GIT – это система для хранения и ведения истории изменения файлов. Это своего рода аналог хранилища 1С, но со своими особенностями и ограничениями.
Большинство статей о GIT демонстрируют только процесс его первоначальной настройки и подключения. Они не показывают, с какими проблемами столкнулись авторы во время его использования, как их решали, и какие нехорошие мысли у них возникали в процессе.
Как обычно внедряется GIT

Как обычно внедряется GIT:
-
фаза 1 – внедрили GIT;
-
фаза 2 – ?
-
фаза 3 – все отлично.
Так хочется узнать, что скрывается под этим вопросом во второй фазе. В этом докладе на примере истории разработчика Андрюши мы пройдемся по примерам использования GIT на практике и разберем основные ошибки, с этим связанные.

Чтобы не возникало вопросов, давайте определимся с терминологией.
-
Репозиторий – это каталог, где хранятся все версионируемые данные GIT.
-
Commit – это фиксация текущих изменений и внесение их в историю вашей ветки.
-
Конфликт – это ситуация, возникающая при объединении веток, когда изменения есть и с той, и с другой стороны. При этом GIT объединить их в автоматическом режиме не может.
-
Merge – объединение одной ветки GIT с другой.
-
Pull request – запрос на добавление ваших изменений в другую ветку. Он используется в том случае, если вам запрещен доступ для обновления через commit (пул-реквесты часто используются для объединения веток master и develop).

Дисклеймер: образ Андрюши является собирательным. Все возможные совпадения с реальным человеком случайны.

На слайде разработчик Андрюша. У него есть мечта – разрабатывать правильно, в большом коллективе единомышленников, и чтобы каждый был доволен процессом.
В свои молодые годы Андрюша уже “осознал” каково это – использовать хранилище 1С на практике. А может и вы сталкивались с таким?
Не приходилось ли вам восстанавливать затертые доработки форм в хранилище?

Или, может, просили “корень” у коллеги? А может быть, у вас была доработка одного и того же объекта?
Из-за таких вот ситуаций казалось, что GIT – это решение всех проблем.
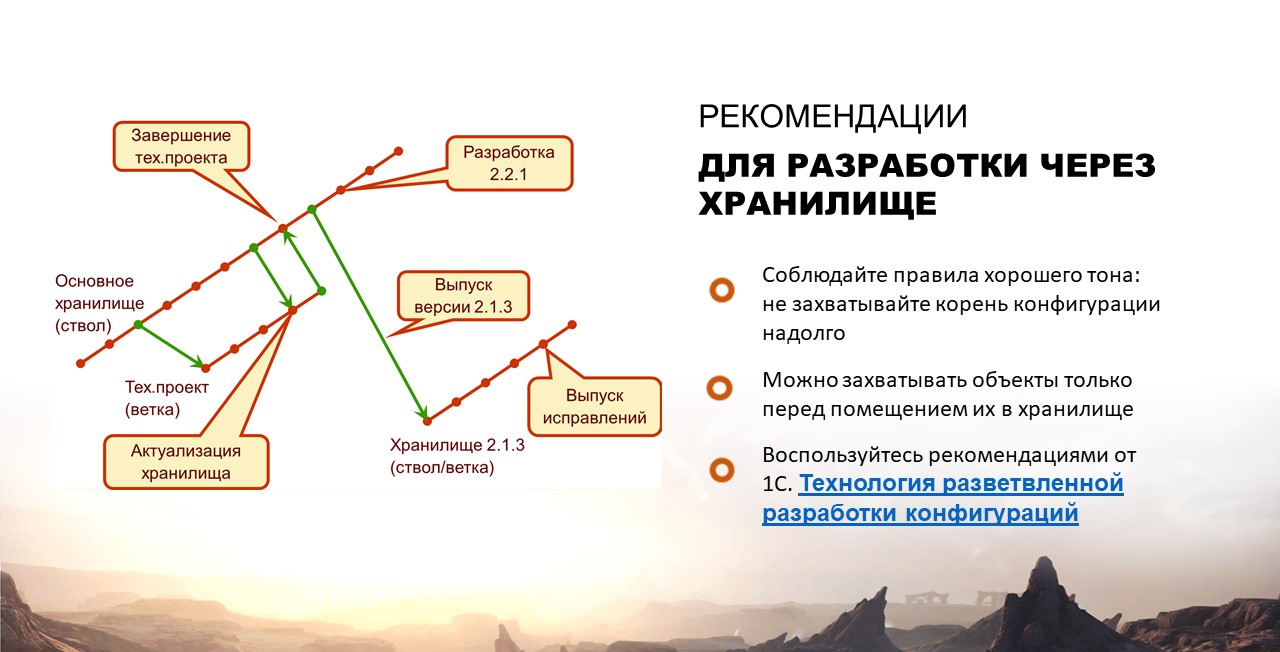
Рекомендации для разработки через хранилище
Некоторые возразят, что хранилище 1С – это очень удобный инструмент, просто нужно грамотно настроить процесс разработки. Например:
-
не захватывать надолго корень конфигурации;
-
либо захватывать объекты только перед помещением в хранилище;
-
или вообще воспользоваться рекомендациями фирмы 1С «Технология разветвленной разработки».
И с этим можно согласиться, но спишем стремление нашего молодого человека к GIT на его неопытность и желание опробовать новый инструментарий.
По счастливой случайности, а может и божественному провидению, Андрюша все же нашел ту самую “компанию мечты”, где 1С-ники недавно отказались от хранилища 1С в пользу использования GIT и вместе с нашим Андрюшей им предстояло пройти тернистый путь командной разработки.
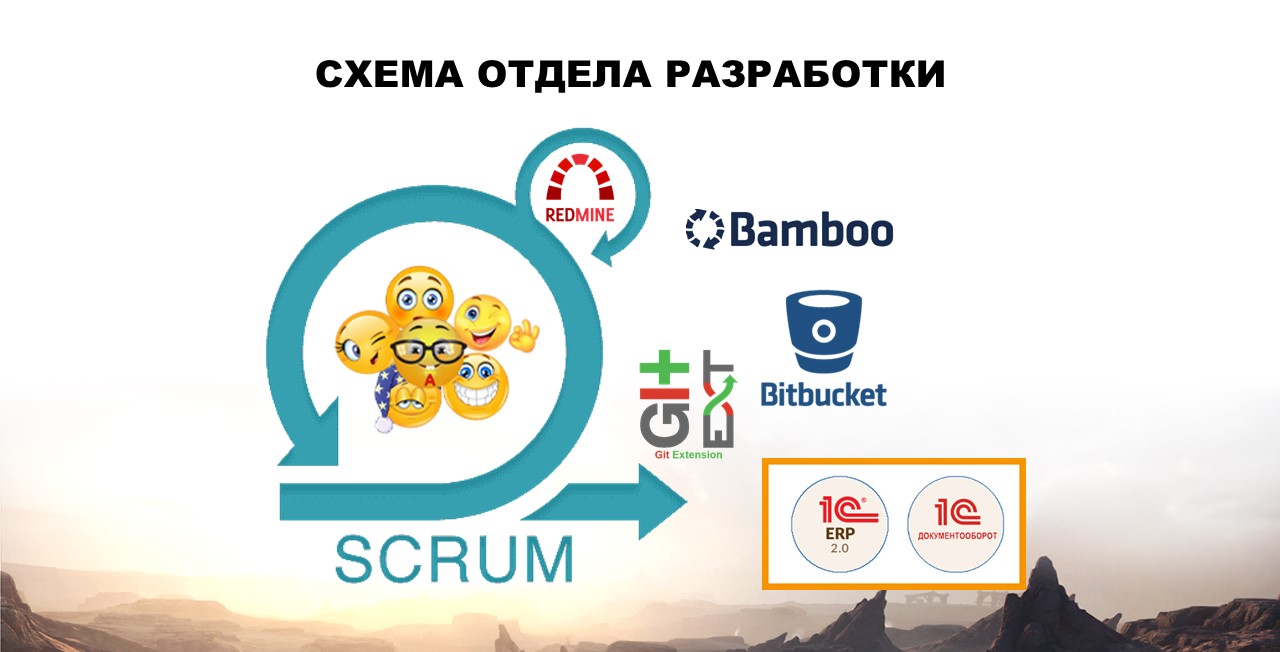
В процессе разработки поддерживалось две конфигурации.
-
Жутко старый «Документооборот» еще первой версии, который был подключен к хранилищу;
-
1С:ERP, разработка которой перешла на GIT.
Сам процесс разработки велся по SCRUM. У каждого разработчика были собственные базы, которые они могли сами актуализировать из копии продуктива.
Помимо этого, использовался:
-
Redmine – для учета задач и трудозатрат;
-
Bamboo – для тестирования, формирования релизов и дополнительных служебных операций (в частности, для обновлений баз разработчиков);
-
сервер Bitbucket, как система для версионирования, хранения и рецензирования кода;
-
GIT Extension – локальный клиент для GIT. Он удобен тем, что бесплатный, имеет простой и удобный интерфейс, логирует действия пользователей и не вылетает при большом количестве файлов в одном коммите.

