Перевод разработки в 1C:EDT. Зачем?

Первый вопрос, на который хочется ответить – зачем переходить на 1С:EDT?
-
Если вы уже пытались работать в 1С:EDT, то могли увидеть, что это не Конфигуратор. Действительно, это не Конфигуратор – это лучше.
-
Но, к сожалению, у этого улучшения есть одна проблема – повышенные требования к оборудованию. Тут, увы, ничего не сделать, придется апгрейдить компьютер: вам потребуется, как минимум, SSD-диск.
-
Наверное, вы могли заметить, что первый запуск 1С:EDT по сравнению с запуском Конфигуратора очень долгий. На самом деле, это не совсем так – если вы попробуете запустить в Конфигураторе на вашей конфигурации расширенную проверку или АПК, то увидите, что и АПК, и расширенные проверки работают гораздо дольше. И сама по себе 1С:EDT работает медленнее, чем обычный Конфигуратор в обычном режиме, когда вы ничего не проверяете. Но она работает гораздо быстрее, чем Конфигуратор в режиме расширенной проверки.
-
В 1С:EDT вы получаете проверки стандартов на лету. В первый раз проект будет собираться долго, но потом при открытии любого модуля или объекта ошибки будут видны сразу.
-
При этом есть вычисление типов: допустим, если вы используете структуру, 1С:EDT умеет подсказывать, какие поля в ней есть, а каких нет. И для любителей строгих типов недавно добавили строгие типы на комментариях. Конечно, это не полноценные строгие типы, как в других языках. Тем не менее, если вам раньше хотелось видеть в 1С строгие типы, вы можете их включить и порадоваться. Возможно, вас удивит, насколько значительно потребуется доработать код, чтобы у вас была строгая типизация.
-
Ну и последнее, что хорошо – если вы когда-то слышали о стандарте 709, где описана технология разветвленной разработки конфигураций, то тут вы фактически получаете этот стандарт «из коробки».
Как перейти в 1C:EDT одному, оставив остальных на Хранилище

Соблюдение технологии разветвленной разработки конфигураций достигается за счет того, что вместо хранилища вы начинаете использовать GIT.
-
В GIT поддерживается разветвленная разработка с помощью веток.
-
Это дает легкое объединение с чужими изменениями – 1C:EDT за вас отслеживает, какие изменения сделали вы, а какие не вы. Если вы одновременно с коллегой внесли изменения в единый общий модуль: одну процедуру поменяли вы, а ваш коллега другую, то 1C:EDT с помощью GIT определит, что вы меняли разное, и автоматически эти изменения объединит. Понятно, что GIT умеет так делать и без 1C:EDT, но когда вы объединяете формы, у вас только с помощью GIT корректно это сделать не получится, а 1C:EDT умеет объединять формы по элементам.
-
Благодаря GIT в 1C:EDT поддерживается смешанный режим работы. Вы просто регулярно выгружаете данные хранилища в одну из веток GIT, и тем самым даете вашей команде возможность работать на 1C:EDT частично. Кто хочет – работает в 1C:EDT. Кто не хочет – работает в конфигураторе. При этом результаты общей работы вы получаете в рамках единого репозитория.
-
Нет монопольного захвата – не нужно складывать мусор, чтобы освободить корень конфигурации или какой-то общий модуль. Вы разрабатываете в отдельной ветке, и только когда разработали, складываете, легко обновляя.
-
Благодаря GIT можно организовать легкое обновление группы релизов. Когда фирма «1С» выкладывает свои релизы, она пишет, с каких релизов можно обновляться. Конечно, с помощью готового файла конфигурации вы можете сразу обновиться на любой релиз, но клиенты на КОРП-рынке говорят: «Нет, так нельзя, нужно обновляться только в том порядке, в котором фирма «1С» написала». И приходится делать цепочку обновлений из двух, трех, пяти релизов. Благодаря веткам в GIT вы, во-первых, можете легко сделать последовательное обновление, а, во-вторых, если кто-то из разработчиков что-то внес в основной релиз, вы легко это донесете до финального релиза.

Помимо использования GIT локально, вы можете использовать любой GIT-сервер – а вместе с ним вы чаще всего получаете встроенную систему CI/CD, которая позволяет:
-
Автоматически проверять каждый коммит. Или каждую закладку в хранилище, если вы или ваши коллеги используете хранилище.
