На каждой конференции Инфостарта находится человек, который спрашивает: «Почему растет tempdb и что с этим делать?» Попробую рассказать, что за волшебные вещи творятся с tempdb, почему она может внезапно распухнуть, и как этого избежать.
Пару слов о себе. Меня зовут Александр Криулин, с 1С я работаю уже 8 лет.
Начинал в местном франче, как и все, стажером. Затем работал в системном интеграторе. Время от времени сталкивался с проблемами тормозов, и мне стало интересно с ними разбираться – находить причину, что вообще происходит, а не просто по очереди перезагружать все сервера.
Прошел некоторые курсы, почитал статьи, сдал на эксперта. Теперь, когда периодически сталкиваюсь с какими-то интересными проблемами производительности, стабильности систем, стараюсь их решать.
Об одной из таких проблем как раз сегодня расскажу.
Как работает tempdb

Начну с самого простого – с документации MSDN.
Согласно определению, tempdb – это системная глобальная база данных, доступная всем пользователям в MS SQL Server.
Она хранит в себе два вида данных:
-
Временные пользовательские объекты, которые созданы явно – в нашем случае это как раз временные таблицы.
-
И некие внутренние служебные объекты, создаваемые именно ядром MS SQL Server для какой-то его корректной, правильной, оптимальной работы.

На слайде – банальный запрос создания временной таблицы на 1С: я выбираю справочник, помещаю его во временную таблицу ВТ, и потом выбираю данные из ВТ.

Платформа делает из этого запроса пять простеньких запросов:
-
Сначала она ищет временную таблицу с определенным именем, если она уже есть.
-
Если нет, она ее создает – с определенной структурой, с типами данных колонок.
-
Далее идет в нее вставка.
-
Далее из нее выбирает через SELECT.
-
И в конце – оператор TRUNCATE TABLE, то есть очистка таблицы. Здесь важно, что таблица не удаляется через DROP, она остается, просто очищается.
Пара нюансов.
-
Во-первых, первые два оператора могут выполняться не всегда. Когда вы выполняете запрос, платформа вам выдает некий номер соединения с СУБД – например, 55. И когда вы повторно можете выполнить этот же запрос на эту же временную таблицу, и платформа вам выдаст этот же номер соединения, вот эти первые два оператора (SELECT и CREATE TABLE) выполняться не будут, так как платформа уже знает, что у этого номера соединения уже есть такая таблица. Это такая небольшая оптимизация от платформы, но рассчитывать на нее особо не стоит, потому что платформа вам может вполне спокойно выдать другой номер соединения, и эти шаги будут выполняться точно так же.
-
И небольшой нюанс как раз по последнему оператору, по TRUNCATE. У меня в примере самый простой запрос без менеджера BT. Если вы используете менеджер временных таблиц, то временная таблица будет жить столько же, сколько живет менеджер. Что, в общем-то, логично – так сейчас сделано в большинстве типовых конфигураций. Когда где-то выполняется запрос, менеджер временных таблиц помещает туда, и этот менеджер потом гуляет еще по 20 модулям, и там эта таблица используется. Когда переменная менеджера перестает использоваться в коде, таблица очищается.
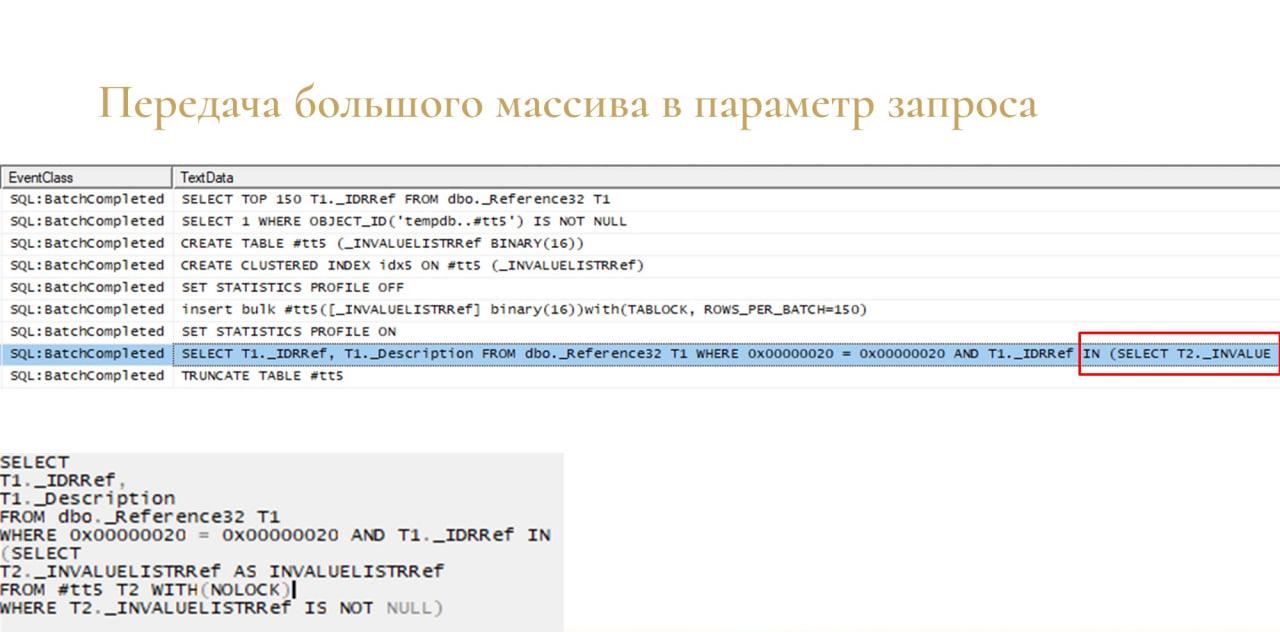
И еще один небольшой нюанс – когда вы передаете в параметр запроса большой массив, платформа использует tempdb неявно.
В этом примере я выбрал 150 элементов справочника, выгрузил их в массив и передал эту выборку в параметр запроса.
На слайде видно, что платформа сделала примерно то же самое:
-
Создала временную таблицу.
-
Создала по ней кластерный индекс.
-
Вставила элементы справочника в эту таблицу.
-
И в конце добавила в мой результирующий запрос условие с IN, где вложенным запросом обратилась к этой временной таблице.
Это нормально, этого пугаться не стоит. Просто имейте в виду, что у вас на один и тот же запрос 1С могут быть разные тексты запросов SQL и разные планы запросов. Это нормально.
Какие проблемы возникают, как их диагностировать и решать

С простыми примерами разобрались. Теперь про проблемы. Основных проблем – две:
-
Потеря свободного места, когда tempdb резко как-то непонятно разрастается на сотни гигабайт, и непонятно, что происходит.
-
И скорость работы, производительность.
Я сегодня буду больше говорить как раз про разрастание, но в конце чуть-чуть поговорю про другие проблемы.
