













В данной статье хотим рассказать об одном нашем непростом расследовании, в котором удалось собрать сразу несколько проблем на разных уровнях инфраструктуры заказчика и изначальной методологии ведения учета. Само расследование в какой-то момент стало напоминать детективную историю, с роялями в кустах, ошибками платформы, странным поведением пользователей и магическим поведением хорошо знакомых механизмов. Но мы реалисты, поэтому все проблемы были выявлены и устранены J
Инфраструктура
Платформа 1С:Предприятие 8, версия 8.3.17.1549
1С:ERP Управление предприятием 2, версия 2.5.5.77
Сервер СУБД: MS SQL Server
Виртуализация средствами VMware
Количество баз ERP: 20+
Все 20 ИБ работают в режиме «20 кластеров на одной ВМ»:
- один сервер приложений 1C
- один сервер СУБД
- один сервер лицензирования
Проблема, с которой пришел заказчик
В одном крупном отечественном публичном акционерном обществе, в более 20 дочерних организаций (далее ДО) учет ведется в 1С:ERP Управление предприятием 2 (далее ERP) – по базе на ДО. В одной из баз ДО (наиболее крупной) процедуры быстрого закрытия месяца выполнялись неприемлемо долго.

Детализация проблемы – понимаем масштаб бедствия
Что показало обследование текущего положения дел:
1. Сроки выполнения закрытия месяца не устраивали заказчика абсолютно. Например, в самой крупной ДО вся процедура стала выполняться более суток!
2. А самая длительная операция – непосредственно расчет себестоимости, – выполнялась порядка 9-11 часов.
3. Длительность операции отражения документов в регламентированном учете достигала 12 часов.
4. Кроме этого, сам расчет себестоимости далеко не всегда завершался успешно. Часто возникала ситуация, когда фоновое задание внезапно неожиданно прекращало свою работу. Все приходилось начинать заново, что катастрофически замедляло весь процесс и требовало «ручного» контроля выполнения требуемых операций.
5. Исходя из аппаратных мощностей заказчика были попытки запустить на одновременное выполнение закрытие месяца в 20+ баз ERP, но эти попытки к успеху не привели – фатальная деградация производительности возникала и в этом случае.
На момент обращения к нам у заказчика был организован такой порядок: закрытие месяца запускалось последовательно в каждой базе ERP. С дежурством ответственных лиц по круглосуточному графику.
Самое начало – декомпозиция проблемы
После обследования проблему заказчика укрупненно разбили на две подзадачи:
- поиск и устранение проблем стабильности, то есть выявление и борьба с таинственным завершением задания расчета
- поиск и устранение проблем быстродействия (производительности)
Решение задачи стабильности
Решать задачи быстродействия без устранения проблем стабильности было бы не корректно, поэтому начинаем со стабильности.
То, что фоновое задание расчета регулярно «падало» без каких-либо явных причин, на наш взгляд, требовало первоочередного решения.
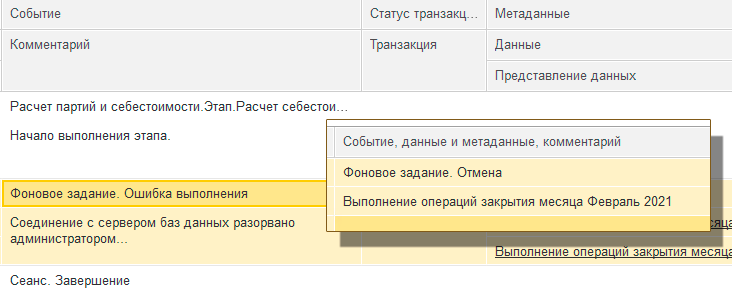
В момент прерывания фонового задания единственное, что появлялось в Журнале регистрации 1С (далее ЖР 1С) – это запись, что фоновое задание «отменили». Здесь важно отметить: пользователи «всё отрицали», а сама отмена происходила по ночам, когда люди никак на это не влияли (спали).
Для начала нужно убедиться, что аппаратные (в данном случае – средства виртуализации), средства СУБД, сервера приложений и другие программные средства работают в штатном режиме. То есть исключить ошибки и проблемы на этом уровне – провести аудит инфраструктуры.
Для этого обновили параметры Технологического журнала 1С (далее ТЖ 1С) с целью сбора более полной картины работы платформы 1С. Также настроили сбор счетчиков загрузки оборудования при помощи perfmon.
На инфраструктурном уровне было выявлено три ключевые проблемы:
1. Ощутимо длительная миграция Виртуальных машин (далее ВМ).
2. Большое количество переподписок на уровне хостов.
3. Софтверное ограничение на количество операций ввода-вывода для дисковой подсистемы в настройках ВМ, особенно на дисках под СУБД.
