Здравствуйте, коллеги! У нас сегодня необычное выступление, нас сегодня двое – парный доклад. Итак, Андрей Овсянкин и Никита Грызлов. Мы в 1С довольно давно. И хотим с вами поделиться нашим опытом по оптимизации запросов, а именно, по просмотру планов запросов.
Оптимизация производительности это почти всегда тюнинг запросов

Андрей: Стоит ли говорить, что всем нужна скорость. Чем быстрее система работает, тем счастливее люди. И ни для кого, наверное, не секрет, что в работе приложения 1С наибольшее влияние на скорость оказывают именно запросы. То есть, код 1С по сравнению с запросами выполняется относительно быстро. А когда что-то тормозит, то, скорее всего, проблема в запросах, и смотреть надо на запросы.
Наверное, каждый при написании того или иного запроса задавался вопросом: «Мне здесь условие написать в ГДЕ или в СОЕДИНЕНИЕ?» или «Как лучше – сначала отсортировать, а потом применить условие или наоборот?»
Как вы решали этот вопрос? Что делали, чтобы принять решение? Наверное, делали замер производительности? Кто сказал: «План запроса»?
План запроса

Андрей: Итак, план запроса:
-
Кто слышал это слово?
-
А кто знает, что это такое?
-
А кто умеет читать план запроса и использовать его в работе?
Никита: Хорошо, контрольный вопрос – а на Postgres?
Чем хорош Postgres – на нем легче научиться понимать механику работы СУБД с помощью плана запроса. Он в целом заставляет разбираться в этом, потому что сами планы запросов периодически получаются очень навороченными и сложными. И сейчас мы разберем самые частые моменты оптимизации запросов в Postgres.
Маленькая ремарка – наш сегодняшний доклад будет касаться обычной 1С-ной сборки от Postgres Pro и возможно, некоторые вещи, про которые Олег Бартунов рассказывал в коммерческих редакциях, будут неактуальны. Но, я думаю, что большинство людей (90%) пользуются именно «халявным» Postgres – либо от сайта 1С, либо от Postgres Pro – поэтому для большинства наши рекомендации будут актуальны.
Давайте разбираться

Андрей: Давайте разбираться, что такое план запроса, и почему вообще он нужен?
Ну, во-первых, несмотря на то, что сервер СУБД очень сложное инженерное сооружение, он, в принципе, оперирует достаточно понятными и общеизвестными вещами. Там нет никакого космоса, он оперирует той же самой памятью, дисками, процессорными ресурсами и т.д. У сервера есть в принципе все то, что понятно и знакомо, никакого космоса внутри особо нет.
Ну и, конечно, к каждому серверу СУБД в заводской поставке прилагается админ в коробке. У вас не прилагался? Поройтесь там, в опилках, может быть, потерялся. Наверняка есть. Или он сбежал в подсобку у вас – его на пиво можно выманить.
У СУБД должен быть админ.
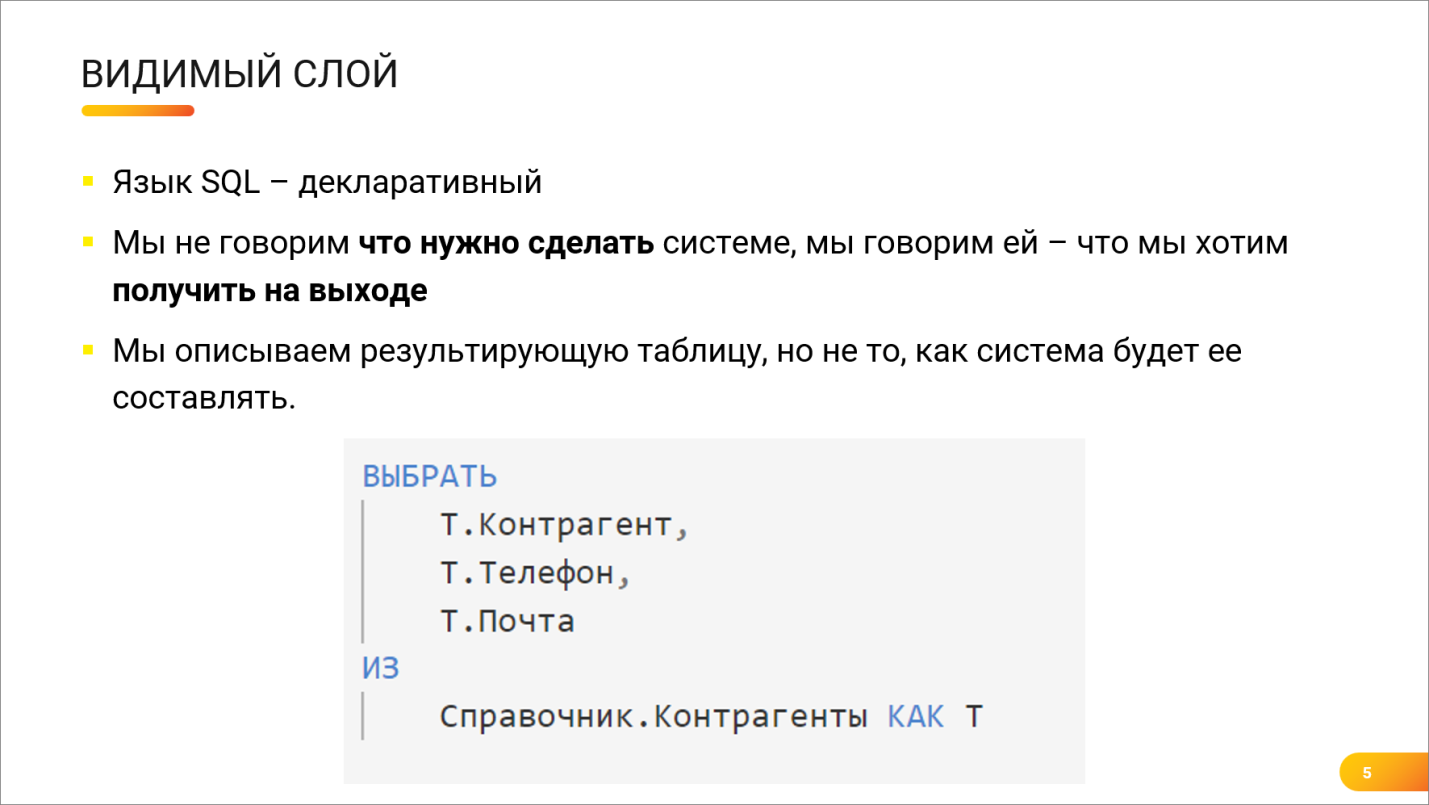
Андрей: Когда мы пишем запрос, мы находимся на самом верхнем слое прикладной логики.
-
Язык SQL – декларативный.
-
Мы не говорим базе данных, какие команды ей надо выполнить, мы говорим ей, какой результат хотим получить на выходе – описываем поля, условия и т.д.
-
А как именно будет выполняться запрос, как именно сервер должен добыть эти данные, нас на уровне языка SQL не интересует.

