- Autovacuum в Postgres – конкурентное преимущество или неизбежное зло?
- Зачем копаться в мусоре если Autovacuum все делает сам?
- Основное правило уборки мусора – быть в нужное время в нужном месте, ловить момент.
- Как сосредоточиться на бизнес логике, когда вокруг …
Человечество, мой друг, делится на две половины: одни мусорят, а другие убирают. (Из фильма «Первый троллейбус» 1963 г.)
Autovacuum в Postgres – конкурентное преимущество или неизбежное зло?
В ИТ вроде есть разделение труда и в теории команда из программиста, администратора СУБД, системного администратора - может решить любые проблемы мозговым штурмом. Вот только в проектировании архитектуры Highload решений это уже не работает, потому что Вам заранее нужно знать, еще до возникновения проблем:
- Где будут узкие места Вашего решения?
- Какие слабые места и пределы выбранной платформы и СУБД?
А если Вы заложили архитектурный изъян – никакой agile software development не спасет. Просто попробуйте переделать фундамент под построенным домом. Особенно это актуально для 1С, где rapid application development не располагает задумываться о последствиях. С прототипом долго играться не дадут, поэтому слабые места нужно знать заранее, бить в точку, а значит осознавать весь стек разработки, и только тогда будет гештальт.
Если кто-то думает, что в 1С можно ограничиться знанием уровня ORM (языка 1С) и не лезть в СУБД , поверьте, Вы даже с администратором СУБД не сможете разговаривать. Один метод .Записать() создает десяток DML и их понимание принципиально влияет на Highload в 1С.
Тем, у кого 1С на Postgres, рано и ли поздно придется тонко настраивать такую странную вещь, как Автовакуум.
Почувствовать настройки Автовакуума в 1С очень просто – подвигайте итоги назад и вперед.
Пример: из двухтерабайтной базы 1С:Бухгалтерии (регистр Бухгалтерии) двигаем итоги несколько раз назад и вперед, при настройках Autovacuum по умолчанию.
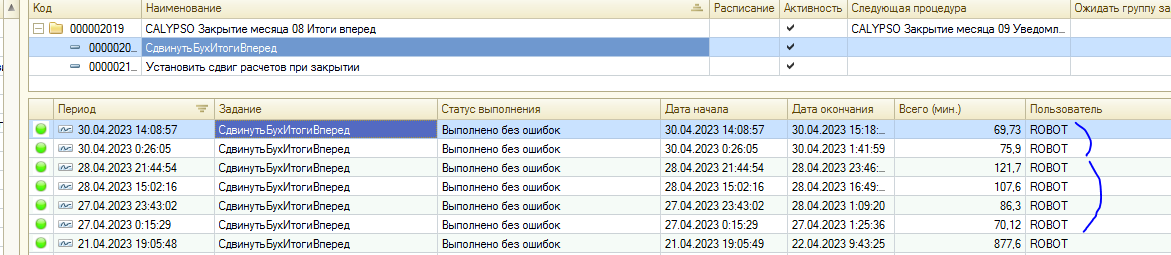
В основной таблице регистра бухгалтерии «_AccRg<n> – таблица движений регистра бухгалтерии.» всего лишь 177 270 973 сто семьдесят миллионов записей (за пару лет). С ней связано несколько таблиц с итогами.
AccRgAT0<n> – таблица остатков и оборотов по счетам и субсчетам.
_AccRgAT<i><n> – таблица остатков и оборотов по счетам, субсчетам и субконто. Эти таблицы создаются в том случае, если регистр бухгалтерии ссылается на план счетов, у которого максимальное количество субконто больше нуля. Номер i изменяется от 1 до максимального количества субконто.
_AccRgCT<n> – таблица итогов оборотов между счетами. Эта таблица создается только для регистра бухгалтерии, поддерживающего корреспонденцию.
_AccRgOpt – таблица настроек хранения итогов. Эта таблица создается одна на все регистры бухгалтерии.
_AccRgED<n> – таблица значений субконто регистра бухгалтерии. Эта таблица создается в том случае, если регистр бухгалтерии ссылается на план счетов, у которого максимальное количество субконто больше нуля.
В самой большой таблице с итогами по субконто _AccRgAT0<n> 89 927 298 записей – всего в два раза меньше.
