Меня зовут Артем Кузнецов, я тимлид самого крупного МФО в России. Кроме обязанностей тимлида я также занимаюсь тем, что мне больше всего нравится в разработке. В частности, оптимизацией запросов и в целом кода – увлекаюсь этим в свободное время.
База у нас уже больше 7 терабайт. Мы прирастаем в неделю на 10-50 ГБ. Поэтому нам нужно разрабатывать так, чтобы фронт работал.

О чем пойдет речь в докладе?
-
Расскажу, зачем вообще оптимизировать код. Очень часто в 1С встречается подход, когда вместо того, чтобы уделить неделю или месяц разработки на рефакторинг, докупают железо. Потому что это проще. Железо купил, воткнул – код начал работать быстрее. Нам это уже не помогает. У нас хорошая корпоративная серверная по цене боинга. Мы себе уже все самое топовое железо купили, но оно уже не вывозит, поэтому мы смотрим в сторону оптимизации.
-
При разработке любых новых запросов, вне зависимости от их размера и сложности, мы всегда стараемся следить за соблюдением стандартов и проводить код-ревью. Потому что это вырабатывает привычку, а привычка – это самое главное. Когда человек по привычке уже пишет хорошо, и код-ревью быстро проходит, и система работает стабильно.
-
Еще расскажу про практику оптимизации при деградации легаси. Легаси у нас есть, еще до моего прихода в компанию появилось, и оно периодически деградирует. Например, какой-то запрос два года работал, не менялся, и потом почему-то вдруг взял и положил нам базу. Такое бывает сплошь и рядом. Разбираемся, что произошло, и оптимизируем.
Ключевая метрика

Ключевая метрика, на основании которой мы определяем, что нужно что-то оптимизировать – это так называемый «спидометр», которые выведен на отдельный большой экран. Такие экраны у нас висят на стене в отделе разработки, в техподдержке, у админов, у топ-менеджмента – у них тоже есть отдельный экран с таким спидометром.
У этого «спидометра» есть несколько состояний.
-
Первое состояние – нормальное, зеленое, когда все занимаются своими делами, спокойно работают в потоке. «Зеленый спидометр» характеризуется тем, что среднее время выполнения ключевых операций не превышает четырех секунд. Мы замеряем время всех операций, которые выполняют фронт-менеджеры на местах в офисах, и выводим на экран среднее значение. Этот показатель смотреть в моменте нет смысла, он обязательно должен смотреться на каком-то промежутке времени. Он может в какой-то момент подскочить в какую-то высокую красную зону. Но потом тут же вернуться обратно, это нормально.
-
Оранжевая зона – это так называемый первый «звоночек». Когда этот показатель начинает держаться в оранжевой зоне, то начинают появляться обращения в чате техподдержки, ищем виноватых в так называемом чате эксплуатации, разбираемся, откуда все это пришло.

-
Дальше – красная метрика – это все плохо. В чате техподдержки творится апокалипсис, у ИТ-директора и руководителя отдела разработки заплата начинает капать в обратную сторону. Все бросают свои дела и занимаются поиском проблем, подключаются разработчики, дополнительные люди, еще кто-то, чтобы хоть кто-то нашел причину и быстро с ней разобрался.
-
И, наконец, значение, к которому мы стремимся – эта метрика была снята в два часа ночи, причем, мне пришлось ее поискать в моменте просто для скрина. Но мы стремимся вот к этому мифическому единорогу, когда в праймтайм база работает в таком режиме. В этом случае нам, наверное, купят Playstation на отдел, мы сможем спокойно пить смузи и играть в Playstation целый день. Я очень надеюсь на это.
RLS