Андрей: И сервер, прочитав наш запрос, начинает думать:
-
В какие файлы надо залезть, по каким адресам это все собрать, где, что лежит – а тут параллельно еще и другие пользователи работают, надо еще и блокировки с изоляциями обработать…
-
Слишком много сложных операций, нужно составить план действий!
Устройство плана запроса
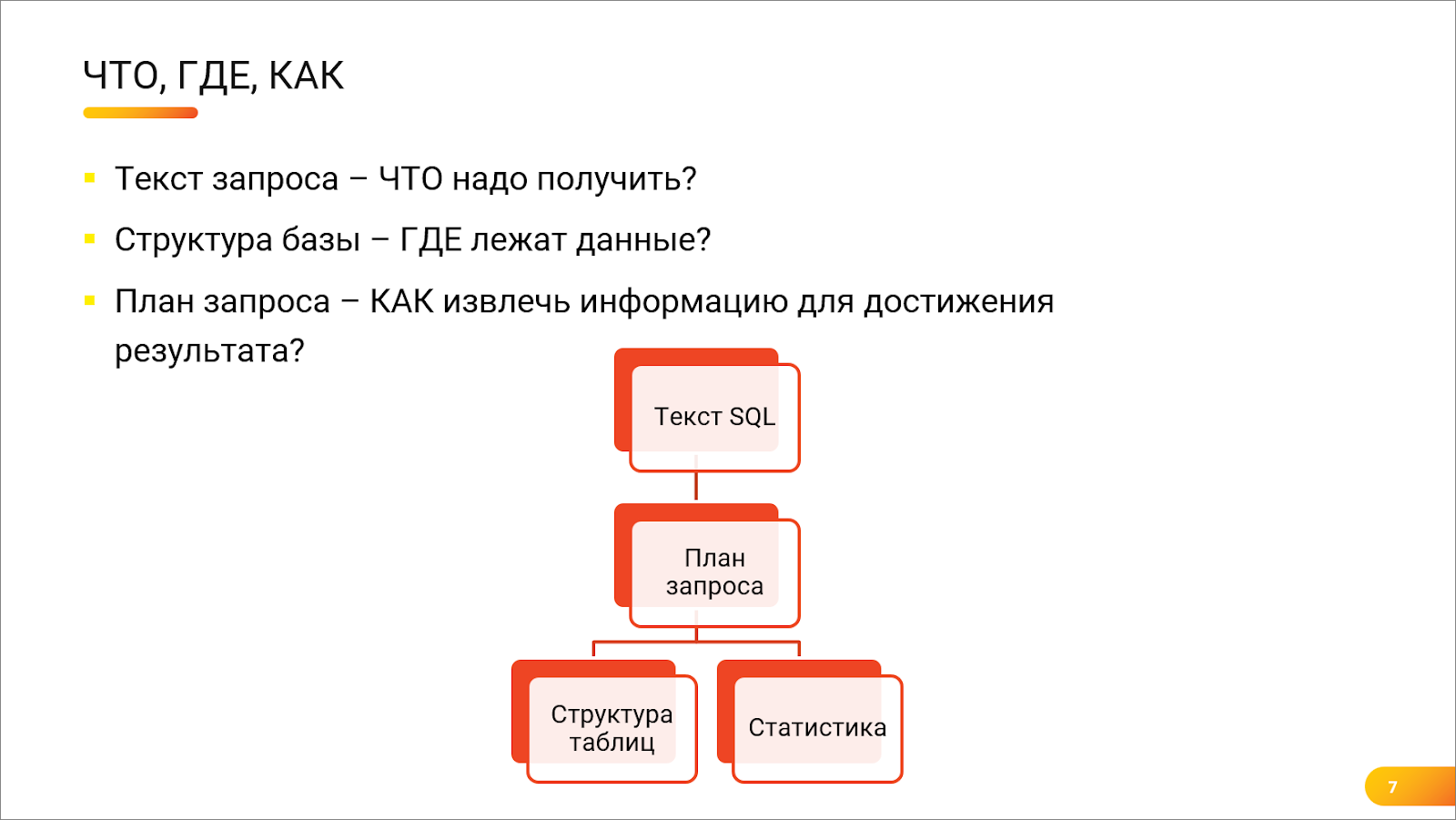
Андрей: План запроса – это некое «Что? Где? Как?» про базы данных:
-
Текст запроса – отвечает на вопрос «ЧТО». Что надо получить на выходе?
-
Структура базы данных – отвечает на вопрос «ГДЕ». Где лежат запрошенные данные, в каких файлах, в каких таблицах.
-
А вот КАК достать эти данные из структуры таблиц, чтобы выдать результат за вменяемое время – на это и отвечает план запроса. Как правило, для запроса существует более одного способа извлечения данных. И далеко не все эти способы быстро сработают.
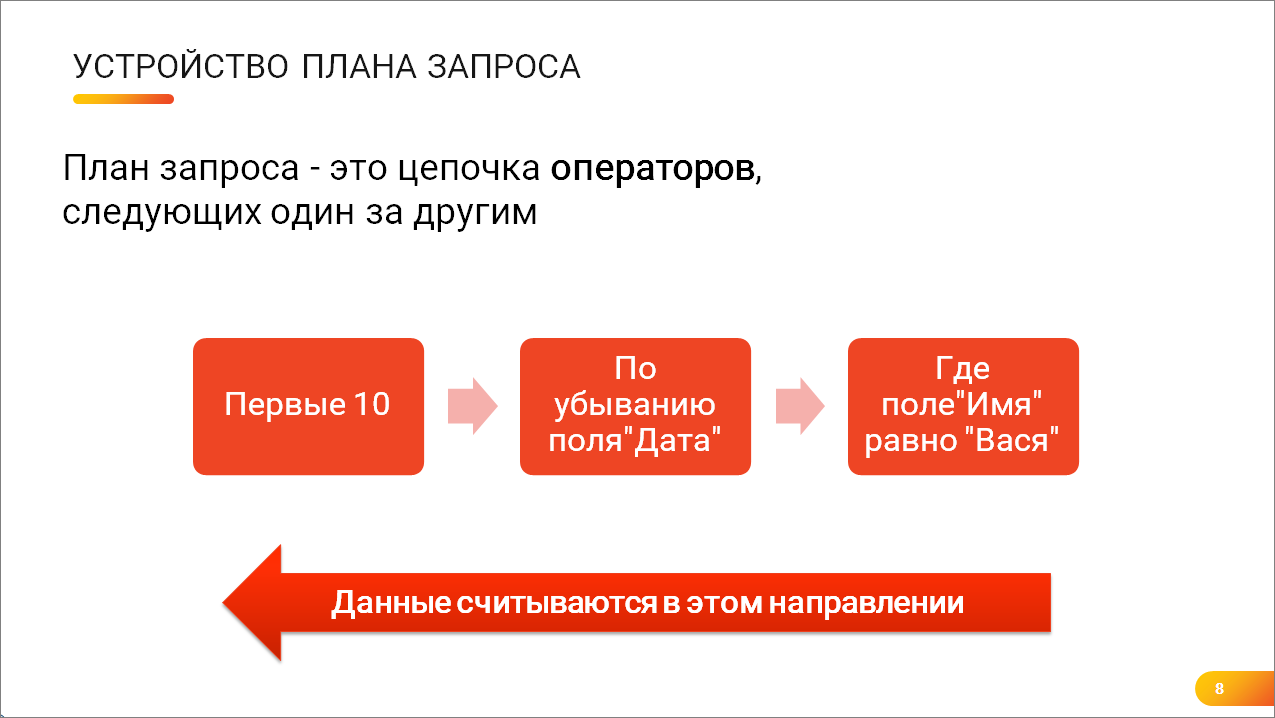
Андрей: Как устроен план запроса?
-
План запроса состоит из операторов – это цепочка операторов.
-
Каждый оператор – это некий «черный ящик» с одним методом «Дай следующую запись».
-
Когда эти операторы выстроены один за другим, они вызывают друг друга.
-
И данные начинают считываться в том направлении, которое идет по стрелке – от самого дальнего оператора к самому ближнему.
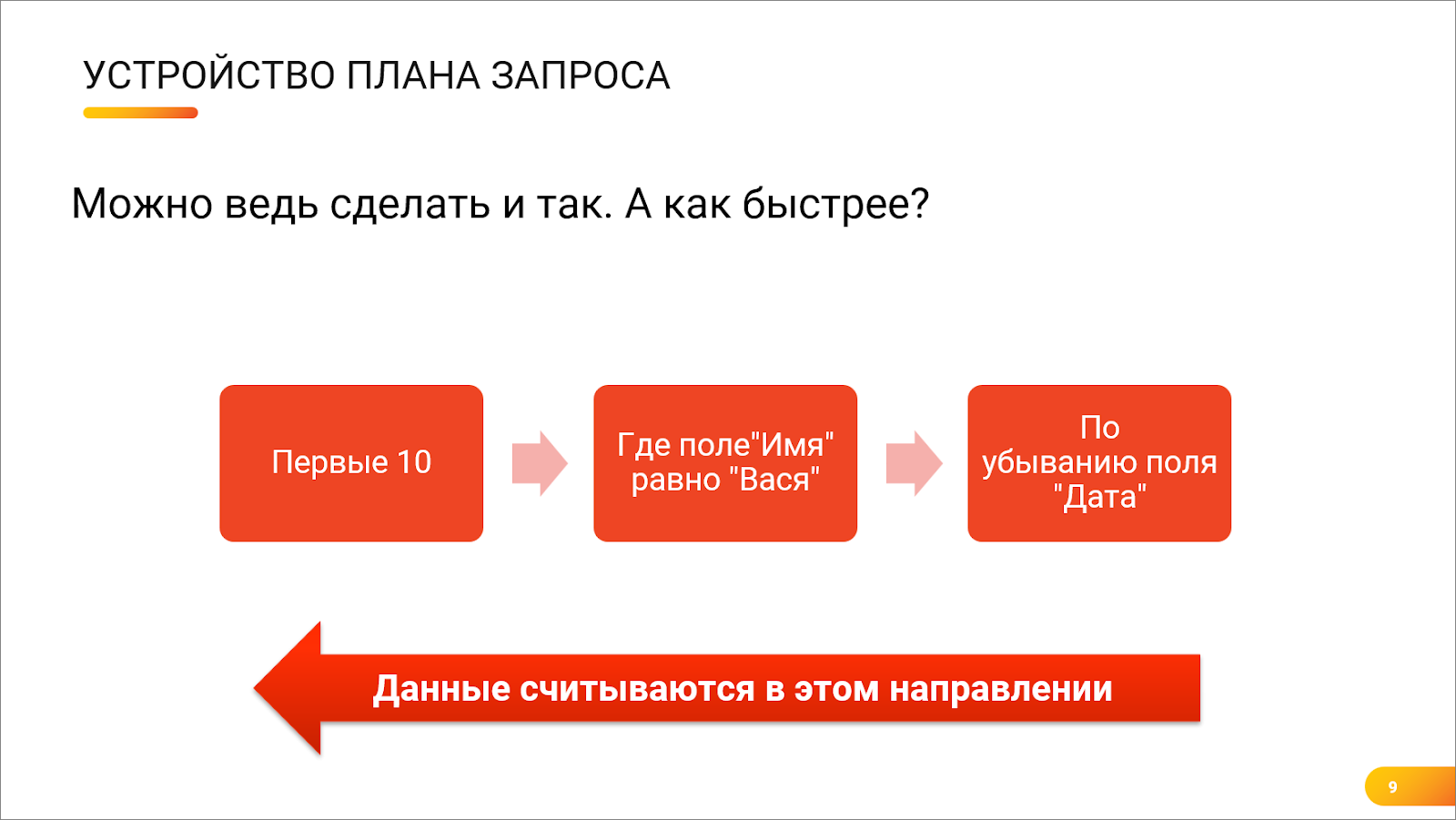
Андрей: Но эти кубики можно поставить и наоборот – можно сначала отсортировать, а потом отфильтровать по имени. Как будет лучше, не знаешь?
Никита: Сложный вопрос, зависит от многих факторов – и от статистики, и от распределения, но Postgres как раз таки занимается тем, что строит правильный план запроса и пытается получить данные как можно быстрее.
Никита: Вот так выглядит план запросов PostgreSQL. Изначально он, конечно, представлен в виде текста или в виде JSON, но есть несколько визуализаторов (на скриншоте один из них), которые позволяют его покрутить. С помощью этих просмотрщиков можно удобно и быстро понять, где у нас есть проблема – видно, какие операторы самые проблемные, и видна вложенность этих операторов.
Так вот, чтобы разобраться, какой вариант запроса работает быстрее, нужно посмотреть на операции, которые выполняет СУБД. И чтобы это сделать, нам надо понимать, какие операторы что делают.
Основные операторы плана PG SQL
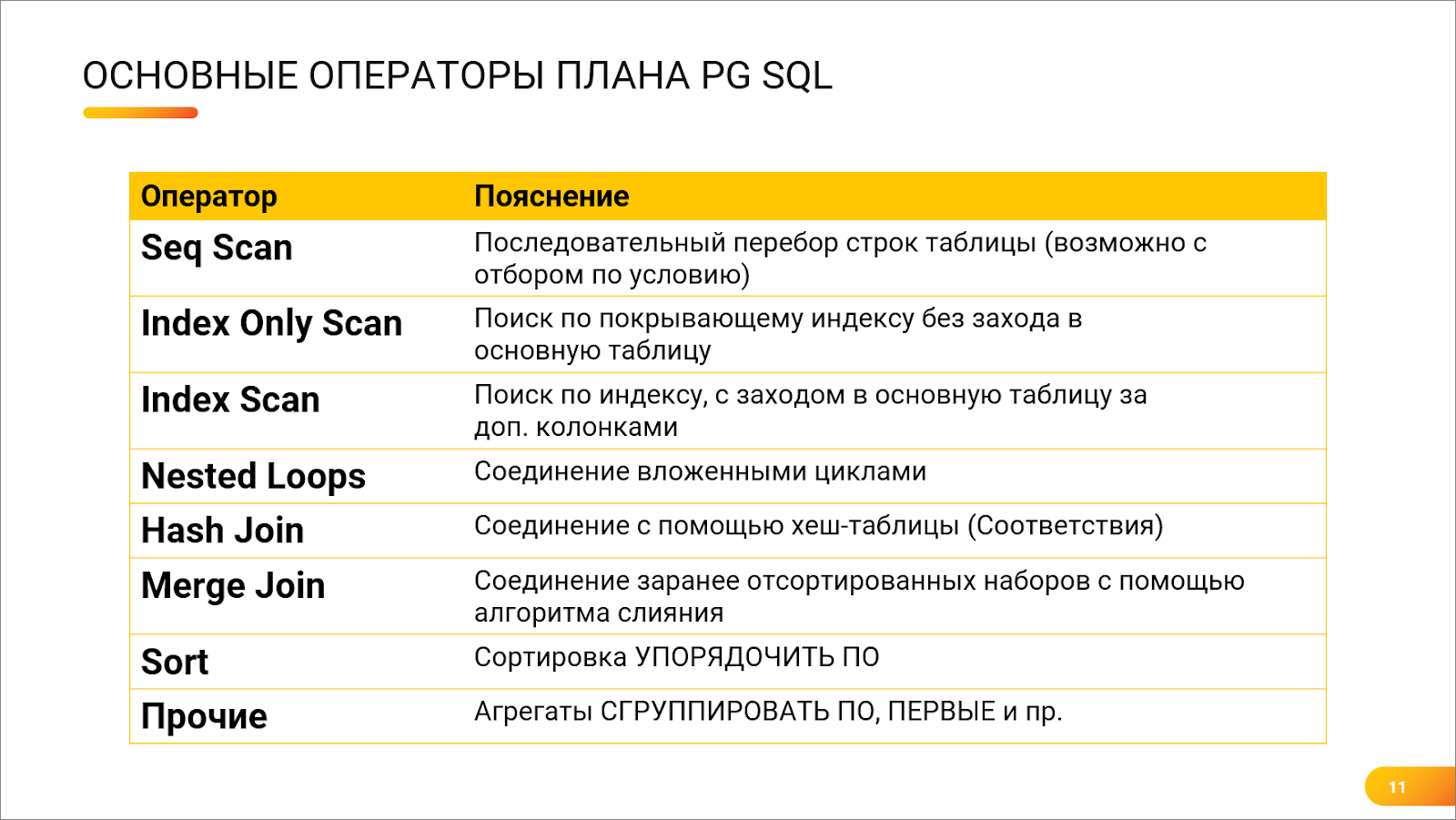
Андрей: А как понимать-то всех этих операторов? Я вижу, что что-то написано в плане. Я, например, слышал, что есть такой оператор Scan – сканирование таблицы. Я слышал, что это вроде как очень плохо. А про остальные операторы вообще непонятно, что это такое.
Никита: Как таковой Scan – это не плохо, это миф. Мало того, в Postgres их несколько.
-
Есть Sequential Scan, его аналог в MS SQL – это Table Scan. Это, действительно, последовательный перебор таблицы и, да, он может в каких-то случаях работать медленно и неоптимально.
-
И есть еще два вида сканирования индексов:
-
Index Only Scan – это когда поиск идет только по индексу (когда все поля выборки включены в индекс) и не надо лезть в основную таблицу;
-
Index Scan – это когда после нахождения нужной строки в индексе мы еще залезаем в основную таблицу за дополнительными данными. Например, нашли по измерениям что-то в регистре сведений и вытащили ресурсы. Иногда такая операция будет работать даже медленнее, чем последовательный перебор таблицы.
-
Андрей: Хорошо, я смотрю, здесь есть еще и несколько видов Join-ов.
Никита: Да, видов соединений очень много. Сейчас мы про них расскажем. Но перед тем как рассказывать про соединения, нужно немного сказать про индексы.
Индексы

