План доклада

В ходе доклада:
-
Поговорим о возможности кэширования внутри сложных алгоритмов. Забегая вперед, скажу, что в типовых решениях есть спагетти-код. Не всегда удается эффективно “прокинуть” кэш через все эти процедуры.
-
Рассмотрим многопоточную обработку – это модная тема, которая здорово ускоряет код.
-
Обсудим возможности получения данных с помощью СКД.
-
Я поделюсь примерами с предыдущих проектов. За предшествующие докладу два года накопилось много интересных проектов и кейсов – на реальных примерах посмотрим, как я решал те или иные задачи.
Кэширование внутри сложных алгоритмов

Первое, что мы рассмотрим – это кэширование внутри сложных алгоритмов.
Кэширование нужно для оптимизации – вместо того, чтобы постоянно обращаться к базе данных, мы создаем кэш в оперативной памяти и таким образом оптимизируем наши алгоритмы.
Здесь, конечно, нам нужно не забывать про балансировку ресурсов – если у нас большая выборка (много документов или большой справочник), то каждый раз загружать все данные полностью в оперативную память неэффективно, память может кончиться. Поэтому такое кэширование нужно создавать аккуратно.

На двух примерах посмотрим, как нам может помочь кэширование и зачем оно нужно. Сначала разберем на простом примере, а потом – на примере, близком к типовым конфигурациям.
Пару слов расскажу про базу, которую я сделал для иллюстрации примеров. Это упрощенный пример одного из предыдущих проектов, где я столкнулся с производительностью типового решения. Столкнулись очень жестоко, долго оптимизировали – пытались сделать так, чтобы клиент получил планы производства не через неделю, а хотя бы через день. По итогам той проблемы я подготовил упрощенный пример для вас, чтобы вы поняли приемы, которые я применял.
В этом примере автоматизируется производственная компания, которая что-то производит. Есть номенклатура, у номенклатуры соответственно есть спецификации производства.
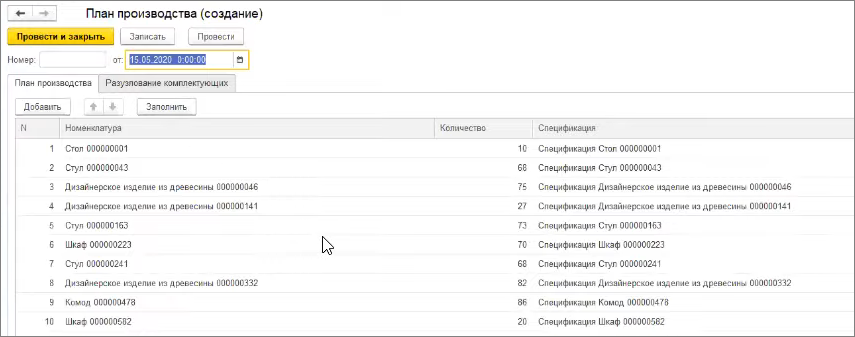
И у нас есть документ План производства.
-
На первой закладке мы заполняем ту продукцию, которую будем производить.
-
А на второй закладке эту продукцию разузловываем до материалов.
При этом продукция производится из материалов с использованием полуфабрикатов – то есть у нас появляется рекурсивное разузлование.
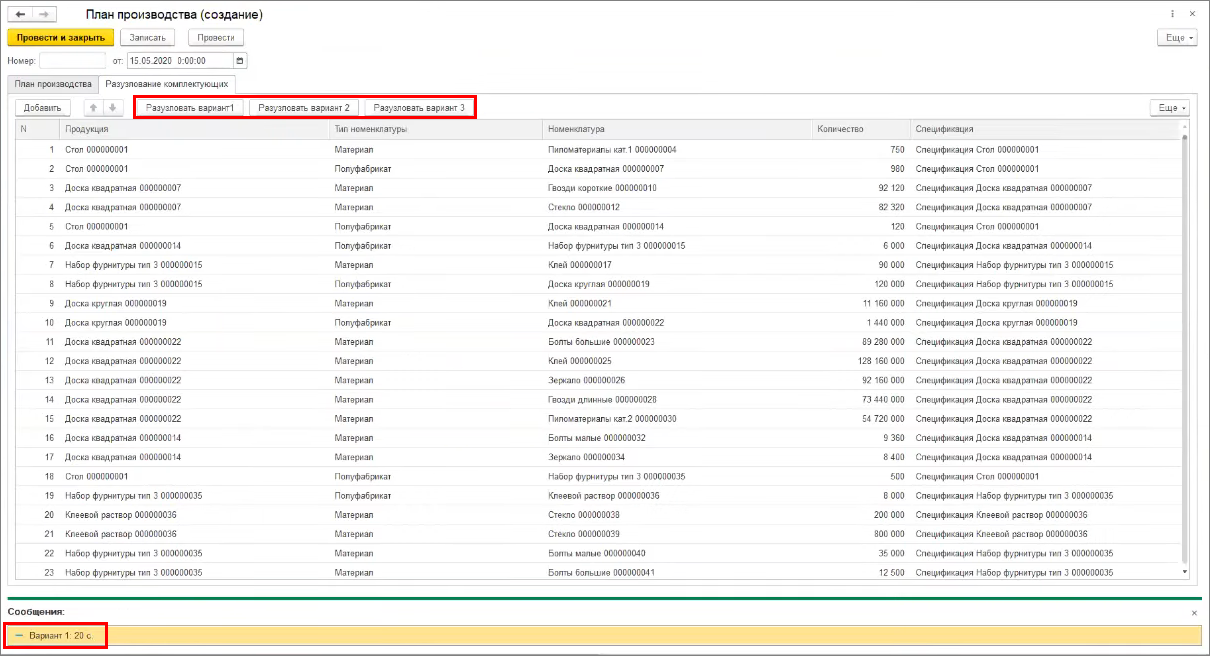
Что такое разузлование? Наша продукция, например, делается из древесины, стекла и еще чего-то. Это могут быть как материалы, так и полуфабрикаты. Если мы встречаем полуфабрикат, мы его разузловываем по его спецификации в элементы более низкого уровня. У нас получается дерево, и такие разузлования как правило выполняются рекурсивными алгоритмами.
Разузлование по первому варианту у нас завершилось за 20 секунд.
Давайте посмотрим, как это выглядит в конфигураторе.
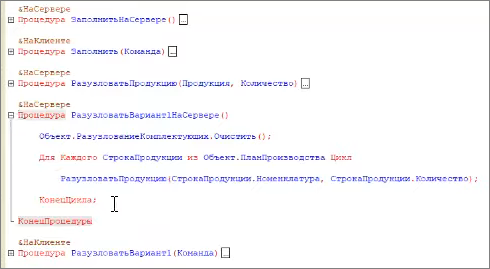
Вот процедура, которая выполняет разузлование по первому варианту. Мы просто перебираем строки плана производства, и по каждой строке получаем подчиненные материалы.
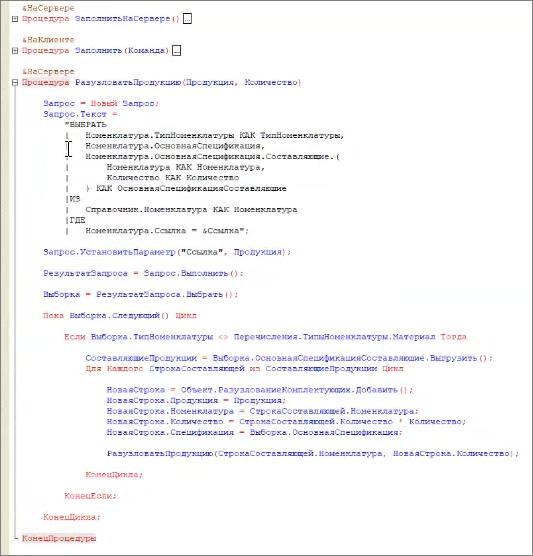
Причем в процедуре мы выполняем запрос, получаем спецификацию. Если попадаем на полуфабрикат – уходим в следующий рекурсивный уровень этой же процедуры.
Очевидно, что мы имеем запрос в цикле. Думаю, что любой специалист по 1С знает, что запрос в цикле – это плохо. Так делать нельзя.
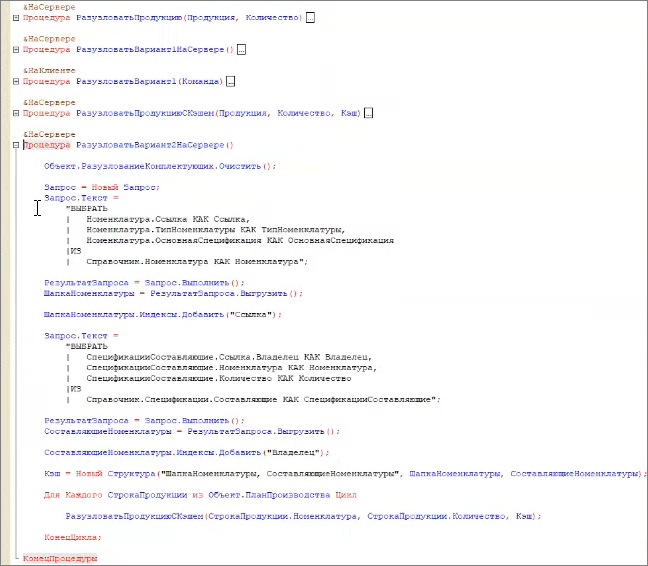
Решается такая ситуация очень просто – до того, как запустить рекурсивную процедуру, мы просто получаем все данные справочников «Номенклатура» и «Спецификации» в таблицы значений. И эти таблицы значений обязательно индексируем.
Индексы – классная штука, они очень сильно ускоряют поиск по таблице значений. Мой любимый вопрос на собеседовании: «Что такое индексы в таблице значений?» Нормально на этот вопрос мне отвечают только 20%.

