Статья написана на основе доклада Методы ускорения группового проведения документов, прочитанного мной на конференции "Infostart tech event 2024", и подробно раскрывает одну его главу: "Параллельно-последовательное проведение".
Предпосылки
Групповое проведение документов (а также любая другая обработка данных) в несколько параллельных потоков - тема не новая, и в разных вариациях уже неоднократно применялась. Главным условиям применения многопоточной обработки данных является разделение входных данных на независимые пачки, которые никак не конфликтуют между собой, и вполне могут обрабатываться параллельно.
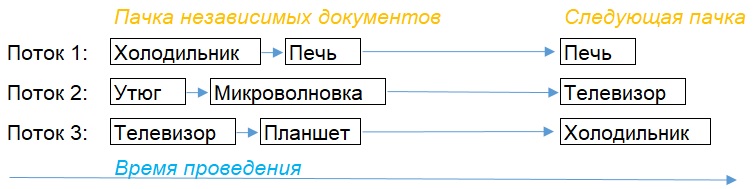
Но увы, - так бывает не всегда. Как бы мы ни хотели, нередко идущие подряд документы содержат в себе совпадающую номенклатуру, одинаковые контрагенты или договоры и т.д. Каждый раз в коде проведения нужно выбирать остатки из регистров по одним и тем же измерениям, которые меняются по результатам проведения предыдущих документов.
Так, теряется возможность разделить их в параллель, и приходится проводить снова последовательно.

Гибридное проведение
Наша идея в том, чтобы только зависимые участки кода проводились последовательно, а остальные участки кода - параллельно.

Анализируя код проведения документа, его можно условно разделить на блоки: есть независимые участки кода, которые вполне можно проводить параллельно в разных потоках, и есть зависимые участки кода, которые должны проводиться строго последовательно.

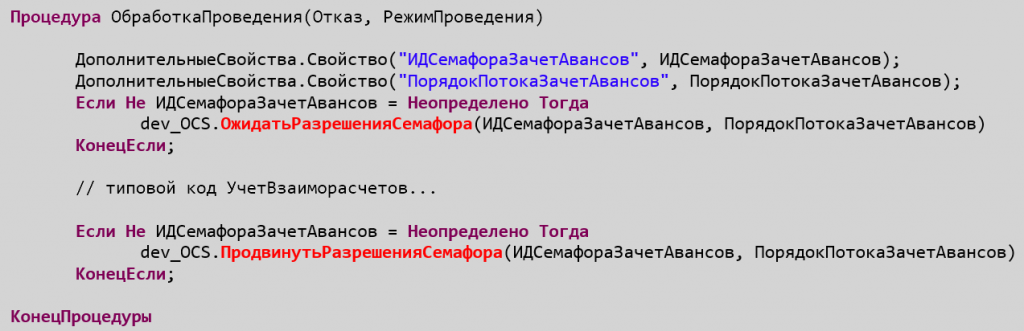
На примере конфигурации Бухгалтерия 3.0 - вполне реально выделить целиком отдельные процедуры зависимого кода, либо найти вполне конкретные места начала и окончания такого кода.
// пример
Процедура ОбработкаПроведения(Отказ, РежимПроведения)
// ... независимый код
// ... начало зависимого кода
// Таблица взаиморасчетов с учетом зачета авансов
ТаблицаВзаиморасчеты = УчетВзаиморасчетов.ПодготовитьТаблицуВзаиморасчетовЗачетАвансов(
ПараметрыПроведения.ЗачетАвансовТаблицаДокумента, ПараметрыПроведения.ЗачетАвансовТаблицаАвансов,
ПараметрыПроведения.ЗачетАвансовРеквизиты, Отказ);
// ... зависимый код
Движения.Записать();
// ... окончание зависимого кода
// ... снова независимый код
Обычно начало зависимого блока - это запрос по остаткам регистра, а окончание - это запись движений по этому регистру. Далее - новые остатки сформированы, и их уже вполне может читать другой поток для проведения следующего документа.
