Сейчас все больше крупных информационных систем реализуются на платформе 1С, и для крупных внедрений повышенные требования к производительности 1С – это норма.
Традиционно этим занимаются эксперты 1С, сертифицированные специалисты. Считается, что работа с производительностью требует повышенной квалификации, причем ключевой элемент работы экспертов – это диагностика проблем производительности, а не их непосредственное решение. Правильная диагностика важна, потому что она определяет вектор дальнейших работ, но расследовать проблемы производительности довольно сложно.
Сложность расследования проблем производительности
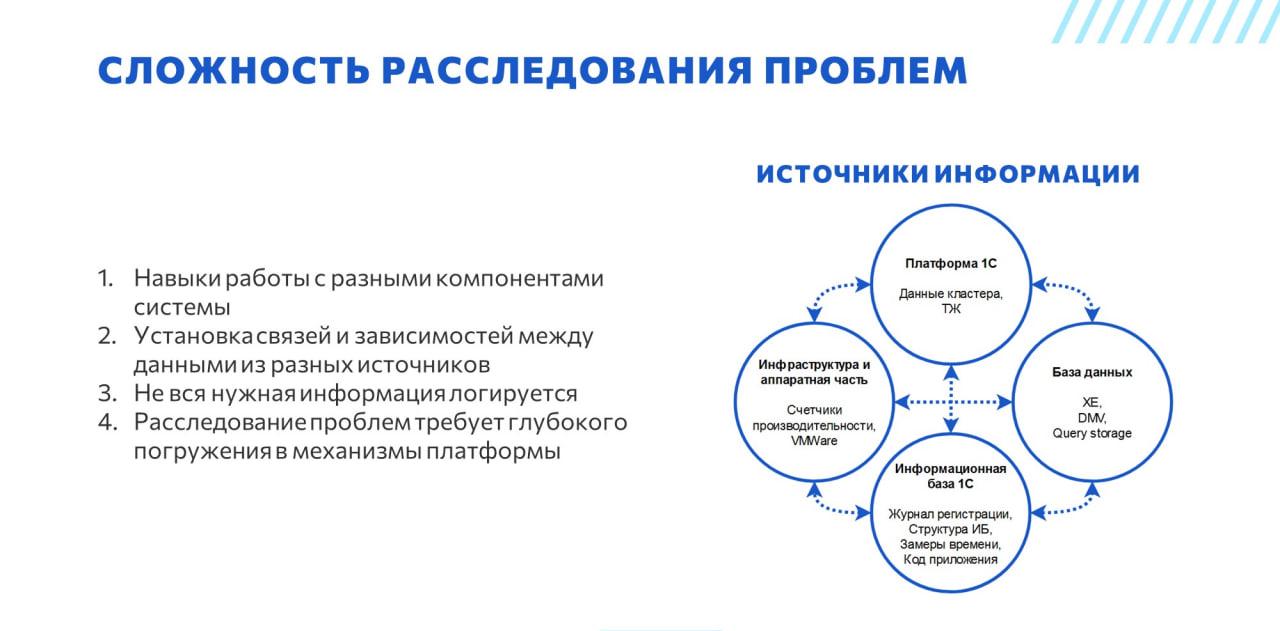
Почему расследовать проблемы производительности сложно?
Во-первых, потому что человеку, который этим занимается, нужно уметь работать с различными компонентами системы – уметь получать из них данные и понимать, что они означают. В качестве источников информации могут быть:
-
Платформа 1С.
-
База данных.
-
Информационная база 1С, потому что часто у конфигурации есть какие-то нюансы, которые определяют логику хранения данных и работы с объектами. Зачастую лучше знать об этих особенностях заранее – особенно, если мы говорим про типовые решения.
-
Счетчики производительности операционной системы.
Даже если вы знаете, как получить эти данные, их нужно собрать и установить между ними связи и зависимости (а также разобраться, по каким полям соединять данные из разных источников). На сбор и сопоставление этой информации уходит очень много сил и времени. При этом эти операции являются по сути рутинными и повторяются из раза в раз. Все усугубляется тем, что все инструменты получения данных разнородные:
-
Management Studio выдает информацию СУБД себе в интерфейс.
-
Технологический журнал – это простой текст.
-
Журнал регистрации без платформы 1С не прочитать.
-
Консоль кластера – тоже не самый удобный интерфейс. Например, в списке сеансов около сорока колонок. Если у вас тысяча сеансов и нет поиска, нет фильтрации, нет выбора колонок, найти нужную ячейку очень сложно. Пока найдешь, оказывается, что сеанс уже завершился, данные уже не актуальны, надо еще куда-то идти.
Не помогает расследованию и тот факт, что информация о текущем состоянии системы не логируется. Например, не сохраняются данные о состоянии рабочих процессов и сеансов, получаемые через консоль, не сохраняется информация о текущем состоянии процессов и ожиданий СУБД.
И четвертый момент – платформа 1С имеет свою специфику, и понять, что там происходит внутри, можно только имея реальный опыт работы с высоконагруженными системами. Документации зачастую недостаточно, и эксперты добывают знания в бою. Такой опыт нельзя получить в домашних условиях – сложно проверить, как система работает под нагрузкой, если у тебя нет нагрузки. В результате эксперты превращаются в подобие шаманов, которые знают, как работают компоненты системы, но кроме них об этом не знает никто. Некоторые эксперты пишут об этом статьи, но необходимые нюансы в них описаны далеко не всегда.
Снижение сложности расследования проблем

Чтобы решить эти проблемы, мы начали разрабатывать свое решение, которое называется Алькир.
-
Во-первых, мы сделали единый интерфейс, чтобы анализировать данные из разных источников, соединять их как-то между собой и комбинировать.
-
Мы сохраняем данные кластера и логируем состояние рабочих процессов и сеансов. Это делает возможными некоторые задачи, которые без логирования сделать невозможно. Например, мы можем постфактум связать данные рабочих процессов с какими-то данными ТЖ – и визуализировать эти взаимосвязи, построить какие-то графики.
-
В результате получились готовые инструменты, которые учитывают особенности работы платформы. Например, при анализе выполнения запроса можно увидеть и контекст, и пользователя, и номер сеанса 1С, и все, что может потребоваться. При этом пользователю системы нет необходимости знать о том, как между собой связаны события технологического журнала CALL и SCALL, по каким полям их соединять, как связать текущие данные кластера и текущие запросы на СУБД.
