





Проблема – обязательно появятся новые тексты ошибок через некоторое время после начала эксплуатации, которые могут не отнестись ни к одному классу или классифицироваться не верно.
Замечание: Технически данное поведение связано с тем, что слова из текста новой ошибки, могут принадлежать множеству заданных нами классов, и в результате в алгоритм вычисления может не верно классифицировать эту новую ошибку на наш экспертный взгляд. Или наиболее приемлемый вариант не классифицированы вообще.
Система в данном случае с помощью алгоритма "мешка слов" (continuous bag-of-words model, CBOW) будет выбирать наиболее подходящий класс на основе косинусного сходства.
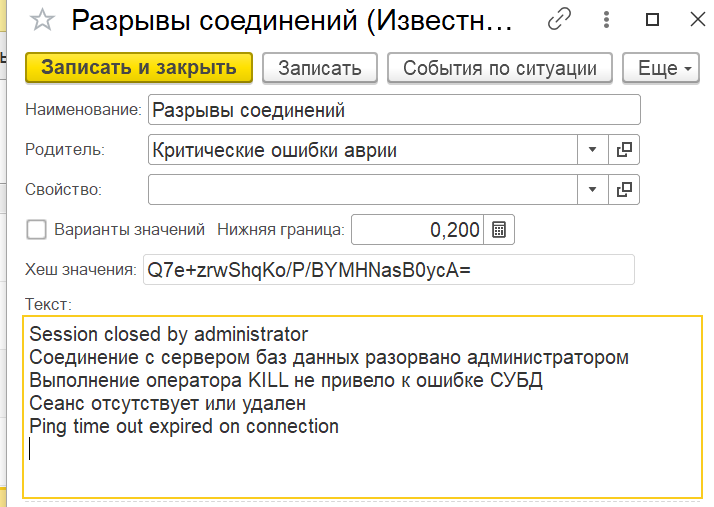
Можно увеличить точность классификации использовав алгоритм skip-gram. Классифицировать не по словам, а по словосочетаниям. Этот алгоритм более сложный в настройке пользователем из-за необходимости выявления этих словосочетаний. В текущей реализации частичную его имитацию можно выполнить через замену фраз синонимов, т.е.«ошибка доступа» на «ошибка_доступа». Но более правильно будет все же «ошибк доступ» на «ошибк_доступ». В планах у нас стоит модификация и улучшение алгоритма, но пока не хватает ресурсов и нас удовлетворяет пока текущий уровень классификации.
