
Меня зовут Александр Денисов. Долгое время я работал аудитором производительности, изучал, как работают системы, подсказывал, как их ускорить, как переписать правильно запросы, как следить за базами и так далее.
Сейчас я ушел в Sportmaster Lab, занимаюсь аналитикой, но старые знания у меня остались, я все еще держу руку на пульсе и по возможности делюсь со специалистами полезной информацией.
Хочу рассказать про фрагментацию индексов – про то, как с ней бороться. Но прежде чем разбираться, как с ней бороться, давайте разберемся, на что она вообще влияет: как устроены индексы, и как фрагментация может нам помешать добиваться хороших результатов.
Как устроены индексы?
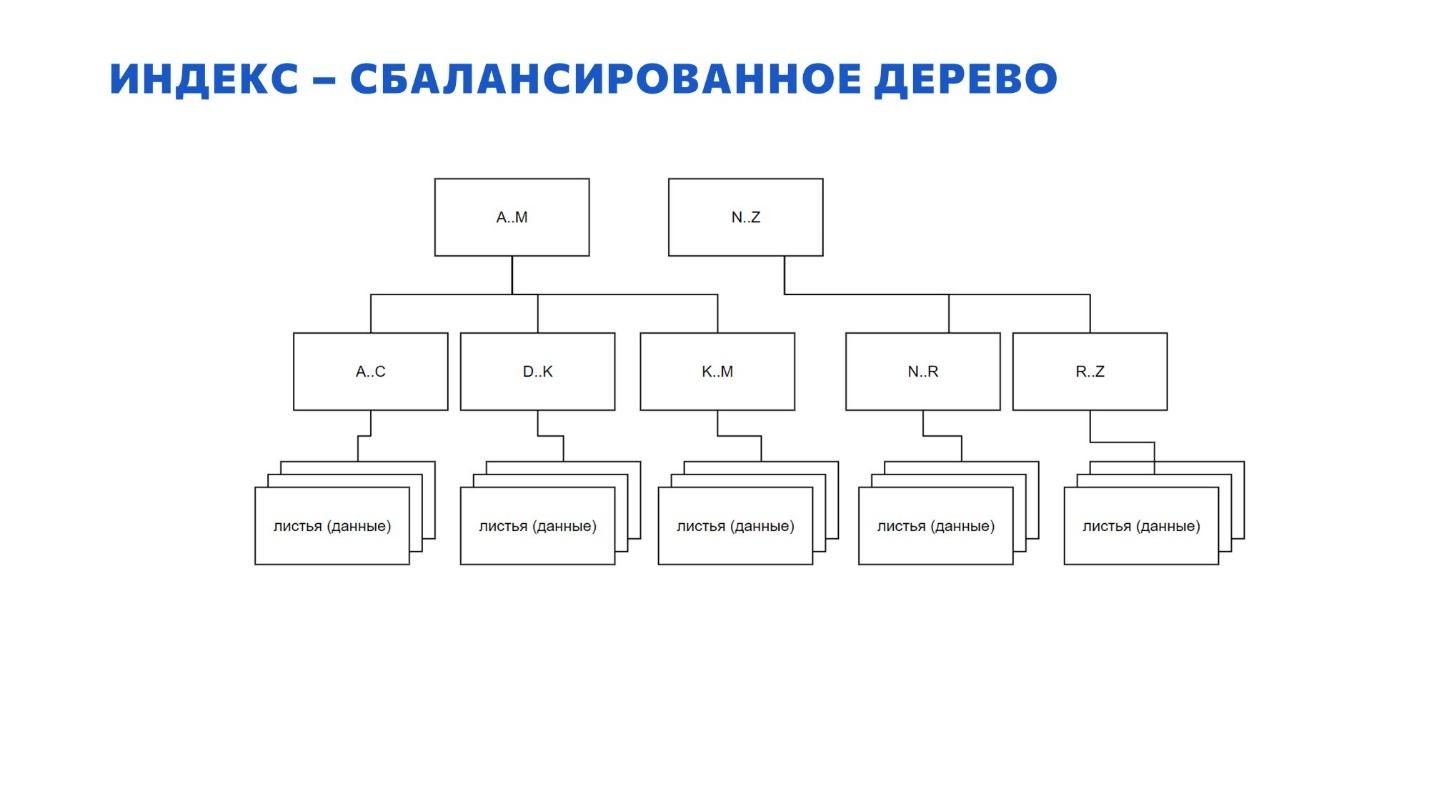
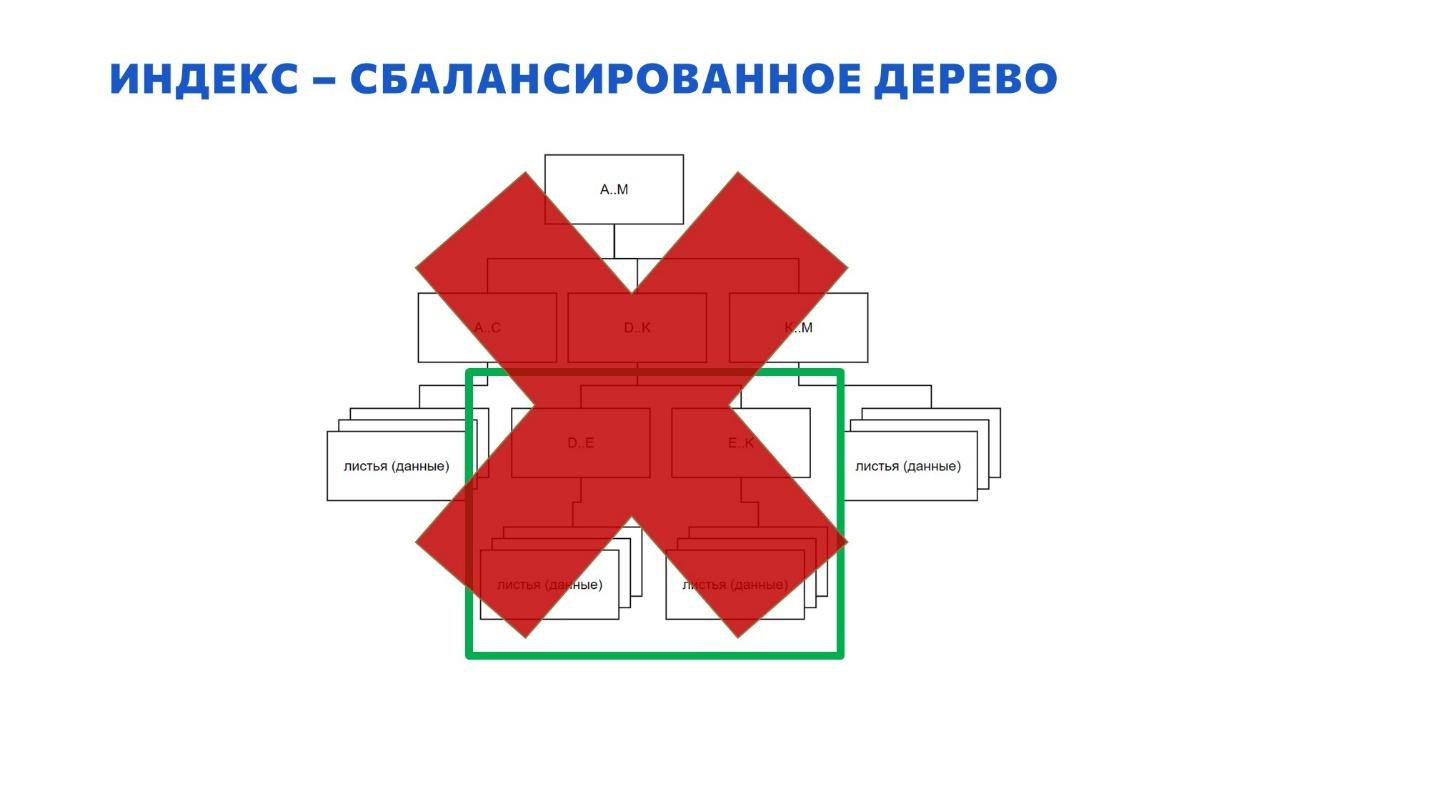
На слайде – схематичное представление структуры индекса.
