Предположим, что для преодоления проблем механизма планов обмена, используемого в распределённой информационной базе данных (РИБД), было принято решение о реализации альтернативного обмена данными с гарантированной доставкой при помощи очередей сообщений.
Реализация подобного варианта обмена данными рассмотрена в моей статье "DaJet Exchange: обмен данными с 1С (часть 1)".
Так же, как и РИБД 1С, альтернативная реализация должна предусматривать выявление коллизий и их разрешение.
Первым делом необходимо сформулировать практически целесообразные требования к системе обмена данными по типу РИБД, имеющей топологию "звезда".
Требования к асинхронному обмену данными:
1. Сообщения доставляются и обрабатываются при помощи очередей FIFO.
2. Используется гарантированная доставка при помощи брокера сообщений.
3. Изменение данных и отправка сообщения выполняются в одной транзакции.
4. Получение сообщения и изменение данных выполняются в одной транзакции.
Правила разрешения коллизий:
1. Root node always wins!
Центральный узел всегда имеет наивысший приоритет своих изменений по отношению к изменениям любого периферийного узла.
Все узлы должны получить и принять изменения центрального узла.
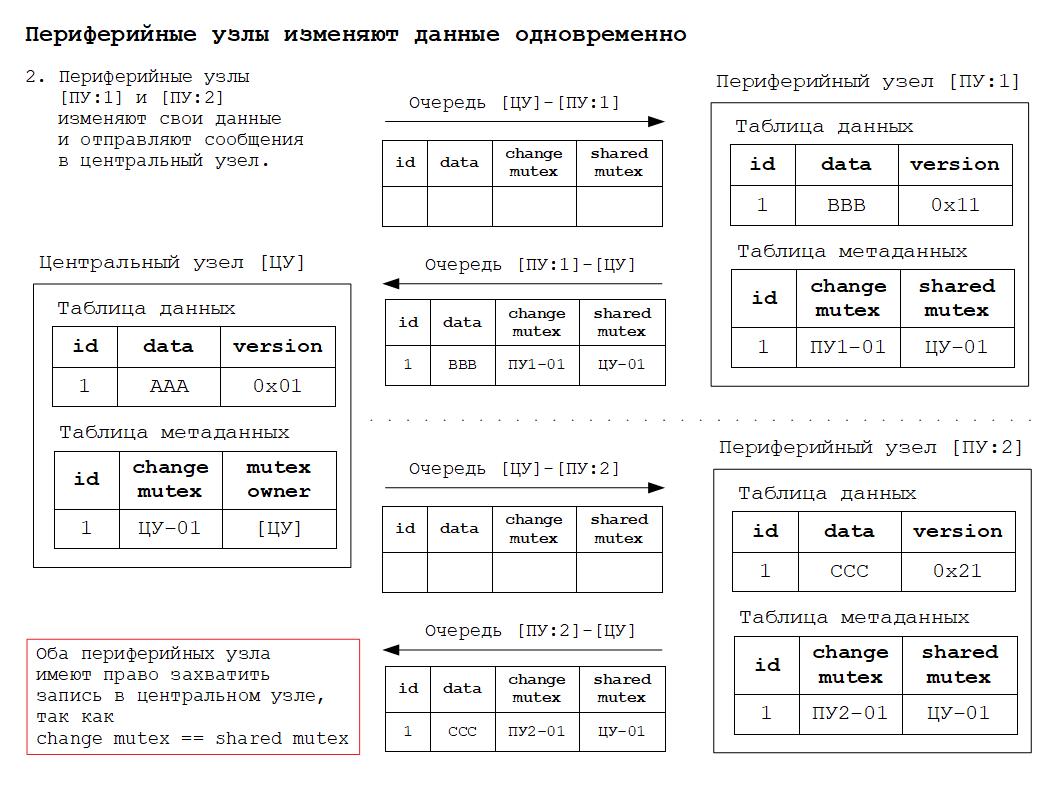
2. Leaf node may be allowed to make changes.
До тех пор пока центральный узел не сделал изменений, любой периферийный узел может предложить свои изменения.
Центральный узел и заинтересованные периферийные узлы должны получить и принять предложенные инициирующим периферийным узлом изменения.
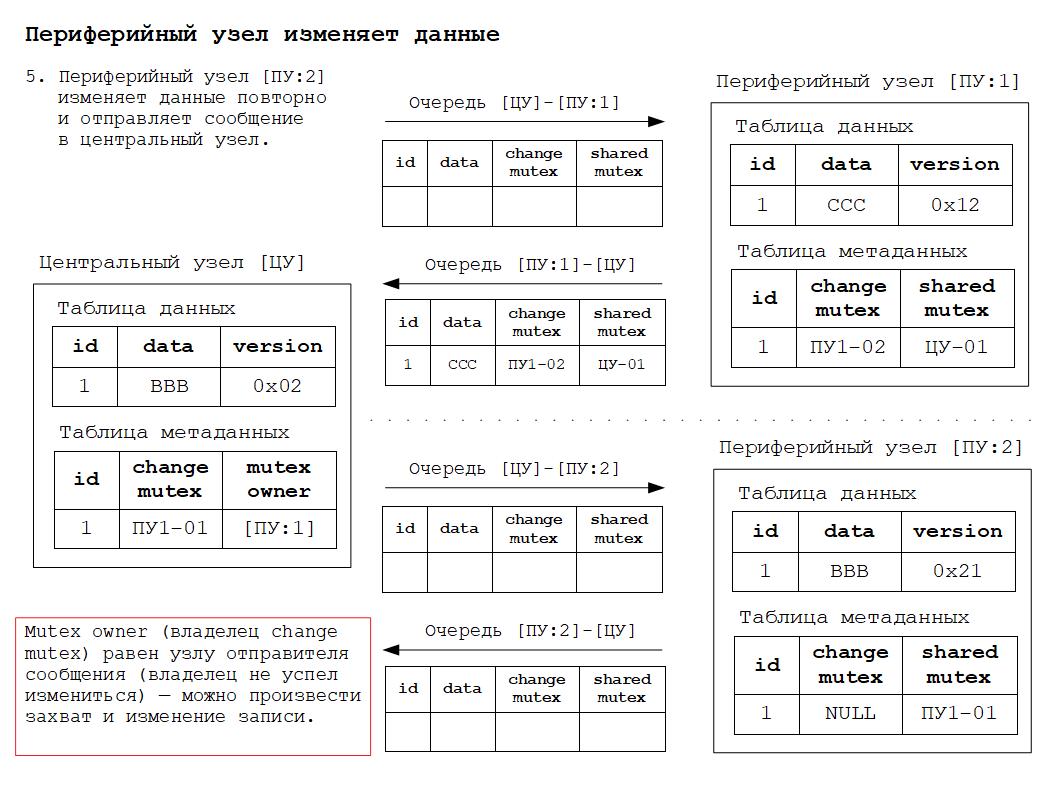
3. First leaf node wins!
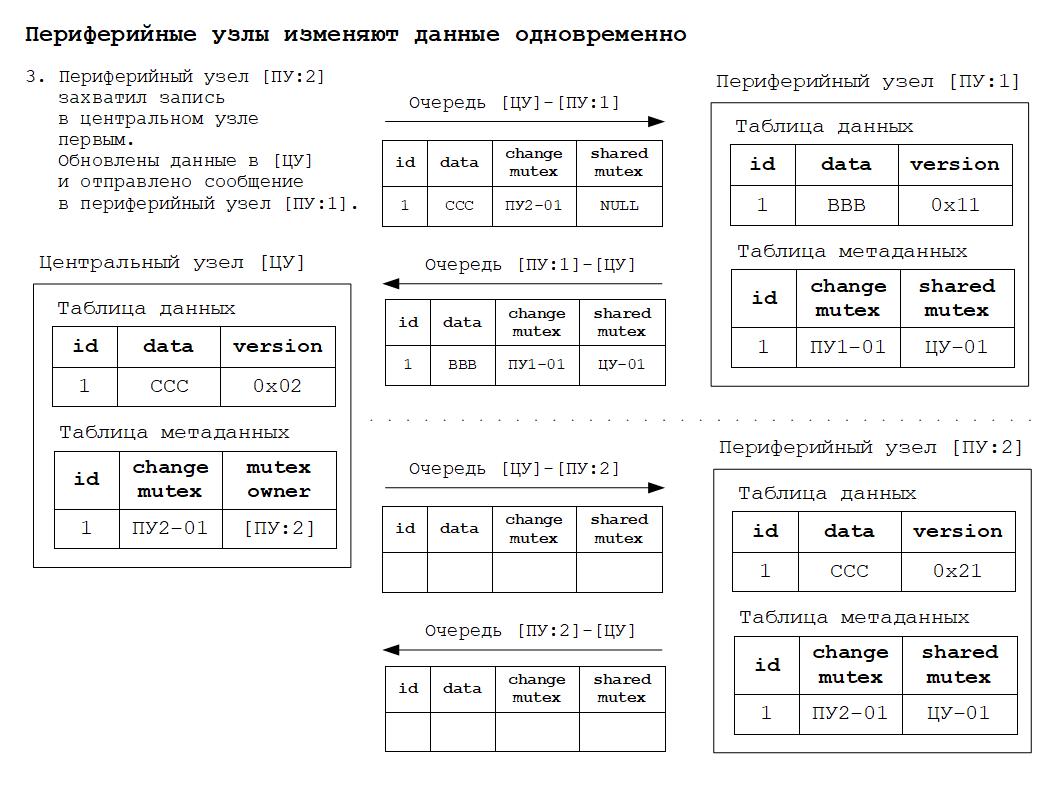
Первый периферийный узел, предложенное изменение которого было зафиксировано в центральном узле, имеет приоритет по отношению к изменениям, одновременно сделанным в других периферийных узлах.
