



















Мы опишем результаты наблюдений и выводы по состоянию производительности системы через мониторинг RAS 1C основанный на наших наблюдениях и мнении/советах коллег по цеху. Наиболее показательны изменения для больших баз по количеству работающих пользователей на одном кластере. Иначе требуется проводить агрегирование показателей таких как очередь какого-нибудь свойства, если на сервере много кластеров или на реальном много виртуальных машин для общей оценки сервера.
Также на поведение параметров контролируемой целевой базы 1С будет оказывать влияние версия платформы, окружение, конфигурация и это также нужно будет учесть при сравнении. Однако, динамика и характер поведения должны быть похожи. Мы выполняли анализ на версиях 8.3.14, 8.3.15, 8.3.16 и конфигурации ERP 2.4.
I) Свойства процессов
|
Свойство |
Синоним |
Функция агрегации |
Описание |
|---|---|---|---|
|
line-number |
номер строки |
count |
Номер строки (по порядку) |
|
memory-size |
память КБ |
max |
Содержит объем виртуальной памяти, |
|
memory-size |
память КБ |
sum |
-//- |
|
available-perfomance |
дост. произв. |
min |
Средняя за последние 5 минут доступная |
|
available-perfomance |
дост. произв. |
sum |
-//- |
|
available-perfomance |
дост. произв. |
avg |
-//- |
|
connections |
кол-во соединений |
sum |
Количество соединений рабочего |
|
avg-call-time |
avg |
Показывает среднее время обслуживания |
|
|
avg-call-time |
max |
-//- |
Параметр состояния процессов avg-call-time
Параметр avg-call-time – позволяет увидеть проблемы загрузки хоста, если один из них находится под нагрузкой
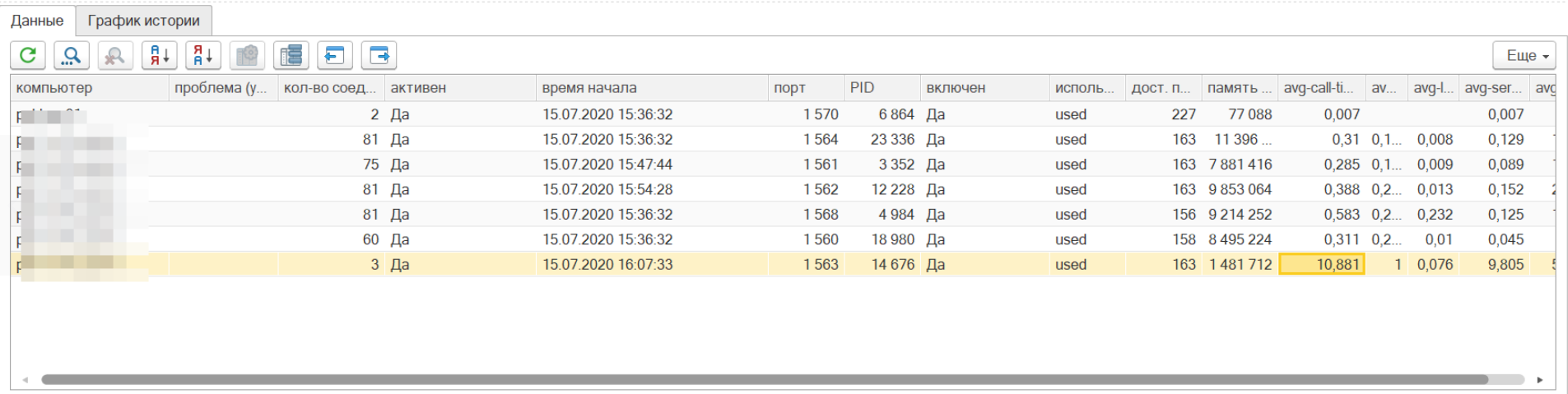
Вот так выглядит график средней нагрузки

В этот момент было запущено тяжелое задание по пересчету регистра. Всем тем, кто-попадал на этот процесс было «плохо».
Если же все процессы показывают рост нагрузки, то скорее всего проблема возникла у менеджера, и он перестал корректно разруливать ситуацию.
Можно поставить оповещение о изменении данной ситуации, нормальное среднее значение должно быть значительно менее 1. При значениях от 1 до 2-3 возможны проблемы. При значениях более 7-10 можно считать, что мы потеряли пациента.
Во всех случаях серьезных проблем с хостами рекомендуем выполнить мягкий перезапуск.
Вот так выглядит показатель среднее avg-call-time при проблемах на сервере.
Вот так выглядит нагрузка на процессор в этот момент:

Количество процессов
Изменение количества процессов, также график позволяющий определить проблемы. Резкий рост или превышение некоторого установившегося количества, также является критерием того что у нас происходят какие-то проблемы.
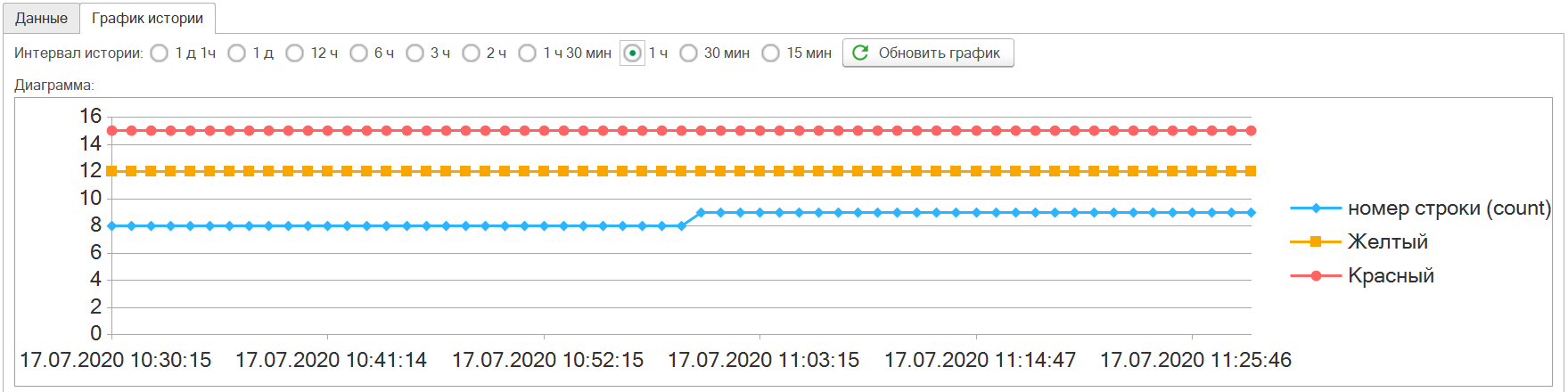
Вот так меняется количество процессов при аварии:

Показатель расхода памяти
Показатели расхода памяти особенно проявляются с увеличением количества процессов. Рост памяти выше доступных в системе приведет к остановке служб. На графике ниже можно проследить рост потребления после запуска нового процесса.
