


- История создания
- Сервер приложений 1С
- Сервер СУБД
- Примеры выявленных проблем
- Как встроить обработку в вашу систему
- Идея для развития
- Заключение
История создания
Когда-то давно, когда я готовился к экзамену 1С эксперт, то в одном известном курсе услышал от преподавателя идею про эталонную ключевую операцию-маркер, которая выполняет каждую минуту какое-то простое действие типа проведения одного и того же документа или выполнения отчета. Затем смотрим как менялся показатель этой эталонной операции в течение дня, и соотносим с периодами замедления, если они были в вашей системе. Если периоды замедления были, то смотрим на счетчики оборудования, не было ли это "узким местом". Если нет, то тогда уже нужно искать дальше, что же является причинами деградации системы, оптимизируем и в итоге мы должны прийти к тому, что наша эталонная операция-маркер должна стабильно выполняться одно и тоже время в течении дня.
Я записал эту идею в свой конспект, который вел при просмотре курса.
Спустя время, не помню точно при каких обстоятельствах: то ли при просмотре конспекта, то ли из-за возникновения какой-то проблемы, я вернулся к этой идее и решил ее реализовать.
На тот момент у нас был реализован мониторинг ключевых операций по методике APDEX следующим образом:
- мы разрабатывали корпоративную информационную систему, зоны ответственности которой были поделены между командами, например, команда № 1 отвечала за блок централизованных оплат, команда № 2 за товародвижение и тд.
- за каждой командой был закреплен свой профиль ключевых операций, в которым были собраны только критичные для бизнеса операции. Если APDEX достигал заданного уровня (плохо и ниже) и удерживался на нем n периодов подряд, то срабатывал алерт.
Необходимо было написать код для ключевых операций, который бы показывал возможные проблемы на одном из серверов: 1С или СУБД (сервера приложений 1С и СУБД всегда были разнесены по разным машинам, на одной никогда не находились).
Для каждого из этих серверов было решено написать по 2 маркера таким образом, чтобы они оценивали различные характеристики сервера.
Сервер приложений 1С
Для сервера приложений 1С было решено замерять выполнение арифметической операции в цикле и сериализацию.
Маркер "СП обход строк ТЗ"
В данном маркере выполнялось 2 действия на стороне сервера приложений:
- Выгрузка результата запроса в таблицу значений (250 тысяч записей) - задействуем оперативную память сервера приложений.
- Циклический обход таблицы значений с осуществлением операции присвоения значения.
По сути это чем-то похоже на то как вычисляется доступная производительность для каждого из рабочих процессов кластера 1С, только более наглядно, т.к. мы знаем какой конкретно код выполняется:
Запрос = Новый Запрос(
"ВЫБРАТЬ ПЕРВЫЕ 250000
| АвансовыйОтчетТабличнаяЧастьДокумента.Ссылка КАК Ссылка,
| АвансовыйОтчетТабличнаяЧастьДокумента.НомерСтроки КАК НомерСтроки,
| АвансовыйОтчетТабличнаяЧастьДокумента.Сумма КАК Сумма,
| АвансовыйОтчетТабличнаяЧастьДокумента.СтавкаНДС КАК СтавкаНДС,
| АвансовыйОтчетТабличнаяЧастьДокумента.СуммаНДС КАК СуммаНДС
|ИЗ
| Документ.АвансовыйОтчет.ТабличнаяЧастьДокумента КАК АвансовыйОтчетТабличнаяЧастьДокумента");
Результат = Запрос.Выполнить();
КлючеваяОперация = "СП_ОбходСтрокТЗ";
НачалоЗамера = ОценкаПроизводительности.НачатьЗамерВремени();
ТЗ = Результат.Выгрузить();
Для каждого СтрокаТЗ Из ТЗ Цикл
СтрокаТЗ.СуммаНДС = СтрокаТЗ.Сумма;
КонецЦикла;
ОценкаПроизводительности.ЗакончитьЗамерВремени(КлючеваяОперация, НачалоЗамера);
Маркер "СП сериализация XML"
Идея данного маркера у меня возникла не просто так.
