Если вы думаете, что для перехода на PostgeSQL достаточно просто загрузить dt-шник из другой СУБД, и все заработает, то вы ошибаетесь – это не совсем так.
Но и излишне напрягаться из-за возможных проблем в PostgreSQL тоже не стоит. Если при переходе правильно подойти к вопросу оптимизации, вы сможете нормально работать. И с ERP на PostgreSQL работать тоже можно – вам просто нужно будет вложить «немного» ресурсов в доработку.
Фирма «1С», со своей стороны, тоже адаптирует ERP под работу на PostgreSQL. Мы проводили замеры, сравнивали работу старых версий ERP (2.2, 2.4) и версии 2.5. В последних версиях решено очень много вопросов и проблем – видно, что они над этим работают. И с каждым новым релизом ERP работает на PostgreSQL все лучше и лучше – у ее разработчиков сейчас вообще нет вариантов не проверять конфигурацию на PostgeSQL.
Правда, добавляются новые проблемы – но куда без этого.
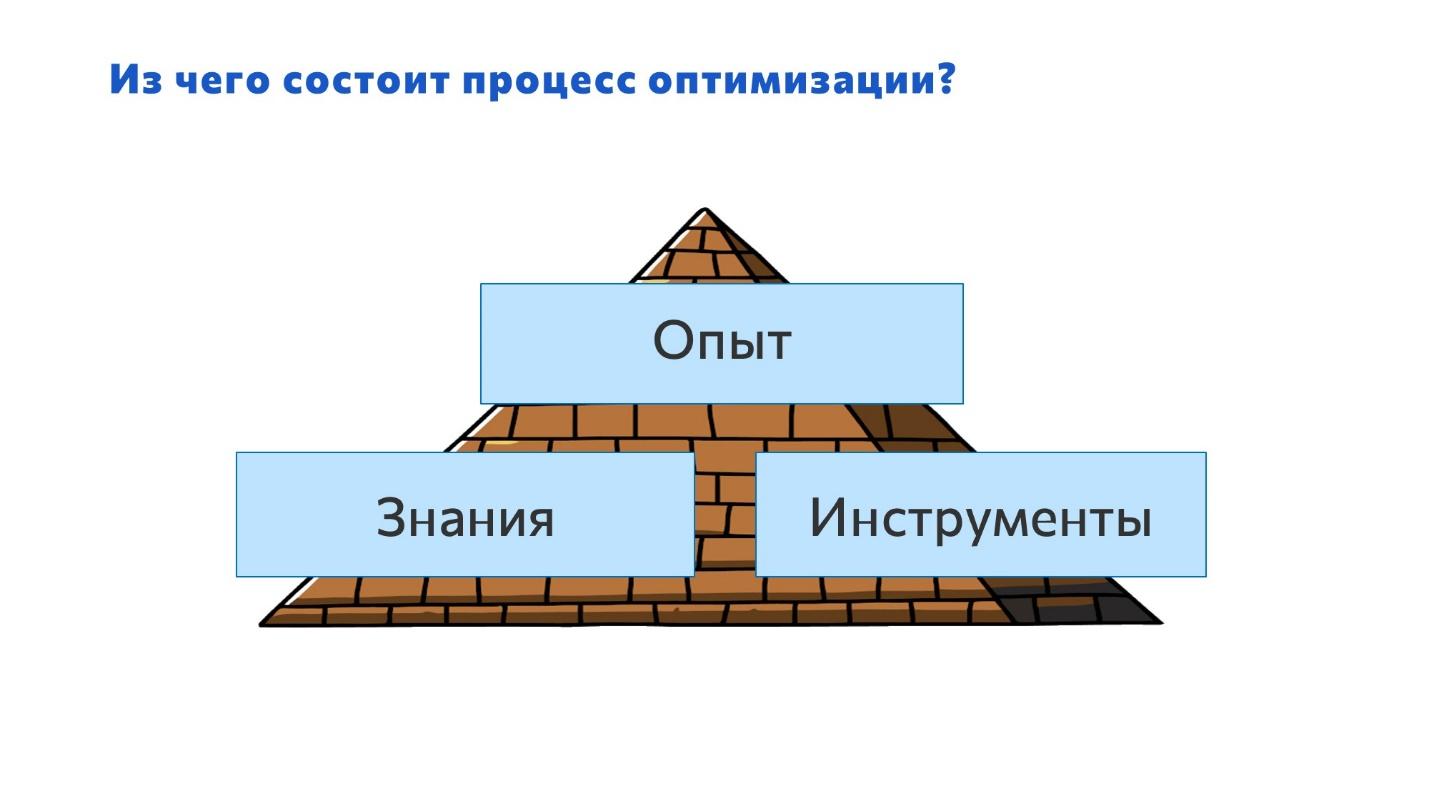
Когда вы начинаете работать с PostgreSQL, как и с любой другой системой, у вас должен быть определенный набор необходимых кирпичиков – это инструменты, знания и опыт. Эти три блока – основа, чтобы вы могли нормально работать. Причем, одной составляющей для успешной работы мало:
-
Если у вас есть инструменты, но нет знаний и опыта – вы не сможете их применить. Например, если у вас на машине прокололось колесо и есть домкрат, но вы не знаете, как с его помощью поменять колесо – вам домкрат не поможет.
-
Если есть знания и опыт, но нет инструментов – вы тоже ничего не сможете сделать.
-
И если у вас есть инструмент и инструкция по применению (знания), но нет опыта – у вас тоже возникнут проблемы.
Инструменты, знания и опыт – это три базовые вещи, которые вы должны использовать, чтобы успешно работать. Наверное, самое простое – это инструменты, потом появляются знания, а опыт приходит со временем.
Инструменты

Начнем с инструментов для анализа работы 1С на PostgreSQL – таких инструментов немного, но они есть.

Те инструменты, с которыми мы работаем, перечислены на слайде. Каждый из этих инструментов позволяет решать определенные задачи, а совместно они нам дают базовые возможности для решения практически любой задачи.
Перечисленные инструменты можно условно разбить на два класса:
-
инструменты, связанные с PostgreSQL;
-
и инструменты, тем или иным образом связанные с 1С.

Начнем с инструментов для PostgreSQL.
Когда вы начинаете работать с PostgreSQL, первым делом включите два плагина: pg_stat_statements и auto_explain.

Плагин pg_stat_statements собирает статистику по выполняемым запросам от вашей базы. Он позволит вам получить наиболее частые запросы и запросы, которые потребляют много данных. Также можно получить длительные запросы или те, которые активно работают с жестким диском.
Здесь есть:
-
информация о среднем времени;
-
максимальное время;
-
информация о чтении и записи на диске;
-
и самое ценное – здесь есть сам запрос. Правда, есть нюанс: поле для отображения текста запроса ограничено, а в 1С запросы обычно монстроидальные. Поэтому на первое время увеличьте его размер – вы сможете поймать хотя бы часть запроса и понять, с чем связана проблема.
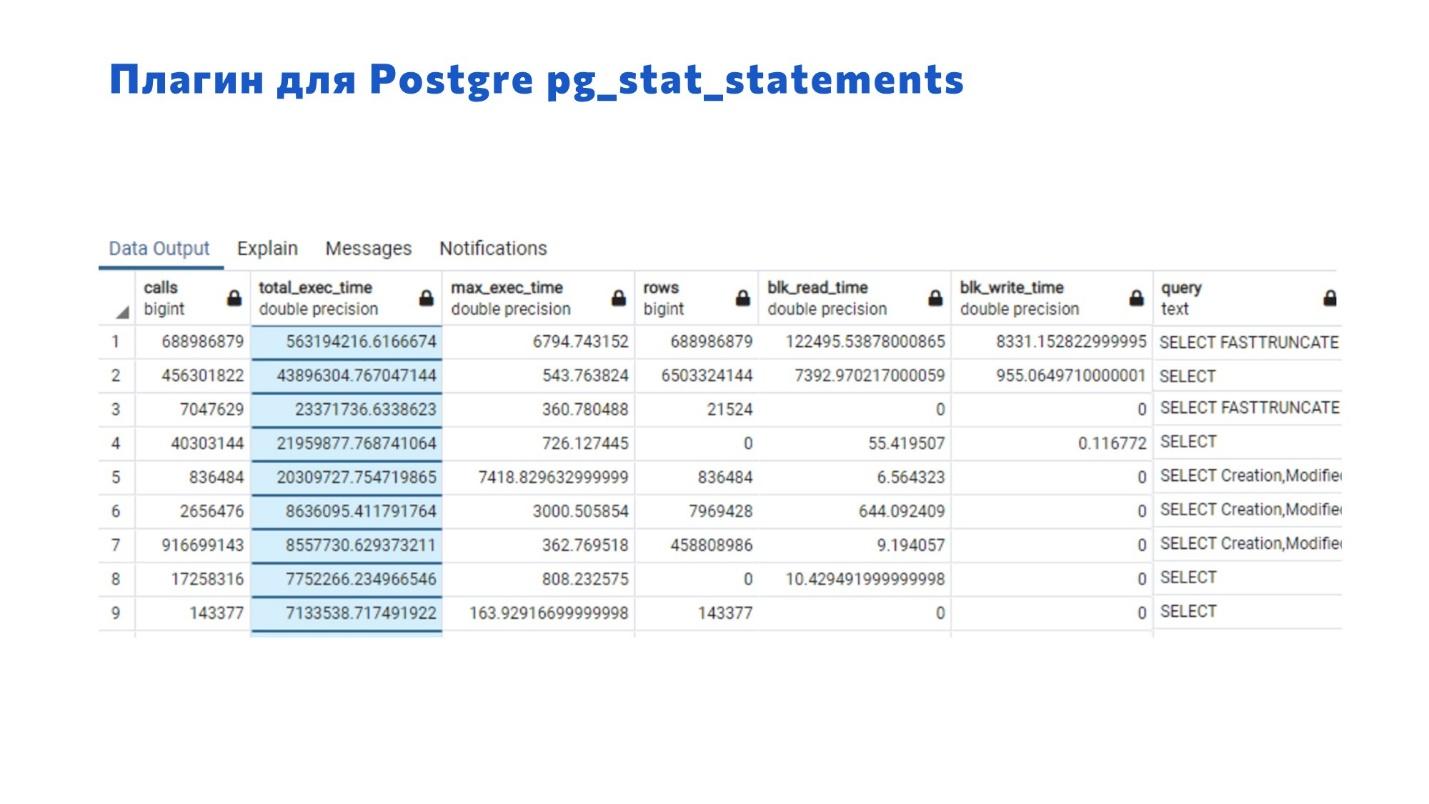
Плагин pg_stat_statements позволяет сортировать список обращений к базе данных:
-
по длительности;
-
по количеству повторяемых запросов;
-
и так далее.
Таким образом мы можем получать в топах самые проблемные запросы и анализировать их на необходимость оптимизации.

