







{kind=link}
-
Будь проще, и люди к тебе потянутся. СУБД с человеческим лицом?
-
Почему не все дистрибутивы Postgres одинаково полезны для 1С
-
Подготовка для Windows. Установка locale
-
Установка VCRUNTIME
-
Отключение борьбы за экономию.
-
Собственно инсталляция.
-
Инициализация кластера – лучше через initdb
-
Настраиваем доступность по сети и первый старт.
-
Настройка кластера Postgres под 1С.
-
Настройки Postgres.conf для профиля OLTP нагрузки
-
Параметры, связанные сеансами и соединениями.
-
shared_buffers = 12020MB
-
max_files_per_process = 10000
-
max_parallel_workers_per_gather = 0
-
temp_tablespaces = 'ssd_temp'
-
Параметры журнала предзаписи (WAL)
-
Параметры планировщика
-
Параметры автовакуума и сбора статистики.
-
Использование символа \ для экранирования.
-
Параметры для мониторинга
-
Скрипт установки более агрессивных настроек
-
И это все?
Будь проще, и люди к тебе потянутся. СУБД с человеческим лицом?
Большинство любит смотреть картинки, а не читать книги, а тем более руководства. Здесь нет ничего плохого, если картинка быстро и сразу доносит необходимую информацию. Однако развертывание Postgres напоминает нам о прошлом, о котором я читал только в книгах. Прошлое, когда ИТ инфраструктура была настолько дорогая, квалифицированных специалистов было больше, чем машин. Все крутились вокруг очередной суперЭВМ или стояли в очереди на сеанс машинного времени.
Microsoft SQL Server уже показал хороший пример системного ПО для человека, хотя его внутреннюю архитектуру трудно ставить в пример, как Oracle. Машин стало больше, чем квалифицированных специалистов, и как бы пора меняться.
Действия по данной инструкции – могла бы сделать программа инсталляции, запросив лишь профиль нагрузки (например, OLTP), а дальше уже по параметрам оборудования
- Провести настройку окружения.
- Показать лог установки
При таком подходе руководства могли бы пригодиться только для творческого тюнинга, планов развертывания, но не рутинной работы.
Дистрибутивы от release.1c.ru и 1c.postgrespro.ru такого не делают, только в PostgresPro выставили некоторые рекомендуемые параметры 1С. Как результат, мы не увидим лучшие практики и каждый пойдет настраивать Postgres в меру своего понимания, поскольку документация Postgres написана для всех случаев, а не для OLTP приложений
Ситуация вряд ли будет быстро меняться, поскольку санкции это хороший стимул жрать кактус, тем более в ИТ за сложность и платят.
Замечу, что Postgres ставят не только администраторы, но и программисты для создания локальных баз разработки, создания внешних схем данных и так далее.
Здесь все изложено для жесткого OLTP, которое создает платформа 1С, независимо от талантов программиста 1С. Те, кто не верит, что 1С может быть жестким OLTP, почитайте простой тест тут Концепция ORM как двигатель прогресса – выявит слабое место Вашей СУБД . В этом тесте только запись, без конкурентных блокировок. А когда идет запись в регистр с итогами, все еще веселее.
Изложение идет на примере Windows , но установка параметров справедлива и для Unix. В данной части внимание уделено базовой настройке, позволяющей переварить нагрузку при параллельной записи данных и дать 1С возможность приемлемо работать на Postgres. Остальные вопросы, такие как блокировки, большие запросы на чтение, тюнинг индексов, безопасность имеет смысл обсуждать, когда оптимизирован самый ресурсоемкий процесс в OLTP
Почему не все дистрибутивы Postgres одинаково полезны для 1С
Допускаю, что на просторах интернета есть сборка и дистрибутив Postgres, который большую часть работы по установке сделает за Вас, но в 1С мы ограничены двумя бесплатными дистрибутивами и вот почему.
Поиск по слову 1С:Предприятие в документации PostgresPro выдаст следующие ссылки
«Этот модуль был разработан для улучшения поддержки системы 1С:Предприятие, самой популярной в России CRM и ERP-платформы.
Он содержит реализацию типов MCHAR и MVARCHAR, которые с точностью до ошибок совместимы с типами MS SQL CHAR и VARCHAR, соответственно.»
«Модуль fulleq предоставляет дополнительный оператор равенства для совместимости с Microsoft SQL Server.
Этот модуль требуется для поддержки системы 1С:Предприятие.»
Postgres Pro Standard : Документация: 16: 13.3. Явные блокировки : Компания Postgres Professional
«Кроме того, для поддержки системы 1С:Предприятие реализованы ещё два режима блокировок. Эти режимы не конфликтуют ни с какими режимами, описанными выше. Их можно использовать, но лучше вместо них применять рекомендательные блокировки, которые предоставляют ту же функциональность.»
