Меня зовут Екатерина Соколова, я разработчик в компании Postgres Professional. Хочу рассказать, зачем «подглядывать» в подробности выполнения наших запросов на PostgreSQL, и какие инструменты для этого доступны.

Ответ на вопрос «Зачем подглядывать?» простой – мы всегда хотим все сделать быстрее. Но одного желания для улучшения ситуации недостаточно. Иногда и всех трех желаний не хватит. Поэтому начнем по порядку.
Ускорение в контексте работы с СУБД начинается с грамотных настроек. Только после этого можно переходить к оптимизации запросов, которой мы сегодня будем заниматься.
Первым делом выделим подозрительные запросы, к которым стоит присмотреться. Это могут быть:
-
долгие запросы – для них нет универсального определения, их длительность будет зависеть от каждой конкретной ситуации;
-
запросы с ошибками в логике построения;
-
блокирующие запросы;
-
запросы, которые активно расходуют наши ресурсы;
-
и многие другие.
Как вычислить подозрительные запросы?

Начнем с того, что попробуем попросить PostgreSQL фиксировать долгие запросы, а точнее запросы, выполняющиеся дольше какого-то определенного количества времени.
Для этого в файл конфигурации postgresql.conf добавим строчку:
log_min_duration_statement = “пороговое время в мс”
После каждого изменения файла postgresql.conf не забываем обновить конфигурацию командой:
SELECT pg_reload_conf();
Либо перезапустить сервер.

Давайте установим пороговое значение – 10 секунд и запустим запросы.
На тех из них, что длятся дольше порогового значения, сработает таймер – в нашем случае такими запросами будут: «SELECT sleep(12);» и еще какой-то жуткий запрос снизу, который исполнялся несколько минут.
По ним в logfile у нас сразу отобразится информация со временем выполнения, текстом запроса и другими параметрами.
Потом мы сможем вернуться в logfile, посмотреть, как же у нас обстояли дела. Либо это можем даже сделать не мы, а какой-нибудь анализатор наших логов.

Но долгий запрос – не всегда плохой. А плохой запрос тоже не всегда должен быть долгим. Убедимся в этом на примере модуля pg_stat_statements.
Чтобы установить этот модуль, первым делом добавляем в файл конфигурации postgresql.conf строчку:
shared_preload_libraries = ‘pg_stat_statements’
В кавычках должно быть указано название модуля либо несколько модулей через запятую.
После чего запустим из psql команду:
CREATE EXTENSION pg_stat_statements;

Модуль pg_stat_statements реализует в базе данных PostgreSQL соответствующее представление, которое фиксирует каждый запрос, выполненный с момента установки модуля, либо с перезапуска сбора статистики.
Поля представления pg_stat_statements перечислены на слайде, здесь:
-
query – текст запроса;
-
calls – количество раз, которое этот запрос вызывался.

Под одинаковыми запросами в представлении pg_stat_statements подразумеваются запросы, отличающиеся только на константы. Для примера:
-
Первые два запроса сохранятся в разные строчки, несмотря на их похожесть.
-
А второй и третий запрос считаются одинаковыми и повышают счетчик calls.

Также в представлении pg_stat_statements отобразится:
-
total_exec_time – общее время, затраченное на все такие запросы;
-
min_exec_time – время, которое выполнялся самый быстрый из них;
-
max_exec_time – время, которое выполнялся самый долгий из них;
-
mean_exec_time – время на запрос в среднем;
-
и интересный параметр – stddev_exec_time, стандартное отклонение по времени. К этому параметру стоит присмотреться. Если его значение подозрительно большое, это значит, что запрос выполняется то очень быстро, то очень медленно. Почему он так делает? Возможно, с ним что-то не так.
В представлении pg_stat_statements предоставляется больше информации, чем перечислено на слайде, но мы сегодня будем смотреть только на эти параметры.

Давайте сделаем запрос к представлению, чтобы узнать, как же у нас обстоят дела, и сделаем сортировку по среднему времени выполнения:
-
сверху топа окажутся самые долгие запросы – мы с вами их и так уже умеем регистрировать;
-
в середине списка – другие запросы, которые мы можем захотеть проанализировать;
-
а до самого низа мы, скорее всего, смотреть не будем – там что-то быстрое.
Вроде все логично, но при таком подходе можно упустить некоторые подводные камни.

