
Свой доклад я хочу начать с утверждения Мартина Клеппмана, автора книги «Архитектура высоконагруженных систем», который как-то сказал: «Самая лучшая интеграция – это отсутствие необходимости в ней».
Я бы согласился с этим утверждением, если бы мы жили в мире, где везде главенствует монолитная архитектура.

Представьте, что вы живете именно в таком «монолитном» мире и решили открыть небольшой бизнес – например, хотите печь пирожки.
Вы решаете автоматизировать оперативный учет для своей деятельности, идете к вендору и покупаете систему класса ERP. Других систем не продается – существуют только монолиты.
И всё. Считайте, что вам повезло. Если в дальнейшем вам потребуется планировать производство или вести учет взаимоотношений с клиентами – пожалуйста! Включаете соответствующие функциональные опции, и у вас появляются нужные возможности. Все замечательно и прекрасно.
Вот только проходит какое-то время и приходит понимание, что нужно дополнить какую-то подсистему, что-то в ней поменять. А сделать это уже будет весьма проблематично. Можно, но выйдет в копеечку.
Слава Богу, мы живем в другом мире – нам действительно есть из чего выбирать.
-
Мы можем спокойно заинтегрировать наш монолит с другими же системами такого класса.
-
Можем порезать наш монолит на микросервисы, которые будут взаимодействовать друг с другом в рамках микросервисной архитектуры.
-
Или можем создать собственное приложение, задействуя только внешние сервисы.
Такой подход позволяет нам оперативно масштабироваться, чтобы реагировать на быстрорастущие потребности бизнеса.
-
Допустим, вы захотели поменять подсистему CRM – пожалуйста, на рынке более 200 облачных платформ, выбирайте любую.
-
Потребовалась маркировка товаров, потому что государство требует ее вести на то же пиво – здесь тоже есть облачные системы, выбираем подходящую.
-
А если вдруг потребуется организовать какую-то массовую sms-рассылку, можно посмотреть в сторону function-as-a-service (FaaS), который есть у того же Яндекса или Amazon.
-
А еще есть IoT – интернет-вещей, который с активным появлением и развитием технологий 5G тоже вклинивается в нашу жизнь.
На самом деле все эти облачные сервисы как услуги, IoT и прочее – это тренд уже даже не последних 3-4 лет, это тренд десятилетия.
Но при всей крутизне микросервисов и IoT, у всех этих подходов есть минус – зачастую эти сервисы и системы либо слабо связаны, либо вообще никак не связаны между собой. А чтобы наладить для них правильную интеграцию, потребуется затратить время. Т.е. это – та еще задача.
Вариант интеграционного решения №1: свой велосипед

Конечно, в нашем мире для решения интеграционных задач уже все давным-давно изобретено. Но мы – программисты-разработчики – любим делать системы с нуля.
Нам, чтобы принять какое-то решение, не хочется оглядываться на легаси. Мы можем любой свой полет фантазии организовать в виде продукта и в дальнейшем его развивать.
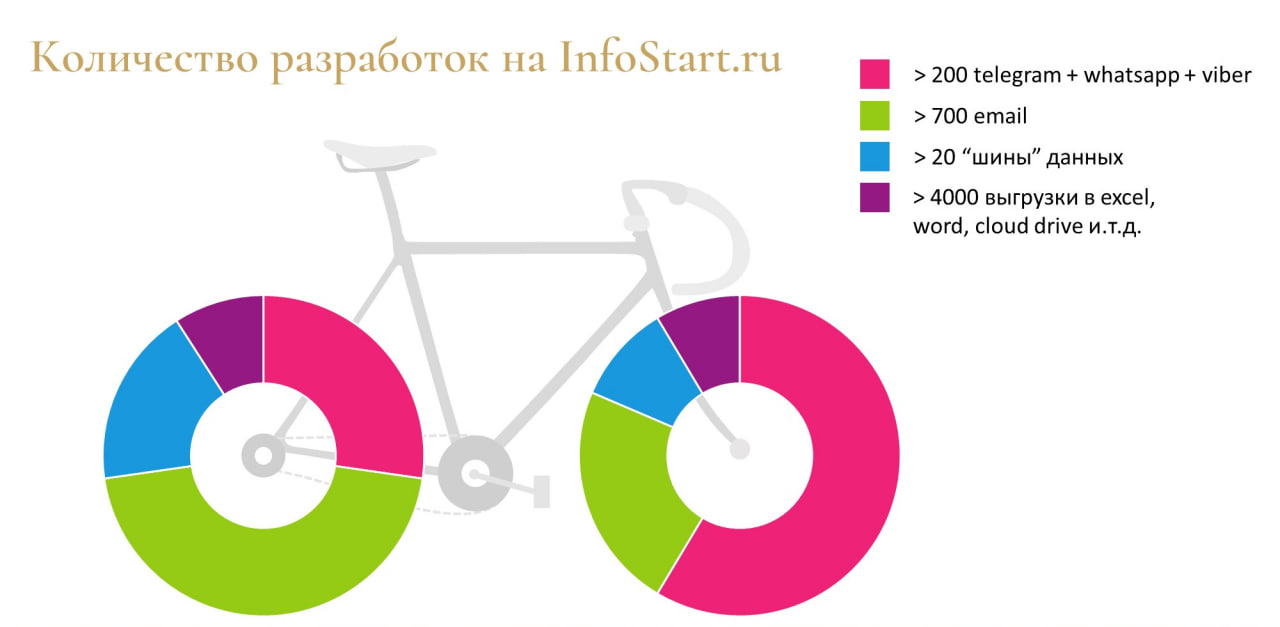
Но в таком подходе есть существенный минус. На данном слайде я привел краткую статистику по велосипедоинструментам, которые есть на сайте Infostart.ru.
Зачастую эти инструменты повторяют друг друга – не только функционально, но и в коде.
Я понимаю, что конкуренция – это здорово, но избыток одинаковых инструментов не нужен. Потраченное время можно было потратить на создание чего-то нового, уникального – чего, к сожалению, не происходит.
Вариант интеграционного решения №2: использование проприетарной шины данных

Второй подход в интеграциях – это использование проприетарных решений, тех, что стоят денег.
По этому пути можно пойти, если у вас очень много денег и очень крепкая нервная система. Потому что внедрять платные интеграционные шины и механизмы по взаимодействию с ними дорого и долго.
Нужно еще понимать, что вокруг таких инструментов зачастую создается излишний ажиотаж. Многие маркетинговые доклады умело маскируются под технические, и это как-то дальше продвигается: «Внедрите нашу облачную систему по подписке, это вас избавит от всех забот».
В реальности, с такими платными решениями все не так просто. Мы были на этом пути, и я честно скажу, это стоило нервов, денег, людей. Нам это не очень понравилось.
Вариант интеграционного решения №3: open source

Мы пошли по третьему пути – это использование open source-инструментария.
Вообще open source-инструментов по интеграции много, мы использовали не все инструменты, которые есть на рынке. Мы посмотрели в сторону систем, которые отвечают подходам low-code и no-code.