Второй плагин auto_explain – ключевой. Он важен, потому что дает основную информацию для оптимизации:
-
время планирования запроса;
-
текст запроса SQL – по тексту запроса SQL вы можете понять, что вообще 1С здесь запрашивает, найти этот запрос в конфигурации и оптимизировать;
-
и последний, третий пункт – это план запроса, который вам покажет, что идет не так (если вы умеете читать планы запросов). В коде 1С не всегда понятно, почему он плохо работает, а план запроса помогает увидеть, в чем проблема – заглянуть в «черный ящик» или «под капот» нашей системы.

При работе с сырым текстом запроса есть особенность:
В конфигурации 1С у вас запрос содержит классные человекопонятные названия. Документ.ПриобретениеТоваровИУслуг, регистр ОстаткиТоваровНаСкладах.
А когда вы смотрите текст запроса из СУБД, там какая-то китайская белиберда.
Приходится смотреть название таблицы в тексте запроса, искать, какому объекту конфигурации она соответствует, пытаться понять, что такое – это очень неудобно.
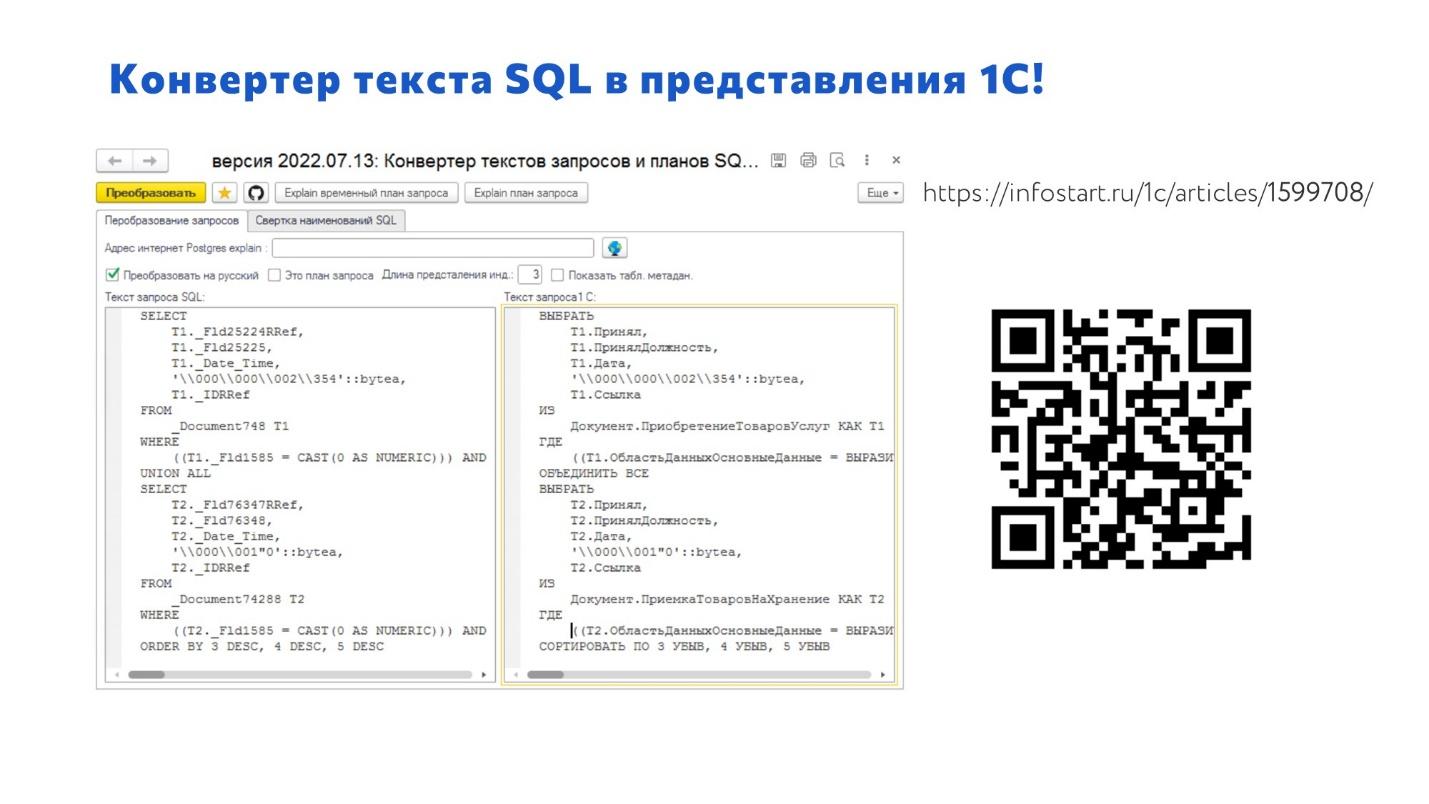
Поэтому мы написали специальный конвертер текста SQL в представления 1С. Он значительно помогает сократить время на анализ планов запросов.
Там ничего сложного нет – я его написал практически за 4 часа на коленке. Просто разбил слова по пробелам, нашел совпадающие и заменил, чтобы в результате преобразования у нас получился читаемый запрос. В некоторых случаях вы даже сможете выполнить полученный запрос в 1C.
Важный момент:
-
Конвертер позволяет преобразовывать как текст запроса SQL – вы можете его преобразовать, увидеть там обращение к таблице документа ЗаказКлиента и пойти искать, где такое встречается.
-
И также конвертер может работать с планами запросов – их тоже преобразует.
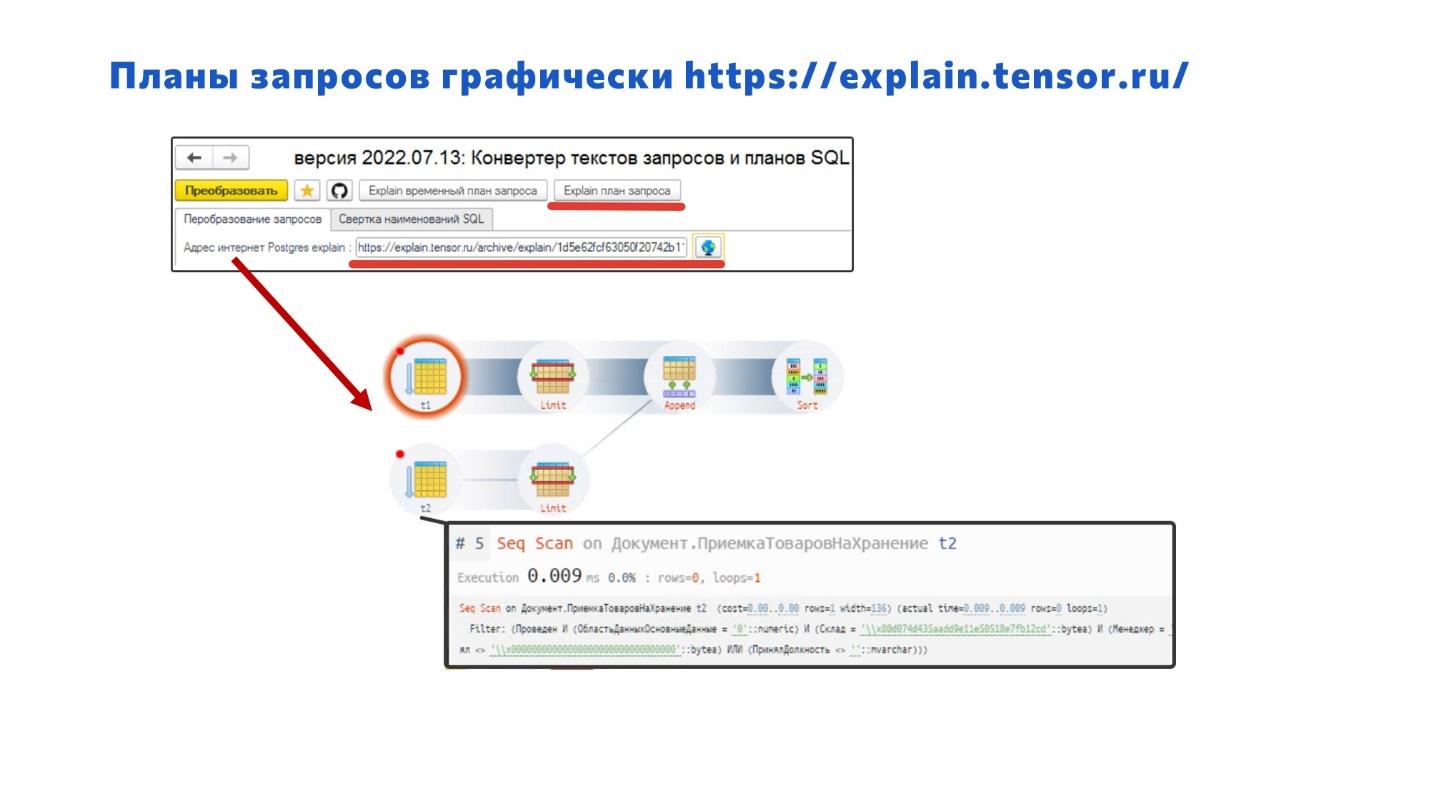
Раз уж мы заговорили про план запросов, расскажу про классный ресурс https://explain.tensor.ru/ – ничего подобного для MS SQL я за все время работы не нашел.
С помощью этого сервиса наш конвертер позволяет вам в два клика преобразовать сырой текст запроса SQL и открыть для него в браузере схему запросов, в которой можно производить детальный анализ. В большинстве случаев без этого никуда. Позже я на примерах покажу, как с этим работать.

