







 Временные таблицы в 8.3.23
Временные таблицы в 8.3.23
Давайте рассмотрим механизм работы платформы 1С с временными таблицами.
Выполним запрос создания временной таблицы:
ВЫБРАТЬ
Контрагенты.Ссылка КАК Ссылка,
Контрагенты.Код КАК Код,
Контрагенты.Наименование КАК Наименование
ПОМЕСТИТЬ ВТ_Контрагенты
ИЗ
Справочник.Контрагенты КАК Контрагенты
ИНДЕКСИРОВАТЬ ПО
Ссылка
Платформа выполнит следующие запросы к БД:
// 1. создаем ВТ. Если ВТ с таким именем уже существует, то сначала уничтожим ее.
drop table if exists tt1 cascade;create temporary table tt3 (_Q_001_F_000RRef bytea, _Q_001_F_001 mvarchar(9), _Q_001_F_002 mvarchar(25) ) without oids
// 2. Запишем либо прочитаем информацию о созданной ВТ. Данная функция выполняется на стороне сервера 1С.
Func=lookupTmpTable
// 3. Удалим индекс tmpind_0, если он существует
drop index if exists tmpind_0
// 4. Создадим индекс tmpind_0 на созданной ВТ
create index tmpind_0 on pg_temp.tt3(_Q_001_F_000RRef)
// 5. Вставим данные в ВТ
INSERT INTO pg_temp.tt3 (_Q_001_F_000RRef, _Q_001_F_001, _Q_001_F_002) SELECT
T1._IDRRef,
T1._Code,
T1._Description
FROM _Reference54 T1
// 6. Рассчитаем статистику на ВТ
ANALYZE pg_temp.tt3
// 7. Удаляем индекс
drop index if exists TMPIND_0
// 8. Очищаем ВТ
SELECT FASTTRUNCATE ('pg_temp.tt3')
Если еще раз выполнить из того же сеанса этот же запрос, то будут выполнены все те же самые запросы к БД кроме п.1 - создания временной таблицы. Почему так происходит?
При первом создании временной таблицы на стороне сервера приложений сохраняется примерно следующая информация (это не описание с ИТС, а предположение, исходя из имеющихся фактов):
| База | Состав колонок |
Номер соединения СУБД |
Имя временной таблицы |
| erp_prod | _Q_001_F_000RRef bytea, _Q_001_F_001 mvarchar(9), _Q_001_F_002 mvarchar(25) | 224789 | tt3 |
Поэтому при повторном выполнении платформа 1С понимает, что временная таблица с таким составом и типом полей существует, если обращение к базе данных идет по номеру соединения СУБД, в рамках которого она была создана, и переиспользует ее вместо создания новой. Это позволяет экономить время на создание новой таблицы и удалении существующей (вместо удаления оставляем ее, чтобы использовать снова).
Создадим еще одну временную таблицу, но с другим составом полей, уберем выбор поля "Наименование":
ВЫБРАТЬ
Контрагенты.Ссылка КАК Ссылка,
Контрагенты.Код КАК Код
ПОМЕСТИТЬ ВТ_Контрагенты
ИЗ
Справочник.Контрагенты КАК Контрагенты
ИНДЕКСИРОВАТЬ ПО
Ссылка
Т.к. структура колонок отличается, то в этом случае будет создана новая временная таблица, а на стороне сервера приложений будет храниться примерно следующая информация:
| База | Состав колонок |
Номер соединения СУБД |
Имя временной таблицы |
| erp_prod | _Q_001_F_000RRef bytea, _Q_001_F_001 mvarchar(9), _Q_001_F_002 mvarchar(25) | 224789 | tt3 |
| erp_prod | _Q_001_F_000RRef bytea, _Q_001_F_001 mvarchar(9) | 224789 | tt4 |
То, что обе временные таблицы продолжают существовать, можно убедиться из данных СУБД.
Для этого сначала определим схему, в которой созданы наши 2 временные таблицы:
SELECT n.nspname AS schema_name, c.relname AS table_name
FROM pg_class c
JOIN pg_namespace n ON n.oid = c.relnamespace
WHERE c.relname in ('tt3', 'tt4') AND n.nspname LIKE 'pg_temp%';
Результат запроса:
schema_name | table_name
-------------+------------
pg_temp_27 | tt3
pg_temp_27 | tt4
(2 rows)
Посмотрим на состав этих таблиц:
SELECT a.attrelid::regclass, a.attname, t.typname AS data_type
FROM pg_attribute a
JOIN pg_type t ON a.atttypid = t.oid
WHERE a.attrelid in ('pg_temp_27.tt3'::regclass, 'pg_temp_27.tt4'::regclass) AND attnum > 0;
Результат запроса:
attrelid | attname | data_type
----------------+------------------+-----------
pg_temp_27.tt3 | _q_001_f_000rref | bytea
pg_temp_27.tt3 | _q_001_f_001 | mvarchar
pg_temp_27.tt3 | _q_001_f_002 | mvarchar
pg_temp_27.tt4 | _q_001_f_000rref | bytea
pg_temp_27.tt4 | _q_001_f_001 | mvarchar
(5 rows)
Для того чтобы посмотреть, какие данные хранятся во временной таблице, необходимо выполнить запрос "select * from pg_temp_27.tt3" - результат будет пустой, т.к. наши временные таблицы после выполнения функции SELECT FASTTRUNCATE стали пустыми.
