



























Не дай Вам Бог жить в эпоху перемен!
Спасибо Конфуций, но это не про нас. Мы проектная команда, мы разработчики и архитекторы, консультанты и методологи. Мы живем в мире, который постоянно изменяется, поставщики базовых конфигураций выпускают новые релизы, 1С выпускает новые платформы, у заказчиков изменяются требования. Мы живем в эпоху сжатых сроков и дедлайнов. (Если написанное слева выше в этом абзаце не про вас - дальше статью можно не читать=) Мы как молекулы в броуновском движении двигаемся и сталкиваемся (конфликтуем) и чем больше плотность (размер проектной команды) и выше температура (меньше сроки) тем сложнее управлять общим процессом, чтобы он не сдетонировал... Мы не можем делать доработки долго мы должны их делать быстро и качественно, чтобы снизить риски конфликтов при объединении наших доработок с доработками других.
Одна из основных причин, почему я использую EDT/Git: это возможность быстро и удобно проводить рефакторинг конфликтного кода и форм при слиянии. Все слияния проводятся всегда со сравнением по базе, отбрасывая принятие решения по изменениям, не требующие внимания и допускающие автоматическое объединение и позволяющее максимально сконцентрироваться на местах конфликтов, где кроме человека пока ещё никто разобраться не может...
Итак...
Всё зависит от целей. Если Ваша цель просто версионировать свои изменения в личном проекте, то это может быть и общая папка в сети или локально на ПК, а может быть один из сервисов в интернете (та же ссылка на русском, описывающая все известные и популярные на этот момент системы хранения версий). Надо отметить что Российский Облачный сервис хранения репозиториев исходного кода GitFlic пока в этом списке отсутствует, однако контур CI/CD в "самохозяйственном" варианте заявлен... Есть и другие сервисы, которых википедия обошла стороной например Git Stack. Если у Вас командная разработка то лучше, если это будет надежный сервис, хотя это может быть так же общая папка в сети. Выбирать Вам, но для наших целей нам потребуется контур CI/CD. Это может быть Jenkins (как его настраивать и использовать лучше Литвиненко никто не рассказывал здесь) + любой из сервисов Git, поддерживающий веб обработчики. Это может быть что то совершенно своё, но нам будет нужно нечто, умеющее собирать при наступлении определенных условиях актуальные конфигурации/расширения из веток Git в приложение 1С: CF/CFU/CFE и уметь актуализировать ими тестовые и эталонные ИБ.
Мой выбор в своё время был сделан в пользу Gitlab, так как он умел работать с большими файлами без LFS (которую в 2016м году EDT не поддерживал), имел сервис обсуждения задач, имеет неплохой API и самое главное контур CI/CD. И всё это в одном флаконе.
Чтобы упростить рутинные операции по поддержке сборочной линии в актуальном состоянии и добавить сервис управления информационными базами было разработано решение "Управление сборкой" на базе СППР.
4 года назад, ещё ничего толком не понимания чем Gitflow отличается от Github но хорошо зная что такое разветвлённая разработка в 1С, насколько она сложна в обслуживании и поняв что система контроля версий Git полностью покрывает её требования было принято решение разрабатывать требования, которые описаны в этой статье, дабы забыть о разветвленной разработке как о страшном сне. В статье "многобукаф" отвечая просто на вопрос "сколько и какие ветки нужны": вначале ветка будет одна - master, некоторое время вам её будет достаточно, но это очень не долго. Если вы разрабатываете конфигурацию не с нуля, вам точно потребуется ветка с изменениями базовой конфигурации: standart или vendor. Как только начнется разработка потребуется ещё одна develop (разработка) - черновик.
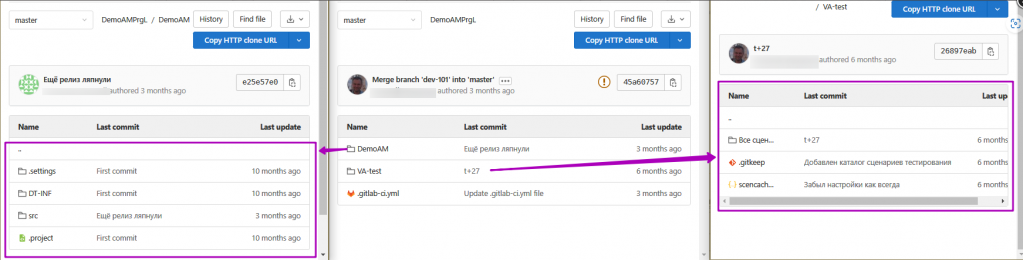
Обычно проекты мы инициализируем загрузкой типовой конфигурации в ветку master, пока идёт этап моделирования процессов актуализируем её, загружая от поставщика новые версии. Пример хранилища под новый проект:
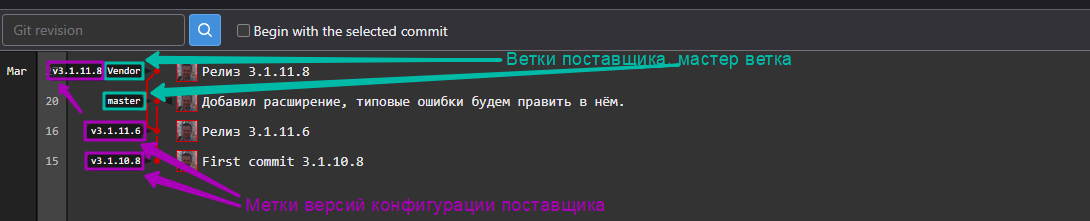
В приведенном выше примере ветка разработки отсутствует, её роль выполняет ветка master, так как на этапе моделирования выявляются ошибки в типовой конфигурации и их нужно либо исправлять, либо купировать, параллельно начиная дискуссии с поставщиком о методиках и способах их исправления. По мере увеличения активности разработчиков в проекте вам потребуются все ветки, которые описаны в этой статье.
Странный вопрос - скажут те, кто работал с хранилищем конфигурации 1С, конечно же конфигурацию проекта!
А вот и не так. В хранилище Git можно хранить многое:
- В папке проекта EDT - основную конфигурацию вашего проекта, а возможно в ещё одной ещё и второй проект.
- В папках проектов EDT расширения и внешних отчеты/обработки.
- В отдельной папке сценарные тесты и данные для тестов, они должны дополняться с каждой новой доработкой.
- Если документация в виде обычного текста, то её тоже можно хранить в Git. При проведении доработок можно изменять соответствующие разделы в документации, при слиянии они будут объединены. Но если документация в файлах doc или odt, то при слиянии веток будут конфликты и их устранить будет не просто, так как для Git это бинарные файлы.
- Чтобы обновлять тестовые и эталонные базы автоматически, без участия пользователя: по расписанию, при наступлении определенных событий, например по мере готовности нового функционала.
- Чтобы максимально быстро начать разработку или исправление ошибки на нужной эталонной или тестовой базе, взяв на себя длительные по времени операции.
- Чтобы запустить автоматизированное тестирование ветки доработки при оформлении запроса на слияние.
- Чтобы выгрузить, а возможно и загрузить новые версии на сервер заказчика.
- Чтобы каждое утро нового дня были готовы новые версии эталонных ИБ, готовые к загрузки и быстрой привязки к проекту EDT разработчиком. Так же смотри совет Как не тратить время в EDT на полной сборке? Точнее как её избежать.
Если никто не контролирует разработку, то все подряд. Но это не наш путь. У проекта, как и у любой нормальной семьи должны быть мама (функциональный архитектор) и папа (системный архитектор). И если вопросы о внешнем виде реализованного функционала принимает первый (либо бизнес - аналитик, которому делегировали полномочия ФА), то в тонкостях технической реализации и подтверждению её корректности разбираться второму. Ему же и принимать запросы на слияние в ветки версий и мастер ветку. Ему же проводить просмотр кода (CodeReview). При слиянии доработок, в идеале, конфликтов быть не должно, разработчик должен позаботиться, и слить свою ветку с веткой версии (develop) чтобы конфликтов не было. Но это допустимо, только если вся проектная команда работает на EDT, но это далеко не так, поэтому будут и конфликты, и фантомы. Об том, как быстро разрешать конфликты не прибегая к EDT при слиянии и про фантомы чуть позже в вопросе: Как сливать ветки без EDT?
По сути сборочный конвейер это пакетный файл, который будет исполнен командным процессором оболочки системы.
Для каждой ОС командный процессор свой. Для Windows это CMD или PowerShell, для Linux это dash или bash. Самое главное, чтобы эта оболочка могла запускать другие пакетные файлы и приложения и поддерживалась бегуном (runner's) той системы, на базе которой будет построен ваш контур CI/CD.
Помимо самих команд оболочки ОС настроечный файл содержит служебные команды и параметры конвейера, например, условия выполнения команд оболочки, формирования окружения и инициализации контейнера в котором будут исполняться команды и т.д.
Я постараюсь абстрагироваться от использования той или иной системы сборки, но расскажу что именно нужно будет в итоге сделать. чтобы получить те или иные действия.
Для примера условимся, что у нас есть тестовый контур функционирующий на сервере TEST-SERV под управлением ОС Linux где уcтановлен сервер 1С и сервер СУБД postgres. На этом же сервере запущен некий исполнитель команд, который должен в итоге сделать следующее:
Получить из Git последнюю версию проекта из ветки develop и обновить им тестовую базу TEST-SERV\Proto. При этом предполагаем, что в базе могут быть пользователи, работу которых нужно завершить.
Таким образом все действия в простейшем варианте можно разделить на:
- Установка блокировки работы пользователей в базе TEST-SERV\Proto и ожидание завершения работы.
Здесь можно использовать запуск приложения:
export DISPLAY=:99; /opt/1cv8/x86_64/8.3.21.1644/1cv8c ENTERPRISE /S TEST-SERV\\Proto /N UserName / P Password /UC UpdateDB /С "ЗавершитьРаботуПользователей, , , Сообщение=Блокировка установлена по причине обновления информационной базы, КодРазрешения=UpdateDB, ОжиданиеМин=2"
где UpdateDB - код разблокировки, 8.3.21.1644 каталог версии 1С предприятия. Предполагается, что прикладное решение использует БСП версии не ниже 3.1.5. И ранее интерактивно была хоть раз запущена вручную блокировка работы пользователей с указанием варианта COM или RAS. Для исполнения команды нужен виртуальный или реальный GUI команда export DISPLAY=:99; перенаправляет вывод на виртуальный дисплей Xvfb.
- Получение из Git в папке проекта EDT последней версии требуемой ветки
/home/user/git/GreatProject$git checkout develop
/home/user/git/GreatProject$git pull
Это лишь один из вариантов, предполагающий, что текущий каталог: /home/user/git/GreatProject$ - это корневой каталог проекта git, характерный признак корневого каталога проекта Git - наличие подкаталога .git
- Преобразование файлов проекта EDT в формат файлов конфигурации 1С XML
/home/user/git/GreatProject$ring edt workspace export --project MainPrj --workspace-location /tmp/ws --configuration-files /tmp/conf
Где MainPrj - папка, содержащая проект EDT (ключевые признаки каталога проекта вложенные каталоги .project, src, DT-INF) внутри проекта Git, /tmp/conf - каталог в который утилита разместит результирующие XML файлы конфигурации 1С.
- Загрузка новой конфигурации в тестовую базу
/opt/1cv8/x86_64/8.3.21.1644/ibcmd.exe infobase config import /tmp/conf --dbms=PostgreSQL --db-server=TEST-SRV --db-name=Proto --db-user=postgres --db-pwd=PG_PWD --user=UserName --password=Password
/opt/1cv8/x86_64/8.3.21.1644/ibcmd.exe infobase config apply --force --dbms=PostgreSQL --db-server=TEST-SRV --db-name=Proto --db-user=postgres --db-pwd=PG_PWD --user=UserName --password=Password
Где PG_PWD - пароль пользователя postgres, UserName и Password пароли пользователя с административными привилегиями в ИБ.
- Снятие блокировки пользователей
export DISPLAY=:99; /opt/1cv8/x86_64/8.3.21.1644/1cv8c ENTERPRISE /S TEST-SERV\\Proto /N UserName / P Password /UC UpdateDB /С "РазрешитьРаботуПользователей"
Некоторые задачи из этого списка можно исполнять параллельно, тем самым сэкономить время сборки, например пока устанавливается блокировка в п.1 Можно смело исполнять п. 2,3 но к моменту загрузки новых файлов в конфигурацию в п 4. п.1 должен уже закончится.
Естественно нужно не забыть удалить временные файлы и на этом можно было бы закончить, но по факту такая сборка не будет очень удачным решением и вот почему - читаем дальше.
У нас в проектах сборочным конвейером заведует СППР с установленным модулем "Управление сборкой" шаблон его в СППР создаётся один раз, иногда правится, конечно же, в процессе работы. Но в основном, подстановкой информации какие ИБ для каких веток собирать и тестировать происходит автоматически.
Ранее упоминалось про CFU. Понадобится это вам, когда ваш проект пройдёт точку миграции, и размер ИБ резко увеличится за пару месяцев с 5 Гб до 55 Гб, а то и выше. Каждое обновление через CF станет очень длительным. Надо отметить, если у вас база будет максимум 5 Гб с учётом миграции и работе пользователей в первые несколько месяцев, возможно всё, что написано ниже будет не актуально, речь идёт именно о тяжёлых ИБ: УХ, ERP-УХ, ERP. Если вы ведёте разработку в расширениях, то, возможно, эти рекомендации Вам так же не понадобятся. Почему? Весь камень преткновения в объёме сборки и обновления базы.