Если вы хотите научиться качественно оптимизировать, учитесь читать планы запросов. Изучайте, какой оператор что значит, что происходит с данными в каждом из них: как отображается виртуальная таблица, а как – внутреннее соединение и так далее.

Теперь попробуем подойти к сбору информации со стороны 1С.
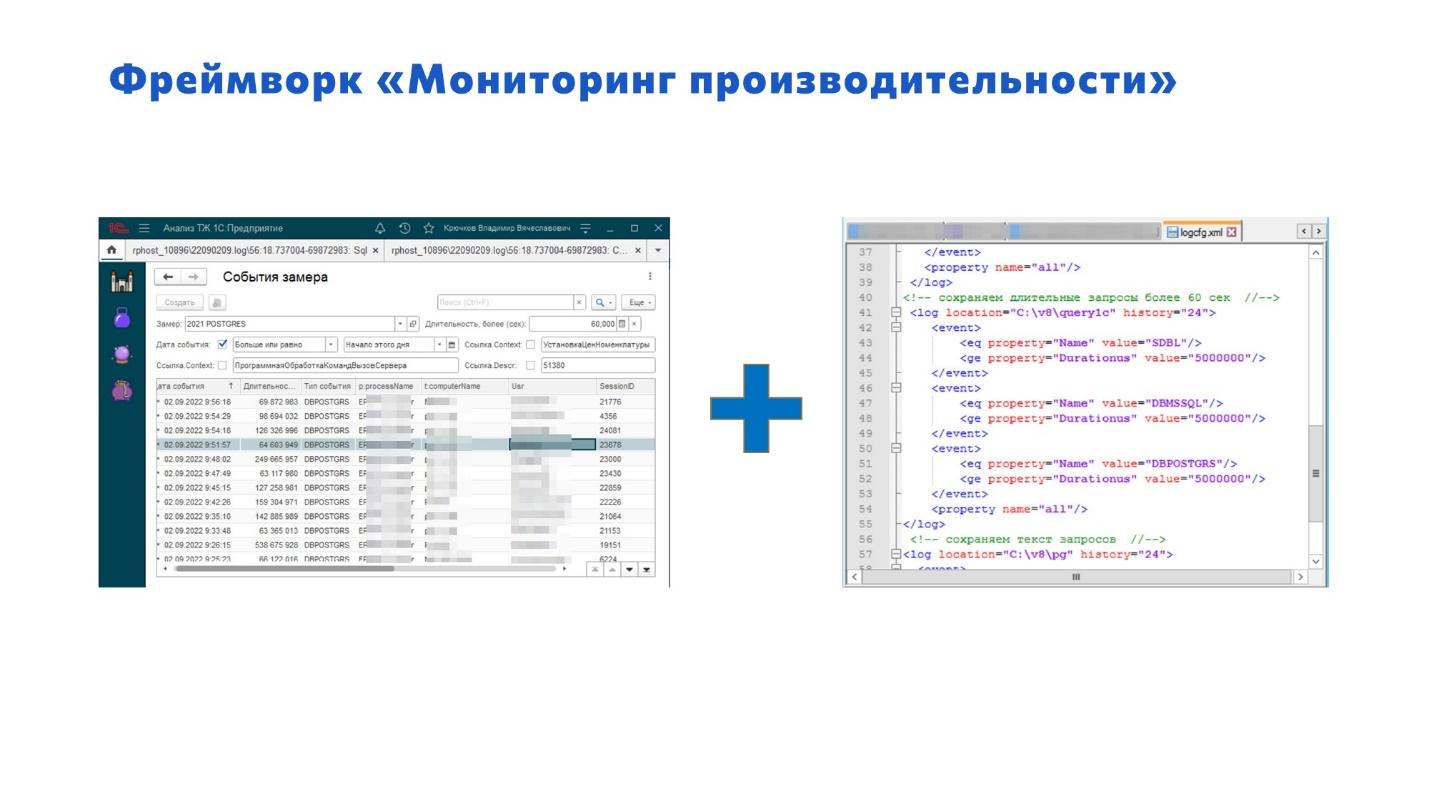
1С тоже предоставляет мощную базу для сбора данных для анализа производительности. Только здесь перегибать палку не надо – решайте задачи поэтапно: сначала переработайте самые проблемные запросы, потом переходите к следующим и т.д.
Со стороны 1С мы используем фреймворк «Мониторинг производительности» и настройки технологического журнала – с их помощью мы получаем длительные запросы.
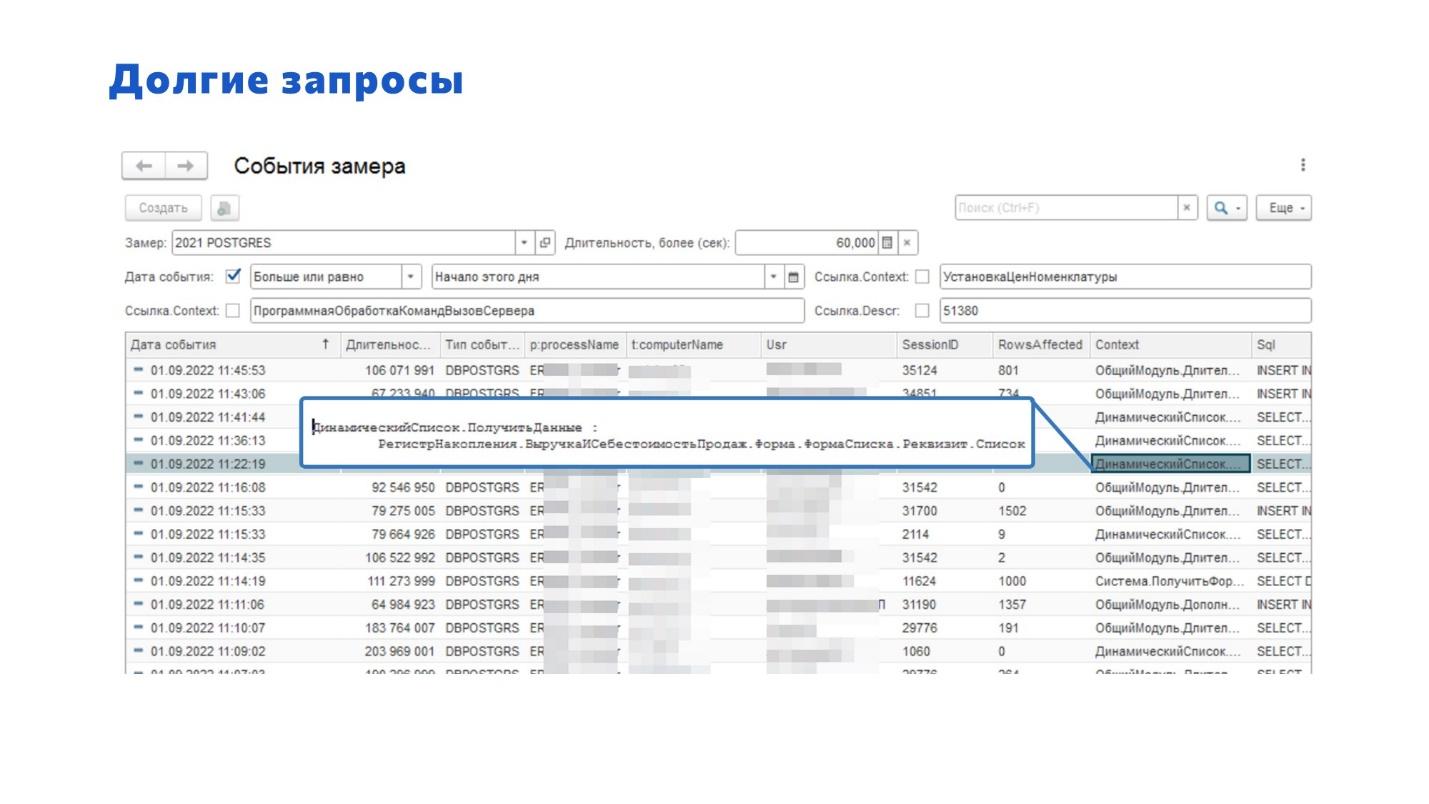
Без фреймворка «Мониторинг производительности» мы бы не смогли нормально провести переход с MS SQL на PostgreSQL и решить все проблемы, о которых нам писали пользователи.
Здесь мы фактически все проблемы видим заранее. Это помогает нам искать проблемы при работе на тестовых стендах, до выпуска релиза. И дальше, когда пользователь нам сообщает о проблеме, мы её ищем и находим по ней всю сопутствующую информацию:
-
имя пользователя;
-
количество строк, которые он получает;
-
длительность его запроса;
-
база, с которой он работает;
-
и самое интересное, мы получаем точку возникновения – контекст.
Например, пользователь говорит: «У меня есть проблемы». Мы получаем контекст, открываем конфигурацию, сразу находим этот запрос и можем его проанализировать. Если мы видим проблему сходу – отлично, если нет – изучаем контекст дальше.
Сейчас в работе еще один плагин – для сбора массовых запросов. Он позволит искать наиболее частые запросы и получать их контекст (на момент создания статьи этот плагин был выпущен в релиз, поэтому пользуйтесь – Поиск часто повторяющихся запросов).
Знания и опыт
Итак, мы сказали про инструменты – они вам дадут информацию о том, какие проблемы есть в базе, вернут вам набор данных для анализа.
Теперь ваша задача – проверить полученный набор данных на ошибки.

