





















- Постановка задачи
- Заполнение документа "Резервы по оплате труда" в базе ЗУП
- Описание проблемы
- Как планировщик делает оценку по таблицам без статистики
- Как работает платформа с временными таблицами, создаваемыми из таблицы значений
- Решаем проблему с помощью плагина online_analyze
- Расчет себестоимости за период в базе УХ
- Описание проблемы
- Сравниваем данные логов СУБД и "1С"
- Анализируем окружение и готовим скрипты
- Неожиданный результат
- Причины долгой вставки
- Перепроведение документов в базе УХ
- Заключение
Меня зовут Александр Симонов, я руководитель направления развития и поддержки 1С в компании "Тантор Лабс".
В рамках клиентских пилотов по миграции на СУБД Tantor Special Edition 1C мы сопровождаем процесс приемо-сдаточных работ и оказываем поддержку в ходе тестирования.
В данной статье рассмотрим пример доработки СУБД Tantor под потребности 1С, а также расследуем причины медленного выполнения запросов у одного из наших клиентов.
Постановка задачи
Тестовый стенд
Название |
ОС |
ПО |
Конфигурация |
|||||
| Сервер приложений |
|
|
|
|||||
|
|
|
|
|||||
|
|
|
|
Оба сервера СУБД виртуализированы. Они сильно различаются по характеристикам, но организовать равноценные стенды у заказчика не было возможности.
Тестируемые операции:
- Заполнение документа "Резервы по оплате труда" в базе ЗУП.
- Расчет себестоимости за период в базе УХ.
- Перепроведение документов в базе УХ.
Каждая из них сначала выполняется на MS SQL, а затем – на Tantor.
Заполнение документа "Резервы по оплате труда" в базе ЗУП
Описание проблемы
Были получены следующие результаты:
MS SQL – 478, Tantor – 855 сек.
Созвонившись с заказчиком, выясняем, что настройки Tantor у него дефолтные. Настраиваем систему в соответствии с нашими рекомендациями и получаем результат 697 сек.
Разница более 200 секунд, это плохой результат, поэтому начинаем разбираться в причинах. Заказчик собрал технологический журнал и логи СУБД. Проанализировав его, видим, что у нас есть топ запросов, которые долго выполняются.
Все эти запросы характеризует то, что в них идет соединение временных таблиц, отсюда напрашивается вывод: скорее всего, это типичная проблема, когда во временной таблице нет подходящего индекса и оптимизатор неверно выбирает план.
Находим проблемный запрос в логе СУБД, получаем план и видим причину: дело в том, что планировщик неправильно оценил количество строк во временной таблице:

 Но почему планировщик может так ошибаться? Ведь для таблицы должна рассчитываться статистика, т.к. при ее создании платформа 1С сама вызывает команду ANALYZE. Ситуация выглядит странно.
Но почему планировщик может так ошибаться? Ведь для таблицы должна рассчитываться статистика, т.к. при ее создании платформа 1С сама вызывает команду ANALYZE. Ситуация выглядит странно.
После этого мы развернули пустую конфигурацию ЗУП и нашли запросы по проблемному контексту:
|
Документ.РезервыПоОплатеТруда.Форма.ФормаДокумента.Форма : 2403 : Результат = ДлительныеОперации.ЗапуститьВыполнениеВФоне( |
Временные таблицы в этом случае создавались путем передачи таблицы значений как параметра запроса. Мы рекомендовали при создании этих временных таблиц в запросе сразу создать индексы для тех полей, по которым далее идет соединение в проблемных запросах. На это заказчик ответил, что код полностью типовой, и они не готовы его переписывать, но смогут обезличить свою базу и передать нам для анализа.
Полученную базу мы развернули на своем стенде:
Назначение |
ОС |
ПО |
Конфигурация |
|---|---|---|---|
| Сервер приложений | Astra Linux 1.7.5 | Платформа "1С" 8.3.23.1997 | CPU 6, 16 Gb RAM |
| Сервер СУБД | Astra Linux 1.7.5 | "Tantor SE 1C" 15.4 | CPU 4, 16 Gb RAM |
Проблемные запросы у нас выполнялись так же долго, и мы cобрали лог технологического журнала (ТЖ) по событию DBPOSTGRS без фильтра по длительности, и из такого лога причина стала понятна: по временной таблице не была рассчитана статистика. Поговорим немного о ней.
