Наша компания продвигает 1С на западных рынках – это Канада, Великобритания и некоторые страны Европы. И у большинства западных клиентов при работе с 1С основной запрос: «Сделайте нам интеграцию с одной системой, с другой системой, с третьей системой». А поскольку работать с СКД очень удобно, мы решили выводить данные через СКД сразу напрямую в необходимый формат – например, в JSON или в CSV.
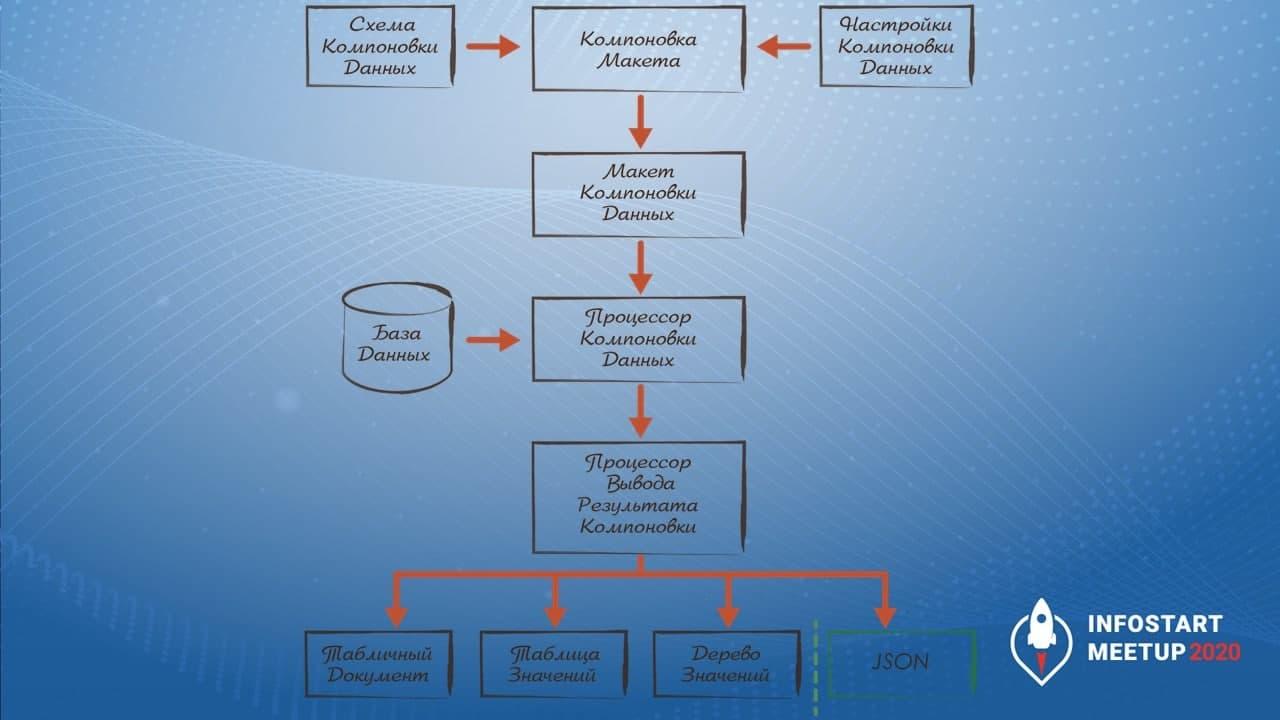
Стандартная схема программной работы с СКД выглядит следующим образом:
-
Берем схему и настройки компоновки данных, передаем их в компоновщик макета и получаем макет компоновки данных.
-
Дальше мы инициализируем этим макетом процессор компоновки данных.
-
И потом можем воспользоваться процессором вывода результата компоновки данных и вывести информацию:
-
в табличный документ;
-
в таблицу значений
-
и в дерево значений.
-
Но я вам хочу показать, как можно написать свой процессор вывода результата компоновки данных. Например, в JSON или в тот же CSV. И, соответственно, поделиться некоторой кодовой базой, чтобы вы могли после митапа сами попробовать и сделать вывод в еще какой-то формат. Например, в тот же XML.
В своем докладе я продемонстрирую, как это работает, чтобы вы могли взять для себя максимум информации.
Демонстрация механизма
Чтобы вы могли оценить производительность нашего процессора вывода результата компоновки данных, у меня есть готовая конфигурация, где я предварительно набил некоторые схемы компоновки данных.
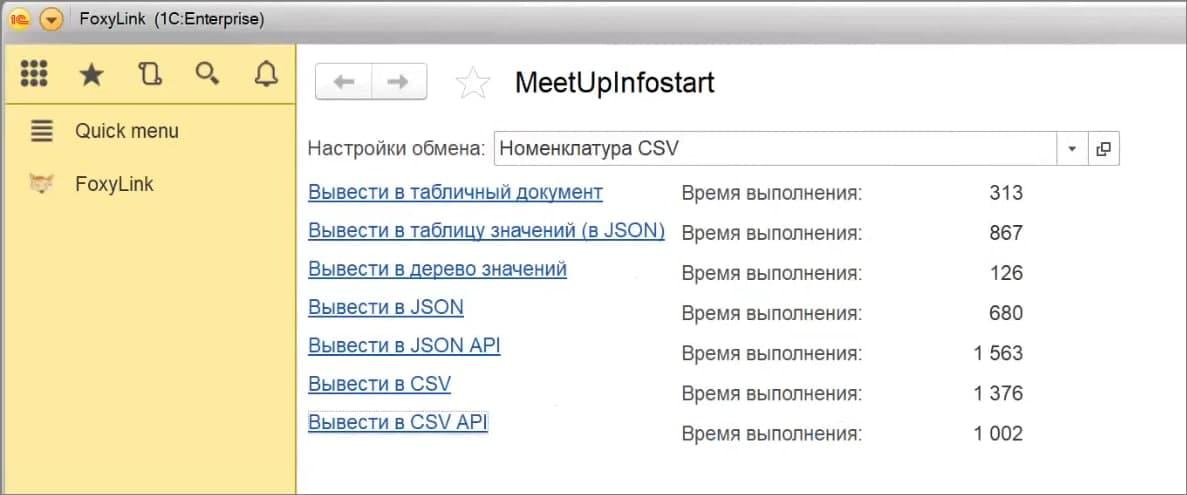
Например, здесь в поле «Настройки обмена» я выбираю схему компоновки данных, которая выводит данные 10 тысяч номенклатур.
-
Стандартный вывод этого запроса в табличный документ занимает в среднем 300 мс.
-
Если мы выводим результат этого запроса в таблицу значений, которую потом перегоняем в JSON – вывод занимает уже 867 мс (здесь тоже используется стандартный вывод).
-
Отдельный вывод в таблицу или в дерево значений выполняется максимально быстро, 126 мс.
-
Дальше я уже оцениваю производительность своего процессора вывода результата данных в JSON – здесь результат запроса выводится чуть быстрее, чем стандартный вывод в таблицу значений с конвертацией в JSON, 680 мс.
-
В варианте «Вывести в JSON API» есть возможность задать формат вывода JSON, который мы хотим получить на выходе. Соответственно, здесь вывод занимает уже немного больше времени – 1.5 с.
-
Процесс вывода результата в CSV – занимает 1.4 с
-
И в варианте CSV API – примерно столько же.

