Меня зовут Евгений Винниченко, я представляю компанию WiseAdvice.Tech.
Хочу поговорить об API-first подходе при проектировании интеграций на базе REST API между разнородными системами. Скорее даже я хочу вас убедить в том, что это – единственно верный подход при проектировании таких интеграций.
Но обо всем по порядку.
Сравнение подходов Code-first и API-first
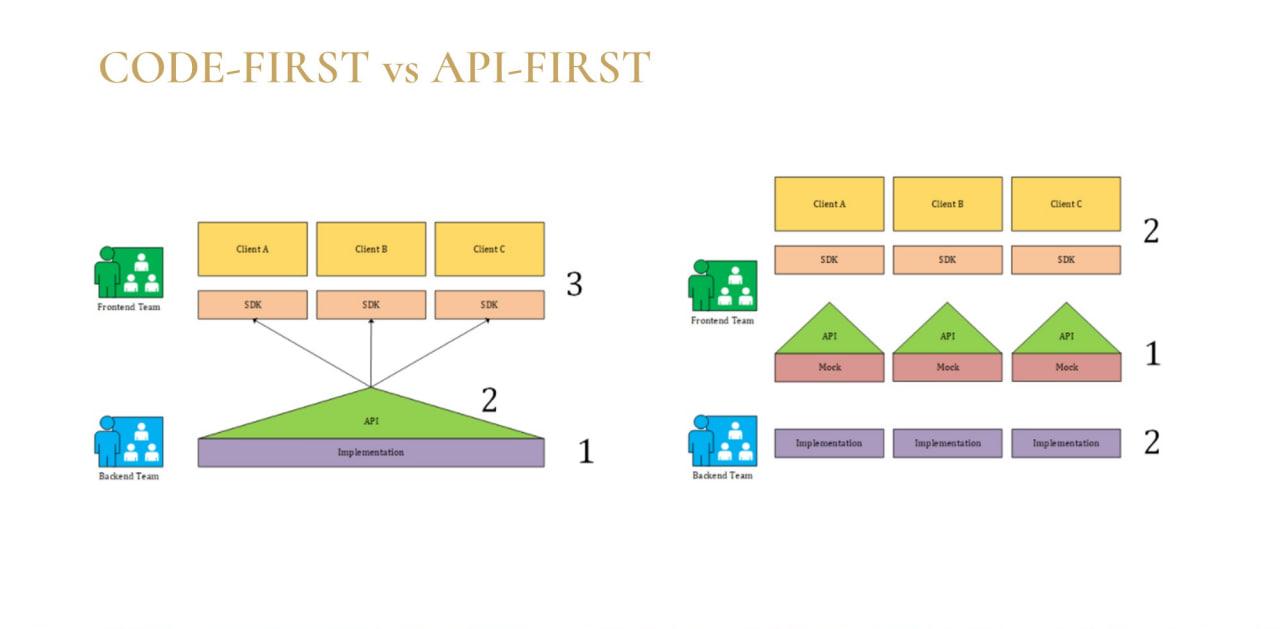
Давайте разберемся, что такое API-first. А для этого пойдем от обратного и вспомним, что такое Code-first.
Code-first – это когда:
-
сначала поставщик сервиса на своей стороне реализует бизнес-логику;
-
потом с помощью какого-то программного обеспечения формирует для этой логики API;
-
и только потом потребитель сервиса на своей стороне занимается имплементацией данного сервиса в свою бизнес-логику.
Не кажется ли вам, что именно так работает интеграция через HTTP-сервисы в 1С?
-
У нас тоже разработчик 1С сначала добавляет в конфигураторе HTTP-сервис и публикует его на веб-сервере.
-
Потом делает какое-то описание API, которое, не дай Бог, в Word, в Excel, письмом или сообщением в Телеграме передает потребителю.
-
И только потом потребитель пытается интегрироваться и использовать этот сервис.
Действительно, в рамках платформы 1С заложен исключительно Code-first подход.
А подход API-first – это когда:
-
сначала мы выдаем потребителю описание сервиса;
-
и только потом занимаемся реализацией данного сервиса в системе поставщика сервиса – понятно, что реализация должна соответствовать той спецификации, которую мы предоставили ранее.
В случае с API-first самыми главными краеугольными камнями выступают два элемента:
-
первое – это спецификации;
-
и второе – это mock-серверы.