Алгоритм пересчета простой –
- удаляются старые итоги из _AccRgAT0<n> _AccRgAT<i><n> _AccRgCT<n>,
- берутся итоги за предыдущий период (например март).
- добавляются суммарные данные из _AccRg<n> (за апрель) и все это записывается в таблицы итогов.
Все это идеально подходит для возникновения мертвых кортежей в таблицах итогов. А поскольку по таблице итогов делаются запросы за предыдущий период, то важна и актуальность статистики.
Деградация производительности идет, если двигать итоги за три месяца (13% от объема данной таблицы)
Впечатляет? А это только начало погружения. Как только это увидел, я поправил в Postgres.conf параметры со значений по умолчанию на
- "autovacuum_vacuum_scale_factor" = 0.01
- "autovacuum_vacuum_threshold"=50
- "autovacuum_naptime" оставил 20 sec
и обрадовался, что деградация прекратилась. Автовакуум запускается каждые 20 секунд, но стал срабатывать при update or delete 1% записей, ранее было 10% . Дальше можно не читать?
Если хорошо подумать - в 1С Бухгалтерии больше тысячи таблиц, плюс метаданные, которые отражают специфику компании. Эти параметры в Postgres.conf выглядят как антибиотик с неприятными побочными эффектами, а не как систематическое лечение – о чем будет рассказано ниже.
После работы с MS SQL или Oracle database невольно удивляешься – почему в Postgres так много внимания уделяют очистке таблиц от мертвых кортежей (dead tuples) и заодно пересбору статистики через Autovacuum? Конечно, в руководстве все написано Postgres Pro Enterprise : Документация: 15: 24.1. Регламентная очистка : Компания Postgres Professional, кто-то даже оставит настройки срабатывания по умолчанию, до первого звонка. А когда сравниваешь архитектуры Postgres с MS SQL или Oracle – вопросов становится больше
Документация объясняет нам необходимость AUTOVACUUM следующим образом
«В Postgres Pro команды UPDATE или DELETE не вызывают немедленного удаления старой версии изменяемых строк. Этот подход необходим для реализации эффективного многоверсионного управления конкурентным доступом (MVCC, см. Главу 13): версия строки не должна удаляться до тех пор, пока она остаётся потенциально видимой для других транзакций. Однако в конце концов устаревшая или удалённая версия строки оказывается не нужна ни одной из транзакций. После этого занимаемое ей место должно быть освобождено и может быть отдано новым строкам, во избежание неограниченного роста потребности в дисковом пространстве. Это происходит при выполнении команды VACUUM.»
Опытные знают, что, например, в MS SQL есть понятие ghost record, и Вы даже можете увидеть после массового удаления записей вот такую картинку
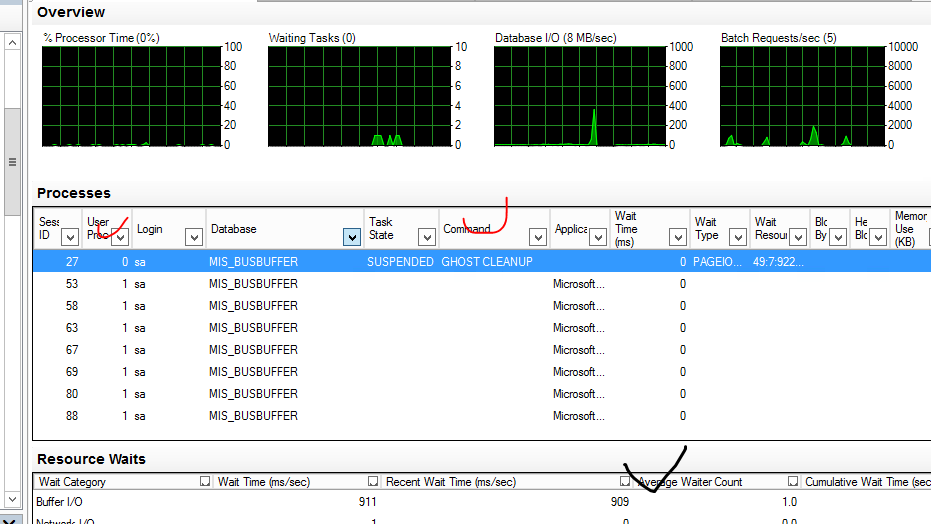
Но этот процесс идет по своей логике, и его еще нужно поймать.
