Прежде, чем говорить о том, что делать со вторым сервером в кластере 1С, надо понять, зачем он там появился, и когда ему пора появляться.

Как ни странно, любой даже очень “сильный” сервер в итоге может не справиться с нагрузкой. Сервер 1С, скорее всего, перестанет справляться со своей нагрузкой быстрее, чем сервер СУБД, потому что так устроена 1С – вся математика у нас на сервере приложений, на СУБД вычисления не выполняются, СУБД просто играет роль хранилки.
Но нам же надо как-то понять, что сервер устал, и ему стало плохо. Как понять? Когда всё тормозит, это вообще ничего не значит. Не факт, что виноват сервер 1С, не факт, что вам не хватает железа.
То, что неоптимальный код в 1С надо править – это факт, и этот процесс бесконечен. Но иногда даже идеальный код создает настолько много операций или требует настолько много ресурсов, что сервер не справляется. Поэтому нам нужно научиться хотя бы на верхнем уровне быстро понимать, что наша ломовая лошадь устала, и с этим нужно что-то делать.
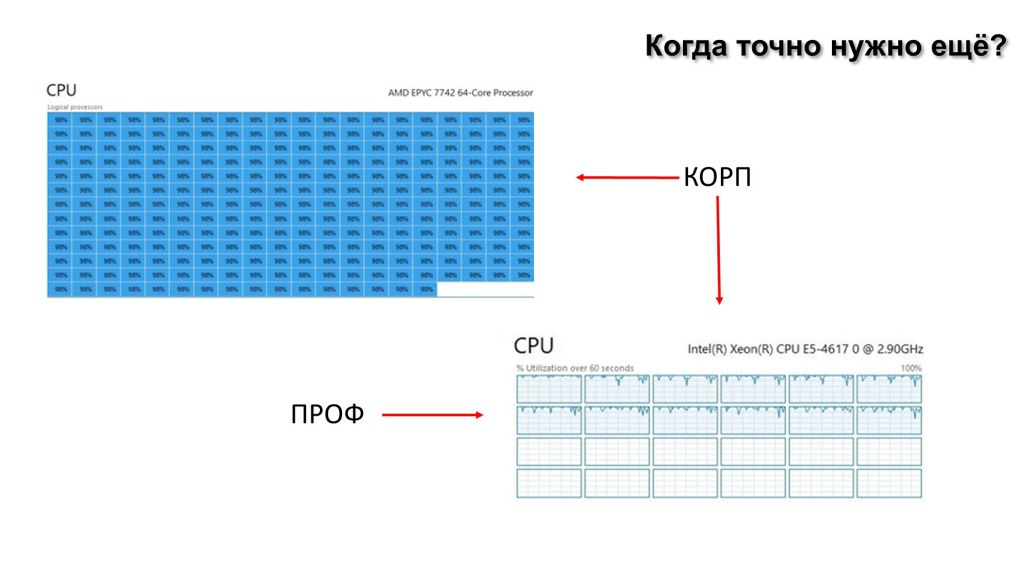
Первая очевидная вещь – это нагрузка на процессор.
Бывает, что процессор на 64 или даже на 96 ядер встает в 100% загрузки – все тормозит. Конечно, пользователи идут к 1С-никам, говорят: «Все тормозит, ваша 1С не работает!»
А 1С-ники, кого не спроси, отвечают: «Мы ничего не трогали, код не заливали». Кого ни спроси в случае проблем – никогда ни один 1С-ник код не заливал. Проблема не на их стороне – они, естественно, ничего не трогали. Они вообще ничего не трогают, за что деньги получают – неизвестно )))).
Значит, надо идти к админам – это их железки не работают. А админы показывают график с какого-нибудь Zabbix или Grafana и говорят: «Смотри, 50% нагрузки на ЦПУ – от вашей 1С. Она тормозит, иди разбирайся».
На самом деле все правы – и пользователи правы, что все тормозит, и админы правы, что 1С грузит ЦПУ только на 50%, и 1С-ники код не меняли...
1С-ник оказывается между молотом и наковальней, потому что админы не собираются разбираться в особенностях платформы 1С, а 1С-ник по идее не должен быть админом.
И если с картинкой слева еще понятно, что делать: здесь сервер устал, он отдал все 100% ресурсов. Такая нагрузка возможна только на версии платформы КОРП, потому что платформа КОРП, в отличие от платформы ПРОФ, не ограничена 12 ядрами.
И это маленькая подсказка к нижней картинке, где видно, как срабатывает ограничитель ПРОФ-версии. Админ будет говорить: «Сервер ничем не занят», а у вас все тормозит. Вы заняли 12 ядер, и вам этого мало, но больше ядер вы занять не сможете.
Но если внимательно посмотреть, то к нижней картинке почему-то и от КОРП тоже идет стрелочка.
Как так? Они же не ограничены 12 ядрами. На самом деле возможно и такое. Это написано на ИТС. Но при возникновении проблем почему-то читают только мантры, ИТС никто не читает. А там вообще-то рассказана эта ситуация.
Дело в том, что rphost, рабочий процесс сервера 1С, заперт в одной Numa-ноде – он не может работать более чем в одной Numa-ноде. Грубо говоря, если есть два процессора, и rphost родился в первом, он не сможет задействовать ядра второго процессора.
