







Начиная с версии 8.3.18 платформы 1С появился механизм оптимизации RLS. С данной особенностью мы столкнулись при анализе проблемы быстродействия конфигурации ERP. Проведем небольшой анализ и посмотрим что это такое и как оно работает.
В запросах ограничения доступа к данным реализована возможность заменять подзапросы, которые не зависят от защищаемой таблицы, на результат их работы. Поддерживается замена одного подзапроса для каждой защищаемой таблицы. Результат вычисления таких подзапросов кешируется в оперативной памяти рабочего процесса. - источник
Исходные условия проводимого анализа:
- исследование проводили на 5 СУБД: MS SQL, Postgres Pro, Postgres 11, Postgres 13, Postgres 14!
- использовали 3 версии платформы 1C: 8.3.16, 8.3.19, 8.3.20.
- операционные системы Windows server для 1с и postgre SQL, MS SQL; linux под postgre SQL.
- база использовалась для исследования конфигурация ERP с достаточным объемом данных (заказы клиентов ~600 000 документов, регистр заказов ~7 500 000 записей);
- для тестов использовались 3 пользователя с различными RLS ограничениями и администратор;
- для демонстрации были использованы более 20 тестовых запросов, а были выбраны в статью 2 примера (этого достаточно).
Исследование
Если проанализировать шаблон, то что в нем не изменяется? Это под запрос, определяющий группы доступа пользователя.

С точки зрения логики — можно вообще посчитать это значение один раз при входе пользователя и передавать в шаблон, как массив доступных значений. У ребят из Раруса где-то была подобная статейка на сайте - "Оптимизация типового шаблона RLS (получение групп доступа)". Кто у кого подсмотрел?
Давайте посмотрим, как эта платформенная особенность выглядит в работе. Открываем базу под любым пользователем с RLS, берем консоль запросов и вбиваем простой текст — эмуляция динамического списка заказов клиента конфигурации ERP/УТ/КА:
ВЫБРАТЬ РАЗРЕШЕННЫЕ ПЕРВЫЕ 45
Т.Номер КАК НомерДокумента,
Т.Дата КАК ДатаДокумента,
Т.Организация КАК Организация,
Т.Контрагент КАК Контрагент
ИЗ
Документ.ЗаказКлиента КАК Т
В логах сразу перед искомым запросов должен быть требуемый запрос определения RLS.
SELECT
T1._Reference116_IDRRef AS ACCESS_GROUPRRef
FROM _Reference116_VT3635 T1
INNER JOIN _InfoRg36262 T2
ON (T2._Fld36264_TYPE = '\\010'::bytea AND T2._Fld36264_RTRef = '\\000\\000\\001,'::bytea AND T2._Fld36264_RRRef = '\\272-\\000PV\\2346\\034\\021\\354X0\\246}4\\017'::bytea) AND (T2._Fld36263_TYPE = T1._Fld3637_TYPE AND T2._Fld36263_RTRef = T1._Fld3637_RTRef AND T2._Fld36263_RRRef = T1._Fld3637_RRRef)