Спецификации
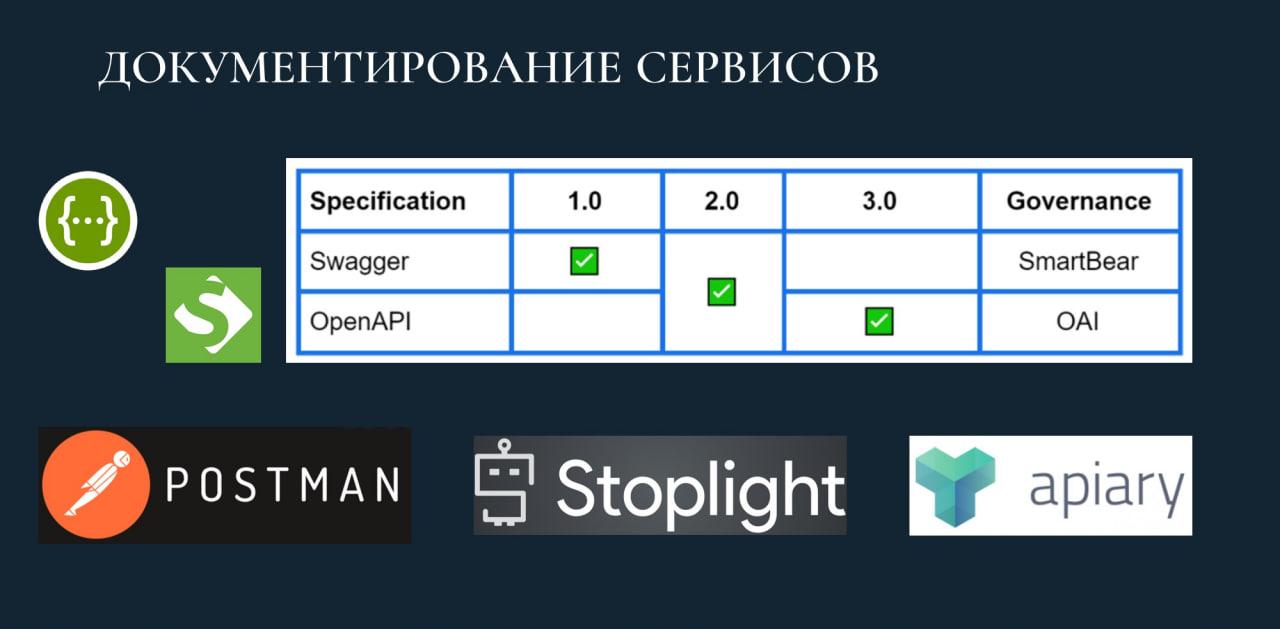
Если у вас сервис SOAP на XML – у вас в качестве спецификации будет WSDL, без вариантов.
Но если вы хотите REST или легковесный JSON, тогда перед вами открывается прекрасный и дивный мир разных спецификаций, с помощью которых можно описать сервис и предоставить это описание для использования потребителем.
На текущий момент существует несколько разных версий спецификаций, с помощью которых можно выполнить описание HTTP-сервиса. Но, к сожалению, 1С на уровне платформы не поддерживает чтение или формирование описаний сервисов ни по одной из этих версий спецификаций. Именно поэтому в свое время родилась прекрасная библиотека Swagger, написанная на OneScript. Она парсит исходный код конфигурации и формирует спецификацию в рамках OpenAPI 2.0 по тем HTTP-сервисам, которые есть внутри конфигурации.
Но с точки зрения Code-first она нам не подойдет – у нас все равно все начинается с конфигуратора. Сначала разработчик должен зайти в 1С, сделать в нем сервис и что-то написать. Никакого преимущества API-first тут нет.
На слайде я попытался отразить несколько инструментов, с помощью которых можно быстро описать API в рамках общеизвестных форматов и передать это описание кому-то для использования. Это – Swagger SoapUI, Postman, Stoplight, Apiary.
Причем с помощью этих инструментов API можно не только описать, но и замокать.
Mock-серверы
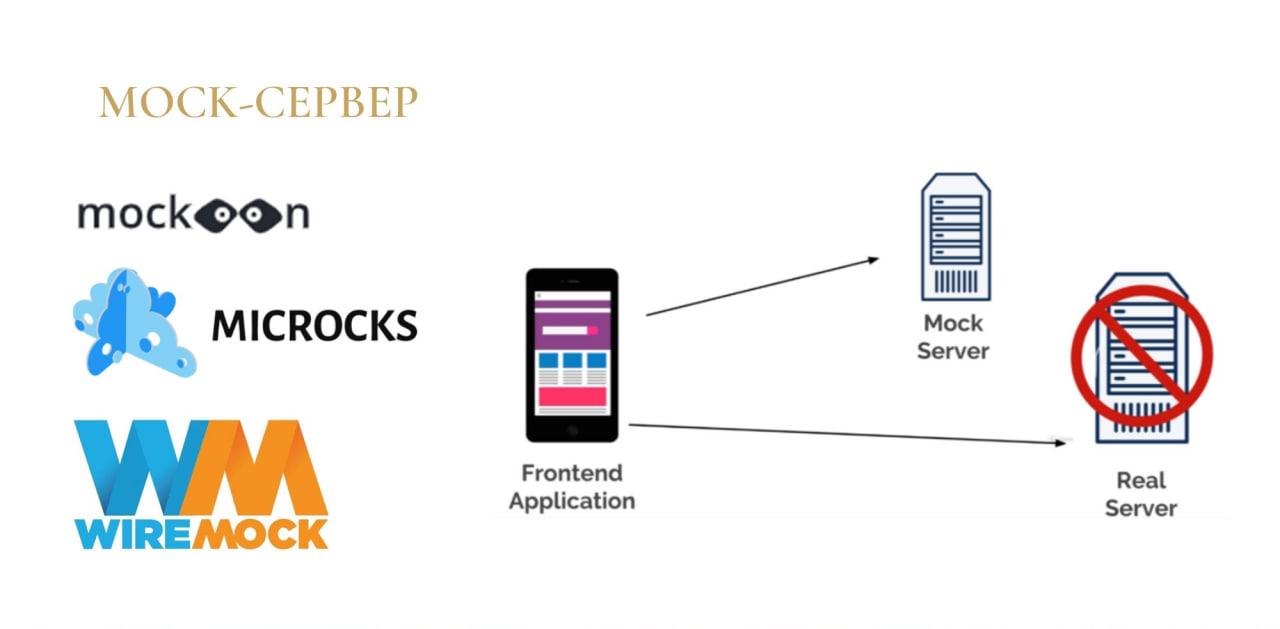
Теперь кратко пробегусь по теории для mock-серверов.