Задача: исправить и улучшить качество классификации.
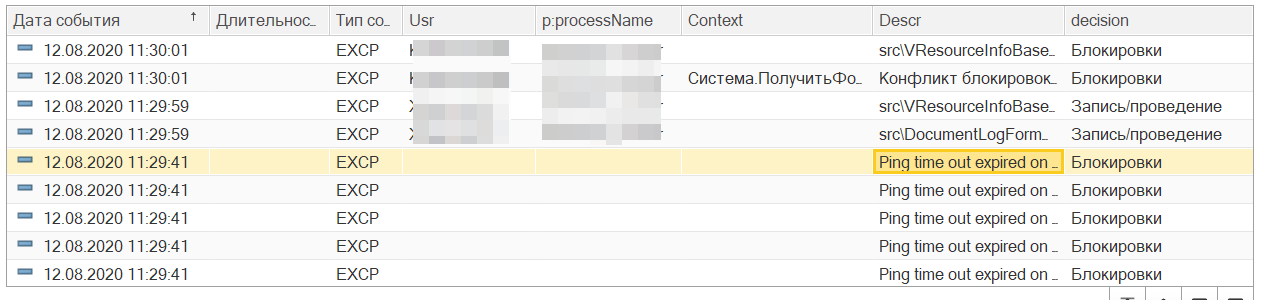
Пример. После смены платформы мы получили новый тип ошибок и видим не корректную классификацию:
Последовательность действий:
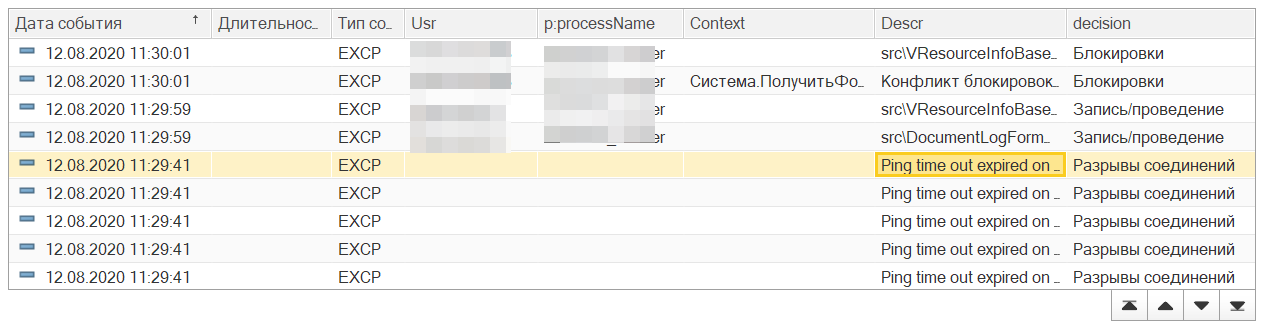
1) Получаем текст ошибки. Берем и копируем текст ошибки: Ping time out expired on connection
2) Выбираем верный класс. Наиболее подходящим классом для нас является: Разрывы соединений
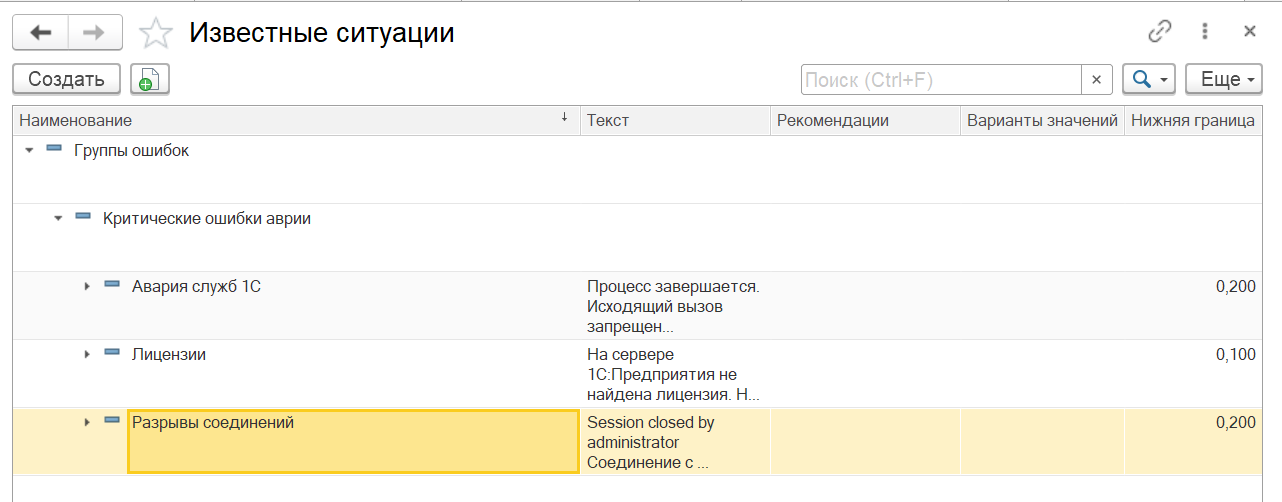
3) Обновляем текст класса. И добавляем этот текст в выбранный класс и сохраняем
4) Выполняем проверку и перенастройку (при необходимости). Иногда (если мало изменений), можно не пересчитывать базис и достаточно проверить, что классификация верно выполняет обработку:
а) Идем в настройки и проверяем как изменилась классификация. Для этого открываем команду в дополнительных отчетах и обработках подсистемы замеры "Настройка 'Авто классификация ошибок технологического журнала'".
б) Подготавливаем математику.
- Загружаем классификатор. Для этого переходим на вкладку "2) Данные из базы"->"Выбрать данные из классификатора" и нажимаем на кнопку "Выбрать данные из классификатора".
