Как говорится, админы делятся на тех, кто делает бекапы, и тех, кто уже делает. А из тех, кто уже делает, выделяются те, кто эти бекапы проверяют (народная мудрость).
К сожалению, если есть выгрузка базы в .dt, есть ненулевой шанс эту выгрузку не загрузить обратно, с чем мне в последнее время несколько раз и пришлось столкнуться. И это даже не касается крупных баз, которые не могут загрузиться в файловый вариант. Просто файловая база может быть незначительно повреждена, так что при работе это незаметно, и выгружаться нормально, но выгруженные повреждения не дадут базу загрузить обратно. Например, в результате повреждения в таблице образовалось несколько пустых строк, но по таблице построен уникальный индекс. Или образовалось null-значение в поле с ограничением not null. Или строковые данные повредились, и 1С из строкового поля "на 10 символов" выгрузит 200 символов мусора. Все эти проблемы всплывают только при попытке воспользоваться выгрузкой.
К сожалению, формат DT закрытый, и просто так проблемы в нём поправить нельзя. Мне в таких случаях помогла загрузка базы в серверный вариант с PostgreSQL.
Во-первых, PostgreSQL молча обрезает слишком длинные строки. А во-вторых, используя триггеры, можно модифицировать данные при загрузке, чтобы исправить ошибки. Работать в PostgreSQL можно из "штатной" утилиты pgAdmin.
1С загружает базу в следующем порядке:
1. удаляются таблицы базы если они были
2. Создаётся и загружается таблица CONFIG и прочие служебные таблицы и создаётся новая структура таблиц.
3. Таблицы заполняются данными
4. После заполнения очередной таблицы создаются индексы, и начинается заполнение следующей таблицы.
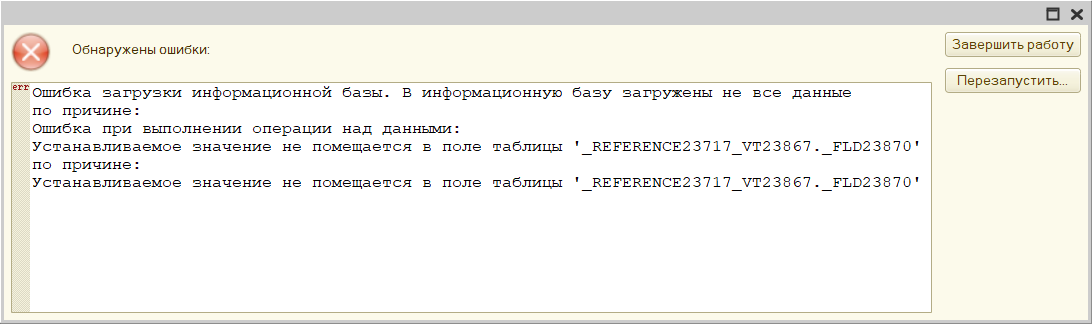
Возможно, встретится ошибка с таким сообщением:
Попытка вставки неуникального значения в уникальный индекс: РегистрСведений.ЦеныНоменклатуры
23502: ERROR: null value in column "_fld16137_type" violates not-null constraint
DETAIL: Failing row contains (0001-01-01 00:00:00, \x00000000000000000000000000000000, \x00000000000000000000000000000000, \x00000000000000000000000000000000, 0.00, f, null, \x00000000, \x00000000000000000000000000000000, f, \x00000000000000000000000000000000, 0).
CONTEXT: COPY _inforg16131, line 6537
Ключевое здесь сообщение "null value in column "_fld16137_type" violates not-null constraint". Тогда можно поступить следующим образом:
Нужно создать триггерную функцию такого вида:
CREATE OR REPLACE FUNCTION public.qqqq()
RETURNS trigger
LANGUAGE 'plpgsql'
COST 100
VOLATILE NOT LEAKPROOF
AS $BODY$
BEGIN
IF (NEW._period IS NULL)
OR(NEW._recordertref IS NULL)OR(NEW._recorderrref IS NULL)THEN
RETURN NULL;
END IF;
IF NEW._lineno IS NULL THEN
NEW._lineno=0;
END IF;
IF NEW._active IS NULL THEN
NEW._active=false;
END IF;
IF NEW._fld18947rref IS NULL THEN
NEW._fld18947rref='\\x00000000000000000000000000000000';
END IF;
IF NEW._fld18950 IS NULL THEN
NEW._fld18950=0;
END IF;
RETURN NEW;
END
$BODY$;
Для каждой таблицы с такими проблемами по своей функции. Здесь имена полей нужно брать из сообщения об ошибках. В этом примере - если не заполнен _period или _recordertref или _recorderrref запись просто пропускается. Если не заполнены остальные поля - им присваиваю значение. Скорее всего это повреждённые записи, с утерянными или мусорными данными, решение тут надо принимать на месте - возможно стоит просто пропустить эту запись. Если нужно запись сохранить - значение нужно смотреть по типу использования
При загрузке 1С не удаляет триггерные функции, но назначить триггер придётся таблице после её создания. Это можно попробовать сделать через событийный триггер (см. ниже), но я делал есть вручную. Нужно назначить таблице триггер, указать созданную триггерную функцию и событие - BEFORE INSERT
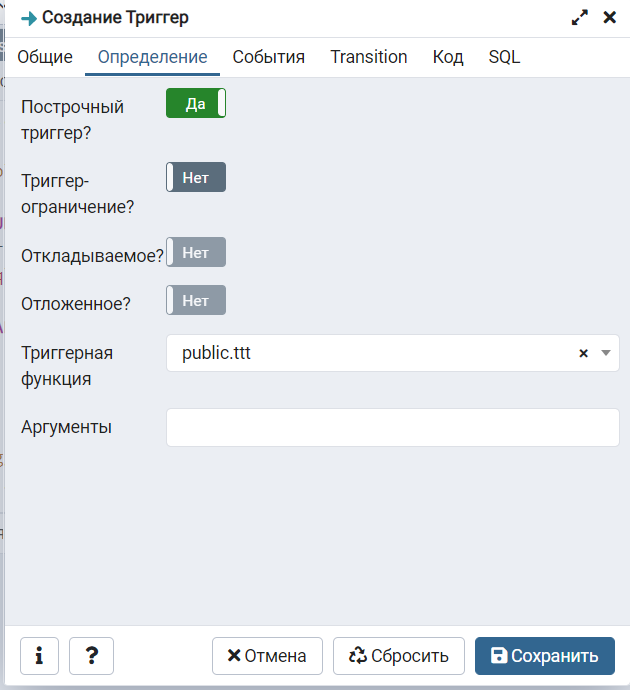
Создать можно в диалоге, или таким запросом:
CREATE TRIGGER tbl1_flt
BEFORE INSERT
ON public._acc50
FOR EACH ROW
EXECUTE FUNCTION public.qqqq();
Где tbl1_flt - произвольно заданное имя
_acc50 - имя таблицы, вставку в которую данных фильтруем
qqqq() - имя созданной триггерной функции
Т.е. сначала нужно создать функцию, затем начать загрузку, и когда таблица появилась - назначить триггер.