Mock-сервер – это комплекс программного обеспечения, который эмулирует работу реального API, не являясь реальным API. Он отвечает только заранее заложенными в него экземплами или заранее известными ответами.
Обычно конфигурационными файлами для mock-серверов выступают те же самые спецификации сервисов, о которых я рассказывал на предыдущем слайде.
Программ для mock-серверов много, многие из них – open source. С помощью этих программ мы, при наличии спецификации, можем быстро развернуть mock-сервер и использовать его для разработки разнородных систем, которые интегрируются между собой на базе REST API.
Когда мы у себя в рамках некоторых продуктов переходили от подхода Code-first к API-first, нам хотелось иметь какую-то платформу, которая одновременно позволяла бы: генерить документацию, формировать спецификации и описания, поднимать моки, проводить тесты, показывать мониторы – чтобы это все было в комплексе.
Так мы пришли к Postman.
Возможности Postman
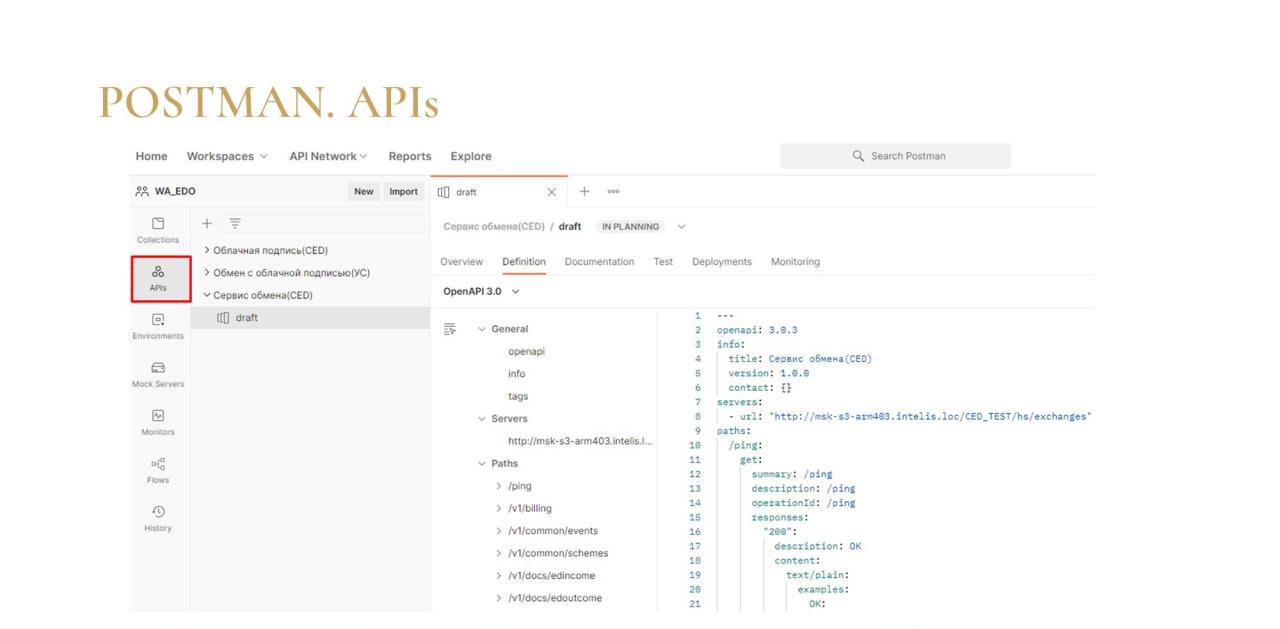
Представьте, у вас есть какое-то API, для которого уже есть какая-то спецификация – вы ее где-то уже набросали. В этом случае вы заходите в Postman в пространство API и можете загрузить туда эту спецификацию.
Или другая ситуация. У вас есть конфигурация, но нет спецификации. Берем библиотеку Swagger, натравливаем на конфигурацию, получаем спецификацию, идем в Postman, загружаем, приступаем к работе.
Postman читает фактически все – актуальные, неактуальные, старые версии спецификаций. И если спецификация в рамках определенной версии успешно проходит валидацию, из нее фактически в пару кликов можно:
-
сформировать документацию, которая будет условно в публичном доступе;
-
поднять мониторинг – если ваш сервис развернут на продакшене, и там есть любой метод вроде ping, который не влияет на изменение системы;
-
поднять тесты – если, опять же, ваш сервис на это заточен;
-
в том числе, можно поднять mock-сервер.