Другие узлы должны получить и принять такое изменение.
Следствия из правил разрешения коллизий:
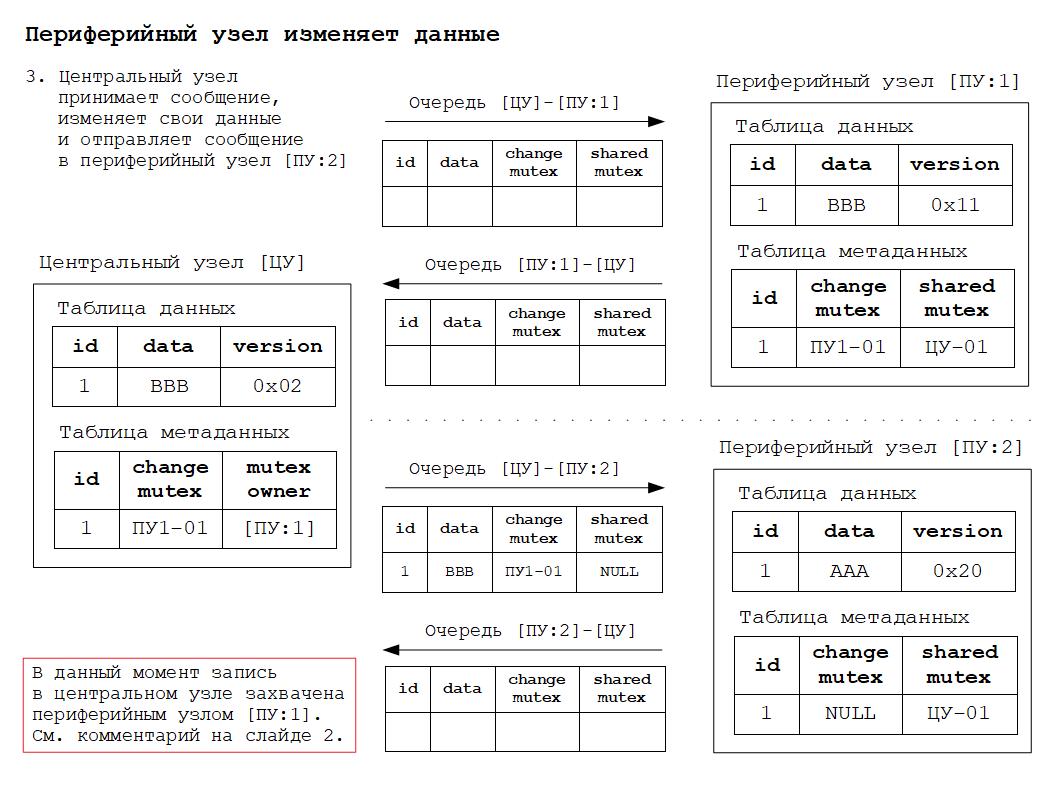
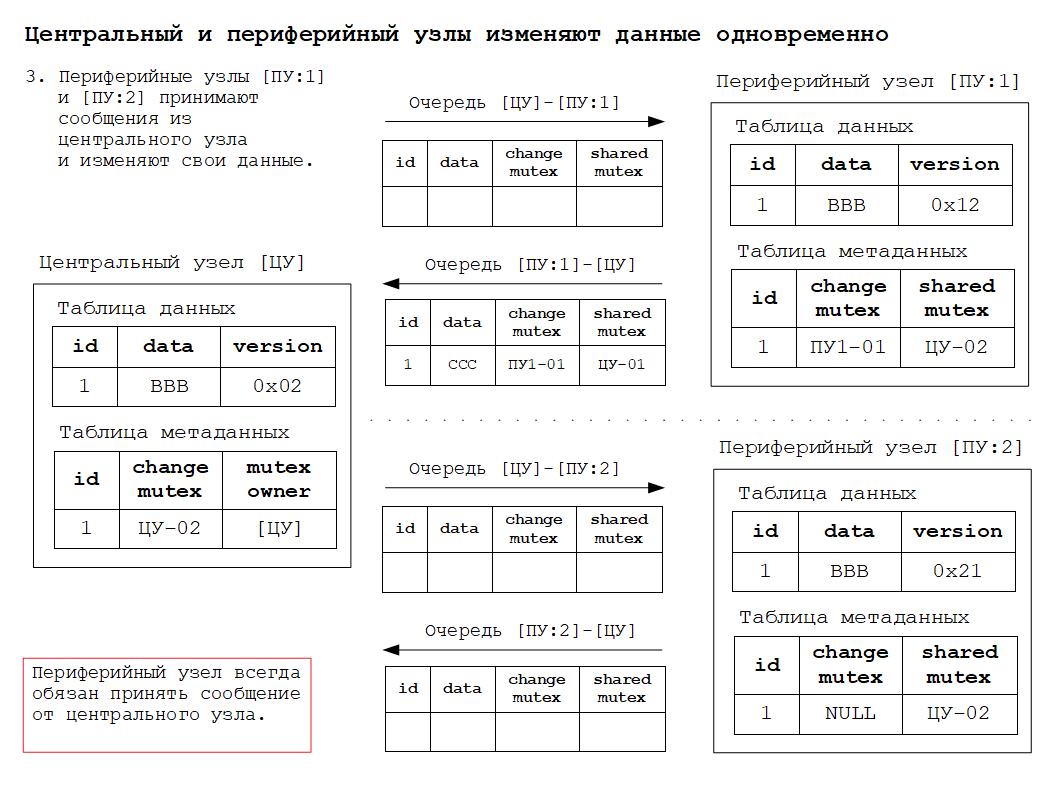
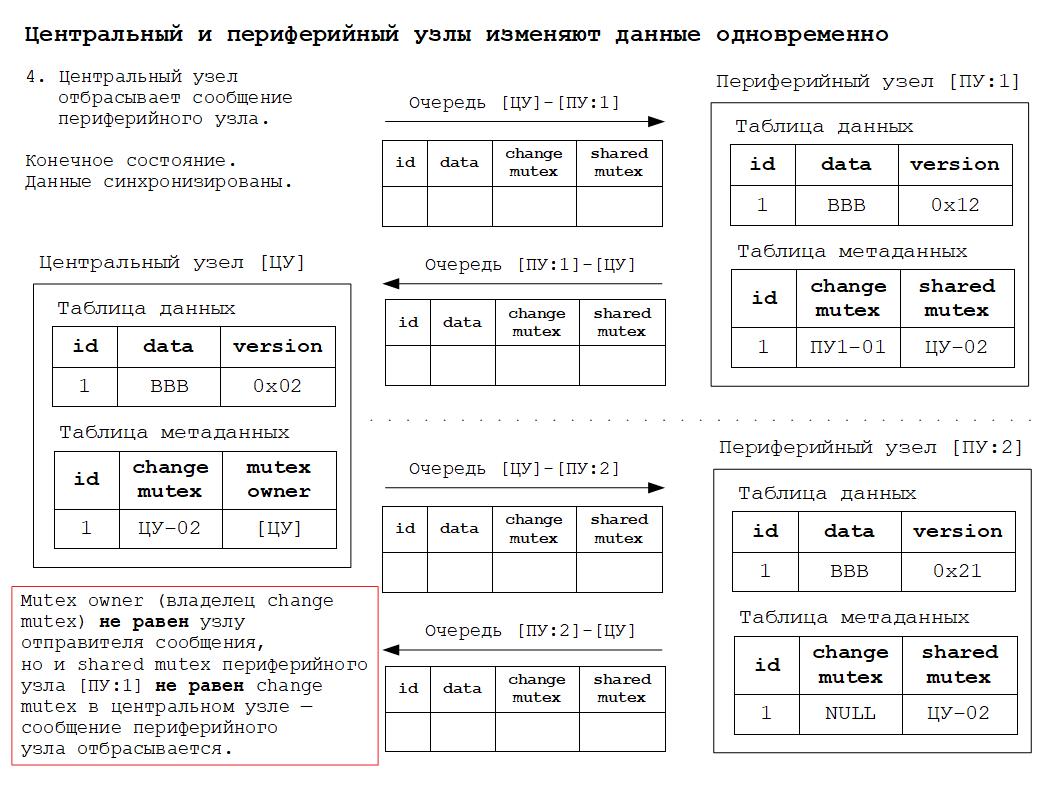
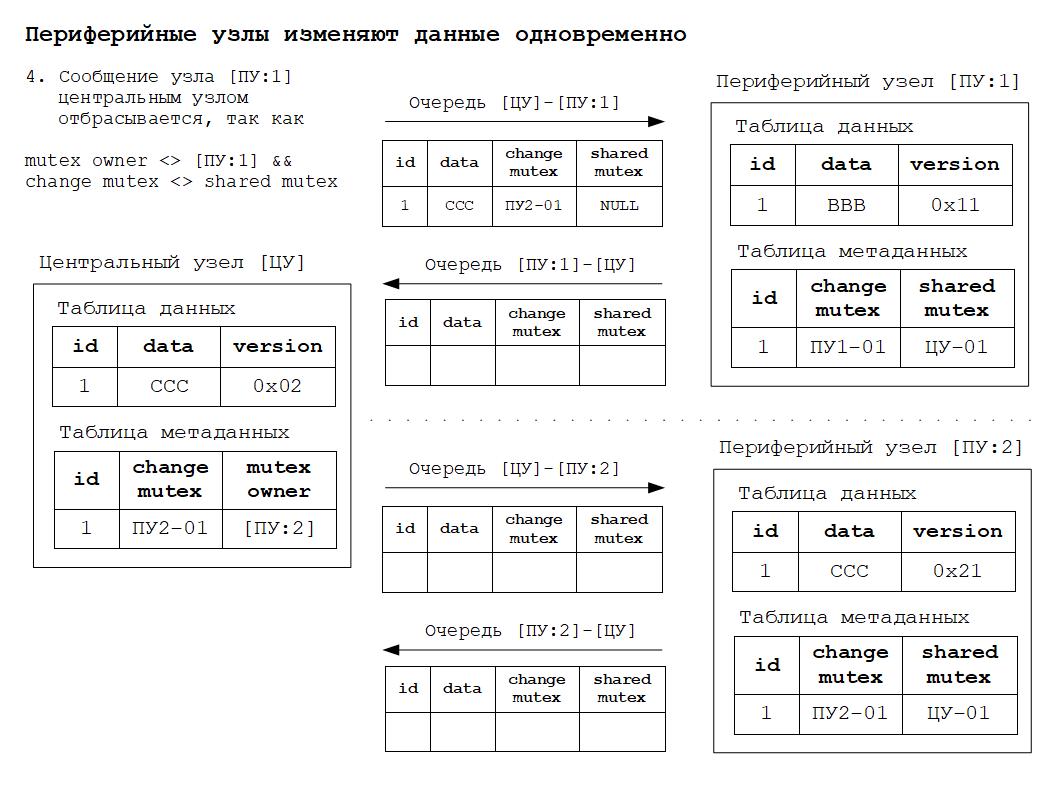
1. Центральный узел при получении сообщения от периферийного узла должен принимать и маршрутизировать