В компании "Магнит" есть такой ежегодный процесс как переход на последнюю версию платформы 1С всех информационных систем компании, и во время одного из переходов на конфигурации ЗУП как раз и возникла проблема: сериализация стала утилизировать значительно больше ресурсов сервера приложений 1С. На тот момент я думал, что следующий код как раз и поможет нам в будущем выявлять такие случаи:
Запрос = Новый Запрос(
"ВЫБРАТЬ ПЕРВЫЕ 100
| АвансовыйОтчет.Ссылка КАК Ссылка
|ИЗ
| Документ.АвансовыйОтчет КАК АвансовыйОтчет");
Выборка = Запрос.Выполнить().Выбрать();
КлючеваяОперация = "СП_СериализацияXML";
НачалоЗамера = ОценкаПроизводительности.НачатьЗамерВремени();
ЗаписьXML = Новый ЗаписьXML;
ИмяФайла = ПолучитьИмяВременногоФайла("xml");
ЗаписьXML.ОткрытьФайл(ИмяФайла);
ЗаписьXML.ЗаписатьОбъявлениеXML();
ЗаписьXML.ЗаписатьНачалоЭлемента("data");
Пока Выборка.Следующий() Цикл
ЗаписатьXML(ЗаписьXML, Выборка.Ссылка.ПолучитьОбъект());
КонецЦикла;
ЗаписьXML.Закрыть();
УдалитьФайлы(ИмяФайла);
ОценкаПроизводительности.ЗакончитьЗамерВремени(КлючеваяОперация, НачалоЗамера);
Будущее думало иначе: этот маркер действительно показал нам проблему не один раз, но они не были связаны с сериализацией, и позже вы поймете, почему. Либо посмотрите внимательно на этот код и попробуйте понять какие компоненты инфраструктуры, на которой работает информационная база, он еще способен протестировать.
Сервер СУБД
Если с сервером приложений маркеры было придумать довольно просто, то с СУБД дела обстояли иначе.
Сервер СУБД – более производительный компонент, чем сервер приложений 1С, и если нужно сделать какие-то ресурсоемкие вычисления, то, конечно, правильно их делать на сервере СУБД.
Поэтому здесь замерять операции типа расчета арифметической операции смысла не имело.
Маркер "СУБД выборка бухгалтерских проводок"
Давайте сначала посмотрим на запрос данного маркера, а потом разберем его логику:
КлючеваяОперация = "СУБД_ВыборкаБухгалтерскихПроводок";
НачалоЗамера = ОценкаПроизводительности.НачатьЗамерВремени();
Запрос = Новый Запрос(
"ВЫБРАТЬ ПЕРВЫЕ 10000
| Бухгалтерский.Период КАК Период,
| Бухгалтерский.Регистратор КАК Регистратор,
| Бухгалтерский.НомерСтроки КАК НомерСтроки,
| Бухгалтерский.Активность КАК Активность,
| Бухгалтерский.СчетДт КАК СчетДт,
| Бухгалтерский.СчетКт КАК СчетКт,
| Бухгалтерский.Организация КАК Организация,
| Бухгалтерский.База КАК База,
| Бухгалтерский.Филиал КАК Филиал,
| Бухгалтерский.ВалютаДт КАК ВалютаДт,
| Бухгалтерский.ВалютаКт КАК ВалютаКт,
| Бухгалтерский.Сумма КАК Сумма,
| Бухгалтерский.ВалютнаяСуммаДт КАК ВалютнаяСуммаДт,
| Бухгалтерский.ВалютнаяСуммаКт КАК ВалютнаяСуммаКт,
| Бухгалтерский.КоличествоДт КАК КоличествоДт,
| Бухгалтерский.КоличествоКт КАК КоличествоКт,
| Бухгалтерский.Содержание КАК Содержание,