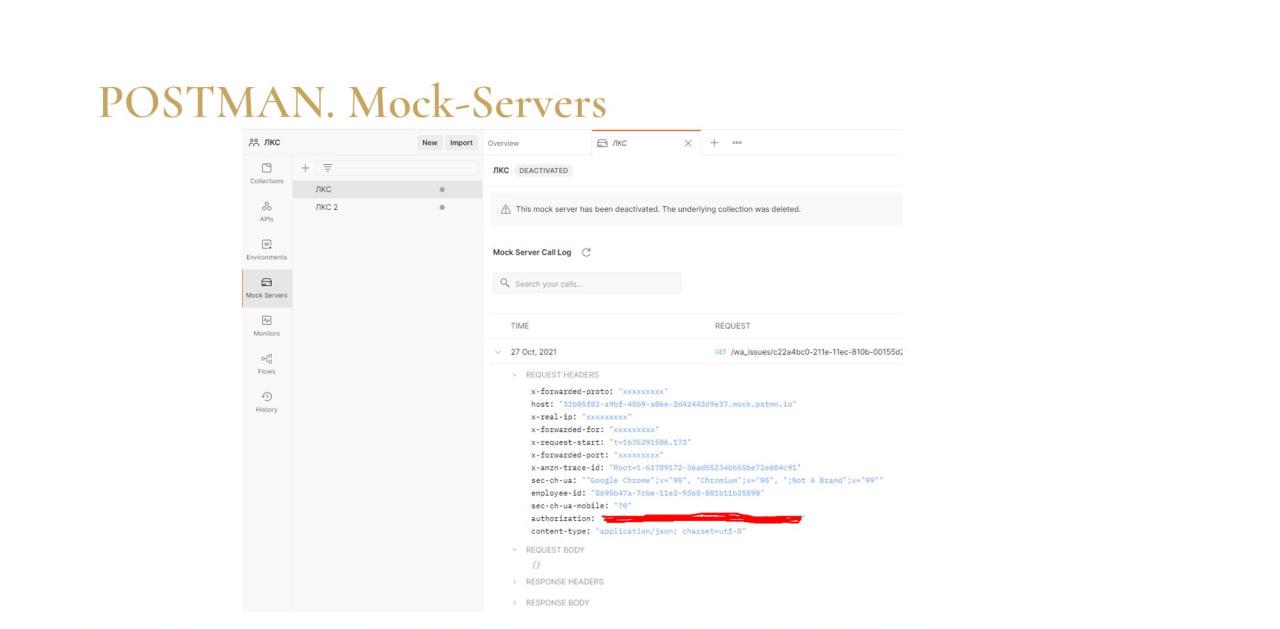
При успешно пройденной валидации mock-сервер вообще поднимается в два клика.
Мы нажимаем «Создать mock-сервер», Postman немного думает и выдает нам в рамках wildcard mock-сервер, который можно фактически взять и уже отдать нашему потребителю.
Вот это – настоящий low-code. Мы не написали в 1С ни одной строчки кода, не сделали вообще ничего. Мы просто потыкали и уже можем попытаться загрузить данные от того, кто будет когда-нибудь использовать наш сервис.
И это при том, что сервиса у нас еще нет. У нас, возможно, даже 1С еще нет. А мы уже придумали и кому-то дали наше API на имплементацию.
Понятно, что потом нам нужно будет обрабатывать всякие риски, соответствовать своей репутации. Но это уже второй вопрос.
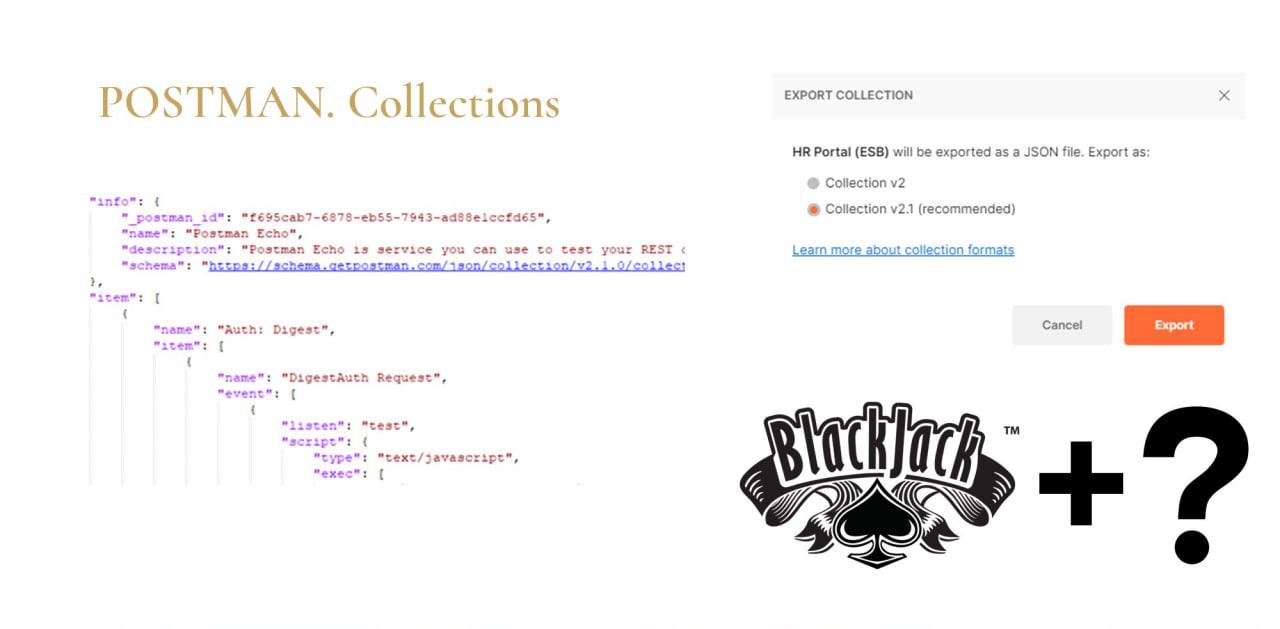
Давайте немного заглянем в Postman под капот.
