
Наш проект заключался в переводе на PostgreSQL базы данных крупного заказчика – компании Полипластик.
Компания работает в облаке на конфигурации ERP2.4. До перехода база размещалась на СУБД MS SQL Standard.
В базе порядка 3 000 пользователей, онлайн работает около 1 000 – когда на Дальнем Востоке пользователи завершают свою работу, заходят пользователи в Центральной части России, поэтому график немного сглаживается.
В какой-то момент в базе начались определенные проблемы с производительностью, причем интенсивность этих проблем постепенно увеличивалась – это происходило месяца за три до всем известных событий.
Усугубляло ситуацию то, что в ближайшее время должно было открыться еще две площадки – это еще 150 пользователей плюсом.
Продолжать оперативную деятельность было бы проблематично. Поэтому мы поставили бизнес в известность о возможных проблемах. А бизнес спросил нас, что мы можем сделать. Мы дали два варианта – про оптимизацию мы не говорим, потому что мы ей и так занимались. Мы сказали, что решения проблемы нужно задействовать дополнительные мощности.
-
Первый вариант – это MS SQL Enterprise. В тот момент Microsoft подняла цену на него еще на 40% – он стал хорошим и дорогим.
-
И альтернативный вариант – попробовать PostgreSQL. На тот момент уже были некоторые успешные примеры.

Заказчик сказал: «Давайте попробуем. Только вы должны обещать, что все будет работать хорошо».
Мы восприняли это так, что, прежде чем переходить, нужно все предварительно хорошо проверить и протестировать. Качество сервиса нужно держать на высоком уровне.
Переход на PostgreSQL – серьезный проект

Прежде чем продолжить, давайте посмотрим, в чем отличия между MS SQL и PostgreSQL.
-
Первое отличие в том, что MS SQL вы все прекрасно знаете, все с ним работаете. По MS SQL куча докладов, знаний. А PostgreSQL все рассматривают как какую-то изюминку, просто необычную штуку, с которой вроде некоторые люди работают.
-
Второй момент – у нас, конечно, был опыт работы с PostgreSQL, но не для таких высоконагруженных систем. И когда мы начали исследовать эту тематику, была информация, что PostgreSQL работает немного медленнее. Мы провели ряд синтетических тестов на 1С и выяснили, что отставание PostgreSQL составляет приблизительно 20-40%.
-
Основное преимущество MS SQL в том, что ее планировщик запросов – более «умный», и это как раз сильно влияет на то, что PostgreSQL в обработке запросов оказывается медленнее. Это наиболее критично для высоконагруженных систем, где не просто 2-3 человека работают, а 500-1000 и больше.
-
Следующий момент, который мы заметили – фирма «1С» до определенного момента не очень уделяла внимание СУБД PostgreSQL. Сейчас они уже стали более активно работать в этом направлении, но на тот момент было так.
-
И конечно же, есть отличия в инструментах работы с PostgreSQL – там по-другому работает статистика, бэкапы. Когда вы будете решать этот вопрос у себя, обязательно принимайте это во внимание.
Примерный план работ по переходу
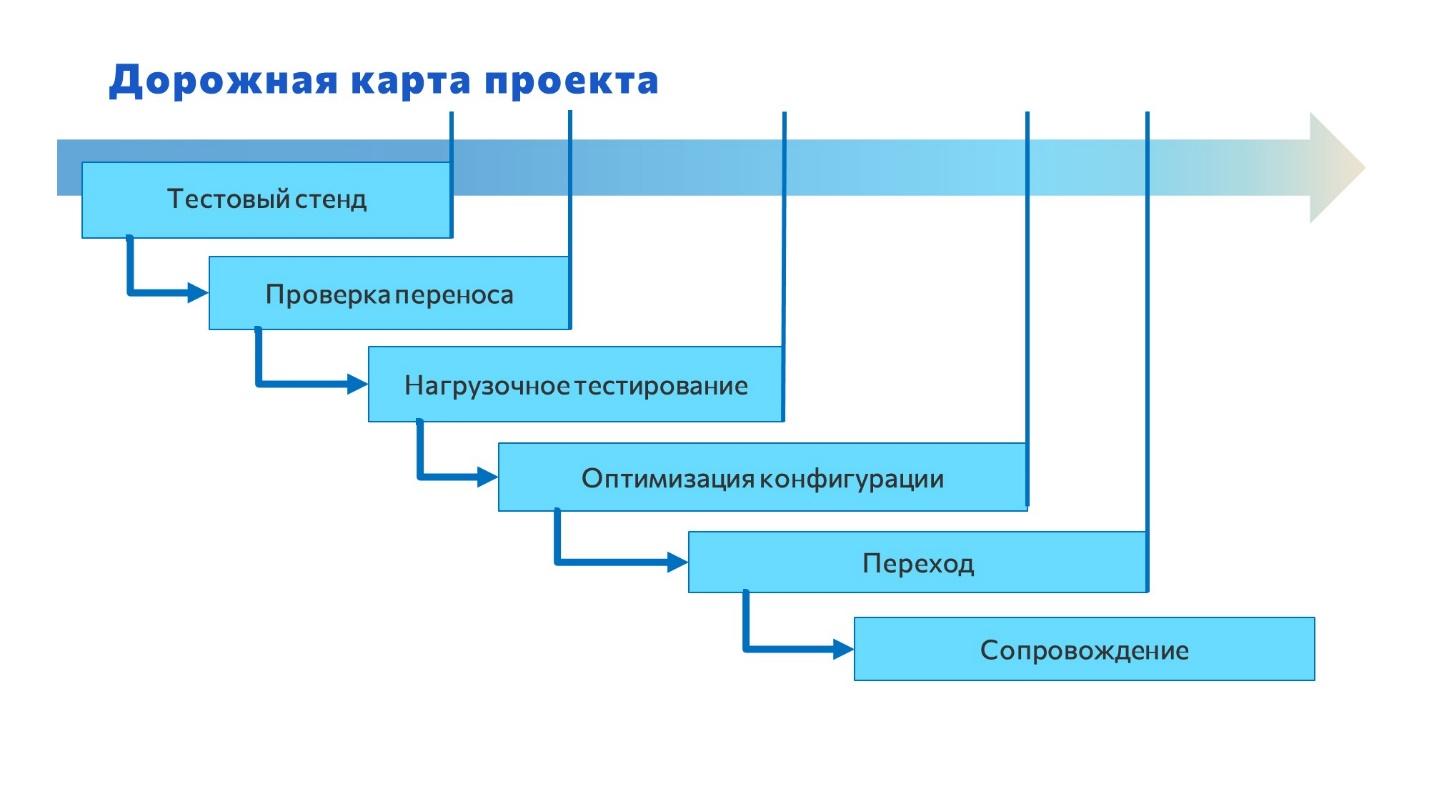
Для нас переход на PostgreSQL – это был проект. На слайде я привел набор шагов, который мы рассматривали – это дорожная карта, где показаны этапы с привязкой ко времени.
Выделить можно три основных этапа.
-
Первый этап – подготовительный. В него входят подэтапы: тестовый стенд, проверка, нагрузочное тестирование и оптимизация.
-
Второй этап – это непосредственно сам переход, перевод базы с одной СУБД на другую.
-
И последний этап – это сопровождение.
Здесь каждый этап важен – нет таких, которые можно просто так обойти.

