





{kind=link}
Так получилось, что форматы файловых баз 1CD и файлов конфигураций CF достаточно подробно описаны, и сделано множество утилит для работы с ними. Разумеется, для рабочих целей их не используют, но иногда они незаменимы для восстановления поврежденных баз. С помощью Tool1CD уважаемого awa (светлая ему память) было восстановлено бесчисленное количество баз.
А вот описания формата DT мне не попадалось, и утилит работы с ним было пересчитать по пальцам одной руки фрезеровщика со стажем. Надеюсь, эта статья исправит положение и станет основой для новых разработок. Сразу предупреждаю - описание не исчерпывающее, и 1С периодически вносит изменения и дополнения, да и не все секреты получится описать в одной статье.
Внимание! Комментарии вида "А какой смысл в поле 8 описания таблицы в DBSchema" из чистого любопытства не приветствуются - что знал то описал. Наоборот, содержательные дополняющие комментарии приветствуются.
Не секрет, что файл содержит заголовок 1CIBDmpF (очевидно сокращение от 1C Informational Base Dump File - файл выгрузки информационной базы 1С, внезапно), ещё один символ - 1, 2 или 3 - версия формата, а дальше идут сжатые алгоритмом Deflate данные.
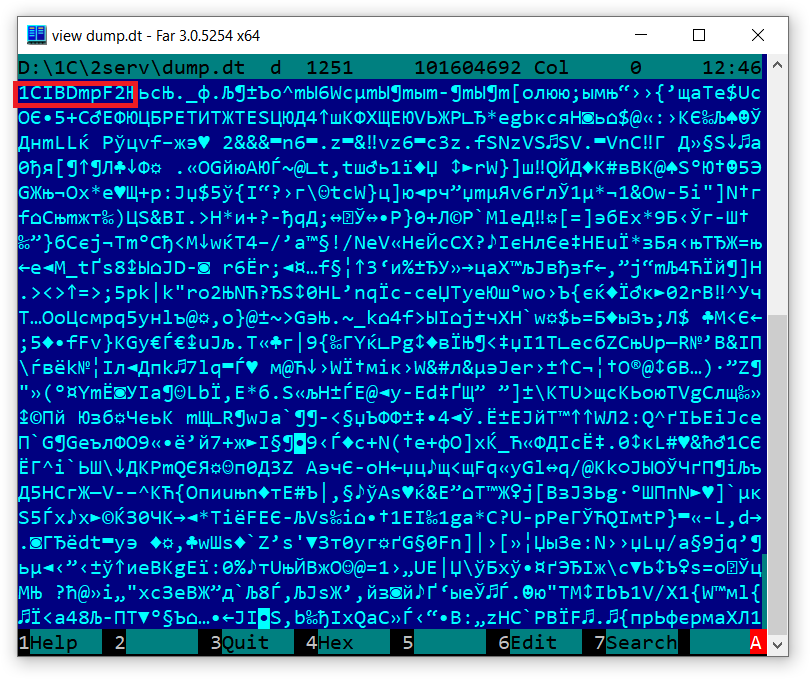
Для старого формата "1", который использовался в платформе 8.0 и 8.1, после распаковки структура данных была почти очевидна. Распаковка давала любимую 1С скобочную запись с описанием конфигурации и данных.
