


Ранее мы искали проблемы через поиск длительных запросов и рассматривали событие технологического журнала DBPOSTGRES (5 простых шагов и 15 минут на разворачивание инструмента мониторинга проблем производительности базы 1С), сейчас поговорим про поиск проблем через длительные операции исполнения кода 1С на сервере.
CALL - это входящий удаленный вызов (на стороне приемника). Мы запросили с клиента что-то на сервер.
SCALL - исходящий серверный вызов. Например, rphost обратился к rmngr. Более подробная информация по этим событиям находится на ИТС.
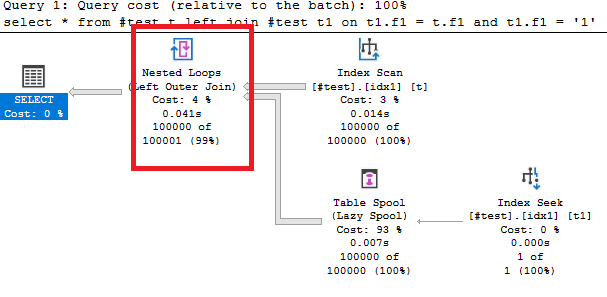
Иными словами мы нажали на кнопочку на форме, по вызову которой на сервере выполняется некоторая последовательность действий. А интервал от начала вызова до момента возврата результата является временем действия этого события. И теперь мы хотим сохранять все события, при условии что время работы их будет больше определенного порога, например, в 5 с.
1. Настройка технологического журнала
Прежде всего нам потребуется настроить технологический журнал на сбор событий. Ниже приведен пример для сбора вызовов CALL, которые выполняются больше 5 с.
<?xml version="1.0" encoding="UTF-8"?>
<config xmlns="http://v8.1c.ru/v8/tech-log">
<log location="C:\LOGS\CALL" history="12">
<event>
<eq property="Name" value="CALL"/>
<ge property="Durationus" value="5000000"/>
</event>
<property name="all"/>
</log>
</config>
Замечание! Для настройки сбора серверных вызовов следует использовать название события - SCALL.
Вторым шагом нам нужно будет настроить замер в конфигурации мониторинг производительности, чтобы получить готовый разобранный результат технологического журнала в удобном формате. При желании вы можете использовать и другие инструменты.
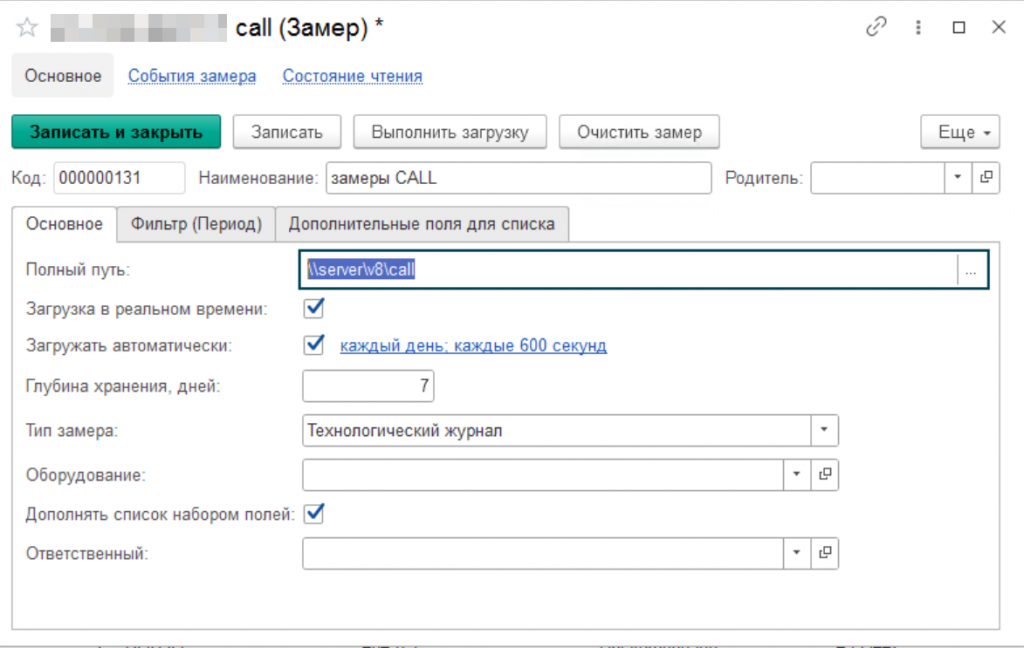
Рис. Добавление замера событий CALL
Теперь мы можем начать анализировать длительные вызовы и переходим к следующему разделу.
