Я работаю с 1С уже около 15 лет. Участвовал в проектах для разных отраслей, на разных ролях. И всегда стараюсь изучать все новое.
Что касается EDT – с самого начала, как она появилась, у меня появился к ней интерес. Поэтому когда в нашей компании встал вопрос по разработке небольшого внутреннего продукта, мы решили перевести его разработку на EDT.
На примере этого небольшого продукта я покажу, как мы работаем в EDT, и что в нем планируем для себя реализовать. Потому что в перспективе мы планируем перевести на разработку в EDT наш большой основной продукт.

Я представляю компанию «Финтех Решения», мы находимся в Северодвинске. Вся наша команда фактически распределенная – в частности, я живу в Калининграде, а так у нас вплоть до Читы и даже дальше команда работает.
Сегодня расскажу о том, что мы сделали, чтобы научить Jenkins работать с EDT. В том числе покажу, как у нас выглядит итоговый пайплайн Jenkins.
Как мы работаем сейчас

Уже сейчас при работе с конфигуратором мы используем достаточно большое количество продуктов:
-
Jenkins
-
SonarQube
-
плагины SonarQube – у нас оба плагина (и от Серебряной пули, и от сообщества 1C-Syntax)
-
GitLab
-
Jira
-
журналы регистрации и технологические журналы мы перегоняем в Greylog и смотрим все это в Grafana
-
сбоку к этому еще прикручен мониторинг с помощью Zabbix, но это уже чисто админские фишки
-
и как средство коммуникации у нас используется Microsoft Teams, у него, кроме обычных задач, обсуждений и групп, есть возможность прикрутить интеграцию – в частности, Jenkins в нем хостит результаты заданий, которые он выполняет.

Основная разработка у нас сейчас ведется с использованием трех хранилищ – develop, prerelease и release.
-
Develop – это когда мы кидаем все задачки в кучу.
-
Потом, когда задача уже готова, сформирован под нее код, все проверено, разработчик переносит чистый код в хранилище prerelease.
-
И когда уже все задачи релиза реализованы, исходные данные уже попадают в хранилище release.
Грубо говоря, в develop валится все, в предрелизе – чистый код. А в хранилище release каждая версия – это новый релиз.

Как при этом не сойти с ума? У нас достаточно большая команда, порядка 40 разработчиков. Если все кидать в develop, то как потом найти код, который ты закидывал? Нам в этом помогают:
-
Gitsync – он перегоняет код хранилищ в ветки репозитория. У нас порядка 45-50 хранилищ, потому что мы обслуживаем много продуктов – и наш основной продукт, и обыкновенные УПП, БП и т.д. Плюс мы частично ведем разработку в расширениях – еще есть пачка расширений, для каждого из которых тоже три хранилища. Чтобы с этим жить, у нас есть Gitsync.
-
Jira работает с Gitsync в связке – благодаря тому, что мы в каждой версии хранилища указываем номер задачи, коммиты в репозитории привязаны к задачам.
-
И третий пункт – собственные средства автоматизации. У нас есть небольшая утилита на OneScript, которая собирает все измененные объекты по номеру задачи. Разработчик пишет номер задачи, пишет хранилище, из которого нужно собрать изменения, а эта утилита выводит список объектов, захватывает их целевым образом в хранилище предрелиза и открывает в хранилище разработчика окно сравнения и объединения текущего состояния и выбранной версии. Разработчику это здорово облегчает задачу, ему не нужно вспоминать, что же он в рамках задачи менял. Это особенно актуально для долгоиграющих задач. И при переносе из предрелиза в релиз аналогично – работает эта же самая утилита, только у нее в качестве параметра передается уже не номер задачи, а номер релиза в Jira. Но собирает она то же самое. Это здорово нам помогает.
Порог качества SonarQube (качество кода + покрытие), как критерий принятия кода

И рядышком у нас еще крутится SonarQube.
Поскольку у нас есть разбор хранилищ в Git, мы запускаем проверку SonarQube настолько часто, насколько можно. Проверка качества изменений в проекте у нас занимает полчаса – разработчик сразу в течение получаса получает список ошибок, которые есть у него в коде и поправляет их.
-
В хранилище разработки мы выставили период анализа в 21 день. Этого времени достаточно, чтобы, даже уйдя в отпуск, разработчик вернулся и закрыл замечания, которые у него вылезли. И здесь такой момент: в хранилище разработки мы разрешаем нарушать порог качества SonarQube – это допустимо. Конечно, нужно как можно быстрее поправить, но можно и не отрабатывать.
-
В хранилище предрелиза мы анализируем каждую версию. И там разрешен только зеленый порог качества. Когда он красный – мы не пропускаем. Есть исключения, когда много копипаста добавилось, либо когда обновили и замечания прилетели из внешней системы. Но это исключительная ситуация – не правило.
-
В релиз у нас идет только чистый новый код без замечаний вообще. Мы все замечания убираем.
По поводу правил – мы используем практически все правила, которые поставляются для 1С в SonarQube (и в коммерческом плагине, и в комьюнити-плагине). Какие-то совсем нерелевантные к нам правила мы исключаем. Таких правил немного – это единичные исключения. В основном, мы работаем на полном наборе правил.
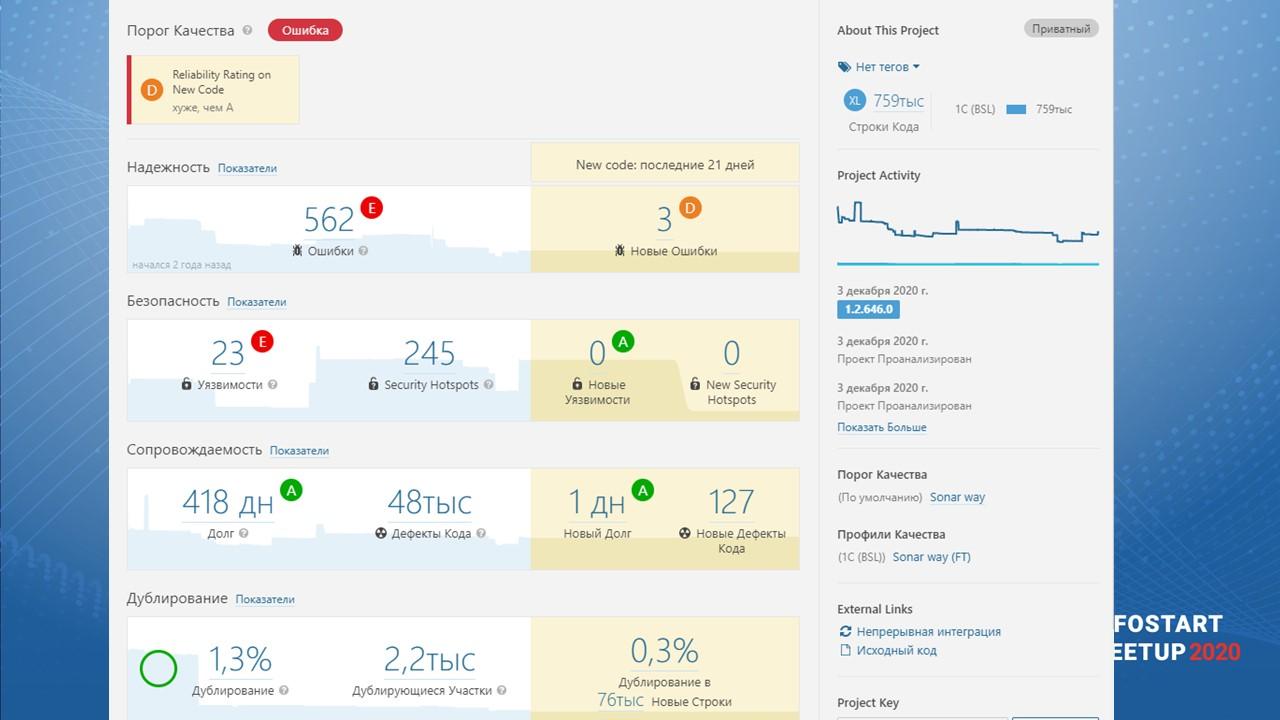
Вот так у нас выглядит текущее состояние проекта в SonarQube в ветке разработки. Три новых ошибки за 21 день. И 127 дефектов кода. Это при размере проекта почти 800 тысяч строк в коде.
Старый долг у нас набрался – разработка в хранилище у нас ведется порядка 4-х лет, а в SonarQube мы последние года три. Есть еще определенная история до SonarQube, поэтому такой большой долг.
Но новые дефекты мы стараемся не генерить. Все эти замечания за 21 день – они переходящие, там нет ничего серьезного.
Разработка по гитфлоу с изолированием задач

