Сегодня поговорим про такие замечательные технологии, как «Кролик» и «Редиска», то есть RabbitMQ и Redis Server. Меня вообще очень радует, что наша отрасль начала применять такие промышленные технологии. Спасибо Андрею Овсянкину, который приложил свою руку к тому, что они появились в мире 1С. Также большая благодарность Даниилу Коневу (//infostart.ru/profile/597444/) – вместе с ним мы реализовывали те проекты, на примере которых я буду рассказывать про эти технологии.
Зачем 1С-нику знать про RabbitMQ и Redis Server?

В финансовой сфере, где я некоторое время назад имел счастье работать, эти технологии уже применяются, и с их помощью строятся очень интересные, производительные, мощные, отказоустойчивые решения. Давайте разберемся, зачем специалисту по 1С вообще знать эти технологии?
Во-первых, чтобы не изобретать велосипед. Ко мне периодически приходят с такой проблемой – у нас есть интернет-магазин, есть 1С, интернет-магазин из 1С что-то получает, но периодически падает. Залезаешь в модуль этого web-сервиса, а там запрос на три экрана. Это, конечно, бред – работать это будет плохо, медленно и ожидаемо, что это будет падать.
Чтобы таких костылей не изобретать, не оптимизировать неэффективное решение – лучше пересмотреть архитектуру, взять уже готовый промышленный паттерн проектирования, который можно применить и получить успех. Кроме этого, очень интересно строить такие сложные архитектуры, гетерогенные ландшафты, когда много систем друг с другом общаются. Это, действительно, очень сложно, это для многих, я думаю, будет новым уровнем. Поэтому такие технологии нужно знать.

Сегодня мы поговорим про две технологии:
- первая – это брокер сообщений RabbitMQ, который организует очереди;
- и вторая – это Redis, кэш-сервер. Я подробнее расскажу, что это такое, с чем его едят, и как я его применял.
Все, о чем мы будем говорить, построено на моей практике. Сегодня не теоретический доклад, я не буду вам теорию или википедию пересказывать. Все из моей практики, из недавних проектов.
Первый кейс – сбор лицензионных отчислений правообладателю от упоминания в интернете

Итак, первый проект. Заказчик этого проекта решил «забанить интернет» – в частности, инстаграм.
Какая в этом проекте была идея: в инстаграме очень много лицензированных изображений, у которых есть правообладатель – они защищены авторскими правами. Никто сейчас не следит за этим, потому что правообладателям это не особо надо. А раз никому не надо, эти изображения и висят. И вот заказчик этого проекта решил помочь правообладателю, при этом компании, которые размещают эти нелицензионные изображения, вроде бы и рады заплатить, потому что каждая публикация с той же «Машей и Медведем» приносит хорошие деньги. Они бы и рады заплатить, но некому.
Соответственно, заказчик этого проекта решил помочь и тем и другим. Первым – обеспечить возможность оплаты, вторым – помочь обеспечить защиту своих прав согласно четвертой части ГК РФ по интеллектуальной собственности. И какая-то часть этого денежного потока должна была перепасть заказчику.
Соответственно, заказ был такой – нужна информационная система, которая этих нарушителей в инстаграме находит (планировалось охватить все соцсети, но первый этап был – инстаграм), предъявляет им претензию автоматически и какое-то время ждет денег. Если денег нет – она этих нарушителей банит (у инстаграма есть для этого специальные механизмы).
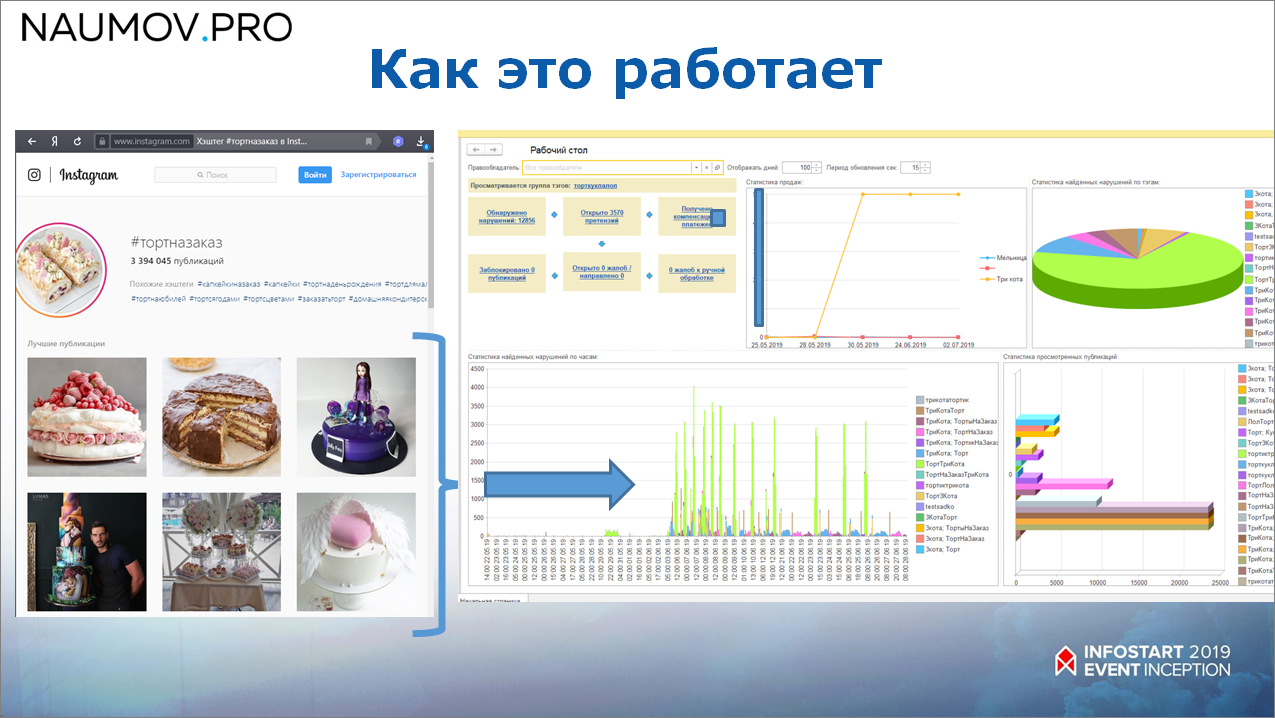
Как это работает? Все публикации сканируются с помощью системы поисковых роботов, а управляет всем этим процессом, естественно, 1С. Если нарушитель был найден, то это фиксируется в системе, и если он, например, публикацию на какое-то время скрыл, 1С его все равно потом найдет.
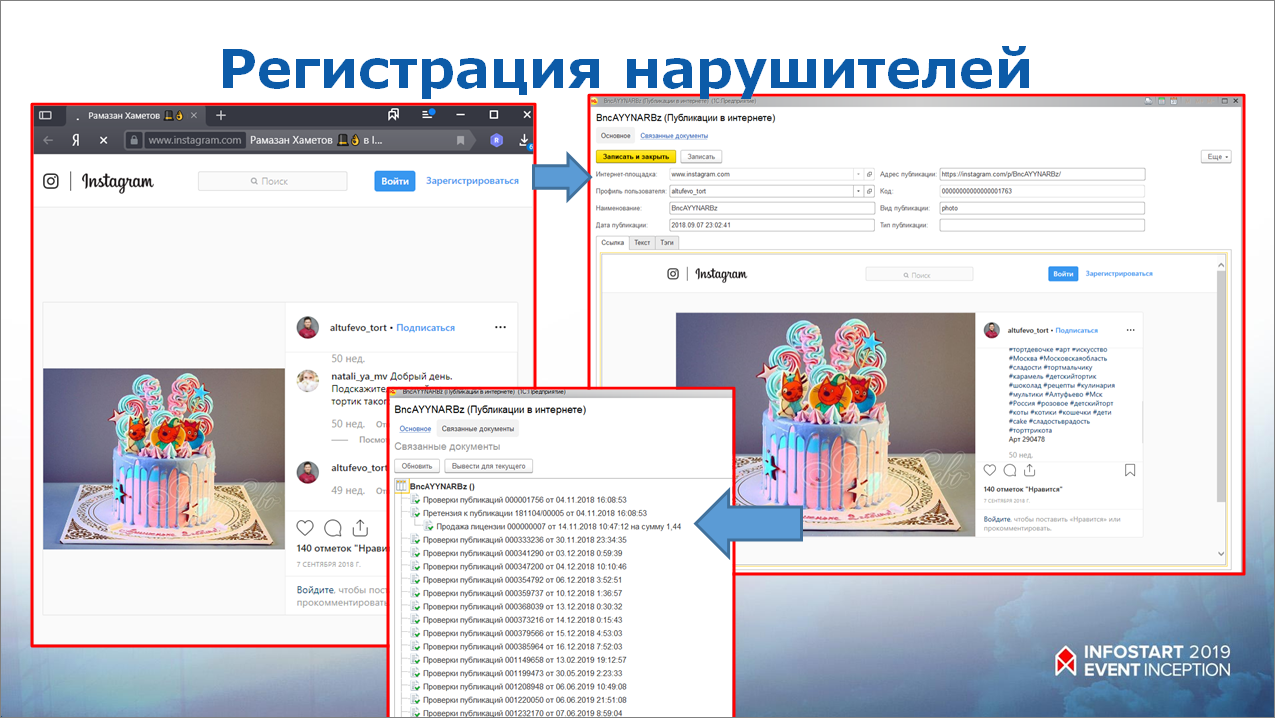
Например, мы нашли публикацию, которая нарушает авторские права. В 1С полностью загрузилась вся информация по этой публикации, сохранились контакты этого человека, которые можно было найти по описанию публикации или из профиля.
И дальше на средней картинке видно, что система еще периодически отсматривает эту публикацию, проверяет – удалил он ее или нет.
