Меня зовут Сергей Лихтенвальд. В 1С я уже чуть более 8 лет. Прошел путь от младшего консультанта-аналитика до руководителя отдела развития 1С в компании ABI. Сейчас тружусь в команде «Самоката» в качестве ведущего аналитика 1С.

Тема взаимодействия с брокером сообщений RabbitMQ давно не новая, и она не раз освещалась на Инфостарте. Но я хочу с вами поделиться именно практическим кейсом – как мы с помощью единого архитектурного решения по взаимодействию с брокером сообщений RabbitMQ подошли к унификации интеграционных обменов между 1С и другими системами.
Наш единый подход поделился примерно на три шага:
-
Описание структуры обмена;
-
Единая архитектура взаимодействия с RabbitMQ;
-
Единая настройка обмена в системе 1С.
В больших компаниях для разных учетных задач используются различные системы. Я работал в холдинге, где:
-
в части организаций для ведения оперативного учета использовалась Microsoft Axapta 2003;
-
а в остальных организациях группы компаний – Microsoft Axapta 2012;
-
центральная НСИ велась в Microsoft Axapta 2012;
-
был портал для пользователей на SharePoint;
-
для финансового и регламентированного учета использовался 1С:ERP;
-
для кадрового учета – 1С:ЗУП;
-
для управления ремонтом – 1С:ТОИР.
Очень много различных систем
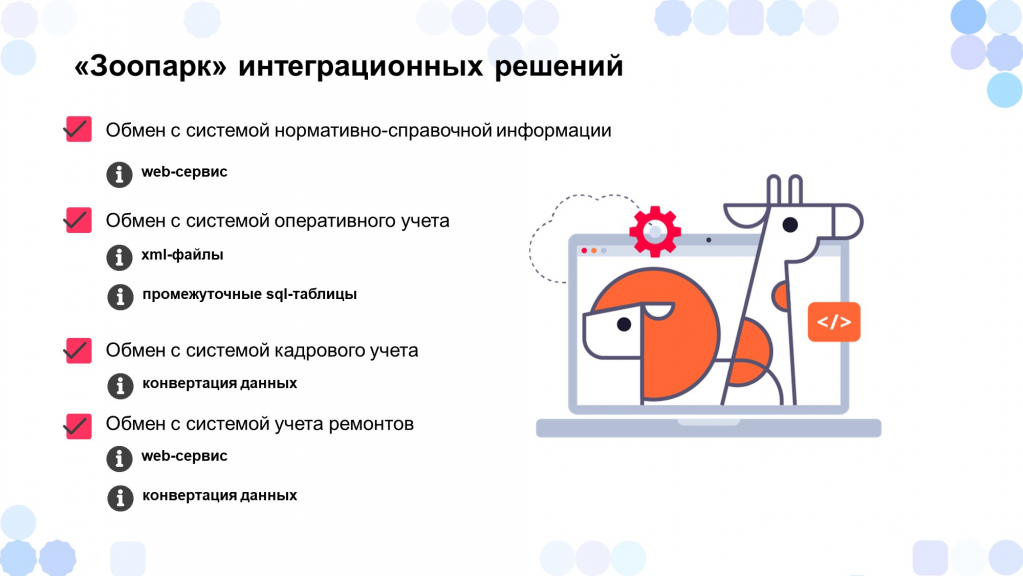
Все эти системы обменивались между собой информацией по различным протоколам.
-
Обмен с системой нормативно-справочной информации происходил через веб-сервис;
-
Обмен с системой оперативного учета происходил через XML-файлы – необходимо было зайти в одну систему, выгрузить данные, а потом зайти в другую систему и загрузить этот XML-файлик.
-
Также был обмен через промежуточные SQL-таблицы: данные загружались в эти таблицы, а потом 1С:ERP их забирал.
-
Обмен между системами 1С тоже был неунифицированным: в одних базах обмен происходил через «Конвертацию данных», а в других – через веб-сервисы.
Был очень большой «зоопарк» – как учетных систем, так и интеграционных решений. Все это с каждым днем становилось все тяжелее и тяжелее поддерживать. И в какой-то момент представители бизнеса попросили что-то поменять.
Отправной точкой для изменений был обмен, который осуществлялся через промежуточные SQL-таблицы – система корпоративного хранилища данных забирала данные из оперативной системы, складывала их в промежуточную таблицу, а потом пользователь на стороне учетной системы 1С:ERP заходил и забирал эти данные через хранимые процедуры. С каждым днем данных становилось все больше, бизнес рос, и пользователей уже не устраивал данный подход.

Мы решили, что нужно навести порядок во всем этом.
-
Объем данных становился все больше и больше, времени на передачу данных требовалось все больше, а закрытие месяца в регламентированном учете необходимо было успевать завершить в сжатые сроки;
-
Так исторически сложилось, что где-то отсутствовала документация: кто-то давно какие-то обмены написал, а информации об этом нет – чтобы разобраться, как это работает, нужно было заходить в код.
-
Бизнес рос, добавлялись новые направления деятельности, под них заводились новые информационные системы – надо было как-то это все унифицировать.
-
С каждым днем увеличивались затраты на поддержку всего этого «зоопарка», потому что не все разработчики и аналитики знают используемые в обменах технологии. Чтобы разобраться с какой-то новой технологией и понять, как тот или иной обмен работает, нужно было потратить много времени.