-
Запускать всевозможные тесты, которые захотите.
-
Если вы используете дополнительные инструменты, вы можете видеть динамику изменений.
-
Вы получаете возможность сравнить качество для новой и релизной конфигурации – например, у вас было одно качество конфигурации, а когда добавили новую функциональность, стало другое.
-
И у вас появляются так называемые «ночные» сборки.
Все это можно легко сделать с помощью GIT-сервера. Понятно, что это можно сделать и без GIT-сервера, но с ним начинать удобнее.

Возможен даже такой вариант, когда вы вообще не используете 1C:EDT в разработке, а используете ее только для проверок кода на CI. Делается это просто.
-
Нужно скачать офлайн-версию 1С:EDT и установить ее на сервер.
-
Чтобы пользоваться возможностями 1С:EDT, вам нужно будет один раз запустить ее на сервере – с любой рабочей областью, хотя бы пустой.
-
Далее вам нужно будет установить плагины, которые помогают проверять качество конфигурации.
-
И вам необходимо использовать GitConverter – настроить его на разбор одного или нескольких ваших хранилищ в GIT, чтобы в GIT конфигурация была уже в формате 1C:EDT.
CI/CD на GitLab

Расскажу об использовании в качестве GIT-сервера GitLab. Почему именно о нем?
-
Во-первых, GitLab Community Edition бесплатный. Вы можете его скачать, развернуть в инфраструктуре внутри вашей компании и начать использовать.
-
У GitLab есть простой запускальщик GitLab Runner – это агент, который нужно поставить на один или несколько серверов. Его задача – запускать скрипты в нужной последовательности.
-
В качестве скриптового движка я использую 1С:Исполнитель.
-
Основная причина, почему я выбрал 1С:Исполнитель – это решение от вендора. Потому что когда на КОРП-рынке сталкиваешься со службой безопасности, им надо обосновать, почему используются те или иные решения. А когда есть решение от вендора, они обычно дальше уже не задают наводящих вопросов и на все соглашаются.
-
Недавно вышла статья на wonderland.1c.ru, где фирма «1С» рассказала, что нас ждет новая технология разработки 1C:Предприятие.Элемент, в основе которой лежит язык 1С:Исполнитель. Поэтому, если вы потратите время на изучение этого языка, ваши усилия не пройдут даром – вы сможете его использовать в новой технологии.
-
-
С помощью запуска нескольких GitLab Runner, CI на GitLab позволяет разделить тестирование вашей конфигурации на клиентское и серверное.
Сценарии проверки для CI
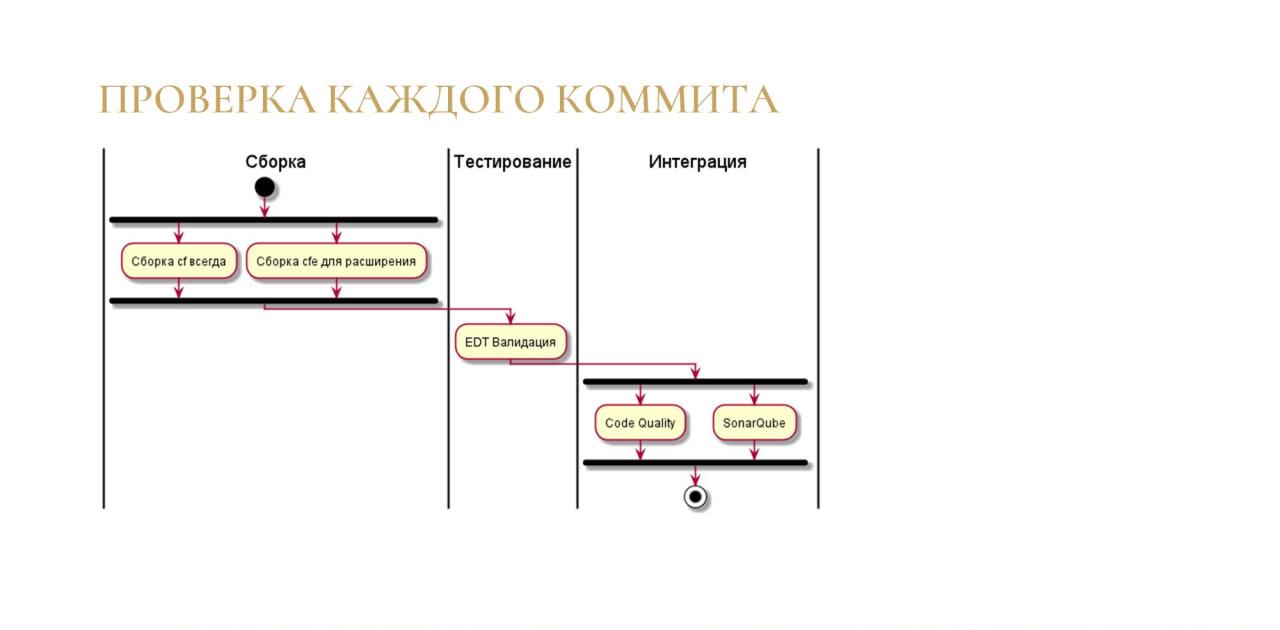
Расскажу три сценария тестирования, которые мы используем в своей работе.