сообщения, соответствующие правилу № 2. Все остальные сообщения центральный узел отбрасывает.
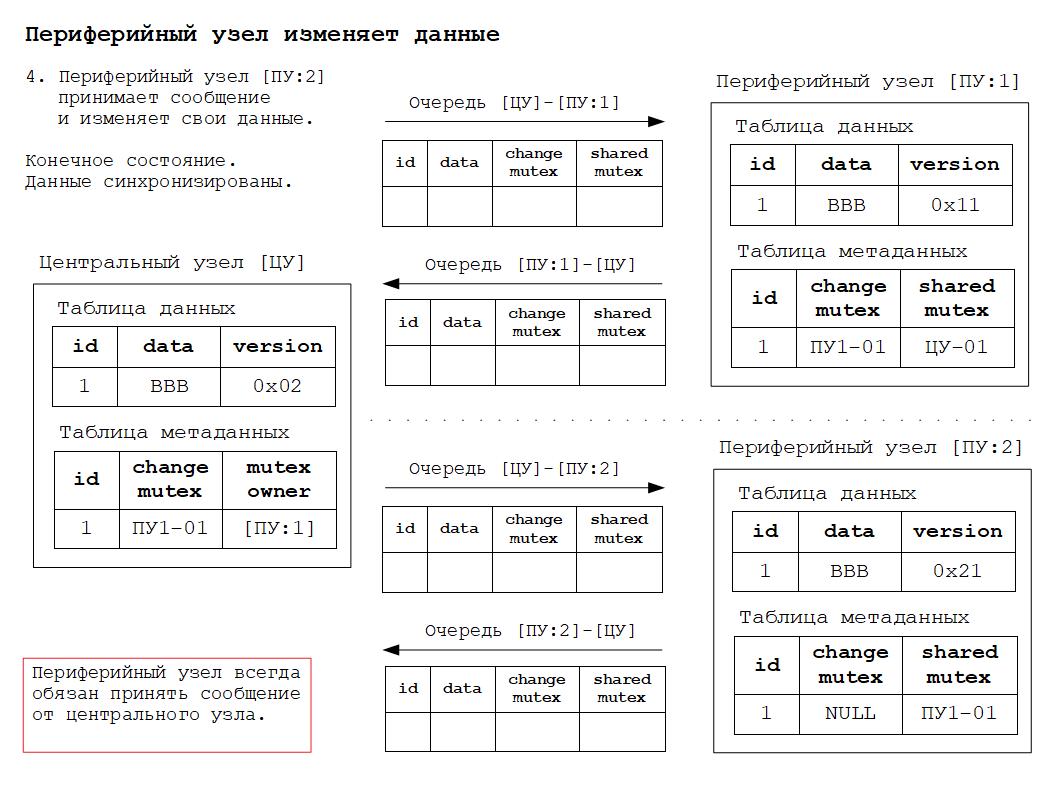
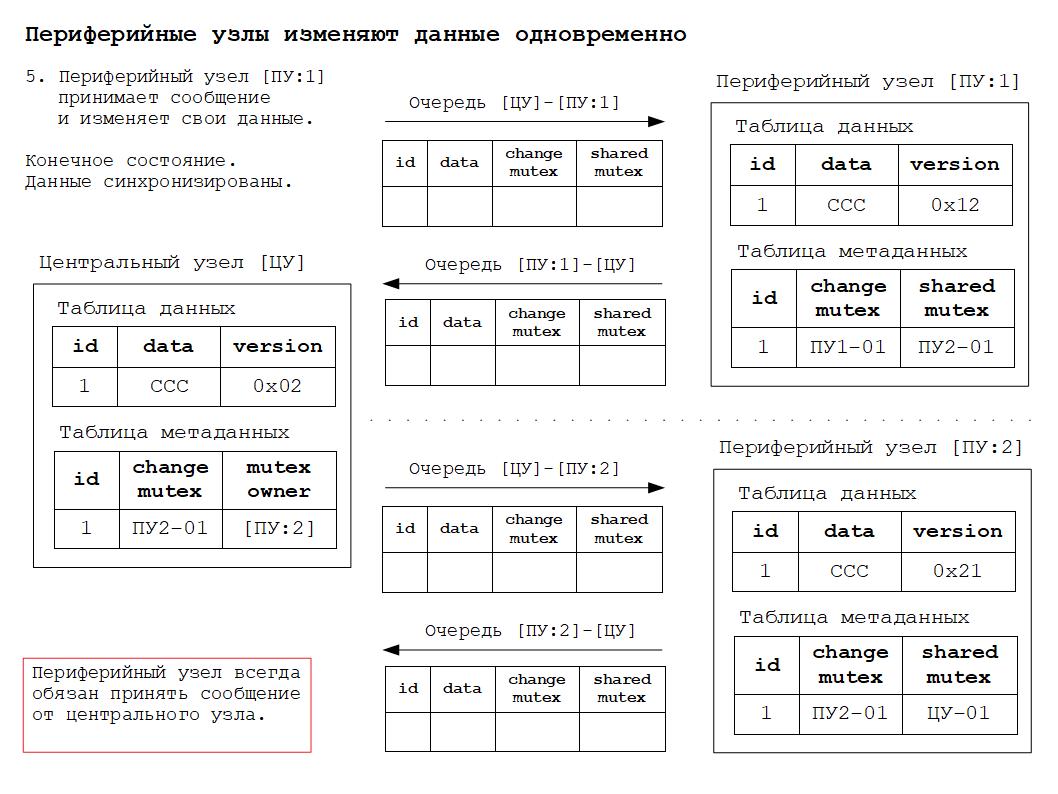
2. Периферийный узел всегда обязан принять сообщение от центрального узла, так как именно центральный узел обеспечивает строгое соблюдение всех правил разрешения коллизий.