Все знают, что индекс – это B-дерево, B – от слова balanced, сбалансированное.
Есть такое заблуждение, что в корне индекса на самом верху всегда должна быть одна единственная страница. Это не так – их может быть несколько. Дальше страницы спускаются вниз по уровням и выглядит это примерно так, как на слайде.
Видно, что путь до каждого листа на этой картинке одинаковый – к какому бы листу мы не шли сверху вниз, длина маршрута будет одной и той же. Именно поэтому B-дерево индекса и называется сбалансированным.
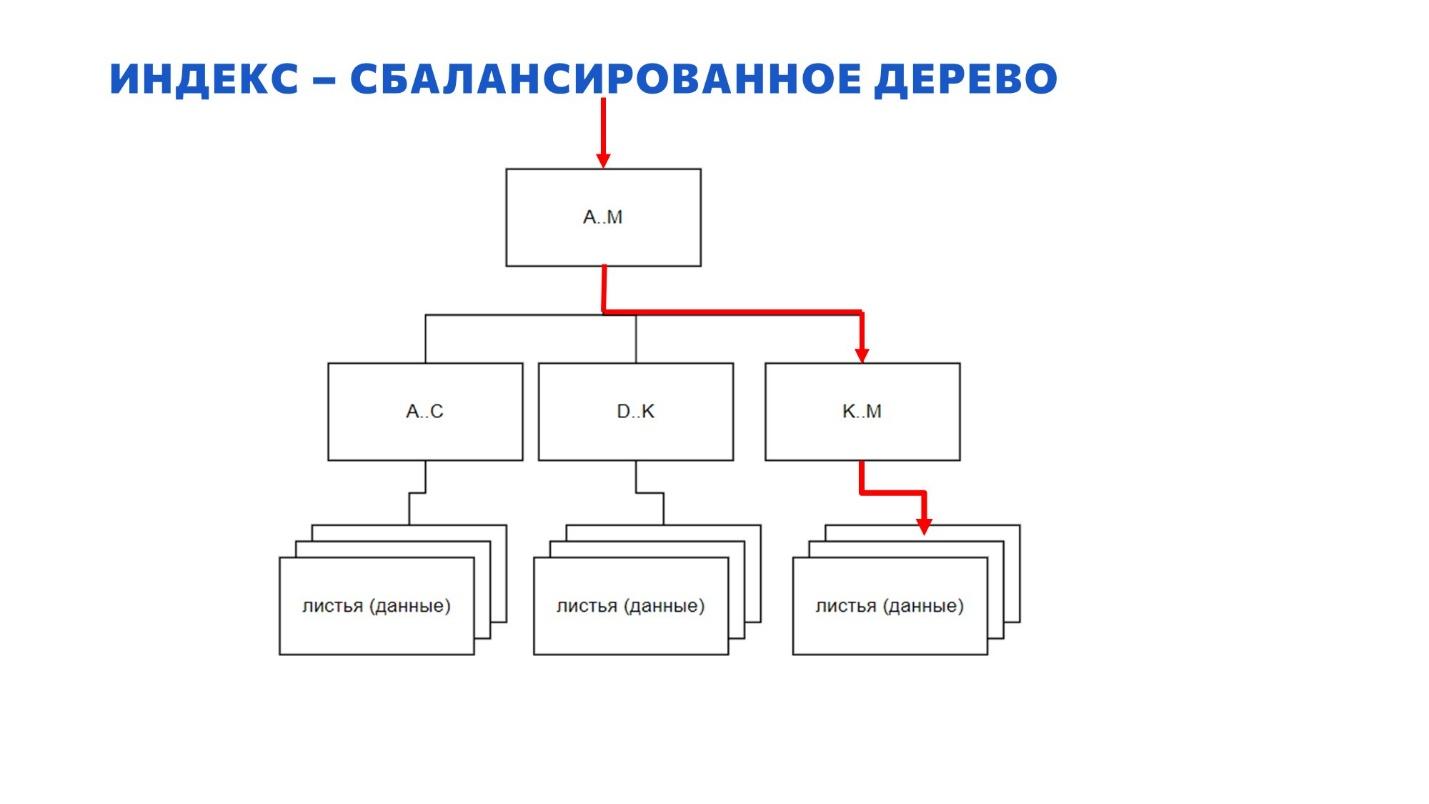
Здесь я немного увеличил картинку – взял один маленький куст. Когда мы ищем данные оператором index seek – запрос спускается сверху вниз по индексу до листовых данных так, как показано на слайде.
