Статья написана на основе доклада на Infostart Event 2021 Post-Apocalypse. Кому больше нравится видео-формат, прикладываю запись с выступления:

Ну а любителям текста добро пожаловать под кат.
Постановка задачи
Как известно, нет ни одной организации с ворохом мелких баз, которая не мечтала бы их объединить в одну, как и нет крупных организаций с одной монолитной базой, которая не мечтала бы ее разъединить.
Сегодня речь пойдет о первом случае. Обратился к нам клиент – очень крупное производственное объединение. Один из лидеров в своей отрасли. Суть заключалось в следующем: на тот момент они работали в нескольких информационных базах на 1С:УПП объединенных в РИБ. 1С:УПП уже морально устарела, поддержка прекращается и заказчик выбирал новую ERP-систему.
Выбор в то время был не особо большой: это или 1C:ERP или SAP. Как мы сейчас можем убедиться, выбор 1C:ERP оказался в итоге оправдан и по политическим причинам, но статья не об этом. Тогда же внутри организации были сторонники и противники обоих вариантов. В частности, сторонники SAP утверждали, что одна база 1С не выдержит их огромного объема документов. Само собой система должна была иметь и некоторый запас прочности, т. к. в планах компании было дальнейшее активное развитие.
И вот с такой задачей представители клиента и обратились к нам, чтобы проверить, в общем-то, насколько реально будет работать в 1С на имеющихся у них мощностях, причем с удвоенным от текущего объема документооборотом.
Это был далеко не первый проект нагрузочного тестирования, который мы проводили. Но раньше это были, скажем так, подпроекты в рамках наших же больших внедрений. А с такой постановкой мы столкнулись впервые и, конечно же, взялись за работу.
1С:ERP и Тест-центр
На старте проекта необходимо было сразу определиться с инструментарием, но тут выбор, на самом деле, очевиден.
У 1С есть отличный специальный инструмент для нагрузочного тестирования – Тест-Центр, который входит в состав КИП и опыт работы с которым у нас уже был.
Но, на самом деле, если у вас приобретен программный продукт 1С:ERP, то вы можете не приобретая КИП использовать специальную демо-конфигурацию вот с таким вот сложным названием: «Специализированная демонстрационная база на основе решения "1С:ERP Управление предприятием 2", включающая в себя интегрированный инструмент "Тест-центр" и необходимые дополнительные тестовые обработки с готовыми тестовыми сценариями»
Это очень крутая конфигурация, которая представляет собой 1С:ERP c внедренным в нее в виде подсистемы Тест-центом. Но это еще не все. Главное, что там же содержится и большое количество готовых скриптов тестирования для всех основных подсистем. Конфигурация доступна для скачивания на странице релизов 1С:ERP, нужно прокрутить вниз до дополнительных материалов.

Как я сказал, можно вообще без программирования сразу из коробки начать нагрузочное тестирование на имеющихся сценариях. А они, на самом деле, довольно большие и подробные.
Например, для подсистемы продажи реализованы различные варианты обеспечения, корректировки-возвраты, ордерная схема, возвратная тара, различные условия продаж и т. д. Вот небольшая часть полного скрипта по тестированию:
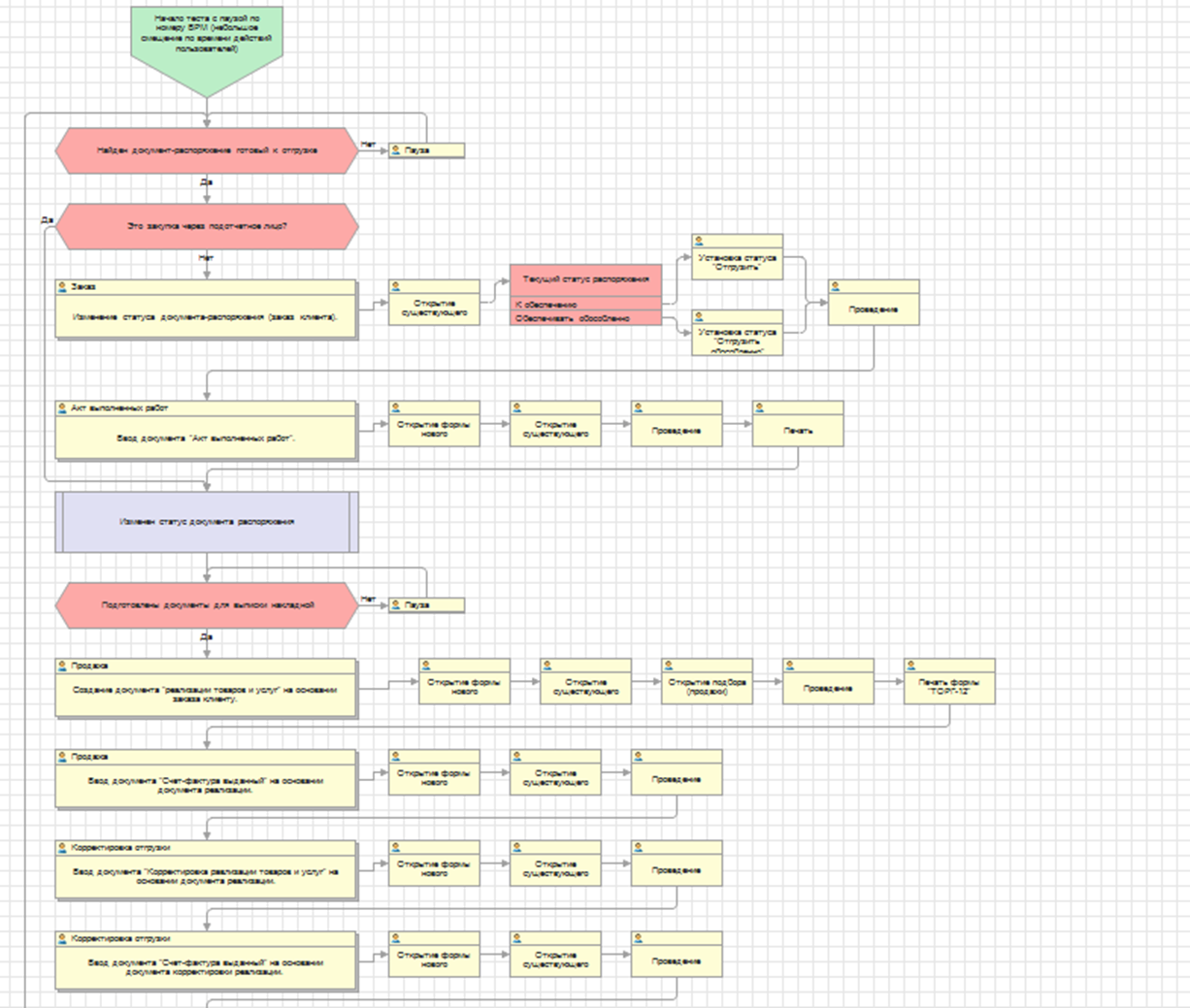
Здесь и создание новых документов и открытие существующих, ввод на основании, печать и другие типичные для пользователя системы действия. Ну и такие довольно подробные сценарии разработаны для всех основных подсистем конфигурации:
-
Продажи
-
Закупки
-
Производство
-
Взаиморасчеты
-
Складские операции
-
Регламентные операции
Если не хотите тестировать на имеющихся скриптах, можно создавать с нуля и свои скрипты – каждый тест, это отдельная обработка в дереве конфигурации. Или же можно модифицировать типовые тесты под свои нужны – как мы в итоге и делали.
Про нагрузочное тестирование с помощью данной конфигурации у 1С есть подробный 3-х часовой вебинар, где рассказывается про структуру, устройство и запуск тестов. Если вы планируете также использовать данную конфигурацию, то рекомендую начать с этого видео.
Подготовительный этап
Итак, мы приступили к реализации проекта, бОльшую часть которого занял, как ни странно, подготовительный этап.
Мы провели анализ центральной информационной базы заказчика. Посмотрели общее количество документов в базе. По этому количеству обозначились основные процессы, которые происходят на предприятии. Ну и далее, после согласования с заказчиком, выделили критичные и ресурсоемкие схемы документооборота, которые в дальнейшем и собирались тестировать.
Для каждой из подсистем, у нас получился примерно такой документооборот:
-
Продажи – примерно 12 тысяч документов в ДЕНЬ. Эта вся цепочка документов: заказ клиента, счет на оплату, реализация, счет-фактура, корректировка реализации, расходный и приходный ордера – у заказчика ордерные склады.
-
Сравнимые объемы для других подсистем.
-
И обязательное закрытие месяца.