И картинка снизу – это классическая ситуация, когда rphost занял все ресурсы одной Numa-ноды.
Что делать? Очень просто – rphost-ов всегда должно быть в два раза больше, чем Numa-нод. Это регулируется настройкой количества соединений на процесс. Тогда операционная система с большой долей вероятности распределит следующий rphost на другую Numa-ноду.
Операционная система – штука умная. Она всегда распределяет на менее нагруженную Numa-ноду. Поэтому у вас в итоге будет ровная нагрузка, и всё будет классно работать, пока мы не придем к верхней картинке, где всё плохо.
Это один показатель, из-за чего 1С может тормозить – из-за того, что тормозит процессор.
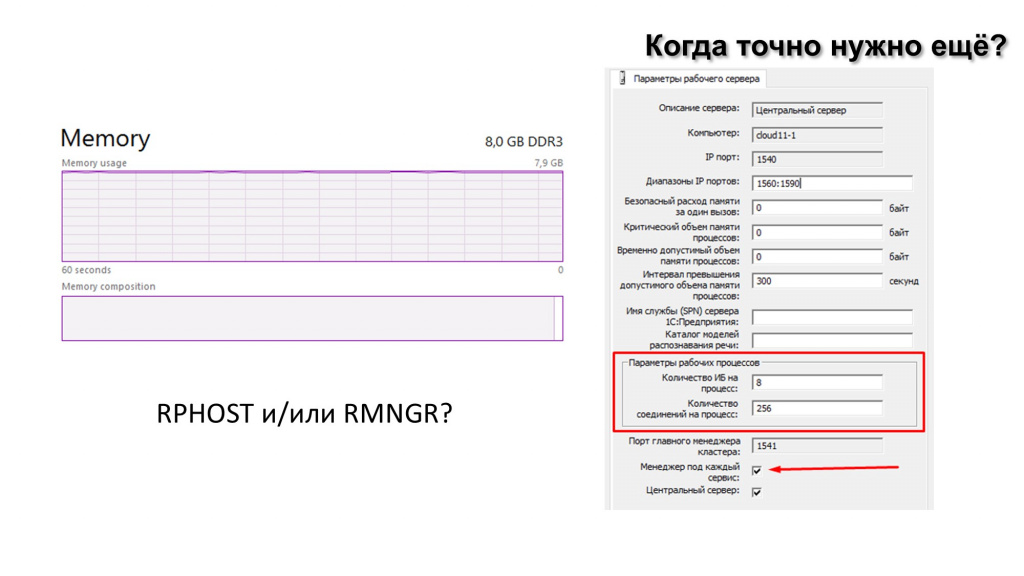
Второй вариант – кончилась память.
Обнаружить это легко – сразу видно, что память кончилась. Причем мы можем определить, кто «съел» память – rphost или rmngr. В Windows это можно сделать в диспетчере задач, а в Linux – с помощью Htop/top.
Если память съел rphost, первое, что скажет любой 1С-ник: «Опять в платформе утечка памяти». Но это не так, утечка памяти в платформе – очень редкий кейс. Просто код платформы написан так, что он использует память. К этому тоже надо быть готовым, и каждая следующая итерация платформ будет требовать больше оперативной памяти на серверах, потому что нет ничего быстрее, чем работа процессора с памятью – все, что можно засунуть в память, будет засунуто в память. Если вы планируете закупать железо на ближайшие 5 лет, закладывайте в бюджет увеличение памяти. Через 5 лет потребление памяти у вас точно будет больше, и это не надо путать с утечкой. Платформа развивается, становится быстрее, и это правильно.
Но есть одна особенность работы процесса с памятью – дефрагментировать память крайне дорого, поэтому её переиспользуют и освобождают только полностью незанятую “справа”, из-за этого через какое-то время (для всех систем разное) наступает ситуация, когда rphost занимает неприлично много памяти, хотя вроде в базах никого нет.
Чтобы этот эффект имел минимальное воздействие на скорость работы, как раз и дана возможность перезапускать рабочие процессы по таймауту.
С rphost вроде все понятно. А что, если память съел rmngr, менеджер кластера? Это же вообще «черный ящик». Там есть какие-то 30+ сервисов (в зависимости от версии платформы 1С) – полнотекстовый поиск, журнал регистрации, сервис нумерации, сервис времени, сервис управляемых блокировок и т.д. Что они там делают? Что из этого у нас съело память либо нагрузило процессоры? Как это выяснить?
Нужно поставить волшебную галочку – «менеджер под каждый сервис». Ставить на проде ее на постоянку нельзя. Это отладочная галка. Когда вы ее ставите, то у вас на каждый сервис (еще раз напомню, что сервисов 30+) родится по одному процессу менеджера кластера. Дожидаемся опять потребления оперативной памяти либо утилизации ЦПУ и смотрим, какой из процессов менеджера кластера это делает – теперь у нас за каждый конкретный сервис отвечает конкретный менеджер.
Идем в консоль администрирования и получаем ответ, что это, оказывается, журнал регистрации – кто-то в нем что-то начинает искать, и память кончается. Потому что, опять же, нет ничего быстрее, чем работа памяти с процессором. Журнал регистрации – это текст, когда вы начинаете в нем искать, все это сначала загружается в память, а потом ищется. Это правильно, потому что так – быстро, и так будет работать.