Первый блок, который нам сильнее всего аффектит базу на данный момент и в целом по истории – это RLS.
Система Record Level Security – это ограничение прав на уровне записи стандартное 1С-ное, стандартная система в базах данных.
Расскажу, как мы с ней работаем и какие у нас требования при работе с RLS
-
Мы используем ВЫБРАТЬ РАЗРЕШЕННЫЕ при любом обращении к физическим таблицам, даже если там нет сейчас RLS. Он может появиться, и все упадет. Поэтому «РАЗРЕШЕННЫЕ» должно быть всегда. Если нет RLS, оно не нагружает запрос. Даже если влияет, это настолько мизерно, что риски, что все упадет, гораздо выше.
-
Делаем предвыборку данных с максимальным сокращением выборки. Если нужно что-то разыменовать и достать какие-то дополнительные данные, достаньте их в конце. Оставьте максимально сокращенную выборку, не включайте в нее данные, которые вам по коду запроса не нужны.
-
Если из одного объекта (грубо говоря, из контрагента), нужно достать три поля, не нужно это делать в трех разных запросах пакета, соберите это в одном месте, это будет работать в три раза быстрее. Это действительно так.
-
У нас есть разыменование более одной точки, но оно допустимо только при последовательной индексации полей цепочки – в конкретном ограниченном списке ситуаций, которые для нас являются стандартными. В остальном мы не используем разыменования более одной точки. Используем соединения – внутреннее или левое, если нужно достать NULL. Через четыре-пять точек не разыменовываем, это плохо.
-
Кроме этого, когда мы обновились на БСП 3.1, у нас появилась проблема, что даже если для RLS установлен признак «Все разрешено», он все равно срабатывает, и начинают появляться вот эти дополнительные запросы к базе.

С точки зрения 1С RLS выглядит достаточно просто.
Есть регистр накопления, из него достаются какие-то поля.
На слайде показана та самая цепочка допустимых разыменований – они все последовательно индексированы, и это работает достаточно быстро.
Выглядит легко.

А это – то, что происходит уже на уровне запроса SQL. Это только половина запроса, даже чуть меньше, потому что все остальное даже не влезло на экран, я не стал мельчить. Это – то, что SQL выполняет при простом обращении к RLS по одному подразделению.
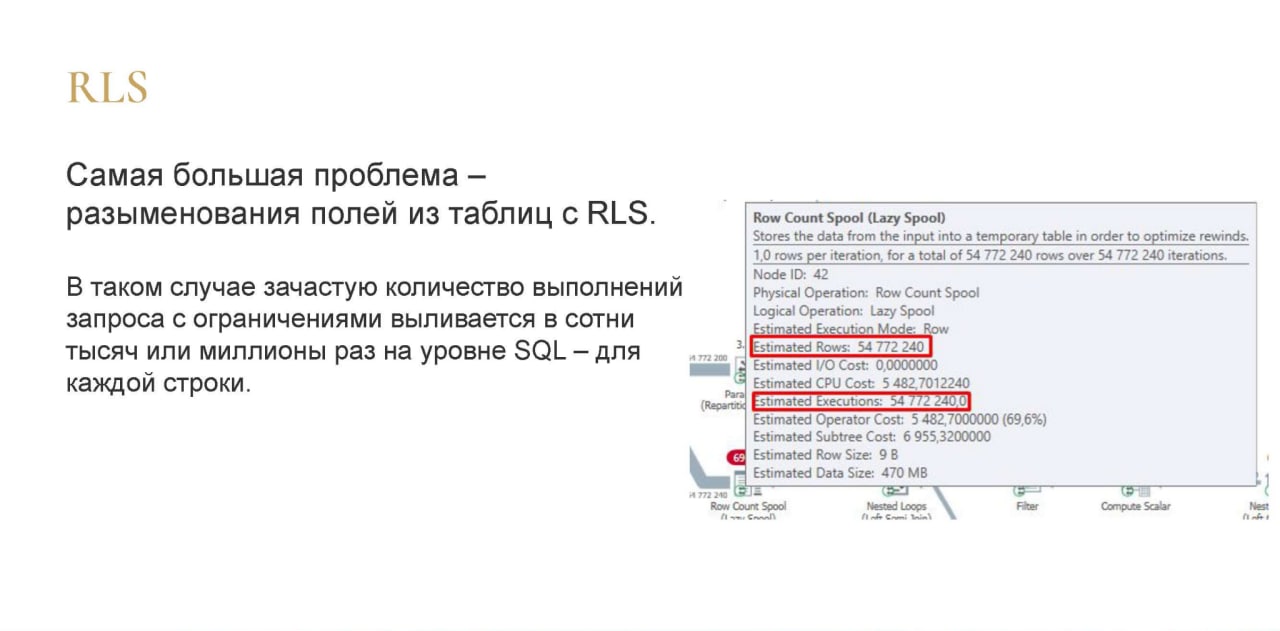
Наша самая большая проблема – это разыменования полей из таблиц во время запросов с RLS.
В таком случае количество выполнений запроса с ограничениями выльется в сотни тысяч миллионов раз на уровне SQL. В запросе это выглядит кратенько, красиво, но по факту получается 54 миллиона выполнений одного и того же запроса. 54 миллиона строк выбралось и для каждой из этих строк выполнился этот запрос. Это все из-за того, что у нас есть такие запросы в RLS.
Это очень тяжело, очень нагружает и систему, и, естественно, долго выполняется.
Нюансы поведения RLS

