Опорная инфраструктура.
Перед Новым Годом наши пользователи работали особенно активно, стала заметна медленная работа 1С, решено провести работы по оптимизации. Надежда на успех подпитывается наблюдением: в выходные апдекс 0.7 в будни апдекс 0.6 (пользователей и операций больше в десять раз). То есть быстродействие деградирует с ростом числа пользователей и операций, что свидетельствует о наличии в системе «узких мест». Для мониторинга ресурсов используем PRTG - это намного удобнее, чем Performance monitor. Хосты под управлением гипервизора удобно смотреть в разделе VMWareCenter.
- Сервер СУБД на отдельном (физическом) хосте.
- Сервер приложений на виртуальной машине. Выделено ровно 12 ядер, больше служба 1С не использует согласно лицензии.
- Большинство клиентов располагаются на нескольких терминальных серверах, подключения к которым распределяет nginx. Терминальные сервера – виртуальные машины под управлением WMware. Вся архитектура построена до моего прихода, 1cFresh не используется.
- В качестве накопителей данных все серверы используют промышленное хранилище.
Беглый осмотр параметров производительности (сенсоров PRTG) не показал проблем: RAM достаточно, сеть не загружена, средняя загрузка CPU от 40 до 70%, очередь чтения/записи на диск отсутствует. Но проблемы были: при обычной работе в 1С экран зависал, становился неактивным. Через несколько дней размышлений, вспомнил курс 1С:Эксперт: возле самого медленного узла должны быть очереди. Стал смотреть не процент активности (доступности), а очередь:
- Очередь обращений к CPU на терминальных серверах необычно большие значения. Конечно, процессор быстрее жесткого диска, но любая очередь воспринимается пользователем как замедление. Было принято решение зарезервировать частоту виртуальных ядер, чтобы гипервизор не тратил времени на изменение частоты, а слабое ядро не зависало под нагрузкой. После резервирования частоты ядер, зависания на клиенте исчезли, хотя очереди остались. Виртуальные ядра искажали процент загрузки CPU. На графике до конфигурирования: загрузка 60, очередь 383.
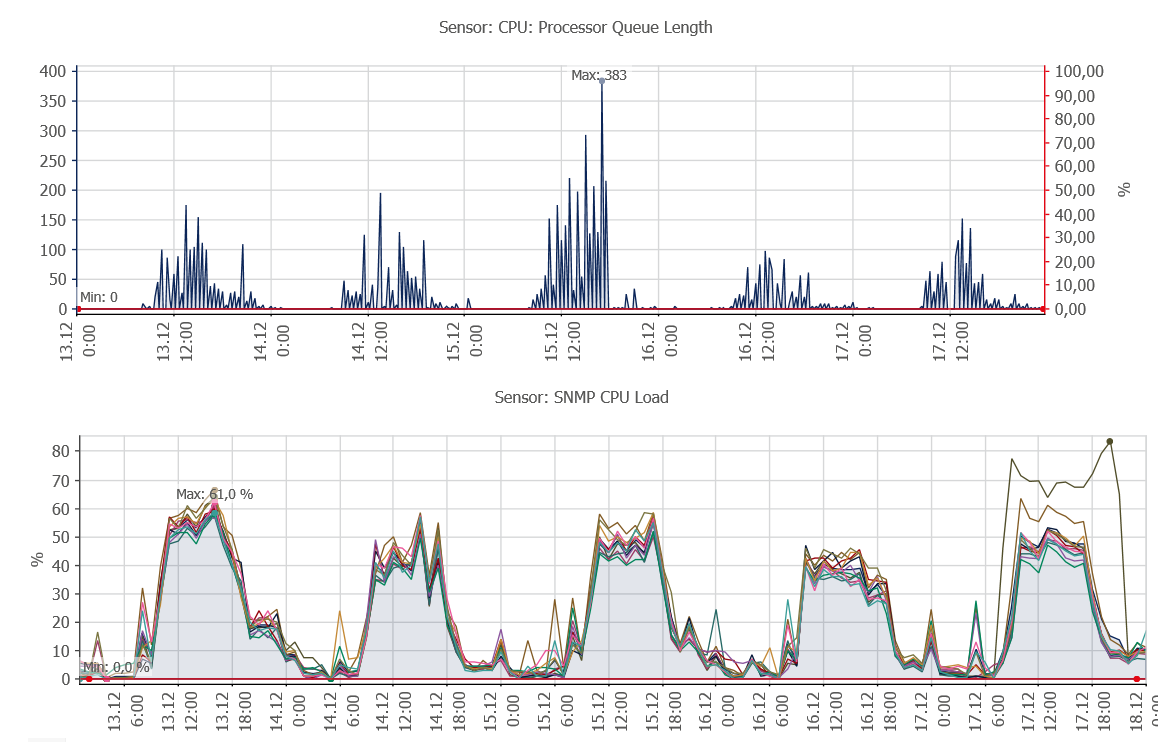
На графике измерения с шагом 30 секунд, ХХ пиков в час. Если бы шаг измерения был 1 секунда, то пиков было бы в 30 раз больше. Также надо умножить на количество терминальных серверов, чтобы охватить всех пользователей. В общем, получается много.
