В статье подробно описан процесс выгрузки данных из технологического журнала 1С и их загрузки в Elasticsearch с использованием Logstash.
Это позволит организовать гибкий поиск и аналитику по журналу в Elasticsearch Kibana.Сможете увидеть информацию о работе 1С в виде красивых графиков и дашбордов.
Рассмотрены шаги по настройке 1С, установке и конфигурированию Logstash, подготовке Elasticsearch для приема данных.
Цель
Целью данного решения является организация хранения и анализа данных из технологического журнала 1С с использованием стека Elasticsearch + Logstash + Kibana.
Компонентный состав решения
Основные функции Logstash:
- Чтение исходных данных из разных источников (файлы, базы данных, API)
- Парсинг и нормализация данных
- Фильтрация и обогащение данных
- Трансформация данных в нужный формат
- Отправка данных в нужное хранилище
Без Logstash пришлось бы делать всю эту работу вручную при подготовке данных для Elasticsearch. А с Logstash весь процесс выгрузки и преобразования данных описывается конфигурационными файлами.
Таким образом, Logstash берет на себя всю рутинную работу по обработке данных от источника до приёмника. Это экономит время разработчика и избавляет от сложной ETL-разработки.
Kibana необходима для удобной визуализации и анализа данных, хранящихся в Elasticsearch.
Elasticsearch нужен для реализации быстрого и гибкого поиска и аналитики по данным технологического журнала 1С.
Обычно Elasticsearch используется для решения таких задач:
- Поиск информации - быстрый и точный поиск по большим массивам текстов, файлов, данных.
- Аналитика - построение срезов, выявление тенденций, группировки. Позволяет извлекать ценные знания из данных.
- Мониторинг - agregaция и визуализация метрик в реальном времени.
- Лог-аналитика - хранение, поиск и анализ логов систем и приложений.
- Программная аналитика - анализ кода и данных о разработке ПО.
- Геопространственная аналитика - поиск и визуализация геоданных на картах.
Основные преимущества Elasticsearch:
- Высокая скорость поиска и анализа больших данных.
- Масштабируемость - легко расширять ёмкость кластера.
- Отказоустойчивость - данные реплицируются по узлам кластера.
- Гибкость - можно хранить и производить поиск по данным в любом формате.
- Простота - документно-ориентированный подход, прост в освоении.
Logstash нужен для извлечения данных из технологического журнала 1С и их преобразования в формат, пригодный для загрузки в Elasticsearch
Подготовка
Для того чтобы приступить нужен будет фрагмент журнала регистрации и установленный докер.
Установка kibana и elastic
Создаем такое докер композ файл:
version: "3.7"
networks:
elastic:
name: elastic
driver: bridge
services:
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:7.15.0
container_name: es
restart: unless-stopped
networks:
- elastic
ports:
- "9200:9200"
- "9300:9300"
environment:
- discovery.type=single-node
- xpack.security.enabled=false
logging:
options:
max-size: "100m"
max-file: "3"
kibana:
image: docker.elastic.co/kibana/kibana:7.15.0
container_name: kibana_lg
restart: unless-stopped
networks:
- elastic
ports:
- "5601:5601"
depends_on:
- elasticsearch
logging:
options:
max-size: "100m"
max-file: "3"
Основные возможности Kibana:
- Построение графиков и диаграмм по данным из Elasticsearch
- Создание информационных панелей (дэшбордов)
- Визуальный конструктор запросов и фильтров
- Быстрый поиск по данным с подсветкой результатов
Без Kibana пришлось бы использовать только текстовый API Elasticsearch для поиска и анализа данных. Это крайне неудобно.
Kibana делает работу с данными в Elasticsearch понятной и доступной для пользователя без навыков программирования. Это opened-source альтернатива BI-инструментам вроде Power BI.
Думаю тут особо ничего не надо комментировать, единственное про logging options включенные могу добавить, что это чтобы логи много места не занимали, т.к. там все в лог будет писаться, а это огромные объемы данных в обычном текстовом виде.
После команды
docker-compose up -d
Появятся запущенные контейнеры кибаны с эластиком:

На этом все с эластиком и кибаной, кибана будет доступна http://localhost:5601/
Еще может потребоваться VPN, чтобы загрузить образы для контейнеров.
