









{kind=link}
Анализ метрик СУБД
Кейс 1
Проблема:
Падение нескольких ключевых операций.
Решение:
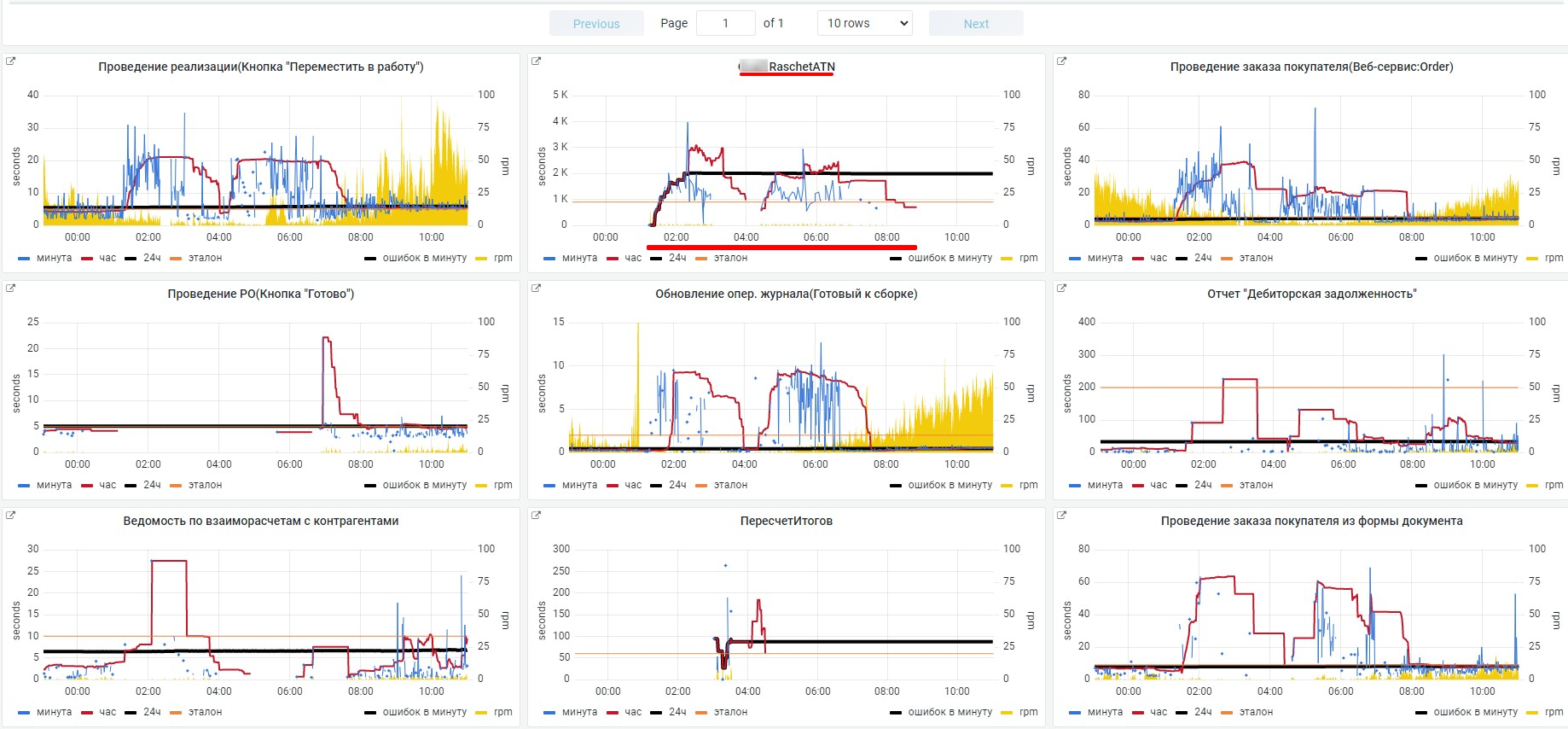
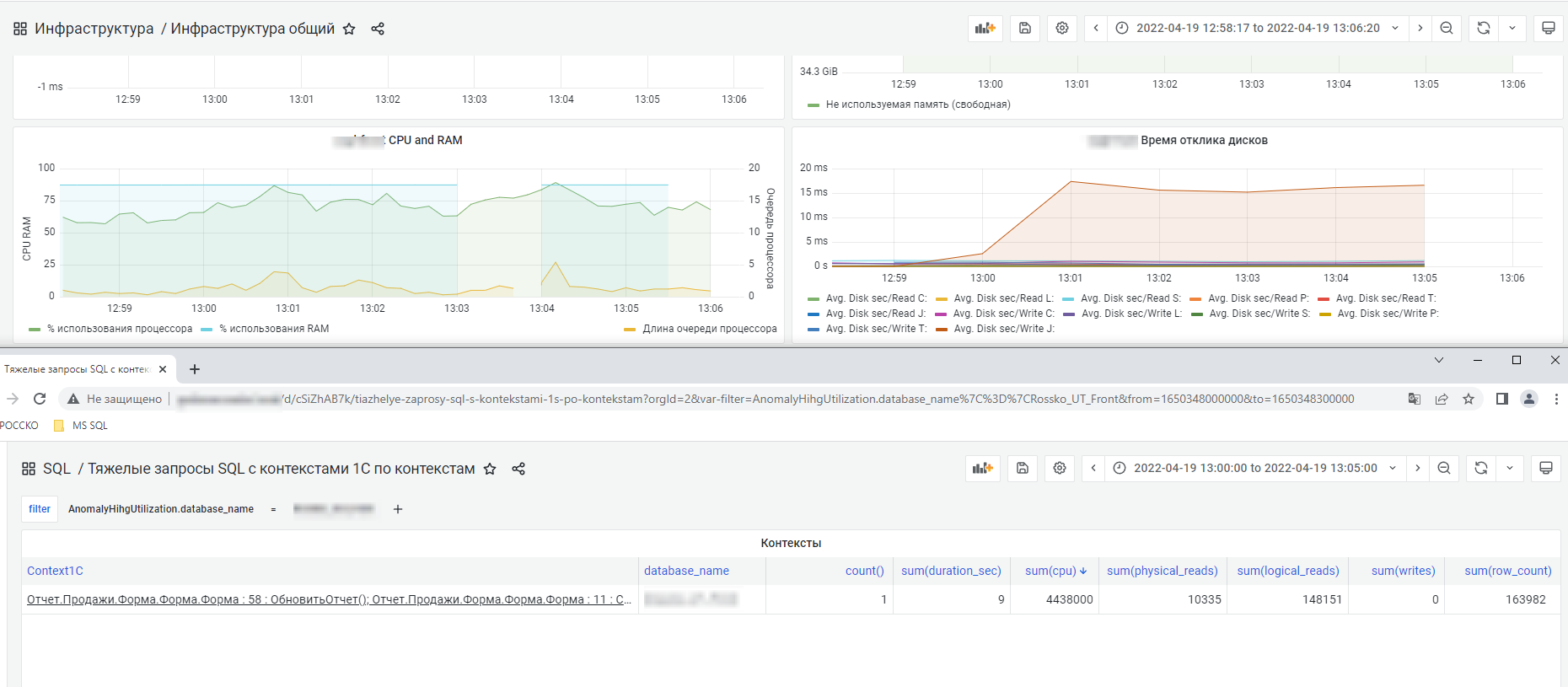
В метриках инфраструктуры видим большое потребление ЦПУ.
Проверяем потребление ЦПУ, видим в т.ч. "большой" отчет.
Возврат отчетом от 10 тыс. строк и выше намекает о целесообразности проанализировать отчет и наложение отборов.
На практике пользователи забывают ставить отборы, в этом случае помогает запрет на формирование без отборов или программный сброс подобных сеансов.
Кейс 2
Проблема:
Падение конкретной ключевой операции.