- Как работает EDT? Каждый раз, обновляя ИБ, привязанную к проекту, он инкрементально догружает изменённые файлы, поэтом если требуется реструктуризация, то реструктуризируется только то что изменено, и это не долго. Если вы решите пересобрать конфигурацию целиком, а иначе иногда по другому и не получается, при обновлении конфигурации ИБ вы получите реструктуризацию всех таблиц. Даже тех, которые ни разу в EDT не изменяли. Происходит это потому, что в исходных файлах EDT хранит идентификатор ОМД (на картинке ниже он левее идентификатора версии), но не хранит идентификатор версии ОМД. На изображении ниже структура файла ConfigDumpInfo.xml, вокруг которого "пляшет" конфигуратор принимая решение о необходимости реструктуризации ИБ:
 ,
,
и поэтому каждый раз, когда при сборке конфигурации вы записываете, к примеру файл регистра бухгалтерии "src/AccountingRegisters/МСФО/МСФО.mdo" даже если не изменяя его структуру, вы все равно будете проходить реструктуризацию этой таблицы. Она будет пересоздана, а существующие элементы скопируются из старой таблицы в новую. Время копирования будет напрямую зависеть от размера таблицы, на создания её и индексов и копирования в неё данных. Потому что каждый раз номер версии для этого ОМД в ConfigDumpInfo будет новый. Можете сравнить, воспользовавшись местом хранения текущего CDI в метаданных проекта. Поэтому, когда вы собираете ИБ целиком, вы обновляете все идентификаторы ConfigVersion. И именно по этому все таблицы ИБ будут созданы заново. - В сборочной линии нет возможности собирать инкрементально, этот секрет хранится в EDT за 7ю печатями под грифом секретно. Возможно кто то и разгадал его, но не делится :) Поэтому каждый раз, как бы мы не пытались накатить новую версию на нашу тестовую базу ConfigVersion будут всегда новые после сборки конфигурации из файлов XML формата 1С. И поэтому, ваша огромная база, более 55 гигабайт, будет реструктуризироваться полностью. После 3х месяцев работы пользователей с окончания 2х месячной миграции в системе длительность обновления при реструктуризации начала доходить до 2,5 часов, что естественно ни в какие ворота не лезло никак. А учитывая, что все тестовые базы были клоны рабочей общее время сборки стало очень большим 4 часа и более.
- Выход: для обновления тестовых и эталонных ИБ использовать CFU. Поэтому в отличии от примера в предыдущего раздела полученные на 3м шаге XML 1C должны загрузиться в новую пустую файловую базу (уже практически доказано, что файловая база собирается быстрее всего). Из которой нужно будет сделать файл поставки относительно первоначальной конфигурации. Для этого конфигурации всех тестовых баз всегда держим "на замке", в таком случае, конфигурацию можно выгрузить и сохранить как основу, для создания CFU, т.е. вам не нужно хранить предыдущую версию CF, которой создавалась ИБ. Таким образом, сначала из XML собирается абсолютно пустая файловая база, из которой потом создаются файлы поставки: CFU, а в качестве базового релиза подставляется та самая предыдущая конфигурация, которую нужно отдельно собрать. Таким образом мы в CFU имеем только изменения метаданных, и ConfigVersion изменится только у изменившихся ОМД. Далее в пакетном режиме CFU накатывается на тестовую базу, и, реструктуризации, возможно, не будет совсем, если поменялись, к примеру, только модули. Это сократило в моём случае время сборки проекта до стабильных 58 минут, о которых упоминал выше. Понятно что после каждого обновления версии от поставщика, время сборки будет выше, так как объём изменений и рефакторинга будет естественно больше и обновление будет дольше. Это так же важно, если CF придётся передавать в бегун гитлаба, который физически на другом ПК. Прогрузить через артефакты 3 МБ CFU гораздо быстрее, чем 800 Мб CF. Нам, например, заказчик "навязал" тестовый контур на процессоре с тактовой частотой 2,4 Ггц. Этап сборки CF на этом процессоре длился 48 минут, а конвертация EDT --> 1C XML 12 минут! Мне пришлось буквально выклянчать у своего шефа отдельную ВМ с нормальным процессором 4,4 Ггц, где эта же операция проходила за 23 минуты, а конвертация в 1С XML из за большого количества ядер и того 4 минуты! Почувствуйте разницу. Но платой за это была передача артефактов через интернет, и если CFU выгружались и скачивались быстро, то начальный CF в 800 Мб скачивался через интранет (ВПН) со скоростью 100Мбит/сек и это был предел, но всё равно получалось быстрее, чем собирать всё полностью на "тормозном" CPU. По факту, в одной сборочной линии отрабатывали 3 бегуна. Один запускали из под обычным пользователем, для блокировки/разблокировки ИБ, увы нужен GUI. Получение СF тестовой базы, обновление тестовой базы через CFU на том же ПК, но под повышенными привилегиями из под учётной записи SYSTEM и без GUI, и третий отрабатывал на получение и конвертацию XML из Git, сборку CF/получение CFU совершенно на другой площадке.
- Одним из неприятных моментов могут оказаться платформенные ошибки, которые мне не позволяли обновлять готовыми CFU тестовые базы за один проход. Среди них была ошибка обновления ИБ если сервер находится в режиме отладки по HTTP, но мы не могли не использовать отладку. Для этого пришлось разнести на разные этапы обновление самой конфигурации и обновление конфигурации ИБ, причём на обновление конфигурации сделать 2 попытки, потому что с первой не всегда это проходило. Возможно последует резонный вопрос: "Почему не могли отключить отладку в тестовом контуре? по HTTP?" Но это предмет следующей темы.
- Очень сильно могут омрачить жизнь USB лицензии проброшенные через USB AnyWhere в тестовый контур. В моём случае процентов 20 упавших сборок, по вине недоступности физического ключа и отсутствия лицензии. Пользуйтесь программными лицензиями, это решает проблему с доступностью лицензий раз и навсегда.
- Немаловажным фактором являются контрольные точки ВМ тестового контура. В процессе их создания ВМ может так "колбасить" что будут обрывы сетевых соединений, как результат проблемы со скачиванием и загрузкой файлов, которые так же могут приводить к ошибкам сборки.
Потому, что одной из задач в проектах всегда преследовалось максимально быстрая реакция на расследование причин ошибки. Требовалось воспроизвести в отладчике проблемную ситуацию на уже готовой базе в тестовом контуре, при этом отладчик и разработчик физически был подключён к тестовому контуру по ВПН, и производил удалённую отладку ИБ. Около 70% случаев мелких ляпов удавалось отсеять и исправить даже не копируя ИБ себе. EDT, ничего кроме HTTP протокола не поддерживает. Процесс примерно происходил так, в ошибке всегда регистрировалась версия релиза из продуктивной базы в 99% ошибка воспроизводилась в последней копии, разработчик извлекал ветку версии на фиксации, сразу после слияния в master и подключал сценарий удалённой отладки:
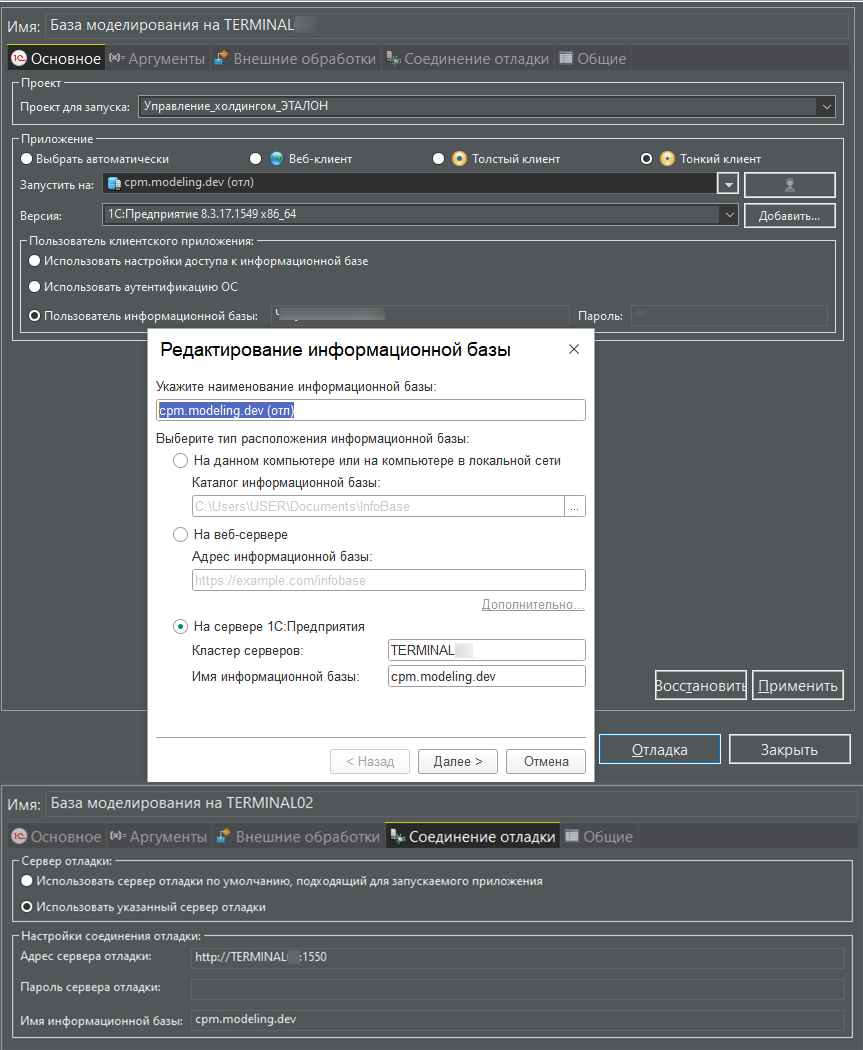
в момент, когда EDT предлагал обновить удалённую базу (так как по его данным она не была синхронизирована с проектом), но мы то точно знали, что конфигурация ИБ соответствует этому коммиту, поэтому отказывались от сборки и сразу начинали отладку. Надо отметить, что возможность запуска отладки без сборки поломали в релизе 2023.3.X и восстановили только в 2024.1.X. Перестала работать отладка приложения на удаленной ИБ · Issue #1434 · 1C-Company/1c-edt-issues
По умолчанию, каждая фиксация в ветку будет сопровождаться началом сборочного конвейера. Так работают большинство систем хранения версий, при фиксации генерируется событие, которое вызывает API сборочного конвейера и начинается сборка очередной версии. Для веток технических проектов это нормально, обычно один технический проект = один разработчик, можно и больше, но они друг другу в одной ветке явно мешают, так как им периодически требуется сливать фиксации друг друга к себе. Для веток версий и тестирования технология, когда сборка начиналась при каждом помещении, мы пришли к выводу, что это не всегда удобно, особенно, когда много разработчиков (более 3х) возникает часто ситуация, что в течения дня каждый фиксирует исправления ошибок, и база постоянно собирается (в моём случае быстрее, чем за 58 минут собрать не получалось). Её просто некогда тестировать. Пришли в выводу, что запуск сборки по расписанию - самое то. В gitlab есть настройка запуска сборочных линий по расписанию... Я думаю в других системах контроля версий и контуров CI/CD есть аналогичные механизмы. Два раза в сутки в обед и после 18 часов для ветки тестирования, и раз в сутки рано утром часов в пять до начала рабочего дня для ветки версии - вполне достаточно. Если нужно "экстренно" собрать - всегда можно это сделать запуск сборки вручную.
В Gitlab, чтобы задания в сборочной линии стартовали не каждый раз при фиксации в удалённом хранилище Git, а только когда требуется достаточно в секцию only прописать следующее:
only:
changes:
# позволяет заданию при событии push стартовать, только если в каталоге были какие либо изменения.
# нужно отметить что это условие работает исключительно для CI_PIPELINE_SOURCE == push или merge-request
- cpm/src/**/*
refs:
- develop
variables:
# добавление такого условия позволит включать задание в сборочную линию только если запуск
# произведён из веб интерфейса (вручную) или по расписанию.
- $CI_PIPELINE_SOURCE == 'web' || $CI_PIPELINE_SOURCE == 'schedule'
В других системах сборки, 100% есть аналогичные настройки.