Никита: Индексы – это своего рода оглавление в телефонном справочнике. Если мы хотим позвонить Овсянкину, то находим букву «О», понимаем, какой у него телефон, и начинаем набор номера.
Но в Postgres индексы сделаны в виде деревьев, и, если индекс составной, у нас на каждом уровне дерева идет следующее поле, которое входит в индекс. Поэтому, если вдруг мы будем искать по индексу, пропуская какие-то поля, то поиск будет неэффективным.
Андрей: Например, у нас в регистре есть индекс по трем полям – «Организация», «Склад» и «Номенклатура». Если я хочу поискать только по двум полям – «Организация» и «Номенклатура», у меня все будет тормозить?
Никита: Это зависит от многих факторов – например, от распределения. Если у тебя в таблице 100 тысяч уникальных организаций, то индекс по первому полю (по «Организации») действительно будет очень быстрым.
Но обычно – да, есть очень высокая вероятность, что поиск будет неоптимальным, потому что в индексе пропущено второе звено, и, по сути, мы сначала отфильтруем только организацию, а потом уже последовательным перебором будем искать номенклатуру. И в данном случае есть вероятность, что обычный Sequential Scan (Table Scan) будет работать быстрее, потому что будет выполняться меньше физических операторов.
Андрей: Но вот справа здесь у тебя показан какой-то кусочек плана запроса – это хорошо или плохо?
Никита: Здесь Postgres угадал. Он взял индекс, который построен по «Организации», «Складу» и «Номенклатуре», и попытался найти по «Организации». И полученный результат уже будет фильтроваться по «Номенклатуре».
Основные виды соединений – Nested loops и Hash Join
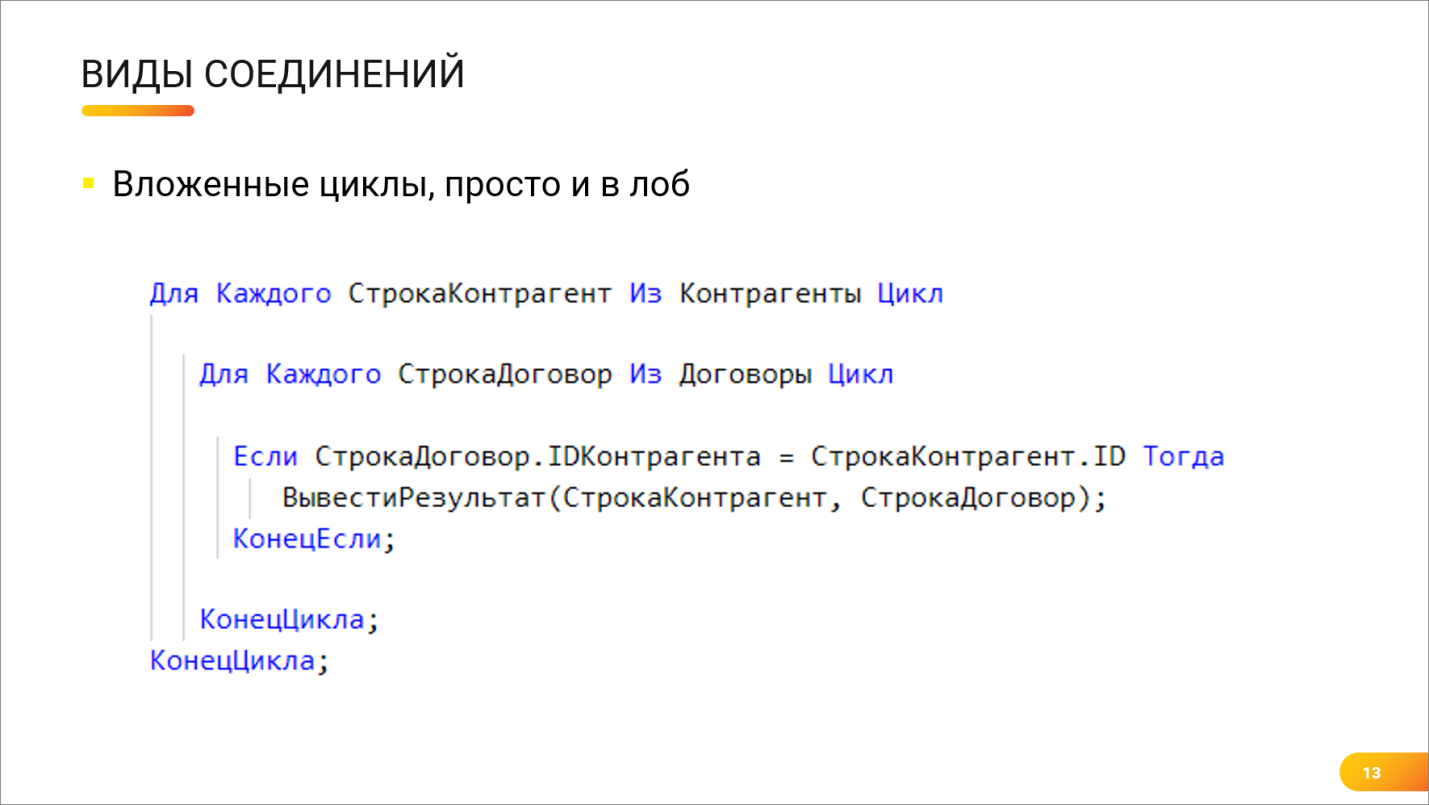
Андрей: Ты нам обещал рассказать про соединения. Первый самый простой способ соединений я знаю – это вложенные циклы (Nested loops).
Никита: А что там рассказывать? Делается два вложенных цикла по двум таблицам, внутри проверяется условие совпадения.
Андрей: Ну да, это самый простой вид соединения. Если бы мы описывали вложенные циклы на языке 1С, то это выглядело бы, как два вложенных цикла, показанных на экране: внешняя таблица, внутренняя таблица, для каждой записи выполняется сравнение, и, если поля соединения совпали, то строка попадает в результат соединения. Такой код может написать любой школьник, но иногда он самый эффективный из возможных вариантов соединения.