Напомню, что мы должны были тестировать систему с удвоенным документооборотом, поэтому итоговые схемы у нас получились такие:

Всего почти 50000 документов в день. Кроме того, заказчик настаивал на том, что сейчас и в будущем они будут закрываться каждую ночь.
Далее мы определили среднее количество строк для каждого из вида документов, понятно что в цепочке количество строк примерно одинаковое, т. к. много документов вводится на основании. В целом у заказчика документы были не очень большие, но иногда попадались и довольно весомые. Например, для тех же продаж у нас 9 из 10 документов содержали 10 строк, но каждый 10 документ был «тяжелым», т. е. со 100 строками различных позиций в табличной части. Примерно такой же подход и по другим документам.
И, что очень важно, нам необходимо было определиться с количеством срезов, на которых мы будем проводить тест и количестве различных НСИ. Данные мы брали также из текущей информационной базы и также согласовывали с заказчиком.
Опять же, на примере подсистемы «Продажи», как самой тяжелой, у нас получились такие срезы.
-
2 организации
-
50 складов
-
1000 номенклатурных позиций
-
500 контрагентов
-
1000 договоров и 3000 партнеров (компания работала преимущественно с сетями).
Аналогичные, но примерно такие же срезы у нас были и по другим подсистемам. Изначально данные были не такие круглые. Например, 50 складов здесь не просто так. Дело в том, что у нас планировалось 25 кладовщиков, каждый из которых работал с 2 складами. Вообще, забегая вперед, стоит отметить, что типовой Тест-центр не умеет работать с наборами НСИ и нам пришлось немного его доработать: мы добавили регистр сведений, где хранили для каждого рабочего места динамический диапазон НСИ, с которыми он работает.
Ну и наконец, определились со способом ввода документов. У заказчика, как, наверное и на любом предприятии, было очень много разных интеграций. В частности, 70% всех заказов прилетали из внешних систем. Также около 50% реализаций создавались автоматчики без участия пользователя. Банковские документы, понятно, также создавались обработкой «Обмен с банком». И с такими сценариями мы поступили довольно просто: написали несколько регламентных заданий, которые на сервере по заданному расписанию создавали пачками документы. На самом деле, эти регламентные задания нам очень пригодились.
Дело в том, что у нас была чистая база, т. к. заказчик работал в УПП, мы не могли взять ее за основу. И нам необходимо было нагенерировать документы не только за текущий месяц, чтобы проверить длительность закрытия месяца, но нам хотелось добавить и, насколько получится, исторических данных.
Поэтому, как только мы написали эти регламентные задания за первые 1-2 дня разработки, мы тут же создали по несколько экземпляров каждого из заданий и они у нас круглосуточно в несколько потоков практически на протяжении всего проекта работали и генерировали документы в прошлых периодах. Это вот, на заметку тому, кто тоже вдруг будет заниматься чем-то похожим.
Затем, для оставшихся «ручных» документов мы определились с количеством пользователей для каждой из роли – всего получилось 400 пользователей. Определились с временем и очередностью ввода каждого из видов документов. Вот такая в итоге у нас получилась общая схема тестирования.
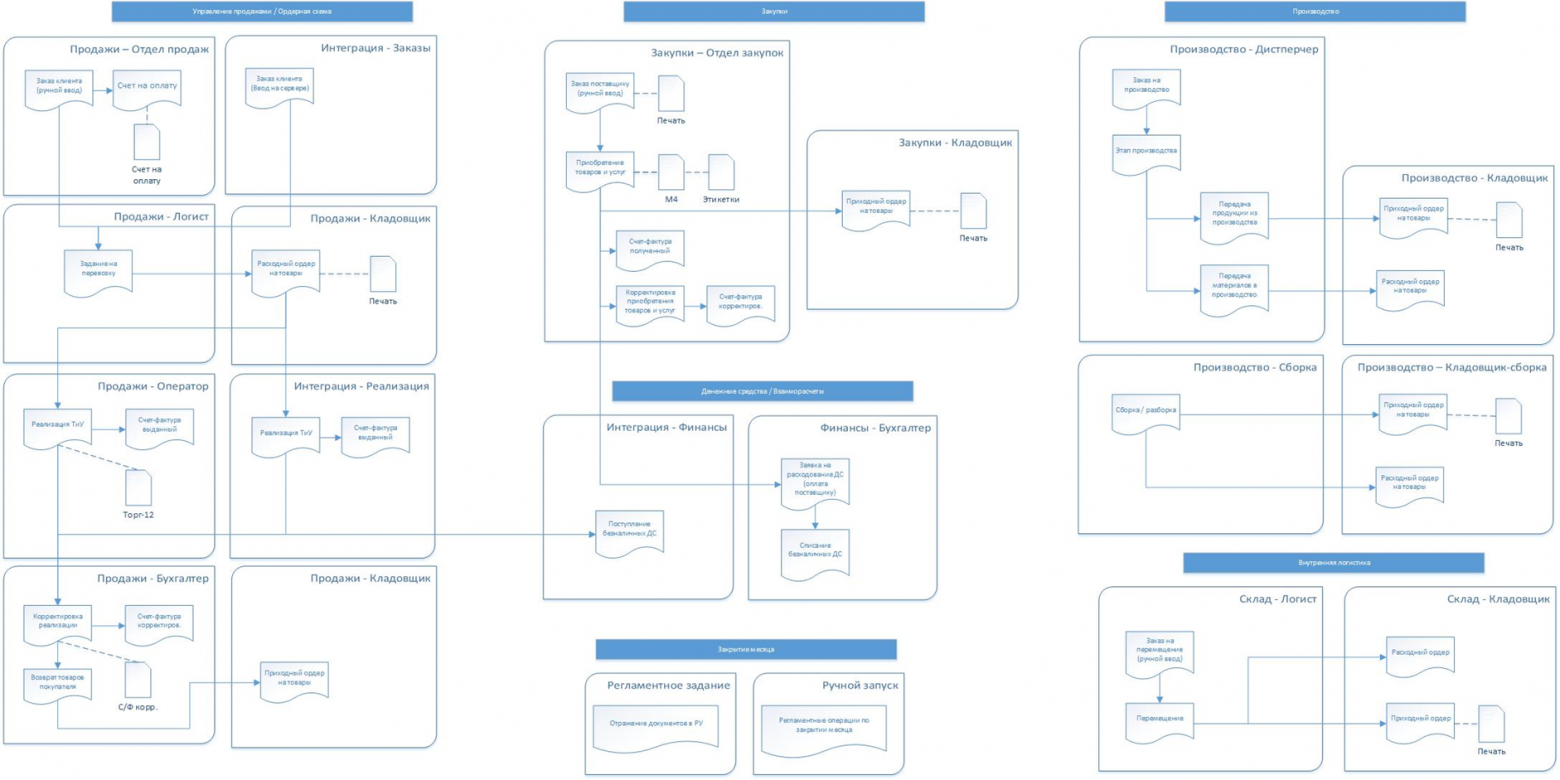
Ну и отдельным, скажем так, непростым квестом было собрать желаемое время выполнения ключевых операций для подсистемы APDEX.
Как я сказал, сбор этих сведений занял чуть ли не половину проекта. Но мы очень старались делать это параллельно с разработкой, насколько это было возможно. Подготовительный этап получился такой:

Программно-аппаратная часть
Специально для проекта заказчиком были арендованы сервера, аналогичные тем, которые предполагалось использовать уже на продуктиве, если переход состоится:
-
сервер баз данных
-
сервер приложений
-
6 терминальных серверов
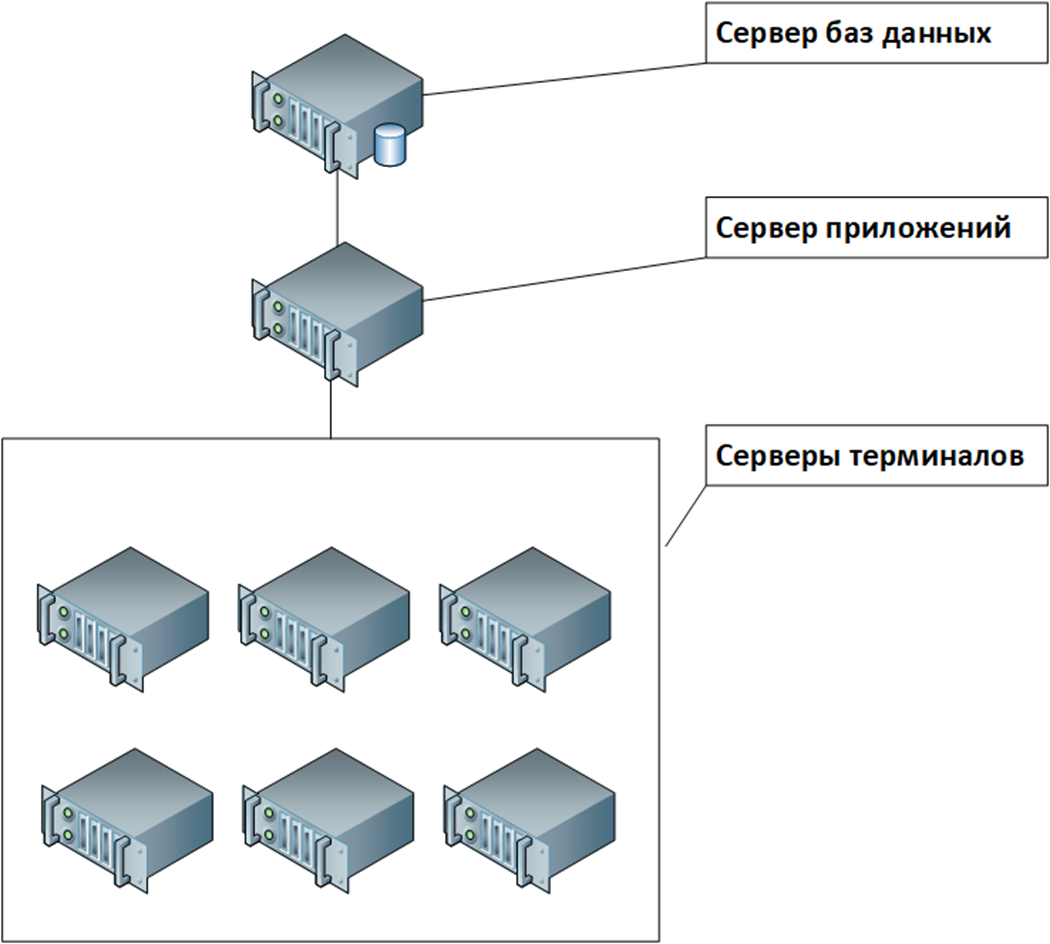
В целом, сервера довольно мощные, правда немного подвели процессоры.
Сервер СУБД:
-
Процессор:
-
Socket 1: Intel(R) Xeon(R) Gold 5120 CPU @ 2.20GHz (4 ядра)
-
Socket 2: Intel(R) Xeon(R) Gold 5120 CPU @ 2.20GHz (4 ядра)
-
Socket 3: Intel(R) Xeon(R) Gold 5120 CPU @ 2.20GHz (4 ядра)
-
Socket 4: Intel(R) Xeon(R) Gold 5120 CPU @ 2.20GHz (4 ядра)
-
-
Оперативная память: 384 ГБ (EDO)
-
СХД: Huawei dorado 5000 v3 на nvme дисках HSSD-D6D23DL3T8N
Сервер приложений (кластер 1С):
-
Процессор:
-
Socket 1: Intel(R) Xeon(R) CPU E5-2640 v4 @ 2.40GHz (20 ядер)
-
Socket 2: Intel(R) Xeon(R) CPU E5-2640 v4 @ 2.40GHz (20 ядер)
-
-
Оперативная память: 128 ГБ (FPG, 1001 МГц)
Серверы терминалов:
-
Процессор:
-
Socket 1: Intel(R) Xeon(R) CPU E5-2640 v4 @ 2.40GHz (8 ядер)
-
Socket 2: Intel(R) Xeon(R) CPU E5-2640 v4 @ 2.40GHz (8 ядер)
-
-
Оперативная память: 64 ГБ (FPG, 1001 МГц)
На сервере СУБД и сервере приложений были процессоры с тактовой частотой всего лишь 2.2 и 2.4 гигагерца. Но что поделать, высокочастотных процессоров, как правило, в дата центрах нет или они стоят очень дорого.
Итак, сервера арендованы. Конечно же, это были виртуальные среды. В качестве ОС - Windows Server 2016 Standard, СУБД - Microsoft SQL Server 2012 Enterprise
Мы использовали платформу 1С:Предприятие КОРП версии 8.3.14 – так как, во первых, ее использовал заказчик, ну и это была на тот момент довольно стабильная версия. И последнюю на тот момент версию ERP.
Стоит сказать, что все продукты Microsoft также были арендованы, а вот для получения корпоративной лицензии 1С нам пришлось обратиться в фирму 1С. И под данный проект нам выделили программные лицензии КОРП с 3-месячным сроком действия, за что компании 1С отдельное спасибо.
Были настроены счетчики производительности Windows. А для получения данных о производительности системы использовалась типовая подсистема из состава БСП, основанная на методике APDEX.