2. Поиск проблем
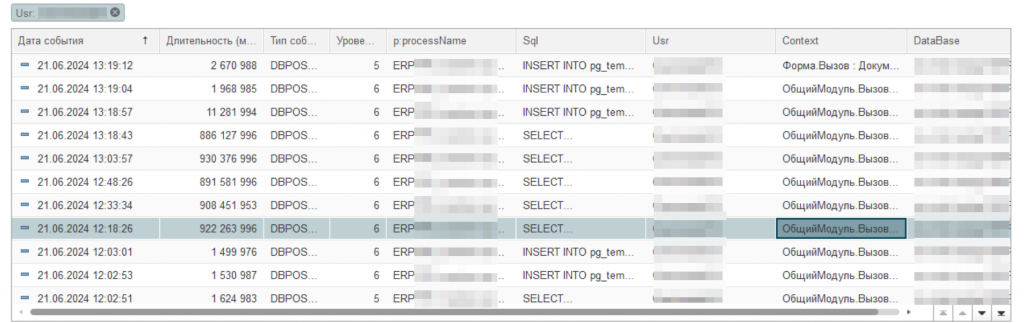
Через некоторое время после настройки у нас должны появиться данные, которые следует проанализировать. При беглом просмотре результатов, нами было обнаружено несколько событий, которые вызывают серьезные вопросы к быстродействию системы. Рассмотрим первое событие, которое выделено на рисунке ниже. Время выполнения составляет порядка 4 567с или около 1,5 ч.

Рис. События CALL
Теперь давайте посмотрим, были ли какие-нибудь длительные запросы внутри интервала CALL. У нас сбор таких событий конечно же настроен. В этом случае, достаточно просто сделать отбор по пользователю и интервалу. Интервал у нас получился = 12:00-13:19. Начало интервала = время окончания за минусом длительности события.
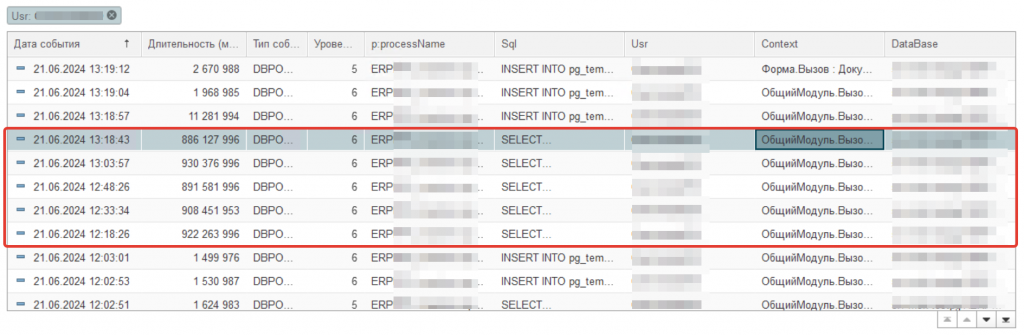
Рис. Длительные запросы DBPOSTGRES в интервале события CALL
Как мы видим внутри временного интервала находятся целых пять длительных запроса. Если посмотреть контекст каждого, то можно выяснить, что все они обращаются к функции "СуммыПоЗаказам" модуля менеджера документа "Реализация товаров и услуг".

Рис. Context события картинка
Теперь откроем конфигуратор и посмотрим что это за запрос такой. В глаза бросаются сразу две части, которые приводят и могут приводить к проблемам. Они выделены на рисунке ниже красными прямоугольниками - это обращение к полям через точку от составного типа. И еще одно потенциально проблемное место - вложенный запрос.