Никита: Следующий вариант уже посложнее – Hash Join. Знаешь, что это такое?
Андрей: Вообще-то я 1С-ник, я, когда слышу слово Hash, я начинаю пугаться. Это что-то страшное, это с бухгалтерией не связано. Я попробую сейчас объяснить.
Hash Join – это использование соответствия. Мы все знаем класс «Соответствие» в 1С. Сначала мы берем одну таблицу, бежим по ней и в некое соответствие закидываем ключи, по которым мы будем соединять. А потом берем вторую таблицу, бежим по ней и проверяем – есть ли такой ключ в соответствии, и, если есть, то выдаем результат.
Примерно так это и работает.
Как читать план запроса

Андрей: И как же все-таки прочитать план запроса? Например, у меня есть самый простой запрос:
SELECT * FROM test WHERE i=1
Ниже написан план этого запроса – рассмотрим его подробнее.
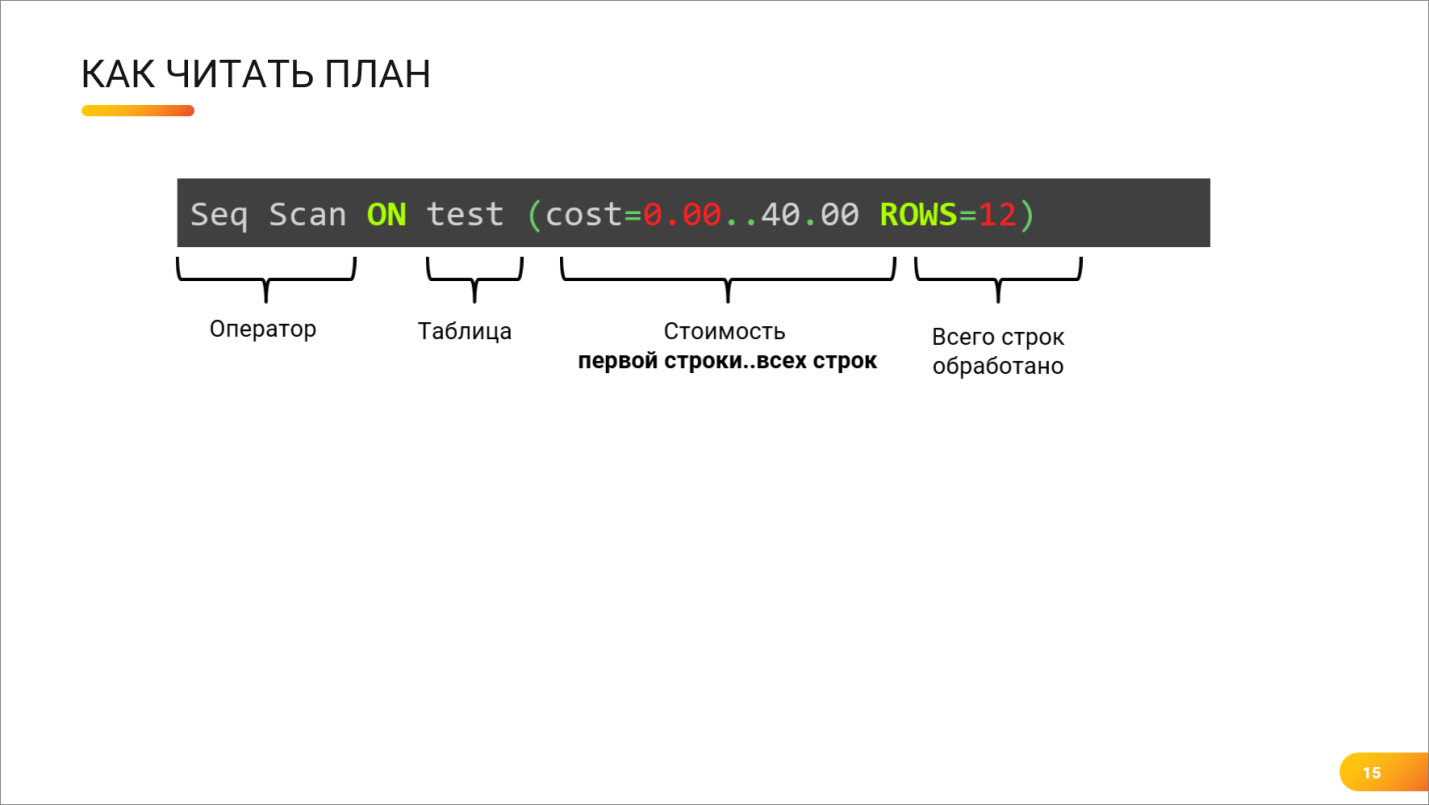
Андрей: Например, я – 1С-ник, беру технологический журнал, открываю план запроса. Что я могу вынести из этой информации?
Допустим, я вижу, что у меня используется скан, выбрано 12 строк, и есть какая-то стоимость. Но что это за стоимость, и почему она так странно написана?
Никита: Стоимость в Postgres записывается через многоточие.
-
Первая цифра означает, грубо говоря, количество времени, которое потребуется оператору для того, чтобы отдать первую строку.
-
А вторая цифра – это уже время на отдачу всех строк, которые этот оператор собирается предоставить.
Но нужно понимать, что стоимость – это условная величина, и вы, в принципе, даже можете сконфигурировать Postgres так, чтобы эти цифры имели другой порядок.
Важно понимать разность. Если разность между двумя этими числами большая, значит, это плохо.
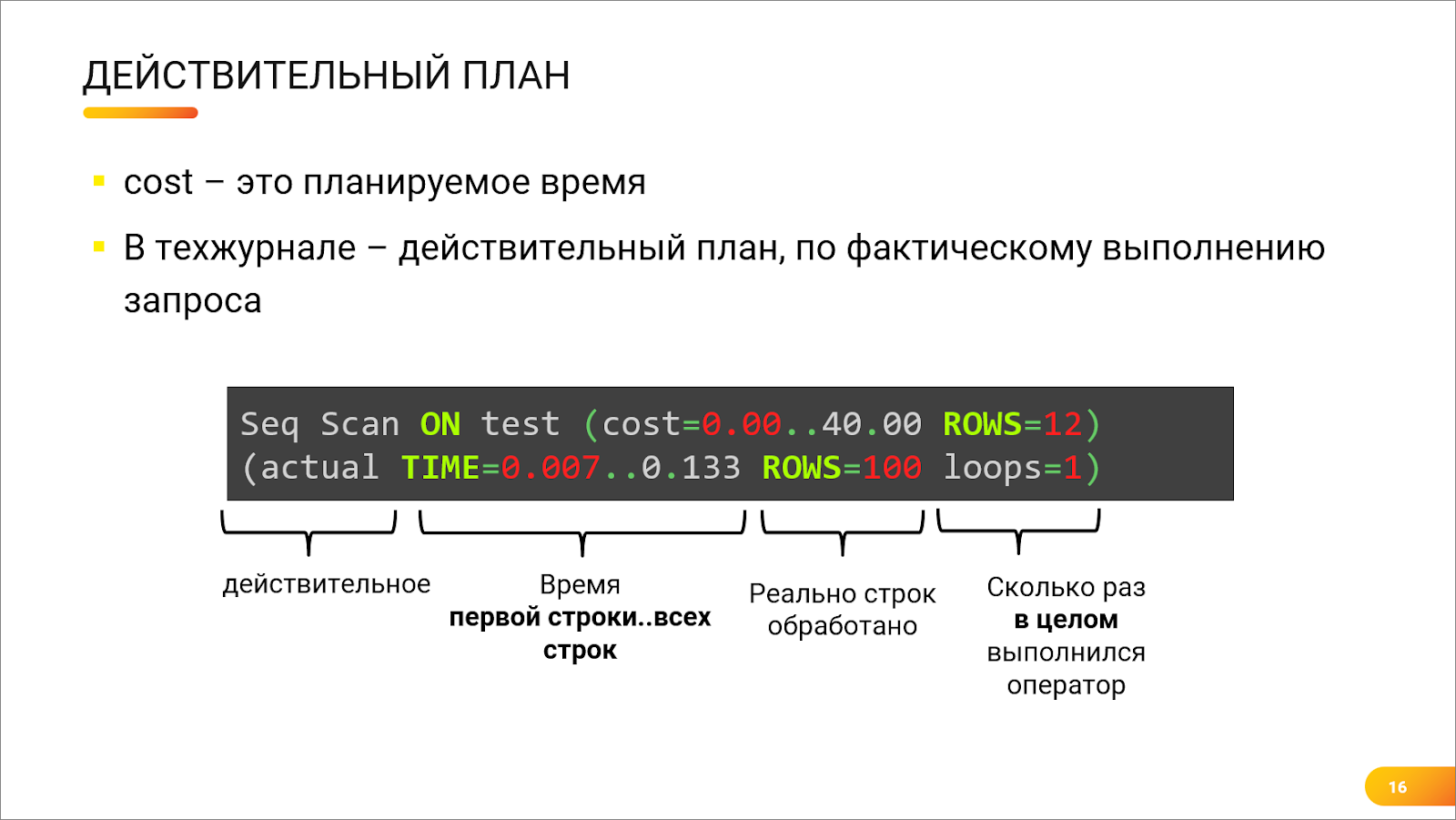
Андрей: Стоит сказать, что на предыдущем слайде – это был оценочный план. Сам запрос еще не выполнялся, это прикидки планировщика. А вот так выглядит «действительный план», который мы видим в технологическом журнале. У него есть слово actual в описании. Здесь уже Postgres показывает не только примерную прикидку по стоимости, но и реальное время, которое заняло выполнение того или иного оператора, и реальное количество строк, которое выполнил оператор.
Оценка и реальность могут различаться. Главное, чтобы они не различались радикально.
Никита: Добавлю, что действительный план запроса можно вытащить, например, из технологического журнала. Там есть пара ключей, которые заставят его туда выводиться. Естественно, не нужно на проде это делать постоянно, это довольно трудозатратная операция.
Плюс есть пара родных инструментов для Postgres, в которых этот план запроса можно получить.

