Промо:
- анализировать технологический журнал вручную долго, а в реальном времени практически невозможно для даже слабеньких систем, это все должно быть автоматизировано;
- автоматическая классификация текстов ошибок;
- автоматическое формирование и рассылка сообщений по аварийным и критическим ситуациям на основе анализа логов;
- у Вас появилась возможность использовать частичную функциональность систем искусственного интеллекта здесь и сейчас.
Описание проблемы:
- Сложность анализа и постоянный контроль - При анализе текстов записей технологического или регистрации журналов Вам требуется оперативный анализ по категориям/классам: блокировка, ошибка доступа, программного кода или еще что-то. Вычленить понятие события из текста содержащего кучи GUID, стека вызовов и всяких там технических терминов – сложная и трудоемкая задача. Просмотреть (часто большой текст сообщения) можно вручную (не оперативно) если этих событий 10 или 100, но вот если их более чем 1000, да еще и каждый час, то этот набор сырых данных превращается в китайскую грамоту, и мы быстро начинаем уставать – терять сосредоточенность, что-то пропускать, игнорировать и т.д.
- Оперативность реагирования - Требуется максимально оперативно узнать, что появилось критическое сообщение в журнале и поставить алармы/ярлычки на какие-то определенно встречающиеся опасные события/сообщения в технологическом журнале. К примеру, новая неизвестная ошибка (особенно уместно после обновления конфигурации) или сообщения падения хостов, агента, СУБД – типа «На сервере 1С:Предприятия не найдена лицензия. Не обнаружен ключ защиты программы или полученная программная лицензия!», «Процесс завершается. Исходящий вызов запрещен» или «Сервер недоступен (Не отвечает, завершается аварийно или порт занят другим приложением)».
Если все это Вам требуется - то эта статья с практикой применения для Вас.
Небольшой флешбек:
Вопрос автоматической классификации ошибок был поставлен у нас еще до появления самой конфигурации. Однако основная и первичная задача стояла в автоматическом мониторинге состояния системы в облаке и сообщении о проблемах производительности. Эти задачи на текущий момент решены и улучшаются время от времени. Теперь поговорим о варианте выполнения автоматической классификации ошибок. Информацию по данной тематике мы преподнесем в двух публикациях. В первой и текущей публикации мы кратко коснемся вопроса теории, а во второй более подробно остановимся на этом важном, на взгляд авторов аспекте.
Скажем сразу фактически никаких иных инструментов, кроме 1С, т.е. никакого зоопарка из кучи инструментов типа python и т.п. мы не использовать не будем)
Задача:
Отнести текстовое сообщение об ошибке на основе данных технологического журнала к одному из заранее определенных классов.
В качестве математики будем использовать механизм преобразования текстов в векторное пространство и косинусное сходство.
Структура статьи:
- Настройки и порядок выполнения работ
- Видео-урок
- Замечания, советы, ссылки.
I) Практика
1 Шаг. Скачиваем необходимые ресурсы
А) Скачиваем обновленную конфигурацию «Мониторинг производительности» и обработку «АвтоматическаяКлассификацияОшибокВекторноеПространство.epf». Устанавливаем конфигурацию, если еще не стоит.
Б) Добавляем обработку в дополнительные отчеты и обработки. Подсистему выбираем «Замеры».