Установка logstash
Дополняем докер композ файл:
logstash:
image: logstash:7.16.1
container_name: log
environment:
discovery.seed_hosts: logstash
LS_JAVA_OPTS: "-Xms512m -Xmx512m"
volumes:
- ./logstash/pipeline/logstash-tj.config:/usr/share/logstash/pipeline/logstash-tj.config
- ./logstash/pipeline/patterns:/usr/share/logstash/pipeline/patterns
- ./logs:/var/log/logtj
ports:
- "5005:5005/tcp"
- "5005:5005/udp"
- "5044:5044"
- "9600:9600"
depends_on:
- elasticsearch
networks:
- elastic
logging:
options:
max-size: "100m"
max-file: "3"
command: logstash -f /usr/share/logstash/pipeline/logstash-tj.config
Структура каталогов следующая:
Основные возможности Kibana:
- Построение графиков и диаграмм по данным из Elasticsearch
- Создание информационных панелей (дэшбордов)
- Визуальный конструктор запросов и фильтров
- Быстрый поиск по данным с подсветкой результатов
Без Kibana пришлось бы использовать только текстовый API Elasticsearch для поиска и анализа данных. Это крайне неудобно.
Kibana делает работу с данными в Elasticsearch понятной и доступной для пользователя без навыков программирования. Это opened-source альтернатива BI-инструментам вроде Power BI.
Папка
./logs - тут будут хранится логи которые будем парсить, т.е. каталоги rphost_* с логами.
./logstash/pipeline/patterns - файл с паттернами грока, примерно что это такое можно быстро глянуть тут.
./logstash/pipeline/logstash-tj.config - сам конфиг пайплайна логстеша.
Настройка Logstash
Структура конфигурационного файла logstash
Конфигурационный файл Logstash имеет следующую структуру:
- Input - настройка источника данных. Может быть файл, сетевой порт, база данных и т.д. Определяет откуда брать данные.
Пример:
input { stdin { } }
- Filter - фильтры и преобразования данных. Используются для парсинга, структурирования, модификации данных.
Пример:
filter { grok { match => { "message" => "%{COMBINEDAPACHELOG}" } } }
- Output - настройка куда помещать обработанные данные. Может быть Elasticsearch, файл, Kafka и др.
Пример:
output { elasticsearch { hosts => ["http://elasticsearch:9200"] } }
В целом конфиг по схеме - откуда брать, как обрабатывать, куда класть данные.
logstash-tj.config
input {
file {
path => "/var/log/logtj/*/*.log"
start_position => "beginning"
sincedb_path => "/dev/null"
tags => [ 'onec' ]
codec => multiline {
pattern => "^[0-5][0-9]:([0-5]?[0-9]|60).[0-9]{6}"
negate => 'true'
what => 'previous'
}
}
}
Что означает эта настройка:
- file - означает, что источником данных являются файлы.
- path - указывает путь к лог-файлам, из которых будут считываться данные. Здесь это все файлы с расширением .log в директории /var/log/logtj/ и её поддиректориях.
- start_position - указывает, что читать файлы нужно с самого начала.
- sincedb_path - временная БД для хранения текущей позиции чтения из файлов. Здесь указан /dev/null, то есть эта БД не будет использоваться.
- tags - добавляет метку onec ко всем событиям из этих файлов.
- codec - настройка multiline фильтра для обработки многострочных сообщений:
- pattern - регулярное выражение для определения нового сообщения. Все строки до строки, подходящей под выражение, будут объединены.
- negate - true означает, что pattern применяется ко всем кроме подходящих строк.
- what - previous объединяет текущую строку с предыдущим сообщением.
То есть эта настройка input извлекает все лог-файлы из директории, объединяет многострочные сообщения и помечает события тегом onec.
filter {
if "onec" in [tags] {
grok {
patterns_dir => ["/usr/share/logstash/pipeline/patterns"]
match => { "message" => "%{TIME:MoH}[0-9]{3}-%{DURATION:duration_msec:int},%{TYPE:event},%{NESTING:nesting_level:int}" }
match => { "message" => ",process=%{PROCESS:process}" }
match => { "message" => "p:processName=%{PPROCESSNAME:pprocessname}," }
match => { "message" => "t:applicationName=%{WORD:application},"}
match => { "message" => "t:clientID=%{WORD:clientid},"}
match => { "message" => "Usr=%{USERNAME:username},"}
match => { "message" => "DataBase=%{USERNAME:infobase},"}
match => { "message" => "OSThread=%{WORD:osthread},"}
match => { "message" => "SessionID=%{WORD:sessionid},"}
match => { "message" => "Regions=%{REGION:region},"}
match => { "message" => "Locks=[\"\']%{INSIDEQUOTES:locks}[\"\'],"}
match => { "message" => "WaitConnections=%{WORD:waitconnections},"}
match => { "message" => "Context=[\"\']%{INSIDEQUOTES:context}[\"\']"}
match => { "message" => "Descr=[\"\']%{INSIDEQUOTES:description}[\"\']"}
match => { "message" => "Sdbl=[\"\']%{INSIDEQUOTES:sdbl}[\"\']"}
match => { "path" => ".*%{DaHFILE:DaH}\.log"}
break_on_match => false
}
mutate {
add_field => { "MyTime" => "%{DaH}%{MoH}" }
remove_field => [ "DaH", "MoH" ]
}
date {
match => ["MyTime", "yyMMddHHmm:ss.SSS"]
timezone => "Europe/Moscow"
remove_field => [ "MyTime" ]
target => "@timestamp"
}
ruby {
code => "
event.set('duration_sec', if event.get('duration_msec').to_i > 0 then event.get('duration_msec').to_i / 1000000 else 0 end)
event.set('duration_minutes', if event.get('duration_msec').to_i > 0 then event.get('duration_msec').to_i / 60000000 else 0 end)
"
}
}}
Эта настройка filter в Logstash выполняет разбор и обработку логов 1С, помеченных тегом onec. Рассмотрим по порядку:
- Секция if проверяет наличие тега onec.