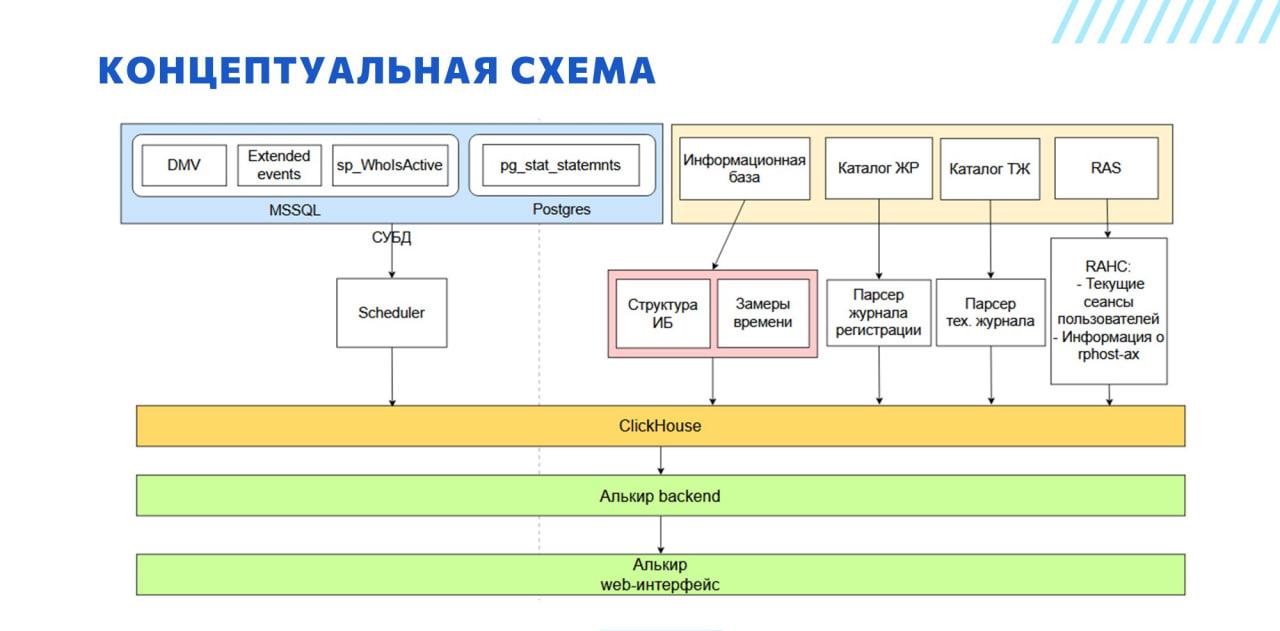
На слайде – упрощенная концептуальная схема инфраструктуры Алькира.
Прежде всего, мы исходили из того, что мониторинг, который мы строим, должен оказывать минимальное воздействие на систему, поэтому все тяжелые процессы вынесены на отдельные серверы. В частности, у нас используются самописные парсеры журнала регистрации и тех. журнала, написанные на C#. Они располагаются на отдельном сервере и забирают файлы из сетевой шары по NFS.
Мы хотим сделать так, чтобы все данные, которые могут потребоваться эксперту для работы, были собраны в одном месте. Мы по регламенту собираем все, до чего можем дотянуться:
-
Из СУБД собираем:
-
планы запросов, данные о выполненных запросах, блокировках, эскалациях через расширенные события;
-
данные DMV;
-
-
Из информационной базы собираем:
-
замеры времени;
-
структуру информационной базы, чтобы расшифровывать тексты запросов;
-
-
От кластера серверов 1С получаем:
-
текущие сеансы и текущее состояние рабочих процессов;
-
журнал регистрации;
-
технологический журнал.
-
Эти данные занимают большой объем, и чтобы их хранить, мы используем современные и высокоэффективные технологии – а именно СУБД ClickHouse.
Для нас важно соблюдать информационную безопасность:
-
Поскольку некоторые данные, которые мы собираем из СУБД (в частности, получение данных DMV), требуют админских прав, мы сделали хранимую процедуру, которая выполняется под админскими правами и получает из СУБД только информацию для мониторинга. Наша система подключается к СУБД через отдельную учетку с правами на выполнение только этой хранимой процедуры – ничего, кроме нее, она в базе выполнить не может. Поэтому риск что-то сломать или скомпрометировать отсутствует. А контролировать сохранность одной хранимой процедуры – несложно.
-
Чтобы собрать данные информационной базы, предусмотрено специальное расширение. Там тоже права очень сильно ограничены – только на объекты подсистемы «Оценка производительности».
-
Доступ к каталогам журнала регистрации и технологического журнала настраивается средствами операционной системы – только на чтение.
-
При подключении к RAS тоже используется отдельная авторизация.
Давайте посмотрим несколько примеров – что получается, если собрать все данные в одном месте. Как их можно автоматизированно обрабатывать, и какие результаты получить.
Пример: Длительное выполнение операций
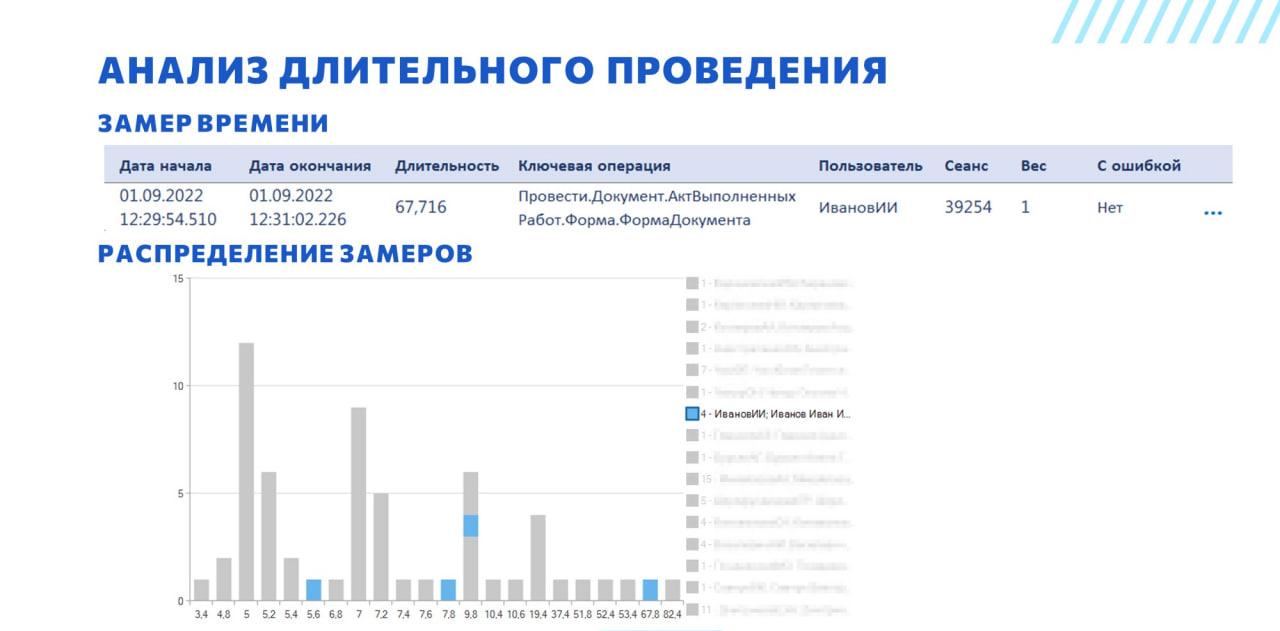
Первый пример – один из самых частых кейсов. Пользователь приходит и говорит, что у него документы проводятся 10 минут, и работать вообще невозможно.
Анализ будем проводить последовательно, отбрасывая возможные причины проблемы и сужая круг поиска. Начнём с проверки достоверности жалобы пользователя.
Напоминаю, что в Алькир есть замеры времени. Мы находим нужный замер, видим, что он проводится 67 секунд, и в последней колонке видим, что он завершился без ошибки. Мы можем опираться на этот замер в своем анализе.
Вообще, если строить какую-то иерархию событий, замеры времени – это самая высокоуровневая сущность. Они включают в себя и клиентское время, и серверное время, если оно там было (при условии, что замер правильно сделан). Действительно, у замеров есть ограничения – они подходят не для всех типов операций, но для операции проведения подходят очень хорошо.
Например, мы можем построить распределение замеров по ключевой операции. У нас на графике внизу длительность замера, а по шкале Y – количество замеров с таким временем. Мы видим, что обычно операция выполняется за 5-7 секунд, ещё видим пик в районе 10 секунд. Но 67 – это явное отклонение.