Изменим сортировку на общее время выполнения – тогда картина поменяется. Мы внезапно можем заметить, что некоторые запросы, которые до этого были где-то внизу, подскочили уже в видимую нами область. У меня для примера это SELECT $1.
Запрос SELECT $1 – это, по сути, пинг коннекта, который проверяет, точно ли мы подключены к базе, не отвалились ли мы. Запрос совсем короткий, выполняется меньше половины миллисекунды, но, если у нас будет несколько миллионов таких запросов в день, за сутки это уже выльется в ощутимый временной промежуток.
Наверное, что-то с этим стоит сделать.

Мы даже можем сделать «финт ушами» и отсортировать не только по total_exec_time, а по параметру, который у меня условно называется cpu_perc или загрузка ЦПУ, и будет вычисляться как:
100 * total_exec_time / sum(total_exec_time)
Т.е. отношение времени, потраченного на этот конкретный запрос, ко времени, потраченному вообще на все запросы.
Если какие-то короткие запросы вносят большой вклад в диаграмму общей загрузки ЦПУ, наверное, стоит что-то с ними сделать (что именно - мы тоже обязательно узнаем).
Важно понимать, что слово «короткий» тоже зависит от конкретной ситуации. Например, 5 секунд – это короткий?
-
Если мы за 5 секунд пытаемся подтянуть видео из какого-нибудь удаленного хранилища – да, короткий.
-
Но если мы 5 секунд пытаемся отобразить приветственную надпись на главной странице нашего сервиса – это излишнее ожидание.
Поэтому короткие запросы тоже периодически надо оптимизировать.
Как анализировать подозрительные запросы?

Хорошо, мы вроде научились искать подозрительные запросы. Что же с ними можно сделать?
Например, можно убить. Это кажется бесполезным советом, но это единственный способ, в котором мы можем улучшить ситуацию с миллионами SELECT $1. Нужно перестать постоянно спрашивать у базы: «Точно ли мы не отвалились?», а посмотреть, когда это делать нужно, а когда – не нужно:
-
Если мы постоянно спрашиваем у базы одну и ту же информацию, которая не меняется с течением времени, получается, что мы излишне нагружаем базу – лучше ее себе один раз сохранить.
-
И вообще – не спрашиваем ли мы что-то, что впоследствии использовать даже не будем?
-
Если запрос нам все-таки нужен, следующий вопрос, который стоит себе задать – нужно ли его выполнять прямо сейчас? Потому что, если у нас есть какой-нибудь аналитический запрос, который будет выполняться несколько часов, наверное, логично перенести время его выполнения на ночь, а не на пик загрузки сервиса.

Но что делать, если нам запрос и нужен, и отложить его выполнение мы не можем?
Самый популярный совет, который встречается – это смотреть в EXPLAIN.
Посмотреть в EXPLAIN нет никакой проблемы. Проблема в том, чтобы увидеть там что-то содержательное. Поэтому давайте разберемся, куда в EXPLAIN надо смотреть.
Команда EXPLAIN нам распечатывает дерево с планом запроса. В каждом узле дерева – операция, которая отвечает за выполнение своего кусочка запроса. Вышестоящие операции используют результаты нижестоящих операций.
Команду EXPLAIN мы можем запустить в любой момент времени до выполнения запроса. Можем даже сам запрос потом никогда не выполнять, но узнаем, как он будет выполнен, если нам потребуется.
Воспринимать текст, который выдает EXPLAIN, не совсем легко, поэтому существуют различные визуализаторы результатов EXPLAIN, визуализаторы текста планировщика. Текст, который выдаст EXPLAIN, можно запустить в них и получить уже чуть более понятную картину.
В каждом узле плана у нас будет сохранена некоторая информация, такая как:
-
cost – стоимость, очень интересный параметр, мы потом обязательно к нему вернемся;
-
rows – количество строк, которые будут обработаны;
-
width – ширина.

Как я сказала, EXPLAIN мы запускаем до исполнения запроса, но если мы добавим флаг ANALYZE, тогда наш запрос все-таки будет выполнен.
К информации, которую планировщик предполагал, добавится информация о том, как на самом деле запрос был выполнен:
-
times – сколько времени мы потратили на каждом этапе;
-
rows – сколько строк получили;
-
loops – сколько циклов прошли.
Напоминаю, запрос все-таки будет выполнен. Поэтому, если мы запускаем команду EXPLAIN ANALYZE в экспериментальных целях, и нам не нужно, чтобы результат был записан, оборачиваем ее в транзакцию. В этом случае вы сможете откатиться, и результат не сохранится.

Так куда все-таки смотреть в результатах команды EXPLAIN ? Давайте разберем на примере.
Запустим EXPLAIN нашего запроса – получим дерево, описанное текстом. Оно нам не очень понятно, поэтому для красоты давайте сразу перерисуем его в дерево.