Когда мы предварительно собираем данные в таблицу по второму варианту, система завершает разузлование всего за 4 секунды – простым приемом мы оптимизировали код в 5 раз.
Если индексы убрать, то разузлование займет 19 секунд, потому что я нагенерировал в справочниках очень много данных, чтобы продемонстрировать вам производительность.
Это простой пример оптимизации, но мы не всегда можем его применить в чистом виде, потому что ситуации, когда мы пишем базы с нуля, не так часты.

Чаще всего мы имеем дело с типовыми решениями, которые выглядят как-то так: «РазузловатьПродукцию» –> «РазузловатьПродукциюТут» –> «РазузловатьПродукциюТам» –> «РазузловатьПродукциюГдеТоЕще» и т.д.
Тащить кэш через все эти процедуры довольно неудобно, потому что потом обновляться будет сложно.
Я сам разрабатывал в 1С и знаю, что обычно такая ситуация чем-то обусловлена. Например, в ERP вполне логичный, нормальный код. Но в результате того, что УТ вырезается из ERP, какие-то куски удаляются, и кажется, что там спагетти-код. Но специально так никто не делает.

Мы добрались до нашей глубоко закопанной процедуры, где и был наш запрос в цикле. Оптимизировать его сложно. Какое решение здесь есть?
Для хранения закэшированного результата запроса можно применять повторно используемые модули.

Здесь в первой строке я с помощью повторно используемого модуля я получаю ссылку на таблицу значений и дальше в коде эту таблицу наполняю.
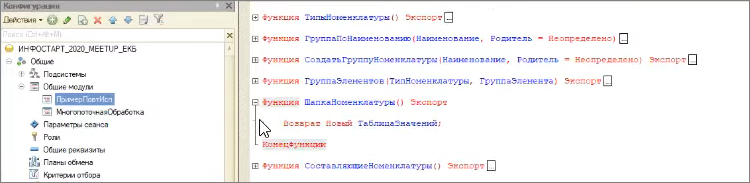
Причем сам повторно используемый модуль у меня ничего не делает – он просто создает пустую таблицу.
При повторном обращении к этой процедуре вы снова получите таблицу значений, но уже с учетом всех предыдущих изменений. Это очень удобно, потому что каждый раз выгружать весь справочник в оперативную память зачастую невозможно. Чаще всего я работаю с очень большими базами, и мне удобнее кэшировать куски, которые действительно нужно закэшировать, к которым частые обращения.
Поэтому удобно не делать логику внутри повторно используемого модуля, а получить ссылку на таблицу, и уже в контексте самой процедуры, когда мы понимаем, какие данные нам нужны - эти данные закэшировать.
При рекурсивном выполнении в первый раз код заполнения кэша выполняется, а во второй раз уже не выполняется.
Такой кэш удобно делать, он получается очень гибким.