При этом мы видим, что такие отклонения бывают и у других пользователей, не только у нашего Иванова.
Отсюда мы делаем два вывода.
-
Во-первых, документ проводится не 10 минут.
-
Во-вторых, он проводится долго не всегда и не у всех пользователей.
Таким образом, можем критически оценить ситуацию и принять решение, надо ли все бросать и бежать смотреть, можно ли закончить текущую задачу или может можно вообще отложить анализ этой проблемы.
В некоторых случаях длительное проведение документа связано с его наполнением – либо там какой-то неправильный период стоит, либо ему в табличную часть засунули несколько тысяч строк. Лучше этот вариант сразу отбрасывать на начальном этапе анализа. Поэтому на втором этапе проверим корректность работы пользователя.
Чтобы это сделать, мы можем взять данные из замера времени и установить отбор по журналу регистрации:
-
по период замера;
-
номеру сеанса из замера;
-
имени пользователя из замера;
-
типу события журнала регистрации.
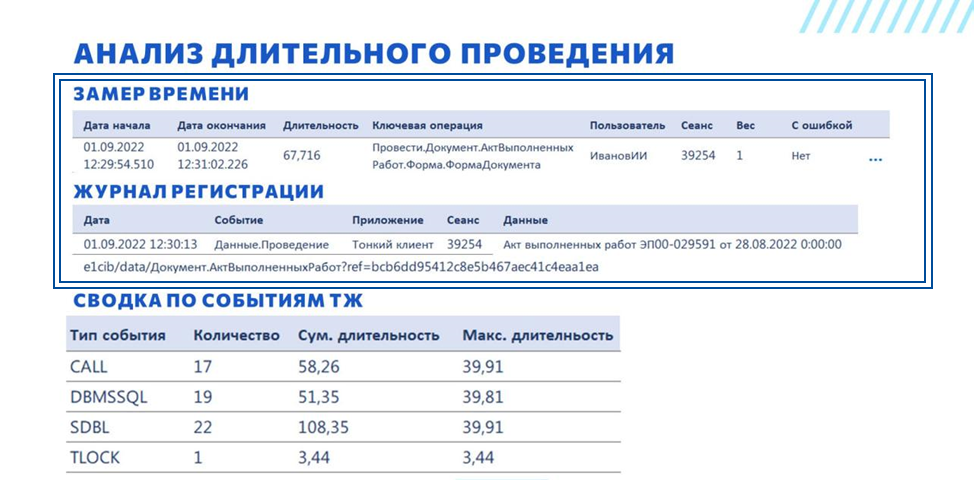
В списке находим событие Данные.Проведение, которое нас интересует – по нему у нас есть: во-первых, представление документа; во-вторых, мы можем получить на него ссылку.
Дальше идем либо в копию, либо в прод, открываем документ, смотрим, что там пользователь все-таки проводил. В данном случае документ был заполнен вполне корректно, у него было около 40 строк в табличной части, поэтому мы идем дальше – проблема не здесь.
На данном этапе мы более точно описали проблему и исключили ошибку пользователя. Теперь можно перейти непосредственно к анализу причин длительного проведения.
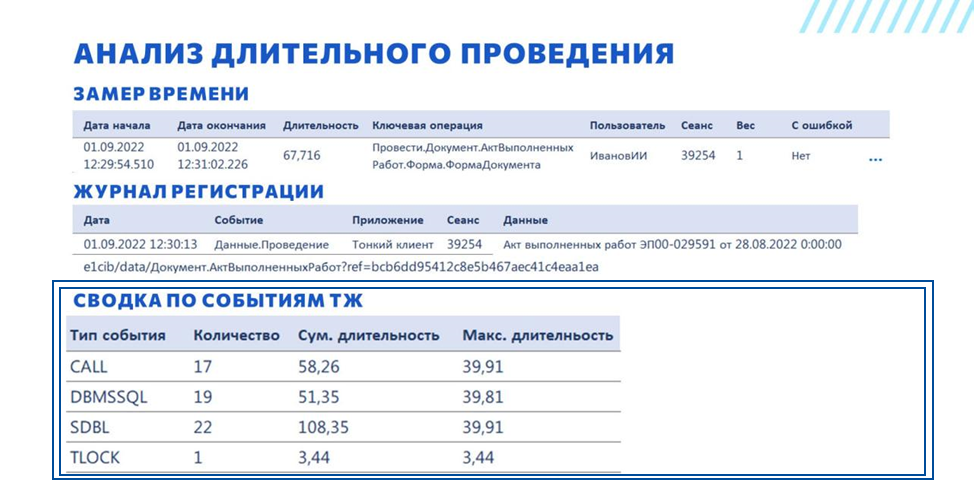
По такой же логике как с ЖР получаем все события технологического журнала – берем период, номер сеанса, пользователя. Событий там может быть очень много, события DBMSSQL, SDBL, TLOCK могут быть вообще огромными, и просто скроллить и читать все события - не наш метод. Вместо этого мы группируем все события по типу. Выводим количество таких событий, суммарную длительность и максимальную длительность.
-
По количеству событий CALL на одно проведение документа 17 серверных вызовов – это многовато. Скорее всего там есть какая-то проблема, есть какой-то цикл.
-
Основная длительность уходит на обращение к серверу СУБД – события DBMSSQL и SDBL.
-
И есть событие TLOCK длительностью примерно 3,5 секунды – это ожидание на управляемой блокировке.

Если замер – это сущность самого высокого уровня, то событие технологического журнала CALL – это уровень пониже. Это событие включает в себя серверный вызов и все остальные события, которые происходили на сервере.
Поэтому дальше мы берем только события CALL и группируем их по контекстам.
-
Видим, что на серверный вызов записи документа у нас ушло около 10 секунд. Мы можем развернуть контекст и увидеть все входящие события технологического журнала, которые у нас выполнялись в этот временной интервал. Видим, что у нас есть блокировка TLOCK на регистре сведений «ЗаданияКЗакрытиюМесяца». Выводится пространство блокировки и все остальные свойства, которые есть в технологическом журнале. В самой таблице события выводятся не целиком, потому что иначе бы таблица была очень большая. Но все свойства события можно просмотреть, если его развернуть.
-
Дальше мы видим 15 серверных вызовов с проверкой позиции номенклатуры (вторая строка в группировке). Судя по названию, предполагаем, что это действительно какая-то обработка в цикле, на которую ушло 8,5 секунд. При этом помним, что у нас в документе было около 40 строк, а серверных вызовов только 15. Возможно, что мы часть серверных вызовов не увидели, потому что они не прошли по фильтру технологического журнала, т.к. мы собираем эти события с отбором по длительности. Можно предположить, что 25 событий мы не собрали из-за настроек ТЖ, и влияние этого контекста на общую длительность замера ещё больше.
-
Самый большой вклад в длительность операции сделало обновление динамического списка. Это классика жанра – динамический список обновляется при записи документа. Если в нем установлены какие-то неэффективные настройки, он обновляется долго. Проведение документа и обновление списка - это разные операции, но пользователями они воспринимаются как одна.

Развернув строку с контекстом события CALL, относящемуся к обновлению списка, видим, что большая часть времени ушла на выполнение запроса.
Свойства SQL и свойства SDBL здесь не выводятся, потому что они большие. Но, опять же, каждую строчку можно развернуть и посмотреть все свойства события. А дальше по тексту запроса определить, есть ли у нас какие-то фильтрации или сортировки по неиндексированным полям.
