









Перевод https://docs.sentry.io/product/data-management-settings/event-grouping/ как ответ комментарий в //infostart.ru/1c/articles/1678579/
Общая информация
Отпечаток (fingerprint) - это способ однозначно идентифицировать ошибку, и он есть у всех событий. События с одним и тем же отпечатком пальца группируются вместе в проблему.
По умолчанию Sentry запускает один из наших встроенных алгоритмов группировки для создания отпечатка события на основе информации, доступной в событии, такой как трассировка стека (stacktrace), исключение (exception), и сообщение (message).
Если способ, которым Sentry группирует проблемы для вашей организации, уже идеален, вам не нужно вносить никаких изменений. Однако, если набор проблем выглядит похожим, но они не группируются автоматически, или у вас есть другие потребности в группировке, вы можете расширить поведение группировки по умолчанию или полностью изменить его. Вы можете сделать это, используя комбинацию следующих опций, перечисленных от наименее до наиболее сложных:
В вашем проекте путем объединения проблем
Объединяет воедино аналогичные проблемы, которые уже были созданы. Для этого не требуется никаких настроек или изменений конфигурации.
В вашем проекте, используя правила отпечатков
Устанавливает новый отпечаток пальца для входящих событий на основе совпадений. Это не влияет на уже существующие проблемы.
В вашем проекте, используя правила трассировки стека
Устанавливает правила для того, как следует обрабатывать входящие события на основе сопоставлений. Это не влияет на уже существующие проблемы.
В вашем SDK, используя SDK для формирования отпечатков
Устанавливает новый отпечаток пальца для входящих событий на основе сопоставлений в SDK. Это не влияет на уже существующие проблемы. Обратите внимание, что это не поддерживается в WebAssembly.
Правила трассировки стека могут работать как комбинация настроек SDK и проекта. В результате мы храним документацию в одном месте.
Вы можете увидеть отпечаток, открыв проблему, щелкнув ссылку JSON и найдя свойство fingerprint в этом файле. Если использовалась группировка по умолчанию, вы увидите там надпись "по умолчанию"(default). Если использовалась другая группировка, вы увидите само фактическое значение отпечатка.
Алгоритмы группировки
Каждый раз, когда поведение группировки по умолчанию изменяется, Sentry выпускает его как новую версию. В результате изменения поведения по умолчанию не влияют на группировку существующих проблем.
При создании проекта Sentry автоматически выбирается самая последняя версия алгоритма группировки. Это гарантирует согласованность поведения группировки в рамках проекта.
Чтобы обновить существующий проект до новой версии алгоритма группировки, перейдите в Настройки > Проекты > [проект] > Группировка проблем > Группировка обновления (Settings > Projects > [project] > Issue Grouping > Upgrade Grouping). После перехода на новый алгоритм группировки вы, скорее всего, увидите, что создаются новые группы.
Все версии сначала рассматривают трассировку стека, затем исключение и, наконец, сообщение.
Вы можете увидеть отпечаток пальца, открыв проблему, щелкнув ссылку JSON и найдя свойство fingerprint в этом файле. Если использовалась группировка по умолчанию, вы увидите там надпись "по умолчанию". Если использовалась другая группировка, вы увидите само фактическое значение отпечатка пальца.
Группировка по трассировке стека
Когда Sentry обнаруживает трассировку стека в данных события (непосредственно или как часть исключения), группировка фактически полностью основана на трассировке стека.
Первая и самая важная часть заключается в том, что Sentry группирует только по фреймам трассировки стека, которые SDK сообщает и связывает с вашим приложением. Не все SDK сообщают об этом, но когда эта информация предоставляется, она используется для группировки. Это означает, что если две трассировки стека отличаются только частями стека, которые не связаны с приложением, эти трассировки стека все равно будут сгруппированы вместе.
В зависимости от доступной информации для каждого кадра трассировки стека могут использоваться следующие данные:
- Имя модуля
- Нормализованное имя файла (с удаленными хэшами версий и т.д.)
- Нормализованная контекстная строка (по сути, очищенная версия исходного кода затронутой строки, если она предоставлена)
Эта группировка обычно работает хорошо, но две конкретные ситуации могут сбить ее с толку:
- Свернутый исходный код JavaScript разрушит группировку пагубным образом. Чтобы избежать этого, убедитесь, что Sentry может получить доступ к вашим исходным картам.
- Изменение трассировки стека путем введения нового уровня с помощью декораторов изменяет трассировку стека, поэтому группировка также изменится. Чтобы справиться с этим, многие SDK поддерживают скрытие нерелевантных кадров трассировки стека. Например, Python SDK пропустит все кадры стека с локальной переменной с именем __traceback_hide__, имеющей значение True.
