
Я представлю вам три кейс-проекта. Кейс-проект – это эксперименты и отработка методики. После нескольких успешных проектов, подходы можно тиражировать, повторять пройденное и не наступать на одни и те же грабли.
-
Первый кейс-проект, про который расскажу – это оптимизация обменов в оптово-розничной компании. У одного из наших клиентов по этой схеме было пере-подключено 100+ распределенных баз магазинов и несколько РЦ.
-
Второй кейс-проект – по централизации управления НСИ в холдинге. Расскажу, какие мы применяем приемы для «зоопарка» систем, чтобы велосипедов было поменьше.
-
Третий кейс, достаточно необычный, но он хорошо выстрелил. Это шина кэширования вызовов веб-сервисов – решение интересное и работающее под хорошей нагрузкой.
-
В конце расскажу про прочие лайфхаки и приемы интеграции.

Коротко о себе – работал в фирме «1С», написал «Конвертацию данных», обработку «Универсальный обмен данными в формате XML», разработал различные стандарты обмена, систему авто-тестирования платформы и так далее.

Сейчас у меня компания 2iS, мы специализируемся на интеграции, консолидации и управленческом учете.
Уже 9 лет выпускаем тиражный продукт 2iS:Интеграция, который позиционируется как платформа для разработки сервисов по интеграции бизнес-процессов, систем и документации.

На Инфостарте 2iS:Интеграция была опубликована в 2012 году.
В 2018 году ПО внесли в единый реестр российских программ.
Неоднократно подтверждали сертификацию на 1С:Совместимо.
В 2017 году я докладывал на конференции о внедрении нашей шины в ПАО «Газпром нефть».
Кейс-проект 1: Оптимизация обменов в опте и рознице – более 100 магазинов + Зоопарк

Схема первого кейса, наверное, многим знакома – она типичная для интеграции в компании.
-
У нас есть операционная база – это может быть УТ, УПП, ERP, «Комплексная автоматизация» – что угодно.
-
Она обвязана со всех сторон обменами:
-
с сайтом;
-
с управленческой системой;
-
с «Бухгалтерией»;
-
если мы говорим про розницу с большим количеством магазинов, то там, как правило, используется РИБ – распределенная информационная база, «Розница», «Управление торговлей», «АСТОР», любые отраслевые решения и так далее.
-
В итоге, у нас операционная база перегружена. Помимо того, что в ней работают пользователи, формируют отчеты, она еще обслуживает десятки узлов интеграций, а этих связей легко бывает и под сотню. Те, кто сталкивался с РИБ, знают, что с ней много различных проблем:
-
тяжело обновлять конфигурацию, необходима синхронность всех узлов для того, чтобы данные «гуляли» без проблем;
-
бывают сбои с обновлениями;
-
и самое главное – производительность, потому что чтение объекта из базы и сериализация выполняются в операционной базе столько раз, сколько у вас узлов. Если у вас 100 узлов, и зарегистрировался один контрагент, этот контрагент будет получаться из базы запросом 100 раз, и 100 раз будет преобразовываться в XML, JSON, или преобразовываться по правилам Конвертации данных.
Схема получается неэффективная.
Ускоряем прокачку, маршрутизируя объекты «один ко многим» через интеграционную шину
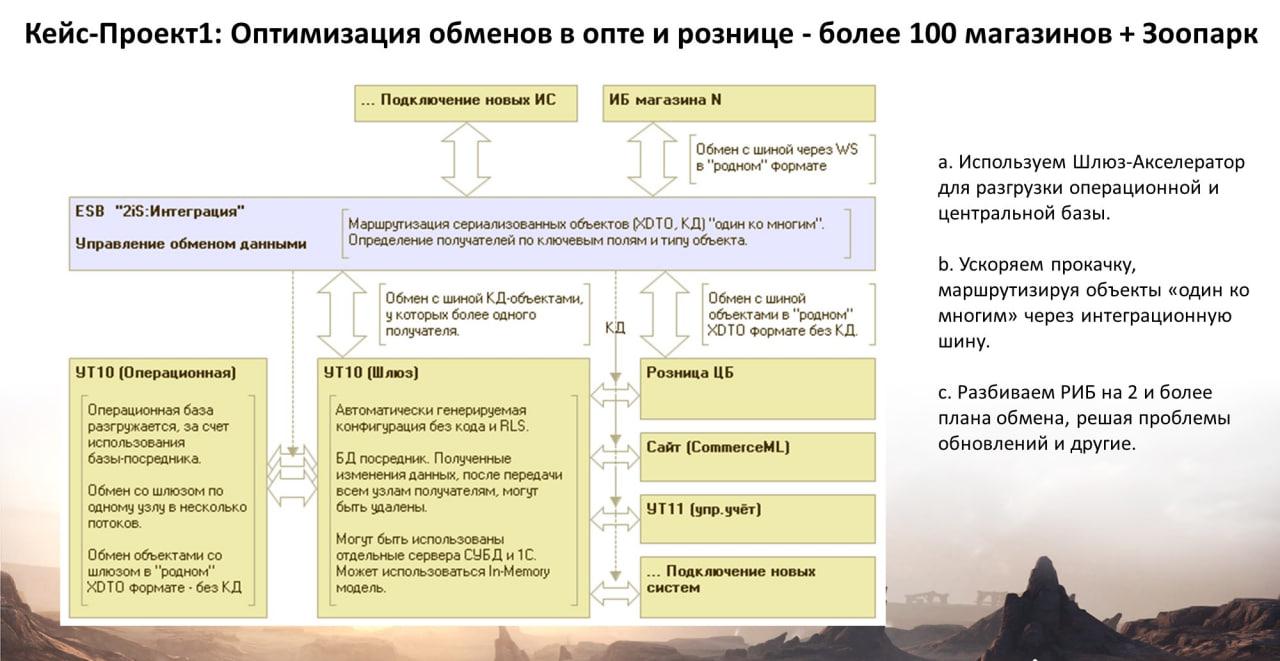
Было предложено оптимизировать эту схему, выделив отдельную базу-шлюз.