Конечно же, все эти системы были на английском языке, ведь нужно приучаться к культуре тру-девелоперов и расширять свой словарный запас словечками: мердж, пул, фича и так далее.
Как выглядит схема ветвления GIT и какие данные можно поместить

Схема ветвления веток GIT похожа на GitFlow:
-
основная ветка «develope»,
-
от нее формировались задачи «feature», соответствующие номерам задач из Redmine;
-
при выполнении задачи, разработчик мерджил эту ветку с веткой «test»;
-
ветка «test» была подключена к отдельной базе, на которой отдел сопровождения проверял доработки;
-
после проверки ветку разработчика объединяли с веткой «develope»;
-
раз в день, после проведения автоматизированных тестов, ветку «develope» объединяли уже с веткой «master», и из нее формировался релиз, который загружался в продуктив;
-
помимо этого существовала ветка «origin1c» – в ней была размещена конфигурация поставки, ее использовали для обновления конфигураций через GIT и для сравнения, чем модуль из «develope» отличается от типового.

Версионировались не только файлы конфигурации, но и расширения, внешние отчеты, обработки и правила обмена:
-
Внешние отчеты и обработки выгружались стандартным способом через пакетный режим конфигуратора.
-
Правила обмена – для выгрузки использовалась утилита Gitrules, разработанная Олегом Тымко. Утилиту пришлось немного доработать, добавив поддержку выгрузки не только правил конвертации, но и правил регистраций и их сборку.
-
Конфигурация и Расширения. Раньше они выгружались стандартным способом через команду «Выгрузить конфигурацию в файлы», но разработчики вскоре перешли на другое решение – утилиту автономного сервера ibcmd.
Утилита не требует лицензии 1С и не блокирует конфигуратор при выгрузке конфигурации в файлы, что позволяет при выгрузке одновременно работать и в конфигураторе. Плюс она не зависит от самого автономного сервера и ее можно использовать отдельно.
Пример команды для выгрузки конфигурации в файлы с помощью утилиты:
"C:\Program Files (x86)\1cv8\8.3.18.1334\bin\ibcmd.exe" infobase --dbms=MSSQLServer --db-server="Имя сервера" --db-name="Имя базы" --db-user="Имя пользователя SQL" --db-pwd="Пароль пользователя SQL" config export "Путь к репозиторию GIT" --base="Путь к ConfigDumpInfo.xml"

В таком процессе и начались рабочие будни нашего Андрюши.
Все было бы хорошо, и можно было бы сказать, что GIT – это удобный и практичный инструмент, но точно не для 1C:ERP.
В ней все очень тормозило: переключение между ветками, сравнение 2-х коммитов или веток.
Неприятной проблемой стало обновление на новый релиз – при этом коммитился cf-файл поставки, и в изменения попадали сразу все объекты конфигурации.
Разработчиков это сильно не устраивало. Стали искать способы ускорения - один из них стал GIT LFS.