На вход он работает через API. А ядром у него выступает пространство Collections. В рамках коллекции можно начать работать, даже не имея спецификации сервиса. Можно набросать структуру, которая самостоятельно уже позволит вам:
-
сформировать тот же самый mock-сервер;
-
сформировать документацию;
-
поднять какие-то тесты, если этот сервис существует в каком-то продакшене.
Единственный минус – все это нужно будет делать руками. То есть фактически можно, но вроде как неприкольно.
Еще коллекцию можно импортировать из другого источника – с импортом у них все хорошо.
Но экспорт возможен только в формате Postman. Это закономерно, потому что экспортируются и моки, и тесты, и мониторинги. А спецификации на это, понятно, не рассчитаны. Поэтому это закономерно и логично.
Возможности Mule ESB
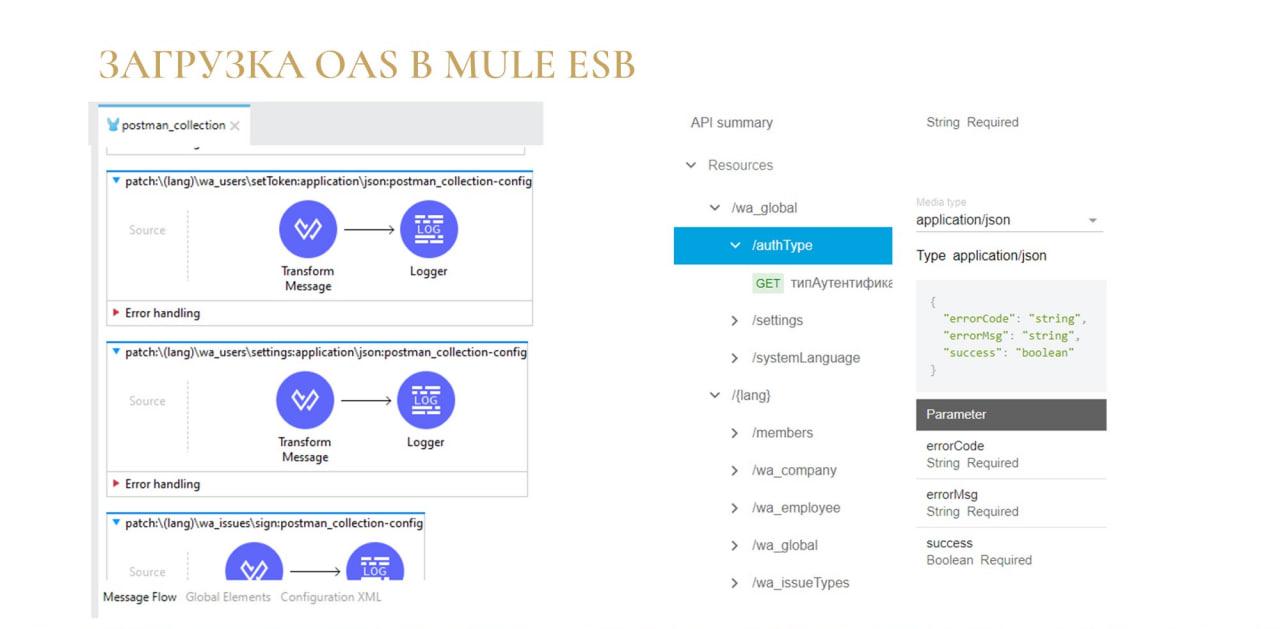
Помните, я сказал о том, что в 1С отсутствует возможность чтения или работы с какой-то спецификацией с описанием REST API? На слайде показан пример из шины Mule ESB, которая фактически в три клика реализует API на базе описания по спецификации:
-
ты ей говоришь: «У меня есть вот такая спецификация», выбираешь файл спецификации и нажимаешь «Загрузить»;
-
а она тебе сразу генерит все роуты, все связи, все трансформы;
-
дополнительно это все внутри себя логирует;
-
а тебе при необходимости остается только докинуть использование каких-то конечных эндпоинта – и все, продакшн сервер готов.
Я не только один из главных приверженцев использования API-first подхода при проектировании и разработке систем, которые состоят из разных элементов, но еще я везде, где могу, всегда использую шины данных ESB.
У программного обеспечения класса ESB есть определенный ряд преимуществ.
-
Например, отсутствие необходимости публиковать 1С-ную базу наружу. Конечно, это можно спокойно реализовать и без шины через nginx, прокси и завязку на какой-то отдельный сервис. Но с шиной это более безопасно.
-
Кроме этого, шина упрощает прохождение 1С-ной авторизации для нашего сервиса. Мы на шине внутри нашего контура прописываем использование каких-то логинов, паролей и наружу это все не выходит. И снаружи мы уже проходим как будто внутрь базы по тем параметрам, которые заданы заранее. И реализуем авторизацию для сервиса уже на уровне самой 1С, а не на уровне той системы авторизации, которая реализована на текущий момент в 1С.
-
Нужно, допустим, добавить асинхронность – пожалуйста, рядом с шиной ставим RabbitMQ, Kafka, коннекторы. Ни потребитель сервиса, ни поставщик сервиса ничего у себя не меняет, но она работает в асинхроне.
-
Нужно добавить какое-то специфическое логирование – пожалуйста, рядом ClickHouse, Elasticsearch, коннектор кинули, асинхронно отвели, пожалуйста, все залогировано.