На слайде, конечно, много надписей – я готовил презентацию для клиента, поэтому здесь в качестве операционной базы УТ10.
Как это работает?
-
Шлюз – это фактически «скелет» конфигурации операционной базы, который формируется автоматически – путем выгрузки и разбора конфигурации в XML файлы. Из этой выгрузки полностью удаляется программный код и удаляются настройки RLS – остается чистый скелет базы данных. Раньше мы такой «скелет» делали руками. Сейчас у нас есть кнопка в шине «Очистить конфигурацию от кода» – это действие мы также повесили на задание, которое выполняется в сценарии обновления конфигурации. Шлюз хорош тем, что это – легкая конфигурация и база, – данных в которой изначально нет. Задача шлюза – только прокачивать данные через себя.
-
У шлюза, на обмене с операционной базой – фактически один узел, но мы научились распараллеливать любые обмены (встроенный режим многопоточности). Таким образом, обмен с одним узлом, при необходимости может быть разбит на 3-5 потоков .
Могу сказать, что многопоточность в 2-3 потока работает практически везде. При большем количестве потоков – начинаются блокировки, и уже необходимо разбираться со структурой метаданных.
В шлюзе, так как никакого прикладного кода нет и лишнего ничего не выполняется, – вероятность блокировок существенно меньше, поэтому обмен между шлюзом и операционкой максимально быстрый, и в несколько потоков, при необходимости. -
Шлюз автоматически очищается. Разработали задание, которое раз в сутки удаляет все объекты, переданные всем узлам, более чем N дней назад. Работает стандартное квитирование по планам обменов.
-
Поскольку все обмены переключаются на шлюз – операционная база разгружается и вся нагрузка по обменам и трансформации идет на шлюз, который размещается на отдельном сервере (или в отдельном кластере) и на отдельных быстрых дисках, поскольку база шлюза – не разбухает.
-
Важный момент, и отличие схемы со шлюзом от прямого подключения операционной базы к Шине, заключается в том, что не нужно переписывать исторический код, правила обмена КД, рефакторить обработки обмена и так далее. Всё работает практически без изменений – только теперь на отдельном сервере.
-
По поводу шины, как брокера сообщений, в принципе, большой разницы нет, – что у нас в качестве шины используется. Достаточно популярны RabbitMQ, Kafka и прочие. Я рассказываю про опыт использования нашей шины 2is:Интеграция. Отмечу, что большая часть, из того что рассказываю, реализована в продукте и настраивается, как говорится, «из коробки». Но такие вещи, как шлюз, например, вы можете разработать и сами, а в качестве брокера – использовать того же «кролика». Шина 2is:Интеграция, как минимум, «из коробки» умеет работать с данными в формате XDTO и в форматах «Конвертации данных».
-
В данной реализации, если посмотреть на схему, центральная 1С:Розница в РИБ-е у нас подключается к шине и передает в нее уже не 100 объектов сериализованных для каждого узла, а один объект в свернутом формате (XML \ FastInfoset \ JSON). Если мы говорим про аналог РИБ, то, соответственно, используются штатные методы Прочитать\ЗаписатьXML или формат XDTO, который соответствует структуре метаданных – без преобразований. И вот эта сериализация и чтение объекта из базы выполняются один раз для объекта, а не 100 раз – для каждого узла плана обмена.
-
Далее выполняется маршрутизация в Шине по ключевым полям пакета с объектом. При создании сообщения обмена, формируется дополнительный Заголовок, который содержит в себе значения ключевых полей, используемых для настройки маршрутизации в Шине. Это могут быть организации, подразделения, склады, магазины и так далее. И по этим полям в шине уже настраивается, что если организация такая, то база №1, а если организация другая, то база №3. А сам объект – не разворачивается, он в шине хранится как «черный ящик» – уже готовый, сериализованный для дальнейшей передачи.