| Бухгалтерский.НомерЖурнала КАК НомерЖурнала,
| Бухгалтерский.МоментВремени КАК МоментВремени
|ПОМЕСТИТЬ ВременнаяТаблица
|ИЗ
| РегистрБухгалтерии.Бухгалтерский КАК Бухгалтерский
|ГДЕ
| Бухгалтерский.Период МЕЖДУ &НачалоПериода И &КонецПериода
|;
|
|////////////////////////////////////////////////////////////////////////////////
|ВЫБРАТЬ
| ВременнаяТаблица.Период КАК Период,
| ВременнаяТаблица.Регистратор КАК Регистратор,
| ВременнаяТаблица.НомерСтроки КАК НомерСтроки,
| ВременнаяТаблица.Активность КАК Активность,
| ВременнаяТаблица.СчетДт КАК СчетДт,
| ВременнаяТаблица.СчетКт КАК СчетКт,
| ВременнаяТаблица.Организация КАК Организация,
| ВременнаяТаблица.База КАК База,
| ВременнаяТаблица.Филиал КАК Филиал,
| ВременнаяТаблица.ВалютаДт КАК ВалютаДт,
| ВременнаяТаблица.ВалютаКт КАК ВалютаКт,
| ВременнаяТаблица.Сумма КАК Сумма,
| ВременнаяТаблица.ВалютнаяСуммаДт КАК ВалютнаяСуммаДт,
| ВременнаяТаблица.ВалютнаяСуммаКт КАК ВалютнаяСуммаКт,
| ВременнаяТаблица.КоличествоДт КАК КоличествоДт,
| ВременнаяТаблица.КоличествоКт КАК КоличествоКт,
| ВременнаяТаблица.Содержание КАК Содержание,
| ВременнаяТаблица.НомерЖурнала КАК НомерЖурнала,
| ВременнаяТаблица.МоментВремени КАК МоментВремени,
| БухгалтерскийСубконто.Период КАК Период1,
| БухгалтерскийСубконто.Регистратор КАК Регистратор1,
| БухгалтерскийСубконто.МоментВремени КАК МоментВремени1,
| БухгалтерскийСубконто.НомерСтроки КАК НомерСтроки1,
| БухгалтерскийСубконто.ВидДвижения КАК ВидДвижения,
| БухгалтерскийСубконто.Вид КАК Вид,
| БухгалтерскийСубконто.Значение КАК Значение
|ПОМЕСТИТЬ ВременнаяТаблица2
|ИЗ
| ВременнаяТаблица КАК ВременнаяТаблица
| ЛЕВОЕ СОЕДИНЕНИЕ РегистрБухгалтерии.Бухгалтерский.Субконто КАК БухгалтерскийСубконто
| ПО ВременнаяТаблица.Период = БухгалтерскийСубконто.Период
| И ВременнаяТаблица.НомерСтроки = БухгалтерскийСубконто.НомерСтроки
| И ВременнаяТаблица.Регистратор = БухгалтерскийСубконто.Регистратор");
ТекДата = ТекущаяДата();
Запрос.УстановитьПараметр("НачалоПериода", ТекДата - 12*3600);
Запрос.УстановитьПараметр("КонецПериода", ТекДата);
Запрос.Выполнить();
ОценкаПроизводительности.ЗакончитьЗамерВремени(КлючеваяОперация, НачалоЗамера);
А логика в следующем:
- Прочитать данные именно с диска, а не буферного кэша. Для этого мы выбираем проводки из регистра бухгалтерии за последние 12 часов с упорядочиванием по возрастанию. Для чтения задействовался именно кластерный индекс MS SQL, в котором данные упорядочены по полю "Период" (данные в Postgres не хранятся в упорядоченном виде, но т.к. в этом случае мы будем читать данные из индекса с полями "Период", "Регистратор", "НомерСтроки", то данные будут отсортированы согласно полям этого индекса, и дополнительно указывать сортировку в запросе необходимости нет).
