Миссия невыполнима?
При обработке большого количества данных на 1С приходится применять не только горизонтальное маштабирование (пример реализации см. тут Язык мой враг мой), но внимательно смотреть за эффективностью планов запросов, исполнения DML и мыслить как DBA. Приближаясь к пределам платформы 1С 8.х, все чаще вылезают проблемы, которые можно обойти, но не средствами 1С, т.е. миссия средствами 1С невыполнима. Одна из таких проблем изложена ниже. Все проверено на платформе 1С:Предприятие 8.3 (8.3.18.1334), но в новых версиях платформы эти проблемы не исправлялись.
Ловушка общих реквизитов-разделителей
Механизм общих реквизитов-разделителей данных - это жизненная необходимость прежде всего для облачных сервисов Fresh, нежели чем для холдингов или аффилированных юрлиц. Даже если она не используется, соответствующее поле автоматически добавляется в новые объекты, индексы и текст запроса к СУБД. В принципе, с этим можно жить даже на базе в 5 терабайт, основанной на Бухгалтерии 3.0 (Пример базы тут Методика похудения для 1С 100%), но поведение этого механизма с временными таблицами все портит (кратко и емко о механизме см. Официально о механизме разделителей данных).
И, как уже говорилось в статьях других авторов Об общих реквизитах, механизм создает излишнюю\негативную нагрузку на структуру базы данных, поскольку дополнительное поле разделителя добавляется в каждую таблицу и индекс первым, даже если по факту оно не используется в типовой конфигурации, см. структуру индексов (Структура индексов 1С).
Конечно, можно написать свою конфигурацию без использования этого механизма, но типовые конфигурации базируются на свежей БСП, где ОбластьДанныхОсновныеДанные (см. Работа в модели сервиса) тянется из данной библиотеки.
Что происходит с общими реквизитами\разделителями при сохранении во временную таблицу?
Возьмем несложную таблицу, которая хранит версии сделок и операций (почему именно версии, подробно описано тут Язык мой враг мой)
Таблица РегистрСведений.СУУ_АгрегированнаяСделкаКП (на MS SQL _InfoRg18968)
|
Период |
_Period |
|
ОбластьДанныхОсновныеДанные |
_Fld628 |
|
ИсходнаяСистема |
_Fld19138RRef |
|
ИдИсхСистемы |
_Fld19139 |
|
ОсновнойСчет |
_Fld19140RRef |
|
НогаСделки |
_Fld19141RRef |
|
ТипОперацииВИсходнойСистеме |
_Fld19142RRef |
|
Удалено |
_Fld19143 |
|
Дата |
_Fld19144 |
|
ТипСделкиОтносительноОсновногоСчета |
_Fld19145RRef |
|
BufferMsgCounter |
_Fld19146 |
|
НКД |
_Fld19147 |
|
ДатаПоставкиФакт |