Мы решили перейти на единую систему транспортных сообщений и выбрали RabbitMQ.
Почему RabbitMQ?
-
В первую очередь, потому что проект https://github.com/rabbitmq – это open-source, и вендор уже предоставляет компоненту, с помощью которой можно обмениваться с этим брокером.
-
RabbitMQ хранит сообщения до момента, пока подписчик их не получит и не скажет, что получил данные.
-
Самым главным для нас плюсом была гибкая маршрутизация.
-
И гарантированная доставка – данные будут доставлены в 100% случаев.
Здесь можно провести параллель с нашей компанией «Самокат», которая сейчас набирает высокие обороты за счет удобства и популярности – мы делаем заказ в приложении, и через 5-7 минут заказ уже доставлен.
RabbitMQ можно сравнить с нашим курьером. Мы RabbitMQ данные отдали, сказали, куда их доставить – он практически моментально данные доставил, и мы уже можем их забирать.
Унификация. Шаг №1: Единый подход к описанию обменов. «Дизайн интеграции»
Перед тем как переходить на новую систему транспортных сообщений, мы решили описать все обмены в единой документации, чтобы любой человек мог зайти, изучить документацию и понять, как работает тот или иной обмен.
Такой документ мы у себя назвали «Дизайн интеграции». Расскажу подробнее, из каких пунктов он состоял.
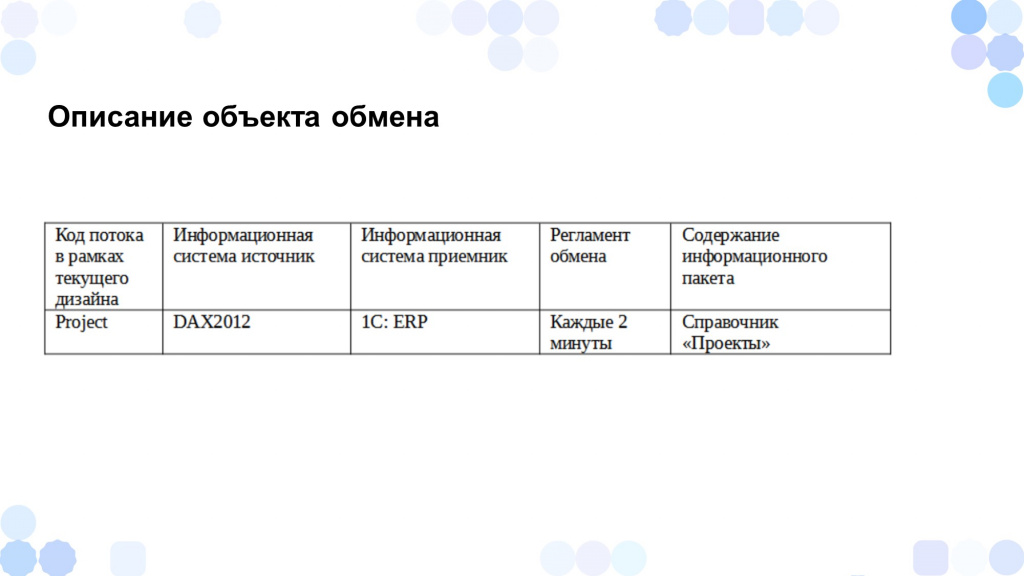
В первом пункте «Описание объекта обмена» мы разместили таблицу с полями:
-
Код потока – в случае, когда мы обмениваемся данными справочника «Проекты», код потока Project.
-
Информационную систему источник – DAX2012.
-
Информационную систему приемник – 1С:ERP.
-
С какой частотой обмен будет выполняться – каждые 2 минуты.
-
И какие данные будут передаваться в рамках данного обмена – справочник «Проекты».

Следующий основной пункт – «Описание точки обмена очередей, которые будут добавлены либо изменены в RabbitMQ». Здесь мы указываем:
-
Код обмена – в данном случае Project.
-
Наименование обмена, который нужно добавить либо изменить.
-
Наименование очереди, которая добавляется либо изменяется.
-
И параметры маршрутизации.

Обратите внимание, что мы унифицировали наименования очередей и обменов с помощью конкретного шаблона, состоящего из следующих блоков:
-
Имя системы получателя – в нашем случае это 1CERP;
-
Область данных – это либо справочные данные ref, либо транзакционные tr;
-
Тип передаваемых данных – если мы передаем нормативно-справочную информацию, то NSI;
-
Имя объекта передаваемых данных – когда мы передаем проект, то Project;
-
И область видимости – приватный priv либо публичный pub.
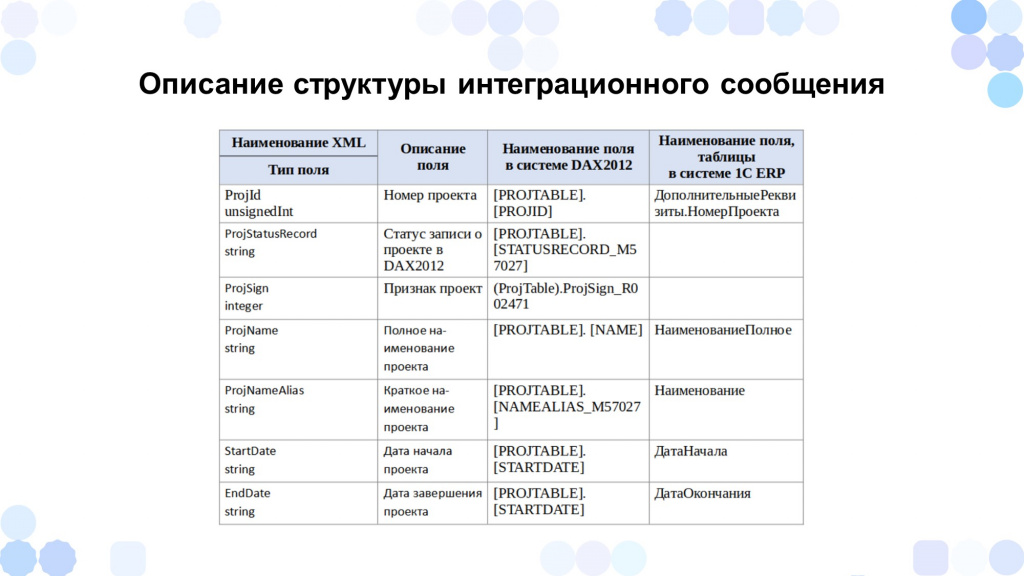
Следующий пункт – «Описание структуры интеграционного сообщения».
У нас было так построено, что инициатором изменений обмена выступала именно система приемник. Например, когда мне, как аналитику со стороны ERP, нужно было получить из DAX данные для справочника «Проекты», я:
-
Смотрел, какие данные из системы источника мне нужно получить, и указывал в структуре интеграционного сообщения наименование тега в XML, его тип и описание.
-
Затем я обращался к аналитикам системы источника – в данном случае это Axapta, где была размещена центральная система НСИ, и говорил им, что мне нужны такие-то данные. Мы встречаемся и договариваемся, какие у них есть данные. Если каких-то данных нет, решаем, как их дополнить.
-
Потом аналитик со стороны источника описывает, из каких полей и таблиц будут заполняться теги в интеграционном сообщении.
-
А я как аналитик со стороны приемника уже описываю, как будут заполняться поля в приемнике – как будет заполняться справочник «Проекты” на основании интеграционного сообщения.
-
Если же есть какая-то сложная логика заполнения полей, я описываю, как их нужно заполнить для программиста.
Полученный дизайн интеграции можно использовать в качестве технического задания для программиста – передать ему для работы.