Как планировщик делает оценку по таблицам без статистики
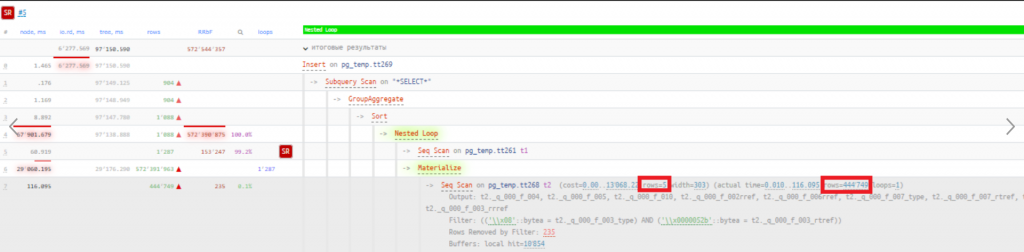
Каким образом планировщик получил оценку в 5 строк (метка 1 на рисунке ниже), если по таблице нет статистики?


В подобных случаях планировщик оценивает количество строк, исходя из размера файла с таблицей и ширины строки (метка 2 на рисунке).
Оценка в 5 строк учитывает наложенные отборы из поля Filter (метка 3 на рисунке). Для колонок, по которым нет статистики, планировщик использует фиксированную оценку – 0.5% от количества строк. У нас отбор накладывается на 2 колонки, и эту оценку планировщик дает для каждой из них. В итоге мы можем получить формулу:
Количество строк в таблице * 0.005 * 0.005 = 5.
Давайте вспомним базовые уроки алгебры и вычислим, сколько, по мнению планировщика, в данной таблице строк (до наложения отборов): 5/(0.005*0.005) = 200 000
Получается, исходя из ширины одной строки и размера файла, планировщик подумал, что в таблице tt268 примерно 200 тысяч строк. После наложения фильтра по указанной выше формуле получается оценка – 5 строк.
Как работает платформа с временными таблицами, создаваемыми из таблицы значений
Давайте вернемся к нашей проблеме и посмотрим какие команды выполняются при создании временной таблицы из таблицы значений.
Такая временная таблица создается конструкцией "COPY pg_temp.tt FROM STDIN BINARY" вместо привычной конструкции "INSERT INTO pg_temp.tt (список колонок) SELECT ... FROM ...", которая используется при создании временной таблицы выборкой из результата запроса.
Создание временной таблицы без индексов
Запрос 1С:
|
ВЫБРАТЬ |
В этом случае на СУБД будут выполнены две команды, согласно данным ТЖ событий DBPOSTGRS:
|
1. Создание временной таблицы tt1 |
В поле RowsAffected содержится количество строк, помещенных в созданную временную таблицу.
Создание временной таблицы с индексом
Если при создании временной таблицы сразу создать в ней индекс, получится следующее:
Запрос 1С:
| ВЫБРАТЬ ТЗ.Поле1 КАК Поле1 ПОМЕСТИТЬ ВТ ИЗ &ТЗ КАК ТЗ ИНДЕКСИРОВАТЬ ПО Поле1 |
В этом случае, по данным ТЖ событий DBPOSTGRS, на СУБД будут выполнены следующие команды:
|
|
| // 1. Создание временной таблицы tt1 Sql='drop table if exists tt1 cascade;create temporary table tt1 (_Q_000_F_000 numeric(12, 2) ) without oids ',RowsAffected=0 // 2. Заполнение ВТ tt1 данными, переданными в запрос как таблица значений Sql=COPY pg_temp.tt1 FROM STDIN BINARY,RowsAffected=4 // 3. Создание временной таблицы tt2 с такой же структурой колонок как и у tt1 Sql='drop table if exists tt2 cascade;create temporary table tt2 (_Q_000_F_000 numeric(12, 2) ) without oids ',RowsAffected=0 // 4. Если существует индекс tmpind_0, удалим его и создадим новый индекс tmpind_0 на временной таблице tt2 Sql=drop index if exists tmpind_0,RowsAffected=0 Sql=create index tmpind_0 on pg_temp.tt2(_Q_000_F_000),RowsAffected=0 // 5. Вставляем во временную таблицу tt2 все записи из tt1 Sql='INSERT INTO pg_temp.tt2 (_Q_000_F_000) SELECT T1._Q_000_F_000 FROM pg_temp.tt1 T1',RowsAffected=4 // 6. Вызываем расчет статистики на временной таблице tt2 Sql=ANALYZE pg_temp.tt2,RowsAffected=0 // 7. Очищаем временную таблицу tt1 Sql="SELECT FASTTRUNCATE ('pg_temp.tt1')",RowsAffected=1 |
Получается, что платформа не выполняет команду ANALYZE по временной таблице (создаваемой в результате передачи таблицы значений в запрос), если при этом в ней сразу не создать индекс.