Если вы задумались над тем, чтобы перейти на PostgreSQL, обратите внимание, что вам нужны чуть большие ресурсы:
-
Если вы работаете в облаке, обязательно используйте выделенный сервер. Если вы делите один сервер с соседом, ваш сосед может начать что-то считать, у вас просядет производительность, и вы будете долго искать и не понимать – что происходит и почему.
-
Вам понадобятся знания Linux и PostgreSQL, а также эксперты по производительности – те, кто будет все оптимизировать.
-
Чем больше рисков вы хотите снизить для HighLoad, тем больше денег вам потребуется в это вложить на первоначальном этапе.
-
И, конечно, вам нужно время на адаптацию – девять женщин за месяц ребенка не родят.
Подготовка к переходу. Тестовый стенд

Здесь я показал список этапов, которые включала в себя подготовка к переходу – сейчас мы их все подряд рассмотрим.

Первый вопрос, с которого мы начали – это сам тестовый стенд. До этого у нас была машина, где располагался сервер 1С и сервер MS SQL на Windows, а здесь нам нужна была другая среда и нужно было понять, как ее настроить.

Если у вас уже есть понимание, как работать с PostgreSQL – это здорово. Но если такого понимания пока нет, прежде, чем приступить к работе, вы должны разобраться с тем, как работает система, и настроить всякие фишки DevOps – резервное копирование, мониторинг и т.д.

Первый момент – PostgreSQL для рабочей базы нужно разворачивать только на Linux. Если у вас для разработки используются стенды с Windows, оставьте их, там можно будет поставить PostgreSQL, и она будет работать, но в ее работе будут отличия от варианта на Linux.
В любом случае рабочее и разработческое окружение лучше разделить, и для рабочей базы PostgreSQL обязательно должна быть на Linux.

Еще бывает, что на одном сервере одновременно крутится 1С и СУБД. И вы можете захотеть ещё и 1С сразу перевести на Linux. Не делайте этого. Разделите этот переход на итерации.
В процессе перевода на Linux у вас, скорее всего, возникнут определенные проблемы, и вы забудете про какой-нибудь обмен на COM-объектах, взаимодействие с Excel и т.д. – это прибавит вам головной боли.
Настройка PostgreSQL

Когда мы поставили Linux, установили на него PostgreSQL, первый вопрос, который возникает – как настроить, чтобы он работал?
При установке MS SQL от нас требуется совсем немного настроек, а в PostgreSQL – открываем конфигурационный файл, и там огромный документ на несколько листов с кучей настроек.
Рекомендация: Воспользуйтесь советом от Антона Дорошкевича – разверните отдельно сборку от Postgres Pro, возьмите ее настроечный файл и скопируйте его к себе.
Или введите в поисковой строке Яндекса «1С postgresql.conf» и почитайте статьи с ИТС, с сайта Гилёва, с Инфостарта, которые окажутся в результатах. Настройте самостоятельно согласно найденным рекомендациям, и этого будет достаточно.
Мы же, конечно, не доверяли всему этому и решили попробовать сами. Но по результатам этого эксперимента когда мы подкрутили одни параметры – большие аналитические запросы стали работать лучше, но маленькие – хуже. Покрутили другие параметры – стали хуже работать большие запросы и т.д.
А в готовых настройках этот баланс выстроен изначально – возьмите их за отправную точку, и дальше уже в процессе работы подстраивайте.
Скорее всего, у вас появятся нюансы, особенно при работе с памятью, но это можно будет увидеть, собирая логи и статистику.
Третий момент – при установке соединения с PostgreSQL 1С, конечно же, кое-что за нас переопределяет. Например, когда мы смотрели планы запросов, я очень удивился, что ни разу не видел такой оператор, как Merge Join – его просто отключили. Не могу сказать, почему, им виднее.