Сами схемы компоновки данных задаются в соответствующем справочнике.
Мы можем в каждую схему зайти и как-то ее отредактировать.
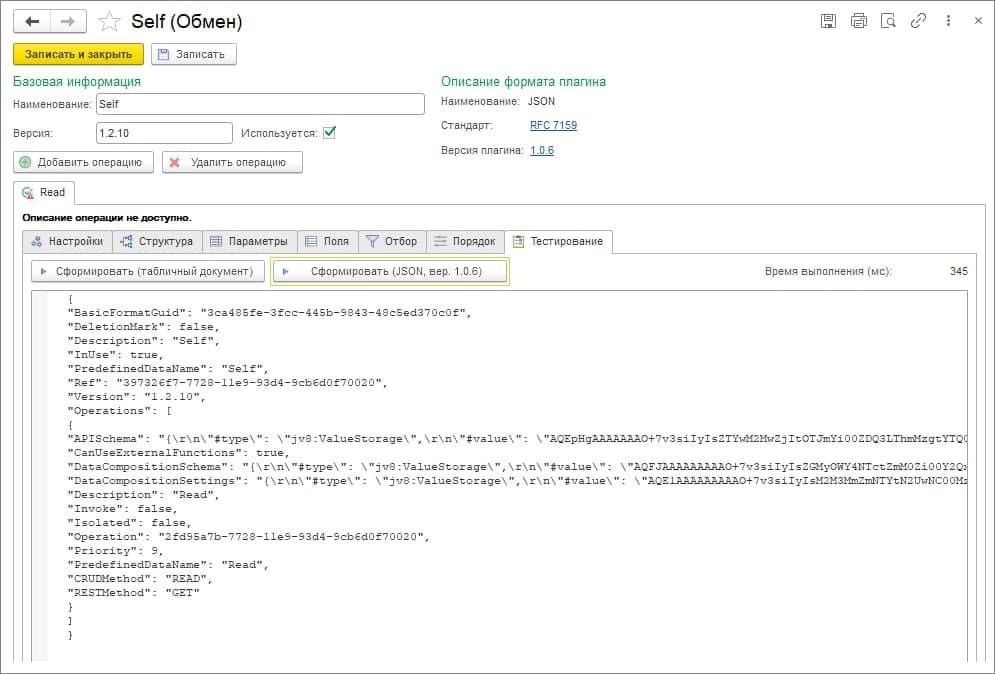
Также здесь можно ее протестировать – вывести ее результат в табличный документ или в формат json.
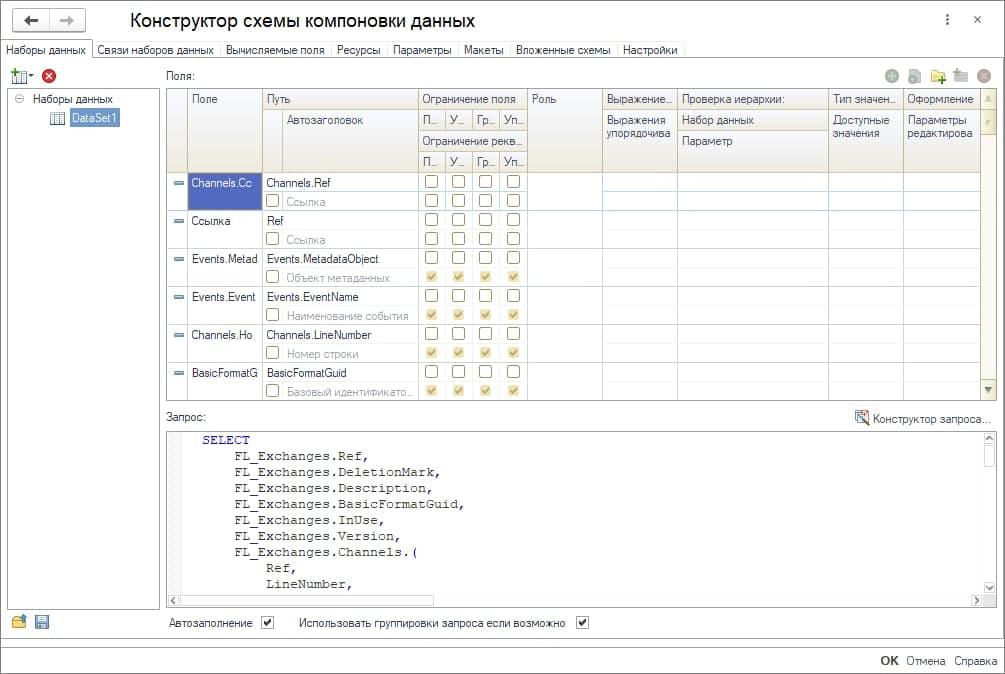
Например, здесь есть схема Self, где происходит выборка полей элемента справочника «Настройки обменов», ссылка на который указана в параметре.
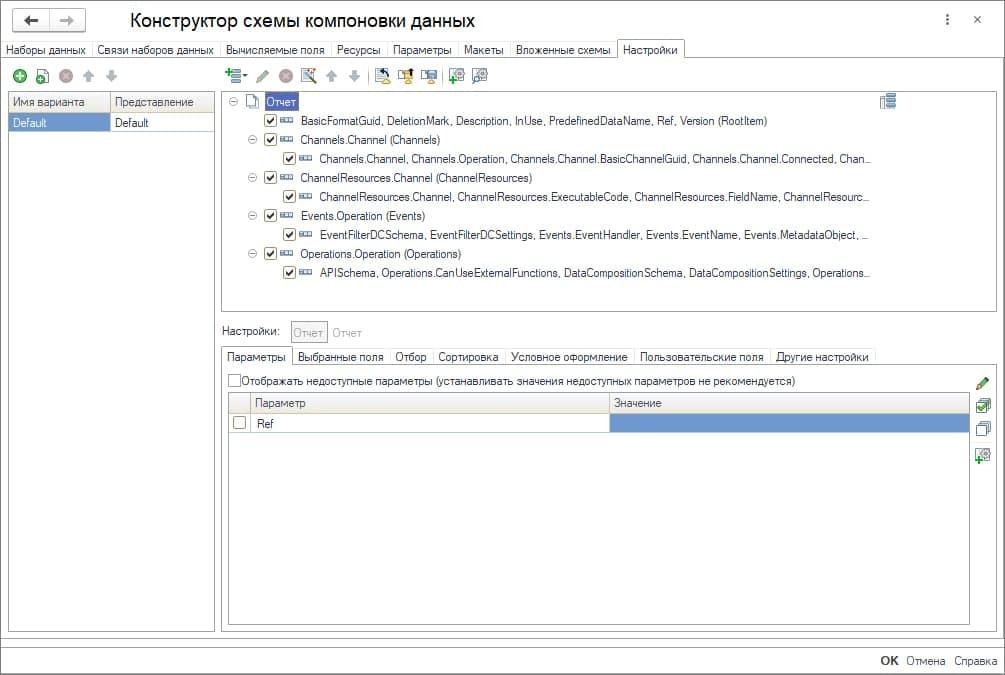
На закладке «Настройки» задана структура отчета.
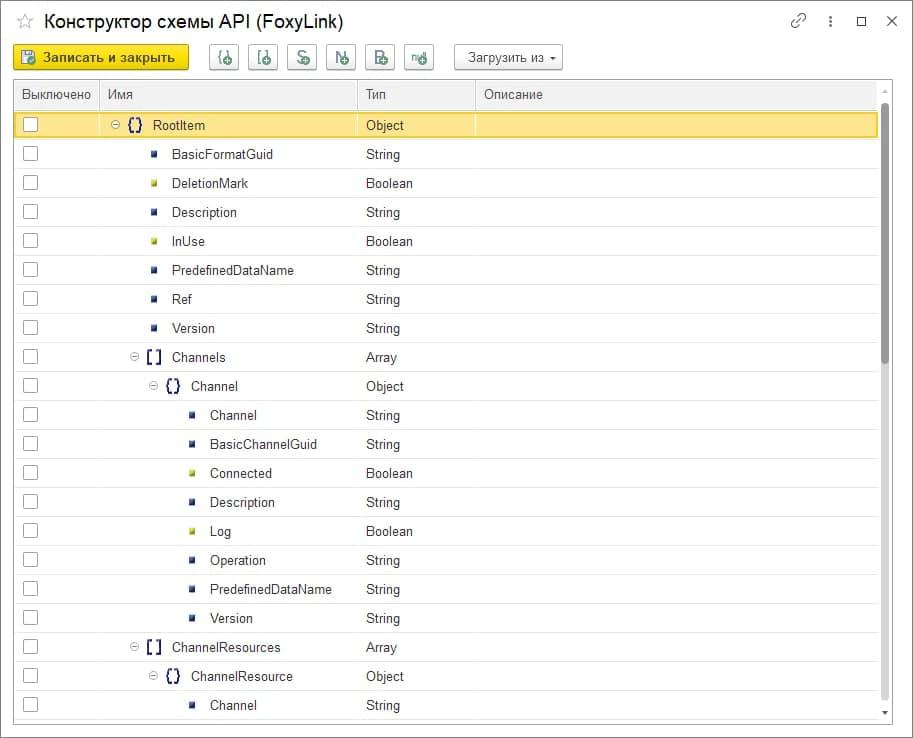
Эта структура сформирована на основании описания схемы формата API, которая здесь задана (она может быть загружена из текста или из Swagger).
Соответственно на выходе мы можем получить необходимую схему JSON.
Что это нам дает? Если мы интегрируемся с какой-то системой или с поставщиком данных какого-то клиента, то мы можем очень быстро изменить вывод, перенастроить все, и у нас все будет дальше работать.
Если брать стандартную разработку, то здесь возникают проблемы, потому что это нужно спланировать, найти и поднять документацию.
Хотя если описать API внешней системы через JSON-схему формата API – она, по сути, уже сама себя описывает.
Вывод в табличный документ

Перейдем к коду, чтобы рассмотреть, как это работает.
Мы инициализируем новый табличный документ, в который будем выводить.
Дальше – инициализируем переменные (из выбранной настройки обмена загружаем схему компоновки данных и настройки компоновки данных).
Дальше – создаем компоновщик настроек и в процедуре InitSettingsComposer компонуем схему компоновки данных и настройки компоновки данных. Это самое важное.

Здесь мы сначала передаем в компоновщик настроек нашу схему компоновки данных и инициализируем.
Дальше – если настройки у нас заданы, загружаем их в КомпоновщикНастроек. Если не заданы – загружаем из схемы компоновки данных настройки по умолчанию.
Тут, к сожалению, есть платформенный баг – если мы задавали для полей в схеме компоновки данных какие-то псевдонимы, мы их должны перенести вручную, поэтому здесь вызывается метод CopyTitlesFromSchemaToComposer
Дальше мы должны обновить КомпоновщикНастроек, чтобы он восстановил связи полей схемы и настроек текущего пользователя – если некоторые поля были удалены, то он их отсюда заберет и т.д.
Дальше у нас идет вызов процедуры NewTemplateComposerParameters, которая возвращает структуру для настроек макета.

Эта структура имеет поля для схемы, макета, данных расшифровки и условного оформления.
И далее мы заполняем структуру настроек макета схемой и макетом, который мы получили из компоновщика настроек.
Следующим шагом нам нужно сформировать параметры вывода – они необходимы для процессора.

Для параметров вывода мы включаем внешние источники, если они есть, расшифровку детальных записей и флаг, определяющий, может ли процессор использовать внешние функции и настройки макета.
Заполняем настройки макета в параметрах вывода результатами предыдущего шага.
И, соответственно, уже выводим данные в табличный документ.
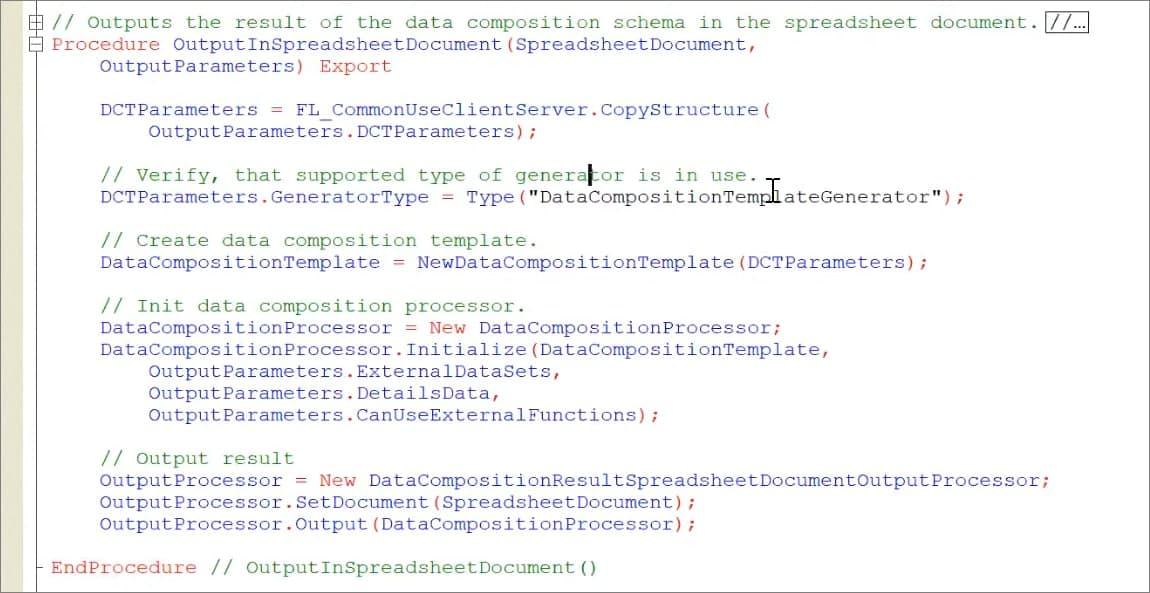
Здесь все стандартно и понятно:
-
мы задаем, какой тип генератора будет;
-
компонуем макет компоновки;
-
инициализируем процессор компоновки;
-
инициализируем процессор вывода результата компоновки в табличный документ;
-
устанавливаем ему в качестве документа наш табличный документ;
-
и выводим туда данные.
Все просто – большинство из вас что-то похожее делали.
Вывод в таблицу значений (в JSON)

Тот же самый подход к выводу данных в таблицу значений.
Мы все задаем и передаем таблицу значений – в нее будут записываться наши данные. Как я уже говорил, я здесь добавил перегонку в JSON.