Первый сценарий – это простая проверка каждого коммита.
-
Мы разрабатываем в 1С:EDT конфигурации и расширения, и каждый проект конфигурации или расширения у нас находится в своем репозитории. Если разработчик делает коммит в проект конфигурации, собирается файл конфигурации. Если он делает коммит в проект расширения, собирается файл конфигурации и файл расширения. При сборке автоматически проверяется, на какой версии платформы разрабатывался проект внутри 1C:EDT, и сборка CF и CFE реализуется с этой версией платформы. Например, если у вас написано 8.3.18, то скрипт поищет на сервере самую последнюю версию платформы 8.3.18 и запустит ее.
-
После того как скрипт все соберет, он запустит валидацию 1C:EDT и проверит ошибки. Причем, начиная с релиза 1С:EDT 2021.2 вы можете сами настраивать для каждого проекта критичность каждой проблемы. Например, вы можете снизить критичность проблем, которые на вашем проекте несущественны.
-
Эта критичность также будет попадать в SonarQube.
-
И в механизм GitLab Code Quality, про который я расскажу чуть позже.
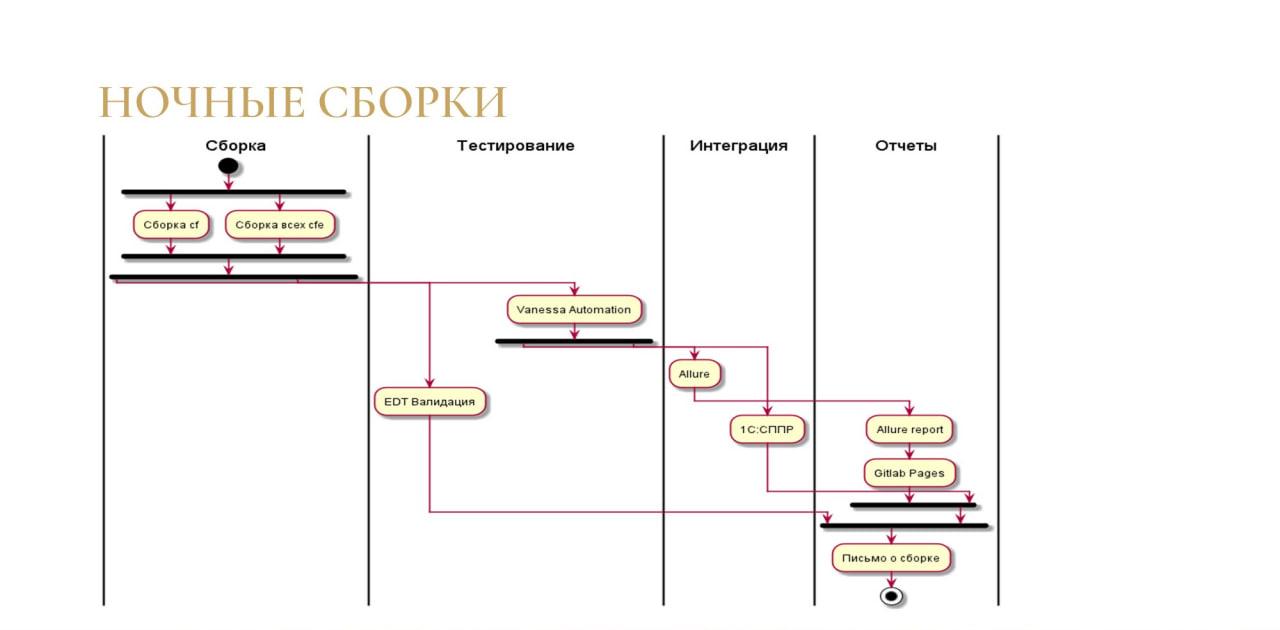
Второй сценарий – это ночные сборки.