Таким образом мы практически перешли на гитфлоу в той мере, в которой это можно сделать с хранилищами.
-
В 1С есть отдельная технология работы с хранилищами через формирование отдельных хранилищ для каждой ветки, но мы пока живем с тремя хранилищами.
-
С помощью наших средств автоматизации мы имеем изоляцию задач, но она не технологическая.
-
У нас есть даже ревью в бизнес-процессе – я его чуть позже покажу.
Но полноценно сделать гитфлоу можно только в рамках EDT.
Гитфлоу – это не просто какая-то волшебная технология, нам от гитфлоу нужны конкретные пять требований.
-
Конечно же, это изоляция кода в рамках задачи.
-
Второй момент – это помещение кода в репозиторий один раз. Это очень важно, потому что сейчас разработчик должен поместить код в репозиторий два раза. Один раз – в черновик, второй – в чистовик. Как в школе домашние задания раньше делали, так они до сих пор и работают. Это, конечно, дает небольшой перерасход времени, но пока вот так.
-
У нас сейчас есть ревью кода, но оно не имеет технической реализации. Тимлиды смотрят изменения по истории коммитов и анализируют, что там, но мерж-реквеста как отдельной сущности у нас нет. Хотелось бы, конечно, это получить.
-
Отдельный вопрос, конечно – это длинные и короткие задачи, другими словами, багфиксы и фичи. В ветках гитфлоу они друг другу не мешают, а для разработки по хранилищам – да, есть проблема, потому что, если нужно поправить ошибку в модуле, который сейчас захвачен, это превращается во что-то не очень удобное, так как модули у нас есть очень большие. Мы пытаемся их разделять, но все равно есть огромные модули на десятки тысяч строк.
-
И следующий вопрос – перенос изменений между любым количеством веток. Сейчас у нас фактически используется три ветки – develop, prerelease, release. Но в будущем, возможно, появится больше веток, потому что у нас есть отдельные продукты, которые даже в рамках конфигурации имеют отличия друг от друга.
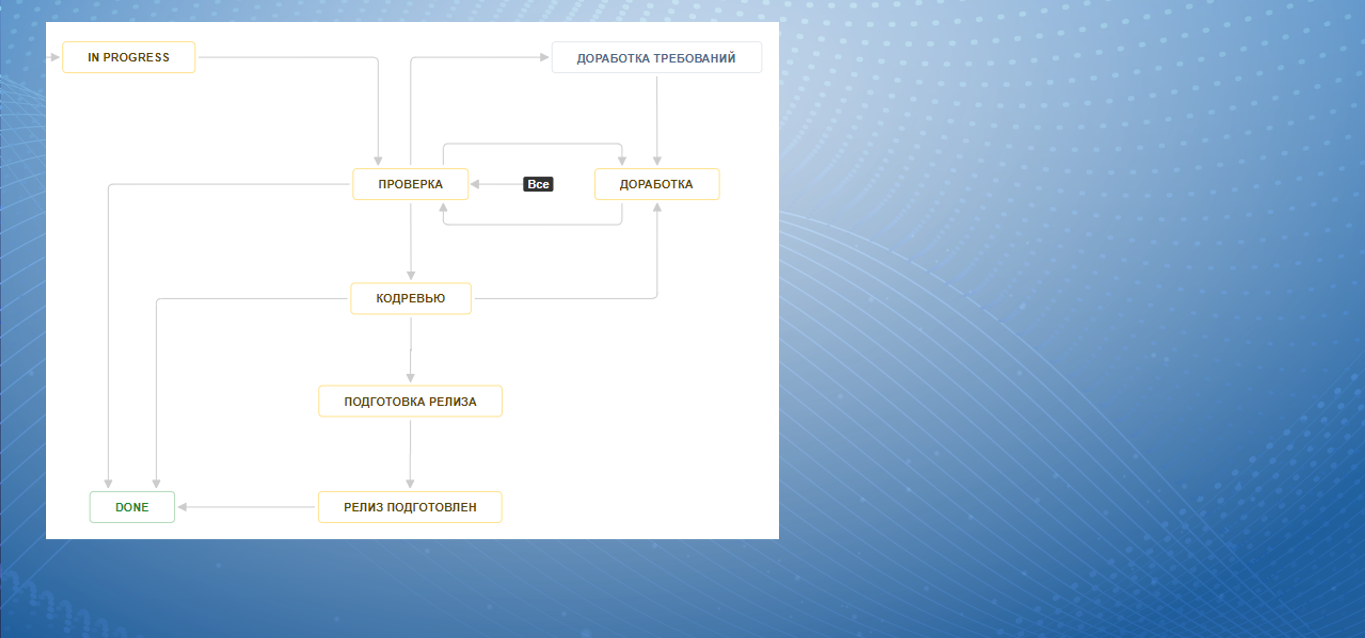
На слайде показан наш текущий процесс, как он выглядит в Jira. Мы видим, что здесь есть:
-
отдельно – кодревью;
-
отдельно – подготовка релиза (тот самый перенос в предрелиз);
-
когда задача готова, все перенесено, выставляется признак «Релиз подготовлен»;
-
а предыдущая проверка, доработка – это обычная работа разработчика.

Вот так у нас сейчас выглядят ветки в продукте, который разрабатывается в EDT.
Две основные ветки – master и develop – и четыре дополнительные ветки,
-
Две из них сейчас активны, в них задачки решаются.
-
Одна ветка уже замержена, но не удалена.
-
И на последней ветке в группе stale branches мы сейчас пытаемся сделать покрытие, затащить его в Jenkins и посчитать.
Анализ качества кода

При работе с EDT у нас есть:
-
работа с SonarQube;
-
кроме того, EDT само внутри себя имеет кучу проверок по качеству кода;
-
и есть механизм интеграции с SonarQube и GitLab, который позволяет вывести информацию о прохождении порога качества в EDT.
Сейчас я покажу, как это все у нас работает.