У фирмы «1С» на ИТС есть страница с типовыми ошибками разработчиков, где приведены варианты ошибок и способы их исправления. Мы также берем этот чек-лист и проверяем – встречаются ли эти проблемы в нашей системе.
На слайде перечислены некоторые пункты этого чек-листа – это самые частые ошибки, отсортированные по степени проблемности (по степени решаемости проблемы).
-
Первый пункт чек-листа – это обращение к свойствам объектов в полях составных типов. Не допускайте такого в ваших запросах, это очень негативно влияет на производительность.
Например, в ERP, УТ и Комплексной Автоматизации есть частоиспользуемый отчет «Расчеты с клиентами». Но, когда пользователь смотрит этот отчет, он хочет видеть информацию не только в разрезе самих заказов клиента, он хочет вытащить из заказов аналитику: договор, соглашение и так далее. Причем, даже если вы посмотрите типовой запрос, вы увидите, что разработчики сами вытягивают эти свойства в запросе прямо из реквизитов заказа.
В базовом варианте отчет обращается к одной таблице регистра «РасчетыСКлиентами», но при попытке вытащить значения свойств заказа платформа автоматически добавляет к вашему запросу еще 20-100 таблиц. Но это еще не все – если у вашего пользователя стоит ограничение по RLS, система к каждому подзапросу начинает автоматически добавлять условия. В зависимости от настроек RLS таких условий может быть очень много – в результате у вас получается монстр, который еле работает.
Эта проблема актуальна как в MS SQL, так и в PostgreSQL. Но в PostreSQL она гораздо хуже влияет на ситуацию.
В ERP версии 2.5 эта проблема решена – там разработчики внесли архитектурные изменения и добавили новый справочник, в котором хранят всю эту информацию – в результате вместо 20 таблиц обращение сжимается до двух.
-
Старайтесь в запросе отбирать только те данные, которые вам нужны. Если мы выбираем все подряд, а фильтруем только в конце – оставляем 2-3 записи, которые нам нужны – у вас выбираются данные всей кучей с учетом RLS, и это всё еле работает. По стандартам использовать условия нужно сразу – на уровне виртуальных таблиц. Не забываем также про память, ее может вдруг не хватить и тогда PostgreSQL перейдет работать на жесткий диск и у вас начнутся реальные тормоза – мы такое уже проходили.
-
Обращайте внимание на индексы – их часто не хватает. Здесь вам придется проанализировать ваши текущие потребности и самим внести необходимые изменения в конфигурацию. Кстати, фирма «1С», начиная с версии 8.3.24, обещает нам возможность наконец-то самим управлять индексами. Если это действительно так, это круто (по последним данным, эти изменения опять сдвинули – уже на 8.3.26 релиз).
-
По поводу кривой архитектуры и банальных ошибок разработчиков ничего конкретного не скажу – это очень объемная тема, и на нее просто не хватит времени. Просто старайтесь повышать квалификацию своих сотрудников и все время работайте над этим.
Примеры проблем и их оптимизация

Рассмотрим примеры – я надеюсь, вы ощутите всю глубину проблем, которые могут возникнуть при нарушении этих пунктов чек-листа. Мы увидим во сколько раз можно повысить производительность некоторых запросов при правильном подходе.
Отборы вне виртуальных таблиц

Запрос с отбором вне виртуальных таблиц. Разработчики часто допускают эту ошибку. Особенно когда тестируют на демонстрационных базах, где 20 или 30 документов. На такой базе невозможно ощутить и увидеть ошибку связанную с производительностью. Все будет работать очень быстро и незаметно, если не знать что искать и где смотреть.
Например, мы часто получаем в запросе цены для товаров. Но если не добавляем внутрь виртуальной таблицы условие по виду цен (это одно из трех измерений), то в большинстве случаев у нас будут проблемы.

Исправляется запрос элементарно – добавляем вид цен, и все начинает работать очень быстро и оптимально на сколько это возможно.
Теперь немного об особенностях. На MS SQL мы с этим запросом проблем не видели – он работал очень хорошо. Проблемы проявились только после перехода на PostgreSQL версии 11, потому что здесь выбор операторов зависит от количества данных.
Мы даже эксперимент проводили – до 10 тысяч записей запрос отрабатывает быстро, а больше 10 тысяч записей может 5 минут крутиться. Здорово, да?
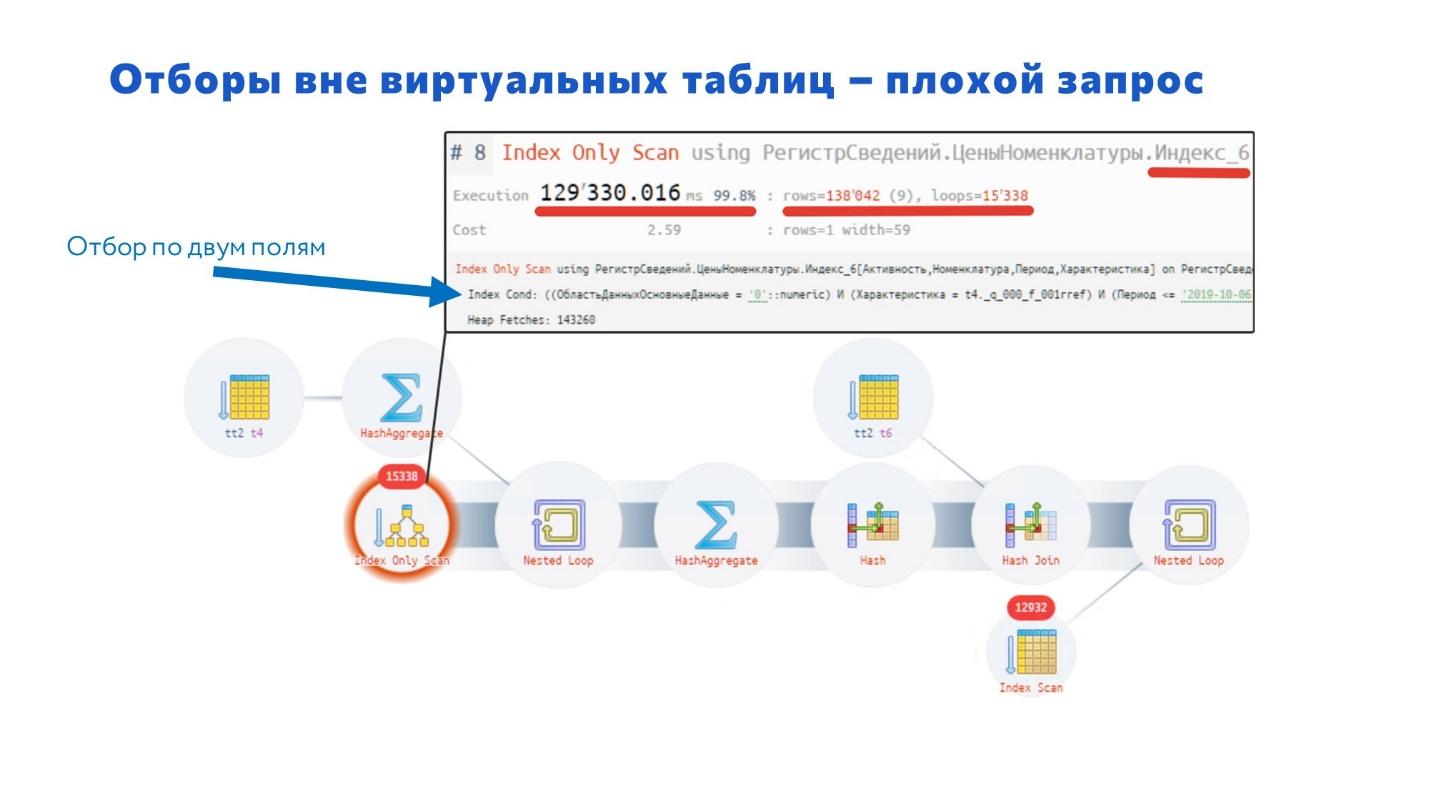
Объясню, почему это происходит.
С помощью плагина auto_explain находим проблемный запрос, берем его текст SQL, преобразуем с помощью конвертера и идем на сайт https://explain.tensor.ru/ – он нам выводит наглядную схему запроса, с ней работать очень просто.
Когда будете работать с запросами на сайте https://explain.tensor.ru/, обращайте внимание на эти красные кружки – именно в этих местах, скорее всего, проблемы.
Если к ним подвести мышку, всплывает подсказка, и в ней мы видим:
-
время выполнения;
-
и сколько этот оператор занимает в процентах.
В данном случае отбор был произведен по двум полям – запрос прочитал порядка 140 тысяч строк и дальше их отфильтровал, осталось 30 тысяч.
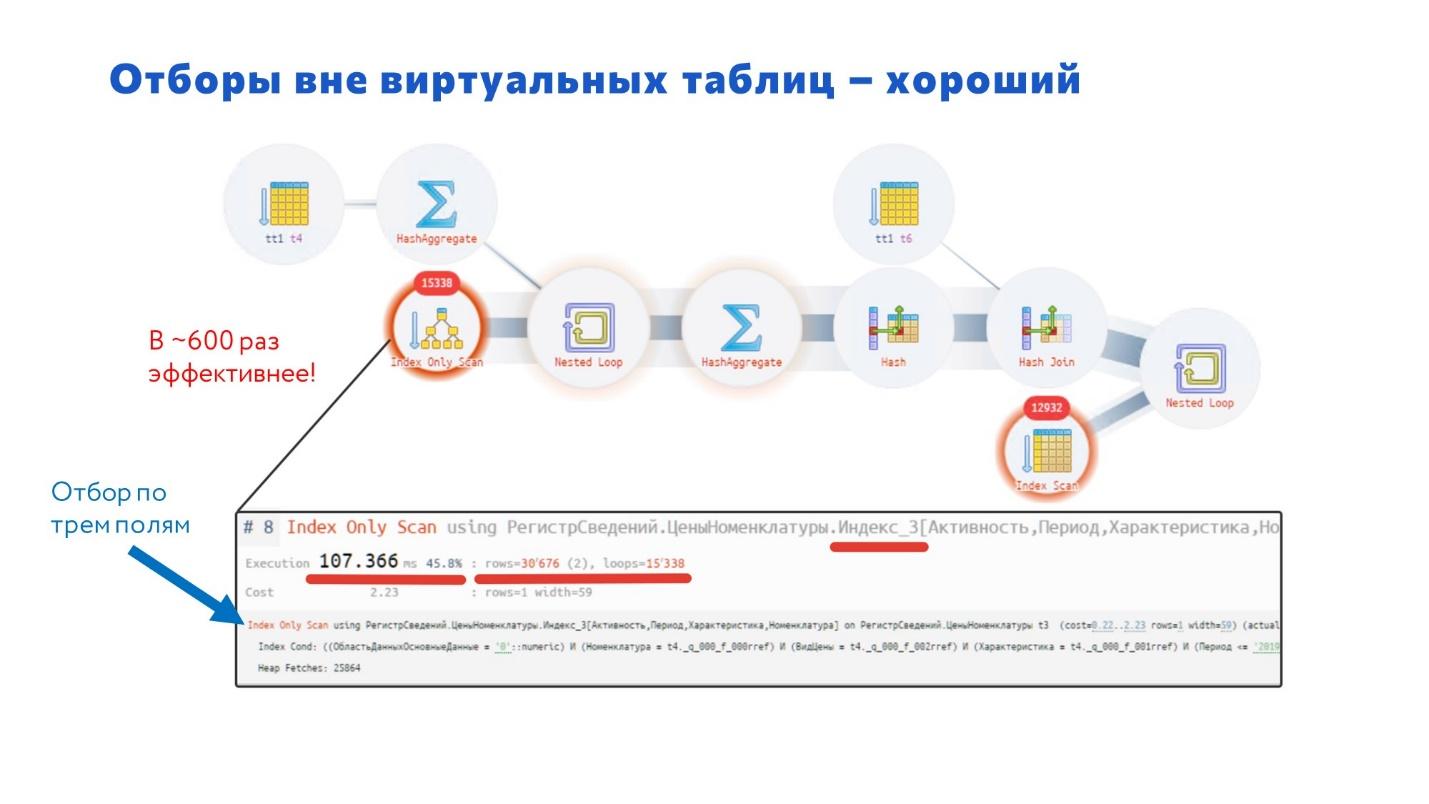
А теперь посмотрите, как выглядит исправленный запрос. Здесь отбор идет по трем полям: Номенклатура, Характеристика, Вид цены – т.е. сразу отбирается уже порядка 30 тысяч записей. Этот запрос работает в 600 раз эффективнее.
В MS SQL этой проблемы нет, потому что там есть механизм Predicate Pushdown, который проталкивает эти условия дальше вниз, он автоматически фильтрует данные уже на первом участке.
Запрос с условием «В»