Решение:
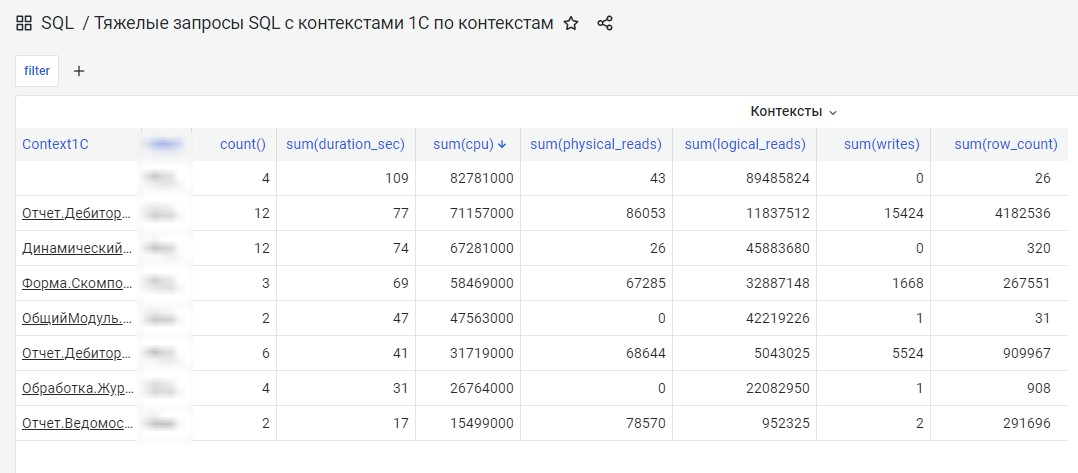
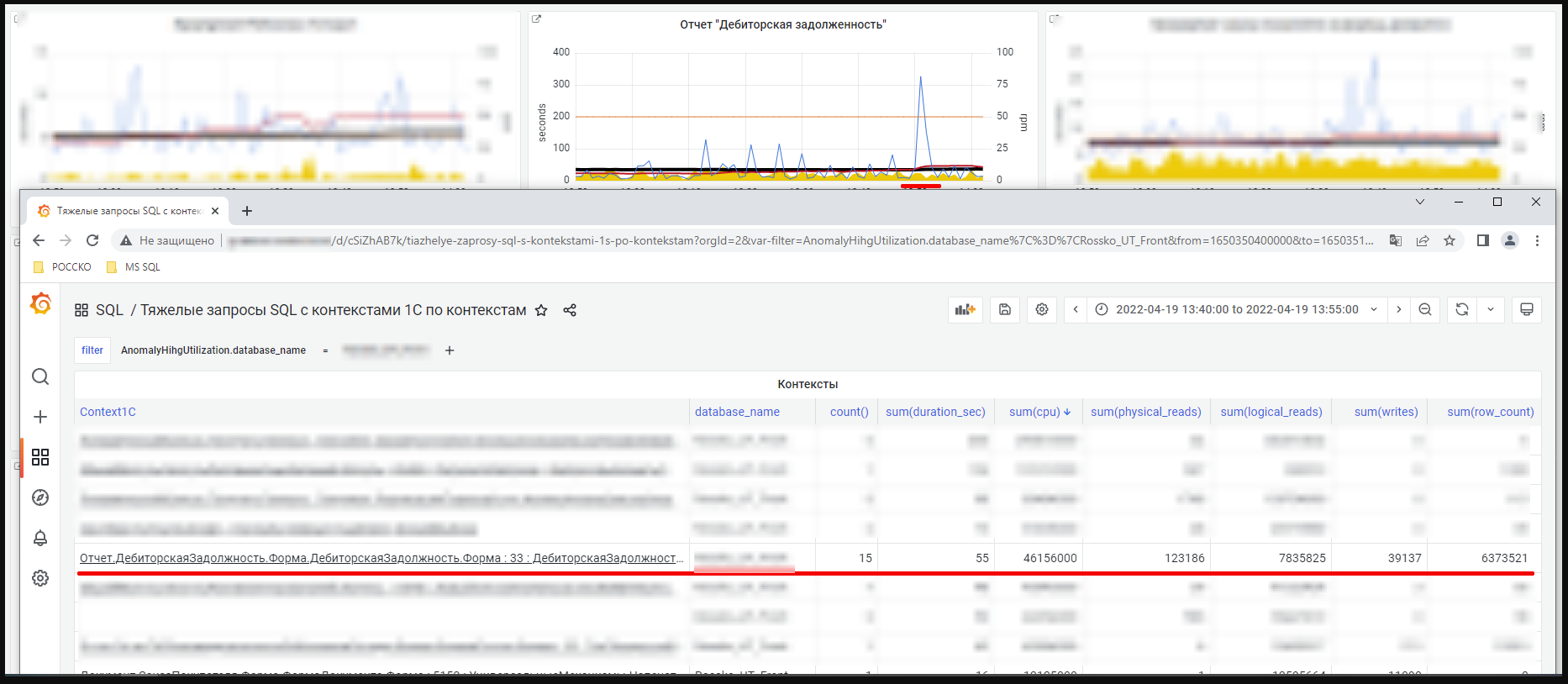
Смотрим, какие контексты были в это время, сколько и каких ресурсов потребляли.
Видим большое количество возвращаемых запросом строк.
Узнаем у пользователя, зачем ему столько, понимаем, что не указал отборы.
