







Итак, у нас есть код, который исполняется на сервере, где последовательно запускается много функций:
Для Каждого Элемент Из Коллекция Цикл
Результат = ЦелеваяФункция(Элемент);
КонецЦикла;
А хочется его ускорить, переписав примерно так:
ПараметрыЗапуска = ПодготовитьКоллекциюКМногопоточномуЗапуску(Коллекция);
КоллекцияРезультатов = ЗапуститьМногопоточно("ЦелеваяФункция", ПараметрыЗапуска);
Тестовый стенд
В качестве тестовой испытуемой функции не придумал ничего лучше, как запрашивать результат http запроса. Это позволяет мне манипулировать задержкой ответа. Единственный существенный минус – это совпадение терминов: таймаут, длительность, процент отказа. Эти же термины применимы и к фоновым заданиям.
Установил сервер апач, прикрутил php. В корень выложил файл index.php:
<? //echo "Hello world<br>";
$crash_persent = (int)$_GET['crash_persent'];
if (rand(0,100) < $crash_persent){
http_response_code(500);
//echo "$crash_persent<br>";
}
echo $_GET['time'];
sleep($_GET['time']);
?>
Этот простой скрипт позволяет мне запрашивать по http, например следующие url:
http://localhost/index.php?time=10&crash_persent=20
Задержка ответа будет 10 секунд, а с вероятностью 20% будет возвращен 500 заголовок в ответе.
Дальше идет минисервер 8.3.21.1709 с пустой конфигурацией. В нем расширение с библиотекой. В библиотеке есть тестовая функция в модуле хе_Тестовые:
Все параметры очевидны, возможно, кроме Пошалить. Он эмулирует выброс исключения или не закрытой транзакции.
Дальше была разработка тестовой обработки и непосредственно самой библиотеки. Но в итоге свести запуск удалось лишь к следующему:
Сразу возникает законный вопрос, что за 100500 параметров у функции Запустить?!!! Хочется заменить две исходные строки на две другие две строчки. А получилось:
Функция Запустить(ПутьПроцедуры,
Дальше придется пойти в теорию. "В теорию" это громко сказано, т.к. думаю, лет эдак 40-50 назад при разработке операционных систем уже давно все придумали, но у нас low code и мы думаем проще.
Так вот, исходная задача была в ускорении работы за счет распараллеливания обработки. Но ведь ускорение произойдет в том случае, если при обработке у нас простаивают какие-то ресурсы. Например: ядра процессора, ожидание ответа от сервера, дисковая система базы данных и т.д. На примере ядер - мы должны были бы добавлять параллельные потоки обработки до тех пор, пока у нас нагрузка процессора меньше 80%. Мы же должны задавать количество потоков заранее.
И основная проблема, это то что у нас нет возможности запросить из запущенного нами фонового задания (потока) следующие данные для обработки. Т.е. данные мы должны заранее разделить и передать частями в поток. Почему это вынесено в параметры? Отвечу примером - запуск 1000000 процедур которые выполняются 1 секунду каждая, и запуск 100 процедур, которые выполняются 10 минут каждая. Очевидно, что параметры распараллеливания будут разные.
Данную проблему можно решить передачей данных через базу данных. Но тут, из-за универсальности, мне никак не хотелось менять мета данные конфигурации. А так вот пример другой: нужно обработать документы - поменять им статус (реквизит статус). В этом случае я бы мог не беспокоиться о порционности данных. Я бы просто запустил несколько фоновых, а в каждом фоновом, процедура запрашивала бы очередной документ к обработке, блокировала бы его, перечитывала бы статус, и если он еще не обработан, то переводила бы в следующий статус. И так в цикле, пока есть документы к обработке. Да фоновые бы немного конкурировали между собой за документы, но скорость обработки очевидно бы что возросла.