- Далее идет разбор полей лога 1С при помощи grok и регулярных выражений. Извлекаются такие поля как duration_msec, event, nesting_level и многие другие.
- Затем дата и время извлекаются в отдельные поля, объединяются в MyTime и конвертируются в timestamp @timestamp.
- Поля DaH и MoH удаляются, так как более не нужны.
- Руби код рассчитывает дополнительные поля duration_sec и duration_minutes на основе duration_msec.
Таким образом из "сырого" лога 1С извлекаются все необходимые поля и метаданные, структурируя данные для дальнейшего анализа в Elasticsearch.
output {
if "onec" in [tags] {
elasticsearch {
hosts => ["http://es:9200"]
index => "onec-%{+YYYY.MM.dd}"
}
stdout {
codec => rubydebug
}
}
}
Эта настройка output в Logstash выполняет следующие действия:
- Проверяет, есть ли в событии тег onec.
- Если да, отправляет событие в Elasticsearch на узел es:9200.
- Индекс в Elasticsearch имеет вид onec-YYYY.MM.dd, то есть данные будут разбиты по дням.
- Также выводит событие в stdout с детализацией в формате rubydebug - это помогает отлаживать.
- Если тега onec нет, то ничего делать не будет - событие игнорируется.
То есть эта настройка выделяет события, помеченные тегом onec, индексирует их в Elasticsearch по дате и выводит в лог для отладки.
Что такое grok в секции filter
Grok - это инструмент в Logstash для парсинга и структурирования неструктурированных данных, таких как логи.
Grok использует регулярные выражения и шаблоны для извлечения данных из текста логов в именованные поля.
Например, есть такой паттерн для парсинга логов веб-сервера Nginx:
%{IPORHOST:clientip} - %{NGUSERNAME:ident} \[%{HTTPDATE:timestamp}\] "%{WORD:method} %{URIPATHPARAM:request} HTTP/%{NUMBER:httpversion}" %{NUMBER:response} (?:%{NUMBER:bytes}|-) (?:"(?:%{URI:referrer}|-)"|%{QS:referrer}) %{QS:agent}
Он извлекает такие поля как clientip, ident, timestamp, method, request, httpversion и т.д.
Пример работы:
Лог: 127.0.0.1 - john [09/Mar/2018:16:45:07 +0300] "GET /api/v2/songs HTTP/1.1" 200 786 "https://site.com/songs?genre=pop" "Mozilla/5.0 (Windows NT 10.0; Win64; x64)
Результат парсинга:
clientip: 127.0.0.1 ident: john timestamp: 09/Mar/2018:16:45:07 +0300 method: GET request: /api/v2/songs httpversion: 1.1 response: 200 bytes: 786 referrer: https://site.com/songs?genre=pop agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64)
Таким образом из "сырого" лога мы получаем структурированные данные для дальнейшего анализа.
Grok - это инструмент в Logstash для парсинга и структурирования неструктурированных данных, таких как логи.
Grok использует регулярные выражения и шаблоны для извлечения данных из текста логов в именованные поля.
Например, есть такой паттерн для парсинга логов веб-сервера Nginx:
%{IPORHOST:clientip} - %{NGUSERNAME:ident} \[%{HTTPDATE:timestamp}\] "%{WORD:method} %{URIPATHPARAM:request} HTTP/%{NUMBER:httpversion}" %{NUMBER:response} (?:%{NUMBER:bytes}|-) (?:"(?:%{URI:referrer}|-)"|%{QS:referrer}) %{QS:agent}
Он извлекает такие поля как clientip, ident, timestamp, method, request, httpversion и т.д.
Пример работы:
Лог: 127.0.0.1 - john [09/Mar/2018:16:45:07 +0300] "GET /api/v2/songs HTTP/1.1" 200 786 "https://site.com/songs?genre=pop" "Mozilla/5.0 (Windows NT 10.0; Win64; x64)
Результат парсинга:
clientip: 127.0.0.1 ident: john timestamp: 09/Mar/2018:16:45:07 +0300 method: GET request: /api/v2/songs httpversion: 1.1 response: 200 bytes: 786 referrer: https://site.com/songs?genre=pop agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64)
Таким образом из "сырого" лога мы получаем структурированные данные для дальнейшего анализа.