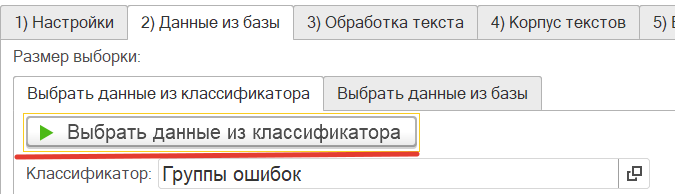
- Рассчитываем векторное пространство и строи по базису из классификатора. Переходим на вкладку "5) Базис". Сначала нажимаем на кнопку "в) Сформировать вектора", а после на "г) рассчитать векторное пространство по классификатору"

в) Начинаем проверку. Переходим на вкладку "7) Проверка". Вставляем текст ошибки в поле строки запроса. Жмем кнопку "Поиск" и смотрим результаты:
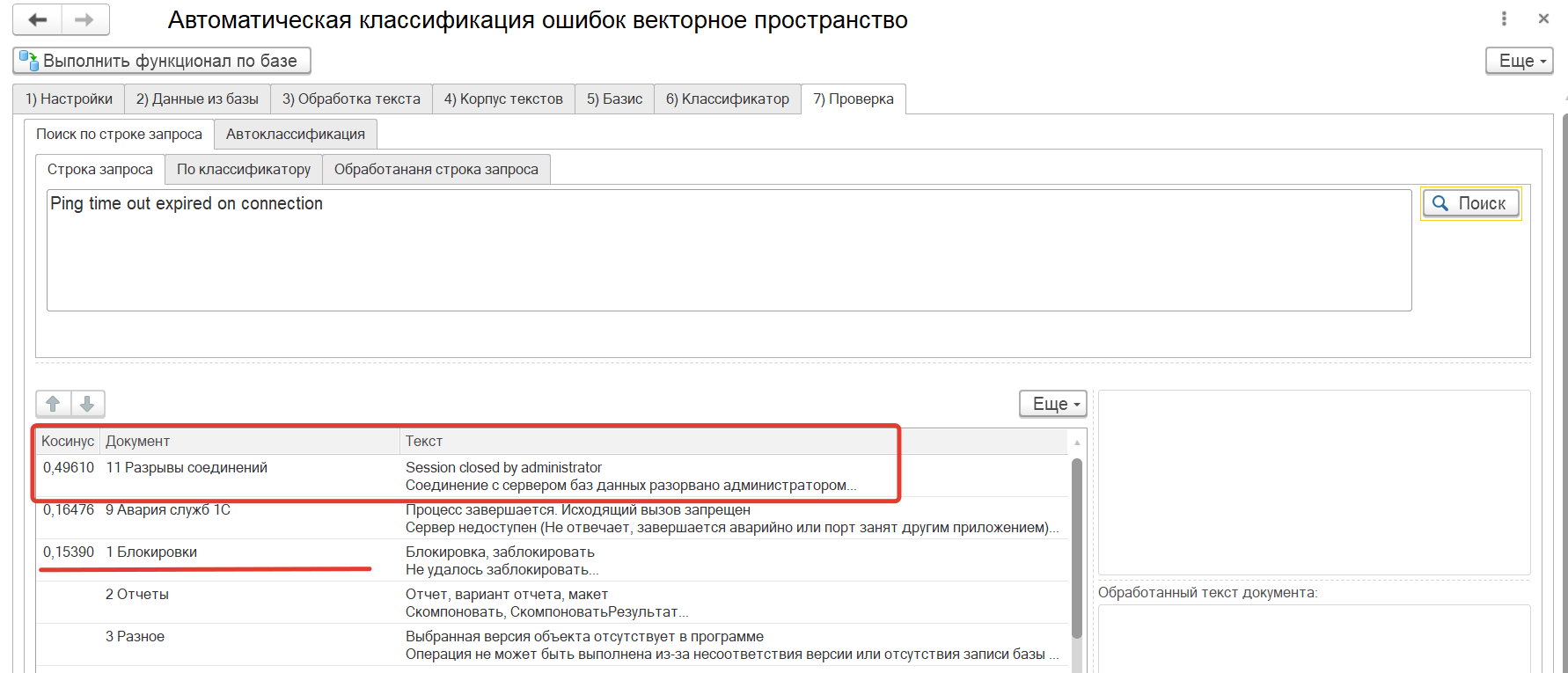
Правильная классификация "Разрывы соединений" должна оказаться на первой строчке таблицы, а все остальные должны быть сильно позади (смотрим на значения косинуса). В нашем случае так и произошло - первая строчка и значительный разрыв относительно двух других блоков. Ранее на первой картинке в статье была показана не верная оценка. С момента выполнения настройки новые ошибки теперь будут верно классифицироваться.