Таких зависимых участков в коде может быть несколько, и конфликтовать они могут с разными документами внутри одной пачки. И как здесь поступить - есть несколько вариантов. Например, можно каждый такой участок проводить последовательно, либо где возможно - параллельно, где нет – последовательно.

Координация потоков 
Мы придумали механизм семафоров для координации одновременно запущенных потоков. Наши семафоры могут показывать "красный сигнал" и много "зеленых сигналов" для каждого кусочка зависимого кода в каждом потоке. Зеленый сигнал - это порядковый номер от 1 до N, где N - это общее количество зависимых кусков кода, требующих последовательного выполнения. Каждому такому кусочку кода перед стартом многопоточной обработки присваивается свой порядковый номер, а в работе они опрашивают состояние семафора, ждут совпадения своего номера с показаниями семафора, и только тогда запускаются в работу. По завершении, семафор продвигается на следующее значение, таким образом давая разрешение включаться в работу другому потоку. А текущий же поток одновременно с этим, завершает выполнение кода, следующего после зависимого участка.
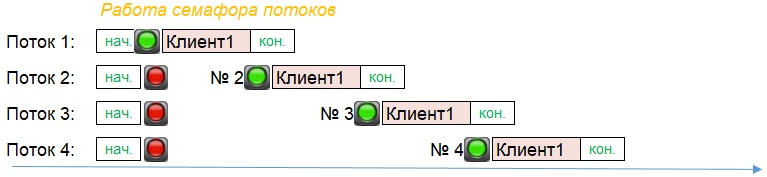
Наш механизм семафоров состоит всего из трёх методов и одного регистра:
1. ИнициализацияРазрешенияСемафора - создаём Семафор с уникальным идентификатором.
Процедура ИнициализацияРазрешенияСемафора(ИДСемафора) Экспорт
ДатаСоздания = ТекущаяДатаСеанса();
НаборСемафор = РегистрыСведений.dev_СемафорыПотоков.СоздатьНаборЗаписей();
НаборСемафор.Отбор.ИД.Установить(ИДСемафора);
НоваяЗапись = НаборСемафор.Добавить();
НоваяЗапись.Активность = Истина;
НоваяЗапись.ИД = ИДСемафора;
НоваяЗапись.Порядок = 1;
НоваяЗапись.ДатаСоздания = ДатаСоздания;
НаборСемафор.Записать(Истина);
КонецПроцедуры
2. ОжидатьРазрешенияСемафора - ждём зеленого сигнала (совпадение со своим порядковым номером).
Процедура ОжидатьРазрешенияСемафора(ИДСемафора, ОжидатьПорядок) Экспорт
Текст = "ВЫБРАТЬ
| Семафор.Порядок КАК Порядок,
| Семафор.ДатаСоздания КАК ДатаСоздания
|ИЗ
| РегистрСведений.dev_СемафорыПотоков КАК Семафор
|ГДЕ
| Семафор.ИД = &ИД
|
|ДЛЯ ИЗМЕНЕНИЯ";
Запрос = Новый Запрос(Текст);
// пока не вижу смысла ставить блокировки, т.к. хоть и читают все, - пишет всегда только один избранный.
Запрос.УстановитьПараметр("ИД", ИДСемафора);
Пока Истина Цикл
НачатьТранзакцию();
Таблица = Запрос.Выполнить().Выгрузить();
ЗафиксироватьТранзакцию();
Если Таблица.Количество() = 0 Тогда
// вообще нет семаформа. вообщето логическая ошибка. никого больше не ждём
Возврат;
КонецЕсли;
ПерваяСтрока = Таблица[0];
ТекущийПорядок = ПерваяСтрока.Порядок;
ДатаСоздания = ПерваяСтрока.ДатаСоздания;
ТекущаяДата = ТекущаяДатаСеанса();
ПрошлоВремени = ТекущаяДата - ДатаСоздания;
Если ПрошлоВремени >= 10 * 60 Или ПрошлоВремени < 0 Тогда
// Таймаут 10 минут, и выходим.
