
{kind=link}
Ни для кого не секрет статья на официальном ресурсе ИТС Технология разветвленной разработки конфигураций. Однако, время не стоит на месте, появляются новые инструменты, и требования подлежат пересмотру. Документ не содержит конкретных рекомендаций по используемому программному обеспечению. В качестве CI/CD могут быть использованы любые конвейеры: Jenkins, GitLab CI и т.д. Конечно же требования к разработке ориентированы в первую очередь для работы команды разработки в EDT.
Авторские права на картинку принадлежат Vincent Dreissen. База для документа - по ссылке выше - компания ЗАО "1С"
Один из вариантов реализации: Управление сборкой. Расширение для конфигурации СППР (infostart.ru)
Замечания и пожелания приветствуются.
Технология разветвлённой разработки конфигураций
#std709
Область применения: управляемое приложение, мобильное приложение, обычное приложение.
Методическая рекомендация (полезный совет)
Цели внедрения технологии:
- Повышение качества разрабатываемой конфигурации
- Повышение культуры разработки и тестирования
- Обеспечение непрерывного развития конфигураций в условиях жестких сроков разработки
Определения
Репозиторий - хранилище проекта, реализованное по технологии git, включающая в себя
- Основное
- Исходные файлы разрабатываемой системы в отдельной корневой папке в формате проекта EDT или формате выгрузки конфигурации в XML
- Дополнительно
- Файлы Unit тестов в отдельной корневой папке
- Файлы сценариев функционального тестирования в отдельной корневой папке
Эталонная ИБ - информационная база имеющая структуру исходной конфигурации, взятой за основу, и содержащая некоторый набор данных для тестирования функционала
Содержимое эталонной базы может варьироваться в зависимости от варианта создаваемой системы. Может быть несколько эталонных баз, например, для функционального тестирования и проведения демонстраций, но одна минимум должна быть всегда.
- Может быть изначально полностью пустой для системы создаваемой с нуля
- Может не иметь никаких первоначальных данных, либо ограничиваться данными первоначального заполнения обычно такие ИБ создаются с целью запуска в них полного интегрального тестирования.
- Для каждой ветви репозитория своя эталонная база, имя ветви обязательно должно присутствовать либо в суффиксе, либо в префиксе имени ИБ.
- При инициализации репозитория для ветвей master, develop она создаётся вручную
- Для ветвей bugfix/*, tech-project/* в случае отсутствия, копируется из эталонной базы родительских ветвей
- Для ветви release первоначально копируется из эталонной базы, привязанной к ветви master, далее производится только обновление ИБ.
- С каждым новым релизом эталонная база ветви master, develop замещается из ветки release (протестированные данные функциональности нового релиза, в совокупности с предыдущими переводятся в основную ветвь)
- Другие изменения в данных в эталонной ветки базы не предусмотрены.
- Обновлённая копия эталонной базы, всегда должна являться одним из результатов сборки.
- Для веток bugfix и tech-project эталонные ИБ должны быть получены из тех веток, из которых эти ветки были созданы.
Сборка - результат работы конвейера (см. ниже)
- Зависит от этапов конвейера, может быть
- Обновлением копии эталонной информационной базы, ассоциированной с ветвью репозитория для которой производится сборка, при отсутствии информационной базы она автоматически копируется из эталонной ИБ, при наличии обновляется.
- Создание установочного дистрибутива, либо дистрибутива обновления. Может являться как Continous Delivery так и Continous Deploy
- Всегда производится для ветвей:
- master,
- Этапы build/compile при условии наличия изменений в папке исходного сода системы (src, для EDT).
- Этапы deploy, testing, publishing - при любых изменениях в ветви.
- develop, аналогично master, возможно ограниченное функциональное тестирование, только в рамках изменённых сценариев
- release, аналогично master, за исключением публикации
- bugfix/*, tech-project/* аналогично develop
- master,
Конвейер - процесс, автоматически запускаемый при изменении состояния веток репозитория.