Вот так выглядит чистое прохождение мерж-реквеста при проверке SonarQube.
Наверняка вам уже знакомо такое окно, если вы раньше видели SonarQube.
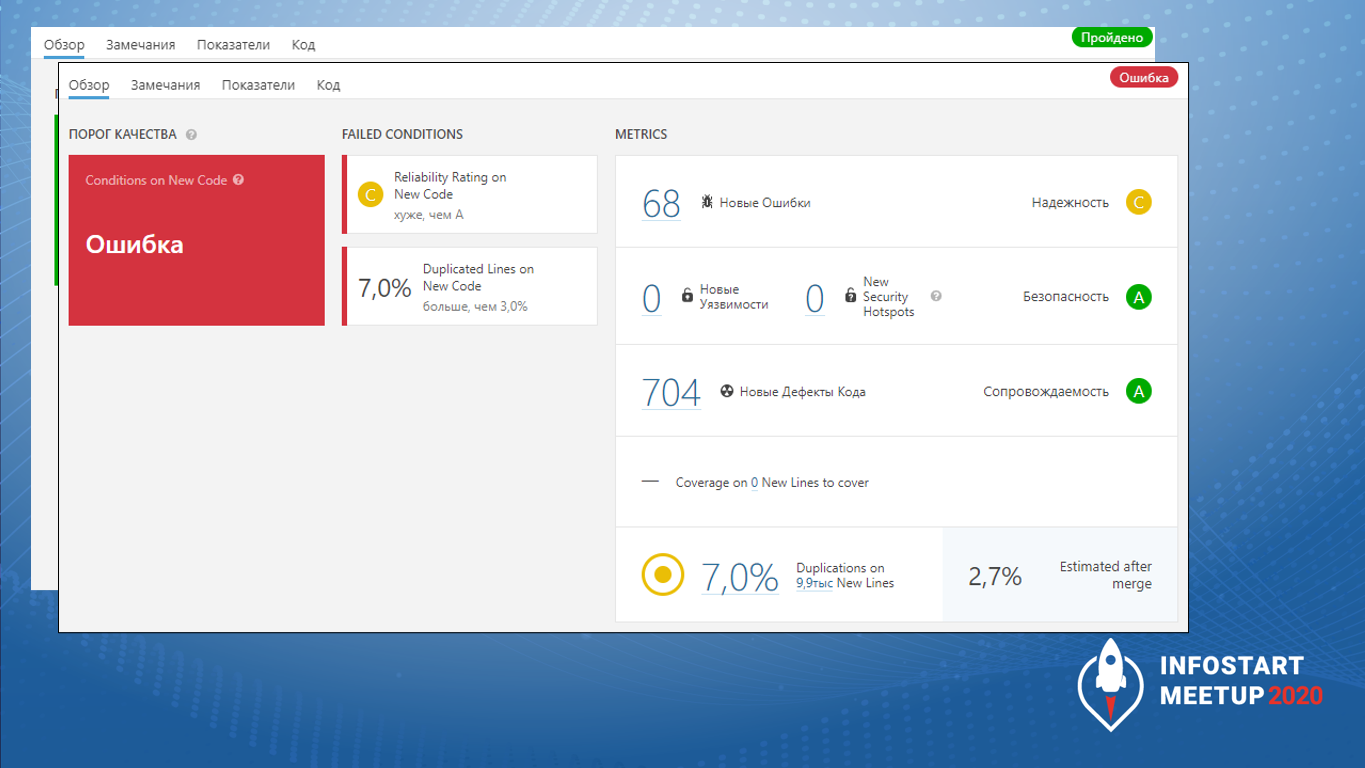
Вот так выглядит ошибка прохождения порога качества – я ее сгенерировал специально.
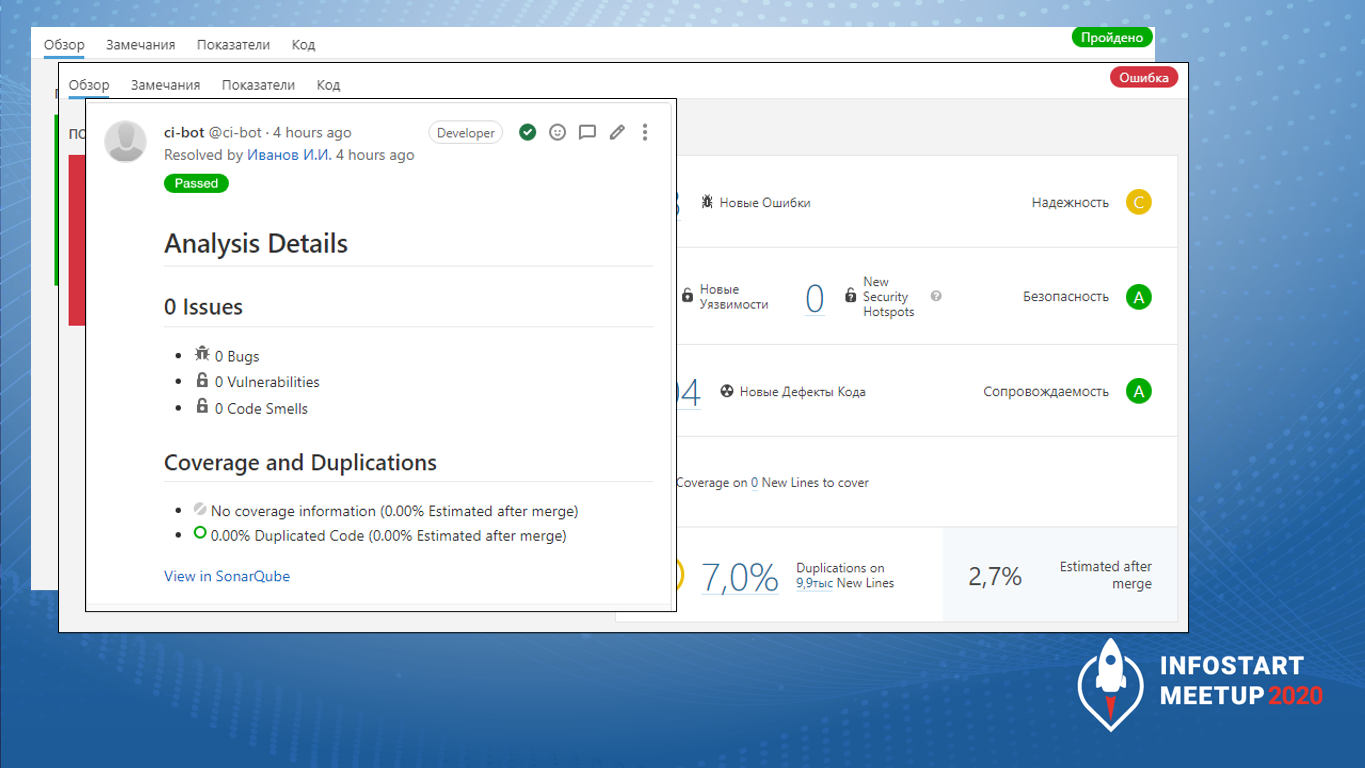
Вот в таком виде человек, который делает код-ревью для EDT проекта, видит замечание по прохождению порога качества.
Прямо в GitLab вывешивается текущий статус проекта, вывешивается количество замечаний. Если замечания есть, на каждое замечание будет открыто отдельное обсуждение в рамках мерж-реквеста в GitLab. И по каждому замечанию нужно будет принять решение: мы его пропускаем, исправляем либо вешаем как тех. долг. Бывает, что мы не исправляем задачки, а оставляем как тех. долг. Жизнь – боль, приходится иногда и пропускать задачки с тех долгом.
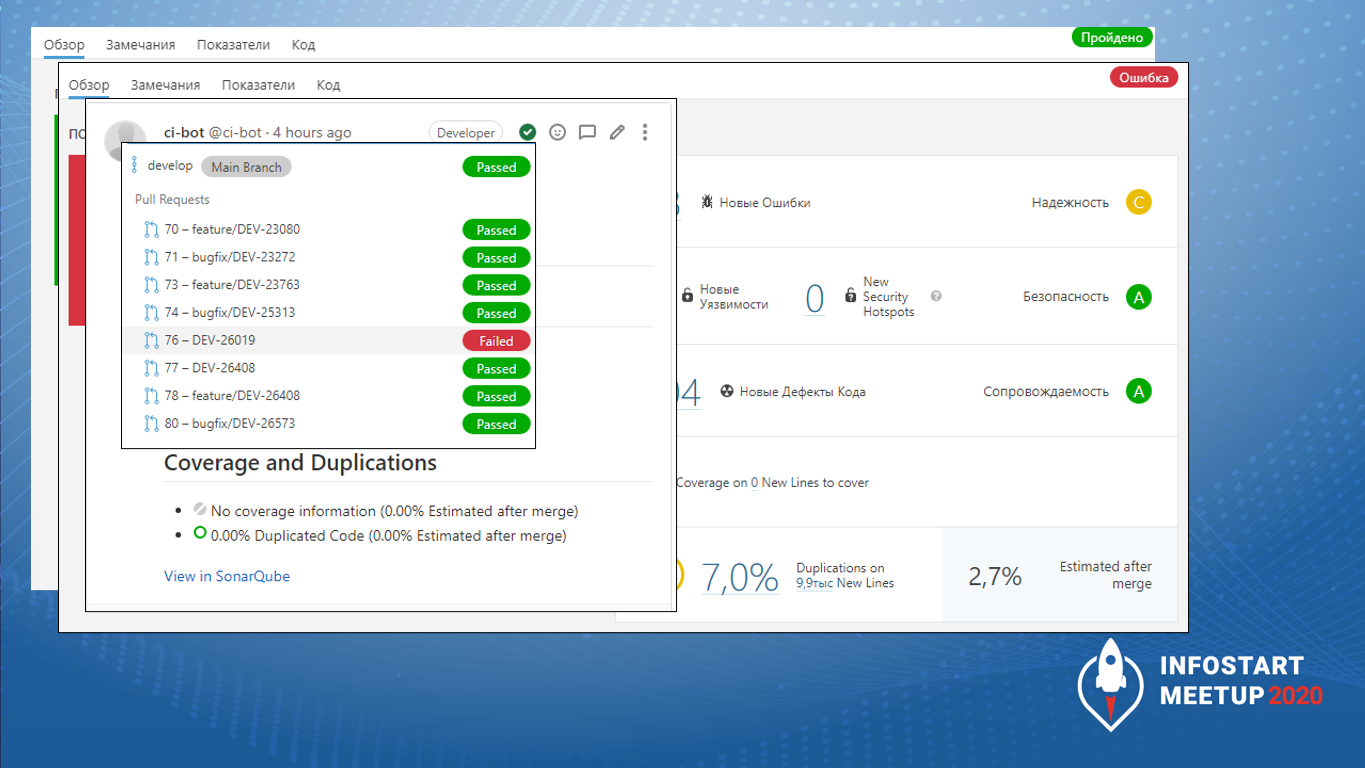
Вот так выглядит сейчас у нас история мерж-реквестов в SonarQube. Такая вот красота.