Вы также можете увидеть, какие события были бы сгруппированы вместе, если бы учитывалось большее или меньшее количество кадров трассировки стека, используя обновленную разбивку группировки (только для ранних пользователей).
Группировка по исключениям
Если трассировка стека недоступна, но информация об исключении доступна, то группировка будет учитывать тип и значение исключения, если в событии присутствуют обе части данных. Эта группировка намного менее надежна из-за изменения сообщений об ошибках.
Группировка по сообщениям
Группировка возвращается к сообщениям, если трассировка стека, тип(type) и значение(value) исключения недоступны. Когда это произойдет, алгоритм группировки попытается использовать сообщение без каких-либо параметров. Если это недоступно, алгоритм группировки будет использовать полный текст сообщения.
Объединение проблем
Если у вас есть похожие проблемы, которые не были сгруппированы автоматически, и вы хотите уменьшить шум, вы можете сделать это, объединив их.
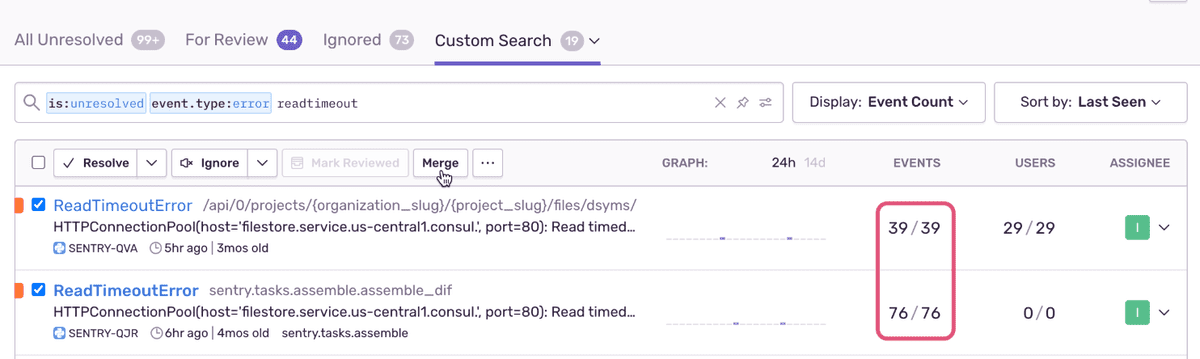
В этом примере перед слиянием есть две проблемы, которые очень похожи, но не были сгруппированы вместе. В одном выпуске за последние 24 часа произошло 39 событий, а в другом - 76:
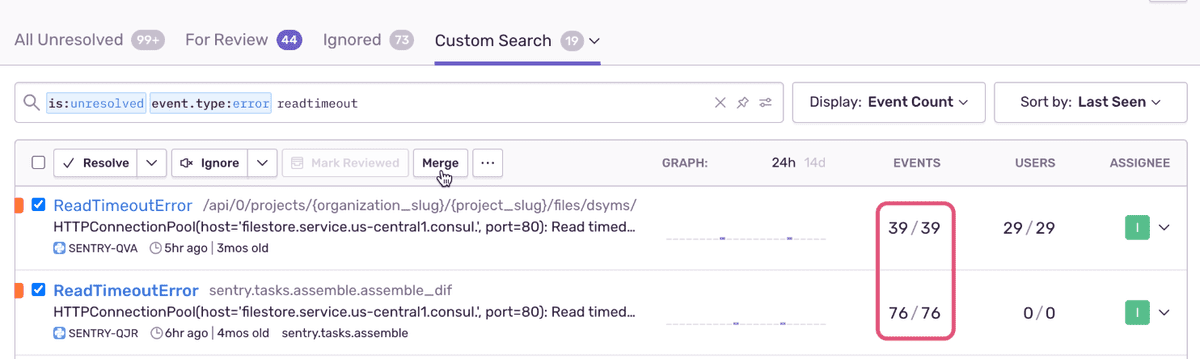
После того, как две проблемы объединены в одну, количество событий 115 по этой одной проблеме отражает, что они были сгруппированы вместе:
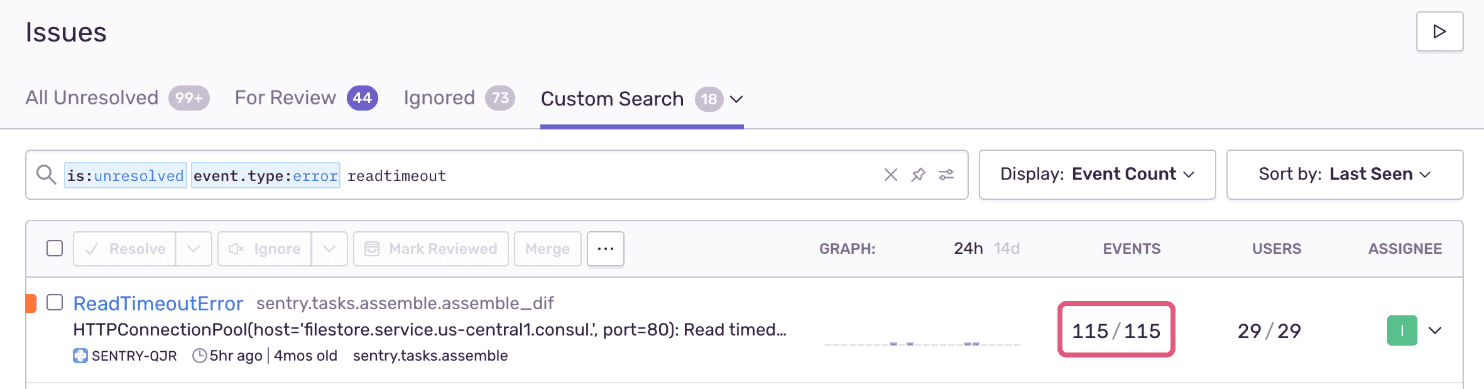
Вы также можете сделать это из одного выпуска. Перейдите на вкладку "Похожие проблемы"(Similar Issues), выберите все проблемы, которые вы хотите объединить, и нажмите "Объединить"(Merge):