- Для каждой ветви / ветвей подходящих под шаблон может быть настроено различное количество этапов сборки
- Сборка (build/compile).
- Создаётся архив эталонной базы (SQL backup, выгрузка в DT и т.д.) перезаписыванием предыдущего или разностный.
- Для ветви master предпочтительнее разностный архив, т.к. позволяет восстановить любой предыдущий релиз, и не занимает много места
- Для других ветвей это может просто архив, замещающий предыдущий.
- Производится загрузка конфигурации или расширение из файлов XML в эталонную базу. Для формата EDT файлы проекта предварительно конвертируются в формат 1С:Предприятия.
- Производится запуск информационной базы с параметрами /ЗавершитьРаботуПользователей, либо блокировка работы пользователя любыми другими способами.
- Производится обновление конфигурации базы данных
- Производится проверка на необходимость запуска обработчиков обновления, например, запуском внешней обработки запущенной в командной строке одновременно с параметром /ОтключитьЛогикуНачалаРаботыСистемы
- Если необходимо,
- Производится запуск информационной базы для отработки обработчиков обновления, дополнительно передаётся параметр /UC ЗапуститьОбновлениеИнформационнойБазы ВыполнитьОтложенноеОбновлениеСейчас РазрешитьРаботуПользователей
- Если необходимости в обработчиках нет, производится запуск с параметром /UC РазрешитьРаботуПользователей
- В случае возникновения ошибок в процессе сборки или запуска обработчиков обновления создаётся копия неуспешной сборки с суффиксом _fail, а эталонная база восстанавливается из архива.
- В случае успешной сборки и прохождения обработчиков обновления никаких действий не предпринимается
- Создаётся архив эталонной базы (SQL backup, выгрузка в DT и т.д.) перезаписыванием предыдущего или разностный.
- Распространение (deploy) полученной конфигурацией CF/CFE обновляются необходимые информационные базы: для тестирования, демонстрационные и т.д.
- Тестирование (testing) - запуск различного рода тестов
- Запуск тестирования проводится на копии обновлённой эталонной базы, в которой отработали успешно все обработчики обновления.
- В случае, если при тестировании были выявлены ошибки, копия ИБ не уничтожается, ссылки на копию фиксируется в артефактах сборки
- В случае. если все тесты завершены успешно, копия ИБ удаляется.
- Запуск тестирования проводится на копии обновлённой эталонной базы, в которой отработали успешно все обработчики обновления.
- Публикация (publishing) передача результатов во внешние источники. Непрерывная передача или развертывание. Этот этап может полностью отсутствовать.
- Сборка (build/compile).
- Этапы могут быть
- Критическими (по умолчанию), в этом случае при обнаружении ошибки линия конвейера останавливается.
- Допускающими ошибки, в этом случае ошибки фиксируются в артефакты, а линия конвейера продолжает работу.
Плановая версия конфигурации – версия, содержащая существенное развитие функционала, срок выпуска которой назначается заранее. Формируется в ветке репозитория release, из запросов слияния завершённых и протестированных веток (см. ниже) Технических проектов (tech-project/<номер техпроекта>).
Исправительная версия (bugfix/<номер ошибки>) – версия, которая выпускается при необходимости срочной публикации исправлений критичных ошибок. В исключительных случаях исправительная версия может содержать какой-то новый функционал (например, доработки, связанные с поддержкой изменения законодательства). Срок выпуска определяется при анализе количества и критичности обнаруженных ошибок плановой версии.
Технический проект – задание на доработку конфигурации. Каждый технический проект имеет четко сформулированную цель и конечный список изменений, которые нужно выполнить, чтобы достигнуть этой цели. Технический проект привязывается в версии планового релиза. Аналогом ветки в классическом Git Flow являются ветки feature
Для организации работ по разработке и сопровождению конфигураций (в т.ч. ведению информации о технических проектах и списка ошибок) рекомендуется использовать Систему проектирования прикладных решений (СППР).

