

{kind=link}
Про интеграцию баз данных 1С и колоночной аналитической СУБД ClickHouse.
Зачем и почему с ClickHouse ? Потому что на сегодня это одна из самых быстрых аналитических СУБД с огромными возможностями масштабирования и готовой интеграцией с аналитическими системами. К тому же это OpenSource решение.
Когда появляется необходимость в подобном решении? Ответ очень простой - при размерах таблиц в миллиарды и десятки миллиардов записей формировать результаты аналитических запросов, используя только возможности 1С, уже весьма затруднительно. И нужные результаты будут получаться слишком поздно, когда они уже не актуальны.
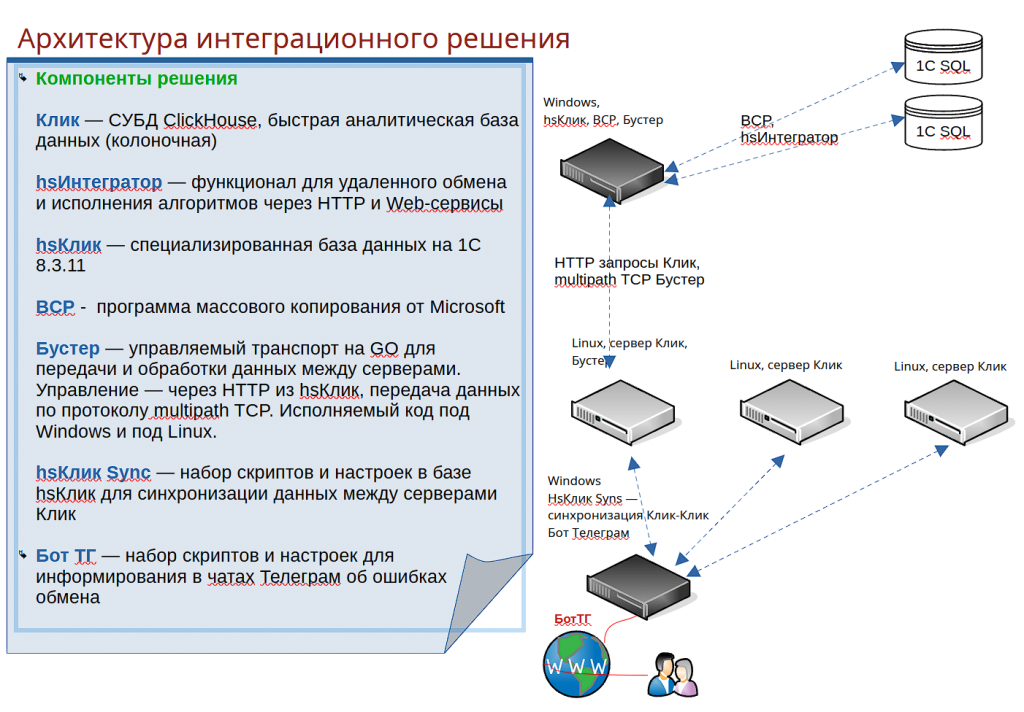
Здесь хочу поделиться обзором архитектуры одного из вариантов эффективной реализации подобного интеграционного решения.
Ядром решения является небольшая конфигурация на платформе 1С версии 8.3.11 или
выше. В эту конфигурацию внедрен функционал hsИнтегратор для обмена с базами 1С. В качестве источников данных используются подключения через веб или http сервисы, опубликованные в базах 1С, прямые подключения к SQL базам 1С, ресурсы на FTP-серверах с данными сторонних систем. А результатом является регулярное обновление данных в базах ClickHouse. Данные ClickHouse используются либо в отчетах 1С, либо другими клиентами (Power BI, Excel, ...).
База данных конфигурации не хранит данные интегрируемых СУБД, но управляет информационными потоками между ними.