WHERE ((T1._Fld1585 = CAST(0 AS NUMERIC))) AND (T2._Fld1585 = CAST(0 AS NUMERIC)) LIMIT 21
или воспользуемся обработкой конвертации SQL в представления 1С
ВЫБРАТЬ ПЕРВЫЕ 21
T1.Ссылка КАК ACCESS_СГРУППИРОВАТЬRRef
ИЗ Справочник.ГруппыДоступа.ТабличнаяЧасть.Пользователи КАК T1
ВНУТРЕННЕЕ СОЕДИНЕНИЕ РегистрСведений.СоставыГруппПользователей КАК T2
ПО (T2.Пользователь = '\\010'::bytea И T2.Пользователь = '\\000\\000\\001,'::bytea
И T2.Пользователь = '\\272-\\000PV\\2346\\034\\021\\354X0\\246}4\\017'::bytea)
И (T2.ГруппаПользователей = T1.Пользователь
И T2.ГруппаПользователей = T1.Пользователь
И T2.ГруппаПользователей = T1.Пользователь)
ГДЕ ((T1.ОбластьДанныхОсновныеДанные = ВЫРАЗИТЬ(0 КАК ЧИСЛО)))
И (T2.ОбластьДанныхОсновныеДанные = ВЫРАЗИТЬ(0 КАК ЧИСЛО))
И эти данные подставляются как массив значений уже в запросе RLS
План запроса
https://explain.tensor.ru/archive/explain/a6ae34c18cc0c12a54c04d6796eeeae3:0:2022-04-05#visio
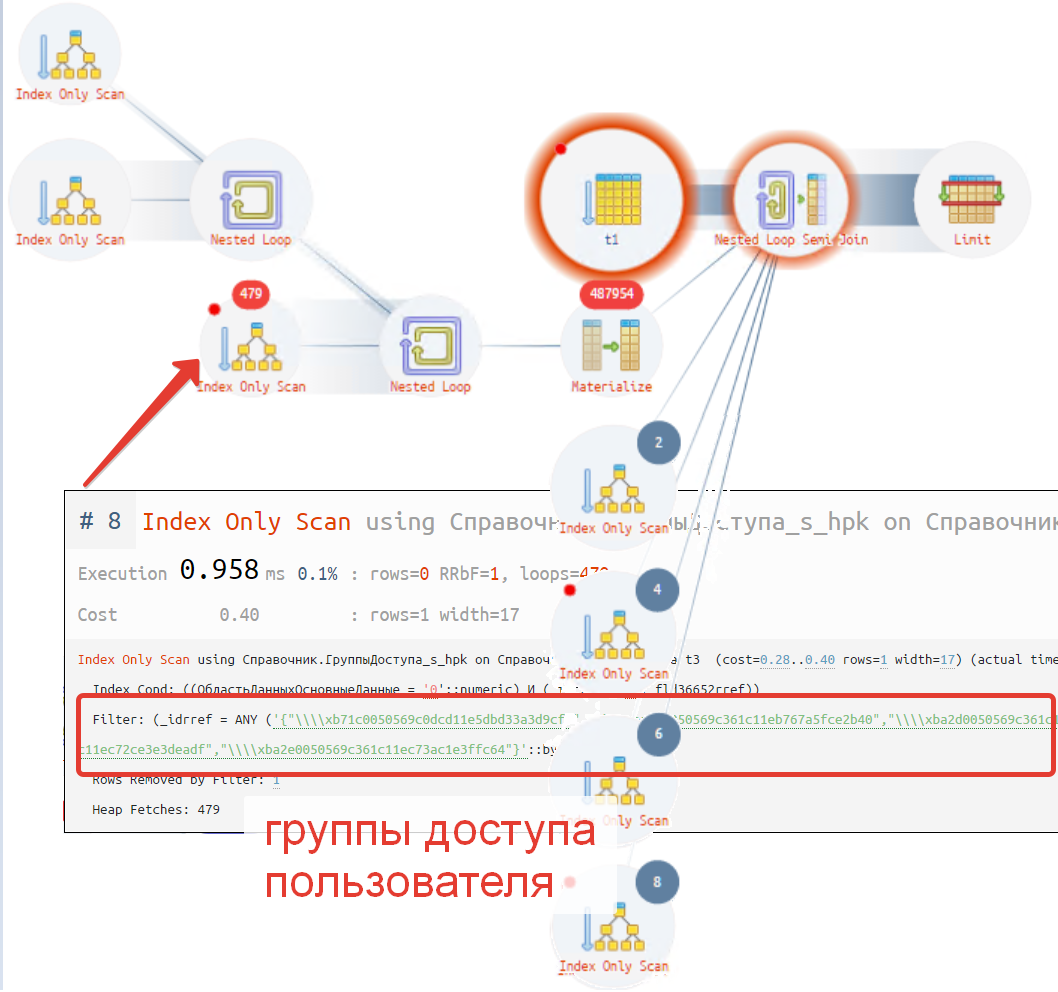
Теперь давайте вручную добавим в запрос группы:
https://explain.tensor.ru/archive/explain/5a6575d3332264f3e01d741488876da4:0:2022-04-05#visio
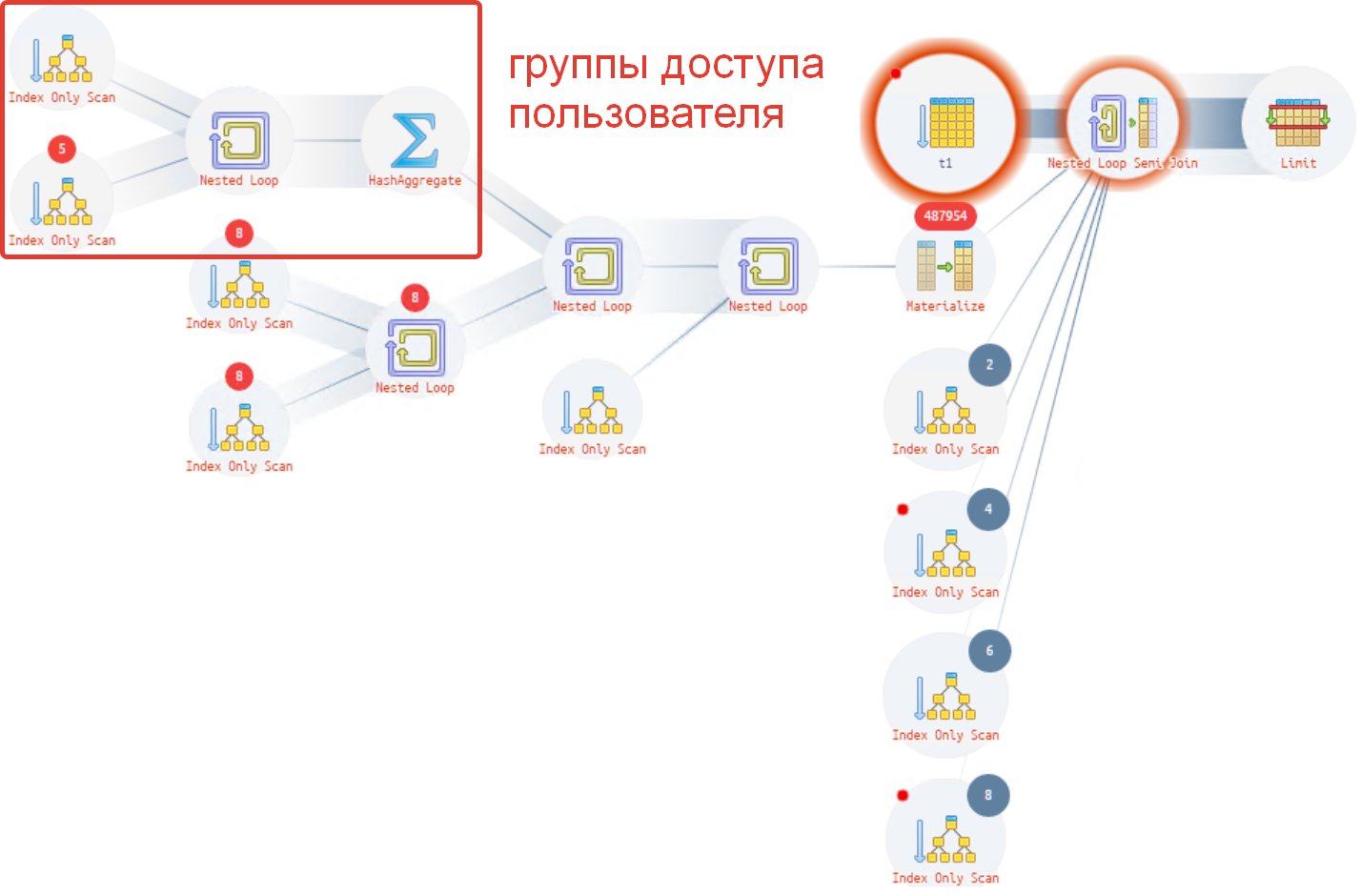
Изменения плана запроса для MS SQL Server имеют похожую структуру оптимизации, только схема плана для postgres выглядит более красиво.