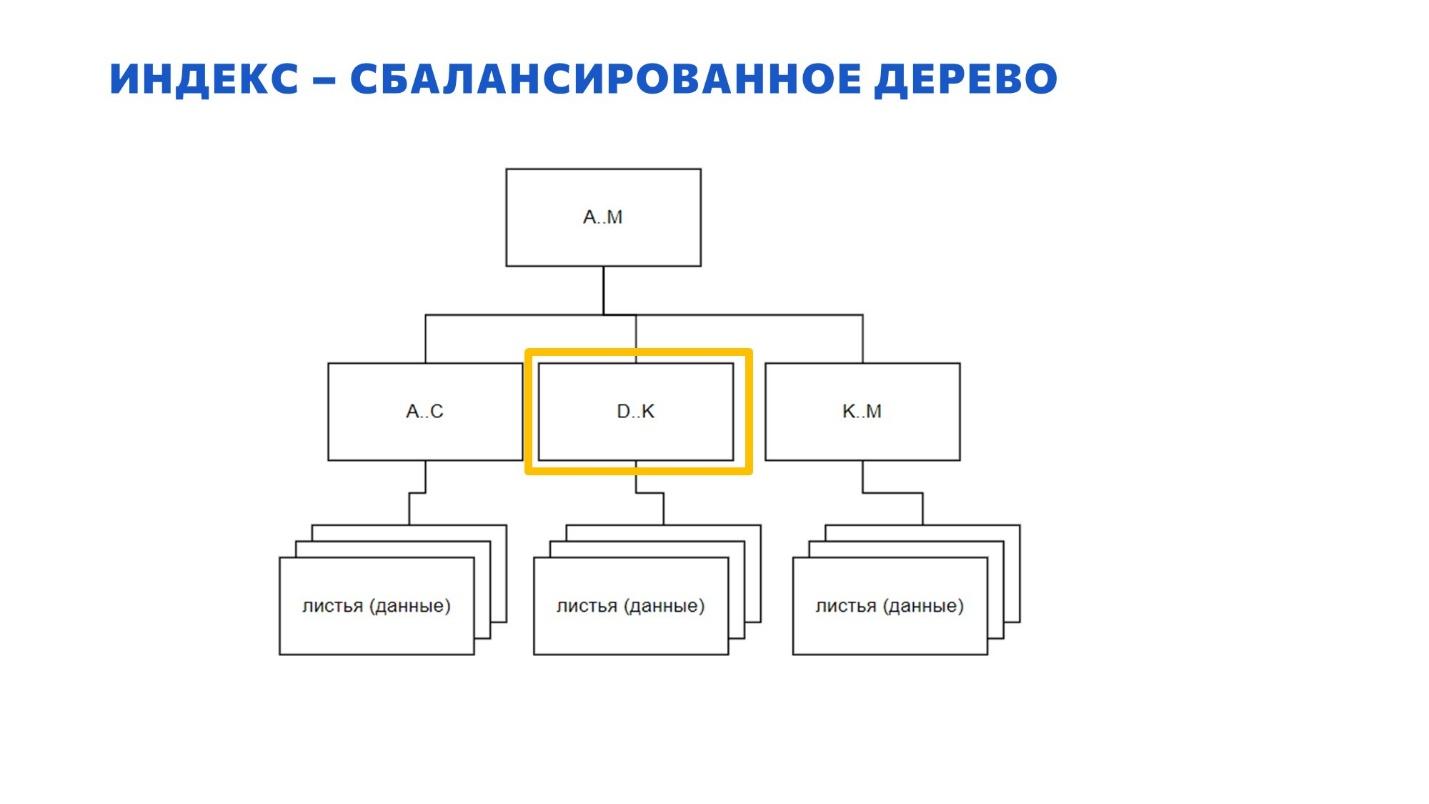
Возникает вопрос: что делать, когда при вставке очередных данных какая-то страница переполнилась? Многие знают, что страница при этом разбивается на две – появляются две новые страницы.
И есть такое заблуждение – честно говоря, я даже сам так раньше думал – что эти страницы появляются внизу, по аналогии с почкованием веток настоящего дерева.
На самом деле, это не так – эту картинку нужно забыть. Новые страницы появляются не внизу.
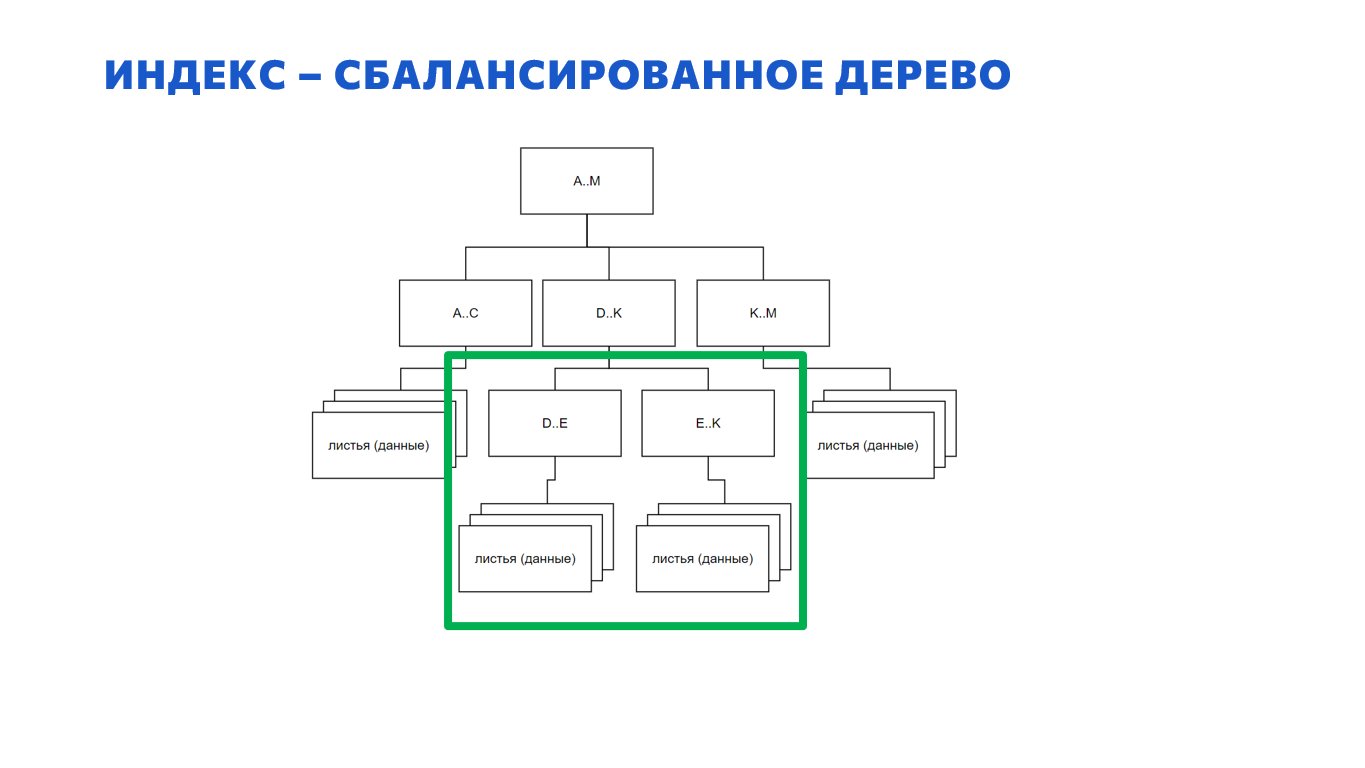
Это работает по-другому – у нас была одна страница.