У подходов low-code и no-code есть существенное преимущество перед подходом code-first, который заключается в том, что мы проектируем какую-то систему, дальше пишем кучу кода, потом получаем MVP, запускаем, а потом пишем еще кучу кода, и так продолжается до бесконечности.
-
При подходах low-code и no-code мы, по сути, пропускаем этап кодинга. Да, мы проектируем, но в дальнейшем мы просто накидываем какие-то готовые блоки в рамках того же MVP и смотрим, насколько это жизнеспособно.
-
Причем MVP за счет таких подходов делается намного быстрее.
-
Благодаря подходам low-code и no-code мы можем легко проверять гипотезы. Например, согласно подходу low-code мы можем сравнивать брокеры сообщений RabbitMQ и Kafka – смотреть по карте интеграции, как работает RabbitMQ, как работает Kafka.
-
Мы можем покрутить это, практически не тратя усилий на написание кода. И затем определиться, что именно нам подойдет.
В этом докладе я хотел бы рассказать о двух инструментах из мира open source, которые мы активно используем в работе. Они значительно облегчают нам жизнь.
n8n.io

Первый инструмент – это n8n.io. Разработчики позиционируют его, как no-code платформу, благодаря которой можно автоматизировать каждодневные рутинные операции. Но несмотря на то, что это решение обычно используется для автоматизации каких-то операций, с его помощью можно легко покрывать и интеграционные задачи.
Расскажу, как мы используем этот инструмент у себя в работе.
Мы у себя в компании мы очень любим Битрикс – мы в нем общаемся, активно ставим друг-другу задачи и т.д. Жизнь в Битриксе кипит. В то же время есть ряд коллег, которые любят Telegram и другие мессенджеры, а в Битриксе предпочитают не общаться. И периодически возникает задача об оповещении наших коллег:
-
о результатах собранных метрик по работе информационных баз;
-
о критических системных алертах от наших приложений;
-
о каких-то значимых событиях – например, у коллеги Иванова через два дня будет юбилей работы в компании, мы делаем оповещение ответственному сотруднику, чтобы он заранее подготовился и поздравил коллегу, чтобы повысить мотивационный дух внутри команды;
-
кроме этого, нам нужно организовывать оповещения, связанные с рисковыми операциями. Мы работаем в финансовом секторе и подчиняемся надзорным органам, в частности Центробанку. Шаг влево, шаг вправо – можно лишиться лицензии. Чтобы не доводить до предела, какие-то критические операции лучше предугадывать заранее. Для этого иногда нужны оповещения такого рода – и не только ответственным сотрудникам, а всем, вплоть до руководителя.

Чтобы организовать такую систему оповещений, конечно, можно взять нашу любимую 1С и написать все на ней. Но лучше вспомнить слайд про разработчика, который тратит время на написание велосипедоинструментов и посмотреть в сторону системы взаимодействия.
Хотя, на мой взгляд, система взаимодействия – тоже не очень практичный вариант, хотя бы потому, что она стоит денег и есть не у всех.
Кроме этого, для нее требуется развернуть достаточно сложный технологический стек. Там бэкграундом ставится:
-
PostgreSQL;
-
Elasticsearch, который используется как полнотекстовый индекс для внутренних механизмов поиска;
-
Hazelcast, чтобы производить кэширование внутри сеансов системы взаимодействия;
-
служба системы взаимодействия.
Все это связывается, и сверху еще нужно прикрутить S3, чтобы можно было обмениваться файликами, и эти файлики версионировались – тогда все получается «шоколадно».
Но есть еще один момент, с которым лично мы столкнулись уже два раза – при обновлении платформы не факт, что у вас не поломается система взаимодействия.
Сначала мы столкнулись с этим на 18-й версии платформы: обновили до версии 8.3.18, и система взаимодействия сказала, что ее нужно обновить до 10-й версии, а 10-й версии на релизе вообще нет, даже в тесте. И «приплыли». Пришлось с 18-й версии откатываться обратно и жить на 16-й.
Та же самая история повторилась на 20-й версии платформы, но в этот раз фирма «1С» была более предусмотрительна: она хотя бы выложила тестовый релиз 11-ой системы взаимодействия. Стало легче, но все равно ситуация неоднозначная.
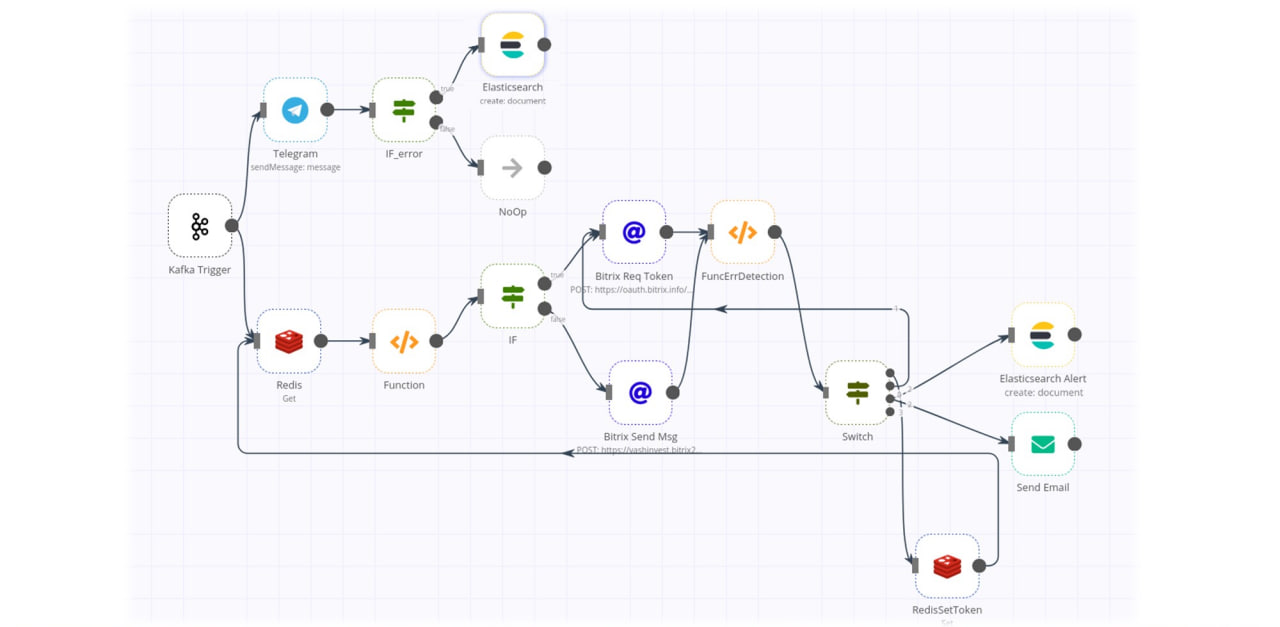
Поэтому мы отказались от системы взаимодействия и взяли n8n.io – она, по сути, представляет собой кроссплатформенную службу, внутри которой настроены рабочие процессы. Рабочий процесс – это некая карта, канва, на которую набрасываются ноды и между ними строится определенная логика взаимодействия.
Здесь на слайде приведен пример решения нашей задачи, связанной с оповещениями – мы оповещаем пользователей в облачный Битрикс24 и в Telegram, так как некоторые коллеги хотят получать оповещения в этот мессенджер.
Ноды, которые набрасываются на канве рабочего процесса, бывают двух видов:
-
Ноды-триггеры. По сути, они являются катализатором рабочего процесса и запускают сам рабочий процесс. В нашем случае есть нода Kafka Trigger, то есть когда появляется сообщение в Kafka, стартует рабочий процесс, и дальше происходит какая-то логика обработки.
-
Ноды обработки данных и отправки в конечные узлы точки. Используются для логики обработки. То есть это могут быть какие-то условные операторы (If или Switch) для роутинга и, может быть, трансформации сообщения, конвертации (например, перевода из XML в JSON).
И в финале мы уже просто отправляем оповещение либо в Telegram, либо в Битрикс, а ошибки, которые могут возникать, фиксируем в том же Elasticsearch.