Кейс 3
Проблема:
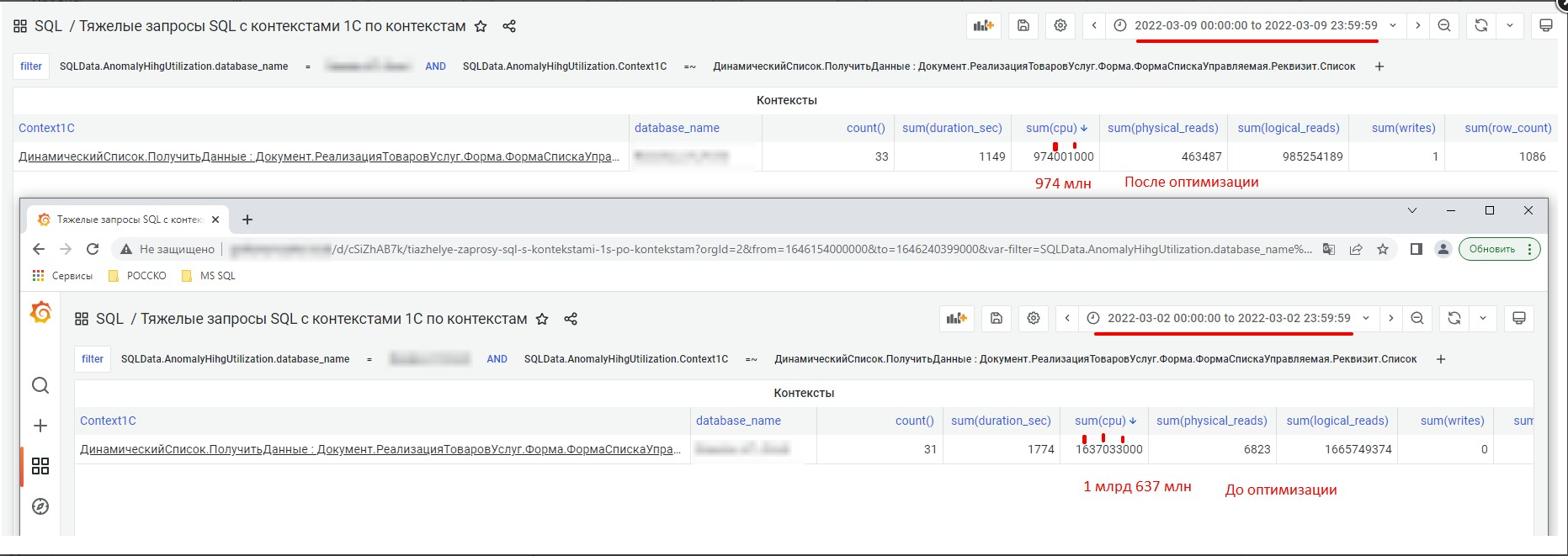
Количественная оценка оптимизации
Решение:
Фиксация изменений до и после выполненных работ.
Кейс 4
Проблема:
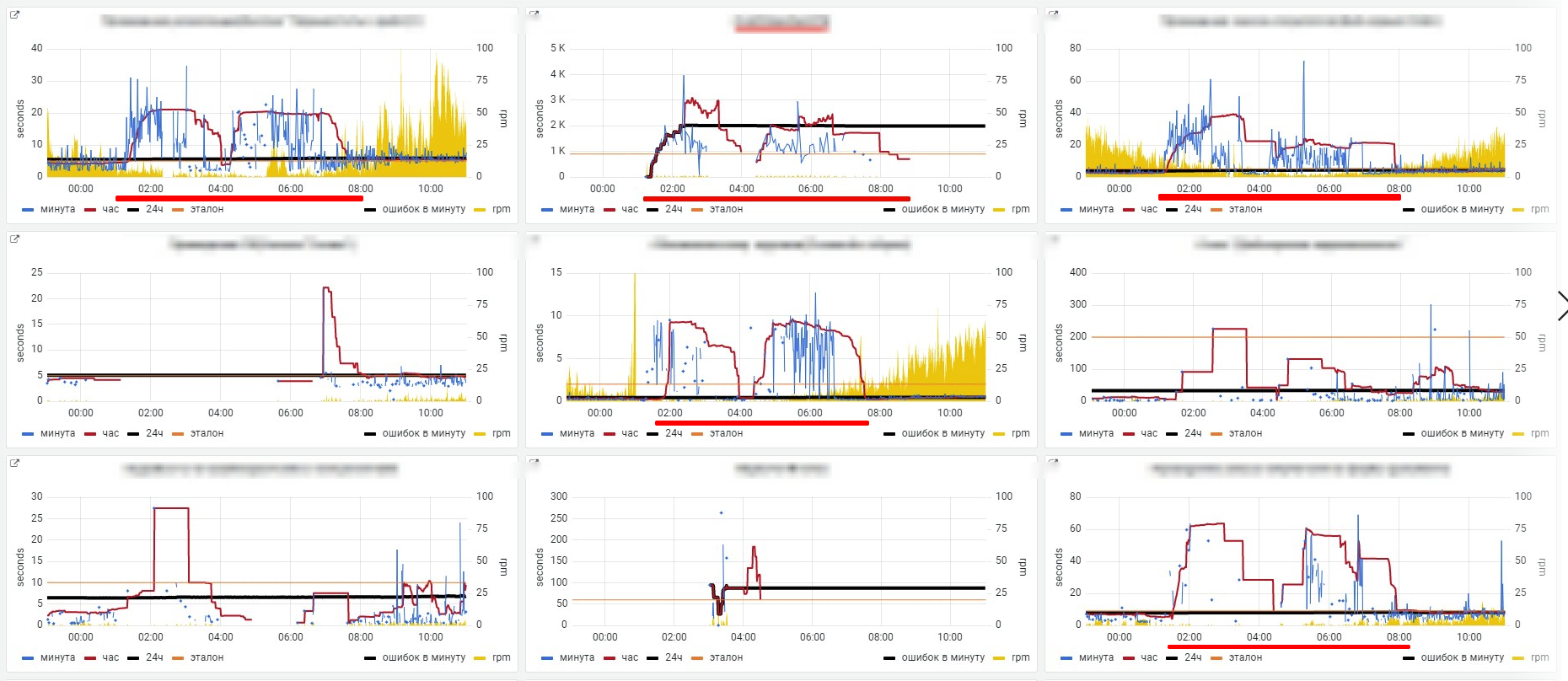
Падение большого количества ключевых операций.