Для реализации правил разрешения коллизий используется адаптированная к вышеуказанным требованиям методика синхронизации потоков при помощи мьютексов.
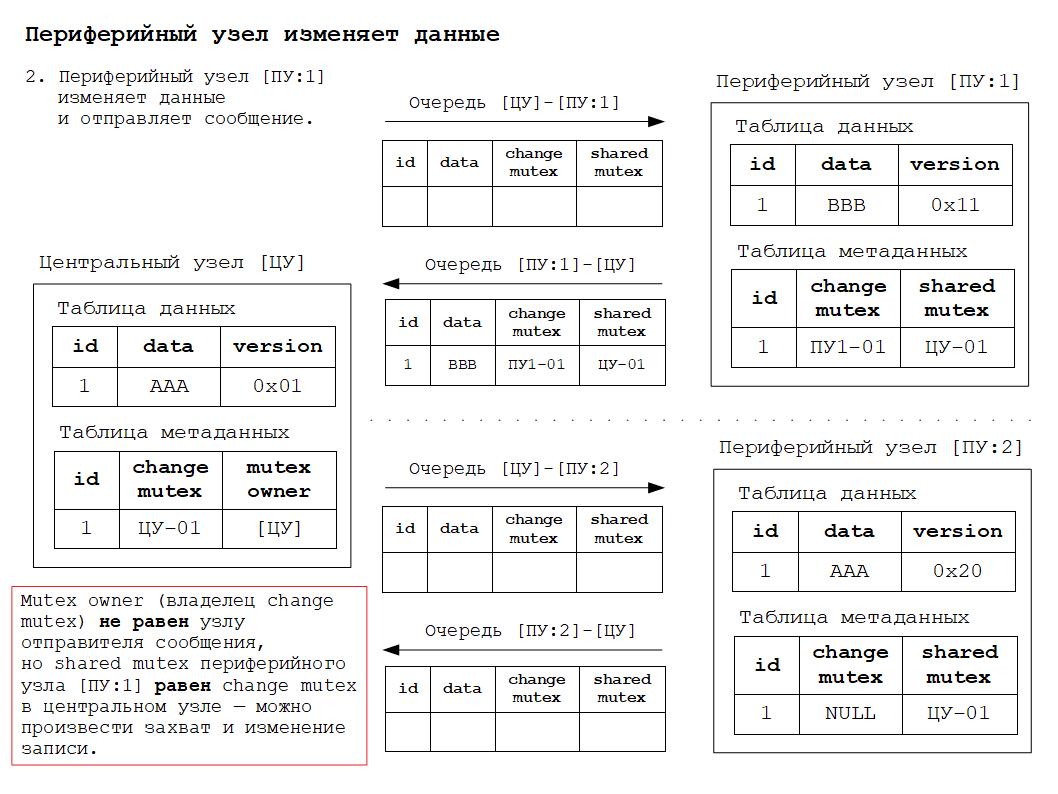
Жизненный цикл мьютекса начинается в статусе мьютекса изменения (change mutex), используемого для захвата данных в центральном узле и их изменения. Change mutex генерируется текущим узлом для исходящих сообщений, его значение должно быть уникально в пределах РИБ. Change mutex используется для захвата записей в центральном узле с целью изменения данных.
В случае успешного захвата данных в центральном узле мьютекс переходит в статус разделяемого мьютекса (shared mutex) для синхронизации изменений между заинтересованными в этих изменениях периферийными узлами. Shared mutex получается периферийным узлом во входящих сообщениях. Получение shared mutex свидетельствует о том, что данные центрального узла были захвачены другим узлом. Таким образом выполняется синхронизация доступа к данным между узлами. Shared mutex необходимо запомнить, чтобы в будущем использовать его для снятия захвата данных в центральном узле.
Жизненный цикл использования мьютекса завершается в статусе вышедшего из употребления мьютекса (obsolete mutex).
Таким образом можно выделить следующие состояния данных РИБ:
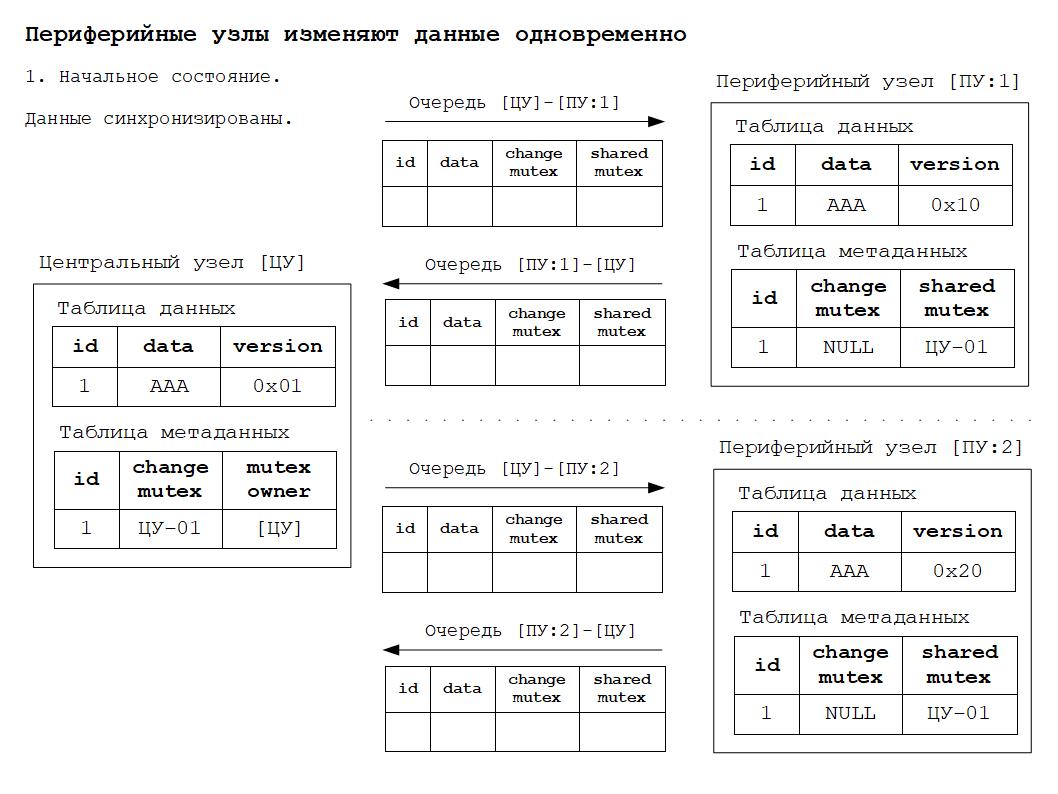
1. Синхронизированное состояние данных - данные во всех узлах идентичны.
2. Изменение данных в периферийном узле и отправка сообщения захвата и изменения данных в центральный узел.
3. Захват, изменение и отправка сообщений данных в центральном узле.
4. Получение, изменение и синхронизация данных в периферийном узле.
5. Новое синхронизированное состояние.