Так как мы занимаемся внедрением, у нас на этапе разработки, который, допустим, идет три месяца, люди каждый день что-то кодируют. И, соответственно, каждый вечер в 22 или 23 часа запускается ночная сборка с полным тестированием, чтобы разработчики с утра знали, что они успели за день сломать.
-
Собираются CF и все CFE, которые есть.
-
Проходит валидация от 1C:EDT.
-
Происходит сценарное тестирование с помощью Vanessa Automation. Мы выбрали Vanessa Automation, а не «Сценарное тестирование», потому что описания тестов можно легко включать в технический проект.
-
Еще Vanessa Automation удобно использовать в связке с 1C:СППР. Если у вас сейчас нет никакой системы регистрации ошибок, и вы выбираете, что взять, попробуйте использовать 1C:СППР, потому что Vanessa умеет автоматически выгружать ошибки в 1C:СППР. Вы ставите Vanessa, ставите рядом 1C:СППР – у вас уже готова какая-то система учета ошибок.
-
Кроме этого, Vanessa Automation умеет выгружать результаты тестирования в отчет Allure.
-
При этом вы можете настроить в сборочной линии, чтобы отчет Allure попадал на GitLab Pages – тогда его смогут открыть только те, кому вы в GitLab настроили доступ к самому проекту. Вам не нужно отдельно придумывать, как выставить отчет наружу в интернет, чтобы его никто, кроме разрешенных пользователей, не увидел. GitLab содержит в себе возможность разграничения доступа, чтобы человек, у которого нет доступа, даже при наличии прямой ссылки не смог посмотреть этот отчет.
-
Когда все собралось, средствами GitLab отправляется письмо о результатах сборки, где есть: ссылки на то, что собралось; ссылки на ошибки; и любая другая информация, которую вы захотите.
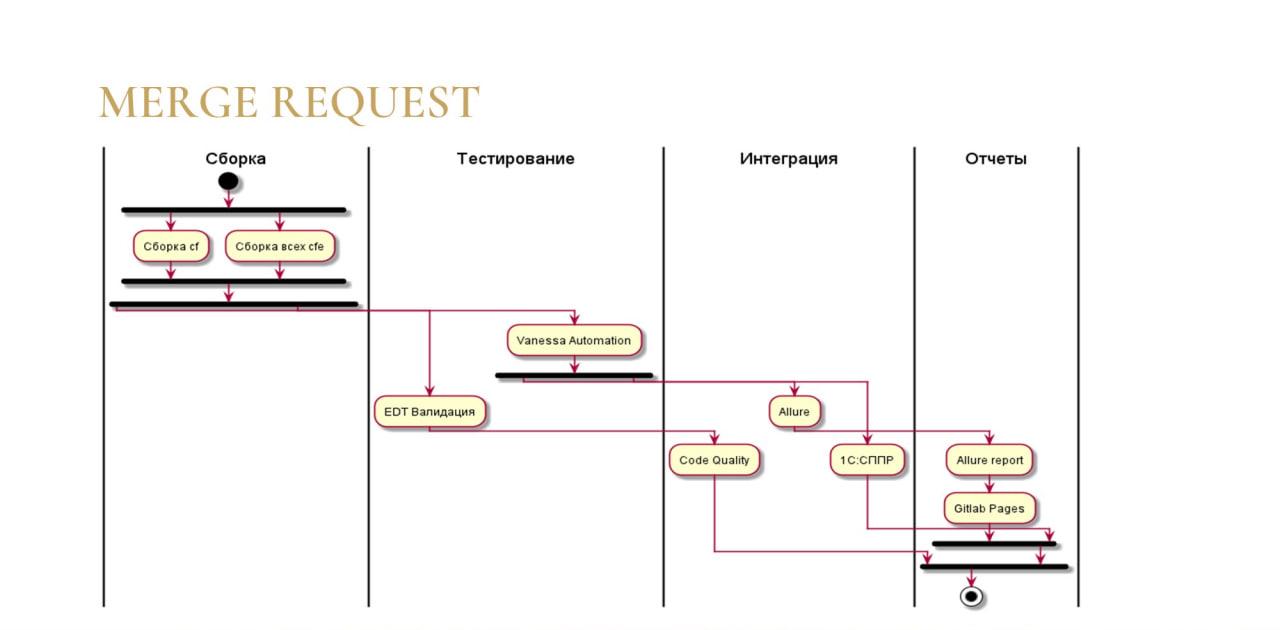
Третий вариант – мне кажется, он самый полезный во всей этой системе – это так называемый Merge Request (или в терминологии GitHub – Pull Request).
