История проекта
Попробую рассказать, как приглядывать за 1С, которая работает на Linux.

Картинка – аллегория на то, с чего все начиналось:
Проект мониторинга начался в 2014 году, когда меня пригласили разворачивать площадку на базе технологии 1С:Фреш. Мы тогда поднимали гибридную площадку, где присутствовали сервера как на Windows, так и на Linux – из-за того, что на тот момент агент сервиса 1С:Фреш не работал на Linux.
Таким образом была поднята площадка, но, поскольку я был привлеченным со стороны специалистом, в мои задачи не входило ее сопровождение – я должен был только развернуть и настроить компоненты системы.
Но я понимал, что работу этих компонентов нужно мониторить. При этом я не понимал, какие метрики вытаскивать.
Так как площадка была гибридной, единой точкой входа для мониторинга 1С стал сервер RAS. Из него можно было вытащить различные данные платформонезависимо – RAS работал как на Windows, так и на Linux. Этот выбор и стал определяющим для дальнейшего развития проекта, который развивается и сейчас – его можно посмотреть в репозитории GitHub https://github.com/slothfk/1c_zabbix_template_ce.
Но на тот момент работы были завершены, и с развитием проекта мониторинга 1С на Linux возникла пауза.
Второй этап развития проекта мониторинга. Преимущества решения

Возврат к теме мониторинга произошел в 2018 году. Я начал с того, что провел обзор: какие свободно распространяемые готовые инструменты мониторинга есть.
Но, поскольку я ничем не впечатлился, было решено продолжить начинание 2014 года «с чистого листа».
Чем отличается проект, который я затеял, от найденных аналогов? На слайде вы видите основные вехи.
-
Первое – он свободно распространяется. Его можно брать и использовать, допиливая как вам угодно.
-
Проект – кроссплатформенный, можно использовать для мониторинга серверов 1С на Linux и Windows.
-
Получение данных минимальным набором «инструментов» сводится к тому, что не хотелось изначально ставить дополнительные инструменты, добавлять точки входа в 1С – хотелось обойтись тем, что установлено на сервере 1С из коробки.
-
При этом минимальный уровень участия пользователя в настройках мониторинга. Пользователь, проставив необходимые шаблоны в Zabbix и скрипты на сервер 1С, и назначив роли на узлы наблюдения, получит данные, не вникая в тонкости.
-
Исключение необходимости сбора больших объемов технологического журнала для расследования возникающих инцидентов, так как по методикам и по статьям, которые имеются в общем доступе, рассказывают о том, как собирают большие объемы технологического журнала, запихивают его в разные базы или просто скриптами анализируют за длительное время. А тут хотелось инструмента, который будет сохранять только тот объем технологического журнала, который необходим для расследования.
-
И еще один момент – это модульный принцип. Изначально, когда это делалось в 2014 году, сбор всех метрик был реализован в одном скрипте, который пытался выгребать данные из RAS. Вернувшись в эту тему в 2018 году, я немного переосмыслил этот процесс и принял решение разбить какие-то вещи по функциональности. Те, кто читали мои статьи на Инфостарте, могли заметить, что в названии скриптов присутствовали названия процессов сервера 1С:Предприятия. Сейчас опять произошло переосмысление, и скрипты поменяли свое название на роли серверов.
Давайте посмотрим, что предоставляют эти модули, какие метрики можно собирать с из помощью.