Узнав причину, вы уже можете что-то с ней делать – например, можно запретить всем смотреть журнал регистрации. Или вообще его выключить, потому что он, скорее всего, и не нужен или сделать скрипт по архивированию ЖР, а на проде оставлять только последние 3 часа и т.д.
Но есть тонкий момент. В параметрах рабочего сервера (на скриншоте справа) указан диапазон портов. Это очень важная настройка. По умолчанию там 32 порта – с 1560 по 1591. Это диапазон, на котором будут рождаться процессы этого рабочего сервера.
Напоминаю, что в платформе у кластера 30+ сервисов. Если мы поставим галочку «Менеджер под каждый сервис», у нас родится 30 процессов менеджеров – 30 из 32 портов будет занято. Если вы эту галочку поставите в рабочей системе, где более двух rphost на проде, вы получите нескончаемые ошибки «процесс не найден». Потому что система будет пытаться родить процесс, а кластер будет ей запрещать, потому что портов свободных нет, а процесс должен работать на каком-то порту.
Это тонкость. Вроде бы все в курсе вот этого диапазона портов, но почему-то всегда забывают, что это вообще-то важная вещь.
Еще одно заблуждение – почему-то считается, что для изменения диапазона нужно залезть в свойства службы, сменить там строку запуска, перезагрузить сервер, и тогда диапазон поменяется - это не так.
Чтобы поменять диапазон портов, достаточно в свойствах рабочего сервера указать новый диапазон и нажать «ОК». Все. Система тут же принимает это и начинает вам рождать новые rphost на новом диапазоне портов.Если у вас настроен Firewall, не забудьте на Firewall тоже расширить эти правила.
Не нужно перезагружать сервер, особенно 1С. Отстаньте от системы, дайте ей работать.
Даже если на сервере проблемы и вам кажется, что перезагрузка может вылечить ситуацию, это не так – она просто мусор под коврик заметет, а проблема выстрелит еще раз и не раз. Вы ее не решили. Ни одна проблема не решается перезагрузкой. Такого не бывает. Да, ошибки в платформе есть – несмотря на то, что это лучшая в мире платформа, там бывают ошибки. Надо их искать, надо дампы делать, отправлять в 1С и так далее. Перезагружать сервер ради избавления от ошибок не надо.
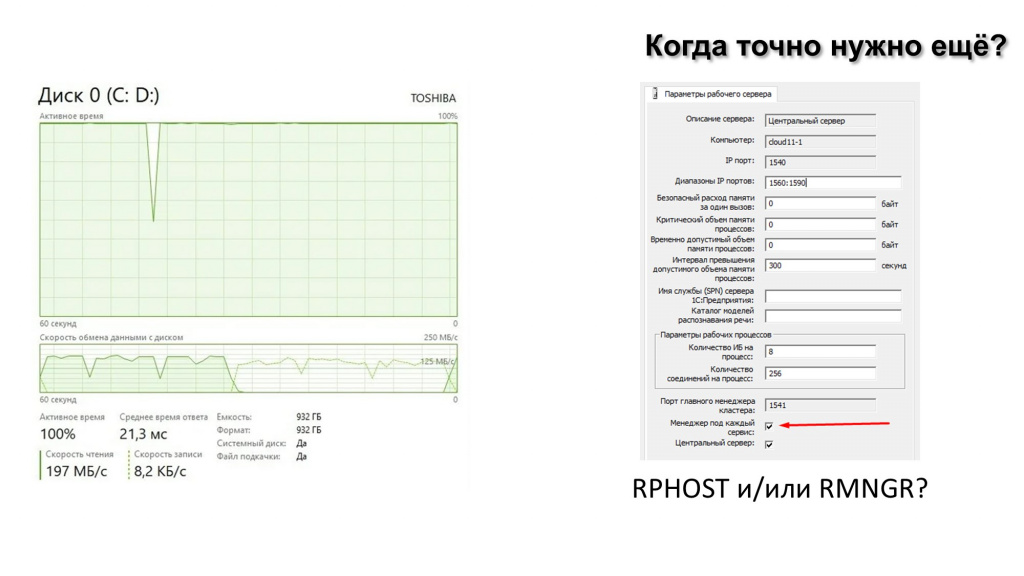
Из-за чего еще может устать наш сервер 1С? Из чего он состоит вообще? Там есть только процессор, память и диск – больше ничего нет, ну кроме сети, но тут уж совсем всё просто - сеть нужно мониторить и вовремя расширять канал. Поэтому следующий момент – это диск.
Здесь все почти то же самое, что с памятью и с процессором. Диск может кушать или rphost, или rmngr – больше некому.
Если кушает rmngr, включаем галочку «менеджер под каждый сервис», смотрим, какой сервис кушает диск – скорее всего, это будет полнотекстовый поиск. Тогда через требование назначения функциональности нужно будет вынести сервис полнотекстового поиска на отдельный сервер – пусть он там кушает свой диск и не мешает центральному серверу, работать.
Формирование или слияние индекса полнотекстового поиска может положить ваши диски. И это приведет к отказу всей системы, потому что вы не вынесли этот сервис на отдельный сервер, а оставили его на центральном сервере. По большому счёту это не ошибка конфигурирования, но это не соответствует хорошим практикам.

Когда мы выяснили, что у нас все-таки лошадь подустала, и работы столько, что мы ее облегчить не можем, нам нужно добавлять второй рабочий сервер в кластер.