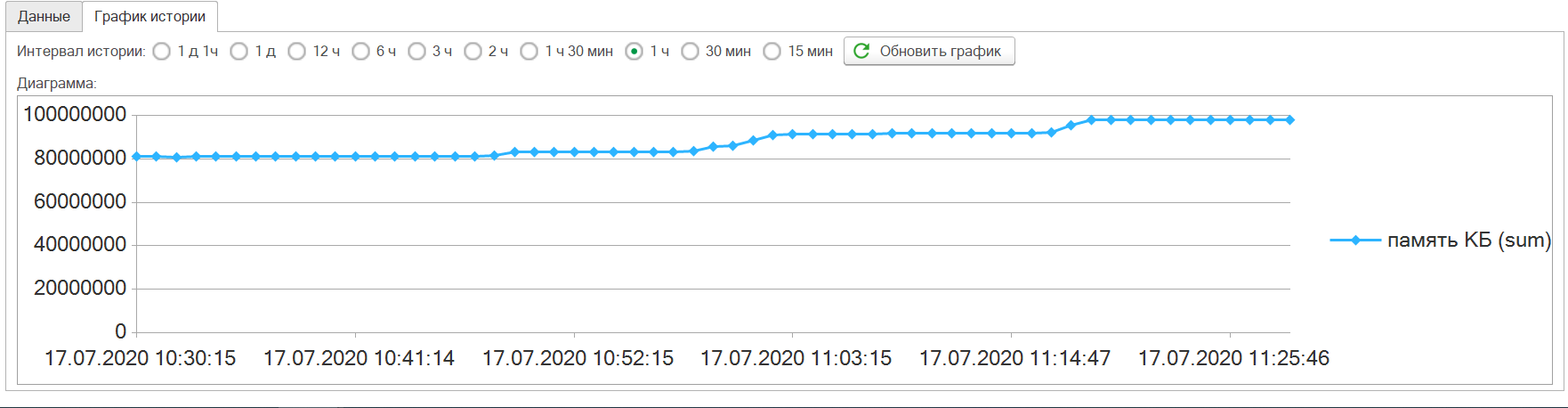
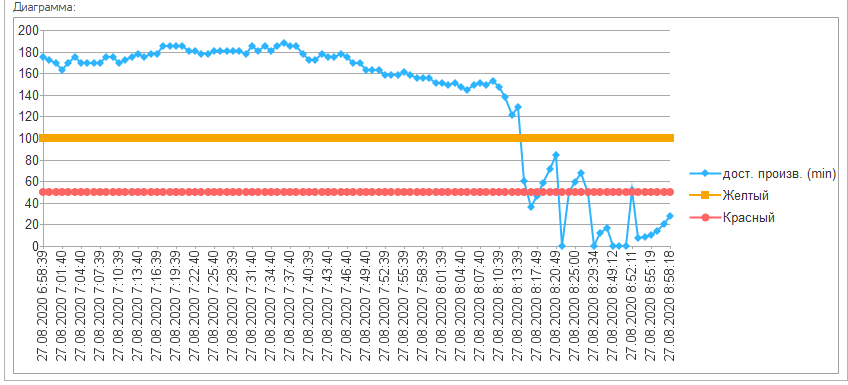
Показатель производительность
Вот так выглядит падение производительности по показателю доступная производительность:
II) Свойства соединений
| Свойство | Синоним | Функция агрегации | Описание |
|---|---|---|---|
|
session-number |
сеанс |
count ЗначениеЗаполнено |
Номер сеанса |
|
conn-id |
count ЗначениеЗаполнено |
Содержит номер соединения. |
|
|
line-number |
номер строки |
count |
Номер строки (по порядку) |
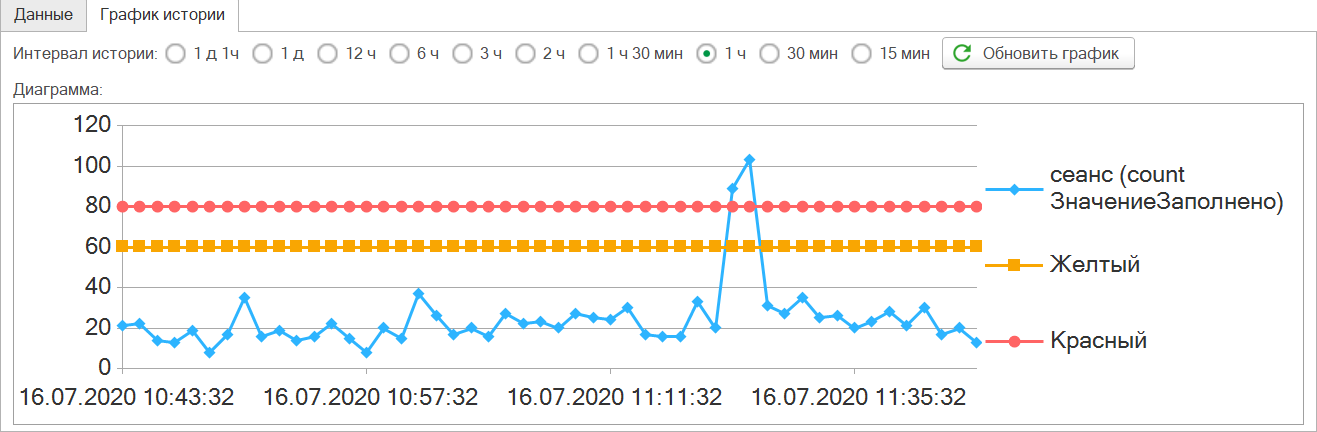
Показатель соединений session-number
Если следить за связью между процессами и сеансами пользователей, то можно легко определить нормальные и не нормальные показатели для состояния системы. Об использовании нейронных сетей для определения критичных аномалий, о которых рассказывал на конференции я буду рассказывать позже (сейчас есть решаемые технические проблемы, которые не позволяют их использовать массово без сторонних приложений и с функционалом из коробки – банально не хватает времени).