Настройки MS SQL Server (отличия от стандартных):
-
Включен флаг трассировки 1118
-
Включен флаг трассировки 4199
-
Maximum server memory (in MB): 360000
-
Max Degree of Parallelism: 1
-
Cost Threshold for Parallelism: 5
Регламентные операции на СУБД:
-
Ежедневное обновление статистики с опцией with FULL SCAN
-
Ежедневное обслуживание индексов
Выполненные настройки базы данных (отличия от стандартных):
-
Recovery model: Simple
-
Auto Update Statistics: False
Настройки кластера 1С:
-
Версия платформы 1С:Предприятия: 8.3.14.1976 (КОРП)
-
Отладка на сервере включена: Нет
-
Интервал перезапуска: 0
-
Допустимый объем памяти (KB):15000000
-
Интервал превышения допустимого объема памяти (сек): 120
-
Допустимое отклонение количества ошибок сервера (%): 0
-
Принудительно завершать проблемные процессы: Нет
-
Количество соединений на процесс: 128
Параметры информационной базы 1С:
-
Версия 1С:ERP: 2.4.7.151
-
Контролировать остатки товаров организаций: Да
-
Метод оценки стоимости запасов: Средняя за месяц
-
Расчет себестоимости: Партионный учет 2.2
-
Время ожидания блокировки данных (в секундах): 20
-
Рабочая область начальной страницы: Отключены все формы (модификация конфигурации)
Разработка скриптов
В общем-то, еще до начала всех согласований, мы уже начали разработку скриптов. Подробно на этом этапе останавливаться не буду. Отправляю всех на уже упомянутый вебинар. Каждый скрипт тестирования – это отдельная обработка в базе данных. Код, понятное дело, пишется на языке 1С. Есть свои особенности, конечно, но в целом порог входа, как мне кажется, здесь не очень высокий. Вы кодом в обработке в специальных процедурах описываете все необходимые действия. Для проверки отрабатывая обработчиков событий формы вместе с конфигурацией идет расширение, в которое добавлены все тестируемые формы и все обработчики сделаны экспортными процедурами, чтобы их можно было вызывать при заполнении полей в тестах.
Кроме того, как я сказал, нам пришлось немного доработать тест-центр. В частности, мы добавили регистр для распределения различных НСИ между рабочими местами и соответственно изменили сам алгоритм выбора НСИ в тестах. Так как у нас было 400+ пользователей, то сделали механизм автоматического определения ролей по номеру пользователя. Кроме того, в тест-центре все рабочие места запускаются одновременно, нам же надо было выстроить особую последовательность действий. Например, сначала шел закуп, потом продажа, потом отгрузка со склада и т. д. Здесь тоже пришлось выполнить некоторые доработки.
Конечно же, в процессе разработки были и неожиданные открытия и на грабли понаступали, не без этого. Но так или иначе, разработку мы завершили недели за 3-4. Как часто и бывает, много времени уходило на различные согласования и принятие решений.
Целью проекта было только тестирование, без изменения конфигурации. Но небольшую доработку типовой конфигурации мы все же сделали. Когда мы просто запустили 400 сеансов 1С, то уже заметили значительную нагрузку на оборудование. Эту нагрузку создавали различные обработчики ожидания, интерактивные формы, в частности, тот же рабочий стол с различной информацией. В результате мы отключили все возможные интерактивные, всплывающие, ожидающе окна, систему взаимодействия и все различные рекламные сообщения. Отключили почти все регламентные задания. В результате получилось добиться почти полного, скажем так, «простоя» оборудовании при простом запуске большого количества сеансов. Если у вас в реальной жизни пользователи не пользуются этим функционалом, может быть имеет смысл его также отключить.
Результаты тестирования
Запуск теста представлял собой отдельный квест. Так как у нас 400 пользователей и 6 терминальных серверов, я запускал по 2 сеанса на каждом терминальном сервере, запускал менеджер тестирования, всего получается 12, и каждый менеджер автоматически начинал создавать рабочие места и выполнять предписанные действия. При необходимости можно было все эти действия и автоматизировать, конечно.
Далее наш тест шел примерно 20 часов. За это время мы создавали весь объем документов, ближе к вечеру запускали закрытие месяца с расчетом себестоимости и все время по расписанию работали регламентные задания имитируя интеграции. Позже мы поняли, что для получения релевантных результатов, можно проводить и половинчатый тест, и позже, я успевал за сутки прогнать тест 2 раза, снизив число итераций.
Мы запускали тесты для 4 основных сценариев, которые хотел проверить заказчик:
-
Текущая нагрузка (200 пользователей)
-
Удвоенная нагрузка (400 пользователей)
-
Удвоенная нагрузка (400 пользователей) с параллельным закрытием месяца
-
Проверка предельного числа пользователей в информационной базе на текущем оборудовании
Я здесь нагрузку считаю в пользователях, в общем случае это, конечно, некорректно, но в данном случае так можно делать, т. к. каждый следующий набор АРМ добавлял соответствующую нагрузку в виде своей порции документов.
Работа 200 пользователей
Запустив тест на нагрузке, сопоставимой с текущей нагрузкой в базе УПП, мы получили и близкие к текущей системе показатели.
Сразу же у нас выявилось узкое место – это рабочее место «Управление доставкой», с документом «Задание на перевозку». Этот функционал был разработан в УПП с нуля, была надежда, что в 1С:ERP можно будет обойтись типовыми документами, но первые же тесты показали, что данную подсистему придется также значительно дорабатывать.
Но, общий показатель производительности получился хорошим, APDEX равен 0.879.
Понятно, что каждый тест мы запускали несколько раз. Здесь и далее я буду приводить усредненные результаты.

Работа 400 пользователей
Когда мы увеличили нагрузку 2 раза, то есть запустили тест на 400 пользователей, время выполнения ключевых операции увеличилось в среднем на 30%. К проблемным документам добавились документы «Реализация» и «Корректировка реализации». А общий результат по системе APDEX снизился до 0.652.