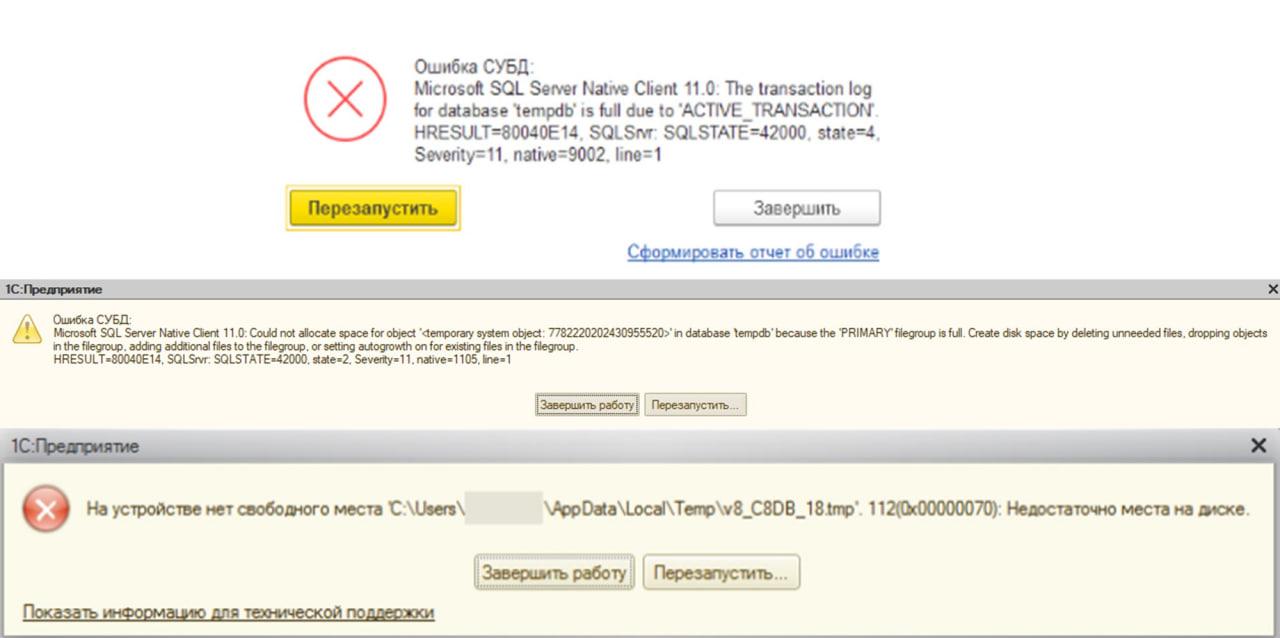
Вот так выглядят ошибки, которые связаны с тем, что tempdb упирается в лимит либо с тем, что у вас заканчивается место на диске.

Возникает вопрос – откуда берется рост? Мы же видели, что в конце каждого запроса выполняется оператор TRUNCATE, таблица очищается. За счет чего ей тогда вообще расти?
Ответ простой. Некоторые думают, что tempdb растет из-за количества запросов. Это не так. Растет она, как правило, из-за одного какого-то конкретного кривого запроса. Максимум двух-трех, которые выполняются одновременно. Но чаще один.

На ИТС на эту тему есть хорошая статья «Методика выявления длительной транзакции, которая привела к значительному расходу tempdb». Всем рекомендую ее почитать. Но я хочу ее немного дополнить.
В статье сказано, как решить проблему, когда у вас tempdb растет прямо сейчас – вы видите рост, и прямо на месте можете быстро поднастроить себе технологический журнал, разобраться и найти виновника.
Зачастую нужно разобраться уже постфактум. После того когда у вас уже все сломалось и вы это кое-как починили. Когда вам нужно найти причину, что случилось – выяснить, исправить, чтобы такого больше не было.
Что поможет разобраться
Что для этого должно быть настроено? Причем это должно быть настроено вообще всегда, не только для этого:
-
Мониторинг запросов на СУБД через Extended Events. По настройке такого мониторинга есть очень много инструкций в интернете. Суть в том, что вы просто сохраняете все запросы на СУБД с фильтром по длительности – я обычно ставлю 3 секунды, но это зависит от нагрузки. Можно поставить хоть секунду, хоть 5, хоть 10. Неважно.
-
И второе – это техжурнал с событием DBMSSQL, из которого вы можете найти контекст запроса, откуда он пришел из 1С на СУБД.
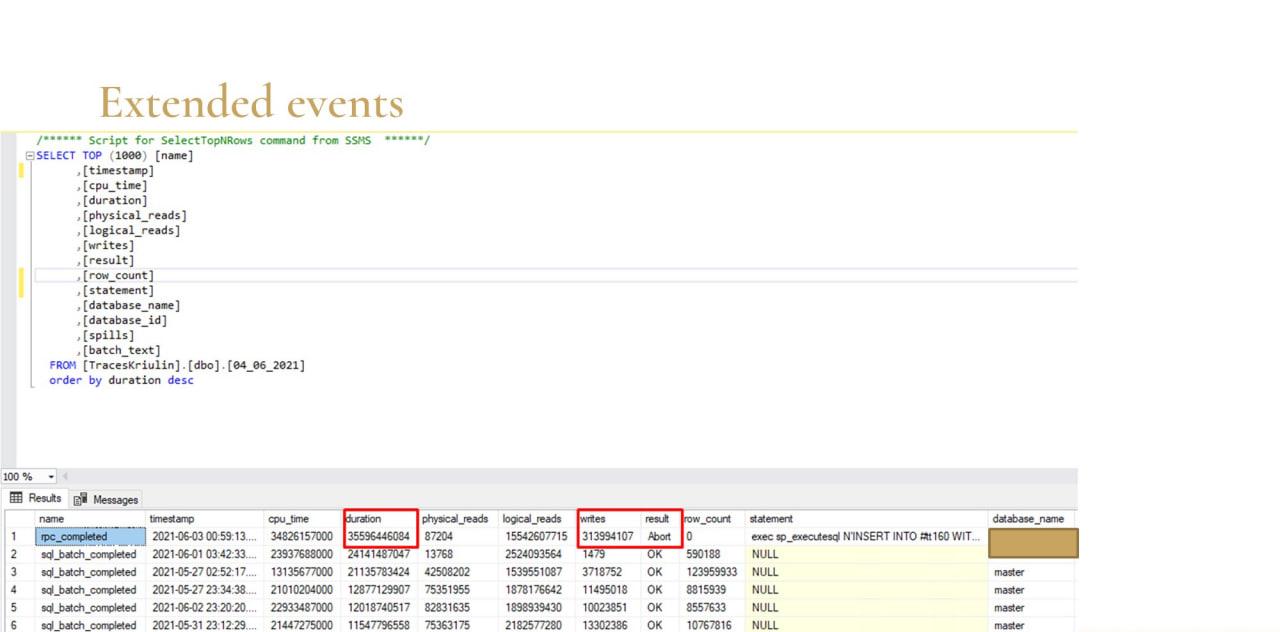
На слайде – один из примеров, когда tempdb вырос до 2,7 терабайт и все рухнуло. Кое-как починили – нужно было прийти разобраться.
Я на следующий день прихожу, сохраняю список Extended Events в табличку. Знаю день и примерное время, когда все сломалось. И сортирую по длительности все запросы.
Тут сразу видно кандидат – запрос, который выполнялся 35 тысяч секунд. Он не выполнился – видно результат Abort. И количество записей – обратите внимание, там 313 миллионов записей. Если грубо посчитать, 313 миллионов записей по 8 килобайт – это 2,5 терабайта, как раз примерно столько tempdb и весило.
Даже по первому оператору текста запроса видно, что это INSERT INTO #tt – очевидно, что это была просто вставка во временную таблицу.
Дальше через технологический журнал находим виновника, наказываем его, говорим, чтобы он так больше не делал.
В этом случае, кстати, был запрос в консоли запросов, когда администратор захотел отладить какой-то запросик, накидал его быстренько в консоли, выбрал две таблицы, поместил во временную таблицу, нажал «Выполнить».
Забыл указать связи. Ну так бывает. Кто так не делал? Срубил сеанс. Сеанс у него срубился, все хорошо, он открыл новый, а запрос не перестал выполняться – он пытался выполниться еще 35 тысяч секунд. Ну и, собственно, случилось вот это.