И, наконец, самое известное
«Модуль fasttrun предоставляет транзакционно-небезопасную функцию для усечения временных таблиц, предотвращающую разрастание каталога pg_class.
Этот модуль требуется для поддержки системы 1С:Предприятие.
Операция быстрого усечения не является транзакционной, так что её действие нельзя отменить и оно немедленно становится видимым во всех сеансах независимо от уровня изоляции.»
Это только то, что изложено в документации Postgres pro. При запросах на поддержку - 1С поддерживает только дистрибутив Postgres собственной сборки (а это не то же самое, что 1c.postgrespro.ru)
Как следствие при всем богатстве выбора другие альтернативы потребуют от Вас глубокое погружение в Postgres.
Подготовка для Windows. Установка locale
Формально установка Postgres состоит из установки исполняемых файлов и создания кластера Postgres. При создании кластера (initdb) можно установить необходимые locale вручную, если прочитать большое руководство PostgreSQL : Документация: 15: 24.3. Поддержка кодировок : Компания Postgres Professional, и точно знать, что Вы хотите. Но есть более простой путь
Для аккаунта, под которым ведется установка Postgres
1) Установите РФ или Ваш регион в Region, Region format
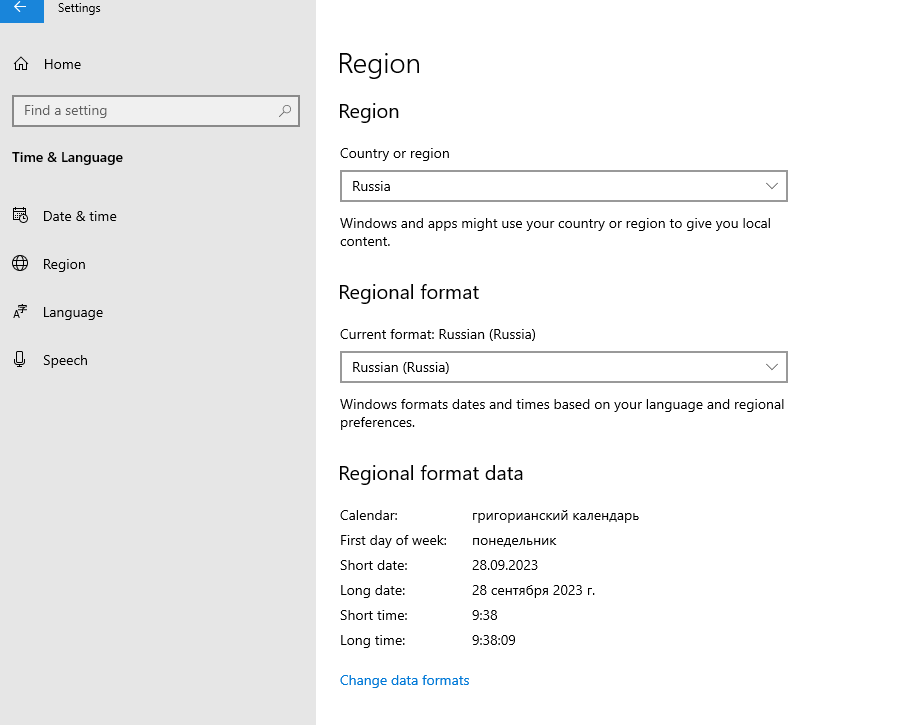
2) И на всякий случай Russia в non-Unicode programs.
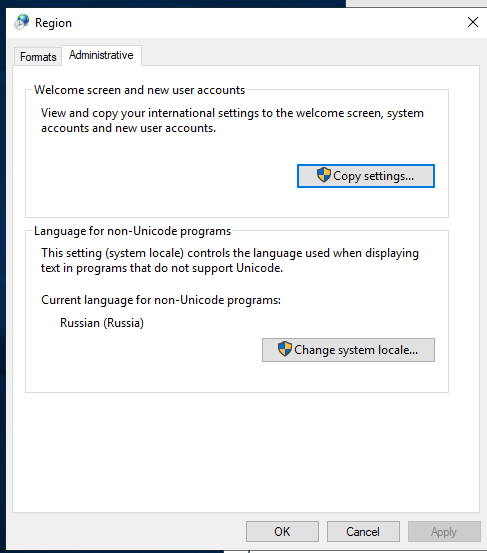
Такие же установки нужно сделать под аккаунтом, с которым будет работать сервис Postgres.