Запуск
Что мы сделали перед запуском:
1. Дополнили файл докер композа логстешем
2. Создали структуру каталогов и файлов, где хранятся настройки и откуда читаются логи
3. Настроили логстеш через конфигурационный файл пайплайна
Итак:
docker-compose up -d
Появятся запущенные контейнеры кибаны с эластиком и логстешем:

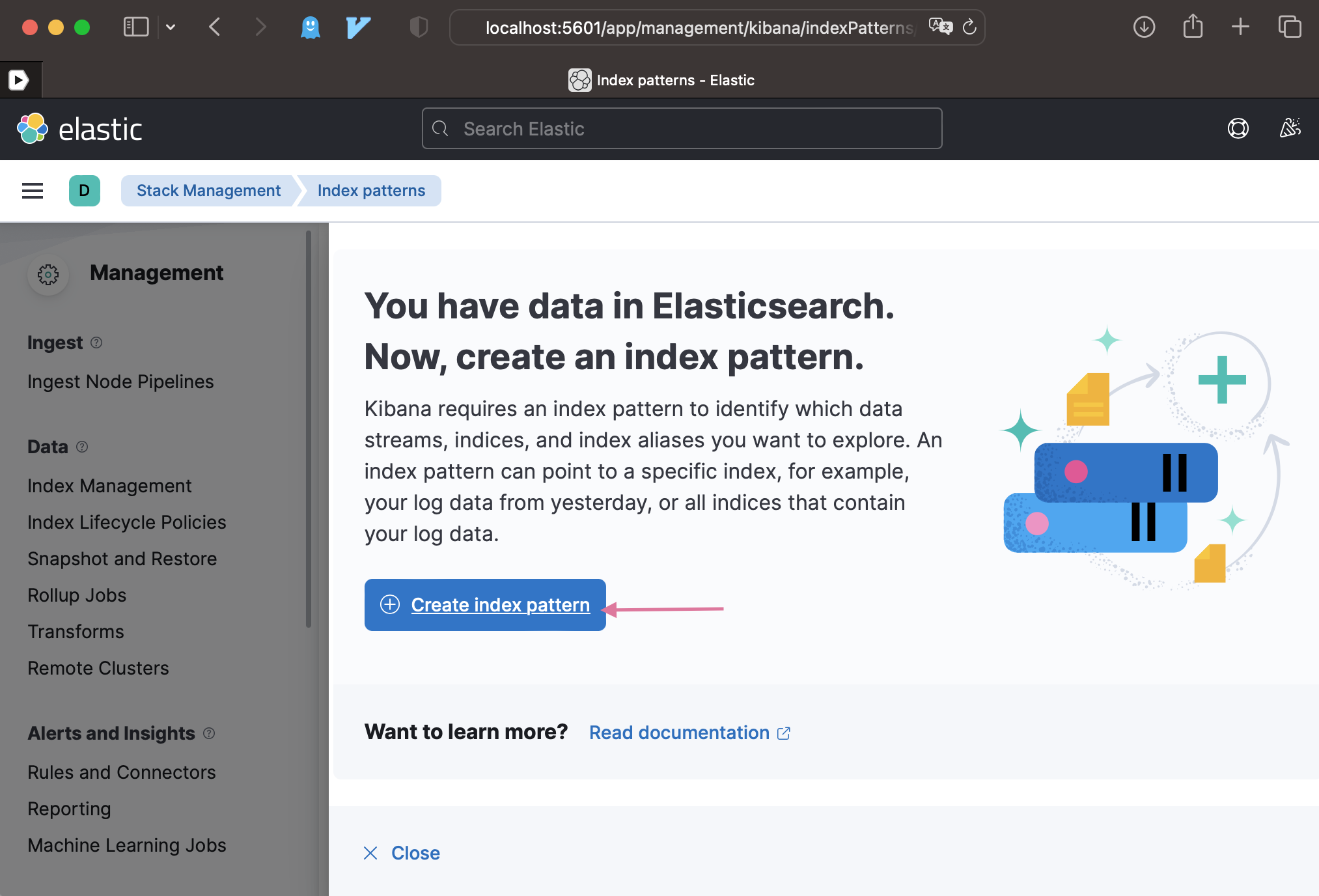
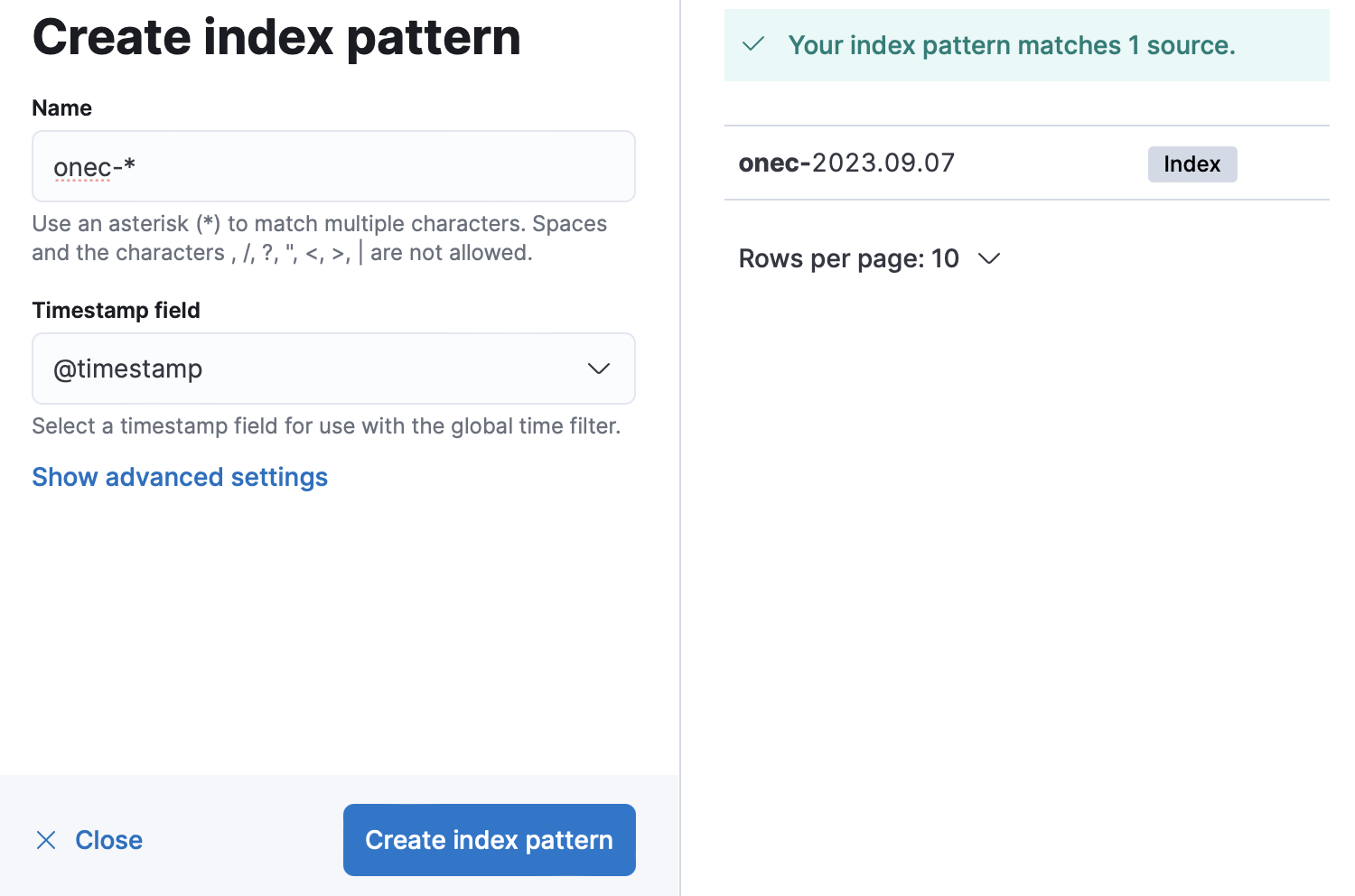
Открываем кибану, создаем индекс
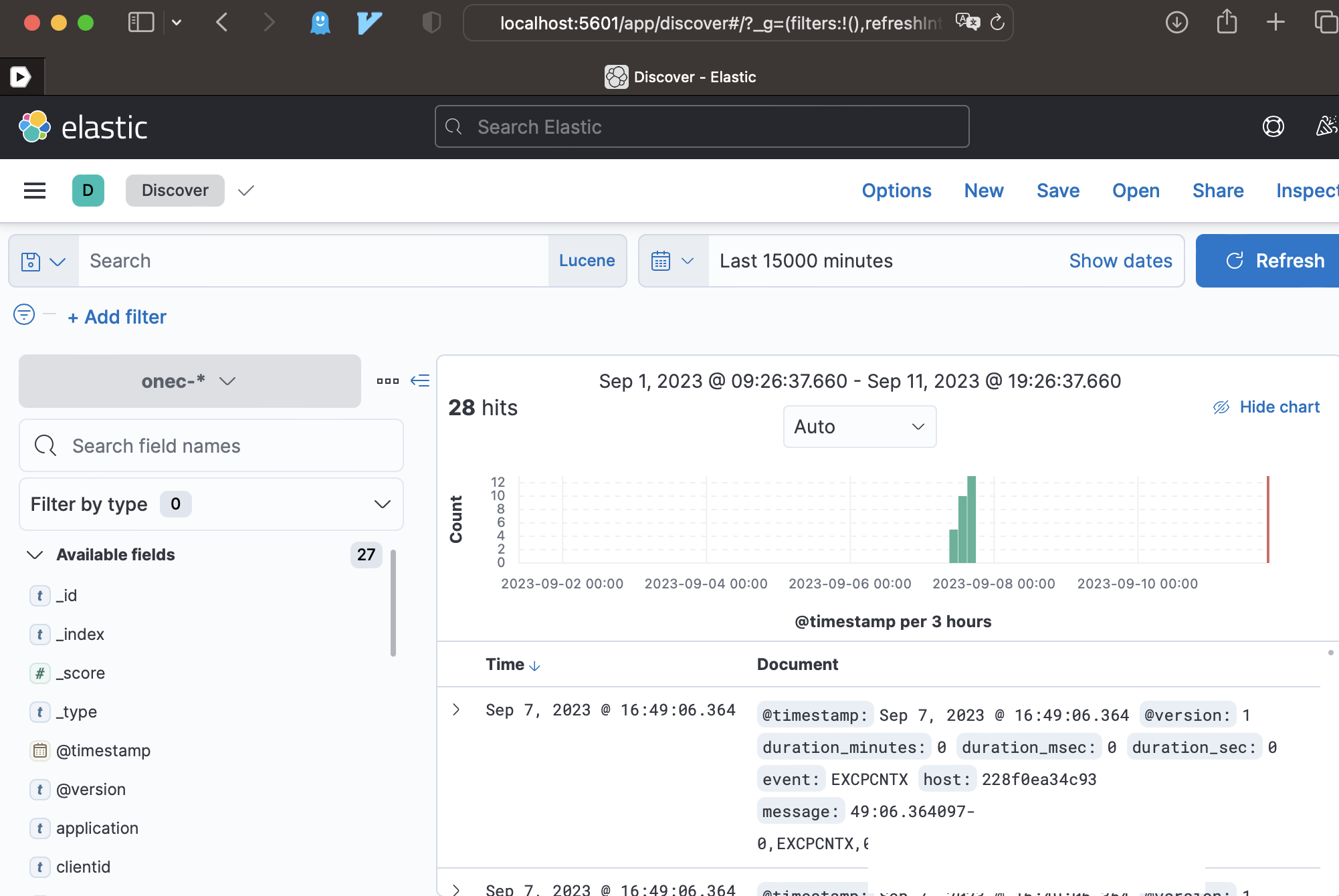