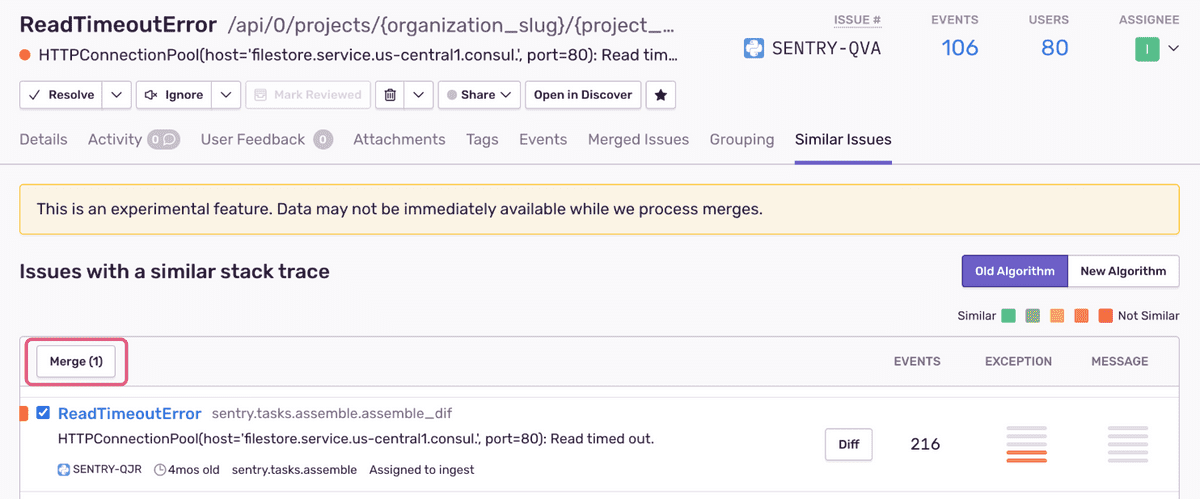
Если вы хотите отменить объединение проблем, перейдите на страницу "Сведений о проблеме" (Issue Details) и перейдите на вкладку Объединенные проблемы"(Merged Issues). Вы увидите отпечатки пальцев, которые были объединены в этот выпуск. Установите соответствующий флажок (флажки) и нажмите "Отключить"(Unmerge).
Важно отметить, что мы не выводим никаких новых правил группировки из тех, которыми вы объединяете проблемы. Будущие события будут добавлены в объединенный набор проблем по тем же критериям, по которым они были бы добавлены к отдельным проблемам, которые сейчас находятся в объединенном наборе.
Правила трассировки стека
Если вы используете трассировки стека для группировки, правила трассировки стека влияют на данные, которые подаются в алгоритм группировки. Эти правила можно настроить для каждого проекта в разделе [Проект] > Настройки > Группировка проблем > Правила трассировки стека ([Project] > Settings > Issue Grouping > Stack Trace Rules).
Каждая строка представляет собой одно правило; за одним или несколькими совпадающими выражениями следует одно или несколько действий, которые должны выполняться, когда все выражения совпадают. Все правила выполняются сверху вниз для всех фреймов в трассировке стека.
Синтаксис правил трассировки стека аналогичен:
matcher-name:expression other-matcher:expression ... action1 action2 ...
Если вы хотите отменить совпадение, поставьте перед выражением восклицательный знак (!). Если строка имеет префикс хэша (#), она игнорируется и рассматривается как комментарий.