Разбиваем РИБ на 2 и более плана обмена, решая проблемы обновлений и другие

Планы обмена с флажком РИБ, для оптимизации, мы разбиваем на несколько планов обмена путем «копипаста» – просто в конфигураторе ctrl-c, ctrl-v. Т.е. был один план обмена РИБ, а стало – два плана обмена (иногда больше).
-
У одного плана обмена флажок РИБ снимаем и оставляем только данные – это план обмена для данных.
-
А у второго плана обмена, у которого флажок РИБ остается, у него наоборот – очищаем состав. Его задача – только регистрировать изменения конфигурации.
Для передачи изменений конфигурации для обновлений периферийных баз – мы предусмотрели два варианта:
-
Типовой вариант, когда с узла РИБ выгружаются именно изменения конфигурации, строго без данных, как «патч».
-
И, второй вариант, когда мы из эталонной базы выгружаем целиком cf-ник и обновляем периферийные базы из cf-файла. Это для возможных чрезвычайных ситуаций – когда в РИБ что-то пошло не так («узел не соответствует ожидаемому»), – есть возможность переключить и обновить все клоны, то есть периферийные базы – из cf-файла.
Что это дает?
-
Фактически, у вас РИБ становится не привязанной к изменениям конфигурации. Даже если конфигурации не синхронны, данные могут «гулять» в любом случае. Допустим, вы добавили в центральной базе новый справочник или новые реквизиты, а все узлы, если у вас их 200, например, не успели обновиться. Обмен в сети продолжает работать.
-
Система обновляет конфигурацию асинхронно в разных базах, и отображает информацию (отправляет уведомления) о том, что из 100 магазинов, к примеру, в 2-ух или 10-ти – конфигурация не обновилась – администраторы выключили компьютеры, или что-то еще, электричество пропало... При этом обмен везде продолжает работать – просто объекты, у которых структура данных не соответствует принятой, – грузятся без учета этих изменений.
-
Здесь, разумеется, наступает ответственность разработчика, который должен понимать: что если он добавил новый реквизит в объект, то его не нужно заполнять и использовать в рабочих алгоритмах, пока не обновятся все узлы, иначе он, вероятно, рискует получить рассинхронизацию данных в сети. Бизнесу важнее стабильный обмен, а данный риск минимизируется регламентом.
Кейс-проект 2: Централизация управления НСИ в Холдинге.
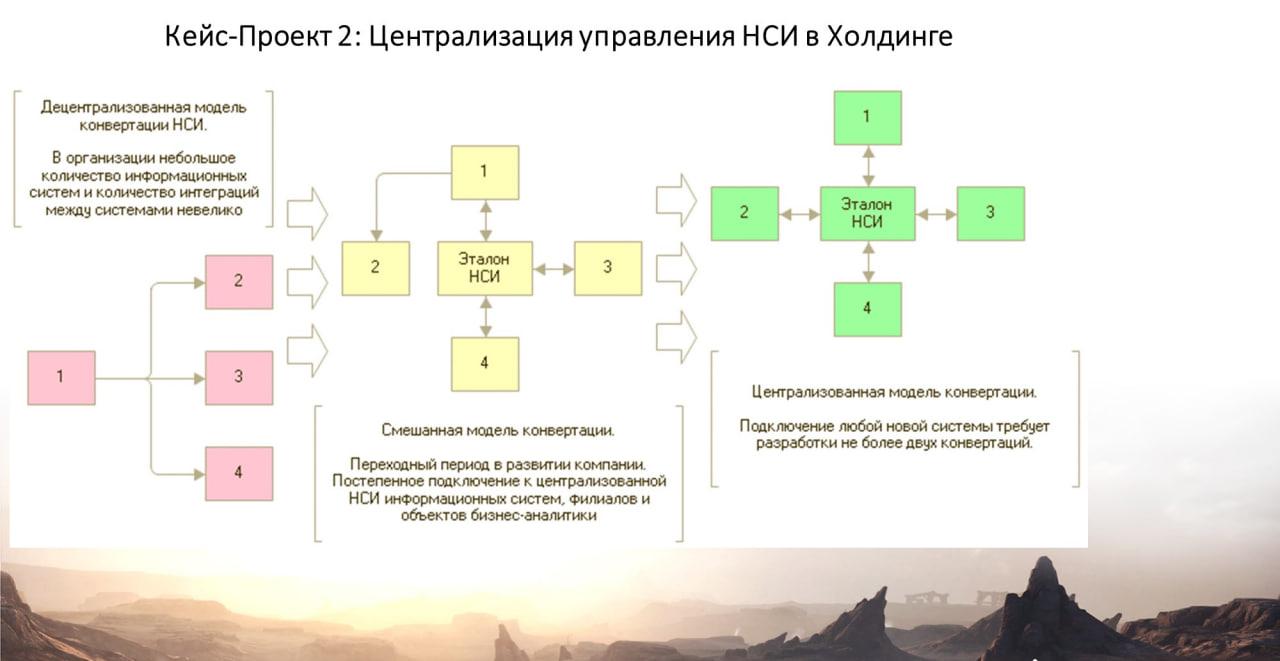
Второй кейс – по централизации НСИ.
На слайде – три схемы.