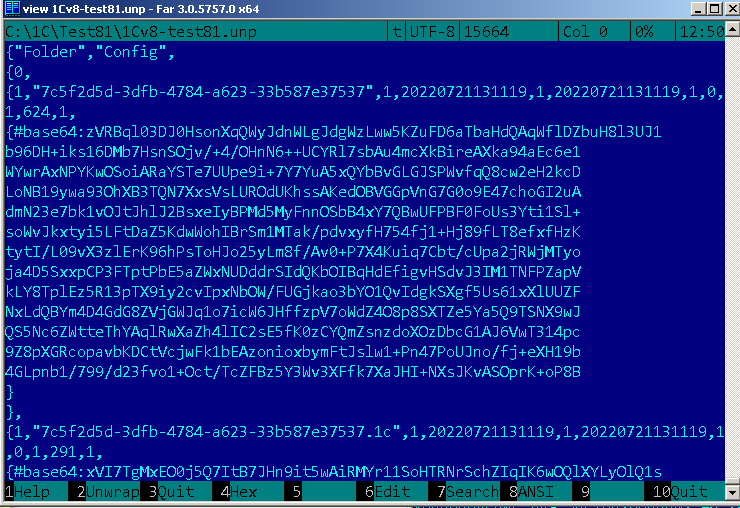
Форматы 2 (от платформы 8.2) и 3 (платформа 8.3) по сути повторяют эту идею, но распаковка даёт "странное" бинарное представление данных. Это - бинарное представление того скобочного формата, которое использовалось в версии 1.
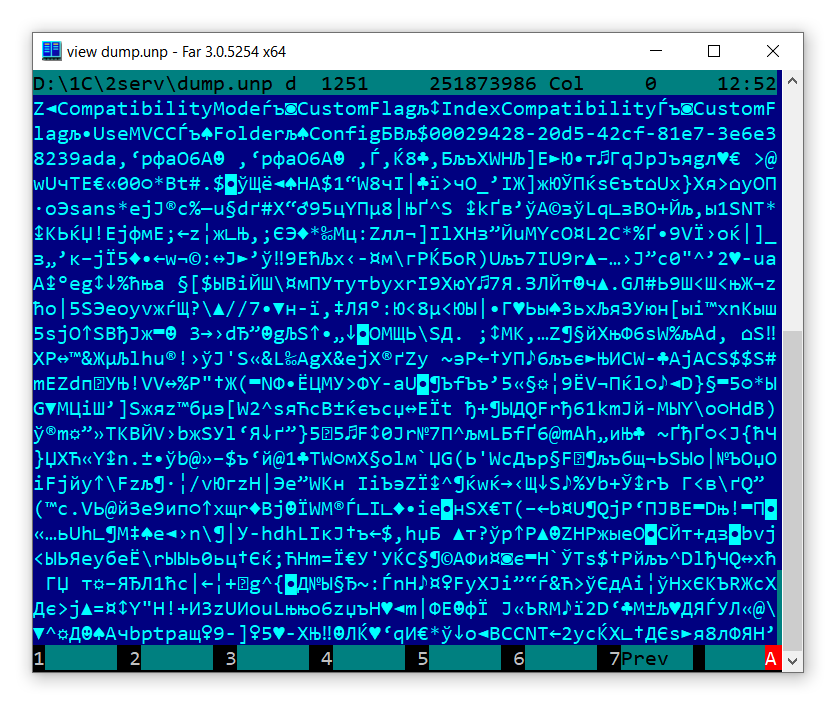
Разобраться с этим бинарным форматом мне помогли исходники Tool1CD от awa. В архиве оказалась заготовка конвертора из бинарного представления обратно в текстовый скобочный.
Итак. Этот бинарный вид - эквивалент скомпилированной скобочной записи. Далее я буду делать вид что всё конвертируется именно в текстовую скобочную запись, хотя есть все основания считать что это просто эквивалент, и 1С промежуточный текстовый формат при распаковке базы не использует. Основа данных - байты-тэги, которые описывают формат следом идущих данных. Основных тэгов 32, с нумерацией от 0 до 0x1F, в младших 5 битах байта. Ещё есть 3 дополнительных тэга, не образующих отдельных байт, а представленные битами в байте-тэге, комбинируются с одним из базовых тэгов. Это бит 6 (0x20) - "закрывающая скобка, закрытие списка", бит 8 (0x80) - "запятая, разделитель значений в списке", и бит 7 (0x40) - "открывающая скобка, начало списка". Обрабатываются они именно в этом порядке.