В Oracle я не видел ничего подобного.
Конечно, в Oracle и MS SQL тоже есть проблемы с фрагментацией после delete\update.
В Oracle, например, ее можно снижать:
- C помощью alter tablespace COALESCE (в Oracle) для объединения свободных экстентов в более крупные
- Либо перестройка кластерных индексов
- Либо экспорт - импорт таблицы с сортировкой по кластерному индексу
Эти процедуры в Oracle, MS SQL, как правило, делаются в технологические окна, когда возникают вот такие эффекты Как влияет фрагментация на план, но в Postgres борьба с мертвыми кортежами это не просто мероприятие, а ключевой шаг в Performance and tuning в режиме Online.
Возникает вопрос – в Oracle тоже есть MVCC и очень давно (в отличие от MS SQL, где его реализовали как дополнительный режим), почему там не нужен AUTOVACUUM? На этот вопрос отвечает хорошая статья MVCC в Oracle и PostgreSQL : Компания Postgres Professional
Если кратко
«Внутренние детали реализации в двух системах существенно отличаются. Постгрес хранит в блоке все варианты строк, которые получаются при их изменении и даже удалении. Снимок определяет, какая именно из имеющихся версий строки должна быть видна. Время от времени блоки очищаются от тех версий, которые больше не видны никому. В Оракле в блоке находятся только актуальные на определенный момент строки, а вместо непосредственного хранения предыдущих вариантов формируется журнал отката. Если блок не соответствует снимку, изменения в нем откатываются с помощью журнала, формируя новую версию этого блока.»
То есть нам намекают, что в Postgres MVCC, как бы это сказать «самый многоверсионный». Это тот самый случай, когда лучше разобраться в деталях и самому составить собственное мнение. Например, Microsoft догонял Oracle в MVCC и определил для хранения снимков предыдущих версий TempDB , по соседству с временными таблицами. А у Oracle изначально rollback сегмент заложен в архитектуре, и реализация MS SQL на этом фоне выглядит как костыль.
MS SQL галочку MVCC поставил? Несомненно, зачем платить больше чем за Oracle? А у Postgres вообще бесплатно, но с AUTOVACUUM … Меньше знаешь - крепче спишь? Тогда выбирай сердцем либо читай How SQL Server MVCC compares to Oracle and PostgreSQL. А можно путь попроще, чем разбираться этих джунглях системного программирования?
Можно – синтетические тесты. Возьмем тест записи в оборотный регистр накопления без агрегатов Postgres как предчувствие. Вычисляем процент импортозамещения в режиме Highload от 1С . Я слышал много презрительных высказываний – «это всего лишь синтетический тест», «это очередной синтетический тест».
В приведенном тесте был обнаружен факт негативного влияния ANALYZE <временная таблица>. Напомню, что в методе .Записать() ANALYZE <временная таблица занимает от 30% времени, делается независимо от объема записываемых данных. Поскольку регистры накопления используются везде и много, все это маштабируется по вашему решению на Postgres с понятным результатом.
Современное приложение не похоже на канализацию, где маленькие трубы идут к большим и Вы на 99% защищены от затора в большой трубе, чтобы соответствующий сервис был доступен здесь и сейчас, иначе... В современном приложении Вы можете наткнуться на бутылочное горлышко, где какой-то важный процесс просто сидит только на одном ядре процессора 1С + MS SQL против Матрицы виртуализации . Поэтому синтетический тест позволяет сосредоточиться на узких местах, которые могут поставить колом всю систему при хорошей нагрузке.
Зачем копаться в мусоре, если Autovacuum все делает сам?
Для синтетического теста регистр накопления с оборотами без агрегатов, проще по структуре регистра Бухгалтерии – в нем есть основная таблица и одна таблица итогов по оборотам.
- _AccumRg<n> – таблица движений регистра накопления.
- AccumRgTn<n> – таблица оборотов регистра накопления. Эта таблица создается, если регистр поддерживает обороты.
Для регулирования процесса autovacuum нам интересны параметры.