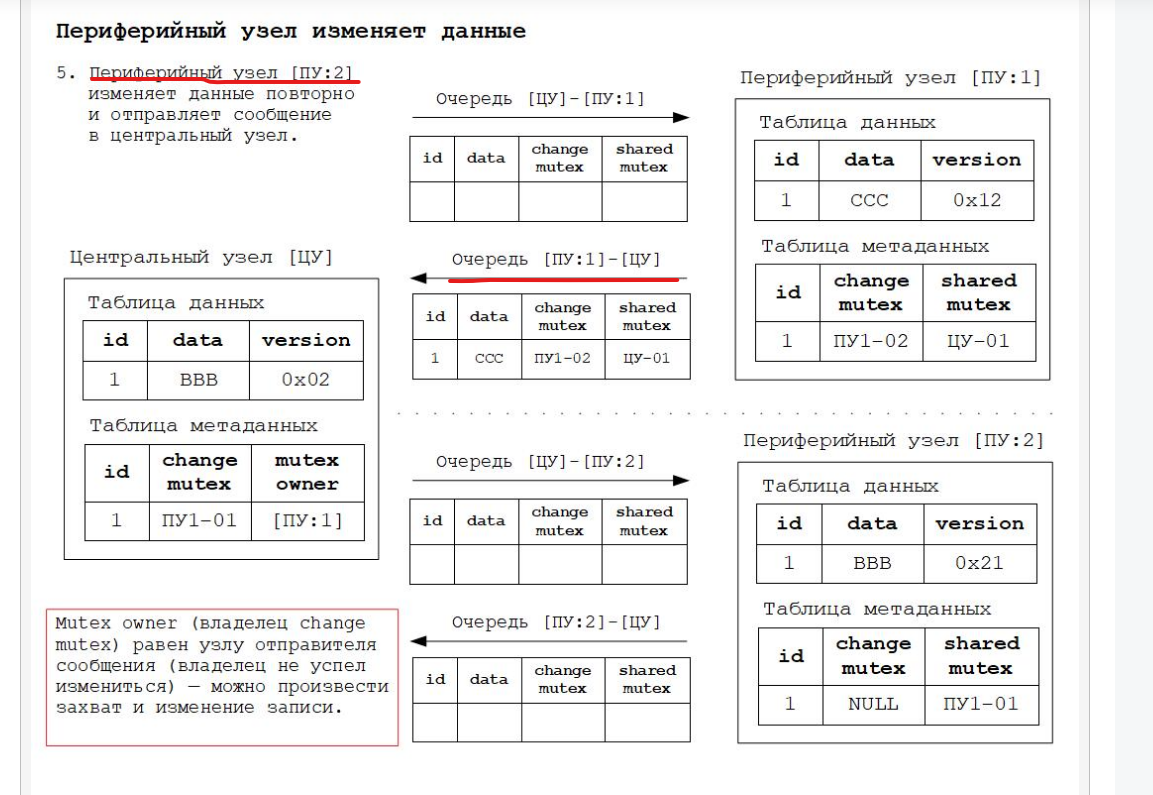
Для того, чтобы было понятнее как работает всё вышесказанное, ниже будут приведены схемы изменения состояния РИБ в зависимости от происходящих в системе событий. Работа алгоритма основана на том, что для каждого объекта конфигурации, участвующего в обмене данными РИБ, создаётся дополнительная таблица метаданных обмена. Данная таблица по сути своей расширяет основную таблицу объекта дополнительными полями для хранения информации о мьютексах.
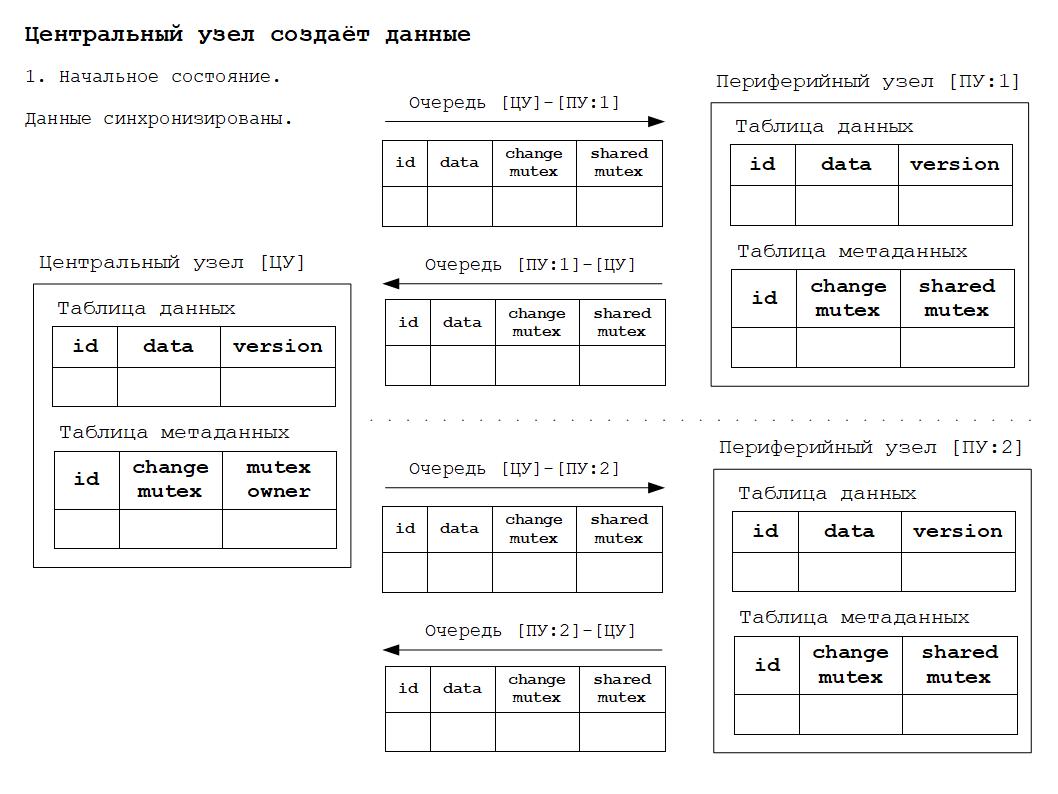
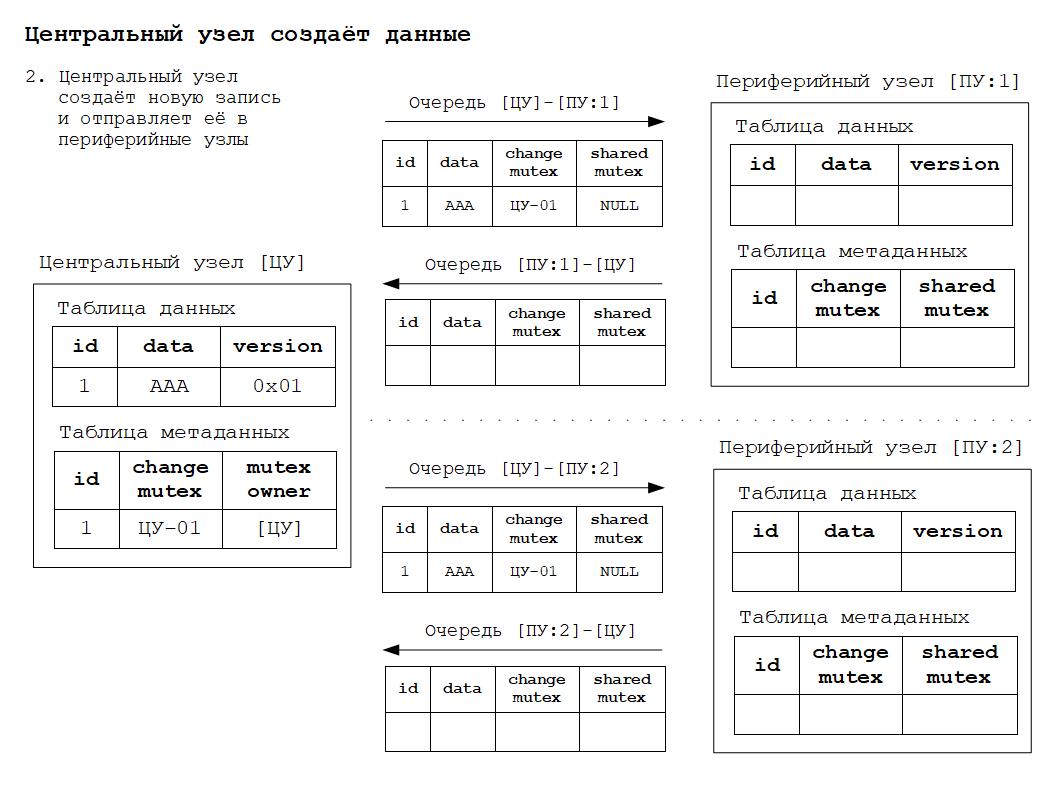
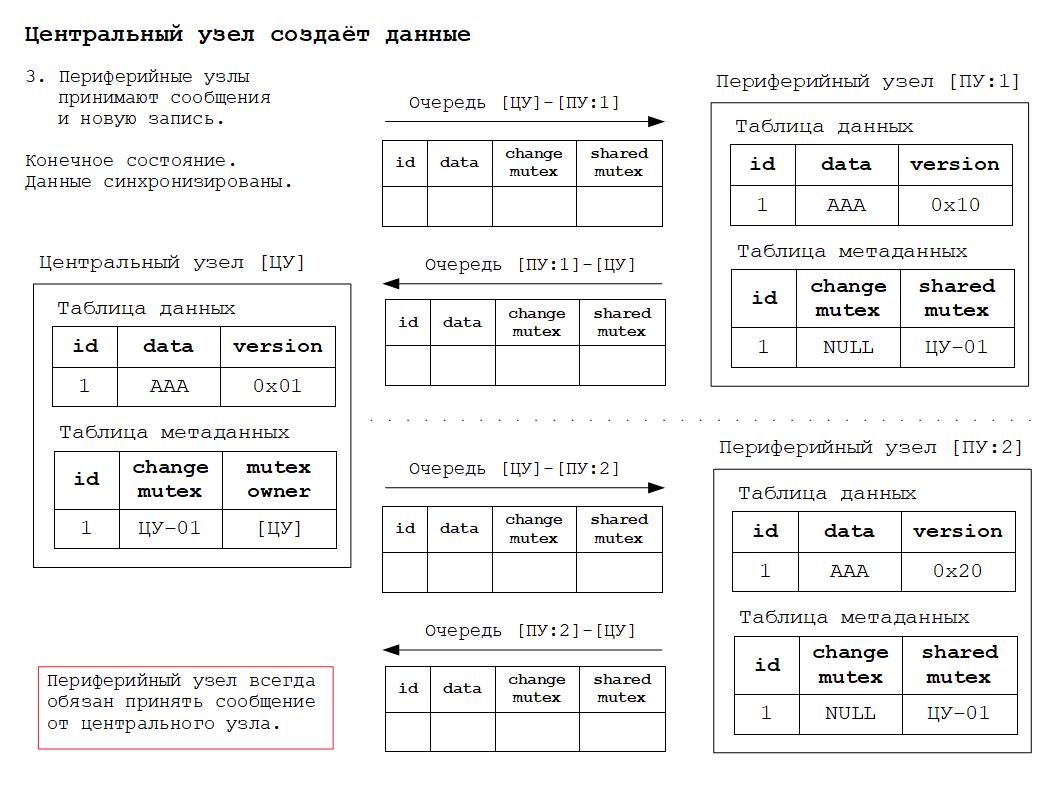
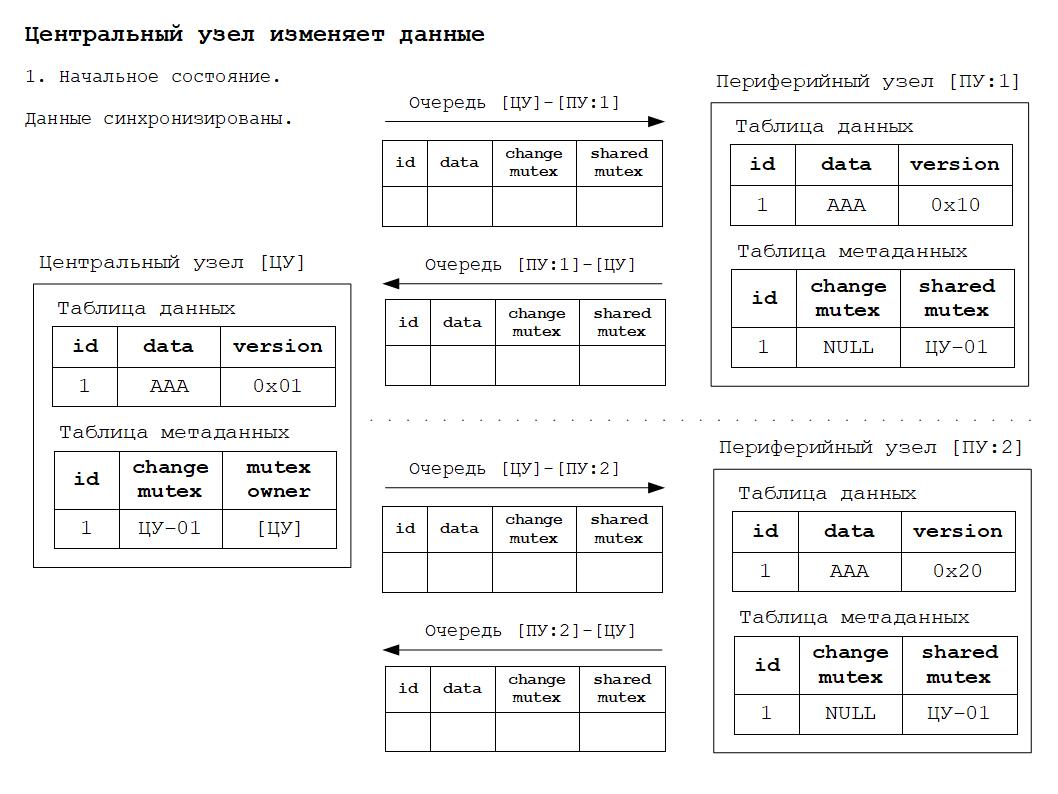
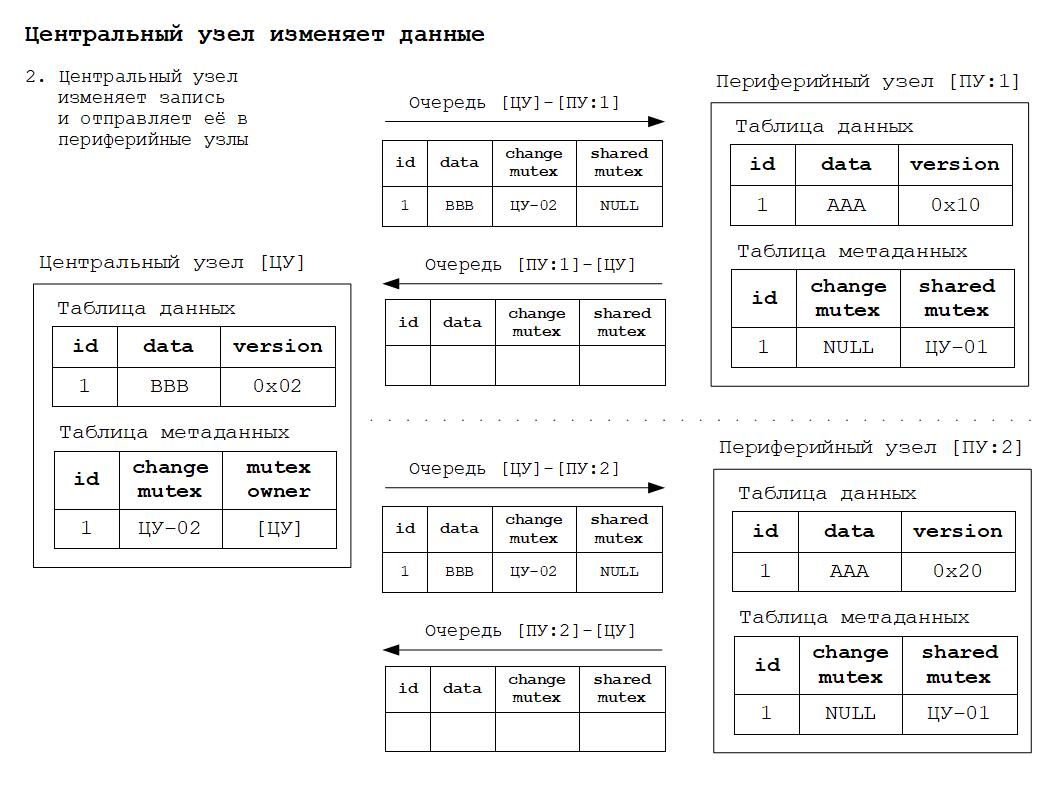
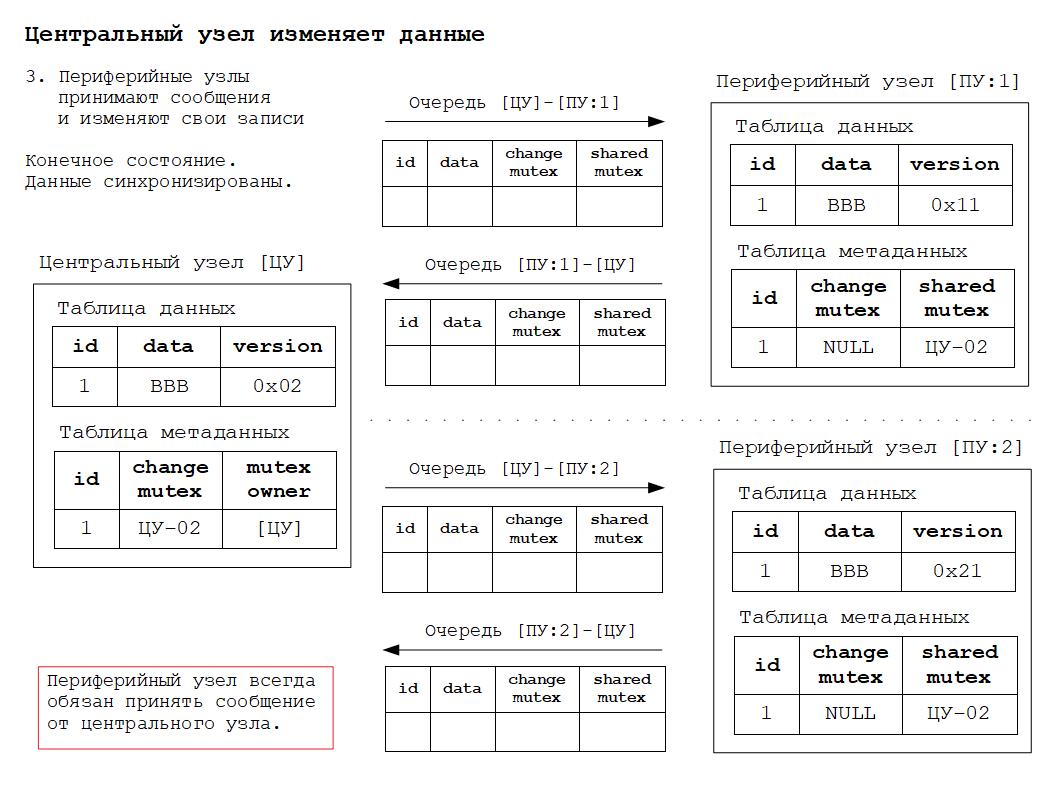
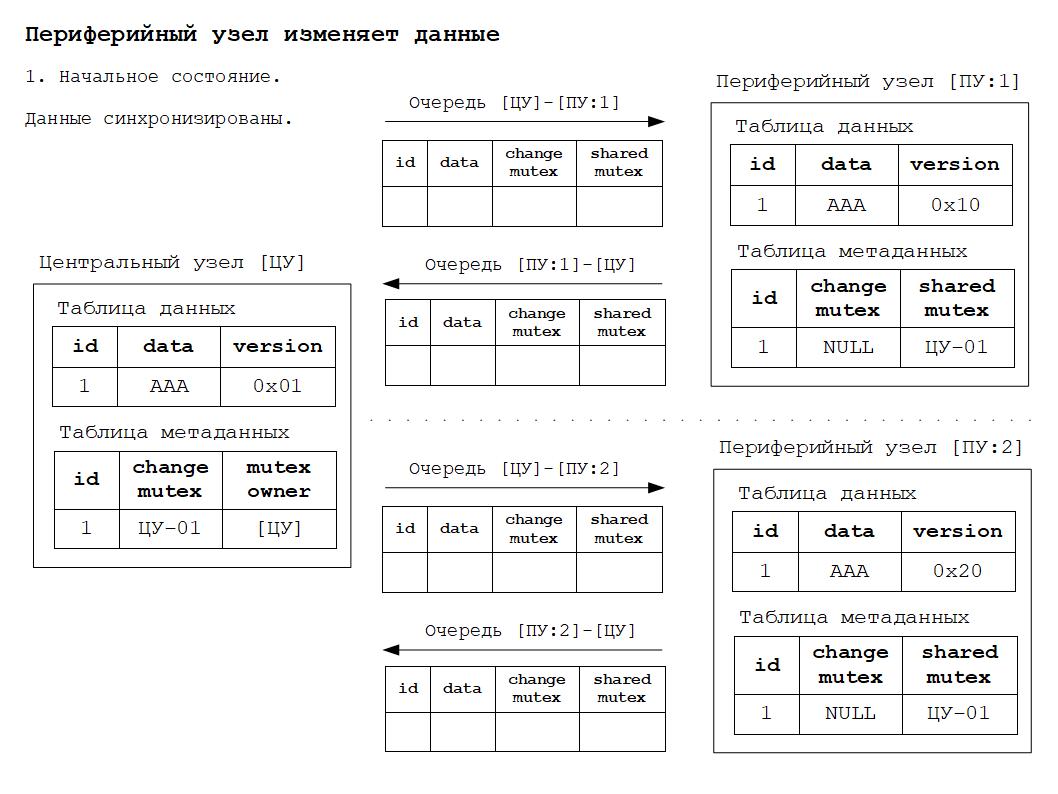
