Меня зовут Максим Козлов, я технический директор сервиса GitFlic. Мой доклад посвящен автоматизации процесса разработки с помощью нашего сервиса. Рассмотрим, как в GitFlic использовать CI/CD и другие востребованные фичи Git-сервера.

Страница продукта GitFlic на Инфостарте – //infostart.ru/soft1c/2048075/
Мы разрабатываем GitFlic с 2020-го года. Это полностью проприетарный сервис, который мы написали сами, ориентируясь на зарубежных конкурентов: GitHub, GitLab, BitBucket и прочие сервисы.
Мы подсматриваем у них фичи, отслеживаем их планы по разработке, смотрим, как у них это работает и пытаемся повторить.
На слайде представлена не вся функциональность, которая доступна нашим пользователям, но я попытался выделить то, что было бы интересно сообществу 1С.
Сразу хочу заметить, что цель моего доклада – не только познакомить сообщество 1С с нашим сервисом, но и узнать, что вашему сообществу хотелось бы видеть в таких сервисах, как GitLab и GitHub, чтобы мы могли это реализовать у себя.
Основные функции сервиса GitFlic:
-
Работа с репозиториями системы контроля версий Git,
-
Хранение больших файлов Git lfs.
-
Механизмы организации процессов разработки – мерж-реквесты и прочие связанные с этим истории.
-
У нас разработан полностью проприетарный механизм CI/CD по образу и подобию GitLab. Он полностью совместим с тем же самым GitLab.
-
И как вишенка на торте – поддерживается работа с реестром пакетов/библиотек (кто как их привык называть). На данный момент доступны Maven, NPM, PyPi и другие пакетные менеджеры. Плюс я сейчас веду переговоры с разработчиками OneScript, чтобы поддержать в GitFlic пакетный менеджер opm и дать возможность сообществу 1С использовать эти дополнительные функции непосредственно у нас в сервисе.
Мой доклад будет состоять из следующих разделов:
-
Немного расскажу про варианты поставки GitFlic, чтобы у вас сложилось понимание, как его использовать в SaaS или у себя на сервере.
-
Расскажу о том, как у нас работают агенты в CI/CD.
-
Покажу пример проекта. Правда, он написан на Java, а не на 1С, но, я думаю, он все равно похож на то, что близко вашему сообществу.
-
Рассмотрим, как в GitFlic работают запросы на слияние.
-
Покажу, как у нас создаются конвейеры (пайплайны).
-
И еще немного рассмотрим, как можно подключать к GitFlic статические анализаторы, чтобы использовать их в рамках тех же пайплайнов.
Варианты развертывания сервиса

У нас предусмотрен ряд различных вариантов поставки.
Есть SaaS-инфраструктура, которой вы можете пользоваться на сайте.
Изначально, когда мы начинали разрабатывать GitFlic, мы ориентировались на модель GitHub. Понятно, что в 2020-м году никто и помыслить не мог о том, чтобы конкурировать на нашем рынке с теми же GitHub или GitLab. Но 2022 год дал нам большие возможности, поэтому теперь GitFlic уже больше похож на GitLab, а не на GitHub, хотя изначально все интерфейсы сделаны по подобию GitHub – я это дальше покажу.
Помимо облачного SaaS-варианта, у нас есть вариант on-premise для развертывания на собственном сервере в двух видах:
-
Бесплатная сборка Community edition,
-
И Enterprise-сборка.
Для каждой из локальных сборок предусмотрены различные варианты поставки.
-
отдельный бинарный файл по примеру того, как это делает GitLab;
-
архитектура из сервисов, которые вы можете развернуть в кластере Kubernetes по отдельности, т.е. мы один бинарный файл делим на несколько отдельных:
-
отделяем административную панель, чтобы для нее был отдельный VPN, и обычные пользователи сервиса не имели доступ к каким-то административным фичам;
-
разворачиваем несколько отдельных сервисов с REST API, чтобы распределить интеграционную нагрузку равномерно – горизонтально масштабироваться, и так далее
-
Варианты поставки различные. Мы всегда подходим к нашим клиентам и партнерам с сервисным подходом. Готовы обсуждать, кому что интереснее. Поможем развернуть тот вариант поставки, который вам более подходит.

Расскажу, какие у нас есть варианты запуска агентов CI/CD. В терминологии GitLab это раннеры, мы их локализовали – назвали агентами. Runner по-английски – бегунок, а для нас это не совсем правильно, поэтому агенты.
Агенты у нас полнофункциональные:
-
Если вы, работая с GitLab, привыкли запускать свои CI/CD-джобы в Docker, в нашем случае это тоже возможно сделать.
-
Можно работать с агентами в Kubernetes.
-
И можно исполнять Shell или PowerShell-скрипты непосредственно на тех виртуальных или обычных машинах, где запущен агент.
В таблице отдельно выделена поставка SaaS. В нашем облаке мы по техническим причинам ничего, кроме Docker-контейнеров для CI/CD предложить не можем. Но попробовать CI/CD в SaaS-варианте уже можно. Т.е. если вы привыкли пользоваться для своих разработок облачным GitLab, вы можете спокойно переместить свои проекты к нам и пользоваться нашим сервисом по аналогии с тем, как вы привыкли.
Краткое описание возможностей
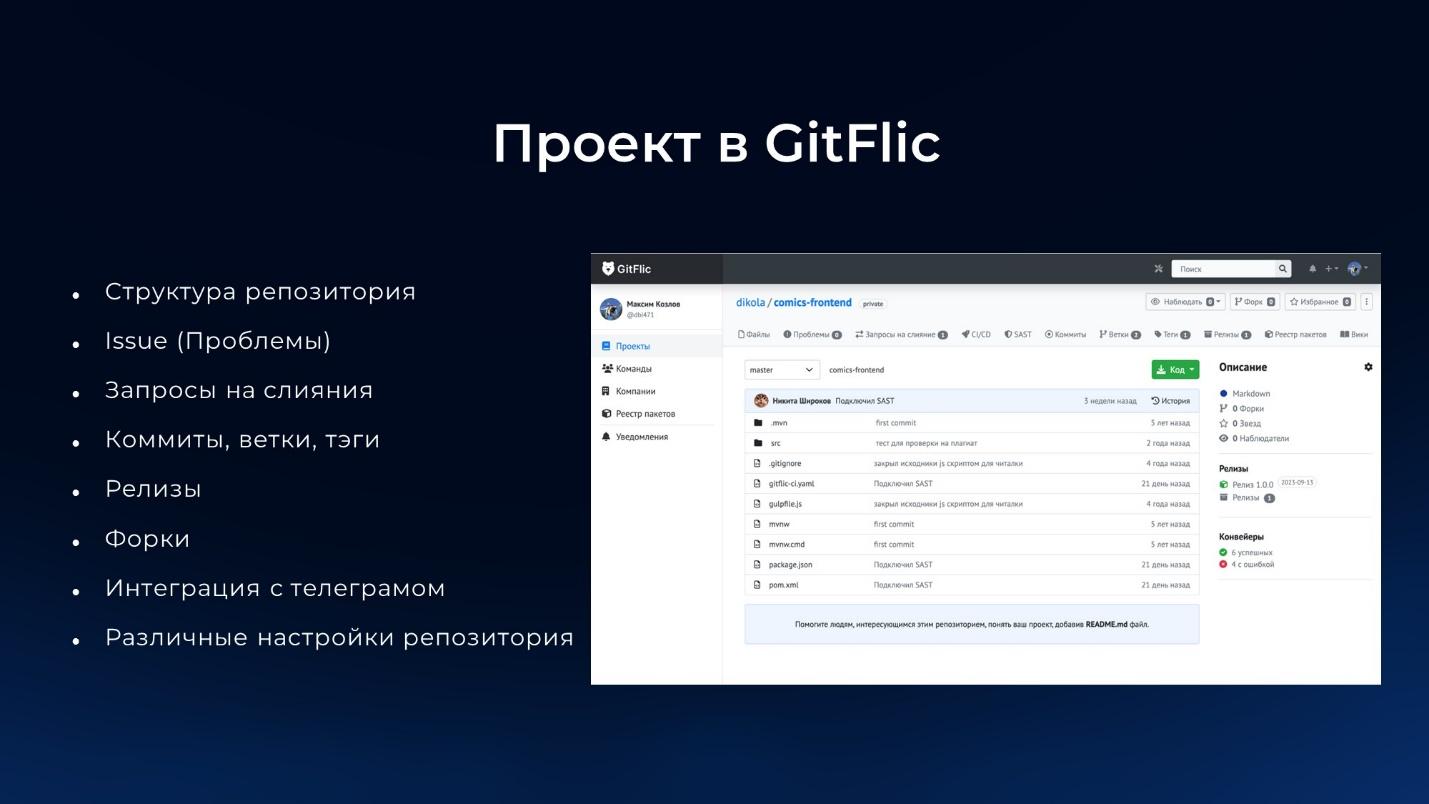
На слайде – пример проекта GitFlic. Интерфейс похож на GitHub. Функциональность, в принципе, тоже.
Расскажу, какие возможности работы с проектом доступны в нашем сервисе:
-
Вы можете хранить в репозитории код и файлы. Причем, поддерживается git lfs.
-
В рамках нашего сервиса реализован интерфейс, который позволяет перемещаться по структуре проекта, открывать файлы и скачивать их по отдельности.
-
Есть функциональность issues – мы их перевели как «Проблемы». Возможно, это не совсем удачная локализация, у нас долго идут споры с нашим сообществом. В ближайшее время мы планируем также развивать свой трекер, поэтому переименуем issues уже в «Задачи» – надеюсь, так всем будет понятнее.
-
Также из всем привычного – запросы на слияние, дальше мы на них посмотрим.
-
Можно смотреть коммиты, диффы коммитов. Создавать и удалять ветки и теги.
-
Можно цеплять к тегам релизы – добавлять отдельные описания и бинарные файлы.
