Расскажу о следующей эволюционной ступени развития тестирования – о тестах в расширениях:
-
рассмотрим, как их писать;
-
чем они отличаются от уже известных нам тестов;
-
и как такое тестирование прикрутить в CI/CD-систему – в частности, в Jenkins.

Написание тестов – неотъемлемая часть процесса разработки. Но почему-то в среде 1С тесты внедряются тяжело – до сих пор очень много команд правят код сразу на проде и считают, что тестирование им не нужно.
От вендора у нас, к сожалению, за все годы существования платформы 1С появилась только одна функция автоматизированного тестирования – связка Менеджера и Клиента тестирования. Она достаточно удобная, немного, конечно, запоздавшая, но все равно очень нужная – мы на своих проектах ей активно пользуемся.
Но, поскольку нам нужно постоянно с этим работать, сообщество пошло по пути разработки своих инструментов, так что текущие реализации позволяют закрыть все необходимые виды тестирования.

Тем не менее в сообществе все время поднимается тема: как начать писать тесты? Это у людей не сразу получается, и возникает куча вопросов:
-
Организационные вопросы. Бизнесу сложно продать тесты. Если вы скажете, что теперь будете писать тесты, вам скажут: «Вы же как-то 10 лет работали без тестов? С чего вдруг они вам понадобились?»
-
Технологические вопросы. Тесты все-таки нужно куда-то встраивать. У вас есть определенный стек технологий, в него нужно впихнуть что-то новое.
-
Технические вопросы – непонятно, как должны выглядеть сами тесты. Есть несколько способов написания, есть несколько видов тестирования.
-
Ну и никуда не деть психологические проблемы, потому что не только бизнесу трудно продать тесты, точно так же трудно и разработчикам продать тесты. Они тоже могут сказать, что 10 лет все пишут без тестов и ничего, вроде живы.
Мы не будем смотреть весь спектр вопросов, посмотрим конкретно техническую сторону проблемы.
Почему расширения

Сейчас в 1С используется два варианта разработки тестов:
-
мы либо пишем тесты на языке 1С (xUnit в Vanessa ADD);
-
либо пишем сценарии тестирования на Gherkin (Vanessa ADD и Vanessa Automation).
Но Gherkin, как ни крути, это все-таки другой язык. Его опять-таки нужно продать – и бизнесу, и программистам. Это сложно.
А при разработке тестов на языке 1С проблема в том, что этот код нужно как-то использовать и подключать к текущему проекту.
Со времен 7.7 исторически сложилось, что единственным способом исполнить внешний код в 1C были внешние отчеты и обработки – дальше будем говорить конкретно про обработки.
Даже фреймворки тестирования, которые мы используем, по сути, тоже являются наборами внешних обработок. Они лазят по каталогам, находят внешние обработки тестов, как-то их узнают и работают с ними.

Из-за обилия тестов в виде внешних обработок возникает ситуация, которую можно охарактеризовать как epf hell. В разработке программ есть dll hell, а у нас в 1С – epf hell.
Проблема заключается в том, что, как только мы начинаем писать тесты, у нас возникает необходимость создать в проекте каталог, где будут храниться обработки. Но мы же не будем их складывать просто списком – мы начинаем для их задавать какую-то структуру.
Тут же вопрос. А какую структуру задавать?
-
Можно создавать отдельные тесты на каждую функциональность. Но у кого есть полный иерархический список функциональности для вашего текущего проекта? Я думаю, что таких единицы, если вообще есть.
-
Можно структурировать по подсистемам – у нас же в конфигурации есть подсистемы, мы уже давно их используем. Но, как только мы выбираем в конфигураторе «Показать объекты, не входящие ни в одну подсистему», оказывается, что там просто целая простыня всего есть. Этот подход тоже не работает. Все равно придется что-то свое изобретать на ровном месте.

Однако в платформе 8.3.6 у нас появился еще один новый способ помещения внешнего кода в проект – это расширение.
Причем, что интересно, расширение с самого своего старта обладает очень интересной функциональностью.
-
В расширениях можно заимствовать уже существующие в конфигурации модули. Когда вы заимствовали модуль, вы получаете доступ не только к экспортным процедурам этого модуля, но и к внутренним, не экспортным процедурам этого модуля.
-
А еще в расширениях есть очень полезная функция именно для тестирования – вы можете взять и переопределить любой модуль, любую функцию. Например, вы можете взять функцию вызова обращения к HTTP сервису, и для режима тестирования ее заглушить. Вместо этого либо перенаправить на mock-сервер, либо самостоятельно реализовать как-то обработку вызова HTTP-запроса.
-
Переопределять можно не только HTTP-запросы – в расширениях можно переопределить все что угодно.

Усложнять легко, упрощать сложно.
Любой продукт или фреймворк развивается по аналогии с «кольцами Маха»:
-
сначала идет расширение функциональности;
-
потом рано или поздно мы понимаем, что нам нужно снизить количество функциональности в системе и старую функциональность откинуть, оставить только актуальную;
-
потом опять набивается новая функциональность и так далее.
Наверное, с выходом расширений у нас в 1С появится возможность очередного сброса устаревшей функциональности и развитие новой.