PostgreSQL : Документация: 15: 20.10. Автоматическая очистка : Компания Postgres Professional
- autovacuum_vacuum_threshold
- autovacuum_vacuum_scale_factor
- autovacuum_vacuum_insert_threshold
и поскольку запуск автоваккуума попутно делает analyze autovacuum_analyze_scale_factor
Они могут задаваться как для всего экземпляра Postgres, так и для отдельных таблиц. Первый вариант не очень хороший, поскольку действует на все, особенно для баз 1С, где в типовой конфигурации более 1000 таблиц.
Я не верю, что можно подобрать общие параметры autovacuum оптимальные для всех таблиц СУБД, даже если указывать это процентом:
Во-первых, он забирает ресурсы – и чем чаще срабатывает, тем больше. Помним - это не только очистка мертвых кортежей, но и обновление статистики.
Во-вторых, в 1С есть бизнес цепочка Документ (включая подчиненные) – Движения в регистры (как правило, несколько регистров) – Обновление итогов по регистрам . Узкое место в каком-либо звене может замедлить весь хвост цепочки.
В-третьих, указание процента autovacuum_vacuum_scale_factor = 1% предполагает, что дневные объемы со временем увеличиваются и превосходят 1% , по мере роста объема всей таблицы. Иначе в течение дня автовакуум по таблице не сработает.
Поэтому лучше указывать на уровне отдельных больших таблиц и не доверять процентам.
Основное правило уборки мусора – быть в нужное время в нужном месте, ловить момент.
Что такое autovacuum_vacuum_scale_factor =1%, для таблицы с сотнями миллионов записей? Это несколько миллионов, которые могут появиться в течение дня. А если их будет чуть меньше и Autovacuum не сработает до достижения порога - мы получим торможение дневных отчетов. И чем больше таблица даже с равномерным наполнением, тем больше фактический порог срабатывания.
К слову, В MS SQL для решения проблем актуализации статистики есть флаг трассировки -T2371 именно по этим причинам.
Для таблиц с миллионом записей – один процент это всего лишь 10 000 записей, и при начальном заполнении порог срабатывания будет более частым.
В общем, имеем бытовую классику: cлишком рано уберешь мусор - это никто не заметит и много усилий потрачено, слишком поздно - скажут срач развел. А корень зла – в организации пространства и процессов, которые этот мусор провоцируют, т.е. в архитектуре СУБД. А у Вас на рабочем столе разве не так?
К счастью, в Postgres есть настройки autovacuum на уровне таблиц. Для 1С их нужно запоминать в скрипт обновления, поскольку при реструктуризации таблиц 1С с большой вероятностью пересоздаст таблицу с настройками по умолчанию, и все Ваши труды уйдут с DROP старой TABLE, включая распределение по Tablespaces.
Возьмем знакомую нам из нагрузочного тестирования Postgres как предчувствие. Вычисляем процент импортозамещения в режиме Highload от 1С / Хабр (habr.com) запись в оборотный регистр накопления с итогами. Все условия синтетического теста можете посмотреть в этой статье. Здесь контур немного другой, но сопоставимый по параметрам. Postgres на Oracle unix.
Сначала выключим Autovacuum, запустим тест несколько раз, и дождемся эффекта деградации – он приходит достаточно быстро. Мы просто моделируем ситуацию, когда автовакуум на таблице не срабатывает вовремя.