GIT LFS – это расширение для GIT, которое преобразует выбранные файлы в текстовые ссылки, перемещая их в отдельное хранилище. После этого размер репозитория существенно сокращался.
Но GIT LFS нужно настраивать сразу при первым коммитом, иначе придется создавать отдельный репозиторий и перемещать туда всю историю изменений – при этом каждый коммит тогда необходимо обрабатывать дополнительно, чтобы он перемещался в GIT LFS.
Таким образом в GIT LFS были перемещены все бинарные общие макеты конфигурации и сам cf-файл поставки.
Общая схема выглядела так:
-
включаем GIT LFS на сервере Bitbucket;
-
на рабочем месте разработчика устанавливаем расширение https://git-lfs.github.com/ , сейчас git-lfs уже включен в дистрибутив git по умолчанию;
-
в консоли репозитория прописываем команду
git lfs install
-
указываем список файлов, которые необходимо отслеживать, командой
git lfs track "*.cf"
git lfs track "/Config/CommonTemplates/*/Ext/*.bin"
Стоит обратить внимание, что GIT LFS по факту удаляет файлы из каталога. Чтобы корректно загрузить конфигурацию из файлов, необходимо вначале получить их из центрального хранилища командой:
git lfs fetch --all
И заменить текстовые ссылки на реальные файлы командой:
git lfs checkout
Популярные задачи с GIT, частые ошибки и их решение
Задача №1: перенести из актуального релиза новый регламентированный отчет
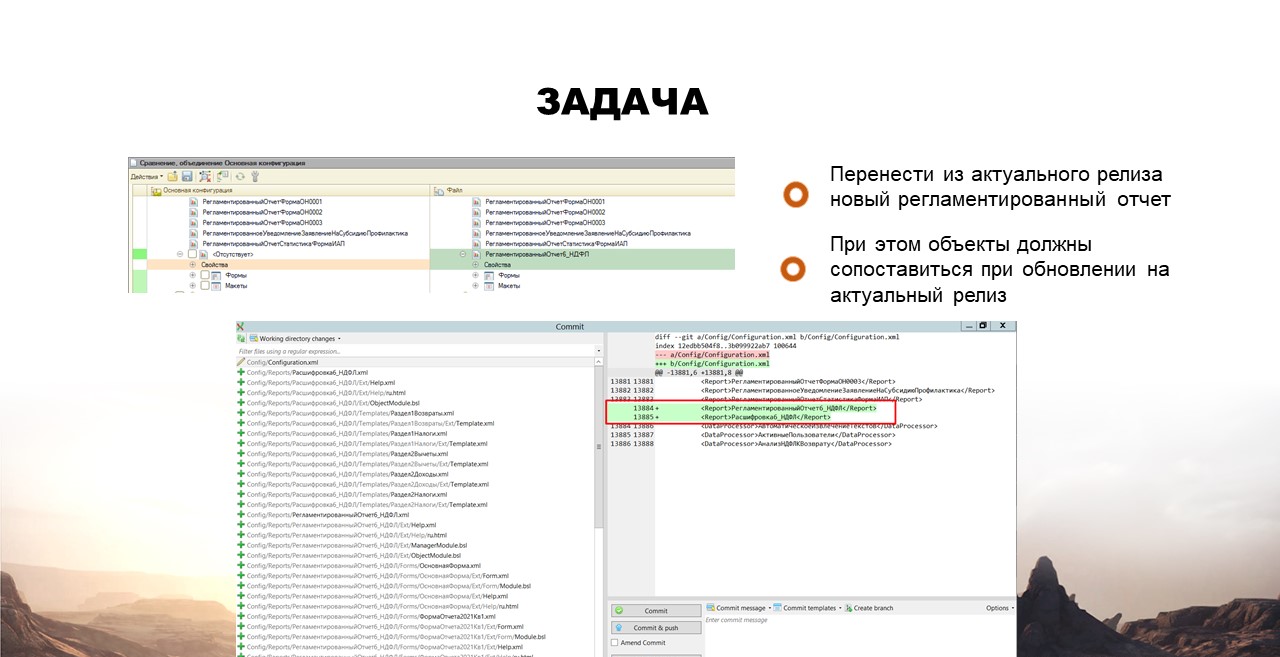
Андрюше поручили перенести из актуального релиза новый регламентированный отчет по 6-НДФЛ. Да так, чтобы все объекты при обновлении сопоставились.
Как хороший разработчик, Андрюша знал, что для корректного обновления объекты должны иметь такие же идентификаторы, что и типовые. Для этого он сравнил и объединил с конфигурацией релиза, отметил отчет для объединения и выгрузил изменения в Git.
Задача отправилась на тестирование и прошла его.
Позже конфигурацию на сервере обновили до актуального релиза – для этого объединили ветку «origin1c» с «develop».
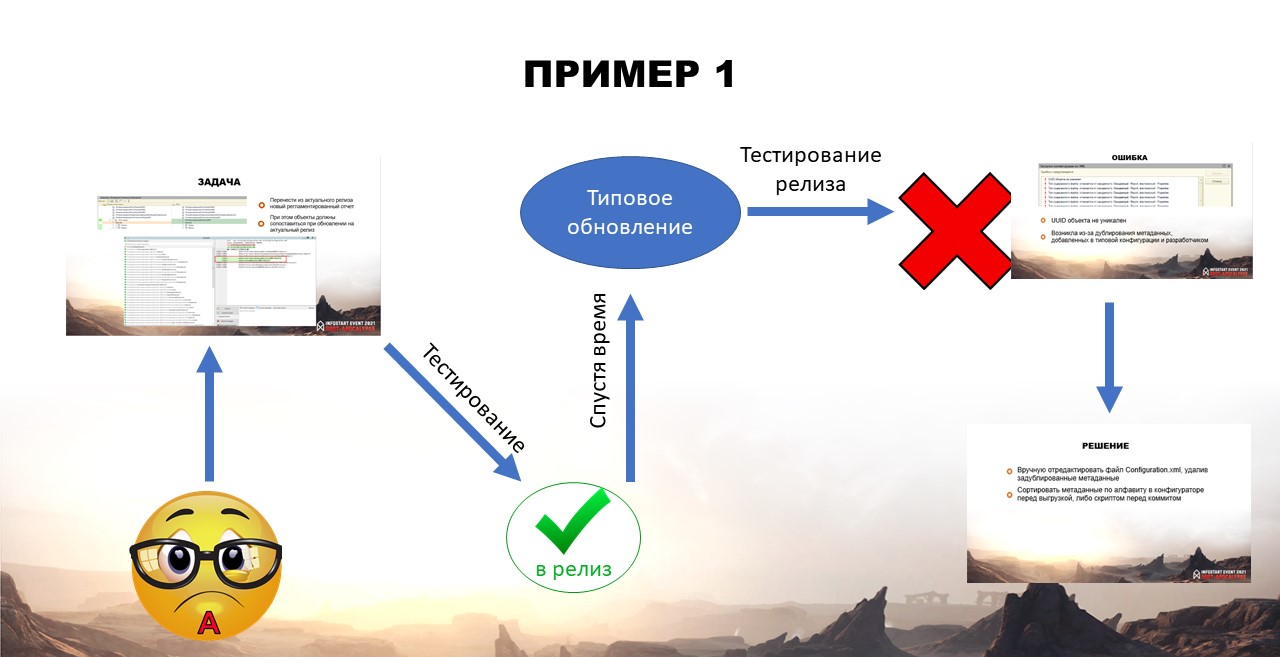
Однако конфигурационный файл с релизом после всех этих доработок сформировать не удалось, потому что задублировались метаданные отчетов.
В чем же была причина?
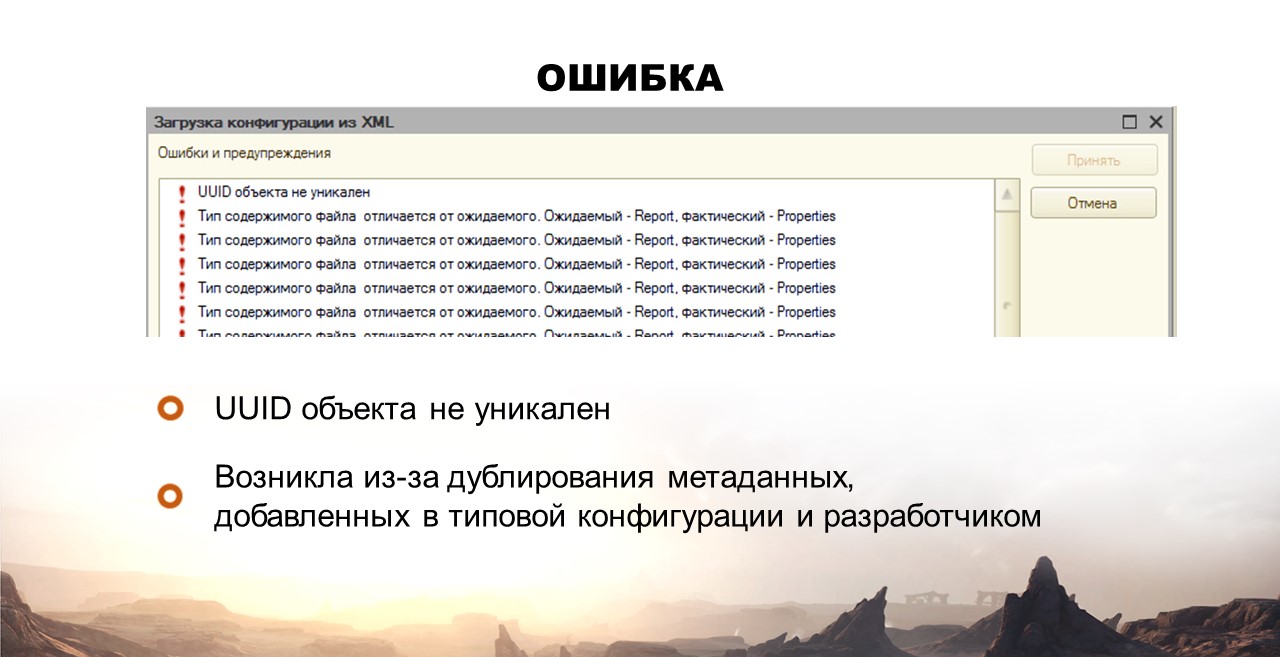
Ошибка: весь список метаданных в выгруженном виде содержится в одном файле configuration.xml. Когда Андрюша добавил новый отчет, он был автоматически добавлен в конец этого списка.
В релизе же все файлы хранятся по алфавиту. А GIT работает с 1С, как с текстом. Доработка и добавление Андрюшей нового отчета и вендором, рассматривались как две разные доработки, так как были добавлены в разные места одного и того же файла. И при этом даже конфликтов не возникало.