Здесь на слайде у нас замечательный Микеланджело Буонаротти:
– Как вы делаете свои скульптуры?
– Я беру камень и отсекаю все лишнее.
Попробуем отсечь лишнее в виде этих внешних обработок тестирования, и на примере простенького проекта посмотрим, как писать тесты.
Как писать тесты, а не их вызовы. Практика
Я думаю, всем знакома фраза Линуса Торвальдса: «Разговоры – это разговоры. Но мы с вами разработчики, давайте посмотрим код».
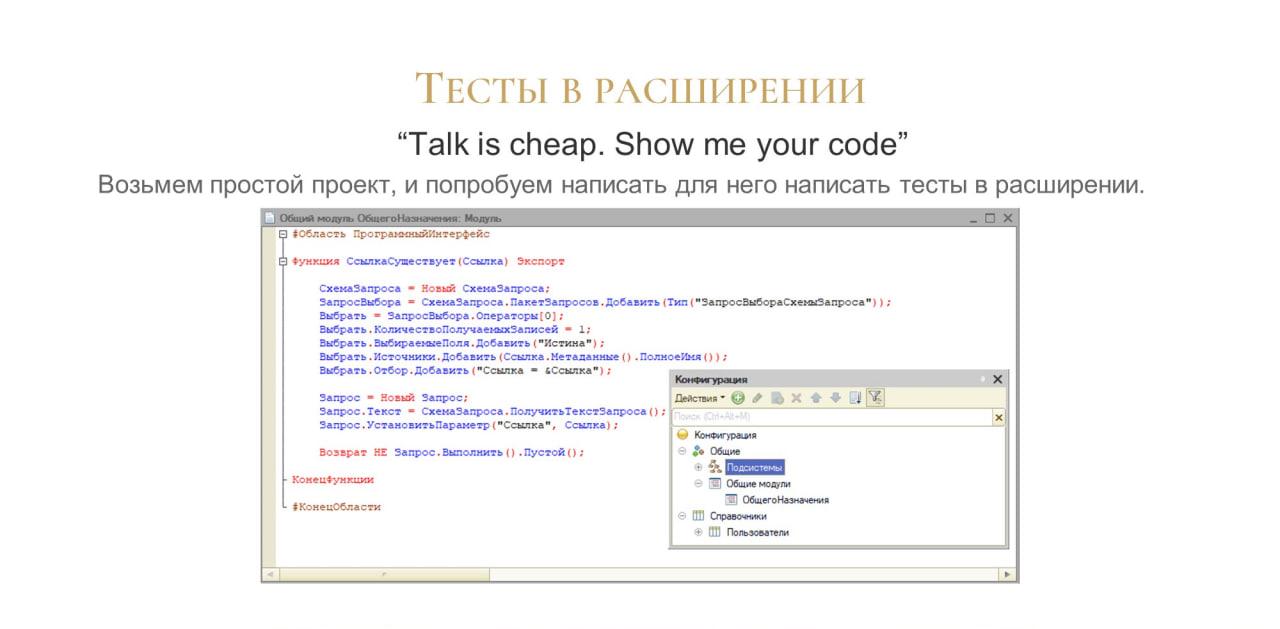
Возьмем самый простой проект – буквально из одной функции и одного справочника. И попробуем написать для него тесты в расширениях. Посмотрим, какую функциональность мы можем использовать уже на старте – что мы уже будем иметь.
Обратите внимание: поскольку у нас есть функция общего модуля СсылкаСуществует(Ссылка), первым тестом мы проверим, что элемент с взятым наугад идентификатором сейчас в справочнике не существует.
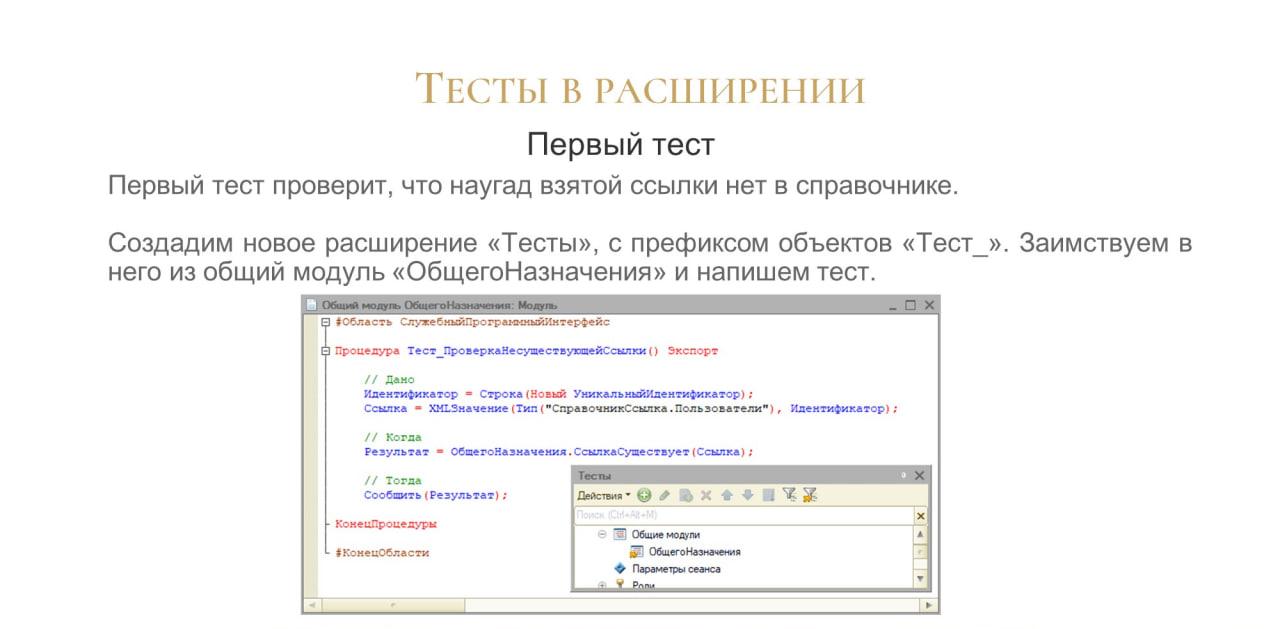
Создадим расширение с префиксом «Тест», и заимствуем в него наш модуль.
Напишем в нем простенький тест, который просто сообщает результат – существует ссылка или нет. Это такой тест, который при запуске просто выдаст – да или нет.