Для тестирования веток предлагается использовать событие merge-request pipelines (старое название - detached pipelines). Под тестированием будем понимать запуск любых тестов: АПК, Vanessa Automation, Unit тесты результатом отработки которых должно быть полное отсутствие ошибок и файл с результатами теста в формате jUnit, именно под него заточена логика CI/CD Gitlab. Логика запуска может основываться на именах и шаблонах имён веток. Например, каждый раз когда сливаем запрос в ветку dev/* можно запускать тест АПК на проверку качества кода, а сам запрос на слияние настроить на автоматическое слияние, если detached pipelines завершено без ошибок. Каждый раз, когда в Gitlab создаётся запрос на слияние, например, мы создали запрос на слияние ветки BF/00-00000180 в ветку develop от последней фиксации (commit) указателя ветки стартует detached pipeline:

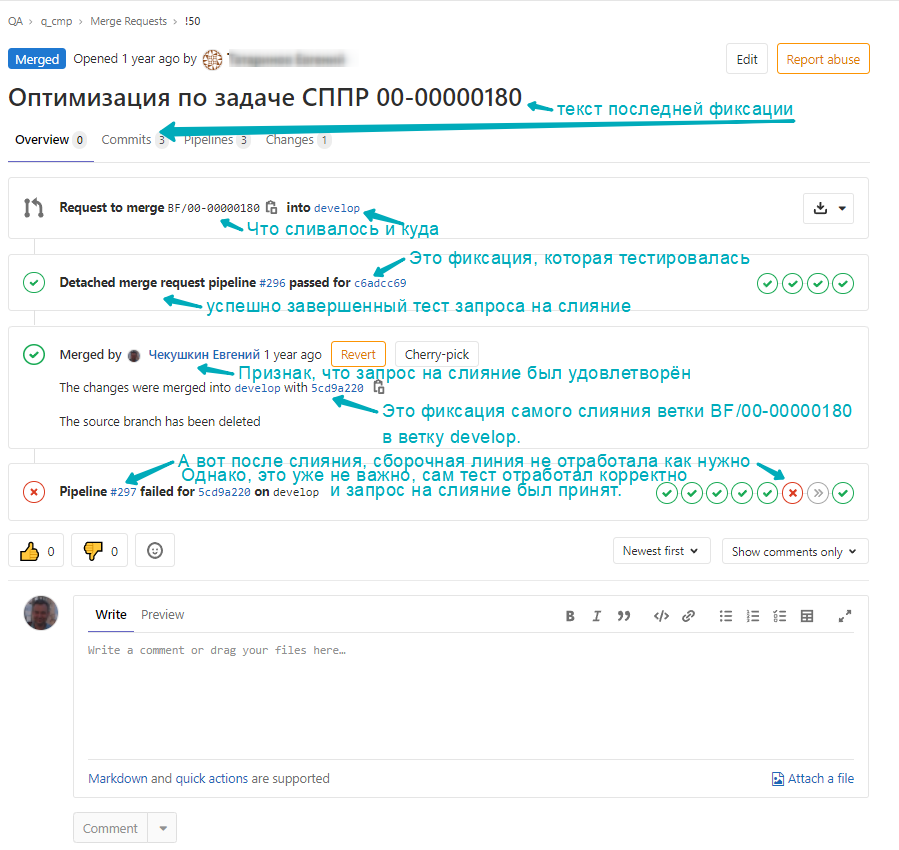
Для того, чтобы определённые задания каких либо этапов запускали тесты при создании запросов на слияние в условия задания необходимо добавить следующее, такие условия должны быть для всех заданий, включаемых в тестирование:
only:
refs:
# для отвязанных сборочных линий всегда вместо ветки служебное значение: merge_requests
- merge_requests
variables:
# такое задание будет включаться только тогда, когда ветка в которую был оформлен запрос
# на слияние в ветку develop
- $CI_MERGE_REQUEST_TARGET_BRANCH_NAME == 'develop'
# имя самой ветки. которая сливается, если нужно хранится в другой переменной:
# $CI_MERGE_REQUEST_SOURCE_BRANCH_NAME, и в нашем примере её значение будет 'BF/00-00000180'
Несколько слов хочется сказать о самом использовании конфигурации АПК для тестирования качества кода. Основная проблема АПК - она однопоточная, кроме этого она использует сервис проверки конфигурации средствами конфигуратора. И это ещё одно из узких мест в проверке АПК, длительность этой проверки типовой конфигурации УХ длится не много не мало чуть более часа. Были случаи, когда алгоритмы АПК уже все проверили, и происходило ожидание тестов [расширенной] платформенной проверки. И это только одно тестирование, а конфигурацию для тестирования нужно тоже собрать, накатить на тестовую ИБ на это тоже уйдёт не менее 35 минут. Суть тестирования в АПК всегда сводится к одному - первый раз вы тестируете все подряд и всё это помещается в исключения. Длится это не много ни мало 12 часов. Это на топовом процессоре i Core7 4,3 ГГц с SSD NVRAM и "вагоном" памяти. После этого вы повторно тестируете ИБ, которая обязательно должна быть обновлена через CFU (вот где оно нам опять потребовалась!) и в этот раз будут тестироваться только изменения, однако типовая конфигурация работает так, что первым делом, она начинает выгружать все файлы из только собранной ИБ снова в XML. О ужас. И на это тратится опять же минут эдак 30-40, и это при условии, что мы только что из этих файлов конфигурацию собирали. Чтобы не тратить ещё полчаса мы АПК немного подкрутили:
 Кому интересно - ссылки на загрузку CFU АПК есть. (как из неё получить полноценную конфигурацию читай ниже). Мы заставили смотреть АПК в определённый каталог, куда подкладывали уже готовые для анализа файлы выгрузки конфигурации 1С (на самом деле это только что сконвертированные из Git, из формата EDT файлы, но АПК их принимает за только что выгруженные из конфигурации). В итоге, нам удалось минимизировать время сборки и тестирования до 105 - 120 минут, это при условии, что количество изменённых ОМД по отношению к предыдущему варианту не большое: пару справочников, их формы, документ. Поскольку тестирование АПК мы реализовывали пилотное, включили все проверки, за исключением некоторых, сразу отключили правила проверки локализации, так как конфигурация системы была только для русскоязычных пользователей. Количество ошибок орфографии, которые делают разработчики, как выяснилось просто безумное множество: в макетах, в тексте модулей, в формах, в наименованиях реквизитов. В итоге, для снижения времени тестирования мы полностью отключили орфографию, и оставили только стандартные проверки без проверок по локализации:
Кому интересно - ссылки на загрузку CFU АПК есть. (как из неё получить полноценную конфигурацию читай ниже). Мы заставили смотреть АПК в определённый каталог, куда подкладывали уже готовые для анализа файлы выгрузки конфигурации 1С (на самом деле это только что сконвертированные из Git, из формата EDT файлы, но АПК их принимает за только что выгруженные из конфигурации). В итоге, нам удалось минимизировать время сборки и тестирования до 105 - 120 минут, это при условии, что количество изменённых ОМД по отношению к предыдущему варианту не большое: пару справочников, их формы, документ. Поскольку тестирование АПК мы реализовывали пилотное, включили все проверки, за исключением некоторых, сразу отключили правила проверки локализации, так как конфигурация системы была только для русскоязычных пользователей. Количество ошибок орфографии, которые делают разработчики, как выяснилось просто безумное множество: в макетах, в тексте модулей, в формах, в наименованиях реквизитов. В итоге, для снижения времени тестирования мы полностью отключили орфографию, и оставили только стандартные проверки без проверок по локализации:
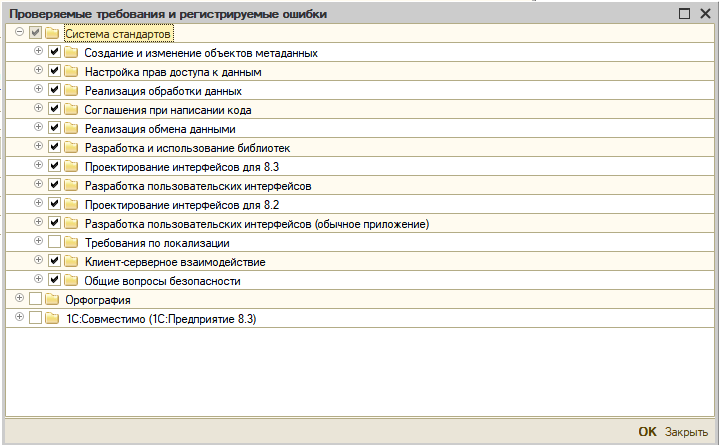
Если по честному, код после исполнения требований АПК становится чище, процедуры поделены по штатным областям, нет лишнего, и выглядит более читаемым, но критичных с точки зрения оптимизаций и полезных проверок в нём мало. Из полезного можно отметить следующие:
- Разыменование составных полей в запросах. Важно для оптимального исполнения запросов.
- Использование конструкции ОБЪЕДИНИТЬ в запросе, однако оно срабатывает всегда, даже тогда, когда не нужно. Оптимальное исполнение запросов.
- Конструкция "Попытка...Исключение...КонецПопытки" не содержит кода в исключении. Снижение рисков получения трудно расследуемого сообщения "В данной транзакции уже происходили ошибки".
- Нарушена схема работы с транзакциями: для вызова "НачатьТранзакцию()" отсутствует парный вызов "ОтменитьТранзакцию()". Корректная работа с транзакциями, то же что и предыдущее
- Нарушена схема работы с транзакциями: между "Исключение" и "ОтменитьТранзакцию()" есть исполняемый код. Корректная работа с транзакциями.
- Нарушена схема работы с транзакциями: не найден оператор "Попытка" после вызова "НачатьТранзакцию()"
- Запрос в цикле. Оптимальное исполнение кода, однако это уже имеет делать проверка, встроенная в EDT, и делает это на лету.
- Отсутствие стандартных областей в коде модуля, как следствие отсутствие областей ПИ, СПИ и СПФ. Исполнение этого требования и двух ниже позволяет снизить риски при обновлениях системы новыми релизами от поставщика, гарантируя хоть немного наличие используемых функций на тех же местах, где они и были.
- Некорректные вызовы библиотечных функций. Вызов из секции СПИ и СПФ функций и процедур чужой библиотеки.
- Вызовы устаревших функций библиотек.
Немного вспомним методику, как проверяет в АПК код команда ERP - они ставят исходную конфигурацию на чистое тестирование и помещают всё в исключения (если УХ -12 часов, то наверное ERP все 20), как ответили на мой вопрос на вебинаре - "мы не торопимся" на выходе, когда функционал протестирован отправляют в тестирование АПК повторно, здесь, видимо, проводится сканирование только изменённых объектов, и, в итоге, получается некий пул замечаний.
В проектной деятельности всё по другому, у нас нет 12 и более часов для первичного тестирования, к примеру ветки исправления ошибки. На исправление критичных ошибок отводится, как правило не более одного рабочего дня, т.е. если выкинуть время подтверждения ошибки консультантами, то разработчику остаётся максимум 4 часа на исправление критичной ошибки. Поэтому мы тестировали так:
- Первоначальное тестирование в АПК производилось только исходной ветки версии (dev/*), при этом всё что нашлось помещалось в исключения.
- Ветки технических проектов стартовали от dev/*, подавляющее чиcло исправлений ошибок: 99% стартовали оттуда же и сливались в итоге в ветку версии.
- АПК, проверяя фиксацию из запроса на слияние ветки технического проекта, допустим это ветка TP/00-00000255, когда видит новые или изменённые объекты, например, созданный справочник или новую процедуру в модуле существующего справочника, которую он ранее не проверял - этих объектов точно нет в исключениях. АПК добавляет в своей структуре метаданных новые объекты и фиксирует замечания по ним если они выявлены.
- Здесь важно, если критичные замечания, которые нужно исправлять, быстренько зарегистрировать их из АПК в СППР. Это можно сделать только в ручную. Автоматически регистрировать ошибки из АПК в СППР я так и не рискнула. АПК - тот ещё спамер и ошибки в СППР просто в мгновения ока вырастут в астрономическом числе... Из найденных ошибок, несмотря что ранее проверялось и попало уже в исключения некоторые появлялись повторно, почему это происходит - предмет отдельной беседы.
- В другой ветке, допустим это исправление какой-то ошибки BF/00-00001024, изменений из ветки TP/00-00000255 нет, и после обновления тестируемой конфигурации все несуществующие объекты АПК посчитает, что их просто удалили, и так же удалит замечания, связанные с ними. Но у нас то в СППР, по ветке TP/00-00000255 всё что нужно уже зарегистрировано, поэтому пусть удаляет. А новое, что появилось в ветке BF/00-00001024 будет проверено и зафиксировано. Важно то, что ошибки добавленные в исключения более живучи, и даже если будет удалён связанный с исключением объект, в исключении он остаётся (надо отметить не все исключения так работают, несколько важных правил, включая (Недопустимый вызов служебной процедуры или функции другой подсистемы (277), Недопустимый вызов служебного программного интерфейса (278)) будут как птица феникс появляться каждый раз, так как для них анализируется целиком изменённый модуль), и если, к примеру снова проверить ветку TP/00-00000255 (для этого достаточно что то поместить в ветку: так как запрос на слияние уже есть, новый detached pipe запустится автоматом). Большая часть требований, которую вы добавили в исключения в прошлый раз уже не появится при новой проверке.
- Таким образом, когда все зарегистрированные АПК ошибки будут исправлены в ветке, после очередной фиксации АПК отметит, что выявленные проблемы устранены, либо не выявит их, если до этого он тестировал другую ветку. Запрос на слияние, если его маркировали как "Merge when pipeline succeeds"
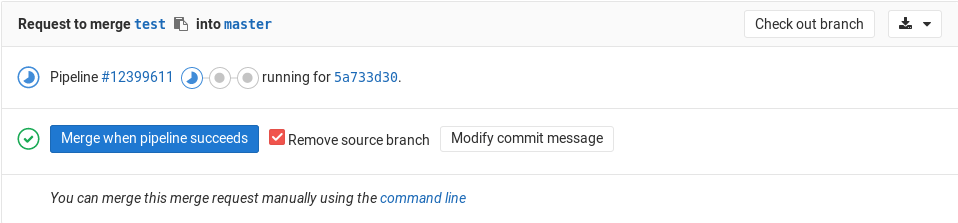 будет удовлетворён (слит).
будет удовлетворён (слит).
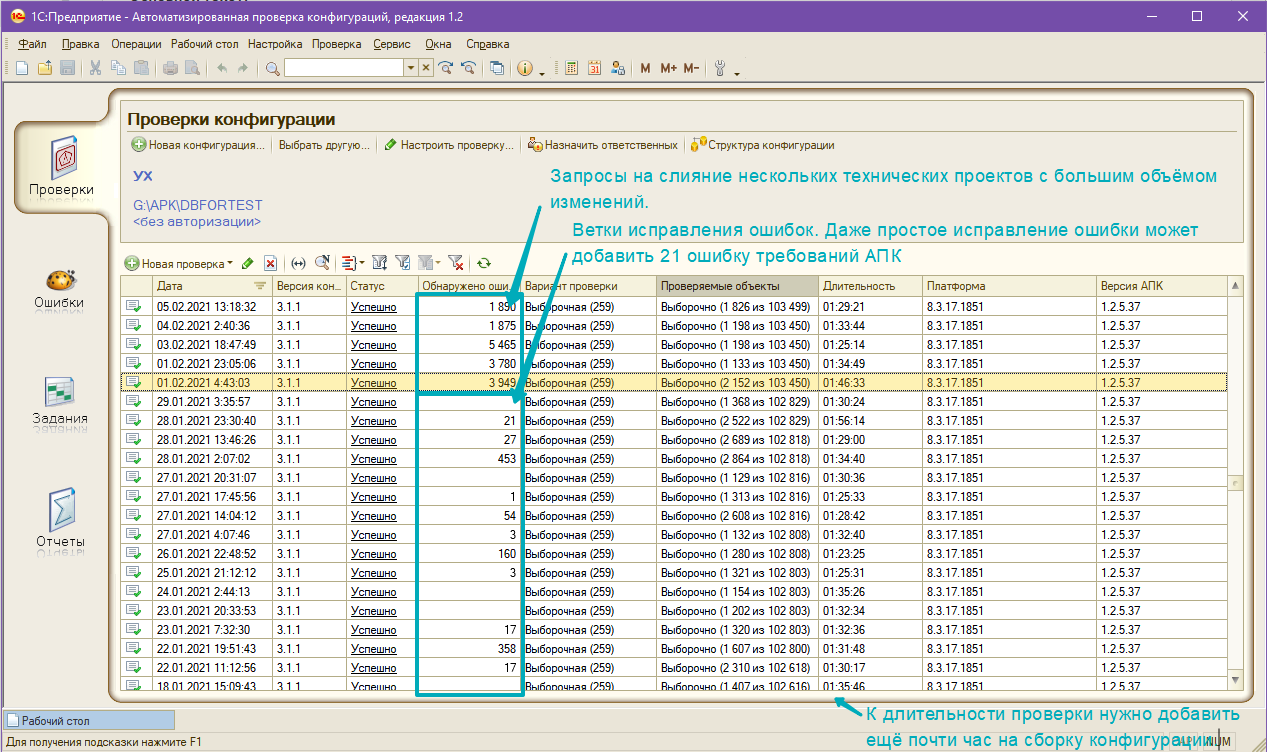
Немного статистики проверки конфигурации УХ в процессе разработки:
1С:Предприятие не умеет программно выставлять коды ошибок. отличные от 0, поэтому, чтобы "уронить" тестирование, если ошибки были, нужно полученный файл с замечаниями в формате XML проверить на наличие ключевой фразы:
find /C "Проверка АПК не выявила ошибок" %FOLDER_APK_SETTINGS%\junit.apk.xml
Если ошибок не было, строка выполнится с exit code 0 и тестирование таким образом будет отмечено как успешное (сигнал для менеджера запросов на слияние CI/CD удовлетворить (принять) запрос на слияние), в противном случае выполнение будет неуспешным.