Витает такой миф, что кластер 1С вообще можно собирать только при КОРП-лицензировании. Нет. ПРОФ-лицензии никак не ограничивают вас в создании кластера. Вы в кластер 1С можете добавлять себе сколько угодно серверов. По-моему, есть ограничение в 256, но я себе не могу представить такую систему – что за вычисления она должна делать, ядерные взрывы просчитывать?
Еще раз: кластер 1С можно собрать из серверов ПРОФ, для этого не нужны КОРП-лицензии, это полностью функциональность ПРОФ.
Казалось бы – добавили второй сервер в кластер, и все сразу заработало. Но самое страшное, что так оно и есть. И это плохо, потому что непонятно – что за чудо свершилось, как это работает? Кластер как-то сам все сервисы переконфигурировал – что-то на второй сервер уехало, что-то на первый.
Вы же когда вторую лошадь в упряжку добавляете, вы же ее как-то к первой лошади пристегиваете – она же не просто рядом бежит? Не бывает же такого, чтобы только от этого ехало быстрее? Нашу новую лошадь надо «настроить», за ней надо как-то поухаживать, чтобы они теперь вдвоем все тянули в одну сторону.

В платформе 8.3.25 появился очень важный момент. На слайде – скриншот встроенной обработки «Управление кластером 1С». Здесь появилась галочка «Установить запрещающее требование назначения функциональности», которая запрещает новому серверу принимать ТНФ на себя. Вы поставили эту галочку, и у вас новый сервер в кластере имеет требование назначения функциональности «Для всех – Не назначать».
Это сделано, например, для случаев, когда мы добавим сервер, а лицензию ему еще не активировали. Если мы добавляем сервер без этой галочки, кластер послушно начнет назначать на него клиентские соединения, и они начнут падать, поскольку нет лицензии.
И платформа не знает, для чего вы этот сервер добавили в кластер, какую функциональность хотите на него подать – сервис полнотекстового поиска, журнал регистрации, сеансовые данные, клиентские соединения либо только фоновые? Поэтому появление такой фишки - крайне полезно.
Самый распространенный сценарий добавления второго сервера 1С – это горизонтальное масштабирование нагрузки, увеличение мощностей, чтобы на втором сервере работали пользователи.
Чтобы разрешить на сервере работу пользователей, а остальное запретить, потребуется всего два требования назначения функциональности:
-
«Клиентское соединение с ИБ – Авто»;
-
«Для всех – Не назначать».
Очень важно, в каком порядке перечислены требования функциональности – платформа 1С считывает их сверху вниз до первого совпадения. Если бы мы сейчас эти требования назначения функциональности поменяли местами, у нас сервер просто не работал бы. Если первая строчка говорит, что на этом сервере все запрещено, он не будет работать.
Не нужно путать порядок следования с приоритетами, которые есть внутри ТНФ.
Порядок следования и приоритет – это разные вещи, но их часто путают, тем более, что в контекстном меню ТНФ в консоли администрирования есть пункты «Повысить приоритет» и «Понизить приоритет», которые указывают не на приоритет, а на порядок следования. А приоритет у ТНФ внутри.
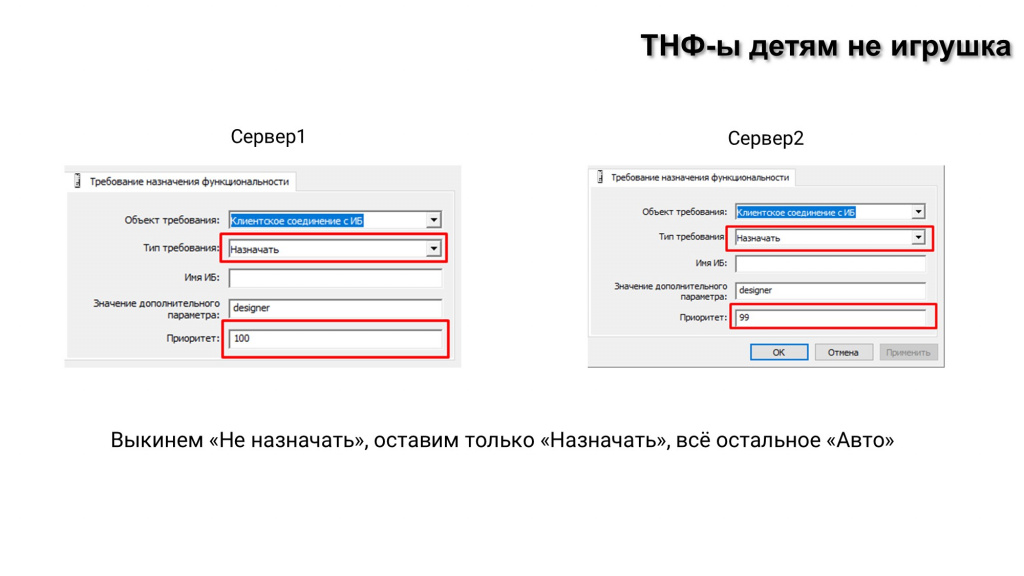
И с приоритетами тоже связаны некоторые распространенные заблуждения.
Многие считают, что значение «Назначать» у требований назначения функциональности как будто ставит его наверх, а потом за ним в очереди стоит требование назначения функциональности «Авто».