_Fld19148 |
|
ДатаПлатежаФакт |
_Fld19149 |
|
Сумма |
_Fld19150 |
|
СуммаСНКД |
_Fld19151 |
|
Цена |
_Fld19152 |
|
ВалютаЦены |
_Fld19153RRef |
|
Количество |
_Fld19154 |
|
ФинансовыйИнструмент |
_Fld19155RRef |
|
ТорговаяПлощадка |
_Fld19156RRef |
|
ВладелецОсновногоСчета |
_Fld19157RRef |
|
СчетКонтрагента |
_Fld19158RRef |
|
Брокер |
_Fld19159RRef |
|
Контрагент |
_Fld19160RRef |
|
ТипОперации |
_Fld19161RRef |
|
СтавкаЗайма |
_Fld19162 |
|
МетодРасчетаЗайма |
_Fld19163RRef |
|
МестоХраненияДеньгиОсновнойСчет |
_Fld19164RRef |
|
МестоХраненияБумагиОсновнойСчет |
_Fld19165RRef |
|
МестоХраненияДеньгиКонтрагент |
_Fld19166RRef |
|
МестоХраненияБумагиКонтрагент |
_Fld19167RRef |
|
ДатаПоставкиПлан |
_Fld19168 |
|
ДатаПлатежаПлан |
_Fld19169 |
|
ВалютаПлатежа |
_Fld19170RRef |
|
ВалютаДоговора |
_Fld19171RRef |
|
СуммаДоговора |
_Fld19172 |
Вот некоторые индексы с полем разделителя
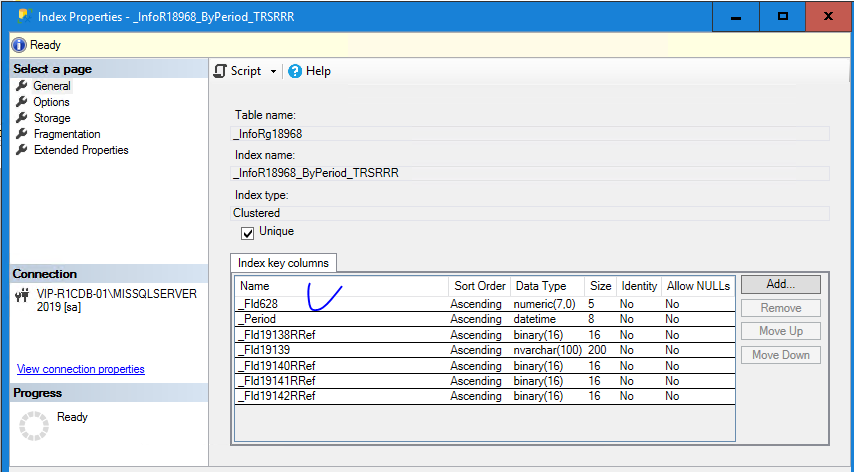
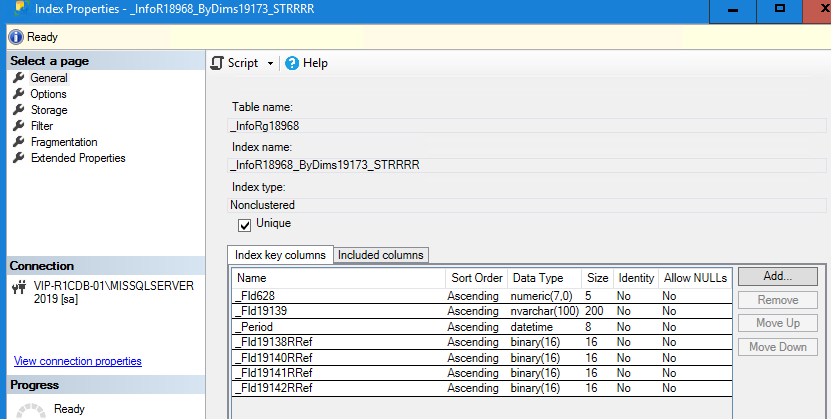
И сделаем запрос по данным полям (запрос упрощен, чтобы увидеть суть проблемы)
ВЫБРАТЬ
СУУ_АгрегированнаяСделкаКП.Период КАК Период,
СУУ_АгрегированнаяСделкаКП.НогаСделки КАК НогаСделки,
СУУ_АгрегированнаяСделкаКП.Сумма КАК Сумма,
СУУ_АгрегированнаяСделкаКП.Дата КАК Дата
ПОМЕСТИТЬ SavedRecords
ИЗ
РегистрСведений.СУУ_АгрегированнаяСделкаКП КАК СУУ_АгрегированнаяСделкаКП
В профайлере MS SQL запрос будет выглядеть так, там же мы можем увидеть соответствие полей регистра и временной таблицы
INSERT INTO #tt3 WITH(TABLOCK) (_Q_001_F_000, _Q_001_F_001RRef, _Q_001_F_002, _Q_001_F_003) SELECT
T1._Period,
T1._Fld19141RRef,
T1._Fld19150,
T1._Fld19144
FROM dbo._InfoRg18968 T1
WHERE (T1._Fld628 = @P1)
Поскольку временная таблица является локальной #, а не глобальной ## – мы не можем штатным способом видеть ее данные из другой сессии MS SQL, но мы можем видеть ее структуру.
Поля созданной временной таблицы определим запросом. В нем важно указать имя таблицы по маске ‘tt3%’ поскольку MS SQL генерит им свои уникальные имена
select top 10 so.name "tab_name", sc.name "tab_column",st.name "col_type" from tempdb.sys.sysobjects so
inner join tempdb.sys.columns sc on so.name like '#tt3%' and so.id=sc.object_id
inner join tempdb.sys.types st on sc.system_type_id=st.system_type_id
Результат будет ниже, всего 4 поля, таких же, как в запросе. Вроде ничего удивительного, но заглянем глубже.
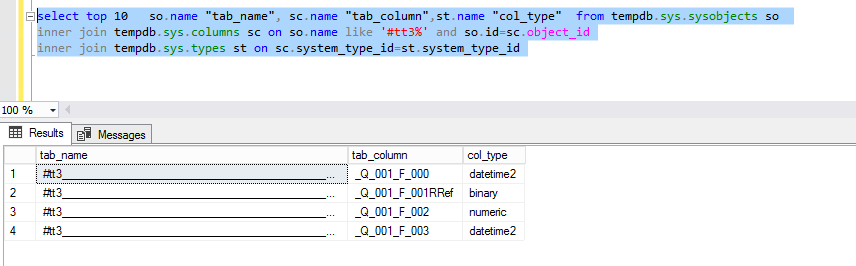
Быстрое соединение с временной таблицей – фантастика!