При успешной проверке АПК в jUnit будет только один успешный кейс. При не успешной все кейсы будут неуспешными - ровно столько, сколько проблем будет найдено.
Важный момент, файл в формате jUnit, который умеет генерировать АПК, который в качестве отчёта может использовать CD/CI не хранится в CI/CD вечно. Длительность его хранения ограничена общими правилами длительности хранения артефактов сборки, и если срок хранения прошёл - (по умолчанию 1 месяц) то отчет будет удалён.
Настройку длительности хранения артефактов конкретного задания можно изменить, указав в секции artifacts модификатор expire_in, например:
artifacts:
# Сколько хранить артефакты
expire_in: 2 week
# Попытка сохранения артифактов будет предпринята в любом случае, удачно или задание отработало или нет.
# нам так и нужно, значение по умолчанию on_success
when: always
# Указываем какие артифакты нужно сохранить
# К относительному пути добавляется каталог клонированного проекта из git
paths:
- logs\.cfu_make.txt
- logs\.build_log.txt
- tempdb\update.cf*
# А вот артифакты из секции reports будут использоваться как отчёт.
# Скачать такие артефакты штатными методами не получится. Если они нужны
# ещё где-то, то их нужно добавить и в секции paths: см. выше и в секции reports:
reports:
junit:
- jUnit/*.xml
Так отображаются тесты АПК в CI/CD Gitlab внутри сборочной линии:
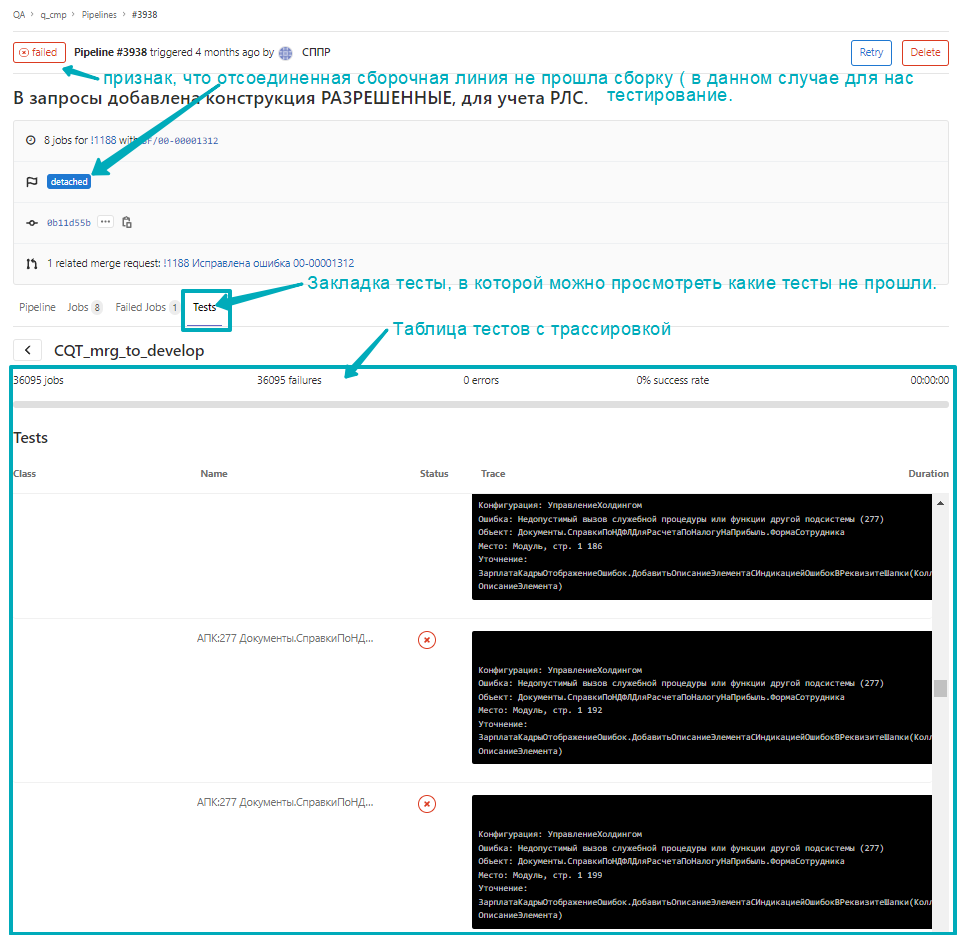
и внутри запроса на слияние:
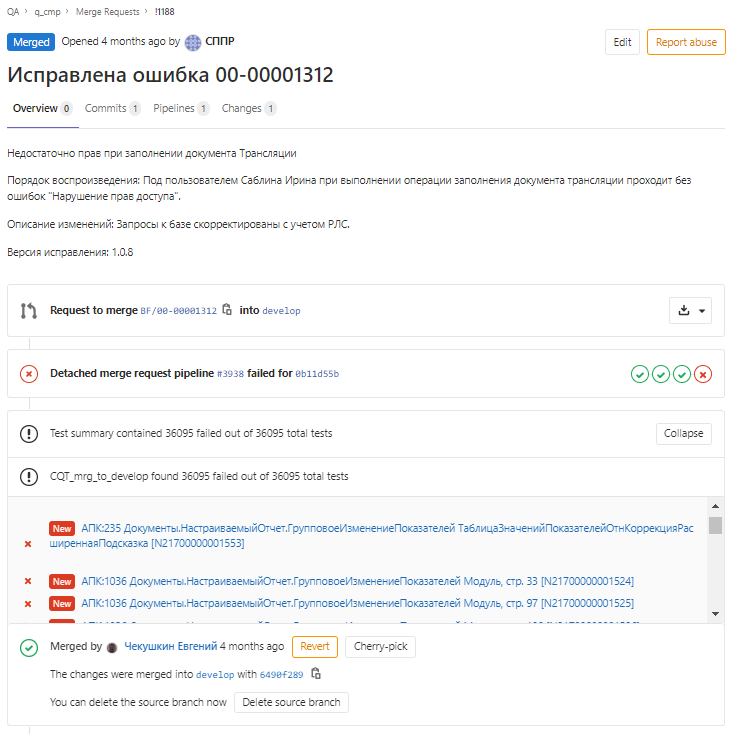
щёлкнув по гиперссылке, можно посмотреть детали каждого теста... В этом примере найденных ошибок было более 36 тыс, это накопилось за 4 месяца в версии, на базе релиза 3.1.1.15, с момента как перестали исправлять ошибки АПК, так как использование АПК в проекте было пилотным. Нужно отметить, что ни с одним участком кода, которые проверяли в АПК и делали при этом code review, не было проблем при обновлении на следующий релиз поставщика с пропуском 14 изменений в третей цифре релиза УХ 3.1.1.15 --> 3.1.15.4. Возможно это и совпадение, но я склонен думать, что нет.
Пример сборочной линии с использованием АПК для линий в запроса на слияние. Тексты скриптов на CMD.
Во вложениях есть CFU конфигурации, с изменениями описанными выше, меня немного поругали, когда я выложила полную CF (была доступна вплоть до 09.04.2023) и вежливо попросили CF убрать. Я человек законопослушный, поэтому специально сделала CFU. Если у вас есть права на скачивание АПК с https://releases.1c.ru/version_files?nick=ACC&ver=1.2.5.37 то вы сможете установить новую пустую конфигурацию 1.2.5.37, применить к установленной скачанный CFU. Используйте обычный режим обновления конфигурации и укажите в качестве обновления это CFU. Ни в коем случае не обновляйте этой CFU сразу вашу рабочую базу, так как при этом конфигурация поставщика 1.2.5.37 будет подменена, и следующие обновления от АПК лягут неверно. Далее сохраните полученную конфигурацию в файл и сравнением объединением из этой конфигурации сможете перенести наработки к себе в рабочую базу. Как вариант, можете накатить CFU сразу куда хотите (если релиз поставщика в ней будет 1.2.5.37) потом просто заместите релиз поставщика в вашей базе.
В целом же, рекомендую взглянуть на последний релиз АПК, 1.2.7.22(39) в нём заявлена новая функциональность:
- Для разнообразия вариантов источника проверки конфигурации реализована проверка конфигураций в формате проекта EDT (Enterprise Development Tools).
Возможно, моя доработка уже более не актуальна, если коллеги из ИЖТИСИ научились корректно выявлять различия от предыдущей проверки и будут проверяться только изменения. У меня влёт не получилось настроить, возникли какие то проблемы с запуском конвертации.
В отличие от АПК Vanessa Automation в файле jUnit хранит как успешно выполненные тесты так и неуспешные:
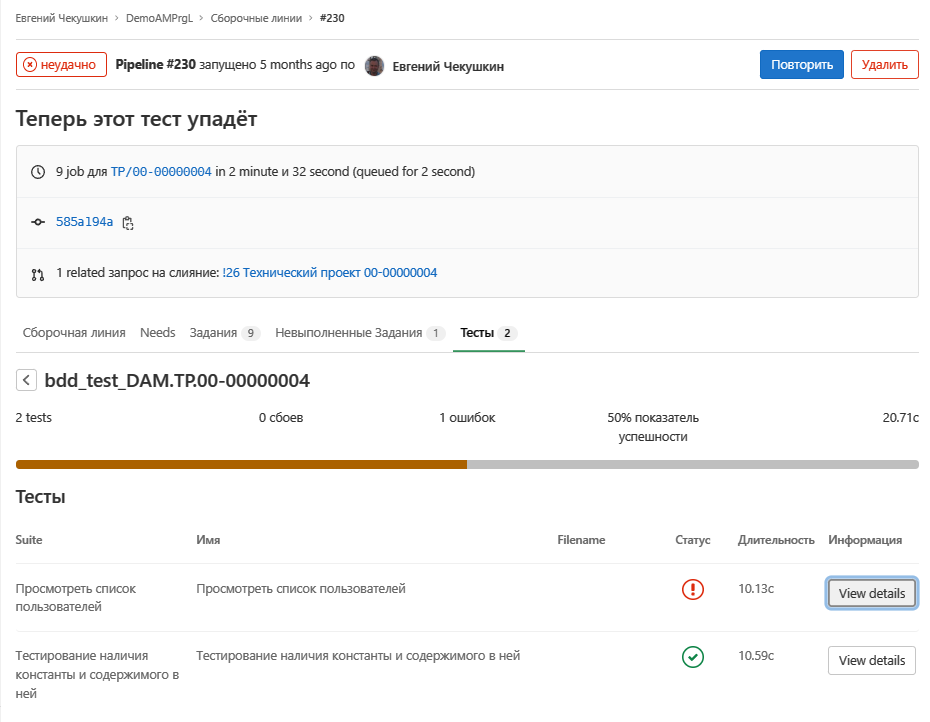
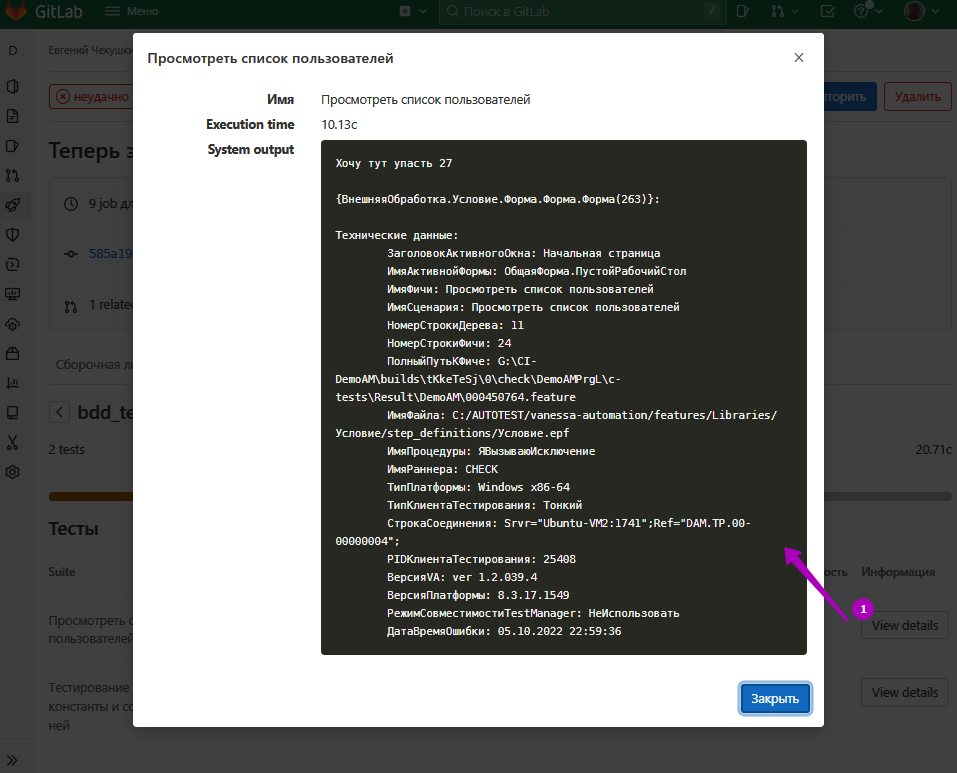
Так же можно посмотреть детали упавшего теста:
Пример сборочной линии с запусками тестирования Vanessa Automation
Сами тесты рекомендуется хранить рядом с проектом EDT в соседней папке:

Ни для кого не секрет, что EDT это всё же сравнительно молодой продукт, с массой плюсов и не меньшей массой минусов. Решение использовать его в работе или нет принимает каждый сам. Я его использую с 2016 года в работе и нет планов отказаться от его использования в будущем, даже с учётом тех больших проблем, которые в нём ещё пока остались:
- Безобразно работает отладка. В некоторых случаях без каких либо видимых причин, скорость шага отладки падает до 20 секунд на строку. В некоторых случаях, в этом виноваты тяжёлые формы с несколькими дин списками, у которых в качестве источника произвольный "многоэтажный" запрос. В новых версиях начиная с 2023.3.6 отладка значительно оптимизирована. не забывайте сворачивать не нужные переменные в инспекторе значений и будет шагать вполне нормально. Так же можно отключить inline отладку (которая выводит типы и значения переменных рядом с текстом). Она полезна только тогда, когда на одной из точек прерывания видны значения переменных и можно отправить скрин разработчику, указав ему - где его неправда.
- СКД - работать не возможно если в пакете больше одного запроса или сложные соединения в одном запросе.
- Медленная работа редактора запросов (не говорю про конструктор запросов) если пакет запросов очень большой
- Длительный старт, длительные операции импорта конфигурации в проект и полная сборка проекта. Эту проблему немного смягчит долгожданная полноценная поддержка автономного сервера, обещанная в ред. EDT 2023. Увы, включительно по актуальный релиз 2024.1.3 поддерживается только файловая версия автономного сервера.