Initdb в этом случае сможет выбрать правильную комбинацию для locale
Установка VCRUNTIME
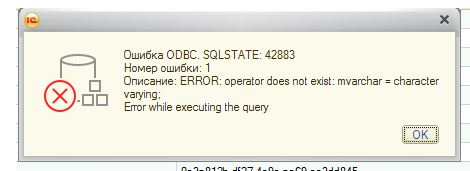
По каким-то причинам дистрибутив 1С не проверяет установку VCRUNTIME, как следствие, приходится его устанавливать вручную, иначе при старте будет ошибка
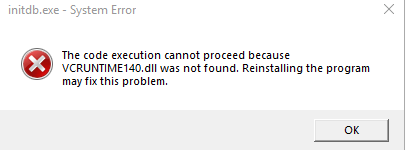
Установить можно отсюда Download Visual Studio Tools – Install Free for Windows, Mac, Linux (microsoft.com)
Отключение борьбы за экономию.
Борьба за экономию электричества настолько слишком глубоко засела в серверах и на уровне операционной системы, и на уровне виртуализации, и на уровне Bios. Все это нужно отключить, иначе у Вас будет периодически просаживаться производительность . Как это случается, можно почитать тут
1C MSSQL Против Матрицы виртуализации – Перезагрузка.
Собственно инсталляция
При инсталляции рекомендую указать только каталоги, а галочку «Установить как сервис» снять. Включение ее приведет к инициализации кластера и заодно сервиса с минимальными параметрами. На моей среде она корректно не работала, а сделать то же из командной строки несложно и гораздо наглядней
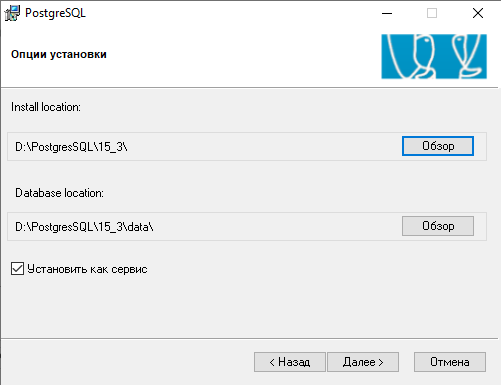
Без флага «Установить как сервис» установка фактически произведет разворачивание файлов в каталог Postgres . Вообще инструкция у 1С еще проще Глава 3. Установка компонентов системы :: Клиент-серверный вариант. Руководство администратора :: 1С:Предприятие 8.3.23. Документация (1c.ru)
Инициализация кластера – лучше через initdb
Кластер баз данных представляет собой набор баз, управляемых одним экземпляром работающего сервера. Очень похож на Instance MS SQL Server .
Инициализация кластера идет через initdb.exe
Подробное описание параметров команды можно прочитать тут PostgreSQL : Документация: 15: initdb : Компания Postgres Professional
На этом этапе мы укажем каталоги для системных баз данных и для <транзакционных логов> журнала предзаписи, именно на этом этапе удобней всего разнести их по разным дискам и именно на этом этапе можно понять, какие проблемы есть при создании кластера
D:\PostgresSQL\15_3\bin>initdb.exe --auth=md5 --encoding=UTF8 --username="postgres" --pgdata="D:\PostgresSQL\15_3\data" --waldir="D:\PostgresSQL\15_3\wal" --pwprompt
The files belonging to this database system will be owned by user "my1cuser".
This user must also own the server process.
The database cluster will be initialized with locale "Russian_Russia.1251".
The default text search configuration will be set to "russian".
Data page checksums are disabled.
Enter new superuser password:
fixing permissions on existing directory D:/PostgresSQL/15_3/data ... ok
fixing permissions on existing directory D:/PostgresSQL/15_3/wal ... ok
creating subdirectories ... ok
selecting dynamic shared memory implementation ... windows
selecting default max_connections ... 100
selecting default shared_buffers ... 128MB
selecting default time zone ... America/Los_Angeles
creating configuration files ... ok
running bootstrap script ... ok
performing post-bootstrap initialization ... ok
syncing data to disk ... ok
Success. You can now start the database server using:
На этом этапе можно часто столкнуться с проблемами настройки прав (а unix там особенно нужно быть внимательным к owner каталогов). Чтобы работать без проблем, рекомендую устанавливать Postgres под тем аккаунтом - под которым он будет работать как сервис.
Если возникла такая ошибка, нужно
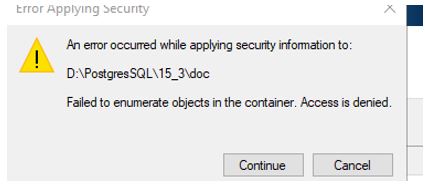
Сделать аккаунт, под которым работает Postgres как owner и не забыть про наследование [Solved] "Failed to Enumerate Objects in the Container" Windows 10 /11 Error (thegeekpage.com)
Настраиваем доступность по сети и первый старт
Отключаем временно Windows Firewall, чтобы проще искать проблемы.
Для разрешения всех коннектов прописать в pg_hba.conf следующее
host all all 0.0.0.0/0 md5
а в postgres.conf нужно раскомментировать
listen_addresses = '*'
В данном случае нам нужно просто проверить работоспособность кластера, а не закрутить побольше гаек в безопасности.