Я добавила флаг ANALYZE, чтобы сразу сравнить время планирования и выполнения запроса.
Обратите внимание, что на схеме мы видим параметр cost – стоимость. Я обещала вам про него рассказать.
Стоимость операции – величина условная. В чем она измеряется – нам знать неважно. Но важно понимать, что чем больше это число, тем больше сил будет потрачено на выполнение именно этого места в плане.
Самые внимательные могут заметить, что числа на самом деле два.
-
Первое – это цена на предварительную подготовку, т.е. сколько сил нам потребуется на подготовку с момента запуска запроса до получения первой строки результата.
-
Для последовательного сканирования это всегда будет 0, потому что сразу начнем получать результат.
-
Для сортировки же наоборот – первое число будет весомым, потому что результат мы не можем получить, пока не отсортируем.
-
-
Второе число – это цена с момента получения первой строки результата до момента получения всего результата, т.е. его последней строчки.
Если мы посмотрим на наше дерево, то увидим, что внизу плана у нас уже большая стоимость. Но такое значение оправданно, потому что мы сканируем всю таблицу.
Давайте исправим эту ситуацию. У нас есть чудодейственный инструмент, который ускоряет обычное сканирование – добавление индекса. Добавим индексы по обеим нашим таблицам, чтобы их соединение работало быстрее.
В большинстве случаев индексы действительно помогут запросу выполняться быстрее, но в нашем случае они почему-то не сработают – при многократном перезапуске нашего запроса мы все равно будем получать это же самое дерево плана.
Как же так? Неужели планировщик обнаглел? Мы ему уже намекнули: «Используй индекс!» Почему он этого не делает?

Разберемся, как в целом планировщик выбирает методы для соединения таблиц.
Сразу предупреждаю, что масштаб на графике ни в коем случае не соблюдается – картинка чисто для визуализации.
У каждого метода соединения таблиц своя сложность. Заранее отмечу, что теоретическая сложность и сложность на практике могут значительно отличаться.
-
Например, стоимость операции Hash Join в теории будет изменяться линейно, в соответствии со сложностью O(N);
-
Но на практике, если мы выберем неоптимальную функцию Hash, либо у нас в запросе будет много повторяющихся идентификаторов, стоимость Hash Join может вырасти до O(N2).
Также для каждой операции потребуется какое-то время на предварительную подготовку.
-
В случае с Nested Loop время на предварительную подготовку практически равно нулю, поэтому, если у нас ожидается небольшое число строк, не превышающие N1, конечно, стоит взять Nested Loop, потому что незачем ковыряться с чем-то другим.
-
Но если строк будет больше, чем N1, но меньше, чем N2, логичнее взять способ соединения Merge Join.
-
А дальше его обгонит Hash Join.
Рассуждения логичны. Что же может пойти не так?
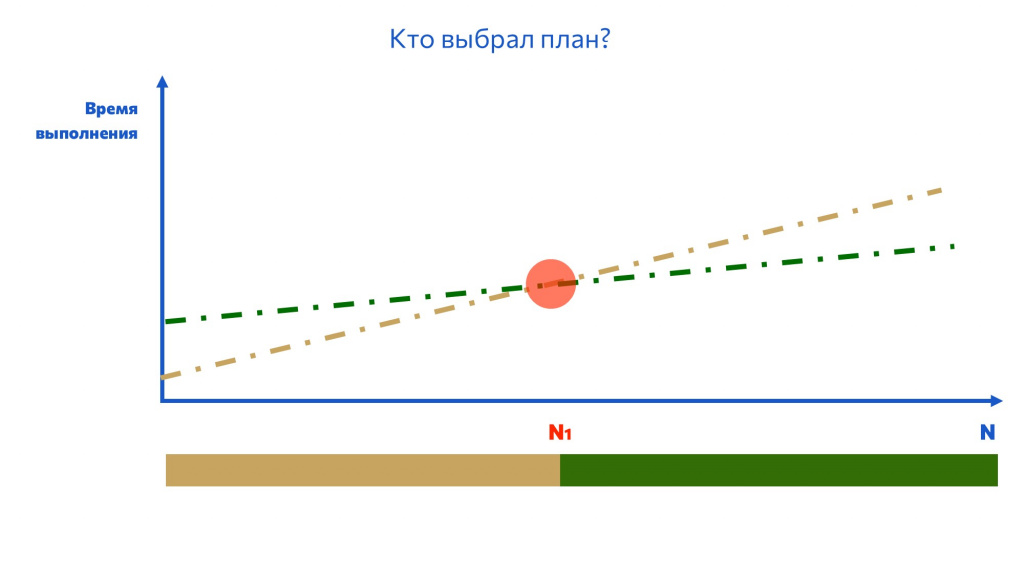
Дело в том, что планировщик предполагает, сколько строк будет получено на том или ином этапе и какая для этого количества строк будет стоимость операции.
Например, у планировщика есть предположения о зависимости количества строк и стоимости для бежевой и зеленой операции. Он делает вывод: если строк будет меньше, чем N1, нужно взять бежевую операцию. Если больше, чем N1 – зеленую.