При выводе графика нужно следить, чтобы период вывода соответствовал периоду сбора данных, иначе возможна большая разница из-за усреднения. В пиках до 871, а в среднем – 37. Обратите внимание: на выходных (06,07 февраля) очереди CPU нет - быстродействие по apdex значительно выше.
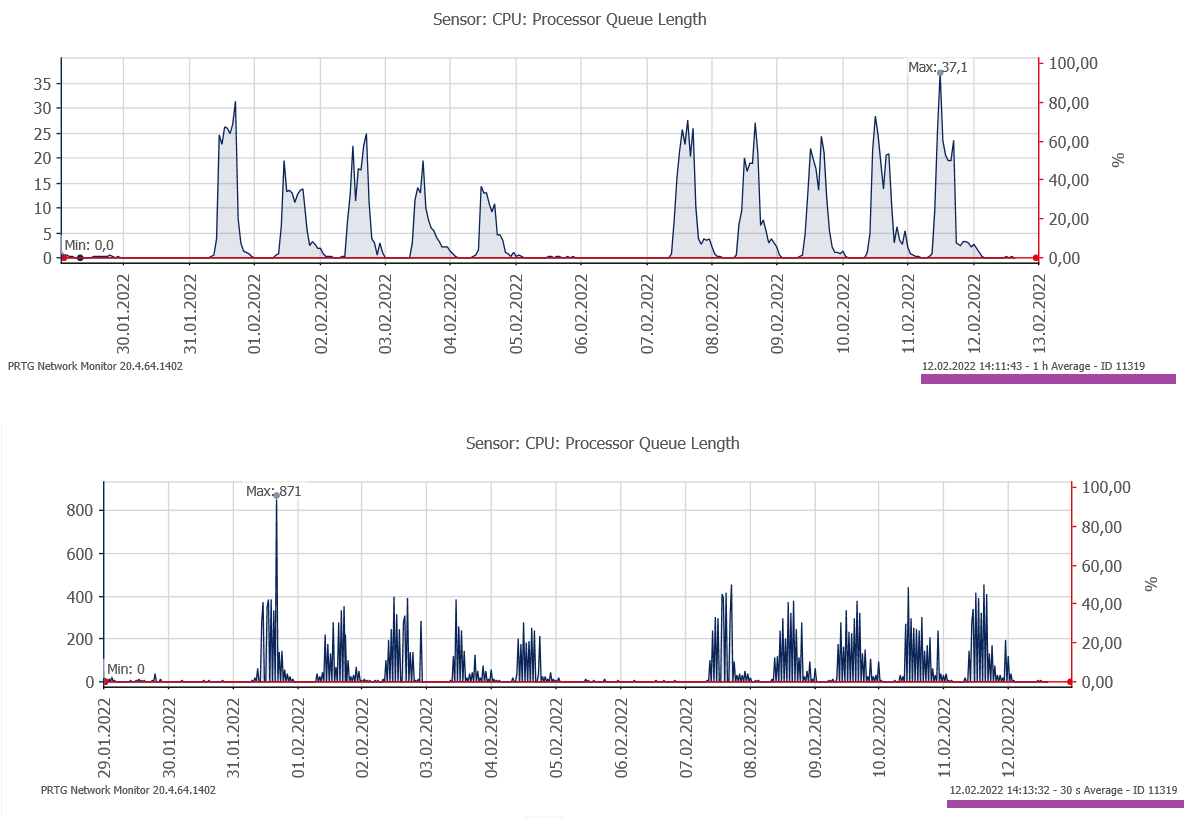
Затраты CPU на обслуживание гипервизора составляют около 10%. Накладные расходы виртуализации.