Подводя итог анализа - замер был 67 секунд, из них:
-
40 секунд – динамический список;
-
8,5 секунд – цикл по позициям номенклатуры;
-
3,5 секунды – управляемая блокировка,
Если мы все это оптимизируем и приведем длительность к нулю (что, конечно, не всегда возможно), мы ускорим операцию до 15 секунд.
С учетом того, что мы поймали не все события CALL, связанные с проверкой номенклатуры, возможно, что ускорение будет еще больше.
Пример: Зависший сеанс
Другой довольно-таки типовой кейс – это зависший сеанс, о котором нам сказал пользователь: «Я запустил, а оно все висит и висит». Или к нам пришел админ и предлагает срубить какие-то зависшие сеансы.
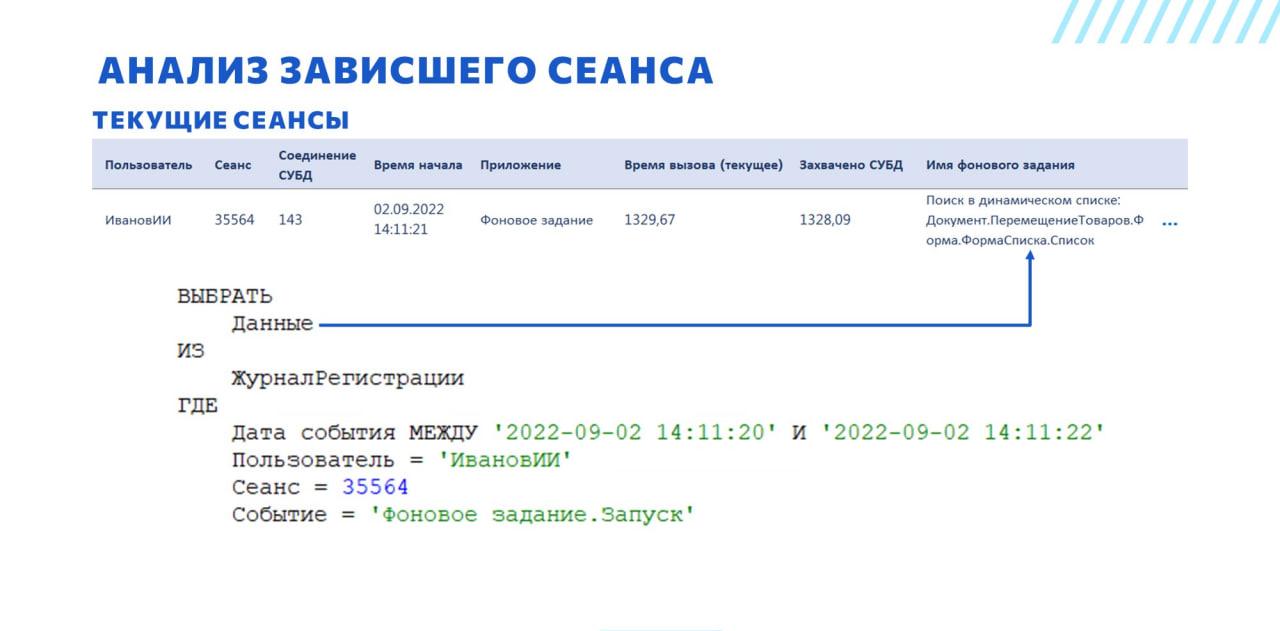
У нас в инструменте текущие сеансы выводятся примерно в том же виде, что и в типовой консоли кластера, за исключением того, что у этого списка есть возможность нормальной настройки и еще добавлена колонка «Имя фонового задания», которая заполняется, если это сеанс фонового задания.
Мы автоматически подключаемся к данным журнала регистрации, который у нас есть, ставим отбор по времени начала сеанса, которое есть в консоли, по пользователю, сеансу и событию, и можем сразу же здесь увидеть, что в этом сеансе выполняется – в некоторых случаях этого достаточно для того, чтобы принять решение о дальнейших действиях.
В данном случае мы видим, что пользователь выполняет поиск в динамическом списке, который и привел к зависанию.
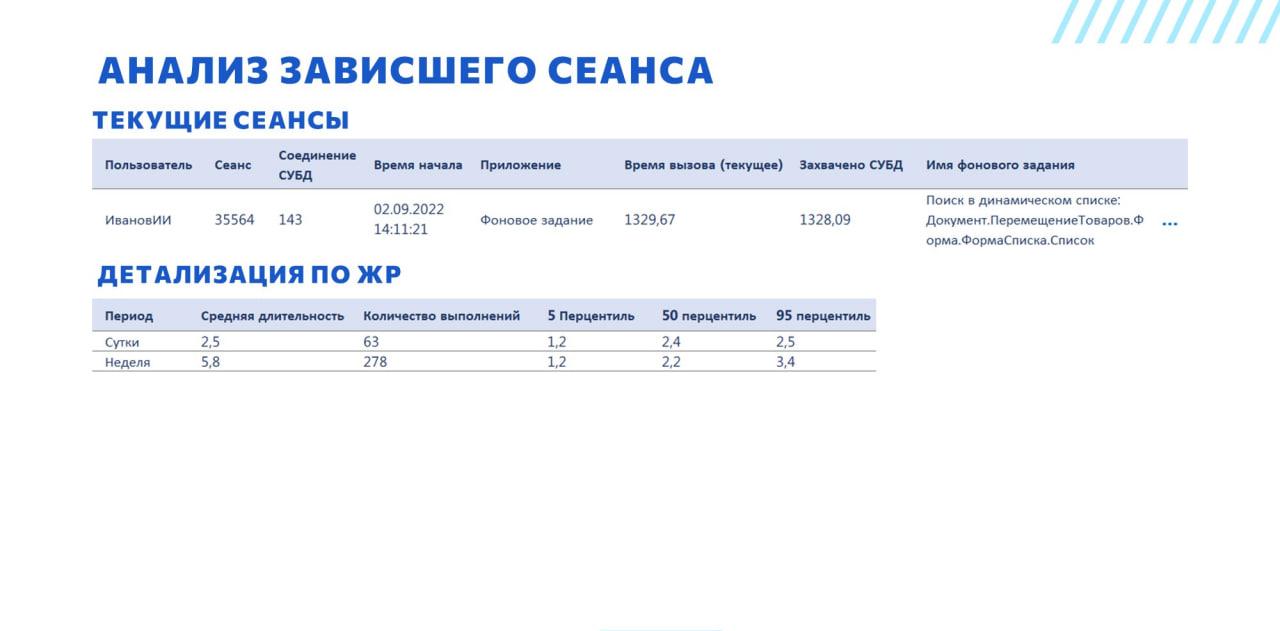
В некоторых случаях мы не можем определить по имени фонового задания является ли текущая длительность отклонением от нормы – может быть, это задание всегда выполняется час. Не надо его рубить, не надо с ним ничего делать, оно так живет всегда.
Для этого есть механизм, который позволяет по журналу регистрации собрать статистику за последние сутки и за последнюю неделю, и показывает, сколько раз это фоновое задание запускалось, какая у него средняя длительность за эти периоды. На основании этого можем оценить, надо что-то делать или нет.
Видим, что у нас отклонение есть, обычно это фоновое выполняется быстрее.