Решение: вручную отредактировать файл Configuration.xml, удалив задублированные метаданные.
Чтобы ситуация не повторялась, необходимо:
-
либо перед выгрузкой конфигурацией файла, отсортировать метаданные конфигуратором по алфавиту;
-
либо сделать специальный скрипт, который бы обходил все выгруженные файлы и делал бы автоматическую сортировку перед коммитом.
Способы сохранения ConfigDumpIngo.xml

Объекты из 1С попадают в GIT с помощью команды конфигуратора «Выгрузить конфигурацию в файлы». Чтобы выгрузка проходила быстрее, разработчики 1С в версии платформы 8.3.10 добавили возможность инкрементальной выгрузки.
При этом формируется файл ConfigDumpInfo.xml, в котором содержатся идентификаторы всех выгружаемых объектов.
Если в процессе разработки объект меняется, меняется и его идентификатор – таким образом, платформа может отследить, что именно изменилось, чтобы выгрузить только изменения.
В теории, по сравнению с тем, что раньше нужно было всегда выгружать всю конфигурацию, это выглядело хорошим решением.
Но на практике вам надо заботиться об этом файле: холить и лелеять его. Не дай Бог, 1С посчитает его не актуальным. Тогда начнется выгрузка всей конфигурации.
ConfigDumpInfo.xml – это файл Шредингера.
Его наличие в репозитории обязательно, но его нежелательно коммитить. Иначе он попадет в конфликты при объединении. И добавить в .gitignore нельзя, так как тогда он пропадет из видимости репозитория, и ты не поймешь, есть он в каталоге, или нет.
Самое забавное, что возможность сформировать этот файл вручную разработчики платформы добавили только спустя два года от появления инкрементальной выгрузки – в версии платформы 8.3.15:
-
для этого необходимо запускать конфигуратор в пакетном режиме с командой «load-config-from-files» и параметром «--update-config-dump-info only»;
-
либо воспользоваться утилитой автономного сервера ibcmd и выгружать с помощью режима «infobase config export info».
До выхода релиза 8.3.15, разработчикам пришлось сделать скрипт, который бы сравнивал два коммита, а разницу загружал в конфигурацию. При этом автоматически формировался актуальный ConfigDumpInfo.xml.
Этот файл ConfigDumpInfo.xml они прятали из видимости GIT с помощью команды git stash – она перемещает выбранный файл в специальное отдельное хранилище, не добавляя в репозиторий.