В связи с проблемами 1 (длительная миграция) и 2 (много переподписок) наблюдались «фризы» гостевой ОС, на которой располагались серверы 1С и СУБД – это показал анализ ТЖ 1С. Такая ситуация приводила к аварийному завершению процессов в кластерах 1С – подсистема отслеживания разрыва соединений 1С завершала их по таймауту, что было вполне штатным поведением в этом случае.
Решением здесь стало устранение миграций ВМ (запретили в настройках). Настроили выделение хостов таким образом, чтобы снизить количество переподписок и их перегрузки. Дополнительно увеличили значения «ping period» и «ping timeout». Теперь время миграции сократилось с минут до секунд, а кластер 1С это переживал штатно и аварийно процессы не завершал.

Вторая проблема была связана с бизнес-процессами заказчика, т.к. каждый ресурс для ВМ предоставляется «как сервис» и настройки изначально были установлены в режим минимального потребления. Ограничение IOPS для дисков с базой данных и tempdb на сервере СУБД было установлено в 8000. Наблюдалось огромное накопленное ожидание времени отклика и очереди к дискам.
Здесь добились снятия ограничений.
Решив проблемы инфраструктурного уровня, вернулись к проблемам внутри 1С. Оказалось, что проблема отмены фонового задания никуда не делась. С одной стороны, мы видим, что оно не завершается аварийно – то есть с точки зрения работы кластера 1С проблем нет. С другой стороны, по факту фоновое задание не завершено успешно.
Складывается ощущение, что какой-то пользователь отменяет выполнение операции (случайно или нет). Клиент утверждает, что так его пользователи в системе 1С себя не ведут. Не забываем, также, про ночь - чаще всего проблема возникает в момент неактивности пользователей.
ОКей. Настраиваем ТЖ 1С. Помимо «джентльменского набора» из событий ADMIN, CLSTR, PROC, ATTN, EXCP, SESN и CONN, которые мы собираем во всех случаях, здесь нам, кажется, придется добавить и события по ”SCALL” и “CALL”, причем с контекстами - мы хотим понять, кто сделал вызов, который привел к отмене задания. Чтобы логи не были большими, добавим фильтр по имени метода MName=cancelJobs:
<event>
<eq property="name" value="CALL"/>
<eq property="MName" value="cancelJobs"/>
</event>
<event>
<eq property="name" value="SCALL"/>
<eq property="MName" value="cancelJobs"/>
</event>
Запускаем контрольный расчет. Дожидаемся очередной «отмены».
Смотрим в ТЖ 1С: на контексты, на пользователей, в них участвующих. Начинаем во всем этом разбираться…
*** По соображениям NDA мы не можем опубликовать здесь логи заказчика, но так как мы хорошо разобрались в проблеме - для статьи воспроизвели аналогичную ситуацию у себя. Публикуем оттуда ключевые моменты ***
Конечно, мы видим в журнале событие ADMIN с Func=killClient:
34:27.654029-0,ADMIN,2,process=rphost,p:processName=ServerJobExecutorContext,OSThread=16140,t:clientID=20,t:applicationName=JobScheduler,t:computerName=ITE-MP-00159,Func=killClient,ClusterID=21a7019b-f1a0-422e-9387-95dab1819984,ConnectionID=0f337f02-6264-4b0d-86a5-917909aa7cc3,Mode=0,Ref=Expert_ERP(Expert_ERP),Host=ITE-MP-00159,Connection=171,Administrator=Unknown,Result=Success
Вслед за ним после нотификации CALL с MName=killConnections видим EXCP, тот самый, который увидел пользователь:
34:27.670002-0,EXCP,4,process=rphost,p:processName=Expert_ERP,OSThread=17276,t:clientID=35,t:applicationName=BackgroundJob,t:computerName=ITE-MP-00159,t:connectID=171,SessionID=5,Usr=Administrator,Exception=95c658d1-d3d5-4ea9-8a81-1bf820fea4a8,Descr='src\rscalls\src\RemoteCallListenerImpl.cpp(4014):
95c658d1-d3d5-4ea9-8a81-1bf820fea4a8: Сеанс работы завершен администратором.',Context='
ОбщийМодуль.ЗакрытиеМесяцаСервер.Модуль : 3322 : Обработки.ОперацииЗакрытияМесяца.ВыполнитьРасчетЭтапов(ПараметрыЗапуска);
Эта информация нам ничего не дает. Зато сделанный примерно в то же время в сеансе пользователя, запустившего фоновое задание, исходящий вызов:
34:26.779013-4,SCALL,3,process=rphost,p:processName=Expert_ERP,OSThread=23516,t:clientID=19,t:applicationName=1CV8C,t:computerName=ITE-MP-00159,t:connectID=1,SessionID=1,Usr=Administrator,AppID=1CV8C,ClientID=46,Interface=90d50089-2b1d-4316-ad85-32c83d325a76,IName=IClusterJobManager,Method=9,CallID=12735,MName=cancelJobs,DstClientID=62,Context='Форма.Вызов : Обработка.ОперацииЗакрытияМесяца.Форма.ЗакрытиеМесяца.Модуль.ЗавершениеЗаданийПриЗакрытииФормы
Обработка.ОперацииЗакрытияМесяца.Форма.ЗакрытиеМесяца.Форма : 1293 : ОтменитьФоновоеЗадание(ИдентификаторЗаданияРасчетаЭтапов, Ложь);
Обработка.ОперацииЗакрытияМесяца.Форма.ЗакрытиеМесяца.Форма : 1939 : Если НЕ ЗакрытиеМесяцаСервер.ОтменитьВыполнениеФоновогоЗадания(ИдентификаторЗадания) Тогда
ОбщийМодуль.ЗакрытиеМесяцаСервер.Модуль : 4732 : СостояниеЗадания.Задание.Отменить();'
Наконец приоткрываем завесу тайны.