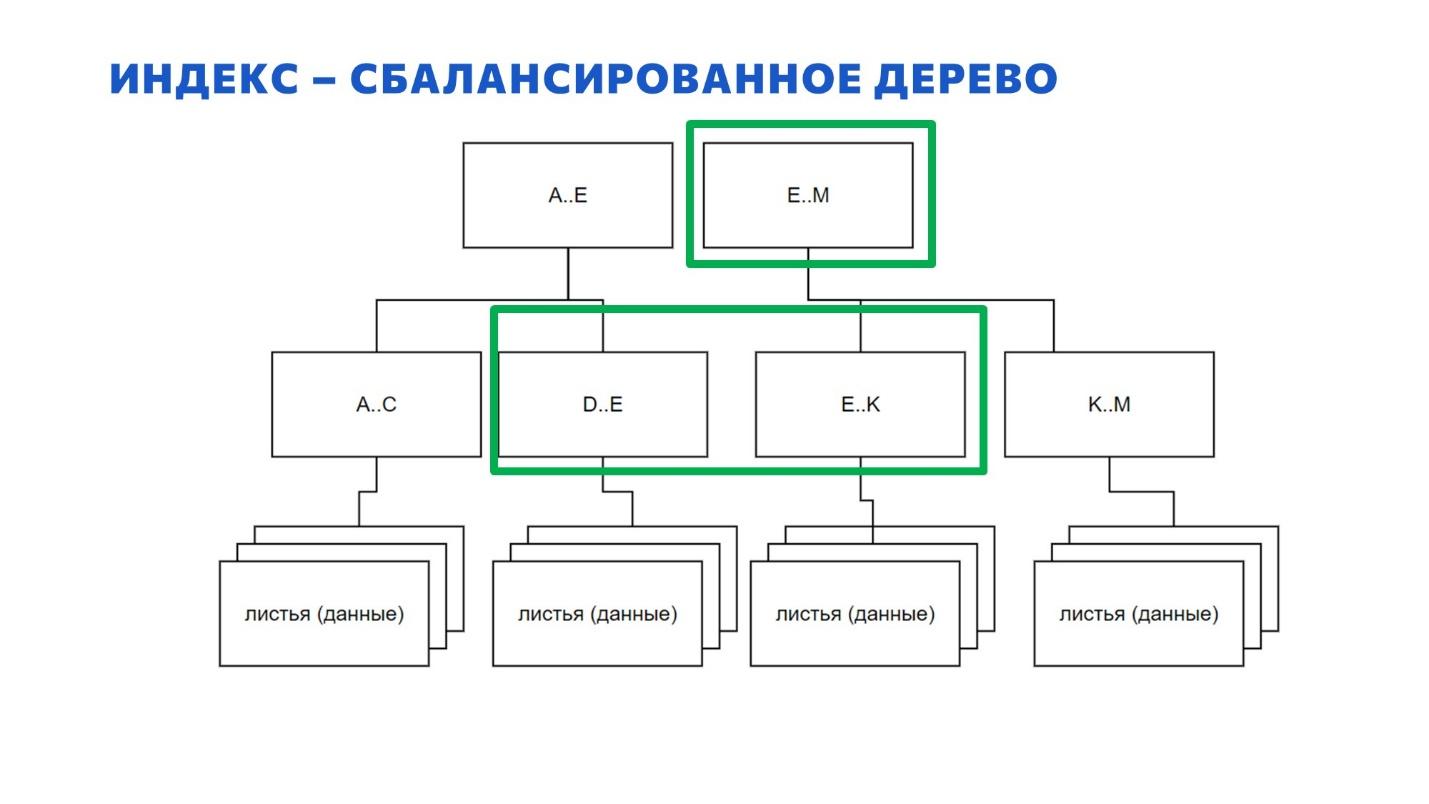
Вместо нее появляются две новых – на том же самом уровне.
Если в родительском узле не хватило места, чтобы их записать, сверху появляется еще одна страница. И так далее, пока эта новая страница не вписывается в существующую иерархию. Получается, что дерево у нас растет не вниз, а вверх. У нас не новые листья внизу появляются, а наоборот – вверху новые корни.

Это означает, что дерево у нас всегда будет сбалансировано. Каким бы случайным образом мы бы ни вставляли данные, дерево всегда остается сбалансированным – фрагментация на это никак не влияет. Ваш index seek в любом случае всегда будет работать эффективно.
Чем же тогда вредна фрагментация?
Тогда вопрос: в чем проблема фрагментации? Почему мы с ней боремся? Как она нам может навредить?