-
Первая – когда все системы обмениваются НСИ друг с другом.
-
Третья – когда есть одна база с эталонной НСИ, которая управляет НСИ для всех остальных баз. Этот вариант достаточно редкий.
-
И вторая, основная схема – это смешанный вариант, когда часть НСИ – в эталоне, а другая часть НСИ, имеет свои мастер-системы и участвует в обменах вида «точка-точка».

Как происходит процесс внедрения НСИ и наведение порядка?
Во-первых, мы определяемся, какая база у нас будет в качестве эталона НСИ:
-
это может быть основная рабочая база;
-
это может быть копия основной рабочей базы, из которой мы удалили все, кроме нужных нам справочников;
-
третий вариант – это эталонные метаданные НСИ, когда мы собираем описания реквизитов объектов из N систем в виде отдельной базы или в виде Подсистемы \ Расширения. Например, мы на ряде проектов использовали приём – когда такая Подсистема, с описанием эталонной НСИ – внедрялась непосредственно в нашу шину 2is:Интеграция – поскольку это «обычная» конфигурация 1С.
Дальше, мы настраиваем по два набора правил конвертации (туда и обратно) – для каждой системы – с этой эталонной базой или подсистемой НСИ.
Если мы используем специализированную MDM-систему, то она не отменяет эту всю работу по сбору аналитики и формированию эталонной НСИ. В одной системе – у контрагента – один набор реквизитов, в другой – другой. В любом случае, необходимо проанализировать реквизитный состав НСИ всех систем, выделить общие и частные атрибуты, провести сопоставление и условное сопоставление значений. В качестве инструмента для этого – мы используем Конвертацию данных, где настроили необходимые отчеты.

Немного про интерфейсы. Когда мы упорядочиваем НСИ и обмены, важно, чтобы у нас интерфейсов было поменьше разных – чтобы количество адаптеров было минимальным.
Мы для себя ограничились и определились, что есть:
-
интерфейс в виде веб-сервисов, который мы, в частности, использовали для обмена с SAP – далее расскажу, как;
-
есть интерфейс обмена с системой типа Oracle через механизм внешние источники данных (ВИД)
-
ну, а с 1С всё достаточно просто – есть XDTO, есть КД
Подключаем SAP через веб-сервис и настраиваем обмен в КД2
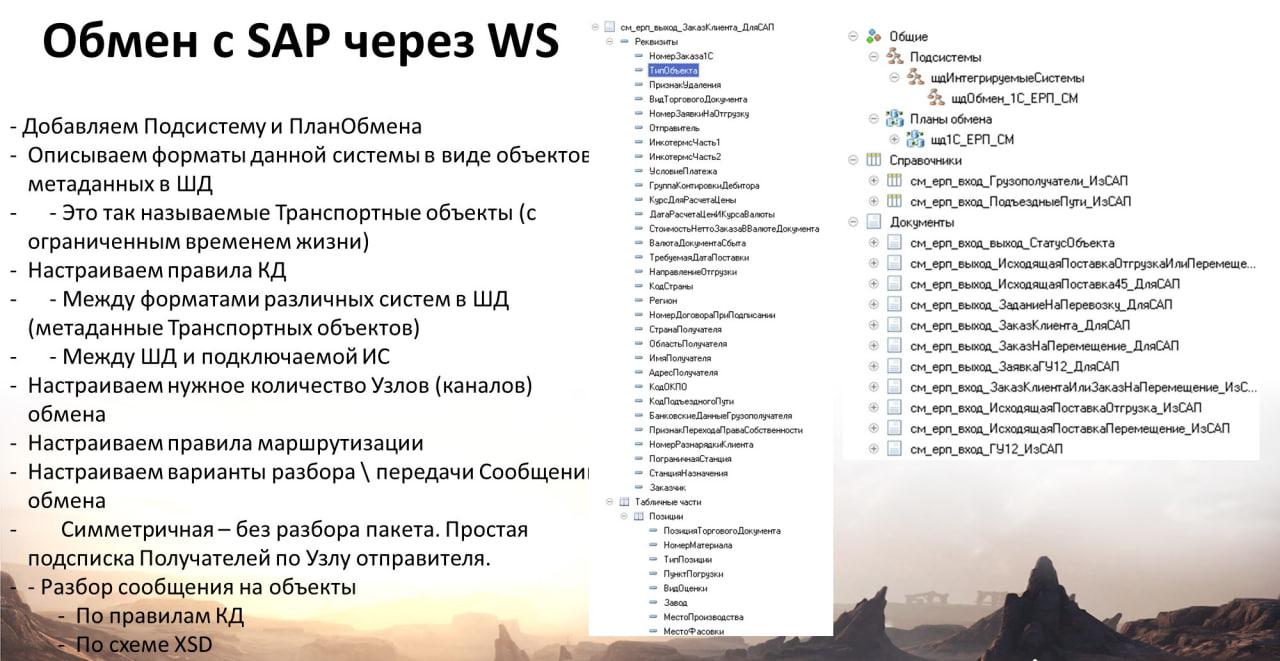
Для обмена с SAP используется веб-сервис, упакованный в подсистему с планом обмена. На слайде приведен реальный пример описания метаданных SAP, но в 1C :-).