Из хранилища его можно доставать командой git stash pop. Единственное ограничение – чтобы git stash работал - надо один раз поместить configdumpinfo.xml в коммит репозитория.
Если вы не сумели сформировать ConfigDumpInfo или забыли его застэшить, вам предстоит увлекательное мероприятие по поиску своих изменений в списке измененных файлов полной выгрузки конфигурации
Так как требуется помещать только свои изменения, по лишним файлам придется откатить изменения, а вероятность случайно затронуть и затереть свои доработки при этом очень высока.
Задача №2: создать «ОченьВажныйСправочник»
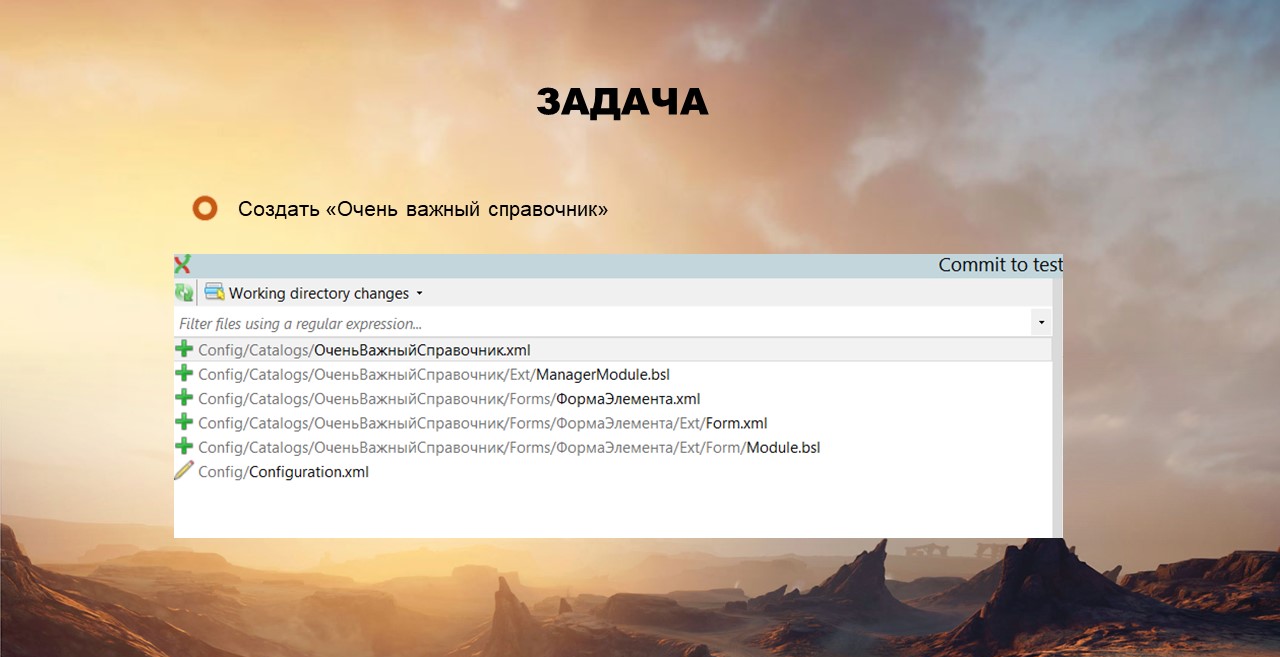
Следующий пример. Андрюша разработал справочник, выгрузил изменения в GIT и отправил задачу на тестирование.
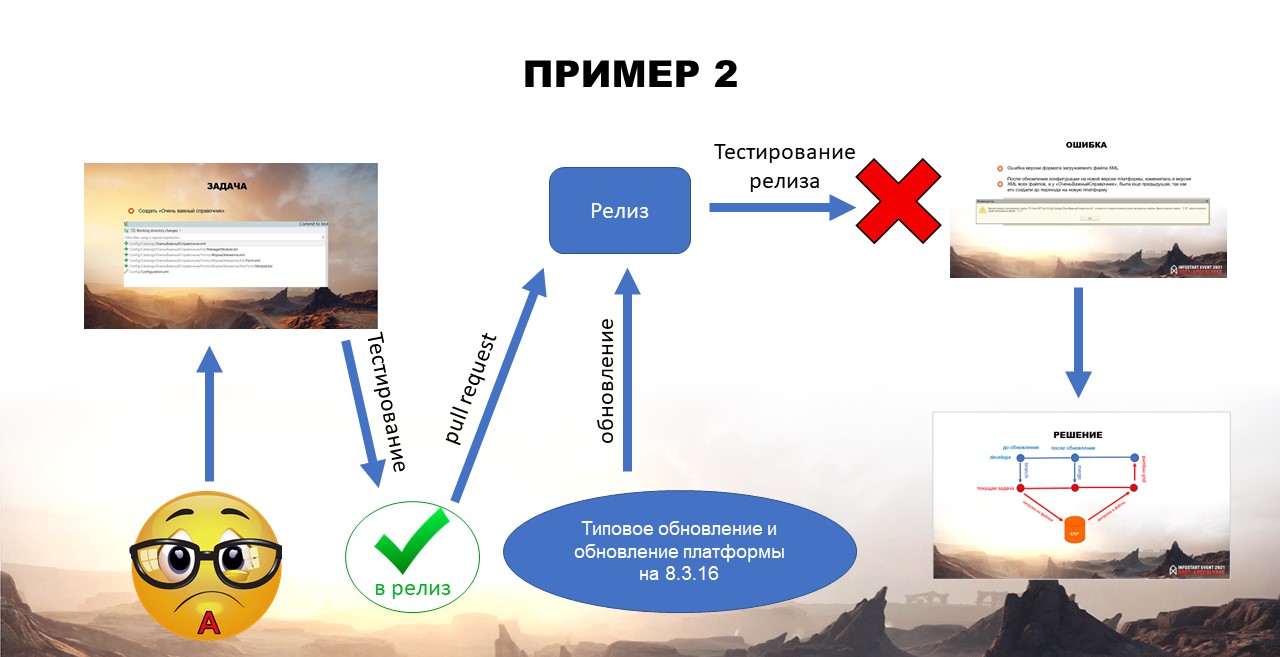
Пока справочник тестировали, на сервере разработки обновили релиз типовой конфигурации и поменяли версию платформы с 8.3.15 на 8.3.16 – сборка релиза проходила на актуальной версии платформы.
Протестированную задачу Андрюши тоже отправили в рабочую базу, но при этом произошел конфликт версий xml.
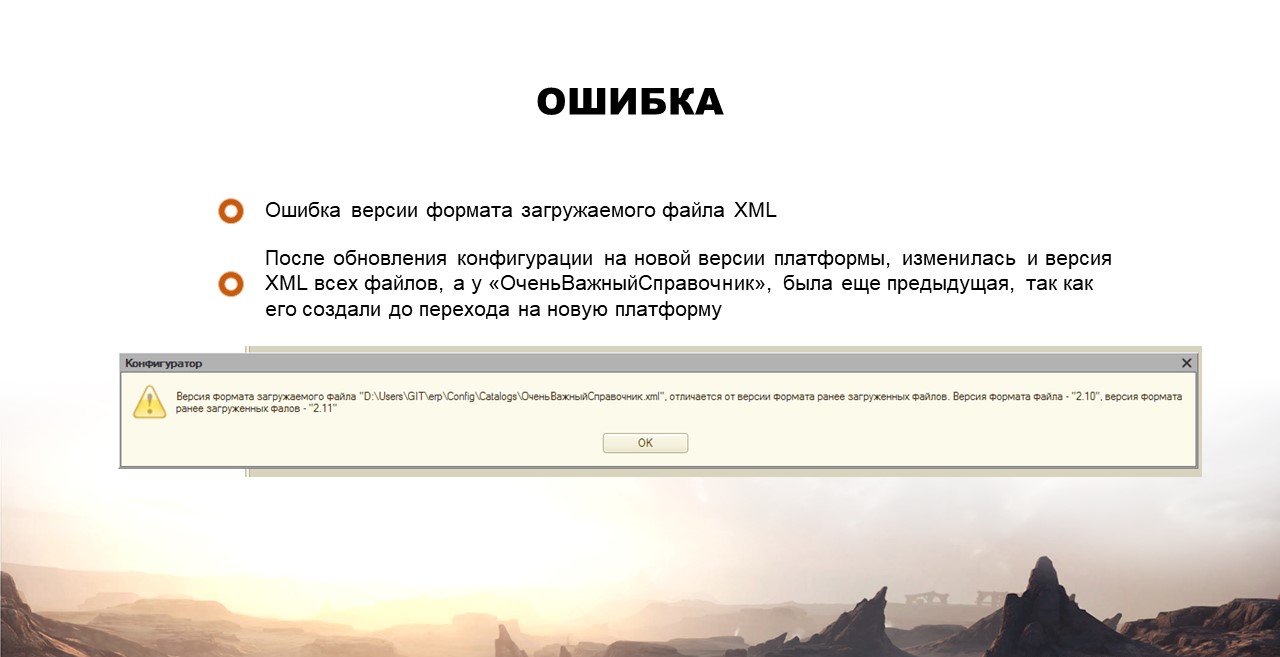
Ошибка: в основном, файлы 1С в выгруженном виде представляют собой XML. В зависимости от версии платформы, структура XML для одного и того же объекта может меняться.
Чтобы отслеживать версию структуры, разработчики платформы добавили при выгрузке дополнительный признак version.
При слиянии типового релиза и изменений Андрюши как раз произошел конфликт этих версий, т.к. у Андрюши справочник был добавлен в более старой версии платформы, а после перехода на новую версию, этот файл тоже изменился – его версия поменялась.
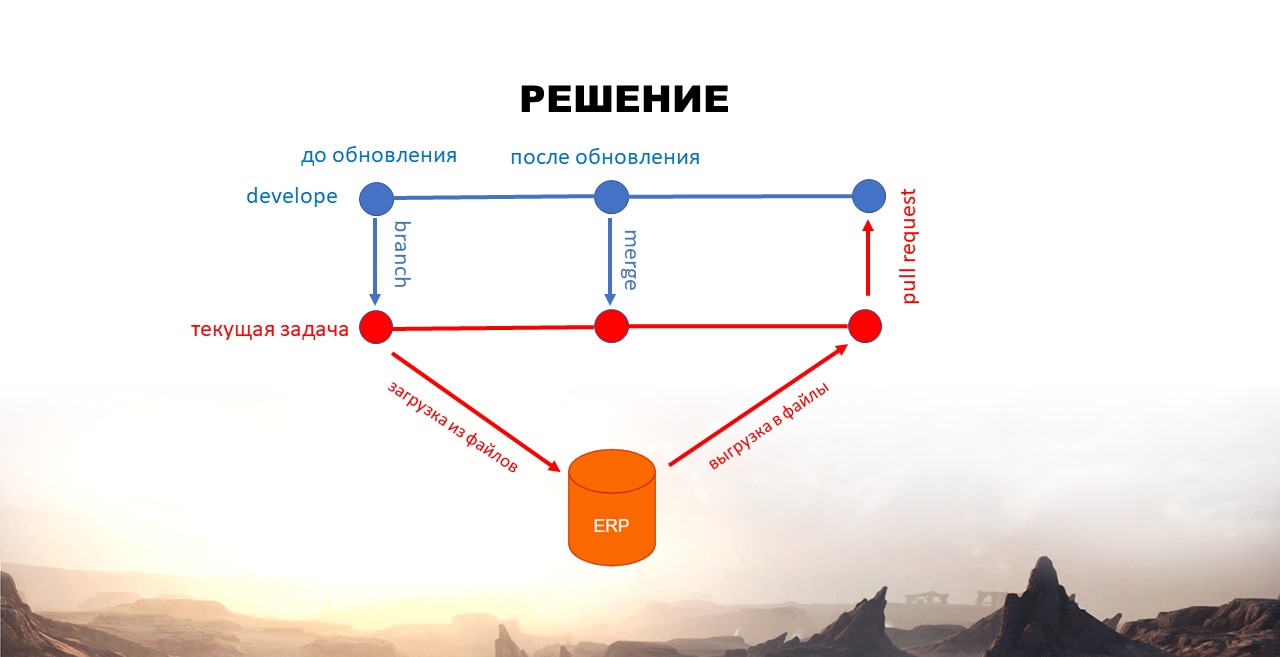
Решение: для правильного решения, Андрюше пришлось бы взять ветку до обновления и загрузить конфигурацию из файлов с этим обновлением. После этого сделать мердж его ветки с веткой «develope» с актуальным релизом. И заново выгрузить конфигурацию в файлы.
При этом 1С обновит структуру метаданных в соответствии с новым форматом. И тогда уже можно делать пул-реквест.
Однако кто в здравом уме будет этим заниматься? Достаточно просто вручную поменять версию XML через блокнот. Ошибок совместимости при этом не замечено.