- Очередь к оперативной памяти – это файл подкачки. Оказывается, наши сервера его используют, даже когда свободно 200 Гб RAM. (Общая память хоста, которую может использовать каждая виртуальная машина) Запрещаем файл подкачки в настройках ОС Windows, если памяти достаточно. Например, для сервера приложений устанавливаем размер RAM виртуальной машины 60 Гб. Максимальный размер rphost будет равен 48 Гб (60 * 80% = 48). Оставшихся 12 Гб хватит для операционной системы. На сервере СУБД размер используемого RAM настраивается в свойствах СУБД. На своих серверах – думайте самостоятельно.
- Очередь к хранилищу данных на запись больше 1 для нас существенна. Потому что у нас пятый RAID. Нужно проверить расписание бекапов, терминальный сервер и сервер приложений можно архивировать гораздо реже, чем рабочую базу.
- Единственное устройство, для которого я не смог найти сенсора очереди – это сетевой интерфейс. Зато я понял, что измерения скорости и объема трафика должны быть для всего хоста, а не для отдельных виртуальных машин.
Появилось понимание, что можно улучшить в инфраструктуре. Подозрение на «узкое место» - CPU сервера терминалов. Проблема была решена: купили дополнительный процессор. Апдекс показал заметный положительный эффект.
Технологический журнал на клиенте.
Соберем технологический журнал. Конфигурационный файл logcfg.xml копируем в каталог conf на всех (клиентских) терминальных серверах.
<?xml version="1.0" encoding="UTF-8"?>
<config xmlns="http://v8.1c.ru/v8/tech-log">
<dump create="false"/>
<log location="C:\Users\Public\Documents\Log" history="24">
<event>
<ne property="name" value=""/>
</event>
<property name="all"/>
</log>
</config>
Анализ обращений к серверу.
При обращении к серверу возникают группы записей VRSREQUEST – SCALL – VRSRESPONSE с одинаковым контекстом, длительность события SCALL равна разности во времени VRSREQUEST –VRSRESPONSE. Данных о загрузке CPU или памяти в этих записях нет, но можно найти наиболее длительные события. Скрипт bash похож на скрипт для анализа событий CALL технологического журнала на сервере.
Проверка сетевых соединений.
00:14.041001-0,CONN,0,process=1cv8c,OSThread=95348,Txt='Ping direction statistics: address=ХХ.ХХ.ХХ.ХХ:1560,pingTimeout=15000,pingPeriod=3000,period=10047,packetsSent=4,avgResponseTime=0,maxResponseTime=0,packetsTimedOut=0,packetsLost=1,packetsLostAndFound=0'
00:54.303001-0,CONN,0,process=1cv8c,OSThread=95348,Txt='Ping direction statistics: address= ХХ.ХХ.ХХ.ХХ:1560,pingTimeout=15000,pingPeriod=3000,period=10063,packetsSent=3,avgResponseTime=0,maxResponseTime=0,packetsTimedOut=0,packetsLost=0,packetsLostAndFound=1'
Сначала пакет потеряли, потом все-таки нашли. Может ли это говорить о проблемах в сети ? Надо убедить администраторов проверить сеть утилитой iperf.
Проверка доступности лицензий.
Один из ключей 500 пользователей, использовано 216, ошибок нет.