Ниже приведен практический пример того, как это выглядит:
# отметьте все функции в пространстве имен std как находящиеся вне приложения
family:native stack.function:std::* -app
# отметьте весь код в модулях узла, чтобы он не был в приложении
stack.abs_path:**/node_modules/** -app
# удалите весь сгенерированный код javascript из всех группировок
stack.abs_path:**/generated/**.js -group
Совпадения
В строке может быть определено несколько совпадений. Доступны следующие сопоставления:
family
Соответствует общему семейству платформ, которое в настоящее время включает javascript, native и другие. Разделите правила запятыми, чтобы применить их к нескольким платформам.
family:javascript,native stack.abs_path:**/generated/** -group
stack.abs_path
Этот сопоставитель не чувствителен к регистру при глобальном поведении Unix на пути в трассировке стека. Разделители путей нормализуются до /. Как правило, если имя файла является относительным, оно все равно совпадает с **/.
# сопоставьте все файлы в разделе "проект" со стеком расширений ".c"
stack.abs_path:**/project/**.c +app
# совпадения по vendor/foo без вложенных папок
stack.abs_path:**/vendor/foo/*.c -app
# соответствует `foo.gen.c`, а также `foo/bar.gen.c`.
stack.abs_path:**/*.gen.c -group
stack.module
Модуль похож на path, но совпадает с модулем. Это не используется для Native, но используется для JavaScript, Python и аналогичных платформ. Совпадения чувствительны к регистру, и доступно обычное сглаживание. Обратите внимание, что модули не являются пакетами, что может привести к путанице в собственных средах.
stack.function
Совпадает с функцией в трассировке стека и чувствителен к регистру при нормальной глобализации.
stack.function:myproject_* +app
stack.function:malloc -group
stack.package
Совпадения в пакете в трассировке стека. Пакет - это контейнер, содержащий функцию или модуль. Это файл .jar, файл .dylib или что-то подобное. Применяются те же правила сопоставления, что и для path. Например, обычно это абсолютный путь.
stack.package:**/libcurl.dylib -group
app
Соответствует текущему состоянию встроенного флага фрейма трассировки стека. да означает, что фрейм находится в приложении, нет означает, что это не так
category
Соответствует встроенной или определенной пользователем категории фреймов. О том, как задать категорию, см. раздел Действия с переменными
category:telemetry -group
Категории по умолчанию
Категоризация фреймов широко используется нашим новейшим алгоритмом группировки, поэтому, если он у вас включен, вы можете сопоставлять по различным категориям, в том числе:
-
system - обнаруженные системой системные библиотеки
-
std - обнаруженные стандартные библиотеки
-
ui - фреймворки
-
driver - графические драйверы и т. д.
-
telemetry - отчеты о сбоях и аналитические фреймворки
Смотрите наш исходный код для получения полного списка встроенных категорий.
Совпадающие Родственные Рамки
Если информация об окружающих фреймах необходима для применения правила к фрейму, используйте синтаксис сопоставления вызывающего/вызываемого абонента. Например:
# Игнорировать фреймы в приложении, если они вызываются телеметрией
[ category:telemetry ] | app:yes -group
# Игнорировать системные фреймы, если они вызывают фреймы приложения
category:system | [ app:yes ] -group
Действия
Существует два типа действий: установка флага и переменных.
Флаги Действия
Флаг определяет действие, которое необходимо предпринять, если все совпадения совпадают, и он использует эти префиксы:
- + устанавливает флаг
- - сбрасывает флаг
- ^ применяется к кадрам выше соответствующего кадра (в направлении сбоя)
- v применяется к кадрам ниже соответствующего кадра (вдали от сбоя)
В качестве примера, -group ^-group удаляет соответствующий кадр и все кадры над ним из группировки.
- app: помечает или удаляет рамку в приложении
- group: добавляет или удаляет рамку из группировки
Переменные Действия
Может быть определен ограниченный набор переменных (variables) (переменная=значение):
- max-frames: задает общее количество кадров, которые будут учитываться при группировании. Значение по умолчанию равно 0, что означает "все кадры". Если установлено значение 3, учитываются только три верхних кадра
Примеры
stack.abs_path:**/node_modules/** -group
stack.abs_path:**/app/utils/requestError.jsx -group
stack.abs_path:**src/getsentry/src/getsentry/** +app
family:native max-frames=3
stack.function:fetchSavedSearches v-group
stack.abs_path:**/app/views/**.jsx stack.function:fetchData ^-group
family:native stack.function:SpawnThread v-app -app
family:native stack.function:_NSRaiseError ^-group -app
family:native stack.function:std::* -app
family:native stack.function:core::* -app
Рекомендации
Эти рекомендации значительно улучшат вашу готовую группировку.