Здесь мы встречаем интересную проблему – если мы выберем сложный СКД-макет, который имеет множество группировок, и попробуем вывести его в таблицу значений, у нас таблица значений будет немного странная – все группировки в колонках и все поля выводятся в таблицу. Соответственно, нужно потратить время, чтобы разобраться и собрать это в нужный нам вид.
А если мы сразу выведем результат запроса СКД в JSON-файл, у нас сразу все будет уже в нужном нам виде.
Вывести в JSON
Поэтому давайте сразу перейдем к JSON и разберемся, как оно работает, «с чем его едят».

Мы инициализируем переменные – загружаем схему компоновки данных и настройки компоновки данных из выбранной настройки обмена.
Чтобы не тратить лишней памяти, мы открываем поток для вывода. Конечно, мы могли бы все записывать в строку, но конкатенация строк плохо влияет на производительность, поэтому мы будем выполнять запись в поток в памяти (эта возможность появилась в 8.3.10).
Дальше – мы вызываем нашу обработку FL_DataProcessorJSON, которая будет выступать в качестве процессора вывода результата компоновки данных. Мы создаем обработку и передаем ей в метод Initialize() поток памяти, чтобы обработка его заполнила.
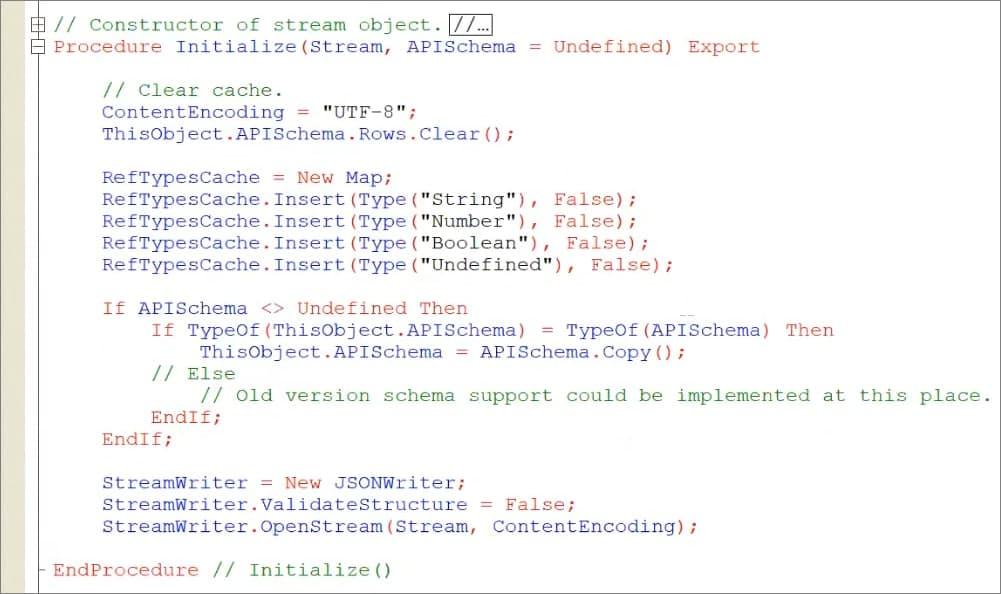
Вот что делает инициализация – здесь мы:
-
задаем какую-то кодировку;
-
кешируем себе какие-то вещи, которые нам потом понадобятся;
-
далее мы инициализируем запись в JSON и указываем, что мы не будем валидировать структуру в JSON – иначе, если мы укажем, что структуру JSON нужно валидировать, вывод очень сильно замедлится;
-
дальше мы указываем, что эта запись в JSON будет использовать наш поток в памяти, и мы будем сюда записывать с этой кодировкой.
Дальше мы компонуем настройки компоновки данных. Формируем параметры вывода и передаем туда настройки.
И следующим шагом уже вызывается метод вывода:
-
для вывода СКД в табличный документ мы вызывали метод OutputInSpreadsheetDocument() – он соответствует вызову стандартного процессора вывода результата компоновки в табличный документ;
-
для коллекции значений мы вызывали «OutputInValueCollection()» – вывод в коллекцию значений;
-
а для внешних процессоров вывода результата компоновки у нас используется команда «Output()», куда мы передаем обработку и параметры вывода.

В обработчике вывода мы копируем эти параметры вывода и задаем для них, что хотим видеть этот вывод в виде коллекции значений.
Дальше мы создаем макет компоновки данных и инициализируем процессор компоновки данных.
Но здесь есть отличие выводом в табличный документ, потому что мы не создаем процессор вывода результата компоновки и не используем его команду Output(), так как мы будем выводить немного по-другому.
Дальше – так как нам нужно понимать, какая структура макета в СКД используется и как выводить, нам нужно сначала обойти макет компоновки данных и получить структуру вывода ReportStructure.
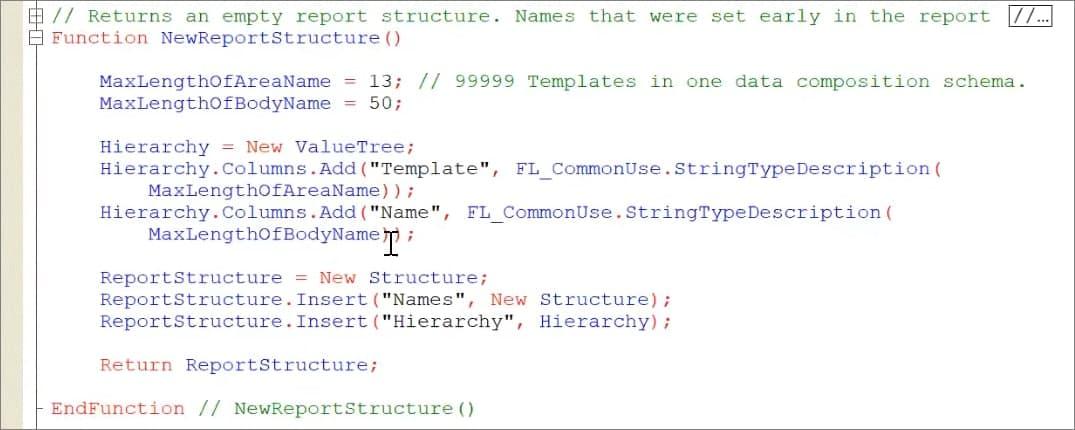
Структура формируется в функции NewReportStructure().
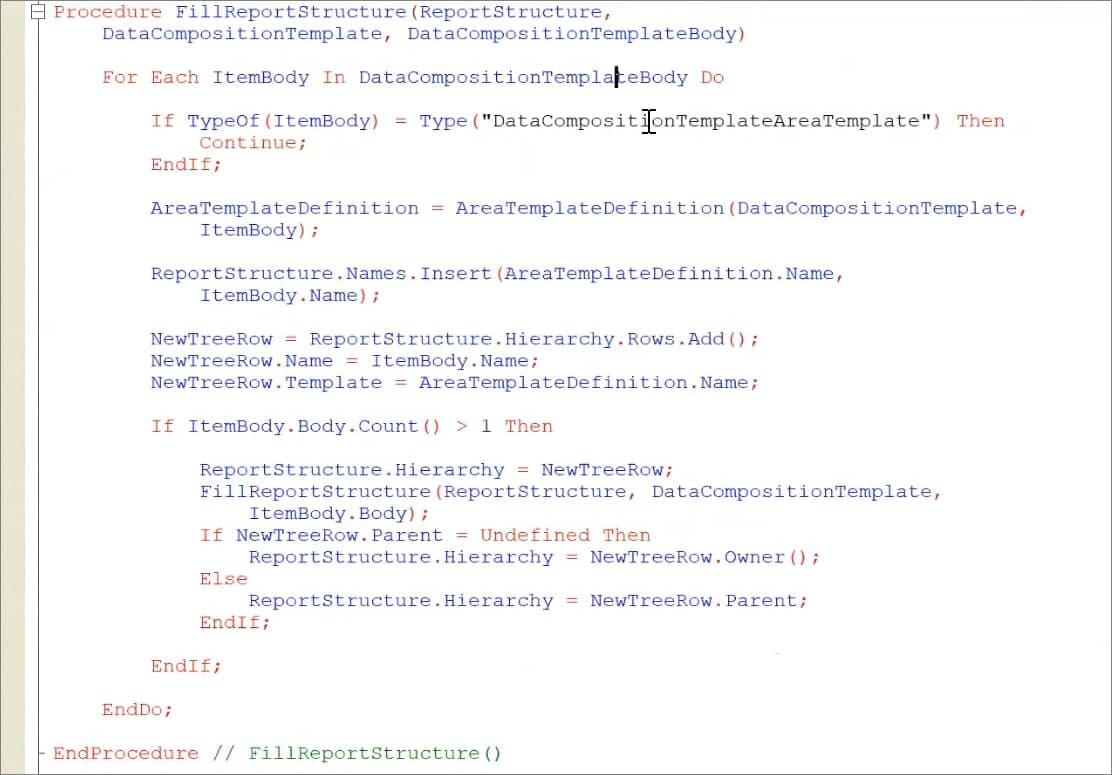
После чего эта структура заполняется данными макета компоновки в процедуре FillReportStructure.