- Поместить во временную таблицу, чтобы проверить скорость работы tempdb: в первом запросе 10 тысяч записей, во втором – до 50 тысяч (на счетах могло быть до 5 субконто).
- Сами выборки данных должны были работать максимально быстро, т.к. точно попадали в условия кластерного индекса основной таблицы и таблицы субконто. Индекс в первой временной таблице по полям "Период", "Регистратор" и "НомерСтроки" не создавался, т.к. записи и так были упорядочены по этим полям, что дает возможность во втором запросе оптимизатору использовать hash join без дополнительной сортировки.
Маркер запускался каждые 5 минут, поэтому за это время каждый раз он должен был читать новые данные. В среднем в рабочее время (с 9 до 18 часов дня) за одну минуту создавалось около 4 тысячи новых проводок в регистре бухгалтерии.
Зачем читаем данные за последние 12 часов? Потому что в нерабочее время интенсивность создания проводок сильно падала, и, если бы мы выбирали, допустим, за 1 час, то проводок могло быть выбрано значительно меньше. А мне хотелось создать равномерные замеры ключевой операции.
Маркер "СУБД неоптимальный запрос"
Этот маркер я создал с той целью, чтобы посмотреть как неоптимальный запрос будет вести себя в периоды высокой нагрузки на сервер СУБД:
КлючеваяОперация = "СУБД_НеоптимальныйЗапрос";
НачалоЗамера = ОценкаПроизводительности.НачатьЗамерВремени();
Запрос = Новый Запрос(
"ВЫБРАТЬ ПЕРВЫЕ 5000
| АвансовыйОтчет.Ссылка КАК Ссылка,
| АвансовыйОтчет.Счет.ПометкаУдаления КАК СчетПометкаУдаления,
| АвансовыйОтчет.ЦФО.ДатаОткрытия КАК ЦФОДатаОткрытия,
| АвансовыйОтчет.ДокументОснование.Дата КАК ДокументОснованиеДата
|ПОМЕСТИТЬ ВременнаяТаблица
|ИЗ
| Документ.АвансовыйОтчет.ТабличнаяЧастьДокумента КАК АвансовыйОтчетТабличнаяЧастьДокумента
| ЛЕВОЕ СОЕДИНЕНИЕ Документ.АвансовыйОтчет КАК АвансовыйОтчет
| ПО АвансовыйОтчетТабличнаяЧастьДокумента.Ссылка = АвансовыйОтчет.Ссылка
|ГДЕ
| АвансовыйОтчетТабличнаяЧастьДокумента.Аналитика1 ССЫЛКА Справочник.МоделиТМЦ
| И не АвансовыйОтчетТабличнаяЧастьДокумента.Аналитика1 В
| (ВЫБРАТЬ
| справочник.моделитмц.Ссылка
| ИЗ
| справочник.моделитмц
| ГДЕ
| справочник.моделитмц.ПометкаУдаления)
| И НЕ АвансовыйОтчетТабличнаяЧастьДокумента.Аналитика1.ПометкаУдаления");
Запрос.МенеджерВременныхТаблиц = Новый МенеджерВременныхТаблиц;
Запрос.Выполнить();
ОценкаПроизводительности.ЗакончитьЗамерВремени(КлючеваяОперация, НачалоЗамера);
Все маркеры готовы, теперь поговорим о том какие проблемы они позволили выявить.
Примеры выявленных проблем
Когда я создавал эти маркеры, то хотел соотносить их с данными ADPEX ключевых операций бизнеса, чтобы выявлять закономерности в периоды проблем. Вот пример графика маркера:

Но далее я расскажу о более глобальных проблемах, которые они помогли выявить.
"Магнит": переход на новую версию платформы
Очередной год и мы переходим на новую версию платформы: это был переход на 8.3.19 в 2021 году. После перехода, как обычно, выявляешь какие-то баги, которые не показало тестирование. Все они как правило некритичны, ибо в процессе подготовки перехода проводятся тщательный анализ всех изменений, которые могут повлиять на конфигурации, и не менее тщательное тестирование.