Сначала проверяем запуск
pg_ctl -D "D:\PostgresSQL\15_3\data" -l "D:\PostgresSQL\15_3\trace\logfile.txt" start
Если в D:\PostgresSQL\15_3\trace\logfile.txt нет ошибок, можно Вас поздравить
Пути и каталоги нужно указывать те, которые на сервере
Даже если старт успешен сразу - нужно проверить, что
netstat -aon | find "LISTENING" | find ":5432"
Показывает
TCP 0.0.0.0:5432 0.0.0.0:0 LISTENING 14712
TCP [::]:5432 [::]:0 LISTENING 14712
На windows ipv6 сейчас приоритетный протокол, и это может влиять на коннект по ipv4. Я предпочитаю использовать ipv4, если нет необходимости использовать ipv6.
Если все стартует хорошо, можно зарегистрировать 1С как сервис, для удобной перезагрузки сервера
pg_ctl register -D "D:\PostgresSQL\15_3\data" -l "D:\PostgresSQL\15_3\trace\logfile.txt" -N PostgresSQLMain
Не забудьте в сервисе поставить LogOn под доменным пользователем (можно через параметры -U -P но почему то пароль не ставился), и Delayed start для надежности.
Далее проверяем как все стартовало
pg_ctl status -D "D:\PostgresSQL\15_3\data"
pg_ctl: server is running (PID: 6088)
d:/Postgres/15_3/bin/postgres.exe "-D" "D:\PostgresSQL\15_3\data"
Настройка кластера Postgres под 1С
Для удобства лучше установить PGAdmin на ПК администратора, чтобы видеть кластер визуально.
При установке с сайта внимательно смотрите на версию Windows – новые версии PgAdmin требуют новых версий Windows Download (pgadmin.org)
Теперь можно выполнить настройки согласно Глава 3. Установка компонентов системы :: Клиент-серверный вариант. Руководство администратора :: 1С:Предприятие 8.3.23. Документация (1c.ru)
Для нормальной работы 1С нужно создать
Обязательные tablespace v81c_index, v81c_data
Tablespace для временных файлов ssd_temp лучше выделять отдельно и на быстрых дисках
Вообще – учитывая огромное количество файлов, создаваемых Postgres - чем больше вы их разведете по дискам, тем лучше
CREATE TABLESPACE ssd_temp
OWNER postgres
LOCATION 'D:\PostgresSQL\15_3\data\pg_ssdtemp';
ALTER TABLESPACE ssd_temp
OWNER TO postgres;
CREATE TABLESPACE v81c_data
OWNER postgres
LOCATION 'D:\PostgresSQL\15_3\data\pg_1cdata';
ALTER TABLESPACE v81c_data
OWNER TO postgres;
CREATE TABLESPACE v81c_index
OWNER postgres
LOCATION 'D:\PostgresSQL\15_3\data\pg_1cindex';
ALTER TABLESPACE v81c_index
OWNER TO postgres;
Настройки Postgres.conf для профиля OLTP нагрузки
В postgres.conf параметров, влияющих на поведение Postgres больше, чем переключателей в кабине самолета. Плохая новость – в вышеуказанных дистрибутивах большинство их закомментировано (применяются значения по умолчанию). Самое интересное, что в дистрибутиве 1С НЕ установлены даже те, которые требует поставить (либо не менять) сама 1С, согласно своей же документации.
В дистрибутиве postgrespro часть этих параметров установлено, что показывает другое отношение к продукту. Здесь я собрал то, что считаю необходимым для OLTP, конечно, сколько бы параметров ни установил, все равно кажется, что список неполный.
Ниже приведены рекомендуемые для OLTP параметры, но прежде чем сделать Copy-Paste, нужно пересчитать их в зависимости (здесь параметры выставлены для баз от 2 до 5 терабайт)
А) Числа коннектов
Б) Количества IOPS , которая выдает Ваша дисковая подсистема
В) И размера таблиц (у меня они могут быть до терабайта, поэтому какие-то значения могут показаться большими)
Как Postgres работает с коннектами – описано тут Postgres Pro Enterprise : Документация: 15: 53.2. Как устанавливаются соединения : Компания Postgres Professional
«Postgres Pro реализует простую клиент-серверную модель по схеме «процесс для пользователя». В такой схеме один клиентский процесс подключается к одному отдельному серверному процессу. Так как мы не знаем заранее, сколько подключений будет, нам нужен «главный процесс», который будет запускать новый процесс при каждом запросе подключения»
С точки зрения 1С каждое активное соединение породит дополнительный процесс на Postgres . Если Вы запустите 20 фоновых заданий 1С это породит 20 процессов на Postgres . Не надо соединение 1С с количеством rphost на сервере , ведь один rphost 1С может обслуживать много соединений.