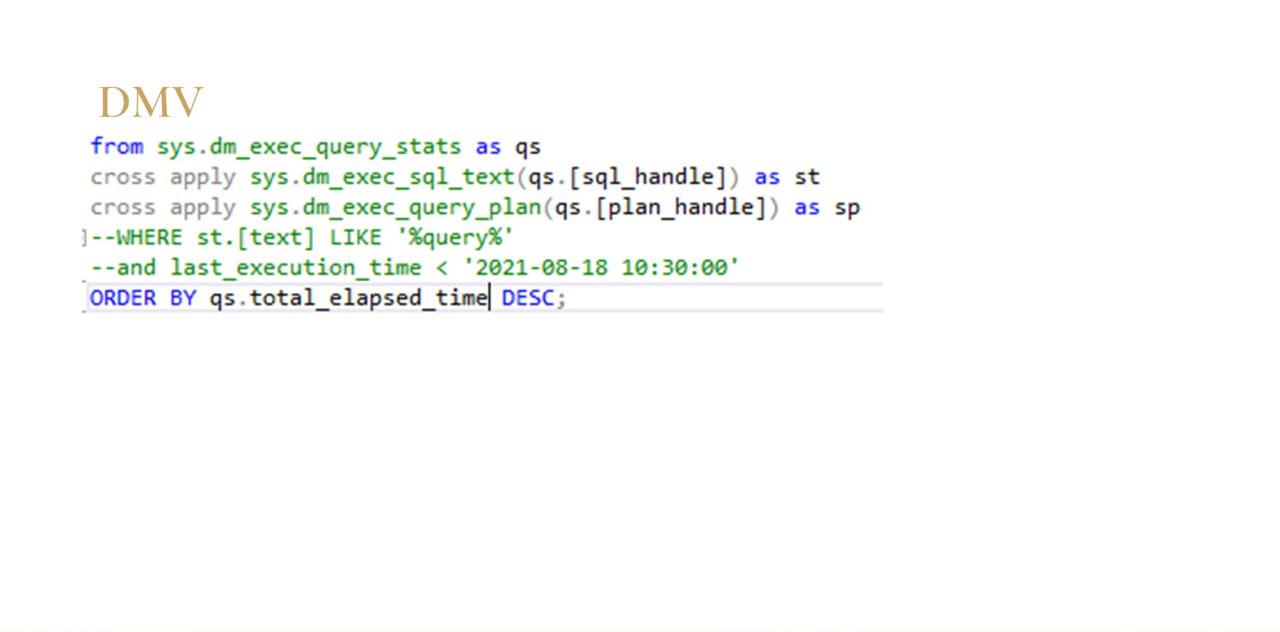
Дальше – немного про DMV. Даже если у вас по каким-то причинам не настроен мониторинг запросов, можно всю ту же самую информацию, которую я сейчас показывал: текст запроса, план, длительность, чтение записи и так далее, выдрать из системных динамических административных представлений SQL.
Но тут есть минусы.
-
Во-первых, если у вас есть что-то рухнуло и кто-то прибежал быстро очинить и перезагрузил сервер, этих кэшей после перезагрузки уже не будет.
-
И второе, у многих в планах обслуживания индексов, статистик есть оператор dbcc freeproccache. И вот в моей как раз этой же ситуации, если вот у меня вечером все упало, я утром пришел разбираться – ночью у меня выполнился регламент, все, у меня уже опять нет никаких данных для расследования.
Поэтому лучше на кэш не надеяться, лучше все-таки делать свой мониторинг.
Проблемы из-за служебных данных
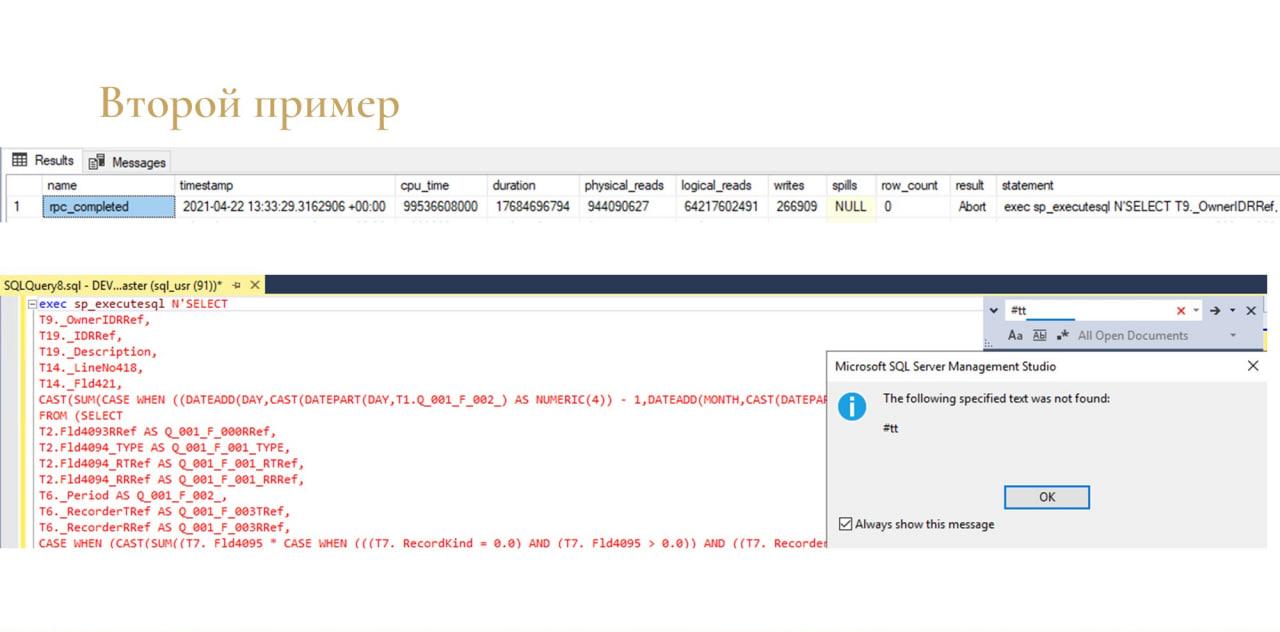
Еще один пример. Похожая ситуация – точно так же все упало, место на диске полностью забилось, tempdb 600 гигов весило.
Точно так же начинаю разбираться. Знаю день, примерное время. Сортирую, нахожу виновника – запрос длительностью 17 тысяч секунд, который точно так же не выполнился. Но здесь нюанс.
-
Во-первых, обратите внимание на количество записей. Если в предыдущем примере у меня было 300 с чем-то миллионов, то здесь 266 тысяч – это не такая уж страшная цифра, не так много.
-
И второе, если развернуть текст запроса – там вообще нет упоминания #tt. Там нет не то что записи вставки в tempdb, даже нет чтения.
Казалось бы, при чем здесь тогда tempdb? Почему оно выросло?
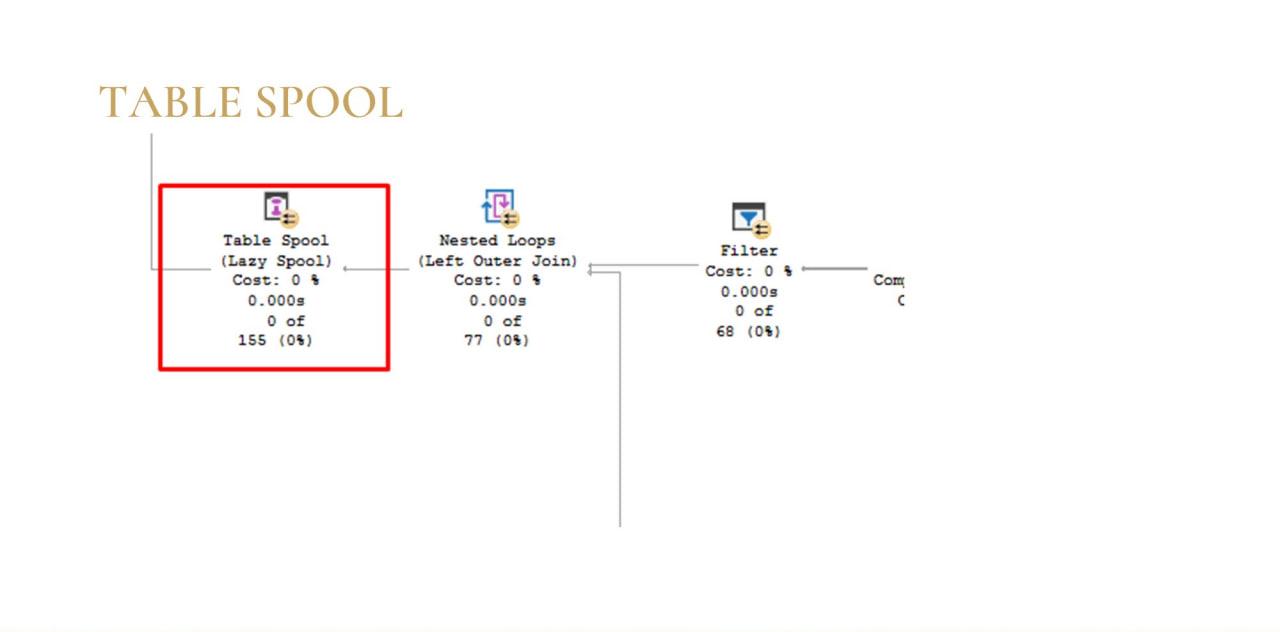
Помните, я вначале говорил, что tempdb хранит временные пользовательские объекты и некие служебные. Теперь чуть-чуть про служебные.