Следующий пример – запрос с условием «В».
Вы, наверное, читали, что есть проблема с быстродействием оператора «В». (Хочу вас обрадовать в PostgreSQL начиная с 15-й версии механизм работы с оператором «В» был переработан и теперь все работает очень хорошо)
В PostgreSQL 11 эта проблема проявляется еще сильнее. Но главная особенность этого запроса в том, что он применяется в шаблонах RLS – т.е. все операции с RLS потенциально могут работать медленно.

Исправить этот вариант можно через внутреннее соединение. Мы переписали, и запрос стал работать быстро и качественно.
Но интересный момент – на MS SQL все сразу работало хорошо и быстро.
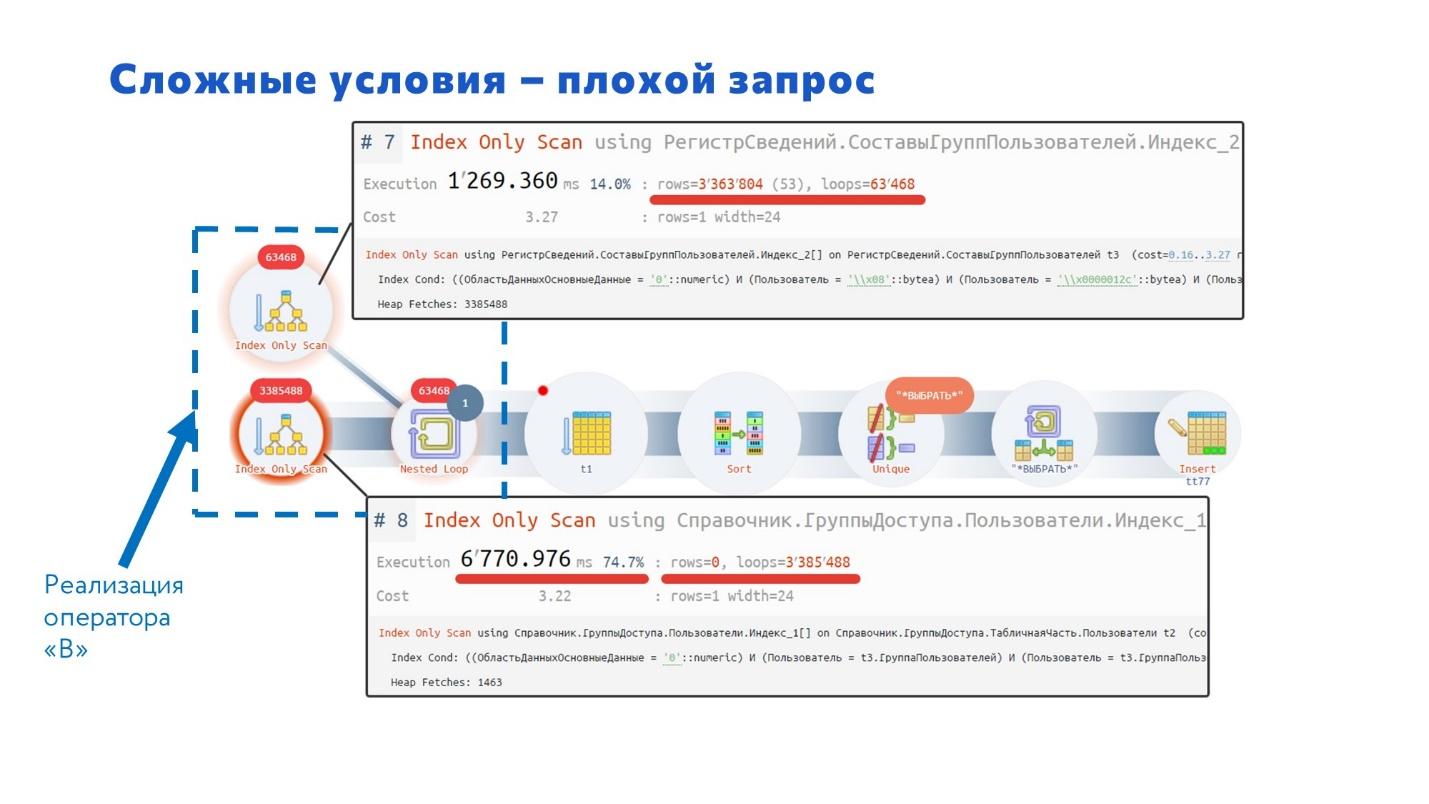
А на PostgreSQL план запроса показал, что выбирается слишком много данных – СУБД для каждой записи получала по 53 строки и так делала 63 тысячи циклов. В результат общее число обработанных строк получилось в районе 3 миллионов 400 тысяч строк.
Т.е. для PostgreSQL реализация оператора «В» неудачная.
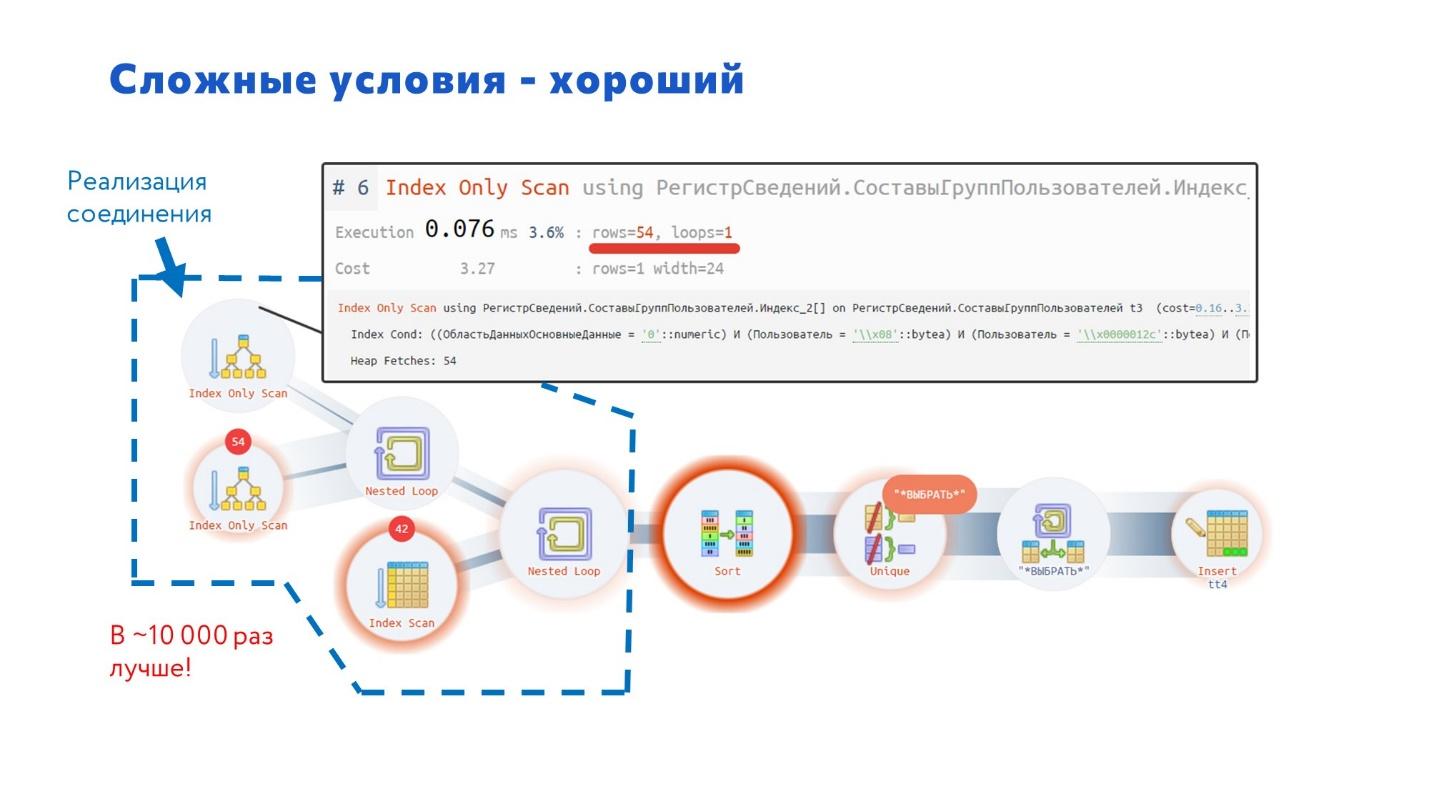
Здесь показано, как стал выглядеть план запроса в PostgreSQL, когда мы его исправили на внутреннее соединение – запрос стал работать в 10 тысяч раз быстрее исходного. Причем в MS SQL планировщик сразу строит именно такой план запроса.
Чтобы вас не огорчать, скажу, что эти скриншоты я снимал на PostgreSQL 11 версии – на ней исходный запрос выполнялся порядка 9 секунд.