…оказывается, пользователь действительно не нажимал никаких «отмен».
НО!
Но пользователь запускал расчет через управляемую форму, которую затем закрывал. И как видно из отрывка кода этой формы – при её закрытии происходило завершение всех фоновых заданий, связанных с ней.

Хорошо. Проблему неожиданной «отмены» фонового задания выявили. заказчику рекомендовали изменить логику поведения формы, ответственных пользователей попросили на период выполнения процесса закрытия месяца – форму не закрывать.
В полной уверенности устранения проблемы пользователь запускает вечером закрытие месяца с фоновым заданием расчета себестоимости, оставляет открытой форму и уходит домой. А утром наблюдает не результат расчета, а очередную ошибку «отмены» фонового задания. Все это попахивает какой-то «магией».
Проводим очередной анализ логов и контекстов. Картина - что и в прошлый раз, как будто бы пользователь закрыл форму. На этот раз выясняем, что на терминальном сервере по таймауту бездействия была закрыта сессия 1С. По коду видно, что завершение работы приложения не вызывало завершения фонового задания, так отрабатывает именно закрытие формы, и почему-то так отрабатывало закрытие сессии в терминале.
Разбираемся с настройками терминального сервера – админы настроили такое поведение для всех приложений, дабы снизить нагрузку на любимый сервер.
ОКей, меняем настройки терминального сервера так, чтобы убрать таймауты и сессии пользователей не завершать.
Теперь [наконец-то] все заработало как ожидалось – пользователь вечером стартует процесс, с утра наблюдает успешное его завершение. Несколько дней в тестовом и продуктивном контурах проходят под нашим наблюдением успешно. Ситуация воспроизводится стабильно корректно и казалось бы – можно завершать расследования по первой части (стабильность) и переходить ко второй (быстродействие).
Но в один из дней в тестовом контуре заказчика мы ловим очередную проблему с тяжелым фоновым заданием. В одном из тестов оно снова завершается досрочно. На этот раз оно не «отменено». На этот раз завершается аварийно. Причина в логах указано как:
Соединение с сервером баз данных разорвано администратором
Обращаемся к администраторам с вопросом, зачем они с нами так. Ожидаемый ответ: «мы ничего не делали». Идем в логи ;)
В логах СУБД чисто – никаких команд на разрыв нет. Сервер СУБД вроде как работает штатно. Опять какая-то «магия».
И про этот этап расследования хочется рассказать более подробно. Дело в том, что быстро и используя знакомые подручные средства выловить проблему не удалось. Мало того, в начале этого этапа мы даже свернули не туда.
При анализе ТЖ 1С видно – процессы не завершаются, на серверах СУБД нет никакой характерной активности (команду «kill» никто, включая платформу 1С, не вызывал). Следов зависаний и перезапуска ВМ – не видим. Как будто бы все работает штатно.
Единственное, за что зацепился глаз – за 20 минут до аварийного завершения фонового задания, один из сеансов записал в ТЖ 1С ошибку соединения с сервером баз данных.
Смутило именно точное число – 20 минут. Поэтому изначально предположили, что речь идет о каких-то кэшах, сеансовых данных и тому подобных вещах. И какое-то время потратили на попытку разобраться, что, где и как может мешать нормальной работе системы. Это на какое-то время отвлекло нас от более глубокого анализа инфраструктуры: изначально мы сразу сделали экспресс-аудит и выдали набор стандартных рекомендаций по самым очевидным вещам, поэтому ожидалось что наши рекомендации учтены и работы по замечаниям выполнены.
Эти «20 минут» не давали покоя, поэтому не найдя ничего на уровне прикладного ПО и СУБД, мы снова вернулись на уровень инфраструктуры. Детальное расследование показало, что в момент времени «за 20 минут до завершения фонового задания» происходила миграция ВМ – очень быстро и кратковременно. Поэтому в ТЖ это даже никак и не отражалось. При таком стечении обстоятельств соединения с СУБД в пуле, сформированном платформой 1С, могут оказаться невалидны: попытка их использования даже спустя 20 минут после миграции выполняется платформой, но тут же завершается ошибкой.