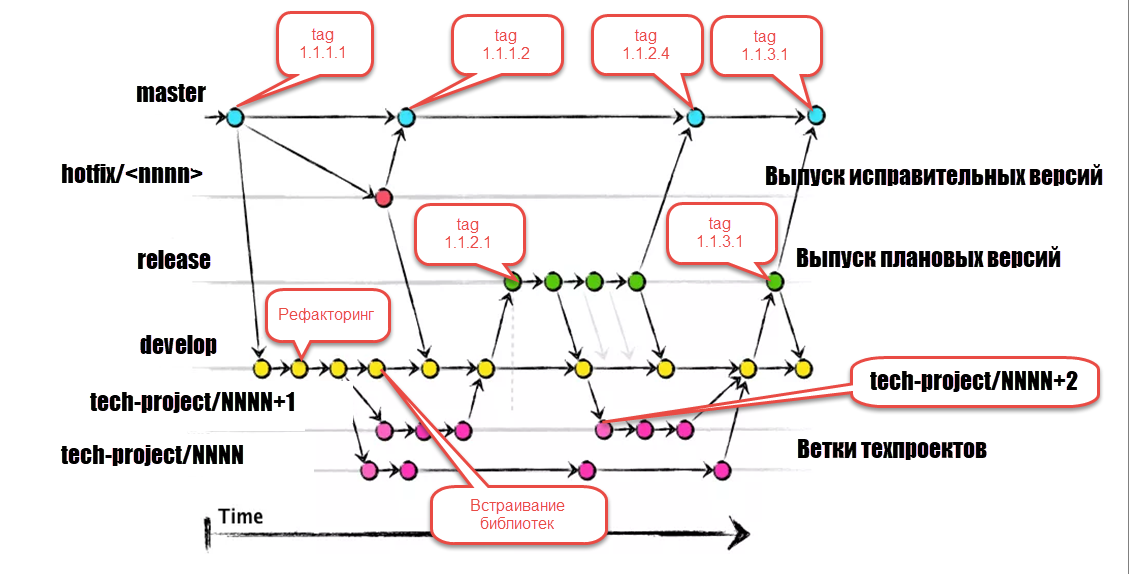
Описание процесса разветвлённой разработки, адаптированной к формату git flow, назначение веток и версий
1. Главная ветка репозитория master
1.1. Длительная, защищённая ветвь. Допускающая изменения только через запросы на слияние.
1.2. Предназначена для хранения историй релизов (версий релизов) разрабатываемой системы, предназначенных для публикации конечному пользователю.
1.3. Фиксации запросов на слияние в главную ветвь репозитория должна осуществляться таким образом, чтобы каждый запрос на слияние переводил ветвь репозитория из одного рабочего (готового к выпуску) состояния в другое.
Не допускается закладка не полностью отлаженного функционала! Главная ветвь репозитория всегда должна находиться в «неразваленном» состоянии, чтобы в любой момент можно быть начать сборку плановой версии.
1.4. В главной ветви репозитория допускается удовлетворять запросы на слияние из других ветвей репозитория:
- ветвей исправления критичных ошибок (bugfix/<номер ошибки>), не требующих перепроектирования, объёмного кодирования и тестирования. Если ошибка требует больших переработок и/или пересмотра проектных решений, то исправление такой ошибки должно вестись в рамках технического проекта. Порядок работы с основной ветвью репозитория должен быть таким же, как и для ветвей других технических проектов - через запрос на слияние;
- ветки release, где сформирован плановый релиз из технического(их) проекта(ов), прошедший(их) все этапы тестирования;
1.5. В запросе на слияние конфликты слияния должны отсутствовать.
1.6. Запрещается переносить изменения из других веток методом переноса указателя (fast forward) даже если запрос на слияние позволяет этого сделать
2. Основная разработка.
2.1. Длительная, защищённая ветвь, именуемая как правило, develop. Допускающая изменения через запрос на слияние и возможность фиксации отдельных персон, контролирующих процесс разработки.