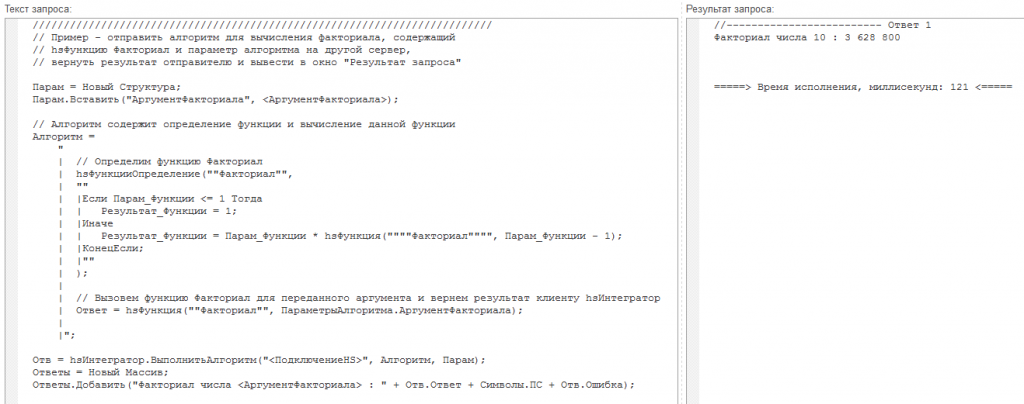
Для того, чтобы интеграционное решение было гибким и имело возможность настройки на различные источники, в конфигурацию входит скриптовой "движок", использующий настройки различных подключений, механизм "сценариев", который позволяет запускать скрипты по расписанию, разбивать алгоритмы на последовательные и параллельные участки. Скрипты могут являться пакетными запросами ClickHouse, алгоритмами 1С (которые могут исполняться, в том числе на удаленных серверах 1С). Алгоритмы 1С могут также содержать различные типы запросов (ClickHouse, 1С, SQL). Пример кода скрипта для удаленного вычисления факториала приведен на рисунке.
Ядро включает в себя механизм преобразования имён объектов 1С в имена SQL, чтобы код запросов не зависел от внутренних имен базы SQL.
Теперь о том, как обновлять быстро данные в ClickHouse. Данные в базах 1С непрерывно изменяются, причём не только добавляются, но и изменяются существующие. Быстрое обновление данных - это не конёк аналитических систем. Такие системы оптимизированы для получения и хранения больших объемов данных, но не для точечных изменений, которые характерны для OLTP баз данных.
И здесь, собственно, о сути статьи - как решить проблему актуализации данных в ClickHouse при непрерывно изменяющихся данных в источниках.
Существует два способа актуализации:
1. Передача потока изменений в источнике и запись данных из потока в приёмник. Такой способ используется, например, для создания онлайн-копий баз данных SQL. Но для аналитических баз способ не подходит, т.к. требует интенсивного внесения большого количества точечных изменений в базы. То есть использовать аналитическую базу в режиме, который категорически не рекомендуется разработчиками и не обеспечивает требуемую производительность.
2. Сравнение данных в источнике и приемнике, передача изменений и обновление данных в приёмнике по полученным данным. Этот способ не обеспечивает минимальных задержек поступления изменений, но аналитические задачи и не требуют этого. В ряде случаев достаточно нескольких десятков минут отставания от актуальных данных. И такой способ часто будет даже эффективнее. Например, если актуализировать каждый час и за это время одни и те же данные изменяются в источнике по несколько раз. При первом способе каждое изменение будет передано и "отработано" механизмом синхронизации. А при синхронизации по результатам сравнения - только один раз, т.к. изменение после предыдущей синхронизации только одно!
Описываемое в статье решение использует этот способ сравнения и передачи изменений для
интеграции данных 1С и ClickHouse.
Теперь о том, как быстро сравнить, получить данные изменения и обновить на основании
полученных данных базы ClickHouse.
Прежде всего синхронизируемые данные можно разделить на две части:
- таблицы, содержащие большое количество (до нескольких сотен) колонок и сравнительно немного строк (до 100 тысяч). Например, данные справочников 1С.
- таблицы, содержащие несколько десятков колонок и миллионы или миллиарды строк.
Например, данные документов.
В первом случае (данные справочников) достаточно производительности веб сервиса 1С для
получения данных из источника. Количество колонок при этом не является жестким
ограничивающим фактором.