Теперь, когда у нас уже есть тело теста, мы попробуем адаптировать его к фреймворку Vanessa ADD.
-
Для этого нам понадобится создать в модуле одну служебную процедуру ЗаполнитьНаборТестов – точно так же, как во внешних обработках, когда мы пишем тесты.
-
И чуть-чуть доработать наш метод – добавить буквально две строчки.
-
Мы передаем в качестве параметра теста переменную Ванесса – контекст Vanessa ADD,
-
и плагином БазовыеУтверждения проверяем результат:
Ванесса.Плагин("БазовыеУтверждения").Проверить(Результат)
-
Фактически, нам нужно поменять в тесте две строчки и добавить в модуль одну функцию – это все доработки.
Это – минимальный набор того, что вам нужно. Меньше, наверное, уже представить нельзя. Технически, наверное, можно было бы убрать эту обвязку, если использовать рефлексию и аннотации к методам. Но, поскольку технически у нас этого нет, вырезать тут уже нечего.
Теперь и в Vanessa ADD

Чтобы прогнать этот тест, у нас в xddTestRunner версии 6.7.0 появился новый пункт в меню – «Загрузить тесты из расширения конфигурации».
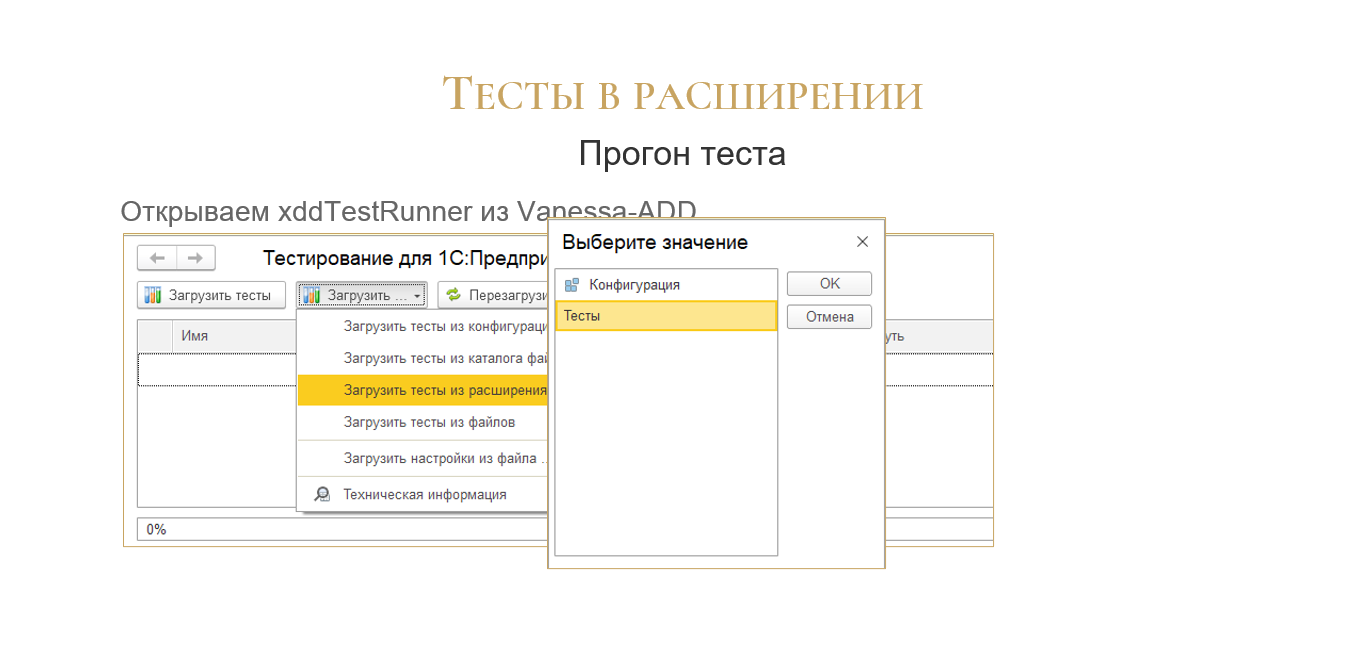
Выбираем здесь расширение.
Можно выбрать и конфигурацию, в этом случае загрузчик пройдется по всем общим модулям конфигурации. А в данном случае он обработает только общие модули конкретного расширения.