-
Можно делать форки, чтобы развивать на базе нашего сервиса open source, как мы привыкли это делать в GitLab или в GitHub.
-
Есть небольшая интеграция с Telegram.
-
И еще для репозиториев в нашем сервисе можно делать различные настройки по правам доступа – указывать защищенные ветки, теги, устанавливать правила для мерж-реквестов и т.д.
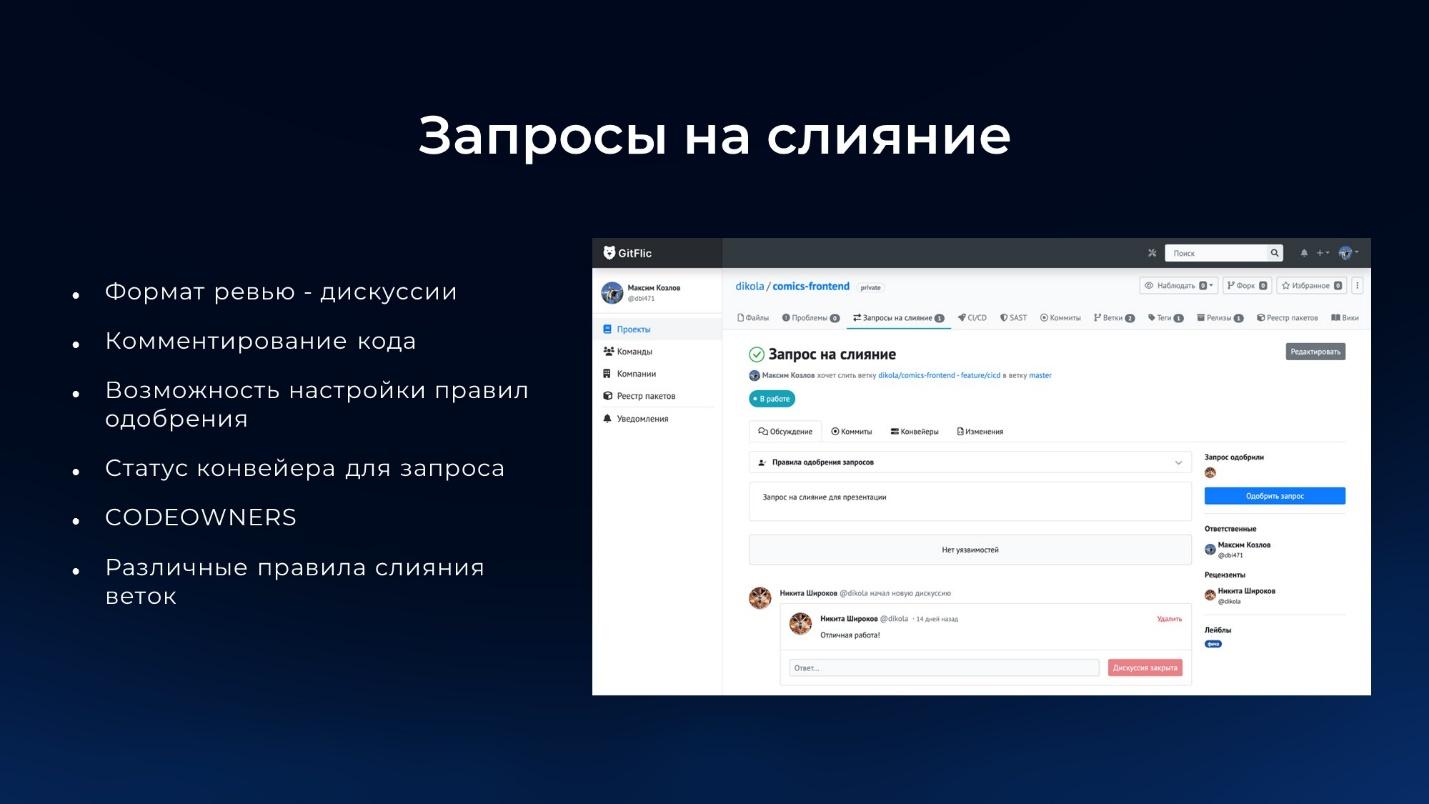
Рассмотрим пример запроса на слияние.
Функциональность мерж-реквестов мы начали развивать в начале 2022 года, когда вопрос импортозамещения встал особо остро. На тот момент мы уже немного отошли от ориентира на GitHub, и интерфейс стал больше похож на GitLab. Т.е. если вы привыкли пользоваться GitLab, наш сервис будет для вас самым близким в части интерфейса и функциональности.
Какие есть возможности у запросов на слияние:
-
Привычный формат код-ревью в виде дискуссии – то, как это реализовано в GitLab.
-
Можно комментировать код.
-
Можно настраивать различные правила слияния – так же, как в GitLab реализован механизм согласования запросов на слияние Merge request approvals.
-
Можно настраивать CODEOWNERS – по аналогии с тем, как это сделано в GitHub, GitLab, Bitbucket и везде, где мы привыкли этим пользоваться. Т.е. можно в специальном файле указать, что если в репозиторий был отправлен мерж-реквест, нужно оповестить об этом таких-то людей – получить от них одобрение, прежде чем будет произведено слияние. Либо, если был изменен другой конкретный файл – нужно оповестить других людей и т.д.
-
И есть различные дополнительные настройки, которые позволяют выстроить правила для процесса запросов на слияние.
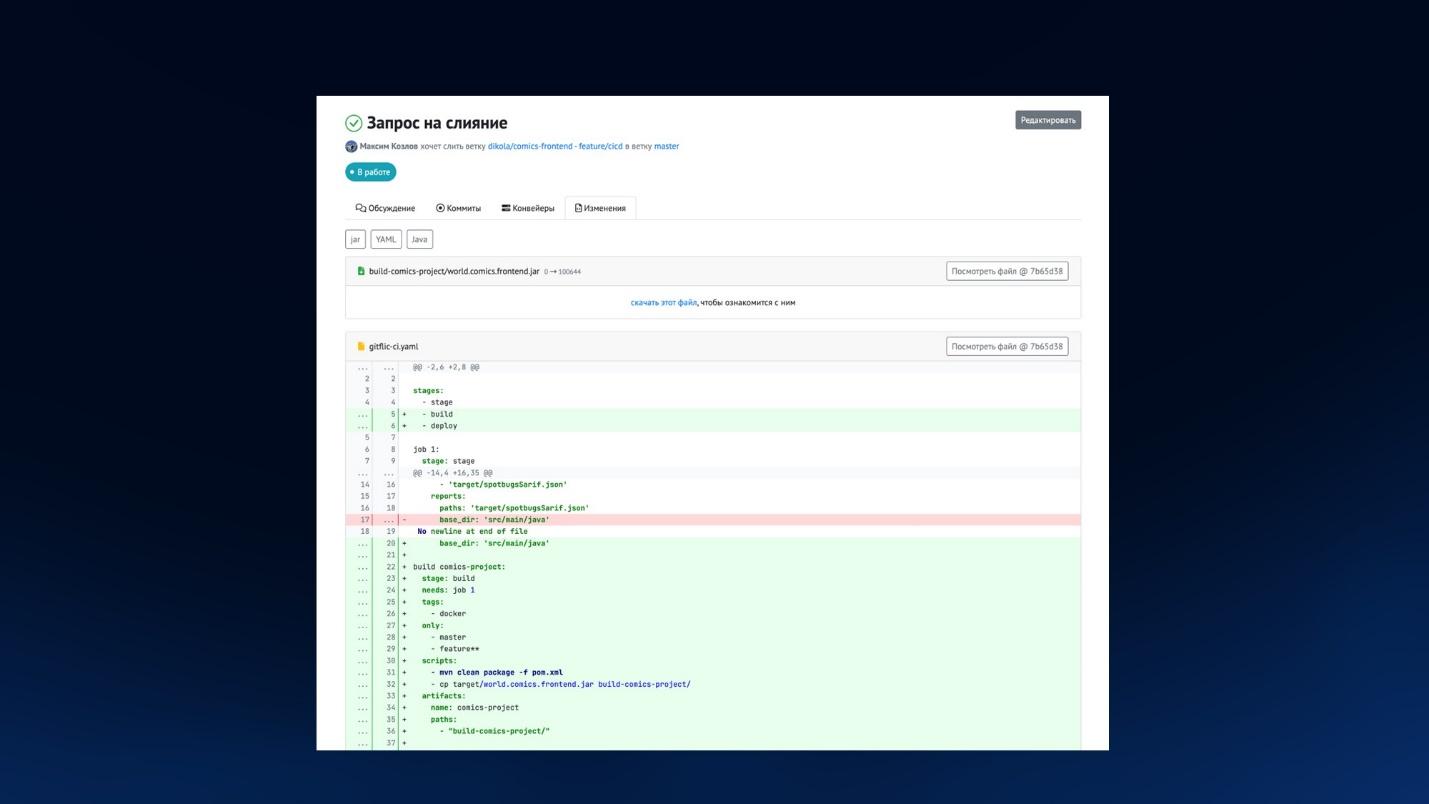
На слайде показано, как выглядит дифф изменений кода при запросе на слияние – видно, что интерфейс похож на GitLab.