Выводы:
-
Кэширование существенно ускоряет работу – простым действием мы ускорили работу в пять раз.
-
Когда мы получаем такие спагетти-процедуры, в них удобно врезаться с помощью повторно используемых модулей. С их использованием алгоритм разузлования занял 4,6 секунд (изначально было 20 секунд).
Многопоточная обработка
Многопоточная обработка – это классный инструмент:
-
Она позволяет распараллелить работу, выполнить больший объем работ за единицу времени.
-
При параллельном выполнении задач аппаратные ресурсы используются более эффективно.
Но есть много сложностей и подводных камней, о которые можно споткнуться.
-
Если сделать очень много потоков, они начинают конкурировать за ресурсы. При этой конкуренции иногда получаются очень сложно расследуемые ошибки, я чуть позже покажу примеры.
-
Количество потоков я подбираю экспериментально – в зависимости от того, чем потоки занимаются, у меня получается один-два потока на процесс. Какую-то более точную формулу я, к сожалению, не смог вывести.
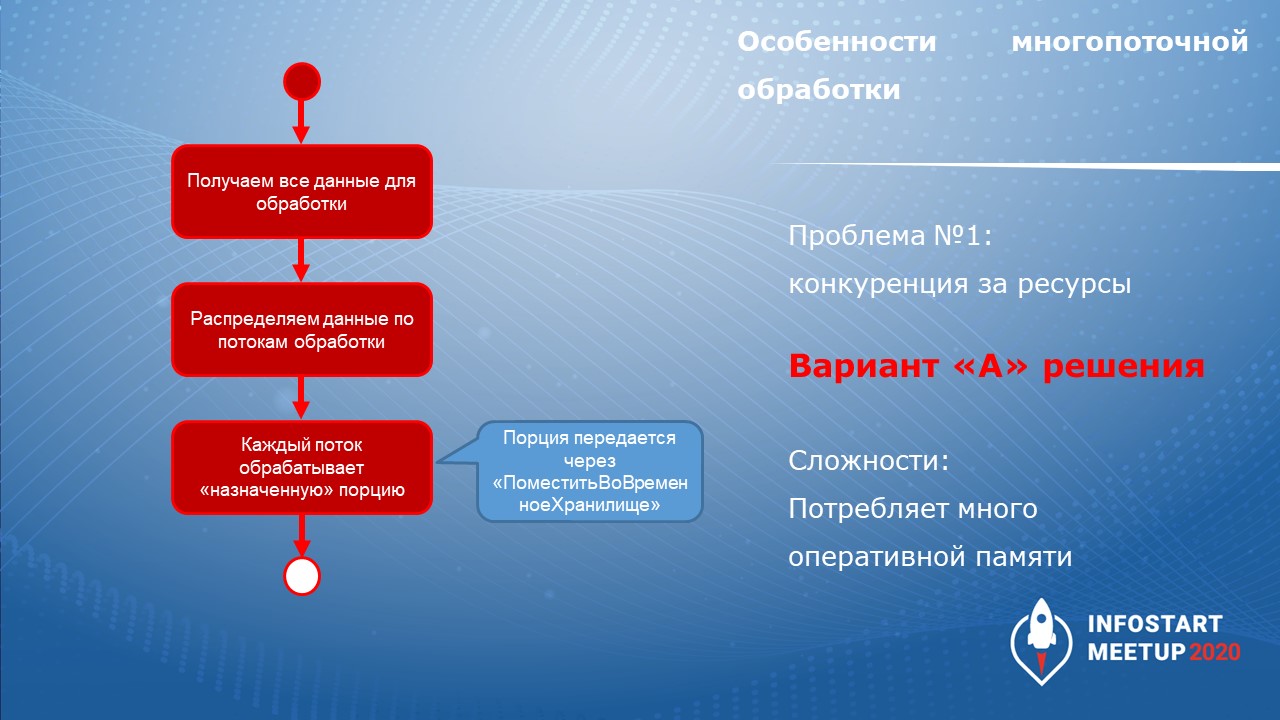
Основная сложность при организации многопоточной обработки – синхронизация потоков.
Первый вариант – в лоб. Получаем все данные для обработки, распределяем их по потокам, и каждый поток обрабатывает назначенную порцию.
При этом есть сложности:
-
Первая сложность – большое потребление оперативной памяти, потому что при получении всех данных для обработки мы вынуждены их держать в оперативной памяти.
-
Вторая сложность – конструкция будет довольно сложная. Ее придется обкладывать логами или механизмами мониторинга. А если поток упадет – его надо перезапускать.