Когда временная таблица будет удалена на стороне СУБД? Она будет удалена, когда будет закрыто соединение к СУБД, в рамках которого она была создана.
Конструкция "Уничтожить"
Что делает конструкция "Уничтожить" в запросе? Выполним запрос:
ВЫБРАТЬ
Контрагенты.Ссылка КАК Ссылка,
Контрагенты.Код КАК Код,
Контрагенты.Наименование КАК Наименование
ПОМЕСТИТЬ ВТ_Контрагенты
ИЗ
Справочник.Контрагенты КАК Контрагенты
ИНДЕКСИРОВАТЬ ПО
Ссылка
;
////////////////////////////////////////////////////////////////////////////////
УНИЧТОЖИТЬ ВТ_Контрагенты
Здесь поведение будет точно таким 1 в 1, как и выше. Это объясняется тем, что функция "Уничтожить"- это есть не что иное, как вызов функции SELECT FASTTRUNCATE. На примерах выше это происходило автоматически, т.к. мы не используем МенеджерВременныхТаблиц, и платформа 1С вызывает функцию SELECT FASTTRUNCATE при окончании выполнения запроса.
А если выполнять запрос с использованием МенеджераВременныхТаблиц и без явного уничтожения временной таблицы в тексте запроса, то функция SELECT FASTTRUNCATE будет вызвана в тот момент, когда мы закроем МенеджерВременныхТаблиц явно, либо он перестанет существовать.
Из этого всего можно сделать вывод, что функция SELECT FASTTRUNCATE нужна для очистки временной таблицы с целью ее дальнейшего переиспользования.
В ходе миграции и сопровождения информационных систем на postgres эта функция часто мне встречалась и показывала себя не с лучшей стороны.
Оптимизация select fasttruncate
Первая встреча
Самый первый раз с долгим выполнением функции SELECT FASTTRUNCATE я столкнулся около 3-х лет назад при переводе базы УХ на postgres.
В базе пользователи не работали, и мы ее использовали только для подготовки отчетности по контролируемым сделкам. Весь тест перехода на postgres как раз и состоял в том, чтобы протестировать функцию загрузки данных из экселя и создание операций по контролируемым сделкам.
Первый тест на postgres показал ухудшение по сравнению с mssql на 70% и по логам технологического журнала львиную долю времени как раз и занимала функция SELECT FASTTRUNCATE.
Долгое выполнение было связано с тем, что по каждой контролируемой сделке шла проверка, которая выполняла запрос и создавала пустую временную таблицу. "Уничтожение" этой пустой таблицы функцией SELECT FASTTRUNCATE и было этим узким местом, занимавшем большую часть выполнения тестируемой операции. В ходе разбора логики я выяснил, что можно заранее определить будет в запросе создаваться пустая временная таблица или нет. Если пустая, то запрос выполнять смысла не было - таким образом и была достигнута оптимизация: если не выполняется запрос с созданием временной таблицы, то и не вызывается функция SELECT FASTTRUNCATE.
Затем я написал кейс на корп поддержку 1С, но у коллег проблема не воспроизвелась - на том история была закончена.
Вторая встреча
Компания "Тантор Лабс" находится в контуре "Группы Астра", в которую входит в том числе одна производственная компания. Свой учет она ведет в базе ERP размером 700 Гб, которая и была предметом нашего исследования.
На продуктивном контуре для мониторинга развернута платформа Tantor, в ходе изучения которой я опять встретился с SELECT FASTTRUNCATE.
Дашборд "Top 5 total query time" показывает топ-5 запросов на инстансе, и наш запрос в рабочее время стабильно входил в этот топ:

Модуль "Профайлер запросов" уже дает более расширенную статистику по конкретным запросам.
Смотрим ее по нашему запросу за последние 24 часа:

Как видим, эта функция занимает 12.9% процессорного времени.