На практике мы можем получить совсем другую стоимость операции. Где-то она будет отличаться больше, где-то – меньше. Но вне зависимости от реальной стоимости операции в N1 мы перепрыгнем на другой план. И да, может получиться так, что мы перепрыгнем на менее оптимальный.

Так происходит и в нашем случае. Нам кажется, что с индексом соединение таблиц заработает быстрее. Но планировщик индекс не использует, потому что считает, что стоимость его операции будет больше.
Нам кажется, что мы правы. И спойлер – мы действительно правы.
Что же в такой ситуации делать?

В такой ситуации нам нужно адаптироваться, а точнее адаптировать представление планировщика о реальной стоимости операции.
Для каждой операции у нас существуют переменные enable_название операции. По умолчанию практически все из них включены. Если мы не хотим использовать последовательное сканирование, давайте его выключим:
SET enable_seqscan TO OFF;
«Выключение» операции ни в коем случае ее не отменяет – оно накидывает ей 10 миллионов условных единиц стоимости. Даже если я выключу Seq Scan, при выборке строк одной из моих таблиц все равно будет использоваться последовательное сканирование – оно все еще более оптимальное, несмотря на большую стоимость.

Но в нашем случае это поможет. Ура, счастье-радость! Мы смогли заменить последовательное сканирование Seq Scan на сканирование по индексу Index Only Scan.
Можно видеть, что плановая стоимость сканирования по индексу действительно была первоначально выше, чем для последовательного сканирования. И у нас даже изменился метод соединения, поскольку мы получили меньшее количество строк.
Но если стоимость операции и ее влияние на выбор различных методов сканирования и соединения таблиц может показаться нам не совсем понятной величиной, давайте посмотрим на изменение времени.
Да, мы накинули пару лишних миллисекунд на планирование, зато сократили время выполнения запроса более, чем в два раза. Как неожиданно и приятно!

Наш планировщик постоянно уточняет имеющуюся у него информацию, чтобы подбирать все более и более оптимальные планы.
Но если у нас нет времени дожидаться этих уточнений, либо мы понимаем, что уточнения никогда не поступят (как в нашем случае), тогда нам может пригодиться модуль sr_plan. Он позволяет сохранить дерево плана запроса, чтобы в будущем выполнять его указанным нами способом, а не так, как предполагает планировщик.
Делать нам это следует тогда и только тогда, когда мы уверены, что наш способ заведомо более быстрый, чем выбор планировщика.
|
UPD: чтобы не адаптироваться к меняющейся базе собственноручно и не пытаться самостоятельно вычислить самый оптимальный способ выполнения, можно использовать расширение aqo - Adaptive Query Optimization. Модуль сохраняет качество предварительной оценки количества строк и статистику выполнения запроса, чтобы с помощью машинного обучения подбирать более оптимальный метод выполнения следующего запроса того же класса. |

Поначалу деревья плана могут показаться нам довольно-таки сложными. Но если мы научимся извлекать из них нужную информацию, мы можем захотеть делать это все чаще и чаще.
Тогда, чтобы не запускать каждый раз команду EXPLAIN вручную, мы можем для всех подозрительных запросов попросить PostgreSQL записывать эти деревья планов в блокнотик, точнее в logfile. Для этого нам пригодится модуль auto_explain.
Предварительно можно настроить несколько параметров конфигурации.
-
auto_explain.log_min_duration (integer) – это пороговое время, после которого мы зафиксируем запрос.
-
auto_explain.log_analyze (boolean) – в этом случае мы можем сохранять не только EXPLAIN, но и EXPLAIN ANALYZE. Но такое логирование все-таки повышает нагрузку, поэтому следует найти золотую середину между тем, насколько нам эта информация важна и тем, сколько сил мы готовы на это потратить.
Куда смотреть, если все плохо здесь и сейчас

Мы научились искать запросы, с которыми следует что-то сделать. Мы поняли, что именно следует делать с ними в долгосрочной перспективе. Но как поступить, если все плохо прямо здесь и сейчас?
Наверняка нас заинтересуют такие вопросы, как:
-
Что у нас вообще сейчас запущено?
-
Что может быть заблокировано?
-
Когда наконец это все уже закончится?