Вот так у нас будет выглядеть окно загрузки тестов – они сгруппированы по общим модулям.
Внутри общих модулей точно так же, как и для обычных обработок, можно создавать группы тестов и уже там группировать внутри тестов, если у вас уже прям такие большие модули.
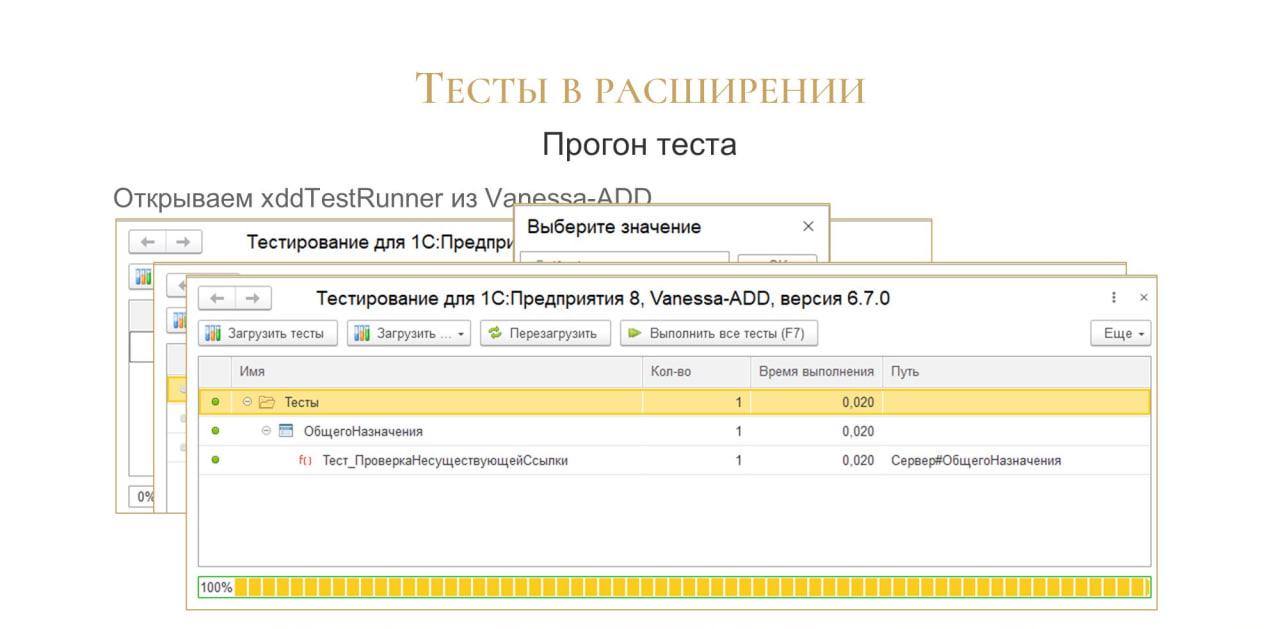
Запустив тесты, мы видим их результат – в данном случае тест зеленый.

Получается, что для встраивания теста в систему тестов нам нужно добавить всего ничего. Нам понадобятся две служебные строки на каждый модуль и одна строка на каждый тест – все, больше ничего не нужно.
Это – минимальный набор необходимых заклинаний. Все остальное для нас делает фреймворк.
Дополнительное преимущество тестов в расширениях в том, что структура дерева тестов будет точно такая же, как структура вашей конфигурации – тесты будут разбиты по тем же самым общим модулям. Мы их заимствовали, и вот, пожалуйста, их структура совпадает со структурой нашего проекта. Ничего не надо придумывать.
Когда мы работаем в обработках, там есть куча нюансов. Все-таки внешняя обработка – это своеобразный модуль.
А когда мы работаем в расширении, код в общем модуле расширения – это такой же код, как и код в конфигурации. Для него справедливы все те же приемы разработки, которые используют обычные программисты при работе просто в вашей конфигурации. Никаких различий нет:
-
для него точно так же работает рефакторинг;
-
там работает поиск объектов метаданных;
-
отбор по подсистемам;
-
сравнение-объединение;
-
даже хранилище можно подключить – разрабатывать тесты в расширении в хранилище. Если у вас нет возможности перейти в разработке на Git – пожалуйста, можно версионировать изменения через хранилище.
Единственный минус по сравнению с разработкой тестов во внешних обработках в том, что, когда вы исправите тест, все-таки нужен перезапуск всего приложения. Но, наверное, это меньшее из зол.
Данные для тестов