Это – поддержка как раз той самой технологии разветвленной разработки, для которой у фирмы «1С» уже давным-давно был придуман стандарт.
-
Разработчик фактически разрабатывает что-то в сторонке и, после того как разработал, он отправляет это не сразу в ветку мастер, а на проверку в отдельную ветку.
-
Идет сборка CF и всех CFE.
-
Все изменения тестируются с помощью Vanessa Automation.
-
Появляется механизм Code Quality – это гитлабовский механизм, который позволяет сравнить ошибки основной конфигурации, и ошибки, привнесенные разработчиком, и показать только дельту. Вам не нужно изучать все сотни и тысячи ошибок, которые выдает для конфигурации 1C:EDT – их никто даже исправлять не будет. Контролируется именно то, чтобы разработчик ничего не испортил. Конечно, то же самое вы можете получить при анализе в SonarQube. Но если у вас SonarQube нет, а есть желание отслеживать качество кода, GitLab дает все это из коробки.

У Vanessa Automation есть особенность – при ошибках в процессе тестирования она умеет делать скриншот экрана, чтобы показать, что было на форме в момент, когда возникла проблема.
Но если вы запускаете GitLab Runner как сервис, 1С в режиме Предприятие тоже запускается как сервис, и Vanessa Automation не делает никаких скриншотов.
Поэтому в том механизме, который я сделал, в скрипте для GitLab предусматривается разделение задач на две части:
-
Те, которые могут запускаться в сервисе.
-
И те, которым нужен экран.
Для этой цели нужно запускать два GitLab Runner:
-
первый – как сервис на серверной Windows;
-
а второй – как программа на терминальном сервере, где у вас сидят разработчики. Там вы держите одну сессию, на которой запущен GitLab Runner.
Автоматизированная проверка и сборка релиза с использованием «1С:Исполнитель»
По ссылке вы можете скачать yml-файл, в котором автоматизируются все три сценария тестирования:
-
buildMaster – для проверки каждого коммита
-
buildRelease – для проверки ночной сборки
-
buildMergeRequest – для проверки мерж-реквестов.
Чтобы сборка работала по этим сценариям, нужно поместить этот yml-файл в корень репозитория.
Или, если вы используете GitConverter, то при первоначальной настройке синхронизации для хранилища можно нажать кнопку «Создать репозиторий Git и установить локальные настройки» и поместить этот yml-файл в созданный каталог.
Туда же в корень репозитория вы можете поместить и настройки ваших диагностик – поменять критичность, установить какие-то исключения, указать дополнительные параметры.
Еще по этому адресу находится скрипт 1cicd.sbsl на 1С:Исполнителе. К сожалению, пока 1С:Исполнитель не умеет делить модули на библиотеки, поэтому скрипт сейчас один – монструозный. Возможно, в нем будет тяжело с ходу разобраться или посмотреть какую-то его часть, но я планирую разделить этот большой скрипт, как только 1С:Исполнитель даст возможность делать модули как библиотеки. Он будет уже поменьше, и там будет описание. Сейчас у него, к сожалению, описания нет. И если вы реально захотите его изучить, вам придется разбираться самому или обратиться ко мне за помощью.
На GitLab CI вы создаете столько репозиториев, сколько у вас проектов. А в специальном настроечном файле указываете их взаимосвязь:
-
один репозиторий под конфигурацию;
-
несколько отдельных репозиториев под расширения;
-
отдельный репозиторий, куда вы будете складывать тесты для Vanessa Automation;
-
и последний пустой репозиторий, куда складываются релизы с сайта https://releases.1c.ru. Он нужен, если вы в ночных сборках хотите обновлять типовую функциональность. Сейчас это, к сожалению, нужно делать руками, но в будущем я планирую это автоматизировать.