Как только количество соединений между процессами и сеансами в единицу времени превышает некоторый порог, то стоит трубить о проблемах. На рисунке ниже показана ситуация аварии, в момент пика службы 1С перестали обслуживать и произошел самостоятельный перезапуск всех процессов с дальнейшим падением менеджера кластера. Он настолько ушел в себя, что не отпустил кэш и пришлось его удалять вручную.
Для хорошо нагруженной системы обычно такой показатель колеблется в районе 30-40 соединений в единицу.
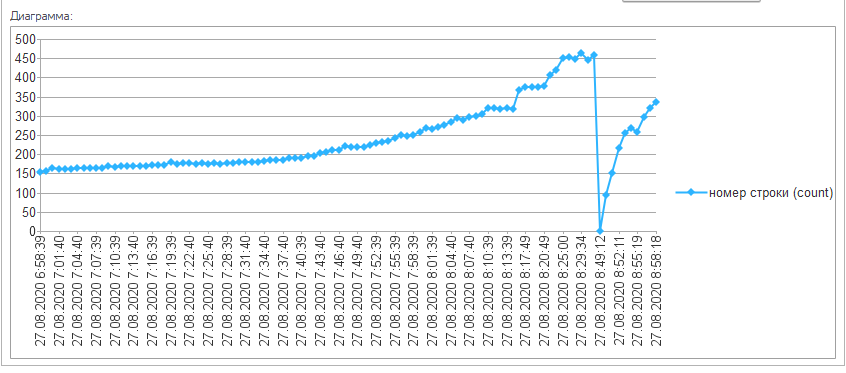
Вот так показатель количество строк при падении производительности с полным зависанием служб.
Рекомендуемые агрегируемые функции:
- session-number - функция количество Значение Заполнено (т.е. для всей таблицы данных считаем только те в которых есть значение отличное от пустого). Определяет очередь из соединенных между собой сеансов и rphost. Чем больше тем хуже. При резком росте характеризует проблемы в управлении соединениями менеджером (или агентом). С ростом этого показателя можно менять удовлетворенность работы пользователей с зелененького на красный.
III) Свойства сеансов
| Свойство | Синоним | Функция агрегации | Описание |
|---|---|---|---|
|
line-number |
номер строки |
count |
Номер строки (по порядку) |
|
duration-current |
время вызова (текущее) |
max |
Содержит интервал времени в |
|
duration-current |
время вызова (текущее) |
sum |
-//- |
|
duration-current |
время вызова (текущее) |
count ЗначениеЗаполнено |
-//- |
|
db-proc-took |
захвачено СУБД |
max |
Если в момент получение списка соединений информационной базы методом |
|
db-proc-took |
захвачено СУБД |
sum |
-//- |
|
db-proc-took |
захвачено СУБД |
count ЗначениеЗаполнено |
-//- |
|
cpu-time-current |
процессорное время (текущее) |
max |
Процессорное время текущее |
|
cpu-time-current |
процессорное время (текущее) |
avg |
-//- |
Как уже ранее рассказывал, то стоит следить сразу несколькими параметрами
Свойство duration-current
Показатель duration-current (время вызова (текущее)) показывает обслуживание пользователя процессом. Если же количество пользователей со значением этого параметра (отличным от 0 в каждый момент времени) растет, то сервисы 1с не успевают обслуживать, кто-то запустил что-то тяжелое и в итоге может привести к серьезному снижению производительности. Обычно значения, превышающие 60 штук (зависит от конкретной обслуживаемой системы) повод задуматься о том, что начинаются проблемы.
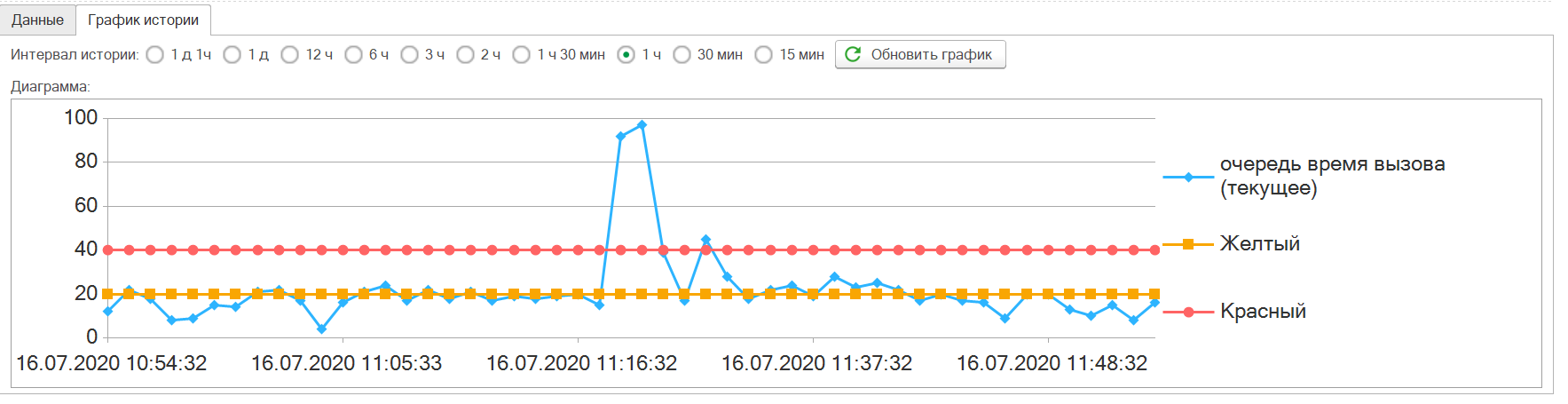
Предполагаем в данном случае отследить пользователя по табличной части «Данные» смотри ниже. Далее связаться с ним и обсудить решение проблемы. Возможно приложение зависло и его достаточно удалить, и система придет в норму, или попросить пользователя не запускать тяжелых задач. А возможно проблема производительности какой-либо формы или обработки и требуется ее оптимизация и рефакторинг.