Когда мы перешли на 14-ю версию PostgreSQL, исходный запрос стал выполняться 500 миллисекунд. Т.е. они оптимизировали работу из коробки. Но все равно нормальное время выполнения – порядка одной миллисекунды, а по умолчанию получается в 500 раз хуже.
Оператор ВЫБОР в условии динамического списка
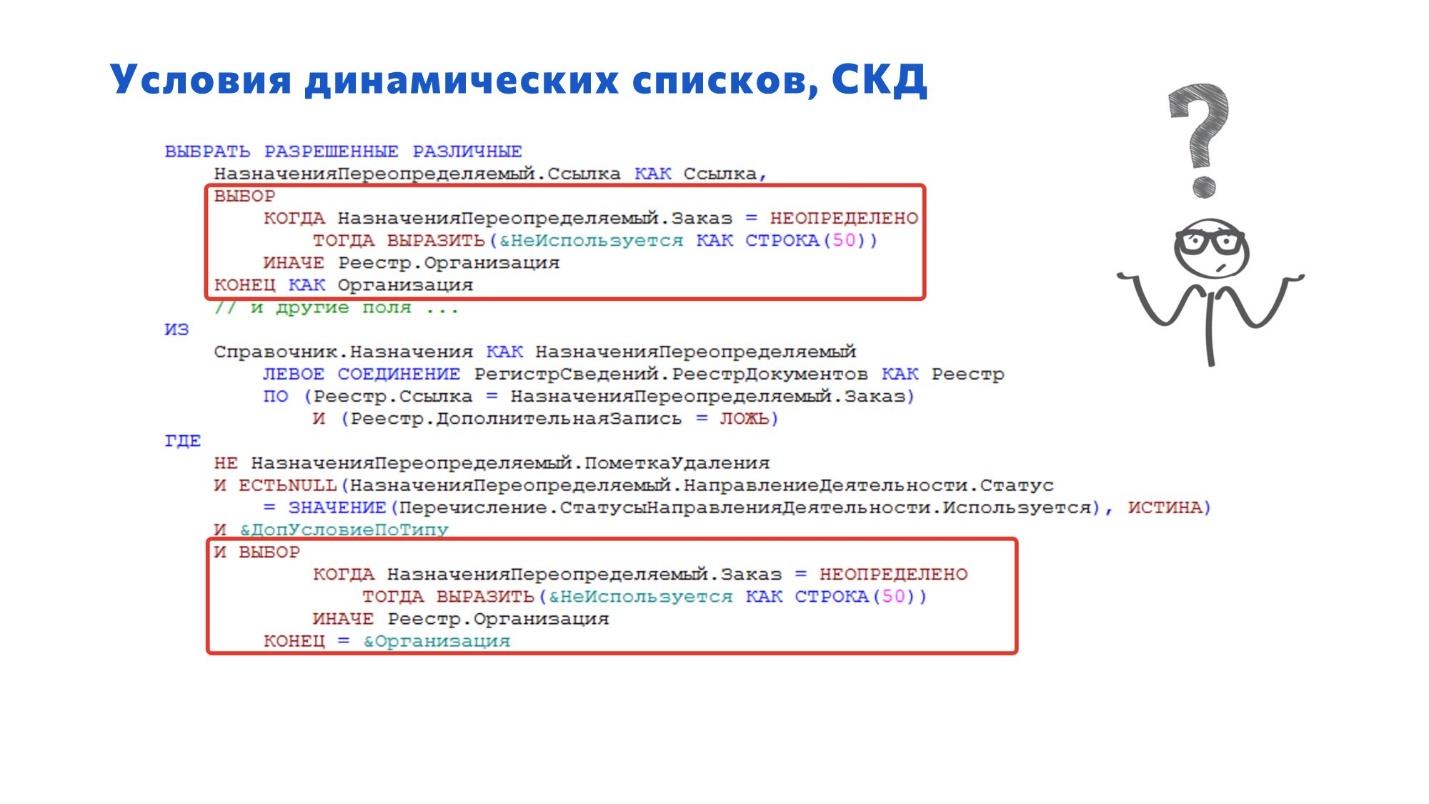
Следующий момент, который тоже часто встречается – это условия в динамических списках.
Мы столкнулись с проблемой подбора назначений в одном из производственных документов. Когда пользователь нажимал в форме документа кнопку «Подобрать назначение», у него всё на 18 часов улетало. Чтобы этого избежать, приходилось подбирать назначение через Ctrl-C, Ctrl-V – из формы подбора поиск назначения просто не работал.
Когда мы это изучили, то увидели, что изначально там бралось значение через две точки. Мы оптимизировали это через реестр, и вроде стало классно работать. Это была первая итерация.
Но этот вариант работал не для всех случаев. Когда пользователь ставил отбор, форма подбора опять начинала тормозить – время открытия с 10 миллисекунд увеличивалось до нескольких секунд. Как же так? Вроде мы ставим дополнительный отбор, все должно работать лучше – почему все наоборот?
Я поясню, в чем проблема. Видите ошибку, которую я обвел? Никогда не используйте в условиях соединения оператор ВЫБОР – это приводит к значительному снижению производительности.