Готовых вариантов нод очень много.
Само решение n8n.io из мира Open source, и все ноды тоже оттуда – вы можете написать свою ноду, разместить и после модерирования вендором она может оказаться в магазине.
Чтобы разместить ноду у себя на рабочем процессе, достаточно зайти из самого решения n8n.io в магазин нод, добавить необходимую ноду, протянуть связь с другой нодой и организовать тем самым взаимодействие.
На слайде я привел пример самых распространенных нод. Возможно, вы какие-то узнаете и, может быть, какие-то из этих приложений вы используете в работе.
Используя ноды, можно легко с этими приложениями коннектиться.

Каждая нода имеет свой уникальный набор свойств.
Допустим, если это – нода брокера сообщений, или, как его сейчас еще называют, стримминговой платформы Kafka, то в свойствах может указываться:
-
адрес брокера;
-
имя топика, из которого мы считываем сообщение;
-
идентификатор группы, который сообщение читает.
При этом используется no-code подход – мы никакого кода здесь не пишем. Мы в пользовательском режиме набросали, что мы хотим, и все – Kafka Trigger начинает работать. Он начинает слушать сообщения, которые поступают к нему на вход.
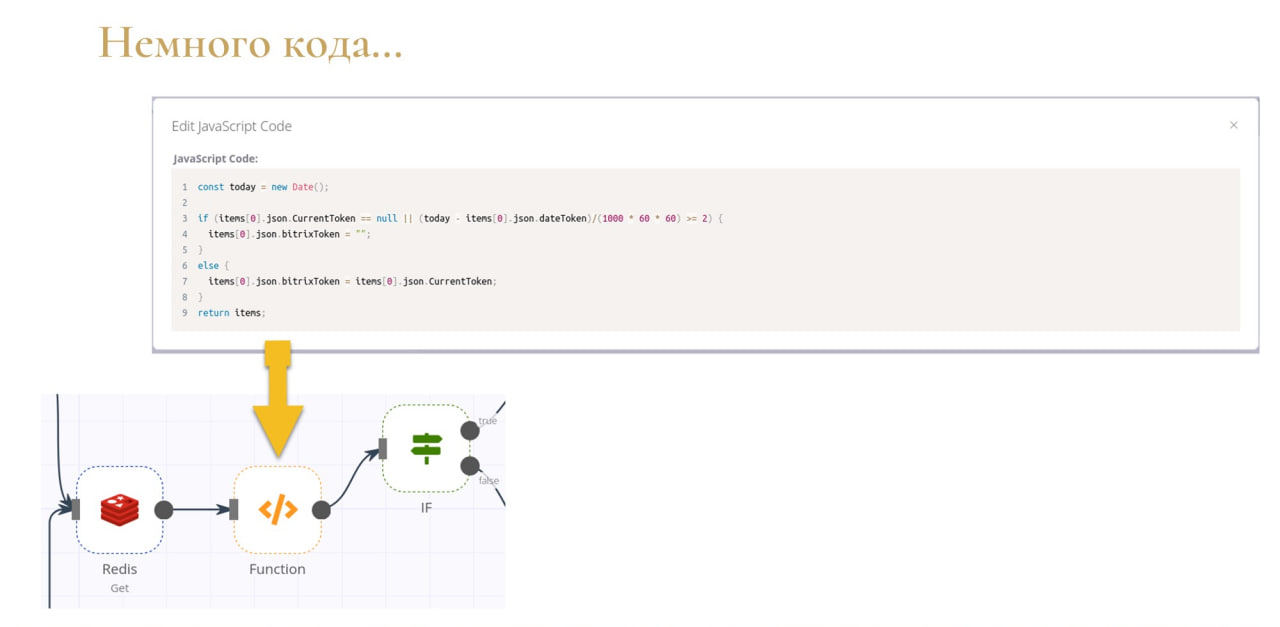
Если возможных свойств нод не хватает, всегда можно задействовать low-code.
Здесь под low-code вендор подразумевает именно код на JavaScript. Язык программирования JavaScript достаточно простой и тривиальный, он сейчас чуть ли не номер один в топе всех используемых языков.
Причем, разработчики позаботились о том, чтобы вы могли размещать этот код у себя без особого знания JavaScript. На сайте у них есть целый раздел сниппетов.
Сниппеты – это готовые участки кода, которые вы можете добавлять в свой проект, немного модифицировать и спокойно использовать. Например, нам для отправки сообщений в Битрикс нужно постоянно иметь актуальный токен. То есть, отправляя сообщение, мы должны убедиться, что токен у нас «живой». При этом Битрикс24 каждые два часа обновляет токен, т.е. его срок валидности – два часа. И, если токен уже «мертв», нам нужно запросить его еще раз. Для этой цели мы написали немного JavaScript-кода, и теперь все хорошо работает.
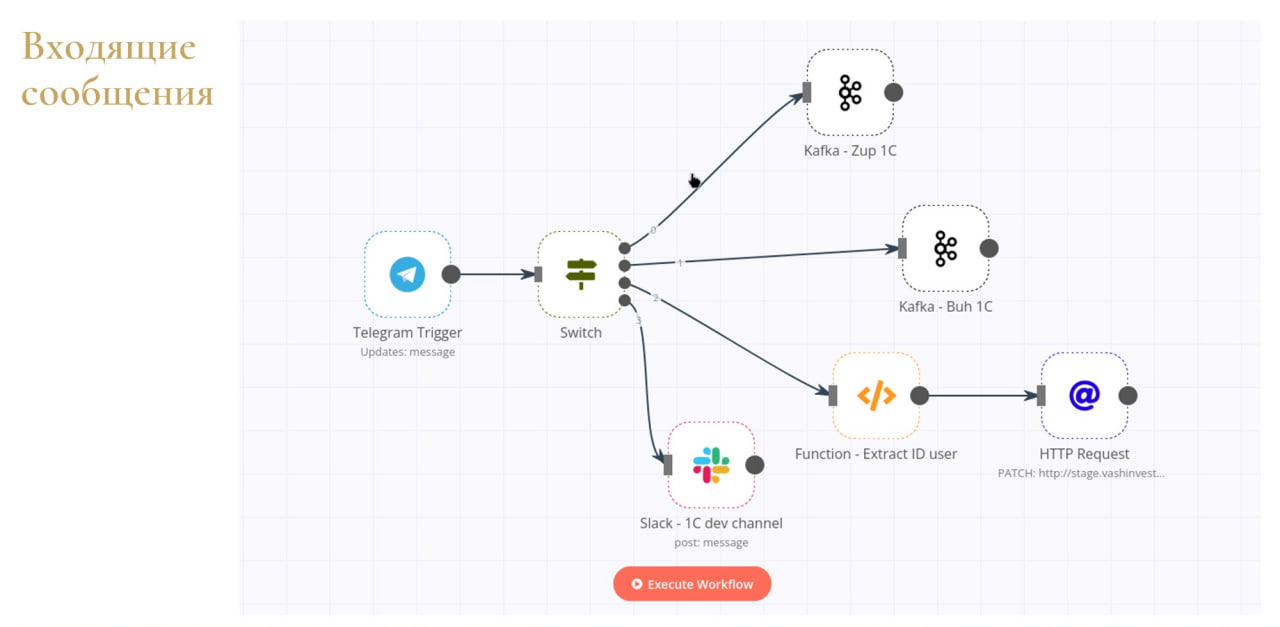
Если с односторонними оповещениями все понятно, для двустороннего сообщения мы использовали взаимодействие с Telegram-ботами.
Положа руку на сердце, скажу, что эти Telegram-боты уже всем надоели. Уже все и на каждом шагу пишут эти боты. Тем не менее с использованием подхода low-code и системы n8n.io это взаимодействие можно легко организовать.
И здесь есть явное преимущество – мы не открываем 1С вовне, мы ее не светим. Мы разместили на n8n.io Telegram-триггер, в который поступают команды и необходимые идентификаторы от бота, а дальше уже на его стороне прописываем какую-то кастомную логику. Например:
-
Мы по одной команде можем обратиться в 1С:ЗУП и там предоставить необходимые данные и вернуть боту.
-
Может обратиться в Бухгалтерию, если нам нужен какой-то отчет.
-
А можем вообще обратиться к сторонним сервисам или сделать то же напоминание какой-то команде разработчиков в Slack.