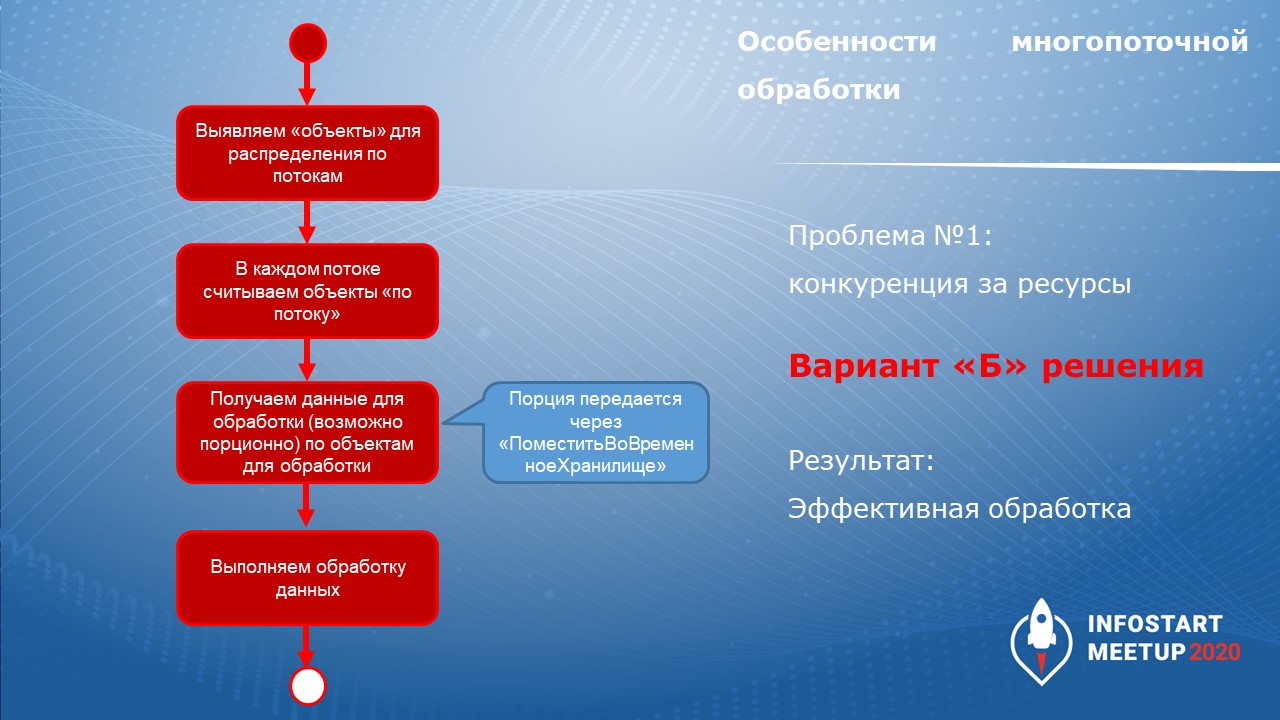
Со временем я для себя принял такую концепцию, что распределять по потокам динамически не надо. Лучше:
-
Выбрать в базе данных объект, на который навесить номер обрабатываемого потока. Например, если у вас несколько складов, и вы пакетно обрабатываете документы реализации – можно номер потока “повесить” на этот самый склад. Или же номер потока можно назначить на клиента.
-
Дальше в каждом потоке вы уже считываете объекты гарантировано по этому потоку. Причем считывать вы их можете порционно.
-
Если что-то упадет, вы гарантировано знаете, что обработалось, а что – нет. За счет того, что вы увидите: есть какие-то объекты к обработке по определенному потоку.
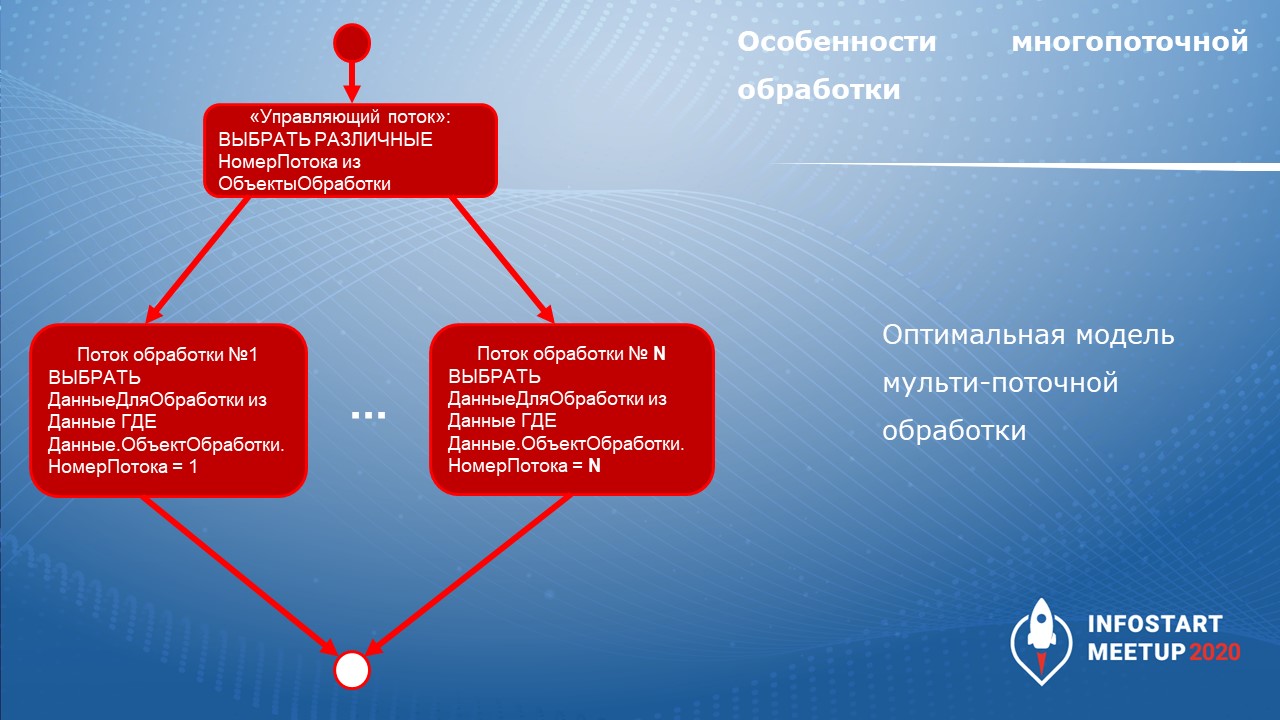
Как это выглядит технически. У нас получается управляющий поток и набор потоков, которые обрабатывают данные:
-
Управляющий поток выбирает различные номера потоков из тех объектов, которые планируется обработать.
-
И дальше запускает столько потоков, сколько объектов нужно обработать – в каждом потоке выбираются только объекты для обработки в рамках этого потока.
-
При этом управляющий поток еще может контролировать, что каждый из потоков, обрабатывающих данные, действительно выполняется, что он не упал. Либо перезапустить или еще что-то сделать.
Небольшой пример, как это может выглядеть в базе данных.
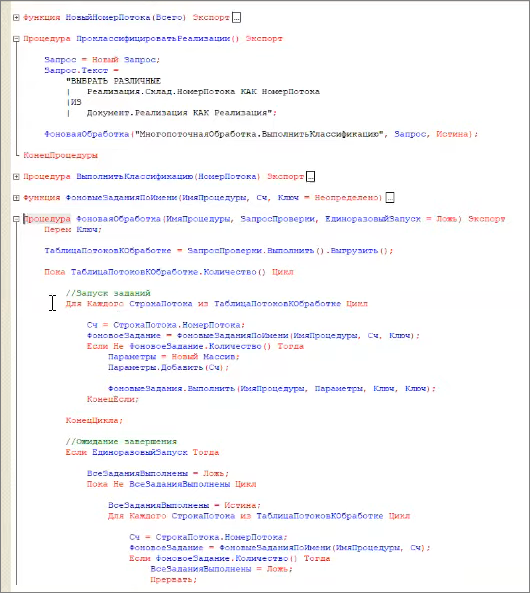
У нас есть документы «Реализация», которые нужно классифицировать по складам.
-
Первым этапом мы выбираем различные номера потоков из складов в «Реализациях»,
-