И как это выглядит в EDT? В EDT у нас есть несколько механизмов проверок.
-
Есть встроенные механизмы проверок, которые помечены на слайде красным подчеркиванием. Это сообщение: «Отделите знак пунктуации пробелом». EDT так реагирует на опечатку, он говорит: «Поставьте пробел».
-
Есть замечательная связка с SonarLint. Она пока в бете, но ей тоже можно пользоваться – прямо из SonarQube сюда затягиваются ошибки.
-
Есть еще плагин от Александра Капралова. Он в свое время написал замечательный плагин, который дотаскивал ошибки из BSL Language Server в EDT. Сейчас в подготовке следующая версия плагина, мы очень планируем на него перейти, как только он появится в более-менее стабильном виде.
Написание тестов

Отдельный вопрос – написание тестов.
При разработке в конфигураторе мы пишем тесты с помощью различных фреймворков – для ADD и BDD. Все это работает. Но делать это правильно и красиво не получается. Постоянно приходится делать это с какой-то болью.
Причем ни в конфигураторе, ни в EDT встроенной функциональности для запуска тестов нет. Но опять же, в EDT есть замечательный плагин написания модульных тестов от Александра Капралова. Он решает как минимум две задачи:
-
Первая – это написание тестов и их прогон.
-
Вторая – это замеры покрытия прямо в EDT. Они прямо там есть. Можно не просто написать тест, а сразу посмотреть, покрыли ли вы этим тестом тот или иной участок кода, или тест мимо прошел.
Мы для себя установили определенный порядок написания тестов в EDT:
-
Создаем расширение.
-
Делаем по одному общему модулю для каждой функциональной подсистемы. Пока что мы делаем по одному общему модулю, но планируем два, отдельно – клиентский, и отдельно – серверный. Пока из-за специфики решения мы используем только серверные модули, до клиентских еще не добрались. Для тестирования клиентских вызовов мы планируем запустить BDD-тестирование, думаем, что это, наверное, задача для сценарных BDD-тестов. А серверную часть мы пока тестируем вот так.
-
Огромный плюс написания тестов с помощью плагина Александра – это то, что тесты пишутся внутри EDT на родном всем нам языке 1С:Предприятие. То есть замечательные языки Gherkin и прочие учить не надо. Вы пишите так, как привыкли работать внутри 1С. Ничего не меняется. Есть просто технология написания тестов – т.е. к тесту есть требования, и вы их реализуете.
-
После того как тесты написаны, не нужно ждать, пока Jenkins отработает или еще что-то. Можно тут же самому их запустить и проверить.
-
И только когда вы увидели, что все работает, помещаете задачу в Git и отправляете на сервер. А потом вам от Jenkins еще раз приходит подтверждение, что все хорошо – вы написали тесты правильно, они не упали.