В моем случае, когда я выкопал план проблемного запроса, там был оператор Table Spool. Этот оператор сбрасывает некий набор данных соединения (не обязательно соединения) в tempdb.
Здесь главный смысл в том, что оптимизатор это делает осознанно. Он подумал, построил план и понял, что ему какой-то вот набор выгоднее сбросить в tempdb и потом с ним работать. Как правило, это не ошибка – оптимизатор вообще очень умный, с ним лучше не спорить. Скорее всего, он здесь прав, а вам нужно разбираться с запросом.
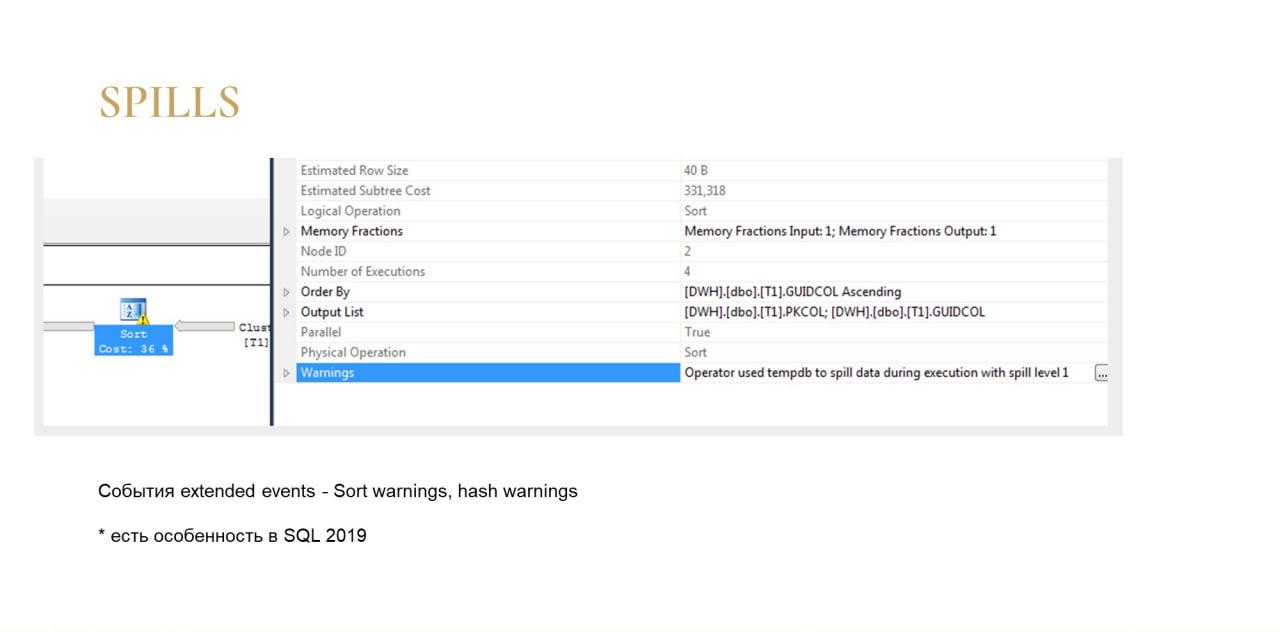
И еще один момент, когда tempdb тоже используется неявно – это когда в планах запроса вы видите вот такие восклицательные знаки. Это, как правило, оператор Sort или оператор Hash Match.
Если их прочитать, там выводится предупреждение о том, что оператор сбросил данные в tempdb.
Здесь, в отличие от Table Spool, он делает это неосознанно. Ему не хочется этого делать, ему приходится.
Оптимизатор перед выполнением запроса выдает СУБД какой-то объем памяти на весь запрос и на каждый оператор. И если оператор Sort, допустим, по статистикам ожидал увидеть у себя на вход 100 записей, а по факту оказалось, что ему пришло миллион записей (это происходит либо от протухшей статистики, либо от плохого, слишком сложного плана запроса). То оператору ничего не остается делать, как сбросить эти записи в tempdb, потому что запрос как-то надо выполнить, и ему приходится сбрасывать.
Т.е. помимо того, что у вас используется tempdb, такие запросы еще и работать будут медленнее, что тоже логично. Ведь если у вас весь запрос в оперативке выполняется, он будет выполняться быстрее, чем с использованием диска.
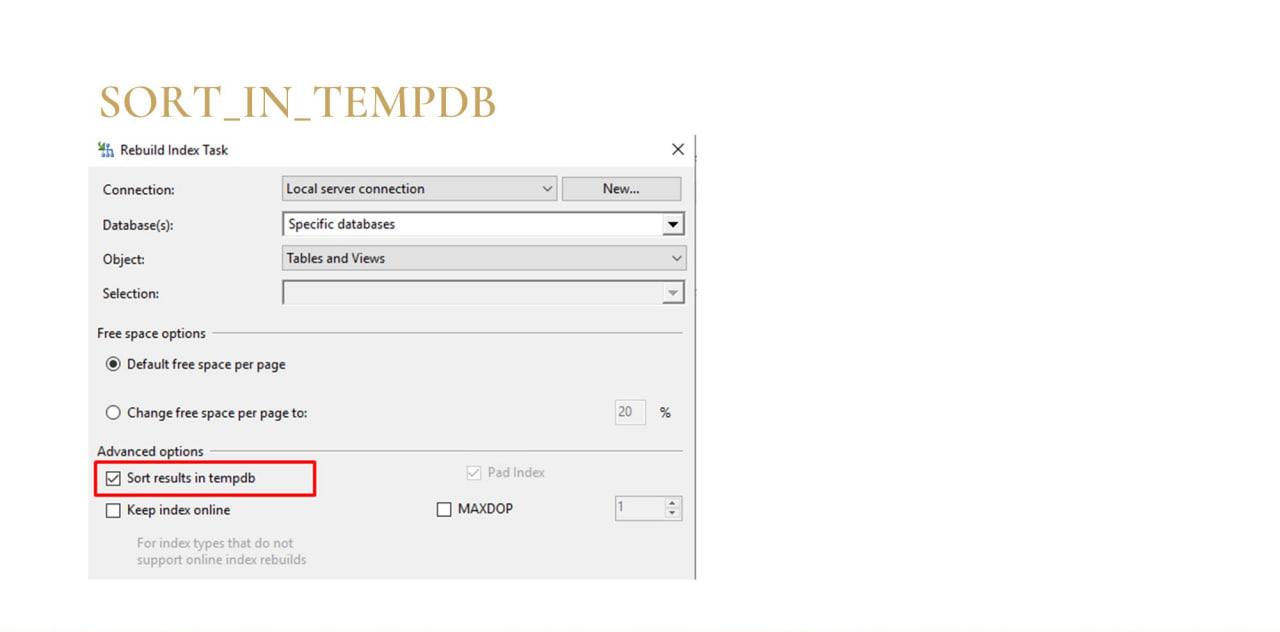
Сразу скажу, 99%, когда разрастается tempdb – это запросы. Но в настройках операции rebuild индексов есть один параметр, связанный с tempdb. Про него тоже на всякий случай расскажу, хотя с ним проблемы бывают очень редко.