Дальше мы запускаем столько потоков, сколько у нас номеров потоков к выполнению.
-
И ждем их завершения.
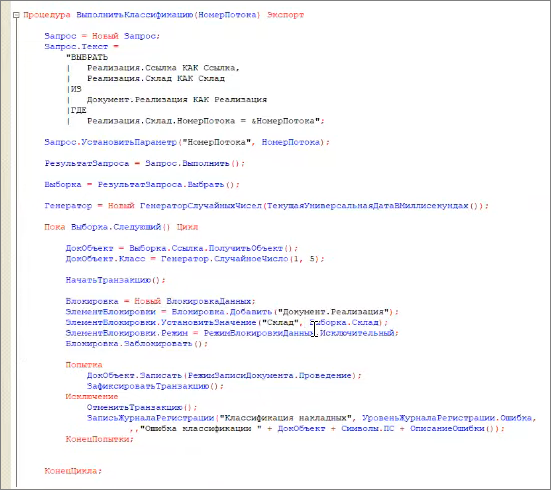
Внутри процедуры «ВыполнитьКлассификацию(НомерПотока)» у нас отбираются реализации строго по этому номеру потока. И дальше обязательно накладываем блокировку.
При этом у нас гарантировано не будет пересечения в блокировках, потому что у нас реализации отбираются по номеру потока из склада – один и тот же склад в несколько потоков попасть не может, и блокировка накладывается довольно эффективно.
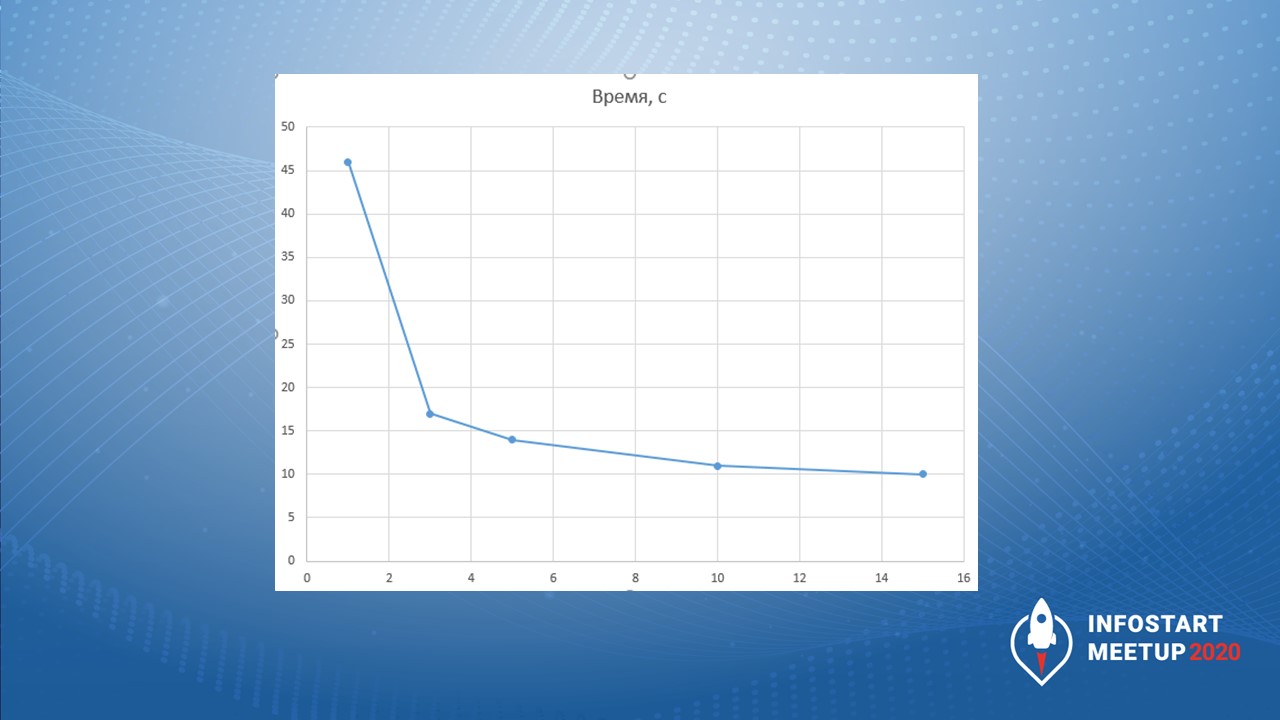
Время обработки 6 тыс. документов для этого примера заняло:
-
в одном потоке – 46 секунд;
-
3 потока – 16 секунд;
-
5 потоков – 14 секунд;
-
10 потоков – 11 секунд;
-
15 потоков – 10 секунд.
Но если продолжить добавлять потоки, то время ползет вверх. Это удивительно, но это так.
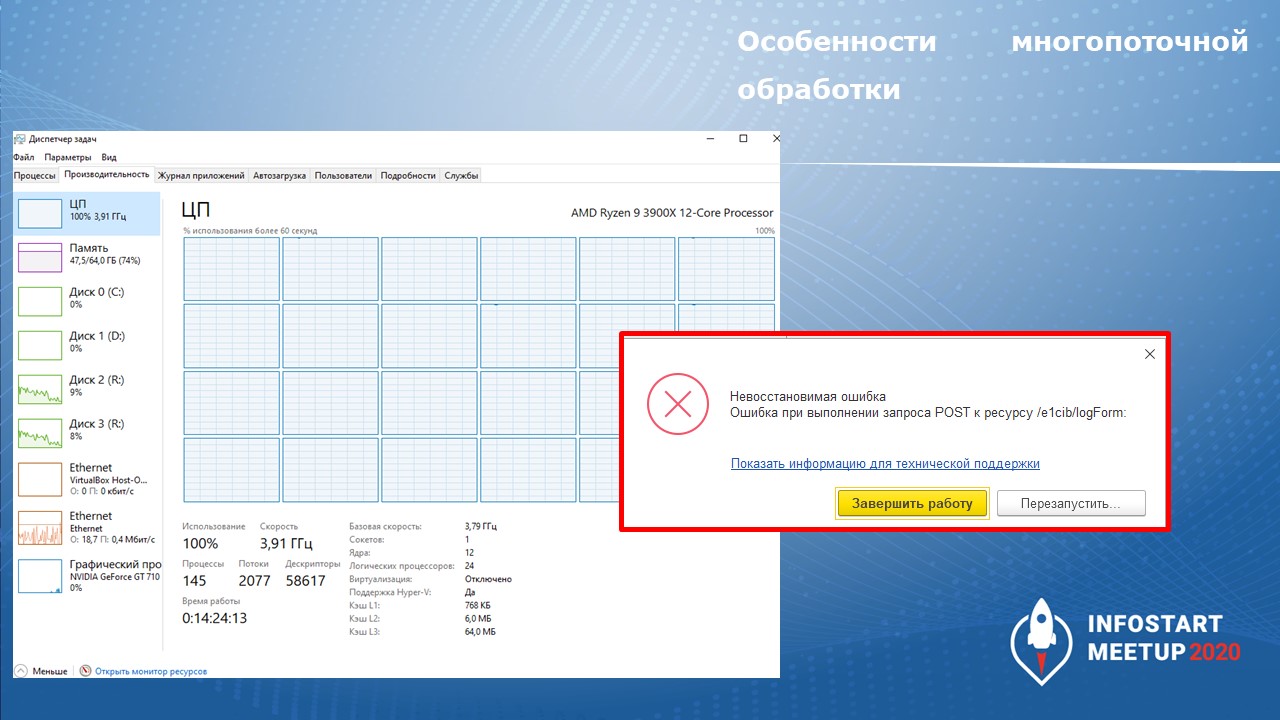
И, например, я у себя добился воспроизведения ошибки. Если на моем домашнем сервере запустить примерно 40-50 потоков – то ровно через 4-5 часов он выдает мне вот такую ошибку.
По этой ошибке не всегда понятно, что происходит, поэтому количество потоков нужно подбирать аккуратно, чтобы не получать странных ошибок.
У нашего клиента сервер себя интересно вел. Мы его загрузили потоками почти под 100%. Понятно, что сервер надежнее домашних компьютеров и сервер успешно обрабатывал данные в фоновых задания, пускал пользователей в базу, но дальше интерфейс не шевелился, ничего не происходило.
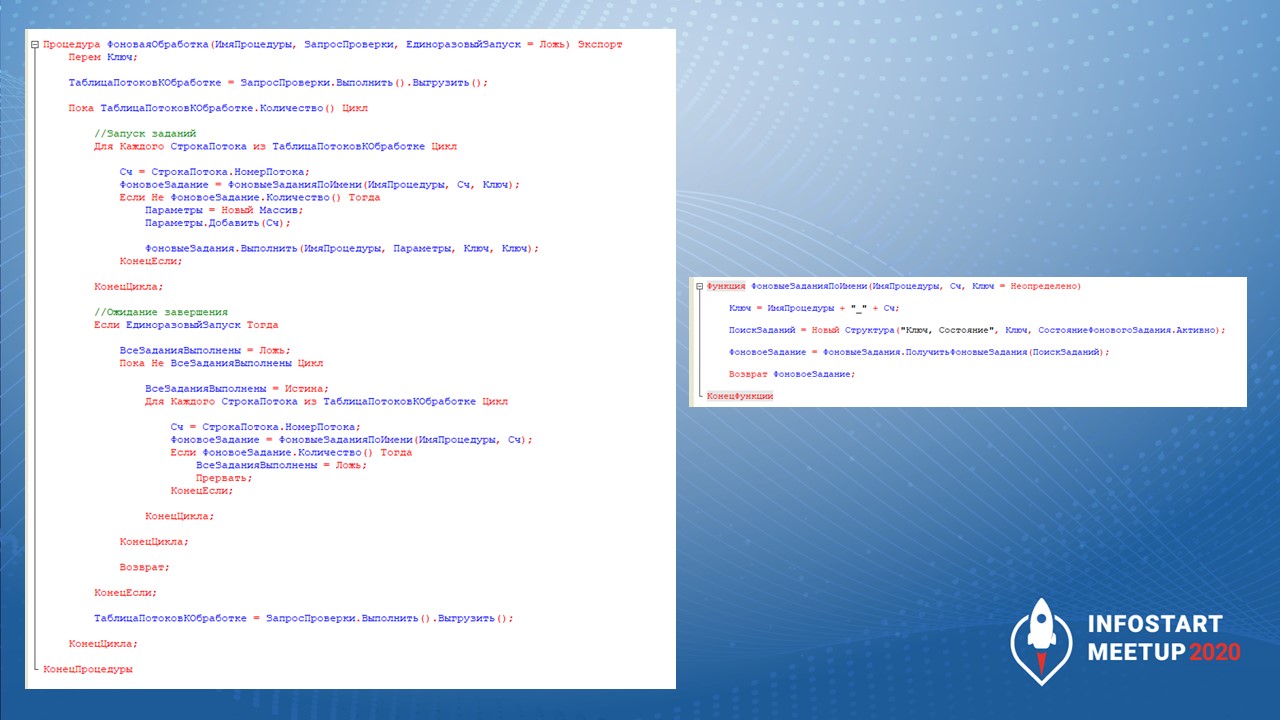
Здесь на слайде показаны процедуры по фоновой обработке, которые мы сейчас посмотрели.