Причем, очень большой загрузки оборудования мы не замечали. Из узких мест – загрузка ЦП на сервере баз данных.
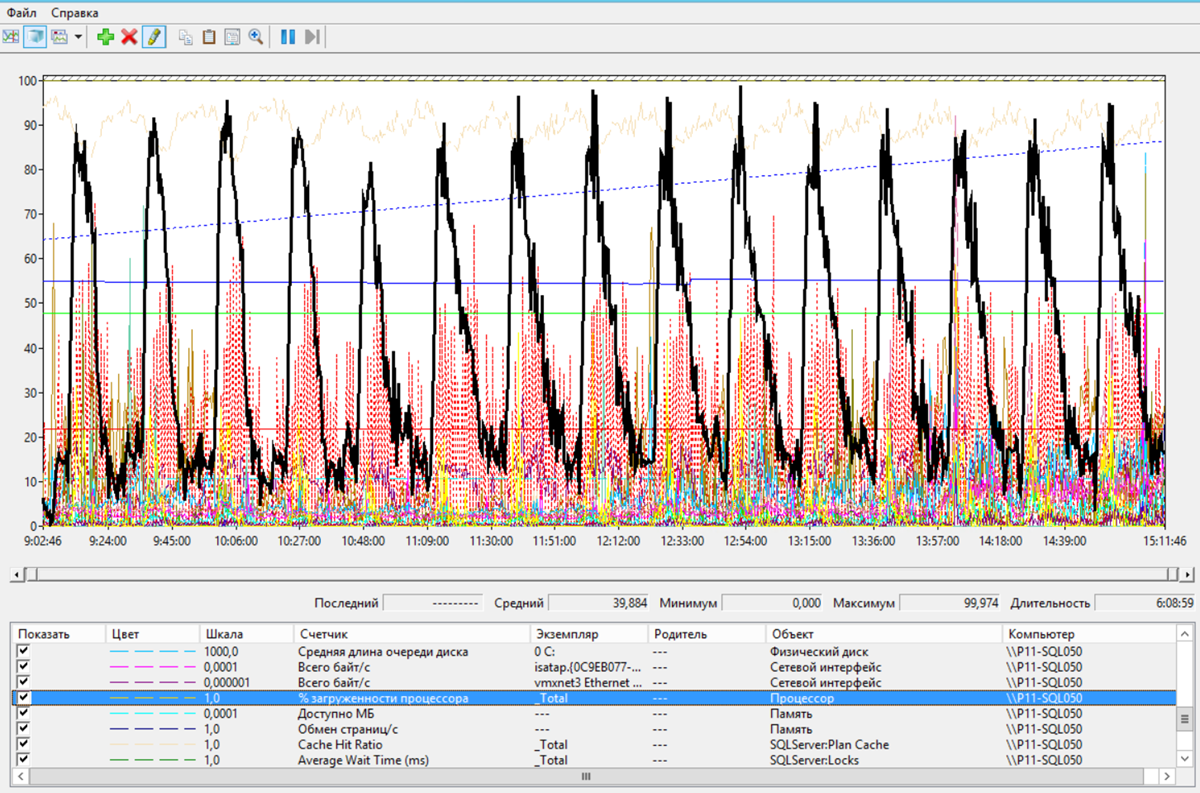
Сервер БД – Загрузка ЦП
И небольшая очередь к диску с базой tempdb.
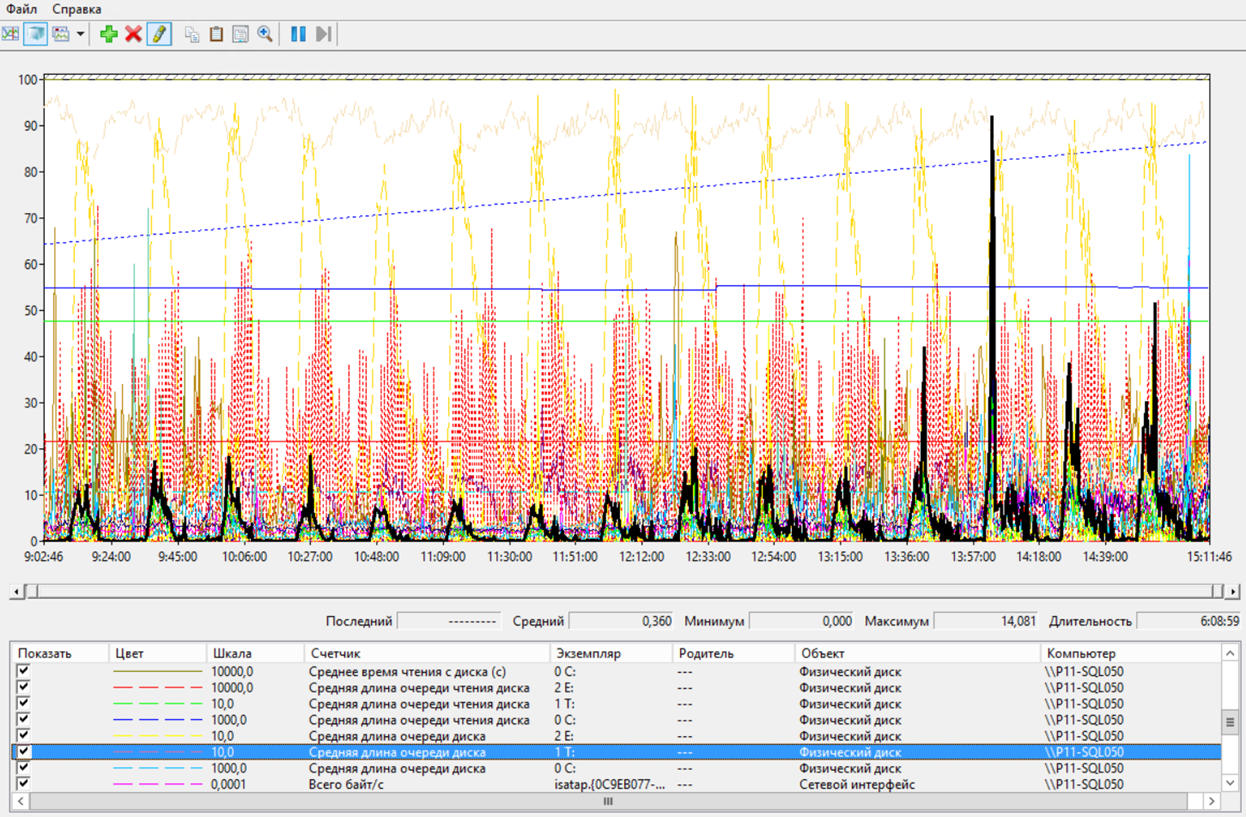
Сервер БД – Очередь к диску с TempDB
Также сильно были загружены процессоры на кластере серверов 1С.
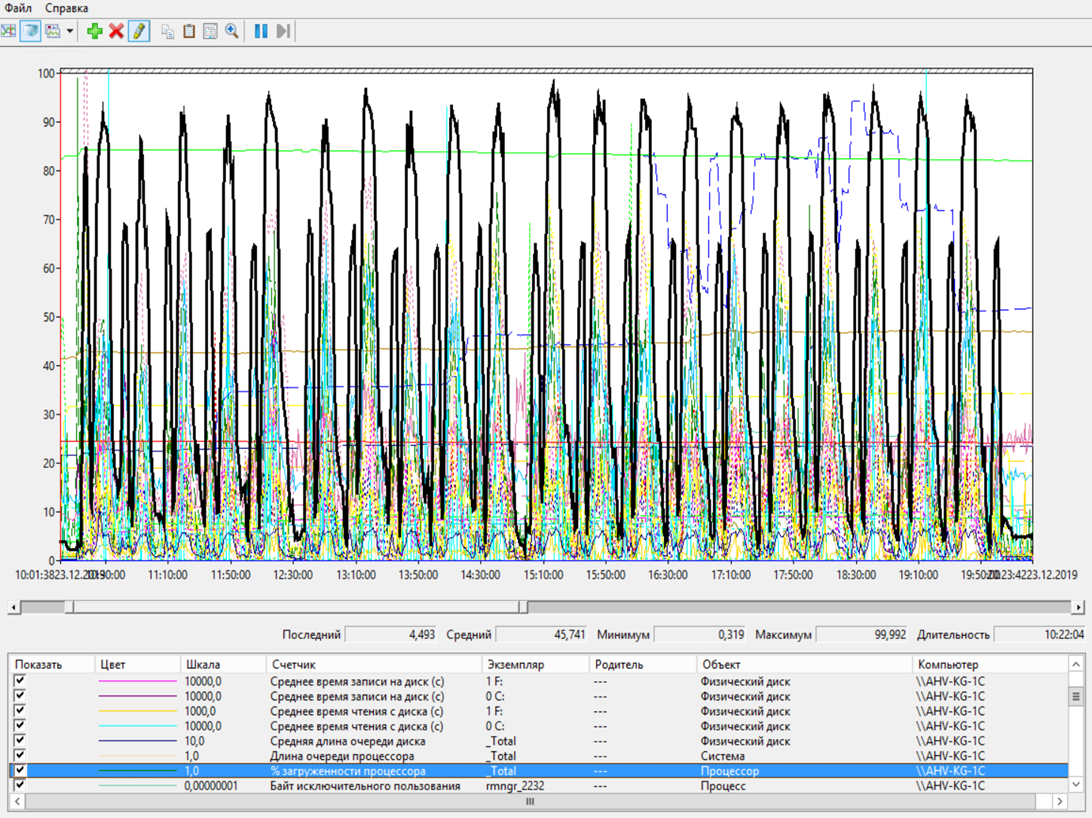
Сервер приложений – Загрузка ЦП
Наблюдалась очередь к процессорам. Но, как я сказал, запас еще небольшой оставался. То есть, возможно, причины медленной работы нужно было искать не в оборудовании, а где то еще.
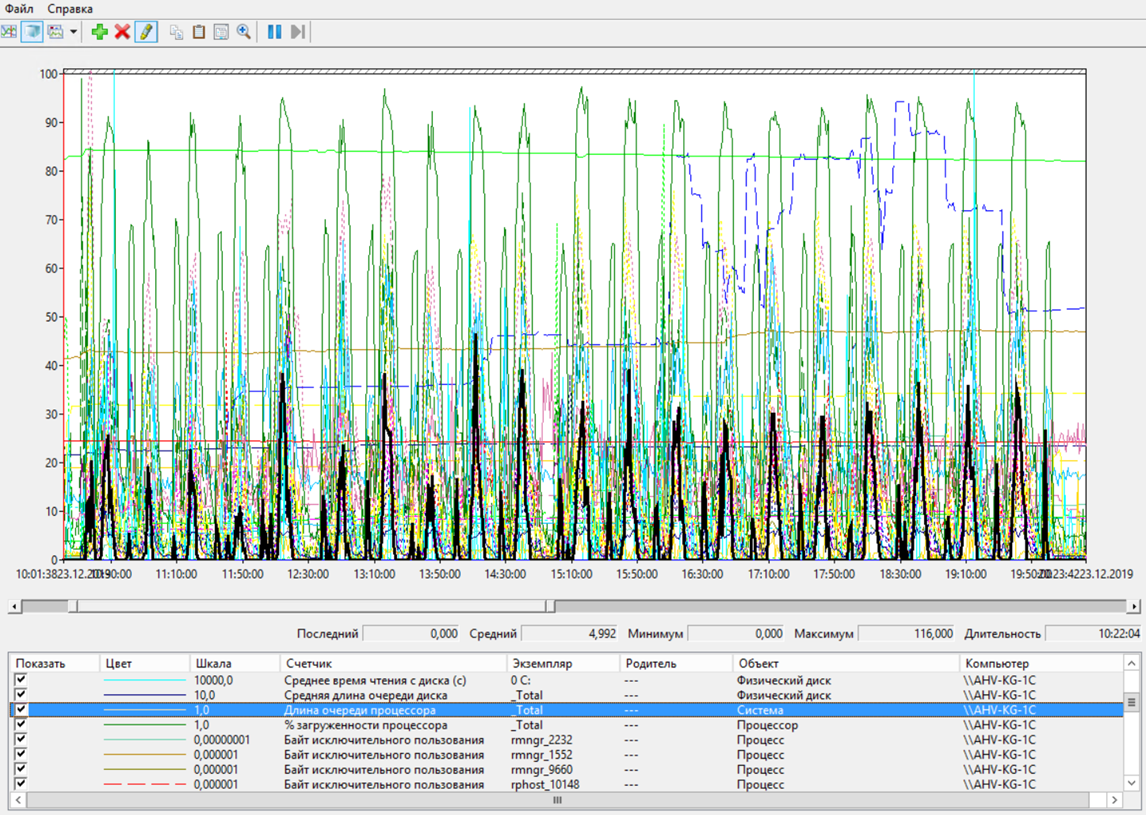
Сервер приложений – Очередь к ЦП
Работа 400 пользователей с закрытием месяца
Когда мы дополнительно запустили еще закрытие месяца, то система повела себя достойно. Общий APDEX со значения 0.652 снизился всего лишь до 0.612. То есть параллельное закрытие не повлияло как то очень уж значительно на общую производительность. Всего, закрытие месяца со всеми этапами длилось примерно 9 часов.