Важно, что мы описывали, в том числе, и xsd-схему интеграционного сообщения. В нашем случае xsd-схему описывал аналитик. Может быть, это немного неправильно, но мы решили, что этим будет заниматься именно аналитик.
Таким образом мы унифицировали интеграционные сообщения для RabbitMQ. Наши интеграционные сообщения состояли из двух xsd-схем.
-
В первой схеме содержались поля:
-
ID сообщения;
-
дата создания сообщения;
-
и тело сообщения, в которое импортировалась основная схема объекта – в нашем случае, Project.
-
-
А на второй картинке представлена xsd-схема Project – схема интеграционного сообщения по проекту.

В результате интеграционное сообщение получается такого вида.

Поскольку системы у нас были разные, нужно было учитывать их особенности – например, в ERP в зависимости от включенных функциональных опций часть реквизитов может быть недоступна. Поэтому к процессу описания интеграционных сообщений я подходил следующим образом:
Сначала я заходил в систему как пользователь и интерактивно создавал документы либо элементы справочников, после чего с помощью консоли запросов выбирал все реквизиты, смотрел, как они заполняются, и описывал их заполнение. Т.е. несмотря на то, что часть реквизитов не видно, они все равно должны быть заполнены – например, их заполнение необходимо для формирования корректных движений по оперативному либо финансовому контуру.
Потом я познакомился с таким инструментом, как обработка «Админка» (редактор объекта). Там можно выбрать объект, и будут показаны все реквизиты этого объекта и их типы – можно отследить их заполнение в зависимости от того, к каким функциональным опциям привязан тот или иной реквизит. Мне, как аналитику, это было очень удобно для описания.
Унификация. Шаг №2. Единая архитектура взаимодействия с брокером сообщений
Вторым шагом унификации был подход к единой архитектуре взаимодействия с брокером сообщений.
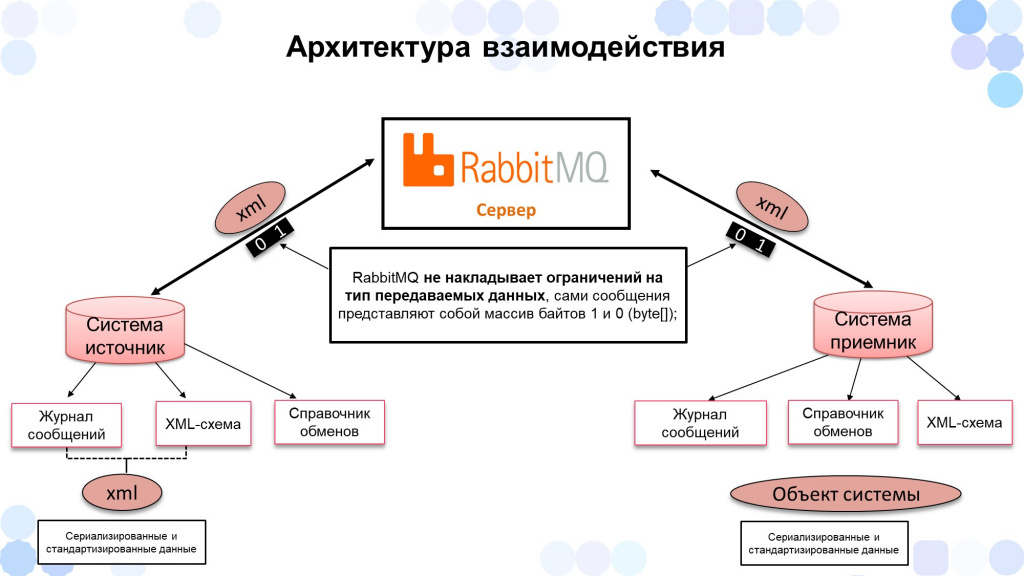
Архитектура взаимодействия для разных систем – как 1С, так и не 1С – была построена единым образом.
-
В каждой из систем был так называемый «Справочник обменов», в котором хранились подключения к серверу RabbitMQ.
-
Сообщения системы-источника хранились в «Журнале сообщений».
-
К каждому интеграционному сообщению применялась XML-схема.
-
По параметрам маршрутизации из настроек «Справочника обменов» сообщение отправлялось в RabbitMQ.
-
RabbitMQ отправлял данные источнику.
-
Источник на своей стороне получал данные, преобразовывал с помощью xsd-схемы и создавал объект.