А проблема была обнаружена довольно случайно спустя несколько месяцев после перехода: в результате проведения работ на одном из продуктивных серверов приложений по ошибке была включена отладка, которая строго запрещена на всех продуктивных серверах.
И в итоге маркер "СП обход строк ТЗ" показал примерно такую картину:
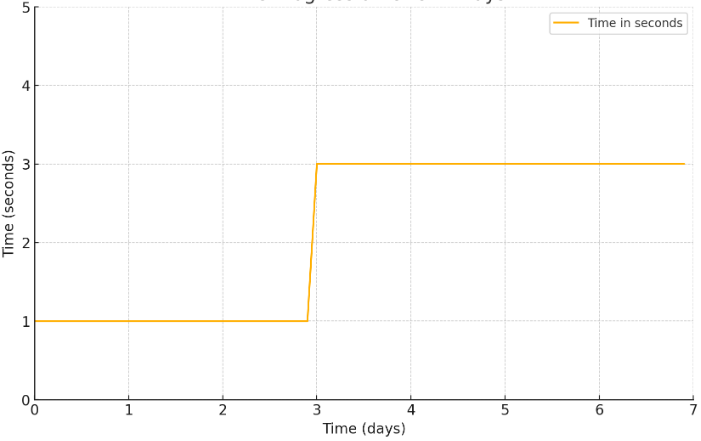
Также у одной ключевой операции бизнеса упала производительность ввиду того, что использовались аналогичные конструкции обхода большого количества строк в цикле.
Итого проблему можно сформулировать следующим образом: при включенной отладке код 1С начинал выполняться медленнее, что особо было заметно в обходах цикла с большим количеством итераций.
Проблему отправили на КОРП-поддержку, и в одном из следующих минорных релизов фирма 1С ее оперативно исправила. Не считаю, что она была критичной, ибо, как уже сказал, отладка в продуктиве должна быть выключена.
А у вас она выключена?
"Sunlight": апгрейд продуктивных серверов
В данной компании получился довольно интересный кейс, когда мы осуществляли замену устаревших серверов приложений и СУБД на новые.
Указанные маркеры я внедрил в информационную систему, в которой работало 500 пользователей и основными их бизнес-процессами были складские операции и товародвижение.
Маркер "СП сериализация XML" выполнялся в среднем за 1,5 секунды.
Новые сервера были установлены в один из ЦОДов компании, и под сервер СУБД и 1С были развернуты виртуальные машины. Миграцию планировали делать постепенно: сначала заменили сервер приложений, а затем делали смену сервера СУБД.
После смены сервера СУБД начались проблемы: CPU стал утилизироваться под 90%, хотя конфигурация сервера была такая же как и до переезда: 48 CPU и 1,5 Тб ОЗУ. Оказалось, что порог стоимости параллелизма (cost threshold for parallelism) был настроен некорректно, и там стояло значение "5" (дефолтное), из-за чего большое количество запросов пыталось использовать параллельное выполнение узлов плана, и им просто не хватало выделенных на сервере ядер. После того как увеличили это значение до такого, которое было на старом сервере, проблема ушла.
После этого мы посмотрели сервер СУБД с ЕРП, у которого также стоял такой же низкий порог параллелизма. На нем вот такой простейший запрос выполнялся 2 сек. из-за использования параллелизма на операции вставки во временную таблицу:
ВЫБРАТЬ ПЕРВЫЕ 10000
*
ПОМЕСТИТЬ ВТ
ИЗ
РегистрНакопления.СебестоимостьТоваров
Поэтому, если у вас MS SQL, то советую лишний раз посмотреть на указанный выше параметр, если у вас включен параллелизм (в моей практике он был всегда у нас включен на высоконагруженных базах, просто нужно правильно подобрать порог).