Модуль Сервер лицензирования (программные лицензии)
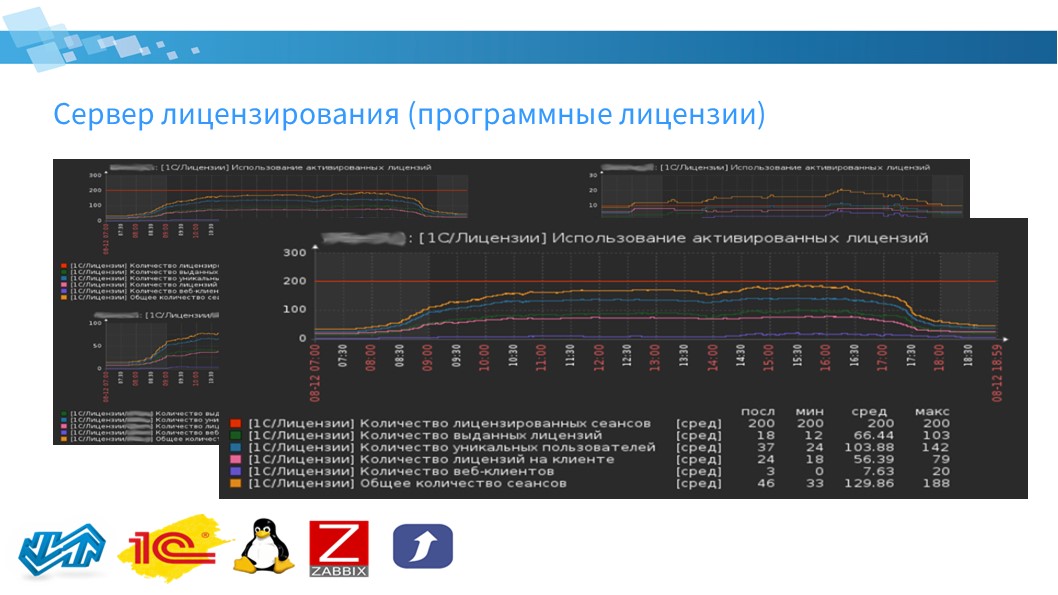
Есть модуль, который отвечает за мониторинг сервера лицензирования. Его основное назначение – сбор данных по утилизации программных пользовательских лицензий 1С, активированных на сервере лицензирования. В данном случае под сервером лицензирования понимается как выделенный сервер, так и сервис лицензирования, если он установлен на общем сервере.
На заднем плане слайда я поместил комплексный экран, который отображает утилизацию лицензий в целом по серверу лицензирования, и есть разбивка по кластерам. Если сервер лицензирования у вас участвует в нескольких кластерах, вы можете получать данные в разрезе кластеров по утилизации лицензий.
Zabbix собирает:
-
общее количество сеансов;
-
количество лицензированных сеансов – на сколько сеансов у вас установлено лицензий;
-
количество выданных лицензий – сколько из этих установленных лицензий выдано сервером;
-
количество уникальных пользователей;
-
количество лицензий на клиенте – это те лицензии, которые клиентское приложение получило у себя локально;
-
и количество веб-клиентов.
Модуль Рабочий сервер
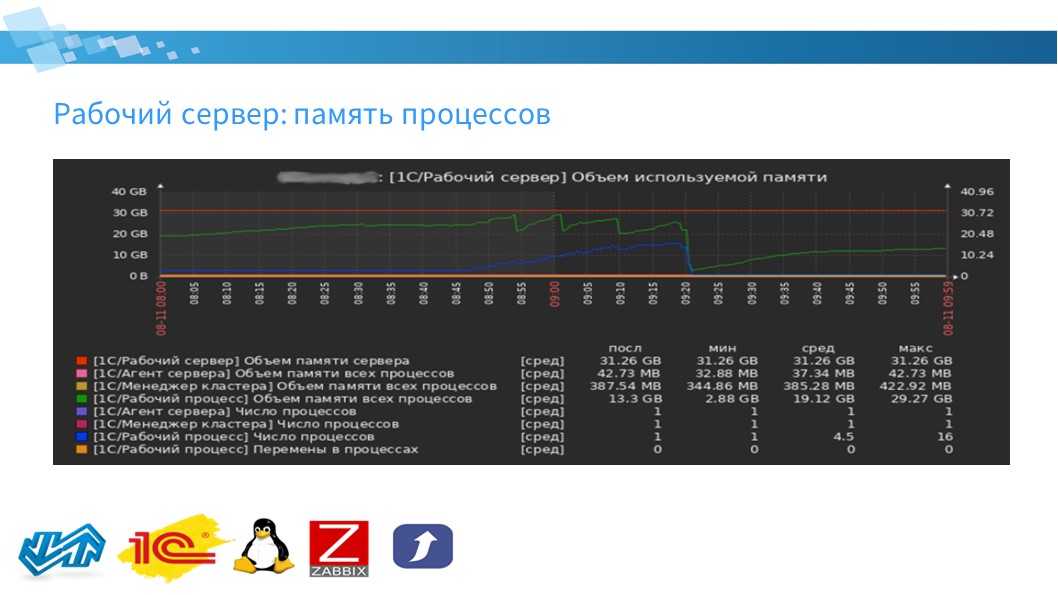
Следующий модуль – модуль рабочего сервера.