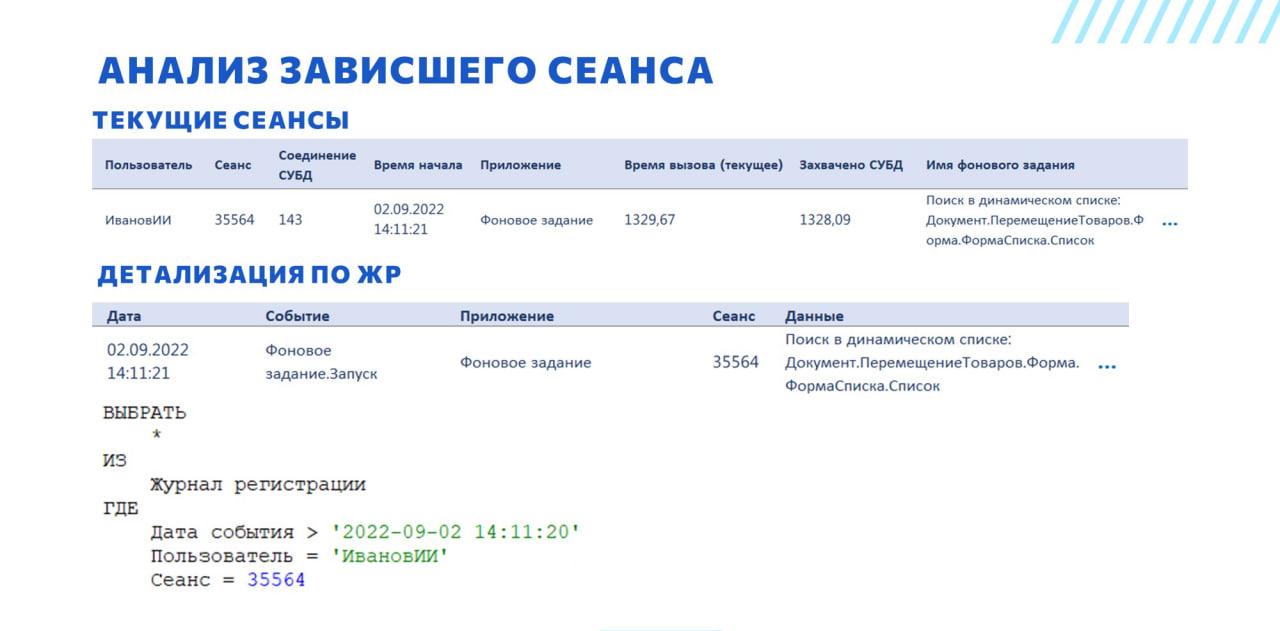
Зная дату начала выполнения серверного вызова, имя пользователя и номер сеанса, мы можем получить все записи журнала регистрации и проанализировать, выполняется ли сеансом какая-то работа.
В данном случае у нас записей в журнал регистрации очень мало – одна запись с запуском фонового задания.
Но в некоторых случаях, если это какая-то фоновая обработка данных, мы можем увидеть, допустим, выполняется ли фоновое вообще, или оно уже зависло.
Если оно еще выполняется, мы можем посмотреть события изменения данных:
-
Например, если у нас каждые 20 секунд изменяется документ и мы знаем, что там должно быть обработано 100 тысяч документов, то 20 секунд на документ слишком медленно – наверное, лучше срубить и оптимизировать обработку.
-
Или наоборот, мы можем посмотреть, какой документ создался последним. И если видно, что мы уже заканчиваем – есть смысл дождаться.
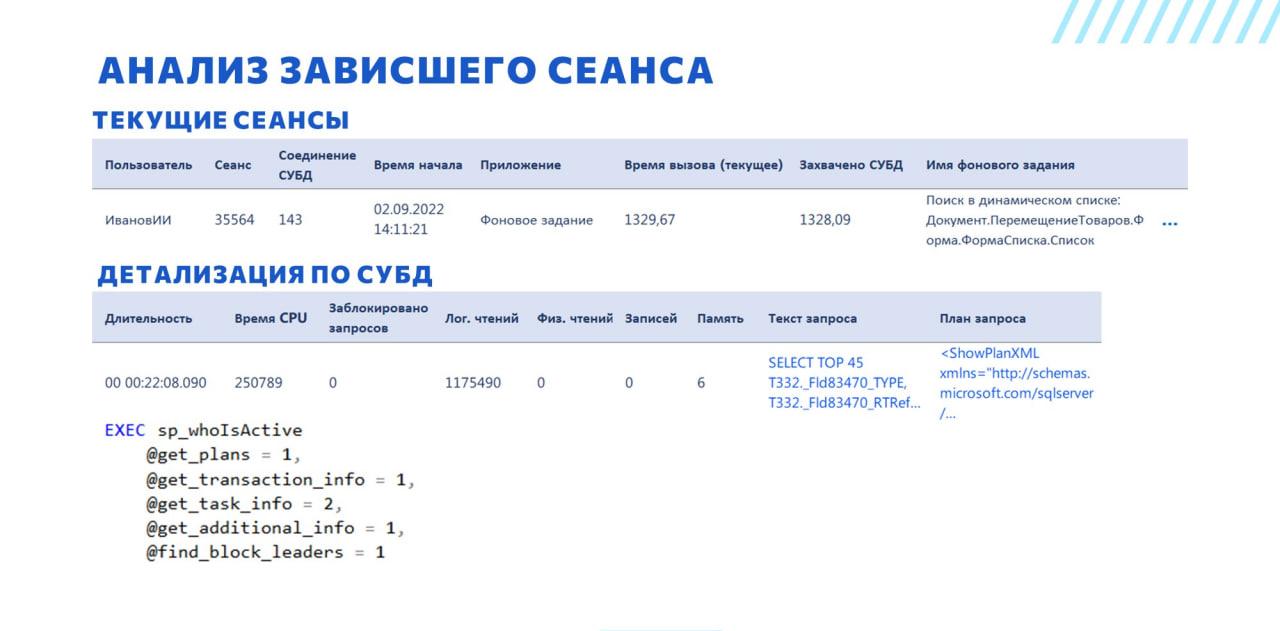
Еще видим, что у текущего сеанса заполнено соединение СУБД, и заполнена колонка «Захвачено СУБД». Это значит, что сеанс висит на выполнении какого-то запроса.