Мы немного отвлеклись от нашего маркера. После решения критичной проблемы работа системы пришла в норму, но маркер "СП сериализация XML" стал выполняться в 10 раз дольше – 15 секунд.
Т.к. его задумка была в том, что он измеряет сериализацию, то выглядело странным, что после переезда на более современные поколения процессоров мы получили деградацию. Посмотрев еще раз внимательно на код маркера, который был написан на тот момент почти 2 года назад, я исключил из него все, что касалось сериализации, оставив его в следующем виде:
Запрос = Новый Запрос(
"ВЫБРАТЬ ПЕРВЫЕ 100
| АвансовыйОтчет.Ссылка КАК Ссылка
|ИЗ
| Документ.АвансовыйОтчет КАК АвансовыйОтчет");
Выборка = Запрос.Выполнить().Выбрать();
КлючеваяОперация = "СП_СериализацияXML";
НачалоЗамера = ОценкаПроизводительности.НачатьЗамерВремени();
Пока Выборка.Следующий() Цикл
Выборка.Ссылка.ПолучитьОбъект();
КонецЦикла;
ОценкаПроизводительности.ЗакончитьЗамерВремени(КлючеваяОперация, НачалоЗамера);
Выполнил – также 15 секунд, т.е. основное время у нас занимает получение объекта.
С точки зрения 1С, получение одного объекта – это серия запросов к базе данных:
- Запрос чтения шапки объекта
- Отдельный запрос для чтения каждой табличной части (например, 5 табличных частей – 5 запросов)
- Запрос чтения версии объекта
Все запросы выполняются в рамках одного соединения с базой данных (dbpid), после каждого запроса результат выполнения, естественно, возвращается на сторону сервера приложений и затем он отправляет команду на выполнение следующего и т. д.
Результат чтения объекта кэшируется в памяти сервера приложений в течении 20 секунд, поэтому выполнять этот запрос нужно с разницей минимум 20 секунд.
Далее я включил сбор технологического журнала, настроил событие в extended events для сбора информации о времени выполнения запросов и получил результаты: по данным ТЖ запрос выполнялся на порядок медленнее, чем по данным MS SQL (разница была десятки миллисекунд).
После этого мы вместе с администратором 1С пошли к нашим администраторам Windows, объяснили проблему, и они сказали, что знают причину: трафик между сервером приложений и СУБД ходит по общей сети компании. Не помню, что сказали админы на вопрос, как было раньше и почему сейчас стало так; в итоге проблема была решена тем, что между сервером приложений и сервером СУБД был поднят отдельный канал через технологию jumbo channels, и размером пакета 8 Кб. После этого значение маркера вернулось в нормальное в пределах 1,5–2 секунд.
"Тантор Лабс": сравниваем сервера приложений
Следующий кейс был уже связан с моим текущим местом работы, в рамках которого я помогаю клиентам разобраться с возникающими вопросами после миграции на СУБД Tantor.
У клиента было 2 одинаковых физических сервера, на одном из которых были развернуты сервер приложений и сервер СУБД на стеке Windows Server + MS SQL, а на другом сервере – то же самое, но на стеке Astra Linux +Tantor SE 1C.
Тестировалась ключевая операция заполнения документа в ЗУПе, и по замерам времени в конфигураторе были получены результаты, по которым стек на Windows показал результат на 30% лучше.
По замерам производительности оказалось, что не только запросы к БД выполняются медленнее, а вообще любой код выполнялся медленнее в среднем на 20%:

(слева Astra Linux, справа Windows)
Но что о таком думают заказчики? Конечно они говорят, что это Postgres плохо работает) И необходимо было наглядно показать, что тут проблема не только в том, что некоторые запросы выполнялись медленнее.
На помощь здесь пришел маркер "СП обход строк ТЗ", который выполняется полностью на стороне сервера приложений. По его замерам, на данных стендах мы получили время выполнения на Windows меньше на 50%: 0.64 сек против 0.91.