Первый вариант архитектуры сканирования инстаграма
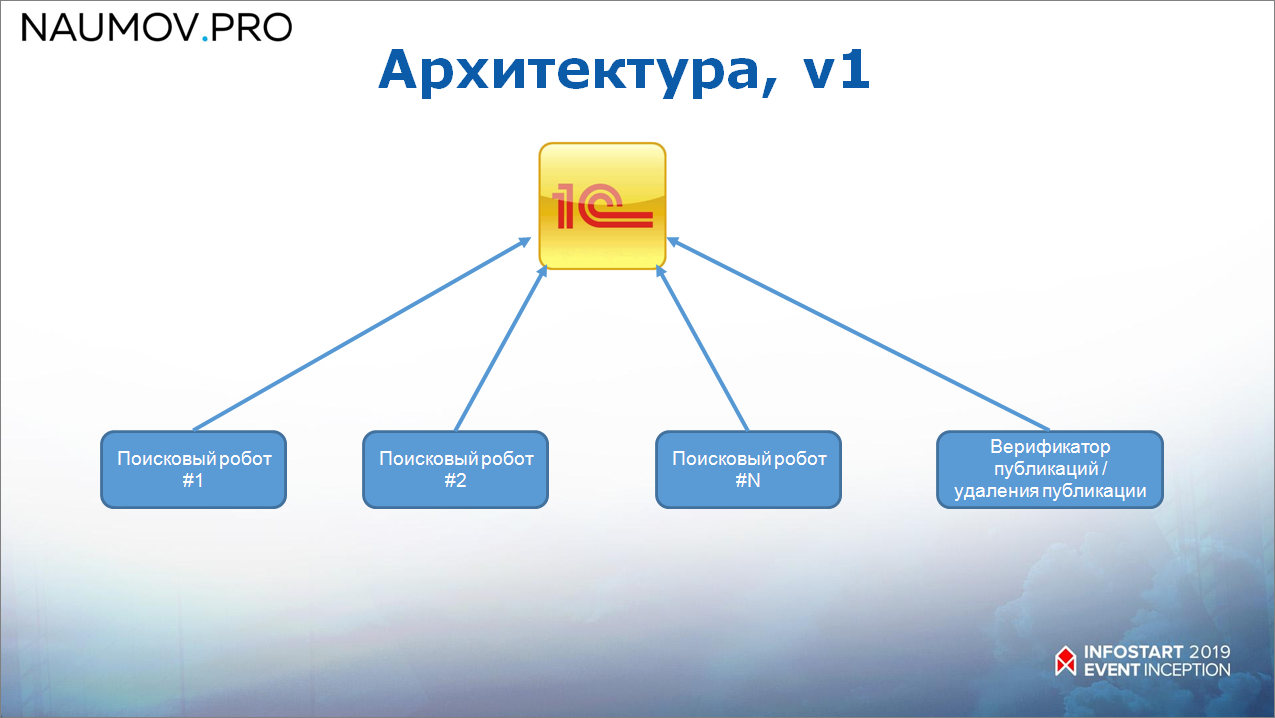
Первый вариант архитектуры мы сделали «в лоб» – это система поисковых роботов, которые «дергают» 1С. При тестировании работало более-менее хорошо.
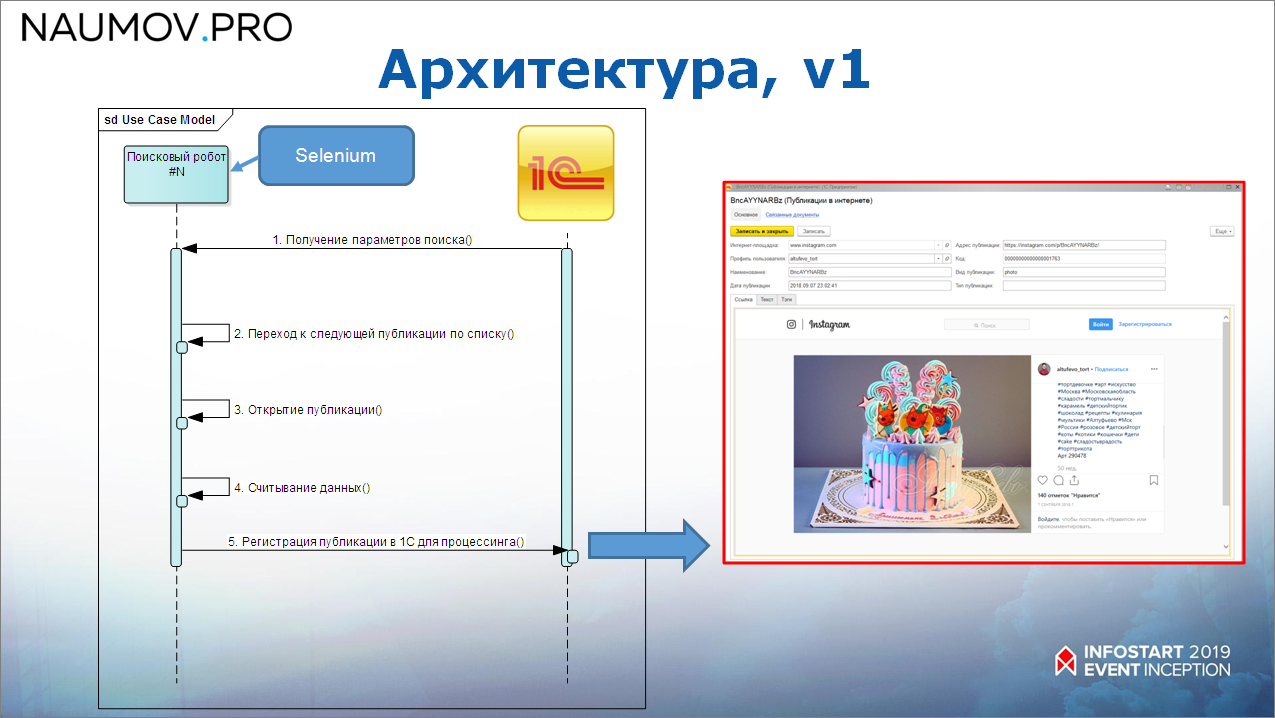
Как это выглядело? Поисковый робот получает параметры поиска у 1С (1С всем этим управляет), дальше переходит к следующей публикации, открывает публикацию, считывает данные и передает данные в 1С – совершенно «в лоб».
Проблемы архитектуры

Когда мы пришли первый вариант системы сдавать, нам заказчик выкатил вот такой список ненайденных публикаций. Он спросил: «А где они в твоем списке?». Проверяем первый экран инстаграма – действительно, что-то не то, через одну публикация не найдена.
Причем, вроде как на тестах все работает, все хорошо – мы гоняем, у нас более-менее все находит. Но на масштабном поиске какие-то публикации почему-то пропускает, и мы с веб-разработчиками и с 1С-разработчиками две недели пытались понять, в чем проблема.
Найти было очень сложно, но мы все-таки нашли. Поисковые роботы были сделаны на Selenium – это фреймворк, который эмулирует работу в браузере, и он периодически пропускал публикации. Это – первая особенность.
Второй косяк в том, что инстаграм очень не любит, когда его сканируют и всячески вставляет «палки в колеса». И даже с помощью системы proxy-серверов не все удалось решить.
Две недели просидели, перепробовали разные варианты, поняли, что надо все переделывать.

К счастью, заказчик у нас адекватный, мы ему сказали: «Нужна новая архитектура, на это нужны новые бюджеты». И он пошел нам навстречу – мы начали делать новую архитектуру.
Еще была очень большая проблема, что 1С не очень хорошо работала при высокой нагрузке на веб-сервисы – из-за того что, этих поисковых роботов очень много, и они все «стучат» в 1С, она периодически либо «зависала» с запросами, либо запросы не проходили по разным причинам. Чтобы выяснить причины, нам пришлось все обложить логами.
Исследование работы HTTP-сервисов 1С
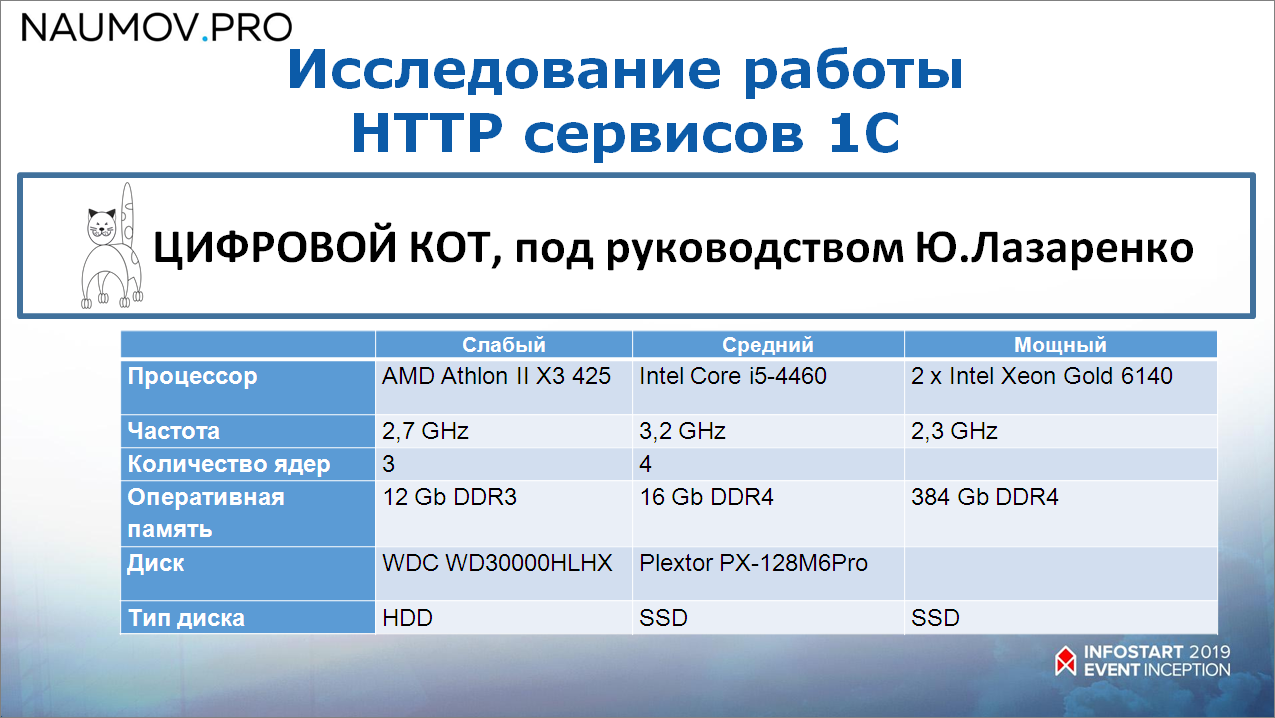
Коллеги из «Цифрового КОТа» под руководством Юрия Лазаренко сделали нам исследование. Параметры исследования такие – взяли три сервера (их характеристики на экране):
- один – совсем слабенький (тот самый «трехядерный» Athlon);
- средний сервер;
- и реально очень мощный сервер, Intel Xeon Gold, который стоил десятки тысяч рублей в месяц только на аренду.