Отмечайте фреймы в приложении
Чтобы активно улучшить свой опыт, помогите Sentry определить, какие кадры в вашей трассировке стека являются "встроенными" (частью вашего собственного приложения), а какие нет. SDK определяет правила по умолчанию, но во многих случаях это может быть улучшено и на сервере. В частности, для языков, где необходима обработка на стороне сервера (например C, C++ или JavaScript), лучше переопределить это на сервере.
Например, следующие метки все фреймы, которые находятся ниже определенного пространства имен C++, находятся в приложении:
stack.function:myapplication::* +app
Смотрите раздел Фреймы в приложении для Apple, чтобы узнать, как SDK sentry-cocoa помечает фреймы как встроенные в приложение.
Правила трассировки стека
Следующее помечает кадры из libdispatch, начинающиеся с _dispatch_, как неуместные.
stack.function:_dispatch_* +app
Вы также можете добиться того же результата, пометив другие кадры как "не в приложении". Однако, если это так, вы должны убедиться, что сначала для всех кадров установлено значение "в приложении", чтобы переопределить значения по умолчанию:
app:no +app
stack.function:std::* -app
stack.function:boost::* -app
Сначала вам нужно принудительно включить все фреймы в приложение, потому что, возможно, уже были некоторые значения по умолчанию, установленные клиентским SDK или более ранней обработкой.
Если вы используете SDK sentry-cocoa, вы также можете добиться того же результата, отметив другие фреймы, отсутствующие в приложении. В следующем примере функции из классов DataRequest и DownloadRequest помечены как не входящие в приложение.
stack.function:DataRequest* -app
stack.function:DownloadRequest* -app
Обрезка трассировки стека
Во многих случаях требуется удалить верхнюю или нижнюю часть трассировки стека. Например, многие базы кода используют общую функцию для генерации ошибки. В этом случае механизм ошибок появится как часть трассировки стека.
Например, если вы используете Rust, вы, вероятно, захотите удалить некоторые кадры, связанные с обработкой паники:
stack.function:std::panicking::begin_panic ^-app -app ^-group -group
stack.function:core::panicking::begin_panic ^-app -app ^-group -group
Здесь мы сообщаем системе, что все кадры от начала паники до места сбоя не являются частью приложения (включая сам фрейм паники). Все вышеприведенные кадры во всех случаях не имеют отношения к группировке.
Аналогично, вы также можете удалить основание трассировки стека. Это особенно полезно, если у вас есть разные основные циклы, которые управляют приложением:
stack.function:myapp::LinuxMainLoop v-group -group
stack.function:myapp::MacMainLoop v-group -group
stack.function:myapp::WinMainLoop v-group -group
Лимитирование фрейма трассировки стека
Это полезно не для всех проектов, но может хорошо работать для больших приложений с большим количеством сбоев. Стратегия по умолчанию заключается в том, чтобы учитывать большую часть трассировки стека, относящейся к группировке. Это означает, что каждая другая трассировка стека, которая приводит к сбою функции, приведет к созданию другой группы. Если вы этого не хотите, вы можете заставить группы быть намного больше, ограничив количество кадров, которые следует учитывать.
Например, если какой-либо из кадров в трассировке стека ссылается на общую внешнюю библиотеку, вы можете указать системе учитывать только верхние N кадров:
# всегда учитывайте только верхний 1 кадр для всех собственных событий
family:native max-frames=1
# если ошибка находится в proprietarymodule.so , учитывайте только верхние 2 кадра
family:native stack.package:**/proprietarymodule.so max-frames=2
# это функции, которые мы хотим рассмотреть гораздо подробнее в трассировке стека для
family:native stack.function:KnownBadFunction1 max-frames=5
family:native stack.function:KnownBadFunction2 max-frames=5
Правила отпечатков
Правила отпечатков также настраиваются с помощью конфигурации, аналогичной правилам трассировки стека, но синтаксис немного отличается. Средства сопоставления те же, но вместо переключения флагов присваивается отпечаток пальца, который полностью переопределяет группировку по умолчанию.
Эти правила можно настроить для каждого проекта в разделе [Проект] > Настройки > Группировка проблем > Правила отпечатков пальцев ([Project] > Settings > Issue Grouping > Fingerprint Rules). Этот параметр содержит поля ввода, в которых вы можете ввести пользовательские правила снятия отпечатков пальцев. Чтобы обновить правило:
- Определите логику сопоставления для группировки проблем вместе.
- Установите логику сопоставления и отпечаток для него.
Синтаксис следует синтаксису запросов Discover. Если вы хотите отменить совпадение, поставьте перед выражением восклицательный знак (!).