Настройка 1C:EDT

Чтобы настроить 1C:EDT на сервере, нужно поставить офлайн-версию 1C:EDT, запустить ее один раз и установить в ней три плагина:
-
https://github.com/1C-Company/v8-code-style – плагин от самой фирмы «1С». Он содержит все проверки 1C:EDT, в том числе, проверки по стандартам. Он сейчас активно развивается, и проверки постоянно добавляются. Его нужно ставить обязательно, чтобы получить вообще плюсы от использования 1C:EDT в CI. Есть вероятность, что скоро все проверки, которые умеет 1C:EDT, переедут в этот плагин.
-
https://github.com/1C-Company/ssl-support – тоже плагин от фирмы «1С», он нужен, если вы разрабатываете конфигурацию на базе 1C:БСП. Он добавляет для результатов процедур и функций БСП механизм определения типов. Например, если вы берете БСП-шную процедуру ЗначенияРеквизитовОбъекта(), в первом параметре указываете ссылку, во втором параметре вы должны строкой указать список всех реквизитов. Этот плагин автоматически читает, какие реквизиты есть, и проверяет, что у вас в строке есть только те реквизиты, которые присутствуют в объекте.
-
https://github.com/marmyshev/edt-editing – это так называемый коммьюнити-плагин, он позволяет установить запрет на редактирование какого-либо объекта. Например, если мы закрыли объект на редактирование, то 1C:EDT его не проверяет. Он умеет закрывать объекты по списку объектов, по подсистеме или по ветке. Например, вы можете объявить свой старый код legacy-кодом, положить в отдельную ветку и сказать – все, что лежит в этой ветке, больше никогда не проверяй. И 1C:EDT внутри себя начнет проверять только тот код, который вы разрешили на редактирование. В эту отдельную ветку вы можете каждый месяц складывать новую версию и говорить, что версия месячной давности – это теперь legacy-код. Не исправили, ну и не исправим. На мой взгляд, это очень хороший способ бороться с тем гигантским количеством ошибок, которые сейчас выводятся в 1C:EDT.
Простейшие дымовые тесты на Vanessa Automation

Теперь про Vanessa Automation.
В сборке используется Vanessa Automation в формате Single, которой на вход подаются экспортные сценарии, т.н. автофичи.
Если вы никогда не тестировали свой код, но хотели бы начать и не знаете с чего, я предлагаю скачать по ссылке экспортные сценарии для каждого объекта метаданных.
В них содержатся простые проверки, которые часто можно назвать дымовыми.
-
Открыть справочник, заполнить, записать, напечатать.
-
С документами то же самое – заполнить, провести, напечатать.
-
Проверить, что к объекту метаданных нет доступа.
Плюс там есть механизм, когда вы в текстовом файле пишете список всех объектов – как их нужно проверять и под какой ролью. И скрипт на 1С:Исполнителе генерирует по вашему файлу фичи – на каждый объект метаданных под каждым пользователем. С его помощью вы можете сразу запустить проверки под каждым пользователем в несколько потоков.
-
Например, у нас для 1C:ЗУП под администратором проверяется, что конфигурация в принципе работает.
-
Дополнительно нам нужно проверить, что под кадровиком и под расчетчиком открываются те объекты, которые им разрешены.
-
И проверяем, что те объекты, к которым у пользователей нет доступа, для них не открываются – например, мы проверяем, что кадровик не может открыть расчетный документ.
Вы тоже можете начать пользоваться этой технологией – взять эти экспортные сценарии и доработать каким-то образом, превратить из дымовых тестов в полноценные.
Если вы интересуетесь развитием Vanessa Automation, то могли видеть, что недавно фирма «1С» выложила тесты для конфигурации «Управление холдингом». Там принцип примерно такой же, как у меня. Единственное, что они пошли от обратного. Если я указываю список проверяемых объектов, они, наоборот, указывают список, который не надо проверять. Но принцип одинаковый – какие-то простые сценарии, которые позволяют проверить всю конфигурацию целиком.