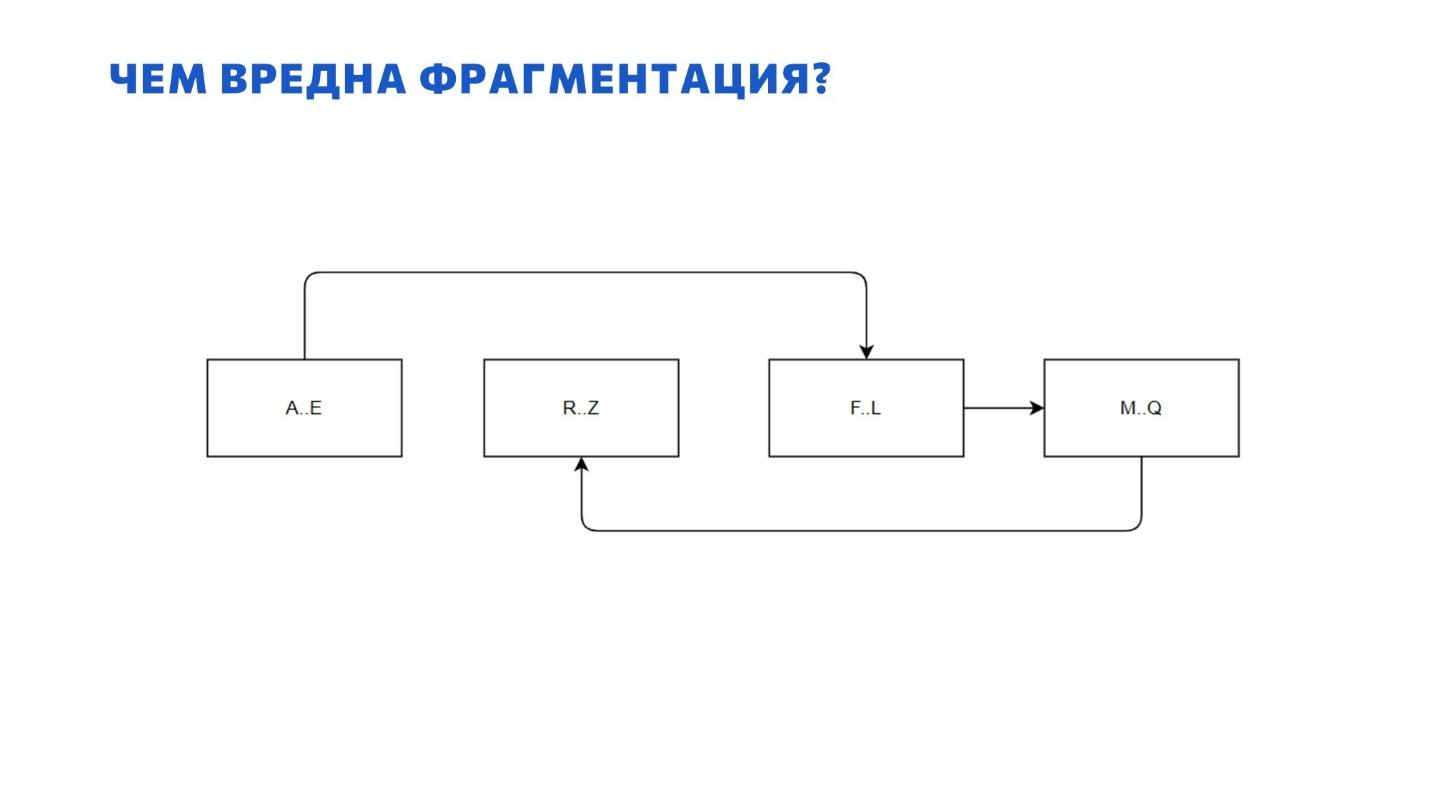
Когда мы случайным образом вставляем в таблицу какие-то данные, наши страницы оказываются раскиданы по файлу данных. И когда после этого мы ищем в таблице не какие-то конкретные страницы, а выгребаем что-то большими выборками за месяц или квартал – приходится сканировать всю таблицу.
Здесь начинается путешествие из одной страницы куда-то в середину файла, а из середины файла обратно. Поскольку элементы данных находятся далеко друг от друга, искать становится сложно – поиск затягивается.

Наверняка половина присутствующих на мои слова сейчас скажет: «Это всё какие-то старинные истории из 2010 года, когда у всех были HDD-диски. Сейчас-то уже давно все на SSD!» И они на самом деле правы. Если у вас база данных лежит на SSD, вам все равно, где и в каком порядке у вас лежат страницы – у вас нет проблемы, которая показана на предыдущей картинке.

Если у вас SSD, фрагментация вас никак не касается – она никак не замедлит вашу работу. А если у вас продуктовая база на HDD – мы ближе к концу поговорим, что с этим делать.
В любом случае продуктовые базы стоит выносить на SSD.
Но неупорядоченность файла данных – не единственная проблема, которая порождается фрагментацией. Есть и другие моменты, о которых я обязательно должен упомянуть.
Чем еще опасна фрагментация?

Какие дополнительные проблемы создает фрагментация:
Во-первых, есть так называемые Ghost-записи (фантомные записи). Вы наверняка знаете, что во всех высоконагруженных системах данные при удалении сразу из индекса не удаляются. Даже в 1C сначала на элемент ставится пометка на удаление, а потом уже он удаляется.
В базе данных то же самое – страница сразу не удаляется, потому что есть вероятность, что будет откат транзакции или что-то еще. Остаются Ghost-записи. Они занимают место в структуре вашего индекса, их нужно как-то почистить.
В MS SQL для удаления Ghost-записей есть отдельная фоновая служба. Не надо ждать ребилда индекса или делать что-то еще, эта служба сама почистит все Ghost-записи – это вообще не проблема.
Есть более сложная проблема – если у вас на какой-то таблице нет кластерного индекса. В этом случае она у вас лежит как «куча», и там со временем могут накапливаться записи перенаправления – forward-записи. В этом случае с таблицей работать сложнее.
Давайте остановимся на этом поподробнее. Если у вас кластерный индекс, у вас каждая строка данных адресуется на странице логическим идентификатором – ключом индекса. И куда бы данные этой строки физически не переехали, сама строка все еще адресуется этим ключом.
У «кучи» кластерного индекса нет, поэтому мы не можем привязать строку к какому-то логическому идентификатору – она привязана к физическому адресу на странице.
Если вы делаете апдейт, и новая версия строки перестает помещаться в то место, которое было для старой, приходится перемещать эту строку куда-то в новое свободное место, а вместо старой оставлять указатель: «Здесь ничего нет, переезжай вот туда».
Чем дольше живет ваша «куча», тем больше у нее копится таких forward-записей – но они возникают, опять же, только если у вас апдейты увеличивают размер вашей строки, и новая версия не помещается на старую.
Это действительно проблема, это очень больно и долго лечится. Но в любом случае дефрагментация вам здесь не сильно поможет. Просто потому, что «кучу» очень сложно дефрагментировать.
Чтобы сделать какую-то дефрагментацию, нужно указать, какой индекс вы будете дефрагментировать. У «кучи» кластерного индекса нет, а некластерные в этом случае не помогают. У вас не получится стандартными способами дефрагментировать «кучу».
Первое, что приходит в голову – сделать этой «куче» кластерный индекс, а потом его удалить. Но это очень плохая история, потому что у «кучи» и кластерного индекса разные принципы адресации страниц.
-
Если вы создаете кластерный индекс, у вас автоматически перестраиваются все некластерные – они теперь должны ссылаться не на физический адрес, а на строку кластерного индекса. Это принципиально другой принцип адресации.
-
Если вы решите этот кластерный индекс удалить, все ваши некластерные индексы автоматически тут же заново перестроятся. До этого они ссылались на кластерный индекс, а теперь адресацию нужно опять переделывать на физические адреса.
Для большой «кучи» перестроение некластерных индексов займет много времени и приведет к разрастанию лога транзакций. Это очень долго и муторно.