На слайде пример простенького запроса – обычный СрезПоследних, пара допустимых разыменований. При этом:
-
на справочнике Договоры есть RLS;
-
на регистре сведений УсловияДоговоров нет RLS;
-
на справочнике Подразделения и Команды тоже нет RLS.
В этом запросе мы ожидаем, что будут выбраны договоры, к которым у пользователя есть доступ.

Реальность:
-
Будут выбраны все записи из регистра, потому что это СрезПоследних.
-
В поле «Договор» будет значение «Объект не найден» для тех, у кого эти объекты недоступны
-
В поле Подразделение для недоступных пользователю договоров будет, естественно, NULL
-
При попытке разыменования NULL мы еще и получим исключение.
Казалось бы, очень простой запрос, а все может упасть очень легко.

Решение достаточно простое – мы формируем предвыборку данных из справочника, и дальше делаем СрезПоследних, передавая внутрь среза эту предвыборку в виде временной таблицы и отбора. Так это работает и быстро, и без ошибок. И выбирает только то, что нужно. Потому что перед формированием виртуальной таблицы среза будет уже предвыбрана заранее таблица договоров, по которым она и будет формироваться.
Пример оптимизации RLS

На слайде запрос, который вроде выглядит как надо, но из-за того, что таблица «Договоры» использует RLS, этот запрос у нас выполняется больше 1800 секунд.

Как мы его оптимизировали? Мы убрали разыменование Договор.Подразделение в отборах виртуальной таблицы – выключили его, перенесли заранее через внутреннее соединение из той таблицы, которую мы передали изначально внутрь среза в отдельную временную таблицу. И далее уже эту временную таблицу передали в СрезПоследних.
И мы получили выполнение запроса вместо 30 минут – 1-2 секунды. Таким простым действием мы на порядки сократили время выполнения.
Виртуальные таблицы

Теперь кратко по виртуальным таблицам – наши требования:
-
Нельзя соединяться с виртуальной таблицей, если она может оказаться справа, потому что когда из нее выборка будет происходить выборка, она может происходить без индексов и это будет работать достаточно долго.
-
Если из виртуальной таблицы Оборотов или ОстаткиИОбороты требуется какая-то часть данных (например, только Приход), их лучше собрать из физической таблицы. Это, как правило, работает быстрее, но не всегда. Все наши требования работают примерно в 95-97% случаев. Оставшиеся 3-5% выстреливают даже с учетом наших требований, и мы к ним имеем уже отдельные подходы, которые нарушают наши требования, но при этом работают тоже. Но изначально мы пишем так, потому что, как правило, это работает.
-
На больших объемах данных, когда больше миллиона строк в таблице не рекомендуется использовать виртуальную таблицу ОстаткиИОбороты – лучше все собирать вручную. По крайней мере, на нашей базе. Эти все правила применимы к нашей базе, у вас могут быть какие-то другие, а мы за три года выработали такой список.
-
Не рекомендуется использовать виртуальную таблицу СрезПоследних для регистров сведений, подчиненных регистратору, потому что там происходят лишние соединения с регистраторами. Особенно, если ресурсы у регистра составного типа.
-
МоментВремени мы используется только если действительно это нужно – как правило, хватает поля Период.
-
Не рекомендуется использовать условие Поле В(<Вложенный запрос>) в отборах виртуальных таблиц, если во вложенном запросе много элементов – это то, что вы видели на предыдущем слайде, когда я передавал временную таблицу в отбор виртуальной. Если во временной таблице много элементов, обратитесь к физической таблице, не используйте виртуальную. Используйте внутреннее соединение и дальше уже нужное вам агрегирование среза или еще что-то.
Примеры оптимизации для виртуальных таблиц