2.2. Основная разработка ведётся в ветви develop, сформированной от ветви master и предназначенной для:
- Удовлетворения запросов на слияние из веток завершённых техпроектов
- Встраивания библиотек
- Проведения рефакторинга (оптимизаций). При рефакторинге не должно производится сложных работ, требующих перепроектирования, объёмного кодирования и тестирования. В противном случае такие работы должны проводиться в рамках отдельного техпроекта.
- Исправлением ошибок, появление которых связанно с предыдущими тремя пунктами.
2.3. Перед исполнением запроса на слияние производится обязательный code review. Выявленные замечания могут быть основанием для отказа слияния техпроекта.
2.4. В запросах на слияние из веток техпроектов конфликты слияния должны отсутствовать.
2.5. Все фиксации в ветку develop должны содержать комментарий.
Содержание комментария зависит от характера выполненных работ:
- при исправлении ошибки обязательно должен быть указан номер и краткое наименование ошибки в системе баг-трекинга;
- при встраивании новой версии библиотеки должно быть указано название библиотеки и точный номер версии библиотеки;
- при слиянии технических проектов – номер проекта в системе ведения проектной документации, а также краткое наименование;
- при выполнении работ (2.7.) по техническому проекту в основном хранилище комментарий, помимо номера и краткого наименования проекта, должен содержать краткое описание сделанных этой фиксацией изменений.
2.6. Все изменения по техническому проекту должны переноситься в ветку develop за одну фиксацию. Если необходимо переносить изменения несколько раз, то нужно открывать дополнительные техпроекты.
2.7. После переноса изменений в ветвь develop можно исправлять ошибки, наведённые слиянием технического проекта. Для пересмотра проектных решений нужно открывать новый техпроект.
2.8. При сборке плановой версии рекомендуется устанавливать метку (tag) с информацией о номере сборки на фиксацию той версии хранилища, конфигурация которой идёт в сборку. Обычно это последняя на момент сборки закладка. См. схему меток на иллюстрации потока git flow выше.
2.9. Запрещается переносить изменения из других веток методом переноса указателя (fast forward) даже если запрос на слияние позволяет этого сделать.
2.10. Допускается заводить несколько веток при начале разработки новой версии или подверсии, при этом ветка именуется как develop/V.SV.R, где V.SV.R - планируемый релиз, согласно нумерации редакций и версий.
3. Исправительные версии, ветви вида bugfix/<номер ошибки>
3.1. Фиксирование и исправление ошибок производится на всех этапах разработки и тестирования.
3.2. Ошибки фиксируются в системе отслеживания ошибок (СППР, git issue). Для ошибки фиксируется информационная база, в которой зафиксирована ошибка и ветка, на основании которой конфигурация информационной базы была получена.
3.3. Для выпуска каждой исправительной версии создаётся новая ветка (bugfix/<номер ошибки>) от ветви, в которой была обнаружена.
3.4. Для воспроизведения ошибки создаётся или модифицируется существующий сценарий функционального тестирования, на котором ошибка воспроизводится. Сценарий тестирования размещается в ветке ошибки, затем при успешном тестировании вместе с исправлением сливается в ветку, от которой была сформирована ветка bugfix. В контролируемые ветки (master, develop, release) перенос исправления со сценарием тестирования осуществляется через запрос на слияние. Сценарий тестирования включается в состав функциональных тестов для исключения появления регрессивных ошибок в будущих релизах.
3.5. В исправительной версии не должно быть объёмных доработок конфигурации, в противном случае нужно пересматривать сроки выпуска плановой версии.
3.6. В случае если исправление ошибки влечёт за перепроектирование, объёмное кодирование и тестирование то исправление такой ошибки производится в рамках отдельного техпроекта.
3.7. Все фиксации в репозиторий исправительной версии должны содержать комментарий. Требования к содержанию комментариев аналогичны требованиям к фиксациям в репозиторий плановой версии (см. п.2.5).
3.8. По окончанию работ с исправительной версией и при условии прохождения необходимых тестов создаётся запрос на слияние в родительскую ветвь. По удовлетворении запроса ветка исправления ошибки, и связанная с ней копия эталонной базы уничтожается.