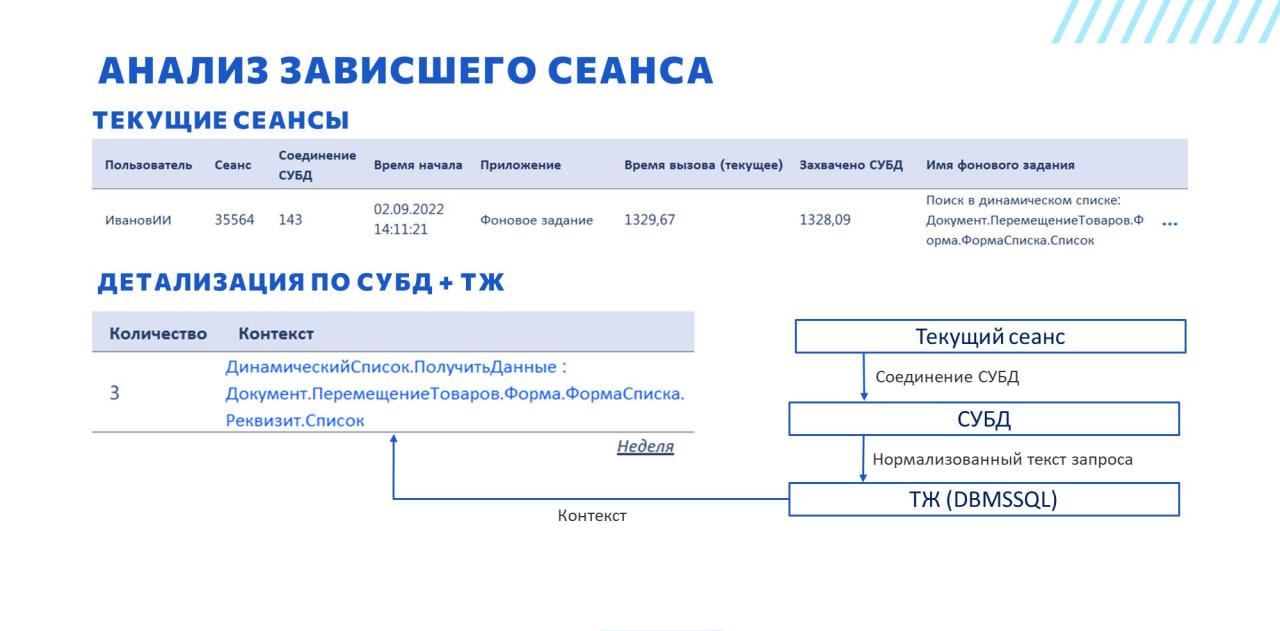
По колонке «Соединение СУБД» мы, опять же, в автоматическом режиме соединяемся с СУБД и вызываем хранимую процедуру sp_WhoIsActive с параметрами, перечисленными на слайде, и можем оперативно оценить, что происходит с запросом:
-
сколько у него чтений;
-
сколько у него записей;
-
какой у него план запроса и текст запроса – по тексту запроса можно уже определить, какие же настройки все-таки сделал пользователь.
В большинстве случаев для анализа и оптимизации запроса надо найти его полный контекст.
В нашем случае искать контекст запроса не имеет практического смысла, потому что для поиска в динамическом списке контекст – это запрос дин. списка формы. Но если запрос выполняется в большом фоновом задании или вообще вне фонового задания, то так просто определить его контекст не удастся.
Напомню, что события в технологический журнал пишутся по мере завершения. Т.е. пока запрос выполняется, события в технологическом журнале не появится.
Для того, чтобы найти контекст запроса, который ещё не завершился, мы делаем следующее:
-
вытаскиваем с помощью хранимой процедуры sp_WhoIsActive текст запроса СУБД, как описано на прошлом шаге;
-
нормализуем полученный текст запроса:
-
Во-первых, события технологического журнала DBMSSQL, расширенные события, и DMV СУБД – все отдают запросы немного в разном виде. Там по-разному передаются параметры, по-разному вызывается хранимая процедура, через которую 1С выполняет запросы. Мы это все приводим к одному виду.
-
Во-вторых, есть известная проблема, что 1С называет временные таблицы #tt1, #tt2, #tt300 – что приводит к генерации разных текстов запроса СУБД для одинаковых текстов запроса 1С. При нормализации, мы не просто убираем итератор у имени временной таблицы, мы заменяем его на свой по порядку обращения к временным таблицам в запросе. Таким образом, текст запроса остаётся читаемым и рабочим. Если просто убрать итератор, будет непонятно, какие поля из каких таблиц выбираются.
-
-
ищем по истории технологического журнала события DBMSSQL с таким же нормализованным текстом запроса. Хотя у нас запрос завис и по нему ещё нет события DBMSSQL, возможно, что этот запрос выполнялся раньше. И скорее всего, если у него текст запроса точно совпадает, контекст будет такой же, как и у нашего запроса.
Видим, что такой же запрос выполнялся за последнюю неделю 3 раза. Из найденных событий DBMSSQL достаем контекст.
Дополнительно мы выводим количество выполнений запроса для каждого контекста, потому что в некоторых случаях у одного запроса СУБД бывают разные контексты. Тогда задача чуть усложняется, но по количеству выполнений можно с некоторой ненулевой вероятностью определить какой контекст у нашего запроса.
Другие возможности
Скриншоты возможностей, которые демонстрировались на слайдах до этого, не совсем соответствуют внешнему виду Алькира, потому что скриншоты у нас все в темной теме, светлой темы нет.
Реальный Алькир выглядит так.
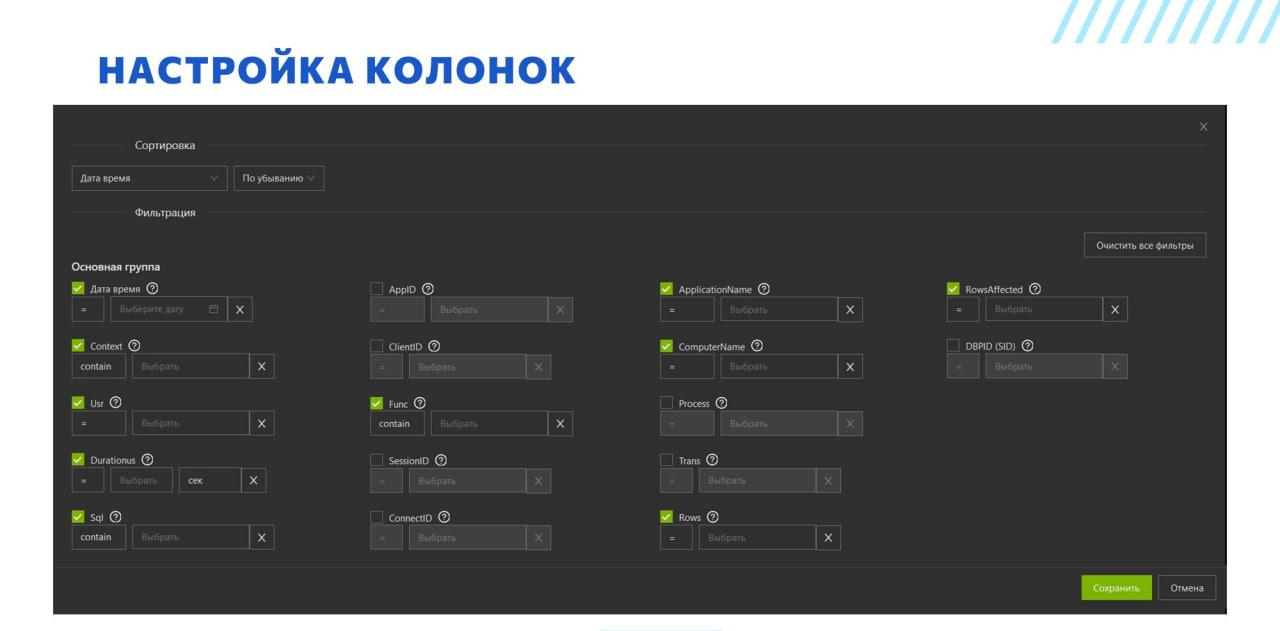
На слайде показана настройка колонок для списка событий DBMSSQL технологического журнала. Здесь у нас есть:
-
сортировки;
-
выбор колонок;
-
установка отборов;
-
у каждого поля есть кнопка с вопросительным знаком, которая позволяет получить информацию о значении этого свойства.
Справка по значению колонок полезна как для стандартных свойств технологического журнала, т.к. не всегда понятен их смысл, так и для каких-то аналитических колонок, специфичных для Алькир. Например, та же хранимая процедура sp_whoIsActive возвращает значения строк, где через запятую перечислены какие-то значения. А ещё некоторые выводимые в Алькир колонки рассчитываются по внутренней логике - их назначение и логика заполнения могут требовать пояснения.