- Очень большие аппетиты по оборудованию, особенно для работы с большими конфигурациями. Процессор Core i7 и выше, доступная память в 32Гб и выше, SSD > 600 Мб/с.
- Ситуации, когда изменения внесенные в проект EDT не попадают в связанную с проектом ИБ.
Не могу отметить, что проблему переключения между ветками с большим различием (чтобы не было длительной вторичной сборки) в ред. 2021 таки победили. Механизм сохранения слепков метаданных реально работает. Теперь, если правильно переключаться на другие ветки например на ветку поставщика, и обратно уже не нужно ждать по часу сборки вторичных данных для больших конфигурации класса ERP.
Однако, выше перечисленные проблемы отпугивают разработчиков от EDT, и сейчас очень много сильных разработчиков, которые даже не смотрят в его сторону. Игнорировать этот факт нельзя. Однако, выгоды от командной разработки в Git, возможности сравнения и объединения проектов, веток, возможности поиска в EDT просто потрясающие. От них невозможно отказаться в проектах, и приходится как то давать возможность разработчикам примкнуть к проекту на конфигураторе. Вроде всё просто - дай разработчику исходную конфигурацию, дай задачу и обеспечь результат работы выгрузить в Git. На словах всё выглядит достаточно просто, да и опыты "на кошках" проходят успешно. В реальности, после полугода работы проектной команды в EDT, в конфигурации накапливается много новых ОМД, и реквизитов, добавленных в существующие ОМД в EDT, которые имеют разное представление если бы эти объекты создали в конфигураторе, а затем сконвертировали в формат EDT. Выражается это примерно так, что когда разработчик, который взял конфигурацию (попросту ИБ), в которой более 1000 новых ОМД и новых реквизитов, было создано в EDT, обратный их импорт в проект EDT будет очень неожиданным. Для каждого такого ОМД будут созданы стандартные реквизиты, и некоторые параметры реквизитов по умолчанию, например минимальное максимальное значение для числовых полей и т.д. В структуре объектов XML EDT они отсутствуют, но если собранную из таких объектов конфигурацию импортировать в проект, то вы будете приятно удивлены, что все эти стандартные реквизиты появятся у вас в Git. Т.е. разработчик в конфигурации просто поправил несколько модулей и больше ничего не трогал, конвертируем его конфигурацию в проект, загружаем изменения и получаем в довесок ещё 1000 > изменённых файлов структуры: mdo, Forms, dss. Вроде бы ничего но "мусорные изменения" мешают делать code review, ты как будто ищешь иголку в стоге сена. Мы подошли к больной теме "Фантомных изменений". В итоге было найдено решение, позволяющее отделять "котлеты от мух". Каждого разработчика прежде чем что то делать в полученной ИБ, прошу сделать "первичное помещение" (запустить пакетный файл. которым разработчик помещает свои изменения в Git) в котором я получаю коммит чистых фантомов, далее разработчик помещает свои изменения, при этом в фиксации присутствуют уже только реально изменённые объекты. Когда принимаем разработку, я просто делаю revert коммита "первичного помещения" прямо в Gitlab. Если повезло - то всё проходит без конфликтов. Процент везения где то около 80%. 17% те случаи, когда revert приходится делать в командной строке, и 3% когда изменений много (причин тут может быть много) и приходится отменять revert и сливать изменения в EDT, совместно с разработчиком, выпытывая, какие именно он объекты изменял. 17% относятся на случаи когда, например, разработчик в процессе реализации задачи например переименовал представление стандартного реквизита, или добавил границы мин/макс для какого то числового реквизита, который был добавлен в EDT. Вот здесь как раз и будет конфликт. Можно конечно совсем аккуратно в EDT слить изменения в редакторе объединения, а можно просто целиком взять файл mdo от разработчика. Ну будет помимо полноправного одного реквизита со значением min/max ещё и остальные несколько со значением Undefined. В дереве Git это выглядит так:
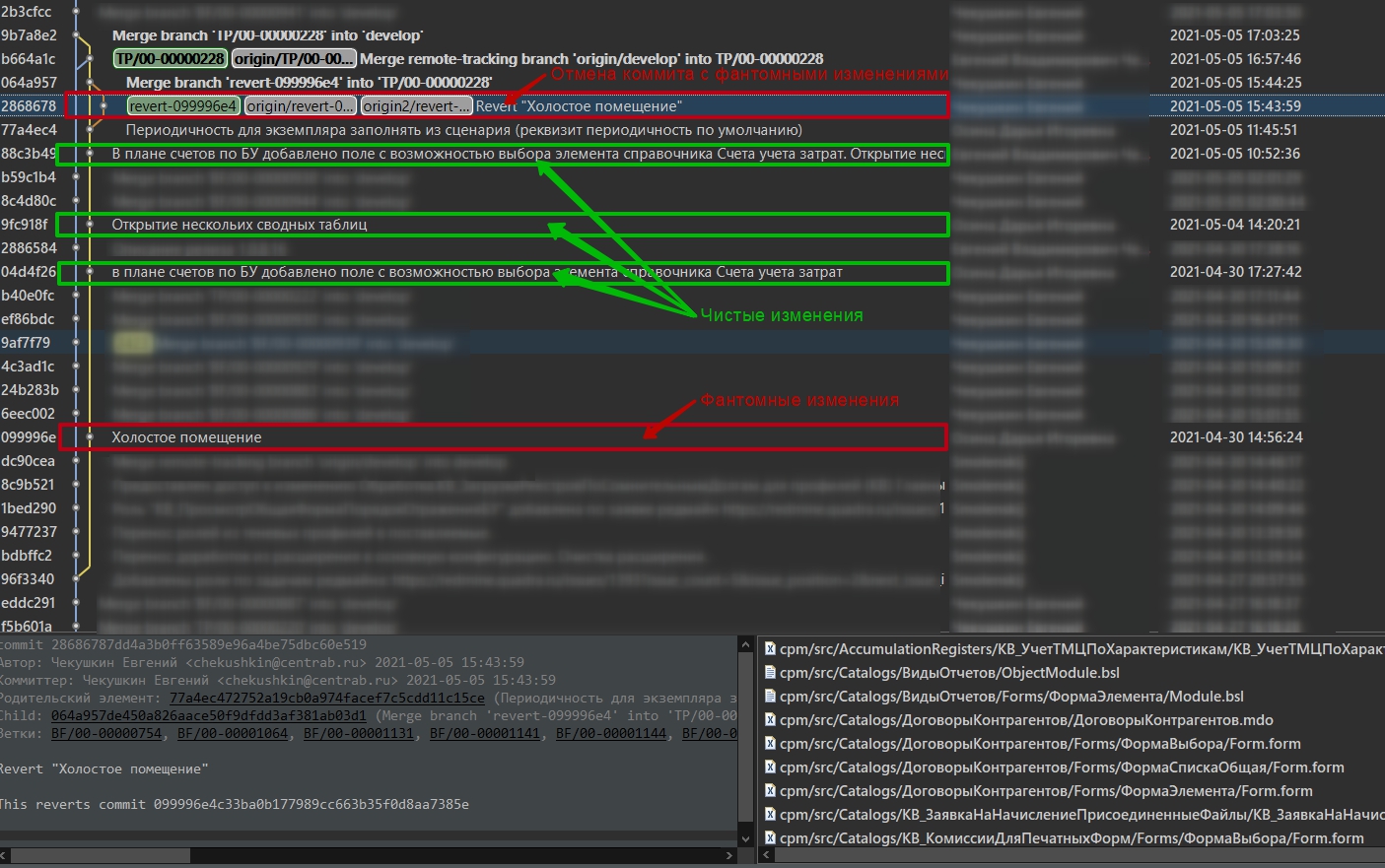 Ну и печальных 3% - это чистое разгильдяйство разработчика. Забрал одну базу, которая соответствовала фиксации, где на ветке версии была создана его ветка доработки, а доработки сделал в другой базе: от другой доработки, или просто взял слил в какие то доработки из другой базы в эту и доделал свои доработки. Предпосылки к такому явлению жесткие и многочисленные конфликты при отмене защитной фиксации, как правило около сотни или более конфликтных файлов.
Ну и печальных 3% - это чистое разгильдяйство разработчика. Забрал одну базу, которая соответствовала фиксации, где на ветке версии была создана его ветка доработки, а доработки сделал в другой базе: от другой доработки, или просто взял слил в какие то доработки из другой базы в эту и доделал свои доработки. Предпосылки к такому явлению жесткие и многочисленные конфликты при отмене защитной фиксации, как правило около сотни или более конфликтных файлов.
Справа внизу видны фантомные изменения, общее количество фантомных файлов в фиксации и отмене 2095... при условии что пользователь изменил всего 5. Этот момент стоит учитывать при планировании в разработке пользователей с конфигуратором.
Очень вероятно, если проект более года что Вам потребуется поднимать версию платформы. Процесс конвертации манифеста проекта EDT очень хорошо описан в интернете, каждый раз при поднятии платформы количество фантомов будет уменьшаться до нуля, но уже через полтора, два месяца их будет больше 100. К сожалению, эта проблема до сих пор не решена в EDT, он по прежнему в структуру файлов для новых реквизитов и ОМД не заполняет реквизиты по умолчанию и стандартные реквизиты. Начиная с версии 2023.3.6 поля по умолчанию в EDT теперь заполняются, так что фантомов стало значительно меньше, но они не пропали совсем. На результат прикладного решения, в итоге, это не влияет никак, но в процессе отслеживания изменений может попить крови немало, если не принять мер противодействия этому.
Ещё немало фантомов прилетает от разработчиков, работающих в Windows и не настроивших конвертацию окончаний строк:
для Windows должно быть всегда:
core.autocrlf true
core.safecrlf true
Всё что они изменяют и что помещается в git помещается с crlf вместо lf и каждый файл - это море изменений. Главное - вовремя заметить, чтобы эти изменения не прошли в ветку версии и другие, ничего не подозревающие разработчики не разобрали "пораженные" файлы в разработку. Найти файлы, подлежащие исправлению можно так: клонировать хранилище с параметром core.autocrlf false, core.safecrlf warn далее воспользоваться любым поиском, способным найти файлы с вхождением crlf, например notepad++, с помощью него же можно и исправить проблемы.
Таким образом с фантомами можно и нужно бороться, фантомные изменения, как ни странно не мешают пользователям никак. Но мешают анализу изменений в системе, заставляя тратить время на поиск реальных изменений.
Вернёмся к теме разработчиков, работающих в конфигураторе. Для них допустимо два сценария: простой и с подливом из ветки версии. Для сложного этапы 4-9 могут повторяться несколько раз.
- Простой. В этом варианте предполагается следующая последовательность:
- Передача разработчику ИБ
- Выгрузка защитной фиксации (помещение изменений с ИБ без изменений)
- Доработки разработчика
- Отмена защитной фиксации
- Долив из ветки версии, при наличии конфликтов
- Принятие запроса на слияние в ветку версии
- Сложный с подливом изменений из ветки версии
- Передача разработчику ИБ
- Выгрузка защитной фиксации (помещение изменений с ИБ без изменений)
- Доработки разработчика
- Отмена защитной фиксации
- Долив из ветки версии
- Здесь возможны взятия фиксаций (cherry-pick) из других веток, если это необходимо.
- Сборка тестовой базы в ветке фиксации слияния
- Передача разработчику новой ИБ, либо конфигурации с тестовой базы, которую он у себя должен загрузить поверх базы разработки
- Выгрузка защитной фиксации из ИБ, полученной на этапе 7
- Доработки разработчика
- Отмена последней защитной фиксации
- Долив из ветки версии, при наличии конфликтов
- Принятие запроса на слияние в ветку версии
Типичный пример по в ветке с "подливом":
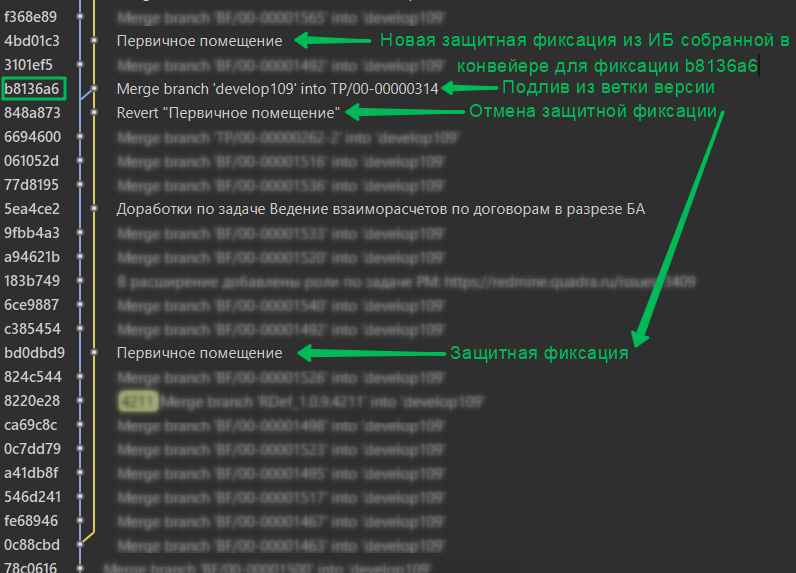
Как быстро сделать revert защитных фиксаций см примеры в последнем разделе. Как сливать ветки без EDT?
Одной из длительной операций при работе с EDT является полная сборка. Имеется в виду когда конфигурация класса ERP, и далеко не пустая, возможно с данными частичной миграции, в общем начиная от 3Гб. Чудес конечно же нет, но некоторые фокусы здесь прокатывают. Хотя, работу ibcmd в платформах начиная с 8.3.20 иначе не назовёшь, но и они не всемогущи. Как известно фокусы - это всего лишь ловкость рук и никакого мошенничества... Многие получив задачу копируют эталонную базу себе, либо разворачивают её из дистрибутива поставщика, затем присоединяют создают приложение для ветки проекта (EDT услужливо предлагает для этой ИБ провести полную сборку) и многие следуют этому предложению и попадают на время, которое длится более одного чаепития и перекура... Да конечно же можно уйти на обед и вернувшись увидеть готовый результат... Но не будем думать о плохом, но на практике часто происходят "нежданчики".