Андрей: Вот так, например, выглядит план запроса с теми самыми вложенными циклами, и вот так на примере вложенных циклов выглядят вложенные операторы.
Как мы помним, соединение по своему смыслу – это объединение двух множеств. Это значит, что в плане запросов у оператора соединения обязательно будут два источника данных, представляющих собой первое множество и второе множество. Под оператором соединения будут два других оператора плана, которые служат источниками соединения.
Мы видим, что один источник – это скан таблицы по какому-то фильтру, а второй – скан индекса (он может внутри иметь еще операторы). Оба этих множества попадают на вход оператора Nested Loop, который и выполняет построчное сравнение и пересылку данных дальше, другим операторам плана запроса.
Так, собственно, и строится план запросов.
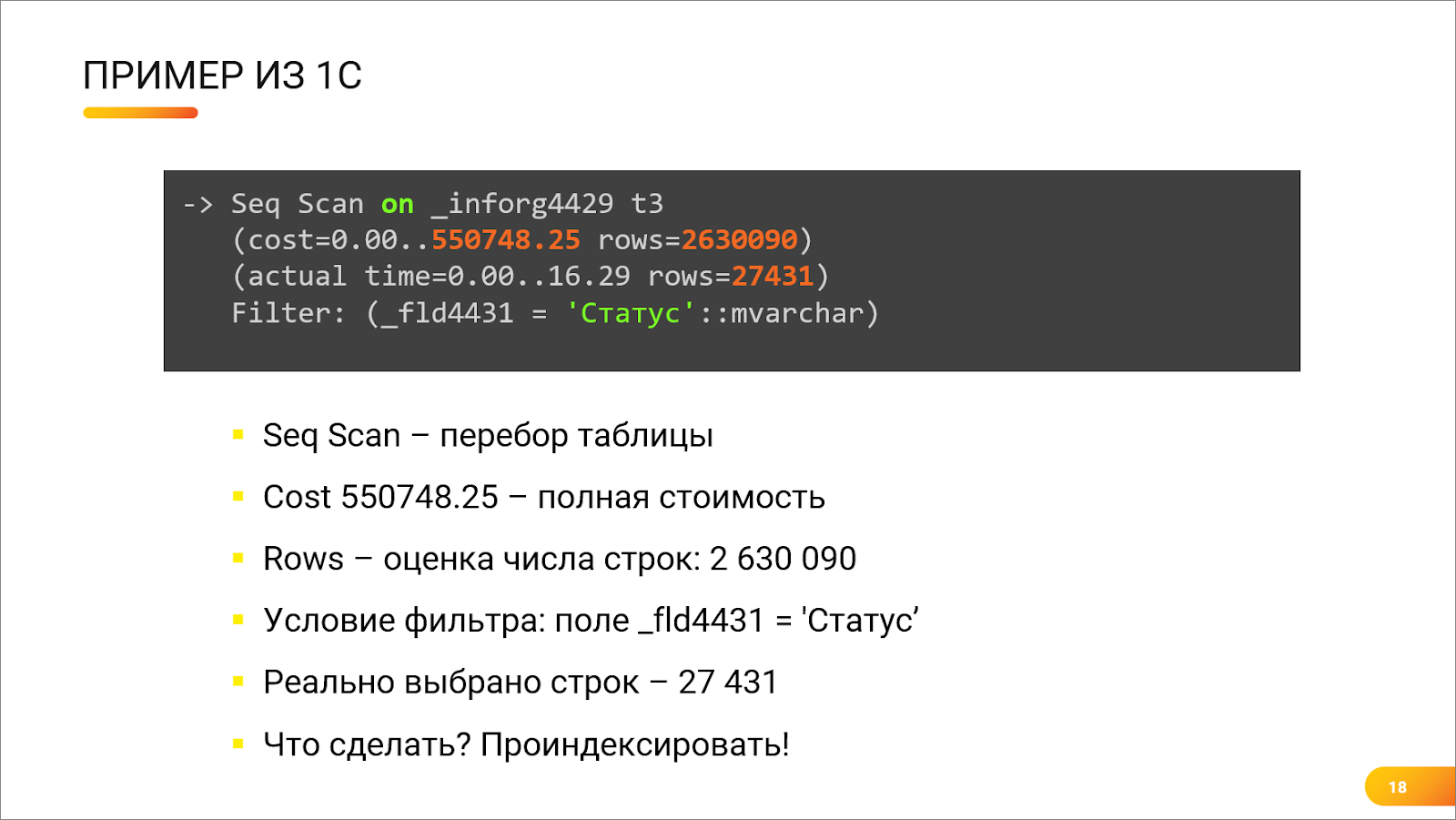
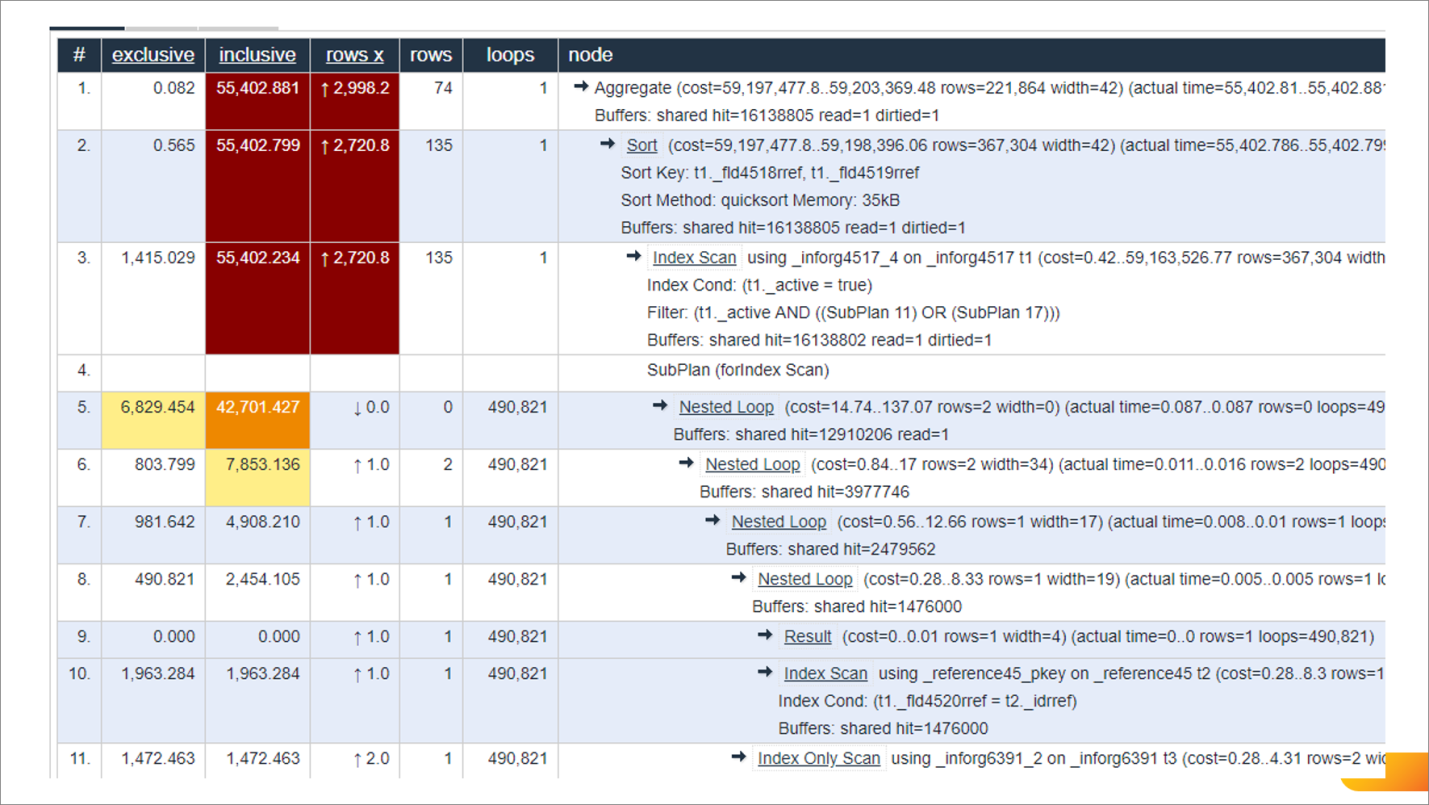
Андрей: Или вот – живой пример из 1С. Сканирование таблицы регистра сведений. Что мы тут видим – это хороший план или нет?
Никита: Не очень. Ключевые вещи здесь показаны цветом.
-
И первое, на что стоит обратить внимание – это первая красная цифра – 550 тысяч. Это – стоимость данного оператора. Цифра довольно большая. Разница между 550 тысяч и нулем как раз и говорит о том, что оператор сам по себе тяжелый, он будет работать медленно.
-
Далее мы видим оценку строк.
-
2,5 миллиона строк будет просканировано, и на них будет наложен фильтр по полю «Статус».
-
Но тут важно обратить внимание на третью строчку на скриншоте там, где написано actual. Это означает, что по данным действительного, актуального плана запроса, который, в итоге, сформировал Postgres, этим оператором на самом деле было возвращено всего 27 тысяч строк – это меньше чем 1% от планируемого количества.
-
Что можно сделать в случае, когда мы видим, что у нас в плане большое количество прочитанных строк не попадает в возвращаемые? Скорее всего, нам не хватает какого-то индекса. Предлагаемое решение в данном вопросе – добавить индекс по полю _fld4431, в котором хранится статус.
Пример из жизни № 1 – срез последних
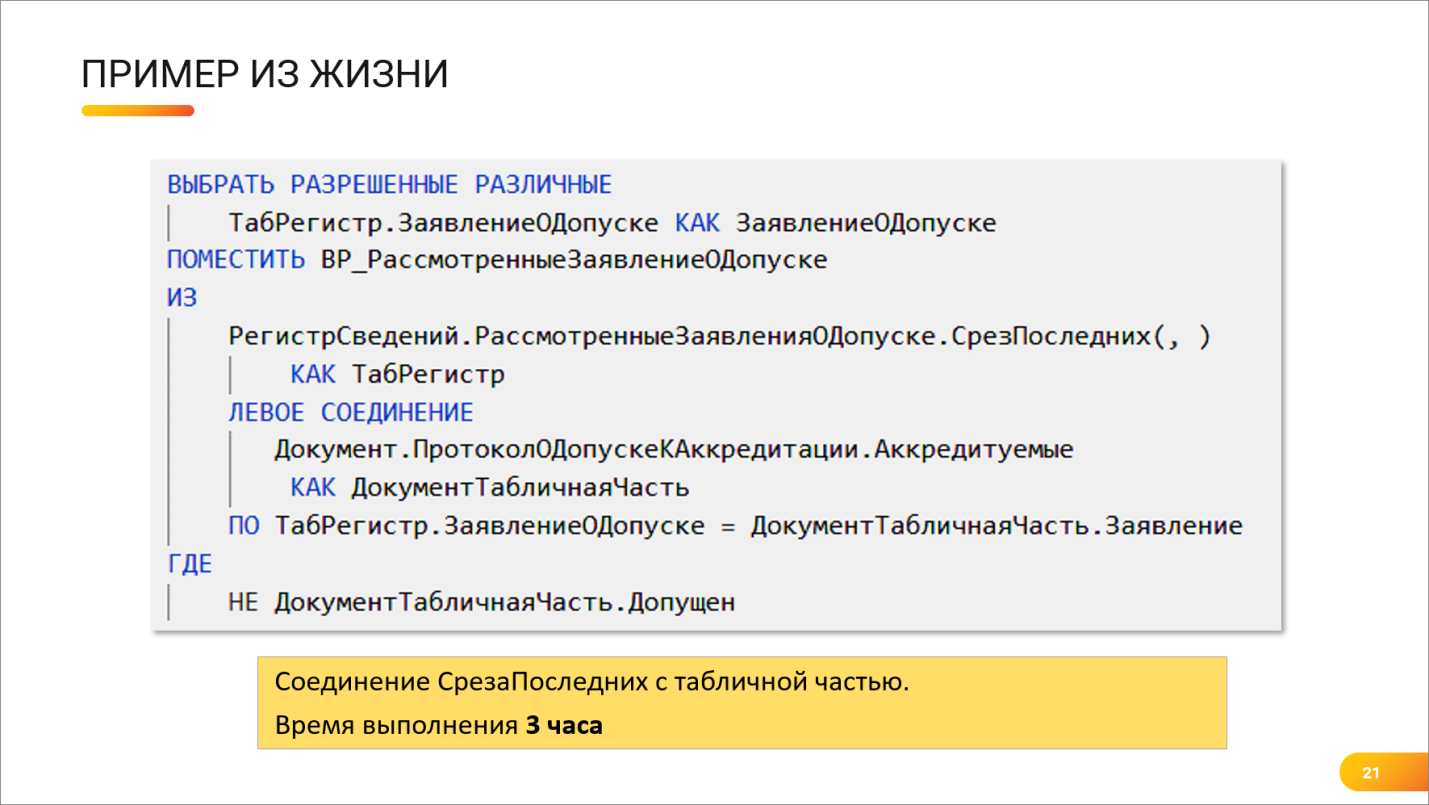
Андрей: Вообще, основная головная боль в Postgres – это виртуальные таблицы «СрезПоследних». Особенно, если регистр сведений довольно большой.
Никита: На слайде показан пример с одного из моих проектов. Не очень большой регистр сведений (порядка 300 тысяч строк) – делается срез последних, и соединяется с табличной частью документа.
Когда мы запустили этот запрос на проде, оказалось, что он выполняется больше 3-х часов. Точнее, мы так и не дождались, чтобы он выполнился. То есть он выполняется минимум 3 часа.
Андрей: Я думаю, что там разработчик в файловой базе на 15 записях потестил и решил, что все отлично, запрос работает, задачу можно запускать в продакшен. Действительно, мы обычно в тестовой базе делаем в справочник три записи, и смотрим, что запрос работает, как ожидается. А потом отправляем в продакшен – там два миллиона записей вместо трех, другой план запроса, и все работает совсем по-другому.