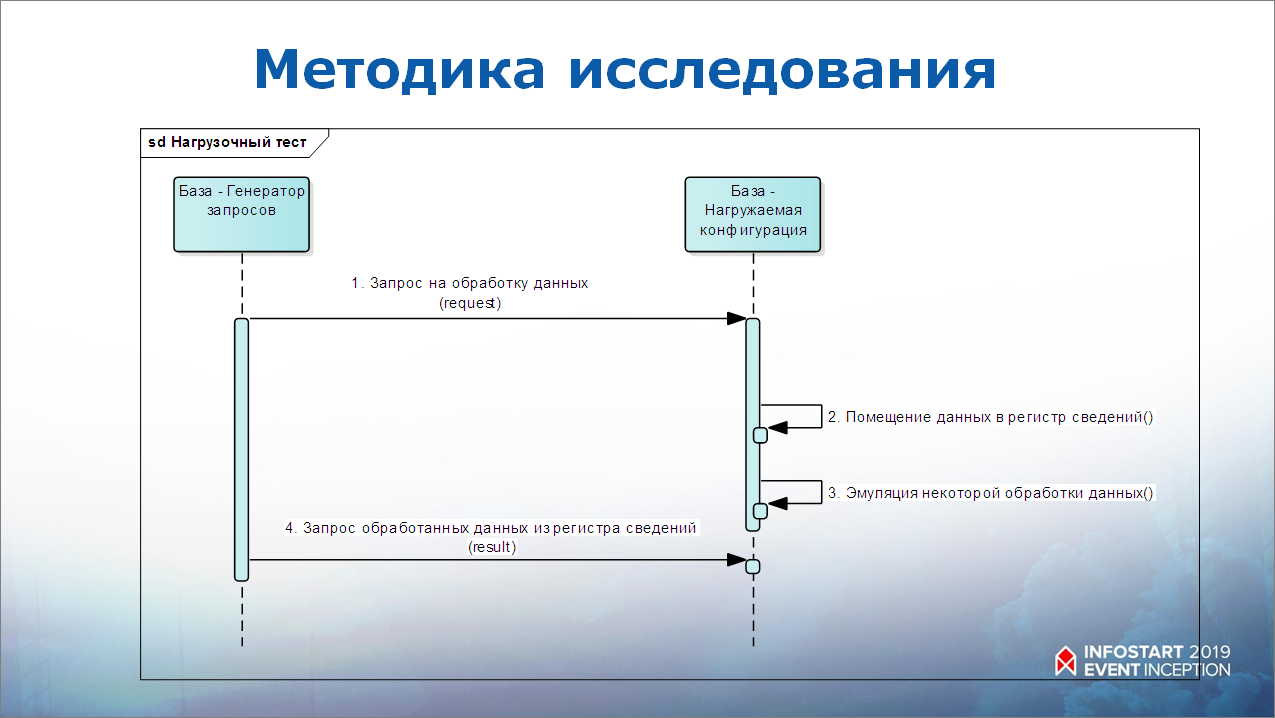
И сделали исследование по такой методике – у нас есть две базы:
- одна база – нагружаемая;
- вторая база – выгружает.
Эмулируются асинхронные вызовы. Сначала одна база кладет в другую некую информацию, ждет условную обработку и через некоторое время получает результат.
При этом внутри модуля HTTP-сервиса никакой обработки, никаких запросов не было – просто положили данные в регистр сведений, а потом их считали из регистра.
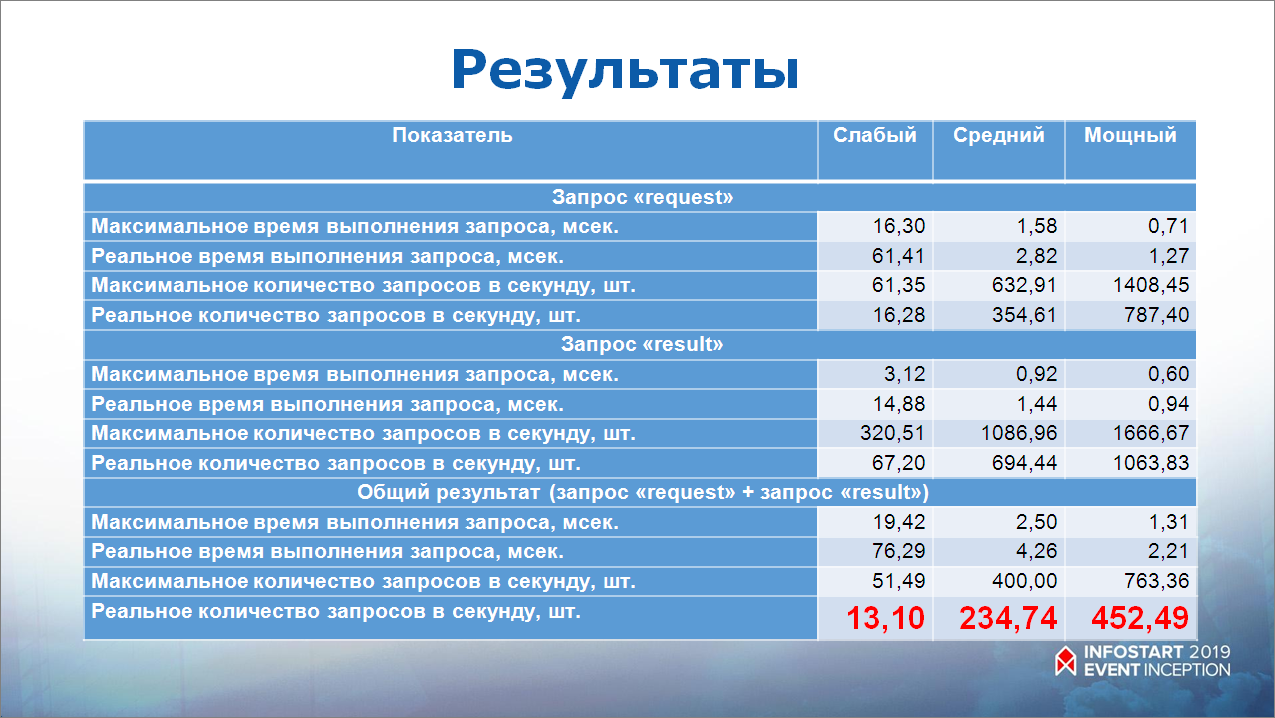
Результаты меня очень удивили. Смотрите – красным выделено, сколько всего запросов в секунду держит 1С. Сканировать инстаграм с такими возможностями не очень хорошо.
Второй вариант архитектуры сканирования инстаграма
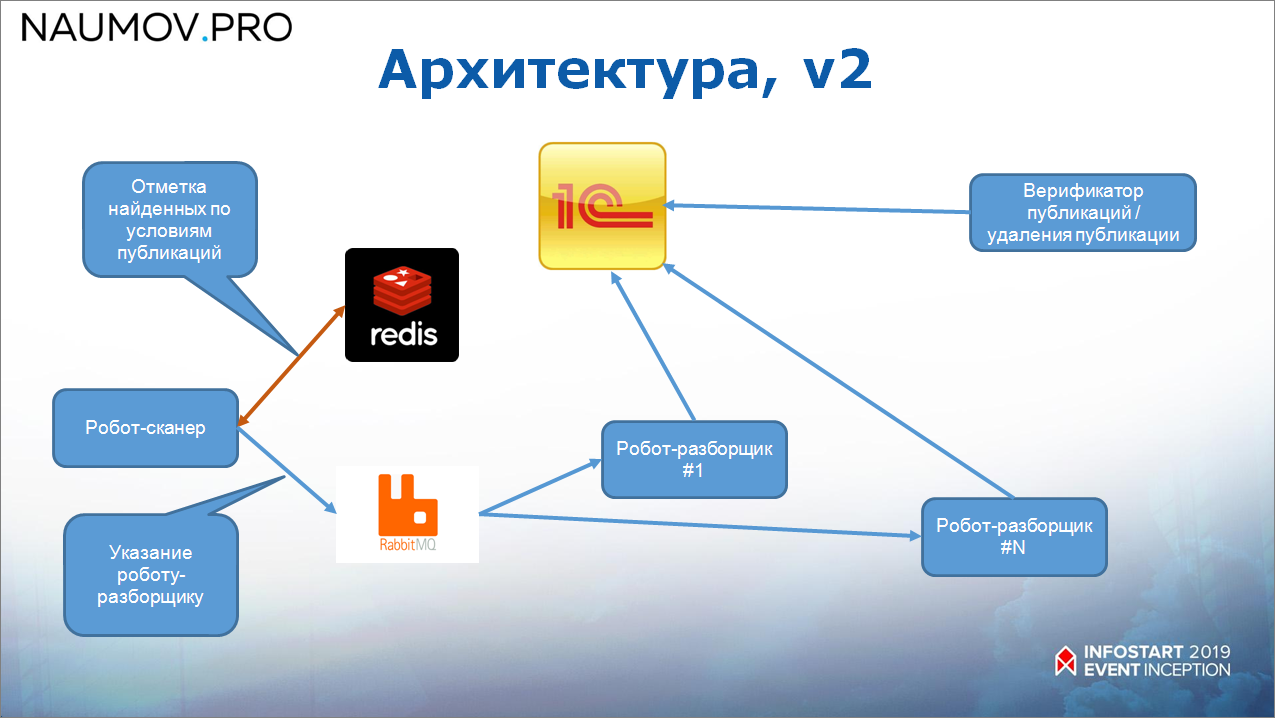
Начали думать, спроектировали новую архитектуру. Новая архитектура выглядит уже таким образом.