Так как я был аналитиком 1С, интерфейс взаимодействия с RabbitMQ был построен в 1С с помощью внешней обработки:
-
В этой обработке хранились параметры подключения к серверу RabbitMQ.
-
Она позволяла смотреть количество сообщений в очереди, а также получать либо отправлять сообщения вручную.
-
В случае ошибок при обработке сообщений она нам отправляла оповещение – в данном случае мы получали еще и оперативное оповещение аналитиков, что есть какие-то ошибки в обмене.
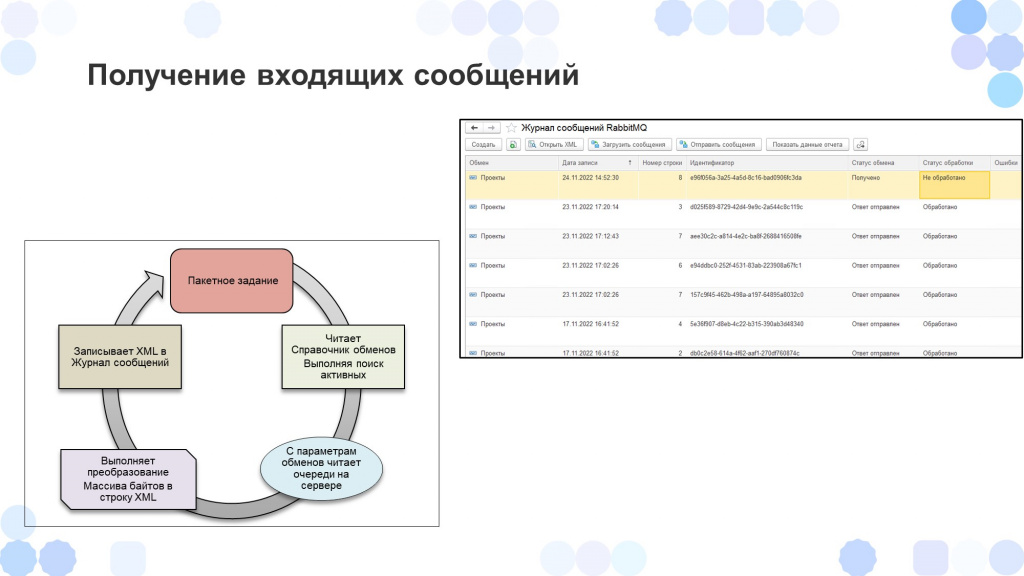
Получение входящих сообщений происходило автоматически.
-
Запускалось фоновое задание.
-
По настройкам «Справочника обменов» шло подключение к RabbitMQ.
-
Забирались сообщения из очередей и складывались в регистр сведений «Журнал сообщений RabbitMQ».
-
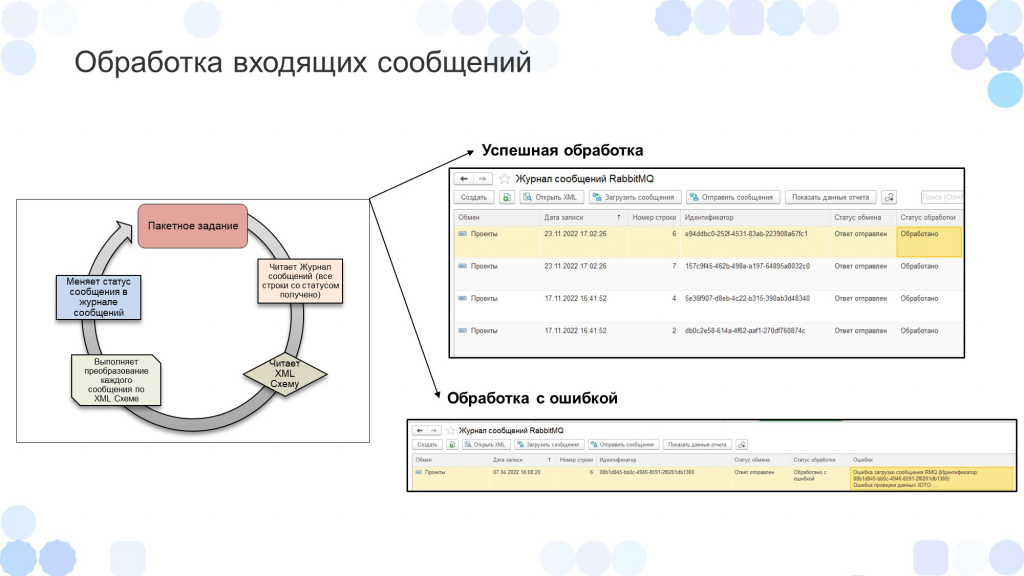
Следующее пакетное задание читало регистр сведений «Журнал сообщений» со статусом «Получено, но не обработано», применяло XML-серилизацию по xsd-схеме и, если не было никаких ошибок, создавало объект.
-
В случае ошибки информация о ней записывалась в регистр и отправлялась на почту ответственному аналитику, чтобы он практически сразу мог отреагировать, не дожидаясь обращений от пользователей о том, что какие-то данные обмена, которые должны были прийти, не пришли.