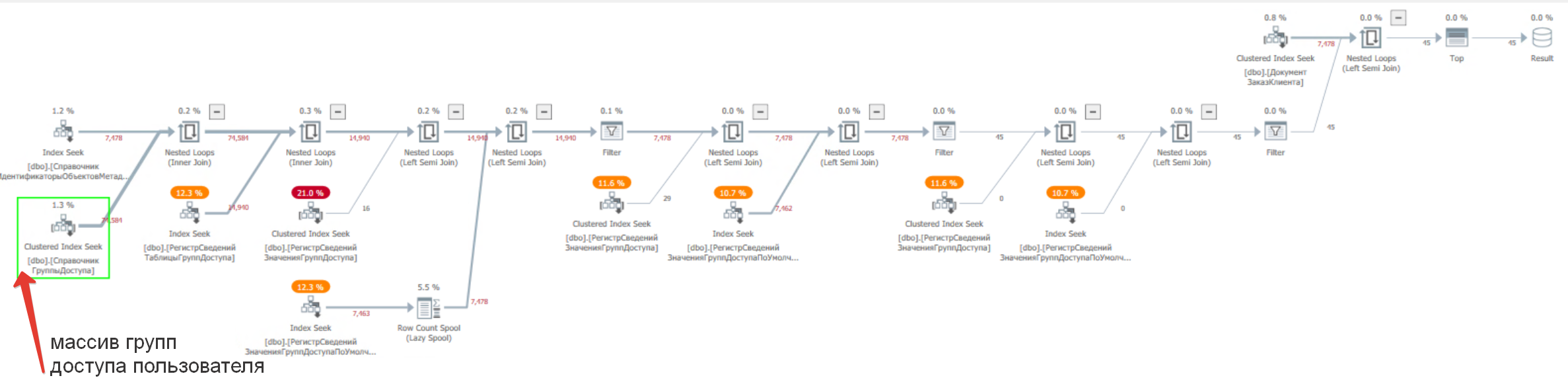
Пример плана с оптимизацией:
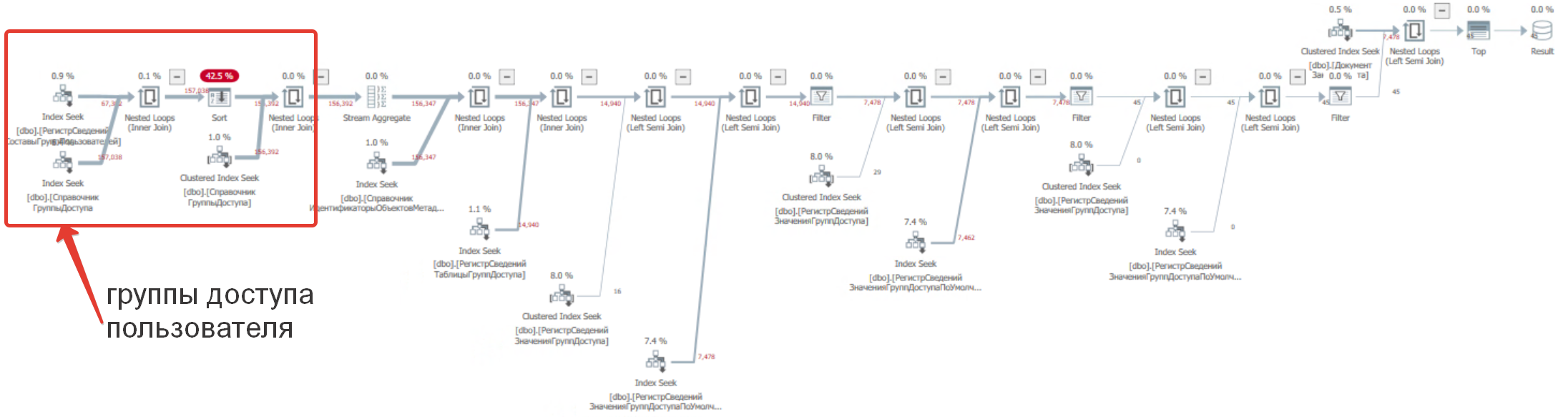
План без оптимизации:
Алгоритм действий платформы выглядит как показано на рисунке ниже. Сначала идет запрос поучающий группы доступа (выделен красной рамкой). Далее идет следующий запрос с подставленными группами доступа в операторе «В» запроса с RLS.
