Меня зовут Станислав Косолапов, я представляю компанию 42Clouds. Хочу рассказать, как мы проектируем, документируем и тестируем REST API.

Давайте сначала немного отвлечемся и посмотрим, насколько популярен REST по сравнению с другими API (прим. ред. доклад от 13 октября 2023 года).
Для этого обратимся к данным ежегодного опроса разработчиков от компании Postman. Как видно, в 2023 году REST побеждает с огромным отрывом. Если вы заметили, что сумма голосов превышает 100%, не переживайте – просто в опросе был предусмотрен множественный выбор.

Давайте теперь рассмотрим обработчик запроса для типичного HTTP-сервиса в 1С.
Чаще всего он содержит код, подобный тому, что на экране – изучая этот код, мы можем понять, что:
-
код ответа, который возвращает обработчик – это 200 или 500;
-
в заголовках ответа присутствует «Content-type» – «application/json»;
-
а тело ответа – это строка в формате JSON.
Но чтобы копнуть глубже и разобраться в структуре ответа или понять, какие query-параметры нужно передавать в данную конечную точку – нужно будет открыть общий модуль «ОбщегоНазначенияИнфостарт». Только там мы сможем понять, что и как работает – что вообще делает данная конечная точка и как ее можно применять. Работа достаточно большая, особенно если код сложный, и конечных точек много.
Таким образом мы логически подходим к тому, что нам для того, чтобы каждый раз не заглядывать в исходники, нужно написать документацию.

К документированию API можно подойти несколькими способами:
-
Самое простое – написать в документ Word все, что мы знаем о своем HTTP-сервисе, дополнить информацией из кода и на этом успокоиться.
-
Можно копнуть чуть глубже – уйти в Confluence, создать там раздел по документации и заполнить его.
Но при ручном составлении такой документации мы сталкиваемся с неочевидной проблемой – нам нужно придумать красивый и удобный для использования шаблон описания, чтобы он явно отражал всю необходимую информацию, был понятным и логичным. А потом заставить всех разработчиков использовать этот шаблон.
Однако существуют уже готовые фреймворки для создания документации к HTTP-сервисам – почему бы нам не использовать их?
OpenAPI

Самый популярный фреймворк для описания веб-сервисов REST – OpenAPI, его еще многие знают под синонимом Swagger.
Однако в 2015 году Swagger Specifications был переименован в OpenAPI Specifications, поэтому все современные версии спецификации, начиная с 3.0, официально носят название OpenAPI.
OpenAPI – это спецификация и фреймворк для описания веб-сервисов REST. Разберем этот фреймворк по частям.

Спецификация OpenAPI представляет собой файл в формате YAML или JSON.
На слайде показан пример описания одного и того же веб-сервиса: слева в формате YAML, справа – в JSON.
Даже не зная устройство этого формата, мы уже понимаем, что:
-
в веб-сервисе есть конечная точка /users;
-
в нее можно отправить POST-запрос, и она вернет коды 200, 400, 409;
-
судя по описанию «Create New User», она, похоже, создает пользователя.

Причем для того чтобы это понять, совсем необязательно ломать глаза, потому что для формата OpenAPI существует большое количество визуализаторов.
Самый популярный визуализатор, который применяется везде – это Swagger UI. Его можно использовать и для 1С (есть инструменты для встраивания), и за его пределами. Практически каждый второй API, который использует OpenAPI и визуализируется, использует этот инструмент.
Может быть, визуализатор Swagger UI не самый удобный, но так исторически сложилось, что он наиболее популярен.