Если вы настраиваете rebuild индексов через мастер, там есть галочка «Sort results in tempdb». Она настраивает rebuild индекса так, чтобы он сбрасывал промежуточные данные сортировки в tempdb.
Это сделано для ускорения операции rebuild, потому что если у вас сделано по-правильному – рабочая база на одном диске, а tempdb на другом, с помощью этой галочки операция немного ускоряется, а также параллелится, балансируется нагрузка на диски.
Но чтобы это стало причиной распухания tempdb, проблема должна быть комплексной:
-
Во-первых, у вас должны быть очень большие индексы.
-
Во-вторых, вы должны их еще и ребилдить постоянно.
Проверьте, в какое время выполняется rebuild, и если tempdb сваливается тогда же, имеет смысл туда тоже посмотреть.

Кстати, обратите внимание, что сортировка в tempdb – это просто параметр в секции WITH. Например, есть очень популярные крутые скрипты от Ola Hallengren для обслуживания индексов статистик, там тоже используется такой параметр.
Мониторинг

Напомню, в первой ситуации tempdb распухла из-за простой ошибки администратора, который забыл настроить между таблицами соединение.
Во второй ситуации выполнили один огромный отчет без отборов за все время существования базы (за 15 лет, грубо говоря). И оптимизатор СУБД самостоятельно решил, что эту операцию нужно выполнять через tempdb – непонятно, то ли этим отчетом ранее никто до этого не пользовался, то ли им всегда пользовались с отборами.
Такие ситуации очень актуальны со всякими старыми legacy-базами, в которых тонна непонятного кода.
Конечно, от ошибок на 100% защититься как-то совсем сложно. Поэтому эти разрастания нужно как-то мониторить.
Сразу скажу, решение очень простое, но я тут немного прошел в обход. Расскажу, что сделал. Может, кому-то будет полезно.

Я буквально на час накатал простой скрипт – то, что знал.
В нем я обращаюсь к системной вьюхе sys.database_files – она показывает размер файлов баз данных на диске. Я взял файлы tempdb, просуммировал их и сравнил с допустимо занимаемым местом – у меня это 200 Гб. И добавил это в план обслуживания, который у меня выполнялся раз в 15 минут.
Если tempdb больше 200 гигабайт, он начинает писать письма – идите, чините, разбирайтесь.
Достаточно тупой простой мониторинг, но он работал.
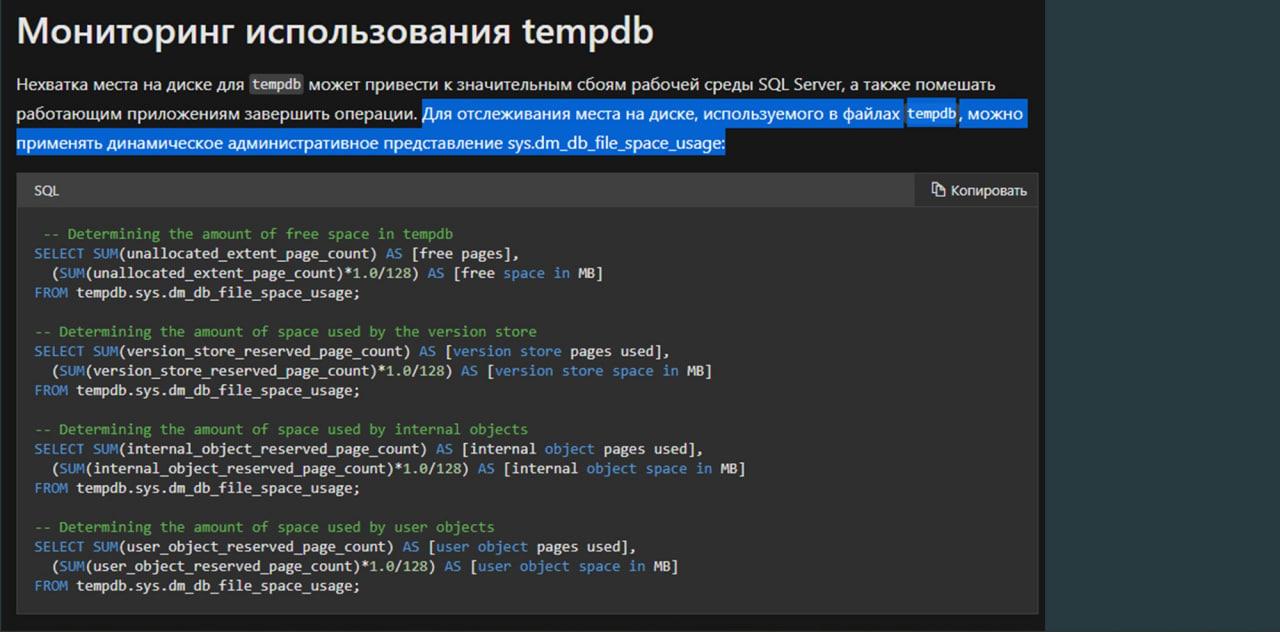
Конечно, хотелось сделать это как-то нормально, красиво, используя Zabbix.
Я пошел опять читать документацию. На MSDN есть глава «Мониторинг использования tempdb». Я здесь надеялся увидеть какой-нибудь счетчик, который можно просто взять и добавить. Но вместо этого MSDN предложил мне вот такой скрипт, опять же, с использованием системной вьюхи sys.dm_db_file_space_usage.
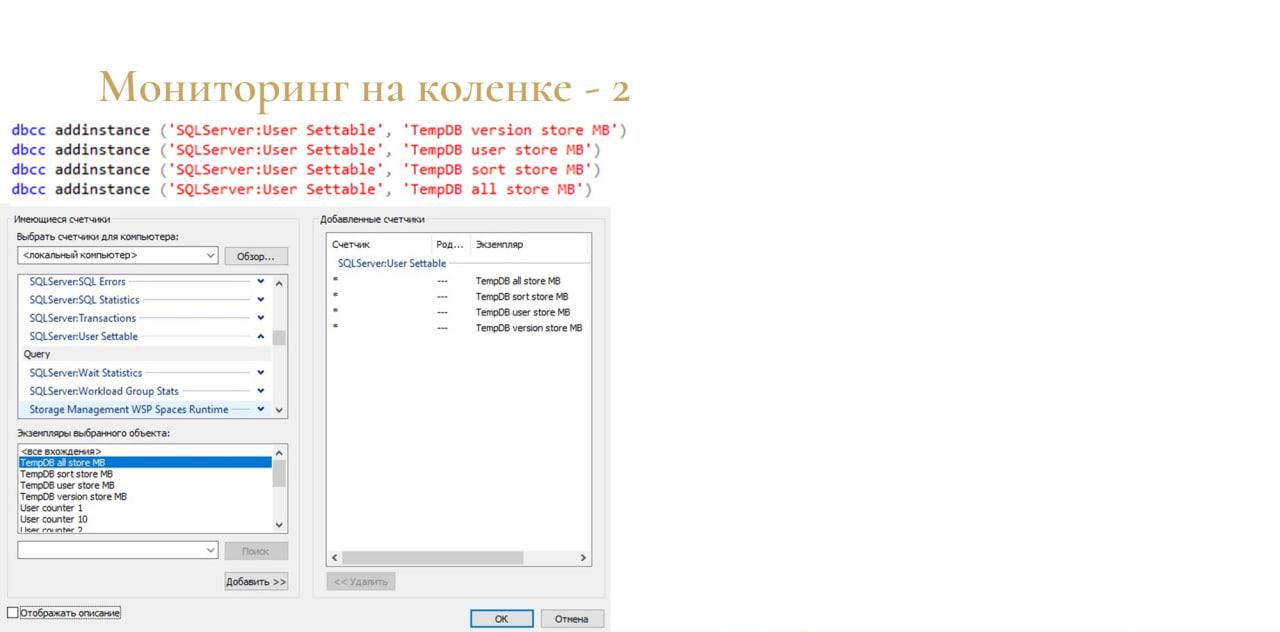
Дальше я нашел такую возможность, что можно подружить MS SQL и стандартный Performance Monitor Windows. Есть недокументированная функция dbcc addinstance, с помощью которой можно добавить счетчики – они добавляются в подгруппу «SQLServer:User Settable» группы «Query». Их можно добавлять сколько угодно.