Сразу после установки PostgreSQL обязательно включите в настройках модуль auto_explain – это сбор долгих запросов и их планов. Очень полезная функциональность.
При начале работы установите для auto_explain значение log_min_duration на 60 секунд – проверьте, встречаются ли у вас настолько долгие запросы и отработайте их.
Потом опускайте планку – уменьшайте значение log_min_duration до 5 секунд, до 3, и так далее.
По опыту, если вы сразу включите протоколирование всех долгих запросов, у вас сильно разрастутся логи. У нас таблица логов очень быстро выросла до 4 гигабайт, и ее уже ничем, кроме конфигуратора 1С, нельзя было открыть.
Второй момент – настройте логирование по суткам, потому что по дефолту там идет чередование понедельник, вторник, среда, четверг, пятница, суббота, воскресенье и по кругу - данные стираются. А вы, скорее всего, захотите сравнить по датам – что было, что стало и так далее.

Из нашего опыта:
-
Мы отключили оптимизатор JIT, потому что выяснили, что он не совсем правильно работает. У него есть набор настроек – можете поиграться с этим, но для нас было выгоднее его просто выключить.
-
В PostgreSQL есть параметр снятия статистики – default_statistics_target. Мы провели эксперимент – увеличили его значение до 10 000. Думали – раз статистики больше, будет лучше работать. И запустили большой аналитический отчет, который делает большую временную таблицу. Оказалось, наоборот, отчет стал подвисать при построении. Т.е. эта штука влияет на время выполнения. А теперь давайте вспомним, как у нас считается себестоимость, какие там таблицы – время расчета будет в разы увеличиваться. Поэтому не рекомендую играться с этими параметрами.
-
Следующий момент, на который я хочу обратить внимание – несмотря на то, что PostgreSQL работает все лучше и лучше от версии к версии, в новых релизах тоже бывают ошибки. Например, оператор memoize в 13 и 14 версиях PostgreSQL промахивался мимо кэша. Это признали разработчики. И только в релизе 14.4-1.1C от конца лета 2022 года фирма «1С» выкатила релиз, в котором это исправлено. Поэтому обращайте внимание на новые особенности, которые у вас появляются.
Выявление возможных проблем. Мониторинг

После того как мы установили сервер, загрузили dt-ник, выгруженный из MS SQL, мы начали сравнивать, как наша база работает на PostgreSQL.
Открыли рядом окно с базой на MS SQL и на PostgreSQL. Взяли часики и стали замерять время одних и тех же операций в первом и во втором окне.
Как вы думаете, что произошло? Все заработало. Я удивился, но это действительно работает. Кнопочки нажимаются, списки мигают. На глаз никаких отличий нет.
Но мы-то с вами знаем, что на PostgreSQL все чуть медленнее работает.
Как узнать, в чем именно могут быть проблемы? Для этого нам понадобились дополнительные инструменты, которые позволят посмотреть, что там происходит внутри.
Здесь возник вопрос об инструментах мониторинга.

Инструменты есть. Их не так много. Они делятся на те, которые применяются со стороны PostgreSQL, и те, что применяются со стороны 1С. На слайде приведены инструменты, с которыми мы работали.
Кстати, насчет ЦКК – фирма «1С» рекомендует ставить две ЦКК: одну ЦКК – боевую, а вторую – которая смотрит за первой. От первой вы получаете вероятность 95%, а вторая вам дает 99%. Это рекомендация от фирмы «1С», проверенная вещь.
Здесь в списке приведена конфигурация «Мониторинг производительности» – это наша разработка, которую мы ведем в Open Source. Удобно, что мы всегда можем ее быстро доработать под себя, если нам это нужно. С ЦКК у нас не заладилось – каждый раз, когда я хотел сделать что-то специфическое, мне приходилось брать напильник и дорабатывать. Это меня в итоге немного напрягло, и я разработал свое решение.

После того как установили среду мониторинга, возникает следующий вопрос – что именно нужно смотреть?
-
Первым делом настройте просмотр долгих запросов. Это можно сделать с двух сторон:
-
со стороны PostgreSQL – включить модули auto_explain и pg_stat_statements;
-
со стороны 1С – включить технологический журнал и там тоже настроить срез на определенный интервал, а потом парсить его лог, вооружившись знаниями RegExp.
-
-
Еще одна важная вещь для высоконагруженных систем – массовые небольшие запросы. Когда у вас пользователей мало, они не столь заметны. Но когда пользователей у вас много, эти запросы накапливаются и могут вас завалить лавиной. У нас был пример: один частый запрос выполнялся порядка 8 секунд, но количество вызовов этого запроса, помноженное на время, составляло 24 часа в сутки. Т.е. запрос крутился на сервере 24 часа – это фактически минус одно ядро.
-
Нужно мониторить стандартные показатели – это нагрузка CPU, очередь к дискам и так далее. Но это косвенные показатели – они говорят, что есть проблема, но где проблема, не говорят, смотрите дальше сами.
-
И обязательно обращайте внимание на показатели, которые предоставляет сама 1С. Вы можете посмотреть их в консоли кластеров, но это неудобно тем, что там нет истории. Либо вы можете получать их значения от RAS. Эти показатели производительности очень полезно анализировать, там очень много информации можно почерпнуть.
Нагрузочное тестирование