Code Quality в GitLab для контроля за своими ошибками с помощью 1C:EDT
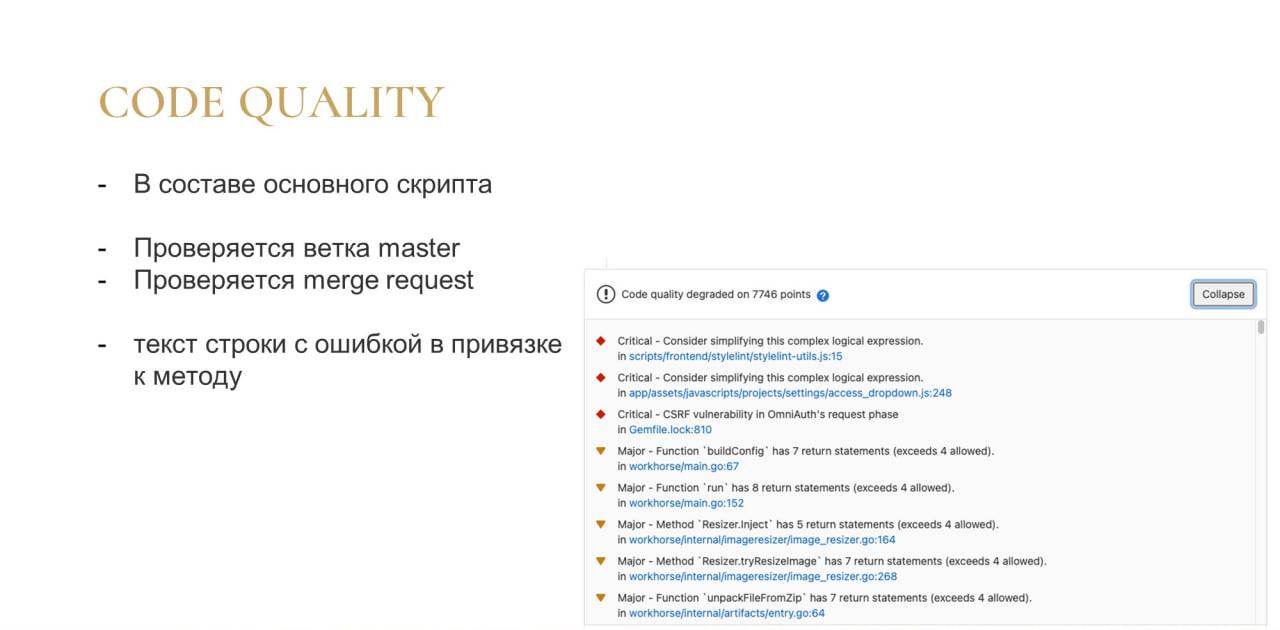
Теперь про Code Quality.
На слайде – пример того, как это выглядит.
При проверке каждого коммита ветки master список ошибок, собранный с помощью 1C:EDT, преобразуется в формат, который понимает GitLab.
Дальше, когда вы проверяете merge-request, GitLab автоматически сравнивает эти два файла с ошибками и выводит список отличий, где указано, насколько изменилось качество кода в результате коммита. На скриншоте со слайда показана ситуация, когда качество кода деградировало – ухудшилось на какое-то количество пунктов. Каждый пункт – это ошибка.
Изменения выводятся на основании того, что запоминается некий отпечаток ошибки. Этот отпечаток, естественно, 1C:EDT генерировать не умеет. Я придумал алгоритм идентификации текста строки с ошибкой в привязке к методу.
-
Сначала мы проверяем, к какому методу относится эта ошибка;
-
Если в строке этого метода с таким текстом такой-то вид ошибки уже был, тогда GitLab понимает, что это одна и та же ошибка, и не показывает.
-
Возможна ситуация, когда поменяли форматирование или добавили в процедуру параметр, а ошибку не исправили. В этом случае GitLab скажет, что вы одну ошибку исправили, вторую привнесли.
Алгоритм открытый – если вы считаете, что на вашем проекте строки ошибок можно отличать как-то по-другому, можете его доработать.
SonarQube

Как настраивается SonarQube:
-
вы его устанавливаете;
-
ставите Sonar-scanner на сервер;
-
ставите BSL Community Plugin – он нужен для того, чтобы EDT-шные ошибки можно было загрузить в SonarQube;
-
В настройках встроенные проверки BSL Language Server отключаются. Потому что моя система рассчитывает на то, что вы используете 1C:EDT. Если вы считаете, что вам не хватает проверок 1C:EDT, можете включить встроенные проверки в BSL Community Plugin. Он будет фиксировать ошибки, которые найдет BSL Language Server.
Отчет о ночной сборке

Напоследок хочется подробнее рассказать про отчет о ночной сборке.