Во-первых, мы выделили роботов по ролям и между ними поставили RabbitMQ:
- Выделили отдельного робота для сканирования – он сканирует инстаграм, находит публикации. Это позволило избежать ошибки, что в инстаграме при обновлении страницы каждый раз будет новая публикация. В предыдущей архитектуре это сбивало робота с толку, а в случае одного потока сканирования он довольно быстро идет и четко ничего не пропускает. То, что он находит, он кладет в Redis, так как это – некоторая оперативная информация.
- А дальше робот-сканер через RabbitMQ делает указание роботам-разборщикам на считывание информации.
Получается, что сканирование идет в один поток, и от него работает штук 20-30 роботов-разборщиков, которые уже стучатся к 1С. Соответственно, не страшно, если 1С выкинула какой-то «финт ушами» (робот-разборщик упал с необработанной ошибкой) – ничего страшного, он потом из RabbitMQ еще раз прочитает и опять отправит.
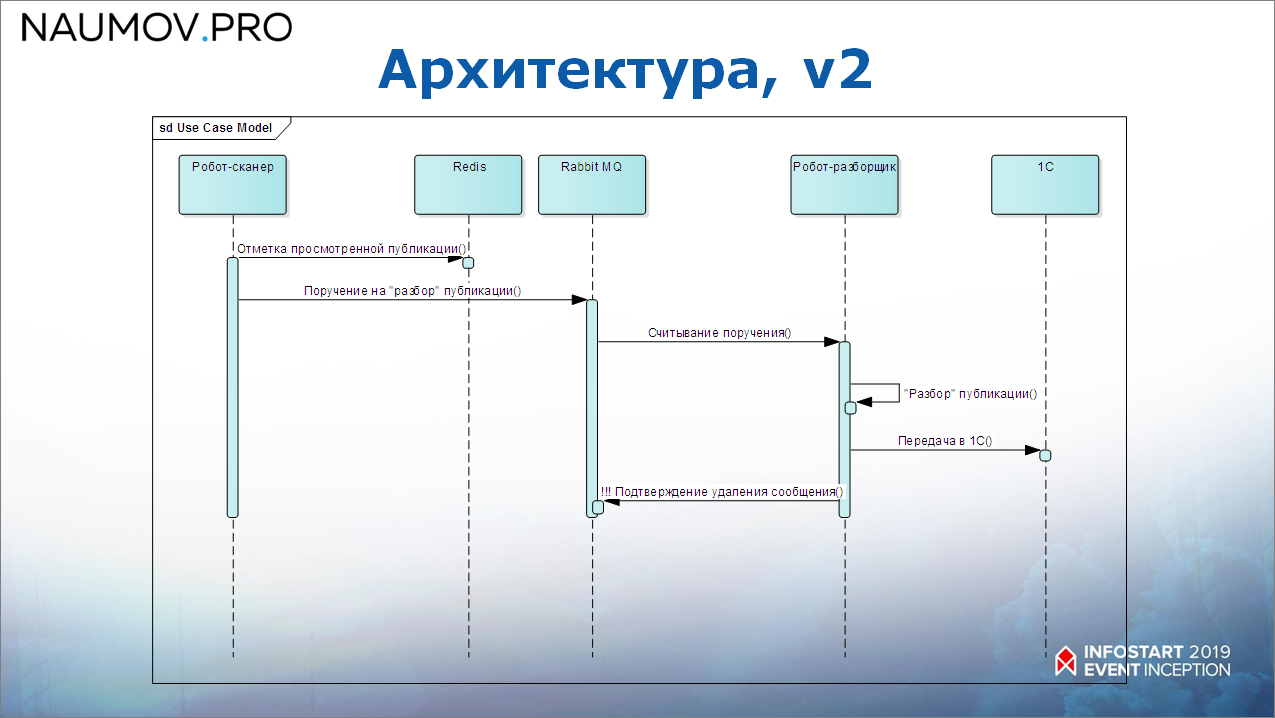
Как это выглядит последовательно?
- робот-сканер отмечает в Redis, что он прошел эту публикацию и дает поручение на ее разбор;
- а дальше – робот-разборщик считывает эту публикацию, и, обратите внимание, он отправляет информацию в 1С, а только потом подтверждает в Redis, что он эту публикацию прочитал, и поручение на ее разбор можно убрать.
Очень удобно.

Так вот, Redis – это NoSQL СУБД, которая работает просто по принципу «Ключ:Значение». У нее много возможностей, но все сводится к тому, что это «Set» и «Get». Set – указать какое-то значение и Get – получить это значение.
А RabbitMQ – это брокер очередей. Его основная задача – гарантированно доставить сообщение. Если ты в него сообщение передал, то на 99.9% можешь быть уверен, что это сообщение дойдет.
Выводы из первого проекта

Какие выводы из этого проекта я сделал?
- Во-первых, не всегда стоит “ковыряться” в коде, иногда лучше подумать и перепроектировать всю архитектуру, потому что мы здесь просто убили две недели.
- Когда у вас есть какое-то слабое звено в архитектуре, не факт, что нужно с этим слабым звеном работать. Возможно, имеет смысл его обложить какими-то вспомогательными инструментами и минимизировать влияние этого слабого звена на весь процесс.
Второй кейс – организация шины данных для финансовой системы

Переходим к следующему кейсу.
Это – довольно амбициозный проект по выводу на рынок нового финансового продукта, полностью построенного на онлайн-взаимодействии.
С какими задачами ко мне пришли? Это куча систем, которые надо интегрировать между собой. Целевые показатели нагрузки – десятки тысяч пользователей.
Я думаю, у многих есть какое-либо банковское приложение. Там примерно такое же приложение, только для стран СНГ. И там планируется выход на разные рынки, на каждом из которых своя специфика (например, с тем же регламентированным учетом). То есть ландшафт быть универсальным, чтобы в него можно было легко подключать новые решения.
Особенности ИТ-ландшафта финансовых организаций

Какие вообще есть особенности у финансовых организаций? Я очень люблю работать с финансовыми организациями, потому что у них очень интересный ИТ-ландшафт.
- В частности, там достаточно сложно реализовать все требования в рамках одной монолитной системы, потому что, например, необходимо интегрироваться с КБ (кредитным бюро), и выгружать туда очень много информации, а когда идет эта выгрузка - это серьезная нагрузка. Соответственно, если вы применяете монолитный ИТ-ландшафт, то с большой вероятностью можете упереться в производительность. Поэтому лучше ставить системы, специализированные под свои задачи, и это позволит избежать таких проблем.
- Также у финансовых компаний большие требования к отклику от системы. Если вы зашли на сайт, хотите взять кредит, нажали кнопку «Рассчитать график», и он считает больше нескольких секунд – вы закроете этот сайт. У системы должен быть очень быстрый отклик.
- Но при этом многие запросы к ИТ-ландшафту, с которыми обращаются клиенты, повторяются. Потому что, если считать график платежей при следующем допущении, что суммы, которые выдаются, дискретные (кратные тысяче рублей, от 1 до 10 миллионов) – то там получается не так много значений.
Проблемы взаимодействия при интеграции напрямую
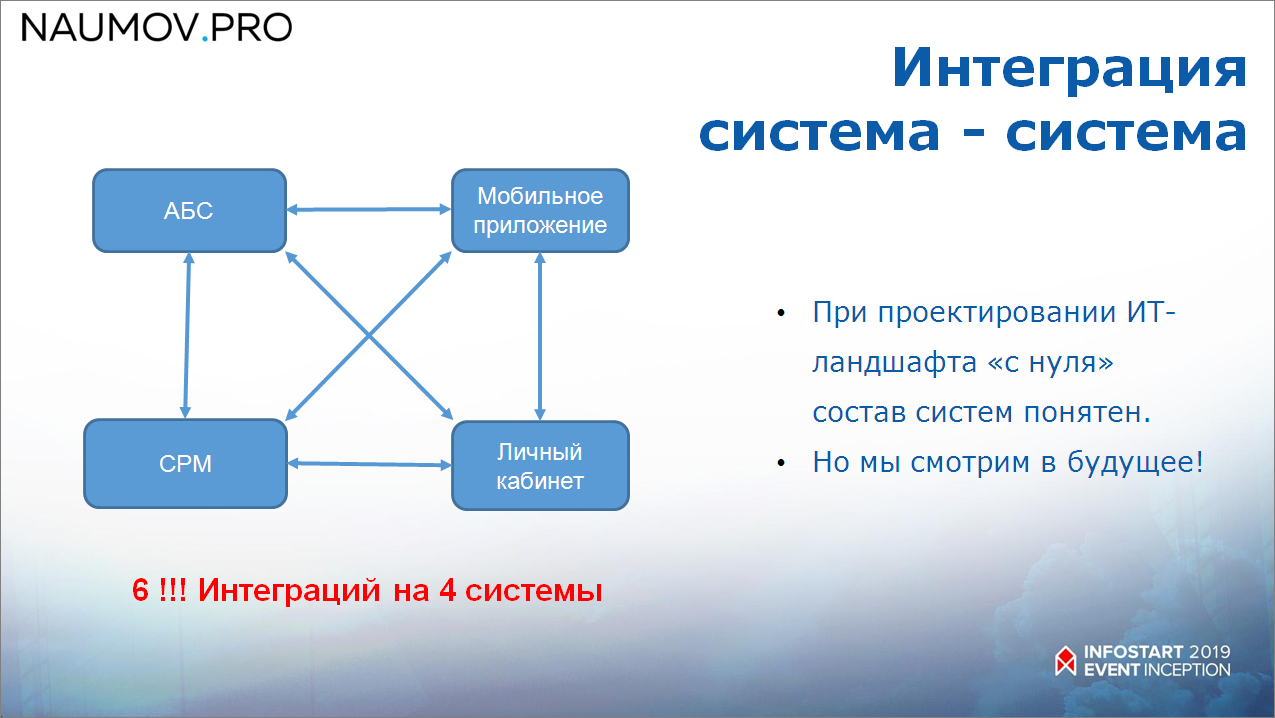
Первое решение, конечно, было «в лоб» – заинтегрировать все системы друг с другом.