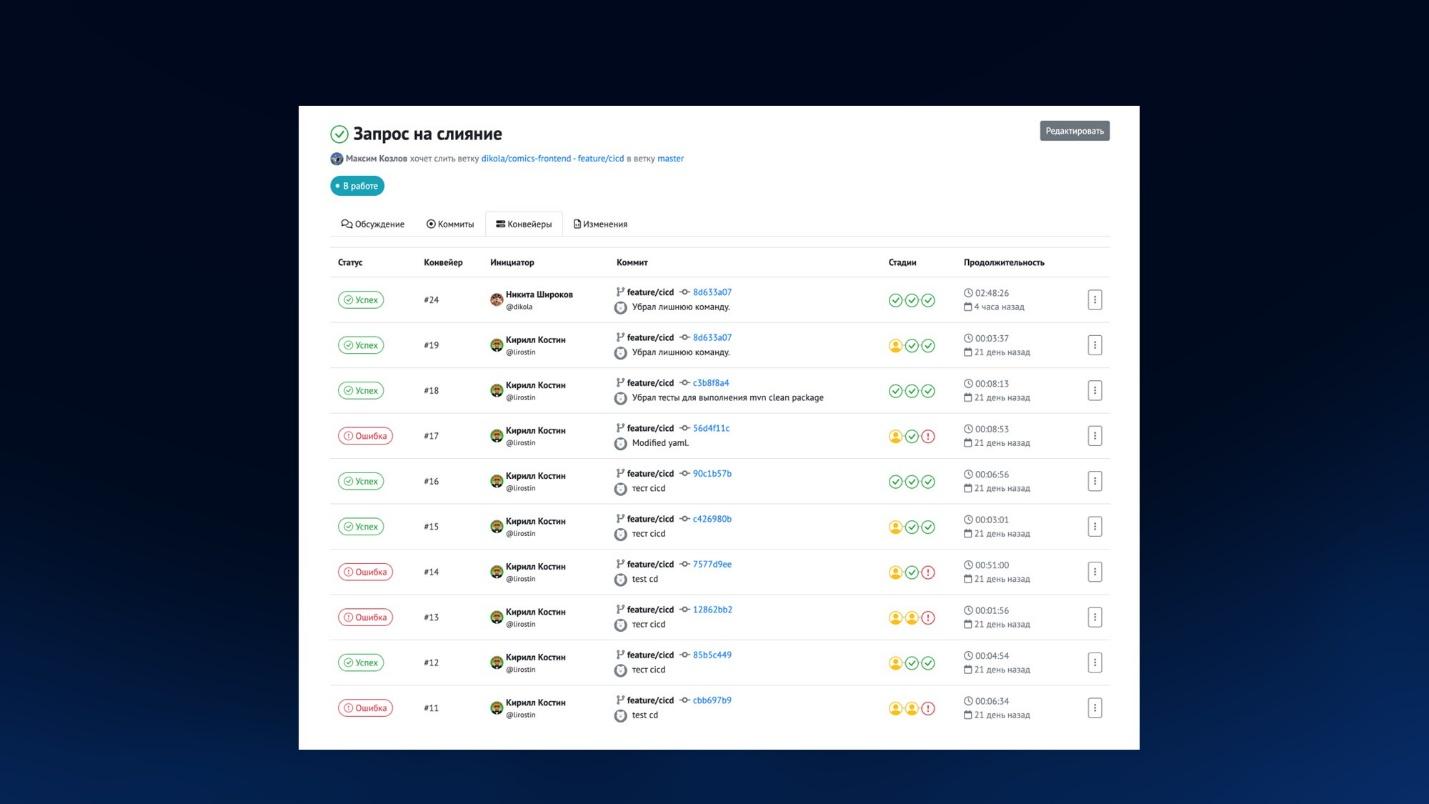
Также в мерж-реквестах можно посмотреть, какие конвейеры были запущены для той ветки, которую мы хотим смержить в рамках мерж-реквестa.
Разработанный в GitFlic инструментарий CI/CD
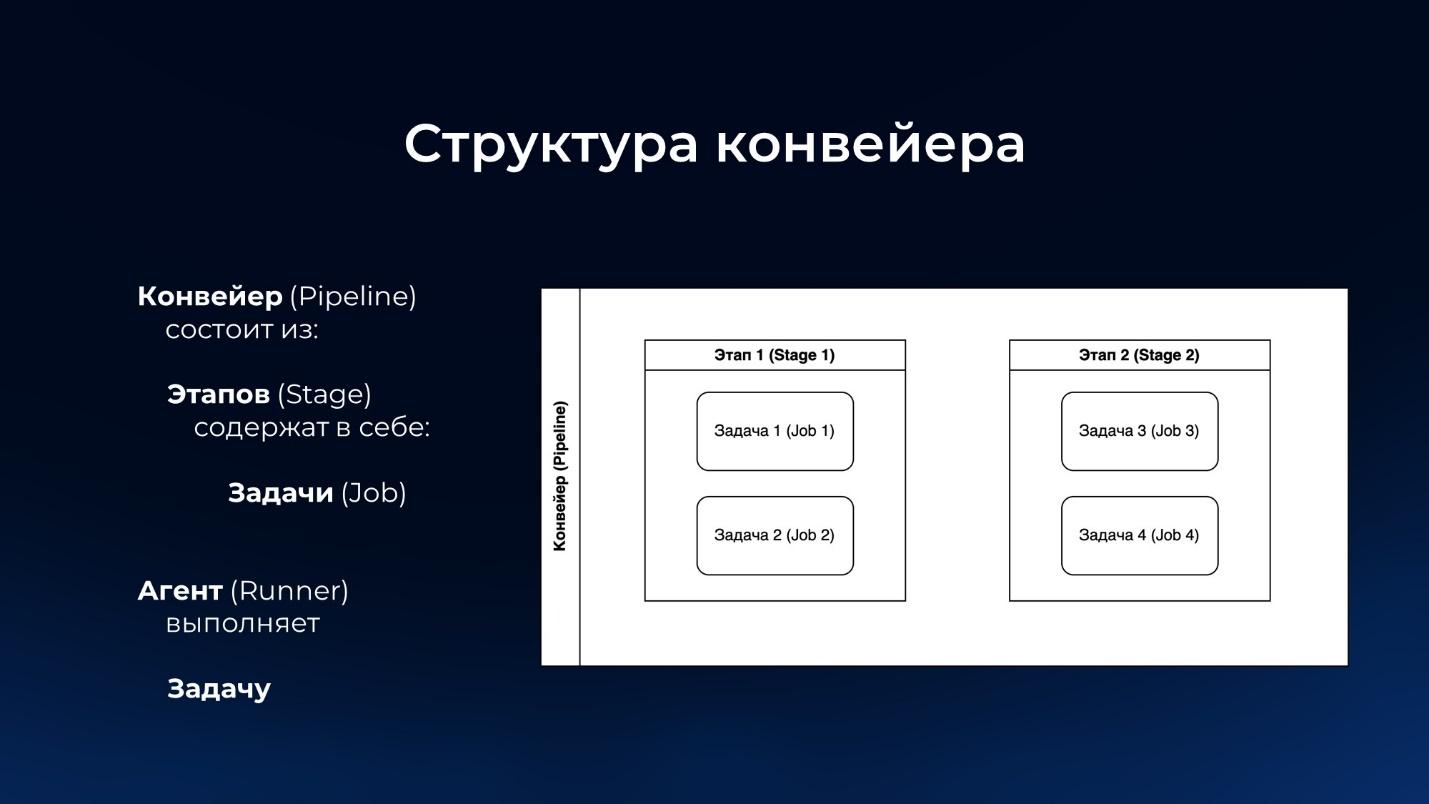
Теперь давайте поговорим о том, как устроены наши пайплайны – в нашей локализации мы назвали их «конвейерами».
Мы не изобретали велосипед, а взяли за основу GitLab. Но в силу того, что мы все-таки разрабатываем на Java, а не на Ruby on Rails, Go или Python, нам пришлось писать свой сервис по мотивам GitLab. И, взяв за основу спецификацию GitLab – то, как у них устроены пайплайны – мы повторили то же самое:
-
Наши пайплайны и конвейеры состоят из этапов.
-
В каждом этапе есть задачи (джобы).
-
И каждый раннер выполняет свою задачу (свой джоб).
По факту, пайплайн (конвейер) – это некая группировка этапов, в рамках которых выполняются джобы.
Джобы могут выполняться параллельно, или можно настраивать некий граф зависимостей между джобами и стейджами – например, если нужно, чтобы, как на слайде, после выполнения задачи №2 была запущена задача №3, не дожидаясь задачи №1.
Причем там дошло до смешного – когда мы это делали, мы ориентировались на GitLab-овскую спецификацию. Посмотрели документацию, и, как у них в документации этот процесс описан, так и сделали.
Хотя, как выяснилось уже позже, в GitLab-е все работает немного иначе. Но, если вы ожидали получить от GitLab то, что описано у них в документации, у нас это точно будет работать именно так, как там заявлено.