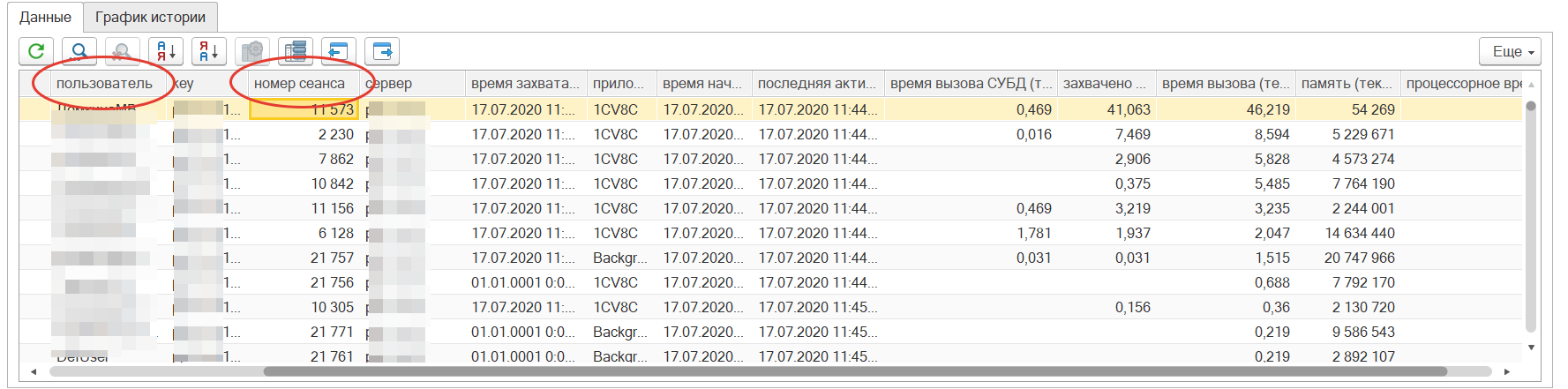
Рекомендуем использовать следующие агрегирующие функции:
- duration-current - функция количество Значение Заполнено (для колонки таблицы количество ячеек в которых есть значение отличное от 0). Определяет очередь пользователей, которые в данный момент обслуживаются rphost. Обычно растет вверх вместе с нагрузкой на процессор и очередью процессора. Если эти три показателя высоки, то характеризует серьезные проблемы в работе пользователей.
- duration-current - функция maximum, т.е. среди всех значений вычисляем максимальное. Может характеризовать зависшие сеансы, обработку больших объемов данных или корявый код. Всем пользователям на этом хосте (на том который завис) будет плохо.
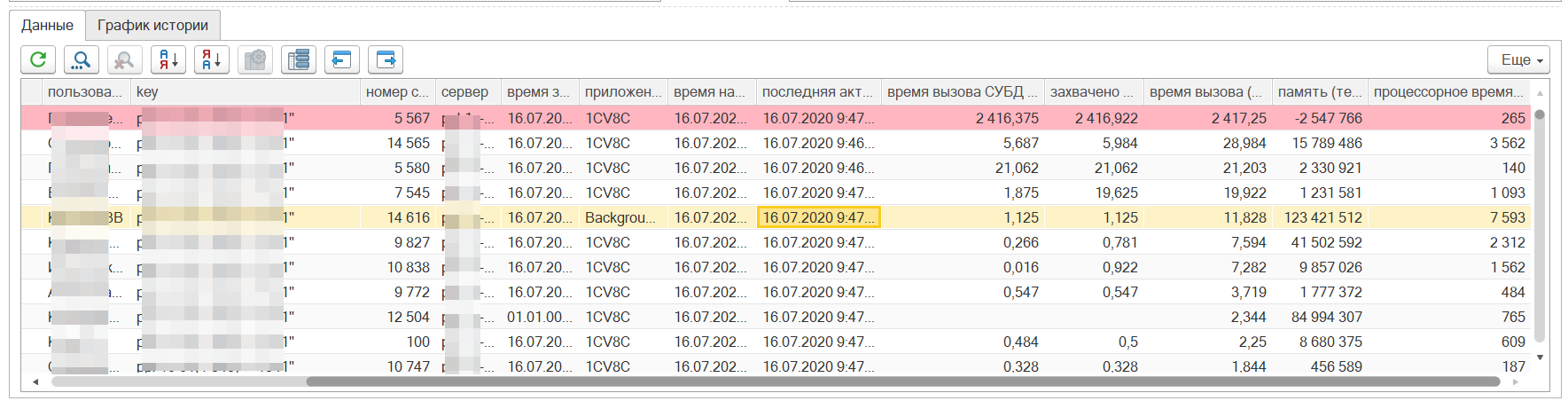
Свойство db-proc-took
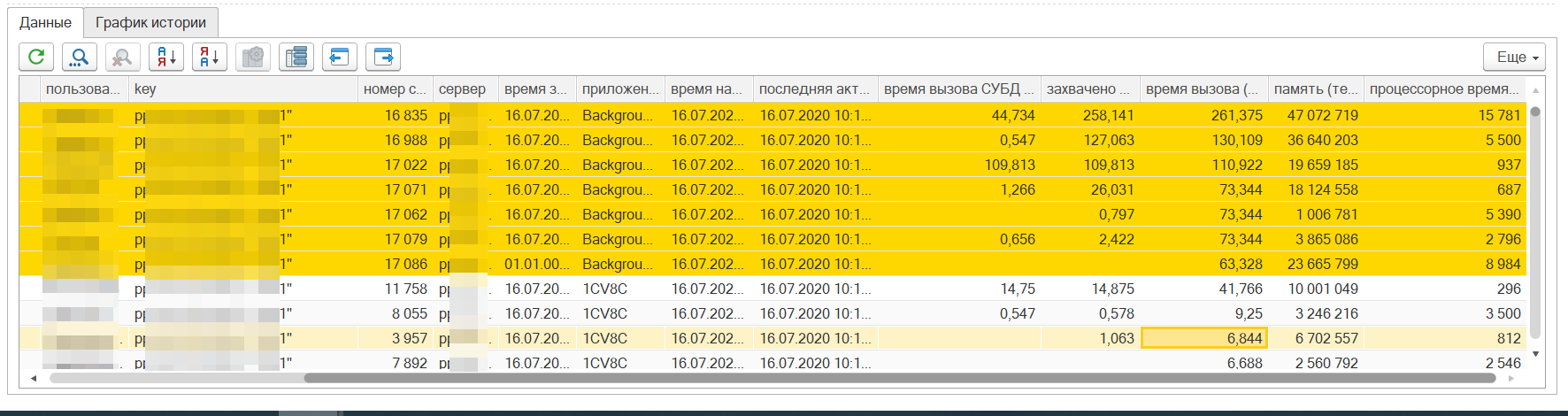
Показатель db-proc-took (захвачено СУБД) характеризует обращение процесса к СУБД. Если количество таких обращений растет в единицу времени, то это говорит о том, что СУБД не успевает обслуживать запросы 1С. Такое поведение может возникать во время блокировок – когда один пользователь захватил популярный регистр, а все другие начинают его ждать. Недостаточной производительности самого сервера СУБД. Наличия большого количества неоптимальных запросов. Наличия операций, которые не рекомендуется запускать в момент высокой нагрузки пользователей – удаление помеченных, пересчет регистров и т.п.