Никита: Давайте посмотрим план запроса, который сформировался по этому тексту.
Обычно я ищу оператор, у которого самая большая стоимость. Под подозрение попадают как раз таки сканы таблиц либо сканы индексов, которые выполняются с заходом в основную таблицу.
Подкрашенная красным нижняя строка – это оператор чтения из таблицы документа. Его стоимость – 5 тысяч. На тех настройках, которые стояли, это – не самое страшное. Но ключевое – это то, что он выполнялся 241 тысячу раз (колонка loops).
Андрей: Получается, что сам оператор стоимостью 5 тысяч, который выдает 491 строку, но при этом сам он выполнялся 240 тысяч раз.
Никита: Postgres, когда строит «СрезПоследних», делает много вложенных запросов, и эти запросы получаются настолько сложными, что он, скорее всего, не будет использовать индекс вообще, потому что, по его мнению, самым оптимальным решением здесь будет – использовать вложенные циклы.
Андрей: Что же тут делать?
Никита: Включать голову.

Андрей: Да, во-первых, все знают, что надо накладывать отборы на виртуальные таблицы. Это позволит закинуть фильтр внутрь того вложенного запроса, который внизу делает 1С.
И очень часто 1С-ники, в принципе, не сильно пытаются подумать, что же происходит внутри 1С, когда создается виртуальная таблица «СрезПоследних». На самом деле, виртуальная таблица «СрезПоследних» – это обычный вложенный запрос, создаваемый платформой. Можно такой же запрос создать самостоятельно руками, причем настроить поля так, чтобы попасть в правильные индексы.
Более того, именно так зачастую можно починить медленный запрос – руками сформировать более точный срез, без лишних операций, добавляемых платформой.