Таким образом мы наглядно смогли показать заказчику, что сам сервер приложений 1С работает медленнее. Не могу сказать, как именно влияла инфраструктура на падение производительности, но проблему решило разделение сервера приложений и сервера СУБД на разные машины – после этого время выполнения маркера стало такое же, как на Windows, и сам код тестируемой операции стал выполняться быстрее.
"Тантор Лабс": опять сетевая проблема?
Один из клиентов обратился к нам с проблемой медленной работы системы, для сбора информации о проблемных запросах мы попросили у них логи технологического журнала 1С и СУБД.
Обычно анализ я начинаю с того, чтобы по логам ТЖ просто получить список топ-контекстов по общей длительности выполнения, и уже в разрезе контекста смотрю, что за запросы долго выполняются.
Лог на стороне 1С и СУБД собирался с отбором по длительности более 1 секунды. И при анализе запроса обратила на себя внимание сильная разница во времени выполнения запросов по данным разных логов. Ниже данные о времени выполнения 5 запросов:
1.
Лог 1С: 00:06.015000-15018996
Лог СУБД: 2024-07-30 14:00:06.009 MSK [85924] LOG: duration: 6864.310 ms plan:
2.
Лог 1С: 00:53.071008-6105003
Лог СУБД: нет в логе, значит выполнялся менее секунды.
3.
Лог 1С: 01:44.991003-13328002
Лог СУБД: 2024-07-30 14:01:44.986 MSK [84645] LOG: duration: 6084.727 ms plan:
4.
Лог 1С: 03:30.152000-15033997
Лог СУБД: 2024-07-30 14:03:30.145 MSK [84645] LOG: duration: 6329.789 ms plan:
5.
Лог 1С: 14:35.804001-13251000
Лог СУБД: 2024-07-30 15:14:35.796 MSK [94400] LOG: duration: 6149.201 ms plan:
Как видно из данных, разница в выполнении составляет 7–9 секунд.
Даем клиенту выполнить маркер "СП сериализация XML", но удалив из него все что связано с сериализацией, получаем среднее время выполнения 4.3 сек, что, по опыту, довольно много, т.к. обычно он выполнялся у меня в диапазоне 1–2 секунд.
Уточняем, как организована сеть: сервера общаются по общей корпоративной сети, и клиент уже сам понял, что это проблема, и запланировал инфраструктурные работы по прямому подключению серверов между собой.
После проведения работ наш маркер стал показывать средний результат 3.2 секунды. Мы просили клиента вручную запускать его на выполнение до и после смены топологии сети. Конечно, тут было бы более показательно, если бы он работал регламентно каждую минуту, чтобы видеть более полную и объективную картину.
Собираем еще раз логи 1С и СУБД: теперь разница при выполнении стала намного меньше – максимум 100 мс. Клиент отметил, что работать база стала заметно лучше.
Но в логах нашли следующий случай:
2024-08-26 11:10:24.276 MSK [25878] LOG: duration: 2351.584 ms plan:
Query Text: SELECT
...
Nested Loop Left Join (cost=12.34..2549.56 rows=1000 width=437) (actual time=0.914..47.454 rows=1000 loops=1)
...
Текст запроса я убрал, ибо он чересчур велик.
Смысл в следующем: запрос выполнялся 2361 мс, при этом по плану запроса он выполнился за 47 мс. В запрос в качестве параметра передавался массив из 1000 значений, которые "весят" 72 Кб, если скопировать их в текстовый файл и посмотреть размер этого файла.
Конфигурация была типовая ЕРП, и у меня был контекст выполнения запроса. Я написал обработку, которая выполнит данный запрос дважды: сначала передаст массив из 1000 значений, а потом – из 500.
Перед тем как отдать, я проверил у себя скорость выполнения данного запроса из 1С:
- массив с 1000 значениями – 20 мс;
- массив с 500 значениями – 12 мс.
У клиента получаем следующий результат:
- массив с 1000 значениями – 3400 мс;
- массив с 500 значениями – 400 мс.