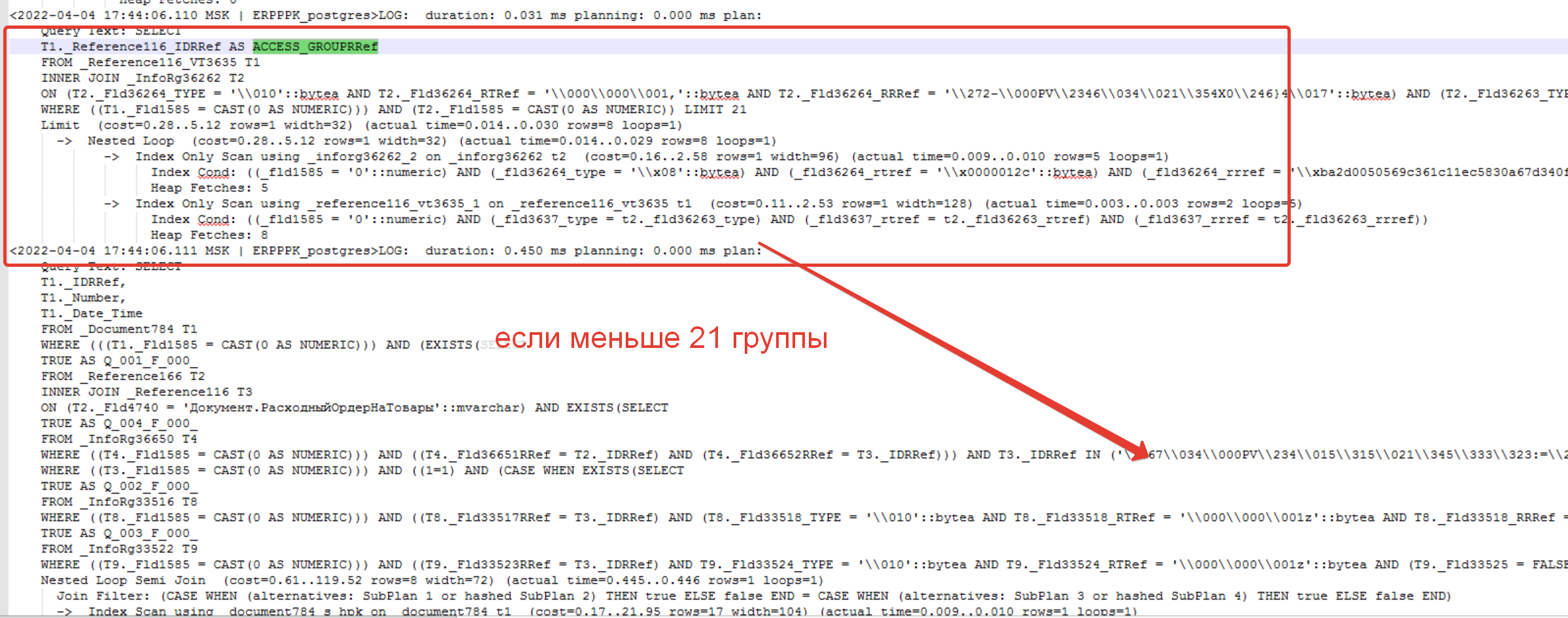
Т.е. выбирается 21 значение. А что происходит, если будет равно или больше? Ответ: оптимизация отрабатывать не будет, см. рис. ниже! Может было надо использовать 42?

