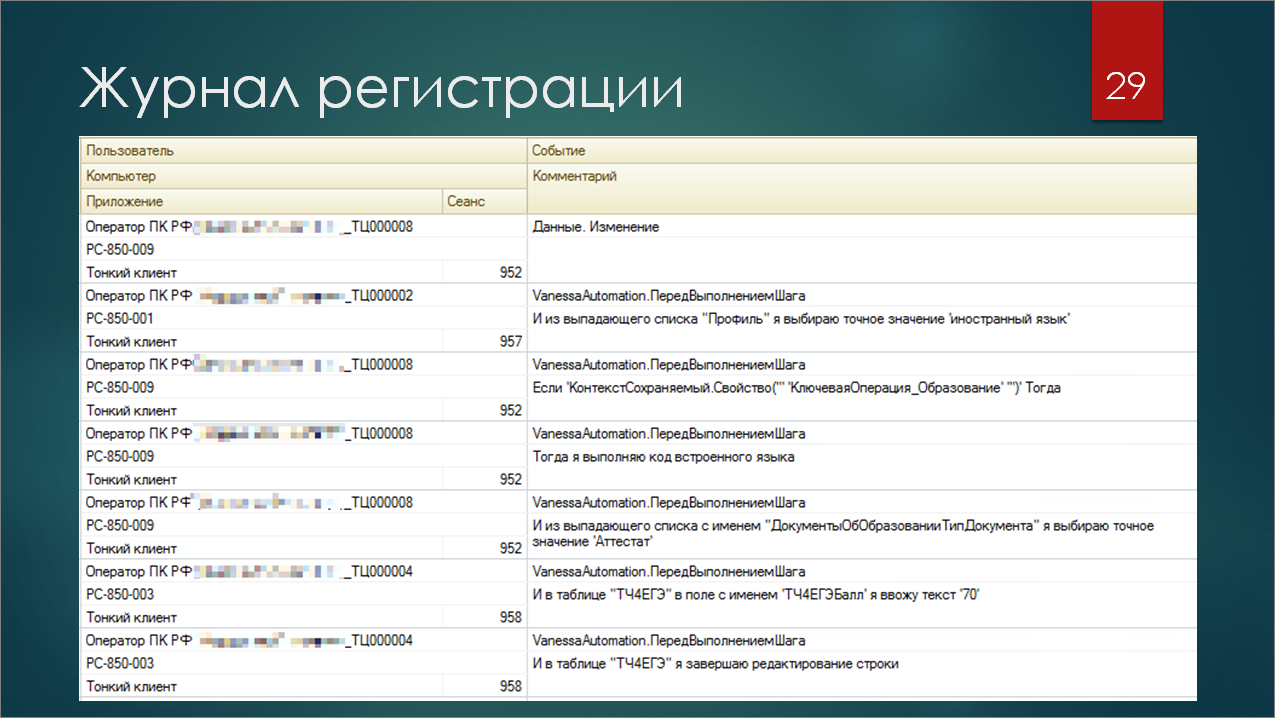
Поэтому наш лучший друг – это журнал регистрации. Каждое действие Vanessa Automation подробно логируется в журнал. Там есть информация о том, какие конкретно шаги выполнялись в то или иное время – с привязкой к сеансам и к пользователю. Плюс в журнал регистрации пишет еще и сам Тест-центр. И если вы проведете работу по анализу всего этого дела, то вы можете получить очень точную картину, в какой конкретно момент у вас что-то упало. Особенно, если в случае каких-то ошибок вы пишите не «Сообщить» и выводите эту ошибку пользователю, а дополнительно логируете ее в журнал регистрации. Тогда у вас будет вся картина того, что пошло не так.
Когда, наконец, все это дело заработало, и я начал разбирать результаты первого нагрузочного тестирования, проведенного на реальном железе, выяснилось, что жутко тормозил мой же код шестилетней давности. Было очень стыдно. Мы с коллегами все поправили, и уже на второй итерации код стал работать быстрее, проблем стало меньше.
Заключение

Вместо итогов я хочу сказать о том, что тесты – это хорошо. Я думаю, несогласных не будет. Тесты бывают разные, бывают функциональные тесты, юнит-тесты, перформанс-тесты (это как раз часть нагрузочных тестов).
Пишите их. Они помогут вам найти не только проблему в бизнес-логике, но и «узкие места», которые разработчик не тестировал вообще – например, по какой-то функциональной опции код исполнялся по-другому.
Либо, в случае, если у вас большая база, много операций, 50-100-150 клиентов, и вы начинаете ловить блокировки, ожидания, дедлоки, что-то отваливается и т.д. Без нагрузочных тестов вы сможете об этом узнать только от заказчика или от бухгалтера, который будет вам звонить и гневно ругаться.
Но все это решаемо, и вы, как разработчики, можете, не отдавая код на продуктив, все протестировать и сделать хорошо.
https://github.com/nixel2007/tc-epf-template
По ссылке находится репозиторий, куда я выложил шаблон тестовой обработки, которая была на скриншотах. Вы можете его скачать, попробовать запустить у себя. Там же есть шаги фич по включению и отключению замеров. Там вариант для БСП 3.0. В комментариях и в Readme описан вариант включения замеров для БСП 2.2. Если у вас используется какая-то другая версия, возможно, их придется чуть-чуть подтюнить, но напишите, подскажу, на что нужно обратить внимание.
****************
Данная статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART EVENT 2019.

Вступайте в нашу телеграмм-группу Инфостарт