Здесь есть показатели:
-
по количеству процессов сервера:
-
для Агента сервера (ragent);
-
для Менеджера кластера (rmngr);
-
для Рабочего процесса (rphost);
-
и общее число процессов.
-
-
по суммарному объему занимаемой ими памяти:
-
для Агента сервера;
-
для Менеджера кластера;
-
для Рабочего процесса;
-
и общий объем памяти сервера.
-
-
также фиксируется количество перемен в рабочих процессах, что позволяет Zabbix фиксировать частые перезапуски рабочих процессов.
На слайде я привел график с реального боевого сервера – здесь можно увидеть рост количества рабочих процессов. Произошел инцидент, и произошло увеличение рабочих процессов, сопровождающееся резким замедлением работы пользователей.
Zabbix позволяет оперативно реагировать на эти ситуации, не дожидаясь звонков пользователей – предпринимать решения до того, как пользователи начали названивать на линию поддержки.
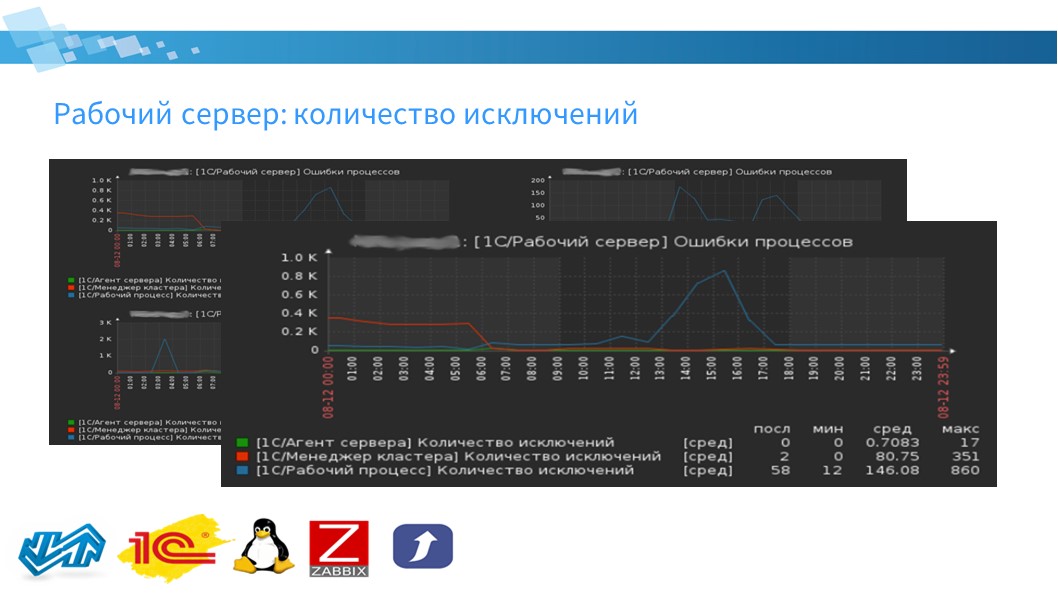
Есть показатели, которые собираются по техжурналу – это количество ошибок/исключений процессов сервера 1С.
Эти показатели собираются один раз в час – можно сделать комплексные экраны по рабочим серверам, которые будут показывать графики количества ошибок.
Здесь на картинке собран комплексный экран с нескольких серверов, который вам в динамике показывает, как меняется количество ошибок по разным процессам.
И, соответственно, можно какую-то аналитику проводить по логам – что происходило в эти моменты.