Дальнейшее расследование привело к регистрации ошибки платформы 1С:

Иными словами, фоновое задание само по себе оказалось ни при чем. Сказалось неудачное стечение обстоятельств в комбинации с работой механизмов платформы 1С и средств виртуализации.
Коллеги из 1С доработали механику поведения платформы в подобных случаях и в релизе 8.3.18 подобного рода ошибки были исключены – платформа 1С стала проверять валидность соединений там, где это возможно.
Заказчику было рекомендовано обновить версию платформы 1С.
Здесь можно подвести некоторые итоги – так сказать, зафиксировать промежуточный результат:
- Решены все проблемы стабильности – в первую очередь в работе длительного фонового задания расчета себестоимости.
- При этом расчет выполняется стабильно, но стабильно медленно J
Переходим к решению вопросов производительности
Изучаем подробный протокол расчета себестоимости. В частности, «топ 10» самых медленных этапов.
На примере самого крупного ДО заказчика показатели были такими:
- расчет согласно протоколу в среднем длился 9 часов
- при этом на этапе Партионный учет: ЗаписатьСформированныеДвижения в течение более 3 часов записывалось свыше 10 миллионов результирующих записей в регистры по итогам этого расчета
Ищем причины такого поведения. Одна из ключевых причин оказалась методического свойства – такое огромное количество записей в регистре порождалось не самыми оптимальными настройками статей расходов и заполнением первичных документов поступления расходов.
Для статей, которые распределяются на производственные затраты по всем подразделениям, установлена аналитика расходов – подразделение. При оформлении поступления таких расходов в документе подразделение указывается в шапке, но затем еще в строках пользователями указывается иная, отличная от подразделения в шапке аналитика затрат. Именно это порождало избыточные записи прихода прочих затрат, которые далее в такой же детализации декартовым произведением распределялись на приходные записи незавершенного производства по всем подразделениям выпуска.
После анализа ситуации пользователям запретили заполнять аналитику по подразделениям в табличных частях документов поступлений расходов. Записи в регистры начали выполняться только с аналитикой из шапки этих документов. На бизнес-логику заказчика это никаким образом не повлияло - потом всё равно всё распределялось на все подразделения выпуска
В итоге нам удалось снизить время расчета с 9 часов до 4.5 часов.
Причем подавляющее время из общего по-прежнему занимала запись движений в регистры.
Для оптимизации этого процесса было решено распараллелить запись движений внутри каждого регистра (настройки по умолчанию подразумевают параллельную запись в разные регистры, но в рамках одного - строго последовательную). Для этого в настройках параметров расчета в ERP разрешили параллельную запись движений в 20 потоков. Кроме этого, в конфигурацию самой СУБД внесли следующие изменения:
- Max Degree of Parallelism (MAXDOP) = 8
- Cost Threshold for Parallelism (cost degree) = 400
- TF 1224 (заранее понимаем, что без него никак)
ВНИМАНИЕ! Настройки СУБД не являются рекомендованными, подобраны в этой конкретной ситуации опытным путем и приводятся только с целью ознакомления.
Результат после применения такой настройки по времени выполнения снизился с 4.5 часов до 2.5 часов.
Казалось бы, целевой показатель на базе самого крупного ДО достигнут и можно выдыхать J
Ан нет!
Все еще осталась проблема медленного выполнения закрытия месяца в случае, когда параллельно запущено закрытие месяца в более чем одной базе ERP. Да, стало работать быстрее, но совокупно работает медленнее в каждой базе, чем если бы запускать ее в одиночном режиме. А быть так не должно.