Таким образом байт тэга обрабатывается таким образом:
1. если в байте тэга установлен бит 6 - ставим закрывающую скобку
2. если в байте тэга установлен бит 8 - ставим запятую
3. если в байте тэга установлен бит 7 - ставим открывающую скобку
4. выделяем младшие 5 бит и обрабатываем тэг оттуда.
Тэги:
0x00 - NOP, отсутствие операции
0x01 - 0x0A - "цифра 0-9", выводим цифру. 0x01 - выводим 0, 0x0A - выводим 9
0x0B - байт uint8. Надо считать следующий байт и вывести (как число)
0x0C - "минус" байт. Надо вывести знак минус и считать следующий байт как число
0x0D - слово (uint16). Надо считать следующие число из следующих 2 байт и вывести как число. Младший байт первым.
0x0E - "минус" слово. Аналогично предыдущему, только с минусом
0x0F - двойное слово uint32. Считать число из 4 байт и вывести
0x10 - "минус" двойное слово. Аналогично, с минусом
0x11 - int64 - 8-байтовое число. Вероятно со знаком.
0x12-0x14 - неизвестно.
0x15 - GUID. Считать 16 байт и вывести. В формате "почти MS" - <uint32>-<uint16>-<uint16>-<uint8><uint8>-<uint8*6>
0x16 - "отмена кавычек". По умолчанию строки выводятся в двойных кавычках, но если перед строковым тэгом будет "отмена кавычек" - значение выводится без кавычек. После вывода строки признак сбрасывается на значение по-умолчанию, "в кавычках"
0x17 - Юникод-строка (UTF-16), до 255 символов. Надо прочитать 1 байт длины, и прочитать указанное число двухбайтовых символов.
0x18 - Юникод-строка (UTF-16), до 65535 символов. Длина указывается 2-байтовым числом.
0x19 - Юникод-строка (UTF-16), до int64 символов. Длина указывается 8-байтовым числом.
0x1A - ANSI-строка или двоичные данные, до 255 символов. Надо прочитать 1 байт длины, и прочитать указанное число символов. Если присутствуют символы с кодами меньше 0x20 или больше 0x7F - считать двоичными данными (выводить шестнадцатеричные значения), если была отмена кавычек - вывести строку как есть, иначе выводить в двойных кавычках
0x1B - ANSI-строка или двоичные данные до 65535 символов. Длина задаётся uint16 - двухбайтовое целое.
0x1C - ANSI-строка или двоичные данные, до int64 символов. Длина задаётся uint64 - 8 байт.
0x1D-0x1F неизвестно.
По этому алгоритму я сделал тестовую программу - распаковщик. Полные исходные тексты выложу когда программу доведу до релизного состояния, а сейчас её буду использовать для иллюстрирования. Скачать можно здесь
Это утилита для командной строки. Командой -unpack распаковывает сжатый поток, команда -dump распаковывает и выводит текстовое представление в скобочной записи, -scan проводит сканирование потока тэгов на предмет ошибок.