Возникшую проблему отсутствия статистики на временной таблице можно было бы решить двумя способами:
- При создании ВТ создать индекс.
- Из созданной ВТ переложить данные в новую ВТ, которую далее и использовать.
Доработка кода 1С выглядит не слишком рациональным решением, поэтому посчитать статистику по такой таблице попробуем заставить саму СУБД.
Решаем проблему с помощью плагина online_analyze
Пробуем включить и настроить плагин online_analyze, который как раз и предназначен для того, чтобы выполнять команду ANALYZE, например, для временных таблиц.
Включаем плагин:
| online_analyze.scale_factor = '0.1' online_analyze.table_type = 'temporary' online_analyze.threshold = '50' online_analyze.enable = 'on' online_analyze.min_interval = '10000' |
|
|
Запускаем снова наш тест – результат такой же. Передаем кейс в команду разработки СУБД и в ходе их анализа узнаем, что в плагине не учтена операция создания таблицы методом COPY FROM, поэтому ANALYZE не вызывается.
Команда СУБД доработала плагин online_analyze, чтобы он учитывал этот метод создания таблицы. Пересобрали сборку Tantor, установили ее на свой тестовый контур и после выполнения теста получили следующий план проблемного запроса, в котором оценка строк во временной таблице максимально близка к реальной:


Результат до оптимизации – 97150 мс, после – 346 мс, т.е. стало быстрее в 280 раз благодаря тому, что планировщик правильно посчитал строки во временной таблице и выбрал более подходящий оператор соединения двух таблиц: Hash Join вместо Nested Loops.
На стенде заказчика с новой сборкой Tantor мы получили результат 545 сек., т.е. на 140 сек. быстрее, чем было, но все равно на минуту медленнее, чем на MS SQL.
На своем стенде у нас оказался совсем другой результат – 398 сек., при этом мы еще раз синхронизировались с заказчиком, чтобы убедиться, что время выполнения операции фиксируем одинаковым способом и данные при тестировании у нас и у них совпадают. Стоит также отметить, что для параметра default_statistics_target в наших тестах было установлено значение по умолчанию – 100. Если поставить 1000, все ускорение выполнения запросов нивелировалось временем, уходившим на выполнение команды ANALYZE для временных таблиц: они создавалось в большом количестве и содержали по 100К-400К строк.
Итого получились следующие результаты:
- MS SQL – 478 секунд;
- Tantor после настройки параметров – 697 секунд;
- Tantor c доработкой online_analyze – 545 секунд;
- Tantor на нашем стенде c доработкой online_analyze – 398 секунд.
Длительность на наших стендах сильно различалась, поэтому мы решили собрать ТЖ событий DBPOSTGRS без фильтрации по длительности и сравнить со своими показателями. Получилось, что у нас суммарное время выполнения всех запросов 137 сек., а у заказчика – 208, что наводит на мысль, что на его стенде, возможно, есть инфраструктурная проблема, которая негативно влияет на результаты. С ней мы подробно разбирались при тестировании следующей операции.
Также мы передали информацию по данному кейсу в фирму "1С". Коллеги оперативно сделали доработки, и исправление выйдет в ближайших июльских релизах.
Расчет себестоимости за период в базе УХ
Для данной операции были получены следующие результаты: MS SQL – 80 мин, Tantor – 300 мин.
В кейсе с УХ Tantor тоже не была настроена. Следовало сначала все-таки ее настроить и запустить повторно: это уберет часть проблем, и мы получим результат, с которым дальше можно работать. Также мы рекомендовали заказчику установить наш последний релиз 15.6 с оптимизациями для "1С".
После этого длительность уменьшилась до 241 мин.
Далее нужно было убедиться, что проблема именно в СУБД, и в этом нам помог собранный ТЖ событий DBPOSTGRS.