В) Выполняем настройку загрузки логов ошибок технологического журнала (если не делали ранее) - 5 простых шагов и 15 минут на разворачивание инструмента мониторинга проблем производительности базы 1С
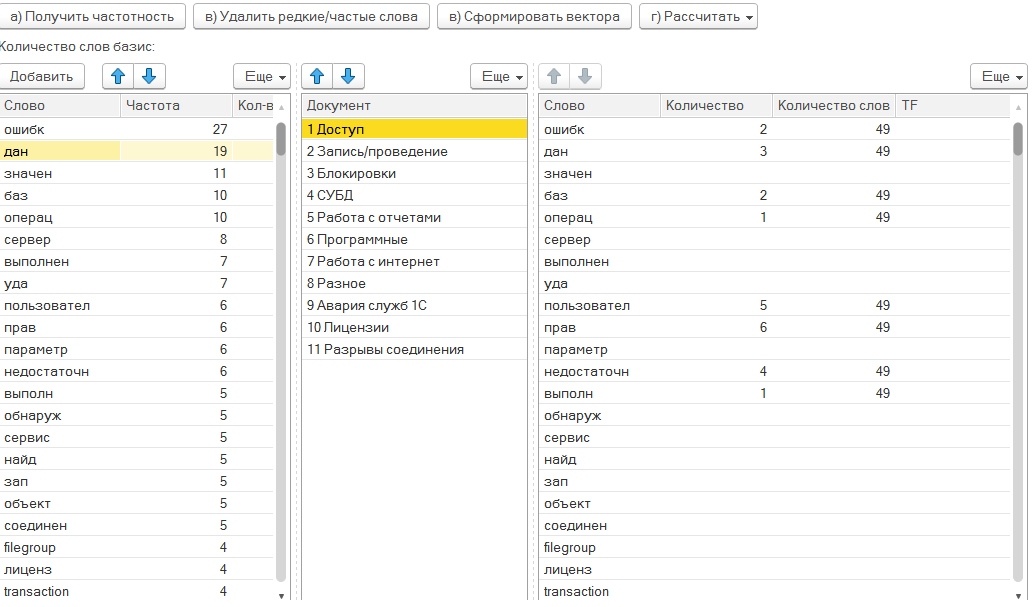
2 Шаг. Заполняем классификатор ошибок.
Открываем справочник "Известные ситуации" в подсистеме "Замеры". Создаем корневой элемент и называем его "Классификатор ошибок ТЖ". А далее создаем набор справочников в соответствии с примером ниже.
Опорные тексты кластеров приведены внутри каждого класса. Обязательно выполняйте настройку под себя изменяя/регулируя тексты, и значения нижней границы. Общий совет - чем меньше текст кластерам и мало в нем уникальных слов, то тем выше необходимо поднимать границу.
- Доступ – ошибка доступа, права и роли. Нижняя граница сходства > 0.1
- Запись/проведение – ошибки записи документов, справочников, регистров и проведения документов. Нижняя граница сходства > 0.1
- Блокировки – блокировка документов, действий, форм. Нижняя граница сходства > 0.1
- СУБД – ошибки взаимодействия сервера 1С с базой данных. Нижняя граница сходства > 0.1
- Работа с отчетами – ошибки, связанные с формированием, выполнением отчетов. Нижняя граница сходства > 0.2
- Программные – ошибки, связанные с выполнением различного кода. Нижняя граница сходства > 0.08