Sentry пытается выполнить сопоставление со всеми значениями, настроенными в отпечатке. В случае трассировки стека учитываются все кадры. Если данные события совпадают со всеми значениями в строке для сопоставления и выражения, то применяется отпечаток:
# Вы можете использовать комментарии для объяснения правил. Сами правила следуют за
# следующий синтаксис:
matcher:expression -> list of values
# Список значений может быть жестко задан или заменен значениями.
Ниже приведен практический пример, в котором исключения определенного типа группируются вместе:
error.type:DatabaseUnavailable -> system-down
error.type:ConnectionError -> system-down
error.value:"connection error: *" -> connection-error, {{ transaction }}
Теперь все события с типом ошибки DatabaseUnavailable или ConnectionError будут сгруппированы в проблему с типом system-down. Кроме того, все события со значением ошибки ошибка подключения будут сгруппированы по имени транзакции. Так, например, если ваши транзакции /api/users/foo / и /api/events/foo/ - оба со значением ошибка подключения - завершаются одинаково, Sentry создаст две проблемы, независимо от трассировки стека или любого другого метода группировки по умолчанию.
Совпадения
Совпадения обычно используют общий синтаксис. Доступны следующие совпадения:
error.type
Совпадения по типу исключения (имя исключения). Сопоставление выполняется глобально с учетом регистра.
error.type:ZeroDivisionError -> zero-division
error.type:ConnectionError -> connection-error
error.value
Совпадения по значению исключения. Ошибки или исключения часто имеют связанные с ними понятные для человека описания (значения). Этот механизм сопоставления допускает совпадение без учета регистра.
error.value:"connection error (code: *)" -> connection-error
error.value:"could not connect (*)" -> connection-error
message
Совпадения в сообщении журнала. Он также автоматически проверит наличие дополнительного значения исключения, поскольку их может быть трудно разделить. Сопоставление не зависит от регистра.
message:"system encountered a fatal problem: *" -> fatal-log
logger
Совпадения по имени регистратора, что полезно для объединения всех сообщений регистратора вместе. Это совпадение чувствительно к регистру.
logger:"com.myapp.mypackage.*" -> mypackage-logger
level
Совпадения на уровне журнала. Совпадение не чувствительно к регистру.
logger:"com.myapp.FooLogger" level:"error" -> mylogger-error
tags.tag_name
Совпадает по значению тега tag_name. Это может быть полезно для фильтрации определенных типов событий. Например, вы можете разделить события, вызванные определенным сервером:
tags.server_name:"canary-*.mycompany.internal" -> canary-events
stack.abs_path, stack.module, stack.function, stack.package, family, app - по аналогии с совпадениями стек-трейса
Комбинирование Совпадений
Когда объединяются несколько совпадений, все они должны совпадать. Средства сопоставления, которые работают с кадрами, все должны применяться к одному и тому же кадру; в противном случае они не считаются совпадением.
Например, если вы совпадаете как по имени функции, так и по имени модуля, то совпадение существует только в том случае, если фрейм совпадает как с именем функции, так и с именем модуля. Недостаточно, чтобы фрейм совпадал только с именем функции, даже если другой фрейм сам по себе соответствовал бы имени модуля.
# это соответствует, если существует фрейм с определенной функцией и именем модуля
# а также выдается определенный тип ошибки
error.type:ConnectionError stack.function:"connect" stack.module:"bot" -> bot-error
Переменные
В правой части отпечатка вы можете использовать постоянные значения и переменные. Переменные подставляются автоматически и имеют то же имя, что и совпадения, но они могут быть заполнены по-другому.
Переменные заключены в двойные фигурные скобки ({{ имя_переменной }}).
{{ default }}
Заполняет отпечаток по умолчанию, который был бы создан при обычной операции группировки. Это полезно, если вы хотите разделить уже существующую группу на что-то другое:
stack.function:"query_database" -> {{ default }}, {{ transaction }}
{{ transaction }}
При этом имя транзакции вводится в отпечаток. Это приведет к принудительному созданию группы для каждой транзакции:
error.type:"ApiError" -> api-error, {{ transaction }}
{{ error.type }}
При этом заполняется имя возникшей ошибки. Когда используются связанные исключения, это будет самая последняя выданная ошибка. Это приведет к принудительному созданию группы для каждого типа ошибки:
stack.function:"evaluate_script" -> script-evaluation, {{ error.type }}
{{ error.value }}
Это заполняет строковое значение возникшей ошибки. Когда используются связанные исключения, это будет самая последняя выданная ошибка. Обратите внимание, что это может привести к действительно плохим группам, когда значения ошибок часто меняются.
error.type:"ScriptError" -> script-evaluation, {{ error.value }}
{{ stack.function }}
Это заполняет имя функции "аварийного фрейма", также известного как самый верхний фрейм кода приложения.