Проанализировали его следующим скриптом:
|
Данный скрипт сначала считает общую длительность всех событий DBPOSTGRS, а затем расшифровывает ее до поля t:clientID. Получился вот такой результат в микросекундах:
| DBPOSTGRS - 14736293002 t:clientID=213 - 1253903 t:clientID=1760 - 46007 t:clientID=1761 - 29848 t:clientID=1753 - 9047605 t:clientID=1764 - 46940 t:clientID=212 - 14725868699 |
Общая длительность составила 245 минут, она возросла из-за того, что был проанализирован лог за 5 часов, куда попали и другие события до и после запуска теста.
В разрезе t:clientID видно, что 99.9% времени ушло на одно соединение, т.е. операция не выполнялась многопоточно, и мы можем сделать вывод, что проблема на стороне СУБД.
Группируем логи ТЖ по запросу и контексту и видим: явного лидера по времени, который бы занимал львиную долю всех 245 минут, нет, но обращает на себя внимание то, что в топе элементарные запросы, например, вставка одной записи в таблицу:
Общая длительность, сек |
Длительность одного выполнения, сек |
Количество выполнений |
Запрос |
Комментарий |
|---|---|---|---|---|
|
129.7 |
0.61 | 210 | INSERT INTO _InfoRg50972 (<Список полей>) VALUES(<Список значений>) | РегистрСведений.ВерсииОбъектов |
| 93.9 | 1.51 | 62 | INSERT INTO _AccRg69297 (<Список полей>) VALUES(<Список значений>) | Основная таблица регистра бухгалтерии |
| 84 | 1.87 | 45 | INSERT INTO _AccumRg68395 (<Список полей>) VALUES(<Список значений>) | Регистр накопления связанный с производством |
Может показаться, что вставка идет долго из-за большого размера версии объекта, но в других примерах, по логике, блобов нет, а также в логе ТЖ есть и другие элементарные запросы типа выборки по ссылке, выполняющиеся по 15 мс, которые, по опыту, должны занимать менее 1 мс:
| SELECT T1._IDRRef, T1._Description FROM _Reference559 T1 WHERE ((T1._Fld2931 = CAST(0 AS NUMERIC))) AND (T1._IDRRef = '\\201\\255\\000PV\\221\\375\\027\\021\\356R\\347#[\\253\\262'::bytea) |
Сравниваем данные логов СУБД и 1С
В этот момент появилось множество теорий, в чем может быть проблема, и для сужения круга поиска решили сделать так:
- Собрать планы запроса, чтобы если время выполнения там будет такое же, увидеть, на что оно тратится. Устанавливаем auto_explain.log_min_duration в 5 мс.
- Не обязательно перезапускать весь тест. Достаточно провести один документ, который создает версию объекта.
Попросили заказчика это сделать и прислать логи ТЖ и СУБД.
Проанализировав эти логи на примере проведения одного документа, получили следующий результат:
Вставка в регистр накопления (версия объекта не создалась, поэтому для анализа мы взяли другой запрос), по данным ТЖ, занимает 844 мс, а в данных плана запроса из лога СУБД – 15 мс. На предыдущем месте работы я сталкивался с кейсом, когда сетевое взаимодействие между СП и СУБД было организовано не по выделенному для этого каналу, а по общей сети и приводило к такой же ситуации. Поэтому подозрение упало на сеть, но мы решили проверить и другое окружение.
Анализируем окружение и готовим скрипты
Антивирус на тестовой СУБД не стоял, но выяснилось, что Astra Linux установлена в самом защищенном варианте —"Смоленск":


На своем стенде мы развернули еще одну ВМ под СУБД с Astra Linux с уровнем защищенности "Смоленск", чтобы сравнить ее с Astra Linux в базовом режиме работы СЗИ ("Орел"). Провели внутренние нагрузочные тесты на базах 1С и выяснили, что выбор варианта "Смоленск" на производительности СУБД никак не сказывается.
Клиент для тестирования также переразвернул ВМ с СУБД, но уже под Astra Linux в режиме "Орел" и провел тест еще раз — результат не изменился.
Мы вернулись к гипотезе с сетью и разработали план диагностики.