Но это работает не так. Требование назначения, которому установлено значение «Назначать» – это непререкаемая воля админа. Кластер не может ее ослушаться. Если вы установили для сервера требование назначения «Назначать» и выключили этот сервер, кластер не будет работать. Потому что ему сказали: «Назначать сюда». И он не будет назначать в другое место, раз этот сервер недоступен – у вас будет ошибка конфигурирования.
«Авто» не замещает «Назначать».
Если вы хотя бы на одном сервере сделали требование назначения «Назначать», вы обязаны продублировать это требование на втором сервере, а дальше разрулить это приоритетами:
-
Если вы дадите требованиям назначения функциональности двух разных серверов одинаковые приоритеты, они оба будут работать с объектами требований одновременно, если эти объекты требований вообще подразумевают одновременную работу – например, если это клиентские соединения.
-
А если вы установите первому серверу приоритет 100, а второму – 99, они будут работать не одновременно – первый сервер будет работать всегда и только если первый недоступен, тогда работает второй, потому что приоритет 100 выше, чем 99. Здесь чисто человеческая логика – чем приоритет больше, тем ты круче, выше в пирамиде стоишь.
Чтобы не путаться, можно запомнить маленькую скороговорку, как работает ТНФ: «Выкинем «Не назначать», оставим только «Назначать», все остальное в «Авто».
Когда вы эту скороговорку запомните, почитайте на ИТС статью, как работают требования назначения функциональности – сразу будет понятно.
Это чудесное свойство ИТС: оно написано такими словами, что очень сложно понять – его надо читать раз 6 или 8. Лучше всего оно читается, когда ты уже наступил на грабли и ничего не помогает. Идешь, читаешь документацию и потом восклицаешь: «А! Так вот же написано!», но это когда тебя уже грабли по лбу ударили. А если ты хочешь заранее все грабли обойти, придется перечитать документацию несколько раз.
&НаСервере
Итак, мы настроили серверы, разрулили ТНФ, но наши возможные проблемы на этом не закончились.
Вроде бы всем понятно, что у каждого сервера 1С – свой каталог временных файлов. Но почему-то большинство сценариев, в которых формируется файл в одном сеансе, а потом использует его в другом сеансе, зачем-то сохраняют этот файл в КаталогВременныхФайлов().
Если у вас в базах есть такие сценарии, они перестанут работать. Причем перестанут работать самым противным способом – они то будут работать, то нет.
Зато у нас, как у 1С-ников, будет железная отмазка. Пользователь говорит: «Не работает, у меня ошибка – «Временный файл не обнаружен». Вы заходите, тут же при нем щелкаете то же самое – все работает. Разворачиваетесь и гордо уходите, потому что не подтверждается: «Такая же нога и вообще не болит».
Вы не успеете обратно к себе дойти, он опять позвонит: «Ну не работает!» Вы скажете: «Ты что, издеваешься? Мне еще раз прийти?» Вы придете, нажмете – все работает. Очень вредная и непонятная ошибка.
Кстати, даже в любой типовой конфигурации, если вы при синхронизации не укажете, куда складывать файлы при обмене, она по умолчанию положит их в каталог временных файлов. И вы будете долго удивляться, почему обмен то работает, то нет. Потому что он положил то на один сервер, то на другой, потом он заберет файл с первого, а там какой-то другой файл лежит, и будет что попало.

Лечение достаточно простое:
-
Если вам требуется в одном сеансе сформировать файл, который будет требоваться в другом сеансе, этот файл должен лежать в сети либо в сеансовых данных.
-
Файлами внутри каталога временных файлов вы можете оперировать только внутри одного соединения, внутри одного вызова. Потому что другое соединение может уйти вообще на другой сервер. А временные файлы – это файлы вашего соединения, а не сервера, и даже не сеанса. Даже в рамках одного сеанса соединение может быть в течение дня назначено на другой сервер.
-
Следующий момент – это уже к админам, они же тоже должны быть в чем-то виноваты. Почему-то всех удивляет, что доступ в интернет теперь нужен всем рабочим серверам 1С, а не только тому серверу, у которого этот доступ уже был. Если у вас в принципе серверный код зачем-то ходит в интернет, это надо разрешить всем серверам. Интернет – это утрированный пример, помимо интернета есть просто сеть, куда что-то ходит. Теперь на другом сервере все доступы должны быть такие же – это такая же вторая лошадка.
-
Следующий момент тоже многих удивляет. Оказывается, что на второй сервер надо поставить все сопутствующее ПО: и офисный пакет, если у вас серверный код с офисными пакетами работает, и криптопровайдера, и сопутствующее ПО наподобие ImageMagick и Native Client в случае работы с MS SQL. Все это, оказывается, теперь должно быть установлено на всех серверах. Либо через требование назначения функциональности надо угонять ваше конкретное регламентное или фоновое задание на один конкретный сервер.
Но тут я вас огорчу. Угнать конкретное фоновое задание или конкретное регламентное задание могут только счастливые владельцы КОРП-платформы.

КОРП-платформа – это тоже не чудо, ее просто можно более гибко настроить, и благодаря этой гибкости она будет работать мощнее. Но, прежде чем запрягать этот большой дилижанс и пытаться его настроить, нам нужно понять – а когда нужна КОРП-платформа?