Следующий вопрос, который тут же возникает – как загружать данные?
Есть способы хранения данных во внешних макетах – в mxl, в виде двоичных данных либо же в текстовом JSON-виде. Пожалуйста, можно работать.
Но при хранении макетов в расширении очень удобно то, что тестовые данные у вас будут являться структурой вашего тестового проекта.
Мы храним данные у себя в макетах, а макеты у нас привязаны к конкретным объектам метаданных.
-
Например, все тестовые данные, которые нужны для справочника «Пользователи», мы загружаем в макет справочника «Пользователи».
-
Для справочника «Контрагенты» – в макет справочника «Контрагенты».
-
С отчетами то же самое – тестируем отчет, прикрепляем весь тестовый набор данных, на котором тестируем, прямо к этому отчету
Все будет храниться в вашем расширении. Не нужно никуда переключаться, писать на Gherkin, открывать какие-то непонятные обычным программистам системы типа Visual Studio Code. Здесь все работает в конфигураторе, никуда из конфигуратора уходить не надо.
Единственный момент – мы у себя храним данные в JSON-макетах. Не в MXL, как исторически сложилось, а в текстовом виде JSON-макетов. В таком виде удобнее отслеживать их изменения при выгрузке файлов в Git.

Подготовим тест с данными.
Заимствуем справочник «Пользователи», и создадим в нем текстовый макет с данными.
Выгрузим в него из базы через «Генератор макетов с данными» какой-нибудь элемент справочника «Пользователи», просто наугад взятый. Можно прям новый создать, еще лучше. Вот у нас готов справочник.
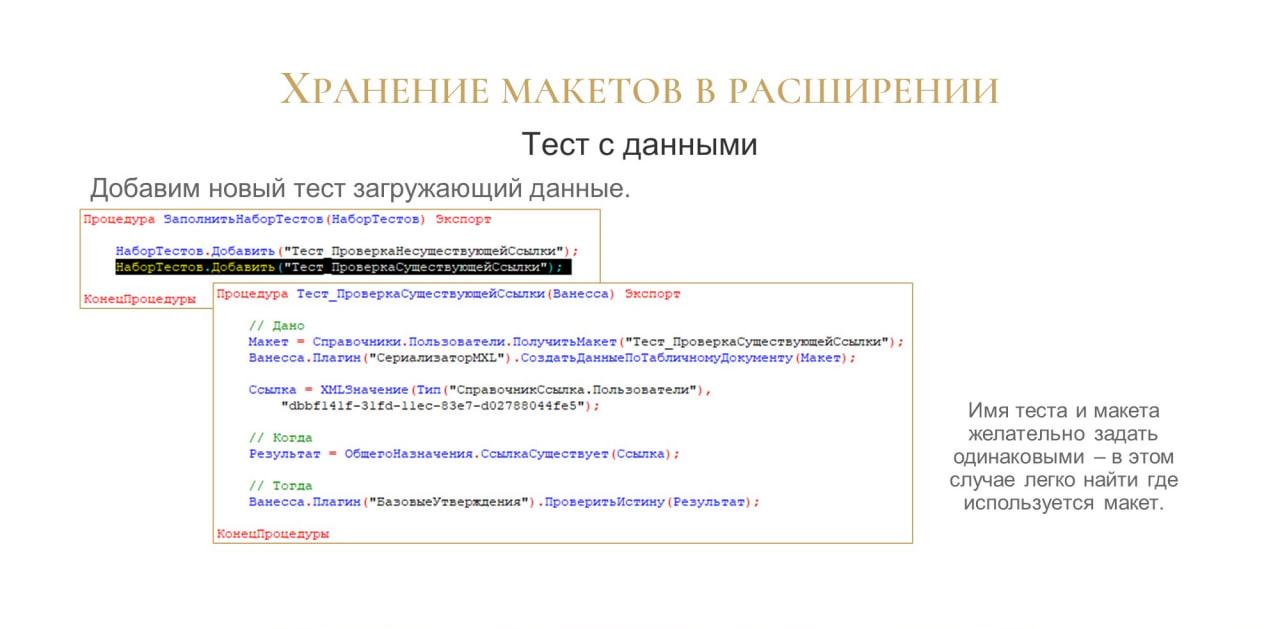
Вот так выглядит тест, загружающий данные.
Добавляем одну строчку – тест, который первым пунктом у нас загружает из макета данные.
Тут же инициализируем ссылку и, собственно, вызываем наш метод еще раз, проверяем, что теперь он тоже возвращает истину, все работает.
Единственный небольшой лайфхак – имя теста и имя макета желательно задавать одинаковыми. Это помогает, когда вы просто в поиске забиваете имя теста и сразу получаете все вхождения, где он есть. В том же Visual Studio Code имя макета тоже высветится вам в поиске. Очень удобный мини-лайфхак
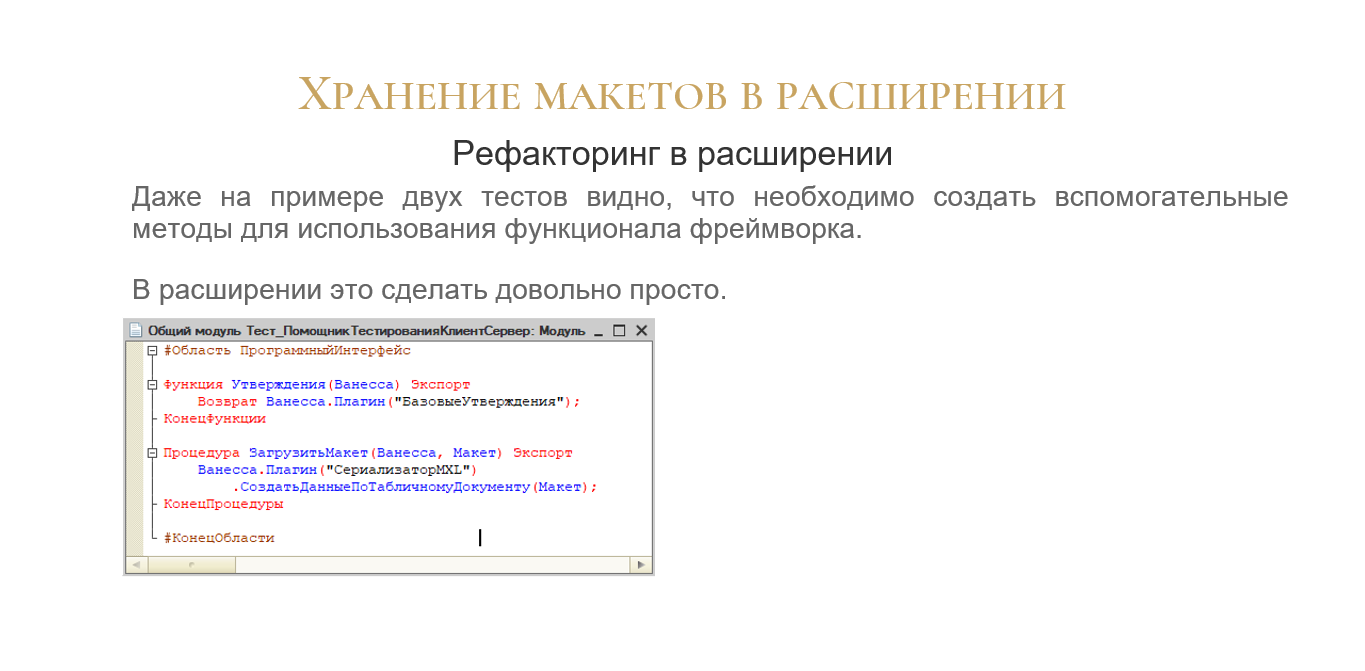
Здесь даже на примере двух тестов можно увидеть, что обвязка тестов везде повторяется. По-хорошему, ее нужно вынести в отдельные вспомогательные методы, чтобы, если что, можно было быстро поменять, там переназначить.
Давайте попробуем это сделать. Поскольку у нас расширение, мы можем спокойно сделать в нем новый модуль, который никак не будет пересекаться с кодом вашего проекта.
Создаем новый модуль Тест_ПомощникТестированияКлиентСервер. В него мы выносим вспомогательные методы для реализации программного интерфейса:
-
Утверждения(Ванесса)
-
ЗагрузитьМакет(Ванесса, Макет)
-
И т.д.
Пожалуйста, вам в расширении доступны все функции полноценной разработки. Вы точно так же можете там делать рефакторинг и все остальное. Ничего необычного нет.