Давай разберем ее исходный код, чтобы подробнее понять, что же она делает:
Далее я поясню основные ее моменты:
text *name=PG_GETARG_TEXT_P(0);
Присваивает имя временной таблицы, переданной в качестве параметра функции, в переменную name.
relname = palloc( VARSIZE(name) + 1);
memcpy(relname, VARDATA(name), VARSIZE(name)-VARHDRSZ);
relname[ VARSIZE(name)-VARHDRSZ ] = '\0';
Извлекает имя таблицы из текстового объекта name и выделяет память для его хранения в переменной relname.
relname_list = stringToQualifiedNameList(relname);
relvar = makeRangeVarFromNameList(relname_list);
relOid = RangeVarGetRelid(relvar, AccessExclusiveLock, false);
По relname получает внутренний идентификатор таблицы в базе данных (OID) в переменную reloid и накладывает эксклюзивную блокировку на эту временную таблицу, чтобы никто не мог ее менять.
if ( get_rel_relkind(relOid) != RELKIND_RELATION )
elog(ERROR,"Relation isn't a ordinary table");
rel = table_open(relOid, NoLock);
if ( !isTempNamespace(get_rel_namespace(relOid)) )
elog(ERROR,"Relation isn't a temporary table");
Сначала выполняется проверка, что таблица является ординарной, затем временная таблица "открывается" для дальнейшего изменения (можно провести аналогию с ПолучитьОбъект() в 1С) и затем проверка, что таблица является временной. Обе проверки выглядят избыточными, т.к. функция написана именно под приложение 1С.
heap_truncate(list_make1_oid(relOid));
Удаляются все строки из временной таблицы (то, ради чего платформа 1С и вызывает эту функцию).
if ( rel->rd_rel->relpages > 0 || rel->rd_rel->reltuples > 0 )
makeanalyze = true;
Если исходя из статистики (именно из статистики, а не фактического количества строк) данной временной таблицы в ней до усечения было строк более 0, то присвоим переменной makeanalyze значение ИСТИНА.
table_close(rel, AccessExclusiveLock);
"Закрываем" таблицу и снимаем наложенную на нее блокировку, теперь она может быть использована другими сеансами.
if (makeanalyze) {
VacuumParams params;
VacuumRelation *rel;
params.options = VACOPT_ANALYZE;
...
rel = makeNode(VacuumRelation);
rel->relation = relvar;
rel->oid = relOid;
rel->va_cols = NULL;
vacuum(list_make1(rel), params,
GetAccessStrategy(BAS_VACUUM), false);
}
Если переменная makeanalyze = ИСТИНА, то пересчитаем статистику по таблице, т.к. мы удалили из нее все записи, и статистика стала неактуальной.
Если перевести на язык 1С и откинуть все неважное, то можно представить это в виде следующего кода:
Функция SelectFasttruncate(ВременнаяТаблица)
ТребуетсяПересчитатьСтатистикуПоТаблице = Ложь;
ВременнаяТаблица.Очистить();
Если КоличествоСтрокВоВременнойТаблицеСогласноСтатистики > 0 Тогда
ТребуетсяПересчитатьСтатистикуПоТаблице = Истина;
КонецЕсли;
Если ТребуетсяПересчитатьСтатистикуПоТаблице Тогда
ПересчитатьСтатистикуПоТаблице(ВременнаяТаблица);
КонецЕсли;
КонецФункции
Мы исследовали данную функцию с помощью perf'а, чтобы посмотреть, какой ее код выполняется дольше всего:

Несложно было догадаться, что основная часть времени уходит на очистку временной таблицы - это рассмотренный выше код "heap_truncate(list_make1_oid(relOid));".
Далее мы решили провести анализ, чтобы определить, как часто функция select fasttruncate вызывается для пустой таблицы.
Как часто создаются пустые временные таблицы?
Для ответа на этот вопрос мы провели исследование на продуктивной базе ЕРП, упомянутой выше.
Был собран простейший ТЖ:
<log location="ПутьСбораЛогов" history="72">
<event>
<eq property="Name" value="DBPOSTGRS"/>
<eq property="p:processname" value="ИмяБазы"/>
<like property="Sql" value="INSERT%pg_temp%"/>
</event>
<property name="RowsAffected"/>
</log>
Пример полученного лога:
55:20.112002-999,DBPOSTGRS,5,RowsAffected=0
55:20.112012-11,DBPOSTGRS,6,RowsAffected=0
55:20.113007-996,DBPOSTGRS,5,RowsAffected=0
55:20.115000-995,DBPOSTGRS,5,RowsAffected=0
55:23.323000-992,DBPOSTGRS,5,RowsAffected=0
55:23.386002-5000,DBPOSTGRS,5,RowsAffected=0
55:23.483003-2999,DBPOSTGRS,5,RowsAffected=0
55:23.506000-1992,DBPOSTGRS,5,RowsAffected=5
55:23.511005-1002,DBPOSTGRS,5,RowsAffected=10
55:23.514000-1994,DBPOSTGRS,5,RowsAffected=53
55:23.517002-2997,DBPOSTGRS,5,RowsAffected=714
55:23.525002-7995,DBPOSTGRS,5,RowsAffected=1892
55:23.540000-13997,DBPOSTGRS,5,RowsAffected=1317
Поле RowsAffected содержит количество строк, которые вставлялись во временную таблицу. Оставалось только агрегировать полученные данные и построить диаграмму для наглядности:

Это данные за день работы продуктивной базы ЕРП, где на диаграмме первое число - это количество строк во временной таблице, а после запятой - доля таких временных таблиц.
Получается почти 5 млн созданий временных таблиц, из них 32% были пустыми.