Вывод: многопоточная обработка – очень интересная штука, но к ней надо подходить аккуратно. При бесконечном увеличении потоков вы существенного выигрыша не получите, а можете налететь на странные ошибки.
Система компоновки данных
Давайте теперь немного поговорим про СКД. Очень интересная вещь, очень люблю на собеседованиях задавать вопросы по ней. Но, как показывает практика, не все ее любят так, как я.
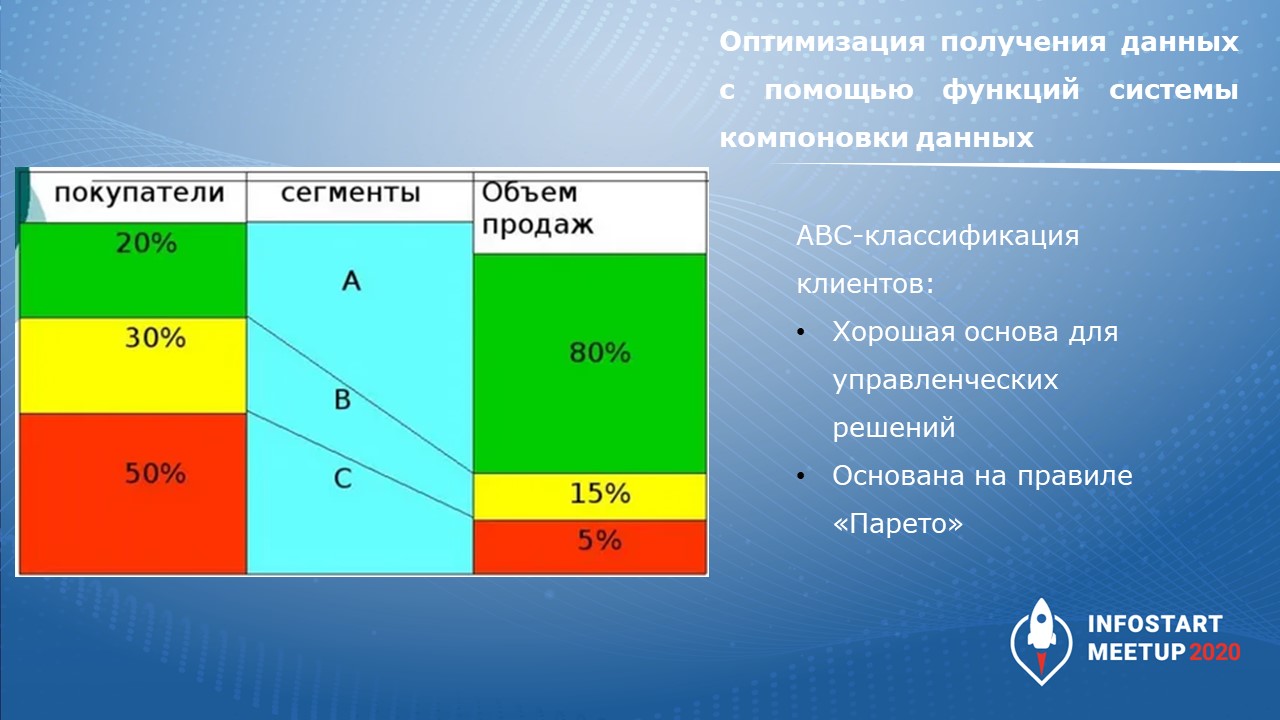
Главная задача: я решил распределить разработчиков по классификации АBC в зависимости от того, насколько сильно они косячат.
-
класс A – мало косячит;
-
В – средне косячит;
-
С – косячит больше всех.
Классификация АВС основана на правиле Парето, которая формулируется как «20% клиентов приносит 80% продаж».
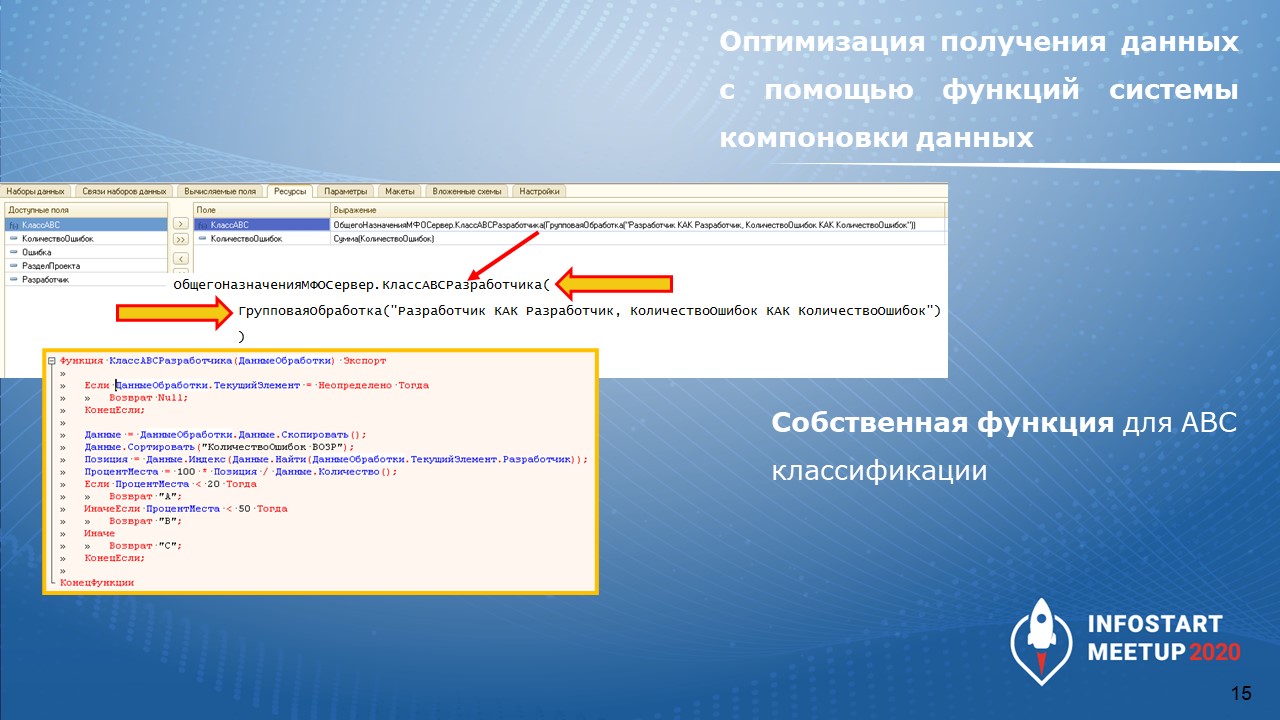
Первым решением – в ресурсе схемы компоновки данных написали собственную функцию, которая выполняла классификацию.
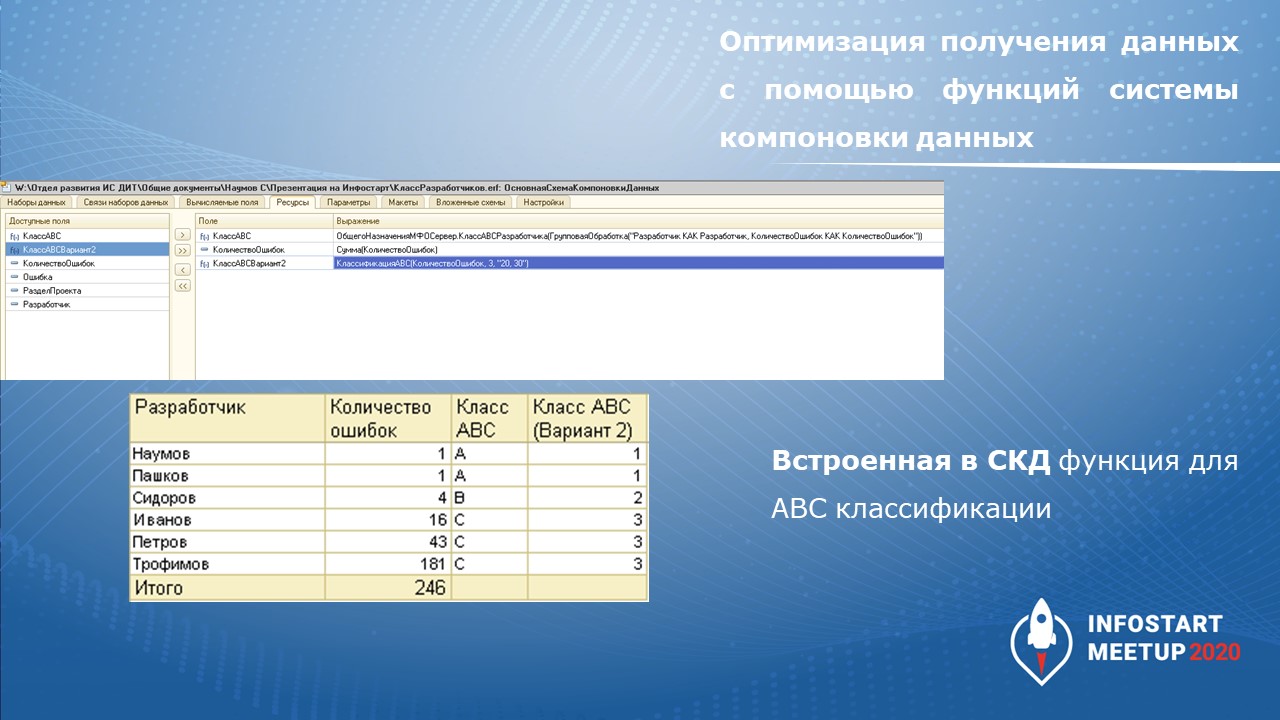
Но, как оказалось, в СКД есть встроенная функция, классификация которой работает не хуже и выдает аналогичный результат.