Разбор проблем можно выполнять в соответствии с рекомендациями выше. А также возможно проверить настройку и работу сервисных заданий на сервере СУБД – обновление статистики, или другие настройки.
Рекомендуем использовать следующие агрегирующие функции:
- db-proc-took - функция количество Значение Заполнено (аналогично выше). Определяет очередь пользователей, которые в данный момент работают с базой SQL. Если есть, то в паре с показателем duration-current.
Характеризует работу с базой данных. При росте очереди может характеризовать- - блокировку (тут надо смотреть блокировки SQL) – в этом случае терпеть или срубать;
- - недостаток мощности сервера SQL – увеличивать мощности;
- - не оптимальность кода – исправлять код;
- - выполнение операций не допустимых в рабочее время (к примеру, удаление помеченных, закрытие месяца и т.д.) – дать по рукам пользователям или перенастроить задания.
- db-proc-took - функция maximum. Если большое, то означает выполнение в транзакции большой обработки данных, или на блокировках.
Показатель cpu-time-current
Данный показатель обычно необходимо смотреть с duration-current. Если он значительно большой, то это говорит о том, что пользователь действительно запустил что-то существенно сжигающее мощность сервера и стоит связаться с пользователем, ограничить или удалить соединение.
Совместный анализ и учет свойств duration-current и db-proc-took
Если захват и время текущее больше нормы, то видно, что пользователь нагрузил сервер. А чем нагрузил можно узнать из журнала действий пользователя по номеру сеанса или ТЖ (удалив сеанс пользователя мы сгенерируем ошибку).
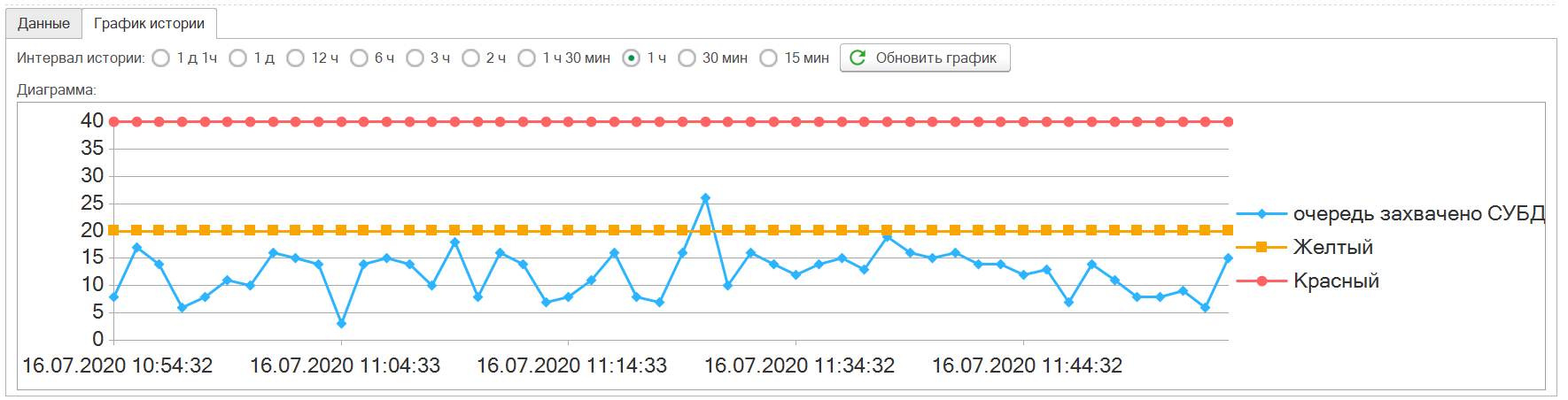
На графике ниже видно, что выполняются ресурсоемкие операции (фоновые задания) с постобработкой данных на сервере 1С (захвачено СУБД менее времени вызова (текущее)). Показатели время вызова и потребления процессора высокие. Но пока не превышена критическая отметка и уровень тревоги «желтый»
Если же у вас среднее состояние каждый день показывает высокую нагрузку, то скорее всего следует обновить ваши ресурсные мощности.
Количество пользователей
Количество пользователей обычно гладкий и равномерный график без резких скачков. Следить необходимо за резким изменением его поведения или резкими изменениями изменения количества спящих пользователей. На рисунке ниже видна аномалия после аварии служб 1С, в результате были выбиты практически все пользователи.