Тестовый запуск закрытия месяца в двух ДО одновременно показывает следующее:
- загрузка процессора на серверах не выше 40 %
- RAM на сервере кластера 1С – свободна на 50%
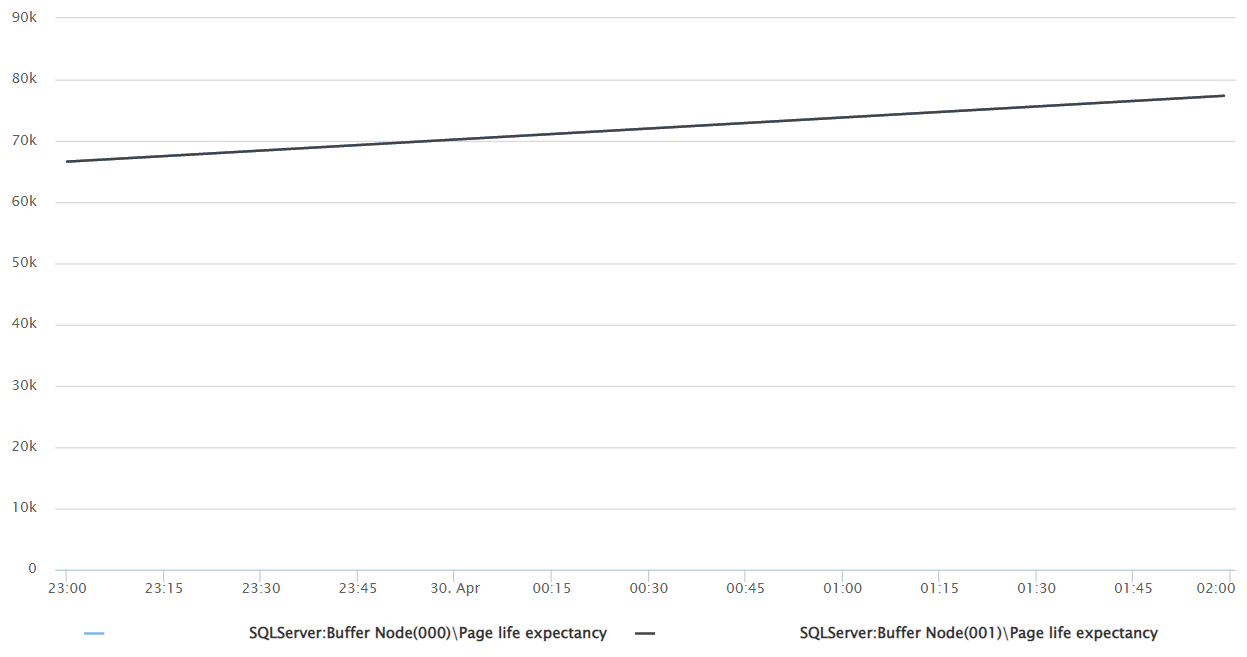
- PLE на сервере СУБД не падает ниже 20-30 тысяч
- buffer cache hit ratio 100%
- время отклика дисков – ниже 10 миллисекунд
То есть показатели «железа» в норме и с большим запасом. Однако время расчета и в основном в части записи движений увеличивается в 1.5-2 раза в случае запуска в нескольких базах одновременно. И все эти показатели почти никак не отличаются от показателей во время закрытия месяца в какой-нибудь одной базе, но скорость самого закрытия в таком режиме – в два раза выше.
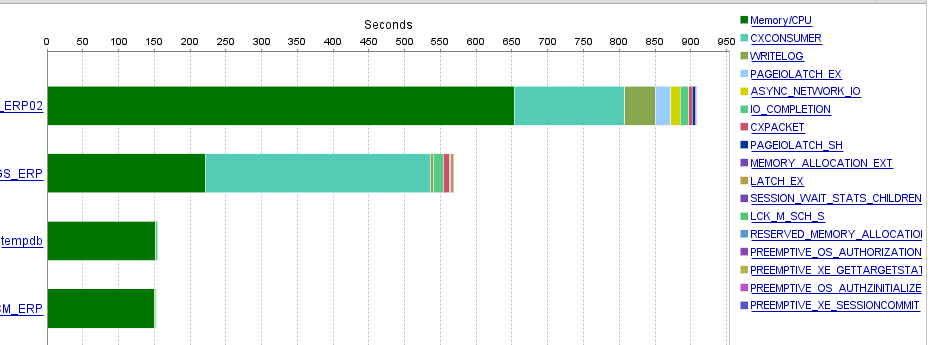