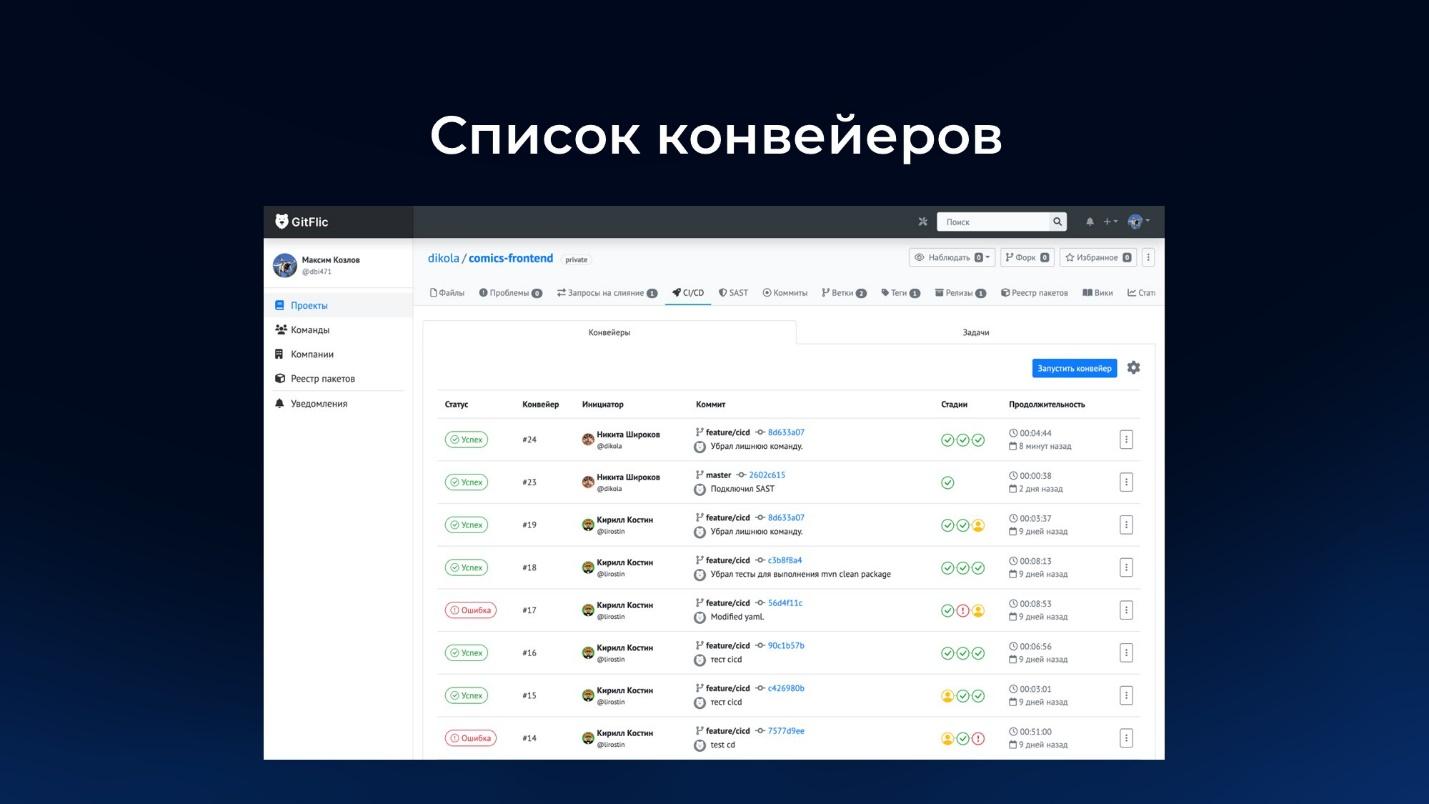
На слайде – пример интерфейса со списком конвейеров (пайплайнов).
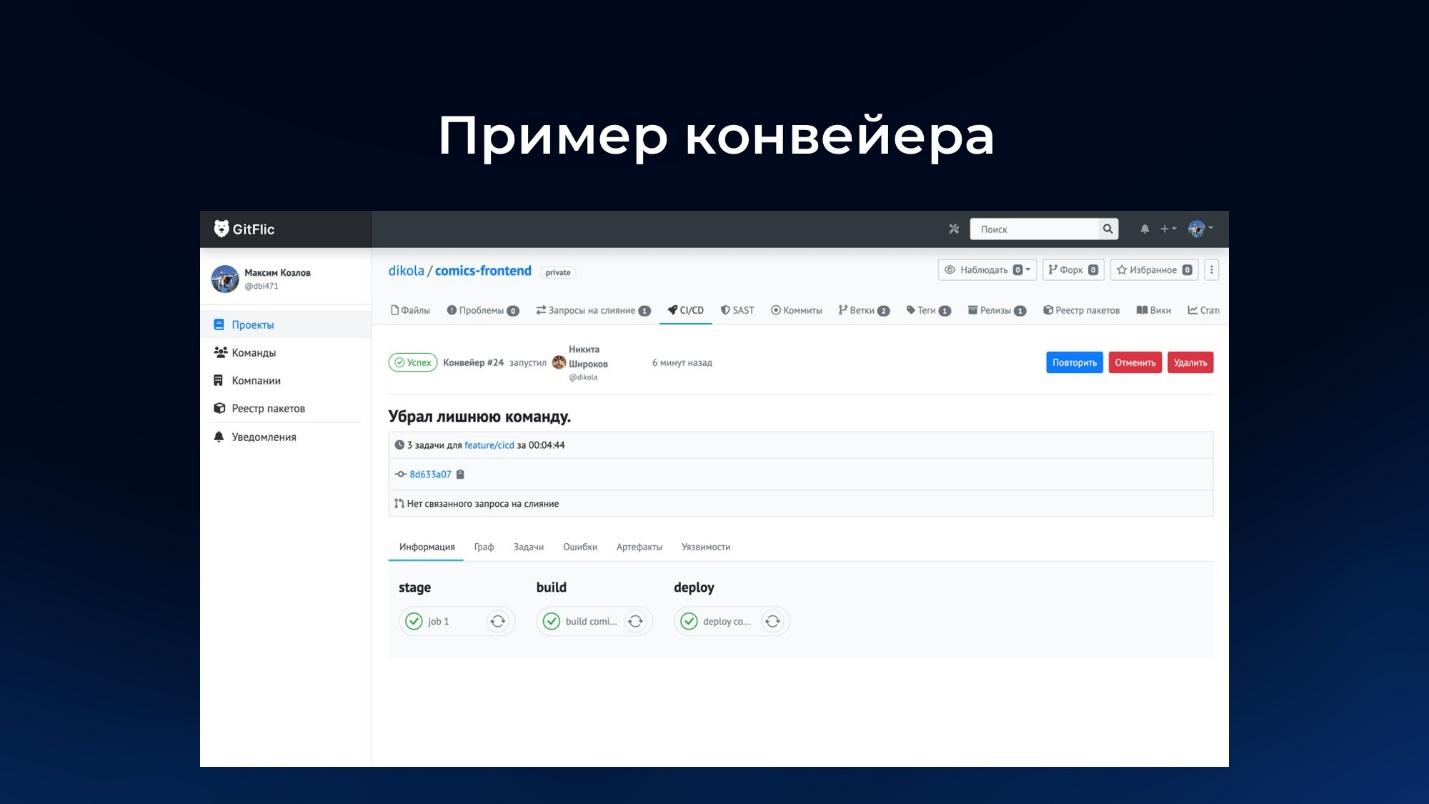
А вот так конвейер выглядит внутри. Как я уже сказал, мы не изобретали велосипед, а ориентировались на то, как это выглядит в GitLab-е – сделали, чтобы всем было привычно.
Подготовка приложений к релизам и деплойменту

Рассмотрим алгоритм выполнения задачи – приведу несколько примеров, как это реализовано у нас:
-
Каждая задача, прежде чем выполниться, клонирует на виртуальную машину сам репозиторий. Этот этап можно отключить, чтобы убрать клонирование и ускорить процесс деплоймента/доставки (то, что называется CD).
-
Дальше из предыдущих этапов выполнения конвейера загружается артефакт.
-
Подготавливается кэш – если в рамках джоба необходимо подтягивать какие-то внешние зависимости, их можно закешировать, чтобы не делать этого каждый раз, и они оставались на тех виртуальных машинах, где эти джобы выполняются.
-
Потом выполняется блок scripts.
-
И после этого все идет в обратном порядке – готовится кэш для следующих запусков.
-
Артефакты, которые могут быть получены в процессе выполнения задачи, упаковываются и отправляются в GitFlic.
-
И в конце, если какие-то агенты запускали SAST, отчеты с результатами отправляются в GitFlic для дальнейшего анализа.
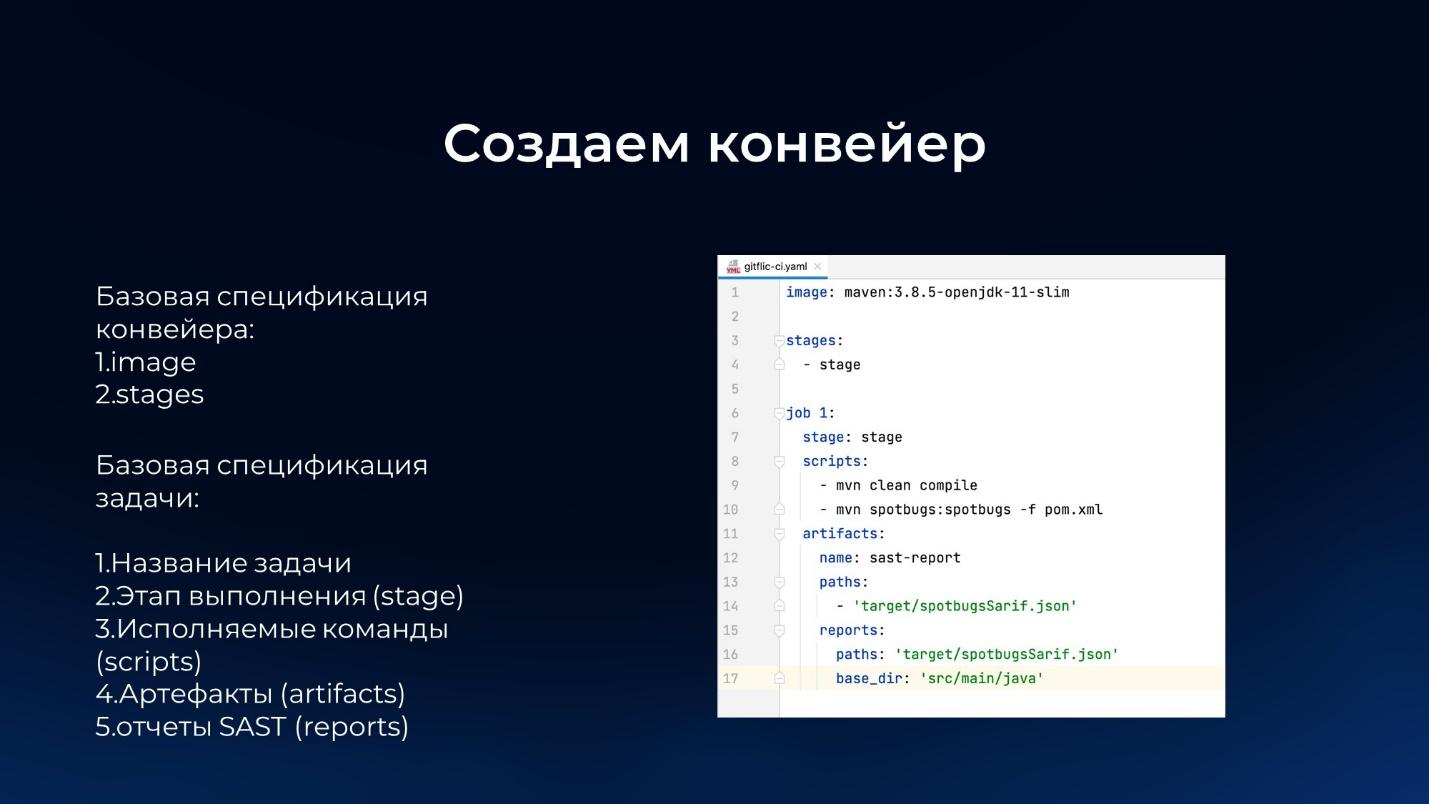
На слайде – пример спецификации конвейера.