- Работа с интернет – не удалось получить данные, превышено ожидание и др. Нижняя граница сходства > 0.2
- Критические ошибки авария (элемент группы) – падение хостов, отсутствие лицензий, отказ служб и т.п.
- Авария служб 1С. Нижняя граница сходства > 0.2
- Лицензии. Нижняя граница сходства > 0.2
- Разрывы соединения. Нижняя граница сходства > 0.2
- Авария служб 1С. Нижняя граница сходства > 0.2
- Разное – все остальные ошибки, не вошедшие в предыдущие классы
3 Шаг. Выполняем настройку обработки
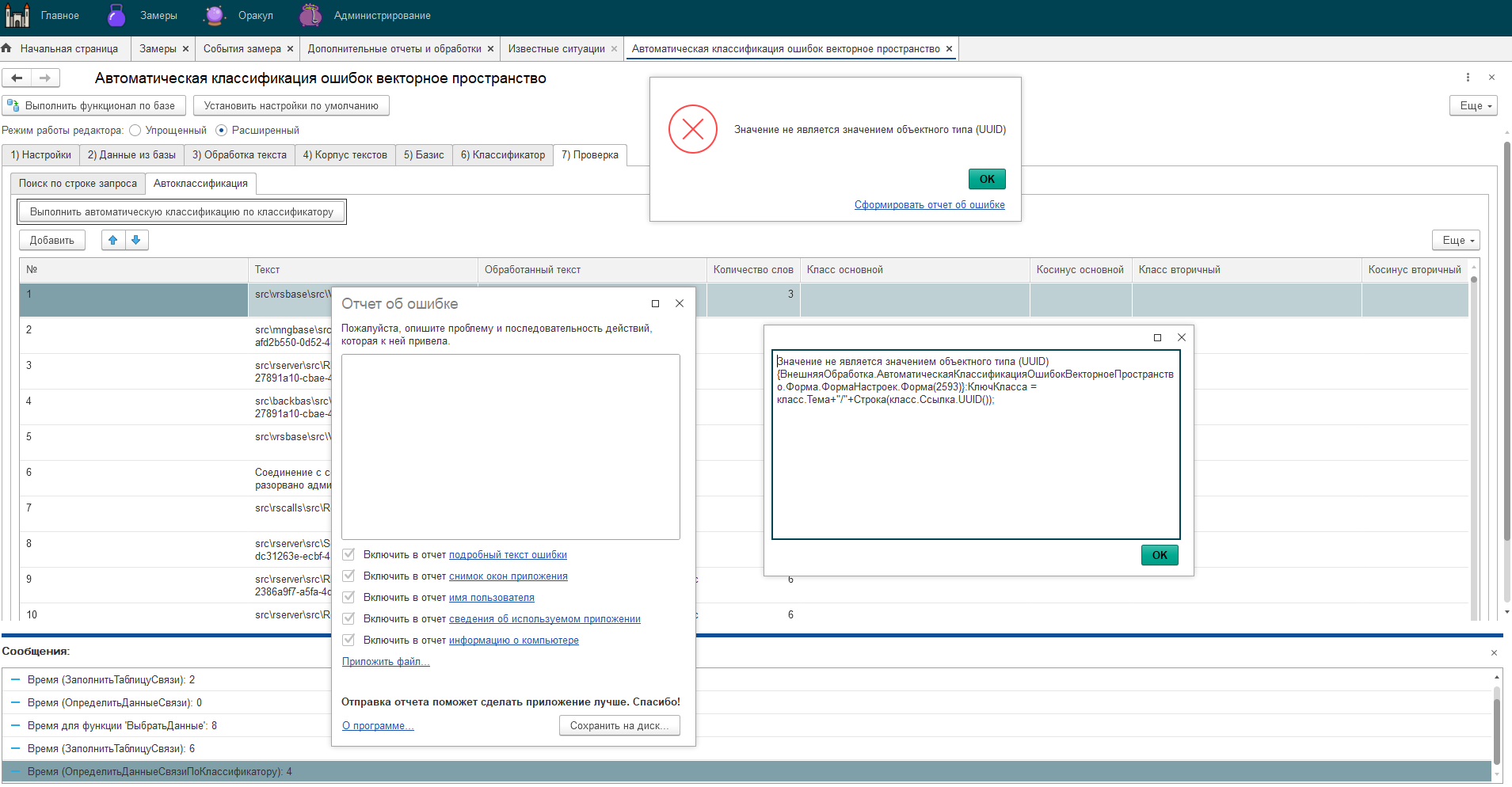
А) Открываем форму "Настройка 'Автоматическая классификация ошибок ТЖ'" дополнительной обработки.
Б) Указываем параметры обработки текстов. Это так называемая процедура подготовки данных для анализа. Настройки можно выполнить согласно рисунку ниже.
В) Указываем стоп слова/ стоп фразы/ синонимы (можете пропустить, если не знаете как и зачем)
Г) Указываем источники для получения данных и выполнения обработки (вкладка 'Данные из базы'/'Выбрать данные из базы'). Обычно это ссылка на замер и свойство 'Descr'.
Д) Используем текстовые данные с текстовым корпусом ошибок из файла или на основе данных базы. Это вкладка "Данные из базы"/"Выбрать данные из классификатора". Жмем кнопку "Выбрать данные из классификатора".