После этого меняем вызовы функций, переопределяем их на вспомогательные и у нас уже получается более-менее прилично выглядящие тесты. Все отлично.
И немного CI

Поскольку мы пишем тесты, желательно, чтобы они выполнялись не только на компьютере разработчика. Это хорошо, что у конкретного «Васи Пупкина» тест вызывается и работает. Но, например, у меня, когда я запускаю его код, не работает.
Единственный способ организовать независимую проверку – прогонять тесты на отдельной базе. Для этого можно использовать CI-системы.
Что делает CI-система? Она прогоняет все ваши тесты на независимой базе – просто создает новую базу и в ней прогоняет тесты. И там уже появляются критерии истинности. Не работает это только у конкретного тимлида, который проверяет тест, а работает у Васи. Либо это не работает у тимлида, не работает в CI, но работает у Васи. Значит, Вася крайний.
Получается, что CI – это арбитр, который может все это перепроверить. Причем арбитр независимый.
Мы всегда знаем, что там создается новая, пустая база. В ней нет никаких изменений, настроек. И весь контекст, который мы подготовили, он либо готов полностью, либо, извините, не готов.
Для CI у нас есть:
-
Jenkins;
-
придется поработать с Git;
-
в этом нам поможет, конечно, vanessa-runner – в дополнение к Vanessa ADD.
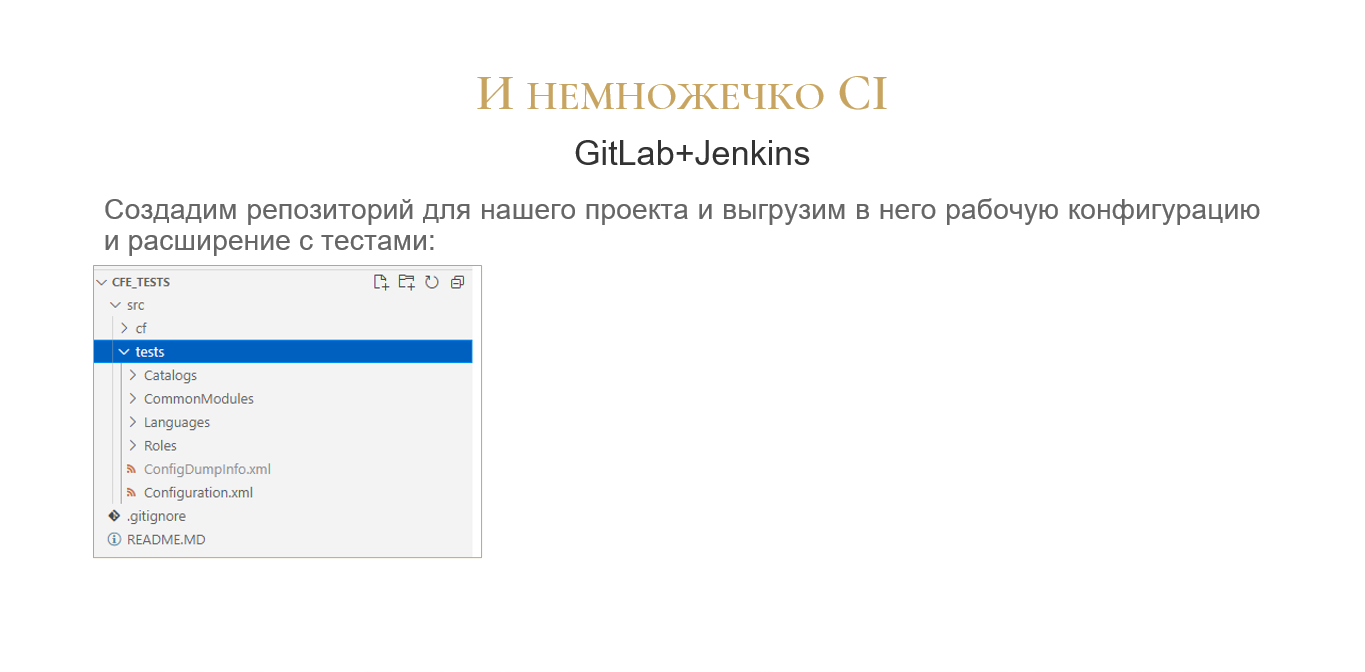
Сделаем простой репозиторий для нашего теста и выгрузим в него рабочую конфигурацию и расширение через меню конфигуратора «Конфигурация» – «Выгрузить файлы».
Вот такая простая структура проекта уже позволяет полностью запуститься и тестироваться.

Сделаем сравнительно небольшой сборочный pipeline. Он, как вы видите:
-
очищает у нас и подготавливает старую область;
-
загружает, собирает у нас проект;
-
загружает расширение с тестами;
-
запускает тесты;
-
и формирует отчет Allure – все результаты тестов сразу появляются в Jenkins.
Такого простого pipeline уже достаточно, чтобы запуститься и работать с тестами в CI.
А при локальном запуске у разработчика работает только вариант с запуском тестов, все остальное у него уже загружено и подготовлено. Ну и Allure, понятно, можно сформировать.

На слайде показано, как выглядит описание стейджа «Запуск тестов» – в нем вызывается vanessa-runner. Его конфигурационный файл vrunnerXUnit.json также показан здесь слева.
Это – все, что нужно. Практически low-code – вы пишете минимальное количество кода. Чтобы все написать, нужны считанные единицы строчек кода.
Это минимально достаточная конфигурация для загрузки тестов. А потом уже можно придумывать кучу всего. Но сначала нужно сделать хотя бы вот это.

В Jenkins создаем задание с конфигурацией jenkinsfile, которая была на предыдущем скрине.
И настраиваем вебхуки на стороне GitLab. Если вы используете какие-то другие сервера для хранения версий проекта, там тоже подобная функциональность есть. Задаем вебхук, чтобы джоба Jenkins срабатывала по событию push, по созданию merge request либо по обновлению merge request.
Таким образом, у вас тесты будут прогоняться в каждой ветке и для каждого merge request – вы в каждом merge request будете видеть, не сломал ли разработчик что-нибудь из старого.
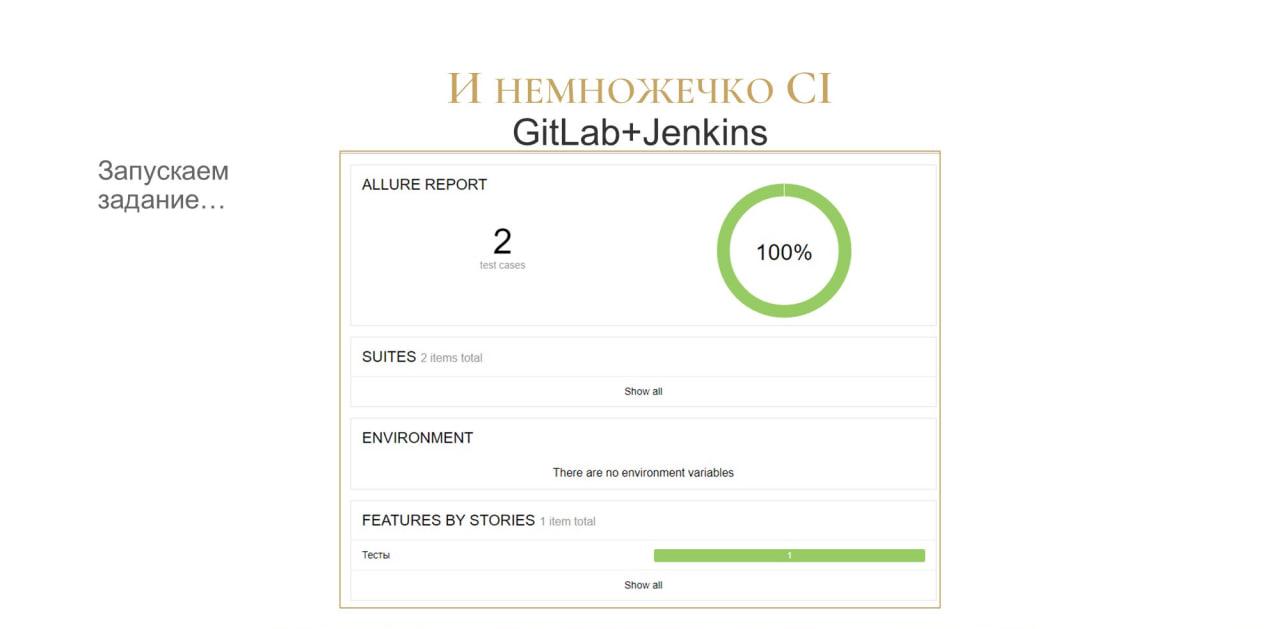
Вот так выглядит Allure для нашего небольшого проекта – буквально с двумя тестами все у нас работает.
Выводы