Как я уже сказал, мы используем спецификацию GitLab. Т.е. если у вас уже есть готовые пайплайны (конвейеры) для GitLab, вы можете загрузить свой репозиторий к нам в GitFlic, настроить агенты таким же образом, как в GitLab, и попробовать запустить свои пайплайны.
Правда, есть небольшие различия в спецификациях. Например, в GitLab паттерн-wildcard для путей (paths) или веток, названных как feature_IDзадачи, будет выглядеть как feature*. Т.е. в GitLab для указания пути можно поставить в wildcard одну звездочку.
А у нас используется не совсем такой же wildcard-матчер. Мы, к сожалению, не смогли повторить этот костыль из GitLab – пришлось использовать то, что есть в Java. У нас этот паттерн будет выглядеть как feature**, т.е. используется две звездочки, но одна тоже будет работать. Это нужно учитывать, здесь могут быть несоответствия ваших предыдущих YML-файлов от GitLab с нашими.
Отдельного интерфейса для создания пайплайна, как в TeamCity или в Jenkins, у нас нет. Мы пошли по пути GitLab, поэтому создаем просто YML-файл.
В этом YML-файле нужно указать:
-
Image – имя образа Docker, который будет использован для запуска задания. Если вы хотите запускать свои джобы в Docker или в Kubernetes, это поле обязательно к заполнению. Пока реализовано так, что image должен быть общий для всех, в ближайших релизах мы сделаем так, что для каждого джоба можно будет указывать отдельный image.
-
stages – список этапов, которые должны быть выполнены в рамках пайплайна.
-
И после этого уже идет описание самого джоба (или задачи) в стандартной для GitLab спецификации:
-
Описание джоба начинается с названия.
-
Мы указываем, на каком этапе (stage) этот джоб должен выполниться.
-
В блоке scripts указываем команды, которые нужно выполнить. Тут показан пример проекта на Java, где мы используем Maven: сначала выполняем команду mvn clean compile, а потом mvn spotbugs: spotbugs -f pom.xml – запускаем статический анализ нашего кода, чтобы сформировался отчет SAST.
-
В блоке artifacts указываем артефакты, которые хотим передать в GitFlic, чтобы потом их можно было использовать в следующих шагах выполнения конвейера. Либо эти артефакты могут быть самим приложением, которое мы собираем.
-
И там же в артефактах в секции reports отдельно указывается отчет SAST – чтобы наш сервис мог понимать, что это не просто какой-то бинарный артефакт, а конкретный отчет, который нужно проанализировать и положить в базу данных.
-
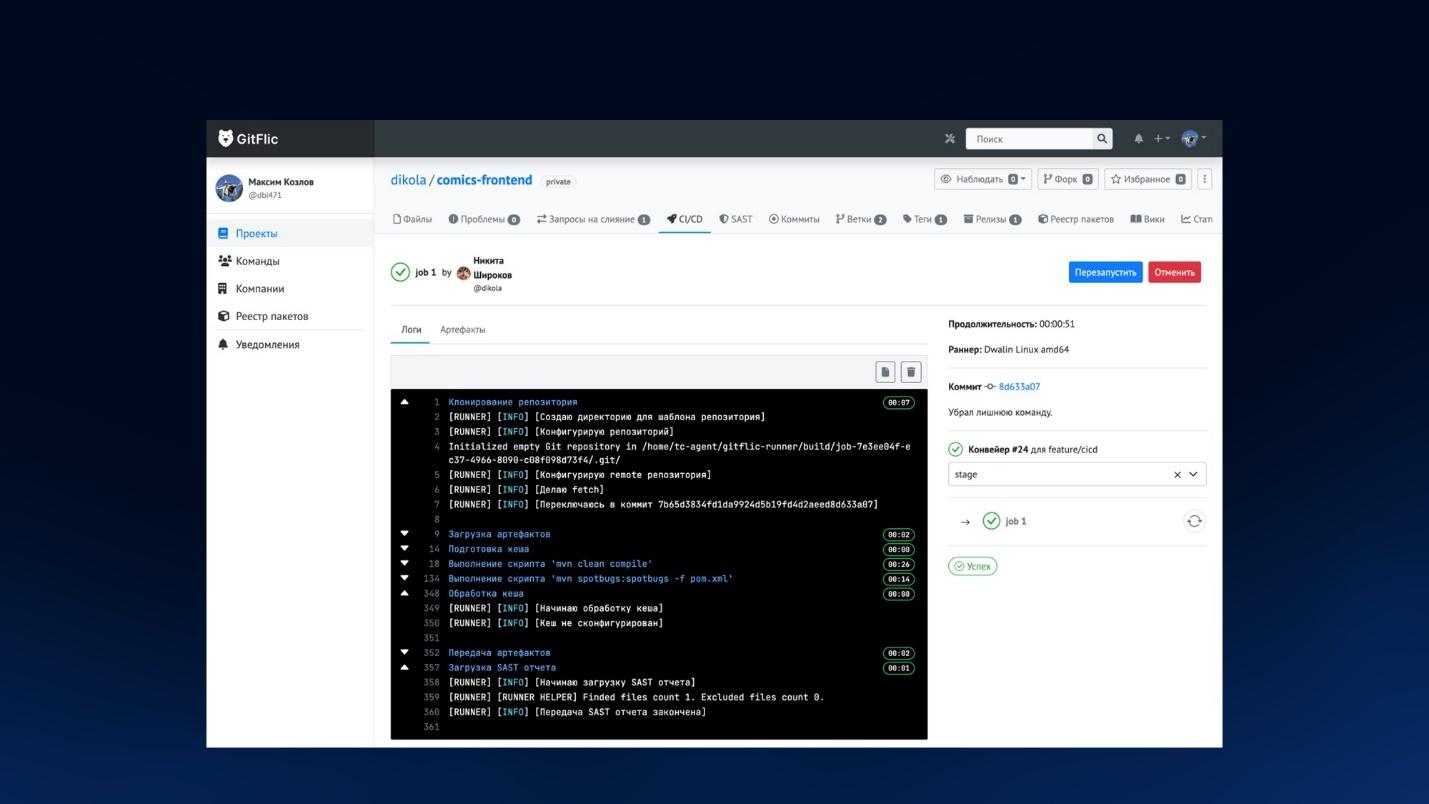
На слайде пример выполнения джоба. Он выглядит так же, как вы привыкли в GitLab: выводятся логи в реальном времени, можно посмотреть артефакты, попереключаться, перезапустить, отменить саму задачу и так далее.
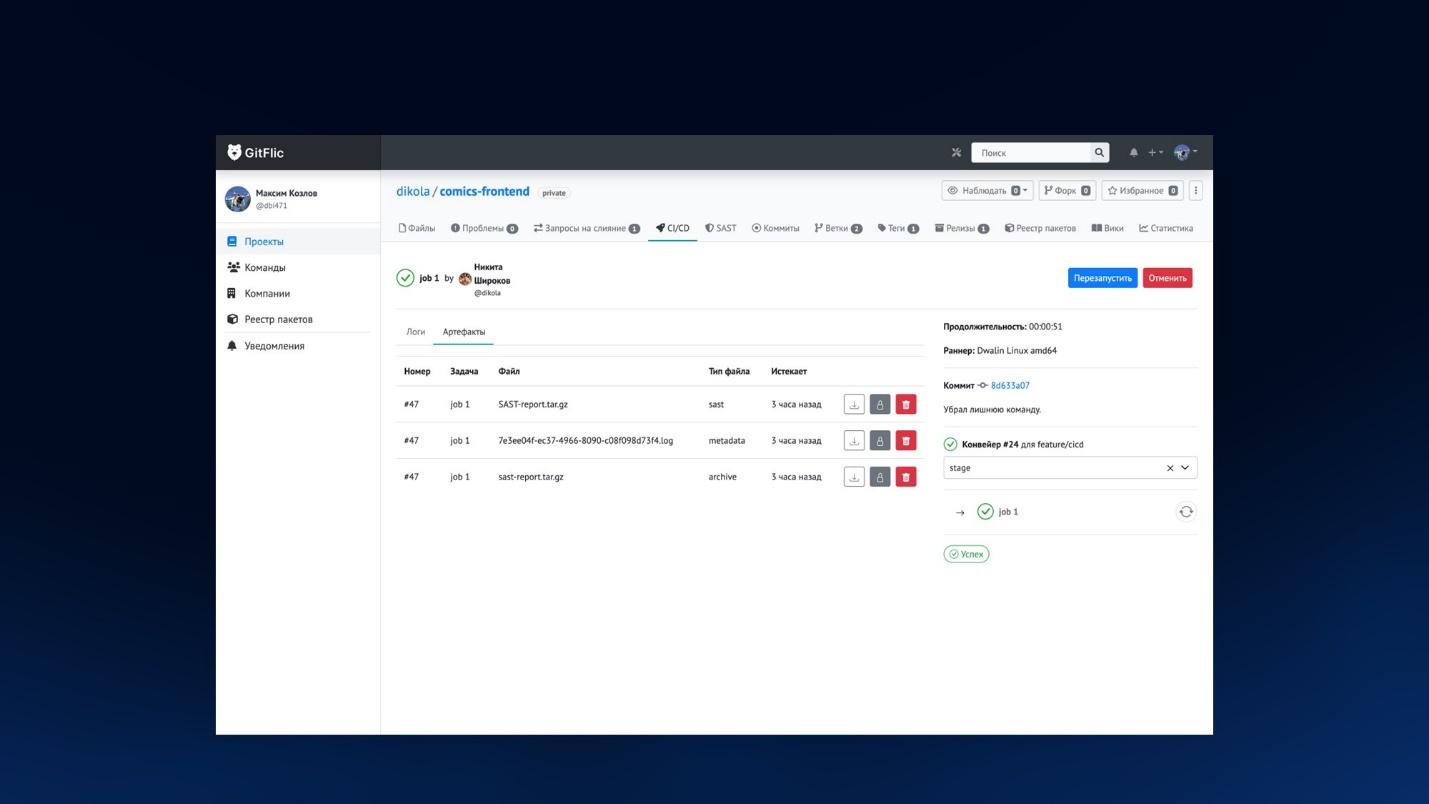
А так выглядит список артефактов – это тоже привычная история:
-
отдельно складываются логи;
-
отдельно – файлы отчетов SAST. Здесь SAST-report.tar.gz – это тот отчет, который мы получили, чтобы дальше проанализировать. Дальше я подробнее про него расскажу.