Типы соединений с большими таблицами описаны тут Типы соединений MS SQL
- Можно соединяться медленно Nested loop, когда индексов НЕдостаточно с обеих сторон
- Можно соединяться быстро Merge Join, когда есть индексы с обеих сторон, которые дают нужную сортировку
- Можно соединяться “как повезет” по Hash join, если оптимизатор MS SQL посчитал, что сумеет по выборке его построить
Пример. Мы сохранили отобранные по сложным условиям сделки во временную #ТаблицаСделок(Номер, Дата, Сумма), проиндексировали по (Номер). Далее решили соединить ее с постоянной таблицей\регистром сведений ТаблицаТрансферов (НомерТрансфера, ДатаТрансфера, НомерСделки, ДатаСделки, СуммаТрансфера), у которой один из индексов по (НомерСделки).
Казалось бы, все есть для успешного Merge join, но нужно учесть, что в трансферах к этому индексу системой 1С будет добавлено еще поле разделителя, и индекс будет выглядеть как (ОбластьДанныхОсновныеДанные, НомерСделки)!!! Во временную таблицу это поле не добавляется (поля физически нет) и его невозможно добавить, следовательно, нет по нему индекса.
Соединение будет «как повезет» либо свалится в loop join и key lookup, либо в каких-то случаях произойдет hash join
Агент Хант как никогда был близок к провалу

Как правило, удается обходить ограничения платформы на уровне SQL, добавляя или в крайнем случае изменяя нужные индексы, но не в этом случае. Рассмотрим варианты обхода
- Добавить параллельные индексы без ОбластьДанныхОсновныеДанные – замедлим и так не блестящую скорость записи в 1С и место потратим
- Отказаться от использования ОбластьДанныхОсновныеДанные в нужных нам таблицах\объектах (явно) - получим проблемы в соединении с таблицами, где от этого НЕ отказались . Например, со справочниками - ведь условия типа WHERE (T1._Fld628 = @P1) не просто так добавляет платформа. Допустим, в справочнике поле осталось, а в регистре убрали, установив Использование=НеИспользовать вместо Автоматически. Соединение регистра со справочником пойдет по неоптимальному плану. Это, кстати, еще один недостаток механизма разделителя!
- Отказаться от использования ОбластьДанныхОсновныеДанные в типовой конфигурации вообще - нужно проверять поведение конкретной БСП
- Отказаться от использования типовой конфигурации – утратим скорость внедрения в разы. Собирать свое на основе БСП тоже не быстрый вариант, ведь собранная помощниками 1С БСП без правки кода не заработает
- Писать запросы без временных таблиц – в теории можно, на практике MS SQL создаст очень плохие планы, которые будут вариациями сканирования кластерного индекса
В общем, пока 1С это не исправит, хорошего варианта нет. Если кто-то знает хороший способ обхода данной проблемы с разделителями
- Отсутствие разделителя во временной таблице
- Неэффективное соединение при частично отключенных на объектах разделителях
Буду рад прочитать.
P. S.
Подождите, а как быть с покрывающими индексами? Подробно о покрывающем индексе написано тут На примере о покрывающем индексе. Если сказать просто - это индекс, в который поля из условия запроса попадают в первые поля индекса, причем без разрыва. В рассматриваемом случае это компенсируется автодобавляемым условием WHERE (T1._Fld628 = @P1), но если вы передадите в виртуальную таблицу 1с\или условие подзапрос с временной таблицей - план тоже пойдет по плохой дороге.
Вообще временные таблицы в 1С странно сделаны, с одной стороны, они одноразовые, т.е. данные туда записать можно один раз а дописать нельзя (странно, ведь субд это позволяет).
Добавить два индекса тоже нельзя, и это на миллионах записей очень неудобно.
Например. Вам нужно в таблице ТаблицаТрансферов (НомерТрансфера, ДатаТрансфера, НомерСделки, ДатаСделки, СуммаТрансфера) иметь два индекса
- Один по НомерТрансфера – для соединения с таблицей\регистром дополнительных реквизитов трансфера
- Второй по НомеруСделки – для соединения со сделками
Сейчас для создания двух индексов нужно дублировать временные таблицы с миллионами.
Вступайте в нашу телеграмм-группу Инфостарт