Разработка тестов в расширении решает несколько проблем.
-
Тесты в расширении максимально сближают разработку продукта и тестов. Вся разработка у вас происходит в одном окне конфигуратора, вы просто переключаетесь между окнами или между закладками. Дело несложное.
-
Разработчик никуда у вас не уходит из конфигуратора – он как работал в конфигураторе, так он и работает. Максимум, для создания тестовых данных ему нужно запустить 1С:Предприятие. Вряд ли это минус – это опять же, наш дом родной.
-
Интересно, что при разработке кода в EDT все работает точно так же. Если вы завтра переводите разработку в EDT, вы точно так же и проект переводите в EDT, и переводите тесты. Точно так же в расширении они у вас в проекте помещаются рядом. Ничего не меняется. Смена парадигмы разработки для тестов не происходит – вы как писали тесты в расширении, так и продолжаете их писать.
-
Ну и дополнительно – тесты в расширениях очень хорошо работают на CI-системах. Для тестирования нужно создать очень небольшой пайплайн, и все будет работать.
Благодарю за содействие и вдохновение
-
Александра Капралова – у него есть замечательный плагин для запуска юнит-тестов в EDT, который использует похожий подход. Я просто разобрал его более подробно для случая, когда мы все-таки работаем в конфигураторе.
-
Ну и Артура Аюханова за замечательный фреймворк Vanessa ADD, в котором реализована поддержка тестов в расширениях.
Мини-проект с примерами тестов в расширении можете посмотреть по ссылке на GitLab. Там все, что я показал, присутствует, и с этим можно работать.
Надеюсь, эта функциональность будет востребована сообществом, и мы все-таки начнем писать тесты на новой парадигме.
Вопросы
Вы показали, что можно запускать тесты из расширения и из конфигурации. Почему вы решили делать тесты именно в расширении, а не в конфигурации? Мне кажется, хранение тестов в конфигурации больше в парадигме стандартной реализации тестирования для других языков, когда мы в основной кодовой базе добавляем какой-то модуль и сразу добавляем рядом модуль с тестами. Если мы ведем разработку в парадигме BDD, мы в мерж-реквесте это видим и можем сразу сказать программисту: «Ты написал код, но не покрыл его тестами. Покрой еще тестами».
У нас тесты тоже включены в состав проекта, и в мерж-реквесте вы тоже можете отследить наличие тестов для нового кода конфигурации.
Но только у нас тесты не в составе самой конфигурации. И в других средах разработки для тестов обычно выделяют отдельное пространство – либо отдельный проект, либо отдельную папку. Что для Java, что для C#. Это все-таки не прямо вот так вперемешку, что мы написали класс, а к нему внизу тут же создали в той же папке тест. Нет, обычно тесты лежат отдельно.
Здесь то же самое – тесты лежат отдельно. Их можно положить рядом, но при этом они будут отдельно. Если у нас расширение с тестами лежит в GitLab, мы выполняем все те же условия, что вы сказали. Тот, кто делает ревью, он сразу видит и замечания, и покрытие тестами, и прошли ли тесты. Все это при разработке проекта у нас есть.
Потом мы все эти результаты загоняем в SonarQube, и декорация мерж реквеста показывает нам и покрытие, и количество тестов, которые прошли или нет, и замечания сонара.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции Infostart Event.
|
30 мая - 1 июня 2024 года состоится конференция Анализ & Управление в ИТ-проектах, на которой прозвучит 130+ докладов.
Темы конференции:
Конференция для аналитиков и руководителей проектов, а также других специалистов из мира 1С, которые занимаются системным и бизнес-анализом, работают с требованиями, управляют проектами и продуктами!
|