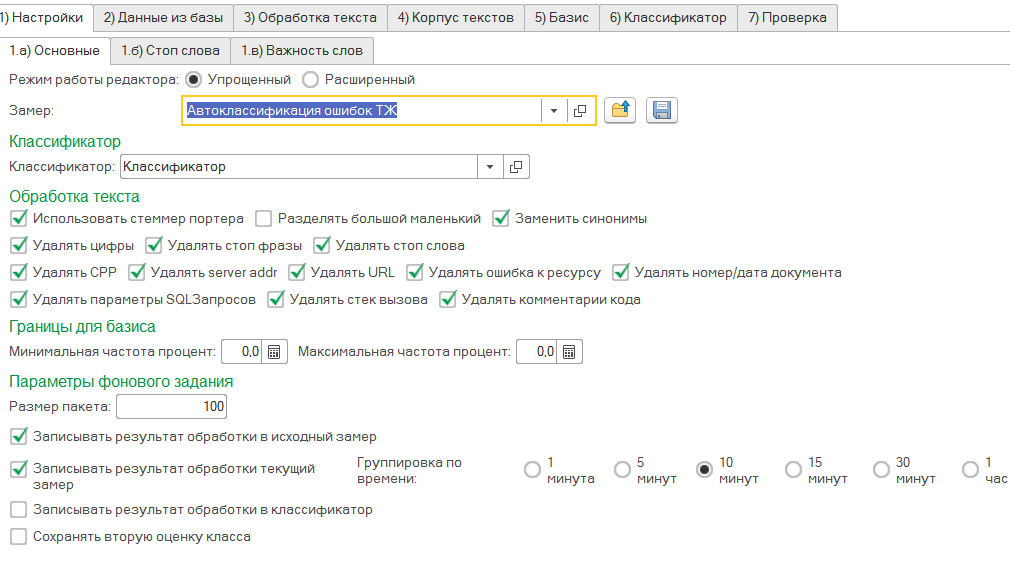
Е) Переходим к формированию базиса и векторного пространства ошибок технологического журнала. Вкладка "Базис".
Ж) Формируем базис данные для классификации. Последовательно нажимаем кнопки "Получить частотность", "Сформировать вектора", "Рассчитать векторное пространство".
З) Сохраняем настройки в замер.
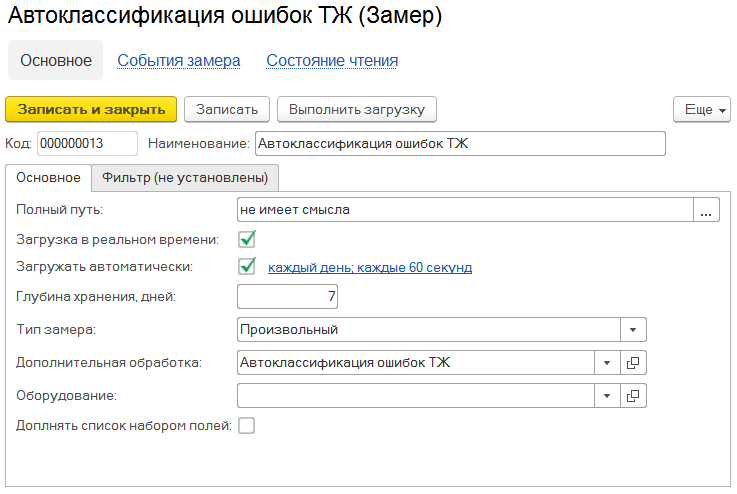
4 Шаг. Выполняем проверку и настройку.
Выполняем оценку качества классификации.
А) Выбираем набор проверочных данных (вкладка 'Данные из базы'/'Выбрать данные из базы'). Жмем "Выбрать данные" (используем период и первые - иначе будет очень долго и тяжело).
Б) После на вкладке "Обработка текста" жмем кнопки последовательно - "Обработать текст", "Заполнить таблицу корпуса слов по текущему тексту".
В) Формируем вектора текстов. На вкладке "Базис". Жмем последовательно кнопки - "Сформировать вектора", "Рассчитать векторное пространство по классификатору".
Г) Переходим на вкладку "Проверка"/"Автоклассификация" формы настройка и выполняем авто классификацию - жмем кнопку "Выполнить автоматическую классификацию по классификатору".
Д) Вычисляем количество верных оценок, принимаем решение о дальнейшей настройки или завершении настроек.
Качество результата обработки можно получить по формуле:
Качество классификации = 100% * Количество правильных классификаций / Количество примеров.
Настройку необходимо производить до уровня не менее 95%. Оптимально - 98-99%.