Возврат;
КонецЕсли;
Если Не(ТипЗнч(ТекущийПорядок) = Тип("Число")) Тогда
ТекущийПорядок = 0;
КонецЕсли;
Если ОжидатьПорядок = ТекущийПорядок Тогда
// подошла наша очередь
Возврат;
КонецЕсли;
СколькоПередНами = ОжидатьПорядок - ТекущийПорядок + 1;
Пауза = 0.1 * СколькоПередНами;
Dev_СемафорыПотоков.Пауза(Пауза);
КонецЦикла;
// недостижимо. выйдем либо дождавшись, либо по таймауту, либо по логической ошибке,
// например - удалена запись регистра о семафоре.
Возврат;
КонецПроцедуры
3. ПродвинутьРазрешенияСемафора - сдвигаем семафор на следующий сигнал.
Процедура ПродвинутьРазрешенияСемафора(ИДСемафора, Порядок) Экспорт
Текст = "ВЫБРАТЬ
| Семафор.Порядок КАК Порядок,
| Семафор.ДатаСоздания КАК ДатаСоздания
|ИЗ
| РегистрСведений.dev_СемафорыПотоков КАК Семафор
|ГДЕ
| Семафор.ИД = &ИД
|
|ДЛЯ ИЗМЕНЕНИЯ";
Запрос = Новый Запрос(Текст);
// пока не вижу смысла ставить блокировки, т.к. хоть и читают все, - пишет всегда только один избранный.
Запрос.УстановитьПараметр("ИД", ИДСемафора);
Таблица = Запрос.Выполнить().Выгрузить();
Если Таблица.Количество() = 0 Тогда
// вообще нет семаформа - удалили извне
Возврат;
КонецЕсли;
ПерваяСтрока = Таблица[0];
// знаем, что наша очередь. проверять не нужно
// ТекущийПорядок = ПерваяСтрока.Порядок;
ДатаСоздания = ПерваяСтрока.ДатаСоздания;
НаборСемафор = РегистрыСведений.dev_СемафорыПотоков.СоздатьНаборЗаписей();
НаборСемафор.Отбор.ИД.Установить(ИДСемафора);
НоваяЗапись = НаборСемафор.Добавить();
НоваяЗапись.Активность = Истина;
НоваяЗапись.ИД = ИДСемафора;
НоваяЗапись.Порядок = Порядок + 1;
НоваяЗапись.ДатаСоздания = ДатаСоздания;
НаборСемафор.Записать(Истина);
КонецПроцедуры
Регистр сведений: Семафоры потоков
 ИД – Уникальный идентификатор семафора.
ИД – Уникальный идентификатор семафора.
При работе с регистром мы не используем ни транзакции, ни блокировки, т.к. вся работа устроена так, что в один момент времени только один поток может записывать в регистр. Все остальные потоки в этот момент однозначно могут только читать из регистра состояние семафора. Количество таких чтений регистра при 10 потоках на практике доходило до полутора тысяч в секунду. Значение кажется фантастическим («Так быстро не бывает!»), но по факту это эффективная работа внутреннего кэша, не буду вдаваться в подробности, где именно. Но тем не менее, для уменьшения количества обращений в цикле к серверу БД, мы используем паузу, когда известно, что наша очередь ещё не скоро. Чем ближе наша очередь, тем пауза меньше. Эффекта от такого подходы мы не заметили, но это и не важно.
Для вставки механизма в свои конфигурации нужно:
1. Перед запуском пачки документов на многопоточное проведение, определиться с количеством семафоров и зависимыми участками кода. Семафоров может быть несколько. Например, если в пачке из 100 документов попалось всего лишь 3 различных договора, то и семафоров будет 3. Либо: семафор на номенклатуру + семафор на договоры, и т.д. Нужно инициализировать необходимое количество семафоров.
2. Привязать каждый зависимый участок кода к нужному семафору, и назначить порядковые номера в этом семафоре.
3. В начале нужного участка – сделать вставку в код с ожиданием семафора.
4. В конце – сделать вставку с продвижением семафора.
Важно: Номера пропускать нельзя! Если в вашем коде возможен досрочный возврат, то желательно понять это на первом этапе, и вообще не назначать семафор. Иначе обязательно пройти ожидание и сдвиг семафора.
Код представлен в прилагаемом расширении конфигурации: общий модуль "dev_СемафорыПотоков", регистр сведений, и обработка "Демонстрация работы семафоров".