- Но, обратите внимание, когда у нас четыре системы, мы получаем шесть интеграций. Но если мы добавляем еще одну систему, у нас количество интеграций значительно возрастает – сами понимаете, в какой прогрессии. Получается совсем неэффективное решение – это, во-первых.
- А во-вторых, мы не обеспечиваем, не удовлетворяем требования того, что ландшафт должен быть расширяемым.
Здесь, к счастью, мы проектировали ИТ-ландшафт «с нуля», поэтому постарались обеспечить все требования.
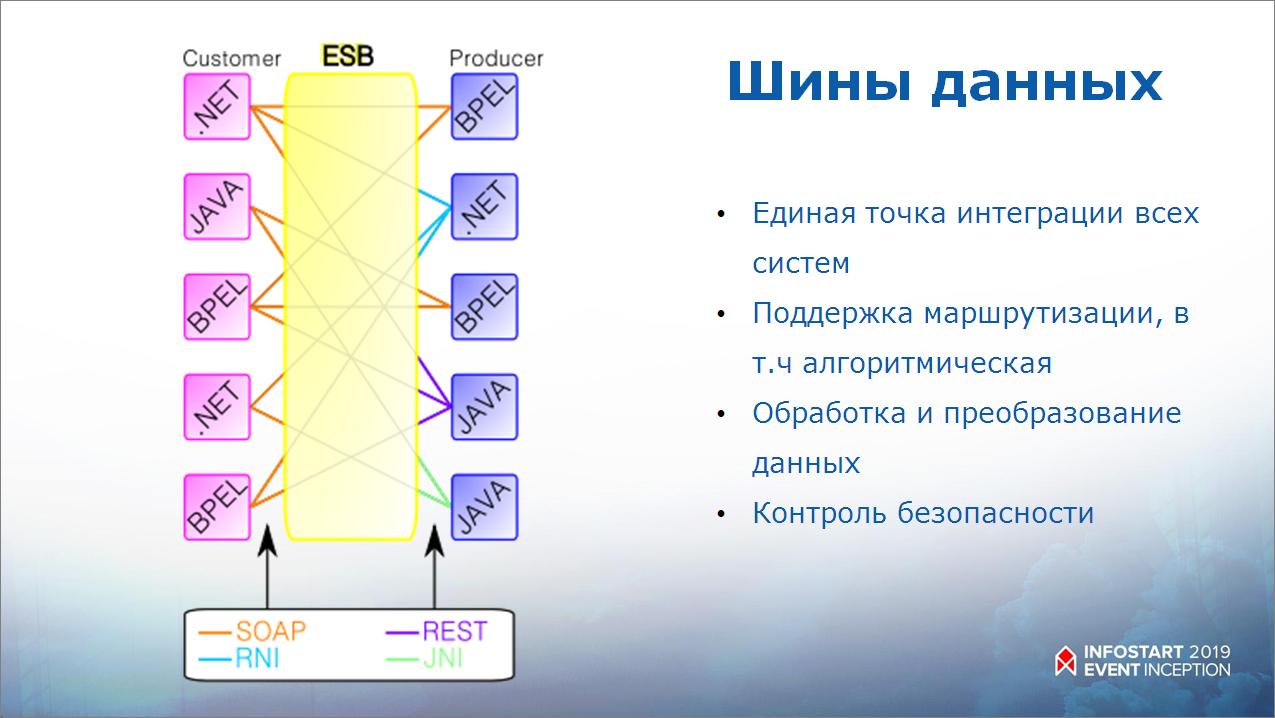
Вообще есть целый класс ESB-систем, шин данных:
- основная задача ESB-систем – быть единой точкой интеграции для всех сервисов;
- ESB-системы поддерживают маршрутизацию – в том числе, алгоритмическую;
- а также они поддерживают сервисные функции по обработке, преобразованию и контролю данных.
Архитектура решения по интеграции различных систем в сложном ИТ-ландшафте
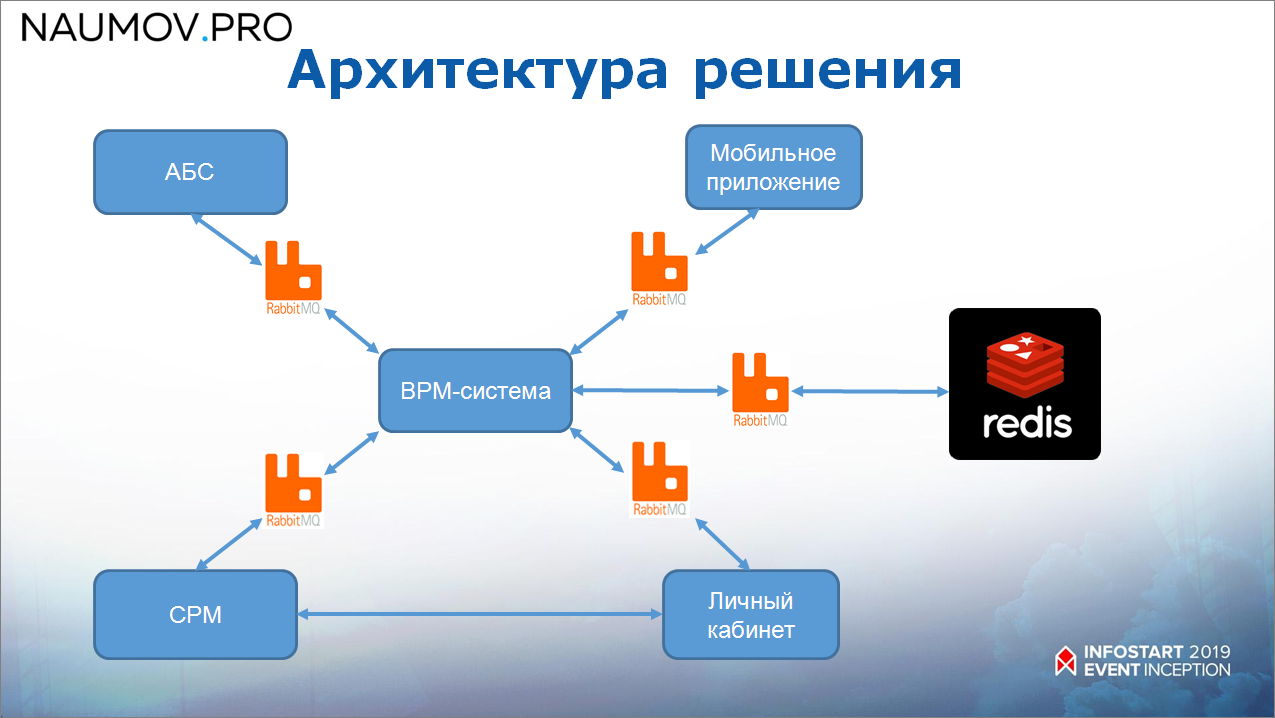
Какая архитектура у нас получилась?
Мы решили интегрировать все системы через BPM-систему.
- Для того чтобы обеспечить гарантированность доставки сообщений, перед ESB стоит RabbitMQ, который гарантированно доставляет сообщения.
- BPM-система в свою очередь эти сообщения маршрутизирует и как-то обрабатывает.
- И для повторяющихся запросов стоит Redis. BPM-система знает, какие сообщения по каким параметрам могут быть закэшированы, и при поступлении запроса обращается в Redis, проверяет – есть данные? Если есть, возвращает оттуда. Если данных нет, то начинает опрашивать системы, которым было направлено это сообщение, собирает с них данные, помещает в Redis и возвращает клиенту.