Все это нужно учитывать для расчета потребления памяти на процесс
Для удобства прилагаю файл postgres.conf
Подробные описания можно найти тут PostgreSQL : Документация: 15: Глава 20. Настройка сервера : Компания Postgres Professional . Ниже только комментарии
Параметры связанные сеансами и соединениями
max_connections = 500
Определяет максимальное число одновременных подключений к серверу БД. Помните - любое фоновое задание 1С или открытый сеанс это уже connection.
temp_buffers = 128MB
Задаёт максимальный объём памяти, выделяемой для временных буферов в каждом сеансе. Эти существующие только в рамках сеанса буферы используются исключительно для работы с временными таблицами. Для 1С это масштабируется на количество сеансов и фоновых заданий. 1С интенсивно использует временные таблицы, поэтому значение по умолчанию 8 мегабайт для нее слишком мало. Даже если Вы явно их не используете в 1С , любая запись в регистр их будет использовать пример Compare by Statements
row_security = off
«В дополнение к стандартной системе прав SQL, управляемой командой GRANT, на уровне таблиц можно определить политики защиты строк, ограничивающие для пользователей наборы строк, которые могут быть возвращены обычными запросами или добавлены, изменены и удалены командами, изменяющими данные. Это называется также защитой на уровне строк (RLS, Row-Level Security»
Поскольку у 1С есть свой механизм RLS , очевидно что она рекомендует не пользоваться аналогом в Postgres.
Ssl = off
В документации 1С считают, что этот параметр может вызвать повышенный расход CPU . Склонность postgres к большему расходу CPU, чем MS SQL, это проверенный факт. Но насколько будет влияние данного параметра, это интересный повод для теста или сколько стоит безопасность.
work_mem = 128MB # min 64kB
«Задаёт базовый максимальный объём памяти, который будет использоваться во внутренних операциях при обработке запросов (например, для сортировки или хеш-таблиц), прежде чем будут задействованы временные файлы на диске.»
Важный параметр, от которого зависит скорость работы и расход памяти в зависимости от активных сеансов.
max_locks_per_transaction = 1000
Значение рекомендовано в документации 1С, значение по умолчанию слишком маленькое 64
«В общей таблице блокировок может храниться max_locks_per_transaction объектов (например, таблиц) для каждого серверного процесса или подготовленной транзакции, таким образом, в любой момент времени может быть заблокировано не больше этого числа различных объектов. Этот параметр ограничивает среднее число блокировок объектов, используемых каждой транзакцией, отдельные транзакции могут заблокировать и больше объектов, если все они умещаются в таблице блокировок»
shared_buffers = 12020MB
Задаёт объём памяти, который будет использовать сервер баз данных для буферов в разделяемой памяти. Поскольку значение по умолчанию 128 мегабайт, очевидно нужно устанавливать свое.
«Существуют варианты нагрузки, при которых эффективны будут и ещё большие значения shared_buffers, но так как PostgreSQL использует и кеш операционной системы, выделять для shared_buffers более 40% ОЗУ вряд ли будет полезно. При увеличении shared_buffers обычно требуется соответственно увеличить max_wal_size, чтобы растянуть процесс записи большого объёма новых или изменённых данных на более продолжительное время.»
max_files_per_process = 10000
В любой типовой конфигурации 1С больше тысячи таблиц, а в Postgres на каждую таблицу будет несколько файлов.
max_parallel_workers_per_gather = 0
Значение 0 отключает параллельное выполнение запросов. Не все запросы хорошо распараллеливаются. В OLTP это только создаст лишнюю нагрузку сервер Postgres, который и так склонен к большему использованию CPU чем MS SQL – проверено тут Postgres как предчувствие. Вычисляем процент импортозамещения в режиме Highload от 1С . Если очень хочется попробовать 1С, рекомендует включать параллелизм только в одном случае Настройка параметра Max degree of parallelism при выполнении реструктуризации информационной базы :: MS SQL Server :: Методическая поддержка для разработчиков и администраторов 1С:Предприятия 8 (1c.ru). Оптимизированный механизм реструктуризации поддерживается в Postgres, поэтому это может помочь.
temp_tablespaces = 'ssd_temp'
Поскольку работа с временными таблицами в Postgres реализована неэффективно – единственный вариант сгладить - вынести функционал на SSD либо RAM диск. По этому поводу есть хорошая статья от конкурентов 1С PostgreSQL и временные таблицы , но помните, что RAM диск должен иметь хорошую реализацию по многопоточности, иначе все повиснет на одном ядре. В этом случае лучше найти быстрый SSD серверного класса, поскольку реализация дисковых подсистем это учитывает
Параметры журнала предзаписи (WAL)
В документации Postgres периодически попадаются глубокие описания PostgreSQL : Документация: 15: 30.1. Надёжность . Журнал предзаписи : Компания Postgres Professional , которые не встретишь даже у Oracle. Рекомендую почитать первоисточник, для понимания, как все работает.