Опыты
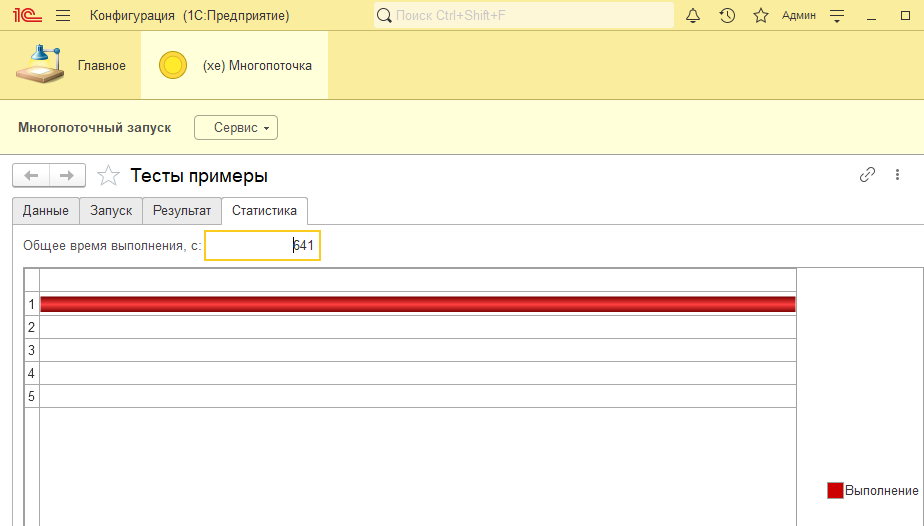
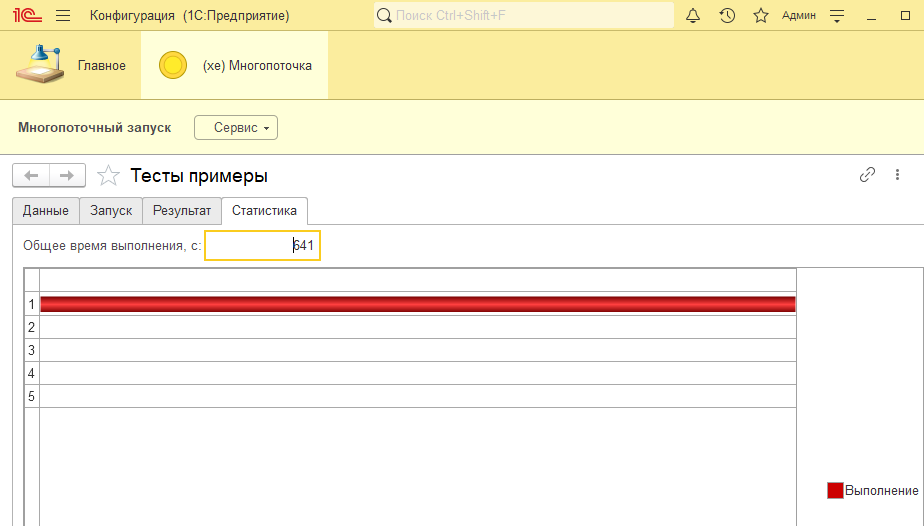
Перейдем к опытам. Я буду мучать 200 заданий. Подбирать потоки и другие параметры. Итак один поток: 641 секунда.
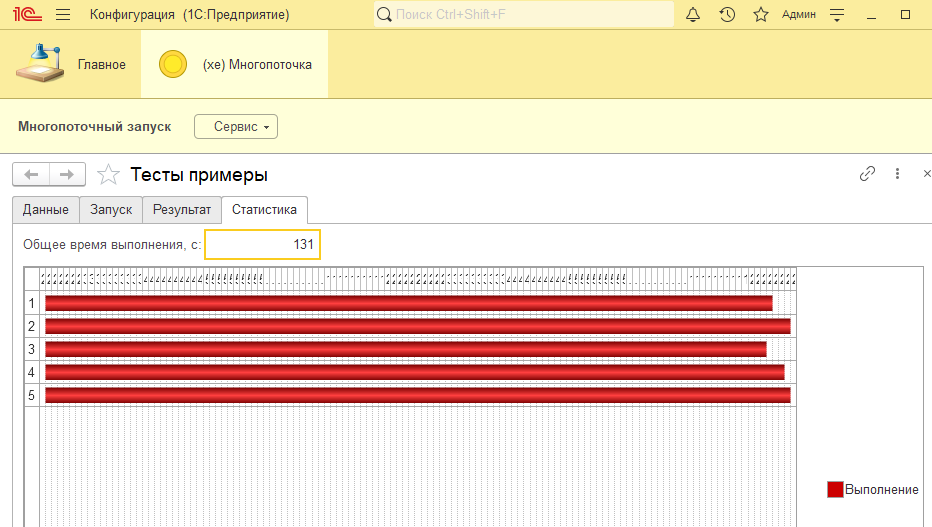
Попробуем разбить на равные части - 5 порций по 40 заданий:
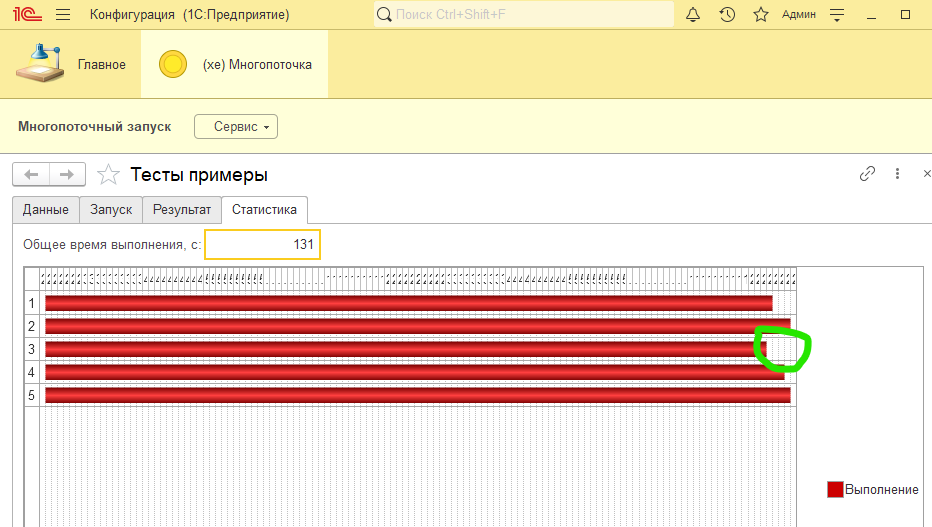
Вау, всего 131 секунда вместо 641! Из замечаний - видим, что потоки исполнялись разное время и в теории при другом характере целевой процедуры могла бы получиться следующая картина:
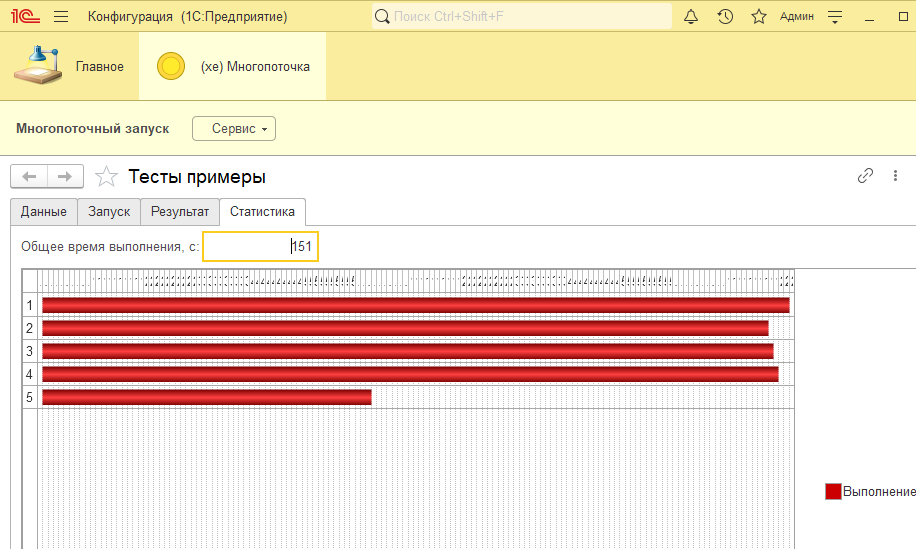
Т.е. что произошло: один поток отработал быстрее других и у нас наметился простой. Общее время работы увеличилось на 20 секунд.
Проблема на самом деле в следующем: допустим, мы запустили поток с 40 заданиями и, например, 3-е оказалось длительным, но оно будет держать все оставшиеся 37. Т.к. из менеджера запуска фоновых мы не знаем, что обработано, а что нет - ждем пока все обработается. И другие задания начинают простаивать.