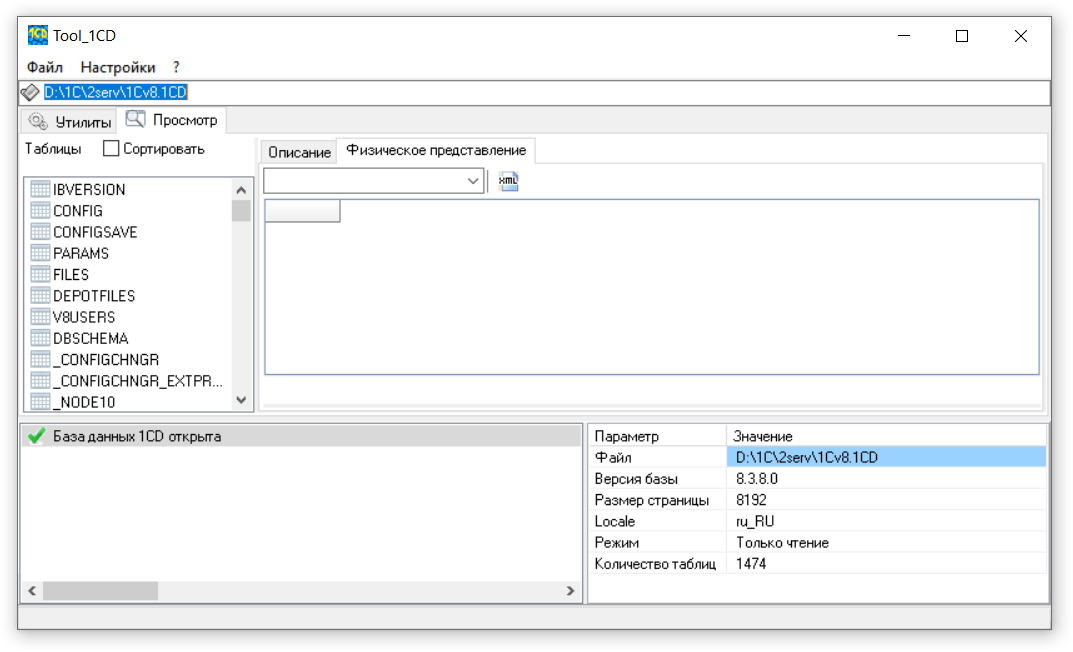
Небольшое отступление. В базе обязаны быть таблицы Config/ConfigSave для сохранения конфигурации базы, ConfigCas/ConfigCasSave для расширений (начиная с платформы 8.3), Params и Files для служебных данных (критически важно значение DBNames таблицы Params - соответствие идентификаторов конфигурации таблицам и полям базы), DBSchema - описание физической структуры таблиц базы данных. V8Users - список пользователей (начиная с платформы 8.1), и некоторые другие.
Что же содержат распакованные данные? Это список объектов, первым элементом списка которых идёт строка с типом объекта.
В формате 1 это были Folder и Database
В формате 2 текстовое заменили на бинарное. Появился объект Users. С платформы 8.2.14 стали появлятся дополнительные "флаговые" объекты CompatibilityMode, CustomFlag
В формате 3 в платформа 8.3.21 заменила Users на UsersSpr, появился PasswordPolicies
Folder описывает служебные таблицы со структурой как у таблицы Config. В списке вторым значением после Folder идёт строковый параметр - имя служебной таблицы: Config, ConfigSave, ConfigCAS, ConfigCASSave, Files, Params, DepotFiles
Все они имеют структуру:
{"FILENAME","NVC",0,128,0,"CI"},
{"CREATION","DT",0,0,0,"CS"},
{"MODIFIED","DT",0,0,0,"CS"},
{"ATTRIBUTES","N",0,5,0,"CS"},
{"DATASIZE","N",0,10,0,"CS"},
{"BINARYDATA","I",0,0,0,"CS"}
Платформа 8.3 добавила в базу поле PartNo для разбиение больших объектов на части, но в выгрузке его нет, всё склеивается в один целый объект
Users или UsersSpr распаковывается в таблицу V8Users со списком пользователей.
Users содержит следующие поля:
{"ID","B",0,16,0,"CS"},
{"NAME","NVC",0,64,0,"CI"},
{"DESCR","NVC",0,128,0,"CI"},
{"OSNAME","NVC",1,128,0,"CI"},
{"CHANGED","DT",0,0,0,"CS"},
{"ROLESID","N",0,10,0,"CS"},
{"SHOW","L",0,0,0,"CS"},
{"DATA","I",0,0,0,"CS"},
UsersSpr добавляет "недостающие" поля, которые платформа раньше восстанавливала по данным:
{"ID","B",0,16,0,"CS"},
{"NAME","NVC",0,64,0,"CI"},
{"DESCR","NVC",0,128,0,"CI"},
{"OSNAME","NVC",1,128,0,"CI"},
{"CHANGED","DT",0,0,0,"CS"},
{"ROLESID","N",0,10,0,"CS"},
{"SHOW","L",0,0,0,"CS"},
{"DATA","I",0,0,0,"CS"},
{"EAUTH","L",1,0,0,"CS"},
{"ADMROLE","L",1,0,0,"CS"},
{"USSPRH","N",1,10,0,"CS"}
Database описывает физическую структуру таблиц базы данных (это описание хранится в таблице DBSchema) и далее сами данные таблиц в порядке их следования в DBSchema.