Это делается командой:
ALTER TABLE _accumrg16920 SET ( autovacuum_enabled = off)
ALTER TABLE _accumrgtn17037 SET (autovacuum_enabled = off)
Смотрим результат в pg_stat_all_tables
В колонке n_dead_tup виден объем проблемы. Не обращайте внимания на значение n_life_tup это не тоже самое, что count(*) и это описано в документации. Также видно, что автовакуум не срабатывал

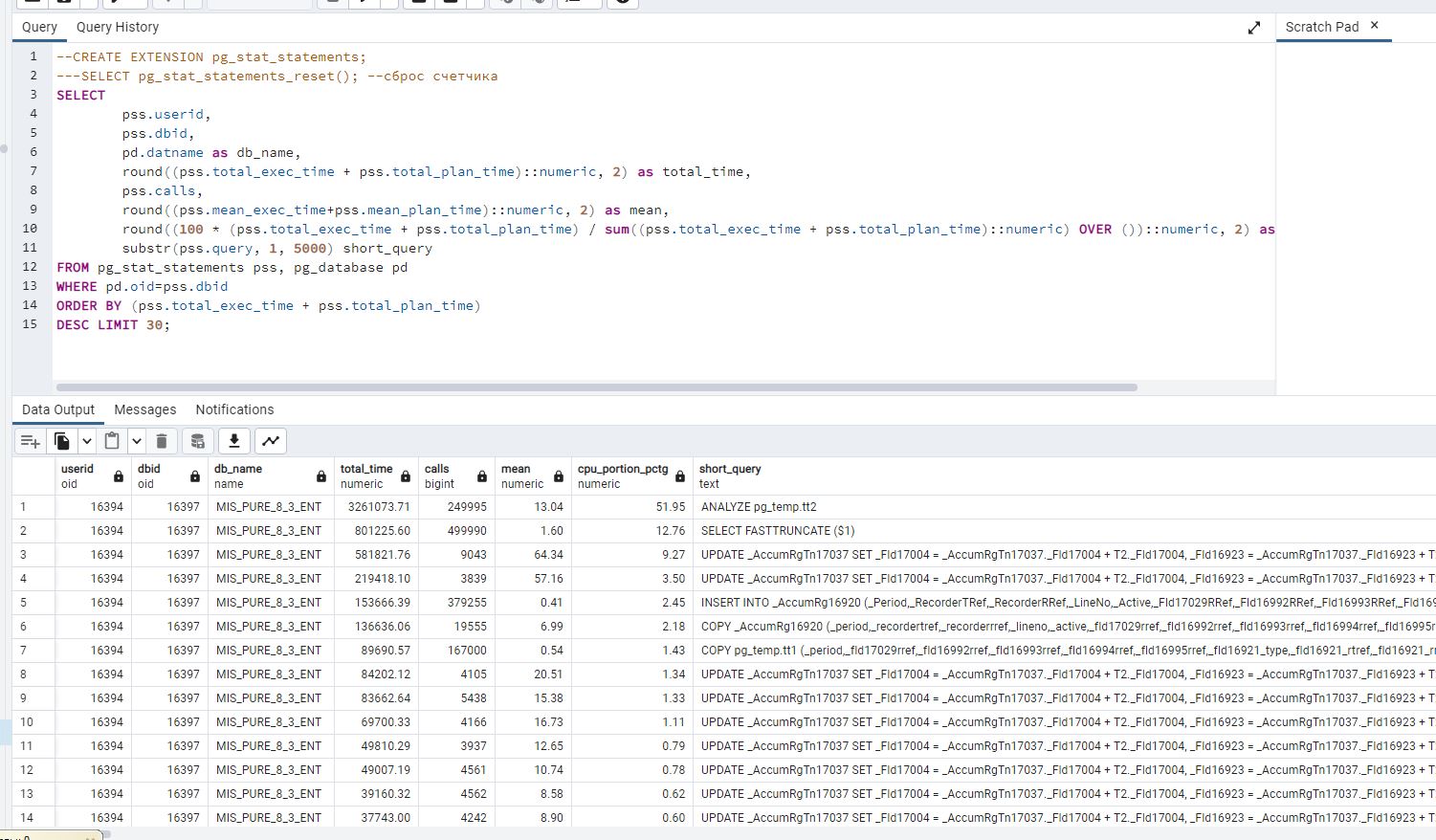