Исходя из этого напрашивается доработка функции SELECT FASTTRUNCATE: по пустой временной таблице нет смысла делать очистку строк, ведь она и так пустая, при этом функция очистки строк все равно выполняется существенное время. А также мы завязались не на оценку строк из статистики, а на реальное количество строк во временной таблице, что на наш взгляд более правильно.
В итоге оптимизированную функцию можно представить следующим кодом 1С:
Функция SelectFasttruncate(ВременнаяТаблица)
ТребуетсяПересчитатьСтатистикуПоТаблице = Ложь;
Если ВременнаяТаблица.Количество() > 0 Тогда
ВременнаяТаблица.Очистить();
ТребуетсяПересчитатьСтатистикуПоТаблице = Истина;
КонецЕсли;
Если ТребуетсяПересчитатьСтатистикуПоТаблице Тогда
ПересчитатьСтатистикуПоТаблице(ВременнаяТаблица);
КонецЕсли;
КонецФункции
Результат оптимизации
Эффект от оптимизации оценивался тремя способами.
Первый. Платформа Tantor позволяет получить статистические показатели по запросу за выбранный промежуток времени. Я взял данные за неделю до оптимизации:
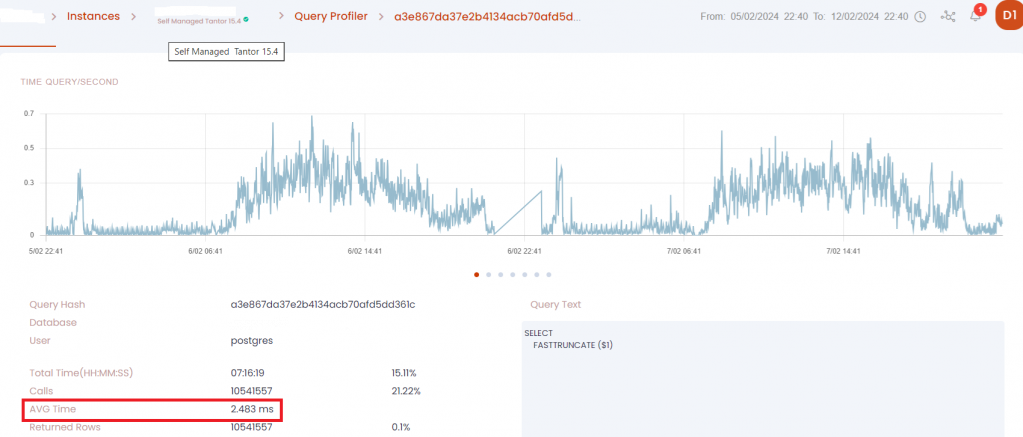
И неделю после:
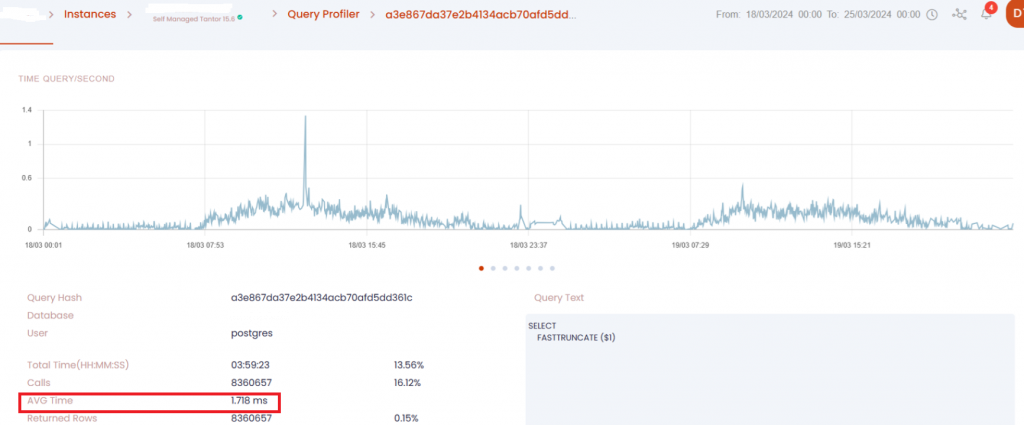
Среднее время выполнения функции SELECT FASTTRUNCATE ускорилось на 44%.
Второй. Также был собран технологический журнал следующего вида:
<log location="ПутьСбораЛогов" history="72">
<event>
<eq property="Name" value="DBPOSTGRS"/>
<eq property="p:processName" value="ИмяБазы"/>
<like property="Sql" value="%FASTTRUNCATE%"/>
</event>
</log>
Список собираемых полей не указан специально, потому что они нам не нужны. Нам нужна только длительность такого запроса, которая и будет собираться - получаем логи следующего вида:
47:12.114004-3995,DBPOSTGRS,4
47:12.115026-4018,DBPOSTGRS,4
47:12.117009-3996,DBPOSTGRS,4
47:12.119011-3986,DBPOSTGRS,4
47:12.121007-5004,DBPOSTGRS,4
47:12.121013-4991,DBPOSTGRS,5
Данные были собраны за 2 дня до и после оптимизации, и мы получили следующий результат
:
| Замер | Количество операций |
Суммарное время выполнения (мс) |
Среднее время выполнения (мс) |
| До | 14572327 | 47400477 | 3.253 |
| После | 10983028 | 22435790 | 2.043 ↓59% |
Среднее время выполнения функции SELECT FASTTRUNCATE ускорилось на 59% (среднее время больше чем по данным платформы Tantor, т.к. событие DBPOSTGRS включает в себя издержки на сетевое взаимодействие между СП и СУБД на отправку запроса на выполнение и получение ответа от СУБД о выполнении запроса).