3.9. После слияния исправительной версии в исходную ветвь устанавливается метка с информацией о номере сборки +1 относительно той версии, в которой ошибка была обнаружена.
4. Выпуск плановых версий
4.1. Выпуск плановых версий производится в ветви репозитория release.
4.2. Ветвь создаваемая только для выпуска очередного релиза, защищённая.
4.3. В ветви release проводится общее интеграционное тестирование очередной версии, полученной из ветки develop
- В ветке размещаются и, при необходимости, корректируются сценарии автоматизированного функционального тестирования
- В случае успешного тестирования функционала ветка сливается в develop и формируется запрос на слияние в master
- В случае неуспеха (наличия существенных ошибок) ветка release, при необходимости, сливается в develop, а затем уничтожается
- В случае несущественных, мелких ошибок допускается исправление непосредственно в ветке release
- Под несущественными ошибками понимается ошибка найденная в терминальном функционале, от которого нет зависимостей:
- Отчёт
- Печатная форма
- Форма объекта метаданных
- Ещё одним критерием оценки существенности является плановая длительность исправления - не более 2х часов.
- Под несущественными ошибками понимается ошибка найденная в терминальном функционале, от которого нет зависимостей:
Рекомендуется использовать реализованные в СППР возможности автоматической генерации текстов комментариев для фиксаций, связанных с исправлением ошибок и встраиванием технических проектов.
4.4. Все фиксации в ветку release должны содержать комментарий.
Содержание комментария зависит от характера выполненных работ:
- при исправлении ошибки обязательно должен быть указан номер и краткое наименование ошибки в системе баг-трекинга;
- при добавлении новых или изменённых сценариев тестирования должно присутствовать краткое описание произведённых изменений.
5. Разработка технических проектов
5.1. Разработка каждого технического проекта ведётся в отдельных ветках tech-project/NNNN, где NNNN номер техпроекта в системе документации. Ветвь техпроекта создаётся от последнего зафиксированного изменения ветви develop.
При использовании СППР ветка технического проекта может быть создана автоматически. Если СППР не используется, ветвь технического проекта нужно будет создавать вручную.
5.2. Ответственный за технический проект может периодически обновлять ветку хранилища из ветви develop. Например, для того, чтобы получить новые версии встраиваемых библиотек. Периодичность обновления разработчик определяет самостоятельно.
На частоту обновления могут влиять следующие факторы:
- затрагивает ли технический проект объекты других ответственных;
- проводится ли в данное время рефакторинг общих механизмов;
- ведётся ли сейчас в других ветвях массовое исправление ошибок.
5.3. После окончания разработки ответственный согласует сроки завершения отладочного тестирования и сроки переноса технического проекта в ветвь develop. Проекты, затрагивающие большое количество объектов рекомендуется переносить в ветвь develop ближе к сроку окончания разработки, чтобы уменьшить влияние на другие проекты.
Ответственные за другие технические проекты могут попросить перенести сроки внесения в основное хранилище.
В СППР согласовывать сроки встраивания технических проектов можно, используя функциональность контрольных точек по техническому проекту.
5.4. Перед переносом в основное хранилище рекомендуется сжать (sqash) полностью ветвь техпроекта, либо сжать только незначащие фиксации и выполнить перебазирование на ветвь develop, форсируя перезапись ветви в основном репозитории при необходимости, для уменьшения дерева разработки в целом.
5.5. Слияние ветви техпроекта в develop должно осуществляться после завершения отладочного тестирования. Под отладочным тестированием понимается успешное завершение на сборочной линии техпроекта функциональных и Unit тестов.
Для начала переноса нужно оформить запрос на слияние, конфликты слияния в запросе на слияние должны полностью отсутствовать, для этого необходимо использовать предварительное получение изменений из ветки develop и слияние изменений в ветку техпроекта. Вторым вариантом является периодическое перебазирование ветки техпроекта на ветку develop.