Что мы сделали? Фактически, мы попросили саперов описать их типы интерфейсов в Excel плоскими таблицами: имя поля в SAP (такое, как ZZ38) – имя поля для 1С, человеческое, комментарий.
И потом залили эту информацию в конфигуратор в виде объектов метаданных: имена – человеческие, а в синонимах объектов и реквизитов – имена полей, как в SAP. Прямой мэппинг. К сожалению, 1С до сих пор не научилась в конфигураторе для объектов метаданных и их реквизитов добавлять свои свойства, поэтому мы запихнули имена SAP – в синонимы. Но поскольку это технические объекты, в идеале, генерируемые, то решение допустимое.
Далее, написали адаптер, который преобразует «канонический» формат SAP – в формат объектов 1С (такой же структуры – см. слайд). Поскольку саповский формат обычно плоский, ну, максимум два уровня – реквизиты шапки, и дальше идут строки табличных частей, то адаптер получился универсальный, мы использовали его потом и на других проектах уже без SAP.
В данном случае, как вы поняли, нам для SAP не нужно дополнительно прописывать транспорт, мэппинг, преобразование – мы повторили его структуру, только в виде метаданных и с нормальными именами.
Дальнейший мэппинг производим в обычной «Конвертации данных». При этом программисту 1С, которому мы хотим поручить разработку обмена с SAP, не нужно ничего знать про SAP и про другие внешние системы. Ему нужно только уметь работать с «Конвертацией данных». Он загружает в «Конвертацию данных» это описание SAP в виде метаданных 1С и затем мэппит эти объекты, разрабатывая обычные правила обмена. Разработать обмен между SAP и Oracle на Конвертации данных? Легко!
Подключаем Axapta и Oracle через быстрые ВИД

Для быстрых обменов 1С с Oracle \ MySQL \ MS Dynamics используем механизм платформы – внешние источники данных (ВИД). На слайде – кусочек описания из v8.1c.ru. Это очень мощный, быстрый механизм, в котором поддерживаются ODBC-драйвера для большого количества систем и СУБД – и на Windows, и на Linux.
Интеграцию через внешние источники мы уже обкатали на крупных внедрениях. Например, для компании тур-оператора Tez-Tour был реализован обмен много-терабайтной базы Oracle (портал tez-tour.com) с базой управленческого учета в 1С. К слову сказать, сама база 1С имеет также английский интерфейс и используется арабскими коллегами для управления туристами в Египте и ОАЭ.

Как это работает?
Внешние источники – это объект метаданных. Для его настройки мы в конфигураторе, настроив авторизацию, получаем окошко, где показываются все таблицы нужной нам базы (например, Oracle):
-
галочками ставим, какие таблицы нам необходимы, и какие поля в этих таблицах;
-
и у нас в конфигураторе под веткой «Внешний источник данных» появляется описание таблиц внешнего источника и их атрибутов (см. слайд);
-
дальше мы «копипастим» эти описания на объекты метаданных 1С – справочники или документы. В буквальном смысле, «ctrl-c» и «ctrl-v».
Мы написали адаптер, который быстро, через механизм ВИД, выполняет репликацию данных внешней БД с 1С (по соответствующим метаданным). Поскольку имена объектов и полей совпадают, практически никаких преобразований выполнять не нужно – получаем в результате просто копии таблиц внешнего источника в нужной нам базе 1С.
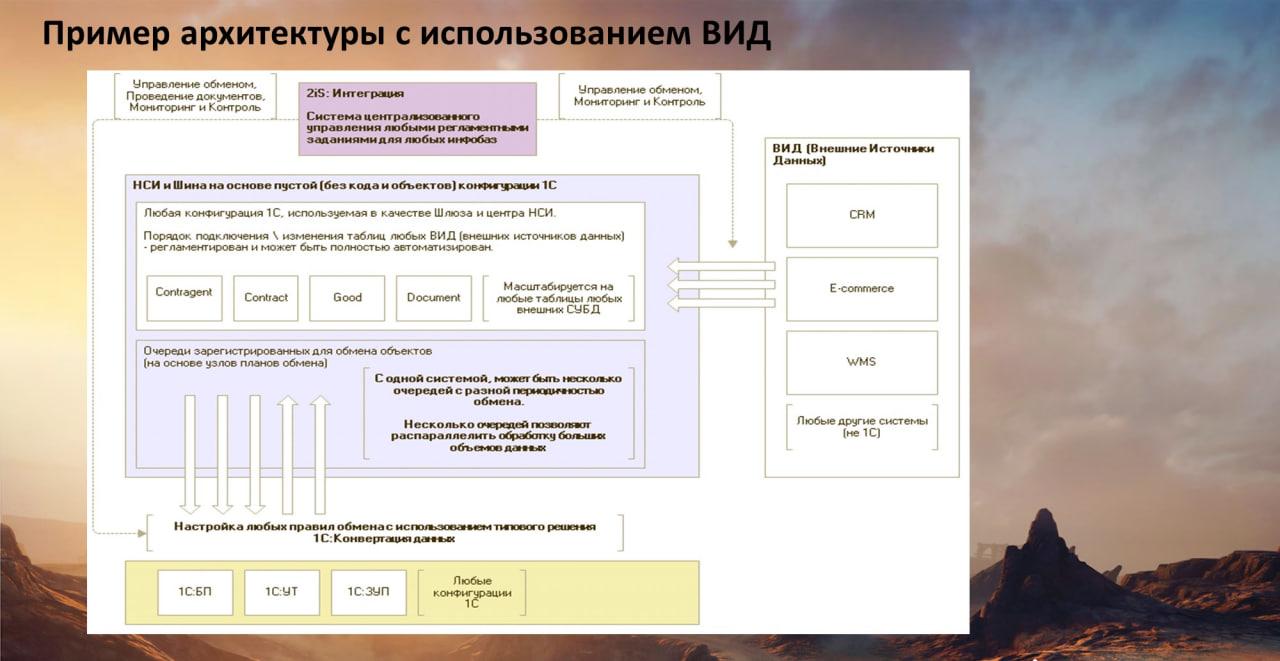
Причем эта база 1С может быть:
-
Отдельная, просто сама по себе – мы в нее залили внешний источник и раскопировали его таблицы на справочники и документы.