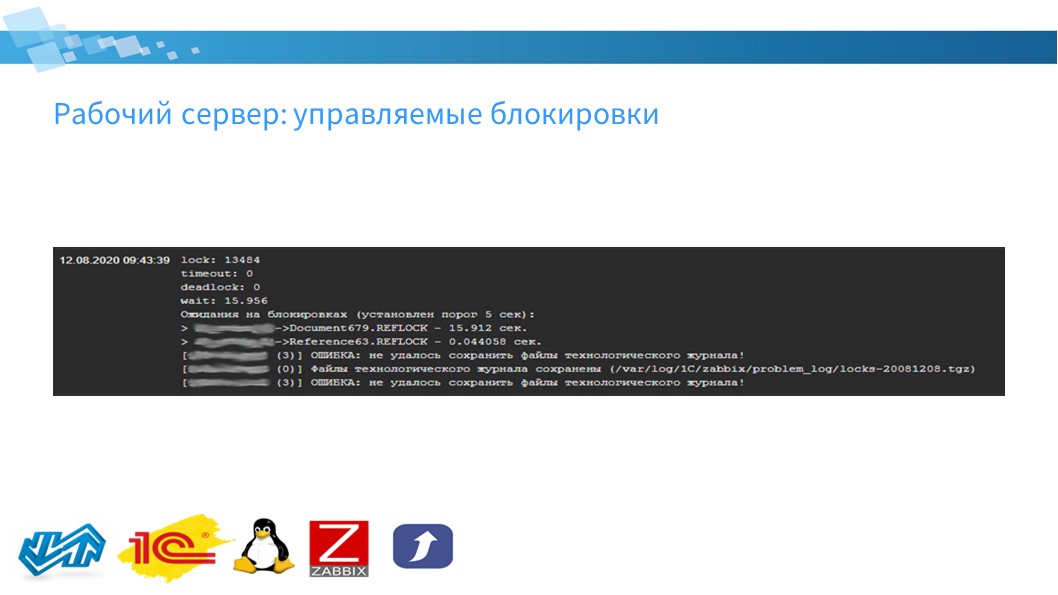
Еще один момент по рабочим серверам – мониторинг управляемых блокировок.
Анализируется технологический журнал раз в час и выдается информация о том, были ли:
-
таймауты;
-
взаимоблокировки
-
ожидания на управляемых блокировках.
Если ожидания были – выдает информацию, на каких измерениях были эти ожидания, и в какой величине.
Если было превышение установленного порога ожидания на блокировках, либо если возникали таймауты, взаимоблокировки – техжурнал сохраняется в каталог. Вы можете видеть, что на сервере файлы технологического журнала сохранены в такой-то каталог.
Причем, файлы технологического журнала сохраняются на всех серверах, входящих в кластер – были ситуации, когда виновник блокировки оказывается не на том сервере, где произошла ошибка. Например, если возник таймаут. В данном случае, функциональность позволяет сохранять технологический журнал по всем рабочим серверам кластера.
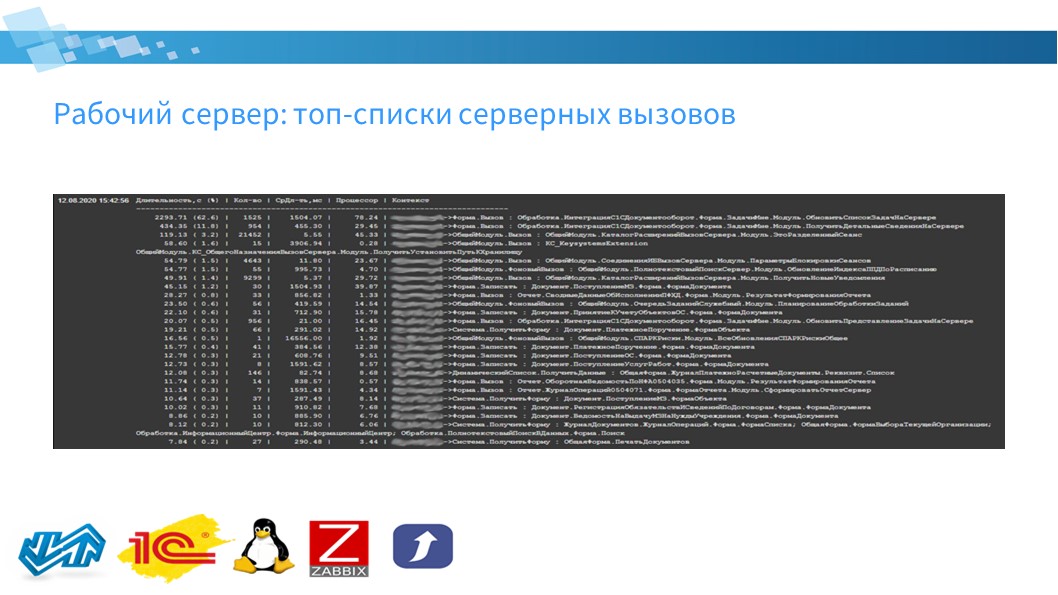
Так же собираются топ-списки серверных вызовов – анализируется технологический журнал за час.