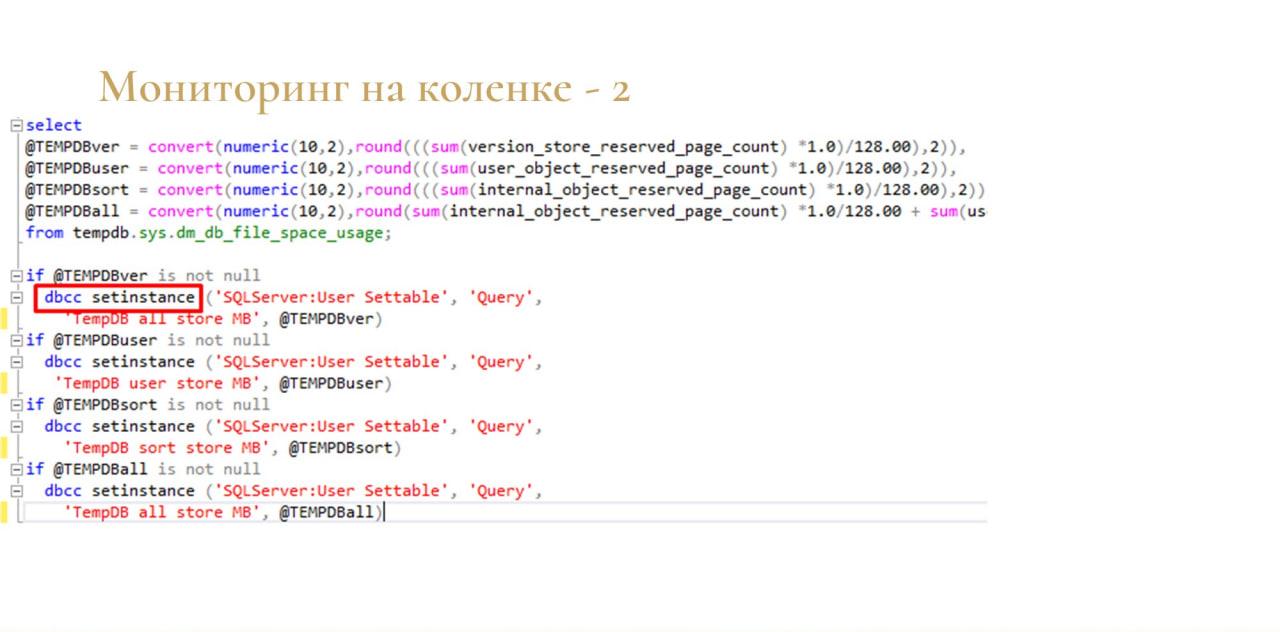
И потом я натравил скрипт из документации MSDN на свои счетчики через еще одну, тоже недокументированную функцию – dbcc setinstance.
И также добавил ее в план обслуживания, чтобы она там раз в минуту выполнялась.
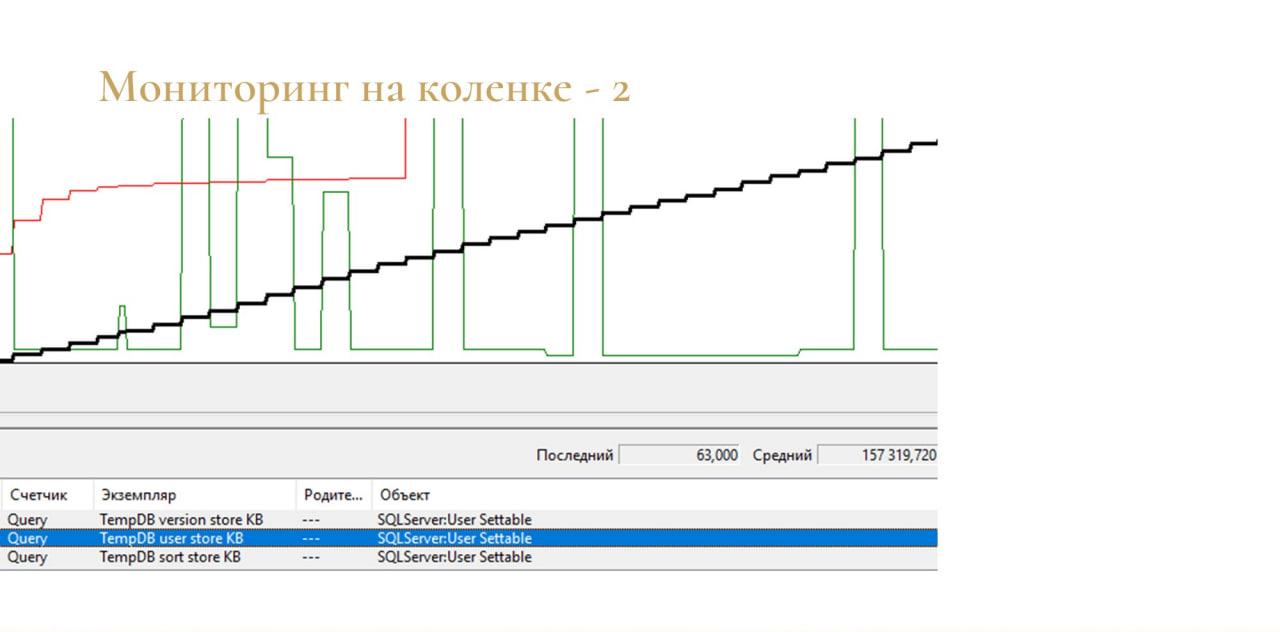
В принципе, это тоже работало. Причем, можно было смотреть занятое место даже по типам данных.
-
TempDB user store – это временные таблицы;
-
TempDB sort store – это данные сортировки;
-
TempDB version store – данные версии.
Мне показалась удобным, что можно прямо из SQL добавлять свои счетчики и как-то их заполнять. Не надо писать какие-то скрипты в PowerShell и прочее.
Но почему-то ни у меня, ни у нашего сисадмина не получилось эти счетчики добавить в Zabbix, чтобы все было в одном месте. Чтобы как-то нормально мониторить и добавить триггер.