Здесь тоже куча теорий заговоров и заблуждений – чего только на просторах интернета не пишут. Самое распространенное заблуждение, которое направлено на то, чтобы выбить бюджет на КОРП-платформу: «Сейчас КОРП-платформу поставим и все заработает быстрее». Нет. Не заработает. Оно заработает быстрее только в том случае, если вы в 12 ядер упирались, а теперь не станете упираться. Это единственный момент, который заработает быстрее.

Так когда нужна КОРП-платформа на самом деле?
-
Самый главный триггер – 500 пользователей. Если у вас ПРОФ, 501-й пользователь в базу не зайдет. Это технический триггер.
-
Следующий триггер неочевидный – КОРП-платформа нужна, когда ваша база должна работать 24/7. Потому что на ПРОФ просто из-за отсутствия гибкости требований назначения функциональности вы не сможете нормально обслуживать базу в таком графике. Понятно, что 24/7 – утрированный режим работы, когда-то вам все равно придется остановить базу, чтобы обновить структуру конфигурации. Но в целом, как это обычно говорят: «У нас 24/7».
-
Еще один триггер – когда вам нужна экспертная поддержка в рамках РКЛ. На больших базах практически всегда нужна экспертная поддержка в рамках РКЛ. А РКЛ без КОРП-платформы не купить.
-
Необходимость в профилях безопасности кластера. На данный момент без профилей безопасности кластера пользователь с полными правами в 1С и доступом в конфигуратор является богом. Он может сделать все что угодно. Мы можем над ним поставить высшее божество – админа кластера 1С, который будет управлять профилями безопасности. Что может сделать человек с полными правами, чтобы серверам стало плохо? Например, он может взять и запустить на сервере калькулятор в бесконечном цикле – админам придется сервер перезагружать, потому что он никогда не оживет. Профиль безопасности много от чего защитит, в том числе от этого.
-
Необходимость в гибкой настройке потребления ресурсов. Все мы знаем, что 1С умеет убивать процессы с превышением по памяти, но в КОРП есть еще более гибкий механизм – вы можете настроить, что если запрос к СУБД длится более 10 минут, надо убить этот сеанс. Тут такая идеология: «Убей одного, чтоб тысяча жила», потому что вам нужно хранить систему, чтобы система работала. Пожертвовать одним запросом – ну и ладно.
Вот причины перехода на КОРП. Других настоящих причин практически нет.
Если у вас меньше 500 пользователей, вы вряд ли упретесь в 12 ядер. Но если и упретесь, вам не нужно будет переходить на КОРП – просто второй сервер рядом поставьте и ваши возможности расширятся.
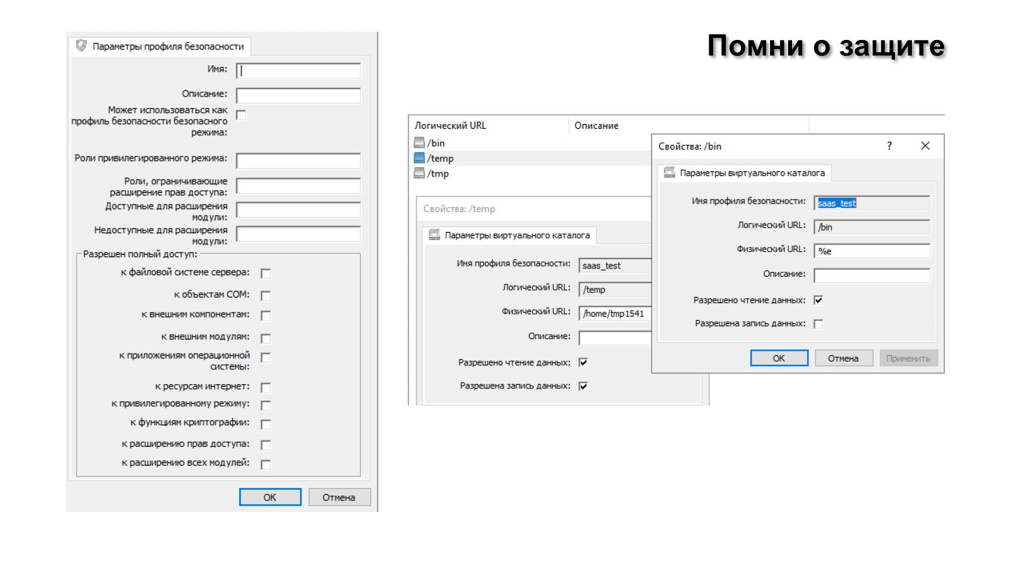
Вот так выглядит настройка профилей безопасности – то, о чем я сейчас рассказывал.
Здесь много чего можно ограничить. В том числе, есть опасная штука – внешние отчеты, обработки, компоненты и так далее. Вы даже это можете ограничивать – это делается по хэшу.
Настройка профилей безопасности – очень важная вещь. Если безопасники знают, что где-то в недрах ИТ существует 1С и понимают, какие данные там хранятся, они много чего требуют – того, что без этой функциональности решить просто невозможно.
