Отраслевая конфигурация, доработанная, на регистрах бухгалтерии и управляемых блокировках.
В журнал регистрации пишется достаточно большое количество событий о взаимоблокировках на СУБД при одновременном выполнении загрузки регламентными заданиями разных объектов конфигурации.
Доступы мне только начали выдавать и я запустил профайлер MS SQL с одним лишь событием "Deadlock graph". Быстро "поймалось" нужное событие:

По метаданным это таблица "ИтогиМеждуСчетами" регистра бухгалтерии, кластерный не уникальный индекс. По характеру взаимоблокировки - скан таблицы при неоптимальном запросе. Но это системная таблица итогов механизмов 1С, там нет самописных пользовательских запросов.
К этому времени мне уже дали доступ к серверам 1С и я настроил технологический журнал на сбор события DBMSSQL только для таблицы "%_AccRgCT76484%", планов запросов и информации о взаимоблокировках, а в профайлере MS SQL дополнительно запустил сбор событий "Lock:Acquired" с фильтром по проблемной таблице и только для U (4) и X (5) блокировок.
Взаимоблокировка поймалась за 2 часа, по логу профайлера было видно, что это настоящий скан таблицы итогов. Из собранного ТЖ я получил план запроса:

Видно, что тут использовался индекс, поскольку оператор Clustered Index Seek, но посмотрев повнимательнее, видим, что Seek идет только по разделителю данных и периоду (а других столбцов у данного индекса и вообще нет), а после Seek идет Where, что означает, что происходит сканирование данных. На всякий случай (у таблицы существует ещё 2 индекса) обновил статистику, реиндексацию индексов, очистил процедурный кэш - ничего не помогло.
Собрал и посмотрел план запроса для типового регистра Хозрасчётный:

Совершенно другая ситуация! Полноценное использование двух индексов, без каких-либо условий.
Открыл структуру таблиц в SSMS, сравнил визуально, проблемная таблица итогов:
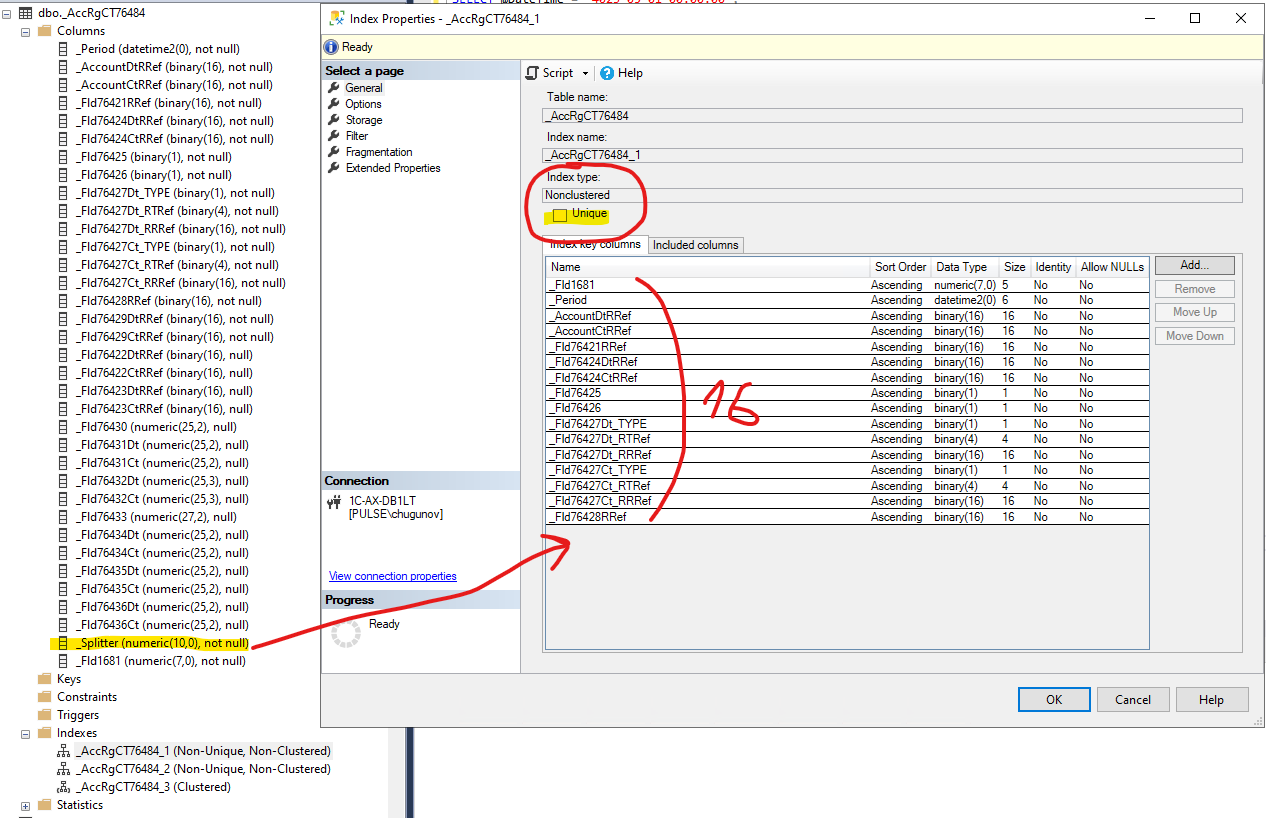
Индекс не уникальный, "потерян" реквизит механизма разделения итогов. Для верификации создал чистую ИБ на платформе 8.3.23.1688 и MS SQL 2019, там ситуация практически такая же:
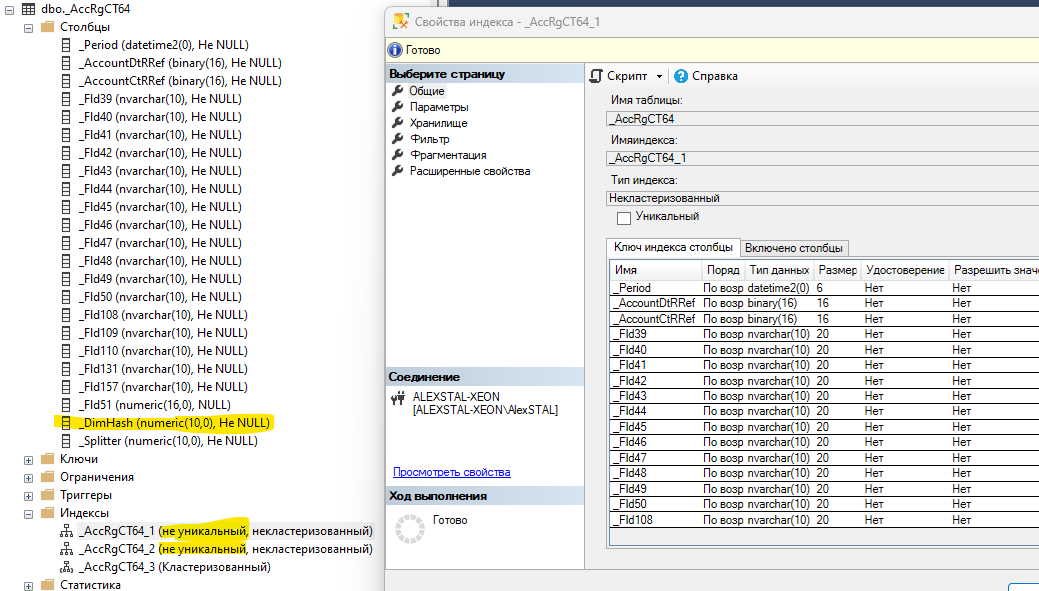
Только в столбцы таблицы добавился "_DimHash" (в индексе его нет так же ка и "_Splitter"). При этом в свежей версии официальной документации "структура данных" он вообще не упоминается:

но зато при этом упоминается в разделе "индексы таблиц":

"ХэшИзмерений" - это вероятно не работающий аналог "DimHash" регистра накопления:

который в свою очередь так же, вероятно, не полностью рабочий:
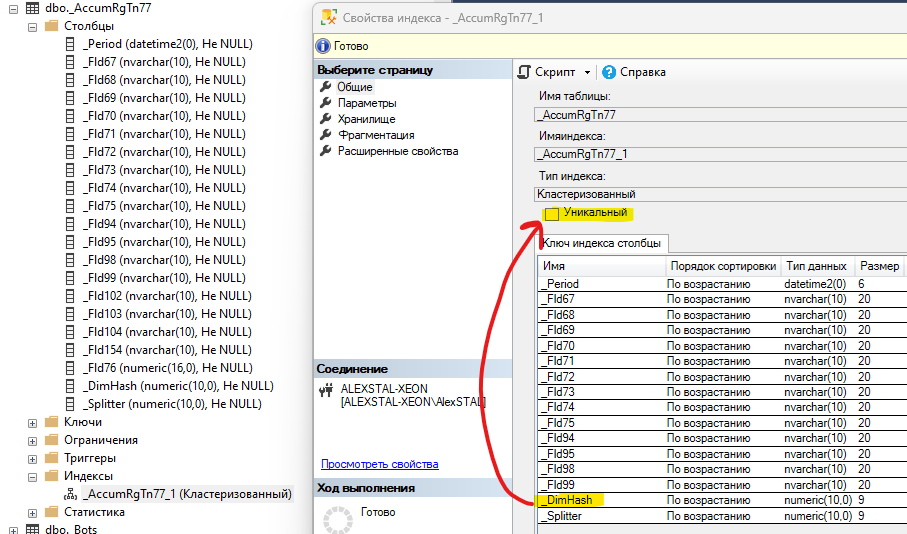
Т.е. искусственный реквизит специально разработан для организации уникального индекса, присутствует и в столбце и в ключе индекса, но у индекса не установлен признак "Уникальный".
После этого я сел и сверил официальную документацию и реальную структуру БД для регистров (сведений, накопления, бухгалтерии), выявил 16 "инцидентов" (ошибок, замечаний и т.п.). К примеру, для регистра сведений, если его измерения имеют составной тип данных создаются вот такие индексы, не бьющиеся ни с официальной документацией, ни со здравым смыслом:
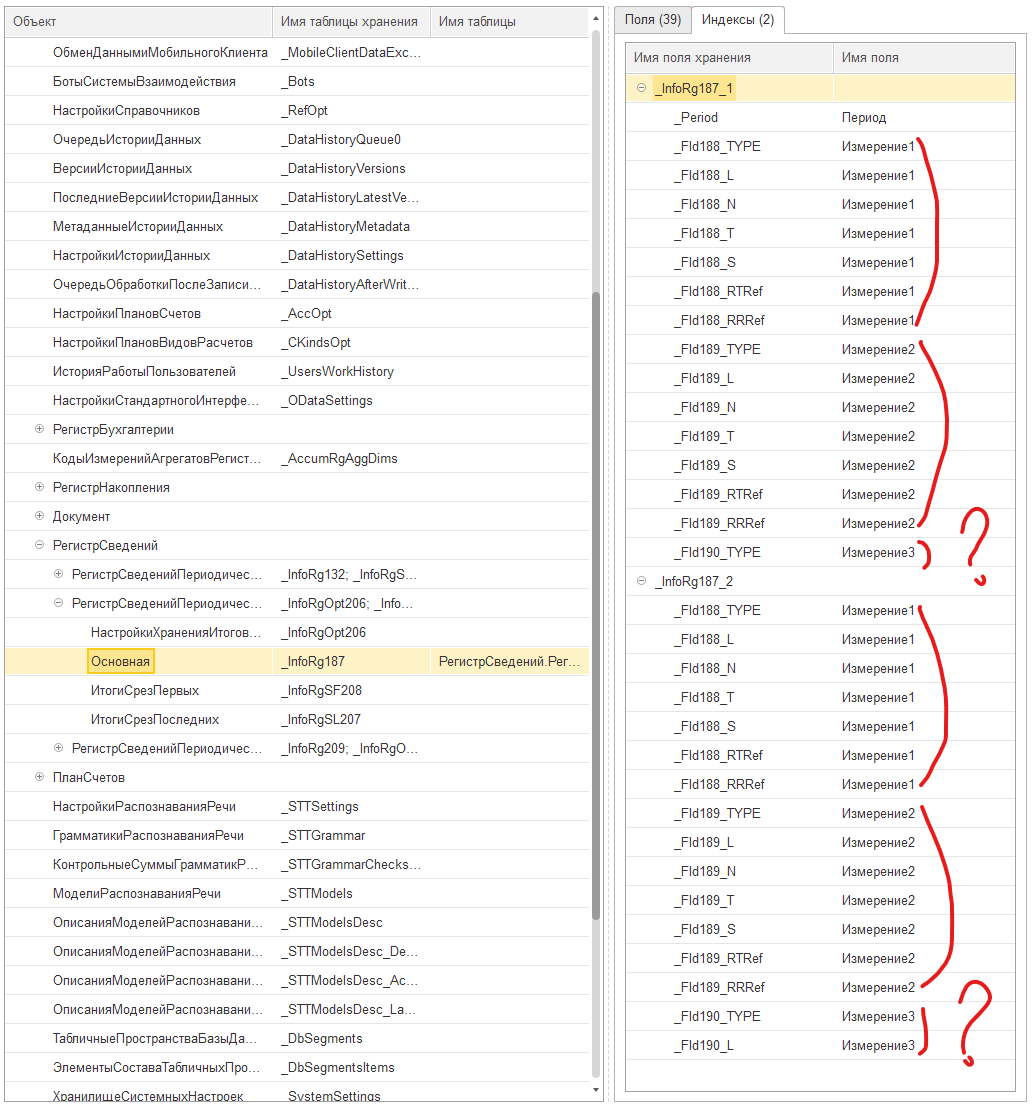
Делаю вывод - существует масса проблем и ошибок, связанных с ограничением на 16 ключей индекса БД (а почему 16, а не 32? MS SQL начиная с версии 2016 имеет ограничение 32, а postgresql вообще ещё раньше мне кажется это поддерживал) при большом реквизитном составе метаданных, некорректно работающих механизмов искусственного нивелирования ситуации ("DimHash") и применению реквизитов с составным типом данных в индексах.
Письмо в 1С написал, поправьте меня в комментариях, если не прав, это мой первый опыт такого разбора.
Вступайте в нашу телеграмм-группу Инфостарт