02:22.429000-15993,HASP,2,process=1cv8c,OSThread=10188,Txt='NETHASP_HASPQUERYLICENSE(,prog=17,ser=ORG8B,,,,)->CurUsr=216,UsrLim=500,type=65535,remain=65535'
02:22.429002-1,HASP,2,process=1cv8c,OSThread=10188,Txt='NETHASP_LASTSTATUS(,prog=17,ser=ORG8B,,,,)->NStat=0,SysErr=0,stat=0,'
Но к сожалению, некоторые действия &НаКлиенте не оставляют след в технологическом журнале.
Например, этот код (не обращается к серверу).
&НаКлиенте
Процедура ПоказатьОтсчет(Команда)
Для Счетчик = 1 По 999 Цикл
Состояние( Цел(Счетчик/10) );
КонецЦикла;
КонецПроцедуры
Некоторые события (Например, сообщения СистемыВзаимодействия) выполняются на уровне платформы, не попадают в технологический журнал. Чем меньше таких событий – тем лучше. Подумайте несколько раз, нужно ли Вам использовать СистемуВзаимодействий. (Администрирование – Интернет-поддержка и сервисы – Обсуждения). Другая тяжелая операция - вывод сообщений, регистр «Напоминания пользователя». Удалите лишние записи регистра.
Наследие Огненной Лисы.
Запустим программу 1С в браузере, откроем меню Другие инструменты – Инструменты веб разработчика – Профайлер. Начнем запись, дождемся, пока откроется окно напоминаний в 1С, захватим запись. В профайлере доступна информация по состоянию окна (скриншоты), загрузка локальных ресурсов Network, GPU, CPU в разрезе pid процессов.
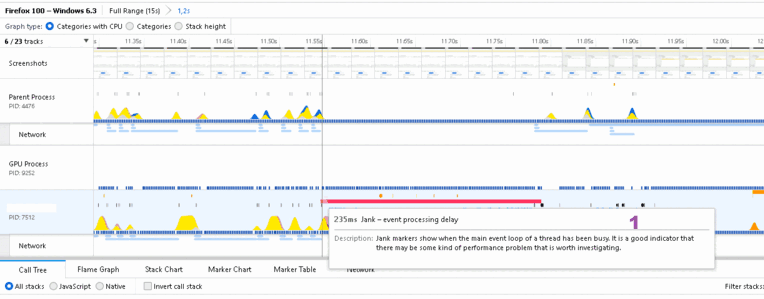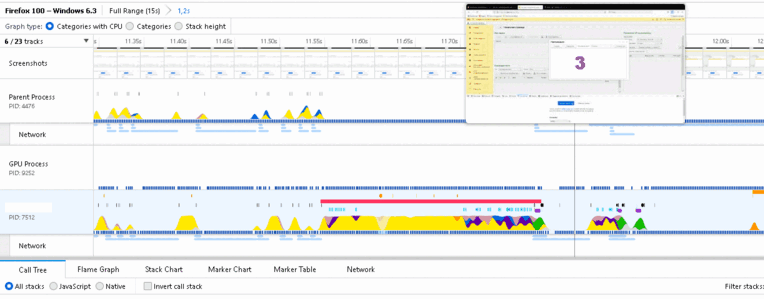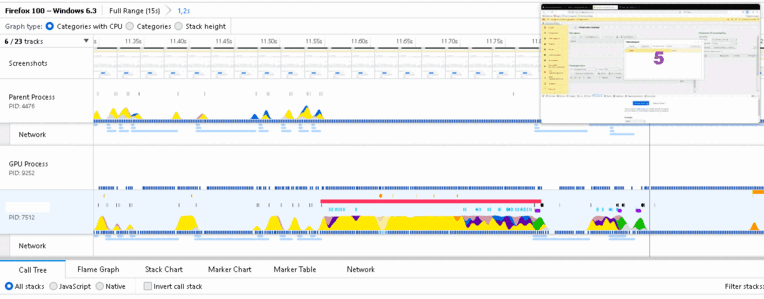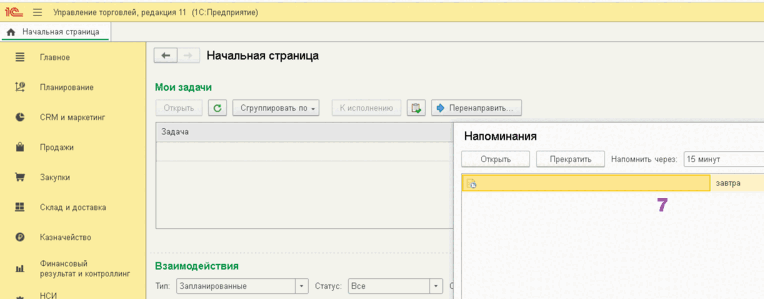
- Красная полоса указывает на проблемы с производительностью. В контекстной подсказке написано «performance problem». Обозначим первый период нагрузки ( 11.55, 11.80 ).