Для СП на Windows Server использовали скрипт для диагностики времени отклика и потери пакетов к серверу СУБД:
| while (1 -eq 1) {$IP = "localhost"; $FullStat = 1; $Fname = "D:\Bases\Ping_"+$IP.Replace(".","_")+".txt"; $Expr = "ping "+$IP+" -n 1 -l 65500"; $S = invoke-expression $Expr; $S = [String]$S; $P = $S.IndexOf("=65500 "); if ($FullStat -ne 1 -and $P -ne -1) {$S = $S.Substring($P+7)}; $P = $S.IndexOf("Статистика Ping"); if ($P -eq -1) {$P = $S.IndexOf("Ping statistics")}; if ($P -ne -1) {$S = $S.Substring(0,$P)}; $timestamp = "{0:yyyy-MM-dd HH:mm:ss}" -f (get-date); $Res = $timestamp+" "+$S; Add-Content -Path $FName -Value $Res -Force; Start-Sleep -s 1} |
Идея и сам скрипт взяты из кейса Виктора Богачева.
Скрипт каждую секунду выполняет команду ping до хоста localhost с размером пакета 65500 байт и сохраняет лог по пути D:\Bases\Ping_localhost.txt. В самом скрипте перед запуском нужно только поменять localhost на IP сервера СУБД и путь сохранения файла.
Для сервера СУБД на Astra Linux составили вот такие скрипт и план действий:
| 1. Запускаем команду ping до нужного хоста (вместо localhost указать адрес сервера "1С") с размером пакета 64000 байт и количеством повторений 16000, что занимает 266 минут (немного больше, чем длительность теста). Результат команды ping пишем в файл ping.txt ping localhost -v -s 64000 -c 16000 | while read pong; do echo "$(date): $pong"; done > ping.txt 2. После запуска нажимаем Сtrl+z и прерываем выполнение команды. 3. Далее выполняем команду bg "%ping", чтобы запустить выполнение прерванной команды ping в фоновом режиме. 4. Проверить, запустилась ли задача в фоновом режиме, можно выполнив команду jobs. Должно появиться следующее сообщение: [1]+ Запущен ping localhost -v -s 64000 -c 16000 | while read pong; do echo "$(date): $pong"; done > ping.txt & 5. Дожидаемся ее выполнения и смотрим результаты в файле ping.txt |
Также мы хотели проверить с помощью утилиты atop утилизацию диска во время теста:
| 1. Устанавливаем atop: apt-get install atop 2. Настраиваем ее конфигурацию: sudo vi /etc/default/atop. 3. Добавляем параметры: LOGOPTS="-R" – анализ активности процессов на сервере; LOGINTERVAL=5 – новые данные будут добавляться в журнал каждые 5 секунд; LOGGENERATIONS=28 – система будет сохранять 28 поколений журналов, что обеспечит достаточно много данных для анализа ее активности; LOGPATH=/var/log/atop – путь к каталогу с логами atop. 4. Перезапускаем службу: sudo systemctl restart atop.service. 5. Проверяем работоспособность командой atopsar -d (должна отобразиться статистика по диску) с интервалом снятия в 5 сек. 6. После проведения теста сохраняем данные atop в файл, выполнив команду sudo atopsar -d > disk.txt. |
Договорились с клиентом еще об одном тесте, подключились, вместе настроили сбор данных по диску и сети, запустили процесс.
И получили результат 19.8 минут вместо 241, а при повторном тестировании на MS SQL – 20 минут вместо 80!
С прошлого раза, когда результаты были совершенно иными, прошло более 3 недель, и мы спросили у клиента, что он поменял в своей инфраструктуре, но ответить на этот вопрос он не смог.