Причем, заметной нагрузки на оборудование мы также не замечали. Из узких мест – загрузка ЦП на сервере СУБД.
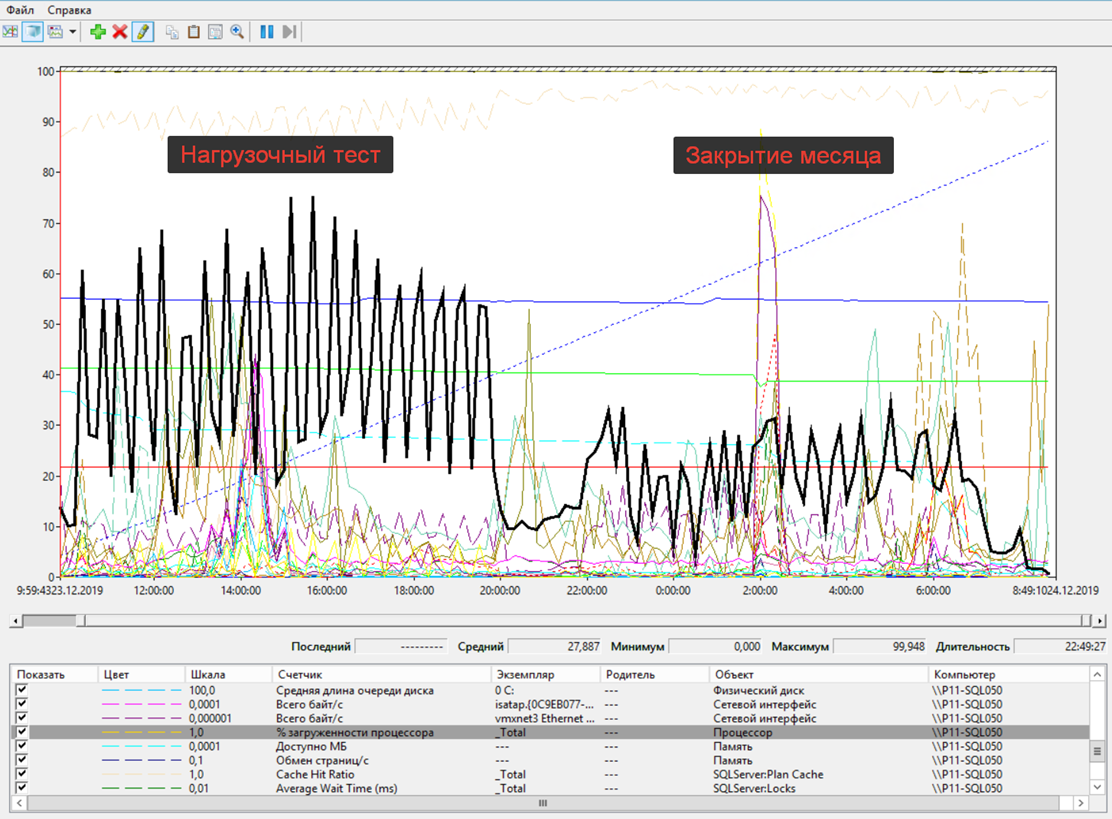
Сервер БД – Загрузка ЦП
Дополнительно появилась очередь к дискам с базой данных. Вот здесь виден пик, когда происходила запись рассчитанных партий в регистр.
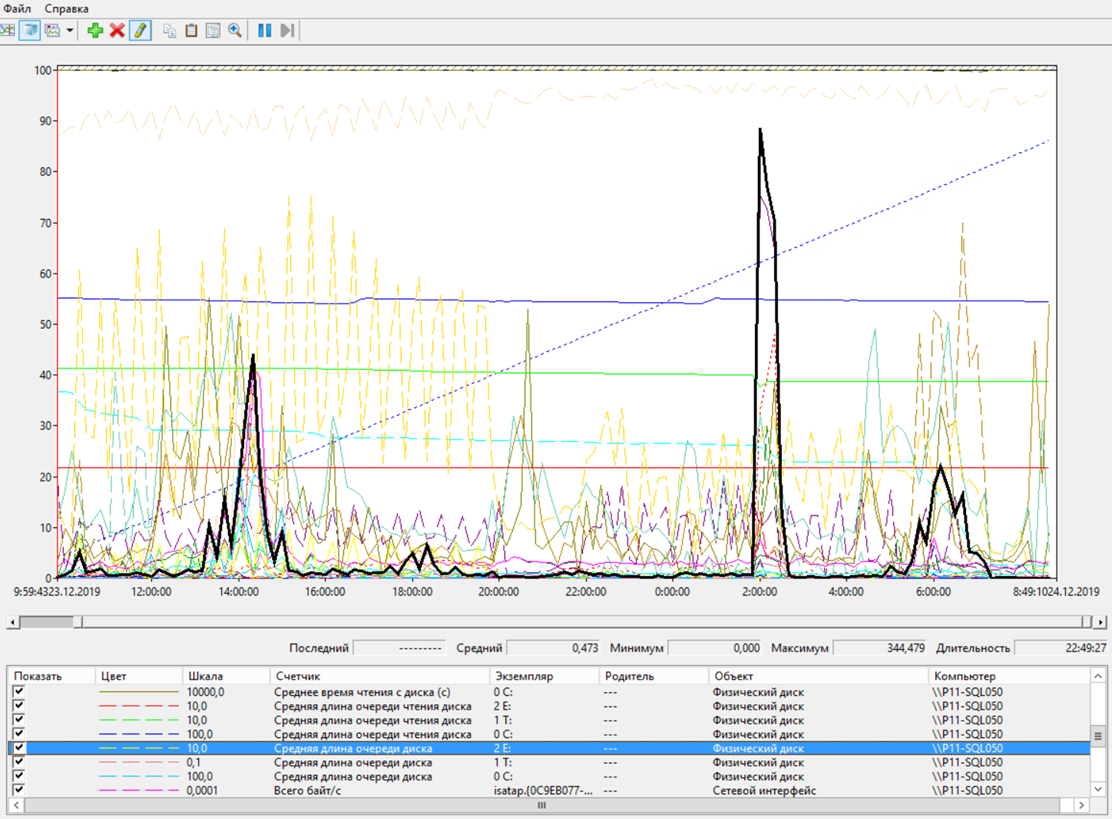
Сервер БД – очередь к диску с базой данных
Проверка предельного числа пользователей
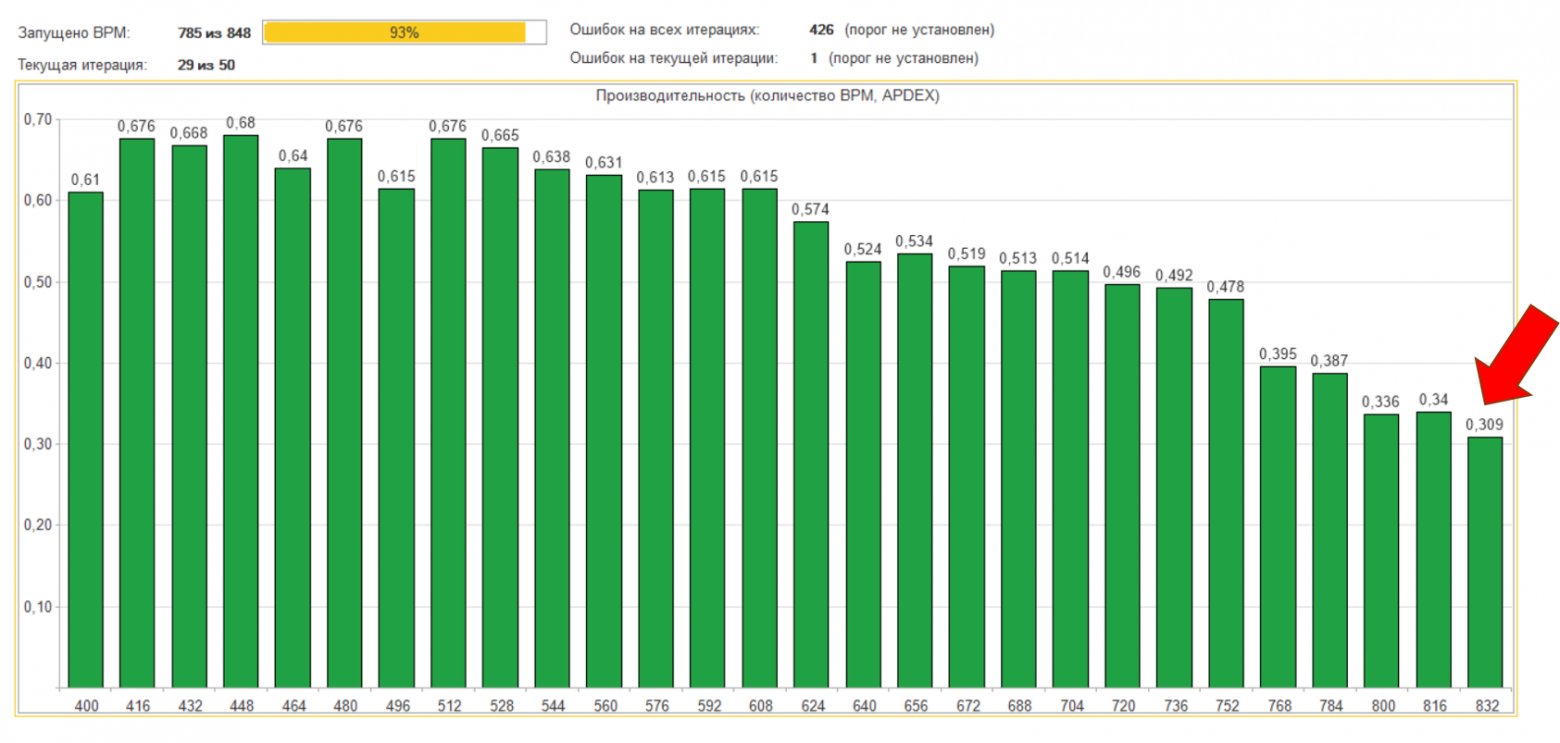
Ну и последнее, нам надо было проверить максимальное количество пользователей в системе. Напомню, что в нашем случае пользователь = нагрузка. Начали мы с 400 пользователей, на каждой итерации добавляли по 16 пользователей. И максимально нам удалось запустить 832 рабочих места.