Вот некоторые показатели, полученные из SolarWind (промышленное программное обеспечение для управления сетями, системами и инфраструктурой) заказчика:
Ожидания СУБД при расчете в одной базе
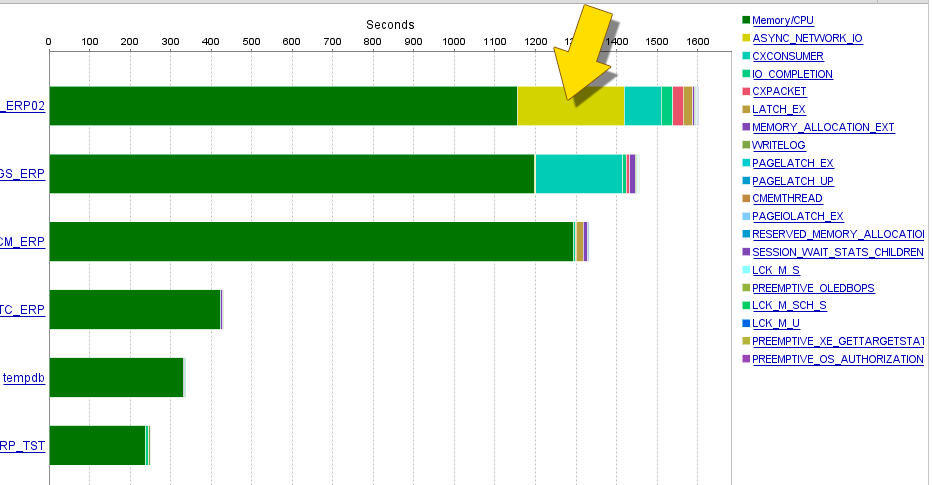
Ожидания СУБД при параллельном расчете в 2 ИБ
СУБД: Page life expectancy
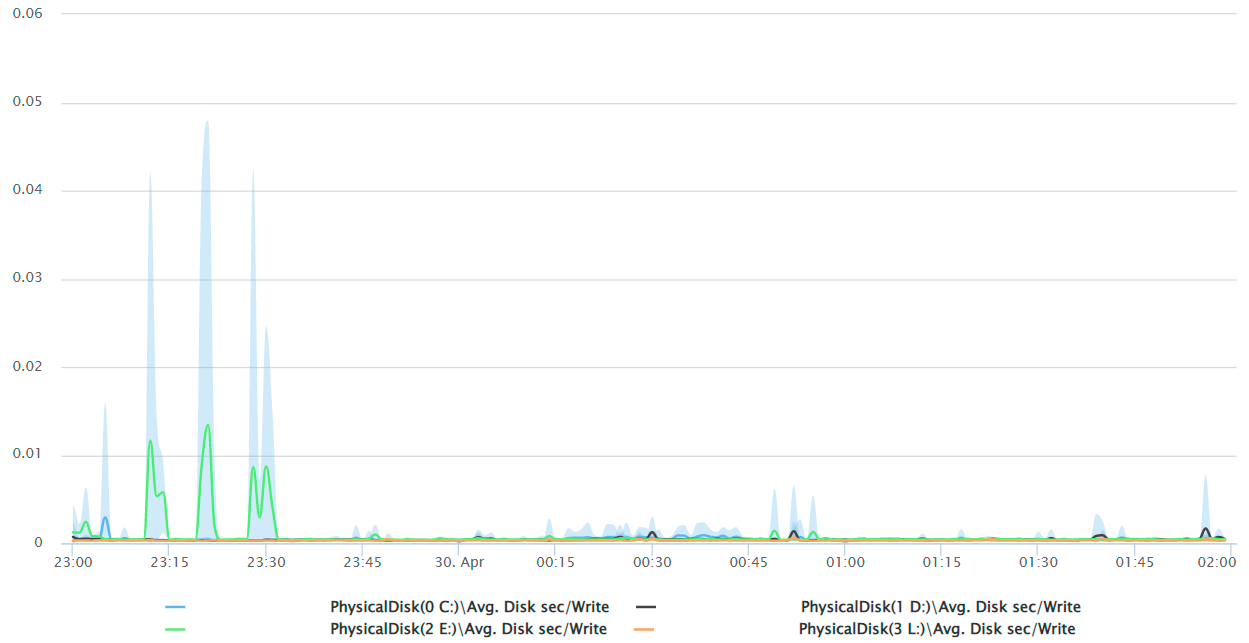
СУБД: Avg. Disk sec/Write
СУБД: % Processor Time
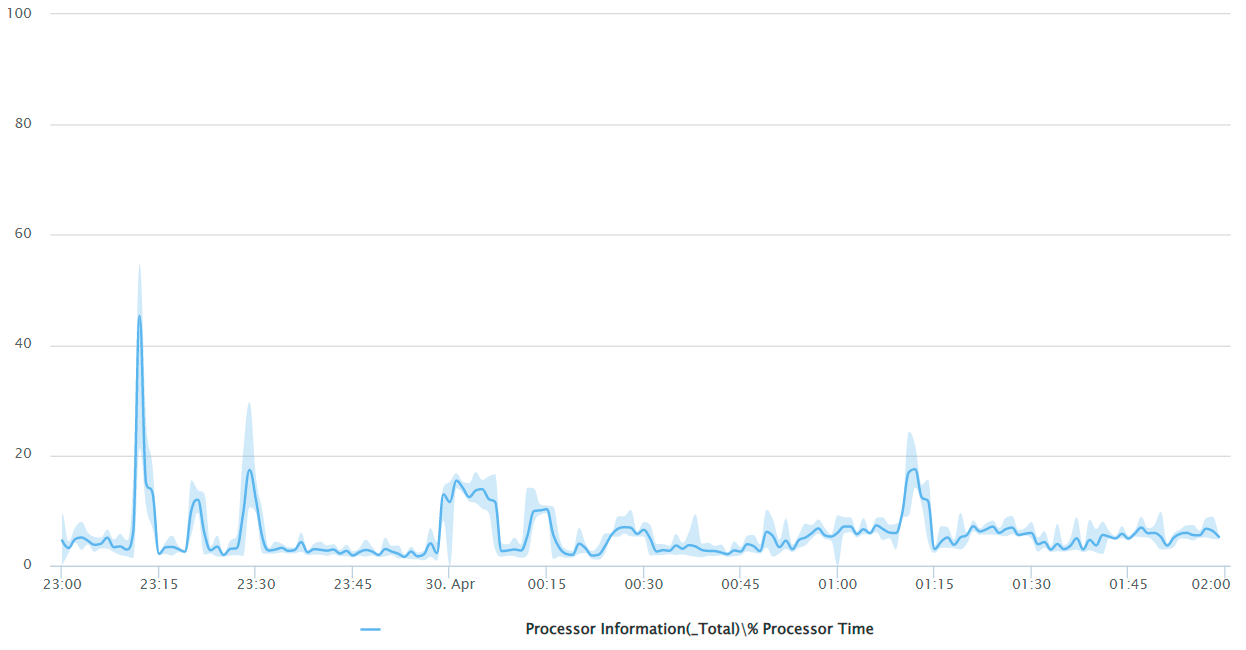
Внимательно все снова изучив (и не по одному разу), предполагаем, что проблема где-то в сети (потому что все остальное у нас покрыто метриками). Точнее понять, что именно и с чем это связано – не получается. Ни один график загрузки оборудования явных подсказок не дает.