Для OLTP с записью в несколько потоков нужно
synchronous_commit = off это сразу расширит бутылочное горлышко, которым является журнал предзаписи, он же transaction log в MS SQL, он же Redo log в Oracle
Польза просчитана и доказана тут на примере MS SQL Delayed durability поможет вашему ORM увеличить производительность на 50% и более, если Вы только будете использовать … и 1С крайне рекомендует для Postgres в своей документации. Данный параметр не следует путать с fsync, который выключать опасно для базы. synchronous_commit = off при жестком сбое может привести к потере последних зафиксированных транзакций, но база останется в целостности в отличии от игр с fsync
commit_delay = 1000 Взят из рекомендаций 1С
«Параметр commit_delay добавляет паузу перед собственно выполнением сохранения WAL. Эта задержка может увеличить быстродействие при фиксировании множества транзакций, позволяя зафиксировать большее число транзакций за одну операцию сохранения WAL, если система нагружена достаточно сильно и за заданное время успевают зафиксироваться другие транзакции.»
Параллельно рекомендуется commit_siblings=5, но он и так в этом значении по умолчанию
max_wal_size = 4GB
min_wal_size = 2GB
«Пока WAL занимает на диске меньше этого объёма, старые файлы WAL в контрольных точках всегда перерабатываются, а не удаляются. Это позволяет зарезервировать достаточно места для WAL, чтобы справиться с резкими скачками использования WAL, например, при выполнении больших пакетных заданий»
Поэтому значения по умолчанию 1гб и 80мб слишком маленькие для нагруженной OLTP
checkpoint_timeout = 15min
Checkpoint
«это точки в последовательности транзакций, в которых гарантируется, что файлы с данными и индексами были обновлены всей информацией записанной перед контрольной точкой. Во время контрольной точки, все «грязные» страницы данных, находящиеся в памяти, сохраняются на диск, а в файл журнала записывается специальная запись контрольной точки.»
Чтобы понять, как он связан с фиксацией транзакций и записью WAL, нужно прочитать PostgreSQL : Документация: 15: 30.5. Настройка WAL : Компания Postgres Professional. По умолчанию checkpoint_timeout =5 минут, но он так же срабатывает при приближении к пределу max_wal_size, если это имеет место раньше. Я предпочитаю ориентироваться на max_wal_size , а не на время.
Параметры планировщика
Результат установки параметров этого раздела самый неочевидный, поскольку они больше рекомендательные для планировщика, а что он решит в итоге будет зависеть множества факторов (документация, актуальность статистики, работа autovacuum, ошибки релиза). Кроме того, влияние их можно проверить только на отдельных запросах, операциях. Для оценки их влияния нужна группа синтетических тестов, где видно, что улучшение одних тестов, не приводит к деградации других.
effective_cache_size = 36060MB # 75% of RAM
В разных источниках рекомендуют effective_cache_size либо 50%-75% Ram либо RAM- shared_buffers . Документация большей ясности не добавила, почитайте сами.
from_collapse_limit = 8
join_collapse_limit = 8
Это достаточно важный параметр для 1С. В 1С почти всегда делается либо СрезПоследних для периодических регистров сведений, либо запросы по итогам. Даже если Вы явно не делаете Join при срезе последних, внутри платформы Join происходит. А если кто-то любит делать так Документ.Контрагент.ИНН, чтобы добраться до нужных реквизитов, все усугубится. Для понимания лучше прочитать этот раздел PostgreSQL : Документация: 15: 14.3. Управление планировщиком с помощью явных предложений JOIN : Компания Postgres Professional
random_page_cost = 1.4
random_page_cost забавный параметр, который 1С рекомендует подкрутить random_page_cost = 1.5-2.0 для RAID, 1.1-1.3 для SSD. Причем меня смущает такая точность, когда значение по умолчанию 4.0 и как пишут в документации.
«Таким образом, можно считать, что значение по умолчанию моделирует ситуацию, когда произвольный доступ в 40 раз медленнее последовательного, но 90% операций произвольного чтения удовлетворяются из кеша.»
А если часть базы на SSD, а часть на HDD? Вопрос философский.
По такой логике остается только выбрать 1.4, а влияния других значений в тесте на запись я не заметил.
Есть параметры, которые 1С не рекомендует отключать, например, PostgreSQL : Документация: 15: 20.7. Планирование запросов Генетический оптимизатор : Компания Postgres Professional geqo, geqo_threshold
Параметры автовакуума и сбора статистики
Параметры по умолчанию для автовакуума и статистики сразу влияют на производительность в 1С, если Вы подвигаете итоги вперед-назад, либо будете использовать текущие итоги. Также он влияет на запись в регистры и чем они больше, тем существенней.