В структуре ReportStructure хранятся имена и иерархия макета (в полях с ключами «Names» и «Hierarchy»).

В поле «Names» хранятся имена группировок макета, причем ключ каждой группировки называется TemplateN (или LayoutN, если это платформа ниже 8.3.17, или МакетN, если это российская локализация платформы), а в значения подтянулись наши группировки – для них указывается имя.

А в поле «Hierarchy» у нас подгрузилось дерево значений с иерархией группировок, по которой мы сможем потом обойти макет.
Далее в функции TemplateColumns мы выясняем, из полей с какими заголовками у нас состоит каждый макет, и запоминаем результат в переменную TemplateColumns.

Эта переменная хранит структуру макетов в удобном виде, потому что стандартно все значения полей в макете шифруются – называются через русскую или английскую П с номером поля. Кроме этого, на каждом уровне макета состав полей и их заголовки могут быть разными.
Дальше нам нужно проверить, соответствует ли структура отчета и его наименования колонок требуемому формату, поэтому мы обращаемся к процедурам VerifyReportStructure и VerifyColumnNames.
Эти процедуры нужны для универсальности, так как мы в метод Output() передаем обработчики для различных форматов вывода – даже напрямую в SQL-базу.
При выводе данных в JSON структура и наименования по умолчанию формату соответствуют, поэтому в обработке FL_DataProcessorJSON процедуры VerifyReportStructure и VerifyColumnNames – пустые.
Дальше мы берем наш процессор компоновки данных и делаем команду «Next()» – сам процессор имеет команду «Следующий()», и мы можем поочередно обрабатывать узлы xml, которые были сгенерированы при инициализации.
-
Первая команда открывает начальный элемент – общий процессор.
-
Следующая команда отображает макет компоновки данных.
-
И третья команда – «Next()» выполняет сам запрос, который находится у вас в СКД.
Соответственно, мы запоминаем в переменную Item начальный узел запроса – здесь у нас находится элемент типа «ЭлементРезультатаКомпоновкиДанных» – и дальше уже переходим в наш процессор вывода – тот, который мы реализовали.