-
Нужно какой-то кэш добавить. Да легко, кинули рядышком Redis, развели все на шине и пожалуйста, у нас горячий кэш, который может управляться.
Мы у себя используем Mule ESB и это – одна из самых классных шин, с которыми мне приходилось работать. А я работал и с WSO2, и с Zato ESB.
У Mule ESB как у шины есть только один недостаток – она условно бесплатная. Там есть бесплатная функциональность, а есть функциональность, которая стоит денег, и немало. Например, мы в WiseAdvice, я признаюсь честно, не смогли купить Mule ESB, хотя когда-то хотели. И не потому, что она очень дорогая, а как минимум потому, что она не продается на территории РФ.
По подходу Mule ESB очень сильно похожа на конфигуратор – кода там фактически нет, достаточно набросать что-то из готовых блоков, которые можно взять в маркетплейсе.
Очень удобно, имея всего лишь описание, на его основе сгенерировать API. В 1С ничего подобного нет – ты можешь только посадить разработчика и заставить его сначала прочитать спецификацию, а потом попытаться реализовать.
ANTI_SWAGGER. Концепция и реализация
Когда мы посмотрели на возможности Postman и Mule ESB, где у нас есть спецификации, описания и моки, мы загрустили. Потому что у нас каждый новый 1С-ник приходит, и у него свое видение на развитие и управляемость HTTP-сервисов.
Но что нам мешает сделать то же самое для 1С? Спецификации нам известны. Да и лучшие паттерны проектирования тоже придуманы еще в 1970-х годах.
Так мы пришли к концепции своего продукта ANTI_SWAGGER. Это open source решение, которое разрабатывается на GitHub, сделано на основе небезызвестного всем OneScript и опубликовано также в хабе пакетов.
Каждый из вас может его спокойно взять, скачать, попробовать, потыкать. И я надеюсь, что когда-то мы начнем его совместно дорабатывать.

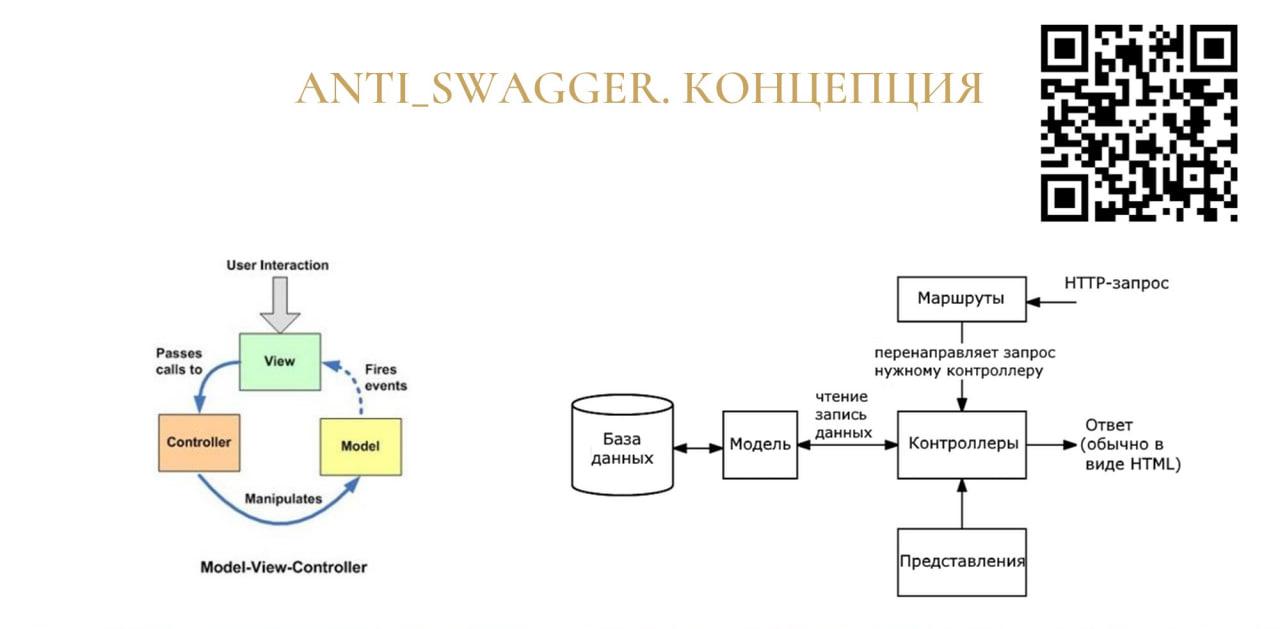
Приложение ANTI_SWAGGER делает то, чего нет в 1С. Ему на вход подается спецификация, а на выходе оно дает расширение, которое сделано в рамках паттерна проектирования Model-View-Control – я надеюсь, это небезызвестные для вас слова.
Кстати, у фирмы «1С» есть одна типовая конфигурация, которую, по их словам, они сделали в рамках паттерна проектирования Model-View-Control. Не поверите, это ЗУП3. Кто-нибудь пробовал писать в ЗУП3? Сколько слез из-за нее было пролито? Но, как только мы понимаем и принимаем схему MVC, мы сразу понимаем, насколько там все продумано.
Недавно в чате «Сообщество 1С-разработчиков» я видел замечание о том, что ЗУП – это флагманское решение фирмы 1С, которое всегда все делает правильно. Оно все правильно считает и все правильно показывает. Это действительно флагманское решение. Я надеюсь, что именно из-за этого ЗУП-разработчики стали отдельной кастой, а не из-за того, что в ЗУП используются никем больше не используемые регистры расчета, вытесняющие начисления и т.д. и т.п.