Чтобы узнать, что у нас запущено, нам может пригодиться представление pg_stat_activity. Оно уже есть в ядре PostgreSQL, ничего подключать не надо.
В представлении pg_stat_activity у нас хранятся записи с информацией на каждый серверный процесс. Если мы запросим эту информацию, то увидим, что у нас есть:
-
Какие-то системные процессы, такие как автовакуум (autovacuum launcher и autovacuum worker), фоновые задания (background worker и background writer) или логическая репликация (walsender, walreceiver и walwriter).
-
Также существуют клиентские бэкенды (client backend) – в них сохранен статус запроса и его текст. Если у нас прямо сейчас в бэкенде выполняется запрос, тут мы сможем увидеть, какой именно. Если же бэкенд отдыхает, здесь будет сохранен последний выполнявшийся на нем запрос.

Выяснить, что может быть заблокировано, можно несколькими способами:
-
Можно использовать инструменты, встроенные в IDE.
-
Существуют специальные программы для анализа блокировок PostgreSQL.
-
Либо можно написать грамотный запрос к представлению pg_locks – все другие существующие инструменты работы с блокировками тоже используют информацию именно оттуда. При этом записи из таблицы pg_locks нам наверняка потребуется объединить с представлением pg_stat_activity, поскольку нас волнует, что заблокировано прямо сейчас.
Например, мы можем написать примитивный запрос:
SELECT * FROM pg_locks pl
LEFT JOIN pg_stat_activity psa
ON pl.pid = psa.pid;
Но при анализе его результатов нам придется самостоятельно разбираться в зависимостях.

Лучше не изобретать велосипед, а обратиться к «коллективному разуму». Зная, что информация о блокировках находится в представлении pg_locks, мы можем спросить у поисковой системы, как получить оттуда информацию – набрать в поисковой строке pg_locks monitoring.
Первая строка выдачи предлагает готовое решение запроса для поиска виновников блокировок. Результат такого запроса отобразит информацию в приятном глазу виде – мы сразу увидим, какой запрос от какого пользователя что именно нам блокирует. Красота.

Если же запрос сейчас выполняется, он не заблокирован – чем он так долго занимается? Тут мы можем заглянуть в представление pg_stat_progress_* (вместо * – название команды). Пока такое представление существует для пяти команд:
-
ANALYZE
-
CREATE INDEX
-
VACUUM
-
CLUSTER
-
Base Backup.
В ближайшее время в PostgreSQL обязательно появятся такие представления и для других команд тоже.
| UPD: Начиная с PostgreSQL 14 также существует представление для отслеживания выполнения команды COPY: pg_stat_progress_copy. |
В зависимости от специфики команды будет немного отличаться получаемая информация, но практически всегда там будет:
-
pid и текст команды;
-
отношение, на котором этот запрос выполняется;
-
фаза выполнения;
-
и количество уже обработанной информации.
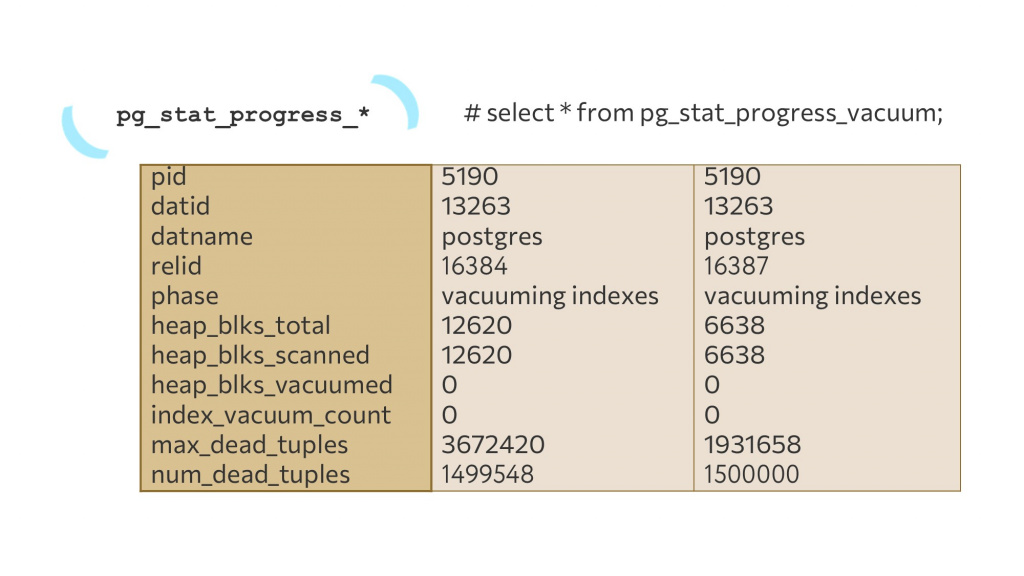
Давайте посмотрим, как это работает, на примере представления pg_stat_progress_vacuum и запроса:
select * from pg_stat_progress_vacuum;
Во второй и третьей колонках таблицы представлены результаты выполнения команды VACUUM с разницей в одну секунду:
Присмотримся, что получилось в результатах:
-
В нижней строчке – информация о том, сколько мертвых строк VACUUM уже нашел. Число увеличилось, он работает замечательно. Более того, я даже знаю, что справа – это полное количество удаленных мной строк. Значит, он прямо сейчас и закончится.
-
Можем обратить внимание на параметр relid – это идентификатор отношения, на котором наш VACUUM выполняется. Он изменился, значит, VACUUM закончил работу с одной табличкой и переключился на другую.