Хотя мы, например, используем другой инструмент – Stoplight Elements, который предоставляет примерно такие же возможности.
Обратите внимание, что здесь прямо из веб-интерфейса можно протестировать конкретный запрос к API:
-
выбрать, какую среду будете сейчас использовать – прод, препрод, дев или другое;
-
указать авторизацию;
-
указать параметры запроса;
-
отправить и посмотреть вывод.
А некоторые другие визуализаторы даже предоставляют возможность интеграции с mock-сервисами для проверки получения фейковых данных, чтобы не стучаться к реальному API.
Все это очень удобно.
Редактор спецификаций
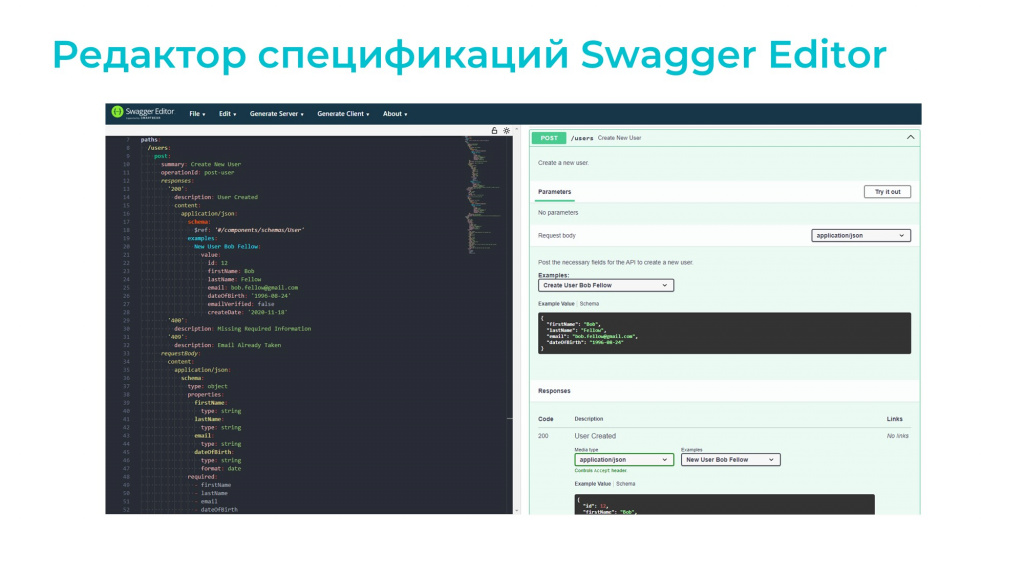
Про визуализацию поговорили, теперь посмотрим на возможности редактирования.
Для редактирования описания API не обязательно набирать в блокноте файл нужного формата и глубоко разбираться в требованиях к его структуре – для этого существуют инструменты.
Первый инструмент – Swagger Editor. Он позволяет редактировать файл спецификации в режиме среды разработки, в которой есть автокомплит, предпросмотр и линтер для поиска ошибок. Минус в том, что для работы с этим инструментом необходимо знать спецификацию OpenAPI и структуру ее формата.
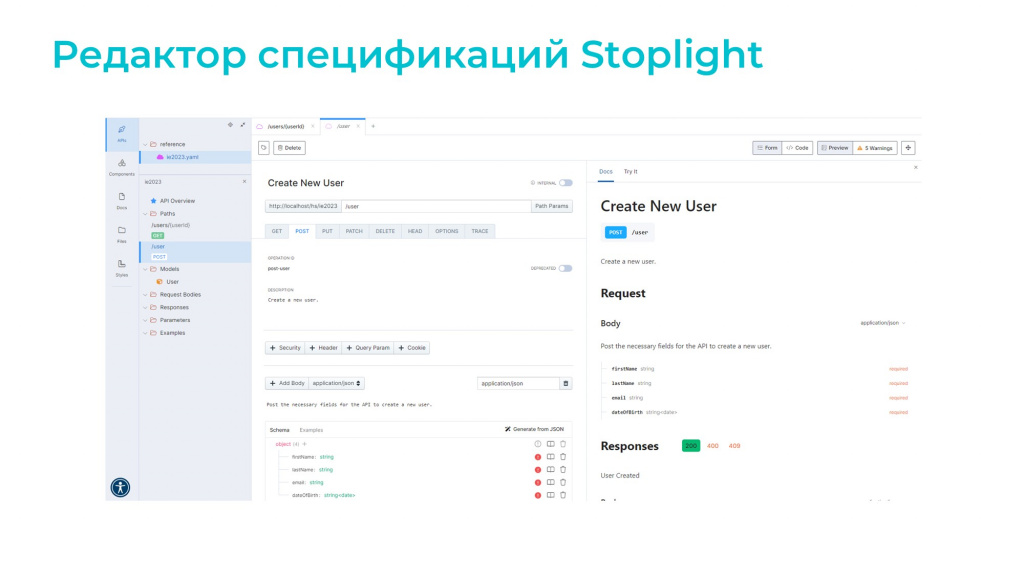
Поэтому посмотрим другой вариант – это редактор Stoplight.
Здесь уже все интуитивно понятно. Вы можете вообще не знать, что под капотом – OpenAPI или что-то другое. Вы просто накликиваете мышкой структуру вашего API, указываете, какие типы данных используются, вводите ограничения на минимум, максимум, длину и так далее. И в итоге получаете готовое описание спецификации вашего API.