Регистр сведений, достаточно большой. В нем все наши телефонные звонки – у нас их достаточно много совершается каждый день.
Соответственно, если мы в параметр &КонецПериода передаем дату окончания, то вероятность, что будет использована готовая виртуальная таблица, которая строится в самой базе при включении виртуальной таблицы СрезПоследних, крайне мала.

Соответственно, здесь мы добавили дополнительный параметр &ПериодДляИтогов, экспортный метод в общем модуле. И проверяем, что если дата окончания больше или равна текущей дате, мы ее просто убираем, оставляем Неопределено, чтобы гарантировать использование готовой виртуальной таблицы, чтобы ее SQL заново не считал. Это значительно ускоряет работу во многих наших отчетах.

Еще пример – регистр СостоянияСобщенийSMSСрезПоследних.
SMS-ок у нас тоже много, при получении СрезаПоследних формируется неоптимальный запрос, что приводит к перебору 115 миллионов записей. В данном случае несмотря на то, что у нас есть отбор по идентификатору.

Тут мы просто сделали ручной срез на временных таблицах.
Главное – проиндексировать первую таблицу. Это тоже дает выигрыш – хоть и не на порядки, но в разы быстрее.

Еще запрос, который кушал очень много памяти.
В регистре накопления «Расчеты» хранятся все наши взаиморасчеты с контрагентами.
У нас есть отдельные регистры для каких-то конкретных направлений, а в регистре «Расчеты» лежит вообще все, что у нас происходит с договорами. В этом регистре сейчас более 500 миллионов записей.
Тут вроде просто получение остатков по концу периода, а дальнейшее внутреннее соединение – это к вопросу соединения с виртуальной таблицами. Если виртуальная таблица оказалась справа, мы получаем 70 гигабайт больше потребления памяти.

Решение – просто занести то, что было соединено, внутрь. Простое действие, но оно опять же, очень сильно ускоряет работу запроса.
Индексы

Теперь расскажу про важность индексации. Многие 1С-разработчики почему-то не любят использовать индексацию, не очень понимают, что это такое.
Наши требования касаемо индексации:
-
Мы всегда индексируем поля временных таблиц, которые участвуют в соединениях, при условии, что эта временная таблица может оказаться справа. Если она всегда гарантировано слева, то ее индексировать смысла нет, из нее выборка сама происходить не будет.
-
Все поля отборов (то, что в конструкции ГДЕ) при использовании ВНУТРЕННЕЕ СОЕДИНЕНИЕ, мы выносим обратно во ВНУТРЕННЕЕ, но если мы можем гарантировать, что среди отборов есть какой-то отбор с высокой селективностью, можно его только оставить в соединении, а все остальное вернуть обратно в ГДЕ. Если мы не уверены, лучше все засунуть во ВНУТРЕННЕЕ СОЕДИНЕНИЕ, планировщик разберется, выберет самый оптимальный, самый селективный отбор – поставит его первым и выполнит запрос быстро.
-
И использование по возможности кластерного индекса – это индекс на таблицы, который создает сама 1С. Он всегда есть изначально – на любых таблицах, даже если ни одного поля не проиндексировано, он всегда есть. На любом регистре, на любом документе. Соответственно при отборе, при соединении по кластерному индексу, это тоже работает очень быстро, потому что в кластерном индексе лежат все поля таблицы – он может оттуда выбрать все.
Примеры оптимизации для задействования индексов

Условие соединения в данном запросе не попало в индекс, соответственно, мы получили полное сканирование. Казалось бы, Договор – должно быть селективное поле, но, тем не менее, мы получили FullScan.