Одна из ситуаций: СРОЧНО!!! Разработчик должен был доделать исправление, но недоделал и не доступен (морально этические вопросы оставим за рамками этой статьи =). Вы, в это время, работаете с другой веткой, где делаете другую задачу. В хранилище Git расклад такой:
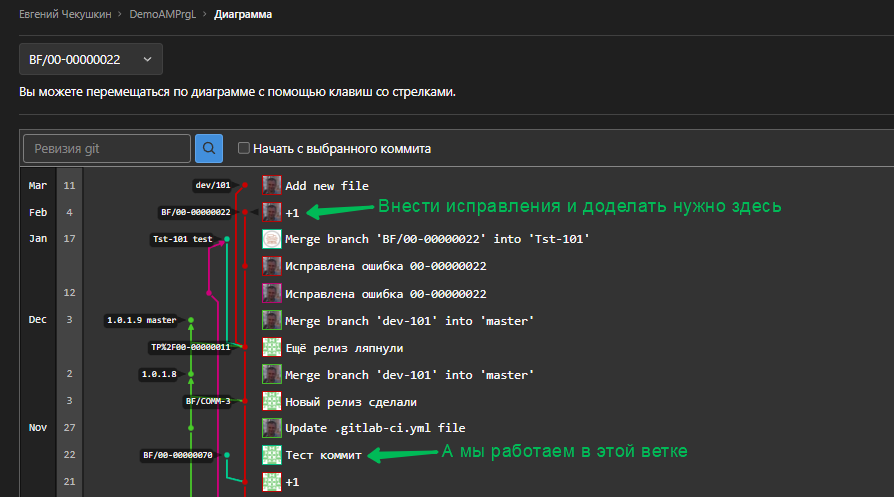
Есть несколько способов как сделать переключение, избежав полной сборки, ну или хотя бы обойтись инкрементальной:
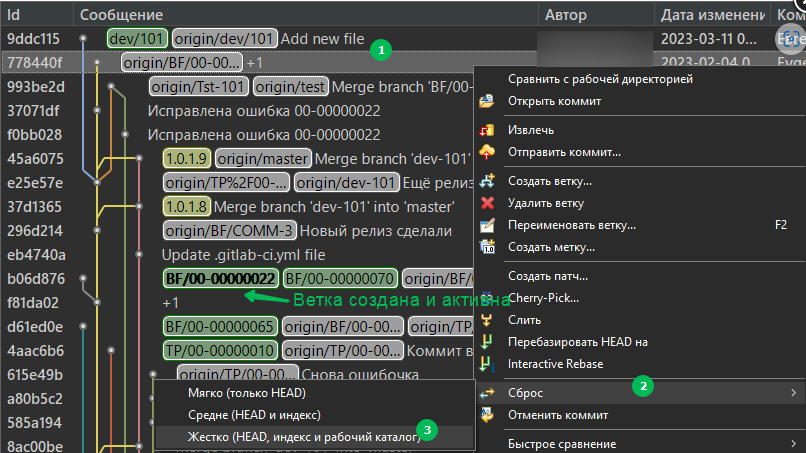
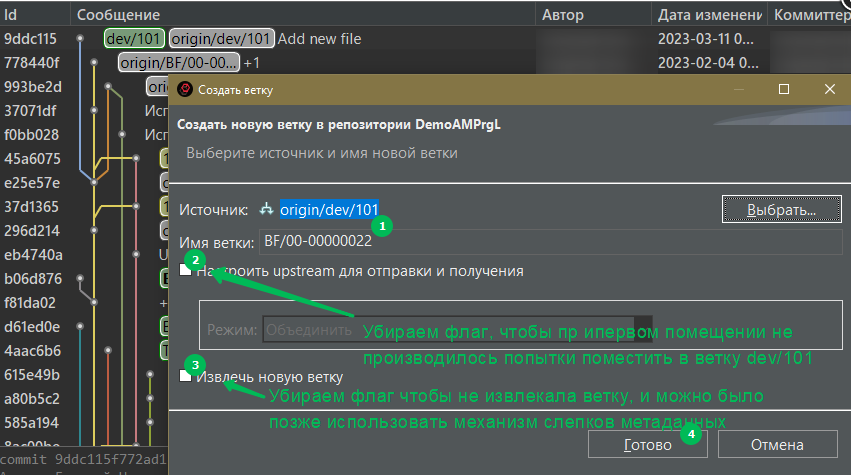
- Если в структуре и данных вашей рабочей ИБ где вы делаете доработки по BF/00-00000070 не критичны, то можно используя диалог: Панель "Разработка"/Создать новую ветку...
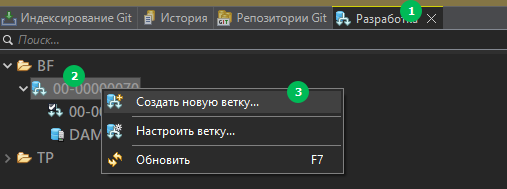
Далее, настроить диалог следующим образом:
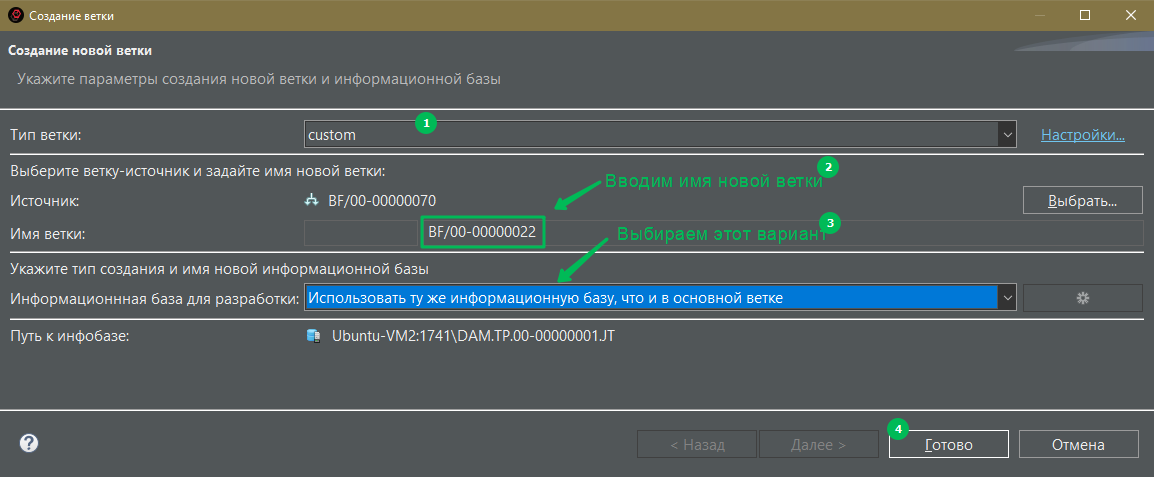
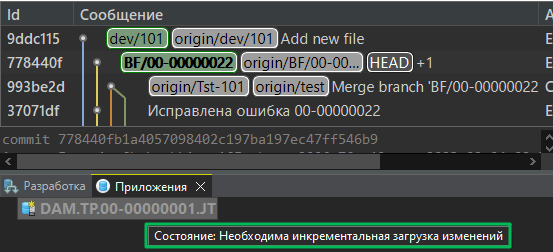
Будет создана нужная ветка рядом с той, в которой работали Вы, и всё что нужно будет сделать потом, так это сделать жесткий сброс на нужную фиксацию:

EDT проведет инкрементальную сборку на разницу в конфигурации между двумя вашими ветками. Полной не будет:
Связывание что одна база на 2 ветки происходит в служебном файле EDT <Каталог вашего воркспейса>\.metadata\.plugins\org.eclipse.core.resources\.projects\<Имя вашего проекта>\com._1c.g5.v8.dt.platform.services.core\.references

Минусы этого способа:- База будет приклеена на веки вечные к двум веткам одновременно как сиамские близнецы, даже если вы базу удалите и создадите и присоедините к одной из них заново, она всегда будет на эти две ветки. Из EDT разорвать связь невозможно - только удалять строку в этом файле.
- После переключения между ветками инкрементальной сборки, если Вы добавляли какие-либо реквизиты в ОМД для своей разработки и заполняли их какими-либо тестовыми примерами будут удалены безвозвратно. Если вам эти наработки жаль, для вас есть вариант 2, читаем ниже.
- Ваша база скорее всего содержит тестового примера, его нужно будет воссоздавать вручную, либо воспользоваться выгрузкой/загрузкой XML.
- Снимки метаданных не работают, при обратном переключении потеряете время на вторичной сборке и инкрементальной сборке базы, привязанной к ветке *70.
- Второй способ через создание копии ИБ от той, где вы вели разработку. Шаги те же, но в диалоге создания указываем уже по другому:
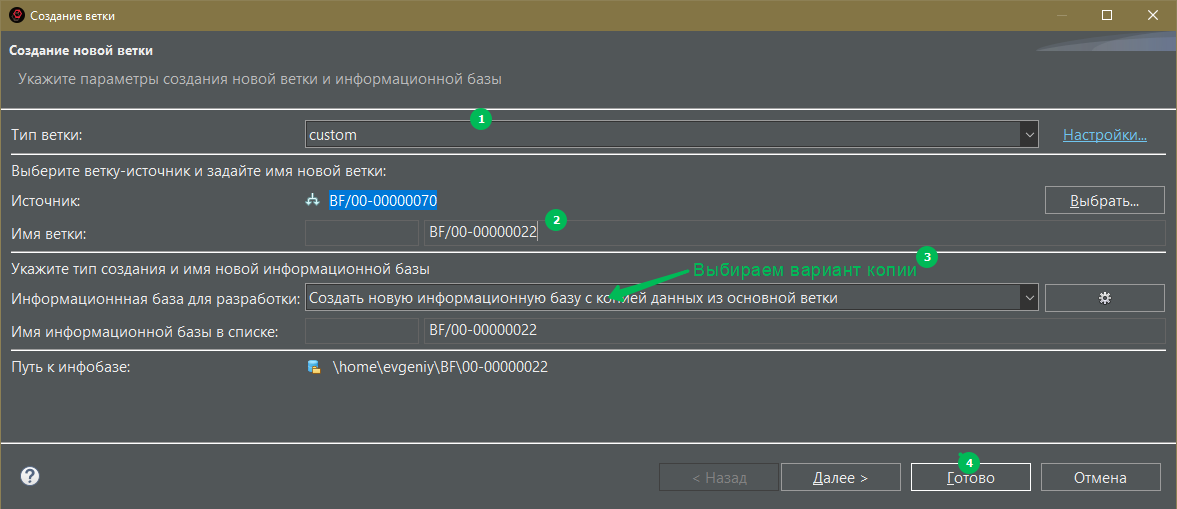
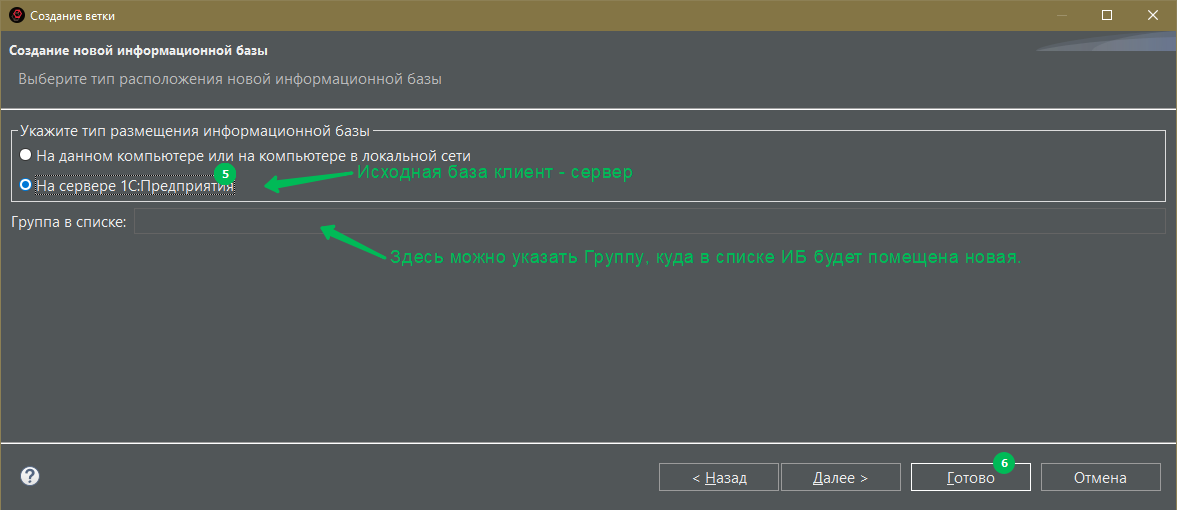
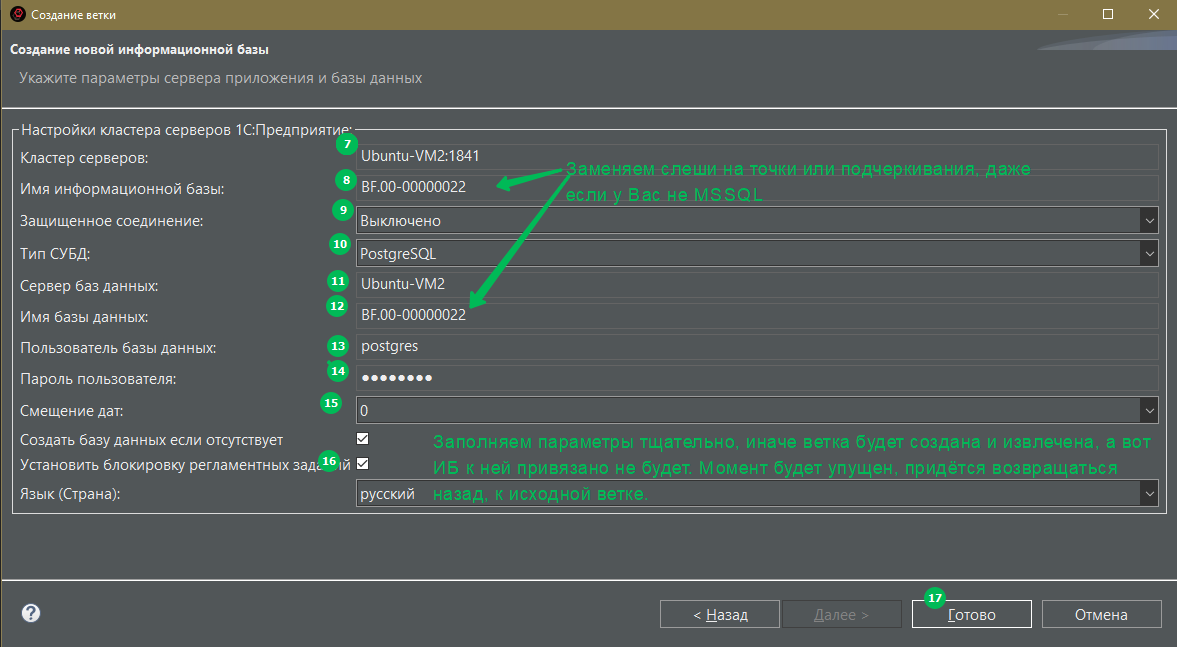
После окончания операции панель Разработка будет выглядеть так:
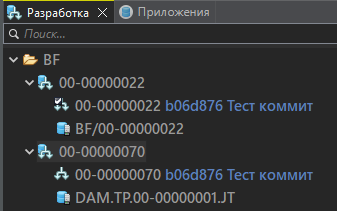
Далее, как и в первом варианте - жесткий сброс.