На слайде показано, как выглядит отчет, который приходит на почту вечером или ночью. В нем – список всех артефактов и полная информация по прохождению сборки. Здесь приложены:
-
Файл конфигурации.
-
Все файлы расширений.
-
Ссылка на отчет Allure – при этом сразу показывается, сколько всего тестов было запущено в процессе сборки. Тут написано 6700 – в основном, это дымовые тесты, которые были сгенерированы автоматически. Вот столько получилось тестов, когда мы их проверяли под тремя разными пользователями. Если какие-то тесты не прошли, сразу пишется, сколько не прошло.
-
Развернутая информация – по какому пользователю сколько тестов не прошло. Если этот отчет смотрит несколько разработчиков и разработчик видит, что по Расчетчику ошибок нет, а по всем остальным есть – можно не смотреть.
-
Если у вас настроена интеграция с SonarQube, здесь также будет ссылка на SonarQube.
Выводы
-
Если говорить про планы, то хочется сделать интерфейс для автоматической настройки этого всего. Когда станет общедоступна технология 1С:Элемент, я постараюсь это сделать.
-
Сейчас, к сожалению, если вы захотите использовать мой скрипт, вам придется в нем разобраться самому и настраивать вручную.
-
Либо вы можете просто использовать мой подход как идею – если вы хотите запустить CI, но не знаете с чего начать. Потому что у нас, например, корпоративные клиенты периодически спрашивают – расскажите хотя бы, как надо.
-
То, что я рассказал – это не мои абстрактные придумки, мы это используем для проектов уже постоянно. К этому подключается все больше и больше людей. И главное, что люди, которые раньше не хотели даже смотреть в сторону 1C:EDT, уже сейчас подходят, просят – протестируйте нашу конфигурацию, пожалуйста. И даже не используя 1C:EDT, получают результат.
Вопросы
Вы говорили, что если кто-то все еще сидит в хранилище, то делается отдельная ветка, и те коммиты, которые делаются в хранилище, попадают в отдельную ветку. Каким образом?
С помощью GitConverter – это конфигурация от фирмы «1С», которая распространяется бесплатно.
GitConverter умеет обращаться к хранилищу, смотреть, есть ли там изменения. И, если есть, помещать их в Git-репозиторий.
При этом, если вы обновляете конфигурацию, работая в 1C:EDT, то ветка хранилища может быть вспомогательной.
Если же вы работаете в 1C:EDT один, а обновляет конфигурацию другой разработчик, тогда ветка хранилища фактически является веткой master. И вы просто из 1C:EDT по «Технологии разветвленной разработки» получаете конфигурацию и вливаете ее в хранилище. Уже после того, как Merge Request вам сказал, что у вас все хорошо.
Бывают ли у вас такие ситуации, когда приходится мержить формы? Как вы из них выходите? Как происходит мерж самих форм, когда два разработчика одновременно внесли в них изменения?
Тут принцип обратный: кто первый, тот и папа.
Первый разработчик, который успел влить свое, вливает форму как есть.
А второй разработчик должен сначала себе забрать изменения первого разработчика. В этом поможет 1C:EDT – она покажет, какие изменения в форму внес первый разработчик и позволит их легко объединить. Только потом эту доработанную форму можно будет отправить на проверку.
GitLab ему покажет, что у него конфликт, и он забирает изменения, которые первый разработчик уже внес, затирая таким образом свои изменения?
Не затирая, а объединяя. 1C:EDT умеет формы объединять поэлементно. Он не стирает форму целиком, а галочки ставит: вот это оставить, а это – удалить.
Основная проблема, почему никто не использует 1C:EDT – потому что он тормозит. Какие конфигурации у вас переведены на 1C:EDT? Есть ли у вас корпоративные проекты уровня 1C:ERP или 1C:УХ, разработка которых ведется именно в 1C:EDT?
У нас в 1C:EDT ведется разработка для проектов внедрения 1C:ERP и 1C:ЗУП.
И как с психическим состоянием программистов, которые его используют?
Во-первых, как я в самом начале доклада сказал, 1C:EDT “тормозит”, только когда проверяет в первый раз.
А, во-вторых, мы бережем психику наших разработчиков, поэтому я придумал механизм, как можно работать и в 1C:EDT, и в конфигураторе.
Т.е. ответ простой – если разработчик не готов страдать, мы даем ему возможность работать в конфигураторе.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции Infostart Event.

Вступайте в нашу телеграмм-группу Инфостарт