Теперь посмотрим, на что ушло время. Про проблемы с analyze и fasttruncate было написано в статье выше. Хуже другое: некоторые Update поднялись в топ, чего раньше не было. Можно, конечно, и планы посмотреть, и поизучать детально, но лучше всего
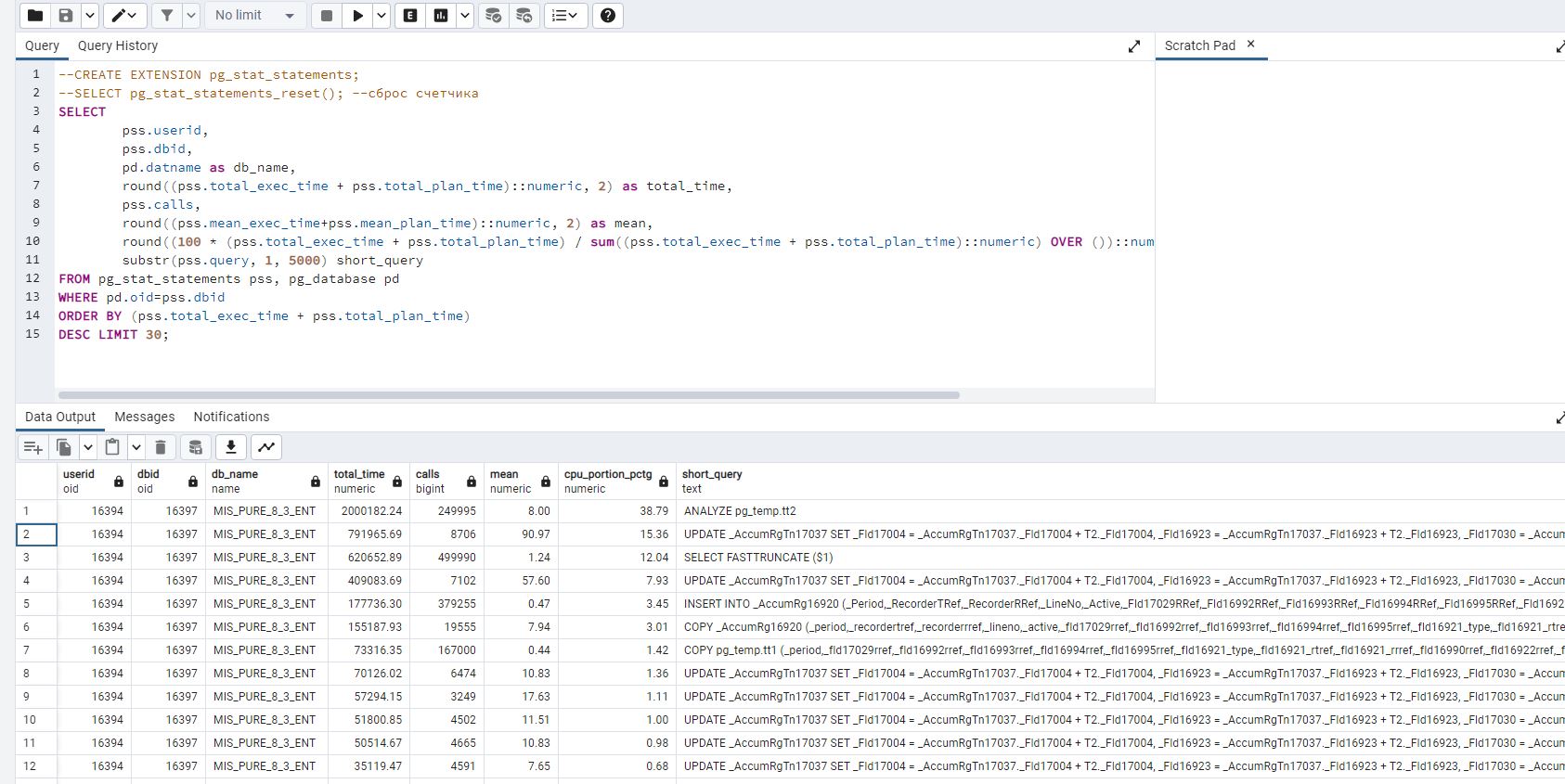
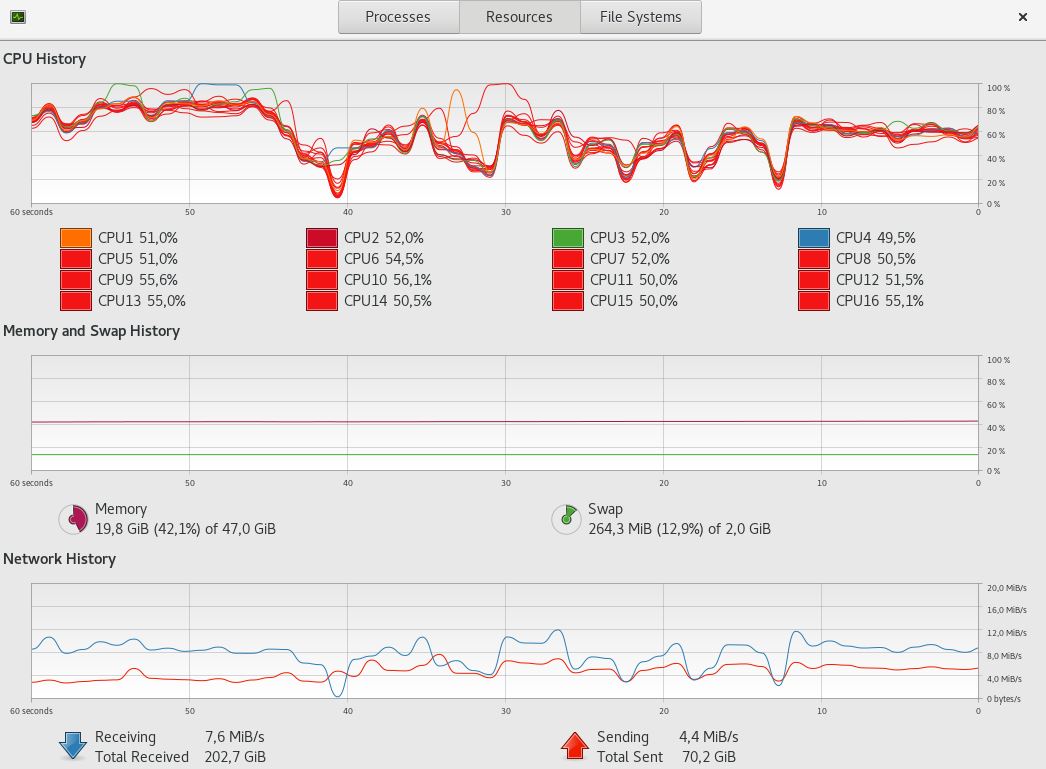
Смотрим загрузку CPU - она зашкаливает за 80% против 40% когда автовакуум срабатывает
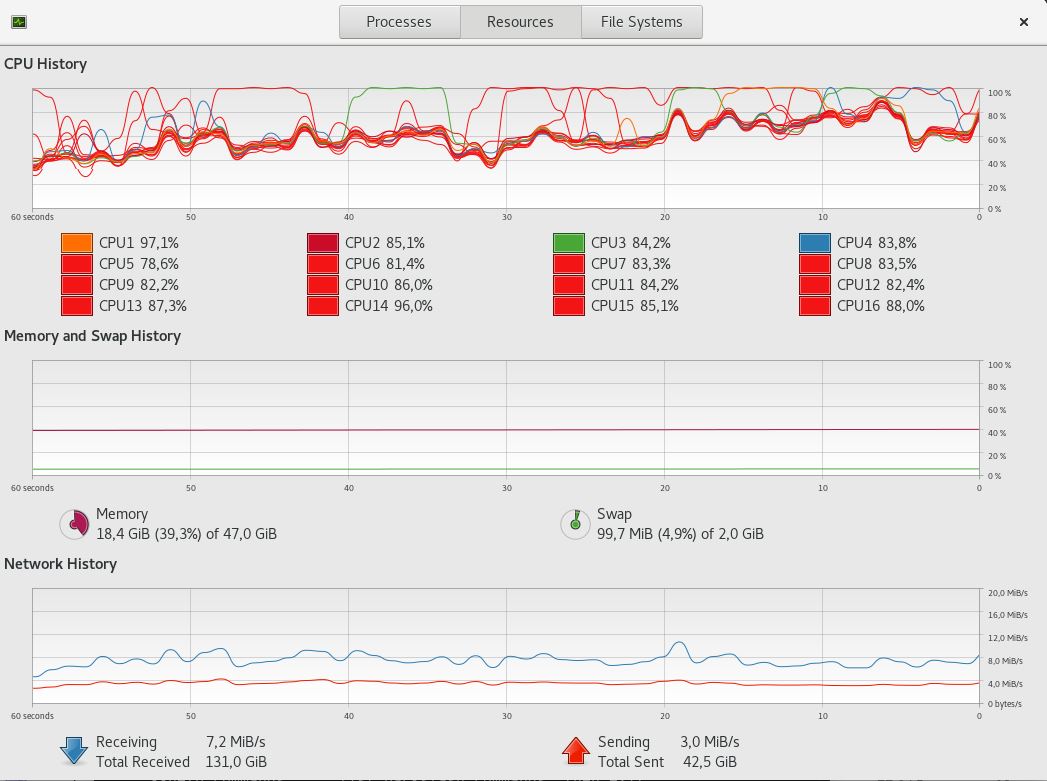
Есть интересный вопрос – от чего идет деградация? От мертвых кортежей или неактуальной статистики? Ответ не такой очевидный – поскольку в теории оптимизатор планов запросов СУБД должен работать не только по статистике, а в первую очередь по имеющимся индексам. Но современные оптимизаторы слишком пренебрежительно относятся к индексам и как следствие к архитектору, и больше ориентируются на статистику – вот такой сложной стала их логика. Вот пример Селективный индекс от 1С — что выберет MS SQL?