error.type:"ScriptError" -> script-evaluation, {{ stack.function }}
{{ stack.abs_path }}
Это заполняет путь к "аварийному фрейму", также известному как самый верхний фрейм кода приложения.
error.type:"ScriptError" -> script-evaluation, {{ stack.abs_path }}
{{ stack.filename }}
Это похоже на stack.abs_path, но заполнит только относительное имя файла:
error.type:"ScriptError" -> script-evaluation, {{ stack.filename }}
{{ stack.module }}
Это заполняет имя модуля "аварийного фрейма", также известного как самый верхний фрейм кода приложения.
error.type:"ScriptError" -> script-evaluation, {{ stack.module }}
{{ stack.package }}
Это заполняет имя пакета (объектного файла) "фрейма сбоя", также известного как самый верхний фрейм кода приложения.
stack.function:"assert" -> assertion, {{ stack.package }}
{{ logger }}
При этом заполняется имя логгера, вызвавшего событие.
message:"critical connection error*" -> connection-error, {{ logger }}
{{ level }}
При этом заполняется имя уровня журнала, который использовался для создания события.
message:"connection error*" -> connection-error, {{ logger }}, {{ level }}
{{ tags.tag_name }}
Это вводит значение тега в отпечаток, который может, например, использоваться для разделения событий по имени сервера или чему-то подобному.
message:"connection error*" -> connection-error, {{ tags.server_name }}
{{ message }}
Это заполняет сообщение о событии (аналогично error.value, но для захваченных сообщений). Обратите внимание, что это может привести к созданию групп с низким качеством данных, если сообщения часто меняются:
logger:"com.foo.auditlogger.*" -> audit-log, {{ message }}
Пользовательские заголовки
Когда вы используете дактилоскопию для группировки событий, иногда может быть полезно также изменить заголовок события по умолчанию. Обычно заголовок события - это тип и значение исключения (или самые популярные имена функций для определенных платформ). При группировании по пользовательским правилам это название часто может вводить в заблуждение. Например, если вы группируете регистраторы вместе, вы можете захотеть назвать группу в честь этого регистратора. Это можно сделать, установив атрибут title следующим образом:
logger:my.package.* level:error -> error-logger, {{ logger }} title="Error from Logger {{ logger }}"
Разбивка по группам
Эта функция доступна только в том случае, если вы участвуете в программе раннего внедрения. Функции, доступные для первых пользователей, все еще находятся в стадии разработки и могут содержать ошибки. Мы понимаем иронию ситуации.
Если вы заинтересованы в раннем внедрении, вы можете включить / отключить статус раннего внедрения в вашей организации в общих настройках. Это затронет всех пользователей в вашей организации и может быть так же легко отключено.
Текущий алгоритм группировки Sentry помещает два события ошибки в одну и ту же проблему, если они имеют одинаковую трассировку стека. Такой подход иногда создает несколько различных проблем для ошибок с одной и той же основной причиной.
Если время от времени возникают две разные проблемы, вы можете уменьшить шум, объединив эти проблемы вручную. В качестве альтернативы, если вы хотите, чтобы по умолчанию были установлены более грубые группы проблем (следовательно, меньше проблем), следуйте описанному здесь процессу.
Использование обновленной разбивки по группам
После включения обновленного алгоритма группировки разбивка по группам позволяет перемещаться по подгруппам проблемы, чтобы увидеть, какие события были бы сгруппированы вместе, если бы учитывалась большая часть трассировки стека. Вы можете сделать это на вкладке "Группировка" проблемы.
Например, если у вас есть функция сбоя, вызываемая из нескольких мест в вашем коде ("промежуточная функция" "1" и "2"), при перемещении ползунка до упора влево для группировки учитывается только фрейм сбоя, и все события сортируются по одной и той же проблеме независимо от местоположения вызывающего абонента:
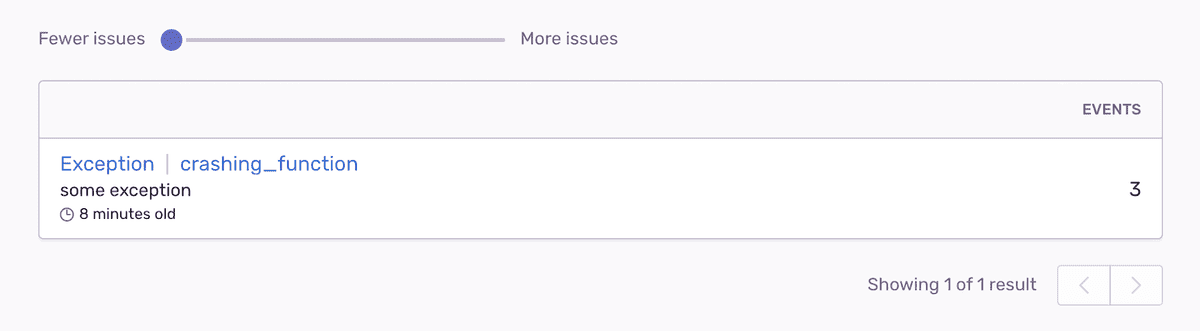
Когда вы перемещаете ползунок вправо, вы можете увидеть, какие группы были бы созданы, если бы также учитывался вызывающий фрейм:

Вы можете добавить еще один уровень, переместив ползунок до упора вправо. Однако это не добавляет никаких новых подгрупп, поскольку обе вызывающие функции сами вызываются из одного и того же местоположения (main):

Сторожевые и Префиксные фреймы
При включенной разбивке по группам Sentry группирует события, определяя наиболее интересную группу кадров, которую он может найти в трассировке стека.