После того как мы все настроили, графики все равно показывали, что всё приблизительно хорошо. Но я-то был в базе один, а в реальной базе пользователей в 1000 раз больше. Нам был нужен нагрузочный тест – не синтетический, а нормальный нагрузочный тест.
Опять же, все в наших руках – мы взяли инструмент, добавили небольшую щепотку искусственного интеллекта, скриптов, и все это дело запустили.
На Инфостарте я выложил статью на эту тему – кому интересно, можете почитать. В ближайшее время выложим и сам инструмент, сможете попробовать его у себя.
Здесь важный момент: обязательно настройте мониторинг и поработайте с ним на старой системе – получите информацию, которая там есть.
А после того, как перейдете, вы получите новые графики и сможете сравнить, что у вас произошло – стало лучше, хуже или осталось так же.
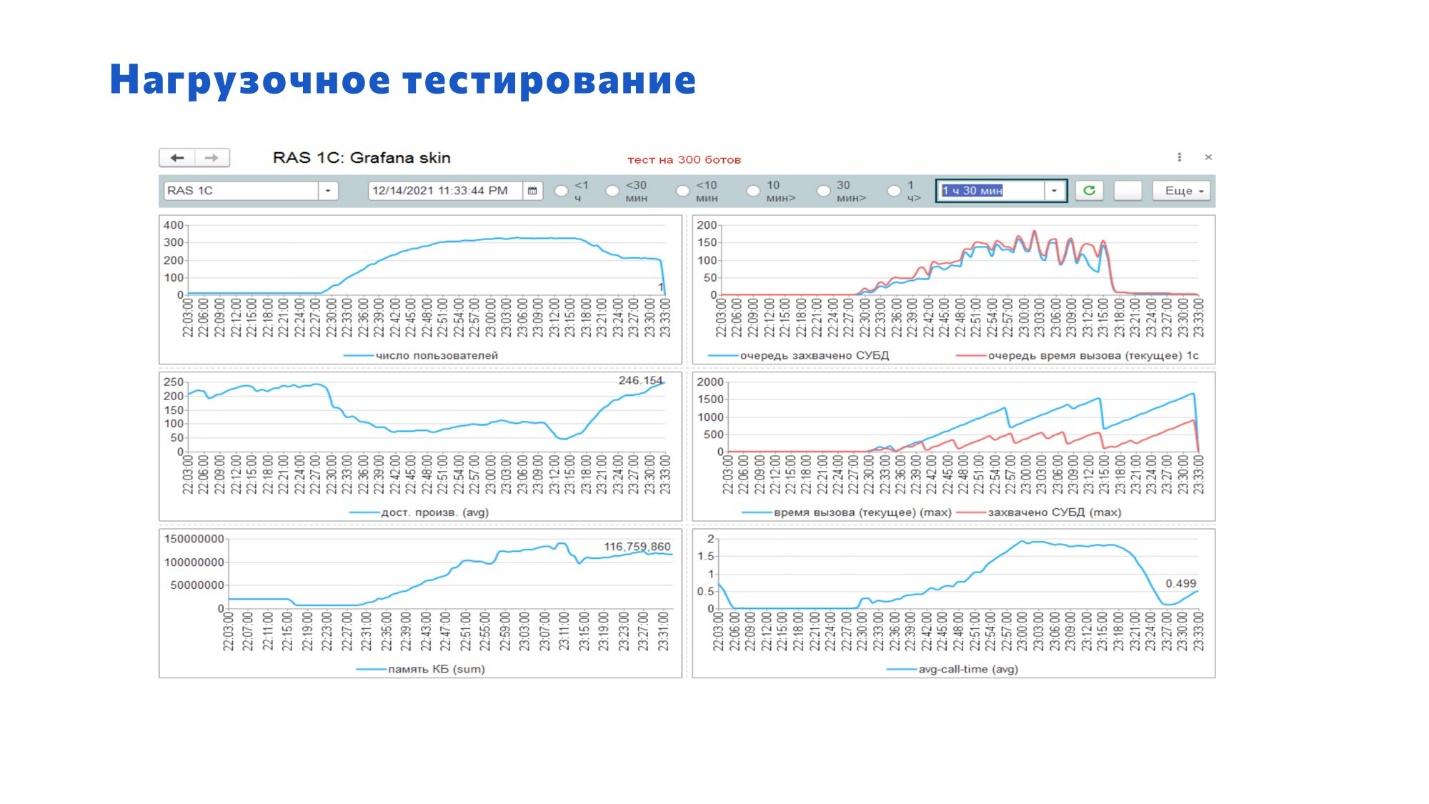
У нас был отпечаток нагрузки с рабочей базы, и мы на его основе создали набор тестов, чтобы приблизить тестирование к реальной боевой нагрузке.
Эти тесты мы писали порядка трех недель и еще две недели проверяли – этот этап у нас занял где-то полтора месяца. Одновременно мы подбирали аппаратную часть:
-
меняли количество ядер на сервере 1С – 24, 48;
-
то же самое делали на сервере с СУБД PostgreSQL – брали 20, 24, 48 ядер;
-
пробовали включать Hyper-Threading – проверяли, действительно он до сих пор не влияет на производительность;
-
добавляли оперативную память и т.д.
И в итоге определили систему, которая позволяет выдерживать похожую нагрузку с небольшим запасом.
На слайде показаны графики, где видно, что:
-
Количество ботов, которыми мы генерили нагрузку в рамках этого теста – порядка 400 штук.
-
Максимальная производительность 1С в самый пик нагрузки достигала 50 единиц – в этот момент сервер PostgreSQL упал, а 1С осталась жить.
-
Внизу отображается график показателя avg-call-time – он показывает среднее время вызова сервисов 1С. Лучше всего, когда он меньше единицы, когда это миллисекунды. Здесь, если посмотреть, он достигает двух секунд.
-
Если сопоставить график времени вызовов с верхним графиком количества пользователей, которые одновременно хотят получить данные от 1С – там порядка 200 пользователей. 200 умножаем на 2 секунды = 400 секунд у нас 1С отвечает всем этим 200 пользователям. И не забывайте, что там другие еще подходят и тоже просят. И вот система отвечала, отвечала и потом упала.
Из этого можно получить очень много информации.