Главный плюс n8n.io в том, что она – масштабируемая.
-
Мы легко можем добавлять ноды и менять их.
-
Можем писать свои коннекторы и свои ноды – это большой плюс.
-
Мы можем повторно использовать создаваемые нами рабочие процессы: например, мы можем тоже превратить их в ноды и добавлять в дальнейшем в наши проекты. Это дает определенный профит и увеличивает скорость разработки.

Мы у себя на проде используем n8n.io для многих случаев, но есть и минусы.
-
Ноды пишутся либо на TypeScript, либо на JavaScript. Языки достаточно простые и не всегда нужно писать эти коннекторы-ноды самому: можно брать готовые, комбинировать, прописывать кастомную логику. Но знание этих языков все равно потребуется, это может быть препятствием.
-
Второй минус связан с производительностью. У нас был случай, когда после отправки сообщений в Kafka у нас просто-напросто лег рабочий процесс и произошла ребалансировка группы. Дело в том, что n8n.io написана на nodeJS – его многие сейчас позиционируют это как бэкграунд-систему, а не фронт, тем не менее с высокими нагрузками n8n.io пока не справляется.
С другой стороны, если у вас нет такой высокой нагрузки, и вам нужны какие-то банальные и тривиальные кейсы, n8n.io может быть идеальным вариантом для автоматизации и закрытия небольших задач интеграции. Или в рамках того же MVP можно спокойно накидать карту и опробовать какое-то решение.
WSO2

Второе решение является полноценной интеграционной шиной, причем абсолютно бесплатной.
Эта шина называется WSO2.

Она состоит из двух основных компонент.
-
Первая компонента – это сервер, можно сказать, сердце интеграционной шины.
-
Вторая компонента – это студия, которая собрана на базе Eclipse.
Вообще-то я совсем не сторонник Eclipse и EDT, считаю, что это – мертвая технология. Особенно, когда ты работаешь с Visual Studio Code – это небо и земля.
Но все равно это не ERP, а просто карта интеграции, куда можно добавлять определенные коннекторы из того же магазина коннекторов и можно писать свои коннекторы, если вы умеете программировать на Java.
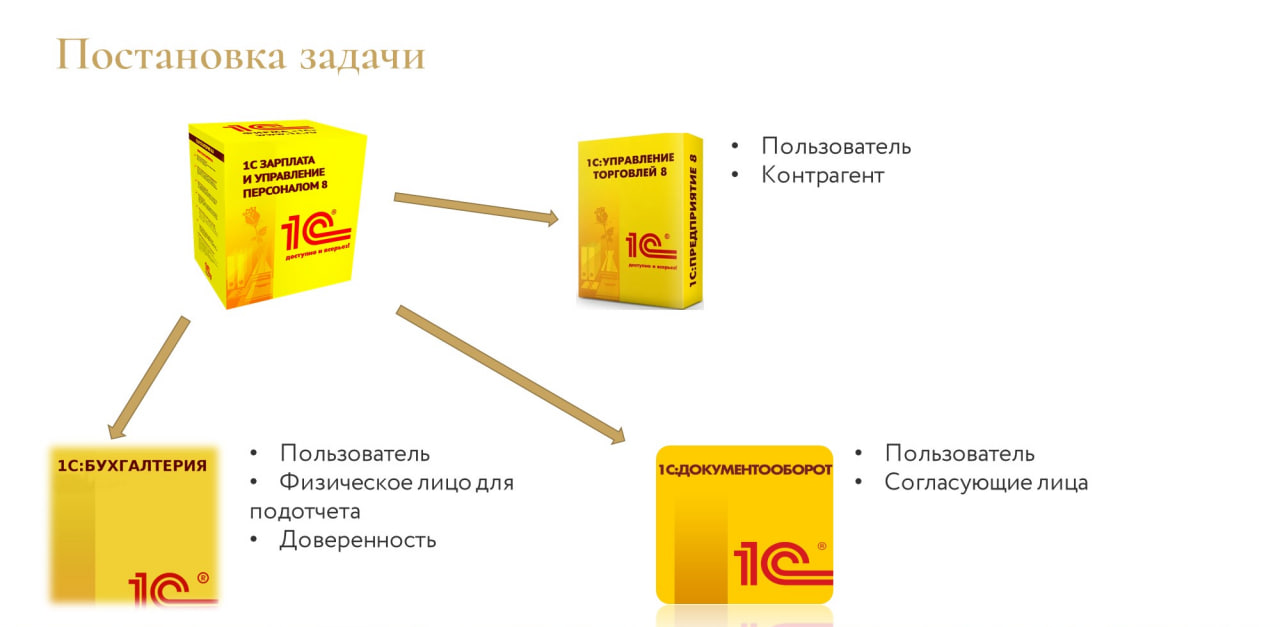
Какие кейсы можно решать?
Допустим, кейс межсистемного взаимодействия.
У нас в компании несколько конфигураций 1С. Иногда возникает ситуация, что к нам приходит новый сотрудник. Сотрудника заводят в ЗУП, а его нужно внести еще и в другие базы:
-
где-то он должен быть заведен как пользователь;
-
где-то – как контрагент;
-
где-то вообще должен быть лицом, которое согласует какие-то документы, например в Документообороте.
Заводить пользователя везде руками – та еще беда. И использовать для передачи этой информации планы обменов я тоже не советую – я их уже давно не использую и считаю, что это тоже мертвая технология.
Как обычно сейчас делают?
-
На стороне базы-источника делают регистр сведений, где копятся сообщения – некий аналог очереди, куда при записи объектов попадают ссылки, которые нужно передать на сторону приемников.
-
Далее на стороне приемника у нас есть HTTP-сервис (т.н. Endpoint).
-
Есть конвертация данных, где мы, по сути, формируем правила.
-
А дальше какое-то регламентное задание периодически опрашивает регистр, конвертирует наши ссылки в сообщения и пуляет их в Endpoint.
-
В результате данные появляются в приемниках.
Но в нашем случае такой подход не очень практичен, потому что:
-
Конвертация данных 2.0 – это хороший инструмент, но сообщения, которые получаются в результате его работы, достаточно тяжеловесные, там много избыточной информации. И эти сообщения имеют формат XML. В эпоху JSON, когда все можно делать практичнее, XML – уже немного убого;
-
Кто сказал, что приемники всегда доступны? Например, база Бухгалтерии может отвалиться, либо начинающий программист может уронить прод, где размещена база ЗУП или Документооборота. Может произойти вообще что угодно. Соответственно, отправив куда-то сообщение, мы не можем быть уверены, что оно туда дойдет.