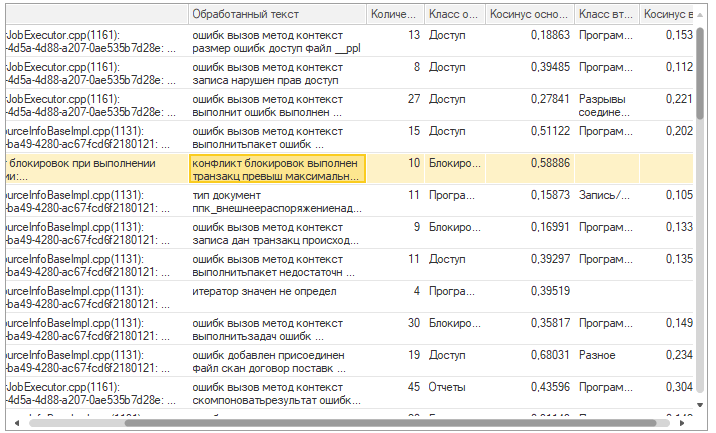
5 Шаг. Запуск в работу!
Запускаем регламентное задание автоматической классификации. На вкладке замера загрузки логов можно увидеть результаты классификации в колонке "decision"

Открываем форму "Монитор 'Классификация ошибок'" анализа данных или журнал замеров и смотрим результат.
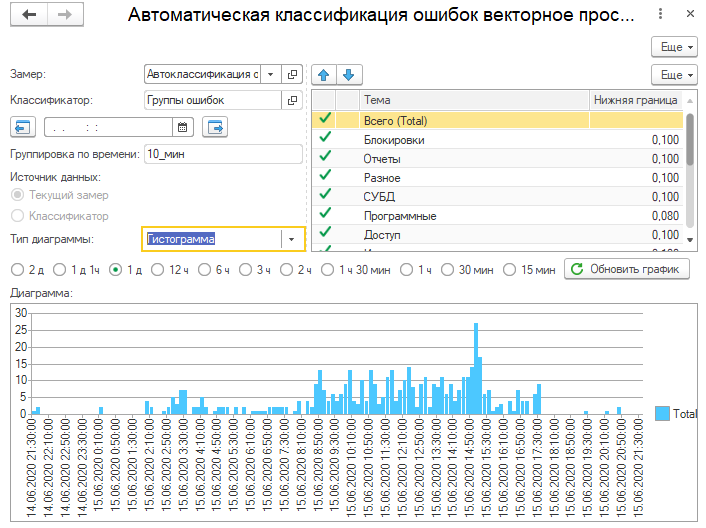
II) Видео-урок.

III) Замечания:
- Чем качественнее составлен базовый вектор (базис слов), тем лучше будет результат. Т.е. если вы поленитесь убирать мусорные слова типа имен пользователей, комментариев и т.п. тем хуже будут результаты.
- При появлении новых ошибок вам понадобится перестроить словарь – дополнить. Критерием этого будут служить появление новых не классифицированных ошибок.
- Аккуратно пользуйтесь важностью слов, т.к. этот критерий будет увеличивать влияние данных слов на результат.
- Формирование классификатора на основании текстов можете использовать для общей группировки, а далее формируйте руками.
- Рекомендуем граничный критерий схожести установить в диапазоне от 0,8-0,86 до 1 (это соответствует радиусу между векторами от 36-30 до 0). При значении косинуса близком к 1 можно сказать, что вектора одинаково направлены на 100% - это максимальное подобие. При значениях в районе 0 или отсутствии – означает, что совсем различны.
- Уточните и заполните Стоп-слова и Синонимы фраз. Это позволит очистить результат от шума и сделать результат классификации гораздо лучше.
- Анализировать данные по темам можно для любой текстовой информации, которую можно добавить в замеры – данные об инцидентах пользователей, письмах на поддержку и т.п.
- Советуем не делать большой базис слов – не более 800-1000 слов. Если у Вас получилось больше, значит у вас много лишних понятий. Проведите чистку.
- Для классификатора корпус текстов ошибок тоже не должен быть большим. Оптимально 5-15. К примеру: «Отчеты», «Проведение/запись документов/справочников», «Доступ», «Блокировки», «Ошибки сервисов»...
Ссылки:
- Фреймворк «Монитор производительности»
- Руководство по эксплуатации.
- АвтоматическаяКлассификацияОшибокВекторноеПространство.epf
- Готовую конфигурацию можно скачать из приложения статьи: Решение проблемы быстродействия в ERP на рабочем примере
Вступайте в нашу телеграмм-группу Инфостарт