Поэтому «куча» – это вообще больное место. Слава богу, что в 1С практически по всем объектам уже давно определены кластерные индексы, и вас эта проблема, скорее всего, уже не коснется.
Ну и последняя проблема – это просто раздувание файла данных. Он становится рыхлый – в нем что-то не там хранится и так далее.
Но честно, это тоже небольшая проблема, потому что как бы вы ни переживали за фрагментацию, все эти пустые пространства внутри страницы данных когда-то заполнятся. У вас же не статичная база, вы все равно что-то нарабатываете. Время для этого места еще придет.
Получается, что я сейчас как развенчатель мифов всем говорю: «С фрагментацией бороться не нужно – это не ваша проблема». И, естественно у многих наверняка возникает вопрос: «Но когда я делаю фрагментацию, мне же это все равно помогает – почему ты говоришь, что это бессмысленно?» Чтобы разобраться, почему дефрагментация все-таки помогает, посмотрим, какие у нас вообще инструменты для борьбы с фрагментацией есть.
Почему-то дефрагментация все-таки помогает?

Основных инструментов у нас три. И самый известный инструмент перестроения индекса, который приходит в голову – это команда ALTER INDEX… REBUILD.
-
Эта команда просто удаляет старую структуру индекса и создает с нуля новую, где все плотно упаковано. Идеальная структура – лучше не придумаешь.
-
Но по умолчанию команда ALTER INDEX REBUILD блокирует весь индекс, с которым она работает – т.е. пока вы REBUILD-ите этот индекс, никто не может ни читать, ни писать в связанную с этим индексом таблицу. Причем эти блокировки, как правило, долгие.
-
Зато в работе этого инструмента есть замечательный побочный эффект – ALTER INDEX REBUILD автоматически пересчитывает статистики по тому индексу, который он обрабатывает. Именно поэтому всем помогает REBUILD индекса. Не из-за того, что он правильно упаковывает индекс, а из-за того, что он автоматом перестраивает связанные с ним статистики. Среди иностранных SQL-ных блогеров даже ходит шутка, что ALTER INDEX REBUILD – это просто дорогой способ пересчитать статистики. Потому что львиная доля выигрыша происходит именно из-за этого.
В любом случае, ALTER INDEX – это классный инструмент. Его использовать дорого, но он помогает.

Что у нас еще есть?
Для счастливых обладателей лицензии MS SQL Enterprise у нас есть ALTER INDEX… REBUILD ONLINE.
-
Он точно так же обновляет статистики, что помогает вам потом быстро работать.
-
К сожалению, эта команда требует наличия лицензии Enterprise, а это дорого.
-
Зато, начиная где-то с 14 SQL, этот инструмент активно развивается, и там появляются дополнительные опции. Например, можно поставить на паузу выполнение ребилда индекса, а потом продолжить. Или установить какие-то приоритеты ожиданий блокировок. Очень крутые опции. Если вдруг у вас лицензия MS SQL Enterprise, обратите обязательно внимание, это может очень круто помочь вам гибко настроить ваши планы обслуживания.
-
И еще одна особенность у меня стоит как плюс, но по факту – это и плюс и минус. ALTER INDEX ONLINE нам обещает, что он работает онлайн, не мешая работе пользователей, но на самом деле, короткая блокировка все равно накладывается. Пока люди работают, ALTER INDEX ONLINE в сторонке делает новую структуру индекса, но потом, когда он большую часть работы закончил, он догоняет то, что успели наработать, синхронизирует этот индекс, и все равно наступает момент, когда ему нужно новый индекс положить вместо старого. В этот момент он естественно накладывает блокировку. Для некоторых этот момент может оказаться очень неожиданным.
Когда-то я рассказывал о той же проблеме в контексте статистики – с ALTER INDEX может произойти то же самое.
-
Предположим, выполняется какой-то длинный отчет – просто SELECT, который длится минут 10. Поскольку это только SELECT, он по определению никому не мешает, никого не блокирует, все классно.
-
В этот момент по таблице, по которой выполняется этот SELECT, по ALTER INDEX REBUILD ONLINE приготовился новый индекс, и готов встать на место старого. Он пытается это сделать, но SELECT держит блокировку объекта – он не мешает никому читать объект, но мешает менять объект.
-
Соответственно, ALTER INDEX REBUILD становится в очередь после вот этого SELECT и собирает после себя очередь всех остальных. Все, кто в этот момент будут пытаться менять или перезаписывать данные, попадут на этот ALTER INDEX REBUILD ONLINE, который хочет подменить индекс.
-
Таким образом получается, что ваш длинный отчет просто подвесит всю базу.
Не нужно делать REBUILD ONLINE индексов тогда, когда у вас происходят какие-то длинные запросы, длинные расчеты. Например, если вы выносите все обслуживание на ночное время, и у вас по всей базе одновременно ребилдятся индексы, считаются витрины и прочее, эта ситуация может очень больно выстрелить.
ALTER INDEX REBUILD ONLINE лучше работать днем, когда у вас преобладают какие-то короткие OLTP-транзакции. Днем такой ситуации может не быть – он просто встанет в очередь за каким-то документом, документ проведется за пару секунд, и после этого произойдет подмена индекса.
Обращайте на это внимание.