Еще один момент из коробки – это APDEX:
-
Определите бизнес-процессы, которые у вас есть.
-
Добавьте в расширение необходимые замеры APDEX.
-
Настройте их сначала на свою основную рабочую базу на MS SQL. Потом, когда перейдете на PostgreSQL, запустите, и у вас будет информация – вы увидите, что стало хуже, что стало лучше. Вы сможете обратить внимание, где надо что-то сделать.
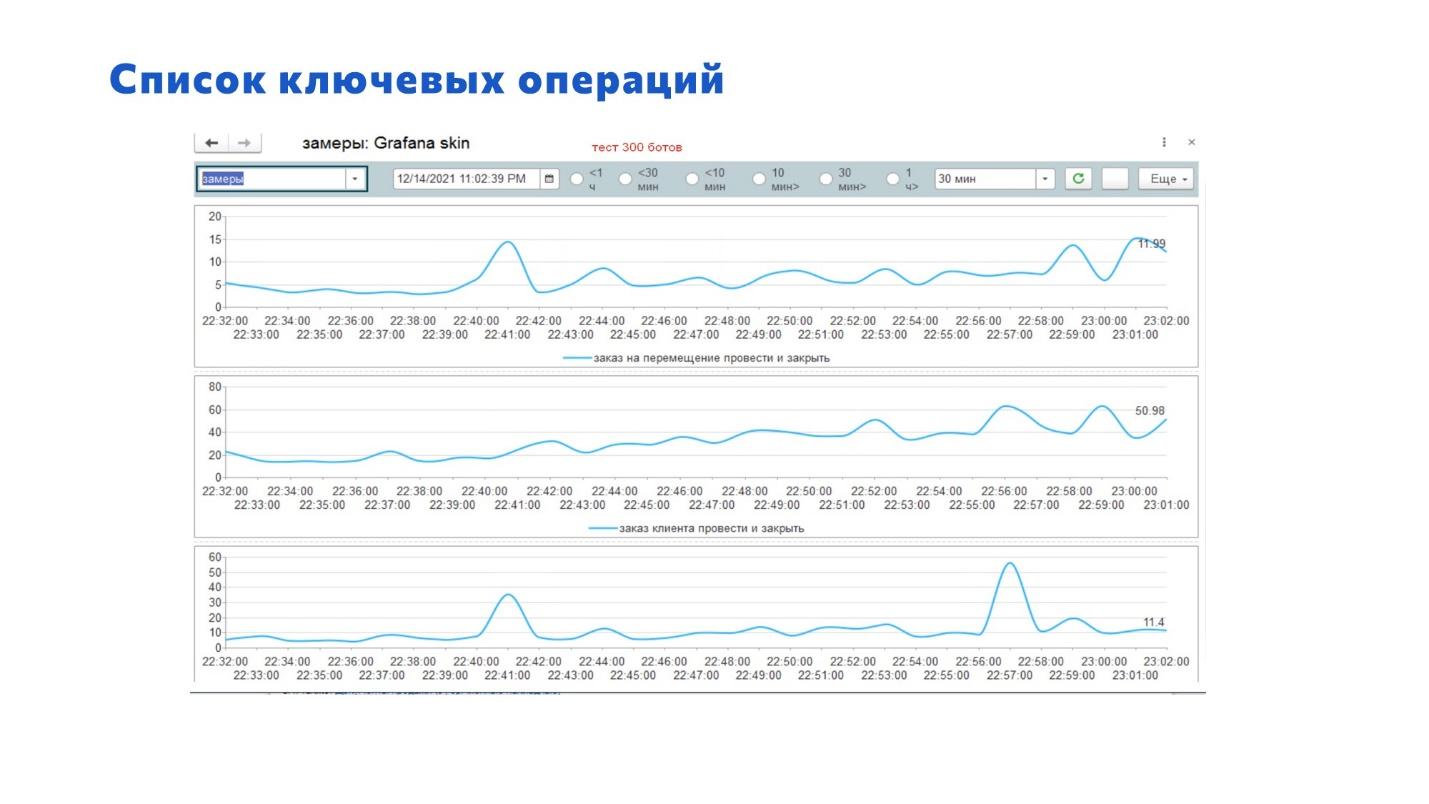
Здесь на слайде приведен график – показано, как это приблизительно выглядит при изменении нагрузки.