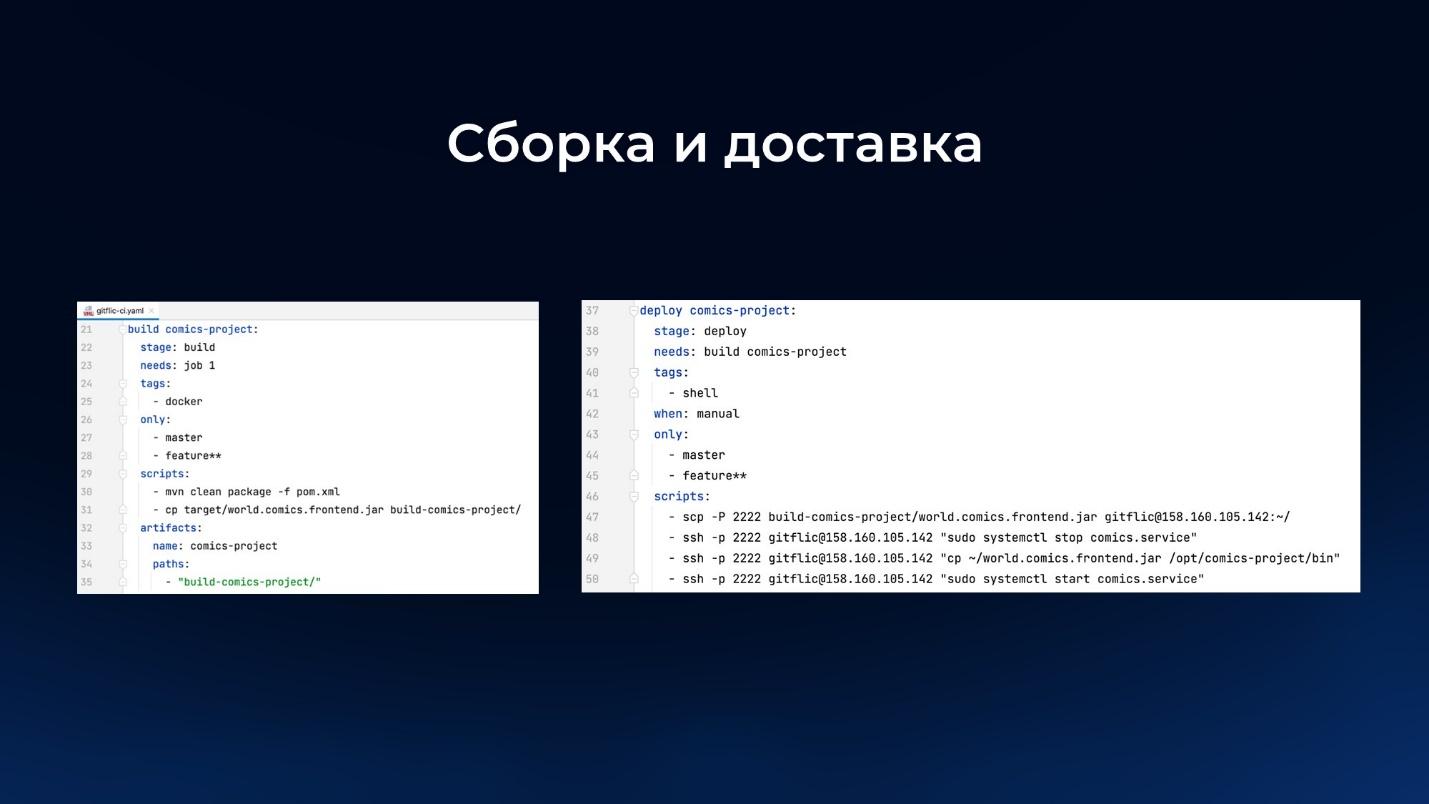
А здесь – пример конвейера для сборки и доставки, где описана пара джобов:
-
джоб, где собирается релиз;
-
и джоб, где результат выполнения сборки отправляется в продакшен или на тестовый контур.
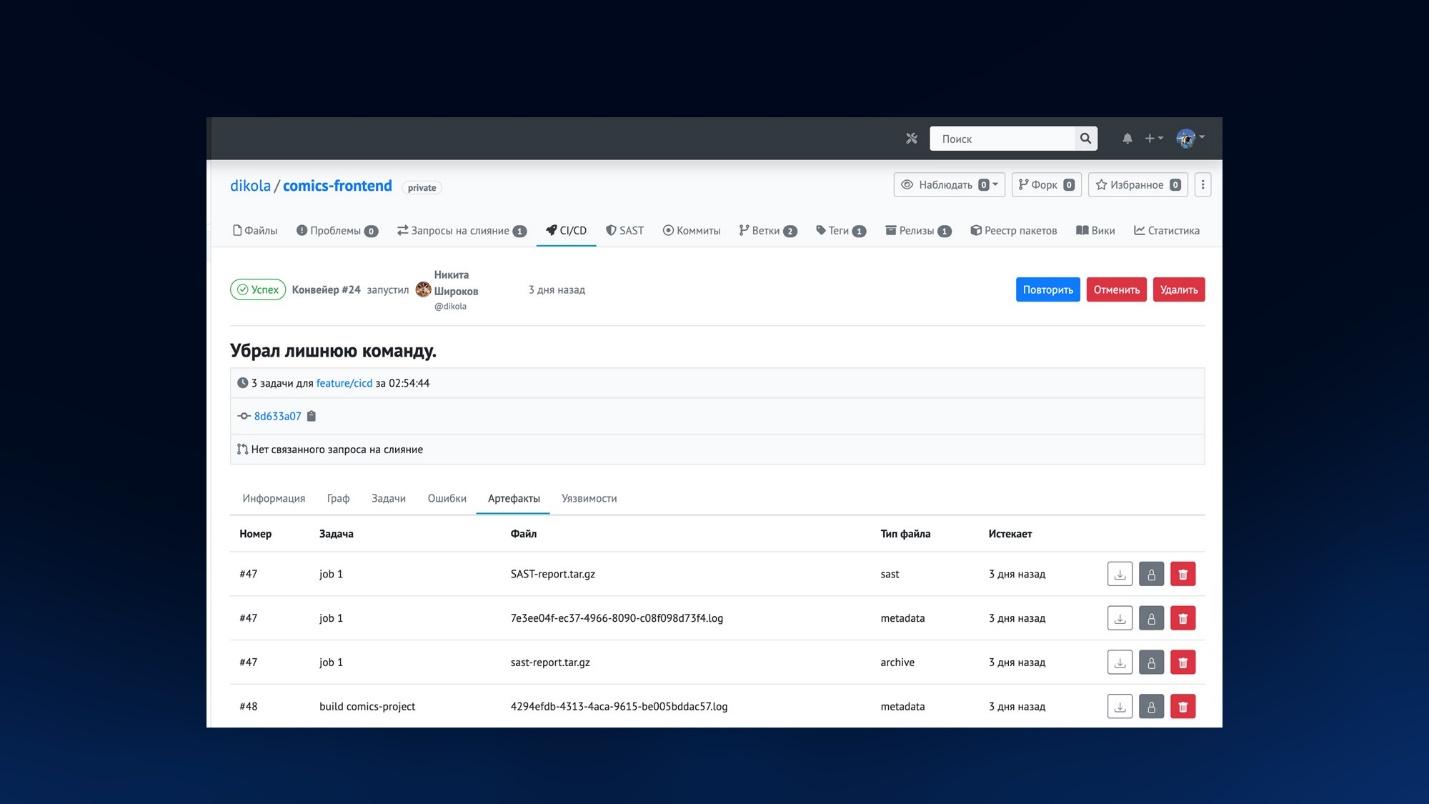
Несколько примеров того, как выглядит пайплайн (конвейер) внутри.
Здесь на закладке «Артефакты» выводятся все артефакты в рамках этого конвейера – их можно скачать, удалить либо заблокировать от автоматического удаления.