Минусы этого способа:- Копия базы делается через выгрузку в DT и загрузку в новой базе из неё. Если у вас у Вас что то типа ERP то запасайтесь терпением.
- Тестовые примеры нужно будет сделать как в эталонной базе, потому что в вашей базе их нет.
- Снимки метаданных не работают, при обратном переключении потеряете время на вторичной сборке и инкрементальной сборке базы, привязанной к ветке *70.
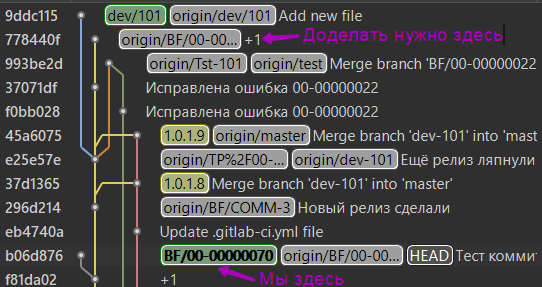
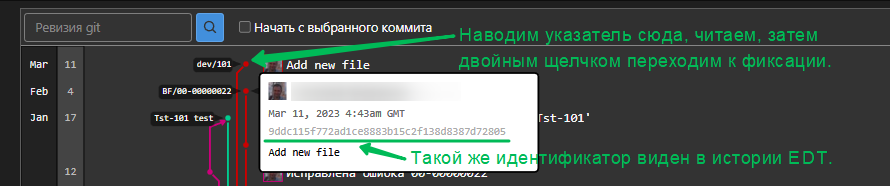
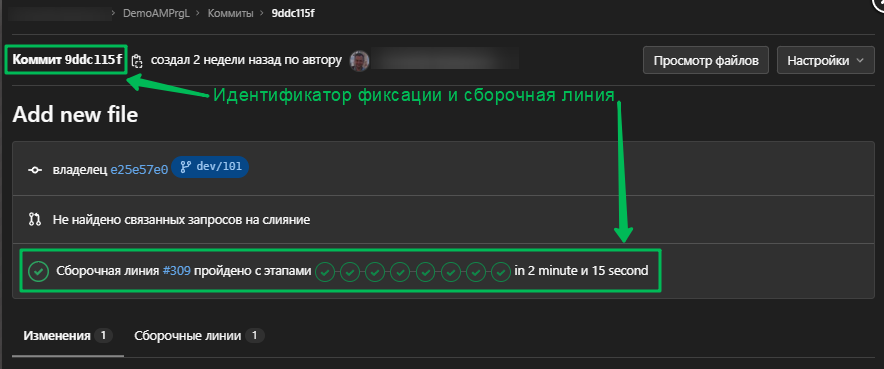
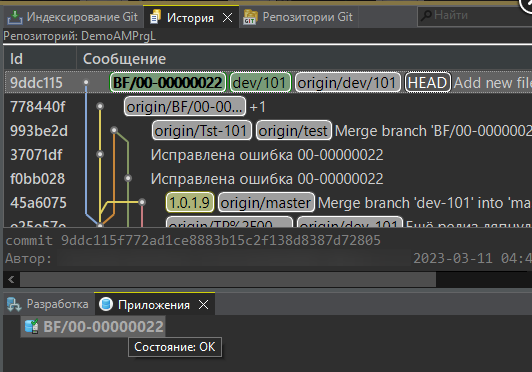
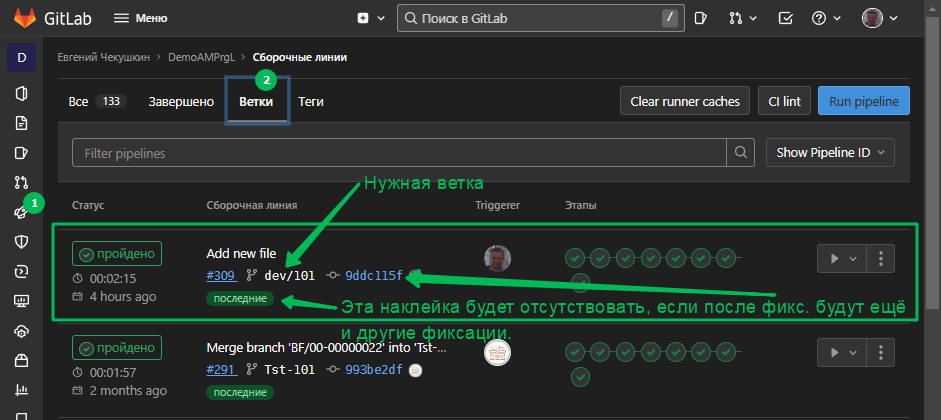
- Я предлагаю этот вариант, лишённый недостатков 1го и 2го способов. Меня, и не только меня в проектах спасает конвейер, который по расписанию утром и вечером собирает и обновляет эталонные базы наработками в ветке версии (dev*). Т.е. в течении дня мы сливаем наработки из веток разработки в ветку версии, а утром у нас уже все готово. Если вдруг даже что то произошло и тестовая база не собралась - всегда есть архив вчерашней. Всё что нам нужно это убедиться, что эталонная база была собрана именно на фиксации 9ddc115... (см. рисунок в условии задачи) Как убедиться? Открываем из графа веток нужную фиксацию:

Видим что сборка проводилась, далее если знаем где на сервере тестового контура эта база находится просто делаем любым доступным и быстрым для вас способом архив, например средствами СУБД, загружаем его себе и разворачиваем локально базу от ветки dev/101.

Конечно же может быть так, что в ветку dev/101 будут добавлены ещё изменения, а сборки не будет, в этом случае будем создавать ветку на фиксации 9ddc115f, так как конфигурация тестовой ИБ соответствует именно этой фиксации. В этом случае искать фиксацию последней сборки эталонной базы нужно здесь:
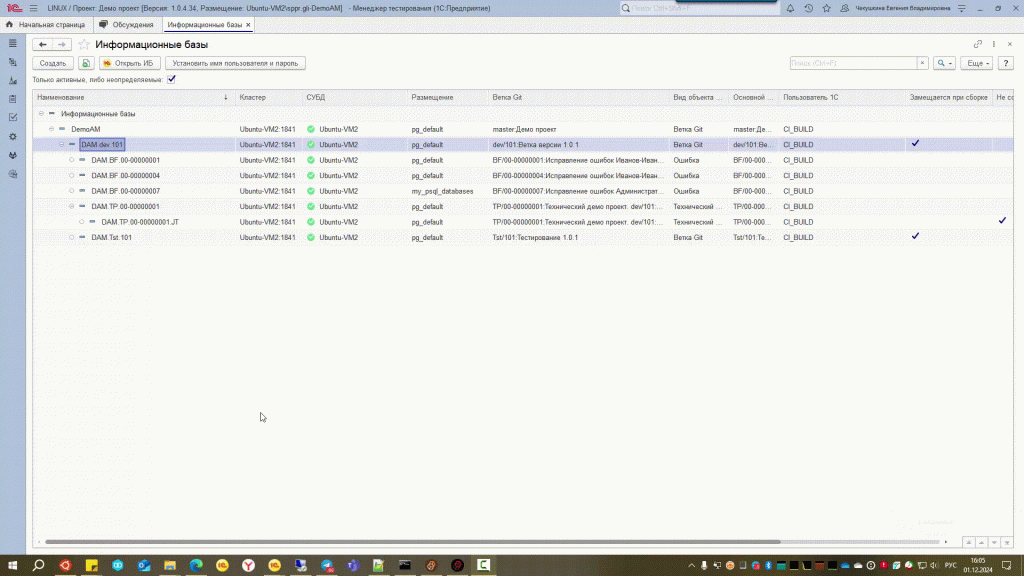
В наших проектах конвейер обслуживает СППР с расширением Управление сборкой, так как в Gitlab, GitHub и других системах контроля версий отсутствуют понятия как ИБ, эталон и т.д. СППР с этой доработкой её хорошо дополняет, н можно и без неё.
Мы делаем это так:
Идентификатор фиксации присутствует в имени загружаемого архива базы на СУБД. Далее распаковываем и добавляем базу в наш локальный кластер (эти шаги я пропущу, думаю все умеют то делать). Мы копируем оба файла ConfigDumpInfo (далее CDI) и бэкап базы. У нас все базы в тестовом контуре "на замке" по причине, описанной здесь. Поэтому пакетный файл загружаемую копию ещё и снимает с поддержки.
Что делаем в EDT:
1. Создаем новую ветку на нужной фиксации без извлечения:
2. Далее, если вы ещё не выгрузили из полученной копии CDI то нужно это сделать. Это достаточно просто, в командной строке сделать так:"C:\Program files\1cv8\8.3.21.1644\bin\1cv8.exe" DESIGNER /S 1CServer\DBName /N AdminUserName /P Password /DumpConfigToFiles C:\TEMP -ConfigDumpInfoOnly"Где AdminUserName - имя пользователя а базе с админскими привилегиями, и "Password" его пароль. 1СServer\DBNmae - имя кластера и имя ИБ в нём. В каталоге C:\TEMP будет создан требуемый файл.
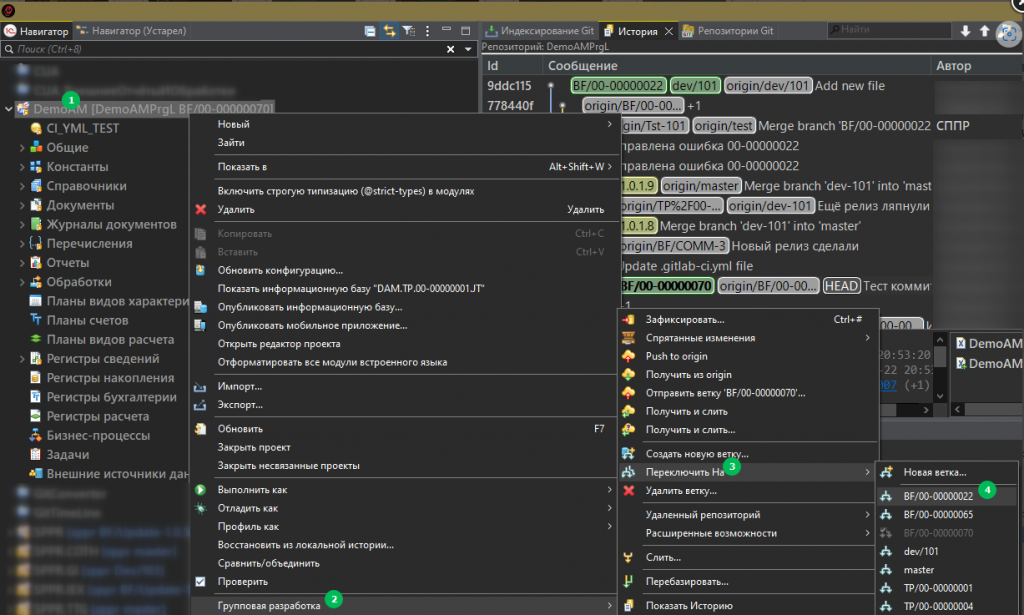
3. Далее через меню групповая разработка переключаемся на новую ветку:
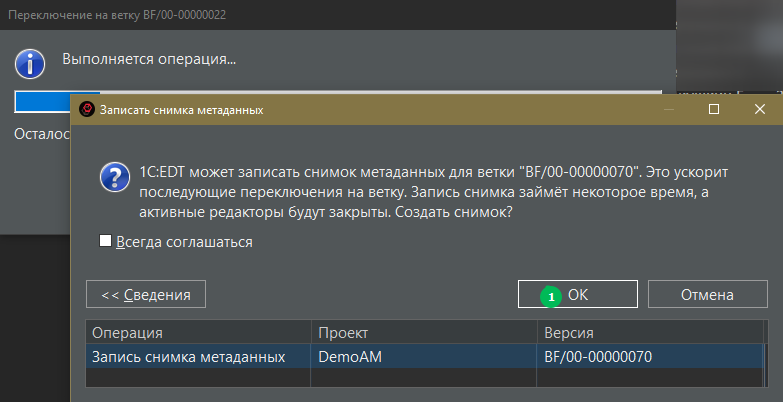
при верно настроенных шаблонах снимков метаданных система должна предложить создать снимок метаданных с текущей ветки:

Это сильно сэкономит время при возврате если разница между ветками 70 и 22 большая.
4. Пока идёт вторичная сборка и расширенная проверка, создаём приложение, добавляя развернутую базу из архива:
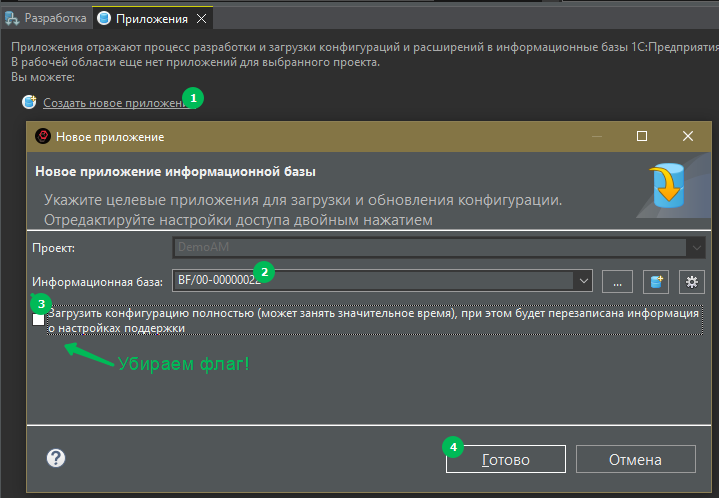
А теперь магия: скопировать файл CDI в каталог:<Каталог рабочей области EDT>\.metadata\.plugins\org.eclipse.core.resources\.projects\<Имя вашего проекта EDT>\com._1c.g5.v8.dt.platform.services.core\refs\heads\<Ваша ветка в примере это BF\00-00000022>\infobase-synchronization\<Идентификатор ИБ, такой же как в файле ibases.v8i 5c4935f7-d68a-4344-b695-9aff55ff1b7f>Далее, если обновление вторичных данных завершено (расширенную проверку можно не дожидаться) закрываем EDT.