После того как мы провели определенную работу, настал черед оптимизации.
Пока мы работали на MS SQL, все было нормально. А на PostgreSQL у нас на этом нагрузочном тесте проявились проблемы – мы взяли напильник и их допилили.
Основные проблемы, которые пришлось исправлять, перечислены на слайде – а самому процессу исправления у меня посвящен отдельный доклад.
Особенно эти нюансы актуальны, если у вас самописная конфигурация или вы что-то дописывали в типовой.
Например, мы в процессе работы допустили небольшое упущение, потому что не учли того, что у нас большое количество внешних обработок.
Не повторяйте наших ошибок – выделите время, посадите какую-нибудь девочку под ограничением доступа, и пусть она прокликает все обработки. Найдите те, в которых есть проблемы. И потом вы их исправите.
Относительно проверки всех процессов, которые есть в базе, здесь играет правило: время – деньги.
Выделите процессы, которые нужно оптимизировать в первую очередь, во вторую очередь, в третью очередь. Самые приоритетные оптимизируйте, а потом какие-нибудь менее значимые вы можете, в зависимости от финансов, разделить – что будете делать, что не будете делать.
Процесс перехода

Выполнили работу и доложили заказчику, что все готово и риски максимально снижены – насколько это возможно за установленные сроки и оплаченную сумму.
Заказчик сказал: «Хорошо, поехали!»

Есть два варианта перехода – я выделил два, но, на самом деле, могут быть гибриды.
Первый вариант перехода – это когда у вас есть технологическое окно, в которое укладывается весь процесс миграции. Для высоконагруженных систем это скорее всего будет не так – если технологическое окно час-два, вам его не хватит.
Процесс перехода выглядит следующим образом:
-
вы отключаете пользователей;
-
выгружаете DT-шник из MS SQL;
-
потом загружаете DT-шник в PostgreSQL;
-
и потом, когда все успешно загрузилось, пользователи заходят и работают в новой базе.
В нашем случае у нас был очень хороший заказчик. И мы подобрали для перехода удачный момент:
-
Был праздничный день, выходной, когда менеджеры практически не работают – работал только склад и производство.
-
С производством договорились, они всё писали на бумажках.
-
Для склада с заказчиком договорились, чтобы они из старой базы, из которой переводили, предварительно распечатали все нужные документы. Включили им базу на чтение, и они оттуда распечатывали. А если кому-то нужно было что-то внести, мы говорили, что они смогут потом внести отдельно.
И выполнили процедуру.
База у нас порядка 400 гигабайт, вся процедура заняла около 9 часов.
Кстати, в версии 8.3.23 появилась классная штука от 1С, которая позволяет значительно упростить процедуру миграции. Они включили в состав 1С 8.3.23 обработку, которая позволяет «переехать» с одной СУБД на другую без выгрузки базы в .dt.
Но мы работали по классической схеме, на тот момент версия 8.3.23 была еще в тесте.

Есть второй вариант – он более надежный. Этот вариант заключается в том, что:
-
вы добавляете план обмена;
-
делаете бэкап средствами MS SQL, выгружаете его и загружаете в копию;
-
в этот момент в основной базе начинают копиться изменения;
-
вы не спеша загружаете копию в новую СУБД;
-
а потом перегружаете все накопленные данные из плана обмена в новую базу;
-
и в ваше маленькое технологическое окно просто переключаете пользователей на новую базу.
Преимущество этого варианта – если у вас ничего не получилось, вы можете быстро переключить все обратно на старую базу. Но для этого выполняйте операции по проверке.
Сопровождение

После того как мы выполнили миграцию – как я уже говорил, это был выходной – мы с замиранием сердца начали смотреть, как работают пользователи.
Вы удивитесь, но графики были шикарны:
-
нагрузка на СУБД была порядка 10%;
-
на сервер 1С – вообще почти никакой нагрузки;
-
пользователей за весь день зашло меньше 150 человек.

Проблемы начались немного позже, и они были не критические, а скорее психологического характера.
Например, у какого-то менеджера что-то одно стало подтормаживать, он говорит: «У вас все стало работать хуже». Пользователи никогда не говорят: «Спасибо за оптимизацию!» Они всегда говорят, что у вас все плохо.
Возникли нюансы и вопросы. И та система мониторинга, которую мы настроили, помогла нам понять, где проблемы, и как их исправить. Мы в течение двух дней закрыли порядка 30 задач.
Часть из них была связана с отчетами. Но встречались и ситуации, которые ничем, кроме архитектурных изменений, не решались – здесь, увы, пришлось дорабатывать систему.