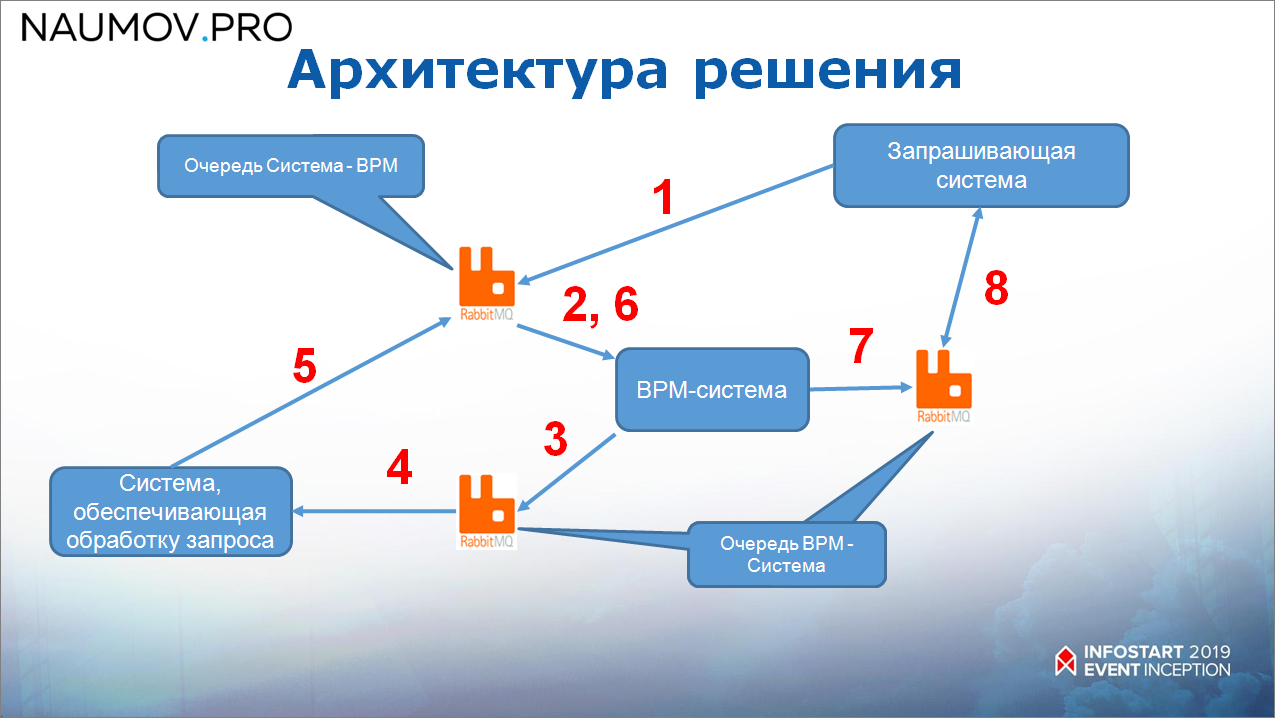
Как все это работает:
- запрашивающая система кладет сообщение в RabbitMQ;
- BPM-система это сообщение считывает и после этого отправляет в целевую систему – также через RabbitMQ;
- и потом прилетает ответное сообщение в обратном порядке.
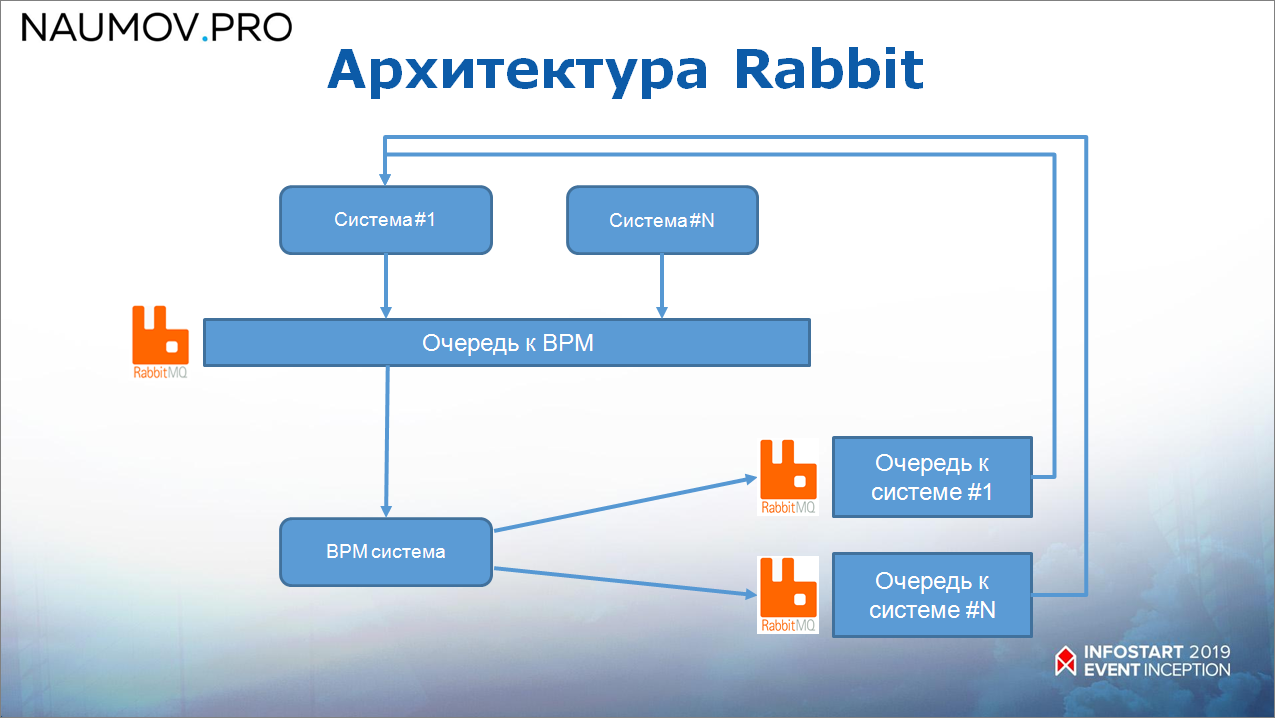
Всего у нас получились следующие типы очередей:
- одна очередь в RabbitMQ к BPM-системе – все системы пишут в одну очередь к BPM-системе;
- и отдельные очереди от BPM к каждой из систем (некоторые именованные направления – для кого пишем).
Особенности реализации
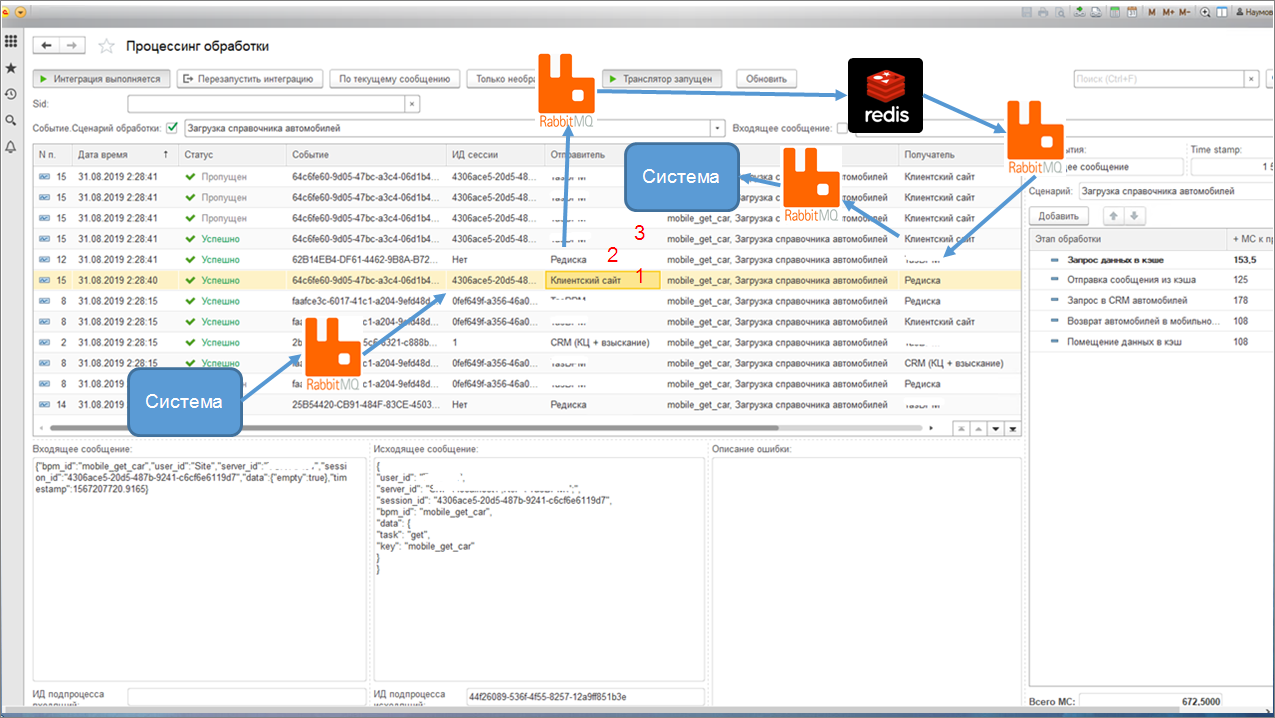
Вот так выглядит главный интерфейс нашей BPM-системы.
Все сообщения логируются – мы даже на этапе тестирования сохраняем текст сообщения.
Мы видим входящие и исходящие сообщения. Например, здесь клиентский сайт запросил данные – это как раз те сообщения, которые прошли по процессу обработки. Сначала мы их проверили в Redis, если они там есть, вернули из Redis и т.д.

1С и RabbitMQ мы интегрировали очень просто. Есть публикация //infostart.ru/public/1051620/, большое спасибо автору. Там описана абсолютно бесплатная компонента, с помощью которой можно легко интегрироваться.
Мы сделали опрос RabbitMQ в цикле – не самое лучшее решение, но мы были сильно ограничены в сроках, и, кстати, из-за ограничения в сроках мы сделали свою BPM, потому что подрядчики, внедряющие промышленные ESB, не подписывались под теми сроками, за которые надо было сделать. Поэтому мы для минимизации рисков взяли знакомый инструмент и быстро на нем сделали то, что нам нужно для запуска этого «стартапа». И в качестве закрытия технического долга поставили себе задачу внедрить в дальнейшем промышленную ESB – теперь, когда у нас уже есть время, мы можем сделать это уже без горячки.