Тут есть команда «Output()» – сейчас мы рассматриваем вариант с базовым выводом (без схемы API).
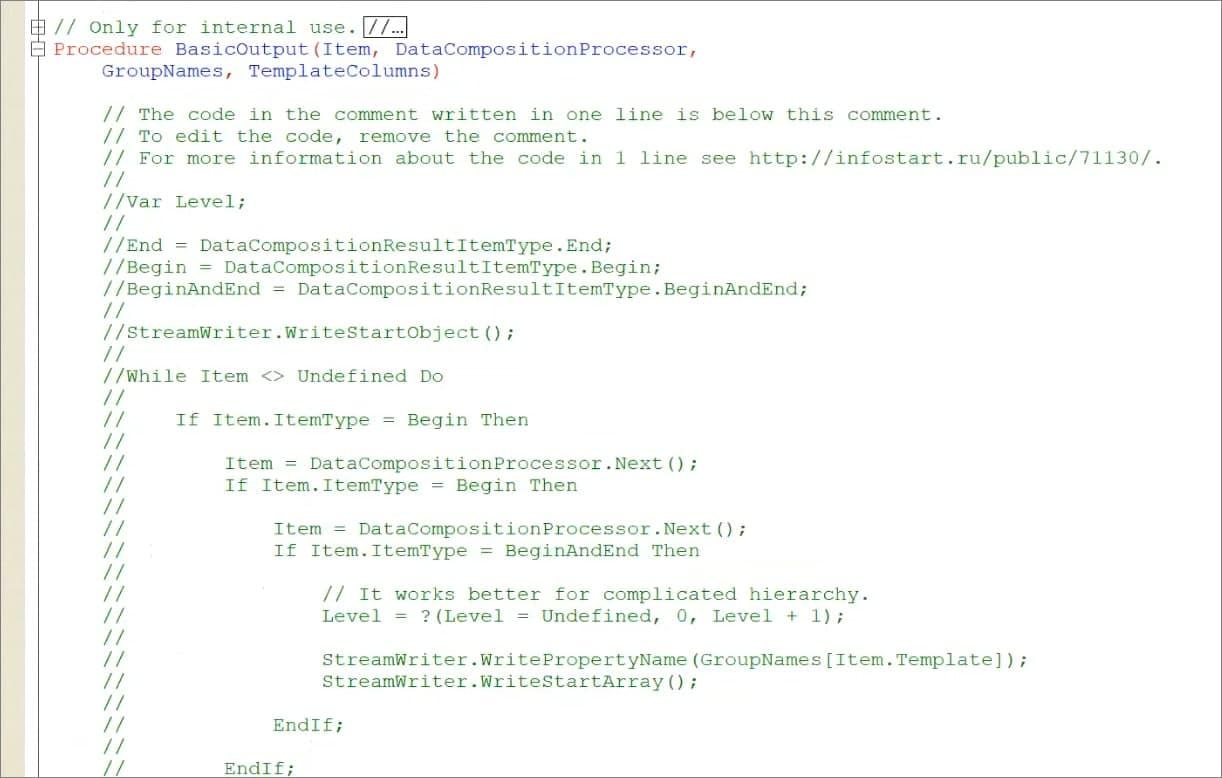
Обратите внимание, здесь применен нестандартный подход – исходный код мы храним закомментированным, а его выполнение укладываем в одну строку.
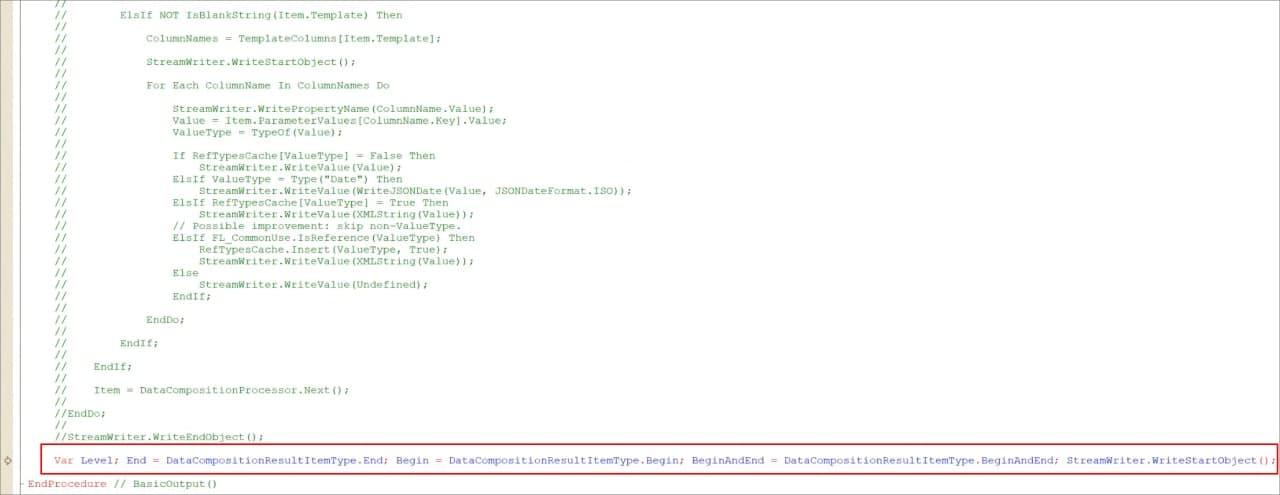
Это нам позволяет в разы сократить время обработки нашего вывода – это преимущество описано в статье //infostart.ru/1c/articles/71130/.
Мы записываем начало объекта StreamWriter, который соответствует объекту ЗаписьJSON.
И дальше мы понемногу идем по той XML, что сформировал процессор, и добавляем узлы в ЗаписьJSON без контроля его закрываемости и всего остального.
И когда мы уже выйдем из этой процедуры, в нашем потоке данных уже будут записаны двоичные данные JSON.
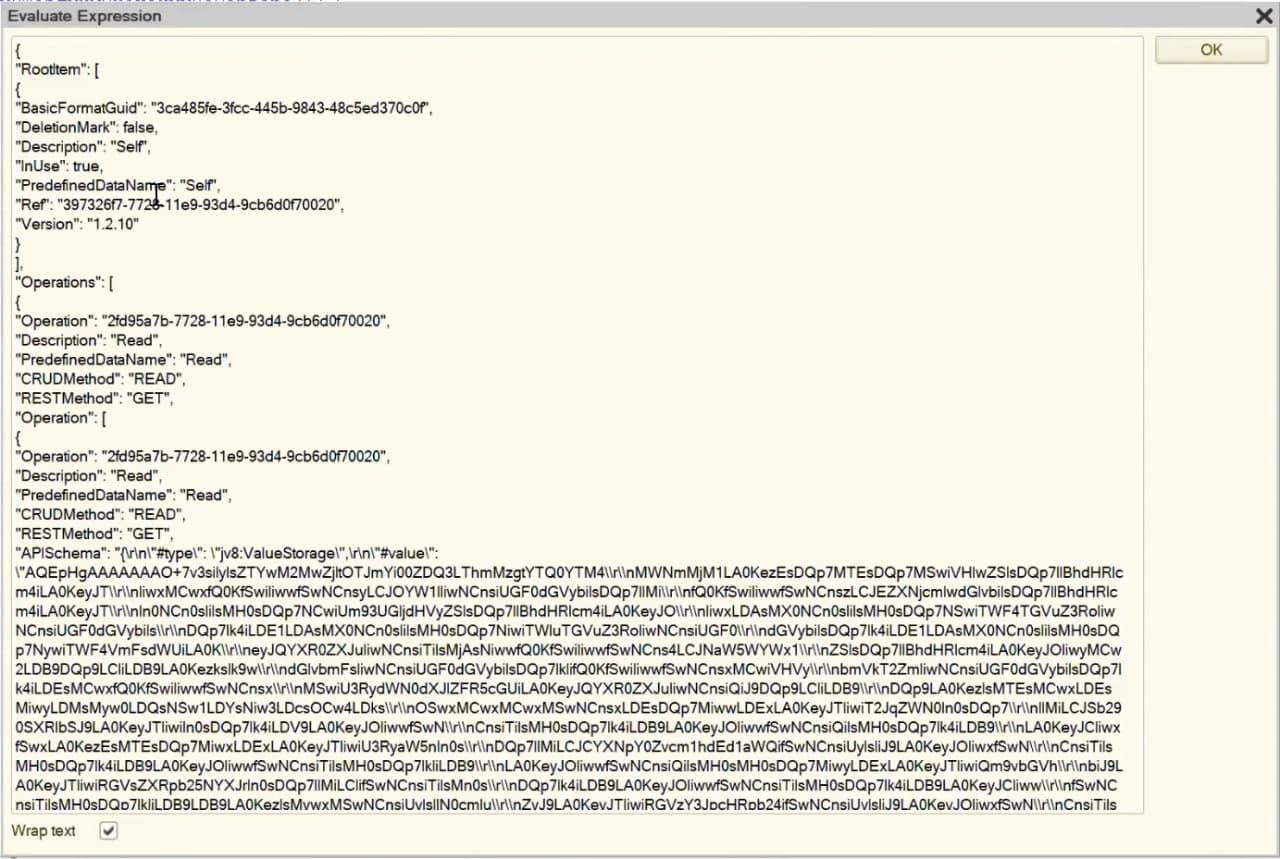
Если мы откроем просмотр функции ПолучитьСтрокуИзДвоичныхДанных(Результат), то ее значение будет выглядеть вот так.
Вывести в JSON API
Что делает JSON API? Простой вывод JSON нам не подходил, потому что у разных поставщиков есть какие-то свои форматы API, поэтому мы реализовали возможность описать структуру JSON с помощью дерева значений.
Например, нам поставщик дает структуру JSON и говорит: «Ты мне должен передать вот это». Соответственно, мы сделали парсер, который создает нам такую структуру по образцу текста результата.
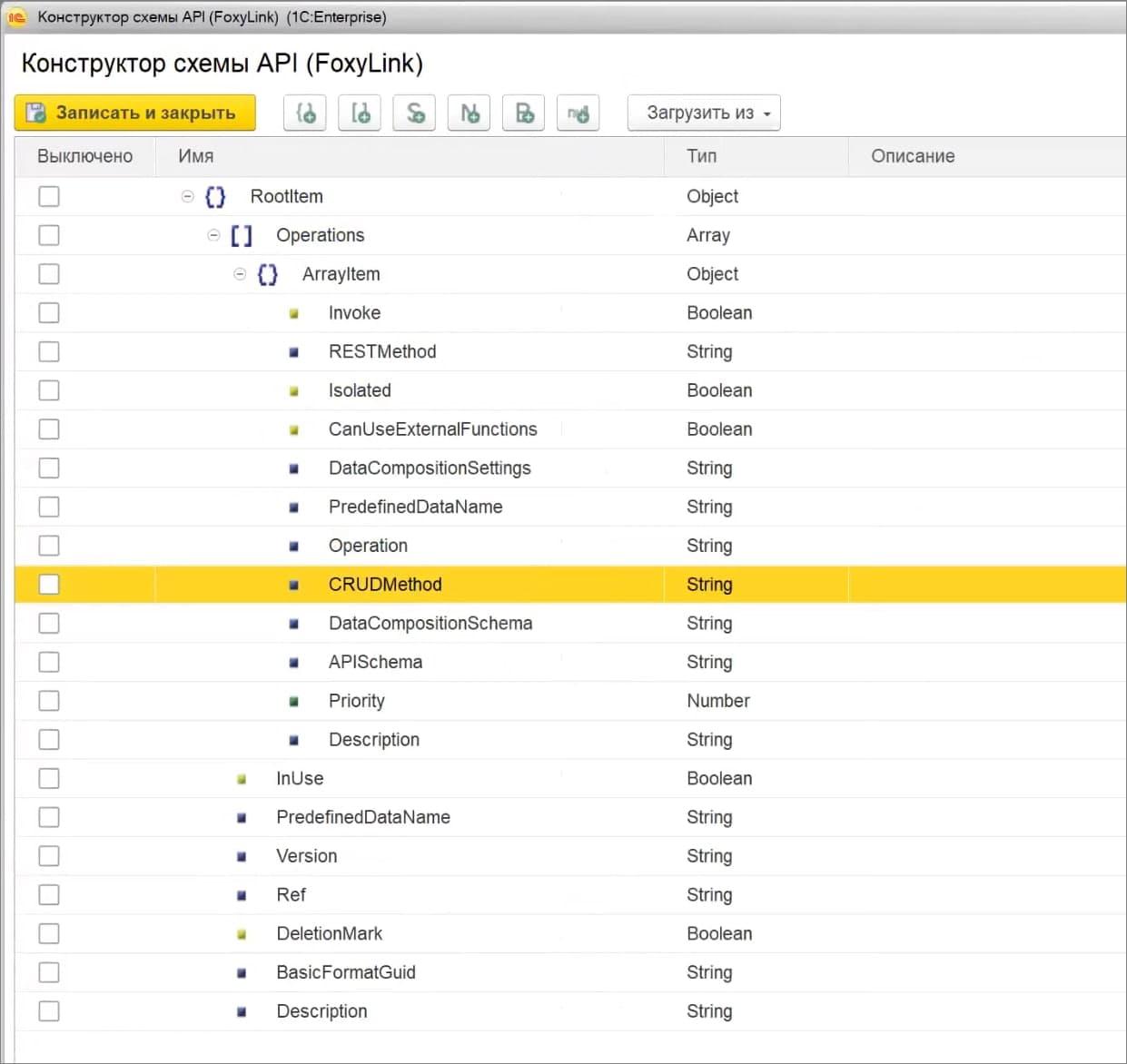
По факту, вывод может немного отличаться, потому что, если по некоторым полям данных нет, то и в СКД их выводить не нужно.
Соответственно, мы в обработке вывода результата компоновки в JSON сделали форму создания API, где можно специфическим образом создать саму схему компоновки данных. И дальше вывод будет в определенный формат.
Я вам сейчас еще раз продемонстрирую – какая разница, если используется простой вывод и уже вывод с приведением к какому-то формату.
Вот так выглядит простой вывод.
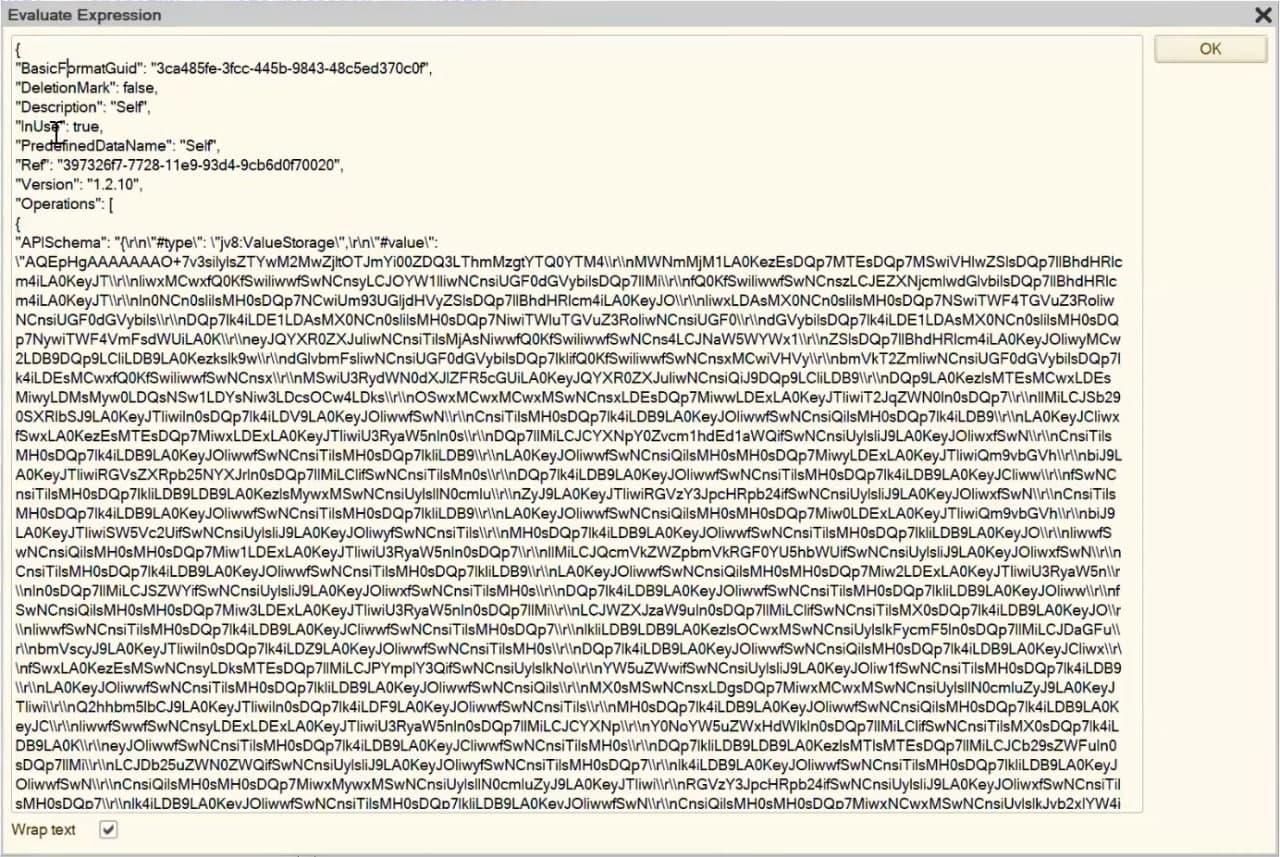
А если мы используем приведение в соответствие с необходимым форматом, то уже получаем вывод четко под формат.
Особенности вывода в CSV
Посмотрим вывод в CSV – в строковый формат. Мы можем использовать команду «Вывести в CSV» или «Вывести в CSV API» – они, в принципе, одинаковые.
По сути, здесь используется обработка, аналогичная обработке вывода в JSON, но у нее есть некоторые нюансы, например, работа с ссылочными полями.
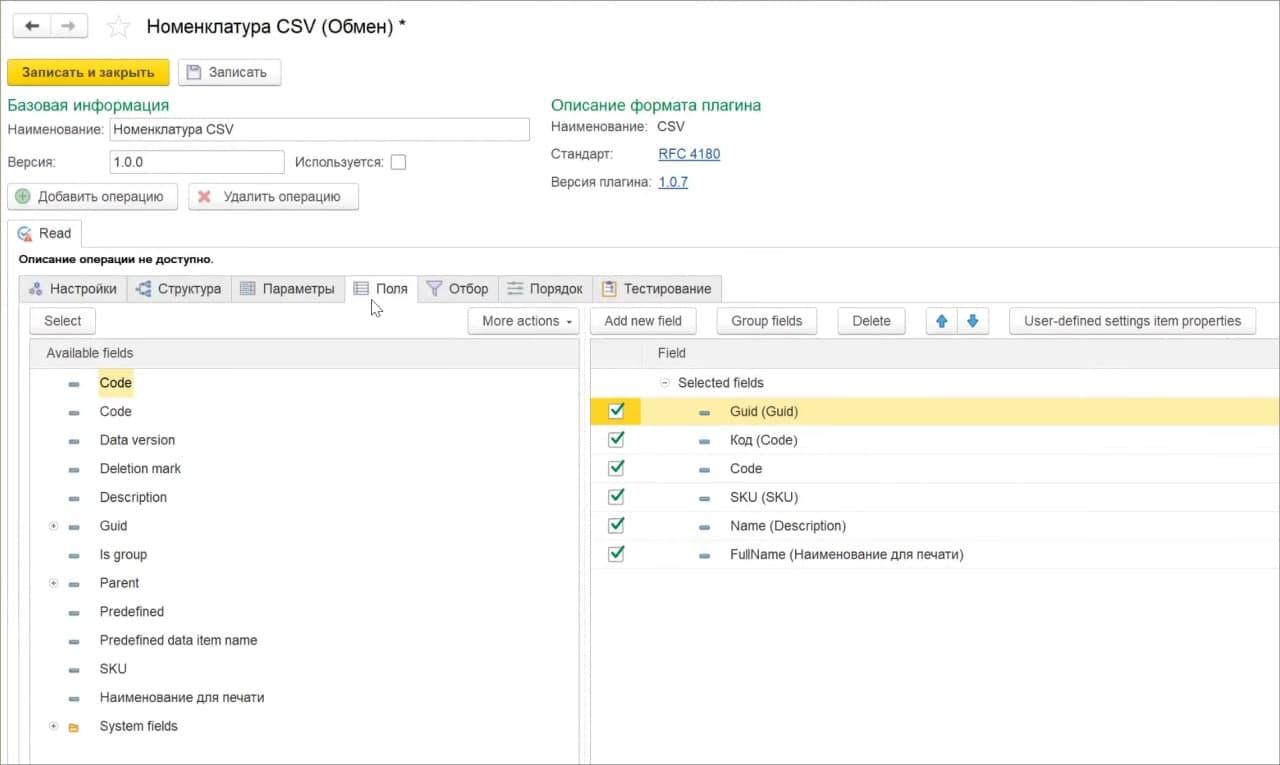
Но как только мы добавляем ссылочное поле GUID, производительность очень сильно деградирует. Поэтому для всех ссылочных полей в запросе лучше – или использовать строковое представление, тогда скорость работы увеличится. Или использовать какие-то заменители этих ссылочных полей.
Формирование структуры результата
Вернемся к нашей структуре отчета ReportStructure, которая содержит в себе дерево иерархии группировок и структуру с именами в виде Template1, Template2, TemplateN.
Разберем подробнее, как ее заполнить.
При заполнении мы смотрим, какой тип макета нам приходит – некоторые макеты мы всегда игнорируем, а некоторые макеты нам очень интересны, чтобы их заполнить и потом искать связи между выводом и схемой API.
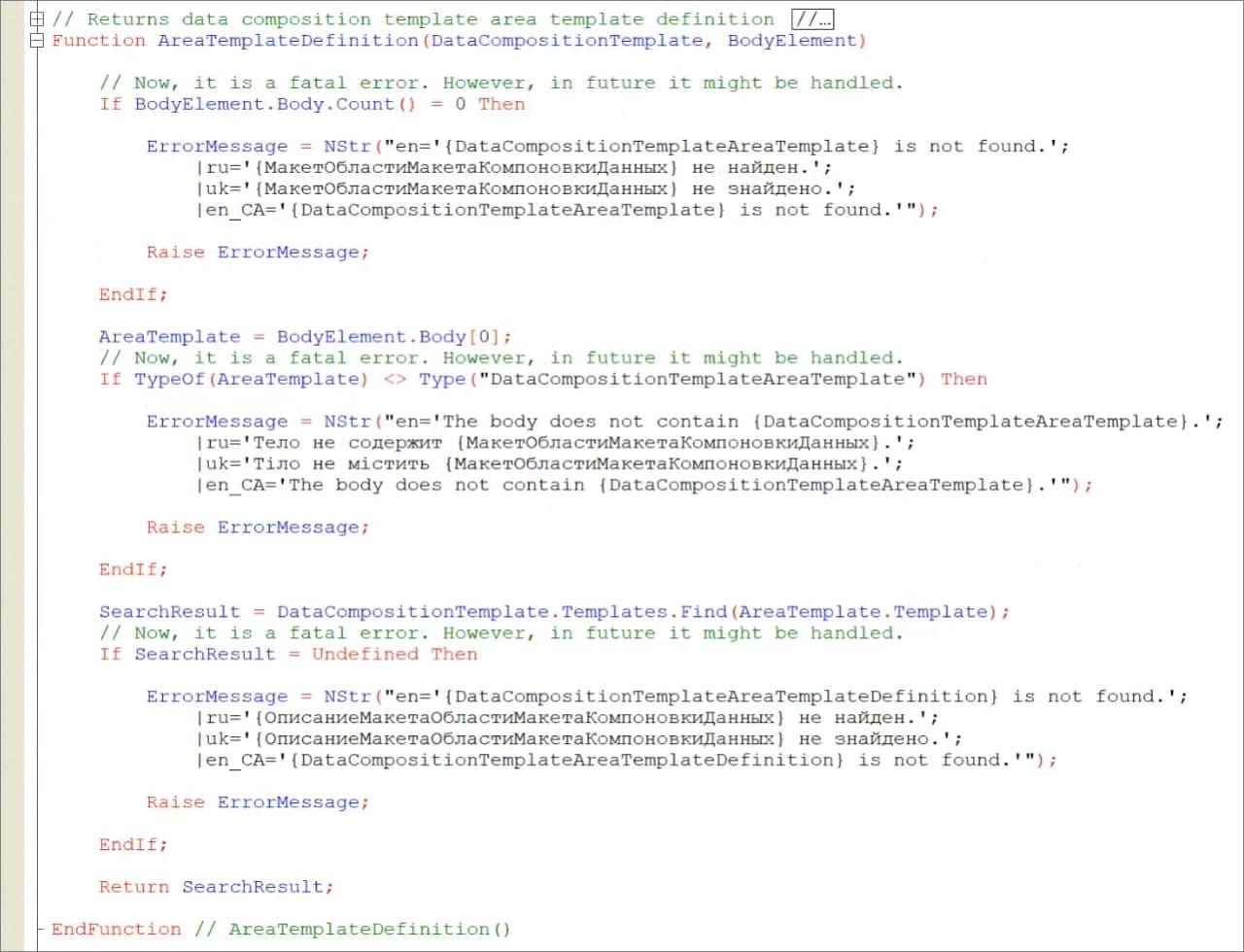
В функции AreaTemplateDefinition мы пытаемся найти в макете компоновки нужный макет области.
-
Если мы передаем элемент, который содержится в макете, но внутри себя не содержит элементов, то значит, такого элемента, по сути, не существует – это ошибка.
-
Также мы проверяем, что это за макет. Если это – макет компоновки данных и отличается от нужного нам типа, мы тоже должны вывалиться в ошибку.