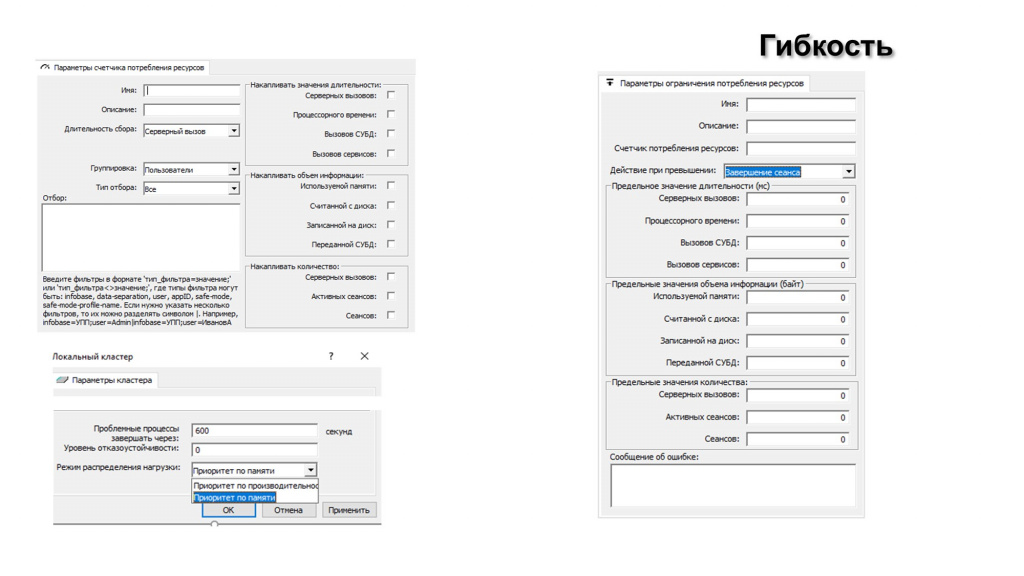
Вот так выглядит настройка потребления ресурсов.
-
Мы настраиваем, за каким параметром следим.
-
Настраиваем, какая будет отсечка этого параметра.
-
И что с этим будем делать – просто в лог напишем, завершим сеанс, либо понизим приоритет. Можно просто понизить приоритет и процессор будет его выполнять с низким приоритетом. Например, можно настроить, что если процесс на сервере 1С потратил больше 10 секунд процессорного времени, нужно понизить его приоритет. Т.е. если операция долгая, пусть она выполняется не сильно нагружая ЦПУ на Сервере 1с.
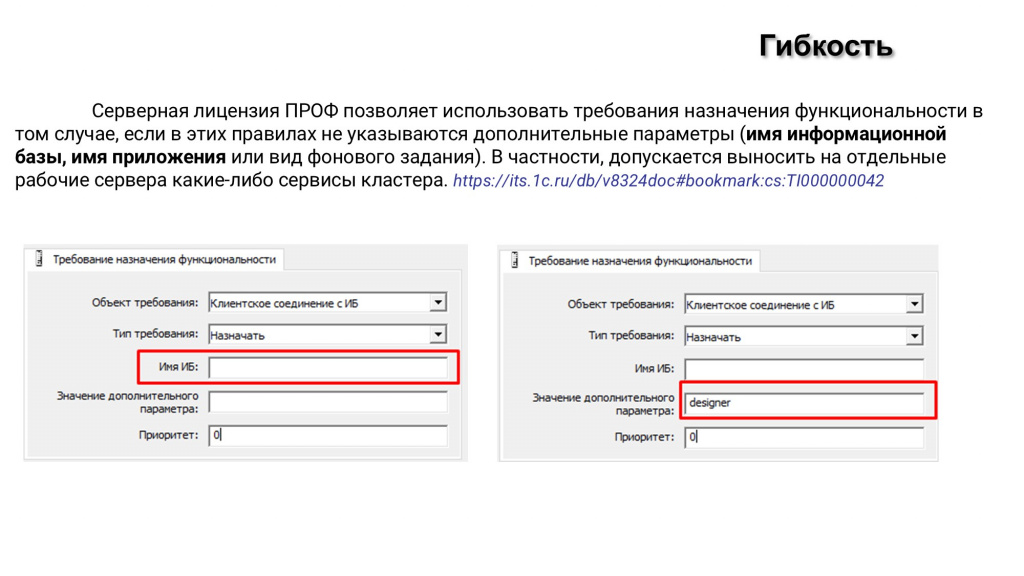
Следующий момент связан с гибкостью ТНФ, которая доступна в КОРП:
В отличие от ТНФ для ПРОФ-платформы, которые всегда работают в разрезе всего кластера, в платформе с КОРП-лицензией в требованиях назначения функциональности можно указывать:
-
имя базы – для какой конкретно базы это требование назначения функциональности действует;
-
имя/тип приложения – конфигуратор, тонкий клиент, толстый клиент и так далее – можно раскидать все приложения по разным серверам;
-
вид фонового задания либо регламентного задания – можно угнать на другой сервер конкретное фоновое либо регламентное задание.
Когда вам все эти плюшки КОРП вдруг стали нужны, тогда и нужно переходить на КОРП.
Практически во всех остальных случаях кластер 1С можно настроить правильно и безопасно при ПРОФ-лицензировании – чтобы он хорошо работал и радовал скоростью пользователей 1С.
Вопросы и ответы
На одной из прошлых конференций Инфостарта вы говорили о том, что в ТНФ не работают приоритеты. И даже регистрировали ошибку в платформе. Эта ошибка уже исправлена, сейчас приоритеты работают?