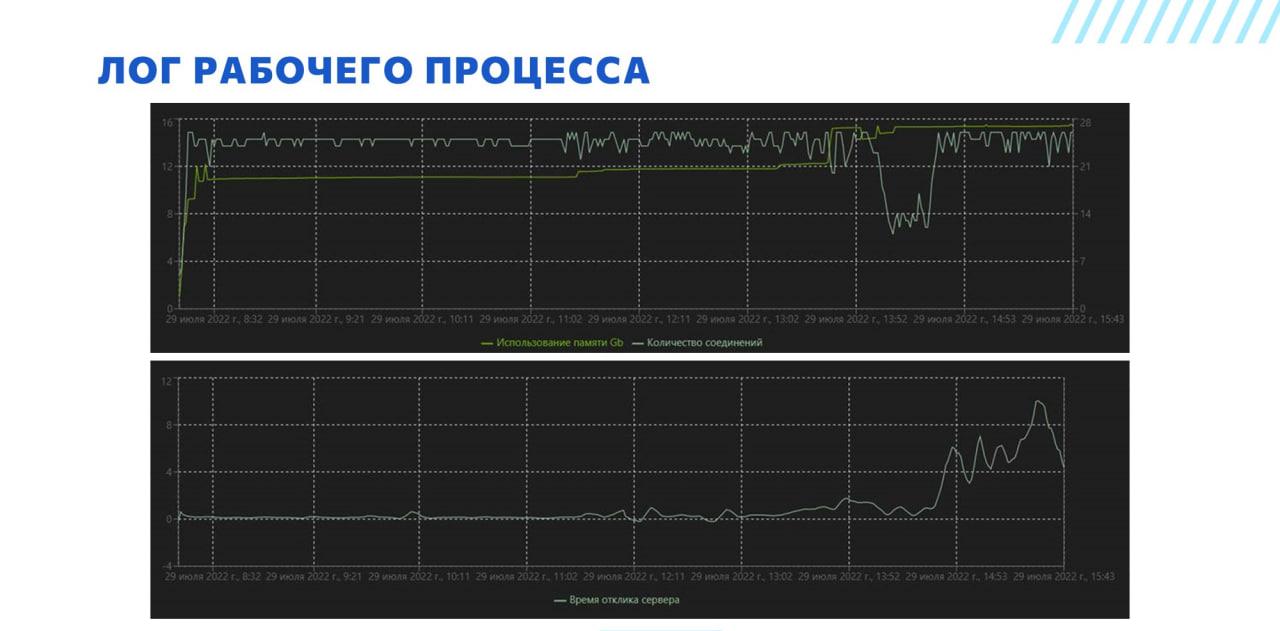
Благодаря тому, что мы сохраняем логи рабочего процесса, у нас строятся вот такие графики.
-
Сверху график зависимости использования памяти и количества соединений.
-
А внизу – график времени отклика сервера. Это стандартная метрика рабочего процесса – в консоли кластеров она почему-то в таблицу не выведена, но если открыть свойства рабочего процесса, она там есть. Конкретно здесь запечатлена печально известная проблема деградации рабочего процесса, когда в результате каких-то необъяснимых причин (судя по всему, связанных с потреблением памяти) все начинает тормозить. Кстати, в последних версиях платформы эта проблема больше не возникает, разработчики ее решили.
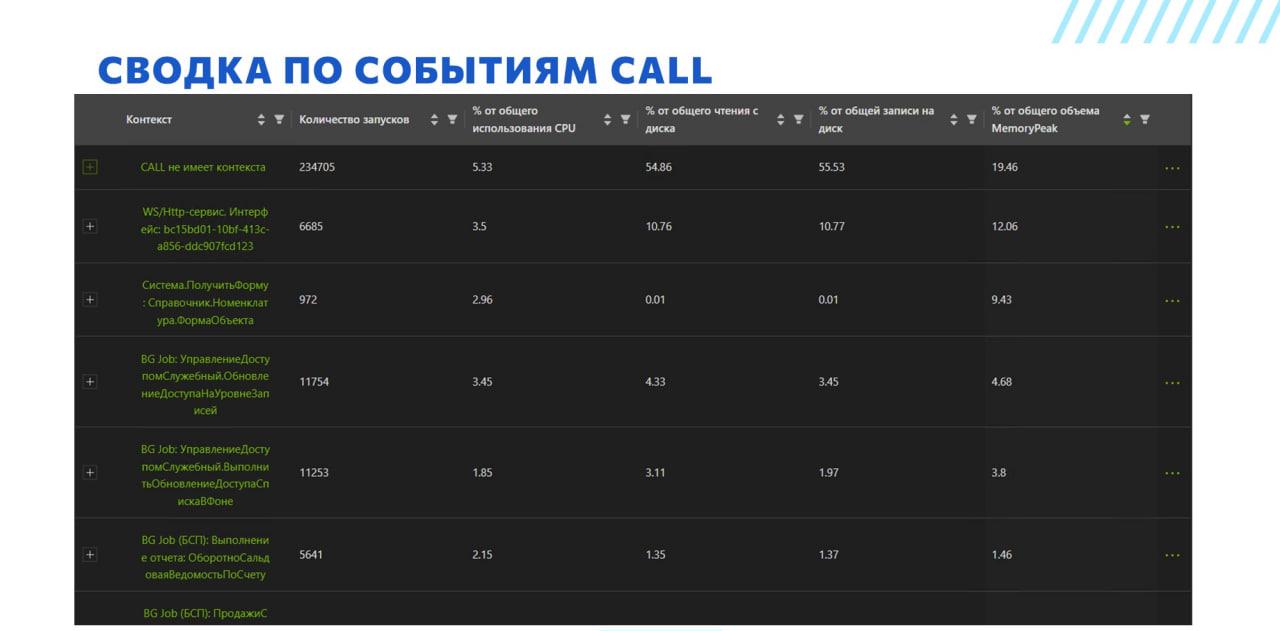
На этом скриншоте у нас сводка по событиям CALL. Этой формой полезно пользоваться, если мы видим, что на сервере 1С у нас какое-то очень большое потребление ресурсов. Здесь мы берем все события CALL, группируем их по контексту и показываем процент от общего использования.
Мы не просто выводим суммарную длительность контекста за период. Мы считаем проценты. Просто суммирование позволяет нам проранжировать контексты и найти самые тяжелые. Но если суммарная длительность по контексту 1000 секунд – это много или мало? Непонятно, какой это процент от общего пула всех контекстов и какой выигрыш мы получим от оптимизации. Оценка в процентах позволяет получить ответ на этот вопрос.
Например, мы можем сразу же посмотреть, что контекст ПолучитьФорму : Справочник.Номенклатура.ФормаСписка – это 3% от общего использования CPU. Если мы разберемся, почему туда уходит так много процессорного времени, мы выиграем 3%. Если бы этот контекст также был в топе, но потреблял только 0,5%, мы бы, скорее всего, его не анализировали, т.к. выигрыш от оптимизации был бы минимален.
Отдельно надо сказать, что колонка «Контекст» – это не свойство Context события CALL, это динамически собираемая колонка.
-
Например, если посмотреть на четвертую и пятую строки, мы видим префикс BG Job. Дело в том, что у событий CALL для фоновых заданий нет свойства Context, зато есть свойства Module и Method. Соответственно, мы динамически собираем это все в кучу, добавляем префикс и получаем вменяемое представление, что это за фоновое задание.