Начинаем этот этап расследования с анализа загрузки сервера СУБД, с учетом странного поведения сети при параллельном расчете (ASYNC_NETWORK_IO на графике параллельной работы двух ИБ выше).
Для этого используем хорошо себя зарекомендовавший Windows Performance Recorder (WPR) в паре с Windows Performance Analyzer (WPA) – подчас именно они выручают в ситуациях, когда «ничего не понятно, но что-то происходит».
Замечаем на сервере СУБД на одном ядре загрузку CPU system time, близкую при параллельном расчете к 100%. При этом остальные ядра могут простаивать. Явно что-то происходит в системных функциях ОС.
Для того чтобы выяснить, что именно происходит в системном слое ОС, включаем трассировку WPR. Открываем в WPA и практически сразу обращаем внимание на системный драйвер «NDIS.SYS» – он с большим отрывом оказался в топе, причем работает действительно на одном ядре в один момент времени - том самом, которое в то же самое время показывало 100% загрузку в привилегированном режиме:
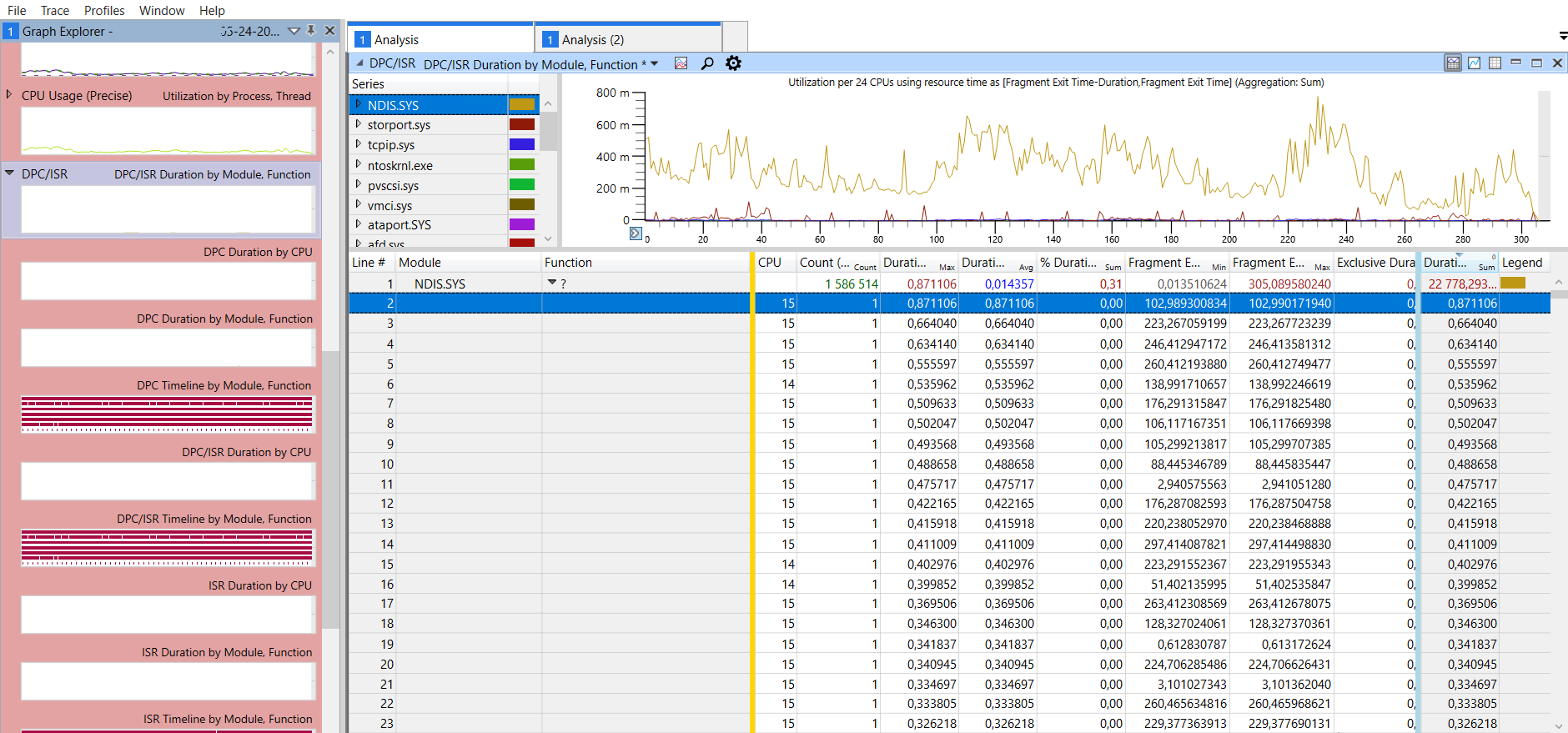
Иными словами, анализ трассировки WPR сервера СУБД подтвердил предположение о том, что наибольшую нагрузку на CPU в привилегированном режиме создает драйвер сетевого интерфейса NDIS.SYS.