Отправка исходящих сообщений практически ничем не отличалась.
-
В данном случае пакетное задание смотрело в регистре «Журнал сообщений» записи со статусом «Новое».
-
К объекту применялась xsd-сериализация.
-
И по настройкам из «Справочника обменов» данные отправлялись в RabbitMQ.
Унификация. Шаг №3. Единая архитектура преобразования данных обменов. «Справочник обменов»
В третьем шаге унификации мы подошли именно к единой архитектуре преобразования и обработки данных. Вся информация хранилась в «Справочнике обменов». Расскажу подробнее, что он собой представлял.
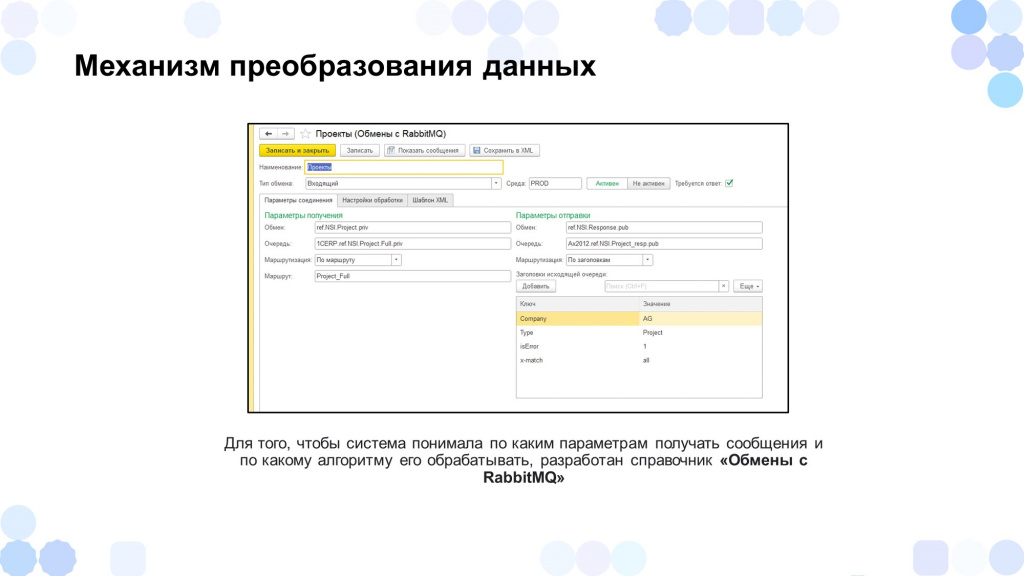
В справочнике «Обмены с RabbitMQ» мы хранили:
-
Параметры получения либо параметры отправки – в зависимости от того, тип обмена был входящий или исходящий.
-
Также там задавалась среда – либо это продуктивная среда, либо девелоперская.
-
Указывалось активный обмен либо неактивный.
-
И еще мы могли указать – требуется ответ или нет. Если ответ требовался, мы при получении данных от системы источника отправляли ответ – успешно обработано сообщение или неуспешно. Так они могли понимать результат и на это реагировать.
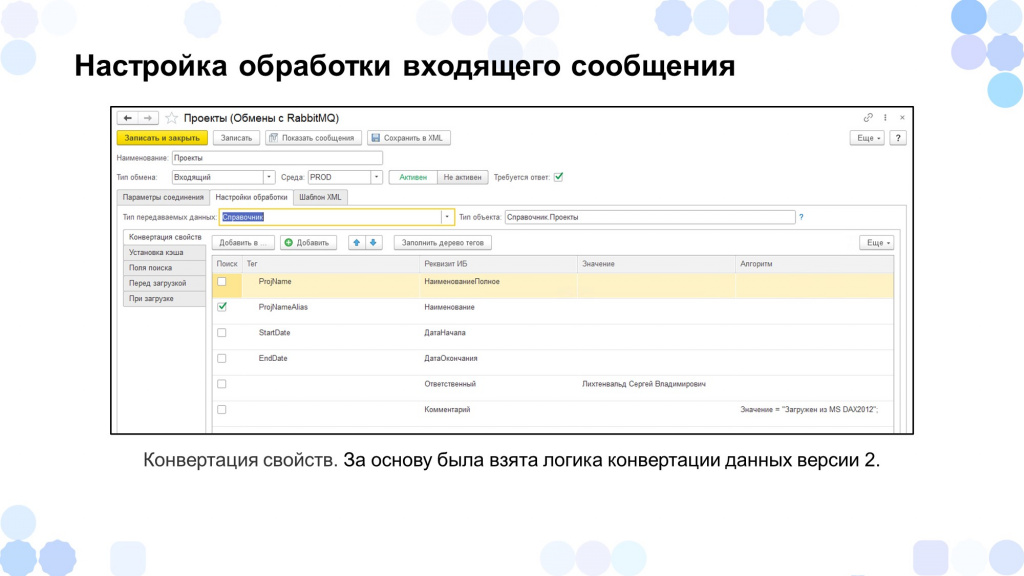
Расскажу, как строилась обработка входящего сообщения.
За основу обработки сообщений мы взяли логику «Конвертацию данных» версии 2, потому что с ней многие разработчики сталкивались, когда переносили остатки из одной системы в другую, и такой вариант показался для нас удобным.
В режиме «Предприятие» мы на вкладке «Настройки обработки» указываем:
-
Тип передаваемых данных – Справочник либо Документ – и тип объекта, который будет обрабатываться.
-
Настраиваем соответствие – какой тег xml в какой реквизит объекта будет записан, если это, например, какие-то примитивные данные.
-
Также мы могли указать поле поиска – отметить галочкой, что по данному реквизиту мы будем осуществлять поиск объекта в системе.
-
Для автоматического заполнения реквизитов, которых нет в системе источника, у нас была колонка значений, где мы могли задать какие-то константные значения.
-
И, если вдруг у нас заполнение какого-то реквизита требовало каких-то сложных преобразований, можно было использовать колонку «Алгоритмы» – в нее в режиме «Предприятие» мы могли написать небольшой код для заполнения какого-то реквизита объекта.
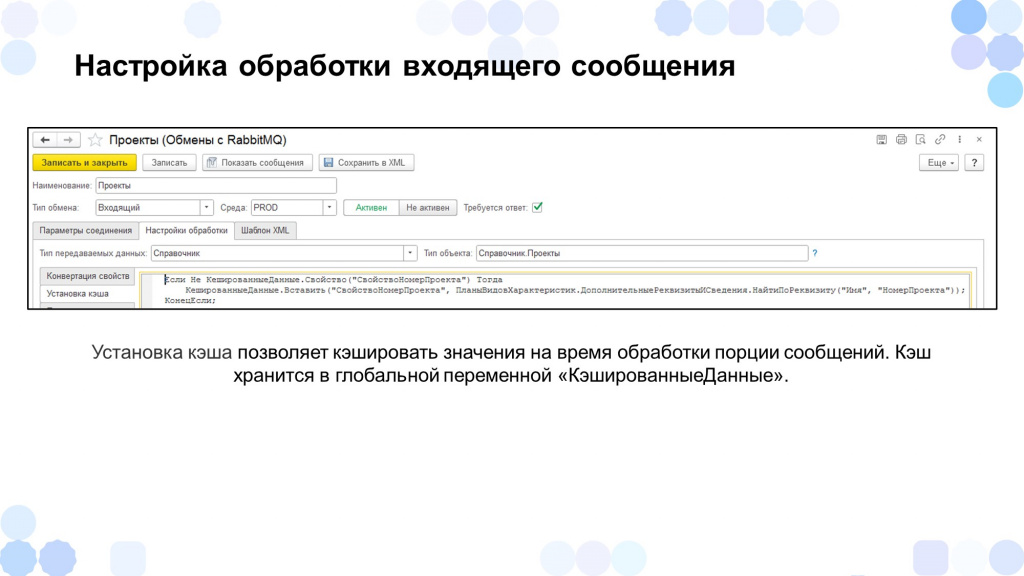
Также у нас была вкладка «Установка кэша» – она использовалась для хранения каких-то константных значений на время обработки порции сообщений. Это было сделано для оптимизации.
В данном примере мы сохраняем значение «СвойствоНомерПроекта», чтобы затем к нему обратиться на момент обработки интеграционного сообщения.
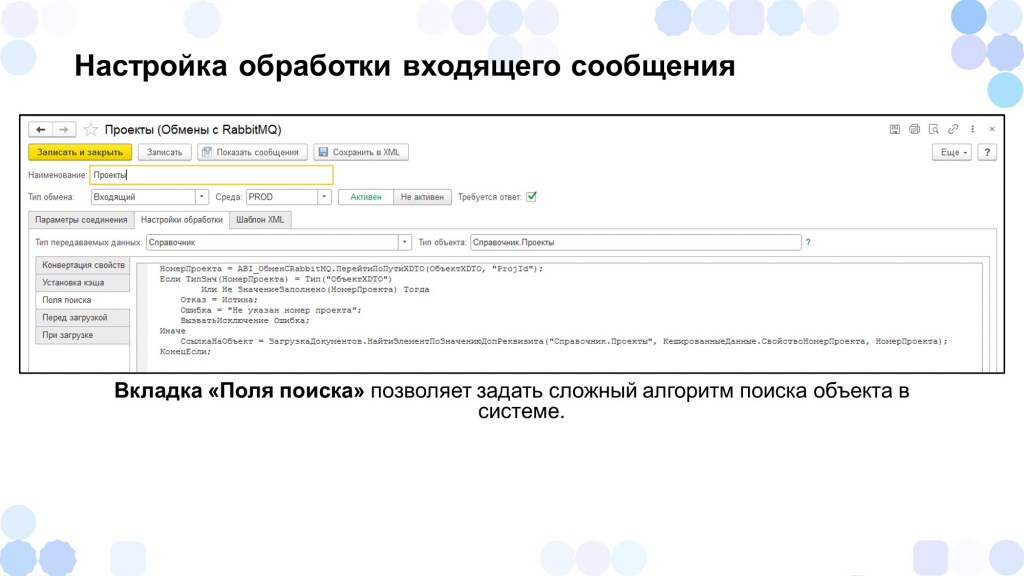
Также мы могли выполнить с интеграционным сообщением какие-то преобразования – например, если по полям поиска объект не найден, мы могли написать какой-то код либо запрос для сложного поиска объекта. Например, в данном случае мы ищем объект по свойству «НомерПроекта».
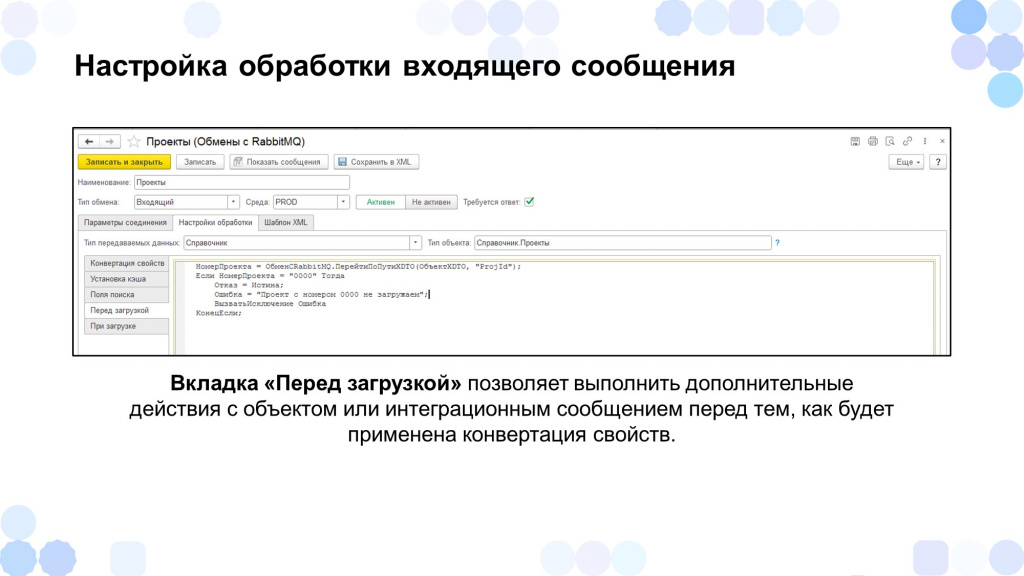
Перед загрузкой мы тоже могли сделать какие-то преобразования с интеграционным сообщением.
Например, если код проекта «0000», мы отказываемся от его загрузки и записываем в сообщение ответ, что мы такие данные загружать не будем.
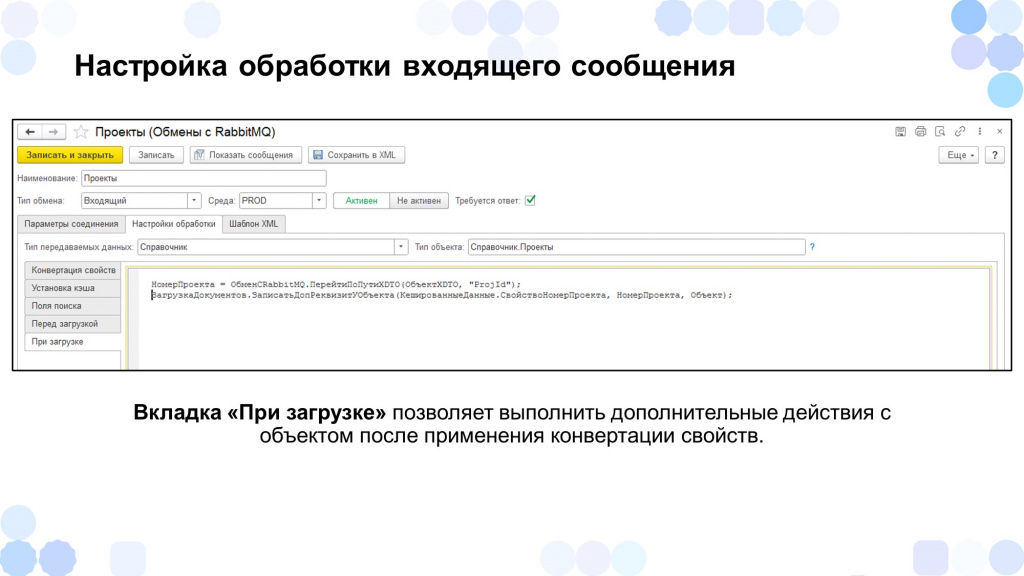
Также при загрузке мы могли выполнить уже какие-то преобразования с самим объектом – например, мы записываем в допсвойства номер проекта.
Все преобразования мы выполняли именно в режиме «Предприятие», практически без участия конфигуратора.
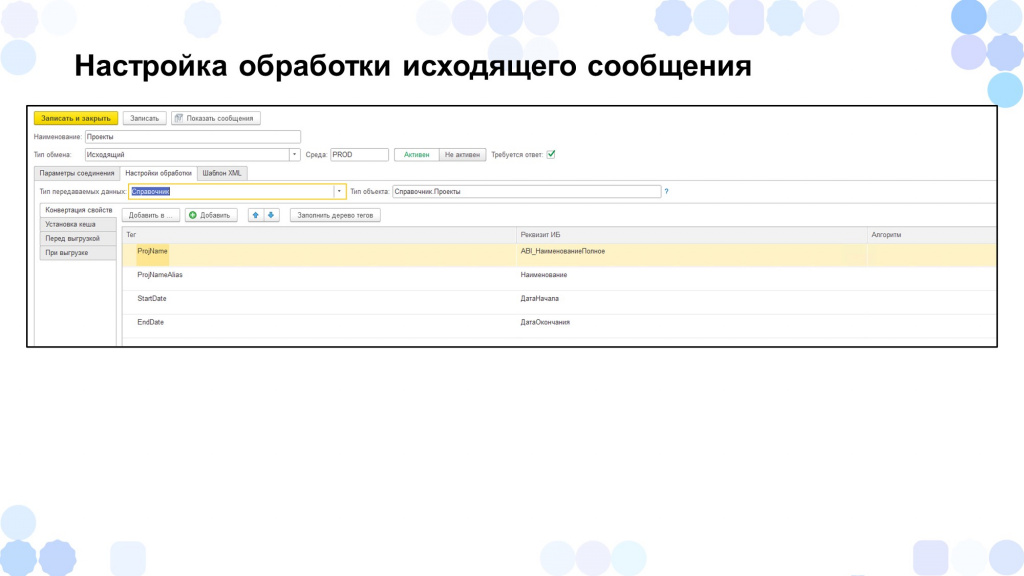
Настройка обработки исходящего сообщения практически ничем не отличалась от обработки входящего.
Здесь мы, наоборот, указывали, в какой-то тег xml какое значение реквизита объекта будет записано, и на основании него уже будет построено интеграционное сообщение.
Результаты