Более правильно решать эту задачу, применяя подход event sourcing. Это – архитектурный паттерн, подразумевающий, что каждое событие, которое произошло в источнике, должно быть хронологически верно и полноценно в тот же момент отражено во всех заинтересованных приемниках.
Этого можно добиться, если использовать:
-
event stream-платформу Apache Kafka (такие платформы еще называют брокерами сообщений);
-
шину данных WSO2, чтобы строить маршруты попадания сообщения в определенные приемники;
-
механизм «История данных», который заложен в платформу 1С;
-
и библиотеку от Артёма Кузнецова 1С Serialization Library – это очень крутая штука, которая позволяет спокойно JSON-ить как структуры, так и ссылки. С ее помощью можно маршализовать данные на стороне источников, а потом демаршализовать из полученной структуры на стороне приемников конкретные сущности – ссылки или записи регистров. Очень удобный инструмент.
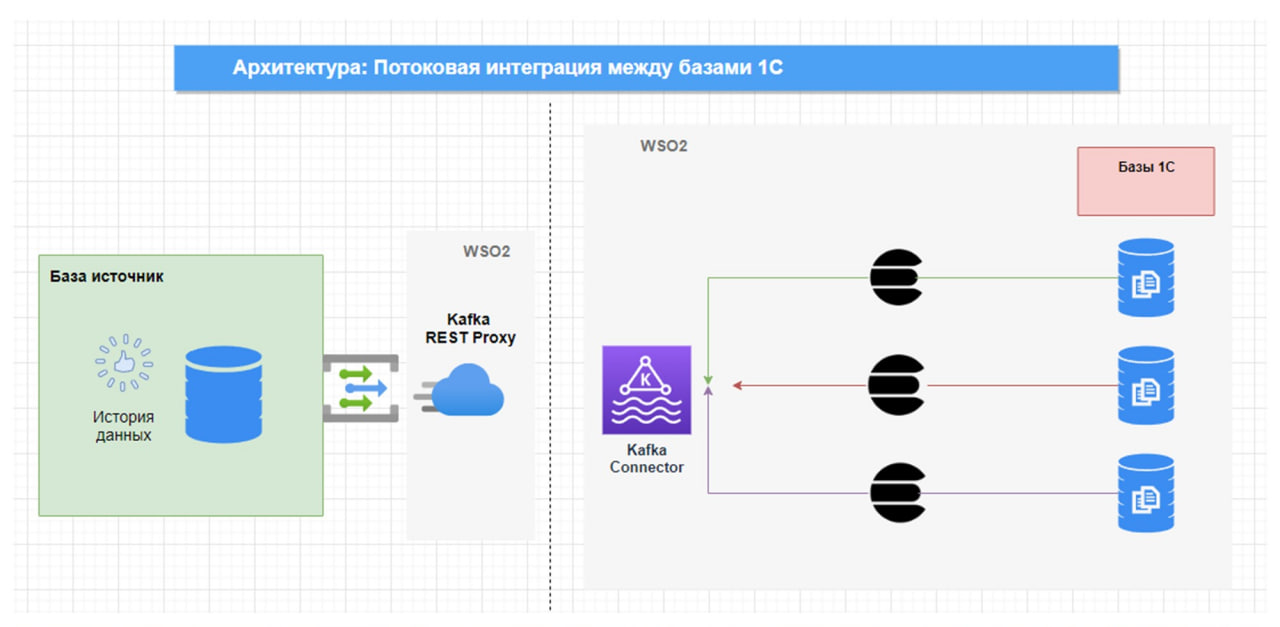
В этом случае архитектура нашего решения становится немного другой. Это не «точка-точка», а она разделяется на два блока – слева и справа.
-
Слева мы просто отправляем все, что у нас произошло в источнике, в какой-то брокер – это может быть Kafka или RabbitMQ.
-
А справа все заинтересованные приемники тянут эти сообщения из брокера и у себя порождают определенные сущности, производя демаршелизацию.
При таком подходе сообщения, которые попадают в брокер, должны быть легковесными, маленькими по размеру – это будет отвечать паттерну event sourcing.

Триггером для того, чтобы сообщения начали куда-то отправляться, по сути, является появление новой версии объекта.
Мы включаем историю данных, и, когда у нас сформировалась новая версия, мы отправляем данные.
Чтобы полноценно использовать историю данных, нужна версия платформы больше 8.3.15. И, самый немаловажный факт, не нужно снимать конфигурацию с поддержки. Практически для любого объекта можно включить или отключить историю данных кодом: на слайде я привел пример, как это сделать.

У механизма истории данных есть существенные преимущества.
-
Первое преимущество заключается в том, что формирование новых версий производится фоново. Длительность транзакции записи не увеличивается, а версия формируется фоновым заданием, которое сама же платформа и запускает.
-
И второй немаловажный факт: у истории данных есть крутая сущность «РазличияВерсий». Это – свойство версии данных, содержащее только изменения, отличия текущей версии от предыдущей. Если вы поменяли 1-2 реквизита, вам не нужно выгружать весь объект в XML или в JSON и пулять его в приемник. Мы просто обращаемся к этой структуре «РазличияВерсий», можем ее просто взять и сериализовать, там всегда находятся простые типы.
-
И есть еще неочевидное преимущество у истории данных. Сами версии содержат внутри себя timestamp (это временная метка) и идентификатор (это номер версии). А это означает, что в любой непонятной ситуации мы можем обратиться к какой-то предыдущей версии, начиная с какого-то номера, и промотать всю хронологию. Например, произошел какой-то сбой, мы где-то в регистре зафиксировали, что последняя считанная и нормально отправленная версия объекта имеет идентификатор такой-то, и мы можем начиная с этого идентификатора снова все отмотать и отправить в тот же брокер. На мой взгляд, это заменяет те самые очереди – регистры, которые уже избыточны в такой архитектуре.