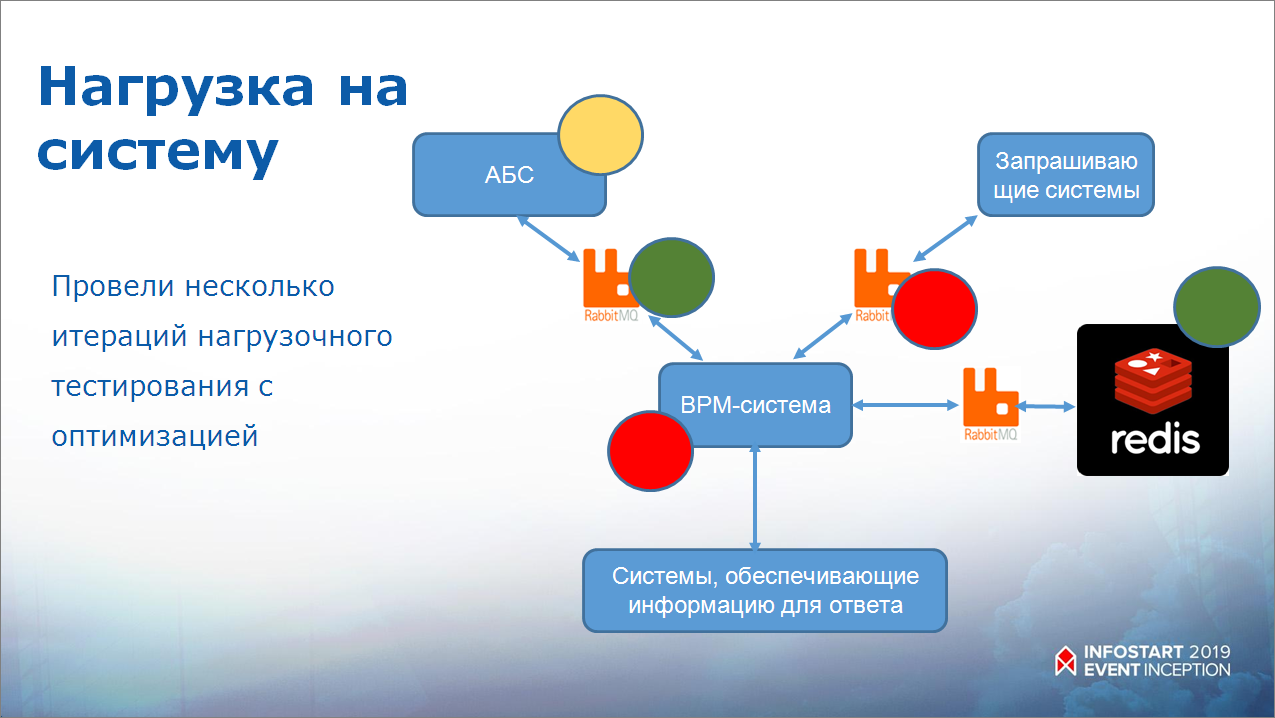
Мы провели очень много нагрузочных тестов – написали кучу сценариев на Python, которые дергали все сервисы в кучу потоков, проводили тесты с нескольких серверов.
Нагрузка распределилась по системам – очевидно, что BPM, как самое узкое звено, высоконагружена, но она хорошо горизонтально масштабируется. Мы понимаем, что, если нам нужно, например, удвоиться, мы просто поставим рядом еще одну BPM-систему.
RabbitMQ, которого опрашивает BPM-система, очень нагружен. Как я уже говорил, мы сделали опрос в цикле, опрос идет в 12 потоков. Но, опять же, это выделенная виртуалка, она занимает 3.7% процессорного времени хостовой машины. Мы посчитали, что для быстрого запуска это допустимая нагрузка – нам нужно было сделать как можно быстрее.
А Redis, в свою очередь, очень порадовал. И сервер не нагружен, и обрабатывает все очень быстро. Вообще разработчики Redis заявляют о 100 тысячах транзакций в секунду, что Redis сможет их выдержать.
Полезный кейс: мини-система моделирования
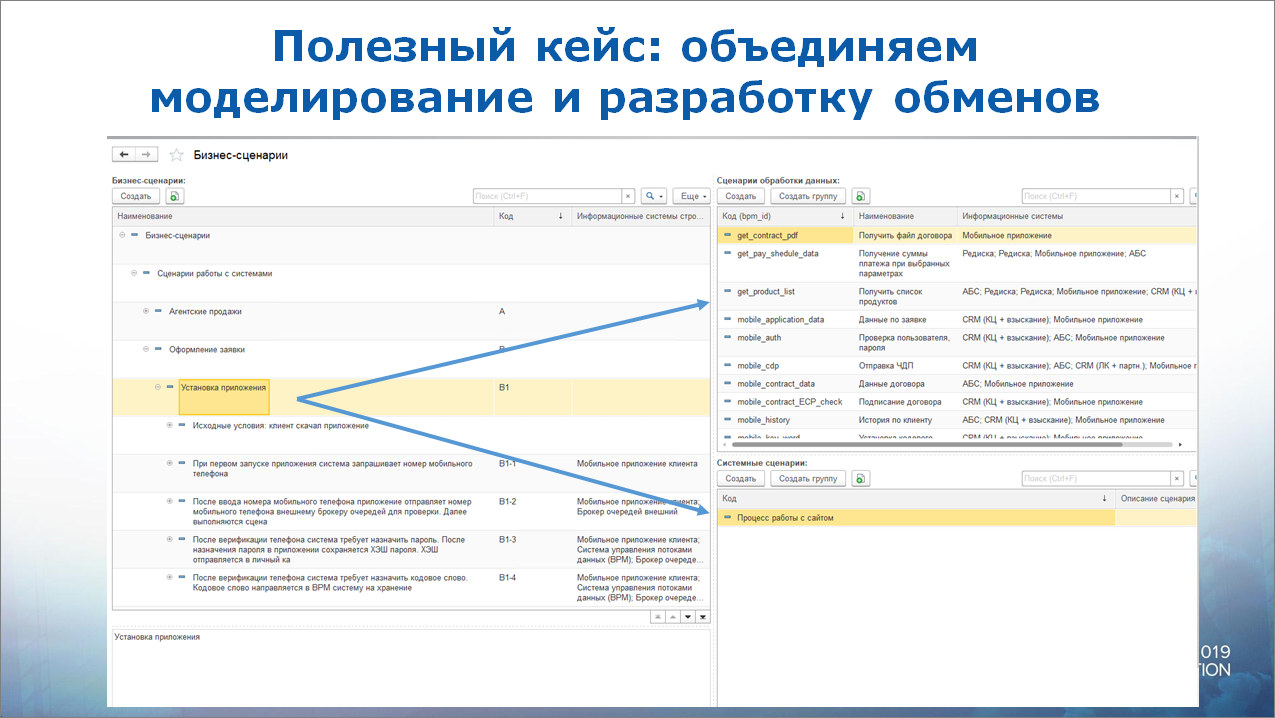
На этом проекте мы применили очень интересный кейс.
У нас есть наша ESB (BPM-система), у нее есть какие-то входящие контракты, которые в ней же описываются. Каждый контракт обрабатывается определенным способом, маршрутизируется на определенные системы. И когда мы их стали делать, этих контрактов перевалило за сотню. Но разобраться в них реально сложно.
Что мы сделали? Мы взяли бизнес-сценарии, которые писались под этот проект, загрузили в BPM-систему, и дальше все контракты разбили по бизнес-сценариям.
Соответственно получилась мини-система моделирования, сразу с описанием технических контрактов. Очень удобно. Это позволило намного быстрее найти общий язык с разработчиками.
RabbitMQ Management HTTP API – как можно и как нельзя использовать
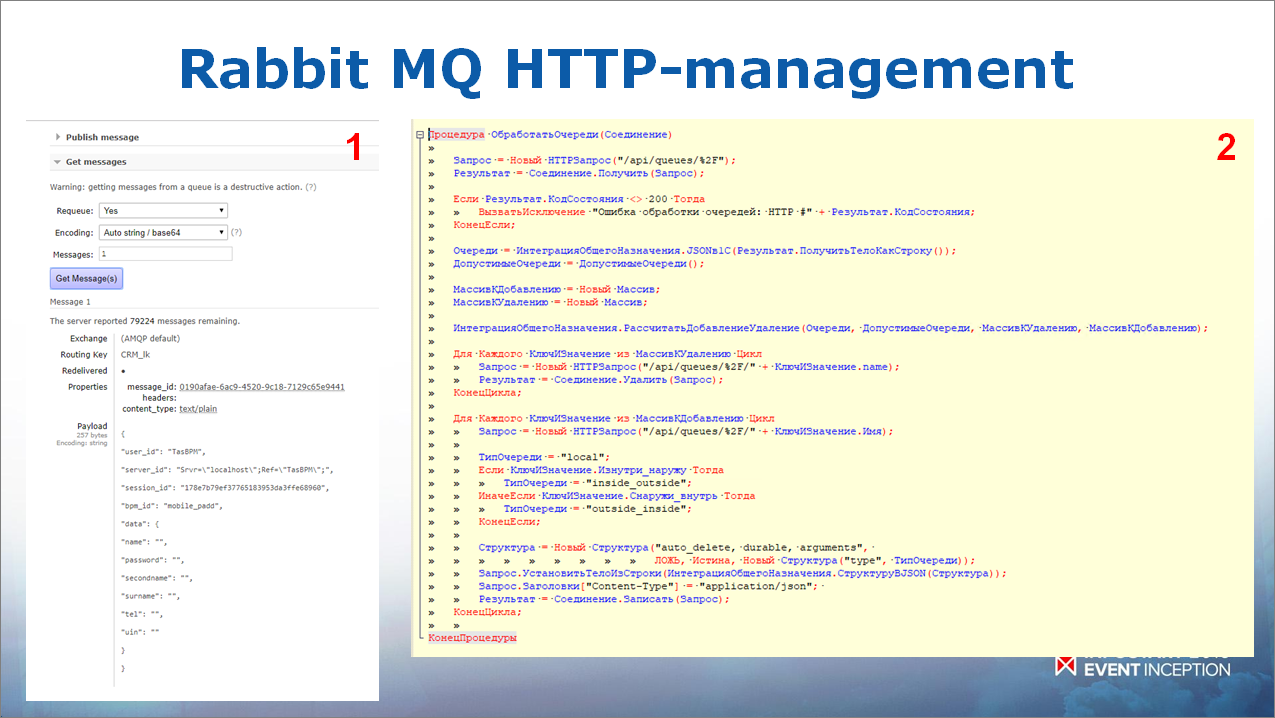
Что касается интерфейса RabbitMQ Management HTTP – это очень классная штука, если его правильно применять. В общем случае, он позволяет проадминистрировать RabbitMQ – посмотреть, какие у нас есть очереди, какие в них есть сообщения, какие Exchange и т.д.