Для анализа хода выполнения других команд в PostgreSQL я рекомендую модуль pg_query_state. Он поможет отслеживать ситуацию с запросами:
-
SELECT,
-
INSERT,
-
UPDATE
-
и DELETE.
Модуль pg_query_state предоставляет возможность получить сиюминутный EXPLAIN ANALYZE запроса.
Важно: Из коробки pg_query_state есть в версии PostgresPro Enterprise, для установки расширения pg_query_state на другие версии PostgreSQL потребуется патч – добавление кода к ядру PostgreSQL. Учитывайте, если для вас это критично.

Мы знаем, что планировщик изначально может ошибаться в своих предположениях, когда пытается понять, сколько и чего мы получим.
Понятно, что после завершения запроса мы получим полноценную информацию, как все проходило. Но во время выполнения запроса иногда хочется узнать, что происходит на узле, который у нас сейчас работает.
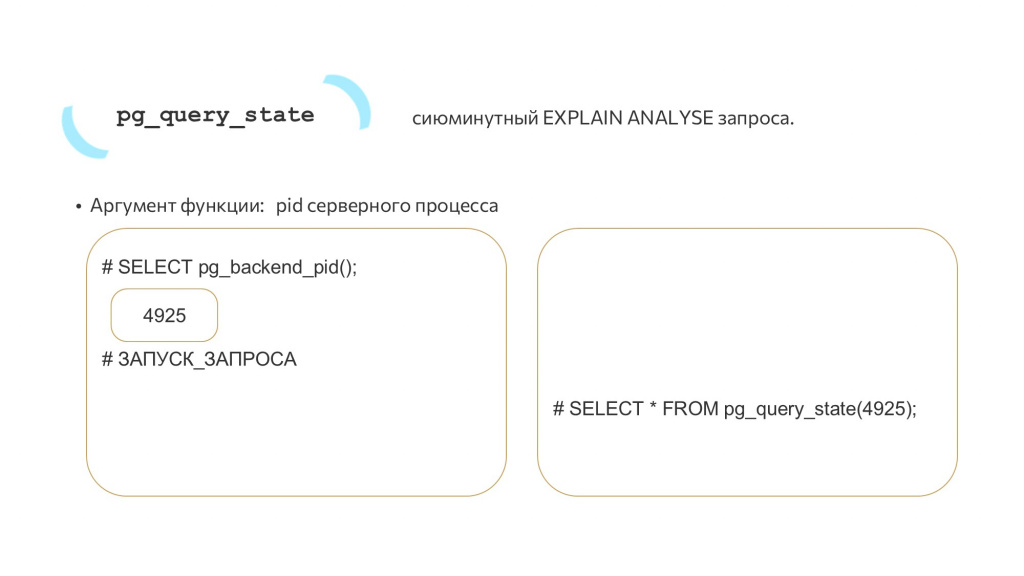
Для этого и нужна команда pg_query_state(). Ее единственным обязательным параметром является pid серверного процесса, к которому мы хотим постучаться.
Получить этот pid можно несколькими способами.
-
Мы можем заранее спросить идентификатор у бэкенда командой:
SELECT pg_backend_pid();
И в случае, если на этом бэкенде когда-нибудь будет запущен долгий запрос, мы из другого бэкенда можем к нему постучаться и спросить: «Как у тебя успехи?»

-
Если мы заранее pid не спросили – тоже никакой проблемы. Мы уже умеем работать с представлением pg_stat_activity. Когда у нас работает какой-то долгий запрос, мы у pg_stat_activity спрашиваем, какой у него pid, после чего также стучимся.