Другой пример работы с СКД – получить срез последних по месяцам. Для демонстрации возьмем известную задачу, когда у нас есть некоторая таблица периодов по месяцам, и нам нужно подобрать ближайший курс валют к этой дате.
-
Можно реализовать запросом соединения меньше либо равно, потом сделать максимум – но это работает это не очень быстро.
-
Можно сделать запрос в цикле – кодом в модуле.
-
А третий вариант – это сделать запрос в цикле средствами СКД.

Для этого в схеме компоновки данных нужно сделать два набора.
-
Первый набор выводит те месяца, по которым нужно подобрать курсы валют.
-
Второй набор – делает запрос к срезу последних курсов валют на дату, которая указана в параметре.
При этом передачу параметра мы делаем через связи таблиц, и СКД автоматически начинает работать так, как будто мы выполняем запрос в цикле.
Тут еще есть интересная возможность. Видите галку «Список параметров»? Если эту галку поставить, система начнет для «Выражения источник» формировать в пакеты по тысяче штук и помещать их в параметр. Выполнять запрос в цикле, но на каждую тысячу штук. Это очень интересная возможность, мой любимый вопрос на собеседовании.

Это всего лишь несколько кейсов, связанных с СКД. Я рекомендую вам самостоятельно изучить различные приемы работы с СКД и ее дополнительные возможности.
Например, из недавнего опыта был интересный кейс – надо было сделать по данным прогноз линейным и экспоненциальным трендом. В принципе, для программиста несложно. Кто знает – это обычная регрессия.
Но в недавних релизах платформы появилась возможность считать регрессию в СКД. Причем, вы можете не только вывести эти тренды на диаграмму с помощью условного оформления. Вы можете также получить параметры этих трендов и с помощью одной формулы рассчитать прогноз. Это очень удобно, возможности СКД очень широкие.
Интеграция система-система
Следующий кейс – система для обработки большого объема данных.Об этом проекте я подробно рассказывал в докладе на Infostart Event 2019. Сегодня я освещу некоторые технические аспекты этой системы.
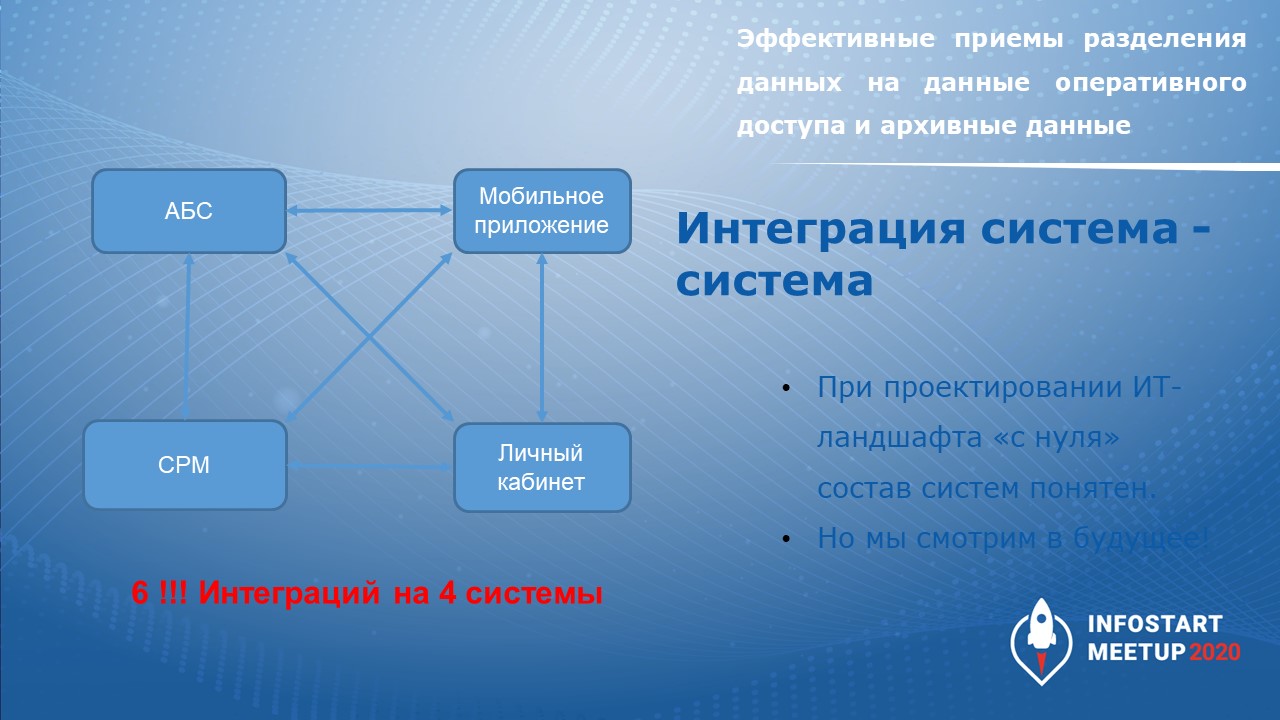
Вы знаете, что чтобы обмениваться данными между 4 системами нам нужно настроить 6 интеграций – это очень много. Поэтому когда у нас встала такая задача, мы пошли по другому пути – решили поставить систему класса «Шина данных».
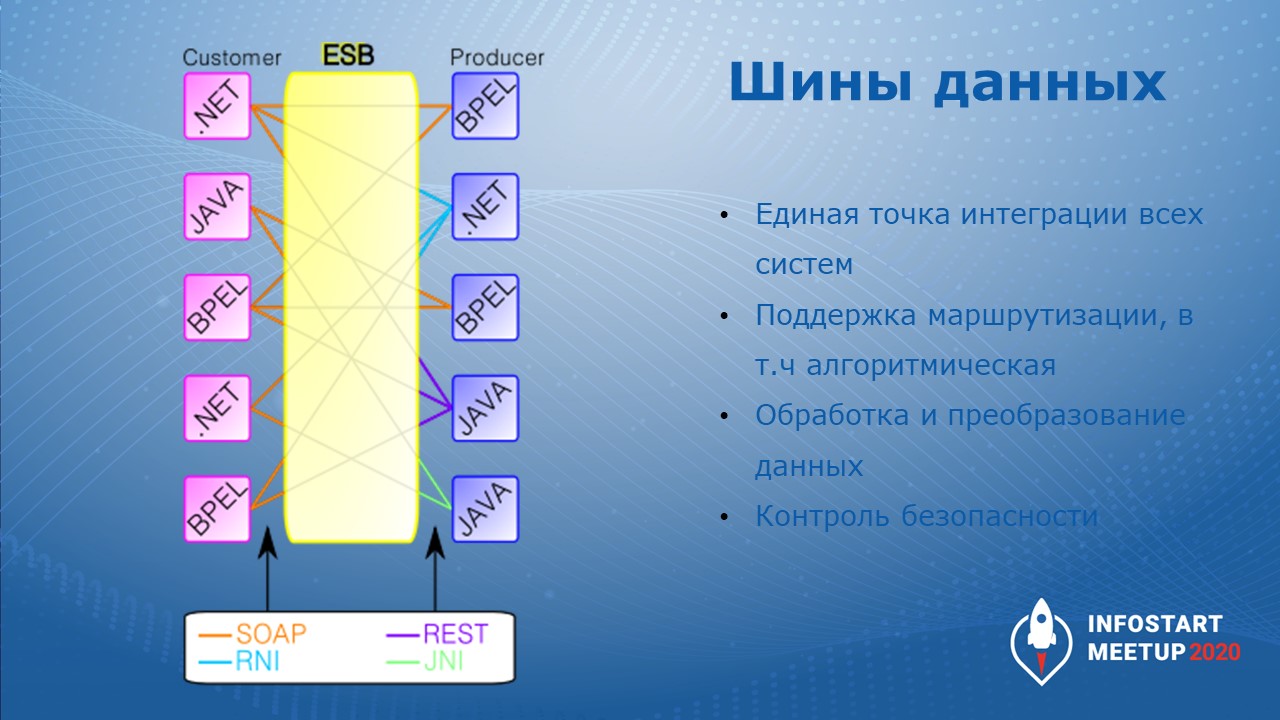
Шина данных или ESB-система выполняет роль коннектора, единого окна для всех систем. Например, когда CRM хочет запросить какие-то данные у АБС (автоматизированной банковской системы), то:
-
CRM вводит сообщения в шину данных;
-
шина данных маршрутизирует запрос в АБС;
-
дожидается ответа от АБС;
-
и возвращает его в CRM.
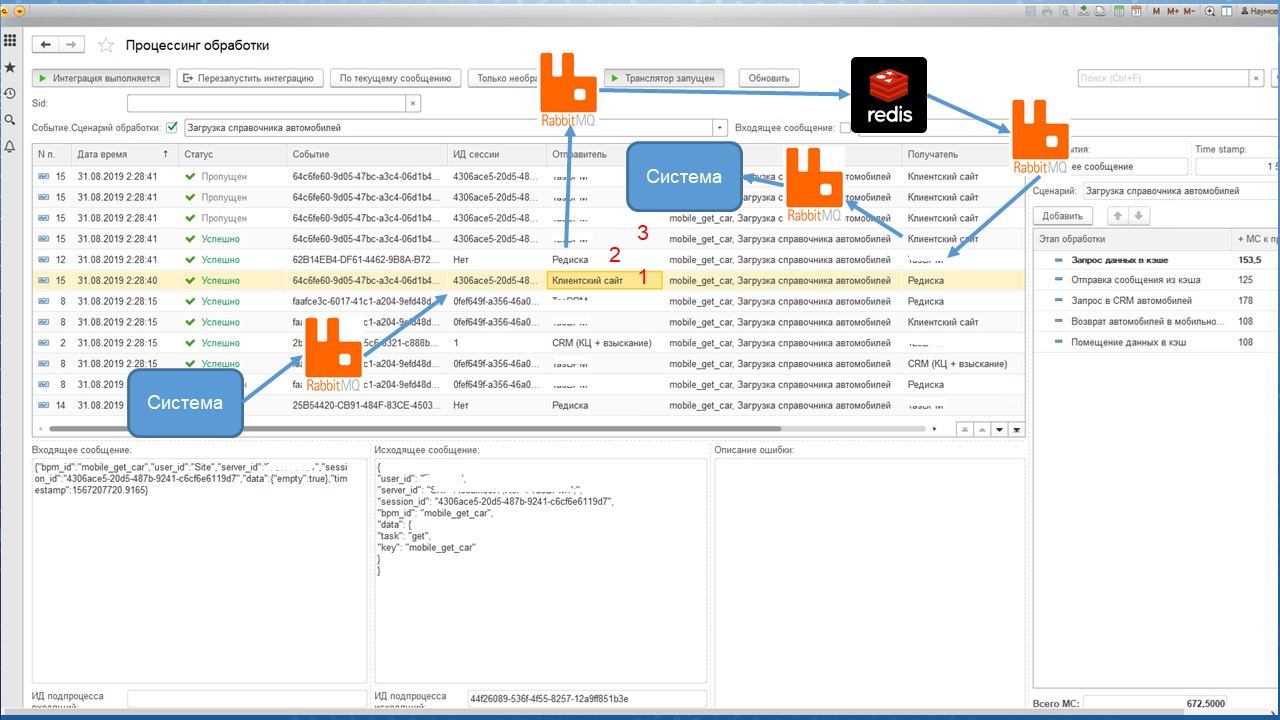
Шину данных мы реализовали собственную, на 1С. Для исключения проблем с производительностью мы обложили ее RabbitMQ и кэшем на Redis.
Идея простая – на слайде показан пример запроса с клиентского сайта на расчет графика платежей:
-
клиентский сайт запрашивает данные;
-
BPM-система проверяет в Redis-сервере наличие готового графика;
-
возвращает его, если он там есть;
-
если его нет – запрашивает его у системы АБС.
В чем сложность? Все сообщения логировались в регистре сведений, и буквально через несколько дней список этого регистра сведений уже не мог даже открыться, потому что данных было очень много – там на момент запуска летало от 400 до 2000 сообщений в секунду.
Потому что через шину работали и мобильные приложения, и сайт, и CRM, и внешний CRM – это было ядро интеграции. Данных было много, поэтому:
-
скорость обработки сообщений деградировала;
-
мы не могли разобраться с инцидентами, потому что у нас этот список даже не открывался.
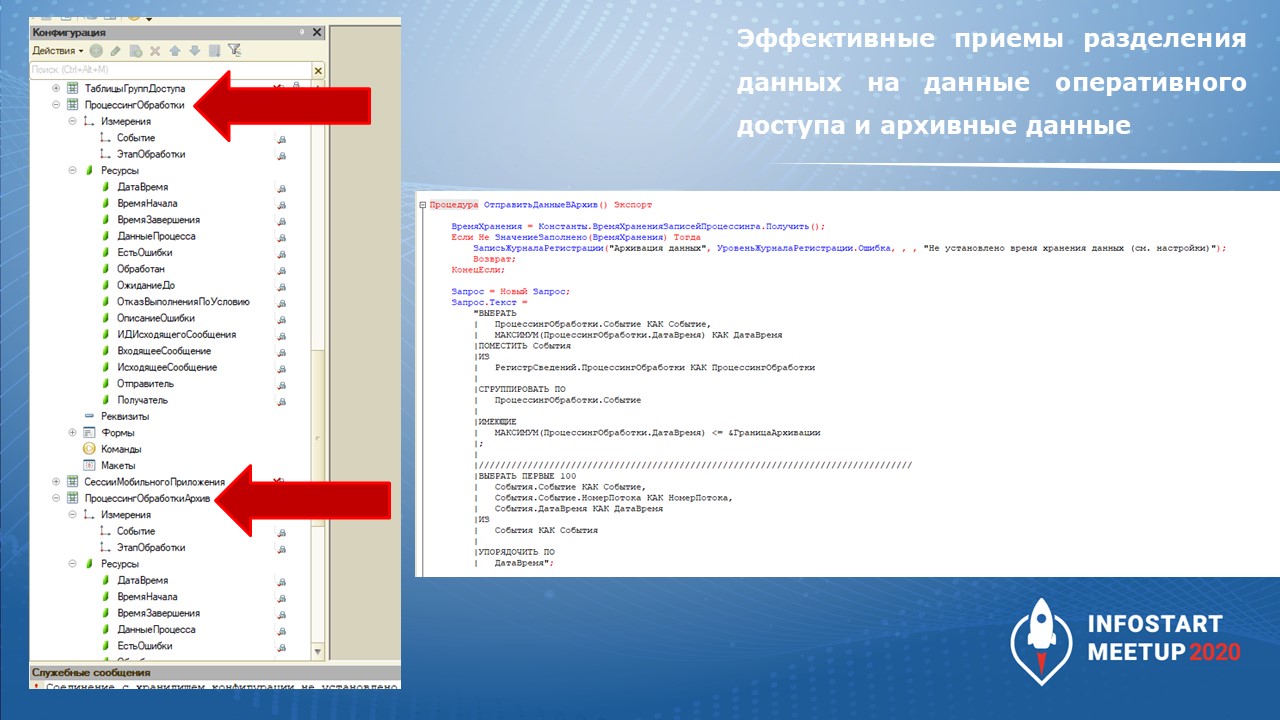
Для решения мы сделали:
-
два одинаковых регистра сведений – один архивный, один основной;
-
и процедуру, которая в фоне раз в пять минут берет все записи, которые старше 5 часов, и перекладывает в другой регистр.