Что в итоге мы получили от унификации обменов:
-
Данные у нас интегрируются онлайн без участия пользователей – данные, которые зарегистрированы в течение 2-3, 10-15 минут, в зависимости от факторов, приходили в систему-приемник автоматически.
-
Мы высвободили ресурсы бухгалтеров и операторов, которые раньше занимались выгрузкой либо загрузкой данных – данные у нас интегрируются онлайн, и им ничего не надо больше делать.
-
Мы организовали мониторинг в виде оповещений об ошибках – если вдруг какие-то ошибки возникали, нам сразу же приходили оповещения об ошибках, и мы сразу же на них реагировали, уменьшая количество обращений к нам в службу.
-
Обмены у нас унифицированы по одному формату и по одному алгоритму.
-
Плюс мы получили единое окно по документации – можно дать документацию новому человеку, он мог спокойно почитать и понять, как это работает.
-
Мы снизили квалификацию разработчиков, потому что для написания обменов им необходимо было знать только «Конвертацию данных 2». Не нужно было знать никакие веб-сервисы, HTTP-сервисы – просто нужно было знать, как настроить обмен. Причем некоторые обмены мог написать даже сам аналитик – если вдруг это какой-то небольшой обмен справочной информации из двух систем – ему необходимо было только настроить соответствие полей объекта, и все.
-
Данное решение было сделано как расширение и встраивалось в любую конфигурацию на 8.3 – мы его использовали в ERP, в ТОИР, в ЗУП и в некоторых других системах.
-
Получили масштабируемость обменов. Если вдруг у компании открывалось новое направление деятельности, нам достаточно было только изменить дизайн интеграции, чтобы нам в Rabbit добавили новую очередь. Мы становились подписчиком на этот обмен, копировали в справочнике обменов логику загрузки этого объекта и немного модифицировали состав обмена под это направление бизнеса.