Если загрузка прерывается по ошибке неуникальных данных:
Попытка вставки неуникального значения в уникальный индекс:
23505: ERROR: could not create unique index "_inforg16131_1" РегистрСведений.ЦеныНоменклатуры
DETAIL: Key (_fld1224, _period, _fld16132rref, _fld16133rref, _fld16134rref)=(0, 0001-01-01 00:00:00, \x00000000000000000000000000000000, \x00000000000000000000000000000000, \x00000000000000000000000000000000) is duplicated.
Это уже этап создания индексов по загруженным данным. В этом сообщении мусорные данные, но они могут быть и не мусорными. В этом случаем нам могут помочь СОБЫТИЙНЫЕ ТРИГГЕРЫ PostgreSQL. В отличие от строчных такой триггер может вызываться перед выполнением SQL команды create index, что позволит подчистить лишнее.
Нужно сначала создать функцию, в которой будем чистить лишние данные. К сожалению, есть сложности с определением какая именно команда и над каким объектом вызывается, возможно возникающие исключения будем гасить. Пример такой функции, удаляющей данные:
CREATE OR REPLACE FUNCTION public.asnitch()
RETURNS event_trigger
LANGUAGE 'plpgsql'
COST 100
VOLATILE NOT LEAKPROOF
AS $BODY$
DECLARE
r record;
BEGIN
-- r:=pg_event_trigger_ddl_commands();
-- RAISE NOTICE 'snitch: % %', tg_event, tg_tag;
BEGIN
DELETE FROM _inforg16131
WHERE _fld16132rref='\\x00000000000000000000000000000000'
AND _fld16133rref='\\x00000000000000000000000000000000';
EXCEPTION
WHEN others THEN
END;
BEGIN
DELETE FROM _inforg16131
WHERE _fld16132rref='\\x008593706655162bac11eb41f32fa23c';
EXCEPTION
WHEN others THEN
END;
END;
$BODY$;
Здесь я просто удаляю мешающие данные, их можно было удалить и на этапе загрузки в прошлом способе. Но если есть цель оставить из неуникальных записей только одну, придётся писать запрос в обработчике событийного триггера.
Функция создана, теперь надо создать триггер. В диалоге:
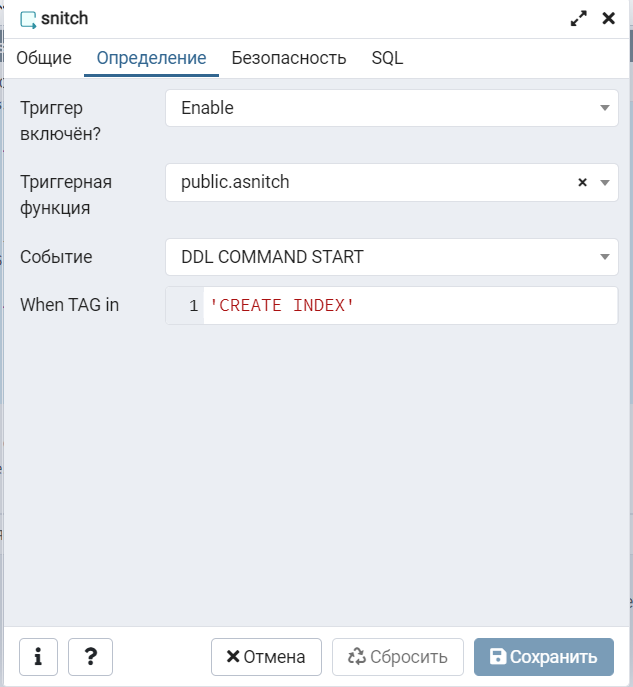
Или запросом:
CREATE EVENT TRIGGER sss ON DDL_COMMAND_START
WHEN TAG IN ('CREATE INDEX')
EXECUTE PROCEDURE public.asnitch();
Таким образом функция будет вызываться перед каждым созданием индексов, и можно производить разные манипуляции над данными.
Для интересующихся - ссылка на документацию по PostgreSQL на русском
Вступайте в нашу телеграмм-группу Инфостарт