Внутри расширения это выглядит вот так.
У нас есть отдельные общие модули с тестами на каждую функциональную подсистему. Есть даже небольшой тест на подсистему «Дополнительные отчеты и обработки», потому что мы вносили в нее небольшое исправление.
Вот так этот отдельный общий модуль выглядит в целом – это прямо целиком модуль тестирования подсистемы «Дополнительные отчеты и обработки». Тут есть тест на добавление команды и другие.
Основной ключ, который нужно написать для теста – это указать для него аннотацию @unit-test. Здесь – вся магия для программиста.
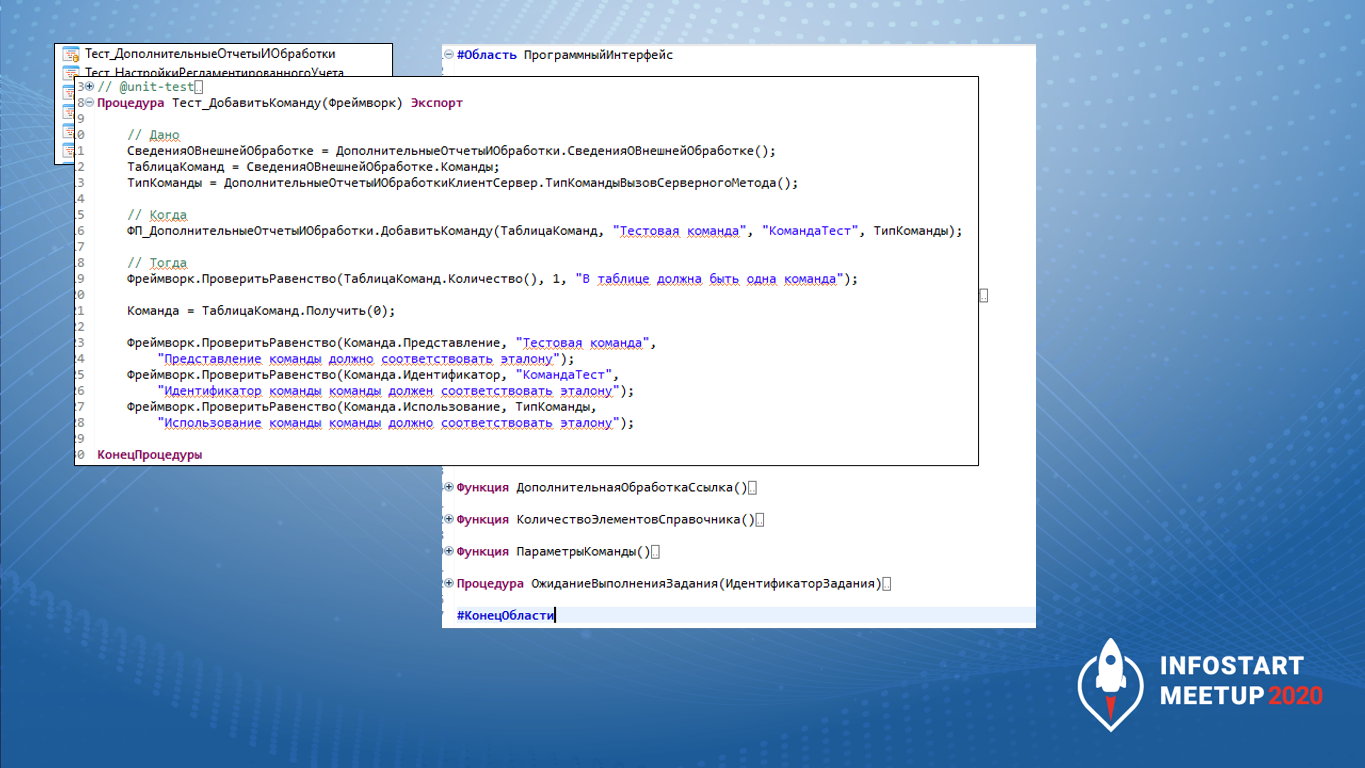
Вот такой код у нас внутри теста. Как видим, ничего сложного нет. Единственный нюанс – это условия: // Дано, // Когда и // Тогда
-
Секция // Когда – это именно проверка того, что есть.
-
Секция // Дано – это формирование контекста
-
И секция // Тогда – собственно вызов того, что мы хотим проверить.
Повторюсь, ничего здесь сложного нет. На мой взгляд, написание тестов таким образом – это минимум телодвижений вообще. Все, что нужно сделать – это поставить аннотацию юнит-тест. После этого все начинает работать.
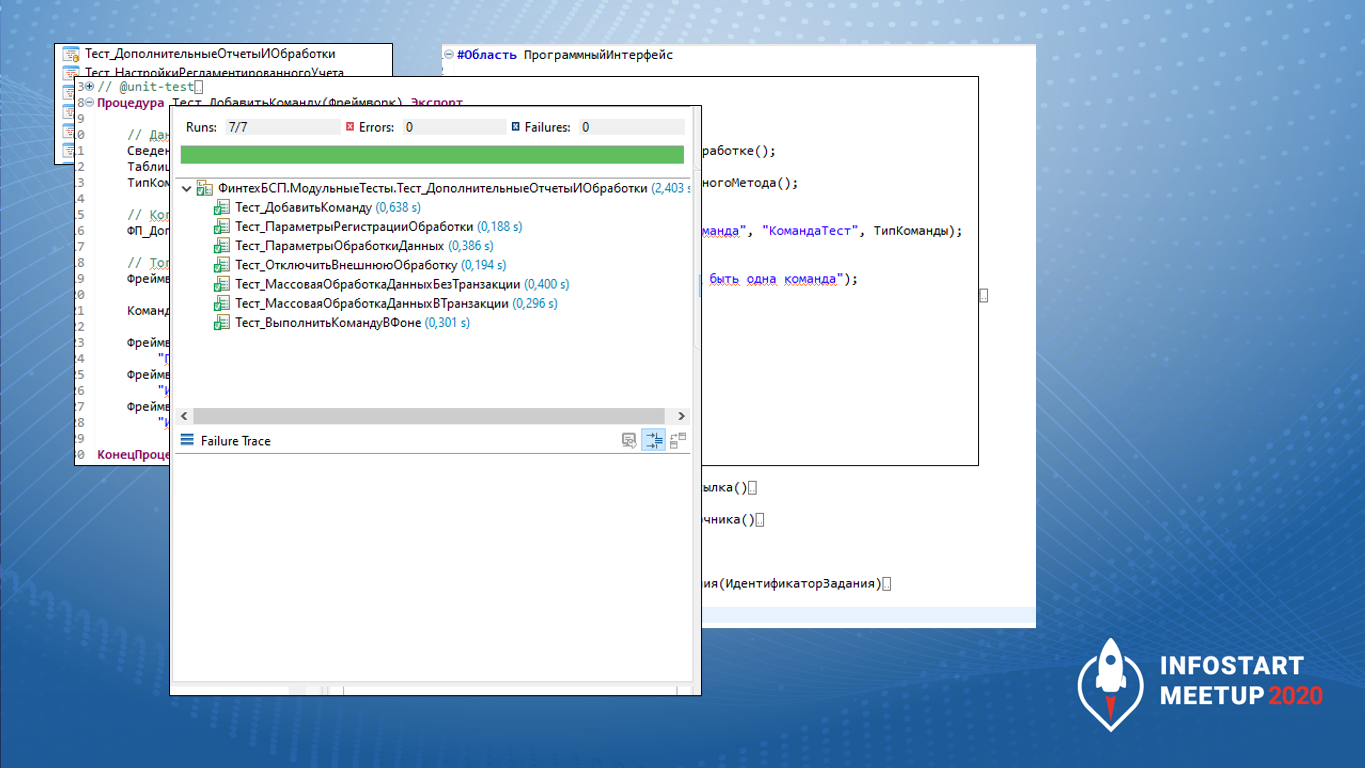
Вот, к примеру, отработали тесты этой подсистемы – они все зелененькие. И все это у нас заняло две с половиной секунды чистого времени.
В реальности, конечно, времени уйдет побольше – пока запустится 1С, пока загрузятся описания тестов. Но само тестирование заняло две секунды. Конечно, чем больше тестов, тем больше будет времени.
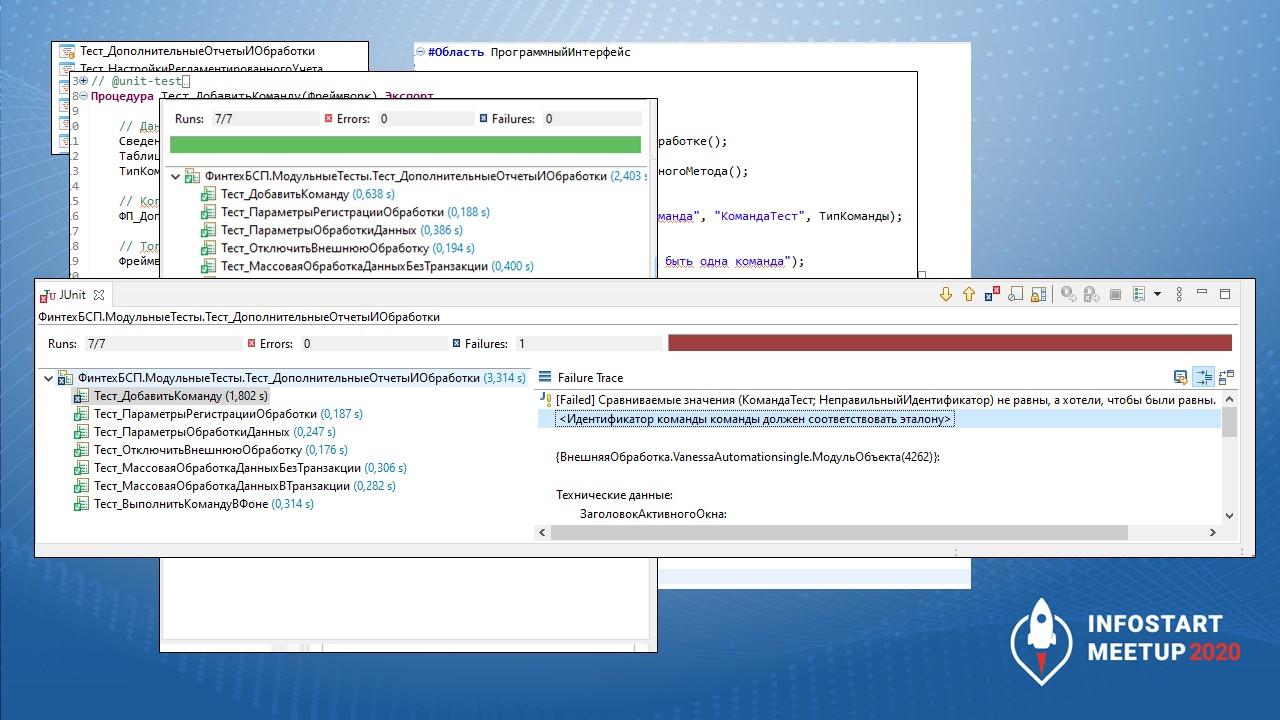
Ну, и для примера – что будет, если тест упадет. Мы это тут же в EDT увидим, нам никуда ходить не надо.
-
Мы увидим, что у нас случилось.
-
Увидим, где у нас это вызывается, в каком тесте это случилось.
-
Увидим, на каком условии у нас упало. Поэтому вот эта штука выделенная: «Идентификатор команды должен соответствовать эталону» – это описание желательно добавлять, когда вы пишете тесты. Потому что, когда у вас условий будет много, вы элементарно не найдете, на чем вы споткнулись. Поэтому у нас требование – к каждому условию писать аннотацию, хотя бы какую-то автосгенерированную. Но чтобы она была, чтобы вы четко видели, что происходит, почему они не равны.
Это огромный плюс в работе. Никуда ходить не надо. Не нужно ничего дополнительно запускать. Все прямо в среде разработки. Вот в конфигураторе это, наверное, нереально пока сделать. Мы сейчас пытаемся подобный подход сделать в конфигураторе для проекта основного, чтобы потом достаточно легко можно было перейти в свое время на EDT.
Вот таким образом у нас это работает.
Покрытие кода тестами