Третий. Был проведен синтетический тест, в котором каждый поток создавал 10 000 раз пустую временную таблицу.


По оси Y указано среднее время выполнения функции SELECT FASTTRUNCATE в мс, по оси X - количество потоков.
Первый график показал ускорение в среднем на 74%, второй график (во временной таблице создавался индекс) - на 115%.
Неожиданный эффект от оптимизации
Перед выпуском каждого релиза мы тестируем сборку на нагрузочных тестах, чтобы убедиться, что внедряемые задачи дают оптимизацию на каких-то ключевых операциях, и нет ключевых операций, ставших хуже.
Нагрузочный тест ERP показал, что ключевая операция проведения документа "Поступление безналичных денежных средств" стала выполняться быстрее. Я нашел запрос, который ускорился, и получилась довольно интересная ситуация.
Первый раз выполнение запроса было одинаково долгим как до, так и после оптимизации - https://explain.tensor.ru/archive/explain/29db90bdcf487abe6e8a5002d31f4476:0:2024-08-05
А вот второе выполнение отличалось. До оптимизации запрос выполнялся 1.7 сек - https://explain.tensor.ru/archive/explain/93d3e65d99949d65797b9a4c6844a8a0:0:2024-08-05, а после оптимизации менее 1 мс - https://explain.tensor.ru/archive/explain/e51134f3e5239038c6741f8563db5979:0:2024-10-07.
Причина ускорения была довольно нетривиальной, попробуйте сами понять почему.
Дам несколько подсказок, которые в дополнении к информации из этой статьи дадут возможность понять причины:
- Перед первым выполнением данного запроса, которое было долгим в обоих случаях, для временной таблицы tt94 не была рассчитана статистика (почему так может происходить, описано в статье //infostart.ru/1c/articles/2142833/)
- Временная таблица tt94 существует между первым и вторым выполнениями, перед вторым выполнением ее "очистка" осуществляется функцией SELECT FASTTRUNCATE.
- Во временную таблицу tt94 вставляется одна запись.
Жду ваших ответов в комментариях!
Данную оптимизацию мы внедрили в нашу СУБД Tantor Special Edition 1C, начиная с релиза 15.6.0.
Временные таблицы в 8.3.25
3 года назад отправлял пожелание по добавлению новых возможностей по работе с временными таблицами в 1С и вот в 25й платформе появились долгожданные новые возможности. Давайте разберем их техническую сторону.
Добавление строк в существующую временную таблицу
Выполним запрос, который создаст временную таблицу со 100К строк, а вторым запросом добавим еще 1 строку.
ВЫБРАТЬ ПЕРВЫЕ 100000
СебестоимостьТоваров.Период КАК Период,
СебестоимостьТоваров.Регистратор КАК Регистратор,
СебестоимостьТоваров.НомерСтроки КАК НомерСтроки
ПОМЕСТИТЬ ВременнаяТаблица
ИЗ
РегистрНакопления.СебестоимостьТоваров КАК СебестоимостьТоваров
;
////////////////////////////////////////////////////////////////////////////////
ВЫБРАТЬ ПЕРВЫЕ 1
СебестоимостьТоваров.Период КАК Период,
СебестоимостьТоваров.Регистратор КАК Регистратор,
СебестоимостьТоваров.НомерСтроки КАК НомерСтроки
ДОБАВИТЬ ВременнаяТаблица
ИЗ
РегистрНакопления.СебестоимостьТоваров КАК СебестоимостьТоваров
Платформа выполнит следующие запросы к БД:
// 1. создаем ВТ. Если ВТ с таким именем уже существует, то сначала уничтожим ее.
drop table if exists tt1 cascade;create temporary table tt1 (_Q_001_F_000 timestamp, _Q_001_F_001TRef bytea, _Q_001_F_001RRef bytea, _Q_001_F_002 numeric(9, 0) ) without oids
// 2. Запишем либо прочитаем информацию о созданной ВТ. Данная функция выполняется на стороне сервера 1С.