Решение:
При одной большой транзакции найти виновника легко.
При наличии множества транзакций выявить причину становится сложнее.
По многим КО произошла сработка
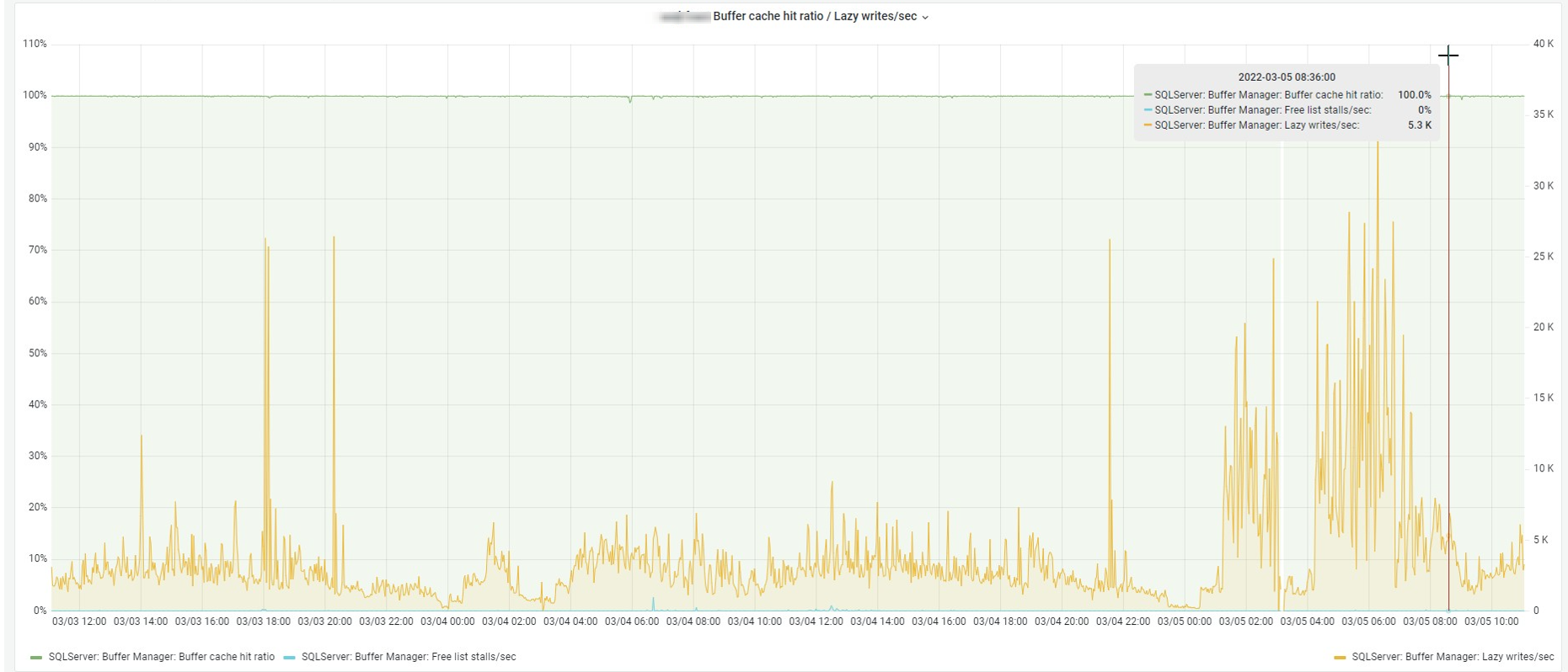
В инфраструктуре тоже видны несколько проблем, но обратим внимание на большую активность ленивого писателя (подробнее о нем SQL Server CHECKPOINT, Lazy Writer, Eager Writer and Dirty Pages in SQL Server). Предполагаем, что одна из операций вымывает кэш, что приводит к удлинению транзакций из-за физических чтений.