Задача №3: исправить ошибку версии формата XML
С переходом на GIT появилась возможность редактировать конфигурацию, не прибегая к конфигуратору. Ведь правильно, зачем нам такая громоздкая IDE, если есть Notepad++ или Visual Studio Code? С более мелкими задачами они прекрасно справляются.
Вернемся к задаче про справочник.

Хитрый и ленивый Андрюша, чтобы исправить версию XML, решил воспользоваться глобальным поиском Visual Studio Code. Правда, когда коммитил, заметил небольшую странность – текст запроса динамического списка почему-то отображался, как «измененный». Хотя никаких изменений он не вносил.
«Видимо глюк», подумал Андрюша GIT, и смело отправил задачу на тестирование.
За такие смелые и быстрые решения его уже стали считать косячником.
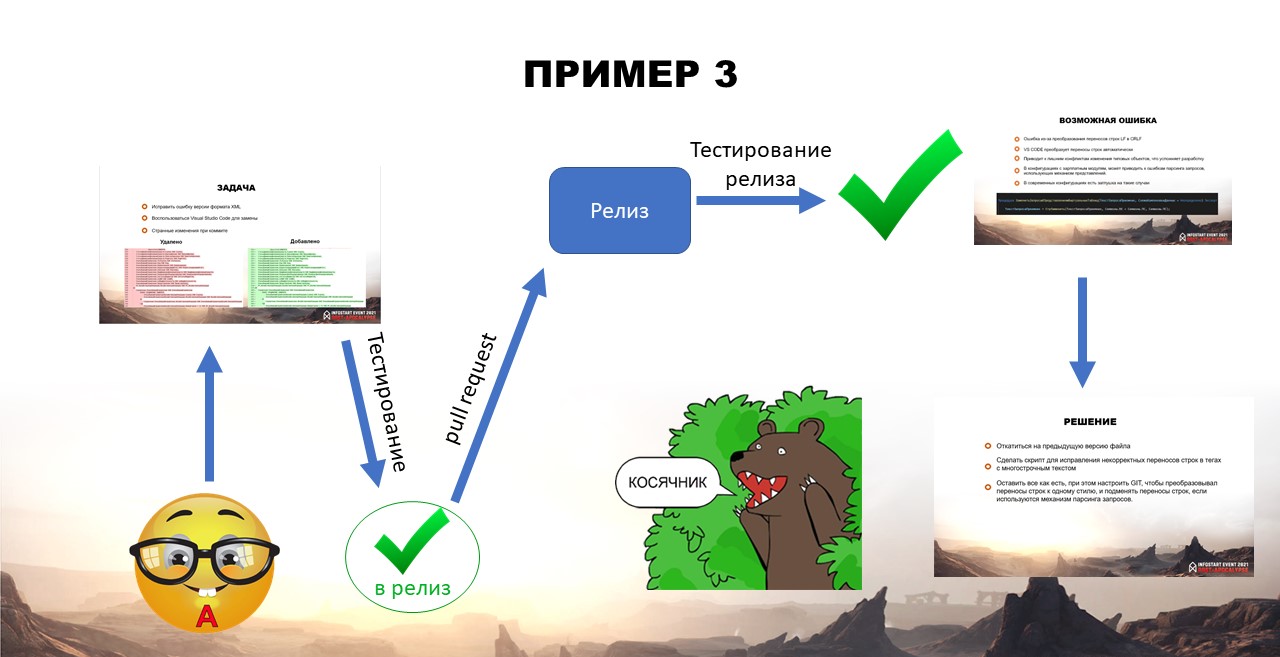
Но как ни странно, у Андрюши получилось сформировать конфигурацию.
Однако ошибка есть. Она не существенная: в рамках текущей задачи ни на что не влияет. Андрюше не пришлось краснеть перед коллегами.

Возможная ошибка:
-
Ошибка из-за преобразования переносов строк LF и CRLF. Проблема была бы, если бы изменения внесли в типовые объекты конфигурации.
-
Редактор VS Code автоматически преобразовывает переносы строк LF и CRLF к единому стилю, которые соответствуют форматам Linux и Windows.
То, что Андрюша увидел как глюк GIT – это, на самом деле, было преобразованием формата переноса строк Linux на формат Windows.
Для 1С – это некритично, но неприятно, потому что перенос строк LF содержится в XML-файлах, которые содержат теги с многострочным текстом. В частности, «ТекстЗапроса» динамического списка или шаблон RLS ролей. -
Невнимательность разработчика может привести к появлению конфликтов в тех объектах, в которые не планировалось вносить изменения. Очень сложно мониторить изменения, когда в списке измененных появляются непонятные доработки.
-
В конфигурациях с зарплатными модулями автоматическая замена LF на CRLF может приводить к ошибкам парсинга запросов, использующих механизм представлений.
Если конфигурация использует механизм представлений, запрос парсится и заменяется на другой. А из-за автоматического преобразования LF на CRLF такой парсинг просто не работает, так как он рассчитан на другие переносы строк. -
В типовых конфигурациях добавили заглушку, которая подменяет переносы строк формата Windows на Linux.