Обратите внимание, что запуск автовакуума это комплекс действий, не ограниченный очисткой от «мертвых» кортежей. Хорошее описание тут PostgreSQL : Документация: 15: 25.1. Регламентная очистка : Компания Postgres Professional
- Для высвобождения или повторного использования дискового пространства, занятого изменёнными или удалёнными строками.
- Для обновления статистики по данным, используемой планировщиком запросов PostgreSQL.
- Для обновления карты видимости, которая ускоряет сканирование только индекса.
- Для предотвращения потери очень старых данных из-за зацикливания идентификаторов транзакций или мультитранзакций.
Проведенный для 1С тест показывает, что автовакуум нужно настраивать индивидуально для каждой таблицы регистров бухгалтерии и накопления и без использования процентов. Как эффективно настроить autovacuum в Postgres для 1С
Но в типовых конфигурациях 1С больше тысячи таблиц, и для (справочников, небольших регистров сведений, бизнес процессов и метаданных с небольшой нагрузкой) удобней использовать и общие параметры.
maintenance_work_mem = 128MB # min 1MB
« Задаёт максимальный объём памяти для операций обслуживания БД, в частности VACUUM, CREATE INDEX и ALTER TABLE ADD FOREIGN KEY. »
max_parallel_maintenance_workers = 8
«Задаёт максимальное число рабочих процессов, которые могут запускаться одной служебной командой. В настоящее время параллельные процессы может использовать только CREATE INDEX при построении индекса-B-дерева и VACUUM без указания FULL»
Учитывая, что даже в типовых конфигурациях любят писать данные сразу в несколько регистров, автовакуум тоже нужно распараллеливать. Значение нужно подбирать, учитывая количество ядер, которые это будут обслуживать
Устанавливая этот параметр, нужно проверить ограничители сверху (по умолчанию 8) max_worker_processes, max_parallel_workers
autovacuum_max_workers = 8
«Задаёт максимальное число процессов автоочистки (не считая процесс, запускающий автоочистку), которые могут выполняться одновременно»
Для понимания этих параметров нужно почитать статью Как эффективно настроить autovacuum в Postgres для 1С . А устанавливать их обязательно, потому что значения по умолчанию слишком большие даже для маленьких баз
autovacuum_vacuum_scale_factor = 0.01
«Задаёт процент от размера таблицы, который будет добавляться к autovacuum_vacuum_threshold при выборе порога срабатывания команды VACUUM. Значение по умолчанию — 0.2 (20% от размера таблицы)»
autovacuum_analyze_scale_factor = 0.005
«Задаёт процент от размера таблицы, который будет добавляться к autovacuum_analyze_threshold при выборе порога срабатывания команды ANALYZE. Значение по умолчанию — 0.1 (10% от размера таблицы).»
autovacuum_naptime = 20s # time between autovacuum runs
Задаёт минимальную задержку между двумя запусками автоочистки для отдельной базы данных. При запуске он проверяет, что порог очистки = базовый порог очистки + коэффициент доли для очистки * количество кортежей и при превышении, которого срабатывает автовакуум. Достижение порога очистки само по себе не инициирует процесс чистки.
vacuum_cost_limit = 800 # 100* autovacuum_max_workers
«Во время выполнения команд VACUUM и ANALYZE система ведёт внутренний счётчик, в котором суммирует оцениваемую стоимость различных выполняемых операций ввода/вывода. Когда накопленная стоимость превышает предел (vacuum_cost_limit), процесс, выполняющий эту операцию, засыпает на некоторое время (vacuum_cost_delay). Затем счётчик сбрасывается и процесс продолжается»
Ну и, конечно, autovacuum = on должно быть включено (установлен по умолчанию) , но чтобы автоочистка работала, нужно также включить track_counts
Важно! В документации написано, что
«Автоочистка не обрабатывает временные таблицы. Поэтому очистку и сбор статистики в них нужно производить с помощью SQL-команд в обычном сеансе.»
Видимо, поэтому 1С сейчас постоянно делает analyze при работе с временными таблицами независимо от ее размера, и это занимает больше 30% времени при тесте на оборотном регистре сведений. SQL команды можно посмотреть SQL DML при записи в оборотный регистр
За автообновление статистики отвечает параметр online_analyze.enable , который 1С рекомендует устанавливать в off.