Кстати, мы собрали данные по сети, и в них время отклика оказалось отличное, а потерь не было. Вот примеры:
СП→ СУБД:
| 2024-05-08 11:22:55 Обмен пакетами с * по с 65500 байтами данных: Ответ от *: число байт=65500 время=1мс TTL=64 Статистика Ping для *: Пакетов: отправлено = 1, получено = 1, потеряно = 0 (0% потерь) Приблизительное время приема-передачи в мс: Минимальное = 1мсек, Максимальное = 1 мсек, Среднее = 1 мсек 2024-05-08 11:22:56 Обмен пакетами с * по с 65500 байтами данных: Ответ от *: число байт=65500 время=1мс TTL=64 Статистика Ping для *: Пакетов: отправлено = 1, получено = 1, потеряно = 0 (0% потерь) Приблизительное время приема-передачи в мс: Минимальное = 1мсек, Максимальное = 1 мсек, Среднее = 1 мсек 2024-05-08 11:22:57 Обмен пакетами с * по с 65500 байтами данных: Ответ от *: число байт=65500 время=1мс TTL=64 Статистика Ping для *: Пакетов: отправлено = 1, получено = 1, потеряно = 0 (0% потерь) Приблизительное время приема-передачи в мс: Минимальное = 1мсек, Максимальное = 1 мсек, Среднее = 1 мсек 2024-05-08 11:22:58 Обмен пакетами с * по с 65500 байтами данных: Ответ от *: число байт=65500 время=1мс TTL=64 Статистика Ping для *: Пакетов: отправлено = 1, получено = 1, потеряно = 0 (0% потерь) Приблизительное время приема-передачи в мс: Минимальное = 1мсек, Максимальное = 1 мсек, Среднее = 1 мсек 7 |
СУБД→СП:
| Ср мая 8 11:22:55 MSK 2024: 64008 bytes from *: icmp_seq=616 ttl=64 time=0.067 ms Ср мая 8 11:22:56 MSK 2024: 64008 bytes from *: icmp_seq=617 ttl=64 time=0.073 ms Ср мая 8 11:22:57 MSK 2024: 64008 bytes from *: icmp_seq=618 ttl=64 time=0.073 ms Ср мая 8 11:22:58 MSK 2024: 64008 bytes from *: icmp_seq=619 ttl=64 time=0.068 ms |
Причины долгой вставки
Спустя несколько недель на нашем внутреннем нагрузочном тесте воспроизвелась та же ситуация с долгой вставкой в таблицу – один в один как у заказчика.
Событие DBPOSTGRS из лога ТЖ 1С – длительность 779 мс:
|
Запрос по логу СУБД (логируется с помощью настройки log_min_duration_statement) – длительность 779 мс:
|
2024-06-09 22:28:25.936 MSK [45145:4/111579] [erp_v] 192.168.5.210(37428) [н/д] СООБЩЕНИЕ: продолжительность: 779.114 мс выполнение <unnamed>: INSERT INTO _InfoRg38221 (_Fld38222RRef,_Fld38223,_Fld38224,_Fld38225,_Fld38226,_Fld38227,_Fld38228,_Fld38229,_Fld38230,_Fld38231,_Fld38232,_Fld38233) VALUES($1,$2,$3,$4,$5,$6,$7,$8,$9,$10,$11,$12) |
План запроса (логируется с помощью плагина auto_explain) – длительность 0.135 мс:
| 2024-06-09 22:28:25.935 MSK [45145:4/111579] [erp_v] 192.168.5.210(37428) [н/д] СООБЩЕНИЕ: duration: 0.135 ms plan: Query Text: INSERT INTO _InfoRg38221 (_Fld38222RRef,_Fld38223,_Fld38224,_Fld38225,_Fld38226,_Fld38227,_Fld38228,_Fld38229,_Fld38230,_Fld38231,_Fld38232,_Fld38233) VALUES($1,$2,$3,$4,$5,$6,$7,$8,$9,$10,$11,$12) Insert on _inforg38221 (cost=0.00..0.01 rows=0 width=0) -> Result (cost=0.00..0.01 rows=1 width=209) |
На "Инфостарте" эту проблему уже рассматривали в статье "Сказ о том, как online_analyze INSERT "удлинял", и в нашем случае причина была в том, что в параметр shared_preload_libraries был добавлен online_analyze, по умолчанию включенный для всех типов таблиц: online_analyze.table_type = 'all'. Чтобы его выключить, необходимо явно указать параметр online_analyze.enable = 'off' либо поменять тип анализируемых таблиц только на временные: online_analyze.table_type = 'temporary'.
Но почему analyze вызывается при каждой вставке в таблицу регистра сведений, в котором 8 млн записей? Выглядит избыточно.
Читаем документацию к плагину, чтобы понять, в каких случаях это может происходить:
- lower_limit – минимальное число строк в таблице, при котором будет срабатывать online_analyze, по умолчанию 0;
- threshold – минимальное число изменений строк, после которого может начаться немедленный анализ, по умолчанию 50.
- scale_factor – процент от размера таблицы, при котором начинается немедленный анализ, по умолчанию 0.1.
У нас все значения были дефолтными, и подходил параметр lower_limit: по умолчанию он настроен так, что при любой вставке должен вызываться analyze.
Меняем его на 10 млн, перезапускаем тест со вставкой одной записи – без изменений, analyze все равно вызывается. По значениям параметров threshold + scale_factor analyze должен вызываться, если изменили 5 записей, но ради интереса мы поменяли значение threshold на 10 млн и опять получили вызов analyze при вставке одной записи.