Поскольку автовакуум одновременно чистит и обновляет статистику, нам это сейчас не так важно.
Поставим другие параметры таблиц
ALTER TABLE _accumrg16920 SET ( autovacuum_enabled = on, autovacuum_vacuum_scale_factor = 0, autovacuum_vacuum_threshold = 10000, autovacuum_analyze_scale_factor =0 , autovacuum_analyze_threshold = 10000 );
ALTER TABLE _accumrgtn17037 SET (autovacuum_enabled = on, autovacuum_vacuum_scale_factor = 0, autovacuum_vacuum_threshold = 2000, autovacuum_analyze_scale_factor =0 , autovacuum_analyze_threshold = 2000 );
Здесь я игнорирую scale_factor, чтобы не зависеть от процента, о чем я написал выше.
Threshold подобрал экспериментально, запуская синтетический тест. Это не значит, что автовакуум будет запускаться каждые 10000 или 2000 записей, он будет запускаться согласно autovacuum_naptime (у меня 20 секунд) и срабатывать, если превысили порог очистки = базовый порог очистки + коэффициент доли для очистки * количество кортежей
где базовый порог очистки — значение autovacuum_vacuum_threshold, коэффициент доли — autovacuum_vacuum_scale_factor, а количество кортежей — pg_class.reltuples .
На самом деле там еще больше деталей, которые можно почитать в документации PostgreSQL : Документация: 15: 25.1. Регламентная очистка : Компания Postgres Professional . Можно увеличить количество процессов автоочистки, и разный другой тюнинг, но это все приведет к загрузке CPU и, как следствие, преждевременному исчерпанию ресурсов одного Instance. Напомню, что в Postgres нет возможности масштабировать Instance на несколько серверов, как в Oracle Real application cluster.
А теперь можно посмотреть на результат:
Автовакуум срабатывает – мертвых кортежей нет, статистика актуализируется

Топ DML операторов изменился, в нем опять Fast truncate и Analyze временных таблиц. Почему 1С делает analyze на временные таблицы, пока вопрос риторический.
Все остальные DML операторы ушли вниз по списку, total_time тоже стал улучшаться
Использование CPU уменьшается
Вот так все просто, на отдельно взятой операции. Синтетический тест, синтетическая статистика.
Как сосредоточиться на бизнес логике, когда вокруг …
За уборкой мусора легко забыть, что вся разработка в 1С делается ради реализации бизнес логики, которая программируется в 1С на уровне языка\библиотек 1С (фактически ORM). Текущие дела становятся важными и срочными именно из-за таких кейсов с мусором. И изучение полного стека мера больше вынужденная, поскольку последствия непонимания видны даже на слабом синтетическом тесте. В 1С тысячи таблиц, и даже если устанавливать параметры в паре десятков самых больших, это тоже работа.
Возможно, есть какие-то альтернативные средства в Postgres, которые это берут на себя, кто знает?
Сейчас хайповая тема это GhatGPT и другие темы искусственного интеллекта, где он в уборке мусора? Там есть место красивым алгоритмам, но капиталистическая экономика устроена по-другому – больше функционала, больше потребителей, больше денег. «Экономика должна быть экономной» - умерло вместе с СССР. Остановить это может только высокая себестоимость поддержки СУБД и специалистов, понимающих , как заставить СУБД эффективно работать. Системные администраторы и программисты 1С не первые в пищевой цепочке, поэтому прихода ИИ в СУБД придется подождать. А пока даже для робота пылесоса Вы должны навести порядок в комнате так, чтобы ему было удобно. До новых встреч на нашем телеграмм канале, новые материалы ждут очереди, когда их напишут.
Вступайте в нашу телеграмм-группу Инфостарт