На слайде показан текст этой процедуры.
Поскольку блокировки мы накладываем на некоторые минимальные размеры данных, потери производительности мы даже не заметили.
При запуске такой архивации основной список стал нормально работать, пяти часов нам хватало для расследования инцидентов. А дополнительную нагрузку по перекладыванию сведений из одного регистра в другой мы даже не заметили.

На этом проекте проявилась еще одна интересная особенность:
Когда приходит новое сообщение, нужно получить предыдущее сообщение и понять, что с ним происходило.
Сначала я использовал для этого запрос с итогами по формуле МАКСИМУМ(Период), но это занимало большое время.
Я попробовал поставить для регистра флаг «Разрешить итоги» и использовать «Срез последних» без даты. Ускорилось классно, запрос стал работать быстро, но запись в регистр просела больше, чем выигрыш от чтения.
Если бы это был регистр, который редко пишется и часто читается, можно было бы прикинуть на калькуляторе что выгоднее. Но у нас количество операций записи и количество операций чтения для этого регистра примерно одинаковое, поэтому нам этот вариант не подошел - мы откатились к старой схеме.
Вывод: с виртуальными таблицами нужно аккуратно. Подбирайте для них оптимальные варианты использования, когда нужно, чтобы обязательно итоговые таблицы были задействованы. Тем не менее, варианты с реальными таблицами тоже нужно проверять на всякий случай.

Когда мы столкнулись с проблемой производительности, у нас первая мысль была – апгрейдить сервер, поиграть с индексами. Но простое разделение на основные и архивные данные здорово повысило скорость работы и помогло завершить проект.
Использование дихотомических алгоритмов для решения типовых задач
Теперь я хотел бы поговорить про мой любимый пласт задач – задачи, которые требуют определенной алгоритмики.

Как и на слайде, я в институте с высшей математикой не дружил. Высшую математику я изучал впоследствии, после института, и об этом не пожалел.
Есть задачи, которые называются задачами оптимизации – для них еще встречается термин NP-полные задачи.
Задача с недавнего проекта – балансировка плана. У нас есть:
-
объем материалов, который закупщики обещают закупить;
-
объем продукции, который продажники обещают продать;
-
есть пропускная способность заводов;
-
и есть ограничения – сколько сырья должно оставаться на складах в тот или иной период времени.
Задача очень легко раскладывается в систему линейных неравенств, минимизируются отклонения от плановых остатков.

Решаются такие задачи разными способами.
-
Первый и самый точный, но долгий – полный перебор. На более-менее серьезных объемах это не сработает, это невозможно.
-
Есть штуки вроде генетических алгоритмов, которые позволяют эволюционно находить лучшее решение.
-
На 1С, по моему опыту, здорово работают дихотомические алгоритмы. Они очень простые в программировании. На том примере с балансировкой планов, который я приводил, мы предварительно просчитывали всю модель в Excel, проверяли через мастер решений, который позволяет найти те или иные оптимальные параметры. И потом сравнивали с тем, как 1С считала дихотомическим алгоритмом – разница получалась в несколько килограммов. Было принято решение, что алгоритм можно запускать в продакшн, и он вполне подходит.

Что такое такое дихотомический алгоритм?
-
У нас есть некоторая функция, желательно, чтобы она была монотонно возрастающей/убывающей. Мы знаем ее область определения, причем область определения мы можем придумать сами.
-
Делим эту область определения пополам, берем на каждом из участков симметричные точки, определяем значения функции на этих точках и находим среди этих значений максимальное.
-
В зависимости от того, значение на каком участке больше, тот участок и продолжаем делить пополам и сравнивать значения дальше до тех пор, пока алгоритм не сойдется в какой-то точке.
Самый смешной случай применения алгоритма в моей практике – расчет размеров торта. Это когда клиент говорит: «Я хочу двухэтажный торт весом 5 килограмм, первый этаж – йогуртового вкуса, второй – сливочного» и нужно просчитать размер заготовок для каждого этажа, чтобы кондитеры брали заготовки нужного размера, не задумываясь.
Директор кондитерской заказал у меня систему, чтобы просчитать размеры такого торта. Но мы столкнулись с тем, что просчитать это невозможно, потому что плотность этажей разная. Здесь дихотомический алгоритм нас спас – мы, подбирая примерные размеры торта, можем получать торт нужного веса.
Алгоритм интересный, пригождается в планировании, чтобы строить вот такие механизмы балансировки планов и ресурсов.
Выводы

Общие выводы по презентации:
-
Призываю вас изучать различные алгоритмы решения нетиповых задач – это интересно и повышает вашу ценность как специалиста.
-
Работайте с готовыми паттернами, и вам не придется изобретать велосипеды.
*************
Данная статья написана по итогам доклада (видео), прочитанного на INFOSTART MEETUP Ekaterinburg.Online.
Вступайте в нашу телеграмм-группу Инфостарт