- На протяжении ( 11.55, 11.80 ) главное окно программы остается неизменным (смотрим миниатюры скриншотов), подготавливается вывод напоминания.
- После 11.80 – появляется окно напоминаний (смотрим миниатюры скриншотов), нагрузка падает.
- На протяжении ( 11.55, 11.80 ) загрузка CPU около 91% процесс pid 7512 (разноцветные горы Рериха на рисунке).
- Обозначим второй период нагрузки ( 11.85, 11.90 ). После 11.90 – в окне напоминаний появляется информационная строка (смотрим миниатюры скриншотов), нагрузка падает.
- На протяжении ( 11.85, 11.90 ) загрузка CPU около 94% процесс pid 7512 (разноцветные горы Рериха на рисунке).
- Так выглядит окно напоминания в типовой программе, которое мы открывали.
Полученные в профайлере результаты указывают, что на подготовку и вывод окна напоминания расходуется 91-94% CPU в течение 300 мс, даже если в нем только одна строка. Не буду указывать параметры своего CPU. Кто захочет – легко повторит. Событие напоминаний достаточно частое, чтобы вызвать зависания клиента, которые накладываются друг на друга, особенно если используется терминальная ферма.
Памятка для пользователей.
Начнем с отвлеченного примера. Пациент говорит врачу: «у меня болит все». Врач старается понять причину: назначает анализы, пытается перевести разговор в конструктивное русло. Если анализы не показывают ничего особенного, а пациент настаивает «у меня болит все», визит заканчивается: российский врач прописывает седативные, американский – антидепрессанты.
- Почему антидепрессанты – самые продаваемые препараты в мире?
- Потому что не на все вопросы можно найти ответы на этой земле, но неправильно заданный вопрос увеличивает шанс получить неполезный (вредный) ответ.
Итак, если «тормозит вся программа 1С» - перезагружаем компьютер. Проблема не ушла и у коллег тоже тормозит – позвоните.
Как правильно создать заявку ИТ, чтобы 1С стала работать быстрее?
Есть методика улучшения быстродействия, фирма 1С издала несколько книг и видео. Основа методики – разбить работу пользователя на ключевые операции и оценивать по времени каждую в отдельности. Примеры ключевых операций – «открыть окно подбора номенклатуры из документа заказ клиента», «найти клиента в списке клиентов по наименованию», «открыть документ заказ клиента» …
Для каждой ключевой операции фиксируем время секундомером до улучшения быстродействия, выполняем улучшения, снова фиксируем время. Ключевая операция «открыть окно подбора номенклатуры из документа заказ клиента» выполняется в среднем 20 секунд. Если мне удастся улучшить ее на 5 секунд – я буду счастлив. Освободятся ресурсы сервера и время пользователей. В перспективе нескольких лет фирма получит хорошую выгоду. В то же время, человек без секундомера разницу между 15 и 20 секунд почти не ощущает.
Нужны параметры ключевой операции. Подбор с остатками открывается дольше, чем подбор без остатков. Чем больше дополнительной информации, тем медленнее открывается подбор. Все справедливо.
Нужно знать имя пользователя, под которым запускается программа. Чаще всего, с полными правами не тормозит, но дать всем полные права – невозможно.