В результате к ручному документированию API можно добавить возможность набросать спецификацию OpenAPI в редакторе, с последующей публикацией в сети.
Обратите внимание, что я здесь выделяю ручное и автоматическое документирование API, потому что при публикации ручного описания API возникает проблема. Если разработчик поменял в коде пару строк – добавил новое поле, убрал старое, поменял логику – но не отразил это в документации, конечная точка будет возвращать другой код ответа. Ценность нашей документации при этом пропадает.
Поэтому нужно постараться синхронизировать документацию и код через автоматическое документирование API. И для этого существует несколько способов – даже в инфраструктуре 1С есть как минимум три инструмента, которые вы можете использовать:
-
oscript-library/swagger – спецификация по метаданным конфигурации;
-
oscript-library/anti_swagger – код по спецификации;
-
bsl-libs/hs_openapi_ext – HTTP сервисы на основании OpenAPI спецификаций.
Рассмотрим каждый из них подробнее.
Инструменты для автоматического документирования API. Подход Code-First
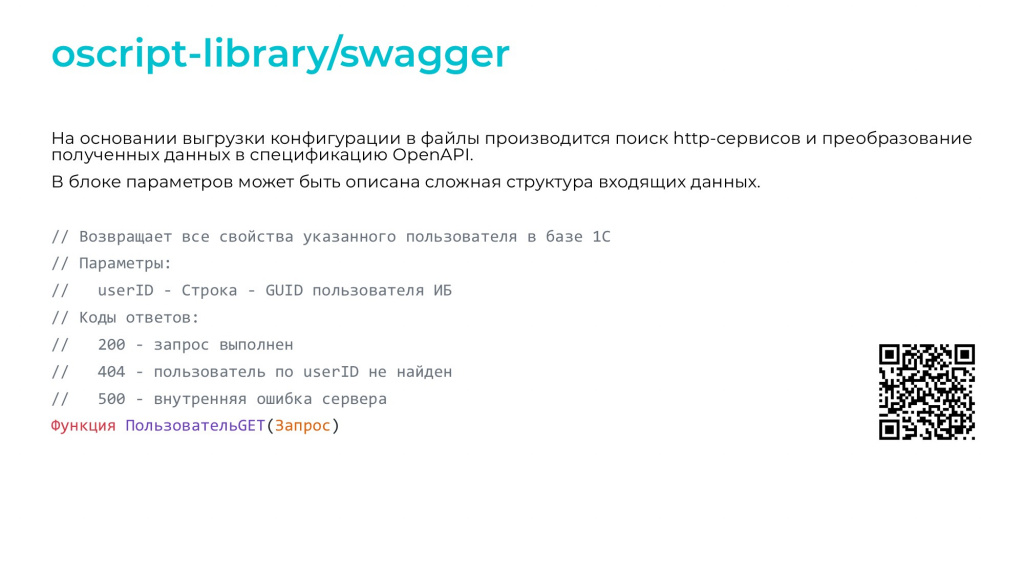
Первый инструмент – это Swagger из состава библиотеки oscript-library. Инструмент представляет собой утилиту, которая принимает на вход файлы выгрузки конфигурации или расширения и, анализируя метаданные, формирует основу для спецификации.
То, что нельзя узнать из метаданных, можно вытащить из документирующих комментариев, которые прописываются в обработчиках конечных точек. На слайде видно, что мы к обработчику «ПользовательGET» дописали:
-
параметры, которые принимает данная конечная точка;
-
и коды ответов, которые можно получить на выходе из нее.
Если у вас есть готовый проект с HTTP-сервисом, вы можете дополнить его методы комментариями, выгрузить код в файлы и натравить на них утилиту Swagger – на выходе вы получите спецификацию. Поменяли что-то в коде, перегенерили спецификацию, и все довольны.