Решение:
-
откатиться на предыдущую версию файла через GIT;
-
либо написать специальный скрипт, который обходил бы все незакоммиченные файлы. Он бы подменял точечно некорректные переносы в тегах с многострочным текстом на корректный перенос строк;
-
либо оставить все как есть. Главное знать, что могут быть проблемы с зарплатными модулями – других проблем не будет;
-
и еще в GIT можно настроить автоматическое преобразование переносов строк.
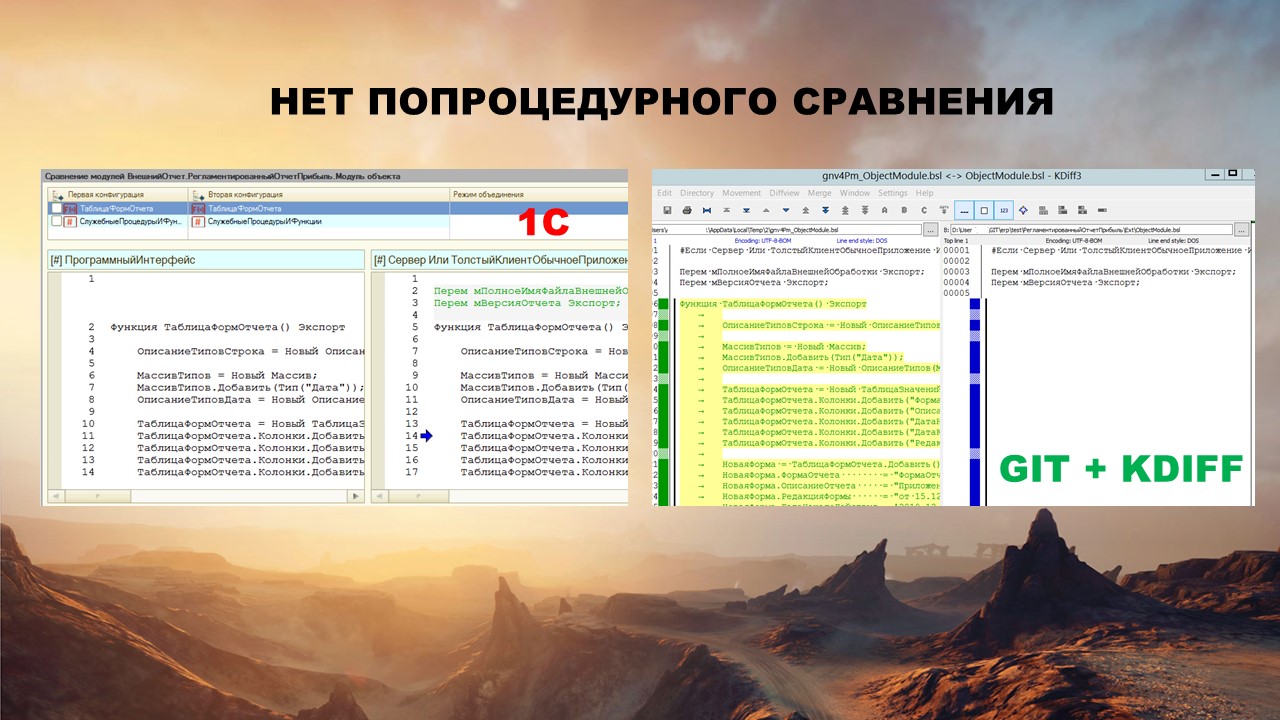
В GIT нет попроцедурного сравнения. С этим просто надо смириться. Реализовать сравнение модулей как в конфигураторе никак не получится.
Задача №4: сменить неприятное имя документа и добавить верхний регистр
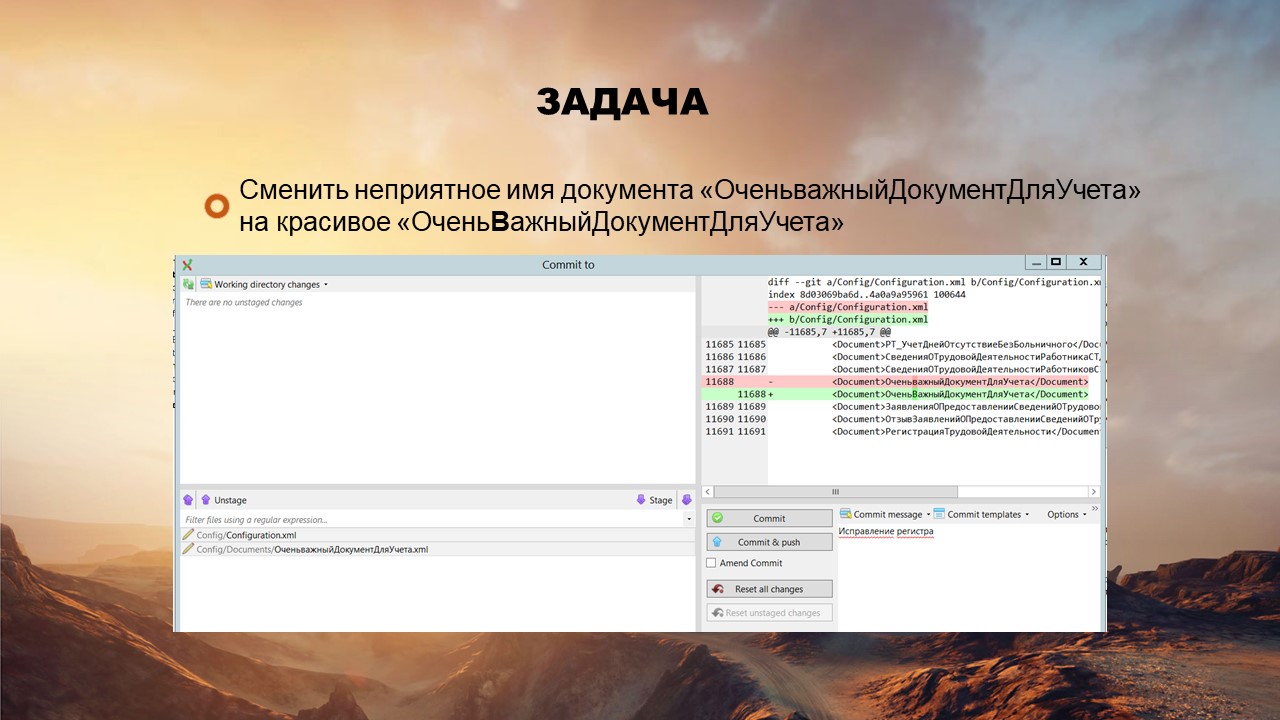
Андрюша увидел, что «ОченьважныйДокументДляУчета» называется неправильно, нарушая стандарт CamelCase – буква «в» должна быть в верхнем регистре.
Руководствуясь благими намерениями, он поправил букву.
Однако в GIT отобразились только два измененных файла: файл Configuration и сам объект, хотя должно быть больше. Не чувствуя подвоха, Андрюша отправил задачу на тестирование.