Func=lookupTmpTable
// 3. Вставим 100К строк в ВТ
INSERT INTO pg_temp.tt1 (_Q_001_F_000, _Q_001_F_001TRef, _Q_001_F_001RRef, _Q_001_F_002) SELECT
T1._Period,
T1._RecorderTRef,
T1._RecorderRRef,
T1._LineNo
FROM _AccumRg50748 T1
WHERE (T1._Fld2488 = CAST(0 AS NUMERIC)) LIMIT 100000
// 4. Рассчитаем статистику на ВТ
ANALYZE pg_temp.tt1
// 5. Вставим еще одну строку в ВТ
INSERT INTO pg_temp.tt1 (_Q_001_F_000, _Q_001_F_001TRef, _Q_001_F_001RRef, _Q_001_F_002) SELECT
T1._Period,
T1._RecorderTRef,
T1._RecorderRRef,
T1._LineNo
FROM _AccumRg50748 T1
WHERE (T1._Fld2488 = CAST(0 AS NUMERIC)) LIMIT 1
// 6. Очищаем ВТ
52:06.452000-4999,DBPOSTGRS,5,Sql="SELECT FASTTRUNCATE ('pg_temp.tt1')"
Видно, что при использовании конструкции "Добавить" по таблице не рассчитывается статистика. Это может приводить к неверной оценке строк по временной таблице. Воспроизведем данную ситуацию.
Изменим пример. Мы будем смотреть по плану запроса сколько строк по оценке планировщика будет во временной таблице:
ВЫБРАТЬ ПЕРВЫЕ 100000
СебестоимостьТоваров.Период КАК Период,
СебестоимостьТоваров.Регистратор КАК Регистратор,
СебестоимостьТоваров.НомерСтроки КАК НомерСтроки
ПОМЕСТИТЬ ВременнаяТаблица
ИЗ
РегистрНакопления.СебестоимостьТоваров КАК СебестоимостьТоваров
УПОРЯДОЧИТЬ ПО
Период,
Регистратор,
НомерСтроки
;
////////////////////////////////////////////////////////////////////////////////
ВЫБРАТЬ
КОЛИЧЕСТВО(1) КАК Поле1
ИЗ
ВременнаяТаблица КАК ВременнаяТаблица
ГДЕ
ВременнаяТаблица.НомерСтроки = 2
План запроса:
Query Text: SELECT
COUNT(CAST(1 AS NUMERIC))
FROM pg_temp.tt1 T1
WHERE (T1._Q_001_F_002 = CAST(2 AS NUMERIC))
Aggregate (cost=1942.92..1942.93 rows=1 width=8) (actual time=11.698..11.699 rows=1 loops=1)
Output: count('1'::numeric)
Buffers: local hit=841
-> Seq Scan on pg_temp.tt1 t1 (cost=0.00..1941.00 rows=1923 width=0) (actual time=0.011..11.599 rows=1865 loops=1)
Output: _q_001_f_000, _q_001_f_001tref, _q_001_f_001rref, _q_001_f_002
Filter: (t1._q_001_f_002 = '2'::numeric)
Rows Removed by Filter: 98135
Buffers: local hit=841
По оценке планировщика 1923 строки, а фактически - 1865. Тут все хорошо, т.к. при первой вставке во временную таблицу статистика по ней рассчитывается.
Теперь выполним запрос, чтобы подтвердить, что планировщик ошибется при отсутствии статистики:
ВЫБРАТЬ ПЕРВЫЕ 0
СебестоимостьТоваров.Период КАК Период,
СебестоимостьТоваров.Регистратор КАК Регистратор,
СебестоимостьТоваров.НомерСтроки КАК НомерСтроки
ПОМЕСТИТЬ ВременнаяТаблица
ИЗ
РегистрНакопления.СебестоимостьТоваров КАК СебестоимостьТоваров
УПОРЯДОЧИТЬ ПО
Период,
Регистратор,
НомерСтроки
;
////////////////////////////////////////////////////////////////////////////////
ВЫБРАТЬ ПЕРВЫЕ 100000
СебестоимостьТоваров.Период КАК Период,
СебестоимостьТоваров.Регистратор КАК Регистратор,
СебестоимостьТоваров.НомерСтроки КАК НомерСтроки
ДОБАВИТЬ ВременнаяТаблица
ИЗ
РегистрНакопления.СебестоимостьТоваров КАК СебестоимостьТоваров
УПОРЯДОЧИТЬ ПО
Период,
Регистратор,
НомерСтроки
;
////////////////////////////////////////////////////////////////////////////////
ВЫБРАТЬ
КОЛИЧЕСТВО(1) КАК Поле1
ИЗ
ВременнаяТаблица КАК ВременнаяТаблица
ГДЕ
ВременнаяТаблица.НомерСтроки = 2
Первым запросом мы просто создаем временную таблицу, вторым добавляем в нее 100К строк. План:
Query Text: SELECT
COUNT(CAST(1 AS NUMERIC))
FROM pg_temp.tt1 T1
WHERE (T1._Q_001_F_002 = CAST(2 AS NUMERIC))
Aggregate (cost=1498.12..1498.13 rows=1 width=8) (actual time=12.345..12.346 rows=1 loops=1)
Output: count('1'::numeric)
Buffers: local hit=841
-> Seq Scan on pg_temp.tt1 t1 (cost=0.00..1497.82 rows=299 width=0) (actual time=0.015..12.244 rows=1865 loops=1)
Output: _q_001_f_000, _q_001_f_001tref, _q_001_f_001rref, _q_001_f_002
Filter: (t1._q_001_f_002 = '2'::numeric)
Rows Removed by Filter: 98135
Buffers: local hit=841
Query Identifier: 209524141104999352
Планировщик сильно ошибается, думая что будет 299 строк вместо 1865 фактических.