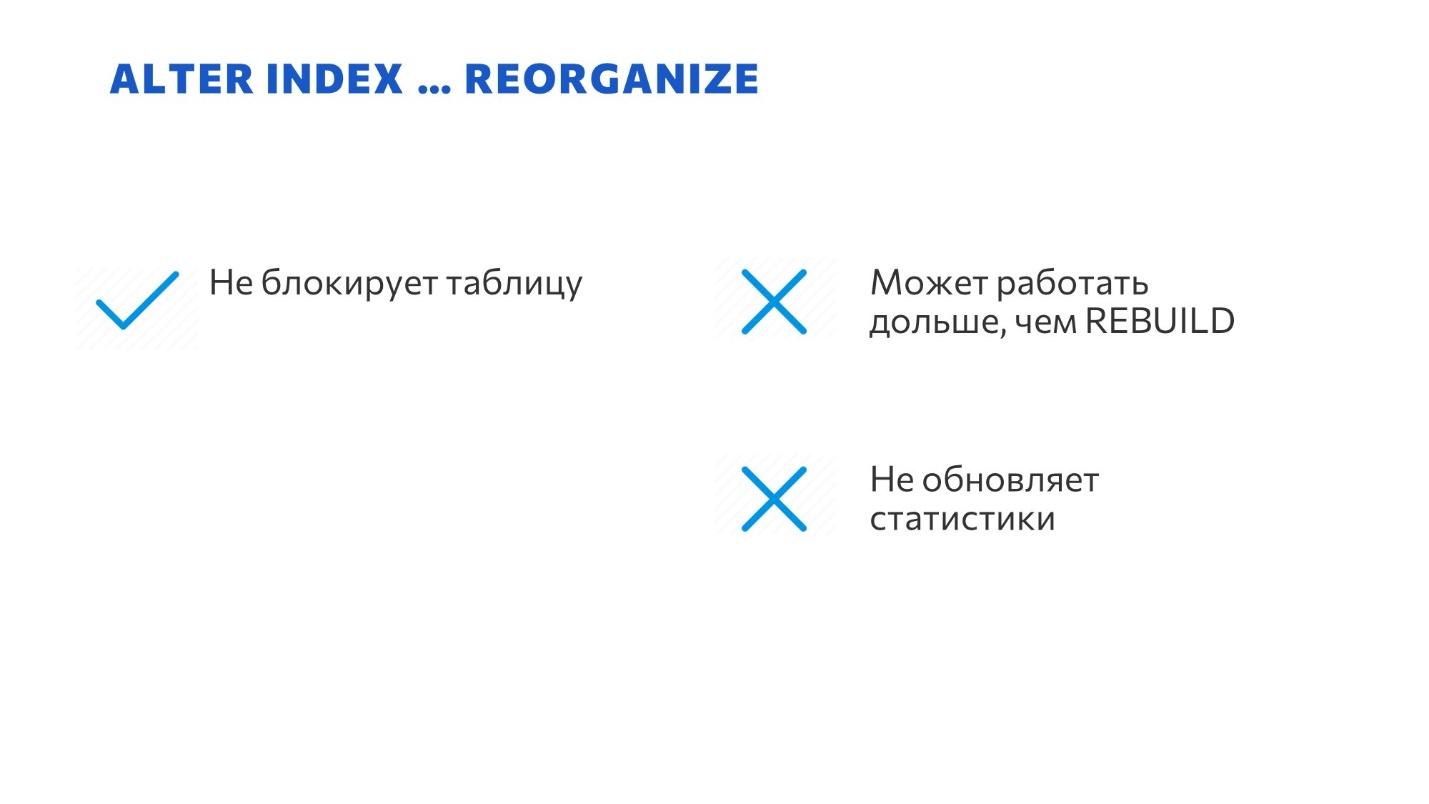
И последний инструмент, который у нас есть – ALTER INDEX… REORGANIZE. В каком-то смысле это такой ONLINE REBUILD для бедных.
Можно найти историю, как он появился. Пол Рэндал писал, что когда он в 1999 году трудился в Microsoft над созданием MS SQL 2000, его попросили придумать инструмент, чтобы обслуживать индексы и никому не мешать. И он придумал ALTER INDEX REORGANIZE.
-
ALTER INDEX REORGANIZE не блокирует всю таблицу и доступен в версии Standard – ему не нужен Enterprise.
-
Но проблема в том, что он не строит новый индекс, а просто страница за страницей перестраивает цепочку в правильном порядке.
По этой причине ALTER INDEX REORGANIZE может работать гораздо дольше, чем REBUILD и создать намного больше лога транзакций, чем REBUILD.
Отсюда знаменитая рекомендация – делать REORGANIZE только если фрагментация индекса меньше 30%. В этом случае вы еще успеете относительно быстро сделать REORGANIZE. Если у вас фрагментация индекса больше 30%, вам проще построить индекс заново с помощью REBUILD. Иначе слишком много будет манипуляций, чтобы все это в правильном порядке выстроить. -
Ну и самое неприятное в команде ALTER INDEX REORGANIZE, что почти перечеркивает ее полезность – она автоматически не пересчитывает статистики.
Я уже говорил, что львиная доля успеха от дефрагментации - из-за сопутствующего пересчёта статистик.
Здесь этого нет, вам придется пересчитывать статистики вручную. И тогда вообще непонятно – зачем с этим связываться, если и так нужно запускать пересчет статистик. Поэтому операцию ALTER INDEX REORGANIZE можно рассматривать, но большого эффекта от нее не будет.
Как перестраивать индексы, если очень хочется?
Если вдруг я вас все еще не убедил, что не нужно перестраивать индексы, давайте поговорим, как же все-таки это нужно делать, и как это автоматизировать.

Какие у нас есть варианты?
Самый простой вариант, который у нас есть «из коробки», это команда DBCC DBREINDEX. Она проходит сплошняком по всем индексам и их перестраивает.
Если у вас никто в базе не работает, есть огромное технологическое окно, и не хочется заморачиваться – это очень хороший вариант. Во всех остальных случаях, когда вам уже нужно втискиваться в какое-то прокрустово ложе, это уже не работает, потому что управлять этой командой практически невозможно.
Можно указать какие-то конкретные таблицы, но тогда уж лучше использовать какие-то более серьезные средства.
Поэтому да – это только для начинающих.

Звезда вечеринки – скрипты Ola Hallengren.
Если вбиваешь в Google запрос «перестроение индексов», первым в выдаче выводится его знаменитый скрипт – https://ola.hallengren.com/sql-server-index-and-statistics-maintenance.html. Это действительно очень удобный скрипт, который дает хорошее окружение. Но у него есть очень неприятные особенности, из-за которых я им никогда, честно говоря, не пользовался.
-
Удобно, что в этом скрипте есть свое логирование.
-
Там есть много вариантов настройки – можно указать пороги срабатывания по фрагментации, после которых он будет работать. Он идет по всем индексам от начала до конца и смотрит: если фрагментация высокая, перестраивает. Если низкая – ничего не делает, ждет следующего раза.
-
Но при этом есть вероятность, что этот скрипт будет пересчитывать что-то, что может спокойно полежать в сторонке. Например, есть какой-то справочник Номенклатура, мы по нему обычно делаем какие-то SEEK-и – вытаскиваем отдельные записи. Даже если он у нас фрагментированный, нам не очень интересно пересчитывать несколько гигабайт этой Номенклатуры. Мы лучше какой-нибудь регистр накопления в это время пересчитаем – выхлопа от этого будет больше. Но настраивать в этом скрипте исключения неудобно. Там есть черные и белые списки, но это, пожалуй, все.

В этом смысле скрипт ADAPTIVE INDEX DEFRAG – мой фаворит. Его придумала команда премьер-поддержки Microsoft – признанные специалисты компании Microsoft.