Чтобы пометить фреймы как интересные, используйте действия +sentinel и +prefix в правилах трассировки стека. Для первого уровня наш алгоритм ищет первый кадр X, который помечен как sentinel. Отпечаток этого кадра добавляется к уровню. Если X также является префиксным кадром, также добавляется следующий кадр Y. Если Y снова является префиксным кадром, добавляется следующий кадр Z и так далее.
Если контрольный кадр не найден, каждый кадр, который вносит свой вклад в группировку в соответствии с обычными правилами трассировки стека (например, +group), представляет свой собственный уровень детализации.
Пример
Рассмотрим трассировку стека с функциями a, b, c, d, e, f, g, h, где a является фреймом сбоя, а h - базой потока. Представьте, что у вас определены следующие правила трассировки стека:
function:b +sentinel +prefix
function:c +prefix
function:f +sentinel
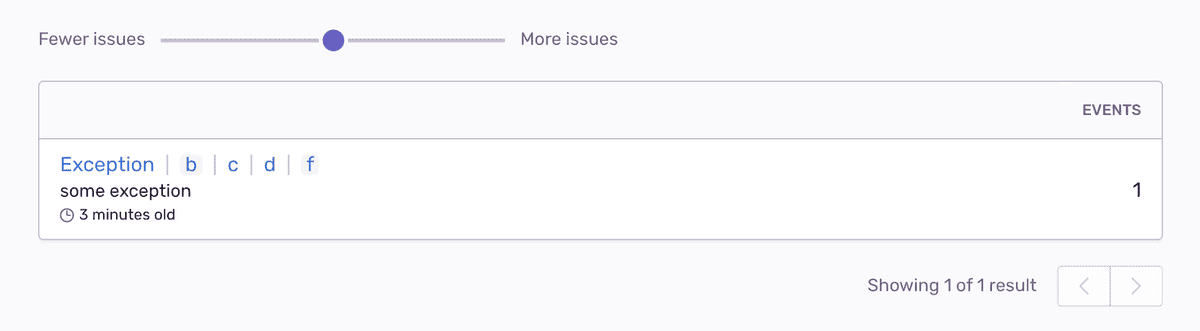
В этом случае
- b используется для группировки, потому что это первый контрольный кадр,
- c используется для группировки, потому что b является префиксным кадром,
- d используется для группировки, потому что c является префиксным кадром.
Это становится видимым на вкладке Разбивка(Breakdown):

Повышение уровня добавляет второго стража:
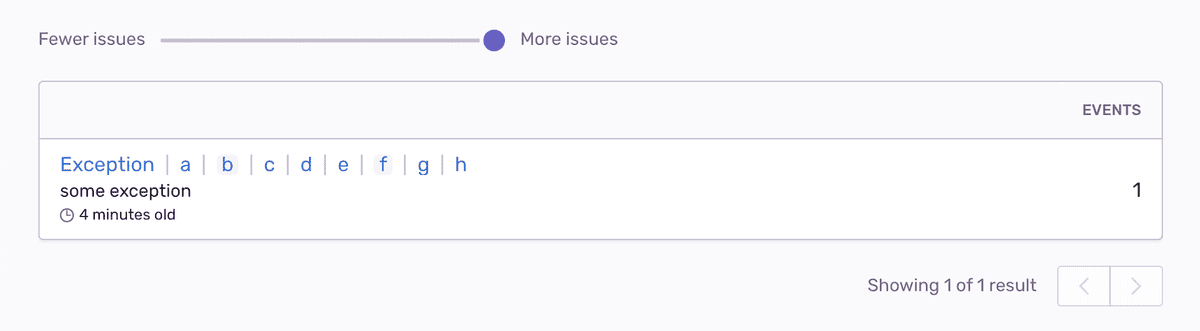
Наконец, самый глубокий уровень содержит всю трассировку стека, игнорируя контрольные и префиксные фреймы:
---
Благодарю за внимание.
Вступайте в нашу телеграмм-группу Инфостарт