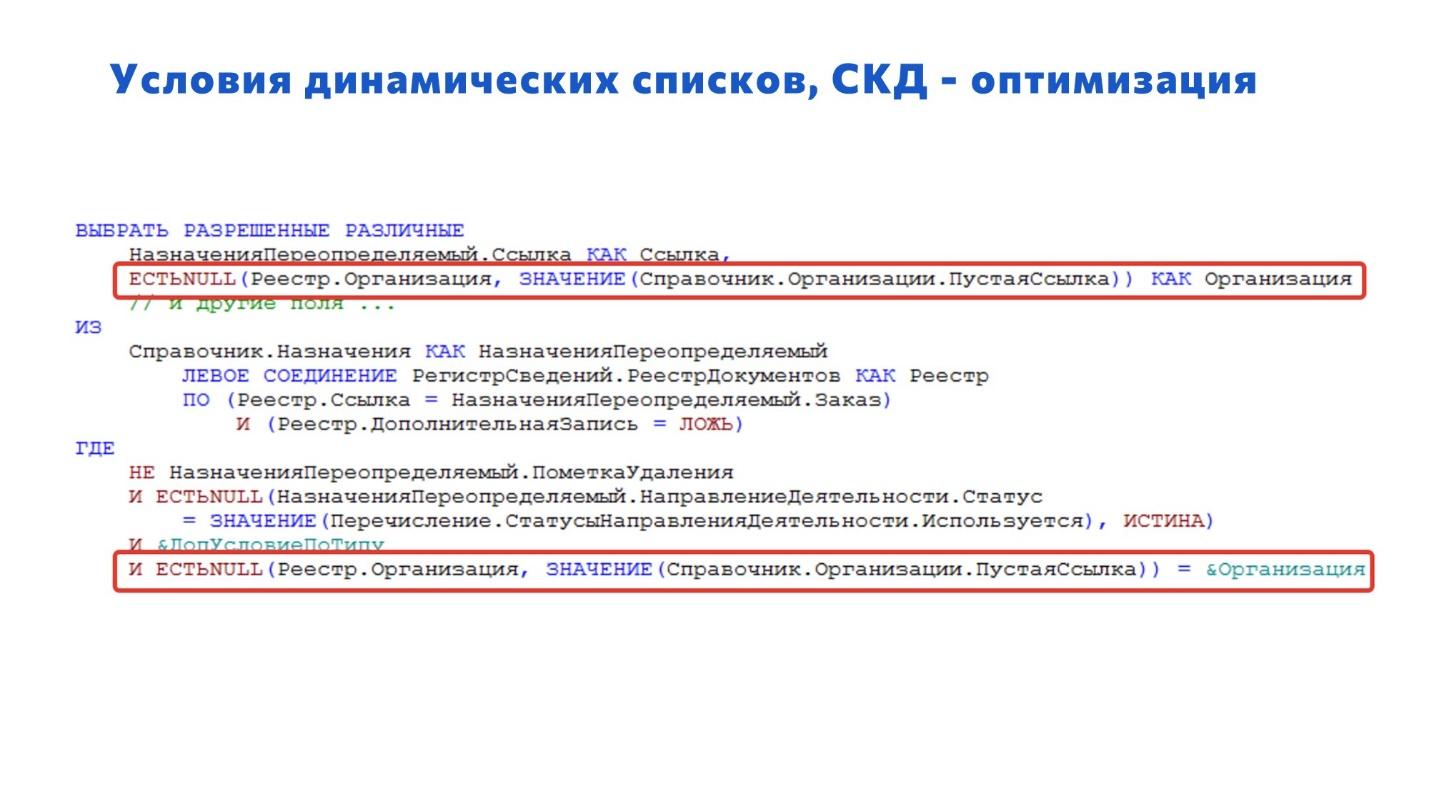
Когда мы использовали вариант исправления через ЕСТЬNULL, этот запрос стал «летать» во всех случаях.
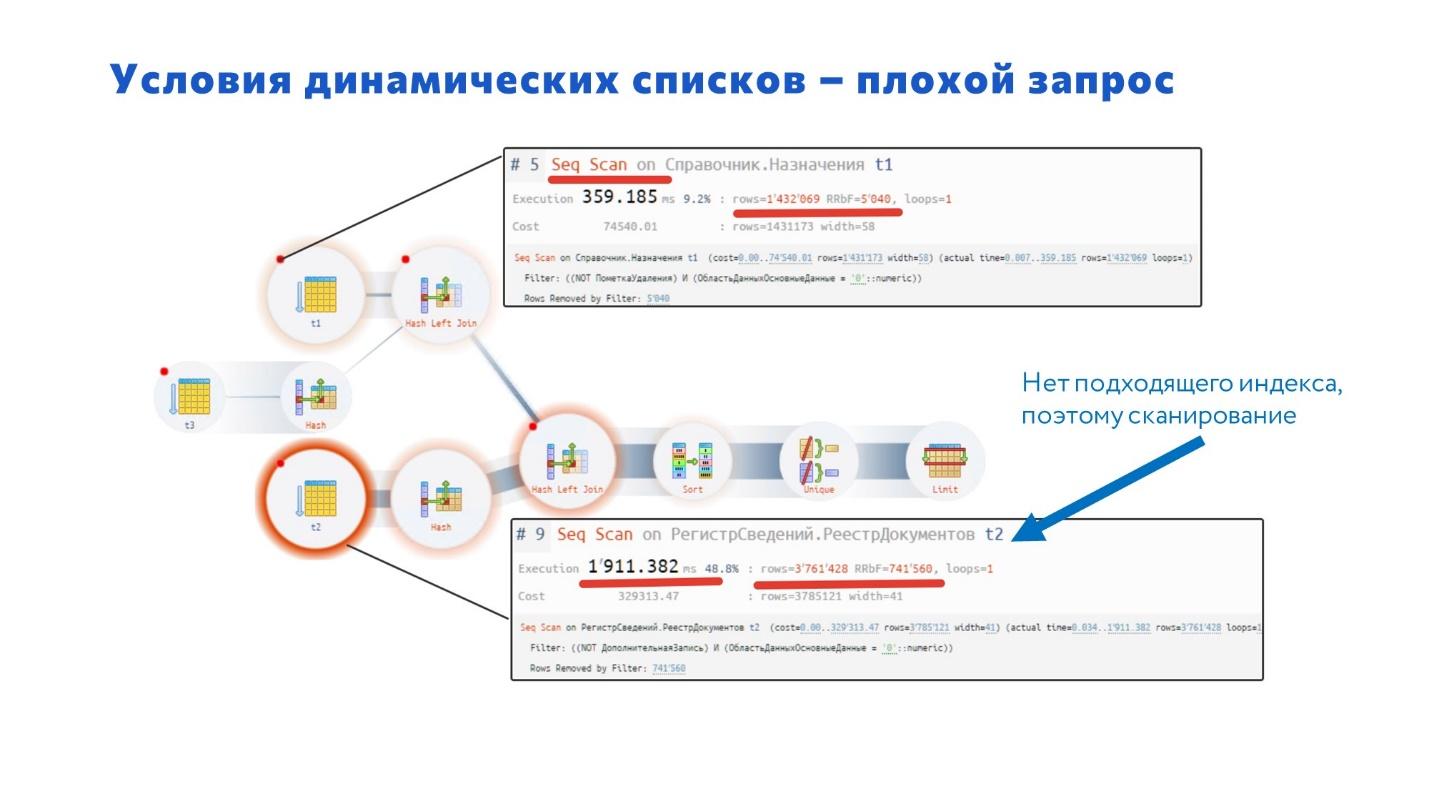
Давайте посмотрим, почему такое происходит.
В плане запроса мы сразу видим красные кружки и оператор Seq Scan – это последовательное чтение данных из таблицы. Если вы видите последовательное чтение, скорее всего, здесь может быть проблема.
Чем плохо последовательное чтение? Тем, что у вас прочитываются все поля, и на них накладываются условия. Если в таблице 100 миллионов записей или 1 миллиард записей, то они будут просмотрены все. А если у нас в результате по условию подходит 1 или 2 записи, какая получается у нас эффективность? Это нехорошо. Индекс – более оптимальная вещь в данном случае.
В итоге планировщик выбрал последовательное чтение, потому что не смог подобрать необходимый индекс. А нет такого индекса от функции выбора у нас в системе. Когда мы указываем в условии: «ВЫБОР КОГДА НазначенияПереопределяемый.Заказ = Неопределено ТОГДА… ИНАЧЕ…», то у планировщика нет выбора – он не смог понять, что нужно сделать.
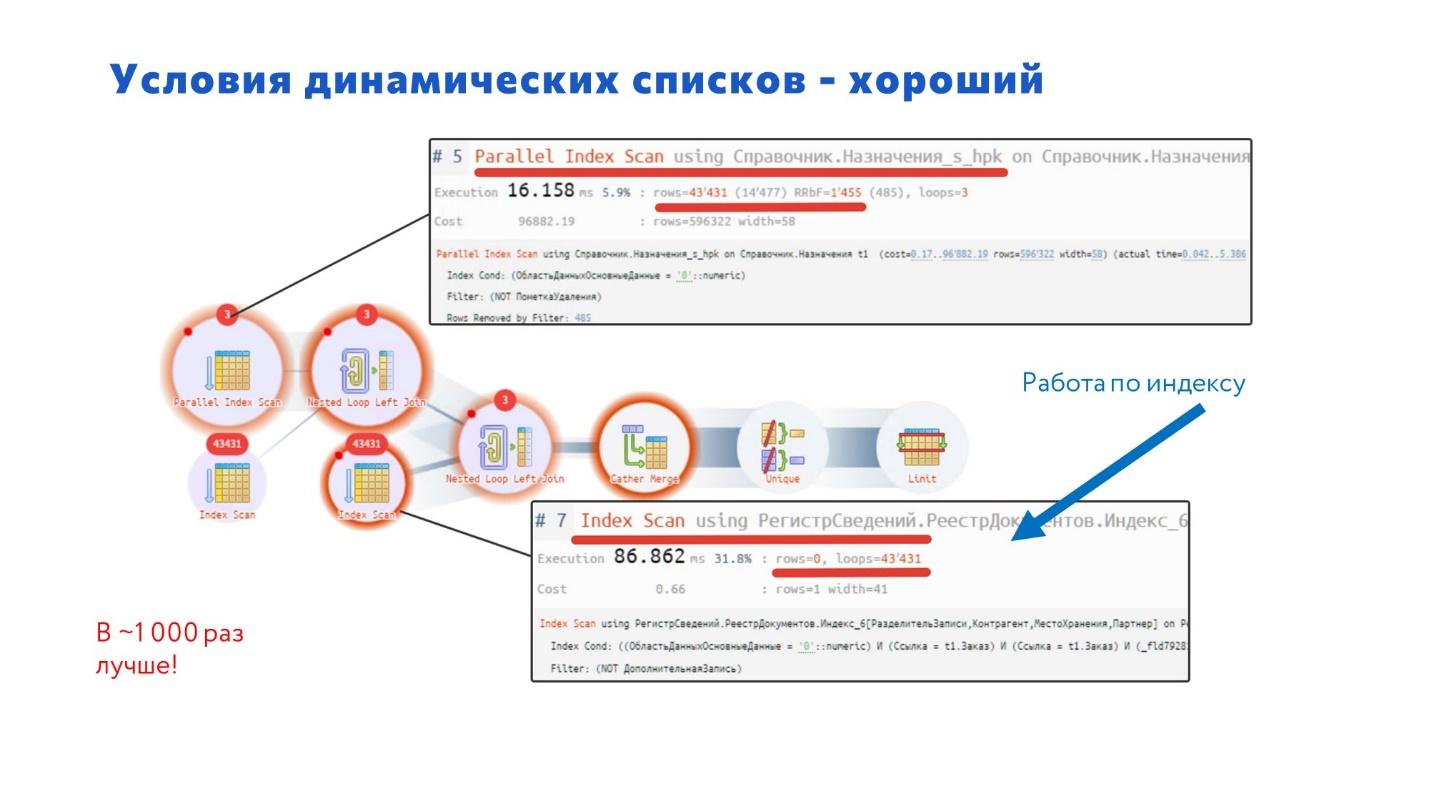
Когда мы исправили на ЕСТЬNULL, индекс у нас появился, и быстродействие сразу увеличилось в 1000 раз. Представляете, насколько система стала лучше работать?
Отборы по составному полю – особенности платформы 8.3.16