Такой подход называется Code-First – когда первоначально пишется код, а после уже на основании этого кода генерируются контракты.
Инструменты для автоматического документирования API. Подход API-First

Другой подход, прямо противоположный, используется в утилите Anti_swagger.
Из названия понятно, что здесь все работает наоборот:
-
Мы сначала пишем спецификацию в одном из редакторов вручную.
-
Потом передаем эту спецификацию на вход утилиты и получаем файл конфигурации или расширения.
-
Открываем результат в среде разработки, дополняем реализацией и все – у нас синхронизирована документация и код.

Есть еще более интересный подход, который реализует инструмент под названием HTTP-сервис на основании OpenAPI, представляющий собой расширение, устанавливаемое в прикладную базу.
-
Открываете инструмент в режиме 1С:Предприятие и подгружаете в него файл спецификации.
-
Для каждой конечной точки, указанной в спецификации, расширение генерирует шаблоны модулей обработок – под них в конфигурации или расширении нужно создать отдельные обработки, перенести в их модули сгенерированный код и дополнить реализацией.
-
А после возвращения в режим 1С:Предприятие для каждой конечной точки указываете, какая обработка будет выступать для нее обработчиком.
Большим плюсом данного расширения является то, что оно выполняет валидацию входящих параметров и опционально валидацию исходящих параметров.
Но, как мне кажется, из минусов – достаточно много работы в режиме 1С:Предприятие.

Мы в 42Clouds используем свою подсистему, которая очень похожа на предыдущий инструмент. Отличие только в том, что все действия выполняются в режиме среды разработки – мы используем EDT и там все настраиваем.
-
У нас каждая спецификация – это общий макет.
-
Для каждого HTTP сервиса мы создаем по одному обработчику (ресурсу) с шаблоном URL «/*», чтобы он мог обрабатывать любой метод.
-
В коде обработчика прописываем макет, который будет использовать данная конечная точка.
-
Из этого макета нужно будет определить, какой конкретный метод вызывается, и передать его в настоящий обработчик.
Все остальные возможности похожи на предыдущий инструмент – та же валидация входящих, опциональная валидация исходящих – все это у нас есть.
Надеюсь, когда-нибудь мы дорастем до того, чтобы выложить все это в open source. Но, может быть, чуть позже.

Все описанные инструменты реализуют подход API-First – это когда первоначально пишется спецификация, и уже на ее основании формируется код.
Сравнение подходов Code-First и API-First

Получается, у нас есть два подхода. Можно долго спорить, какой из них лучше, но по факту они используются для разных целей.
-
Если у вас уже есть готовый проект, вы можете воспользоваться подходом Code-First, чтобы сразу сгенерировать спецификацию, затем немного доработать ее, и этого будет вполне достаточно.
-
Однако, если вы создаете API для нового продукта, над которым одновременно работает несколько команд (одна разрабатывает серверную, а другая – клиентскую часть продукта), более выгодным станет подход API-First. В этом случае вы сразу после проектирования спецификации сможете предоставить Mock-сервер команде, которая разрабатывает клиентскую часть, у вас перед глазами будет документация, и вы сможете работать над проектом параллельно, что сократит время выхода на рынок (time to market).
Про OpenAPI поговорили, вторая часть доклада будет посвящена тому, как же это поможет нам написать тесты.
Тестирование Rest-API
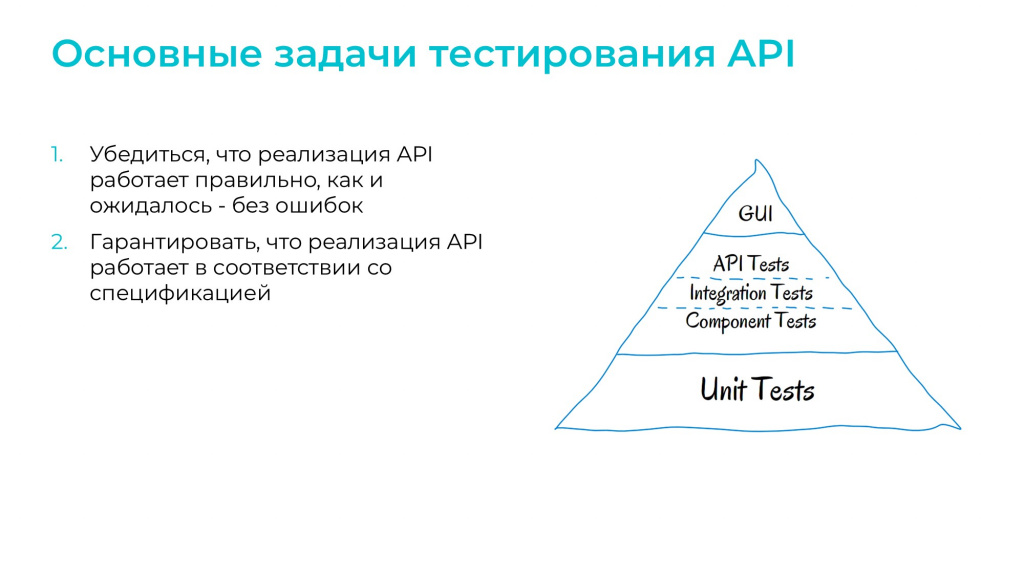
Посмотрим на пирамиду тестирования Майкла Кона – тесты API находятся в самом центре. Это означает, что:
-
по количеству тестов API должно быть меньше, чем Unit-тестов, но больше, чем интерфейсных тестов;
-
и по сложности написания, важности для бизнеса и скорости работы они также находятся примерно в середине – дальше я подробнее расскажу, как средний уровень сложности написания тестов облегчит нам задачу.
При тестировании API мы проверяем:
-
что наше API работает корректно – так, как мы описали, без ошибок;
-
и что оно соответствует той спецификации, которую мы написали – последнее еще иногда называют тестированием документации.
Фреймворки тестирования REST API