Идем в Discover кибаны http://localhost:5601/app/discover
И видим что там есть в индексе записи
Результат
Дальше можем посмотреть графики:
Что у нас по событиям EXCPCNTX
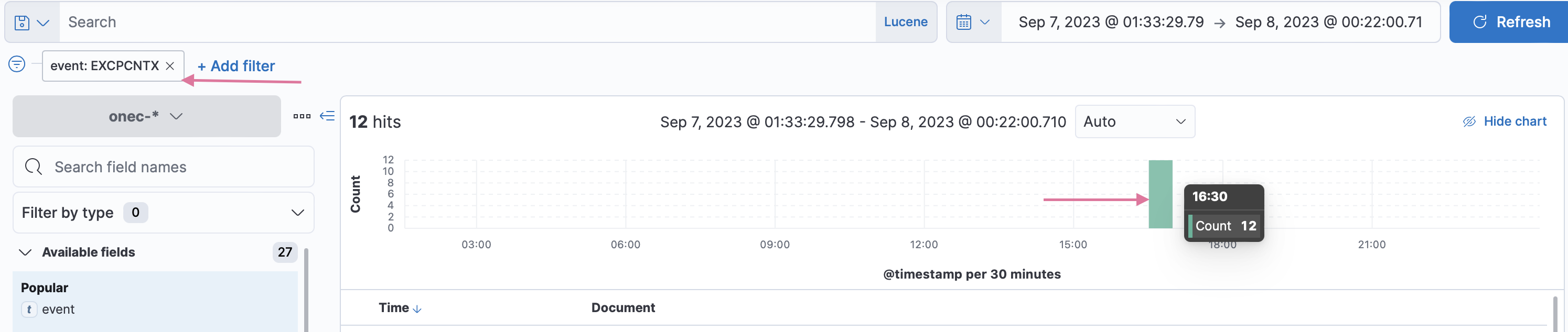 12 событий было
12 событий было