Решение – мы формируем предварительную выборку полей. Тут идет два обращения к физической таблице, но это работает сильно быстрее. Мы предварительно выбрали только поля кластерного индекса регистра по одному договору, потому что это наиболее селективное поле. И дальше снова соединились с регистром, но гарантированно попали в кластерный индекс. Все поля – Период, Регистратор, НомерСтроки – это как раз поля кластерного индекса. И добрали уже нужную нам сумму. Это начало работать гораздо быстрее.
За последний год я такими действиями оптимизировал примерно 20% всех запросов. Просто вынимаешь из запроса выборку по полям кластерного индекса, потом соединяешь ее внутренним соединением с физической таблицей регистра, добавляешь нужные поля. Стало быстрее? Сразу на прод.
Достаточно простое решение. Но оно помогает.
Условия в запросах

Для условий запросов есть достаточно хорошие стандарты 1С. Они есть и как правило работают – мы ими активно пользуемся. Но мы их немного ужесточили – именно для своей базы.
-
Все вычисляемые поля мы предварительно рассчитываем в секции «ВЫБРАТЬ», мы не используем отборы по вычисляемым полям. Даже когда есть какие-то математические операции, мы сначала их лучше во временной таблице выберем и вычислим в секции ВЫБРАТЬ, проиндексируем, если нужно. И потом уже отберем по ним. Это работает быстрее, чем сразу вычислять в условиях, потому что при вычислении в условиях вычисление происходит для каждой строки, что крайне долго.
-
Отрицание в условиях у нас запрещено категорически – кроме булевых полей, потому что там отрицание работает нормально.
-
Мы используем ЕСТЬ НЕ NULL вместо НЕ ЕСТЬ NULL. Казалось бы, вроде одинаковые конструкции, но ЕСТЬ НЕ NULL – это родная конструкция, которая работает гораздо быстрее.
-
За ИЛИ / В() у нас тимлиды отдела разработки готовы убивать, если кто-то это использует в запросах. Если это ИЛИ делаем через ОБЪЕДИНИТЬ, если это В() – через внутреннее соединение. Потому что тогда мы можем гарантировать использование индексов, мы можем управлять планом запросов, управлять тем, как это будет выполняться. И тем самым гарантировать стабильность – что это, по крайней мере, не деградирует.
-
Сравнение ТИПЗНАЧЕНИЯ()=ТИП() не используем, преобразуем в стандартный метод ССЫЛКА
-
Помним, что соединения – это тоже условия, к ним применимы все те же правила, которые для секции ГДЕ
-
И явные соединения со вложенными запросами у нас запрещены – мы не используем соединения со вложенными запросами ни в каком виде. Предвыборка во временную таблицу, индексация и только потом соединение.
Примеры оптимизации для условий запросов

Документ «Заявка» – это наш ключевой документ, с которым работают пользователи.
Этот запрос выполняется при интерактивной работе, когда менеджер ищет клиента в базе. Он занимал 10 секунд. Т.е. клиент пришел, сказал ФИО, дату рождения, его начали искать в базе, он 10 секунд ждет, пока выполнится этот запрос и менеджер его найдет в базе. Это не единственный запрос, который там выполняется, но этот был самый долгий.
Поскольку этот запрос нагружает саму базу, он вызывает замедление работы не только у этого менеджера, но и у всех остальных пользователей базы.