Они выложили его на GitHub – https://github.com/microsoft/tigertoolbox/tree/master/AdaptiveIndexDefrag.
В скрипте ADAPTIVE INDEX DEFRAG:
-
Тоже есть удобное логирование операций и опции для настройки.
-
Но его основное отличие от предыдущего скрипта в том, что сортировка индексов для обслуживания выполняется по числу чтений из них.
MS SQL Server ведет эту статистику – у него есть специальная вьюха sys.dm_db_index_usage_stats, которая показывает, сколько у вас было SEEK-ов по каждому индексу, сколько SCAN-ов, сколько UPATE-ов и так далее. На эту статистику ребята как раз и ориентируются, обслуживая в первую очередь не то, что оказалось первым по алфавиту, а то, с чем реально работают ваши пользователи. Даже если вы не успели за ночь все пересчитать, есть большая вероятность, что самые горячие индексы – те, которые у вас больше всего востребованы – будут обслужены.

И когда я работал на прошлой работе, мы писали свои скрипты для дефрагментации индексов. На слайде – пара мыслей по поводу того, что мы дорабатывали.
-
Мы реализовывали параллельное выполнение в несколько потоков – запускали несколько джобов, каждый со своей очередью. И либо заранее расписывали состав каждой очереди, чтобы объекты не пересекались, либо делали какие-то семафоры – я это делал динамически с помощью sp_getapplock, разным потокам не позволял обслуживать одно и тоже.
-
Делали несколько расписаний с разными «целями». Это тоже очень хорошая идея, потому что как в физике до сих пор нет универсальной “формулы всего”, так и здесь вы тоже формулы всего не изобретёте. Лучше сделать несколько расписаний, которые будут подходить к задаче с разных сторон. Одно расписание будет обслуживать самые горячие индексы, которые точно нужны вам каждый день. А другое расписание будет общего назначения – просто по всему проходить и обрабатывать. Тут нужно думать гибко – это тоже повысит вашу эффективность.
-
Ну и сортировали индексы по статистике использования через sys.dm_db_index_usage_stats – то, что использовалось в скриптах на предыдущем слайде. Там самые используемые индексы определялись по количеству SCAN-ов, но вы, может быть, придумаете более сложную формулу – не просто по числу сканирований, а добавите какие-то другие факторы.
Как я перестал беспокоиться и полюбил UPDATE STATISTICS

Подведем итоги.
-
Если у вас база работает на SSD, вам вообще не стоит переживать по поводу фрагментации. Потому что внутри архитектуры SSD данные уже раскиданы по разным блокам и просто в силу технологии случайное чтение имеет ту же самую скорость, что и последовательное.
-
Обслуживание статистик скорее всего даст вам лучший эффект, чем ребилд индексов, потому что оно работает быстрее, блокировок создает меньше и не создает такой нагрузки.
Немаловажно: если у вас используется always-on или какие-то другие синхронизации, ребилд индексов будет создавать тонну записей лога транзакций, и вы с этим ничего не сделаете. Обслуживание статистик ничего такого не делает – это гораздо более “лёгкая” операция, поэтому стоит, наверное, посмотреть в эту сторону. -
И если вы делаете обслуживание индексов через ALTER INDEX REBUILD ONLINE, делайте его не тогда, когда у вас ночь, а когда у вас преобладают короткие транзакции, чтобы не произошло пересечения с длинными запросами и длинными транзакциями.

И пара советов о том, какие все-таки индексы стоит перестраивать, если очень хочется:
-
Сделайте себе черный список индексов, которые вам не нужны. Например, регистр сведений «Версии объектов» – зачем его обслуживать, если вы на него смотрите раз в полгода? Справочник «Номенклатура» и другие такие же большие статичные таблицы. Просто забаньте их, чтобы не тратить на них время.
-
Перестраивайте только то, что вам нужно. Те индексы, которые у вас реально используются, ищите по sys.dm_db_index_usage_stats.
-
Если у вас HDD, в первую очередь обслуживайте те индексы, которые вы чаще всего сканируете – это, как правило, регистры накопления, бухгалтерии, расчетов, сведений. В последнюю очередь обслуживайте индексы для документов и справочников, потому что там мы редко что-то сканируем.
Вопросы
Оказывается, MS SQL, как и PostgreSQL, ничего сразу не удаляет – там тоже свой VACUUM есть. Еще и индексы у него пухнут – просто не так сильно, как на PostgreSQL.
Да, пухнут, но там действительно есть отдельная фоновая служба, которая за этим следит, поэтому там эта проблема незаметна.
Насколько оправданна тонкая настройка таблиц индексов (коэффициент заполнения FILLFACTOR) для таблиц, которые часто пересчитываются, чтобы уменьшить деградацию самих таблиц?
Настройка FILLFACTOR показывает, сколько процентов свободного места должно остаться после ребилда индекса.
Работает она только после ребилда – когда создается новый индекс, он упаковывается не плотно, а в нем остается чуть-чуть воздуха, чтобы туда можно было вставлять новые данные – чтобы не сразу создавались новые страницы, а оставалось немного места.
Я обычно рекомендовал ставить настройку FILLFACTOR где-то в районе 90-95, потому что, с одной стороны, вы оставляете воздух, чтобы уменьшить вероятность split pages. С другой стороны, вы этот «воздух» читаете – и это лишние чтения.
Там проблема не в том, что фрагментация растет. Если у вас на странице не осталось «воздуха», первая же вставка в переполненную страницу вызывает split pages – разбиение, расщепление страниц. У меня в начале доклада на схеме был приведен пример split pages – когда была одна страница, а вместо нее добавилось две новых, точнее, даже три, потому что еще одну сверху тоже пришлось располовинить.
Split pages – это ресурсоемкая операция. Поэтому есть смысл оставить немного воздуха за счет FILLFACTOR. Не для того, чтобы бороться с фрагментацией, а просто, чтобы у вас страницы реже расщеплялись.
У нас REORGANIZE выполняется очень долго, REBUILD выполняется очень быстро, но мы привели такой тест, сначала делаем REBUILD, а потом делаем REORGANIZE, и она все равно выполняется так же долго. Почему так может быть?
Если честно, не знаю. REORGANIZE должен просто страницы в правильном порядке выстраивать.
Ну, так мы же REBUILD провели, он все выровнял, REORGANIZE вообще ничего не должна сделать в этом случае.
По идее, да. Я думаю, разработчики СУБД просто не догадывались провести такой тест, поэтому не оптимизировали это дело. Наверное, REORGANIZE всегда думает, что там все равно все плохо.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции Infostart Event.
Вступайте в нашу телеграмм-группу Инфостарт