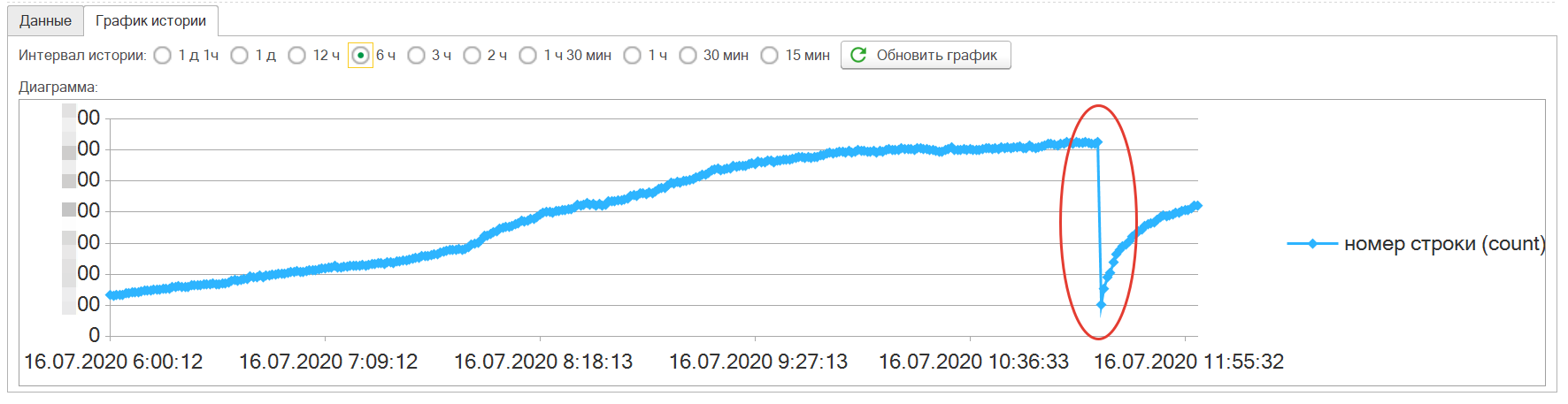
IV) Настройка обработки ситуации по комбинации показателей
Смотреть и анализировать необходимо по комбинации графиков и значений показателей - так мы получим более наглядную картину. Ниже мы приведем таблицу настроек конфигурации "Монитор производительности", по которым у нас настроены оповещения и контроль состояния системы.
Таблица настройки для реакции по комбинациям показателей выглядит следующим образом:
| время вызова (текущее) (max) |
очередь время вызова(текущее) |
захвачено СУБД (max) |
очередь захвачено СУБД |
сеанс (count ЗначениеЗаполнено) |
Решение |
Описание решения |
|---|---|---|---|---|---|---|
|
high |
high |
high |
high |
* |
полное падение производительности |
все плохо |
|
high |
low |
high |
low |
* |
только захват СУБД и 1С время вызова |
найти пользователя и срубить |
|
high |
high |
* |
* |
* |
1С работать невозможно |
срубаем все зависшие сеансы |
|
* |
* |
* |
* |
high |
проблемы с rphost |
rphost не справляется с обработкой сеансов |
|
* |
* |
high |
high |
* |
СУБД работать невозможно |
срубаем захваты |
|
high |
medium |
* |
* |
* |
1С начала формироваться очередь |
пора принимать действия |
|
medium |
high |
* |
* |
* |
1С начала формироваться очередь |
пора принимать действия |
|
low |
high |
* |
* |
* |
1С начала формироваться очередь |
пора принимать действия |
|
high |
low |
* |
* |
* |
1С приложение зависло |
нужно срубить пользователя |
|
* |
* |
high |
medium |
* |
СУБД очередь растет |
пора принимать действия |
|
medium |
low |
* |
* |
* |
1С долго висит |
на контроль |
|
* |
* |
high |
low |
* |
захват СУБД дико долго |
предлагаю срубить пользователя |
|
* |
* |
medium |
low |
* |
захват СУБД |
разобраться в причинах |
|
medium |
medium |
* |
* |
* |
1С долго висит |
на контроль |
|
low |
medium |
* |
* |
* |
1С зависание ушло |
идет в сторону улучшения |
|
* |
* |
low |
medium |
* |
СУБД захват ушел |
идет в сторону улучшения |
|
low |
low |
low |
low |
low |
нормально |
все хорошо |
|
* |
* |
* |
* |
* |
аномалия |
неописанное поведение |
Преобразование показателей из цифрового значения в логическое (токены) выполняется на основе экспертного мнения и для каждого показателя будет свое. Обычно мы выбираем трехуровневую шкалу:
Low – от 0 до допустимого значения
Medium – от допустимого значения до критического
High - от критического до конца.
Наши показатели:
|
Имя свойства |
Начальная |
Низкий до |
Средний до |
Верхняя |
|---|---|---|---|---|
|
время вызова (текущее) (max) |
0 |
60,00000 |
300,00000 |
бесконечность |
|
очередь время вызова (текущее) |
0 |
20,00000 |
40,00000 |
бесконечность |
|
захвачено СУБД (max) |
0 |
60,00000 |
300,00000 |
бесконечность |
|
очередь захвачено СУБД |
0 |
20,00000 |
40,00000 |
бесконечность |
|
сеанс (count ЗначениеЗаполнено) |
0 |
60,00000 |
80,00000 |
бесконечность |
Далее по этой таблице мы запускаем обработку нечетким контроллером (виртуальный ассистент Лариса) и формируем оповещения на почту или скайп/телеграмм.
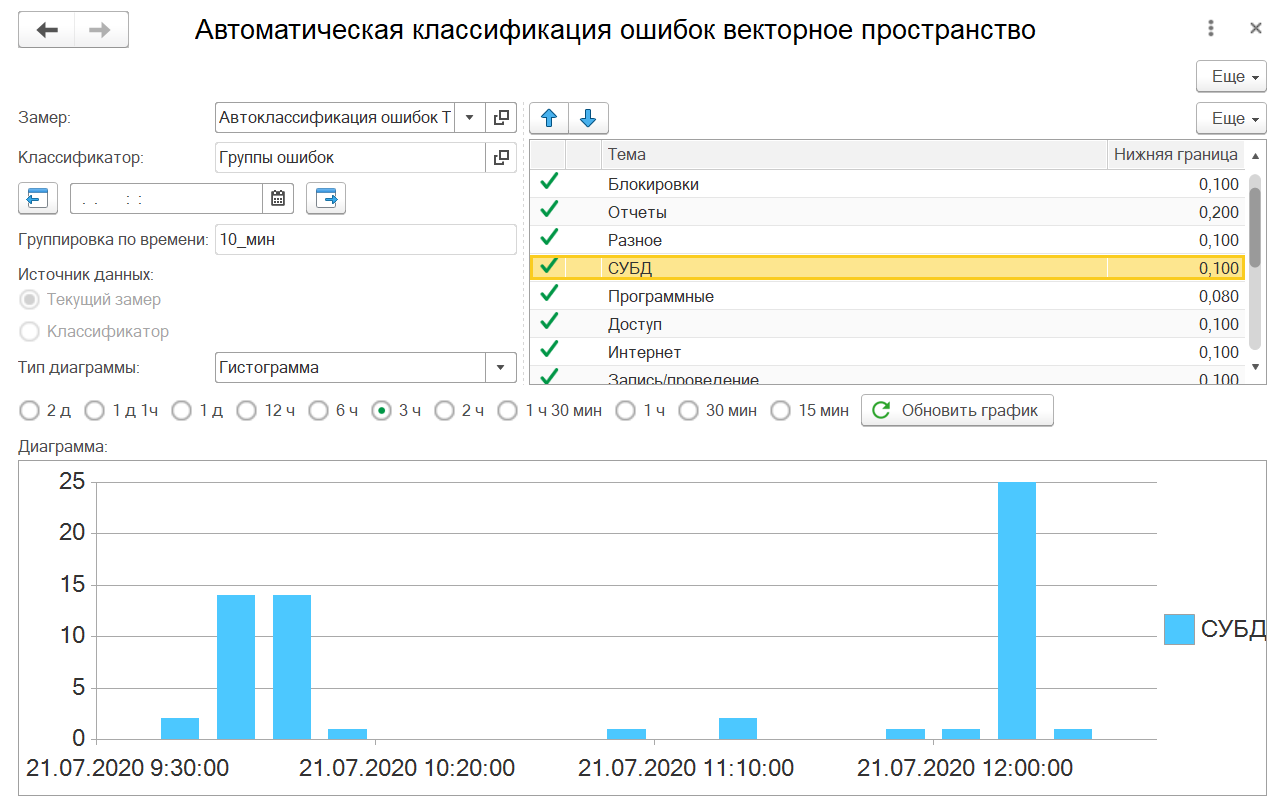
V) Бонус. Используем автоматический классификатор ошибок технологического журнала.