Чтобы отправить информацию из 1С в брокер – неважно, будь это Kafka или Rabbit – нам не нужно использовать внешние компоненты вообще. Ну нужно их писать, не нужно их покупать, не нужно лезть на Stack Overflow, искать коды для Python или Golang и делать какие-то прослойки для того, чтобы что-то из 1С куда-то отправить.
В шине WSO2 мы можем в несколько кликов поднять REST Proxy. Это делается вообще без кода, просто в пользовательском режиме накидываются блоки:
-
прописывается топик;
-
указывается, как мы сообщение отправляем;
-
мы можем его параллельно трансформировать;
-
и в случае возникновения ошибок тут же прологировать их в Elasticsearch.
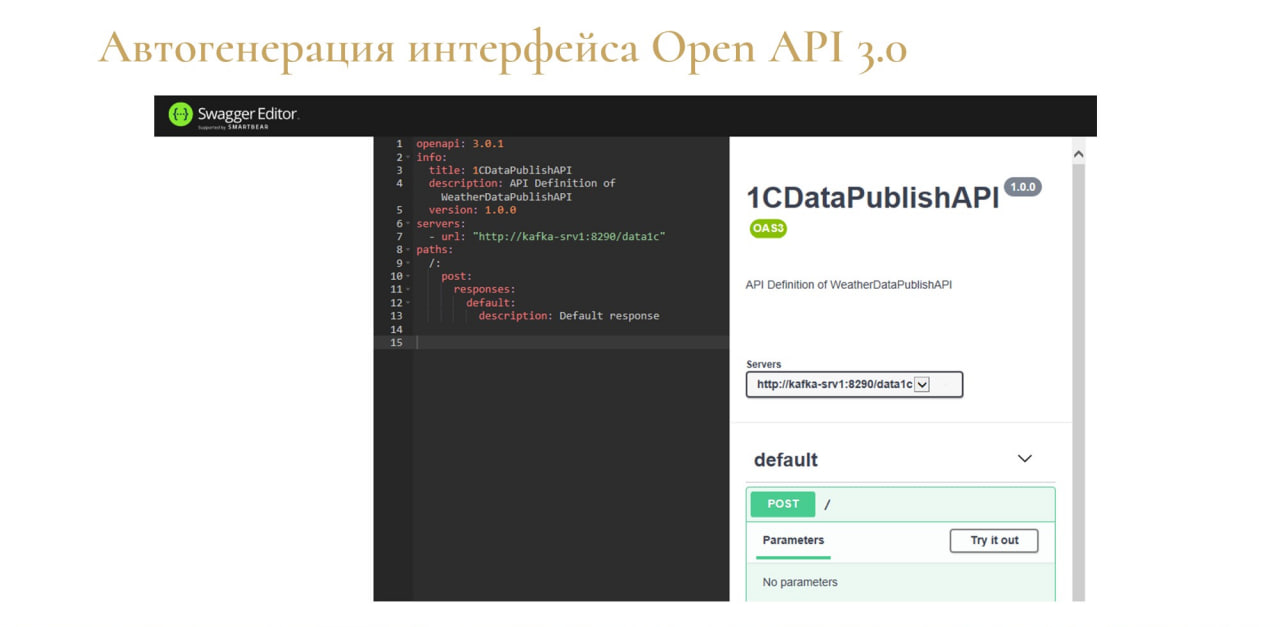
Побочным положительным эффектом такого подхода является автоматическое формирование на стороне шины интерфейса спецификации Open API – его можно дополнительно задействовать и в других приложениях.

Что касается передачи информации в приемник: каждое прослушивание сообщения для приемника – это отдельное приложение, потому что приемники иногда могут быть недоступны.
Мы, конечно, можем сделать все на одной карте автоматизации – взять сообщение и дальше построить какой-то роутинг. Но это сложнее, т.к. если у нас какая-то база отвалится, нам нужно зафиксировать, что это сообщение не прочитано.
Здесь мы прописываем, что в случае возникновения ошибок нужно просто откатить транзакцию чтения сообщения, чтобы оно осталось в Kafka до того момента, пока сам приемник снова не станет активен. Шина опрашивает приемник автоматически, здесь вам никакой логики прописывать не нужно.
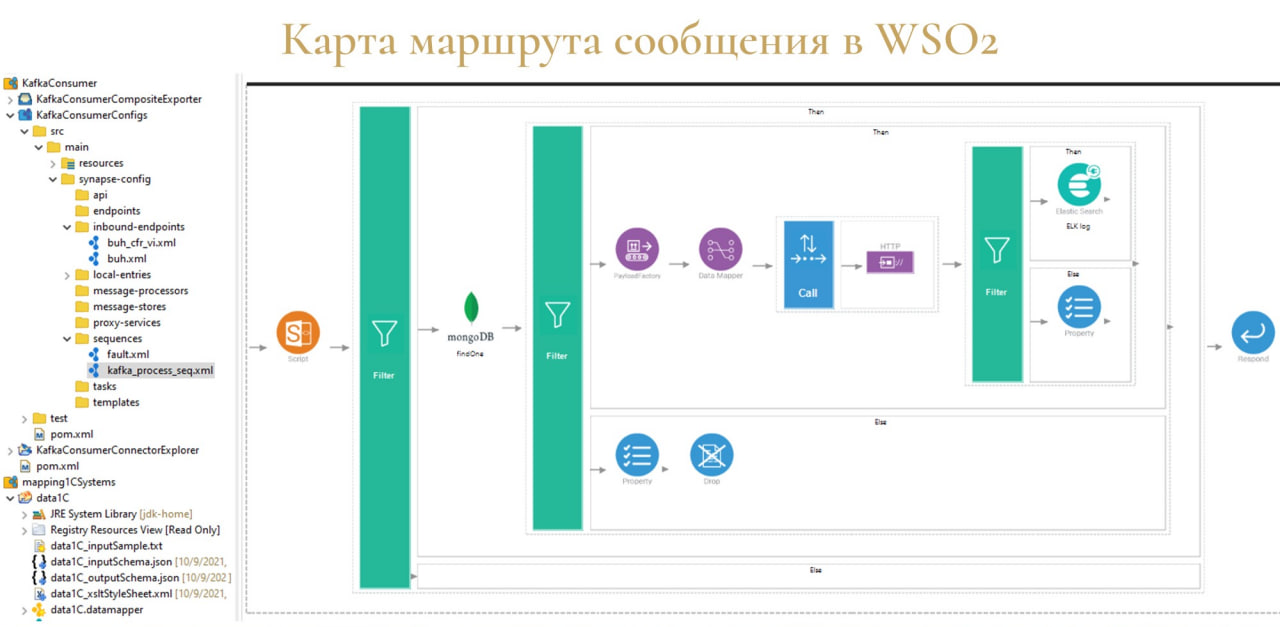
Сама обработка сообщений очень похожа на карту, которую я показывал в n8n.io.
Т.е. при поступлении сообщения мы можем накидать какую-то определённую логику – трансформировать сообщение, а в дальнейшем его уже отправить в необходимый нам приемник.