5.6. После проведения слияния техпроекта или после внесения изменений в основное хранилище разработчики технического проекта совместно с тестировщиками проводят быструю проверку того, что изменения перенесены корректно и не повлияли на работоспособность смежного функционала. Объем проверок и порядок их проведения определяет ответственный за проект.
5.7. После проверки переноса изменений в ветви develop, производится запрос на слияние в ветвь release, где производится интеграционное тестирование конфигурации. Проверку нужно проводить с максимальными настройками. См. выше 4. Разработка плановых версий.
5.8. После переноса изменений в ветвь develop, ветвь техпроекта, и связанная с ним эталонная ИБ удаляются из основного репозитория.
5.9. Если в разработке функционала участвуют несколько разработчиков, то каждый из них может создать свои ветки разработки от ветви техпроекта под каждый функциональный участок (feature), а перед переносом выполнить сжатие и перебазирование своей ветки на ветку техпроекта.
6. Нумерация сборок
Изменение номеров версий регламентируется стандартом Нумерация редакций и версий
Здесь будут уточнены правила изменения номера сборки (четвертое число в номере версии) корня конфигурации или разрабатываемой подсистемы. Для корня конфигурации номер сборки хранится в свойствах конфигурации, для встраиваемой библиотеки номер сборки хранится модуле подсистемы и заполняется функцией ПриДобавленииПодсистемы
Изменение сборки фиксируется установкой ярлыка(метки) tag на ту фиксацию, где было увеличен номер сборки основной конфигурации или подсистемы (БСП).
Важным моментом является то, что при разработке подсистемы, инициирование обновления информационной базы не производится автоматически, и его необходимо делать принудительно, запуская ИБ с ключом ЗапуститьОбновлениеИнформационнойБазы, либо модификацией функции БСП НеобходимоОбновлениеИнформационнойБазы модуля ОбновлениеИнформационнойБазыСлужебныйПовтИсп.
6.1. Номер сборки следует увеличивать в случаях:
- Непосредственно перед сборкой релиза. Это необходимо, чтобы полный номер собранного релиза гарантированно отличался от полного номера предыдущего релиза;
- при закладке в хранилище обработчика обновления информационной базы. Это необходимо, чтобы после обновления из хранилища у всех участников разработки добавленный обработчик обновления запускался автоматически (только для конфигураций, основанных на Библиотеке Стандартных Подсистем).
6.2.1. Обработчик и изменение номера сборки должны фиксироваться в хранилище в рамках одной закладки (коммита). При этом обработчик обновления должен быть «привязан» к тому номеру сборки, который вместе с ним помещается в хранилище.
6.2.3. Если в рамках одной конфигурации обработчики обновления разбиты по технологическим подсистемам (например, в конфигурации 1С:ERP обработчики разбиты на подсистемы УправлениеПредприятием и УправлениеТорговлей), то нужно повышать номер сборки как подсистемы, к которой относится обработчик, так и конфигурации.
6.3. Номер сборки необходимо изменять:
- В свойствах конфигурации.
- В процедуре ОбновлениеИнформационнойБазы<ИмяБиблиотеки>.ПриДобавленииПодсистемы (только для конфигураций, основанных на Библиотеке Стандартных Подсистем).
7. Хранение конфигурации поставщика
7.1. Для работы с конфигурацией поставщика в проекте EDT не рекомендуется использовать штатный механизм 1С:Предприятия, из за того, что конфигурация поставки хранится в виде монолитного файла CF, с которым у EDT очень сложные отношения. Вместо этого рекомендуется при создании импортировать в проект конфигурацию полностью снятую с поддержки.
7.2. Для корректного обеспечения механизмов поддержки рекомендуется создать и поддерживать в актуальном состоянии ветку vendor или stdandart. По мере выхода новых версий поставщика в эту ветку рекомендуется помещать новые релизы и маркировать их метками версий например v3.2.18.6. При этом удобнее не использовать EDT для поддержания ветки в актуальном состоянии, а использовать для этого командную строку приложений 1С:Предприятие, Git и утилиты ring. Последовательность действий следующая:
7.2.1. Создать пустую файловую ИБ
7.2.2. Загрузить из шаблонов конфигурации в пустую базу CF новой конфигурации от поставщика, конфигурацию ИБ обновлять не нужно.