Посмотрим на результат команды pg_query_state(), когда мы обратились к нашему INSERT. Мы видим:
-
query_text – текст исполняемого на бэкенде запроса.
-
plan – результат EXPLAIN ANALYZE. Здесь в дереве плана запроса видно, что мы из 100000 строк уже вставили 35708 строк. Замечательно. INSERT отлично работает. Подождем, каковы будут его успехи дальше.

Также у нас есть параметры frame number и leader pid. На них тоже обращу внимание.
-
Когда мы спрашиваем pg_query_state() какого-то запроса, мы получаем одну строку результата. Но если текст запроса в какой-то момент времени поменяется – например, мы изначально запросили результат функции, а далее функция заменится тем запросом, который на самом деле должен выполниться – текст поменяется. В этом случае мы получим строку для каждого текста запроса, который был у этой команды – эти строчки будут пронумерованы в графе frame number.

-
Графа leader pid практически всегда (null). Но если наш процесс может породить себе параллельных воркеров, исполнителей, leader pid заполнится. Тогда мы получим строчку с результатом не только для нашего запроса, но и для каждого его исполнителя, которого он породил. Тогда в графе leader pid у воркеров появится pid нашего родительского запроса, в то время как у нашего pid по-прежнему не будет «рабовладельца» – у него все еще будет (null).