В результате мы заполняем структуру отчета, которая помогает нам находить в макете компоновки нужные узлы API – такие как Channels, ChannelResources, Events, Operations и RootItem и т.д.
Свой процессор вывода результата
По сути, свой процессор вывода результата – это готовая обработка, которая содержит стандартные процедуры и функции. Если вы их реализуете, то вы получите свой процессор вывода.
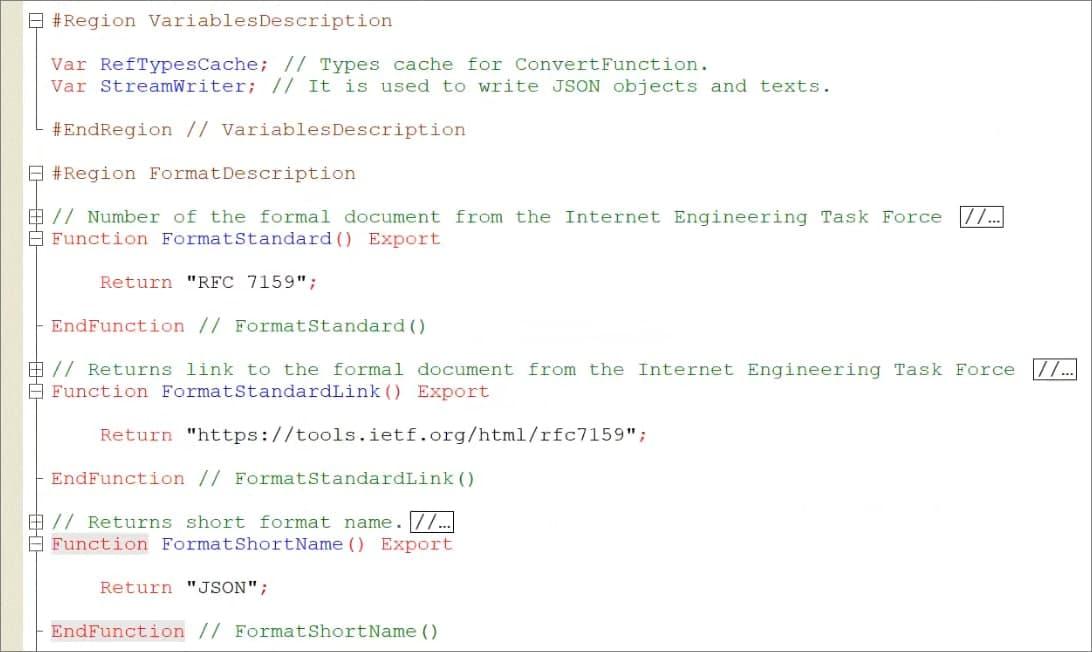
Стандартно здесь:
-
используется переменная StreamWriter – в данном случае она соответствует объекту ЗаписьJSON;
-
в функции FormatStandard() указано, как называется стандарт, который поддерживается;
-
в функции FormatStandardLink() есть ссылка на описание формата;
-
в функции FormatShortName() указано, как формат называется.
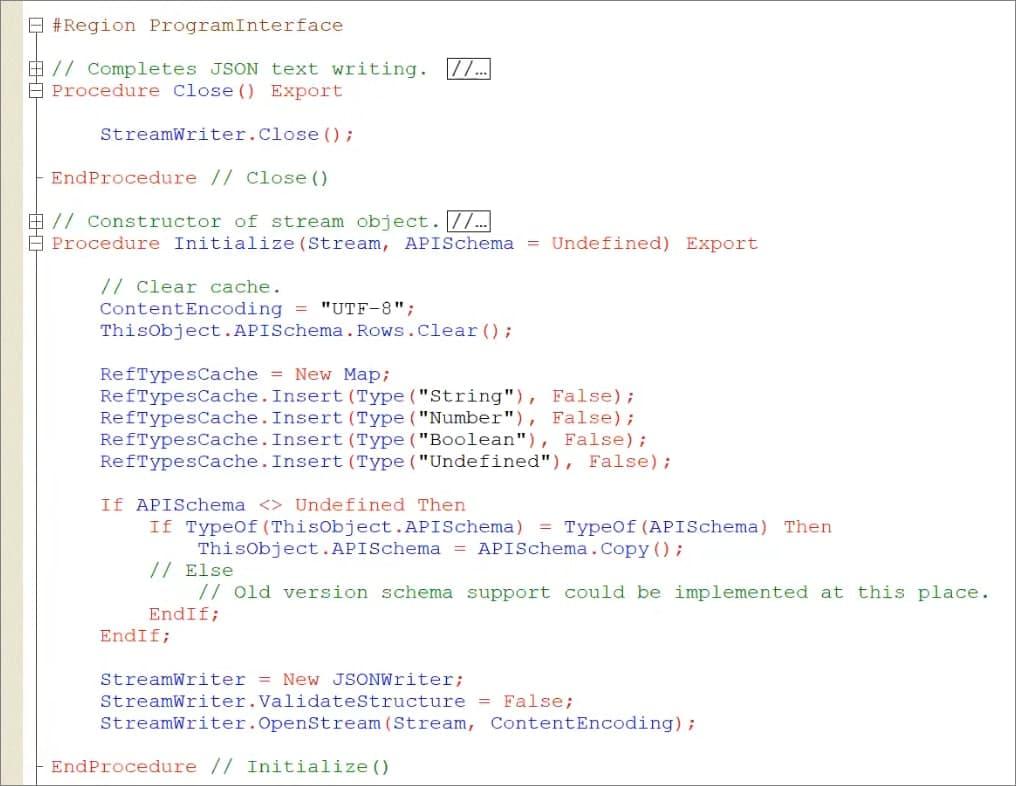
В процедуре Close() мы описываем, что происходит, когда мы закрываем процессор вывода – в данном случае закрывается ЗаписьJSON.
В процедуру Initialize() прилетает поток данных со схемой API, и мы здесь инициализируем какие-то наши данные.
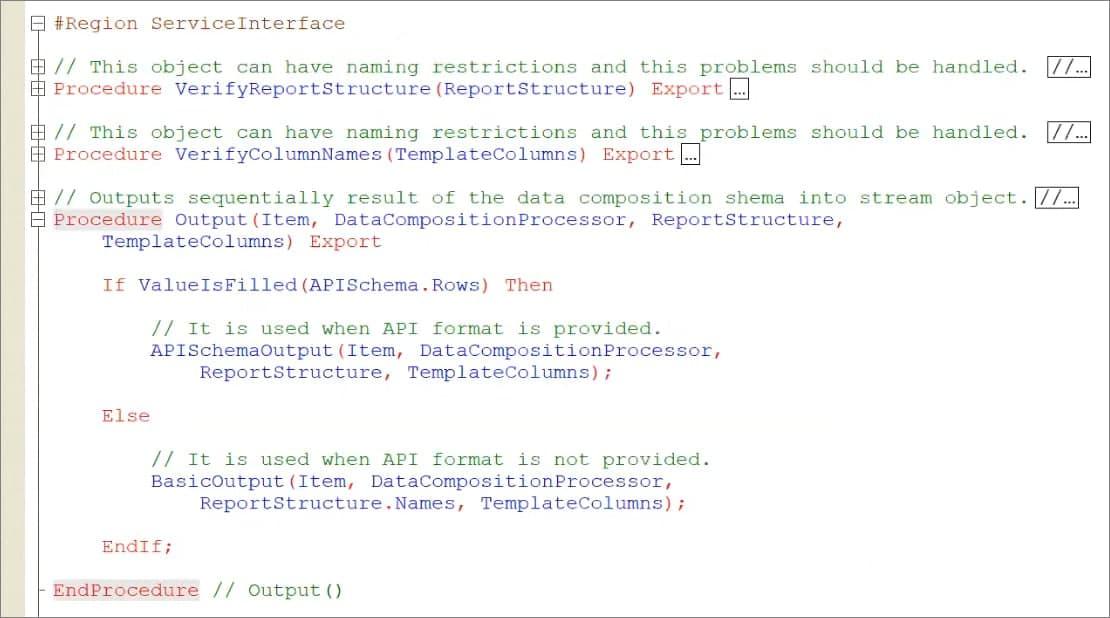
А дальше в сервисном интерфейсе:
-
в процедуре VerifyReportStructure мы проверяем, соответствуют ли формату наши имена группировок;
-
в процедуре VerifyColumnNames – то же самое для имен колонок;
-
и в процедуре Output мы реализуем какой-то вывод – обходим наш процессор.
По этому шаблону вы можете написать процессор вывода результата в свой формат или развивать существующие процессоры вывода.
Программная компоновка данных: что потребуется для получения результата