Смотрим, кто активно использует память, обращаем внимание на физические чтения других сессий.
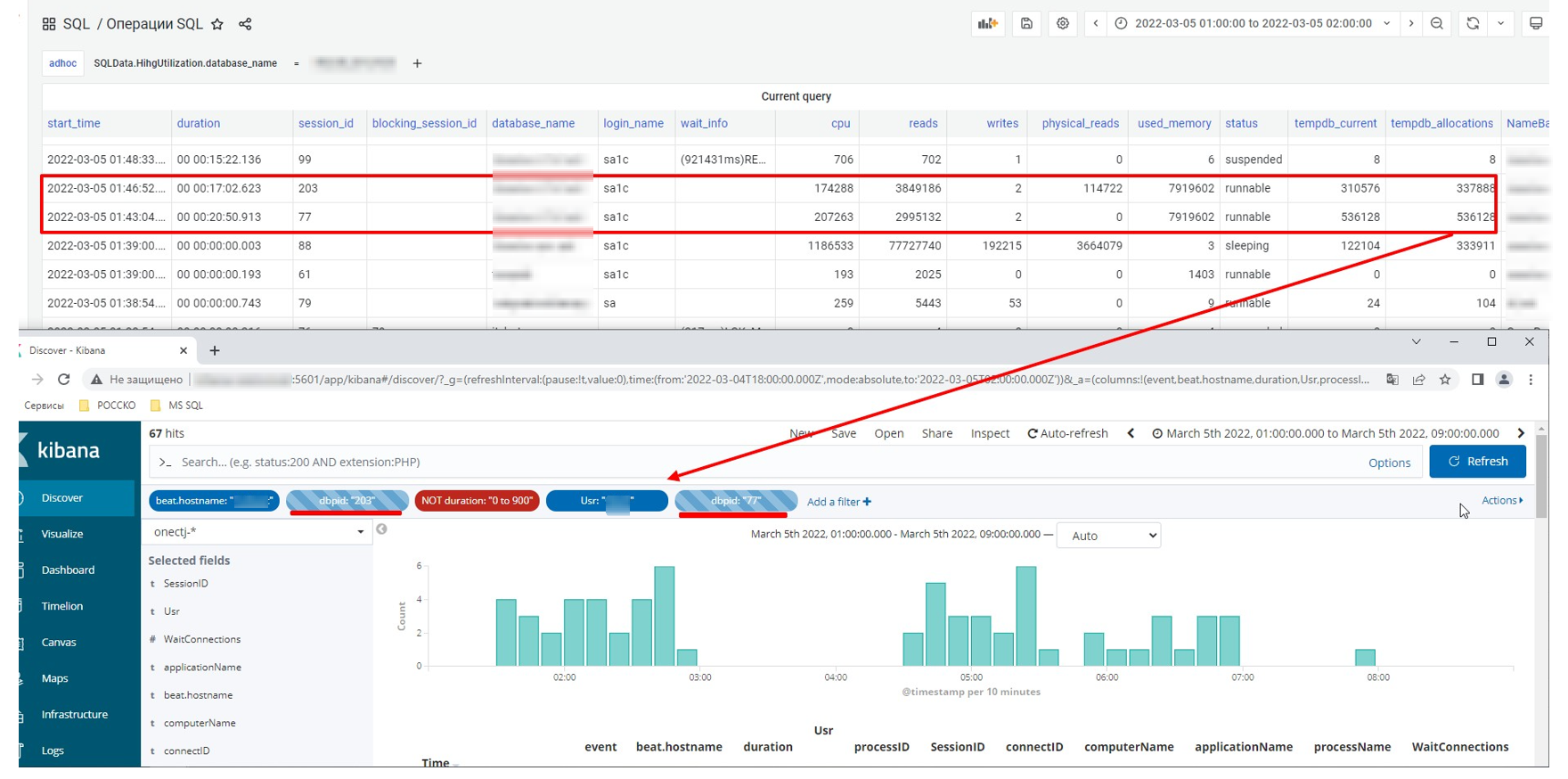
Находим пользователя, смотрим, что он делает.
Смотрим корреляцию работы КО этого пользователя с остальными КО.