Тут нам на помощь может прийти уже забытый плагин online_analyze. Включим его и выполним прошлый запрос еще раз. Получаем план:
Query Text: SELECT
COUNT(CAST(1 AS NUMERIC))
FROM pg_temp.tt1 T1
WHERE (T1._Q_001_F_002 = CAST(2 AS NUMERIC))
Aggregate (cost=1942.83..1942.84 rows=1 width=8) (actual time=12.583..12.584 rows=1 loops=1)
Output: count('1'::numeric)
Buffers: local hit=841
-> Seq Scan on pg_temp.tt1 t1 (cost=0.00..1941.00 rows=1827 width=0) (actual time=0.013..12.459 rows=1865 loops=1)
Output: _q_001_f_000, _q_001_f_001tref, _q_001_f_001rref, _q_001_f_002
Filter: (t1._q_001_f_002 = '2'::numeric)
Rows Removed by Filter: 98135
Buffers: local hit=841
Query Identifier: -6082868411932076458
Планировщик снова угадывает количество строк - 1827 при 1865 фактических.
Исходя из этого можно сделать следующий вывод: если ваша информационная система работает на СУБД семейства postgres, то при добавлении строк в существующую временную таблицу учитывайте, что статистика по ней пересчитана не будет. Это может привести к выбору неоптимального плана запроса. Если вы с таким столкнулись, то решением здесь может быть изменение логики запроса, либо включение плагина online_analyze.
Несколько индексов во временной таблице
Также была добавлена возможность создавать несколько индексов по одной временной таблице. Давайте посмотрим, как это работает, выполнив запрос:
ВЫБРАТЬ ПЕРВЫЕ 100000
СебестоимостьТоваров.Период КАК Период,
СебестоимостьТоваров.Регистратор КАК Регистратор,
СебестоимостьТоваров.НомерСтроки КАК НомерСтроки
ПОМЕСТИТЬ ВременнаяТаблица
ИЗ
РегистрНакопления.СебестоимостьТоваров КАК СебестоимостьТоваров
УПОРЯДОЧИТЬ ПО
Период,
Регистратор,
НомерСтроки
ИНДЕКСИРОВАТЬ ПО НАБОРАМ
(
(Период,
Регистратор,
НомерСтроки) УНИКАЛЬНО,
(Регистратор),
(НомерСтроки)
)
;
////////////////////////////////////////////////////////////////////////////////
ВЫБРАТЬ
КОЛИЧЕСТВО(1) КАК Поле1
ИЗ
ВременнаяТаблица КАК ВременнаяТаблица
ГДЕ
ВременнаяТаблица.НомерСтроки = 2
;
////////////////////////////////////////////////////////////////////////////////
ВЫБРАТЬ
КОЛИЧЕСТВО(1) КАК Поле1
ИЗ
ВременнаяТаблица КАК ВременнаяТаблица
ГДЕ
ВременнаяТаблица.Регистратор = ЗНАЧЕНИЕ(Документ.РасчетСебестоимостиТоваров.ПустаяСсылка)
Создаем на временной таблице один уникальный индекс и один неуникальный. Уникальный индекс означает, что в нашей временной таблице не должно быть 2х записей с одинаковыми значениями полей Период, Регистратор, НомерСтроки.
Платформа выполнит следующие запросы к БД:
// 1. Создаем ВТ. Если ВТ с таким именем уже существует, то сначала уничтожим ее.
drop table if exists tt3 cascade;create temporary table tt3 (_Q_001_F_000 timestamp, _Q_001_F_001TRef bytea, _Q_001_F_001RRef bytea, _Q_001_F_002 numeric(9, 0) ) without oids
// 2. Запишем либо прочитаем информацию о созданной ВТ. Данная функция выполняется на стороне сервера 1С.