Хочу показать, что необходимо для минимальной работы схемы компоновки данных.
Схему компоновки данных мы можем создать из источника данных и набора данных – этого достаточно. Разве что нужно будет выбрать еще поля для набора данных.
Все остальные параметры, которые на слайде не выделены, используются опционально и не обязательны.

Здесь отмечены четыре основных шага для программного создания схемы – в конфигурации FoxyLink для этого используются методы общего модуля:
-
NewDataCompositionTemplate;
-
NewDataCompositionSchemaDataSetQuery;
-
NewDataCompositionSchemaDataSetField;
-
CreateDataCompositionSchema.

Сначала мы описываем структуру источника данных.

Потом описываем структуру набора данных-запрос.

И создаем схему из источника и набора данных.

Следующий этап – это настройки компоновки данных. Для настроек мы должны задать структуру и выбрать поля.
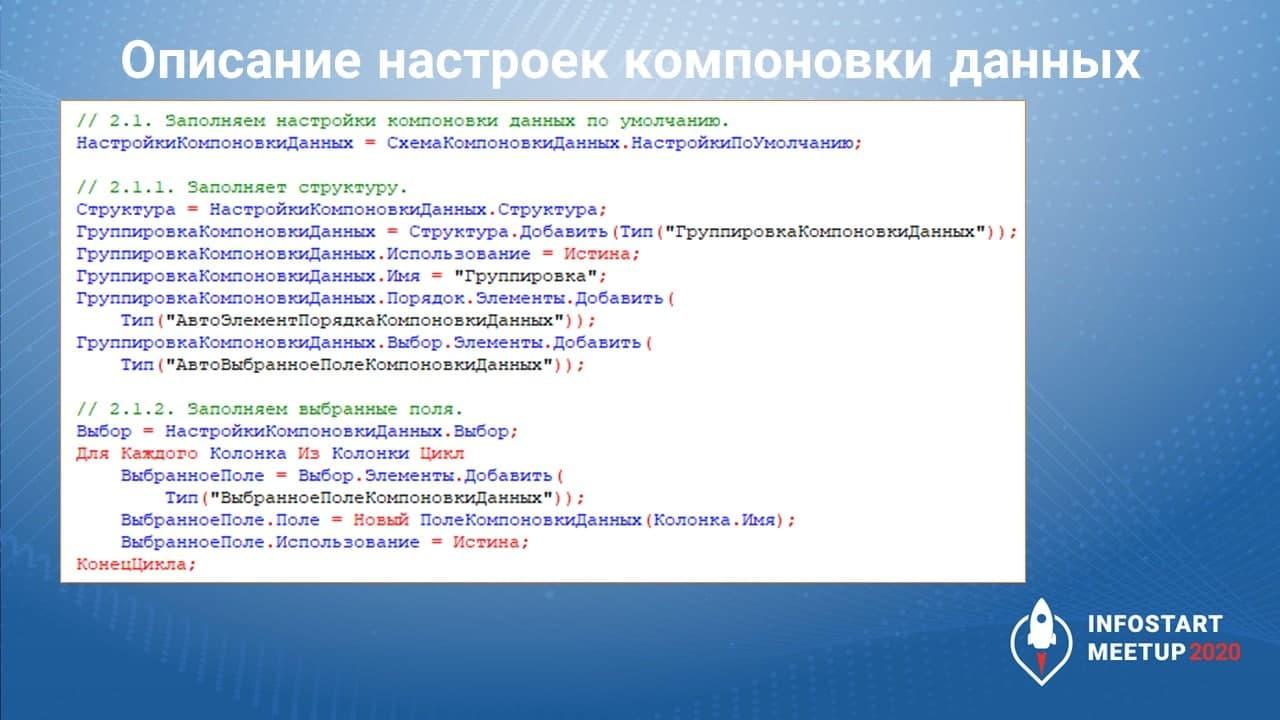
Здесь описан стандартный порядок заполнения настроек компоновки данных по умолчанию.
Настройки нужно инициализировать с помощью компоновщика настроек.