Что произошло?
-
Во-первых, себестоимость, как уже говорил Антон Дорошкевич, у нас не заработала. Просто не заработала. Мы ради эксперимента запустили расчет себестоимости на тестовом стенде, ждали, ждали, ждали, ушли, на следующий день пришли. И я заметил, что там какой-то запрос считался 18 часов. Посмотрели на MS SQL – там порядка минуты. Да, здесь нам пришлось поработать – мы почти весь модуль переписали.
-
Далее, RLS – обращайте внимание, у RLS в работе под PostgreSQL есть особенности. Поэтому ошибки, которые есть в типовых конфигурациях, могут очень сильно снизить вам радость от перехода на новую систему.
-
Важный момент – мы перешли на 11-ю версию PostgreSQL, и нам там было тяжело. По сравнению с текущей 14-й версией (прим. ред. доклад от октября 2022 года) 11-я версия работает хуже. Но 14-й версии пока еще не было в релизе. Скажу так – с каждой новой версией PostgreSQL становится все лучше и лучше. В 15-й версии обещали исправить ряд критичных для нас ошибок, мы хотим попробовать ее – надеюсь, там еще часть проблем уйдет.
Готовьтесь к переходу заранее – снижайте риски и держите руку на пульсе

В результате мы получили бесценный опыт, которым частично поделились с вами.
Если у вас тоже высоконагруженная база и вам интересна эта тема, обратите внимание на статьи, которые мы опубликовали на Инфостарте. Там мы рассказываем про часто встречающиеся проблемы и описываем, как их решить.