Удобно так же смотреть на результат классификации ошибок. Если вы настроили парсинг замеров и автоматическую классификацию, то можно сразу увидеть о проблемах на сервере по данным журнала.
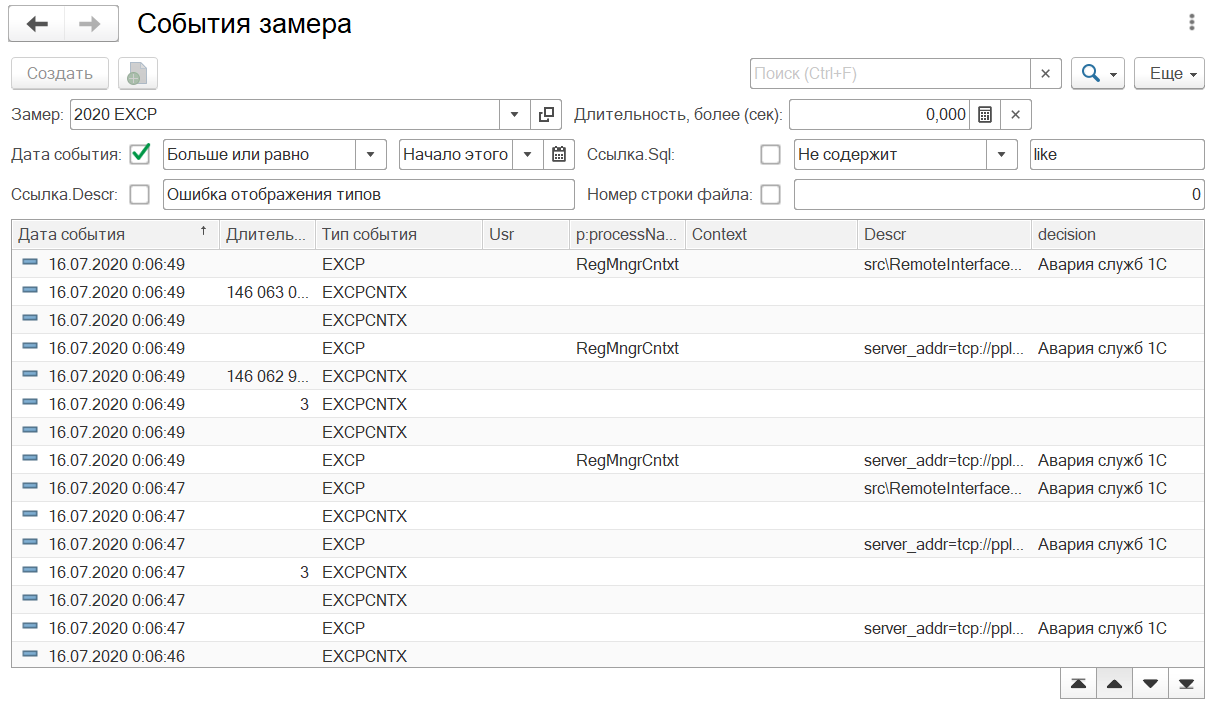
Как видите, то мы тут наблюдаем сообщения об авариях служб 1С и если количество сообщений превышает какое-либо нормальное число (иногда достаточно 1-го сообщения), то необходимо начать проверку. На эти события также можно поставить оповещения ответственных лиц.