Если этого снова будет недостаточно, есть подход low-code. Хотя то, что показано на слайде, я бы не назвал low-code, потому что, когда с этим начинаешь работать, становится немного больно и неприятно. Но, потратив неделю или полторы, я научился писать JS-код внутри XML-документа. Правда еще не научился его отлаживать, но это, думаю, вопрос времени.
Конечно, такой low-code – это минус, но в большинстве случаев кодировать там не требуется.
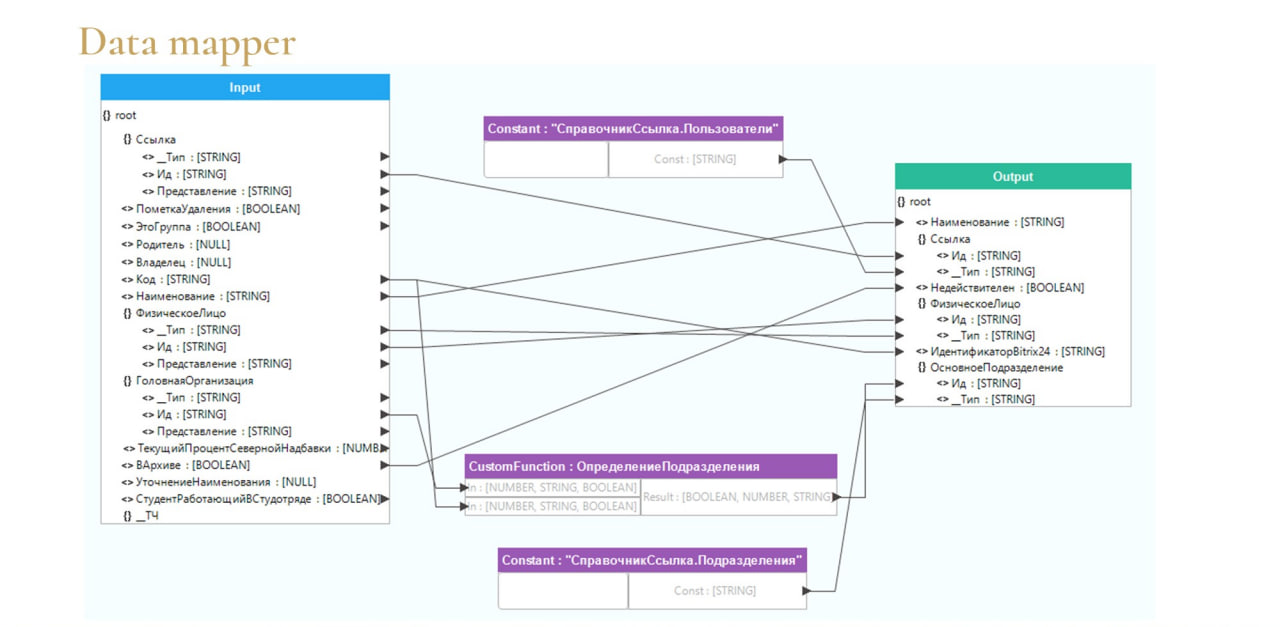
При этом есть большой плюс – это компонента Data mapper. Такой небольшой блок, который мы можем положить на карту интеграции.
Он вполне заменяет конвертацию данных:
-
мы можем в секцию input загрузить наше сообщение в формате JSON, получить его схему;
-
набросать в секции output сообщение, которое мы хотим получить на выходе;
-
и протянуть определенные связи – где-то добавить функции, обработчики.
Тем самым мы трансформируем наше сообщение в необходимый вид для конкретного приемника.
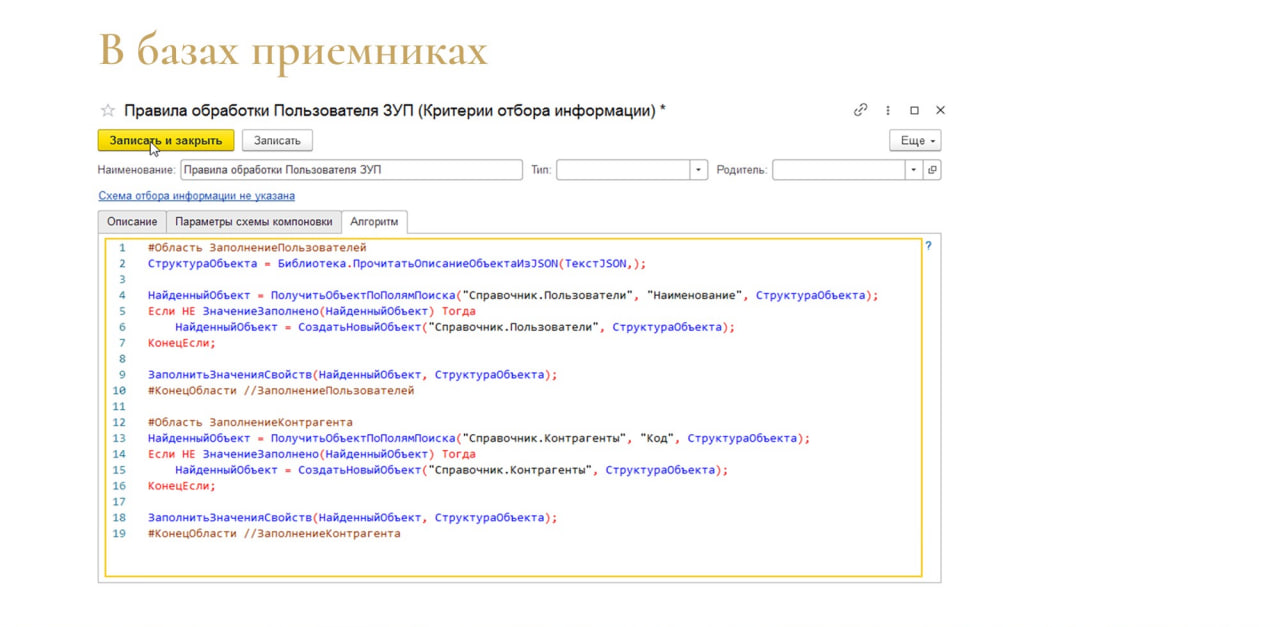
А на стороне 1С у нас – наш любимый 1С-ный low-code.
Все правила мы храним внутри базы – этот алгоритм стартует автоматически, когда сообщение попадает в Endpoint конкретного приемника.
Здесь мы просто сообщение демаршелизуем с помощью библиотеки Артёма Кузнецова и протягиваем определенную логику для поиска ссылок – замещать или создавать новые.
Это все мы делаем в пользовательском режиме.
Итог
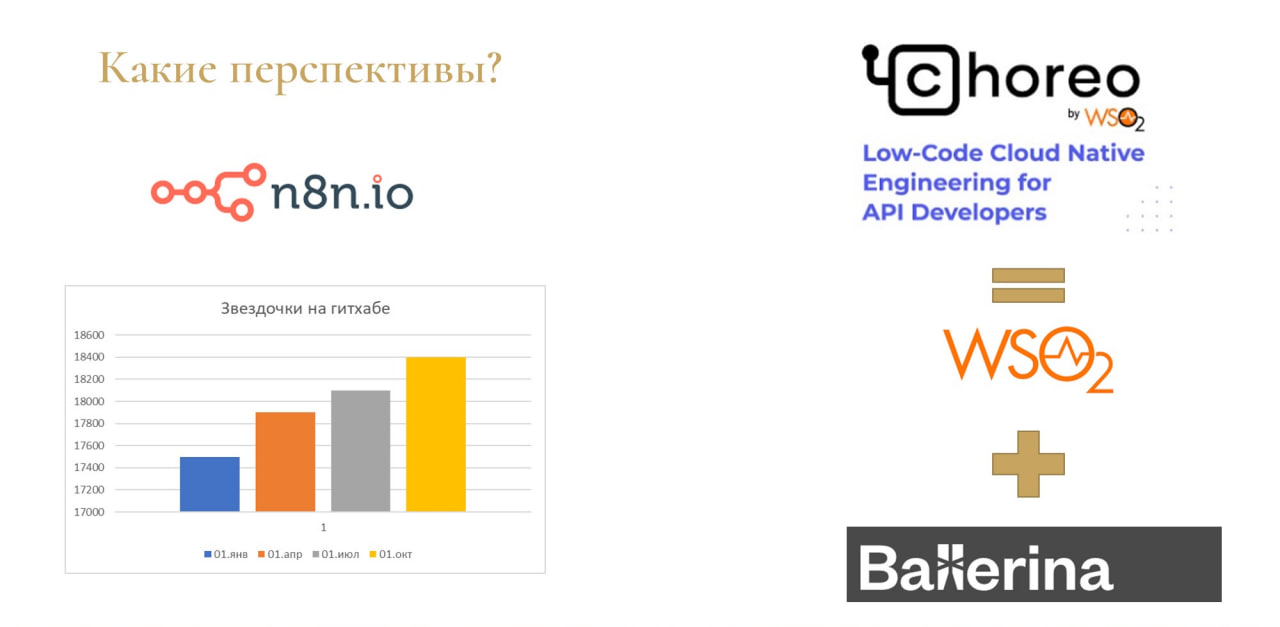
Подведу итог – как развиваются системы n8n.io и WSO2.
-
N8n.io на данный момент имеет более 18 000 звездочек на GitHub – она уже стала цифровой платформой. Вы можете ее поднять в докере, поставить отдельной PM2-службой, или использовать по подписке через браузер – прямо в облаке накидывать интеграцию с внешними сервисами, ничего не разворачивая у себя.
-
Что касается WSO2, она уже тоже стала полноценной цифровой платформой. На данный момент разработчик выпускает продукт choreo, который взял из WSO2 самое лучшее – блок карт интеграции. И они совместили его с языком программирования Ballerina – это язык для интеграций, очень похожий на Python.
И та, и та система, в принципе, развиваются.