-
Или можем подцепить этот кусок метаданных в виде подсистемы к любой конфигурации. Например, на одном из проектов, мы подключали по данной методике ВИД к УТ, при реализации обмена с высоконагруженным сайтом. Заказчик – оптовик запчастей. 200 тыс. транзакций в сутки.
Когда у нас данные появляются в 1С, становится понятно как дальше с этим работать и здесь вариантов много.
-
Можно подключить обработчики событий ПриЗаписи (не рекомендуется, думаю, понятно почему)
-
Можно использовать правила конвертации, чтобы конвертировать данные «внешних» таблиц (на слайде Contragent, Contract, Good и прочих), полученных из внешнего источника – в типовые объекты 1С и в любые системы 1С.
-
Можно регистрировать полученные из ВИД данные на узле плана обмена и выполнять отложенную обработку и т.д.
Кейс-проект 3: Шина кэширования вызовов web \ http-сервисов

Следующий кейс – шина кэширования вызовов веб-сервисов.
Суть механизма в следующем. Внешние системы вызывают веб-сервис Шины, который им возвращает данные, получаемые из различных баз 1С.

На слайде показано описание веб-сервиса – вызов методов с передачей параметров идет фактически через «одно окно». Причем вызовы всех методов (ServiceName) преобразуются к вызовам внешних обработок в различных базах.
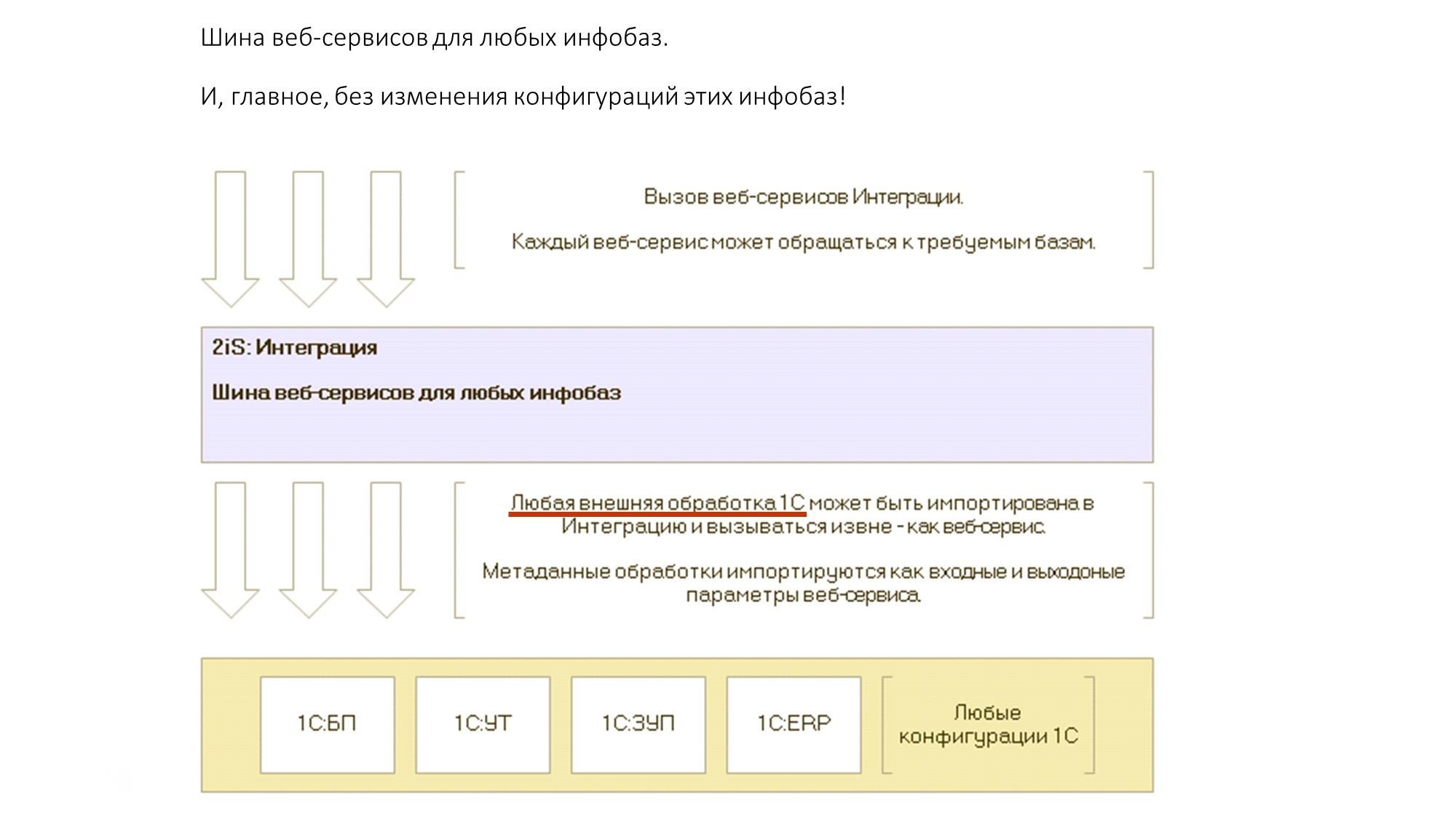
Таким образом любая внешняя обработка 1С может эмулировать веб-сервис за счет импорта в Шину.
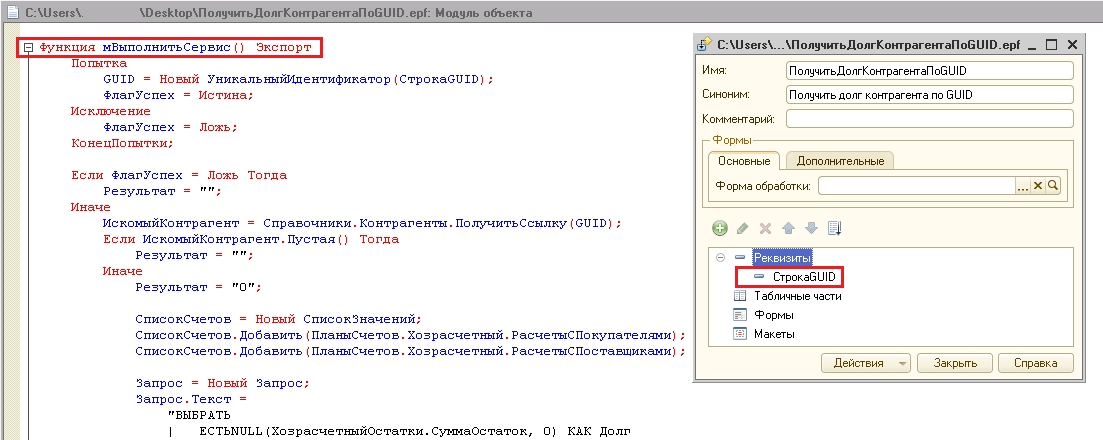
На слайде – код такой обработки с примером передачи параметра.
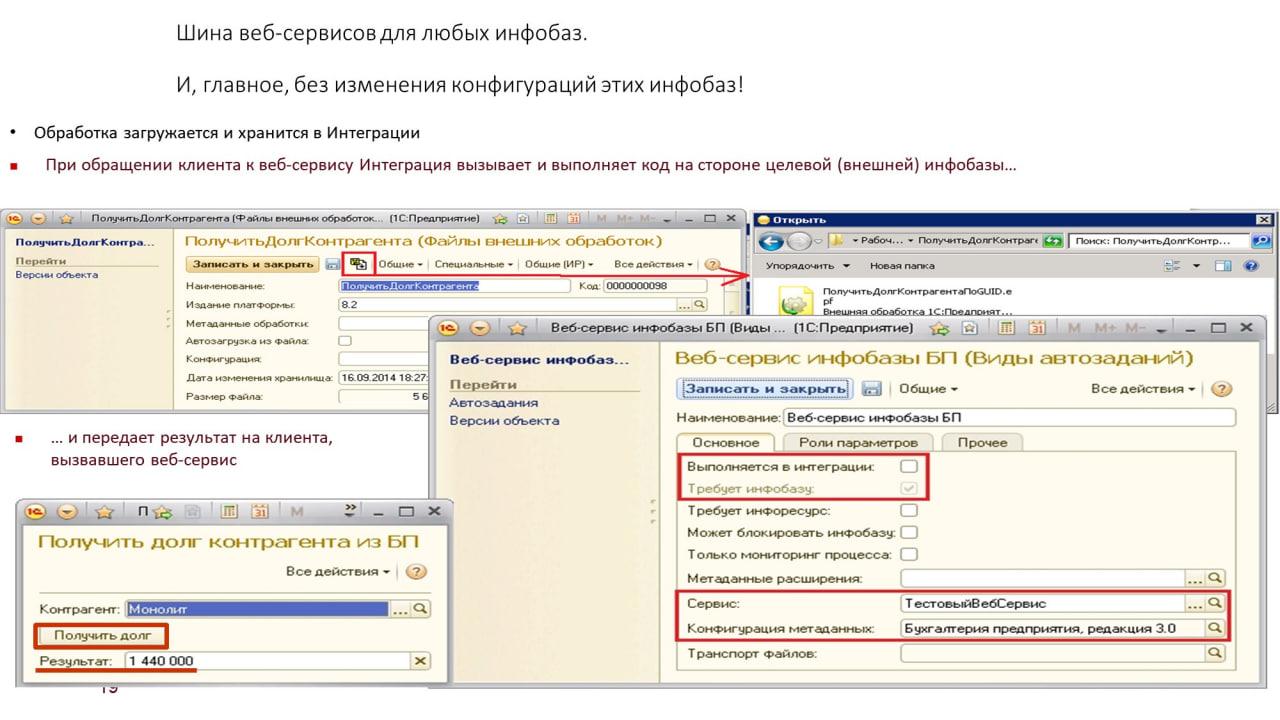
А здесь показано, как обработка загружается в шину.