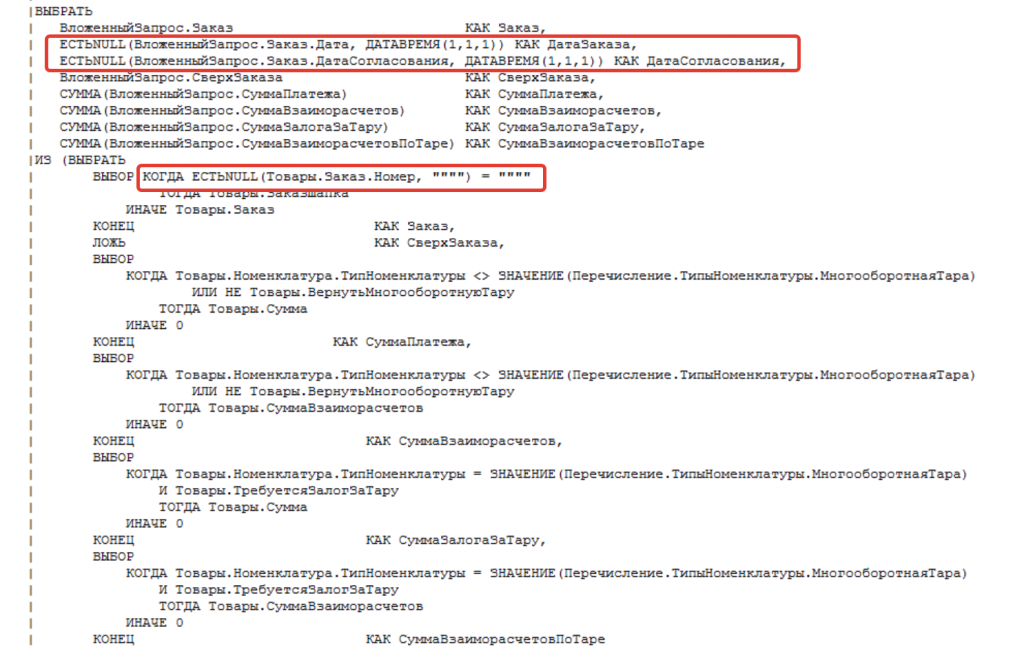
Рис. Текст проблемного запроса с выделенными проблемными местами
3. Анализ проблемы
1) Рассмотрим сначала обращение через точку внутри вложенного запроса. Что разработчики хотели добиться вот таким условием "ЕСТЬNULL(Товары.Заказ.Номер, """")"?
Поле "Заказ", которое в документе соответствует реквизиту "ЗаказКлиента" может содержать ссылку или не содержать. Получается если у нас ссылка будет пустая, то получение данных через точку даст нам NULL. Иными словами проверяется заполнен заказ клиента в шапке или в табличной части.
Замечание! Если документ создан по нескольким заказам, то этот реквизит в табличной части заполняется и взводится флаг в шапке "РеализацияПоЗаказам". Если же один заказ клиента, то заполняется реквизит шапки "ЗаказКлиента".
Иными словами разработчики вместо того чтобы использовать флаг "РеализацияПоЗаказам", который собственно и предназначен для определения где находится ссылка на заказ придумали такую необычную конструкцию. Возможно данный флаг не всегда соответствует вышеуказанному описанию, тогда на него действительно полагаться не следует. Отсюда два вывода:
- С моей точки зрения, было бы удобнее всегда заполнять реквизит заказа в табличной части товары.
- Переписать конструкцию на проверку флага "РеализацияПоЗаказам".
2) Вообще получение данных через точку от поля составного типа, как вы знаете, заставляет платформу добавлять соединения со всеми таблицами, которые находятся в составе. А ситуацию усугубляет еще накладывание RLS на эти таблицы, таким образом общий вред наносимый таким подходом на производительность усиливается. Ну и как вишенка на торте у нас еще выполняется группировка по этим полям)
3) К тому же использование вложенных запросов может дополнительно влиять на снижение производительности. Читатель скажет, там же используется временная таблица, а для временной таблицы статистика рассчитывается, поэтому сильного влияния быть не должно. Это было бы так, если бы не получение через точку от поля составного типа. А в текущем случае у нас получается соединение временной таблицы с двумя таблицами - заказы клиентов и возвраты товаров от клиентов. Поэтому получается ситуация не однозначная, а фактически планировщик ошибается (что рассмотрено ниже).