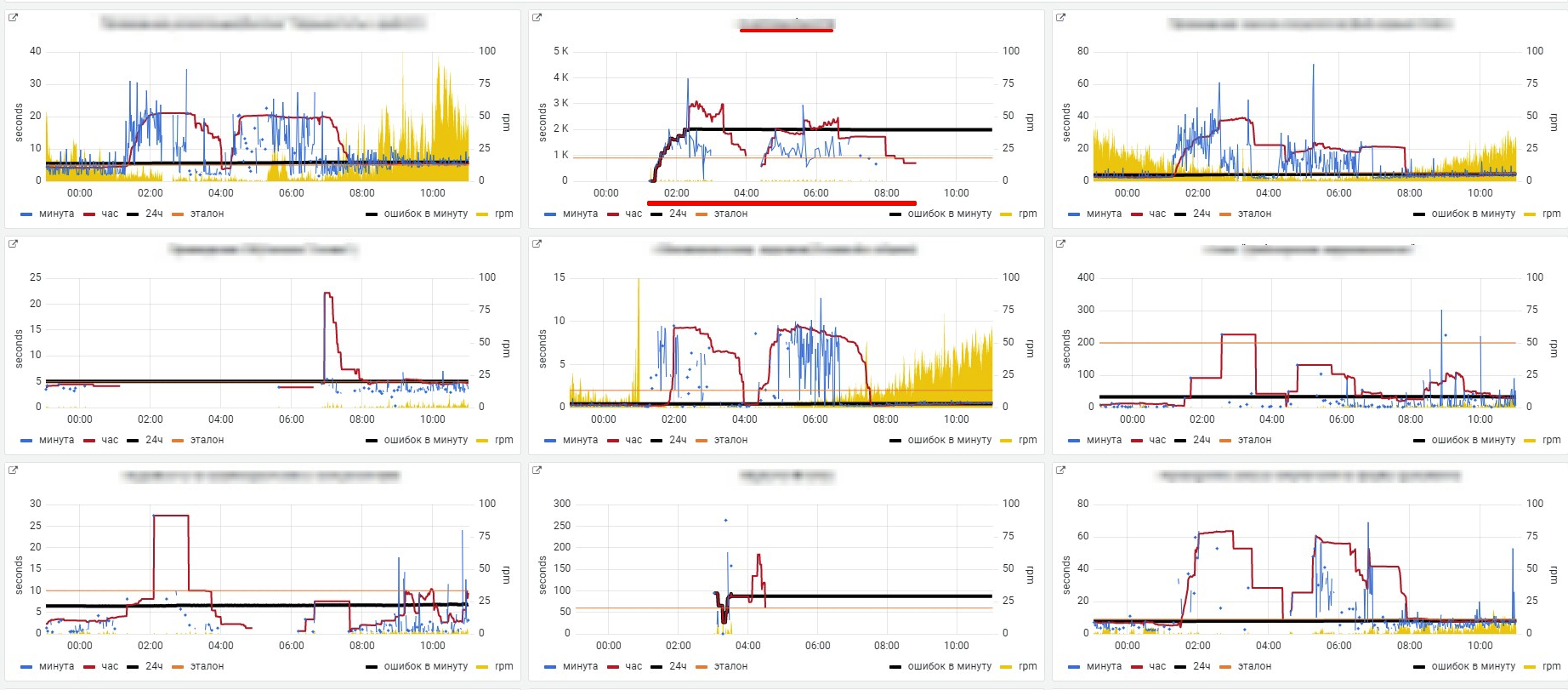
Понимаем что выполнение пользователем работы повлияло на остальных.
Анализируем запросы выполняемые этим пользователем. Оптимизируем.
Кейс 5
Проблема:
Не отработала дефрагментация индексов
Решение:
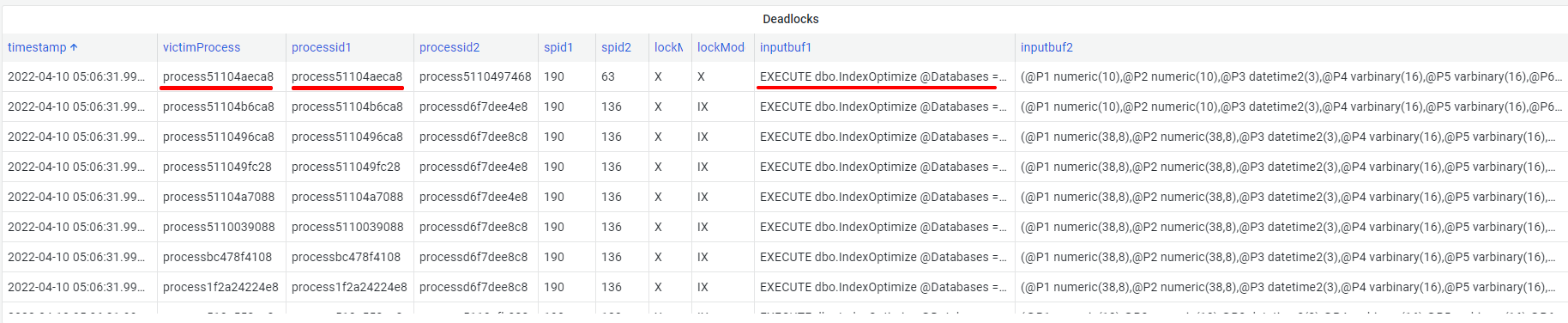
Смотрим на дедлоки СУБД
Идем в лог, видим дедлок.