Тестирование она не прошла.
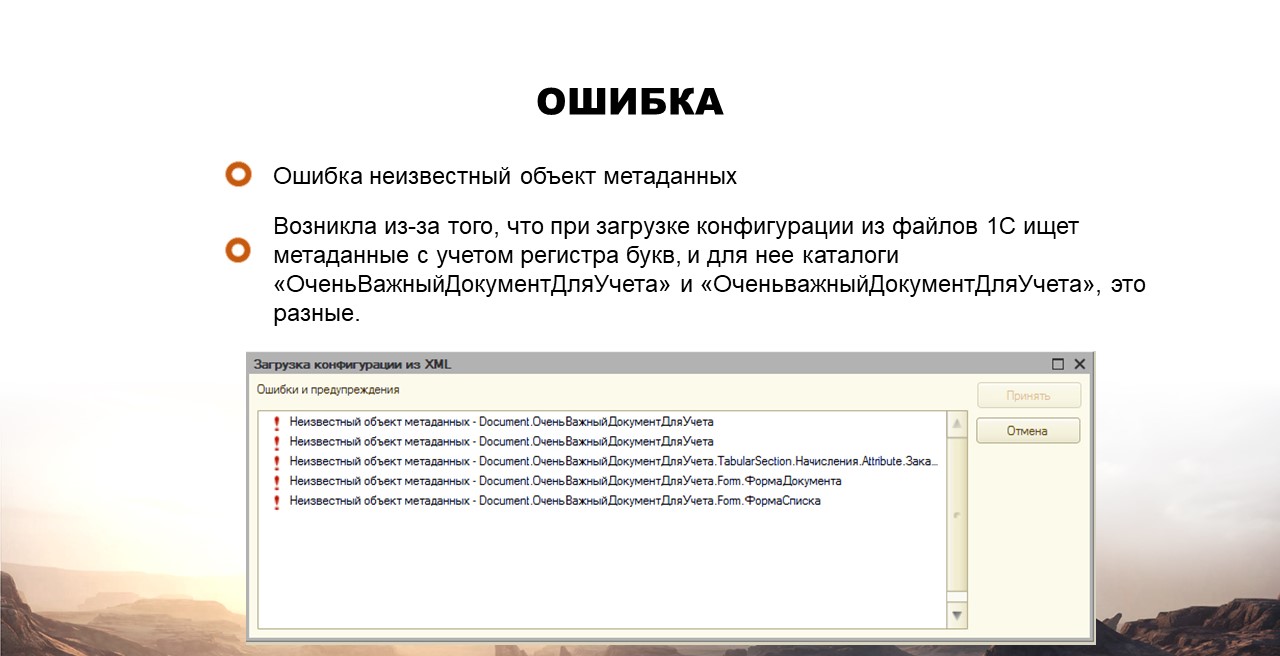
Ошибка: проблема встречалась только на старых версиях GIT, потому что он не понимал смену регистра букв в именах файлов на файловых системах NTFS и Fat32.
А регистронезависимая 1С все-таки учитывает регистр букв, но только в том случае, когда обходит список метаданных в файле Configuration.
1С ищет каталоги соответствующие точно этому списку. Важные документы для учета, которые были уже в правильном регистре, она просто не находила.

Решение: необходимо воспользоваться консолью GIT и переименовать файл через консоль с параметром -f командой
git mv filename.txt FileName.txt -f
Он вносит эти изменения насильно, чтобы это фиксировалось в GIT.

В команде Андрюши все формы редактировались программно. На это были объективные причины, так как, если это сделать интерактивно, возникали проблемы. Например, в таблицу товаров документа реализации добавили колонку «Себестоимость».
Если колонку на форму добавить интерактивно, все выгрузится в GIT, протестируется и отправится в продуктив.

Но ручное редактирование форм может привести к неприятным последствиям:
-
Стоит фирме «1С» что-то поменять в этой таблице, в тех местах, где были сделаны доработки, появится конфликт, который придется решать в текстовом редакторе вручную, что влечет за собой высокую вероятность ошибки при некорректном мердже. Хотя, если у вас прямые руки и хорошее воображение, все пройдет замечательно.
-
Однако конфликт может и не появиться, и тогда GIT объединит все изменения в автоматическом режиме. При этом он может нарушить структуру метаданных XML и при загрузке конфигураций из файлов, конфигуратор будет просто вылетать.
Некоторые скажут, что нужно использовать расширения для редактирования форм. С этим можно согласиться, но:
-
расширение также выгружается в GIT в виде XML-файлов, и теряется наглядность понимания, что именно поменялось на форме;
-
разработчики не раз сталкивались с тем, что когда нажимаешь кнопку «Обновить форму», в захваченной форме слетал фильтр измененных объектов. Измененными становились сразу все объекты. И тогда уже не понять, что именно было доработано.

Также в GIT есть механизм автоматического переименования файлов: в одном коммитe ищется удаленный или/и добавленный файл с одинаковым расширением и определенным уровнем схожести.
Это может привести к ситуации, когда общий модуль преобразуется в общую команду. Это вроде как забавно, пока не появляется конфликт, и нужно определить, что же является источником.
Как убрать такое поведение GIT, Андрюша просто не знал. Он привык, что в каждой системе для каждого параметра есть соответствующий флажок и галочка, как в 1С. Но в GIT он ничего такого не нашел: ни в Git Extensions, ни на форумах разработчиков.
Ситуация разрешилась случайно.

Блуждая по интернету, он забрел на официальный сайт платформы EDT, где на одной из страниц был текст: «Для комфортной работы воспользуйтесь следующими настройками». Последние два параметра как раз и убирают поиск переименования в GIT.

Мораль: не будьте Андрюшами и читайте документацию.
Наверное вы заметили, что здесь практически не упоминается EDT. Это связано с тем, что в компании Андрюши его практически не использовали.
Были попытки перейти, но если для менее большой конфигурации его можно нормально использовать, то для ERP все сильно тормозило. Все плюсы перечеркивались невозможностью такой работы.
Итоги

Прошли месяцы. Если вы решили, что Андрюша сбежал, то это не так.
Хотя и описанные в докладе проблемы позволяют думать, что GIT – это пытка, но Андрюша уже привык.
Он прокачался – ему уже не резали слух иностранные термины, он мог вручную отредактировать коммиты, не внося изменения в конфигуратор, и отсечь чужие доработки, чтобы избежать конфликтов с его доработками.
Смотря на себя из прошлого, он понял, каким был наивным идеалистом: не бывает волшебной кнопки, которая все делает за тебя.
Отмечу, что на GIT очень тяжело перейти, так как это требует больше знаний и большего понимания всех процессов. И тогда некоторые разработчики скажут: «Ну и зачем нам тогда GIT?»

Так данный доклад и не агитирует переходить на GIT. Это просто инструмент, который вы используете. Но надо знать, что у него есть определенные плюсы.
В отличие от хранилища, GIT позволяет работать с большим пулом задач, когда:
-
часть задач на тестировании;
-
часть в разработке;
-
а часть ждет, когда ты к ним вернешься, спустя полгода.
Если рассматривать такую доработку не через GIT, то для каждой мало-мальски крупной задачи приходится создавать отдельное хранилище.
В заключении, не совершайте ошибок, которые описаны в докладе, а совершайте свои и делитесь их решением с сообществом.
Вопросы.
На последней картинке с коммитами GIT я не увидел нормального описания, что сделал разработчик. Я бы посоветовал в тексте описания коммита все-таки писать, что сделал разработчик.
Это так исторически сложилось, потому что настроен специальный скрипт, который парсит эту строку и автоматически закрывает задачи в Redmine. Он немного криво сделан, поэтому нельзя туда добавлять дополнительный текст, кроме стандартного.
Какая конфигурация компьютера использовалась у разработчика? И почему он не мог использовать EDT для разработки ERP?
Был достаточно мощный удаленный сервер – 240 Гб оперативной памяти. Но поскольку это удаленный сервер, на нем одновременно через RDP работало много разработчиков, и в EDT тормозила даже контекстная подсказка – в таких условиях работать было невозможно.
На сайте 1С есть рекомендации по серверам для малых, больших и очень больших конфигураций. Если брать для ERP конфигурацию компьютера, на которой была запущена EDT, то это минимум 16 гигов оперативной памяти и все на SSD дисках. При нормальной конфигурации компьютера это рабочий вариант. Но да, не для RDP, а на одного человека.
Для ЗУПа, для Бухгалтерии, для домашнего компьютера с 32-гиговой оперативкой, я использовал EDT, но на рабочем сервере это было проблематично.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции Infostart Event 2021 Post-Apocalypse.



Вступайте в нашу телеграмм-группу Инфостарт