Мы сделали расширение, которое генерится в рамках паттерна Model-View-Control, как мы его понимаем.
Все начинается с маршрутов. На слайде представлено, как выглядит в созданном расширении часть маршрутов. Здесь и далее я показываю одну и ту же, по сути, примитивненькую процедуру, без нагруженности кода, которая разбивается на четыре составляющие – часть маршрутов, часть контроллера, часть модели и часть представления.

Здесь на слайде показана часть контроллера для этого метода.
Например, когда к нам зашел запрос, мы его сразу транслируем внутрь контроллера.
Задача контроллера – передать контекст в модель. В рамках контроллера мы можем анализировать какие-то показатели, вытаскивать какие-то параметры, что-то с чем-то связывать.
При этом фактически контроллер не относится к модели и к данным – это больше описание самого сервиса. У нас там есть head, options. Он даже может не доходить до модели, а сразу генерить результат и отвечать обратно.

Дальше – часть модели.
В модели выполняется взаимодействие со всеми объектами 1С. Мы договорились о том, что модель – это часть, которая взаимодействует непосредственно с данными.
Представьте, что вы на стороне потребителя сервиса смотрите на API-шку – вы же не знаете, что там. Мы для упрощения договорились о том, что для нас любые объекты, которые находятся внутри 1С, могут быть доступны исключительно из уровня модели.
Фактически, это как слои. Мы из слоя (модуля) модели получаем доступ к какому-то объекту – допустим, к справочнику «Пользователи».
Мы получаем доступ к объектам 1С либо из модели, либо из производных от модели, к которым относятся общие модули, реализующие специфическую логику для записи или чтения из базы данных. Т.е. любая бизнес-логика – это исключительно дело моделей и производных от них.
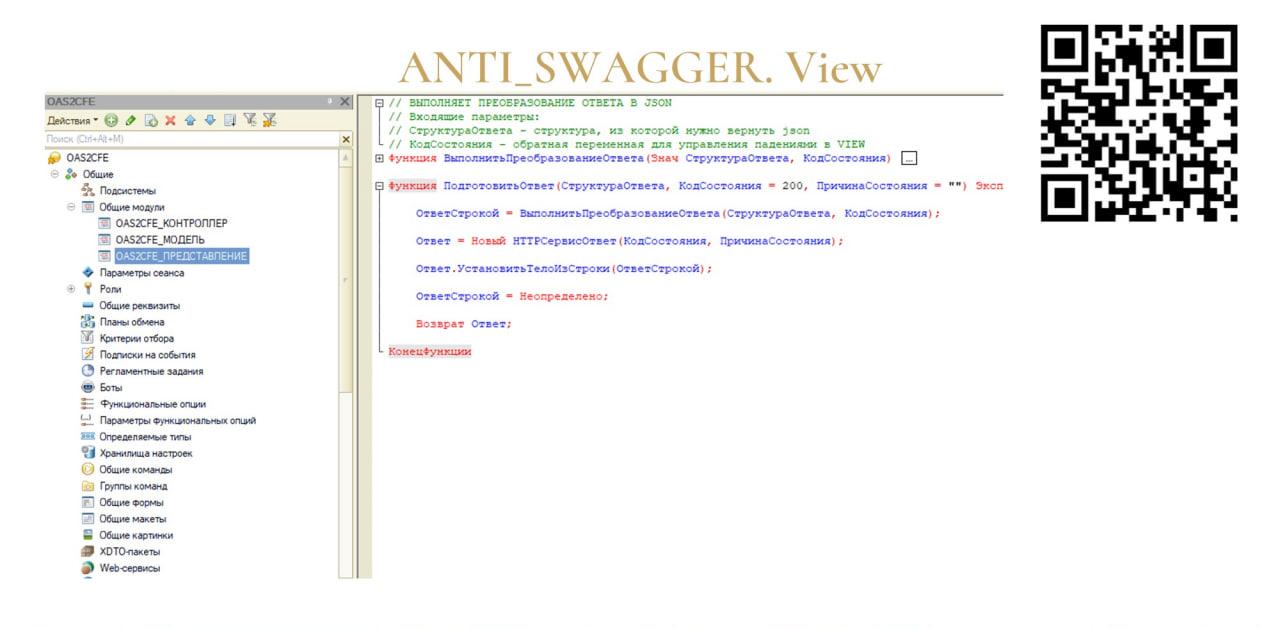
Часть представления (View) отвечает исключительно за представление данных на выходе сервиса.
-
Если нам, допустим, нужно сгенерить ответ в JSON – этим занимается исключительно слой View.
-
Или мы хотим видеть на выходе XML – этим будет заниматься исключительно слой View.
-
Или, допустим, нужно вернуть двоичные данные – опять же, этим будет заниматься исключительно слой View.
ANTI_SWAGGER. Планы на развитие

Приложение получилось классным, я воспринимаю его как некоторый прорыв в рамках своего горизонтального роста.
По сути, приложение построено на принципе классической кодогенерации. Но это первое приложение на моей памяти, которое генерирует код 1С согласно входным параметрам, не имеющим отношения к 1С, без разработчика 1С.
Что хотелось бы отметить по поводу развития приложения?