Следующий момент, который по-любому у вас возникнет, если вы начнете писать тесты: сколько тестов писать?
Без замера покрытия будет непонятно даже: написали ли вы тест, и абсолютно непонятно, закрыли ли вы ту функциональность, которую сейчас писали.
В EDT нет встроенных средств, чтобы показывать покрытие тестами, но они есть в Eclipse, на которой написано EDT. И опять же, плагин Александра Капралова, который позволяет писать юнит-тесты, он же и позволяет показывать покрытие тестами средствами Eclipse.
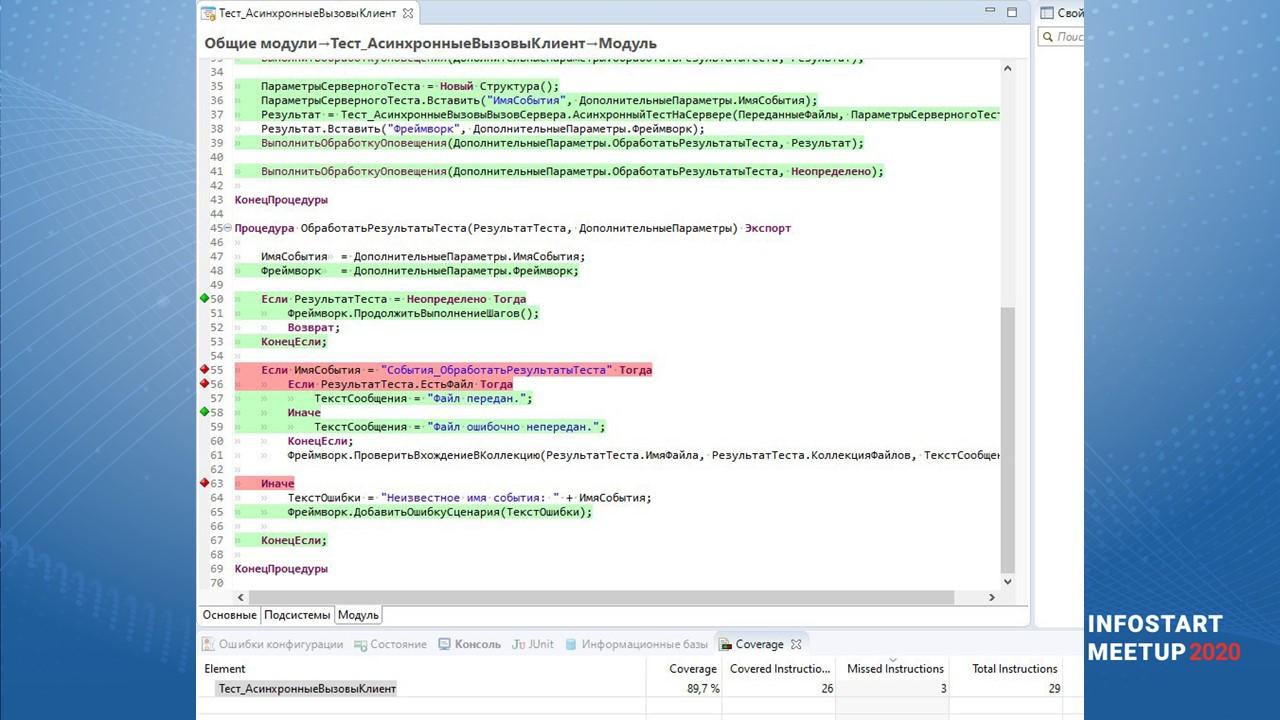
Буквально вот в один клик – запускаем тесты, получаем и результаты работы тестов (предыдущее окно), и вот такое окно. Я его взял у Александра из примеров, но у нас выглядит точно так же.
Зеленым видно покрытые, а красным – непокрытые условия.
Обратите внимание на вот эти зелененькие и красненькие квадратики, ромбики – это не просто покрытие, в данном случае анализируются еще и условия.
-
Первое условие «Если РезультатТеста» выполнилось полностью и покрыто, код зашел внутрь. Когда условие покрыто, оно горит зелененьким.
-
Условие «Если ИмяСобытия» не покрыто тестом – оно горит красненьким.
-
И следующее «Иначе» горит.
Вы видите полностью – что у вас выполнилось, что не выполнилось, какие условия.
Это очень удобно при просмотре. Вы сразу видите, зашел ли ваш тест туда, куда вы хотели, или нет. И как сделать так, чтобы он туда зашел.
Мы понимаем, что в идеале тест должен заходить в каждую ветку кода. Соответственно, у вас должно быть столько тестов, чтобы зайти в каждую ветку кода. Это к вопросу о том, сколько надо – чтобы все работало, нужно учесть все ветки.
И самое главное, внизу есть метрика coverage, которая показывает, сколько кода из данного модуля у нас покрыто.
Тот же SonarQube предлагает в качестве метрики 80%,
-
Мы понимаем, что 100% – недостижимый идеал и совсем хорошо.
-
90% – замечательно, прекрасно и огонь.
-
А 80% – это разумный компромисс, когда мы покрываем достаточное количество кода, чтобы не было неожиданностей. Потому что 80% кода – это, можно сказать, покрытие всех основных условий.