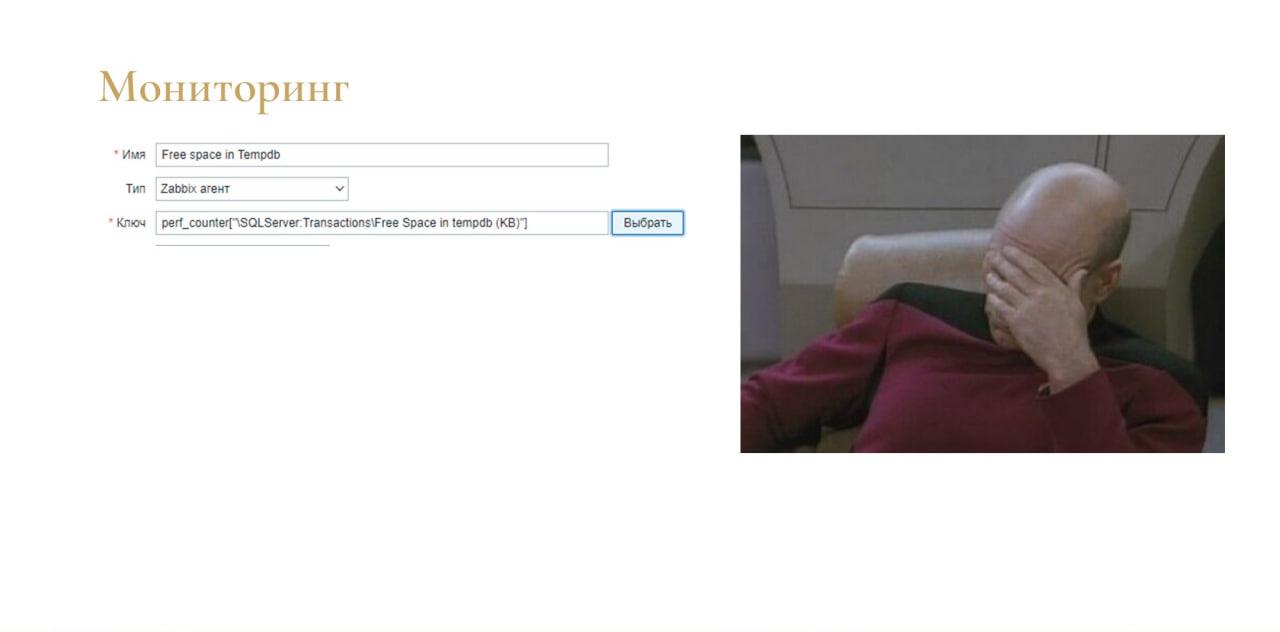
В итоге оказалось, что решение вообще простое.
Оказалось, что в Performance Monitor уже есть нужный мне счетчик, но он работает наоборот. Я искал счетчик, который показывает занимаемое место под tempdb, а существующий счетчик показывает свободное место для tempdb.
Можно добавлять такой триггер в Zabbix – клево, шикарно работает.
Другие проблемы
Чуть-чуть про другие проблемы, кроме разрастания.
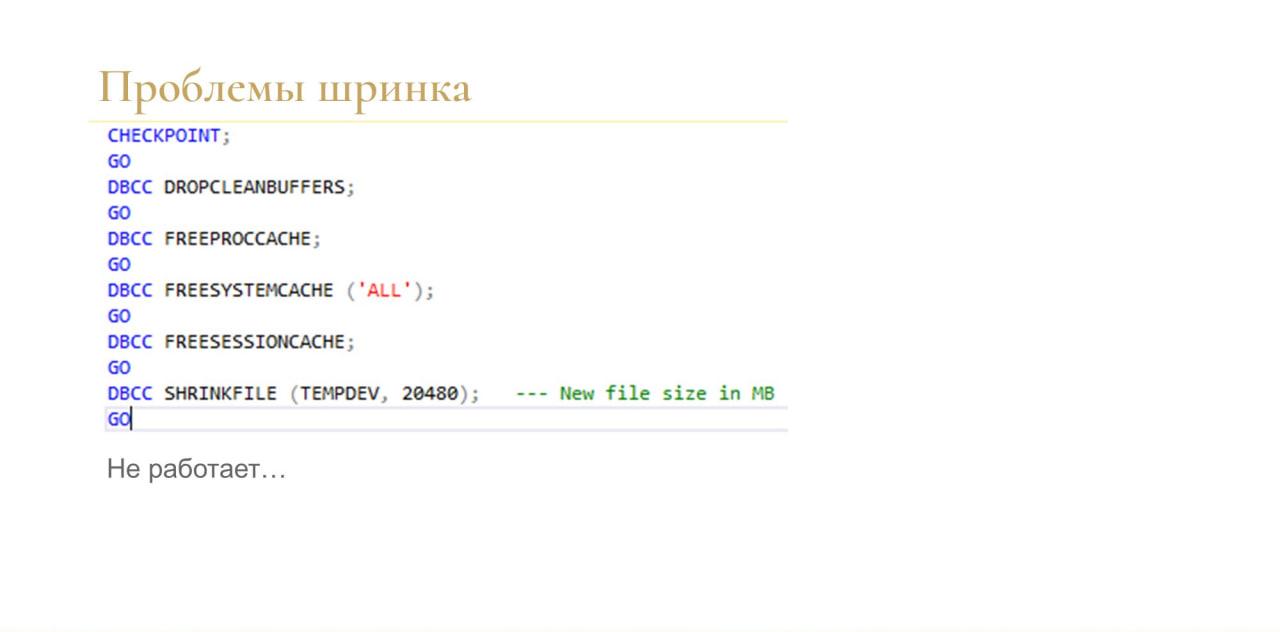
Например, я столкнулся с проблемой шринка – когда у вас tempdb опять разрослась, и вам нужно отжать у нее место обратно.
У меня не получилось. Я испробовал все инструкции в интернете, даже такую, где было написано, что вот точно-точно будет работать. У меня не работает.
Мне помогал только рестарт. Так что лучше не допускать такого вообще.
Производительность tempdb

Производительность. Тут будут немного тривиальные советы.
-
Выделяйте tempdb на отдельный быстрый SSD диск, в идеале – NVMe.
-
Мониторьте его время отклика.
-
Сразу выдайте достаточный начальный размер, чтобы она не приращивалась постоянно – это лучше для всех баз настроить.
-
Про несколько файлов и ожидания чуть-чуть попозже еще добавлю.

Еще один холиварный вопрос – постоянно все спорят, выносить tempdb в RAM или нет.
Мое мнение такое будет – если у вас есть тонна оперативки, никому не нужная, тогда, наверное, можно. Вообще странно, что у вас есть тонна ненужной оперативки.
Если нет, то, наверное, лучше сейчас уже купить диск, потому что современные диски NVMe уже по производительности очень близки к RAM.
Здесь скриншот с доклада прошлой конференции Инфостарта от моего коллеги Виталия Онянова. Мы с ним делали нагрузочный тест на ERP и пробовали его прогонять на разных параметрах. Один из параметров как раз был – вынести tempdb в RAM.
И здесь сравнивалась производительность обычного диска (там на самом деле был хороший NVMe-диск) и RAM.
Видно, что да, RAM везде быстрее. Но вот по APDEX грубая оценка будет здесь 10%.
Ускорение на 10% пользователи у вас не заметят никогда в жизни. Если документ проводится 10 секунд, а стал 9, ну, вряд ли они будут визжать от счастья и говорить, что вы прям молодец. Скорее всего, этого никто никогда не заметит.
Особенности MS SQL Server 2019

И последнее. Добавлю про различия в MS SQL Server 2019 – они сделали там пару интересных штук.
-
Первое – это адаптивное выделение памяти для запроса. Помните, когда я рассказывал про Spiils? В версии 2019 они сделали такую штуку:
-
когда запрос выполняется в первый раз, у вас плана еще нет в кэше. Допустим, он выделил 100 мегабайт на запрос, но ему не хватило – нужен был гигабайт. Соответственно, произошел spill в tempdb.
-
Дальше план кэшируется, и при следующем выполнении SQL ему сразу выдаст гигабайт, и таких спилов уже не будет.
-
И в обратную сторону так же работает. Если он выдал гигабайт, а надо было 100, он лишнее отожмет себе обратно. Больше не отдаст.
-
-
И второе – они добавили параметр MEMORY_OPTIMIZED TEMPDB_METADATA = ON (оптимизированные метаданные tempdb в памяти). По умолчанию он, кстати, выключен, и его нужно включать, причем с рестартом. Этот параметр включает хранение метаданных tempdb в памяти.
-
За счет этого быстрее проходят всякие операции – например, CREATE TABLE или TRUNCATE TABLE
-
И второе – уходят ожидания на LATCH-ах.