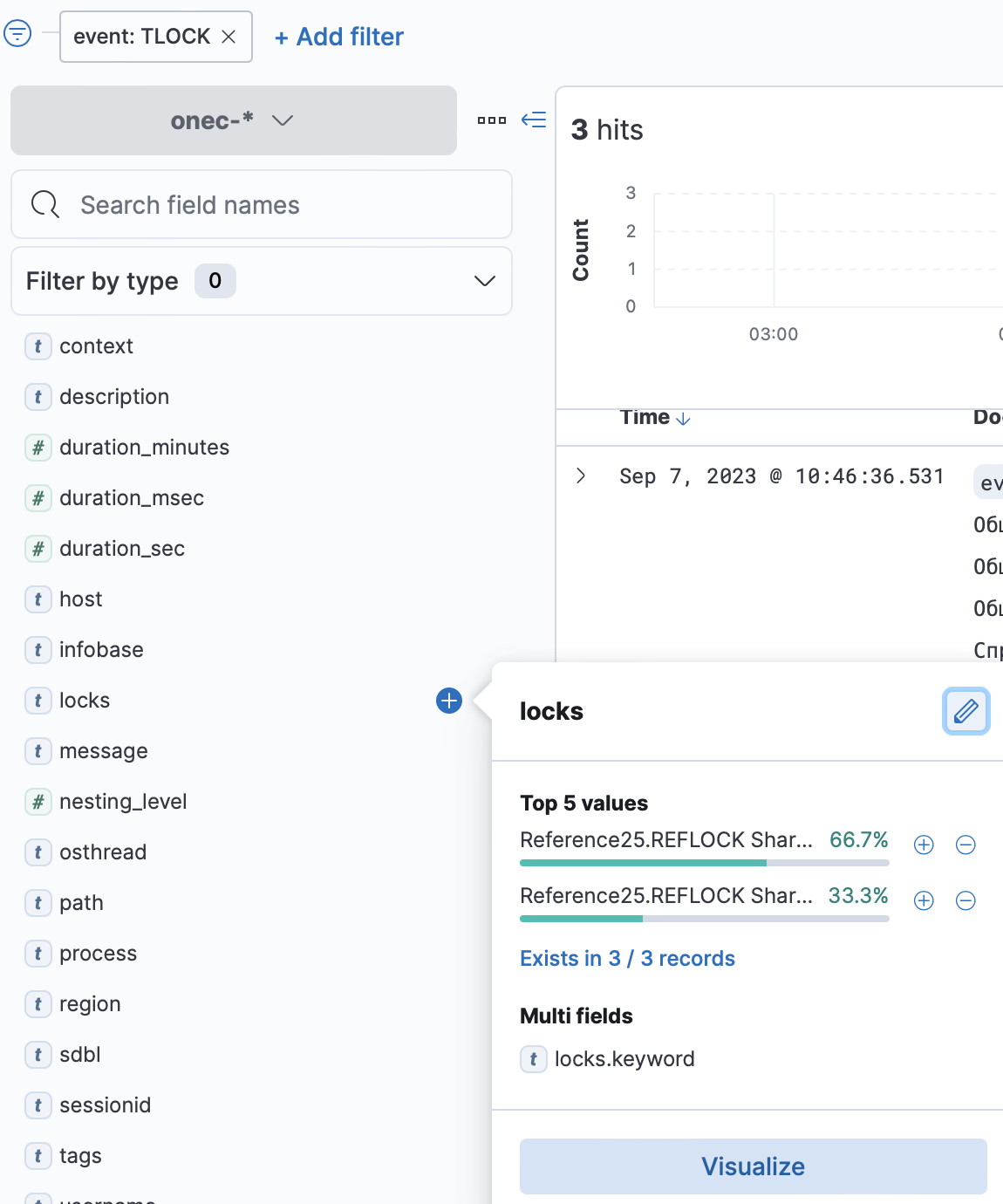
дальше можно сразу посмотреть что за приложение себя плохо чувствовало:
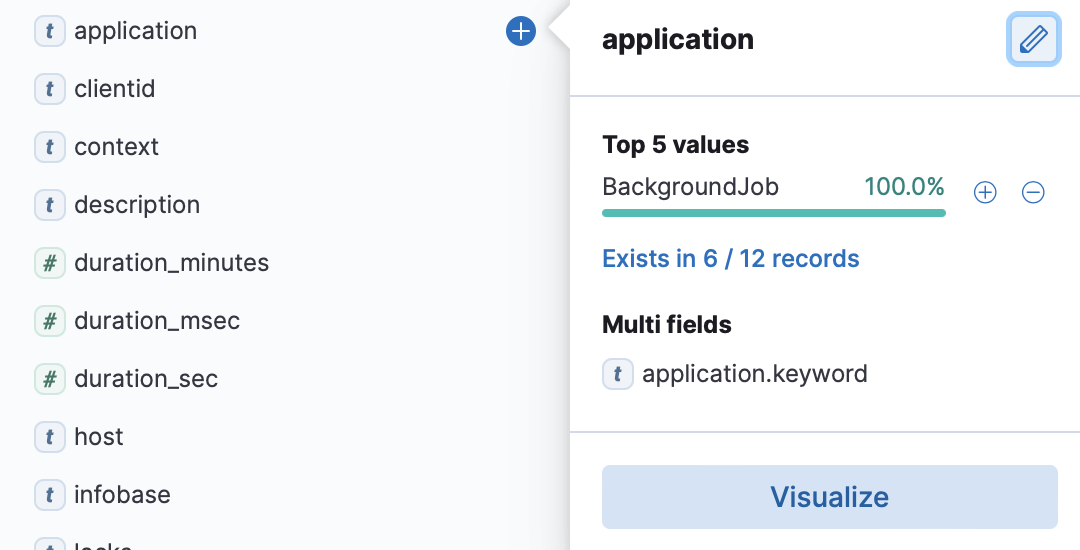
и т.д. дальше можно в один клик посмотреть в каких базах, по каким пользователям...