Длину топ-списков можно настроить: по умолчанию – 25. И сохранить информацию о самых затратных серверных вызовах в Zabbix:
-
на слайде приведен топ по суммарной длительности вызовов;
-
есть топ по суммарному процессорному времени;
-
топ максимальной памяти за вызов;
-
топ «ленивых» вызовов, у которых процессорное время сильно меньше времени вызова;
-
топ по средней длительности.
На слайде видно, что есть сама суммарная длительность и процентное соотношение – сколько времени от общего количества суммарного времени вызовов по этому серверу и по этой базе этот вызов занимал.
Модуль Центральный сервер
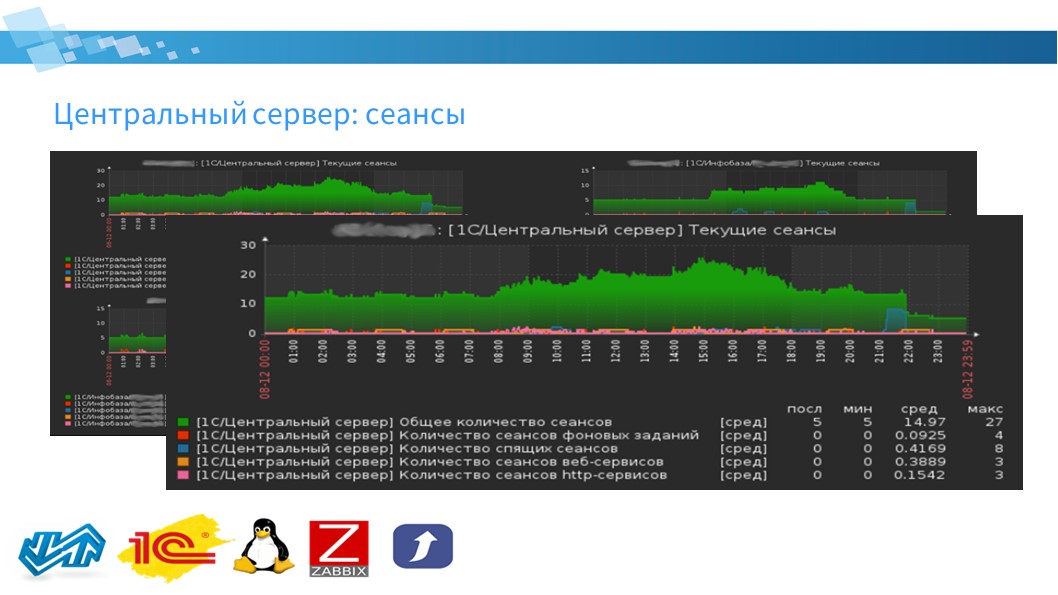
Следующий модуль – центральный сервер. На нем можно мониторить сеансы.
Чем сеансы они отличаются от лицензий? Немного разные контексты.
В сеансах мы можем увидеть:
-
общее количество сеансов;
-
количество сеансов фоновых заданий;
-
количество спящих сеансов;
-
количество сеансов веб и http-сервисов.
Zabbix позволяет собирать эту информацию как в контексте кластеров, так и в контексте информационных баз.
Можно собрать комплексный экран, на котором отобразить информацию по центральному серверу в целом и по информационным базам, если у вас несколько информационных баз в кластере. Или, если у вас несколько кластеров управляемых центральным сервером, можно включить автоматическое обнаружение кластеров и получать аналогичную информацию в данном разрезе.
Это – то, что касается модулей, на которые разделена функциональность решения.
Планы по развитию

Всю информацию по планам на дальнейшее развитие я стараюсь выкладывать в задачах на GitHub.
Основные моменты, на которых стоит акцент:
-
Развитие функциональности в части автоматизации процедуры развертывания на большое количество серверов.
-
Увеличение количества собираемых показателей, в частности, один из интересующих моментов – проверка доступности информационной базы через веб-сервис.