Андрей: Как платформа делает срез последних?
Вообще этот вопрос часто задают на собеседованиях 1С-никам, поэтому можно прямо здесь решить вопрос для собеседования.
Мы можем не накладывать срез последних средствами 1С, а написать такой алгоритм самим, зная, какие поля нам нужны.
Как работает срез последних?
-
Выбираются все записи с условием по периоду, где период меньше заданной даты,
-
Берется максимум от этих строк. Но поскольку у нас в запросе есть не только измерения, но и ресурсы, мы сначала группируем измерения, а после того, как мы сгруппировали, у нас ресурсы пропали из результата группировки.
-
Поэтому нам нужно еще раз соединиться с той же самой таблицей уже по полученному максимальному периоду и по составу измерений для того, чтобы получить значение ресурсов.
-
И уже в таком виде выдается результат.
Так работает срез последних.
Никита: Когда вы делаете обычный срез последних, вы не можете управлять тем, какие конкретно поля будут в этом запросе выбираться, по каким полям будет группировка. А если вы делаете срез последних руками, то можно более оптимально написать запрос, убрать какие-то лишние вложенные запросы, и это позволит спасти такую плачевную ситуацию с трехчасовым запросом.
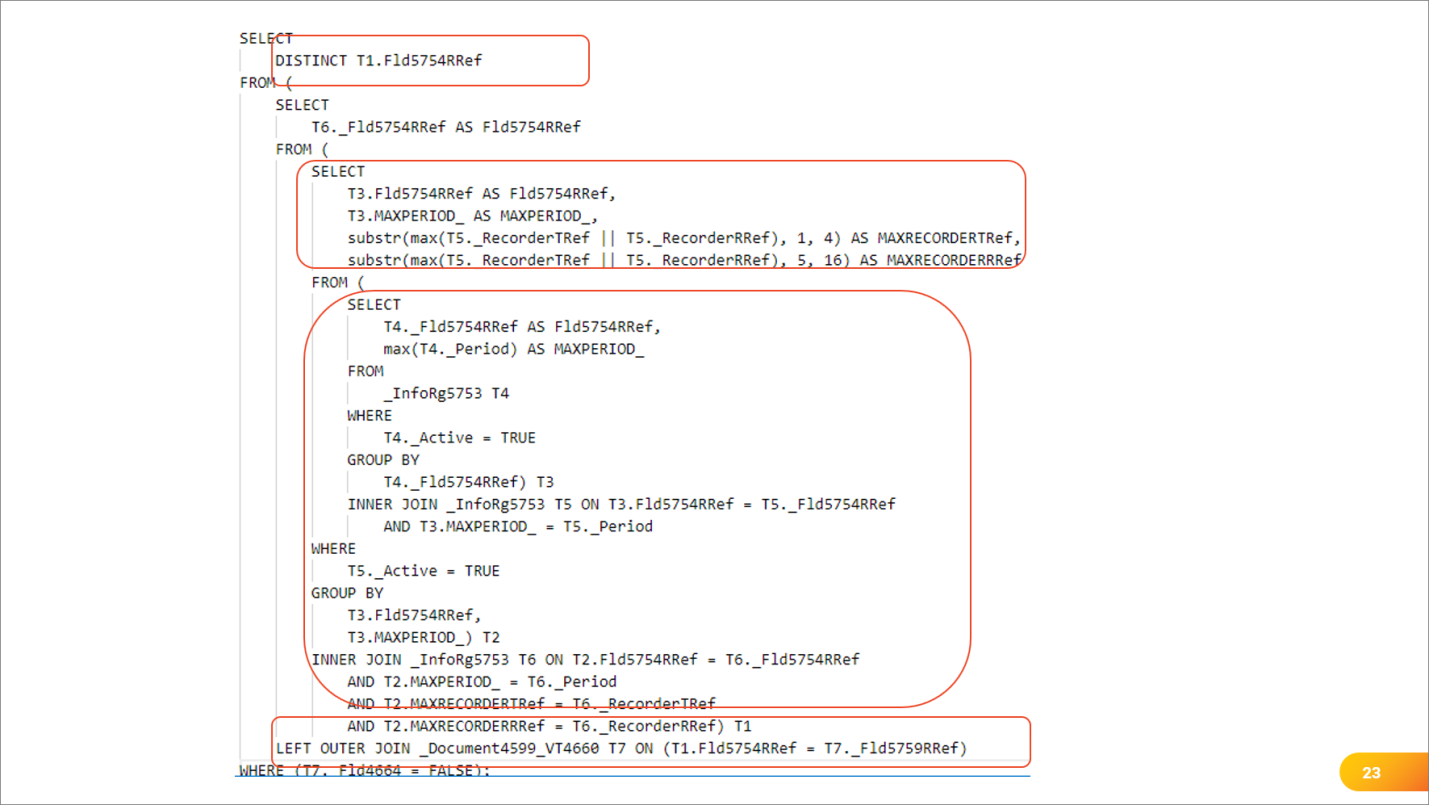
Андрей: Вот, например, как выглядел запрос по срезу последних, который выполнялся 3 часа. Причем, учтите, что это – не весь запрос. Весь он у меня на слайд не уместился, и я его значимую часть подрезал.
-
Итак, в самом верху добываются РАЗЛИЧНЫЕ значения измерений, которые соединяются с таблицей документа.
-
Источником этого набора различных является вложенный запрос, который берет свои данные из еще одного вложенного подзапроса, соединенного с этой таблицей для вычисления МАКСИМУМа по позиции регистратора.
-
А поскольку используется периодичность по позиции регистратора, то начинаются подстроки от ссылки и всякое такое – получается аж четыре вложенных запроса.
И Postgres уже думает – да не буду я тут уже индексы смотреть, тут что-то непонятное, я просто вложенными циклами все это обработаю, и все. И получается медленный большой запрос.

Никита: Мы решили проблему очень просто:
-
во-первых, отказались от вложенных запросов вообще и просто сделали отдельную временную таблицу, в которую вытащили нужное измерение, причем, получилось избавиться от некоторых измерений в запросе, потому что они были не нужны.
-
Также сделали группировку и поместили результат в индексированную временную таблицу.
-
Применительно конкретно к той задаче не нужны были ресурсы регистра сведений. Поэтому соединяться еще раз с самой же таблицей для доставания ресурсов было не нужно. Платформа строит намного более сложный запрос, но за счет того, что мы не используем ресурсы регистра, нам достаточно той самой группировки по максимуму. Мы делали максимум по периоду и набор только нужных нам измерений, и оказалось, что срез последних получался за одно «СГРУППИРОВАТЬ ПО» без всяких дополнительных соединений.
И вместо 4-х соединений получилось только два.

Самое главное в результирующем запросе – добавление индексов в эту временную таблицу с последующим соединением с табличной частью. Именно оно позволило уже оптимально и быстро сработать, и запрос стал выполняться за 5 секунд вместо 3-х часов.
Пример из жизни №2 – сортировка различных