Конечно, у нас были проблемы и факапы.
-
Самым узким горлышком было то, что приходилось обучать аналитиков написанию xsd-схем. Многие, конечно, с этим были не знакомы – уходило до 40 часов, чтобы обучить аналитиков написать схему.
-
Также возникали проблемы, когда какая-то другая служба меняла xsd-схему интеграционного сообщения – нам об этом никто не говорил, и у нас сразу же возникала ошибка в обмене. Благодаря мониторингу мы на это быстро реагировали, но это все равно нужно было переносить это согласовано, поскольку сериализация в xsd и проверка по схеме происходили на нашей стороне.
-
При длительных обновлениях в системах накапливалось большое количество объемов данных для обработки – от этого тоже никуда не деться. Возможно, нам в будущем стоит перейти на многопоточную обработку данных из RabbitMQ.
-
И еще был случай, когда мы вычитали данные из прода RabbitMQ в тестовую 1С, и потом очень много времени потратили, чтобы найти те сообщения и переотправить их. Естественно, потом в тестовой 1С реализовали блокировку отправки.

Немного в показателях обмена в цифрах:
-
Объем передаваемых данных через данный механизм в месяц – где-то 465 тысяч объектов.
-
Скорость отправки данных в RabbitMQ была где-то 230 сообщений в секунду;
-
На данную архитектуру было переведено где-то 237 тысяч объектов обмена – это справочники, документы.