Тогда пробуем следующее - будем разбивать на более мелкие порции, например по 10шт и запускать их последовательно:
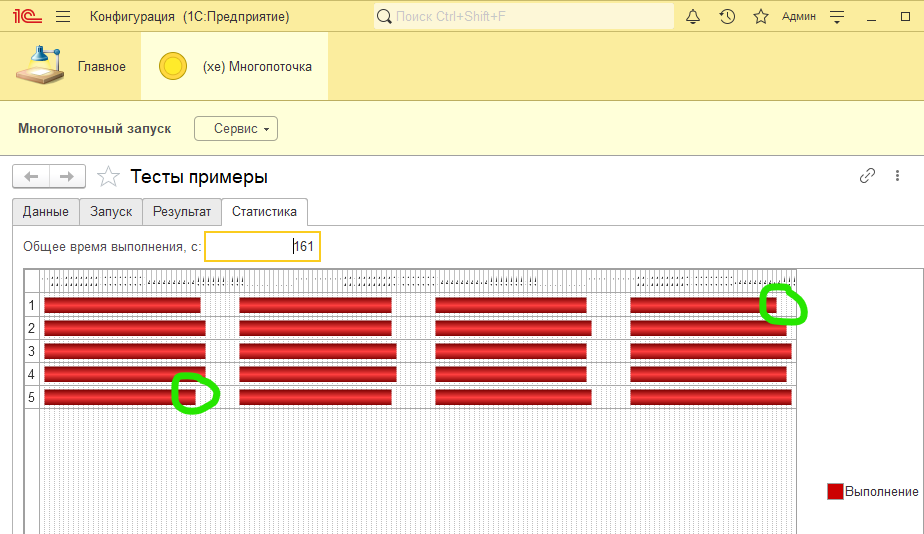
Стало хуже. Но здесь вмешивается следующая проблема - это частота опроса завершения заданий. У меня она 10 секунд (параметр ЧастотаОпросаФоновых) и это сильно повлияло на результат.
На самом деле, здесь таже картина что и в предыдущем тесте, только разбитая но более мелкие 4 части. Но у меня есть еще один параметр - это таймаут фоновых. Поток, после истечения таймаута не будет обрабатывать следующие задания из порции, а завершится и освободит необработанные задания. Зададим его для примера 20 секунд:
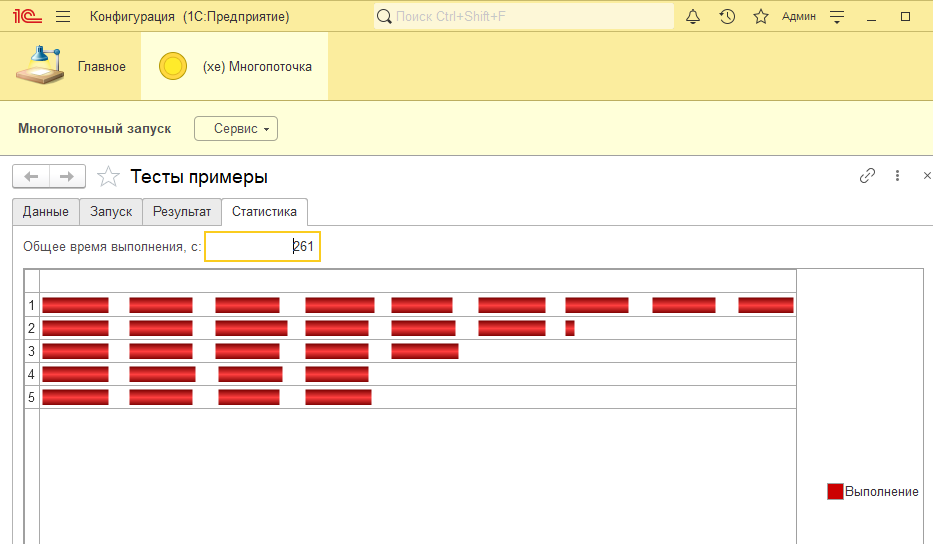
Вообще какая-то фигня получилась :) Что произошло: фоновые прерывались и задания освобождали, но в какой-то момент заданий стало не хватать для всех потоков.