А вот данные измененных документов могут содержать очень большое количество строк. И здесь производительность веб-сервиса уже явно недостаточна. Поэтому в решении используются дополнительные (не 1С) типовые программы, позволяющие
доставить данные изменений из 1С в ClickHouse:
1. Служебная программа bcp позволяет очень быстро выгрузить результат SQL запроса в текстовый файл с разделителями. Поскольку это консольная программа, размер передаваемого ей текста запроса ограничен возможностями консоли. Это примерно 8 килобайт. Для получения необходимых данных документов таких размеров хватает. Но для справочников с большим количеством колонок - уже нет. Использование веб-сервисов для получения данных решает проблему.
2. Дополнительная программа-компаньон с условным названием "Бустер".
Бустер написан на языке GO с целью обеспечить необходимые для интеграции функции, отсутствующие в платформе 1С. Программа управляется по HTTP-протоколу, является сервером HTTP, клиентом и сервером TCP. Устанавливается два Бустера - один на стороне клиента (Бустер1), где выполняются запросы SQL, второй - на сервере ClickHouse (Бустер2).
"Бустеры" передают команды и данные между собой по протоколу TCP, но 1С общается только с Бустером1 (по HTTP).
Сценарий работы с программой:
- из 1С интеграционное решение через HTTP отправляет Бустеру1 данные пакета SQL запросов, которые должны быть выполнены на различных серверах 1С и результаты которых должны быть доставлены на сервер ClickHouse.
- Бустер1 запускает несколько параллельно исполняемых потоков.
В каждом потоке выполняется три последовательных этапа:
- запуск сеанса BCP (без отображения окна) для формирования текстового файла с разделителями. Размеры таких файлов практически ограничены только доступным дисковым пространством и могут достигать сотен гигабайт.
- сжатие текстового файла
- передачу сжатых (zstd) данных по TCP Бустеру2.
Бустер2 сохраняет сжатый файл на сервере ClickHouse и возвращает Бустеру1 результат исполнения.
После завершения всех параллельных потоков Бустер1 возвращает в 1С коллекцию с пакетом результатов исполнения (расшифровки ошибок, если они возникли на одном из этапов последовательного исполнения).
Также Бустер содержит команды удаления ранее загруженных файлов на сервере ClickHouse.
После доставки всех файлов на сервер ClickHouse запускаются алгоритмы обновления данных.
Описанные выше варианты получения данных из источников являются вторым этапом синхронизации.
Но на первом этапе, перед тем, как выгружать данные из источника, необходимо определить, какие именно данные необходимо выгрузить.
А после доставки всех данных с изменениями нужно обновить данные на сервере ClickHouse. Это третий, последний этап, тоже имеет свои нюансы.
Подробнее про первый этап: определение состава выгружаемых данных.
Данные справочников - выгружаются полностью, а данные документов по результатам сравнения 1С и ClickHouse за период (задаётся количество дней от текущей даты). Сравнение документов выполняется по датам. Если за дату обнаружено различие, данные документов за эту дату выгружаются полностью. Конечно, можно использовать и другие разделители, но чем детальнее сравнивать, тем дольше будет сами процедура сравнения. На практике оказалось, что достаточно грубого сравнения по датам.
Используется два алгоритма сравнения.
Сравнивать данные SQL и ClickHouse можно быстро, например по итоговым суммам за день — в этом случае можно пропустить некоторые изменения. Либо по хэш-суммам — такое сравнение медленнее, но найдет «пропущенные» изменения.
Для расчета 32-разрядных хэш-сумм в SQL используются функции T-SQL HASHBYTES и CHECKSUM_AGG для расчета по алгоритму MD5. 64-разрядных аналогов не удалось найти. В ClickHouse также используется расчет по MD5 и результаты расчетов сравниваются затем с результатами из SQL.
Быстрое сравнение используется для актуализации данных в течение дня, а по хэш-суммам один раз в день, утром.
И, наконец, про третий этап - как обновить данные в ClickHouse?