В заключение хочу сказать, какой я вижу интеграционную шину от 1С. Потому что мы же тоже неслучайно взяли эти инструменты и начали ими пользоваться – мы ждем шину.
-
Шина должна быть легковесной, компактной и удобной. Такой, как n8n.io.
-
Разработчик не должен заморачиваться и писать код подключения к той же Kafka, к тому же Rabbit. Зачем? Он просто должен взять необходимые коннекторы из магазина коннекторов, добавить их на свою карту автоматизации, прописать необходимые свойства в пользовательском режиме и все. А дальше он должен заниматься решением конкретной бизнес-задачи.
-
Также шина должна быть производительной, как WSO2. WSO2 действительно выдерживает большие нагрузки. И пусть она немного убогая, но она производительная.
-
Самое главное: шина должна придерживаться подходов low-code и no-code. Только при таких условиях ей, на мой взгляд, обеспечен успех.
-
И еще хочу сказать, что пока шины у нас нет, не стоит кидаться в сторону платных Enterprise-решений – это дорого, долго, и вы не всегда увидите эффект.
-
Не стоит писать что-то снова с нуля. Зачем тратить свое время? Смотрите в сторону Open source-инструментов. Причем в наше время инструменты из такого мира нужны будут больше не для того, чтобы взять и автоматизировать что-то уже готовое, а для понимания, что можно сделать новое. Можно занять, допустим, новые области в бизнесе и тем самым обогнать конкурентов.
Вопросы и ответы
Очень часто сталкиваюсь с ситуацией, когда мы строим систему в том же n8n.io на базе существующих коннекторов, заранее знаем, что нам нужно, куда какие сообщения отправлять – можем заранее построить структуру. Но в какой-то момент в бизнесе внедряется новое решение и такого коннектора нет. Как решать проблему, когда у нас уже есть рабочая структура, но к ней нужно добавить новый коннектор самостоятельно?
Все зависит от того, какое API есть у вашего приложения, с которым вы хотите коннектиться. Если ваше приложение поддерживает подключение через HTTP, существует коннектор HTTP Request и Webhook. Можно сэмулировать коннектор, просто набросав определенные ноды – эти ноды будут делать в принципе то же самое, что бы делал готовый коннектор, которого еще пока нет.
Второй момент – вы можете немного поJS-кодить и сделать свой коннектор. Опять же, есть StackOverflow – там в 90% случаев есть нужный JS-код для соединения с вашим приложением. Ctrl+C, Ctrl+V, и готово.
На одном из слайдов вы демонстрировали Data mapper, который позволяет преобразовать структуру сообщения в другой формат. И там слева была представлена структура в JSON-формате. И в процессе вашей презентации вы делали уклон на то, что XML – это вчерашний день, а JSON – сегодняшний. Тем не менее, как показывает практика, XML довольно-таки широко используется везде, и будет ли такой же Data mapper для входящих сообщений в Soap-протоколе с WSDL?
Он там есть. У компонента Data mapper есть два переключателя: JSON и XML.
XML – это сейчас наиболее распространенный формат, многие legacy-системы крупных банков, госучреждений и прочих не могут отойти от XML. Они на него подсажены. Поэтому это все предусмотрено.
Вы говорили, что для Kafka писать компоненту не нужно. Допустим, для продюсера это может и не нужно, а как же насчет консюмера?
Для консюмера у меня был отдельный слайд. Там тоже не нужно – в том же n8n.io и в том же WSO2 есть компонент Kafka Trigger.
Получается, что, наоборот, сам Kafka уже дергает систему, да?
Нет. Вы в шине делаете коннектор, который в бесконечном цикле слушает топик Kafka. То есть нужно просто указать адрес брокера, топик и идентификатор группы, под которым вы будете прослушивать сообщение.
И всё. Он начинает слушать, пока шина не отвалится – он будет делать это бесконечно, пока у вас живо приложение.
Продюсер работает так же, как консюмер? Тоже в бесконечном цикле слушает?
В случае продюсера мы при появлении сообщения просто передаем его в консюмер. Мы не ждем ничего в Kafka.
Консюмер – да, бесконечно. А продюсер – единоразово.
В чем же концепция и парадигма low-code, no-code? Сейчас это просто выглядит, как отказ от изобретения велосипедов и предварительный обзор рынка на наличие программных продуктов, на best practice. Как вы понимаете эти концепции?
Честно скажу, концепцию no-code я понимаю – мы ничего не прописываем, все накидываем в пользовательском режиме с возможностью параметризации. И этого достаточно, чтобы что-то заработало.
В случае low-code я считаю, что это больше маркетинг. Честно.
Там же какой смысл был у low-code. Мы берем пользователя, который, допустим, химик. Зачем ему заморачиваться с программированием? Он может сделать какое-то моделирование процессов, просто описав все в low-code с помощью компонент.
Но он не сможет этого сделать на самом деле. То есть ему все равно нужно понимать, знать какие-то базовые структуры, какую-то логику и т.д.
И на практике получается, что с low-code могут работать только люди, которые умеют программировать. Поэтому low-code это больше маркетинг.
Да, там есть эффект, но он не такой большой. В этом плане подход no-code лучше.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции Infostart Event Moscow Premiere.


Вступайте в нашу телеграмм-группу Инфостарт