Каждая таблица описывается отдельным списком, первый элемент - число 0, далее список объектов - строк таблицы. Сначала идёт флаг - 0 если значение отсутствует (null) или 1 если следом идёт фактическое значение. Значения типа "B" (binary) описываются не одним значением а объектом, в котором первым элементом списка идёт число 0, а дальше двоичные данные. Данные могут разбиваться на несколько частей запятыми, их следует склеивать. Некоторые частные случаи платформа оптимизирует, например пустая строка может быть представлена числом 0, или один байт двоичных данных может быть представлен не тэгом 1A "строка" а тэгом 0B "байт". Одиночные символы тоже могут быть закодированы тэгом 0B с кодом символа.
Описание таблиц "пользовательских" данных (туда же попадают и таблицы типа ExtensionsInfo, SystemSettings и подобные) восстанавливаются из DBSchema.
DBSchema - объект, первым элементом идёт число 0, дальше вложенный объект со списком описания таблиц. Первым элементом списка идёт количество объектов-описаний, далее сами описания. Каждый объект описания таблицы начинается с имени таблицы, далее идёт символ - "тип" таблицы, "N" - обычная и "I" для подтаблиц (табличные части справочников, документов и т.д.). Далее идёт "номер" таблиц, замет строка - имя родительской таблицы, затем объект - список полей, затем объект - список "подтаблиц", затем список индексов таблицы, неопознанные поля, среди которых два списка - предположительно список полей - для использования "разделителей" данных в режиме Фрэш.
Описание поля таблицы - "логическое" имя поля, признак может ли поле содержать Null, список типов и поля "неопознанного" назначения
У поля может быть несколько типов, и итоговый набор физических полей и их имён нужно строить по имеющимся данным. Для каждого типа поля создаётся минимум одно поле физической таблицы. Если для поля создаётся несколько физических полей к имени таблицы добавляются суффиксы с именами типов.
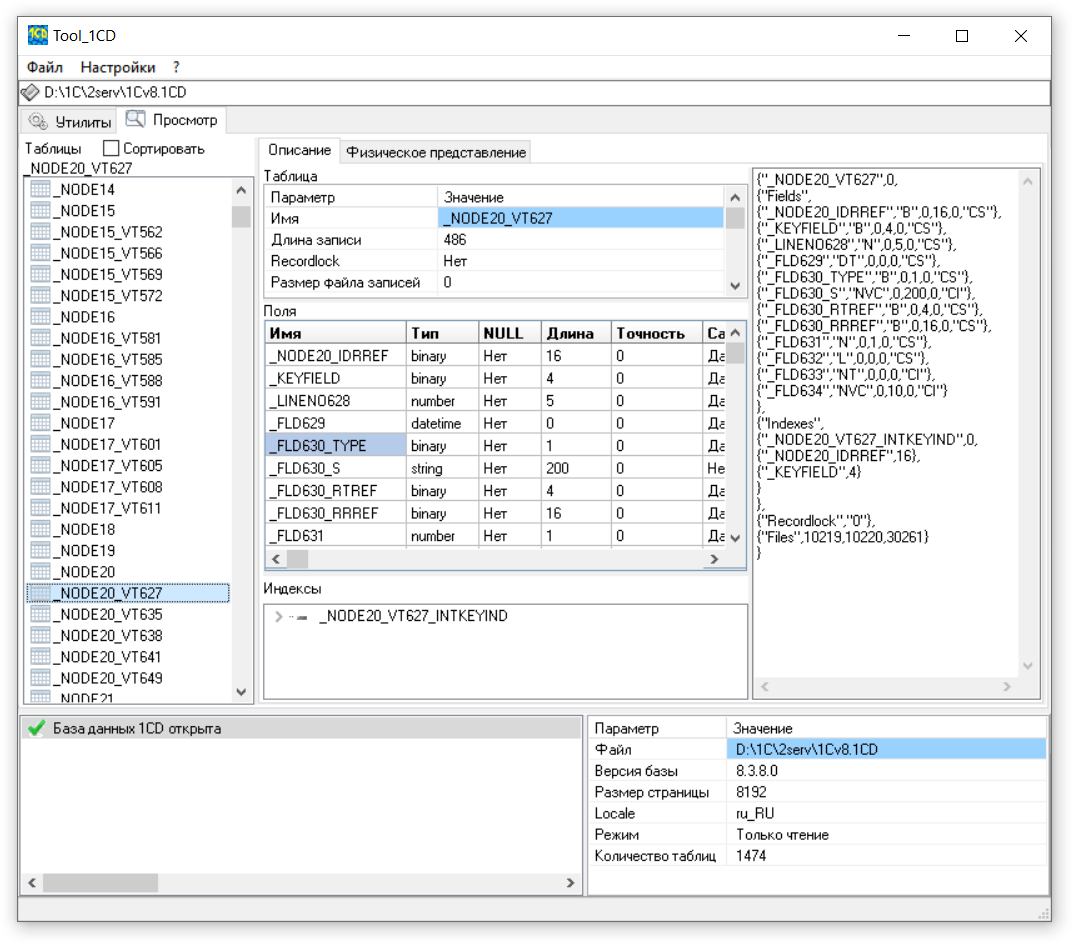
Описание типа содержит символ - код типа, длину поля, точность, имя таблицы на которую может ссылаться значение.