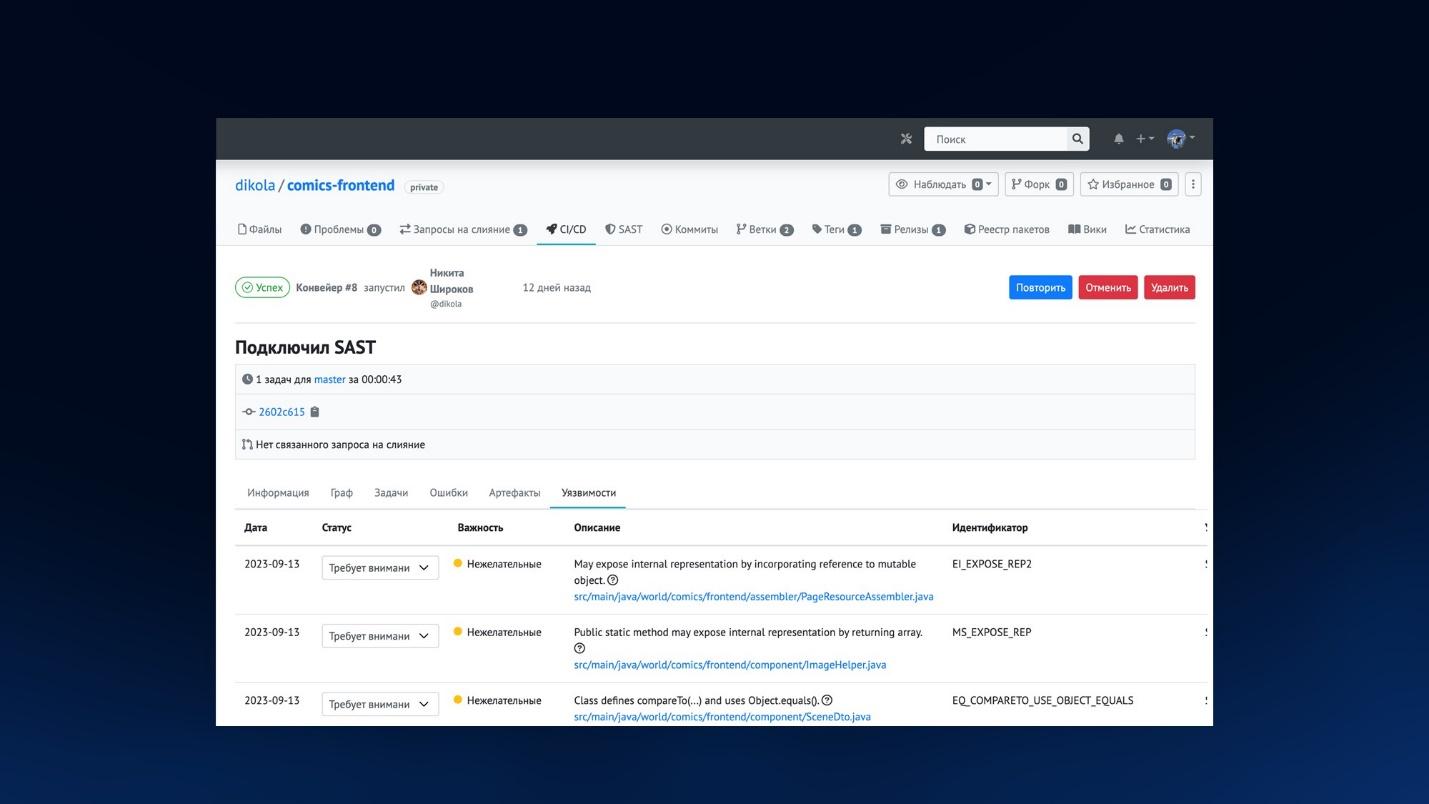
А на закладке «Уязвимости» можно посмотреть отчеты SAST по конкретному пайплайну.
Понятно, что уязвимости могут появиться не в каждом конвейере, но здесь мы их для примера показали.
Интеграция анализаторов исходных кодов (SAST)
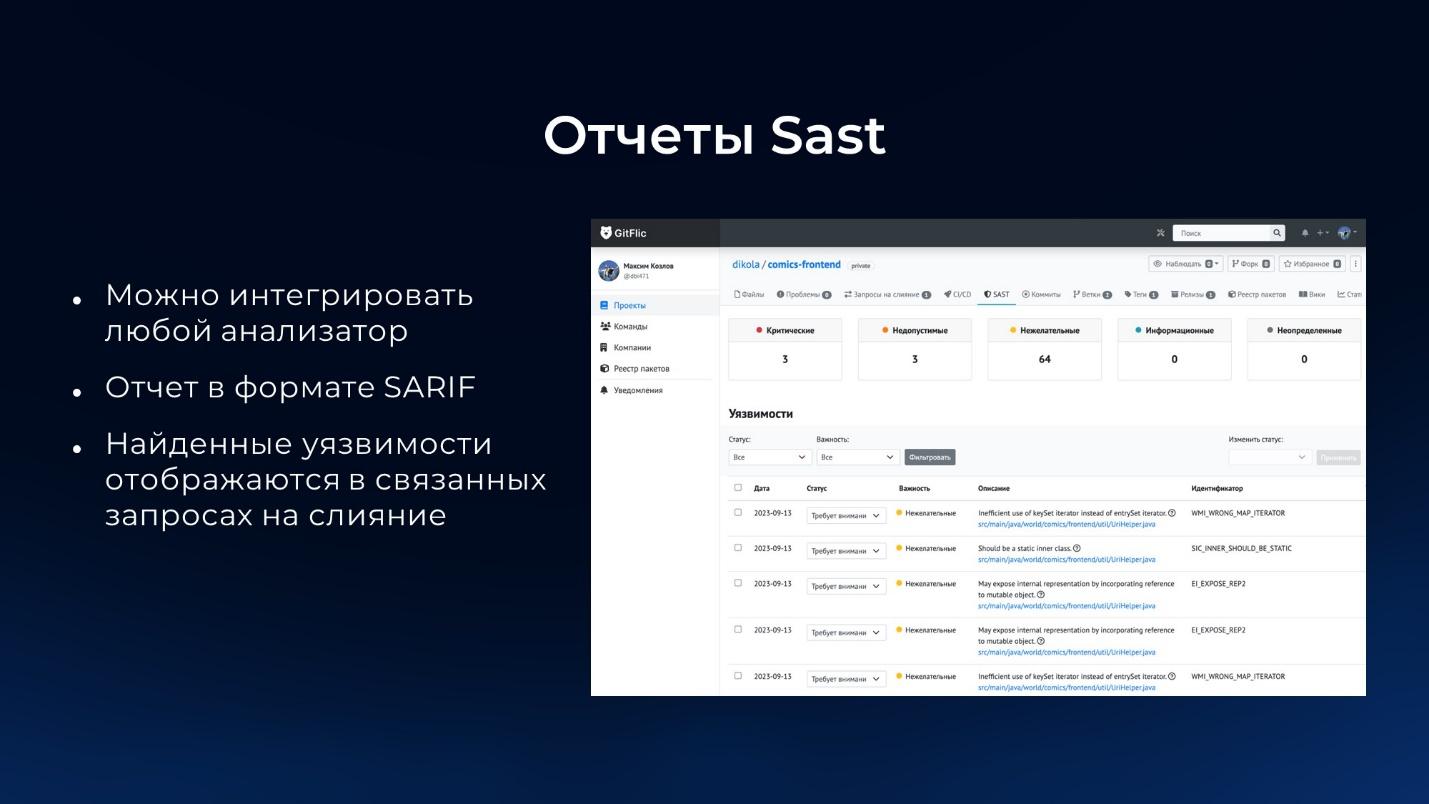
Немного расскажу о том, как у нас обстоит дело по части безопасности.
Процессы управления безопасностью, интеграции с различными статическими анализаторами, которые нам позволяют безопасно вести разработку, мы начали развивать недавно – в начале 2023-го года. На данный момент у нас подготовлены все интерфейсы и интегрирована возможность подключать статические анализаторы кода.
Причем статические анализаторы кода в GitFlic работают точно так же, как в GitLab и в GitHub.
Конечно, сейчас многие привыкли к тому же SonarQube, но у него свой агент, свои анализаторы, свой интерфейс. Мы в данный момент в такую крупную машину не смотрим, но постепенно в этом направлении движемся.
Относительно статических анализаторов в GitFlic на данный момент может:
-
Подключать любые агенты для проведения статического анализа кода, включая линтеры.
-
Важное условие – агенты должны уметь генерировать отчет в формате SARIF. Формат SARIF – это JSON-файл, в котором перечислены все объекты с конкретными найденными уязвимостями. Вызов агента подключается в конкретный джоб, и там нужное количество раз выполняется анализ вашего кода. Например, тот же SpotBugs в Maven не умеет смотреть конкретный проект, если в одной папке лежат сразу несколько проектов. Ему нужно анализировать каждый проект отдельно и отдельно по каждому проекту отправлять отчет. Или можно сделать отдельные джобы.
-
В результате все отчеты статического анализатора кода прогрузятся к нам в сервис, будут разобраны, и информация о замечаниях запишется в базу. А найденные уязвимости будут отображены, в том числе, в связанных мерж-реквестах.
На слайде показано, как выглядит список найденных уязвимостей – они помечены как нежелательные (т.е. критические, недопустимые). Т.е. с точки зрения локализации мы перевели critical, warning и прочее. И здесь по факту можно смотреть все то же самое, что и в том же SonarQube.