Вот общий график падения производительности. Примерно, на 29-ой итерации APDEX становился совсем уж плохим, и система, что называется, вставала. Мы прекращали тест.
Причем, здесь уже процессоры сервера БД упирались в потолок.
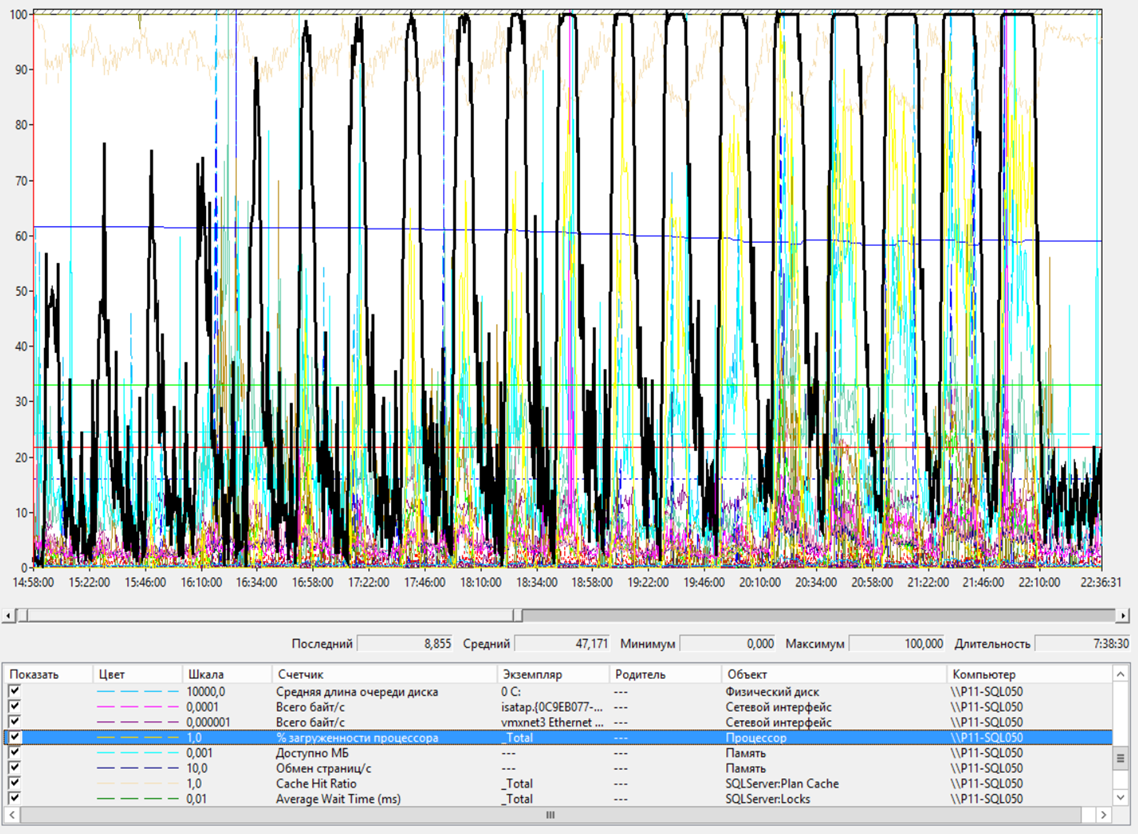
Сервер БД – Загрузка ЦП
Росла очередь к процессорам.
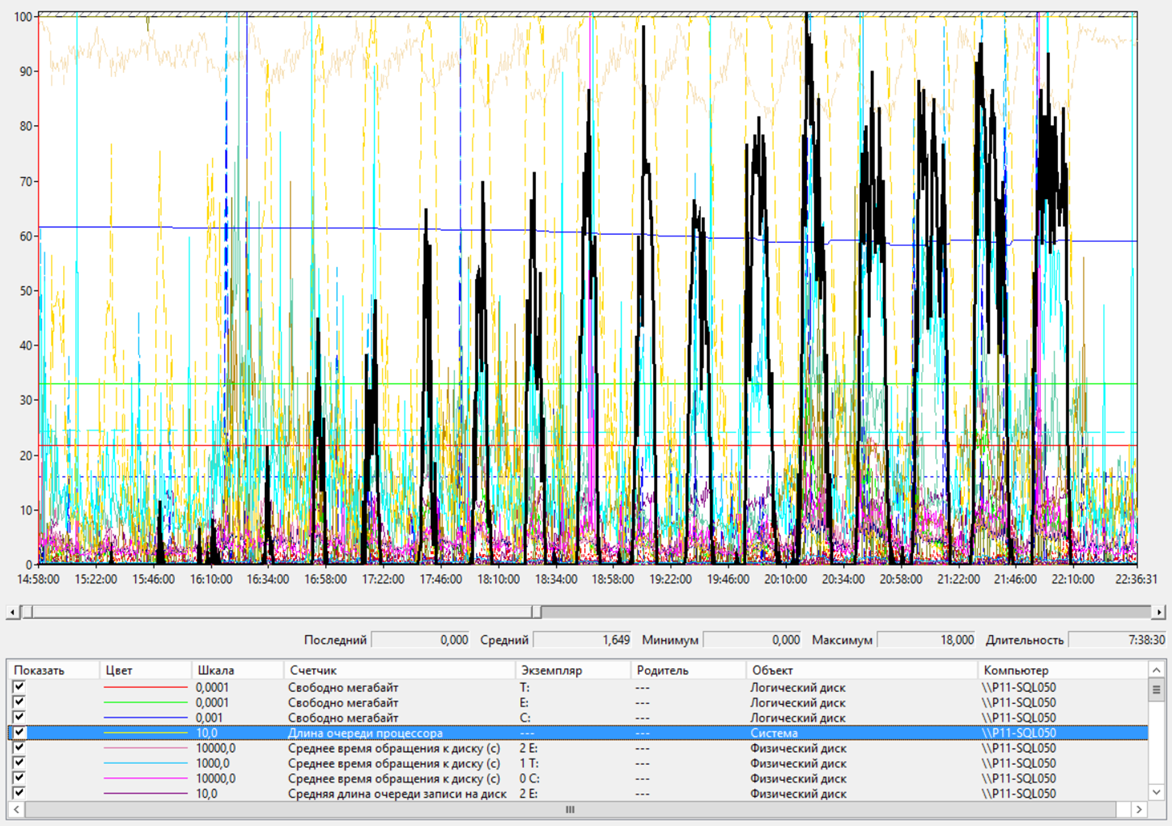
Сервер БД – Очередь к ЦП
Также увеличилась очередь к диску с базой TempBD.
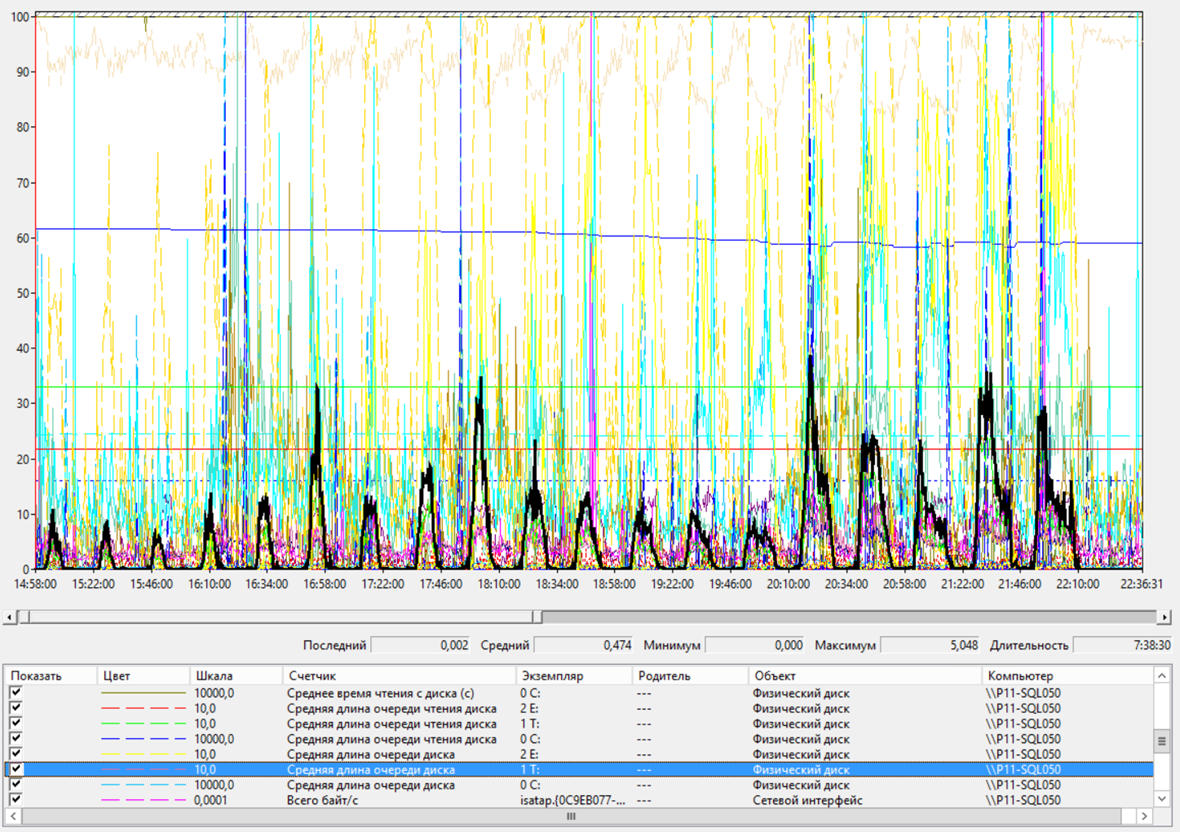
Сервер БД – Очередь к диску с TempDB
А вот на сервере приложений загрузка на ЦП спала. Но это и понятно, т. к. сервер приложений чаще стал ждать ответа от сервера СУБД.
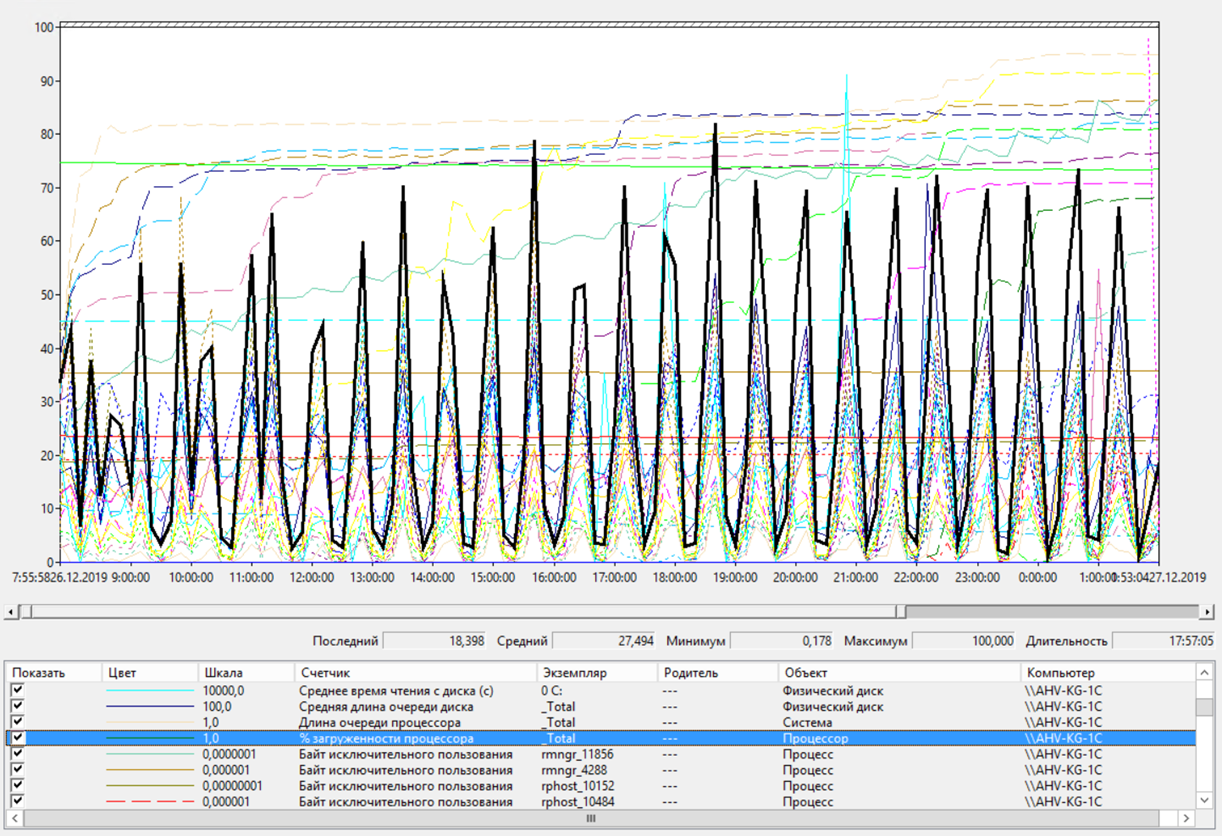
Сервер приложений – загрузка ЦП
В общем, результаты проекта у нас получились такие:
-
Мы показали принципиальную возможность работы в безе 1С:ERP на текущем оборудовании
-
Показали хорошую производительность системы с текущей нагрузкой (по APDEX)
-
Показали удовлетворительную производительность системы с удвоенной нагрузкой (по APDEX)
-
Заранее выявили узкие места в работе системы, на которые необходимо обратить внимание при внедрении
-
Выявили узкие места в работе оборудования
-
Определили приблизительный рост информационной базы с удвоенной нагрузкой - ~60 Гб. в месяц.
-
Предоставили заказчику рекомендации по настройке служб и оборудования
-
Предоставили заказчику готовый контур для проведения нагрузочного тестирования, адаптированный под их бизнес-процессы