-
Плюс в типовых конфигурациях фоновые задания часто выполняются через общий метод ДлительныеОперации.ВыполнитьСКонтекстомКлиента. Следовательно, в лидерах по загрузке всегда будет строка BG Job: ДлительныеОперации.ВыполнитьСКонтекстомКлиента – т.к. очень большой процент фоновых будет выполняться через этот методи контекст у них будет одинаковым. Мы это решаем динамическим соединением с журналом регистрации. В журнале регистрации есть имя фонового задания, которое запускается. И вот если вы посмотрите на предпоследнюю строку, то вы увидите, что там префикс не просто BG Job, а BG Job (БСП) – это значит, что имя фонового мы вытащили как раз таки из журнала регистрации. Таким образом мы существенно повышаем детализацию выводимой информации.
Планы развития

Сделано довольно много, но хочется сделать еще больше.
-
В частности, мы планируем добавить интеграцию с Zabbix для получения инфраструктурных метрик – сейчас этого нет.
-
Полностью развить наш аналог консоли кластера, чтобы в типовую консоль кластера вообще не надо было заходить никогда.
-
Планируем доработать типовые механизмы расследования длительного проведения и зависшего сеанса, которые я показал. А также развивать аналогичные инструменты.
-
Что касается расширения, которое мы встраиваем в конфигурацию – есть идея, как реализовать в этом расширении какие-то механизмы, которые бы позволяли централизованно выполнять настройку каких-то внутренних механизмов платформы, влиять на производительность изнутри. Плюс мы планируем собирать при помощи этого расширения больше метрик.
-
Управление ТЖ тоже хотим реализовать средствами Алькира, потому что если у вас на сервере несколько баз и несколько человек, которые знают, что такое ТЖ и хотят им пользоваться, то им совместная работа с одним файлом технологического журнала не очень удобна. Также, тяжелые настройки технологического журнала могут быстро съедать место на диске, а тот кто их сделал может быть даже не в курсе об этом. На Инфостарте были консоли запросов, которые настраивали очень тяжелый технологический журнал. Я сталкивался с тем, что пользователь, который использовал такую консоль, нештатно завершал свой сеанс, и настройки технологического журнала оставались, генерируя нагрузку и никем не востребованный лог.
-
Создание простого в использовании CI/CD для 1С.
-
Уведомления, оповещения.
-
Конструктор отчетов – мы понимаем, что как бы сильно мы не старались, мы не сможем сделать инструментов, подходящих под все задачи, потому что у эксперта очень много нетиповых задач. Поэтому нам нужен какой-то аналог либо СКД, либо Kibana, который бы позволял в нужных разрезах получать ту или иную информацию.
-
Ну и создание механизмов для автоматизации развертывания копий прода для разработки – только сегодня на конференции я уже два раза слышал потребность в этом механизме.
Подробнее ознакомиться с решением можно на странице Инфостарта.
Вопросы и ответы
Если смотреть на самую первую схему по вашей архитектуре, как это выглядит, то где реализуется вся ваша магия? Начиная от вещей, связанных с убиранием итераторов в таблицах при получении из технологического журнала. Все это происходит на уровне бэкэнда или на уровне сбора, парсинга, обработки, и в ClickHouse мы уже имеем информацию, которой можем пользоваться сторонними средствами для анализа?
Короткий ответ – и там, и там.
Длинный ответ. Нормализация происходит при парсинге. А все сборки происходят уже в бэкэнде, когда запрашиваются данные. Потому что все мы люди, все мы ошибаемся. Если у нас в ClickHouse лежат очищенные данные, готовые к обработке, мы можем поменять бэкэнд и автоматически выводимая информация поменяется. Поэтому нормализация данных происходит при парсинге.
Какие-то вещи происходят вообще в шедулере – например, поиск виновников блокировок.
Ну и да, в принципе, если у вас есть какие-то свои аналитические средства, то по договоренности эту историю можно подключать и крутить уже какими-то вашими средствами.
Часто бывают, что рядом с 1С существуют другие СУБД, например, WMS. Могу ли я сюда отдавать в Алькир какие-то данные со стороны – например, данные SQL, DMV от WMS, чтобы хотя бы по времени что-то сопоставить и посмотреть? Например, у меня идет обмен, туда что-то отдалось, но пакет не пришел, что-то зависло. Чтобы я смог как-то увидеть, что там происходит.
Короткий ответ – да. Длинный ответ – нужно смотреть конкретный кейс.
Подскажите, пожалуйста, с какой периодичностью собираются данные и загружаются в ClickHouse?
Технологический журнал, журнал регистрации парсится онлайн, соответственно, запись появляется в файлике, она улетает в парсинг.
Сбор данных шедулером – в зависимости от типа данных. Например, схему данных самого 1С мы собираем раз в сутки.
Но это все настраиваемо.
Основная идея, чтобы сбор данных минимизировал нагрузку на прод. Есть некие дефолтные значения, но их можно менять – это не некие догмы, выбитые в граните.
У вас парсится еще и журнал регистрации. Он сильно не бесплатный, зачастую создает как раз излишние проблемы. Нет других вариантов получать контекст документа? Неоднократно встречал, что любят внутри транзакции поставить запись в журнал регистрации, журнал регистрации в это время пишет что-то другое большое, в итоге получаем больше проблем от регистрации событий записи документа, чем польза того, чтобы понять, что вообще происходит.
Вы имеете в виду настройки журнала регистрации, которые фиксируют не все события?
Конечно, ставить подробный журнал регистрации на нагруженном проде весьма опасно. Встречалось с таким вообще в практике?
Я не сталкивался, если честно. Парсеру все равно – у него есть файлик, он его парсит. Если вы туда пишете все события, он будет парсить все события. Если вы туда пишете только ошибки, он будет парсить только ошибки. Там вся нагрузка – это сетевое чтение файликов. Но оно не сильно влияет на производительность.
Я говорю о том, что запись журнала регистрации часто как раз провоцирует проблемы. И ставить подробный журнал регистрации на нагруженном проде весьма плохо. Если у вас контекст документа ниоткуда по-другому не получается, мы попадаем в патовую ситуацию – либо ставим журнал регистрации и рискуем тем, что получим проблемы, либо не ставим подробный журнал регистрации и не можем понять, какой документ проводил пользователь.
А у вас есть альтернативный вариант, как без журнала регистрации узнать, какой документ проводил пользователь? Журнал регистрации про это и есть?
Можно из SQL получать уиды, и из них получать ссылку на документ.
Нет, мы так не заморачивались.
Следующий вопрос про журнал регистрации. Не знаю, как сейчас, но в тех журнале раньше запись в журнал регистрации, она регистрировалась как запись в БД и разделить их было невозможно. Мы просто в контексте техжурнала видели, что у нас большие ожидания на блокировках записи в SQL. А что это за запись? Было непонятно.
Нет, журнал регистрации в базу SQL никогда не писался – это совершенно асинхронный другой процесс. И SQLite – это все равно другая база, поэтому поймать в тех журнале контекст DBMSSQL по записи в журнал регистрации невозможно.
Запись в журнал регистрации – это очень простая текстовая процедура. Поэтому странно, что возникает такая проблема. Поэтому нужно разбираться, что именно у вас происходило. Вполне вероятно, что переход на SSD PCI-Express решит ваши проблемы.
Вы упомянули, что была проблема с деградацией производительности, и в последних версиях платформы она вроде как решена. А на каком релизе вам показалось, что она решена?
Мы написали в 1С, получили дежурный ответ, что обновите версию платформы и соберите ТЖ. Мы обновились и проблема не повторяется. Версия платформы – 8.3.20.1914.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции Infostart Event.

Вступайте в нашу телеграмм-группу Инфостарт