Что мы сделали?
Мы сократили время выполнения этого запроса с 10 секунд до менее чем полсекунды.
Это стало возможным за счет того, что мы вынесли НЕ в предвыборку справочника и внутреннее соединение.
Справочник маленький, служебный, соответственно, из него выборка быстрая.
Перечисление – тоже выборка быстрая, В() использовать допустимо.
И дальше – два внутренних соединения.
Почему не проиндексированы первые две таблицы? Потому что они гарантированно маленькие и крайне маловероятно, что СУБД поставит их справа, они практически со 100% вероятностью будут слева, поэтому накладные расходы на индексацию конкретно здесь не оправданы.
Вообще от разработчиков мы требуем индексировать даже в таких случаях, потому что накладные расходы не очень высокие на индексацию, но здесь писал код я, и я позволил себе не индексировать.
А оставшиеся отборы работают достаточно быстро.
Работа с архитектурой решения

Оптимизация через доработку архитектуры решения – когда в коде вроде все выглядит хорошо, но работает все равно медленно, и мы уже не лезем в код, а работаем со структурой самой базы.
Рекомендации, которые мы стараемся поддерживать:
-
Во-первых, мы анализируем использование полей таблиц в условиях. У нас есть ходовой регистр, к которому обращаются много отчетов. И мы, например, находим, что из трех измерений регистра чаще всего используется первое и третье, а второе используется редко. При этом кластерный индекс содержит в себе все три измерения, и при использовании первого и третьего кластерный индекс не используется. Просто поменяв второе и третье местами, мы, не изменив ни строчки кода, ускорили 15-20% фронтовых отчетов. Да, потребовалась реструктуризация, но она влезла в технологическое окно и ускорила нам базу в два клика – очень удобно.
-
Если вы в запросах рассчитываете одни и те же данные, которые не динамические, а статичные изо дня в день (они не зависят от фазы луны, от времени года и всего остального), лучше их рассчитать – регламентно рассчитывать заранее и куда-то складывать. Да, это дополнительное место, это размер базы, но обращаться к готовым данным в разы быстрее, чем считать их «на лету». Считать на лету – крайне плохо с нашей точки зрения, и мы все, что можно вынести в предрасчет и где-то хранить заранее, и потом уже оттуда доставать, мы все выносим.
-
Дальше – если у вас есть большая таблица, из которой стабильно выбирается 3-5% строк, а все остальные 95% строк в отчетах почти никому не нужны (например, они нужны только для каких-то регламентных операций). Соответственно, мы выносим эти 3-5% в отдельную таблицу. В старой таблице их тоже оставляем, но делаем рядом еще одну, которую клонируем и ужимаем – оставляем только эти нужные данные. Да, это время на дозаполнение данных, это объем базы, но это того стоит, если используется часто, и таблицы большие изначально.
-
Включение итогов – тут понятно, что предрасчитанные виртуальные таблицы – это быстро. Да, итоги – это тоже дополнительные таблицы в базе. Но если к ним часто идет обращение, то используем.
-
Стараемся не использовать флаг «Активность», потому что он не индексирован. И чтобы выбрать из 500 миллионов записей 99,9%, у которых есть этот флаг, и 1-2 записи, у которых нет этого флага – не имеет смысла, это, опять же, будет перебор.
-
И ручное создание индексов в SQL по рекомендациям DBA – это запрещено лицензионным соглашением 1С, и мы стараемся его тоже не использовать или использовать временно, до того, как мы найдем какое-то другое решение – это только в крайнем случае. Но оно тоже имеет место быть, тоже ускоряет, от этого никуда не деться.
Примеры оптимизации для доработки архитектуры решения

ЖурналЗвонков – это регистр сведений, который мы уже смотрели. В нем около 150 миллионов записей.
Данный запрос – это программный срез последних – выполнялся 35 секунд. Причем соединение по индексированному полю, идентификатору ИДВзаимодействия, селективность стремится к единице.