Код не привязан ни к какой конкретной конфигурации. Работать может на платформе не ниже 8.3.13. запускали на 8.3.18 и 8.3.24.
Демонстрация работы семафоров
Обработка из расширения:
- детально показывает, как в реальности происходит координация параллельных потоков на примере гипотетической процедуры обработки проведения по схеме "1+1+1", т.е. 1 секунда - независимый код; далее 1 секунда - зависимый код, который выстраивается строго последовательно строго по порядку; и в завершении ещё 1 секунда независимого кода.
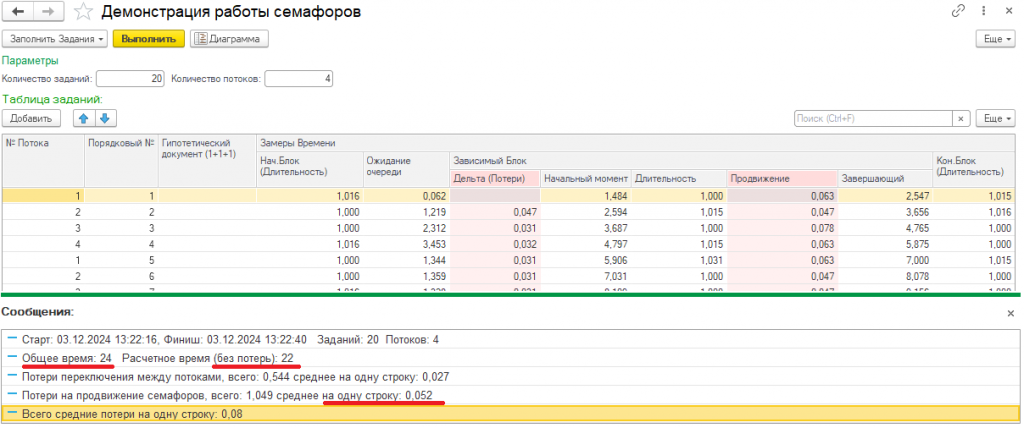
- замеряет время начала и завершения зависимого участка кода, выводит всё в табличку, и показывает потери на ожиданиях и переключениях между потоками.
- можно выбрать количество параллельных потоков, и общее количество документов (гипотетических)
- можно раскидать документы по потокам как равномерно, так и случайным образом.
- нетрудно заполнить табличку своими реальными документами (доработав в них код) и посмотреть на результат.

Нюансы
- На файловой БД - работать не должна и не будет!
- Не выбирайте кол-во потоков больше, чем у вас есть ядер в реальности.
- Пару соседних документов в один поток ставить не нужно, т.к. по факту получится их полностью последовательное проведение. Такие примеры можно увидеть, если выбрать случайное раскидывание по потокам.
- Соседние документы через одного - также нежелательно ставить в один поток (в нашем примере), т.к. последний будет ждать уже не зеленый семафор, а завершение работы над первым документом.
- 5. От трёх потоков, в нашем примере, общее время обработки уже не зависит. В реальности - нужно оценивать соотношение длительности вашего зависимого блока с общей длительностью проведения документа.
- 6. Для работы семафора используется запись в регистр сведений. Это минус, потому что идёт обращение к SQL-серверу базы данных как при записи, так и при опросе состояния в цикле.
Потери на каждую строку таблицы на практике могут составлять от 15 миллисекунд, в среднем 170 миллисекунд, а в пике было 260 миллисекунд. Всё зависит от того, чем ещё занят сервер БД кроме наших семафоров, и множества других факторов.
Например, расчетное время проведения 100 документов (гипотетических, по схеме 1+1+1) при количестве потоков от 3 до 10 - составляет 102 секунды (100 зависимых блоков последовательно, + 1 первый в начале и 1 последний в конце).
Реальное время у нас показывает 122-125 секунд. т.е. примерно 20% потери, но результат всё равно выигрышный: если сравнивать с обычным последовательным проведением в 300 секунд, - это в 2.5 раза быстрее.
Вступайте в нашу телеграмм-группу Инфостарт