Обновление заключается в том, чтобы вначале удалить все данные таблицы по разделителям, которые имеются в доставленном на втором этапе файле изменений и загрузить новые из этого файла. Поскольку синхронизация выполняется регулярно, в том числе и во время получения из таблиц ClickHouse аналитических данных, непосредственное выполнение таких операций на рабочих таблицах приведет к тому, что данные в результатах аналитических запросов будут пропадать. Чтобы избежать такой ситуации, используется уникальная возможность ClickHouse - быстрое создание копий таблиц. Например, с помощью трех запросов:
DROP TABLE IF EXISTS #Клон#
;
CREATE TABLE #Клон# AS #Табл#
;
ALTER TABLE #Клон# ATTACH PARTITION ALL FROM #Табл#"
можно за несколько секунд создать копию таблицы размером в несколько сотен гигабайт (этот размер уже с учетом сжатия колонок, которое весьма эффективно при колоночном хранении данных). После создания мы фактически имеем новое имя (оглавление) для доступа к тем же блокам данных
таблицы. Но в дальнейшем новая таблица полностью самостоятельна. Если в неё вносятся изменения,
то изменяется оглавление только для измененных блоков новой таблицы.
Поэтому выполнение обновления рабочей таблицы выполняется следующим образом:
- вначале создаётся клон (теневая копия) рабочей таблицы
- затем в копии выполняются все действия по обновлению (удаление, добавление данных)
- после завершения обновления рабочая таблица и клон меняются местами (в клике есть команда EXCHANGE) и ненужный уже клон удаляется.
На этом краткое описание технологии синхронизации 1С и ClickHouse можно завершить.
Но есть еще особенности синхронизации с данными, размещенными на FTP.
Механизм обновления таблиц ClickHouse по данным из файлов в этом случае такой же. Но доставка файлов с сервера FTP на сервер ClickHouse средствами 1С вызывает следующие проблемы:
- При большом количестве файлов в каталоге FTP (больше 10 тыс.) штатный метод получения списка файлов по маске *.* выбрасывает исключение. Можно обойти эту проблему, если использовать в цикле различные маски. Но это дополнительный "костыль".
- 2. На сервере ClickHouse не установлена платформа 1С (зачем там лишняя нагрузка ?), поэтому вначале приходится получать данные с FTP на компьютер 1С и, уже потом передавать на сервер ClickHouse.
- 3. Медленно!
Готовое решение проблем доставки данных с сервера FTP на сервер ClickHouse нашлось и не пришлось "изобретать велосипед". Это open source утилита ncftpget. Установка этой утилиты непосредственно на сервер ClickHouse и последующий регулярный запуск позволяет быстро и надежно перемещать файлы по маске с FTP на сервер ClickHouse. И практических ограничений по количеству файлов в каталоге FTP уже нет!
И, наконец, интеграционное решение используется для разворачивания клонов данных сервера ClickHouse на других серверах. Здесь подход похожий - сравнили данные, нашли разницу и, в теневом режиме, обновили рабочую таблицу. Но сравнение выполняется уже с применением 64-разрядных хэш-сумм. Функций, позволяющих вычислить такие хэш-суммы, в ClickHouse большое количество, самая быстрая xxHash64 выполняет расчет с распараллеливанием алгоритма на всех ядрах процессора. На практике расчет 64-разрядного хэша по таблице 20 колонок на миллиард записей занимает примерно 2 минуты, в десятки раз быстрее расчета 32-разрядного хэша сервером SQL. Расчет выполняется, например, в разрезе разделителя "Дата + НомерМагазина / 100". Для каждой таблицы задаётся индивидуальный разделитель исходя из особенностей данных. Например, для маленьких таблиц можно просто задать константное значение. В этом случае обновление будет выполняться полностью для всей таблицы при любом изменении данных в источнике. А для доставки данных используется табличная функция ClickHouse remote.
В статье отражены основные принципы уже реализованной архитектуры интеграции с аналитической СУБД ClickHouse.
Буду рад, если эта информация поможет при решении аналогичных задач.
Вступайте в нашу телеграмм-группу Инфостарт