Мы включили итоги, уложились в технологическое окно. Правда, тогда у нас технологическое окно было больше, сейчас мы бы вряд ли в него уложились бы.
Но это работает только если таблица итогов будет гарантировано использоваться – при пустом периоде. Если таблица итогов используется негарантировано, тут надо уже дважды подумать.
И запрос стал выполняться две секунды вместо 35 – ускорение в 15 с лишним раз.
Заключение

В заключение доклада рекомендую вам – кто раньше писал не по стандартам, забыть это и переходить на стандарты.
Просто пройдитесь по чек-листу в докладе – начните его соблюдать. Если вы привыкнете его соблюдать, в коде ничего нового плохого, что может положить базу, не будет появляться.
И дальше уже по этому примеру рефакторьте старое.
Вопросы
Как проверять правильность написания запроса? Только глазами, через код-ревью или с помощью SonarQube?
Обязательно есть статический анализ с помощью SonarQube, он отслеживает все ошибки в коде, все индексации полей – делает все это очень удобно. Он, конечно, не все подцепляет, но очень помогает. Еще есть код-ревью, которое обычно происходит после SonarQube. Если разработчики привыкнут изначально писать по правилам, дополнительные проверки будут только подстраховывать – если SonarQube пустой, код-ревью проходит спокойно, и у нас дополнительного времени разработчиков на доработку кода для соблюдения стандартов уже не тратится практически. Они уже научились и привыкли, что нужно писать по стандартам, индексировать поля. Когда после того, как разработчик написал код не очень хорошо, это все прилетает ему обратно, времени тратится гораздо больше, чем на изначальное соблюдение стандартов. Поэтому SonarQube есть.
Вопрос про временные таблицы. Я как руководитель группы разработки замечаю повальное использование временных таблиц разработчиками, потому что фирма «1С» в своем стандарте говорит: «Нужно использовать временные таблицы». Правда она потом говорит, что их нужно использовать «...только тогда, когда...». А еще потом говорит, что их не должно быть много. Но временные таблицы же не по факту временные, они все равно физические, и, если таблица большая она пишется во время выполнения в tempdb, которая находится на диске или в оперативке. Есть ли у вас какие-то критерии, когда вы категорически не рекомендуете разработчикам использовать временные таблицы? И критерии, когда вы точно гарантировано требуете использовать только временные таблицы?
Не скажу конкретные критерии. Мы используем временные таблицы повсеместно, потому что мы знаем, что у нас tempdb лежит в оперативной памяти и все это работает быстро. Соответственно, я в докладе рассказал стандарты, которые мы для себя выработали за три года. В других компаниях такие стандарты, естественно, могут отличаться – это нормально. Но это то, что позволило нам за 2021 год не получить ни одного инцидента с новыми запросами, которые бы как-то замедлили базу. У нас есть легаси, мы его рефакторим, оно замедляет базу и периодически «выстреливает». Но ни один новый запрос, даже самые большие отчеты – нам не замедлили базу. Ни разу за весь 2021 год.
Сколько примерно у вас документов в самой большой таблице? Используете ли вы динамические списки в работе? И есть ли у вас с ними какие-то проблемы?
Динамические списки у нас используются крайне мало. У нас весь фронт – это либо отчеты, либо какие-то рабочие места. Динамические списки есть, но они сильно ограничиваются изначально уровнем запроса. Не пользователем, а кодом.
Хочется понять, как у вас организована работа. Сколько примерно у вас в самой большой таблице документов?
Если говорить про регистры, у нас 500 миллионов записей в регистре «Расчеты». Документов – не скажу сколько, мы не работаем напрямую с документами. Мы в запросах работаем с регистрами, обращаться к документу напрямую в запросе – это не очень хорошо.
Пользователи могут форму списка открыть?
Теоретически – наверное, да.
Отбор могут поставить, который заставит сканировать таблицу?
Да, и это может легко положить базу. Такое бывает. Поэтому мы у нас недавно для самого большого документа программно ограничили отборы и сортировки, чтобы можно было выбрать только индексированные поля.
Т.е. теперь нельзя поставить отбор на поле через точку?
Нет, теперь там ничего этого нет, есть только стандартные индексированные поля. Это какой-то стандартный механизм – решилось в три строчки. Ничего другого мы делать не стали, потому что этими динамическими формами списка почти никто не пользуется.
*************
Данная статья написана по итогам доклада (видео), прочитанного на конференции Infostart Event 2021 Moscow Premiere.
Вступайте в нашу телеграмм-группу Инфостарт