К этой статье приложен маленький файл store его копируем чуть глубже в каталог:<Каталог рабочей области EDT>\.metadata\.plugins\org.eclipse.core.resources\.projects\<Имя вашего проекта EDT>\com._1c.g5.v8.dt.platform.services.core\refs\heads\<Ваша ветка в примере это BF\00-00000022>\infobase-synchronization\<Идентификатор ИБ, такой же как в файле ibases.v8i 5c4935f7-d68a-4344-b695-9aff55ff1b7f>\SynchronizationData.storeЗамещая уже существующий там, кому интересно детали описаны в статье. Важно перед копированием этого файла дождаться пока EDT завершит работу, иначе он его содержимое попросту заменит.
5. Запускаем EDT, после запуска магия сработала:

Если сейчас запустить или отправить на отладку - сборки не будет. Сделайте это чтобы убедиться что все прошло удачно. EDT может повисеть некоторое время (обычно не более 2х минут), это в десятки, если не сотни раз не сравнимое со временем полной сборки и запустит приложение. (Он в этот момент выгрузит из базы CDI, так же как мы делали это чуть выше и сравнит его с тем, что мы ему подсунули. и так как они вышли из одной базы разницы не будет. EDT будет считать что база корректна. Ключевая фраза "будет считать" не шульмуйте, не пытайтесь подсовывать ему таким же образом другие какие то ИБ, собранные с других коммитов. Я прямо вот обещаю 100%. Вы получите проблемы с отладкой, будете шагать по несуществующим модулям и по комментариям... )
Не забываем, что нам ещё нужно сбросить ветку до правильной фиксации: 778440f. сделайте это так же как в первом варианте, и будет Вам счастье, пройдёт только инкрементальная сборка.
Минус этого метода: требует "ловкости рук" базу кто то должен всё же собрать. Ну вы же поняли что наличие сборочного конвейера в проекте вещь нужная?





В предыдущем разделе было рассказано как можно избежать полной сборки. В этом разделе вашему вниманию механизм, который все действия от загрузки архива для разработки до привязки его в EDT делает самостоятельно...
...Когда работали с СУБД MS-SQL все было довольно просто. Архив был в одном файле и разворачивался интуитивно понятно и просто. А вот с СУБД Postgres не так всё прозрачно. Либо архив одним файлом - но он создаётся долго и в один поток, либо куча файлов в одном каталоге, но можно параллельно и чуть медленнее чем архив MS-SQL. Плюс ещё привязки распакованного архива к EDT. Для многих разработчиков кто в первый раз увидел EDT это было как кабиина управления самолётом - сложно, много и непонятно. В итоге был разработан скрипт, с помощью которого все действия, пописанные в предыдущем разделе по загрузке и привязке делаются автоматически. Сам скрипт добавлен к этой статье, но прежде чем он заработает, нужно будет всё же немного постараться, и немного предыстории для понимания почему именно так. Мы уже второй год работаем в проектах с импортозамещением, однако полностью на Linux мы не пересаживаемся, так же как и наши клиенты, а используем линукс пока только на серверах. Т.е. это сервер 1С:Предприятия размещённый на Linux (REDOS 7.3.1) + СУБД PgPro Std/Ent, а клиентские части на Windows (хотя автотесты исполняем в среде Linux). Для разработчиков генерируется максимально приближенная к тестовому и продуктивному контурам среда. Мы используем по полной возможности WSL, точнее его 2й версии WSL2. Кластер 1С:Предприятия с лицензией для разработчика развернут внутри WSL (Ubuntu 22.04.4 LTS) там же развернут и СУБД PostgresPro Standart edition. В отличие от обычных виртуальных машин у WSL есть одно большое преимущество - она имеет доступ к файловой системе хоста, и не расходует так много памяти, в отличие от ВМ. Тем не менее в WSL2 вы даже можете запускать графические приложения! Настройку самой WSL, PgPro, Кластера, особенности получения лицензии для разработчиков в таков варианте оставим за рамками этой статьи. (напишите в комментарии если эта тема интересна).
Сам скрипт написан на языке bash, точнее dash (разница есть, и именно некоторые особенности dash оказались полезны) и должен запускаться как:
sh deploy_DB_withPlatform.sh
Скрипт использует переменные окружения описанные в файле .bash_profile:
export usr_ssh=Jane # Имя пользователя под которым производится подключение к тестовому контуру с архивом
export ssh_source=checkushkins.ru:/pg-backup # имя сервера тестового контура с каталогом
export edt_ws=/mnt/w/ws_DEMO # Рабочая область EDT с проектом, к которому нужно привязать приложение
export PJ_name=DemoAM # Имя проекта EDT в рабочей области
export IBASE_folder=/mnt/c/Users/chekushkina/AppData/Roaming/1C/1CEStart # каталог с файлом списка информационных баз на хосте
export Dest_folder=/DEMO # Папка в списке ИБ, в которую нужно поместить загруженный архив
export dest_pg_backup=/pg-backup # папка на WSL куда скопировать архив для распаковки.
Для подключения к тестовому контуру используется подключение ssh по сертификату (чтобы не вводить ни имя пользователя, ни пароль). Обращаю внимание, что при запросе порта кластера, на самом деле вводится порт RAS сервера этого кластера. Если порты не стандартные, соглашение такое, что изменяются только первые части например вместо 1541, 1540, 1545 будет 1741, 1740, 1745. Возможно у вас это не заработает сразу из за ошибочных значений переменных окружения, но заработает точно. Предполагается, что архив ИБ созданный в PgPro и файл ConfigDumpInfo.xml имеют определенные название:
DAM.dev.101.9ddc115f772ad1ce8883b15c2f138d8387d72805.ChekushkinaEV - каталог с архивом ИБ в формате -F d
ConfigDumpInfo_DAM.dev.101.9ddc115f772ad1ce8883b15c2f138d8387d72805.ChekushkinaEV.xml
Имя архива у вас может быть другое (мы шифруем в нём имя базы с которой был сделан архив и ИД коммита с которого она была собрана в CI), но оно должно быть частью имени файла ConfigDumpInfo.xml, иначе вам придётся пакетный файл немного поменять.
Пакетный файл проверялся на работоспособность включительно по версию EDT 2024.1.3 На видео демонстрация в версии 2023.3.6
!ВАЖНО! Скрипт загружает и привязывает только основную конфигурацию проекта, если в проекте у вас есть расширения, то после привязки состояние будет не "Состояние ОК" а "Требуется инкрементальная сборка" Это потому, что основной проект синхронизирован, а расширения нет, но как правило расширения в EDT в подавляющем большинстве собираются очень быстро, даже если это ERP. Почему не привязываем расширения? Всё достаточно просто - в отличие от основной конфигурации для расширения нет команды выгрузки только одного ConfigDumpInfo.xml - его можно получить только вместе со всей структурой расширения, что несколько долго и много лишних файлов.
Как работает этот пакетный файл можно посмотреть на видео ниже:
"Мат - это горькое лекарство, которое нужно использовать строго по назначению, и не применять для связки слов"
Мы говорили много о EDT как об инструменте, который позволяет провести глубокую декомпозицию объектов разработки (как структурных так и кода) и при слиянии очень тонко выявлять конфликтные места. И в этом его сила. Но в жизни системного архитектора бывает много ситуаций, когда использование EDT нерентабельно. Одна из них - это слияние наработок в ветку версии. При этом он должен провести ревизию кода, увидеть какие новые объекты были добавлены в процессе разработки. Спасибо СППР в последней версии 2.0.6.10 это сделано просто замечательно и красиво, очень хочу поделиться этим за рамками этой статьи. Типичная ситуация, когда к 17 часам в хранилище Git около 25 запросов на слияние, причём конфликтных из них порядка 35-40%.
Подождите, подождите скажут многие, разве не обязанность разработчика предоставить свою ветку на слияние без конфликтов? Однако. по факту это не так, ниже два кейса когда конфликты могут быть:
- Три разработчика изменили один общий модуль, одну и ту же процедуру, каждый из них добросовестно влил в свою ветку разработки ветку версии тем самым исключил конфликты для своей ветки. Однако после слияния любой доработки из 3х 2 другие станут конфликтными, так как в доработках 2го и 3го разработчиков изменения 1го не учтены и 2му и 3му их опять нужно к себе залить. А тот кто будет последним. ему придётся делать это ещё раз, чтобы принять изменения ещё и второго разработчика... Конфликты в таких ситуациях настолько прозрачны и просты, что прибегать при слиянии наработок к помощи разработчиков нецелесообразно с точки зрения потраченного в целом времени.
- В проектной команде работает разработчик, который не работает в EDT, а работает в Конфигураторе. Загружая свои доработки в Git изменений в ветке будет очень много (смотри про фантомы) и он не сможет сделать слияние своей ветки с веткой версии, у него просто для этого нет инструмента. Даже если ему такую возможность предоставить, чисто технически это можно: отдавать ему ИБ не снятую с поддержки а со включенными изменениями, перед последним его помещением ему нужно будет из последней сборки ветки версии в конвейере скачать из артефактов CF ( она идет как файл поставки ) далее ему нужно будет просто обновить конфигурацию (так как обновляем от поставщика). Но по сути такое слияние не будет отражено в Git и в gitblame все принятые им изменения будут потом трактоваться как его, что совсем не верно. Кроме того это совсем не поможет в борьбе с фантомами просто так сделать revert защитной фиксации не получится уже. Поэтому увы и ах - слияния с другими ветками в ветку разработки за разработчика делает кто то другой, чаще системный архитектор. Делать это нужно быстро, а EDT тут только усугубит всё. Почему объясню позже.
Итак есть задача слить разработку, которая делалась в не в EDT. Тут необходимо сделать оговорку, разработчикам которые работают в конфигураторе нужно настрого запретить перемещать процедуры и менять местами внутри модулей. Если такая необходимость есть то такое изменение должно быть согласовано.
"Что для текста хорошо, то для XML смерть"
Для решения проблем слияния за спиной у EDT нам нужны будут инструменты (diff tool). Для модулей, и для структурных файлов.
- У EDT есть прекрасный механизм "попроцедурного" трёхстороннего сравнения модулей, но в классическом Git его нет, и diff tool известные на этот момент как KDiff или P4Merge (есть и другие Araxis, DiffMerge, TortoiseMerge) тоже этого делать не умеют. Однако если структура модуля не изменялась и процедуры не менялись местами, то любой из вышеперечисленных работает отлично.
- Со структурными файлами всё гораздо хуже. Git отвратительно сливает XML, думая что это текст. Но там эти правила не работают. 7 лет назад, ещё когда не маячил на горизонте EDT мною, для себя, был открыт OSOXmlMerge. Тогда мне нужно было слить 2 плана счетов так, как конфигуратор делать не умел. Мне нужно было аккуратно заместить идентификаторы счетов, которые появились у поставщика и были добавлены проектной командой, внедрявших решение, чтобы потом эти счета могли обновляться как родные, и избежать тем самым ужасной процедуры обработки проводок за много лет... Суть продукта в том, что он универсален. Его можно настроить под любую структуру XML файла если она формируется по определенным правилам. Во вложении к статье настройки которые мы сделали для основного файла конфигурации Configuration.mdo, mdo объектов - справочников, документов и т.д., ролей (Roles.roles), подсистем - Subsystem.mdo, плана счетов - ChartOfAccounts. В итоге можно смело сливать структурные объекты - проблем не будет. Есть конечно и минусы, ну во первых в файлах могут появиться новые элементы, под которые настройку возможно потребуется адаптировать. Утилита имеет пробный период, но потом будет требовать регистрации. Стоимость лицензии £29. Под линукс варианта нет, только под Windows, в техподдержке ответили, что работы в направлении поддержки Linux ведутся, возможно как-то можно запустить под wine.
Как сливать ветки без EDT продемонстрирую в видео, на примере старых проектов. В EDT такие операцию отнимают гораздо больше времени, потому что:
- При переключении на новую ветку - снимки метаданных не сработают. придётся ожидать вторичной сборки.
- В случае, если revert будет с конфликтом то от EDT не будет никакого толку, так все операции делает EGIT, при этом интерфейс того же P4Merge, чем 3х стороннее слияние EGIT.
- При сравнении/объединении из ветки разработки в ветку версии придётся ждать как минимум вторичной сборки двух фиксаций для базовой фиксации и фиксации второй ветки.
- Итого в среднем для аналогичного слияния на каждую ветку может быть потрачено минимум полчаса. (не забываем что мы ведём речь о больших конфигурациях).
А так, всё видео 20 с немногим минут, с учетом поиска, отката веток и т.д. Лишнее вырезано, промотано и получилось 6 минут.
Если что то непонятно, пишите в комментарии. Расскажу - покажу.
Для использования Oso и P4Merge нужно настроить параметры merge & diff tool:
Их настраивают в системной конфигурации MINGW64 в файле:
C:\Program Files\Git\mingw64\etc\gitconfig
[merge]
tool = p4merge
guitool = p4merge
conflictstyle = diff3
[diff]
guitool = p4merge
[mergetool "p4merge"]
cmd = \"C:/Program Files/Perforce/p4merge.exe\" -C utf8 \"$BASE\" \"$LOCAL\" \"$REMOTE\" \"$MERGED\"
path = C:/Program Files/Perforce/p4merge.exe
keepBackup = false
keepTemporaries = false
[difftool "p4merge"]
path = C:/Program Files/Perforce/p4merge.exe
cmd = \"C:/Program Files/Perforce/p4merge.exe\" -C utf8 \"$LOCAL\" \"$REMOTE\"
[mergetool "Oso"]
cmd = \"C:/Program Files/Oso/XMLMerge/2/OsoXMLMerge.exe\" -merge -base \"$BASE\" -left \"$LOCAL\" -right \"$REMOTE\" -result \"$MERGED\"
path = C:/Program Files/Oso/XMLMerge/2/OsoXMLMerge.exe
keepBackup = false
keepTemporaries = false
[difftool "Oso"]
path = C:/Program Files/Oso/XMLMerge/2/OsoXMLMerge.exe
cmd = \"C:/Program Files/Oso/XMLMerge/2/OsoXMLMerge.exe\" -compare -left \"$LOCAL\" -right \"$REMOTE\"
Конечно же не все можно слить показанным способом, остаются те 3 процента, где без EDT никуда. Ну и обновление типовых конфигураций лучше всего делать только в EDT.
Вступайте в нашу телеграмм-группу Инфостарт

{kind=link}