Следующий момент – сборка поставки. Она у нас реализована средствами Jenkins. Пайплайн сборки достаточно простой, он просто длинный, я его покажу следующим слайдом. В нем 4 блока.
-
Это собственно проверка кода средствами EDT и SonarQube. Сейчас, наверное, будем отказываться в пайплайне от встроенной проверки EDT – смысла нет, SonarQube достаточно плотно покрывает. Раньше в коммерческом плагине от «Серебряной пули» проверка формата EDT не поддерживалась. Сейчас начала поддерживаться. Поэтому мы, наверное, выпилим проверку средствами EDT, а будем полагаться на SonarQube и работу внутри.
-
Затем сборка конфигурации и расширения для тестов.
-
Непосредственный прогон тестов.
-
Если все получилось, и мы находимся в мастер-ветке, то формирование файла поставки, чтобы можно было пользоваться результатом разработки.
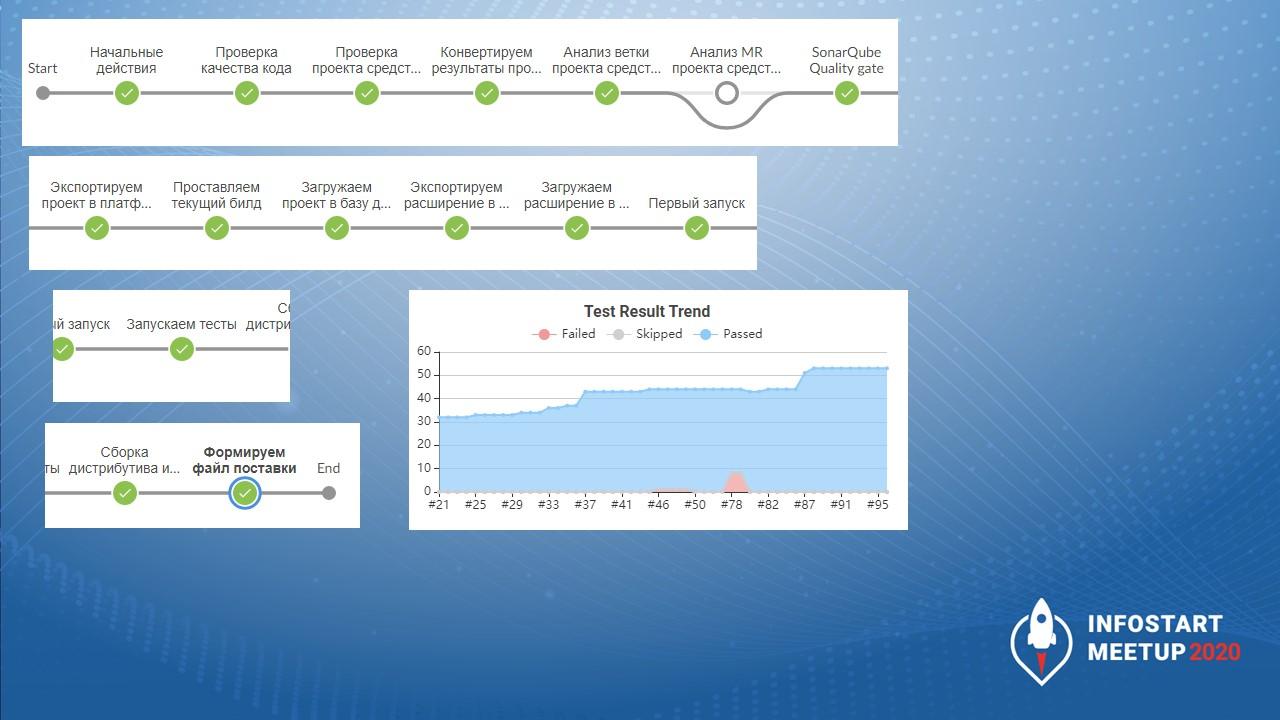
Вот так выглядит пайплайн. Он достаточно длинный, но основное, что у нас работает, это:
-
проверка кода (здесь есть отдельно проверка ветки и проверка мерж-реквеста, они через условия переключаются);
-
и ожидание подтверждения прохождения порога качества, после которого запускаются тесты.
Сейчас мы хотим немного поменять – у нас SonarQube будет последним шагом перед формированием файла поставки и сборки дистрибутива.
Для понимания количества: у нас сейчас на достаточно небольшой конфигурации имеется уже порядка 50 с лишним тестов. Я чуть позже покажу – они покрывают порядка четверти всего кода.
Добавление номера сборки в релизный cf