Нужен режим запуска программы: вебклиент или терминальное подключение. Например, для режима вебклиент, сигнал Москва - Владивосток всегда задерживается на 0,1 секунды. Один-единственный кабель длиной во всю страну, который невозможно заменить, невозможно улучшить. При открытии подбора, обмен данными между пользователем и сервером может происходить десятки раз, задержка вырастает до нескольких секунд.
Нужно знать время, когда ставился опыт, чтобы оценить состояние сервера, сети, интернет-соединения, технологического журнала в это время. У нас все ходы записаны. Контора пишет.
Немало требований, да? И это лишь минимально необходимый набор по методике 1С. Мне пришла удачная идея: снимать монитор пользователя во время ключевой операции на смартфон. Постарайтесь захватить верх монитора - заголовок программы, центр монитора - ключевую операцию с дополнительными параметрами, низ монитора – запущенные программы и время. Видео присылайте почтой, в заявке приложите ссылку.
Хорошие пользовательские истории.
Поиск партнеров по реквизитам.
Попросил пользователя снять на смартфон процесс поиска. Возможности поиска гибкие, можно было найти торгового партнера по части телефона или части наименования. Для того, чтобы найти все варианты, происходит сканирование справочника Партнеры, индексы не используются. Оказалось, пользователь ищет по точному наименованию партнера, со всеми пробелами и запятыми. Согласитесь, это было неожиданно, чаще всего используют часть наименования. Юридическое наименование может не совпадать с нашим внутренним. Вместо универсальной кнопки «Найти» сделал специальные варианты поиска, которые используют внутреннюю структуру базы данных, в прозрачном для пользователя варианте:
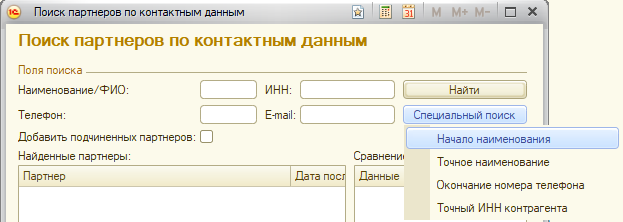
Для поиска по телефону сделал дополнительный регистр с перевернутыми номерами.
Выполнение запроса сделал в привилегированном режиме, без RLS, учитывая, что в запросе явно установлено ограничение по доступным подразделениям.
Убрал автоматический вызов поиска по вводу значения, оставил только по кнопке. (Хорошее правило: если тяжелую процедуру можно запустить вручную – она не должна запускаться автоматически.)
В результате поиск стал выполняться 2 секунды вместо 25 секунд.
Поиск партнеров из списка
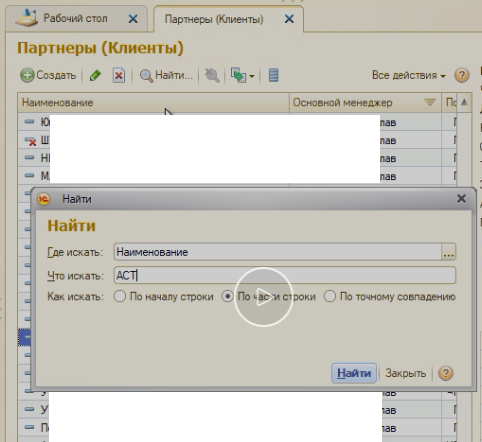
В списке выполняли поиск по части наименования. Поиск занимал дольше 15 секунд. Только благодаря видео удалось заметить, что в списке есть «лишняя» сортировка, найдите ее. Как думаете, сколько раз я посмотрел это видео? Сортировку принудительно убрал в процедуре.
Процедура ПриСозданииНаСервере(Отказ, СтандартнаяОбработка)
Список.КомпоновщикНастроек.Настройки.Порядок.Элементы.Очистить();
КонецПроцедуры
Теперь поиск выполняется 2 секунды. Программисты могут взять на заметку эту особенность реализации динамических списков. Поиск в динамическом списке не является ключевой операцией в классическом смысле.
Вступайте в нашу телеграмм-группу Инфостарт