Func=lookupTmpTable
// 3. Удалим индекс tmpind_0, если он существует
drop index if exists tmpind_0
// 4. Создадим уникальный индекс tmpind_0 на созданной ВТ
create unique index tmpind_0 on pg_temp.tt3(_Q_001_F_000, _Q_001_F_001TRef, _Q_001_F_001RRef, _Q_001_F_002)
// 5. Удалим и создадим еще 2 индекса: tmpind_1 и tmpind_2
drop index if exists tmpind_1
create index tmpind_1 on pg_temp.tt3(_Q_001_F_001TRef, _Q_001_F_001RRef)
drop index if exists tmpind_2
create index tmpind_2 on pg_temp.tt3(_Q_001_F_002)
// 6. Вставим данные в ВТ
INSERT INTO pg_temp.tt3 (_Q_001_F_000, _Q_001_F_001TRef, _Q_001_F_001RRef, _Q_001_F_002) SELECT
T1._Period,
T1._RecorderTRef,
T1._RecorderRRef,
T1._LineNo
FROM _AccumRg50748 T1
WHERE (T1._Fld2488 = CAST(0 AS NUMERIC))
ORDER BY (T1._Period), (T1._RecorderTRef), (T1._RecorderRRef), (T1._LineNo) LIMIT 100000
// 7. Рассчитаем статистику на ВТ
ANALYZE pg_temp.tt3
// 8. Выполним запрос вычисления строк с отбором по НомерСтроки
SELECT
COUNT(CAST(1 AS NUMERIC))
FROM pg_temp.tt3 T1
WHERE (T1._Q_001_F_002 = CAST(2 AS NUMERIC))
// 9. Выполним запрос вычисления строк с отбором по Регистратор
SELECT
COUNT(CAST(1 AS NUMERIC))
FROM pg_temp.tt3 T1
WHERE (T1._Q_001_F_001TRef = '\\000\\000\\004\\270'::bytea AND T1._Q_001_F_001RRef = '\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000'::bytea)'
// 10. Удаляем 3 созданных индекса
drop index if exists TMPIND_0
drop index if exists TMPIND_1
drop index if exists TMPIND_2
// 11. Очищаем ВТ
SELECT FASTTRUNCATE ('pg_temp.tt3')
В запросах платформы к БД нет ничего необычного, видим, что создаются все 3 индекса.
Посмотрим планы запросов, чтобы убедиться, что индексы используются, мало ли. План запроса отбора по полю Номер Строки:
Query Text: SELECT
COUNT(CAST(1 AS NUMERIC))
FROM pg_temp.tt3 T1
WHERE (T1._Q_001_F_002 = CAST(2 AS NUMERIC))
Aggregate (cost=880.63..880.64 rows=1 width=8) (actual time=1.264..1.265 rows=1 loops=1)
Output: count('1'::numeric)
Buffers: local hit=492
-> Bitmap Heap Scan on pg_temp.tt3 t1 (cost=17.23..878.90 rows=1723 width=0) (actual time=0.220..1.173 rows=1865 loops=1)
Recheck Cond: (t1._q_001_f_002 = '2'::numeric)
Heap Blocks: exact=486
Buffers: local hit=492
-> Bitmap Index Scan on tmpind_2 (cost=0.00..17.06 rows=1723 width=0) (actual time=0.155..0.155 rows=1865 loops=1)
Index Cond: (t1._q_001_f_002 = '2'::numeric)
Buffers: local hit=6
А это план запроса с отбором по полю Регистратор:
Query Text: SELECT
COUNT(CAST(1 AS NUMERIC))
FROM pg_temp.tt3 T1
WHERE (T1._Q_001_F_001TRef = '\\000\\000\\004\\270'::bytea AND T1._Q_001_F_001RRef = '\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000'::bytea)
Aggregate (cost=2.33..2.34 rows=1 width=8) (actual time=0.009..0.009 rows=1 loops=1)
Output: count('1'::numeric)
Buffers: local hit=2
-> Index Only Scan using tmpind_1 on pg_temp.tt3 t1 (cost=0.12..2.33 rows=1 width=0) (actual time=0.008..0.008 rows=0 loops=1)
Output: _q_001_f_001tref, _q_001_f_001rref
Index Cond: ((t1._q_001_f_001tref = '\\x000004b8'::bytea) AND (t1._q_001_f_001rref = '\\x00000000000000000000000000000000'::bytea))
Heap Fetches: 0
Buffers: local hit=2
В обоих случаях используются созданные нами индексы, все работает верно.
Заключение
Мы рассмотрели техническую часть работы платформы 1С с временными таблицами. В платформе 8.3.25 появились новые возможности, которые позволят в определенных сценариях ускорить выполнения запросов при использовании нескольких индексов на одной временной таблице.
Стоит учитывать, что при использовании конструкции "ДОБАВИТЬ" по временной таблице не будет пересчитана статистика - здесь вам может помочь плагин online_analyze.
Хорошее знание и понимание работы механизмов платформы позволяют ускорить работу 1С - мы рассмотрели это на примере функции SELECT FASTTRUNCATE.
На текущий момент у нас в работе находятся и другие задачи по дальнейшему улучшению производительности СУБД Tantor SE 1C при массовой работе с временными таблицами. Мы расскажем о них по факту их реализации и обкатки.
Чтобы своевременно узнавать о выходе новых статей, подпишитесь на наш профиль Инфостарта.

DatabaseCompressionTool — сжатие и свертка любой базы 1С
Инструмент DatabaseCompressionTool (DCT) позволяет безопасно сжать и свернуть любую базу 1С, освободив сотни гигабайт и увеличив производительность системы. Доступна демо-версия для оценки эффективности.
Вступайте в нашу телеграмм-группу Инфостарт