Что можно использовать, если вдруг нам не хочется вникать в план запроса? Не важно, чем он сейчас занимается, мы просто хотим узнать, когда запрос, наконец, завершит работу?
-
В этом случае можно использовать команду progress_bar(), которая располагается в этом же модуле pg_query_state. Спросим у progress_bar, какие успехи у нашего запроса:
SELECT * FROM progress_bar(4925);
И получим внятный результат: все выполнено на 61%. Замечательно. -
Либо можем использовать функцию progress_bar_visual(). Второй ее параметр – задержка в секундах. В нашем случае – раз в 5 секунд нам будет распечатана информация о том, насколько наш запрос выполнился. Мы в прямом эфире будем видеть скорость выполнения запроса, догадываться, когда он у нас закончится и так далее, пока запрос полностью не завершится.
| UPD: в свежих версиях планируется переименование функций на pg_progress_bar() и pg_progress_bar_visual() соответственно. Перед использованием стоит уточнить правильность нейминга в документации или README-файле. |
Это все, что я хотела рассказать.
-
Мы научились искать запросы, к которым стоит присмотреться, чтобы их улучшить.
-
Поняли, как их улучшать в долгосрочной перспективе.
-
И что можно о них узнать прямо сейчас, в текущий момент времени.
Дополнение от Антона Дорошкевича
Попробую перевести сказанное на язык MS SQL:
-
Помните в MS SQL системные представления sp_who и sp_who2? pg_stat_activity – это ваш sp_who.
-
Еще в MS SQL есть представление, которое показывает, кто активен и кто кого заблокировал. Его аналог в PostgreSQL – pg_locks.
-
Чтобы в MS SQL увидеть трассировку зависшего запроса в профайлере или технологическом журнале 1С, нужно либо дождаться завершения работы запроса, либо прервать сеанс. А в PostgreSQL можно получить информацию, не дожидаясь и не убивая – через pg_query_state. В MS SQL такое есть только в 19-ом, тоже можно посмотреть, что он делает. Но информации, когда это закончится, в MS SQL нет – процент выполнения можно посмотреть только в PostgreSQL.
И еще хочу сказать про модуль auto_explain. Как вы думаете, что лучше – настроить auto_explain в PostgreSQL или включить сбор планов запросов в технологическом журнале?
Многие помнят, что в одной из версий платформы 1С была допущена ошибка – при установке платформы автоматически создавался файл технологического журнала logcfg.xml, который включал сбор планов запроса. У всех все легло по очень простой причине: когда вы в технологическом журнале заставляете платформу собрать запрос, она вам отправляет EXPLAIN ANALYZE. Но платформа не в курсе, сколько будет длиться этот запрос, она помимо execute одновременно отправляет EXPLAIN ANALYZE – при этом у нее нет возможности отфильтровать запросы по длительности, там нет фильтра по duration. Получается, если вы включите сбор планов SQL в технологическом журнале, у вас будут собираться все запросы. Вы заставите СУБД отдавать вам планы даже на микросекундные запросы. Никогда не используйте это в проде точно, а на тесте – очень аккуратно, когда вы знаете чего хотите получить. Именно из-за этого лучше не использовать сбор планов запросов в технологическом журнале никогда.
А поставить для PostgreSQL auto_explain имеет смысл. Это делается просто – в конфигурационном файле нужно добавить строку:
shared_preload_libraries = ‘auto_explain’
У auto_explain есть параметр auto_explain.log_min_duration – его можно задать, например, 10 секунд. Тогда все запросы свыше 10 секунд скинутся вам в лог PostgreSQL – и текст запроса, и план.
Вопросы и ответы
Расскажите, пожалуйста, как в PostgreSQL отследить ошибки с параллелизмом, в каких случаях PostgreSQL начинает его использовать, как отследить планы запросов, где он неоптимально используется, и можно ли как-то заблокировать использование параллелизма в определенных планах?
Параллелизм начинает использоваться, когда мы поставим соответствующую настройку. Либо она может стоять у нас по умолчанию. Мы всегда можем это отменить и не использовать параллельные запросы.
Если же нас интересует неоптимальность параллельного выполнения, то можно обратиться в pg_query_state – там мы увидим, что именно выполняют параллельные исполнители. И увидим, точно ли они делают то, что нам нужно.
Вы никогда не узнаете, будет ли это оптимально. Планировщик никогда не ошибается. Если он сказал, что это оптимально, это оптимально. Три года назад Олег Бартунов слушал обсуждение параллелизма, а потом встал и сказал: «База 1С – это база OLTP. А для OLTP параллелизм запрещен». С точки зрения СУБД, OLTP-база параллелизму не подлежит, забудьте. Но у нас 1С – это и OLTP и OLAP, нам все хочется. Поэтому аккуратненько – можно.
Вы же и в MS SQL не знаете, будет ли использование параллелизма оптимально. Вы это узнаете потом – по плану уже выполненного запроса. Если планировщик посчитает, что cost выше порога, который вы поставили в настройках включения параллелизма, вы на это повлиять особо не можете.
Можно ли в PostgreSQL отключить параллелизм для конкретного запроса?
На данный момент – нет, он включается и выключается на весь сервер или всю сессию. Можно, конечно, костылить – перед началом запроса вызвать psql, узнать ID-шник сессии, отключить или включить для нее параллелизм, и после того, как запрос выполнится, вернуть все, что вы сделали, обратно.
И еще есть расширение pg_hint_plan – у него есть параметр hints_anywhere. С его помощью вы с помощью текстовых литералов в коде 1С сможете в любой запрос добавлять специальные указания планировщику через конструкцию вида: «ВЫБОР КОГДА 1 = 0 ТОГДА» и далее в кавычках указывать, что вам надо – какие параметры включить, какие отключить. Тогда pg_hint_plan прямо на этот запрос будет это включать и выключать. Запрос выполнился, это все исчезло – меняться будет только для него, больше никому. С расширением pg_hint_plan это можно будет сделать прямо в коде 1С.
Если я принудительно отключил Seq Scan в настройках, у меня отработал запрос, планировщик запомнил, что здесь нужно применять индекс. Потом, если я включу Seq Scan обратно, он будет выбирать неоптимальный вариант?
Да. Если мы нашли, как выполнять запрос быстрее, и отключили параметр Seq Scan, а после этого включили параметр обратно, цена оригинального Seq Scan все еще будет ниже, чем у Index Only Scan, и мы продолжим выбирать неоптимальный план.
Поэтому я рекомендовала модуль sr_plan. С ним мы можем сохранить оптимальный план и использовать его на будущее.
Просто может быть ситуация, что в одном запросе нам нужен этот параметр, а в другом – не нужен. Но мы же его включаем целиком на весь сервер?
Лучше таким не заниматься. Не нужно что-то менять у сервера, меняйте код запросов.
Как посмотреть все сохраненные планы запросов в одном месте, хотя бы с той целью, не забыли ли мы потом его отключить, либо не поменялась какая-то структура? Где они в одном месте все собраны?
В системных представлениях сбора статистики. То, что начинается с pg_stat, там точно получится найти интересующую нас информацию, включая планы, которыми выполнялись наши запросы.
Их можно вывести в список?
Во-первых, планы запросов собирает представление pg_stat_statements.
Второе, если вы будете использовать auto_explain – то в логах.
И чаще второй вариант предпочтительнее, потому что 1С может генерить текст запроса на 40, 50 и даже 100 мегабайт. А в ячейку базы данных помещается 256 символов. Поэтому в pg_stat_statements вы часто не увидите запрос целиком. В этом случае единственный выход – это лог.
| UPD: В качестве альтернативы pg_stat_statements можно использовать модуль pgpro_stats, он целиком сохраняет текст, план запроса и прочую статистику планирования всех выполняемых сервером SQL-операторов. |
*************
Статья написана по итогам доклада (видео), прочитанного на конференции Infostart Event 2022 Saint Petersburg.


Вступайте в нашу телеграмм-группу Инфостарт