Похоже на баг, требуется анализ исходного кода, чтобы понять, почему так происходит. При появлении новой информации обновим данную статью.
А пока мы решили в следующем релизе "Tantor SE 1C" по умолчанию изменить значение параметра online_analyze.table_type с 'all' на 'temporary', чтобы уменьшить вероятность неправильной настройки плагина.
Перепроведение документов в базе УХ
Описание проблемы
В этом кейсе тестировалось перепроведение большого количества различных видов документов, и получены следующие результаты:
MS SQL – 230 минут, Tantor – 510 минут.
При повторном прогоне мы собрали 2 варианта данных технологического журнала:
- Минилог, в котором фиксируются только событие и его длительность:
|
2. Событие DBPOSTGRS для анализа длительных запросов.
Анализируем полученный минилог скриптом, взятым, как и идея, из выступления Юрия Федорова на партнерском семинаре (часть материалов доступна по ссылке):
|
Получаем следующие результаты:
- CALL – 513 минут;
- DBPOSTGRS – 392 минуты.
76% времени занимают запросы к БД. Дальше анализируем их.
Смотрим самые долгие – везде один и тот же запрос, который выполняется при проведении трех документов: "Требования-накладной", "Корректировки назначения" и "Перемещения товаров".
Находим запрос в коде 1С. В нем нарушен стандарт обращения к виртуальным таблицам:
"При использовании виртуальных таблиц в запросах следует передавать в параметры таблиц все условия, относящиеся к данной виртуальной таблице. Не рекомендуется обращаться к виртуальным таблицам при помощи условий в секции "ГДЕ".
Проблемная часть запроса выглядела так:
|
Оптимизация запроса
В MS SQL этот запрос работает быстро, потому что там есть технология Predicate pushdown, которая, по сути, переписывает запрос перед выполнением и добавляет условия внутрь параметров виртуальной таблицы. Переписываем запрос:
|
После оптимизации время выполнения запроса уменьшилось с 4.45 до 0.046 сек.
Внесли изменения в конфигурацию, перезапустили операцию перепроведения документов и получили результат – 240 минут. Можно было и дальше искать, в чем разница с MS SQL, но клиента данное время устроило.
Predicate pushdown в Postgres
В Postgres тоже есть технология Predicate pushdown, правда, она не такая продвинутая как в MS SQL. Давайте упростим наш запрос и посмотрим его план выполнения.
Текст запроса:
|
Текст запроса SQL:
|
Поле Fld68345RRef – это "Организация", а Fld68346RRef – "Номенклатура", и как видим по тексту запроса, накладываются они в отборах в секции "ГДЕ" на таблицу "T1". Она представляет собой вложенный запрос, в котором идут вычисления при выборке данных из таблицы _AccumRg68344 (таблица "РегистрНакопления.СкладскойУчет").
В плане запроса отбор по номенклатуре и организации будет наложен именно на таблицу _AccumRg68344, а не на результат вложенного запроса:


Отсюда и моментальное время выполнения, т.к. для поиска был выбран индекс _accumrg68344_3 по номенклатуре, из которого, согласно нашим условиям, выбраны 24 записи. Predicate pushdown работает.
Теперь перепишем запрос так, чтобы отборы накладывались через внутреннее соединение, а не через "ГДЕ":
|
Текст запроса SQL:
|
Отборы по полям "Номенклатура" и "Организация" у нас также накладываются на таблицу Т1 – результат вложенного запроса.
И здесь в плане запроса видим, что условия отбора не прокидываются ниже во вложенный запрос и накладываются на результат вложенного запроса:


Predicate pushdown для такого условия отбора не работает. Но это временно: такая задача у нас есть в бэклоге разработки.
Заключение
После второго кейса мы перезапустили тест по первому кейсу и получили следующие итоговые результаты:
|
|
|---|
Операция |
MS SQL |
Tantor |
|---|---|---|
| Заполнение документа "Резервы по оплате труда" в базе ЗУП | 7 минут | 8 минут |
| Расчет себестоимости за период в базе УХ | 20 минут | 19.8 минут |
| Перепроведение документов в базе УХ | 230 минут | 240 минут |
Клиента полученные результаты устроили.
Вступайте в нашу телеграмм-группу Инфостарт
{kind=link}