И последний классный пример – о том, как надо писать в фирму «1С» об ошибках.
При работе с платформой 8.3.16 мы столкнулись с особенностью, что запросы для составных типов работали неоптимально.
А с линией консультации 1С тоже надо уметь общаться – они очень любят писать в ответ: «Попробуйте другую версию», и так далее. Поэтому наберитесь терпения и попробуйте дожать вопрос, сделайте мир чуточку лучше – занесите себе плюс в карму.

Запрос довольно простой, наверняка у многих встречается – выборка из регистра накопления «Остатки» с отбором по какой-то временной таблице.
Этот простой запрос у нас на PostgreSQL работал очень долго – на MS SQL он отрабатывал за миллисекунды, а в PostgreSQL время выполнения достигло 25 секунд.

Для исправления нам пришлось типизировать заказ клиента во временной таблице через ВЫРАЗИТЬ – тогда все стало работать быстро.
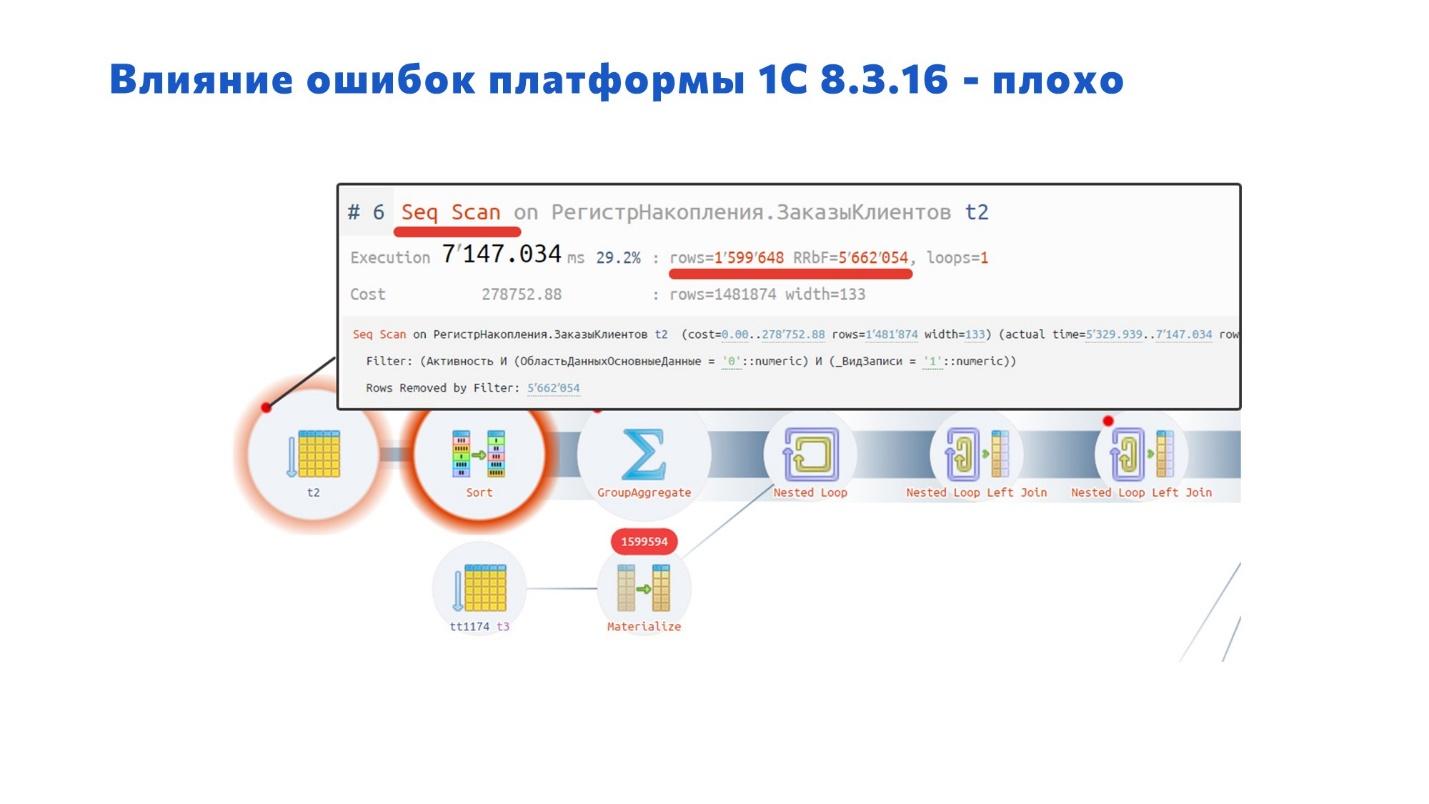
В данном случае наложились друг на друга особенности PostgreSQL и поведение платформы 8.3.16, потому что каждый такой запрос сканировал весь регистр. 10 раз нажали – он 10 раз просканировал регистр. Время сканирования на каждую операцию 7 секунд, а таких операций очень много в базе.
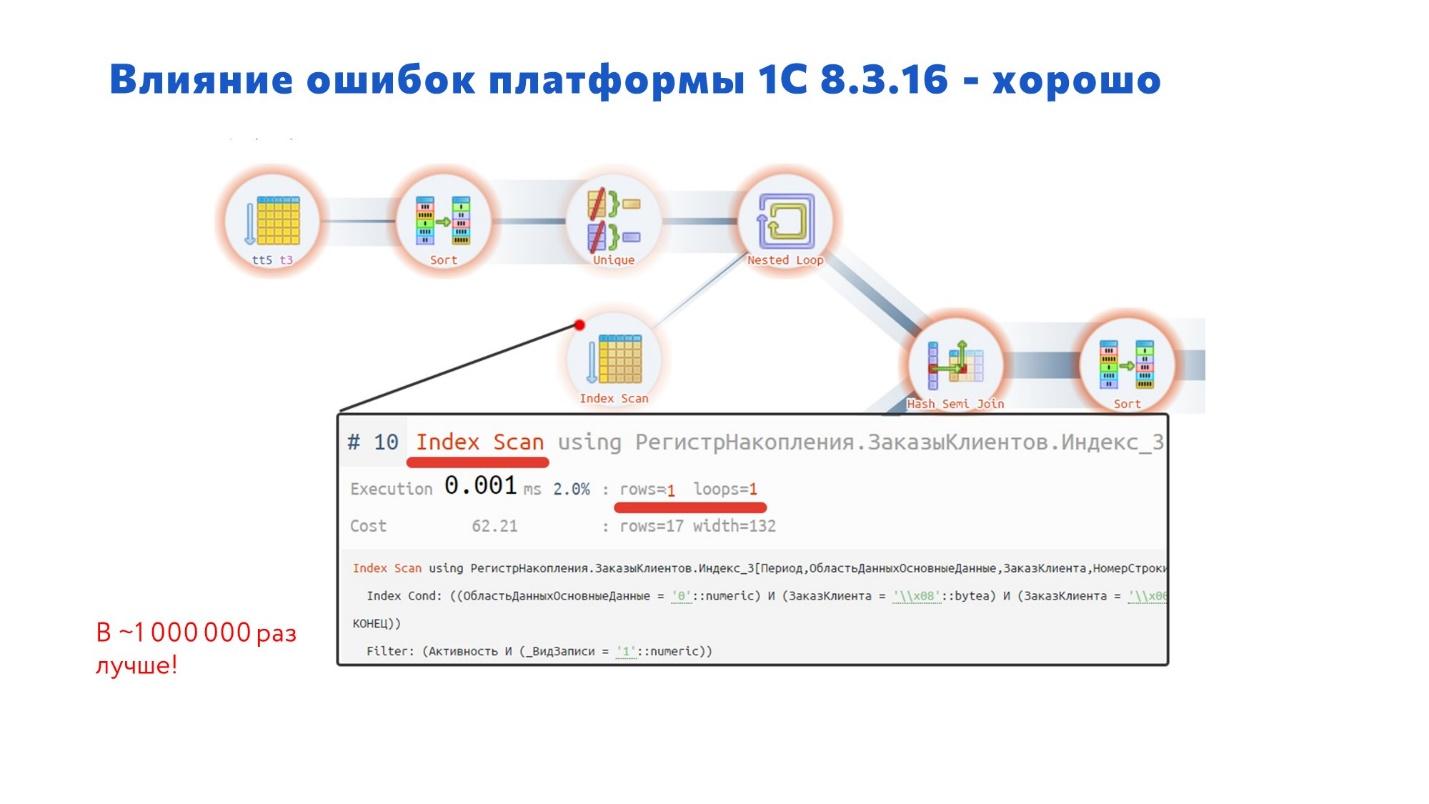
Как выглядит оптимизированный план запроса?
Нам же не нужно сканировать все эти 2-3 миллиона записей – мы ищем одну запись, это должно быть априори быстро.
После оптимизации запрос стал работать в миллион раз лучше! А таких запросов было много, и с ними было очень неприятно работать пользователям.
Учитесь оптимизировать запросы – будьте в тренде

В качестве заключения:
-
PostgreSQL не прощает ошибки. Пишите правильно, качественно. Соблюдайте стандарты – и будет шикарно.
-
Будьте готовы в текущей ситуации потратить ресурсы на оптимизацию производительности своей системы. Конечно, это потребует времени.
-
Учитесь читать и понимать планы запросов. Если у вас еще нет таких знаний, вам сначала придется обучиться – на это может уйти до полугода. Как можно раньше начинайте готовиться.
-
Читайте, практикуйтесь, учитесь – будьте в тренде.
Вопросы
Вы рассказывали про динамический список, где пришлось избавляться от оператора ВЫБОР, а MS SQL нормально отрабатывал этот запрос?
Да. Но после оптимизации под PostgreSQL он стал еще лучше работать на MS SQL.
Любая оптимизация запроса под PostgreSQL так же благодарно воспринимается и под MS SQL. Не бывает такого, что после оптимизации под PostgreSQL запрос стал хуже выполняться на MS SQL. Нет, он будет великолепно работать и там, и там. Правильный код 1С на обеих СУБД работает хорошо. После PostgreSQL вы в любой момент можете вернуть базу на MS SQL, она будет работать только лучше.
А почему MS SQL лучше работает с запросами?
Потому что планировщик MS SQL умнее, чем планировщик PostgreSQL. Но PostgreSQL постоянно учится, развивается, есть надежда, что скоро догонит.
Вы приводили пример запроса с условием «В», который часто встречается в RLS, и говорили, что переделали его на внутреннее соединение в каком-то списке. Но RLS мы на внутреннее соединение не переделаем. Как быть?
Воспользуйтесь производительным механизмом RLS. В некоторых случаях он работает лучше, чем обычный механизм. Но есть там определенная пакость – про минусы производительного RLS я писал в статье. (Напоминаю, что наконец-то в версиях PostgreSQL с 15-й данный механизм был переработан и многие запросы стали выполняться очень хорошо. По крайней мере, те проблемные запросы, которые у нас были, в новой СУБД стали выглядеть просто отлично)
*************
Статья написана по итогам доклада (видео), прочитанного на конференции Infostart Event.


Вступайте в нашу телеграмм-группу Инфостарт