4) Следующий вопрос - почему данный одинаковый запрос с точки зрения SQL выполняется целых пять раз, возможно тут присутствует ошибка реализации и можно сократить количество вызовов. Для этого требуется проанализировать код более подробно. Вполне возможно, что при разработке этого механизма использовалась демонстрационная база, в которой десять документов и подобная проблема просто не могла "выстрелить".
Теперь посмотрим план запроса и посмотрим что на нем не так.
План запроса выглядит так https://explain.tensor.ru/archive/explain/2ff0449484417331128cb2c0a0b82e4e:0:2024-06-21#explain
С точки зрения плана запроса мы понимаем, что в данном случае довольно сильно ошибается планировщик Postgres.
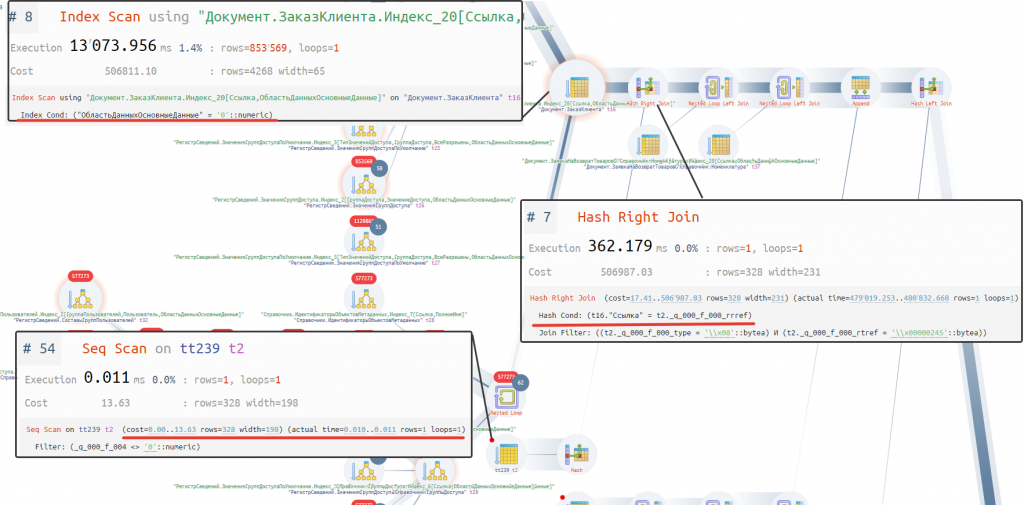
Рис. Часть графического плана запроса
Объясним почему:
- если мы посмотрим на оператор чтения данных из временной таблицы (#54), то мы видим что оценочное количество строк 328, а фактическое 1. Не верная оценка, хотя платформа выполняет анализ временной таблицы.
- оператор получения данных из индекса заказа клиента (#8) использует условие поиска по индексу, только области данных, а нужно было бы по ссылке. Разделители не используются, поэтому таблица будет прочитана полностью, что не эффективно.
- используется оператор соединения хешированием (#7), с условием по ссылке, хотя достаточно было соединения циклами.
Иными словами написали запрос не очень и получили результат выполнения такой же. И подобных ситуаций в одной из предпоследних версий ERP достаточно много. Она может выстрелить, а может и не выстрелить. На мой скромный взгляд, следует переписать подобный запрос для снижения вероятности проблем.
Заключение
Использование анализа длительных вызовов CALL, SCALL позволит вам выделить места в коде 1С, которые занимают достаточно много времени и заняться оптимизацией подобных участков кода. Используйте подобные замеры в дополнении к контролю длительных запросов.
Вступайте в нашу телеграмм-группу Инфостарт