Да. Там не работал приоритет именно клиентских соединений. У сервисов работал, у клиентских соединений нет. Это еще в 2021 году было исправлено.
Я как раз переходил на КОРП ради возможности переключения конкретного фонового задания на отдельный сервер, но столкнулся с такой проблемой. В типовых конфигурациях все фоновые задания запускаются через длительные операции. И получается, что в контексте переключения строка отслеживания звучит как: «ДлительныеОперации.ВыполнитьМетод». И получается, что некоторые фоновые задания в типовых конфигурациях мы так переключить не можем. Нужно именно внедряться в конфигурацию. А есть какая-нибудь другая возможность?
Средствами платформы – пока нет. Если мы ставим в ТНФ параметр BackgroundJob.CommonModule.ДлительныеОперации.ВыполнитьМетод, на отдельный сервер будет переносить все длительные операции.
UPD: В платформе 8.3.27 появилась возможность назначать ТНФ для пользователя и группы пользователей, это легко решает данную проблему.
Насколько драматично будет, если галочку «Менеджер под каждый сервис» включить на горячую без перезагрузки?
Если включаете на горячую, и портов хватает, скорее всего, все пройдет хорошо. Но если у кого-то из пользователей есть длительный активный серверный вызов, его скорее всего сбросит.
Диапазон портов IP на rmngr тоже распространяется?
Это диапазон портов всех процессов рабочего сервера. У рабочего сервера есть менеджер кластера rmngr и рабочие rphost. Диапазон портов распространяется на все.
Когда вы добавляете в кластер центральный сервер, у него прямо указано, что rmngr работает на 1541. А когда вы добавляете в кластер дополнительный сервер, кластер считает, что скорее всего на 1541 уже работает rmngr центрального сервера, и поэтому выбирает для добавленного нового сервера другой порт из этого диапазона.
На самых первых слайдах был показан сервер с ПРОФ-лицензией, нагрузка на процессор у которого заняла 12 ядер, а 12 было свободно. Можно ли на этот же железный сервер поставить второй виртуальный сервер 1С:Предприятие и занять оставшиеся 12 ядер? Нужно ли для этого покупать дополнительную лицензию на сервер 1С:Предприятие?
Да. можно. Надо будет только купить ещё одну серверную лицензию 1С.
Я как-то настраивал второй сервер в кластере, и в определенный момент при запуске 1С появлялась плавающая ошибка о нехватке лицензий на сервер. Настройки все были правильные, в целом все было ок, и помогла только очистка серверного кэша. Это нормальное поведение либо все-таки где-то накосячили?
После любого изменения состава лицензий нужно удалять на сервере лицензионный кэш – он хранится в файлах *.pfl, и они иногда мешают. Их нужно удалить.
Вопрос про лицензии. Если взять один хост на 24 ядра и поднять на нем две службы агента сервера ПРОФ – есть ли какие-то механизмы, чтобы первый агент занял первые 12 ядер, а второй – другие 12 ядер?
В платформе при наличии ПРОФ-лицензии, не КОРП-лицензии, ragent безусловно стартует с параметром 0-11, с нулевого до 11 ядра займет. Но вы можете поставить виртуалку на эту же машину, купить лицензию и вперед.
А можно ли назначить ядра процессоров на процессы конкретного приложения?
Это поможет только до первого перезапуска rphost, потому что новый rphost опять родится с тем параметром. Не надо так делать. На костылях строить инфраструктуру очень опасно.
В платформе 8.3.22 появился полнотекстовый поиск версии 2.0. Как его включить? Требуется ли что-то изменить в регламентных заданиях, чтобы он заработал?
Неохота пересказывать ИТС. Чтобы включить, нужно в «Функциях технического специалиста» найти платформенную обработку «Управление полнотекстовым поиском». Там можно переключить режим с первого на второй.
И потом вам нужно ручками создать регламентную операцию обновления полнотекстового поиска 2.0.
Получается, что типовые БСП-шные регламентные задания по обновлению полнотекстового поиска нужно отключить?
По-моему, в последней 1С:УХ уже все есть, в том числе, и новые регламентные задания. Конфигурации же не сразу применяют все фишки платформы, а платформа 8.3.22 вышла по моему полгода назад (прим. ред. доклад от 12 октября 2023 года). В типовые по-маленьку доезжает – думаю, скоро везде будет.
По поводу настройки ТНФ для двух серверов. Вы не сказали, как настраивать журнал регистрации – его имеет смысл выносить на отдельный сервер?
Там был пример с настройкой ТНФ для второго сервера, где назначения для всех клиентских соединений – «Авто», а все остальное – «Не назначать». В этом случае журнал регистрации всегда работает на первом сервере.
А нужно ли его выносить куда-то отдельно? Если для вас это критичный сервис, выносите, пожалуйста. А так двух ТНФ достаточно, чтобы там работали только клиенты и больше ничего.
Имеет ли смысл включать гипертрейдинг для повышения производительности?
Когда у вас с гипертрейдингом ядер больше, чем переваривает 1С на ПРОФ-лицензии, то от него толку ноль. Просто выключите и все.
Узнать, ведет ли вообще включение гипертрейдинга к потерям производительности, можно только по результатам нагрузочного тестирования на ваших данных и ваших сценариях.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART EVENT.

Вступайте в нашу телеграмм-группу Инфостарт