К слову, предположение о возможной проблеме нами уже озвучивалось ранее в проколе рекомендаций по итогам экспресс-аудита инфраструктуры. Тогда мы отмечали высокую нагрузку на одно ядро на сервере СУБД, источник которой на тот момент не был установлен.
Полезно тут отметить вот что. Важно перепроверять не только свои действия/гипотезы, но и работу других команд в процессе решения общей проблемы. Здесь мы выдали в самом начале рекомендации «как устранить», но не проверили их применение. И отсутствие выполнения работ по нашим рекомендациям потом замедлило и усложнило нам путь в решении проблемы. В общем, принцип «доверяй, но проверяй» работает и на ИТ-проектах. Не наступайте на наши грабли! И мы тоже больше не будем ;)
Разбираемся. В настройках ВМ есть параметр Receive Side Scaling (RSS), отвечающий за способ разбора сетевого трафика – одним ядром это выполняется (выключен), либо распараллеливается (включен и указано количество). И в данном случае RSS был включен для ОС, но выключен для сетевого адаптера vmxnet3:
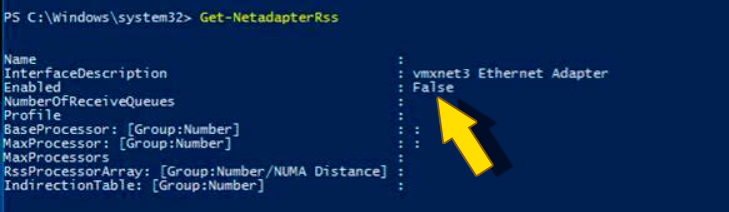
По рекомендации VMware включаем RSS для адаптера и выполняем его настройку, в частности, задаем Max Number of RSS processors = 4.
Проверяем. Вуаля: разницы при параллельном и последовательном расчете в нескольких базах ERP теперь нет. Сервер СУБД наконец-то загружен на все 70-80%.
Заказчик полученными показателями доволен ;)
Надеемся, статья пригодится не только с точки зрения детективной составляющей, но будет также полезна и в качестве примера поиска возможных путей для устранения неполадок в ситуациях с вашими заказчиками.
Благодарим за внимание!
Вместо Post Scriptum
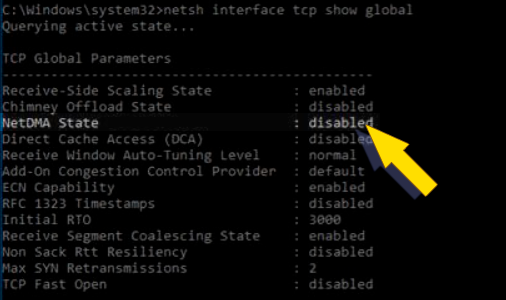
Конечно, процесс оптимизации можно продолжать [бесконечно]. Например, мы выявили что был также выключен прямой доступ к памяти (NetDMA). При необходимости, можно включить и его:
Узнать подробнее про WPR можно здесь:
https://docs.microsoft.com/ru-ru/windows-hardware/test/wpt/windows-performance-recorder
Про WPA там же рядом:
https://docs.microsoft.com/ru-ru/windows-hardware/test/wpt/windows-performance-analyzer
Что такое RSS, как технология обеспечивает распределение обработки входящих сетевых потоков по нескольким vCPU – неплохо описано в базе данных Microsoft:
Рекомендации по включению и настройке RSS от VMware:
https://kb.vmware.com/s/article/2008925
Примеры настройки RSS:
Обязательно убедитесь, что установлены актуальные версии драйверов!
Вступайте в нашу телеграмм-группу Инфостарт