Отдельно у нас стоял вопрос сборки и номера релиза. Одним из требований, которые мы предъявляли к EDT и работе – это то, что каждый прогон задания Jenkins должен формировать уникальный CF-ник.
Если мы будем опираться только на данные внутри исходников, у нас не получится каждый раз повышать версию конфигурации. Придется каждый раз делать новый коммит, а это зависит от внимательности человека и прочее.
Мы решили это обойти. Поэтому внутри конфигурации в качестве номера сборки в последнем числе из четырех частей номера версии всегда стоит 0.
Этот номер сборки проставляется системой CI – в данном случае Jenkins – непосредственно при сборке. Мы меняем номер версии внутри файла configuration.mdo небольшой регуляркой. После этого запускается сборка, и всегда в итоге у нас имеется уникальный CF-ник с уникальной версией.

Вот так это выглядит.
-
На первом скриншоте видно, как выглядит номер версии внутри EDT (в конфигураторе то же самое).
-
Ниже – кусочек, написанный на groovy, который меняет номер сборки внутри пайплайна. Наверное, для большего понимания все-таки лучше этот кусочек переписать на OneScript, но пока он у нас работает так. Будет совсем хорошо, если эту часть вынесут в ring – реализуют команду ring edt set version. Если добавят либо сделают возможность добавления этого непосредственно внутри EDT каким-то образом, вообще будет огонь. Но это, наверное, из пожеланий.
-
Внизу в «Branch master» видим, что был собран артефакт для ветки master. Всегда идет такой номер сборки – сейчас у нас версия 1.0.10.24.
-
И справа на черном фоне видно, как проставляется текущий номер при коммите. Теги мы пока пишем вручную, тег непосредственно в GitLab не проставляется. Мы видим, что номер сборки начинается с версии 1.0.1.1, потом мы запустили 1.0.2.1, 1.0.3.2, 1.0.4.4, 1.0.5.5, потом 1.0.5.6. То есть у нас пока не было необходимости сбрасывать номер сборки, поэтому они возрастают последовательно. Фактически номер релиза – это номер сборки. А номер релиза отвечает за наличие новой функциональности. Т.е. если вы посмотрите релиз 1.0.8, то увидите, что у него было три исправительных сборки – формирование релиза и два баг-фикса, в которых мы что-то чинили.
Таким образом мы при прогоне каждый раз гарантируем, что у нас будет новый CF-ник, и на его номер можно ориентироваться как на какую-то уникальную вещь. Если версия стала больше, значит, она новее. Не будет зависеть от человека, как это работает.
Планы
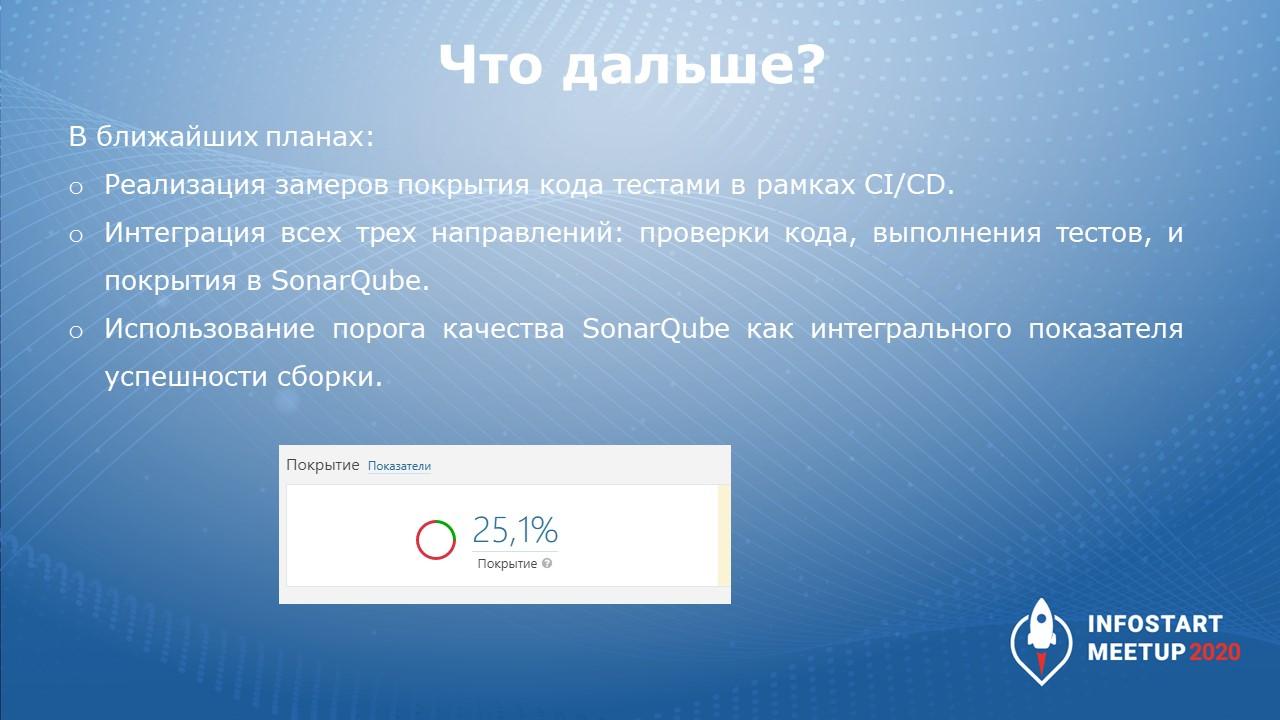
В ближайших планах:
-
реализовать покрытие кода тестами в рамках CI/CD;
-
вынести все три направления: проверка кода, прохождение тестов и результаты покрытия – в SonarQube;
-
и использовать порог качества SonarQube как интегральный показатель успешности сборки.
Сейчас тестовая ветка feature-coverage у нас покрыта кодом на 25%. Причем это покрытие всего проекта (не нового). Мы от всего проекта уже покрыли четверть, хотя только недавно начали его разрабатывать и писать к нему тесты.
Вопросы
Проверка коммита в конфигурации на 800 тысяч строк у вас занимает 25 минут. Это полная проверка или частичная?
Это полная проверка платформенной выгрузки CF-ника средствами SonarQube.
Грубо говоря, у нас SonarQube каждые полчаса доставляет разработчикам новые замечания, которые появились в новом коде.
Почему у нас такое к этому требование? Потому что разработчик, написав код, только через полчаса-час получит замечания. Это не очень хорошо. Мы, конечно, хотим, чтобы все работало еще быстрее. Надеюсь, что ребята с «Серебряной пули» и с комьюнити-плагина постараются и сделают анализ еще быстрее. Но пока – полчаса.
*************
Статья написана по итогам доклада (видео), прочитанного на митапе «1C:EDT Опыт использования».


Вступайте в нашу телеграмм-группу Инфостарт