Андрей: Итак, еще один пример, как работают планы запросов и как они помогают находить «узкие места».
Представьте, что есть вот такой справочник – выбираются различные из справочника и упорядочиваются по наименованию физического лица. Но, как мы знаем, обращение через точку – это еще одно левое соединение.
Как здесь работал Postgres?
Выяснить, почему этот запрос работает медленно, удалось только с помощью плана. Выяснили, что:
-
сначала Postgres делал соединение;
-
потом все это большое соединенное он сортировал. А сортировка – это значит, нужно пересмотреть всю таблицу, переупорядочить записи и выдать наверх;
-
И только потом этот большой массив данных обрезался по объему оператором «РАЗЛИЧНЫЕ» и выдавал результат.
Получалось довольно медленно.
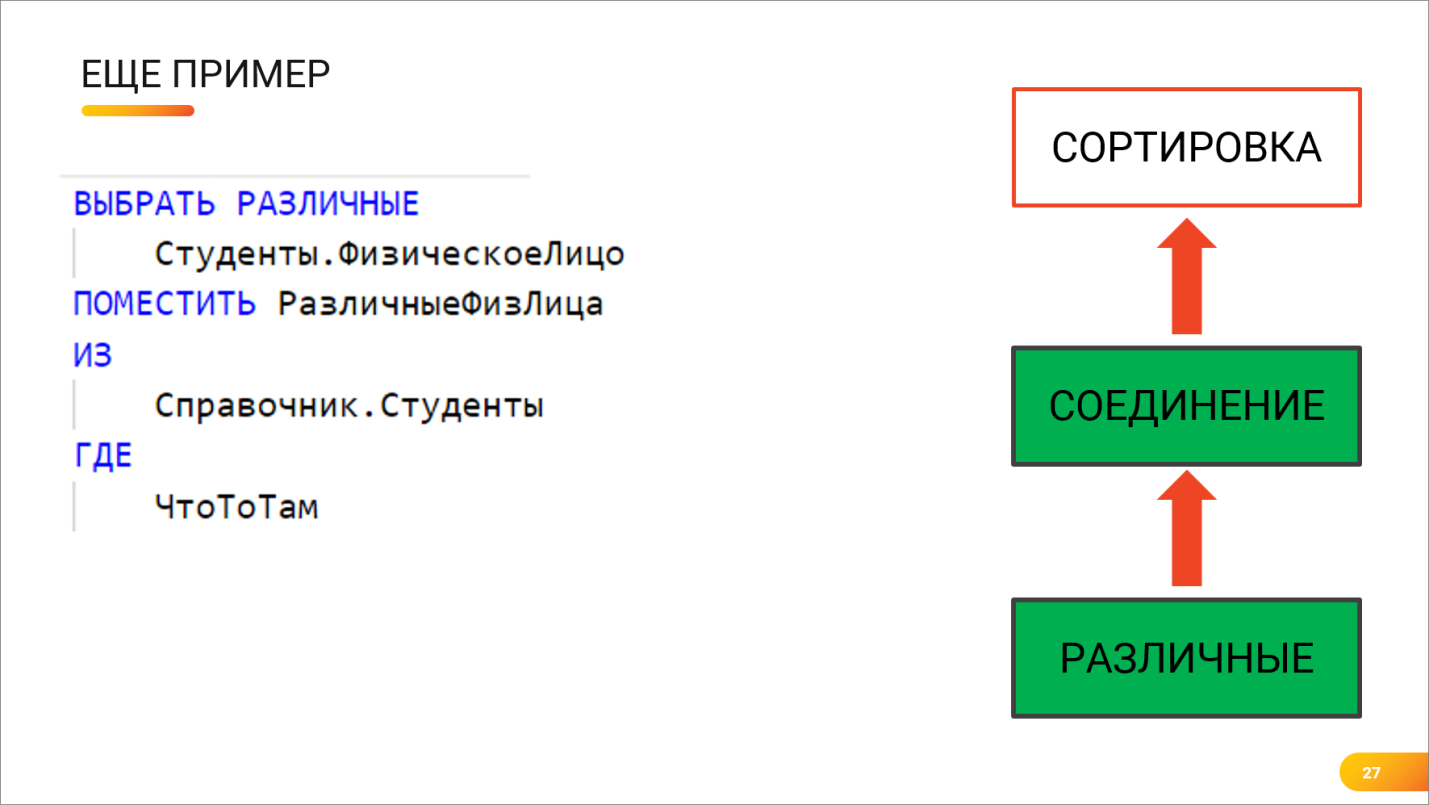
Андрей: Посмотрели на план запроса, поняли, что он делает, и решили заставить его сделать наоборот.
РАЗЛИЧНЫЕ вынесли во временную таблицу. Это сразу обрезало большую часть записей, и соединение с сортировкой выполнялось уже для меньшего количества записей. Это сократило время выполнения почти в 3 раза.
Никита: Действительно, без временной таблицы не получилось. Может сложиться впечатление, что использование временных таблиц – это панацея при всех проблемах Postgres. Нет, это не так. Да, большую часть проблем можно решить через временную таблицу, но к ним нужно подходить осторожно и помнить о том, что временная таблица – это tempdb. Она пухнет, сбрасывается на диск, и вы получите не только ускорение работы запроса от того, что вы используете временную таблицу, но и замедление за счет того, что используется tempdb.
Но в данном случае, после того, как мы сделали различные в предварительной временной таблице, а после этого сделали упорядочивание, скорость запроса выросла в три раза. То есть, если он до этого выполнялся шесть секунд, и мы удивились, что такой простой запрос выполняется 6 секунд, то после оптимизации он стал выполняться 2 секунды. Там действительно много записей.
То есть, выполнение различных отрезало 2/3 записей сразу, а после этого сортировка присоединенной таблицы стала выполняться довольно быстро. Выяснить, что тормозит в таком запросе, помогают планы. В новом порядке видно, что операторы просто выстроены чуть иначе, и все становится хорошо.
Инструменты
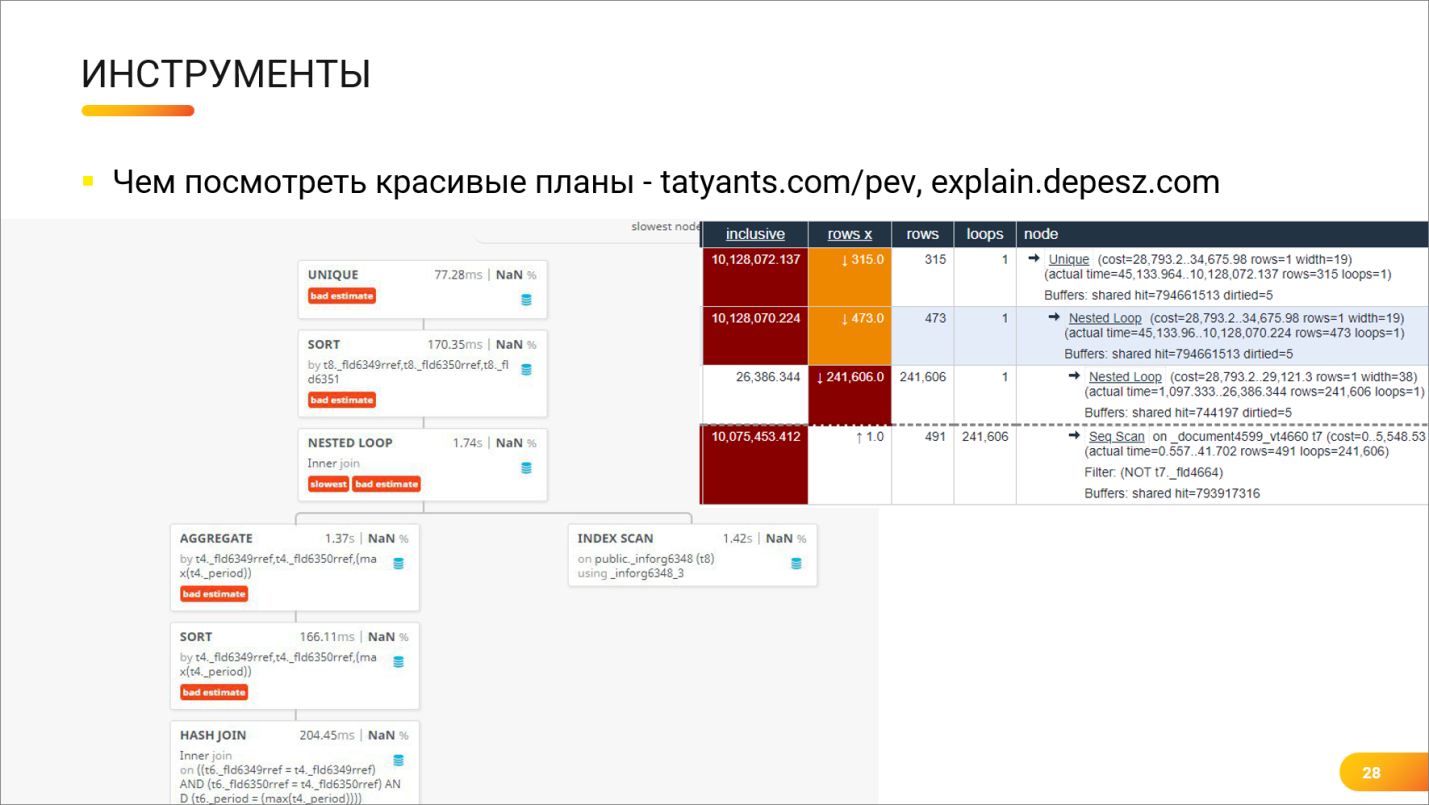
Андрей: Мы тут показываем красивые графики и картинки, а у 1С-ников в распоряжении есть только технологический журнал, в котором можно посмотреть план запроса. И там будут такие тексты, которые до нас показывал Олег Бартунов на своих слайдах, где много разных букв на английском языке.
И чтобы как-то помочь себе, особенно, если запрос тяжелый, особенно, когда план запроса большой-пребольшой, как обычно в 1С и бывает, то помогают следующие инструменты.
Как они работают?
Это – визуализаторы, тот самый набор инструментов, который мы хотели показать. Вы получаете план запроса либо из технологического журнала, либо из pgadmin, если вы выполнили там запрос с Explain Analyze. И вставляете на специальный сайт – либо на один, либо на второй.
-
На первом сайте https://explain.depesz.com/ (в случае левой части картинки) вы видите такое симпатичное дерево, которое раскрывается, складывается, показывает информацию по статистике, по разнице между реальными данными, ожидаемыми данными и т.д.
-
А на втором сайте https://tatiyants.com/pev/ – он вам показывает такое же дерево в виде таблички. Он, в принципе, выводит ту же самую информацию, только в другом представлении.
Мне очень нравится инструмент https://tatiyants.com/pev/ (справа), потому что там есть справка по каждому оператору. Если вы обратите внимание, тут операторы Nested Loop, Unique – подчеркнуты. Это, на самом деле, гиперссылки, и если вы на них нажмете, у вас откроется подробнейшая справка конкретно по этому оператору. То есть, изучая план запроса, вы можете не только пытаться предположить, почему этот оператор работает медленно, но и быстро, буквально на расстоянии одного клика, понять, что конкретно этот оператор делает. Глядя в выдачу технологического журнала, можно только угадывать, что делает план запроса, а загрузив это в визуализатор, можно по каждому оператору почитать подробную справку.
Заключение

Хочется поговорить о важном.
-
Планы запросов – это вообще не страшно, это очень просто. Это всего лишь кубики вызовов функций и больше ничего.
-
Важно просто почитать некую небольшую справку о том, что эти функции делают, и все.
-
Вы можете любой запрос, самый сложный, самый страшный раскрыть. Главное – найти там операторов с большой стоимостью (где большая разность), понять, что они делают, поменять порядок следования их вызовов и всего лишь сделать рефакторинг запроса. Это очень просто.
-
Не бойтесь пользоваться визуализаторами, не бойтесь пользоваться инструментами, есть очень много бесплатных классных онлайн-инструментов.
-
Не бойтесь неизвестного, дерзайте, экспериментируйте.

А если что – вы всегда можете найти нас в интернете.
****************
Данная статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART EVENT 2019.
Вступайте в нашу телеграмм-группу Инфостарт