В случае, если настройки не заданы, загружаем настройки по умолчанию.
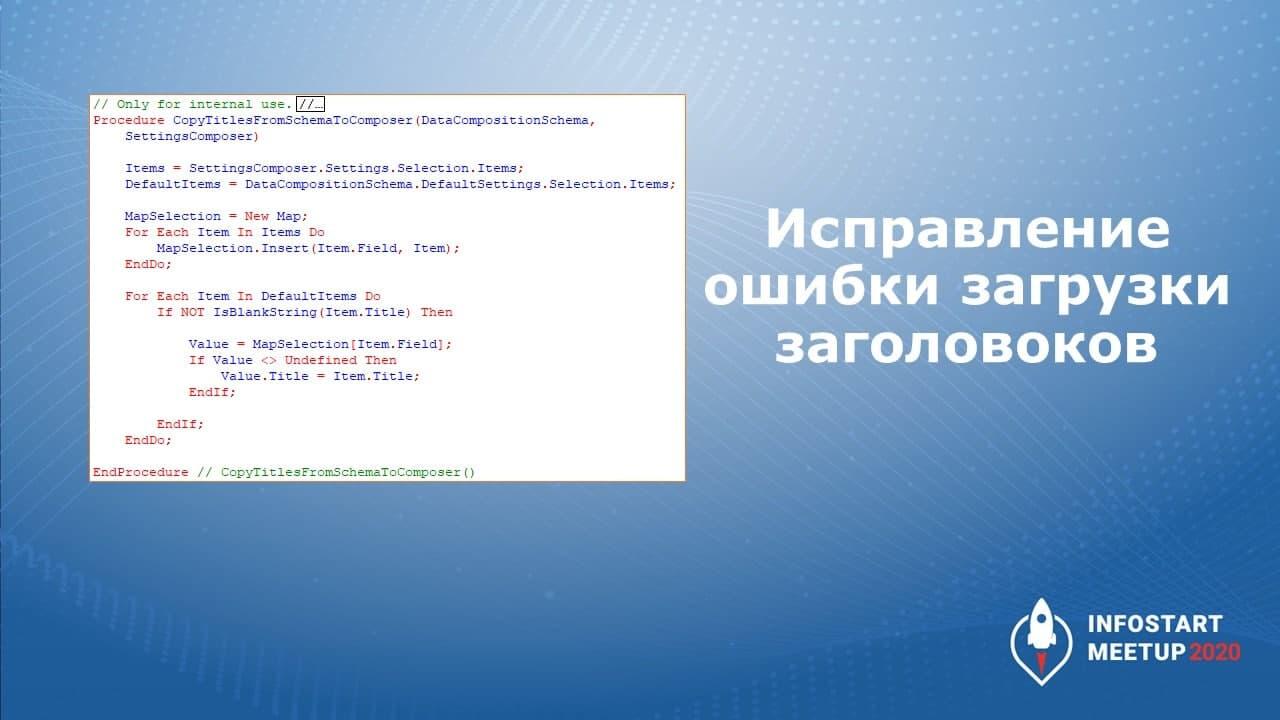
Чтобы исправить платформенную ошибку, обрабатываем заголовки.

После инициализации настроек мы можем уже компоновать макет.
Компоновщик макета требует только схему и настройки. Все, что не выделено, это опционально и не всегда обязательно.

Заполняем параметры макета компоновки данных и параметры вывода.
Компонуем макет компоновки, создаем процессор компоновки и начинаем вывод результата через процессор вывода.
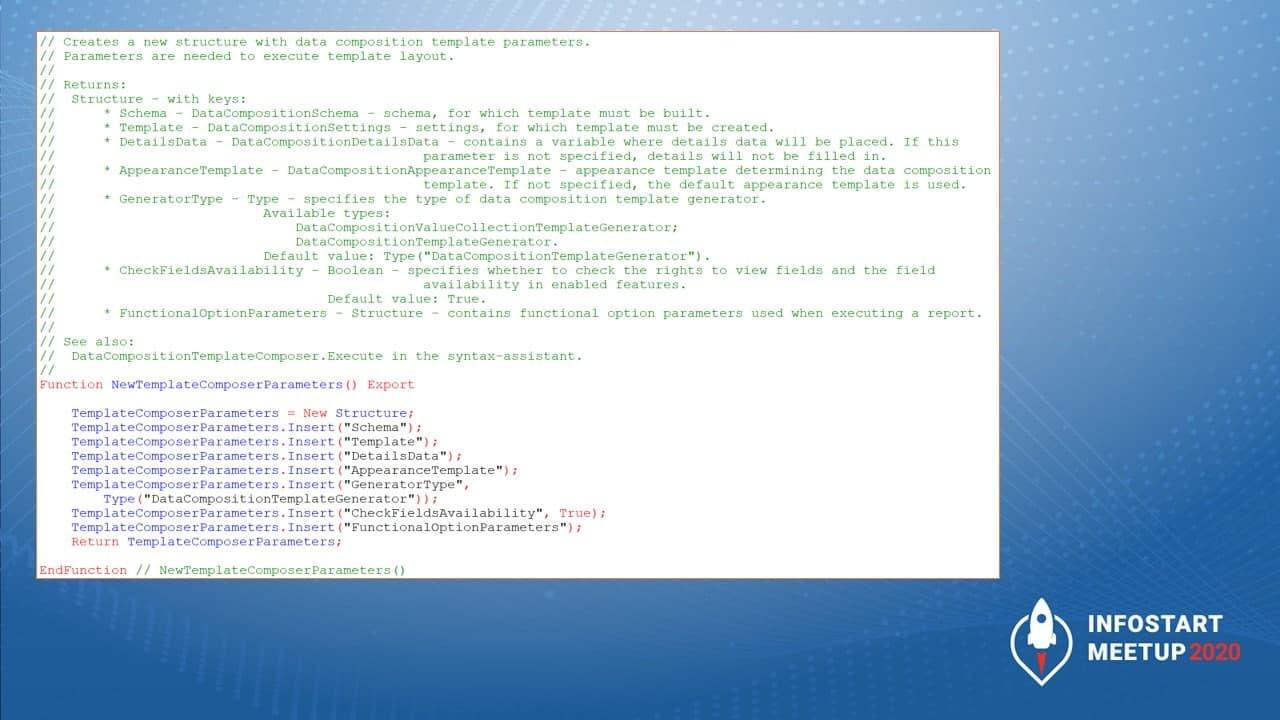
Здесь показано формирование структуры для настроек макета.
Вывод в JSON

Здесь показано, как данные выводятся в JSON – для этого используется встроенная в конфигурацию обработка FL_DataProcessorJSON.
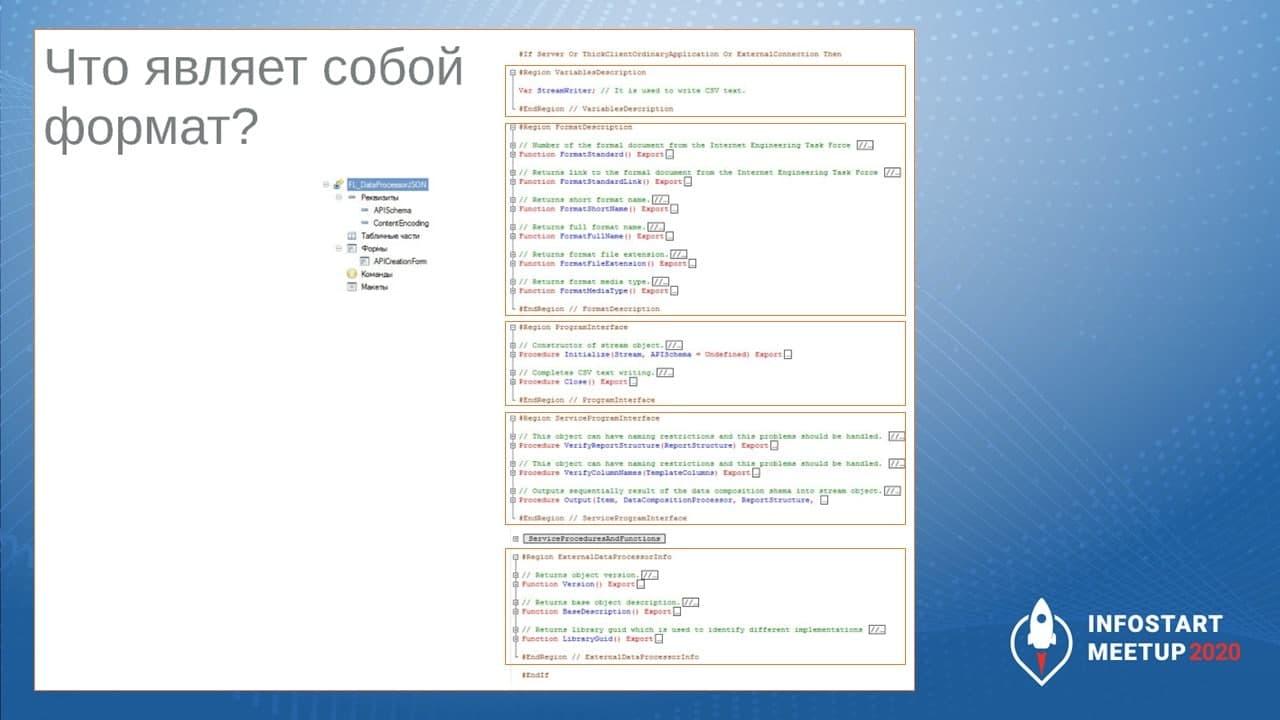
Вот так выглядит формат этой обработки – на такие блоки он разделяется.

И здесь на слайде я отдельно показал, как выглядят структура отчета ReportStructure и структура заголовков полей TemplateColumns на новой платформе и на платформе 8.3.17.
И как выглядит структура начального узла запроса Item, с которого мы начинаем обход результата компоновки данных.
Дополнительные материалы по проекту FoxyLink
Если нужно больше информации по работе с библиотекой FoxyLink, есть несколько видео, где все более-менее детально рассказывается.
-
Формируем объекты в FoxyLink (Хранилище данных для BI системы #1)
-
Первоначальное заполнение Data Warehouse (Хранилище данных для BI системы #2)
-
Онлайн обновление Data Warehouse (Хранилище данных для BI системы #3)
Ссылка, где можно скачать сам проект – https://github.com/FoxyLinkIO/FoxyLink. Вы можете свободно использовать систему и контрибьютить в проект, развивать его.
*************
Данная статья написана по итогам доклада (видео), прочитанного на онлайн-митапе "Практика применения СКД".


Вступайте в нашу телеграмм-группу Инфостарт