Выводы:
-
Для высоконагруженной системы к процессу перехода нужно подходить очень внимательно.
-
Нужно по максимуму снижать риски и объяснить руководству все возможные последствия – без этого никак.
-
Настройте мониторинг – всегда держите руку на пульсе, смотрите, что у вас происходит с системой. Вы должны первыми увидеть, что у вас проблема, и решить ее до того, как ее заметит пользователь. Оперативностью решения проблем определяется качество работы системы.
-
Но, если вы чего-то не знаете или не умеете, обратитесь к профессионалам – на Инфостарте есть люди, которые смогут ответить на ваши вопросы.
Дополнение от Антона Дорошкевича
Владимир упомянул, что в PostgreSQL есть параметр снятия статистики default_statistics_target, и сказал, что его не нужно трогать. Давайте чуть-чуть приоткроем завесу тайны. Почему не трогать?
Мы все, выросшие на MS SQL в 1С, приучены, что UPDATE STATISTICS нужно делать с параметром FULLSCAN. И этот же смысл мы применяем к параметру default_statistics_target.
По умолчанию значение default_statistics_target 100, и нам кажется, что его нужно увеличивать до 10 тысяч. Мы думаем, что default_statistics_target – это глубина расчета статистики. На самом деле, эта цифра почему-то умножается на 300, и это количество страниц на диске, которые будут взяты с каждой таблицы для анализа ее статистики.
Для нас, наученных на MS SQL, кажется, что этот максимум нужно увеличить – чем лучше мы посчитали, тем лучше будет. В целом, наверное, это даже звучит правильно, но есть два «Но».
-
Первое: default_statistics_target = 100 хватает для любых таблиц. Там умный механизм.
-
Второе: почему при увеличении default_statistics_target до 10000 тормозит? Потому что платформа 1С, начиная с версии 8.3.13, после создания и наполнения временной таблицы дает команду PostgreSQL на обновление статистики – дает команду vacuum analyze для этой временной таблицы. И только потом переходит на следующую строчку вашего кода 1С.
Если вы увеличили глубину считывания статистики, то раньше временная таблица из миллиона записей у вас обновляла статистику за 0,0001 секунды. Но как только вы увеличиваете этот параметр, у вас время обновления статистики превращается в секунды. Это тяжело – нужно много поднять, проанализировать большие данные, пересчитать и записать себе в статколлектор.
Так делать не нужно, оно от этого и тормозит. Причем тормозить начнет тупо все, потому что в 1С 99% запросов связаны с временными таблицами. И у вас даже небольшие быстрые операции начнут подтормаживать, если они формируют во временной таблице значительное количество строк.
Вопросы
In-memory и PostgreSQL работает вместе или это что-то несовместимое?
Какой-то in-memory в PostgreSQL есть – у вас все временные таблицы изначально в in-memory, согласно настройке temp_buffer. Пока у вас временная таблица вмещается в temp_buffer, она размещается в памяти.
Поэтому то шаманство, которое мы все любили делать на MS SQL – перенос хотя бы части temp_db на RAM-диск, на PostgreSQL делать не надо. Это полностью бессмысленно. Он за вас это делает в каждом сеансе.
А так, чтобы дать PostgreSQL какую-то команду: «Выполни это в in-memory» – такого нет.
Сколько времени ушло на реализацию всего проекта с момента, когда бизнес принял решение, что нужно переходить?
Два месяца.
Сколько людей было задействовано? Больше роли интересуют – админы, разработчики?
Здесь мы работали совместно с компанией 1С-Рарус – она нам предоставляла услуги сервиса. Всю логику реализовывали мы, а 1С-Рарус – сервис.
Была команда с их стороны – человека три. И с нашей стороны тоже три человека, которые подключались на различных этапах.
Два человека занимались миграцией. А когда допиливали – там чем больше вы народу привлечете, тем быстрее допилите. Один у вас будет пилить полгода. А если вдесятером, то и за месяц можно справиться.
Среднее время перехода большой базы – это два-три месяца на три-четыре человека.
Нужны админы – без них никуда. И нужны ЭТВ-шники – эксперты по технологическим вопросам. Или хотя бы хотящие стать ЭТВшниками.
Если у людей нет квалификации, наверное, за три месяца не получится перейти. Знания специалистов 1С должны быть намного выше среднего.
Вы действительно переписали процедуру расчета себестоимости ERP? А дальше что делать?
Переписал – это неправильное слово. Мы поправили процедуру себестоимости – индексы добавили, в запросах кое-что вынесли во временные таблицы, код поменяли. Но очень много.
Есть еще один путь, которым ходить нельзя, но зато он быстрый, и через 2 минуты можно получить результат.
Дело в том, что на текущем типовом коде расчета себестоимости при определенном стечении данных запрос выбирает nested loop, и получается 18 часов. И главная проблема, что в расчете себестоимости этот запрос выбирается несколько сотен тысяч раз, и каждый раз на вход попадают разные данные. И он только что отбирал данные за доли секунды, а на следующем цикле – пффф – и два дня. Потому что прилетели вот такие данные.
Можно в начале этого запроса запретить серверу использовать nested loop – тогда он всегда будет все считать за 10-15 секунд. А после окончания расчета – опять разрешить.
Но от этого есть очень плохой побочный эффект, потому что nested loop – это очень хороший и очень нужный тип соединения. Если его просто так отключить, за эти 10 секунд все пользователи, которые откроют какой-нибудь динамический список, получат конкретнейшие тормоза.
Все это из-за того, что у PostgreSQL команда Merge Join фирмой «1С» отключена. А есть всего три способа соединения: nested loop, merge join и hash. nested loop мы отключили ради себестоимости, у него остается только hash, а hash далеко не всегда эффективен.
Поэтому такое решение – оно быстрое, но костыльное. Зато обновлять потом легко.
Мы столкнулись с тем, что не всегда DT-шник можно загрузить на PostgreSQL. Например, мы столкнулись с ошибкой попытки вставки неуникального индекса. Один раз получилось ее исправить путем исправления данных в вазе – это было связано с измерениями регистров строкового типа. PostgreSQL не различал пробел и неразрывный пробел. А второй раз для исправления пришлось даже ставить PostgreSQL другой версии. Где почитать, почему так происходит?
У меня в дорожной карте был пункт «Проверка переноса». Действительно, иногда база не загружается. Первым делом рекомендую запустить «Тестирование и исправление».
Дальше – действительно проверьте ваши данные. Причем, кроме неразрывного пробела и просто пробела, PostgreSQL считает одинаковыми символы № и No по-английски, если подряд идет – тоже не загрузите, будет ошибка вставки неуникального индекса.
Измерение – это уникальный индекс. Там просто строки, которые для MS SQL разные, для PostgreSQL – одинаковые. К сожалению, это только исправление данных.
PostgreSQL гораздо строже относятся к локалям. Он в этом смысле строгий и не загрузится, вы получите ошибку вставки неуникального индекса. Но в реальности проблема в ваших данных. Поэтому единственное правильное решение – поправить данные.
Еще мы столкнулись с тем, что база рушилась в момент реструктуризации базы данных, если в этот момент выполнялся бэкап.
Дело в том, что дамп при старте накладывает на схему базы данных эксклюзивную блокировку. А при попытке реструктуризации СУБД создаст новую таблицу и сразу получает отбой – база данных говорит, что у нее все заблокировано.
Дамп нужно делать с реплики, нельзя делать дамп из мастера. Мастер должен просто работать. Поэтому дамп сливайте с реплики, все будет работать без проблем.
У нас тоже была подобная ситуация, но она была более невидимая – у нас запустился vacuum to prevent wraparound. Поэтому следите – никакие служебные операции при реструктуризации выполняться не должны. А бэкап все-таки лучше проводить через base backup.
Две новости о PostgreSQL
Первая новость. Иван Панченко в своем докладе упоминал, что в ближайшее время в состав Postgres Pro должна войти новая версия расширения pg_hint_plan, где через параметр hints_anywhere можно регулировать параметры GUC в любом месте запроса, включая текстовые литералы. Релиз уже вышел – но пока только для версии Enterprise.
Теперь все счастливые обладатели Enterprise лицензии Postgres Pro могут из кода 1С влиять на поведение планировщика, если вы считаете, что вы умнее.
Например, вы можете не ломать код расчета себестоимости, а влиять на планировщик и делать с ним что-то через это расширение.
Вторая новость. Во все последние релизы Postgres Pro, включая бесплатные для 1С, добавлено расширение AQO. Это адаптивный планировщик запросов (adaptive query optimization) – практически искусственный интеллект.
Это расширение, которое нужно включить и настроить, и после этого оно при выполнении каждый раз будет высчитывать разницу между предполагаемым планом и фактическим планом выполнения. И если разница, например, больше, чем в пять раз, она запомнит реальный план этого запроса и положит к себе в базу. И в следующий раз, когда получит такой же запрос без учета параметров, она возьмет это количество и передаст планировщику данные из предыдущего плана, чтобы планировщик выбрал более подходящий план запроса.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции Infostart Event.

Вступайте в нашу телеграмм-группу Инфостарт