Если в длине поля установлен старший бит 0x80000000 - это поле переменной длины.
Коды типов:
- N - число.
- R - ссылка. К имени добавляется суффикс RREF, фактически это тип B(16). Если отсутствует строка с описанием таблицы - то значение может ссылаться на различные объекты в базе, и физически создаётся дополнительное поле с суффиксами TREF (тип B(4)) для номера объекта на который идёт ссылка.
- S - строка. Если длина 0 - это поле неограниченной длины (memo), которое в 1CD хранится в BLOBе
- B - двоичные данные. Если длина 0 - в 1CD значение попадёт в BLOB. Если длина 16 - это ссылка.
- L - логическое, true/false, 1/0
- V - "версия" записи, физически в DT не присутствует.
- T - Дата-время. Хранится в десятых долях количества миллисекунд от 00:00:00 01.01.0001
- E - присутствует если поле составного типа, физически это B(1), добавляет префикс _TYPE, к остальным физическим полям добавляется суффикс _<КодТипа>, а ссылочные поля получают двойные суффиксы _RTREF и _RRREF
Для подчиненных таблиц неявно добавляются поля _ИмяРодительскойТаблицы_IDRREF (R) и _KEYFIELD (B(4)), а так же поля-разделители.
Фактический состав полей предлагаю сверять с физической структурой базы в Tool1CD.
Описание индекса - имя, предположительно признак уникальности индекса, объект-список полей входящих в индекс (состав списка - число входящих полей и их имена), значения неопределенного назначения. Похоже что некоторые поля добавляются неявно, так же некоторые индексы тоже создаются неявно, т.е. их описание не присутствует в DBSchema.
Недавно мне на восстановление дали очень занятный файл выгрузки. Это была единственная копия базы, и она не загружалась с ошибкой формата потока. Оказалось - 1С при выгрузке записала немного мусора в область данных таблицы Config. Хотя сжатие данных было целым, что уже хорошо.
Обнаружилось это с помощью той утилиты в режиме dump
Смог базу вылечить, распаковав (unpack), в шестнадцатеричном редакторе вырезал поврежденный кусок, упаковал обратно, и выгрузка загрузилась. Повреждение конфигурации восстановил загрузив эталонную конфигурацию в базу.
Вступайте в нашу телеграмм-группу Инфостарт