В общем, к чему я это все виду? К тому, что вам все равно приходится по месту подбирать как бы будете распараллеливать обработку. Здесь еще много случаев можно рассмотреть, но я пожалуй остановлюсь.
Напоследок попробую увеличить количество потоков.
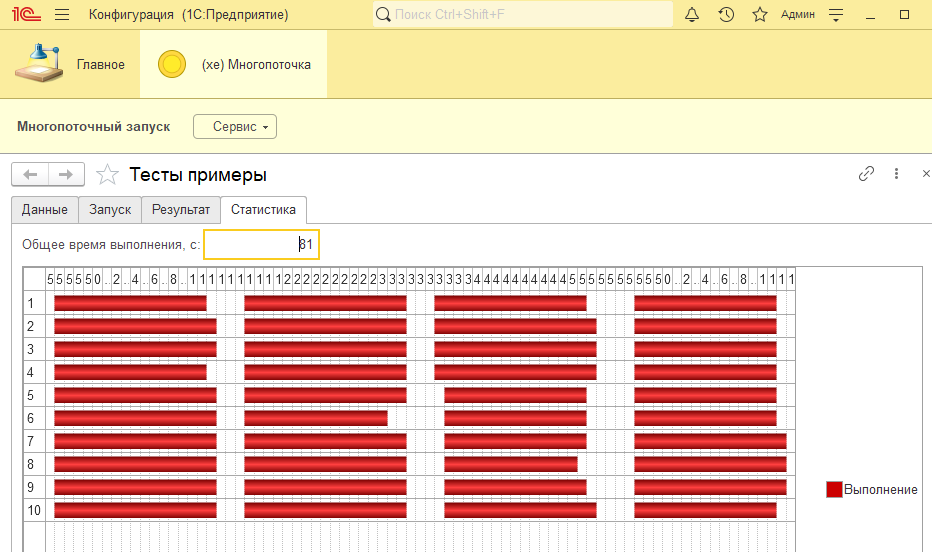
Очевидно, что нужно снижать время ожидания между опросами. Так, еще приходит идея запускать одно фоновое на каждое задание. Эм... ну можно, но из рабочих кейсов, когда у вас 100к-1м заданий, вам все равно придется бить на порции, т.к. сервер будет не рад запуску 1м фоновых.
Примечания.
- Целевое использование функции в расширении, это снижение последовательной обработки обработки до 0-2ч исполнения . Если у вас обработка после распараллеливания занимает больше времени, то надо уходить в регзадания. Более длительное выполнение влечет за собой невозможность кластеру сбросить рпхост, в котором запущена обработка. Что рано или поздно приведет к падению из-за нехватки памяти. Для примера можно посмотреть реализацию регзаданий в БТС (организацию запуска регзаданий по областям) или регзадание Обновление доступа на уровне записей подсистемы управление доступом из БСП.
- Если вам нужно, ускорять обработку данных, за которой следит пользователь, то нужно менеджер управления фоновых переносить на клиент. А далее либо длительные операции из БСП, либо свое.
- Пока писал тестовую функцию, увидел что у HTTPСоединение добавился асинхронный метод ПолучитьАсинх (с 8.3.21). Соответственно, можно не колхозить с фоновыми, а... колхозить напрямую запуском асинхронного получения данных :))
- Выгрузил расширение в файлы и выложил на https://github.com/jekins81/bsl_multithread
UPD
В БСП все-таки добавили тему многопоточности.
Многопоточное выполнение процедуры с помощью ДлительныеОперации
ДлительныеОперации.ВыполнитьПроцедуруВНесколькоПотоков(
Обновил свои базы и посмотрел, что же дает вендор. Как всегда лапша кода, но вроде докопался до сути. В функции
Функция ВыполнитьМногопоточныйПроцесс(ПараметрыОперации) Экспорт
Есть строка:
ОжидатьЗавершениеВсехПотоков(Результаты, ИдентификаторФормы, ПараметрыОперации.ПрерватьВыполнениеЕслиОшибка);
Получается, что все равно не гибкое многопоточное выполнение. Т.е. это вариант, что я рассматривал в первых тестах в статье. но все равно круто, что за это взялись. Как по мне, это нужно в платформу выносить.
Вступайте в нашу телеграмм-группу Инфостарт