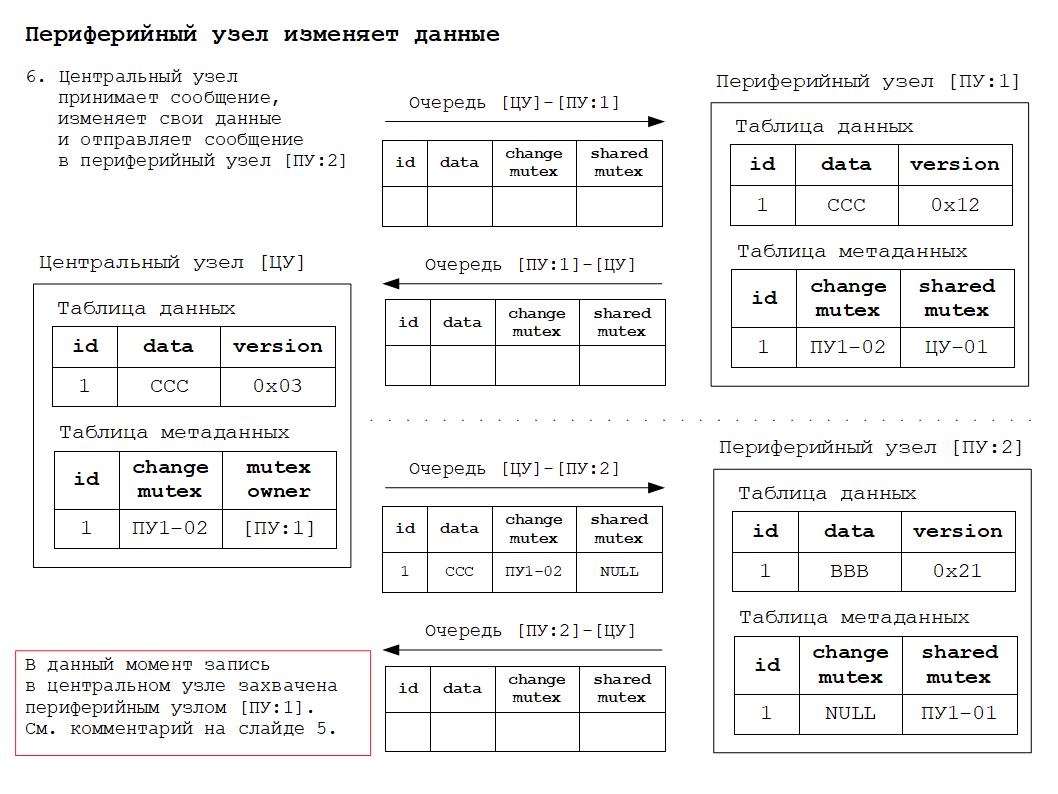
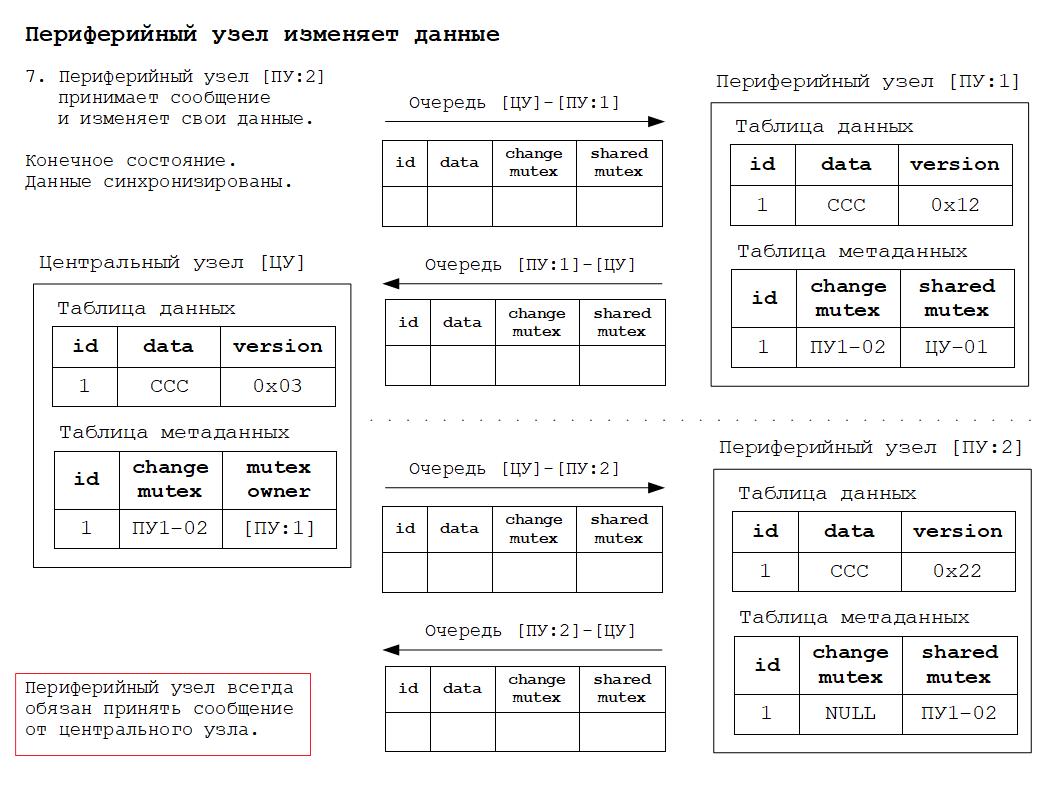
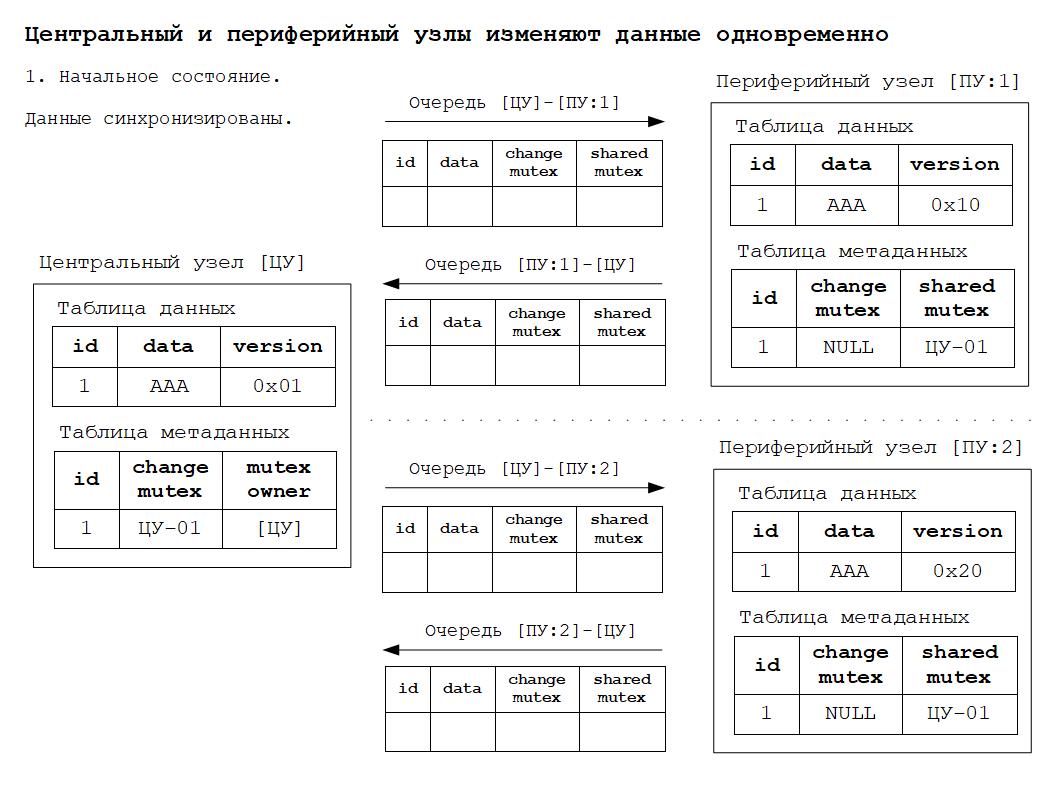
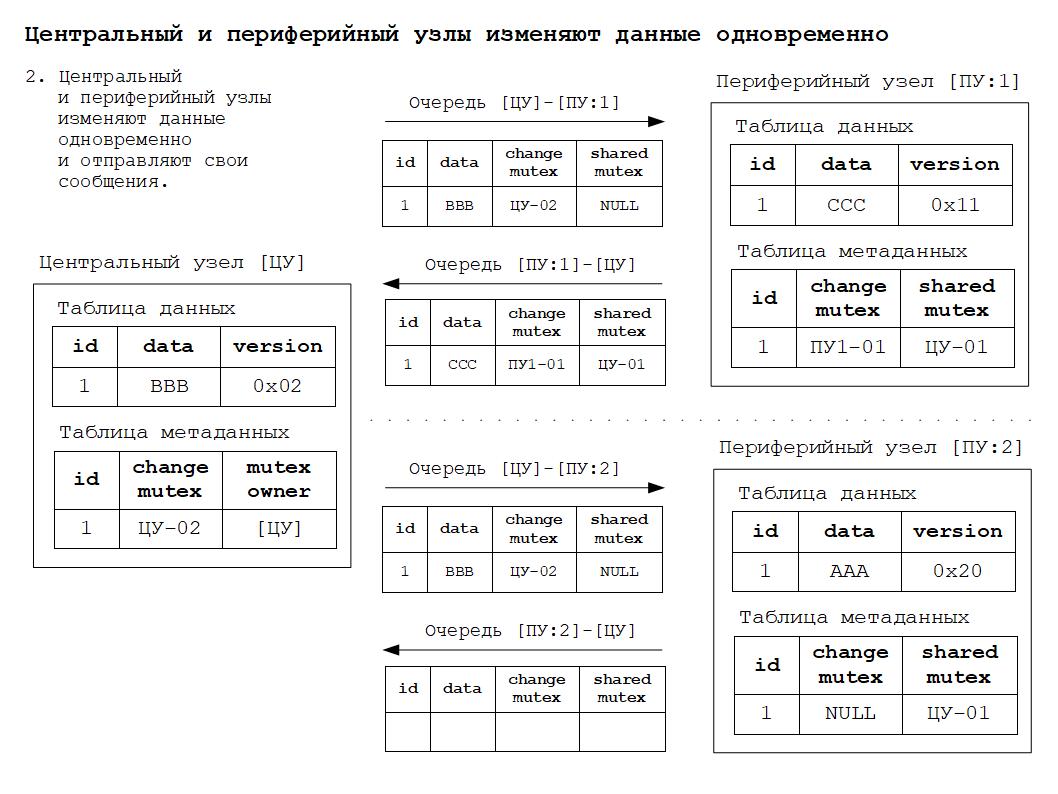
Дополнительные материалы в формате презентаций расположены здесь.
Псевдо код обработки входящего сообщения центральным узлом:
Если (metadata.MutexOwner = message.SourceNode // Владелец мьютекса и узел отправителя сообщения равны
Или metadata.ChangeMutex = message.SharedMutex) Тогда // Мьютекс изменения равен разделяемому мьютексу сообщения
// Начало транзакции
НачатьТранзакцию();
// 1. Обновляем метаданные записи
metadata.MutexOwner = message.SourceNode;
metadata.ChangeMutex = message.ChangeMutex;
ОбновитьМетаданные(metadata);
// 2. Применяем изменения в центральном узле
ОбновитьДанные(message.Data);