Само собой, все написанные скрипты и инструкции были переданы специалистам клиента, чтобы они могли повторять тесты на другом оборудовании, а в последствии, встроить нагрузочное тестирование в разработочный контур на этапа проекта и после.
Проведение нагрузочного тестирования с различными настройками служб
Кроме того, в процессе проведения нагрузочных тестов мы все время искали наиболее производительную конфигурацию оборудования, пробовали различные настройки программ. Проект у нас завершился в конце декабря, впереди были новогодние каникулы, и я попросил заказчика оставить нам все сервера на этот период, на что заказчик, спасибо ему, согласился.
И вот, все каникулы, я круглосуточно запускал тесты, чтобы проверить кое-какие свои догадки и найти максимально удачную конфигурацию. Мы много чего пробовали, я расскажу только о том, что дало какой-то заметный эффект.
Первое, хотелось проверить как влияют разные версии платформы 1С на производительность. Как вы помните, на 14-оей платформе средний APDEX у нас был 0.612. 15-ая платформа показала себя чуть лучше, APDEX стал 0.634. А вот 16-ая платформа показала себя что-то совсем плохо на стандартных настройках. Но, как мы увидим далее, она была более чувствительно на некоторые настройки.
Вывод получился таким: не все платформы показывают одинаковую производительность. Надо пробовать, прежде чем переходить.