Фишка в том, что шина удерживает соединение с базами 1С. А за счет того, что шина может удерживать сразу несколько соединений с базами (COM-соединений или DCOM-соединений), она получает данные из внешних баз фактически онлайн и возвращает внешним потребителям.
По скорости кэширование входных запросов дает выигрыш в 10 раз:
-
30 миллисекунд – вызов веб-сервиса без кэширования;
-
3 миллисекунды – вызов веб-сервиса с кэшированием.
Если у нас поступает повторяющийся вызов, то шина хранит предыдущий результат и возвращает его в течение времени, указанного для каждого веб-сервиса.
Например, мы определили, что долг контрагента актуален 3 минуты. В течение трех минут, если будут одинаковые запросы (по составу значений параметров), шина не будет обращаться к системам, а будет возвращать то, что она сохранила.
Свертка терабайтных баз и РИБ

В 2021 году у нас было несколько проектов по свертке огромных баз и РИБ.
Смысл методики в том, что делается копия рабочей базы, с которой идет постоянный обмен с рабочей. И в копии производится свертка, потому что в терабайтной базе свертка может продолжаться, например, неделю – удаление данных и сворачивание остатков.
За счет того, что это копия, у нас руки развязаны – мы не привязаны ко времени.
Есть конечно нюансы, например то, что перед заменой рабочей базы на свернутую, необходимо перенести состояние узлов планов обмена.
Прочие лайфхаки, приемы интеграции

На слайде – перечень приемов, которые мы применяем, потому что наша специализация, как я говорил, – интеграция. Это – свод тех мероприятий, которые мы проводим.
Что здесь из важного:
-
Пропуск ошибочных объектов с их повторной пере-регистрацией. Мы сделали так, что у нас обмен работает всегда, даже если при загрузке на каких-то объектах возникают ошибки (могут быть ошибки любого рода: ошибка блокировки, ошибка разбора XML, ошибка правил КД и так далее). Пакеты считаются принятыми всегда, отправляется квитанция о гарантированной доставке, а те объекты, которые не удалось по каким-то причинам записать, загрузить, – во-первых, регистрируются в шине как ошибочные, а во-вторых, они повторно регистрируются у отправителя на узле. Этот механизм позволяет сделать обмен стабильным – без каких-то задержек, из-за того что «большой пакет загружался, всё упало», и теперь мы грузим его снова. Такого у нас нет.
-
Режим дозакачки, суть которого в том, что при возникновении критических ошибок (например, упал сервер), после восстановления – система продолжит загружать данные пакета с того объекта, на котором загрузка остановилась. Механизмы пропуска ошибочных и дозакачки – взаимодополняющие. Дозакачка, очевидно, нужна – если клиент, по каким либо причинам, использует определенные обмены с небольшой частотой – раз в сутки, раз в неделю, раз в месяц – что приводит к большим сообщениям обмена. При оптимизации, конечно, всегда стоит рассмотреть возможность увеличения частоты обменов и уменьшения размера пакетов – однако, это не всегда возможно исходя из прикладной логики и архитектуры ИС.
-
Большое количество оптимизаций приходится на правила конвертации. Когда разработчик перегружает правила обмена сложной логикой, безумными запросами – это, конечно, боль. Потому что, через какое-то время, это все начинает жутко тормозить. Тут требуется рефакторинг и еще раз рефакторинг. Часто, лучшим решением является – переписать конкретный обмен с нуля, чем выстраивать очередные костыли…
*************
Статья написана по итогам доклада (видео), прочитанного на конференции Infostart Event.

Вступайте в нашу телеграмм-группу Инфостарт