Внимание! Если данные считаются недостаточно приемлемо, то требуется выполнить перенастройку по алгоритму описанному в статье "Автоматическая классификация ошибок технологического журнала".
5) Выполняем пересчет классификации за предыдущие периоды. Вы можете пересчитать все предыдущие результаты авто классификации или за интересующий период. Для этого:
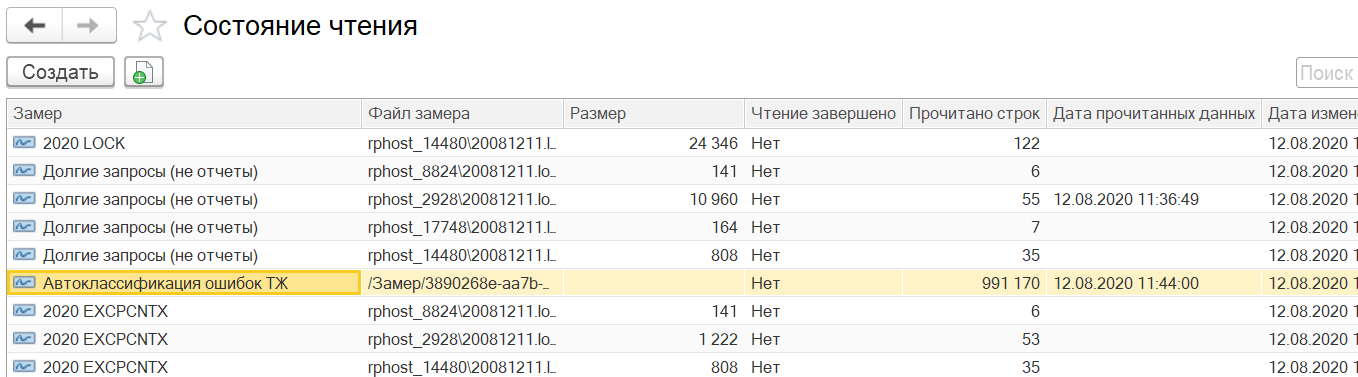
а) Идем в список регистр сведений "состояния чтения".
б) Находим наш замер авто классификации
в) И изменяем дату на точку пересчета:
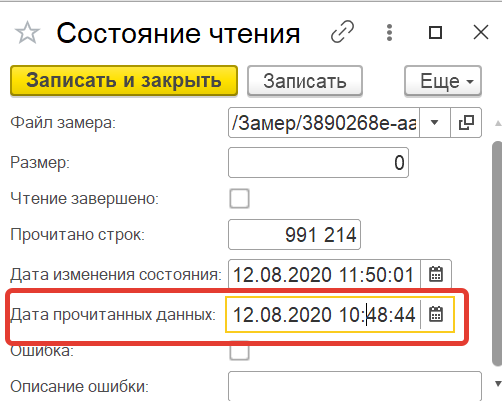
г) Сохраняем и ждем запуска регламентной процедуры. На этом все)
Дополнительно:
- Адрес проекта на GitHub Фреймворк "Мониторинг производительности".
- Статья по настройке с начала автоматической классификации - "Автоматическая классификация ошибок технологического журнала"
- Статья по подключению загрузки логов ТЖ - "5 простых шагов и 15 минут на разворачивание инструмента мониторинга проблем производительности базы 1С"
- Методичка по работе с фреймворком - Фреймворк "Мониторинг производительности". Руководство пользователя
- Готовую конфигурацию можно скачать из приложения статьи "Решение проблемы быстродействия в ERP на рабочем примере" или с GitHub.
Вступайте в нашу телеграмм-группу Инфостарт