Различные версии платформы
Далее, хотелось проверить влияние параллелизма. По-умолчанию, мы по общим рекомендациям, параллелизм на СУБД отключили. Когда же вернули его, то есть установили флаг = 0. То 14-ая и 15-ая платформа ожидаемо показали меньшую производительность. А вот 16-ая платформа, что называется выстрельнула.
Ввод: не все однозначно, надо пробовать различные настройки, в том числе и играться со стоимостью параллелизма. Искать ваш производительный вариант.

Параллелизм на SQL Server
Далее. Как вы помните, у нас наблюдалась небольшая очередь к диску с базой TempDB и хотелось проверить, поможет ли вынос этой базы на RAMDisk. Памяти у нас для этого было достаточно. В результате, 14-ая и 15-ая платформы показали небольшой прирост производительности, а 16-ая добавила в скорости довольно заметно.
Вывод очевиден: вынос TempDB на RAMDisk может быть полезен.

Использование RAMDisk для TempDB
Также в моей практике не раз хороший выигрыш давало сжатие баз данных. В общем случае мы рекомендуем нашим клиентам использовать сжатие. Проверили это и здесь.
Сначала запустили сжатие на всех таблицах базы данных. База уменьшилась почти в 6 раз. Но, ожидаемо, упала и производительность.
Далее, запустили сжатие только больших таблиц, т. е. с объемом большим 1 Гб. Размер базы уменьшился совсем немного, но и производительность никак не изменилась.
Но вот если сжать большие таблицы, но после сжатия не запускать Shrink, то чуть-чуть но можно выиграть в скорости. Результат справедлив для всех платформ.
В данном конкретном случае, нам не удалось добиться повышения производительности путем сжатия баз данных, т. к. у нас дисковая подсистема показала себя очень достойно, а узким местом были процессоры. Но в моей личной практике часто бывает наоборот: узкое место – как раз диски и в этом случае сжатие может дать очень хорошие результаты.
Так что вывод здесь все равно такой: что сжатие имеет смысл при загруженности дисковой подсистемы. Ну и в очередной раз убедились, что Shrink – это вредная для базы данных операция.
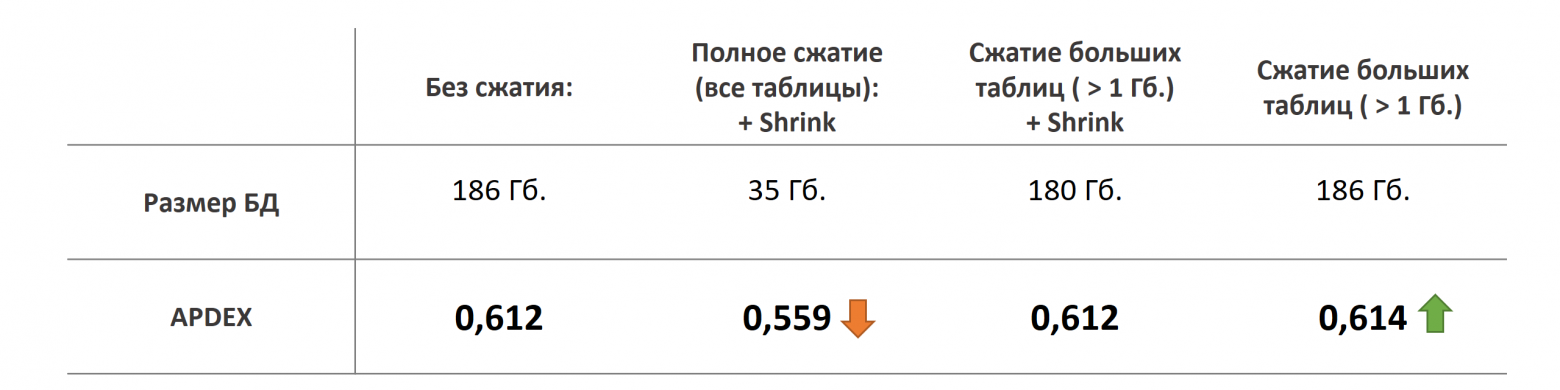
Сжатие баз данных
Также хотелось проверить, какое влияние оказывает на производительность протокол Shared Memory. Для проверки я перенес сервер приложений на сервер СУБД и в настройках базы сначала настроил протокол TCP, запустил тесты, а потом повторил уже с SharedMemory.
Понятно, что полный тест, у меня скорее всего бы встал – на одном-то сервере. Я запускал тест на 200 пользователей. Ну и, опять таки, на 14-ой платформе протокол SharedMemory показал ожидаемый хороший результат. А вот 16-ая платформа повеля себя странно. На TCP работала как и на SharedMemory. Наверное, я чего-то про нее не знаю.
Но, несмотря на это, все равно, думаю, можно сделать вывод, что Shared Memory дает прирост производительности.

Сервер 1С и СУБД на одной машине, тест на 200 пользователях. Протокол Shared memory.
Ну и последнее. Все мы знаем о рекомендации не включать отладку на сервере на продуктивных базах. Я решил проверить, насколько флаг отладки влияет на производительность. И он реально влияет! Но не так как я предполагал. На всех версиях платформы отладка заметно ускоряла сервер 1С. Я повторял тест несколько раз, и каждый раз получал такие интересные результаты. Боюсь сделать здесь какой-то вывод, но, неужели отладка на сервере и впрямь увеличивает производительность? Почему она тогда не включена по-умолчанию?
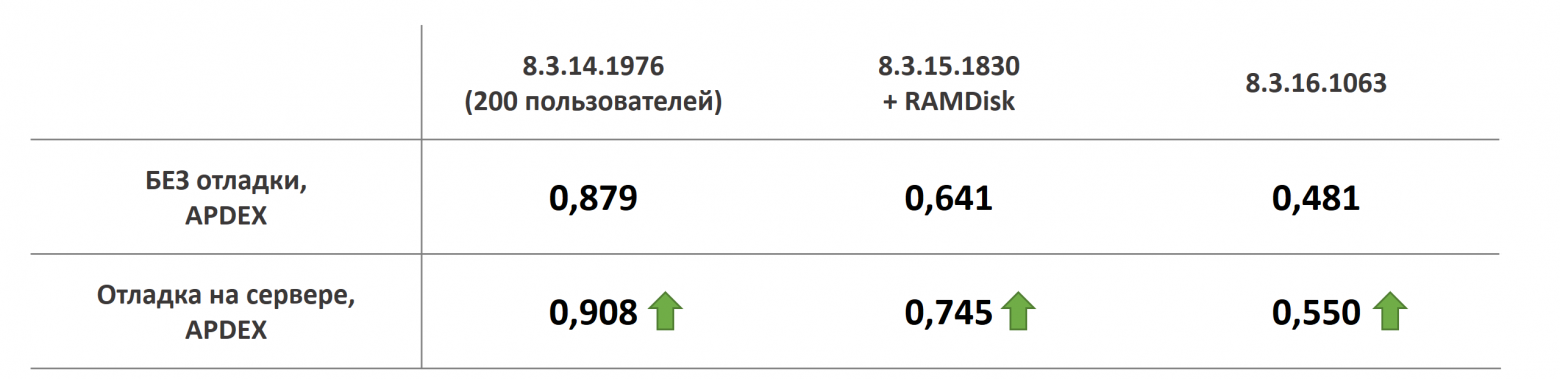
Включение отладки на сервере
В результате, применив все озвученные выше настройки, удалось только лишь настройками программ заметно увеличить производительность системы. С 0.612 до 0.745. Согласительно, очень хороший результат.

Лучшие настройки
Какой здесь можно сделать вывод? Ни в коем случае не надо прочитав статью идти и включать отладку на продуктиве или делать что-то еще, потому что вы об этом где-то услышали. Мало ли, кому что помогло. Разные советы работают в разных ситуациях.
Вывод заключается в том, что необходимо экспериментировать!
Не хочется советовать вам экспериментировать на проде, возьмите хотя бы ту же демку с готовым тестами и начните запускать ее хотя бы по ночам, в поисках конфигурации, дающей максимальную производительность вашей системы.
А у меня на этом все, большое спасибо тем, кто прочитал до конца. Надеюсь, статья была для вас полезной.
*************
Данная статья написана по итогам доклада (видео), прочитанного на конференции Infostart Event 2021 Post-Apocalypse.
Приобретайте 1С:ERP в Инфостарт с бонусом 15%!
- Бесплатное демо продукта и консультация
- Команда экспертов 1С с опытом 10+ лет
- Оценка проекта, четкий план работ, документация, обучение и поддержка
Закажите расчет внедрения ERP - получите дорожную карту в подарок!

Вступайте в нашу телеграмм-группу Инфостарт