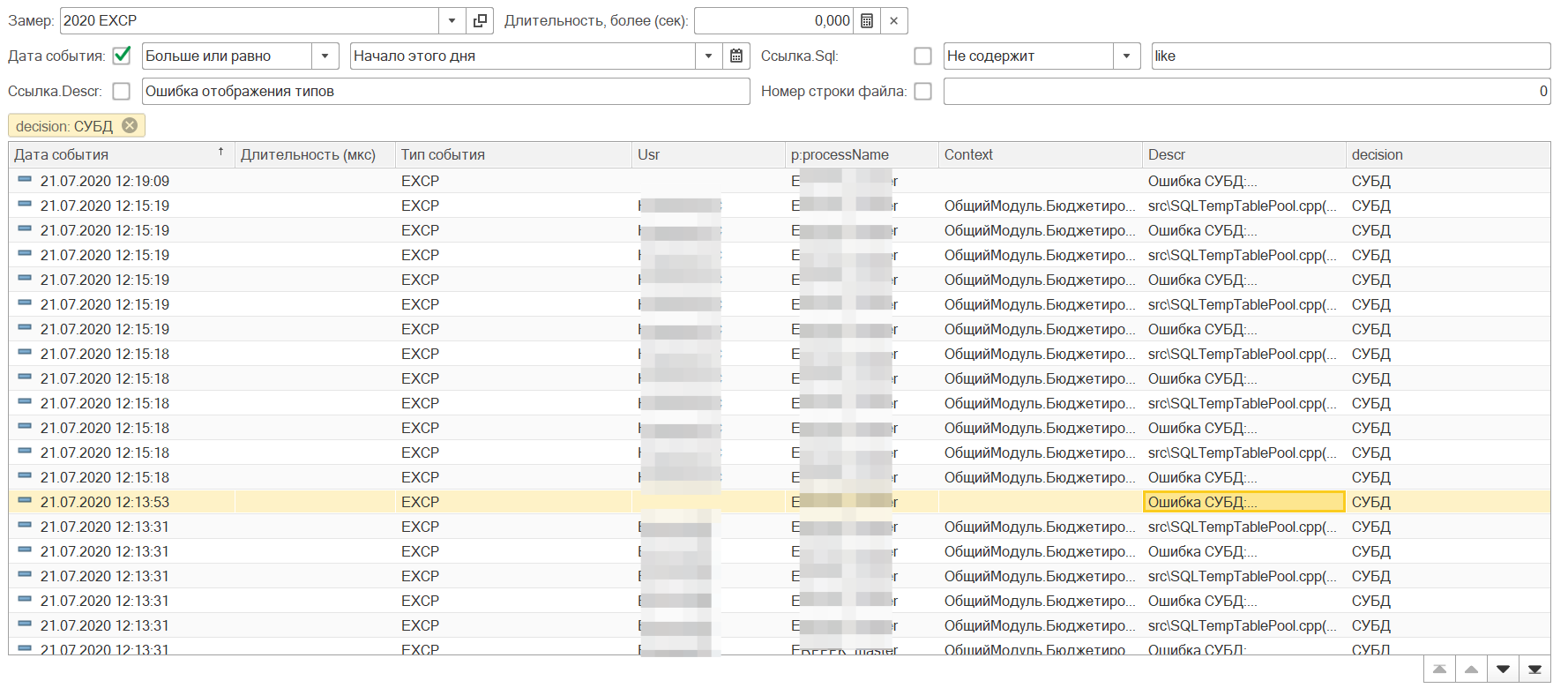
На предыдущем рисунке видим проблемы с отбором по классу ошибок СУБД. Из результатов анализа перед коллапсом и последующим падением служб 1С проявляются подобного рода ошибки. Видимо происходит превышение какого-то лимита и службы идут в разнос (8.3.15 версия 1С).
Пример рассмотрения ситуации по ошибкам на мониторе приведена ниже – обращаем внимание на резкие всплески/пики:
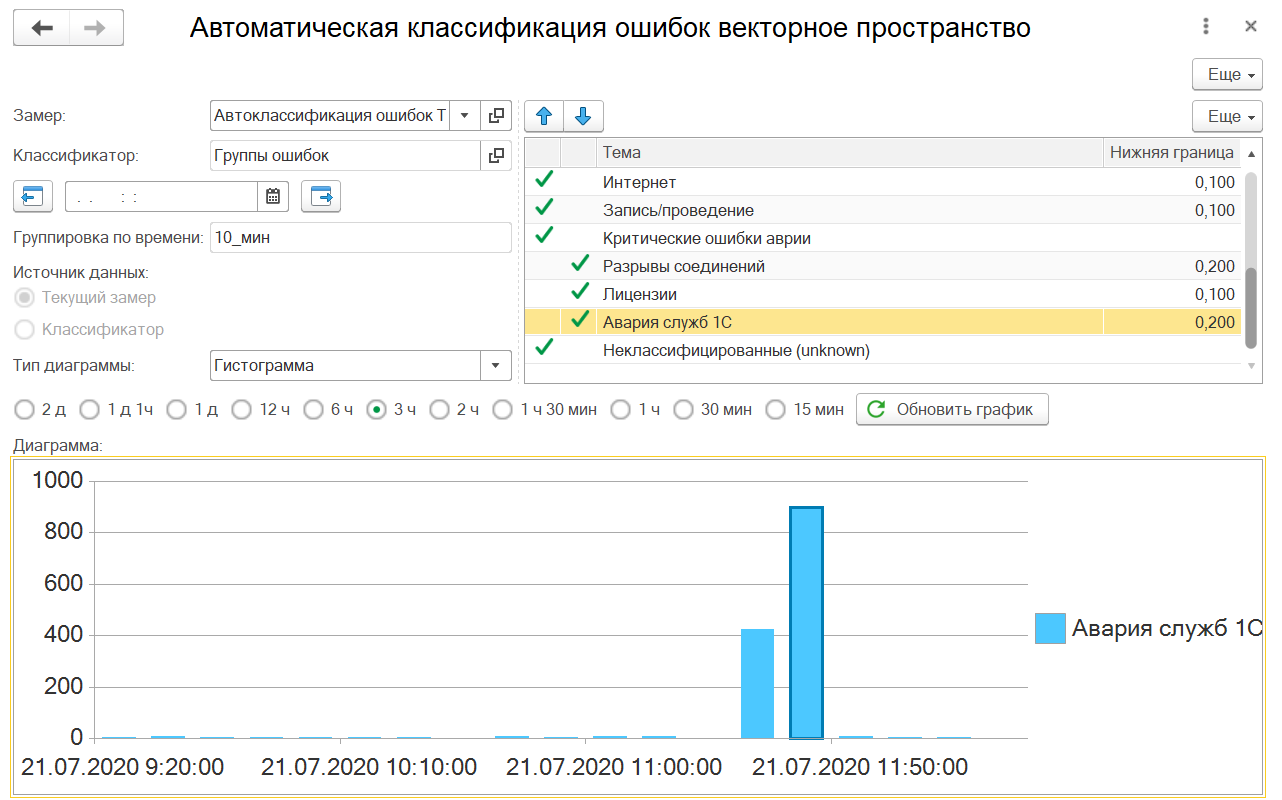
Заключение:
- Фреймворк находится по адресу https://github.com/Polyplastic/1c-parsing-tech-log
- Руководство Фреймворк "Мониторинг производительности". Руководство пользователя
- Настройка замеров Мониторим производительность с помощью 1С RAS
- Свежую конфигурацию можно скачать с GitHub проекта (релизы) или из приложения статьи Решение проблемы быстродействия в ERP на рабочем примере
- Также смотрите другие статьи по теме "мониторинг производительности" автора
Вступайте в нашу телеграмм-группу Инфостарт