-
Список топ-исключений/ошибок, возникающих в рабочих процессах. Чтобы, посмотрев на графике количества ошибок, которые у вас в процессах возникают, можно было параллельно бегло посмотреть, что за это ошибки.
-
Исправление выявленных ошибок, которые находятся в процессе эксплуатации.
-
Оптимизация самих скриптов, которые получают данные, чтобы сократить время их работы и уменьшить нагрузку на прикладные серверы 1С. Те, кто сталкивался с системами мониторинга, знают об «эффекте наблюдателя», когда у вас инструмент, собирающий данные на наблюдаемом объекте, отъедает значительную долю производительности вашего прикладного сервера, чего не очень хотелось бы.
Это был краткий рассказ о том, что я хотел представить вашему вниманию, обозначив то, что умеет этот инструмент. Подробнее с ним можно ознакомиться на GitHub.
Вопросы
На чем написаны скрипты? И сильно ли они заморочены – насколько быстро можно самому в них что-то подправить? И насколько они масштабируемы?
Скрипты написаны на bash. Это был сознательный выбор. И некоторые моменты – платформозависимые. Сбор данных по оперативной памяти и по количеству процессов выполняется на основе данных операционной системы. Не на основе данных, которые возвращает RAS. Моей целью было – отойти от RAS, как от основного источника данных. Не могу сказать, что скрипты сложные. Можно на GitHub их посмотреть и допилить под свои нужды.
Мониторятся ли каким-то образом аппаратные лицензии и есть ли какой-то гибридный мониторинг аппаратных и программных лицензий 1С?
В данном контексте – нет. Аппаратный мониторинг же завязан на сервер лицензирования HASP Licence Manager. Здесь именно мониторинг процессов 1С:Предприятия – то, что можно получить из 1С:Предприятия. История аппаратных лицензий пребывает в стороне. Там получается отдельный инструмент лицензирования. Поэтому данной функциональности нет в контексте этого шаблона.
Еще вопрос про разбор технологического журнала в продакте. Если работает большое число пользователей, технологический журнал при настройке определенных событий будет занимать достаточно много места – там будет много строк. Какая скорость обработки техжурнала – если собирать данные по тем же блокировкам и таймаутам, например.
В тех проектах, которые у нас есть, где в базе работают 500-600 пользователей, технологический журнал по блокировкам, по серверным вызовам за час анализируется меньше 3 секунд, которые выделяет на таймаут стандартный Zabbix-агент . Хотя бывают ситуации, когда скрипт не успевает отработать за три секунды. Здесь решением может быть либо увеличение таймаута Zabbix-агента, либо переход на другой метод сбора (zabbix trapper). Это у нас уже будет не сервер Zabbix опрашивать сервер 1С, а сервер приложений 1С выполнять анализ технологического журнала и отправлять результаты Zabbix-серверу. На тех проектах, на которых у нас внедрен данный инструмент, там анализ ТЖ успевает отрабатывать за отведенный интервал времени. Может быть, на более крупных проектах, где в одной базе работает большее количество пользователей, больше нагрузка, там могут быть с этим какие-то трудности, и тогда придется немного перестраивать схему сбора данных.
Можно ли как-то настроить систему предупреждений, если большое количество ошибок идут в контексте одной формы или с одной строчки кода?
Сейчас настраивается по количеству ошибок на процесс. Есть пороговое значение количества ошибок на один процесс. Мы задали порог – 100 ошибок на процесс. И если этот порог будет превышен, он сигнализирует, что количество ошибок слишком велико, чтобы заглянуть в Zabbix или в технологический журнал, посмотреть, что это за ошибки. Такой гибкой настройки, чтобы конкретно контекст разбирать – такого нет. И, мне кажется, это не требуется на наших проектах так, чтобы привязываться к конкретному контексту. Если такая нужда будет, я думаю, что это вполне легко реализуемо.
Просто это часто встречаемая ситуация, когда какое-то фоновое задание падает вследствие вызова регламентного задания. И ошибки с этого задания начинают копиться, но ты о них не узнаешь, пока не заглянешь в журнал регистрации или в тех. журнал или пользователи не скажут об этом. Если это можно будет гибко настроить в скриптах – будет замечательно.
*************
Данная статья написана по итогам доклада (видео), прочитанного на онлайн-митапе "1С и Linux".


Вступайте в нашу телеграмм-группу Инфостарт