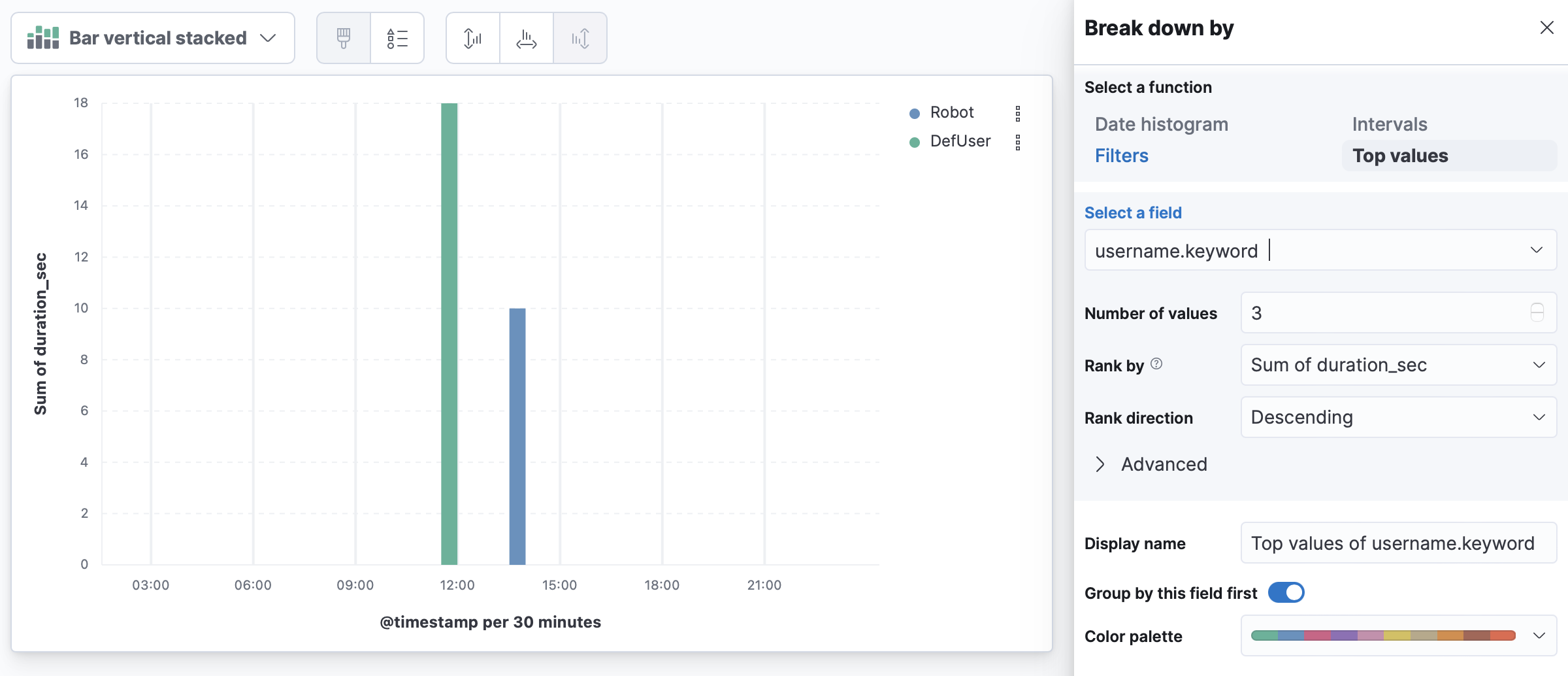 Это график по сумме полей Durations_sec по пользователям.
Это график по сумме полей Durations_sec по пользователям.
Т.е. у одного пользователя было вызовов на 18 сек а у другого на 10 сек.
Прочее:
Проект на github: Logstash_TechJournal_1C.
Обработка "FormCodeGenerator"
Обработка "FormCodeGenerator": Проект на GitHub
Статьи:
Модуль "FormEditor"(РедакторФорм)
Модуль "FormEditor"(РедакторФорм): Проект на GitHub
Статьи:
Модуль Kafka Adapter 1С (Confluent)
Модуль APM Adapter 1C (elastic)