Приведу список полезной информации, позволившей мне, как аналитику со стороны 1С, спроектировать данное решение, а также ссылки на инструменты, которые мне помогали в описании обменов:
-
Курс по написанию запросов.
-
Курс по «Конвертации данных 2», чтобы хотя бы понимать, как этот механизм работает.
-
Статья «Что такое RabbitMQ» – небольшое описание о том, что из себя представляет сам RabbitMQ, и как он работает;
-
Статья «Установка RabbitMQ» – о том, как вообще развернуть сервер RabbitMQ. После 10-15 минут прочтения вы можете спокойно попробовать у себя это сделать.
-
Информация об описании xsd-схем – как вообще это делается.
Вопросы и ответы
Как вы решали проблему, что в регламентированном учете данные должны на 100% соответствовать системе, откуда вы загружаете данные? Как часто вы сверяете и как этот процесс вообще построен?
Процесс сверки был сделан на другой системе, с которой у нас организован обмен с получением данных по запросу. Данная система отправляла в RabbitMQ интеграционное сообщение – допустим, с запросом документов поступления за определенный период.
Она отправляла этот запрос к нам в систему и одновременно в систему источника.
И утром бухгалтер в веб-интерфейсе мог посмотреть, все ли данные у него соответствуют по документам и по оборотке – все ли суммы сходятся.
Какие ключевые поля выбирали для сверки?
Это согласовывалось с бизнесом. Ставилась задача, аналитик встречался с бизнесом, спрашивал, какие им нужны поля. Потом мы составляли ТЗ, что берем такие-то поля в системе источнике, и по таким-то полям будем сопоставляться с системой приемника. Если ТЗ согласовывалось, то именно эти данные мы забирали.
Вы понимаете пределы этой системы, когда нужно будет придумать что-то еще?
У нас все-таки была центральная НСИ, и идентификаторы справочной информации во всех системах были одинаковыми, мапились без проблем.
Сейчас есть продукт 1С:Шина. Оглядываясь назад на практику, которую вы прошли, вы взяли бы эту же архитектуру или все-таки 1С:Шина?
1С:Шина – это немного другое. Она сама данные берет из системы и их трансформирует.
Я с самой 1С:Шиной не работал, не знаю, как она точно работает, но не думаю, что она с той же Axapta быстро задружит.
Мы разработали именно универсальный обмен, который нам спокойно позволял обмениваться с различными системами – в каких-то случаях без программирования.
Я не думаю, что сейчас на рынке мы найдем много специалистов, которые с той же 1С:Шина работали. Мне кажется, проектов-то еще с ней мало, наверное.
Рассматривали ли взять за основу для разработки своей xsd-схемы Enterprise Exchange Data? Либо посмотрели и сказали, что точно нет?
Да, мы посмотрели и сказали, что точно нет.
Enterprise Data все-таки больше настроена именно на логику и на структуру 1С-документов и справочников – она нам не подходила, потому что мы обменивались с различными системами, у которых структура объектов разная.
Нам нужно было придумать универсальное интеграционное сообщение объекта, которое подходило бы ко всем учетным системам.
Если бы мы говорили только про обмен между системами 1С, это подходило бы. Но у Enterprise Data есть еще один минус – 1С часто обновляет этот протокол, а в системах, которые давно не обновляются, используется протокол старого формата. Приходилось бы часто адаптировать их под новый формат.
Вы в начале доклада перечисляли, что у вас были интеграции на основе «Конвертации данных 2.0». И это удобная система, она позволяет выгружать данные большого массива. Но RabbitMQ это все-таки брокер сообщений. Он призван выгружать данные маленькими пакетиками? Как вы решили эту проблему? В «Конвертации данных» можно задавать правила и выгружать объекты ссылочного типа, когда в реквизитах документа используются ссылки на справочники, у которых в реквизитах тоже ссылки на справочники и так далее. Эта цепочка раскручивается. И получается на выходе, что данные могут выгрузиться за неделю, и это будет огромный пакет. Вы разбивали каким-то образом эти объекты? Если разбивали, то в каком порядке?
В «Конвертации данных» мы документ записываем, он регистрируется к обмену. И когда прошел определенных промежуток времени – например, 10 минут – и за это время у нас зарегистрировалось тысяча объектов. Получилось большое интеграционное сообщение – тысяча объектов у нас поехала.
А у нас, если документ в системе отражается, он сразу улетает в RabbitMQ. Мы для каждого объекта формируем одно сообщение – один пакет. Естественно, сообщения получаются маленькие.
Получается, что мы грузим один к одному. Например, если мы тысячу документов записали, у нас будет тысяча сообщений в RabbitMQ – не будет одного большого сообщения, будет тысяча сообщений, но маленьких.
А сопутствующая справочная информация?
Справочная информация интегрируется отдельно. У нас есть центральная НСИ, которая отправляет нам данные сначала по новым контрагентам, по изменению контрагентов, договоров, номенклатуре.
У каждого объекта свой уникальный ключ, который во всех системах единый. По этому ключу как раз и производится сопоставление – поиск этих объектов в других системах.
Перед тем, как выгружать документы, естественно, надо сначала провести работу с нормативно-справочной информацией, чтобы она была одинаковой во всех системах.
Но если грузить по одному документу, при загрузке схемы XML возникают большие затраты по производительности. Она же подгружается каждый раз – и при выгрузке, и при загрузке. На тысячу документов – тысячу раз одно и то же.
Нет, у нас получалось, что она один раз подгружалась и кешировалась. На момент обработки тысячи документов схема XML в памяти уже была – один раз подгрузили, закешировали ее и обработали данные.
Был ли вас механизм мониторинга и контроля статусов обмена в процессе оперативной работы?
Мониторинг обязательно нужен, конечно. У нас была выделена отдельная служба, которая отвечала именно за мониторинг обменов. Они собирали из RabbitMQ показатели по активным обменам: приходят ли туда данные, забираются ли оттуда данные
Если они видели, что данные в обмен приходят, но очередь не уменьшается, они понимали, что в системе источника что-то происходит. Тогда они сигнализировали: «Посмотрите, что с вами происходит, почему вы данные из этих очередей не забираете»
*************
Статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART Анализ & Управление в ИТ-проектах.

Вступайте в нашу телеграмм-группу Инфостарт