-
Вы наверняка знаете, что такое автономный сервер – это программа, которая достаточно легко поднимается, работает в докере и не требует лицензирования до определенного количества пользователей. Он входит в дистрибутив сервера 1С, начиная с платформы 8.3.17. Так вот, представьте, что у вас есть база, в которую вы можете на базе спецификации и известных результатов в два клика загрузить расширение, и она будет работать как mock-сервер. Понятно, что там еще есть нюансы из раздела мониторинга, тестирования, но это отдельная часть. Мы планируем реализовать mock-сервер на 1С, поднимающийся за две минуты, который поможет объяснить новому члену команды, какую часть кода он должен написать в каком месте. Поскольку мы применяем паттерн MVC, мы говорим о том, что с данными – в модель, с параметрами – в контроллер, с представлением – во View.
-
Также есть резервы для развития – на текущий момент авторизация доходит до уровня модели, а хотелось бы оставить ее на уровне контроллера.
-
Еще на текущий момент данное приложение воспринимает данные OpenAPI 3.0. А нам, конечно, хотелось бы развиться до восприятия более старых спецификаций.
-
Также на будущее мне хочется реализовать поддержку коллекций, которые выгружаются из Postman.
-
И хочется дойти до уровня генерации не расширения, а целостной конфигурации, в которой будет завязка, логическое обоснование и возможное применение каких-то других, не только MVC-паттернов проектирования. Например, есть паттерн MVVM (Model-View-View-Model), когда View влияет на Model. Но это – отдельная тема для обсуждения.
API-first для взаимодействия разнородных систем, которые обслуживают разные люди

Расскажу, зачем нам вообще API-first. У нас в компании есть определенный пласт продуктов, которые состоят из двух элементов:
-
из фронта на Angular;
-
и бэка на чистом 1С, который работает через шину Mule ESB.
При этом понятно, что фронт пишут не 1С-ники, а ангулярщики. И когда мы начинали, мы работали с Code-first.
Но пока 1С-ник напишет, опубликует, опишет то, что написал, пока он дойдет до фронта – это сколько же времени потратится на то, чтобы проверить минимальную гипотезу.
И вот тут мы поняли о том, что API-first – это в первую очередь о проверке гипотез, о доставке изменений до целевой аудитории, до конечных потребителей. Это – уменьшение Time To Market.
API-first вам нужен:
-
если ваши системы состоят из разных элементов, и элементы вашей системы обслуживают разные люди;
-
если ваши системы связаны посредством REST API;
-
если у вас есть потребность уменьшения Time To Market.
Конечно, если ваша 1С взаимодействует с другой 1С-системой, вам достаточно использовать подход Code-first. Но в любых других случаях API-first полезен всегда.
Я надеюсь, что застану то время, когда мы перестанем писать код в принципе. Мы будем звонить какому-то боту, наговаривать ему что-либо, а он будет выдавать результаты и предлагать возможные варианты. Это – мои мечты.
Хочу акцентировать внимание, что продукт anti_swagger – это open source продукт. Каждый из вас может присоединиться к репозиторию на GitHub и внести посильную лепту в его развитие.
Сейчас это все сделано на примитивных шаблонах генерации конфигурации. Но каждый из вас может форкнуть и попытаться реализовать что-то свое. Может даже свою спецификацию.
Например, кто мешает запихнуть на вход вместо спецификации OpenAPI язык Gherkin для создания тестов? Любой из вас может сделать так, чтобы anti_awagger принимал на вход Gherkin. Мы не монополизируем наш продукт, а даем возможность развивать его для сообщества.
Вопросы
Вы сказали, что если 1C-ник с 1C-ником интегрируется, им не нужно использовать API-first подход.
Я сказал о том, что API-first подход хорошо работает, когда у людей разные специализации. А 1С-ники в основном взаимозаменяемы – вы можете легко одного 1С-ника пустить в одну систему, а второго 1С-ника в другую систему. Тем более, если они еще и в рамках одной компании работают. Если в разных компаниях работают – тоже, но тут, конечно, могут быть нюансы.
Вы предполагаете, что они в одной компании сами договорятся, без описания, без спецификаций, и пойдут пилить в двух системах?
Конечно они потом оба будут бегать вокруг с напильниками и немного это подтачивать, но ничего, потом все у всех сойдется. Не всегда хорошо, не всегда красиво, но сойдется.
Но ангулярщики же тоже порой не совсем суровые люди.
С ангулярщиками сложнее, они к мокам уже привыкшие. Они привыкли, что спецификация API должна соответствовать реализованному API. И если они косячат, то это чисто их зона ответственности. Это значит, что они в рамках своего фронтэнд-приложения заложили неправильную логику.
Я так понял, anti_swagger реализует модель MVC. А какие запросы помимо простейших POST и GET он может реализовать?
Там строится расширение для обслуживания сервиса в рамках Model View Control, которое реализует все запросы, что есть в спецификации.
Я же делал оговорку о том, что в рамках options или head до модели даже доходить не надо. Оно должно возвращаться с уровня контроллера. Потому что это спецификация самого сервиса, а не модели либо того, что касается каких-то данных внутри базы.
Он сам построит это до контроллера?
Сейчас не построит, но это резервы в рамках anti_swagger, которые реализуем либо мы в рамках развития своих продуктов, так как мы это у себя используем. Либо самостоятельно реализует кто-то, кому этот продукт, я надеюсь, будет нужен.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции Infostart Event.

Вступайте в нашу телеграмм-группу Инфостарт