-
Проблема ожиданий связана с тем, что в каждой базе данных есть некие карты данных – по-простому, это оглавление базы, в котором написано, что такая-то страница занята такой таблицей, такая-то страница – тем-то индексом и так далее.
А так как 1C c temdb работает жестко, экстремально и постоянно создает-очищает в ней таблицы, на этих картах памяти бывает конкуренция, и вы в SQL увидите ожидания типа PAGELATCH_UP.
В MS SQL Server до версии 2019, чтобы избавиться от таких ожиданий, нужно было разбить tempdb на несколько файлов – чаще всего, на 8 (в случае, если у вас в настройках выставлено создавать для tempdb один файл). Начиная с 16-й версии, он по умолчанию ставит для tempdb сразу 8 файлов.
Но у кого-то, видимо, эта проблема даже при разбиении tempdb на 8 файлов не решается. Поэтому в 19-й версии разработчики MS SQL Server кардинально переработали этот механизм – ожиданий теперь нет, и в принципе работа с tempdb идет чуть быстрее.
Выводы

Выводы у меня достаточно простые.
-
Мониторьте запросы всегда и везде.
-
Ставьте под tempdb быстрые диски, да и не только под tempdb.
-
Не бойтесь ходить в обход – можно найти новые прикольные возможности.
P.S. (от Антона Дорошкевича)
Первое. Помните, Александр говорил, что прерывание сессии на сервере 1С не прерывает работу запроса – запрос продолжает работать. Что делать? Сказать админу, чтобы он соединение с СУБД кильнул? Но нужно же понимать, что килять. Если у вас длинный запрос, который надо кильнуть, вы сначала найдите в сеансе номер соединения с СУБД и скажите его админу. А то там будет второй длинный запрос расчета себестоимости, и он кильнет не то. Это важно.
А если вы пользуетесь PostgreSQL, то там в 14-й версии появилась специальная настройка, чтобы не звонить админу. Там появился таймаут сессии, который сам кильнет запрос, если клиента уже не существует – сервер PostgreSQL теперь проверяет наличие клиента, и если его уже нет, сессия кильнется сама.

Второе. Посмотрите еще раз текст этой ошибки. Эта ошибка к tempdb не относится. Она относится к временным файлам пользователя и связана с еще одним заблуждением – что большую базу нельзя выгрузить в DT-шник. Выгрузить можно, но при выгрузке возникнет вот такая ошибка – место кончится. DT-шник выгружается в Temp и только потом копируется туда, куда вы сказали ему выгрузиться. Эта ошибка в 99% случаев говорит о том, что кто-то попробовал выгрузить DT-шник, а место кончилось.
Оставшийся 1% случаев – это когда кто-то во временное хранилище положил что-то очень большое. Но это бывает очень редко – чаще будет ошибка в сеансовых данных. Сеансовые данные можно очень легко убить, написав в коде ПоместитьВоВременноеХранилище() и не написав УдалитьИзВременногоХранилища(). Если вы так сделаете и попробуете переместить, допустим, с сайта Яндекс.Маркета миллион картинок себе в базу, тогда сеансовые данные забьют вам весь диск.
А показанная ошибка чаще всего говорит о том, что кто-то выгружает DT-шник, либо производится какой-то обмен. Обратите на это внимание – это вообще не tempdb, не нужно путать.
Вопросы
Главный вопрос – как понять, из-за чего прямо сейчас растет tempdb? Не завтра понять, почему оно вчера росло, а почему прямо сейчас растет?
Как раз про это – есть статья на ИТС. Но я кратко расскажу.
-
Вы находите длинный запрос на СУБД, у вас есть там sessionID.
-
Потом идете в консоль сервера 1С – там сортируете по колонке «Соединение с СУБД» и находите ваш сеанс:
-
можете быстро настроить технологический журнал с отбором по этому сеансу и посмотреть, что он делает;
-
либо по журналу регистрации посмотреть, что за сеанс;
-
можете срубить сеанс;
-
либо позвонить пользователю и спросить, что он делает.
-
Главная идея в том, что tempdb может расти только от длительного запроса. Если вам прямо сейчас звонят админы в панике, что занятое место на диске стремительно растет, а они его уже не могут увеличивать, наверное, самый первый момент – это посмотреть, кто давно что-то делает.
Может ли влиять на рост tempdb динамическое обновление 1С, либо их количество?
Нет, не может. У вас при динамическом обновлении изменяется только таблица config. Она может влиять на многие другие вещи, но не на рост tempdb. Tempbd не для того, чтобы хранить в себе динамику.
Кстати, в MS SQL Server у таблицы tempdb еще есть лог, поэтому нужно различать – у нас вырос сам tempdb либо у нас вырос лог tempdb. Это две разные абсолютно ситуации.
Проблема может быть связана с ростом лога, а не с занятым местом самой tempdb.
А как это будет в PostgreSQL? Предположим такую простую ситуацию – мы создаем временную таблицу, заливаем туда 10 строк, заходим в транзакцию, удаляем 5, откатываем транзакцию, считываем. В MS SQL сервере она откатится и будет с таблицей 10 строк, потому что tempdb хранит undo log, по-моему, redo log не хранит, потому что после падения она все равно пересоздастся. А в PostgreSQL как это работает? Я видел, что это совсем по-другому.
Да, в PostgreSQL совсем все по-другому, тем не менее, все будет работать.
Но в PostgreSQL у временных таблиц WAL-ов нет от слова «совсем». Они их в shared memory хранят.
Но откат транзакции там все равно есть, и в PostgreSQL останется 5 строк.
Политика PostgreSQL такова – временная таблица, она на то и временная, что там ничего полезного нет. Поэтому сделать что-то с временной таблицей сложно. Если откатился, то дропни ее и заново что-то выполняй.
Зато тут есть другая сторона медали – WAL-ов не требуется, соответственно, переполнение журнала транзакций не произойдет.
А какой уровень лога транзакций нужно ставить у tempdb – полный или простой? По умолчанию там simple стоит. Стоит ли ставить full?
Нет, full не стоит ставить. Этот вопрос связан с общим заблуждением – многие админы считают, что если в tempdb не поставить full, то не будет полного бэкапа. Это вообще не так.
tempdb должен быть всегда в simple, ей не нужно ничего лишнего в лог транзакций писать. Но лог у нее разрастись, тем не менее, может – смотря, что за транзакцию туда засунуть. Если транзакция настолько огромная, что так много написала в лог, может и в логе кончится место.
Если ставишь read commission snapshot isolation, там версии тоже хранятся в tempdb. Они могут разрастаться? Вы с этим не выхватывали проблем?
Нет, не выхватывал. Когда я добавлял счетчики в Performance Monitor, я немного экспериментировал – там разница в данных на порядок получается. Версии весят мегабайты, а какая-нибудь одна временная таблица может весить терабайт. Так что не выхватывал.
Snapshot isolation у вас, скорее всего, повлияет на скорость работы дисковой системы, на которой расположен tempdb. Если раньше эта дисковая система справлялась, то теперь может перестать, поскольку слепки данных будут лежать там. Это почти ZFS, только в части каждой строчки. Как только вы включили snapshot, теперь писатели не мешают читателям, но нужно понимать, что теперь оборудование, на котором выполняется tempdb, должно быть быстрее, чем было. Либо до этого оно вообще ничего не делало, а теперь будет справляться.
Но на объемы – вряд ли повлияет. Он же все равно блокирует на запись частями, таблицами редко. Объем данных все равно не сравнимый с тем, когда туда записывается временная таблица с миллиардом записей. Навряд ли вы миллиард записей за раз апдейтите, такого почти не бывает.
Все ли данные, которые заняли писатели, при включении snapshot isolation сразу попадают в tempdb? Или они сначала в оперативке лежат?
До чекпоинта, до момента, пока транзакция не закоммичена, они лежат в памяти, а потом падают в tempdb.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции Infostart Event 2021 Moscow Premiere.
Вступайте в нашу телеграмм-группу Инфостарт