Я лично не проверял, что 1С делает везде (во всех компонентах ORM) analyze для временных таблиц, а не только при записи в регистры, поскольку это требует длительного тестирования. В 1С временные таблицы также широко используются при работе с пакетами запросов, а недавно добавилась возможность добавление записей во временные таблицы через 1С. Поэтому я оставляю эти параметры в On только для временных таблиц Postgres Pro Standard : Документация: 15: F.31. online_analyze : Компания Postgres Professional Если у Вас есть другая подтвержденная информация – делитесь. Параметры ставлю менее агрессивные чем для автовакуума, поскольку в 1С данные во временные таблицы добавляются как результат запроса , а не мелкими порциями
online_analyze.threshold = 50
online_analyze.scale_factor = 0.1
online_analyze.enable = on
online_analyze.verbose = off
online_analyze.min_interval = 10000
online_analyze.table_type = 'temporary'
online_analyze.local_tracking = on
plantuner.fix_empty_table = on
Использование символа \ для экранирования.
В документации 1С просят устанавливать вот такие параметры, подробности в документации Postgres
escape_string_warning = off
standard_conforming_strings = off
#log_timezone = 'Europe/Moscow'
Параметры для мониторинга
В отличии от Microsoft и Oracle в Postgres хороший мониторинг из коробки не идет. Достаточно попробовать получить качественную статистику ожиданий, и все станет понятно тут Как в postgres получить качественную статистику ожиданий? — Хабр Q&A (habr.com)
Гораздо лучше обстоят дела в Postgres pro Enterprise ( см pgpro_pwr). Но и там сбор данных для мониторинга скриптом может съесть ресурсы на простом скрипте, как описано тут Postgres бесплатный сыр или ступенька к Enterprise версии поэтому применяйте его осмотрительно
А в обычной версии остается использовать только следующие пакеты (online_analyze это другое, описан выше)
#shared_preload_libraries = 'online_analyze, plantuner,pg_stat_statements,pg_wait_sampling'
shared_preload_libraries = 'online_analyze, plantuner,pg_stat_statements'
track_activities = on
#track_activity_query_size = 1024 # (change requires restart)
track_counts = on
track_io_timing = on
track_wal_io_timing = on
track_functions = all # none, pl, all
stats_fetch_consistency = none
Параметры для логгирования.
Параметр -l при старте postgres иногда не срабатывает, либо не работает при запуске сервиса но логгирование всегда можно прописать в postgresql.conf
Для включения логгирования достаточно указать в postgresql.conf
• logging_collector = on
• log_directory = 'D:\\PostgresSQL\\15_3\\trace' #обратите внимание на формат каталога он может отличаться в разных ОС
• log_min_messages = log
• log_min_duration_statement = 0
Скрипт установки более агрессивных настроек
В данной статье Как эффективно настроить autovacuum в Postgres для 1С на нагрузочном тесте было доказано, что указания уровней срабатывания autovacuum в процентах для больших таблиц указывать неэффективно.
Выход простой – установить абсолютные значения срабатывания для наиболее нагруженных таблиц.
do $$
<<first_block>>
declare
gettable RECORD;
begin
-- get the number of films or tablename like '%accrg%' or tablename like '%accumrg%'
FOR gettable IN select tablename from pg_tables where tablespace ='v81c_data' and (tablename like '%inforg%' or tablename like '%accrg%' or tablename like '%accumrg%' ) ORDER BY tablename
LOOP
-- display a message
raise notice 'Process table %', gettable.tablename;
EXECUTE 'ALTER TABLE ' || quote_ident(gettable.tablename) ||' SET (autovacuum_enabled = on, autovacuum_vacuum_scale_factor = 0, autovacuum_vacuum_threshold = 2000, autovacuum_analyze_scale_factor =0 , autovacuum_analyze_threshold = 2000 )' ;
--EXECUTE 'select tablename, tableowner from pg_tables where tablename=$1' INTO gettable USING gettable.tablename;
-- raise notice 'Process table %', gettable.tableowner;
END LOOP;
end first_block $$;
Это не значит что автовакуум будет срабатывать каждые 2000 записей, это значит что он будет срабатывать каждые autovacuum_naptime = 20s , если количество измененных записей превысит 2000
У Postgres богатый язык скриптов и очень удобный как можно увидеть из примера.
И это все?
Как ни пиши инструкцию, всегда найдется повод ее дополнить. Необходимый минимум для OLTP получился не таким уж и маленьким. Не случайно администратор СУБД это отдельная профессия, и судя по росту нагрузок, она такой и останется тем более 24х7 в эпоху тотального интернета уже необходимость, маленький RTO уже необходимость.
Конечно не освещено много других тем, например, блокировки. Просто настройка СУБД должна сразу исключать узкие места, на которых возможны появления ожиданий или излишний расход ресурсов
- Параметры, влияющие на дисковую подсистему
- Параметры, влияющие на кэширование и использование памяти
- Параметры, влияющие на работу отдельных процессов Postgres
- Далее можно переходить к параметрам влияющим на блокировки, эффективного использования ресурсов, балансировки нагрузки, тюнинг индексов, планировщика и …
До новых встреч.
Вступайте в нашу телеграмм-группу Инфостарт