Смотрим дедлоки.
Видим сброс выполнения процесса process51104aeca8 выполняющего EXECUTE dbo.IndexOptimize.
Там же видим что выполнял в это время второй процесс
UPDATE T1 SET _Fld6876 = T1._Fld6876 + -@P1 ... FROM dbo._AccumRgT6878 T1 WHERE T1._Period = @P3 AND ...
Есть сессии СУБД (spid, spid2) по ним можно посмотреть контекст в ТЖ.
Немного о сборе данных
Статьи на ИТС по анализу проблем производительности на СУБД
- Высокая загрузка CPU на сервере СУБД MS SQL Server
- Высокая загрузка дисковой подсистемы на сервере СУБД MS SQL Server
предполагают запуск запросов и сбор информации в момент проблемы.
В одном случае анализируется длительное выполнение запросов, во втором обращения к диску.
В обоих случаях выявление проблемы происходит во время ее появления.
Что делать если проблема уже прошла и необходимо предотвратить ее появление в будущем?
Нужно фиксировать профиль нагрузки постоянно.
Сделать это можно 2 путями:
- Сбор данных с сервера СУБД через определенные временные промежутки (например каждые 10 секунд, )
- Отслеживание активности системы с помощью расширенных событий
Рассмотрим подробнее плюсы и минусы каждого метода
Сбор данных с сервера СУБД через определенные временные промежутки (например каждые 10 секунд)
Плюсы
Срез текущего состояния в моменте
Минусы
Запросы, выполняемые менее определенного промежутка, в сборке не фиксируются (например, при сборе каждые 10 секунд запросы по 1-9 секунд не попадут).
При этом множество подобных неоптимальных запросов может потреблять много ресурсов (например, скан индекса 10000 запросов длительностью по 5 секунд может дать нагрузку до 100% на проц, выявить подобную проблему собирая каждые 10 секунд данные будет трудно).
Более длительные запросы фиксируются, но тоже есть нюансы.
Например, запрос выполняется 40 секунд, сколько раз он зафиксируется при сборе каждые 10 секунд? Несколько. Надо будет убирать дубли для непротиворечивости данных.
Сбор данных через расширенные события
Плюсы
События фиксируются только после выполнения по подходящим условиям отбора.
Фиксируются независимо от времени выполнения.
Отсутствуют дубли.
Минусы
Проблема в необходимости ожидания окончания события для их анализа.
Для расследования текущих проблем до их отражения в расширенных событиях подходит сбор данных запросом.
Для анализа прошедших проблем подходят расширенные события
Фиксируемые показатели через расширенные события:
- Количество выполнений
- Суммарная длительность выполнения
- Суммарное потребление ЦПУ
- Суммарно физические чтения
- Суммарно логические чтения
- Суммарно записи
- Суммарно количество строк возвращенных запросами
Фиксируемые показатели собираемые через интервалы запросами:
- Потребление памяти
- Размер запрошенной памяти
- Ожидания по запросу
- Блокирующая сессия
- Использование временных таблиц
- Физические чтения
- Логические чтения
- Записи
дают понимание текущей нагрузки на диски, временные таблицы, ЦПУ.
Это понадобится для более точного определения узких мест и работы над ними.
Собрали данные на СУБД.
Документация сбора расширенных метрик с MS SQL поможет забрать их с сервера.
Контексты 1С собираем через ТЖ.
Как пример сбора ТЖ можно написать сервис, работающий независимо и переваривающий логи почти в режиме реального времени (журнал регистрации в эластике с использованием службы без использования 1С (.net + elastic) как пример, но по журналу регистрации) или взять готовый, например парсер технологического журнала (golang + redis + elasticsearch).
Для соединения контекстов СУБД с контекстами 1С можно сделать отдельный сервис на любом любимом языке.
Заключение
Метрики СУБД позволяют более точно определять воздействие кода на сервер.
Вступайте в нашу телеграмм-группу Инфостарт