// 3. Маршрутизируем сообщение в другие узлы
МаршрутизироватьСообщение(message);
// Конец транзакции
ЗафиксироватьТранзакцию();
Иначе
// Игнорируем и удаляем сообщение из очереди
УдалитьСообщение(message);
КонецЕсли;
Псевдо код обработки входящего сообщения периферийным узлом:
// Начало транзакции
НачатьТранзакцию();
// 1. Обновляем метаданные записи
metadata.SharedMutex = message.ChangeMutex;
ОбновитьМетаданные(metadata);
// 2. Периферийный узел обязан всегда применять изменения,
// пришедшие из центрального узла
ОбновитьДанные(message.Data);
// Конец транзакции
ЗафиксироватьТранзакцию();
Псевдо код формирования исходящего сообщения периферийным узлом:
// Начало транзакции
НачатьТранзакцию();
// 1. Обновляем метаданные записи
metadata.ChangeMutex = GenerateNewChangeMutex();
ОбновитьМетаданные(metadata);
// 2. Выполняется изменение данных
ОбновитьДанные(data);
// 3. Отправляем сообщение в центральный узел
Message message = new Message(data);
message.SharedMutex = metadata.SharedMutex; // Shared mutex был ранее получен и сохранён
message.ChangeMutex = metadata.ChangeMutex;
ОтправитьСообщение(sourceNode, targetNode, message);
// Конец транзакции
ЗафиксироватьТранзакцию();
Ссылки на дополнительные материалы:
1. Распределенные алгоритмы РИБ 1С
2. Мартин Клеппман: Высоконагруженные приложения. Программирование, масштабирование, поддержка. 2018 год.
3. Why Logical Clocks are Easy (Как легко понять логические часы)
4. Calvin: обеспечение принципов ACID для высоконагруженных распределенных систем
Вступайте в нашу телеграмм-группу Инфостарт