Давайте сравним время выполнения и планы запросов с оптимизацией и без. Без оптимизации будем ручками подставлять порезанную вставку в SQL (мы провели большее количество тестов и среди них выбрали несколько, по остальным картинка подобная).
1. Запрос имитации динамического списка ЗК (приведен выше)
- Postgres 11:
- - без оптимизации (~300 мс) https://explain.tensor.ru/archive/explain/52bdfb1f27799bbd1153d3ca03ecbef3:0:2022-04-05#explain
- - с оптимизацией (~3000 мс) https://explain.tensor.ru/archive/explain/1e6ef5aaa54a28352b227bc46898b00b:0:2022-04-05#explain
- Postgres 13:
- - без оптимизации (~700 мс) https://explain.tensor.ru/archive/explain/4b54684f72f7682512c92501d06872f4:0:2022-04-06#visio
- - с оптимизацией (~700 мс) https://explain.tensor.ru/archive/explain/a56f4509f26754e0cdc21f5f4a235b7d:0:2022-04-06#visio
- Postgres 14:
- На PG 14 поведение не отличается от 13-й.
- На Postgres pro 13 поведение подобное обычной версии
- MS SQL
- без оптимизации (~1300 мс)
- с оптимизацией (~360 мс)
2. Давайте построим более сложный запрос. Добавим выбор нескольких полей через точку и сортировку по полю «ДатаДокумента» составного типа:
ВЫБРАТЬ РАЗРЕШЕННЫЕ ПЕРВЫЕ 45
"test_rg_12345" КАК Ключ,
ЗаказыКлиентов.ЗаказКлиента.Номер КАК НомерДокумента,
ЗаказыКлиентов.ЗаказКлиента.Дата КАК ДатаДокумента,
ЗаказыКлиентов.ЗаказКлиента КАК ЗаказКлиента,
ЗаказыКлиентов.Номенклатура КАК Номенклатура,
ЗаказыКлиентов.Характеристика КАК Характеристика,
ЗаказыКлиентов.Заказано КАК Заказано,
ЗаказыКлиентов.КОформлению КАК КОформлению,
ЗаказыКлиентов.Сумма КАК Сумма
ИЗ
РегистрНакопления.ЗаказыКлиентов КАК ЗаказыКлиентов
УПОРЯДОЧИТЬ ПО
ДатаДокумента
- Postgres 11:
- без оптимизации (~541 с)
- с оптимизацией (~6 900 с)
- На Postgres 13 поведение совсем другое:
- без оптимизации (~8 с)
- с оптимизацией (~8 с)
- На Postgres 14 особых отличий нет
- На Postgres pro 13 поведение подобное обычной версии
- На MS SQL Server
- без оптимизации (16 с)
- с оптимизацией (14 с)
Как так получилось? Оптимизация ухудшает производительность! Давайте взглянем и сравним поведение старшей версии Postgres 13 и младшей Postgres 11. Пример отличий в работе планировщика - в старшей версии по условию вхождения групп ищется по индексу, а в младшей выбирается сначала данные из индекса по условию, а потом накладывается фильтр с группами (это медленнее) см. рис. ниже.