Выполняли это несколько раз и каждый раз был такой сильный разброс по времени. При этом при выполнении исследуемого запроса из пгадмина клиент получал время выполнения не более 25 мс.
Я не являюсь специалистом по сетевой инфраструктуре и ее диагностике, но косвенно через 1С показал клиенту, что у него в инфраструктуре есть проблема. Дальше дело за ним.
А что же маркеры СУБД?
Я не помню, чтобы они помогли диагностировать какие-то проблемы. Единственное, когда кто-то пытался делать вставку в tempdb нескольких млрд записей, то маркер 1 это показывал. Но на такие случаи нашими DBA у нас был настроен отдельный мониторинг.
При этом стоит отметить, что смена версии СУБД происходила более сложно, чем смена платформы 1С, т.к. от версии к версии менялась оценка кардинальности, что приводило к тому, что нужно либо переписать часть запросов либо вернуть режим совместимости и старую оценку кардинальности. Мы это испытали при переходе с 2012 на 2016 и с 2016 на 2017 MS SQL, и проблемы были очевидны и без маркеров.
Как встроить обработку в вашу систему
- Переписать запросы во всех четырех процедурах, т.к. данные там были подобраны под конкретную информационную систему.
- Проверить, что используемые методы начала и фиксации замера производительности соответствуют вашей версии подсистемы "Оценка производительности", входящей в состав БСП.
- Проверьте в режиме "1С:Предприятия", что все 4 маркера отрабатывают корректно, в сообщения выводится время выполнения маркеров.
- Настройте в исследуемой базе РЗ, которое по расписанию будет выполнять данную обработку. Самый простой способ – это в конфигурациях с современными версиями БСП добавить обработку в справочник "Дополнительные отчеты и обработки" и настроить регламентное задание на ее основании. Рекомендую выполнять обработку каждые 1 или 5 минут в зависимости от ваших целей.
- Последите за работой обработки в течение периода, за который у вас, допустим, будут проблемы в исследуемой системе. Соотнесите проблемы с показаниями маркеров и APDEX, сделайте выводы.
- При необходимости настройте алерты на маркеры.
Идея для развития
Как выше мы видели, часто имеет место инфраструктурная проблема, при которой длительность выполнения запросов по данным логов 1С и СУБД сильно отличается.
Если у вас есть время и навыки, думаю, многим пригодился бы инструмент или скрипт, который маппит данные этих логов и показывает запросы, время выполнения которых отличается на то количество миллисекунд, которое задается как параметр.
Для логирования запросов в Postgres нужно установить вот эти 2 настройки:
logging_collector = 'on'
log_min_duration_statement = '1000'
Заключение
Как мы увидели, эти маркеры можно использовать как диагностическое средство для поиска "узких мест" в инфраструктуре. Я бы вам советовал иметь что-то подобное на постоянной основе, чтобы был ориентир эталонных ключевых операций, которые вы можете оценивать при изменениях внутри вашей инфраструктуры или смене версии платформы 1С или СУБД.
Если проблемы начинаются после изменений в инфраструктуре, то вы сможете наглядно показать вашим коллегам-инфраструктурщикам, что проблема на их стороне, а не в 1С.
Я бы мог написать целевое время для каждого маркера, с которым они выполнялись у меня, но это будет неправильно, т.к. на вашей инфраструктуре время выполнения может быть совсем другим, и это нормально. Подходить к этому инструменту нужно с умом, чтобы не получилось, что вы сразу придете к инфраструктуре с претензией, что у кого-то другого этот маркер выполняется быстрее.
Также уделяйте особое внимание ситуациям, когда запросы по данным логов 1С и СУБД выполняются значительно разное время, это может свидетельствовать о проблеме где-то между компонентами вашей информационной системы.
Александр Симонов, "Тантор лабс".
Проверено на следующих конфигурациях и релизах:
- 1С:ERP Управление предприятием 2, релизы 2.5.7.201
Вступайте в нашу телеграмм-группу Инфостарт