Интерфейс также позволяет, обращаясь к нему, создавать очереди – удалять, создавать пользователей и т.д. Мы это используем – у нас в BPM-системе настраиваются те системы, с кем она общается, и все очереди создаются сразу же автоматически из BPM-системы.
То есть сам RabbitMQ нам не нужно администрировать, он администрируется автоматически.

Для чего его точно нельзя применять?
Абсолютно точно его нельзя применять для интеграции. Про это и в документации сказано, но я, конечно же, не поверил и попробовал. Проблема в том, что читает он очень медленно, обеспечивает всего 170 сообщений в секунду, и сообщения, которые вы считываете через интерфейс RabbitMQ HTTP Management, нельзя подтвердить. Там нет такого сервиса. Поэтому очень неудобно.
Интеграция через стандартную компоненту намного удобнее – там согласно нагрузочным тестам пролетает по 2000 сообщений в секунду, плюс есть возможность подтверждения чтения сообщений.
Удачи и сложности проекта

Что на этом проекте у нас получилось хорошо?
- При интеграции через шину архитектура получается расширяемой – можно абсолютно легко поставить рядом еще одну систему – просто сделать новые контракты, или вообще посадить систему на существующие контракты.
- Все запросы аудируемые.
- Redis существенно снижает нагрузку на инфраструктуру, нам не надо те же графики платежей каждый раз считать, они у нас кэшируются. У Redis очень удобно сделано. Там есть возможность поставить TTL, время жизни значения. Соответственно, если мы считаем сегодня, там всегда TTL ставится до 24:00 – таким образом, Redis сам следит за тем, чтобы графики всегда были актуальны.
Что очень сложно у нас проходило?
- Идея единой точки интеграции очень сложно доходила до участников проекта. Очень много приходилось разъяснять: на этом проекте было много подрядчиков, со всеми приходилось вести многочасовые беседы, потому что каждый хотел вытащить свои REST-интерфейсы и по-простому заинтегрироваться “точка-точка”. Но, c таким количеством систем, ни к чему хорошему это не привело бы.
- И были проблемы на старте с тем, что мы не совсем правильно подобрали ресурсы под виртуальные машины с RabbitMQ, соответственно, при больших нагрузках время доставки сообщений увеличивалось, мы не сразу могли это понять. Очень хорошо было бы, если бы какую-то систему мониторинга сразу под это подложили, чтобы она нам просигнализировала, что пора увеличивать.
Выводы из второго проекта

Какие выводы?
Сложные архитектуры очень интересно проектировать и внедрять. Это был очень интересный проект, эти технологии нужно знать, я считаю, потому что они позволяют решить проблему не так стандартно, как мы обычно привыкли – специалист по 1С часто пытается провести оптимизацию через конфигуратор, а здесь мы посмотрели на проблему с несколько другой стороны.
И интеграция в архитектуре «звезда» показала себя очень хорошо – дала и для бизнеса интересные возможности, и нам было ею интересно заниматься.
Вопросы:
- Хотел спросить по поводу BPM-системы. На мой взгляд, маршрутизация в RabbitMQ – крайне гибкая и замечательная. Почему вы не использовали маршрутизацию в RabbitMQ?
- Потому что у нас бизнес-логика была на BPM – там у нас был и контроль сессий мобильного приложения, и непосредственно бизнес-логика. Например, в зависимости от того, есть сессия или нет – могут быть разные ответы.
- А на время отклика насколько повлияла BPM-система? Она же, получается, наиболее медленное звено оказалось в этой цепочке.
- Не медленное, а наиболее высоконагруженное. Там сейчас средний отклик около 200 миллисекунд.
- А каждое сообщение, я так понимаю, пишется в базу данных 1С и только после этого маршрутизируется куда-то еще?
- Да. Время записи действительно влияет, я показывал JSON сообщения, который мы храним. Но это только на время тестов. Если его убрать, там быстрее будет.
- Мобильное приложение у клиента отправляет запрос на обновление каких-то данных. И этот запрос уходит в очередь сообщений, очередь сообщений его направляет в BPM, BPM лезет за данными сначала в кэш, а если в кэше их нет, дергает систему, получает их, записывает в кэш, и потом, соответственно, эти данные должно получить мобильное приложение. А как мобильное приложение эти данные получает?
- Отличный вопрос. Когда мы начали с разработчиками мобильного приложения проектировать архитектуру, это единственные, кого я не смог убедить использовать асинхронные вызовы, поэтому у них это выглядит таким образом – они обращаются к бэкенду мобильного приложения, бэкенд мобильного приложения, соответственно, держит запрос 300 миллисекунд. В основном, мы 80% запросов в эти 300 миллисекунд получаем ответы. Он держит сессию 300 миллисекунд. В это время он кладет сообщение в RabbitMQ, дальше оно проходит контур безопасности – сначала во внешний Rabbit, между ними – сервис-транслятор, который позволяет отключить внешний контур от внутреннего. Сервис-транслятор перекладывает его во внутренний RabbitMQ, из внутреннего RabbitMQ его считывает BPM-система, собирает данные, возвращает. При возвращении данных (там есть MessageID, естественно) бэкенд смотрит, если еще сессия жива (если успели в 300 миллисекунд), то возвращает. Для мобильного приложения получается простой синхронный GET-запрос. Но за ним стоит асинхронность. Если не успел, она его кладет в Redis, но уже в другой Redis. Для мобильного приложения два уровня кэша. Первый уровень кэша – это Redis, который за BPM, а второй уровень кэша – это тот, который стоит на бэкенде. Кладет его в Redis, а мобилка получает 201 статус, если не успеет на 300 миллисекунд (это означает «запроси еще раз») и время, через которое нужно еще раз запросить.
- У нас есть интеграция между 1С с другой системой через HTTP-сервисы. И когда запросов много – условно, несколько десятков, то все начинает жестко висеть. Вопрос в том – то, о чем вы сейчас рассказали, судя по всему, можно применить как раз чтобы накапливать вызовы этих HTTP-сервисов. То есть они у нас непостоянные, может быть секунда, в которую три вызова, есть секунда, в которую 30 вызовов. Можно ли применить то, что вы описали, но насколько это сложно? Есть уже работающая интеграция с каким-то простым HTTP-сервисом. Насколько сложно применить вашу технологию.
- Не сложно, я давал ссылку на описание интеграции с RabbitMQ. Там коллега выложил готовый пример, его просто копируешь, и все работает. Вам нужно просто скопировать этот код в две конфигурации и поставить себе RabbitMQ. И все. И немного, может быть, допилить.
- Что вы можете сказать по поводу отказоустойчивости RabbitMQ? Как вы обеспечили очереди с Durable? Или кластер был?
- Мы еще не прорабатывали отказоустойчивость, это будет следующий этап.
- Поэтому у вас и такие высокие скорости, стоит вам только включить Durable в очередь, у вас упадет все в десятки раз.
- Смотрите, у нас цена потери сообщения – не очень высокая. Если у вас мобилка обновилась за полсекунды и за 0.7 секунды – вы не увидите разницы. Да, если включить отказоустойчивость, скорость просядет, но останется достаточно приемлемой, как правило. У нас в планах объединить RabbitMQ в кластер, и сделать горизонтальное масштабирование BPM-системы.
- У меня тоже вопрос по производительности – какой скорости передачи сообщений в секунду из Rabbit реально удалось добиться и какой средний размер сообщения (в байтах, в чем угодно).
- В байтах размер сообщения я точно не скажу. Самое большое сообщение в JSON, которое я гонял – это график платежей на 12 месяцев. У меня получилось порядка 400 сообщений в секунду на всю инфраструктуру. Не забываем, что там есть 1С, который отвечает не так быстро.
- При каком железе? Чистый Rabbit?
- Rabbit на виртуалке с параметрами процессор e5 и 128 Гб оперативной памяти. Сам RabbitMQ при двух выделенных ядрах и 4Гб оперативной памяти, из 1С давал 2000 сообщений в секунду. Но кто там сейчас тормозит – 1С или RabbitMQ, будем еще расследовать.
- Вернемся к первому проекту. На слайде я увидел, что у вас роботы-сборщики, которые парсили публикации в инстаграме, они общаются с 1С не через RabbitMQ, а напрямую. Почему так? Это связано с объемом данных или с чем-то еще?
- Это было сделано просто для удобства. Потому что из 1С было удобно вытащить HTTP-сервис. Там специфика работы этих роботов-разборщиков – они волнами идут. Сначала, допустим, много сообщений, а потом в конце дня, так как уже все закешировано (кеш 24 часа держится), их мало. Поэтому нам там придумывать RabbitMQ между роботами мы посчитали нецелесообразным. Остались на HTTP-интерфейсе. Когда будем новые соцсети подключать, наверное, перейдем на RabbitMQ.
- Я не совсем понял, зачем там Redis?
- Я напомню, сканер просматривает публикации, и ссылки на эти публикации кладет в Redis. ИД кладет в очередь, робот-разборщик берет ссылку по ИД и открывает публикацию полностью. В Redis мы использовали несколько функций. Во-первых, там хранятся ссылки, во-вторых, если публикацию мы прошли, то следующие 24 часа мы ее не трогаем. Мы просто отмечаем, что мы ее пробежали и устанавливаем “время жизни” - TTL.
- По инстаграму – а публикации вручную просматривали? Как там выявлялось, что используется контент, который требует лицензии?
- Когда мы запускали управляющую систему, там был поиск по хэштегам, этого было достаточно, потому что люди вообще не стесняются. А дальше там они планировали нейросеть и то, что нейросеть не разобрала, идет в отдельное место для верификатора, который уже глазами проверяет.
****************
Данная статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART EVENT 2019.

Вступайте в нашу телеграмм-группу Инфостарт