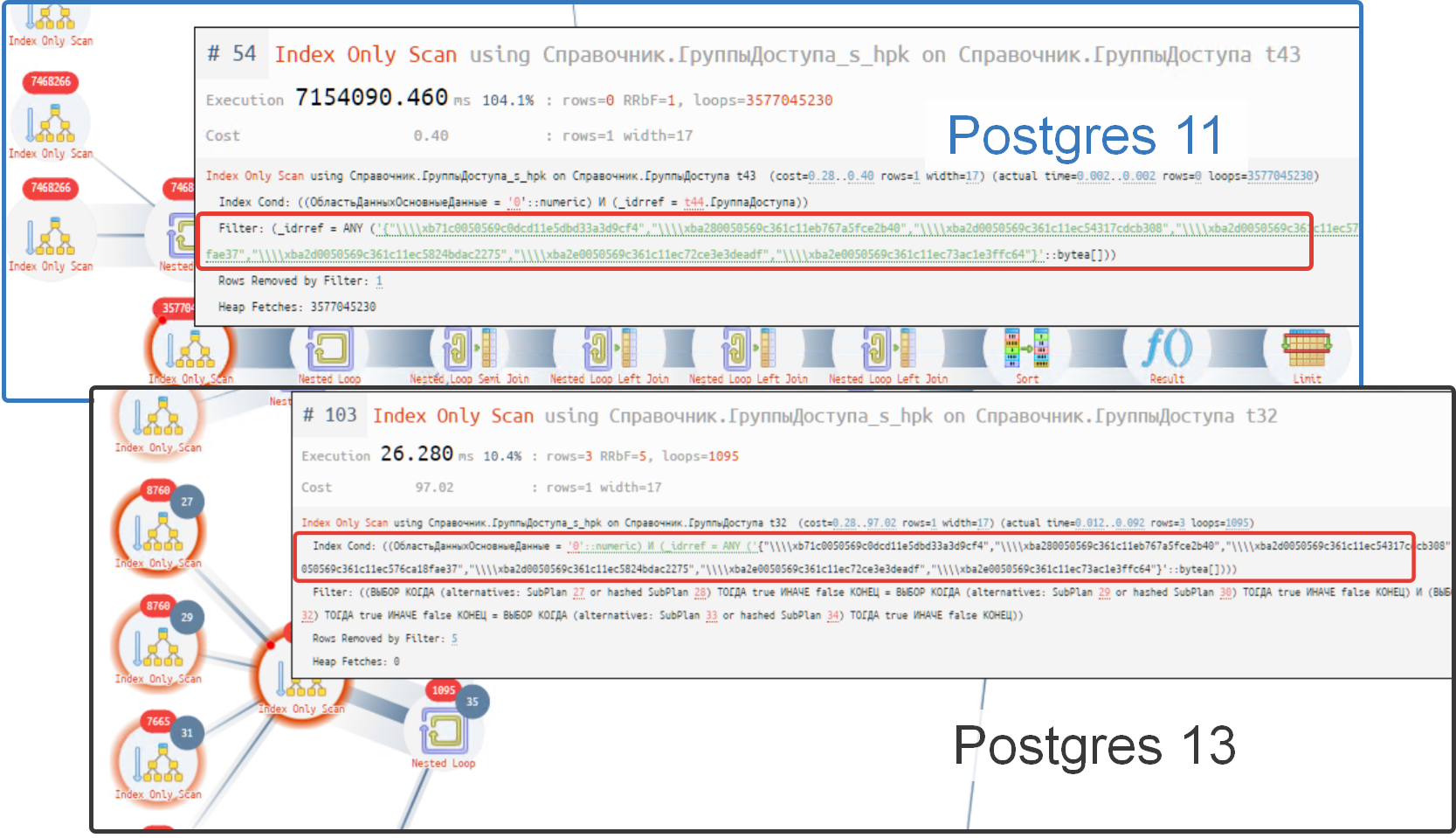
Резюме:
- На MS SQL Server оптимизация работает, эффект виден
- Если вы работаете на 1С в связке с Postgres 11, то срочно переходите на Postgres 13 или 14
- Не увидел в выбранных тестах отличий Postgres pro от Postgres
- Качество работы СУБД Postgreres с выходом 13 и 14 версии положительно удивило и еще больше приблизилось к уровню MS SQL
- На мой взгляд, оптимизация от 1С получилась не однозначной для СУБД Postgres:
- - запросы стали проще, схема плана стала меньше
- - серьезного отрыва в производительности увидеть не удалось
- Можно переходить на версии платформы 1С 8.3.18, 8.3.19 и выше особенно при использовании СУБД MS SQL, положительный эффект будет.
Вступайте в нашу телеграмм-группу Инфостарт