7.2.3. Снять конфигурацию с поддержки.
7.2.4. Утилитой ibcmd (предпочтительнее начиная с платформы 8.3.20) или конфигуратором выгрузить конфигурацию в XML
7.2.5. Утилитой ring (команда ring edt import) преобразовать формат XML в EDT, указав при этом текущую версию платформы проекта. Для ускорения обновления ветки рекомендуется формировать файлы проекта EDT на том же диске. где [будет] размещён проект Git (см. следующий пункт)
7.2.6. Клонировать репозиторий проекта в отдельный каталог, не связанный с EDT если есть существующий каталог проекта Git не использующийся в EDT можно использовать его.
7.2.7. Извлечь ветку поставщика
7.2.8. Удалить папку src и заместить её папкой src полученный в проекте на этапе 6.2.5
7.2.9. Добавить изменения в Git, метку версии поставщика и поместить в удалённое хранилище.
8. Обновление конфигурации поставщика
8.1 Для обновления конфигурации поставщика рекомендуется использовать штатные средства слияния EDT.
8.1.1. Вариант упрощённый, подходит при не больших объёмах изменений.
8.1.1.1. Создать новую ветку версии, например, develop/1.2.1 от master, где 1.2.1 новая версия системы. Слить с веткой поставщика, разрешить конфликты слияния, зафиксировать коммит слияния, провести минимальный рефакторинг и стабилизацию версии.
8.1.1.2. Если объём рефакторинга не позволяет провести его за раз следует использовать возможности сохранения настроек объединения EDT с последующим отказом от слияния. При настройке следующей сессии слияния с веткой поставщика использовать сохранённые настройки объединения, чтобы продолжить не законченную работу.
8.1.2. Вариант при большом объёме рефакторинга. В этом варианте необходимо создаётся дополнительных два проекта EDT в рабочей области, соответствующих базовому коммиту слияния (базовый коммит: git merge-base develop/1.2.1 vendor) и новой конфигурации поставщика (последний коммит в ветке поставщика).
8.1.2.1. Поочерёдно, используя два дополнительных клона git хранилища в одном извлечь ветку вендора, в другой базовый коммит без создания ветки (detached HEAD), присоединить готовые хранилища к EDT, импортировать проекты из них в рабочую область.
8.1.2.2. Провести сравнение объединение, сохраняя файл настроек. При необходимости можно изменить (исправить) исходные модули, например, закомментировав некорректные инструкции препроцессора, чтобы EDT смог по этим модулям провести корректное попроцедурное сравнение/объединение текстов модуля. Если правки затронули дополнительный проект, извлечённый из ветки вендора исправления лучше зафиксировать с отметкой в коммите, что исправлена структура модуля или команды препроцессора с обязательным указанием исправляемой версии V.SV.R.C.
8.1.2.3. В таком варианте удобно сравнивать отдельные объекты метаданных между текущими, новыми версиями и базовым проектом.
8.1.2.4. Сохранить финальные настройки сравнения объединения.
8.1.2.5. Провести слияние с веткой поставщика согласно п.8.1.1.1. применяя сохраненные в п. 8.1.2.4 настройки. Следует учитывать, что при слиянии веток, появятся конфликтные изменения внутренних идентификаторов, которых не было видно при сравнении трёх проектов по базе. Необходимо проанализировать и принять решение относительно каждого из конфликтов по внутренним идентификаторам.
8.1.2.6. Сохранить настройки с учётом идентификаторов, зафиксировать коммит слияния, провести минимальный рефакторинг перед стартом новой версии.
ПРИМЕЧАНИЕ. Для удобства префиксы веток кроме основной (master) можно сделать короче BF, TP, Dev, Ven, Std связано с особенностью отображения ярлыков веток в EDT - их длина ограничена.
Вступайте в нашу телеграмм-группу Инфостарт