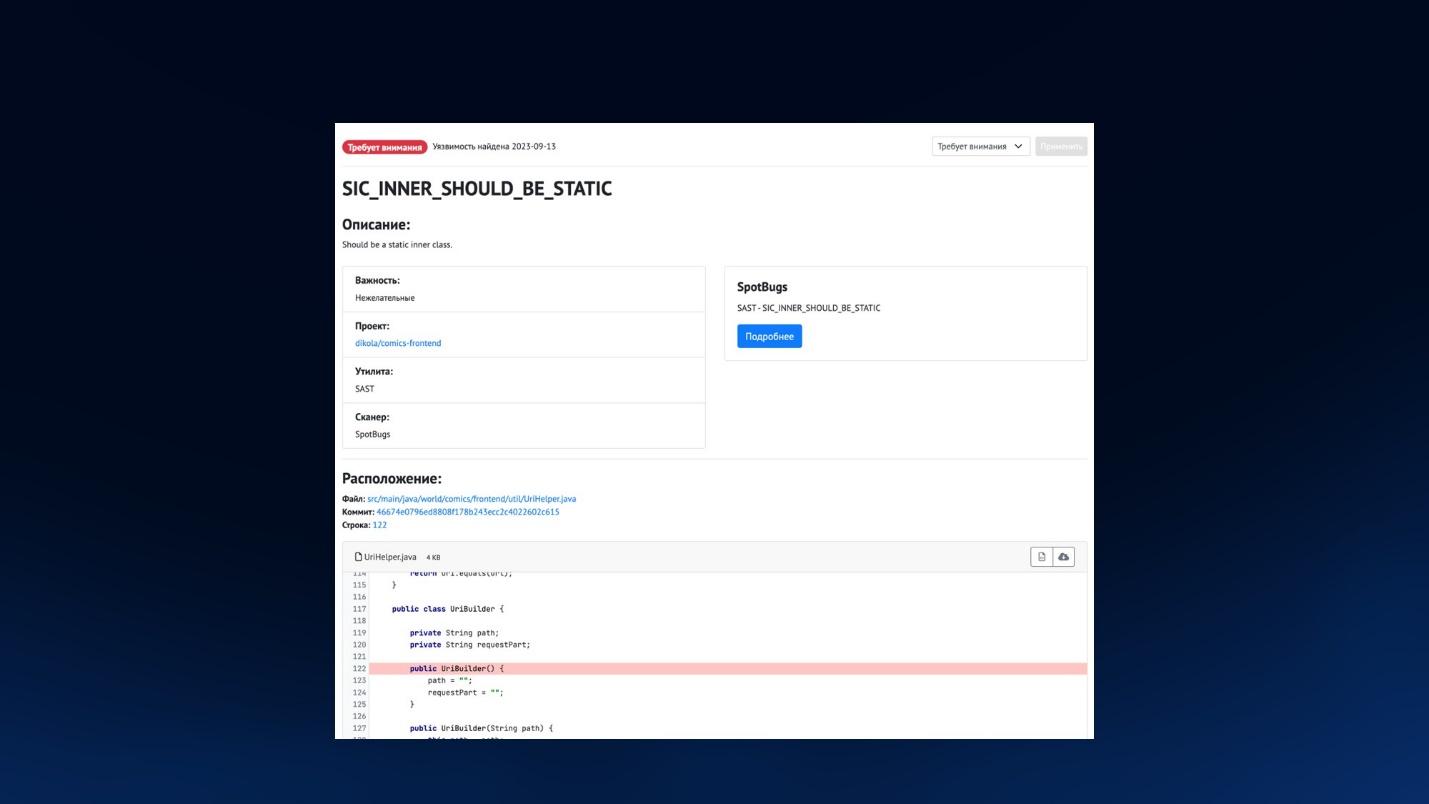
Вот так выглядит страница конкретной уязвимости – видно, каким анализатором она найдена, в каком файле, в каком коммите и в какой строке.
Сразу скажу, что автоматически найденные уязвимости мы не закрываем. Т.е. если вы поправили уязвимость, запушили свои изменения, анализатор их не найдет и отчет пришлет без этих уязвимостей, мы их автоматически не закрываем. Их надо найти в списке и закрыть вручную. С точки зрения безопасности пока решили поступить так, чтобы эти уязвимости никуда не пропадали. И исторические данные тоже хранить, я думаю, было бы неплохо.
В заключение хочу вернуться к той цели, которую я поставил для доклада. К сожалению, наша команда почти никогда не сталкивалась с 1С, поэтому нам, как команде, не совсем понятно, что конкретно было бы интересно для вашего сообщества. Поэтому предлагаю задавать вопросы и вносить предложения в комментариях к публикации. Мы их обязательно учтем.
Страница продукта GitFlic на Инфостарте – //infostart.ru/soft1c/2048075/.
Вопросы
Вы сами для управления разработкой GitFlic пользуетесь?
Все примеры, показанные в докладе, подготовлены в нашем облачном GitFlic. Мы там и код храним, и пайплайны запускаем, и релизы делаем. И вообще все-все-все, что можно делать, мы делаем, конечно же, через GitFlic.
Когда в компании больше сотни проектов, самая удобная возможность, которой отличается GitLab – это хорошо документированное API и построенные на нем Terraform-провайдеры. Потому что администрирование большого количества проектов без Terraform – это достаточно тяжело. Когда в компании несколько десятков разработчиков, много групп и проектов, с помощью Terraform удобно раздавать права. Это не нужно делать руками, достаточно описать параметры нового проекта в конфигурационном файле. Есть ли у вас в планах написать Terraform-провайдеры? Особенно, если учесть, что Terraform недавно ответвился, появился OpenTofu, и можно спокойно брать эту разработку и при помощи вашего API написать свой провайдер.
В докладе я дал вводную информацию для сообщества. А так, конечно, у нас много планов на развитие.
Например, мы сейчас развиваем интеграцию для работы раннеров с Kubernetes. Плюс у нас в SaaS-варианте подключен API Яндекс Облака – там можно автоматически порождать виртуалки и запускать в них раннеры.
Дальше мы планируем переместить наш опыт интеграции с Kubernetes непосредственно в GitFlic, чтобы делать деплоймент сразу там.
И там же Teraform рядом будет – сделаем такую же полную интеграцию.
Конечно, у нас большие планы. И возможностей, на самом деле, намного больше, чем я рассказал.
Спецификацию GitLab-CI можно расширять, используя якори и инклуды – сделать CI-темплейты для схожих проектов. Например, у тебя в GitLab есть некий проект, в котором полностью описан CI для расширений. И в других проектах GitLab-CI будет просто ссылаться на этот темплейт-проект. Не нужно править CI в каждом своем проекте с расширениями, разработчик просто правит пайплайн только в основном проекте, который отвечает за темплейт. И это сразу приезжает на все подобные проекты с расширениями. Есть ли у вас такие планы?
Инклуд у нас есть, это все работает, я просто не стал об этом говорить. Наверное, зря. Экстендов и референсов пока, к сожалению, нет, но до конца 2023 года они появятся – они уже почти разработаны.
Есть ли у вас плагин для работы с мерж-реквестами в VSCode? Например, такой, как сделан у GitLab?
Да, у нас есть планы сделать веб IDE – то, что реализовано в GitHub. Чтобы у вас там виртуальная машина запускалась с IDE, где установлены все нужные компиляторы и пространство для разработчиков.
Мы этим вопросом будем заниматься в 2024 году – как раз в рамках общих задач с группой компаний «Астра».
В том числе, будем делать плагины для VSCode, потому что VSCode основан на тех же технологиях веб-IDE, на которые мы смотрим.
Но это, скорее всего, будет второй квартал 2024 года, может быть, третий.
Вы спросили, что можно сделать для нашего сообщества. У нас есть среда разработки EDT, которая построена на Eclipse. Можете ли вы сделать плагин, чтобы можно было из EDT нативно взаимодействовать с вашим сервисом: смотреть там работу пайплайнов, отслеживать новые задачи и проверять мерж-реквесты?
Это хорошее пожелание, потому что мы давно потихоньку общаемся с разработчиками EDT, но конкретные запросы они нам пока не формулировали.
Ваше пожелание обязательно учтем и будем этим заниматься.
Планируется ли поддержка анализаторов других форматов? У вас есть SAST, это хорошо, но, например, в 1С очень популярен тот же JUnit и прочее. Ведутся ли какие-то разработки в этом направлении?
Сейчас мы реализуем интеграцию с SCA-анализаторами – то, что связано с составом приложения и внедренными зависимостями.
Потом у нас по плану идут DAST – мы их планируем до конца 2023 года внедрить (прим. ред. доклад от 12 октября 2023 года), может быть, в начале 2024 года.
Планируем реализовать контейнеры, реестр контейнеров, к нему анализаторы по безопасности, и все остальное прочее.
Есть ли какая-то статистика, сколько у вас сейчас репозиториев в сервисе? Какие они по размерам? Какие самые большие? Потому что в 1С блобы в репозиториях часто бывают большие – один файл конфигурации в районе гигабайта. И сами репозитории из-за этого получаются огромные.
Если говорить именно про SaaS-вариант GitFlic, там сейчас около 40 тысяч пользователей и столько же репозиториев. Правда, тысяч 20 уже удалили.
Репозиториев много, и они все разные – от 10 мегабайт до 100 гигабайт:
-
Есть большие репозитории под 100 Гб – непонятно, что люди там хранят. Я сразу говорю, мы внутрь не смотрим, только видим, сколько папка репозитория весит.
-
У некоторых заказчиков тысячи проектов.
-
У кого-то – сотни очень больших, которые много весят не в части коммитов, а именно в части блобов. Некоторые хранят в репозитории совсем большие файлы, причем я не имею в виду LFS-файлы – мы их пытаемся потихоньку перевести в Яндекс.Облако.
-
А может быть один репозиторий с ядром линукс, который имеет миллион коммитов – по нему тяжело ходить.
Все это у нас работает. Всегда можно посмотреть, потестировать.
Собрать какую-то единую статистику, насколько быстро работает сервис, пока что сложно. Кто-то глубоко по дереву коммитов ходит – он там долго, может быть, ходить будет. А у кого-то наоборот, блобы большие, но он только дерево коммитов открывает, а сами блобы не смотрит, поэтому у него все может работать быстро.
Мы постоянно наводим у себя в продакшене порядок – например, за последние полтора года провели большую работу по оптимизации работы.
Хочется зазеркалить у вас в SaaS некоторые опенсорсные репозитории, но у обычного пользователя, по-моему, нет возможности автоматически сделать в одном месте зеркала открытых проектов по аналогии с вашим Хранилищем кода Vault. Или все-таки можно?
Все можно. Просто напишите нам. Именно в части зеркалирования мы в целом никого не ограничиваем – просто смотрим, что это за человек.
И мы пока не Microsoft, у нас с дата-центрами есть небольшие проблемы, всем известные.
Поэтому вы нам на саппорт напишите, мы обязательно дадим доступ, и вы там хоть 100, хоть 200 своих репозиториев к нам переносите. Никаких проблем не будет.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции Infostart Event.


Вступайте в нашу телеграмм-группу Инфостарт