Итак, у нас есть задача – написать тесты на наш REST API. Какими подходами мы можем воспользоваться?
-
Самое первое, что приходит в голову – конечно, написать свой фреймворк на 1С или на OneScript. В качестве помощи можно будет взять библиотеку 1connector. Тем не менее кода нужно будет написать очень много, поэтому пока над этим вариантом поставим вопрос.
-
Из других подходов можно посмотреть в сторону от инфраструктуры 1С. Например, существуют популярные инструменты, такие как SoapUI и Postman, которые также позволяют писать тесты, выполнять запросы. Они возьмут на себя всю подкапотную работу с HTTP-запросами, тем не менее тесты и заполнение параметров запросов нужно будет писать самому. Причем в SoapUI в качестве внутреннего языка используется Groovy, а в Postman – JavaScript.
-
Мы для себя решили использовать в качестве основного инструмента Postman и начали развивать эту тему.
-
В результате мы открыли для себя Newman, как инструмент для запуска тестов в CI/CD контуре.
-
А чуть позже открыли еще один интересный инструмент под названием Portman.
-
Portman

Portman – это надстройка над Newman и Postman, которая была создана именно для того, чтобы тестировать REST API на основании OpenAPI-спецификации.
Это утилита принимает на вход спецификацию OpenAPI, конвертирует ее в коллекцию Postman и дополняет множеством встроенных тестов – сами тесты мы посмотрим чуть позже.
Возможностей по модификации коллекции у Portman действительно много. Это не только встраивание тестов, но и написание собственных тестов, преобразование коллекции для фильтрации по тегам и прочее.
Когда коллекция сформирована, Portman может запустить эти тесты на выполнение через Newman и даже загрузить их в ваш аккаунт Postman. Т.е. когда у вас в CI/CD покрутились тесты, вы открыли у себя Postman, и у вас видна вся коллекция с тестами – вы можете их потом проанализировать выборочно и запустить отдельные запросы.

Теперь про сами тесты, которые встроены в Portman. Основные представлены на экране, их семь. Они достаточно простые, тем не менее позволяют понять, что с нашим API все в порядке.
-
statusSuccess и statusCode проверяют коды ответов;
-
responseTime проверяет время выполнения теста;
-
contentType и headersPresent проверяют заголовки;
-
jsonBody проверяет то, что тело ответа пришло в формате JSON;
-
И самый мой любимый – это schemaValidation. Он проверяет то, что тело ответа, которое пришло от сервера, соответствует тому, что написано в спецификации.
Пример спецификации OpenAPI
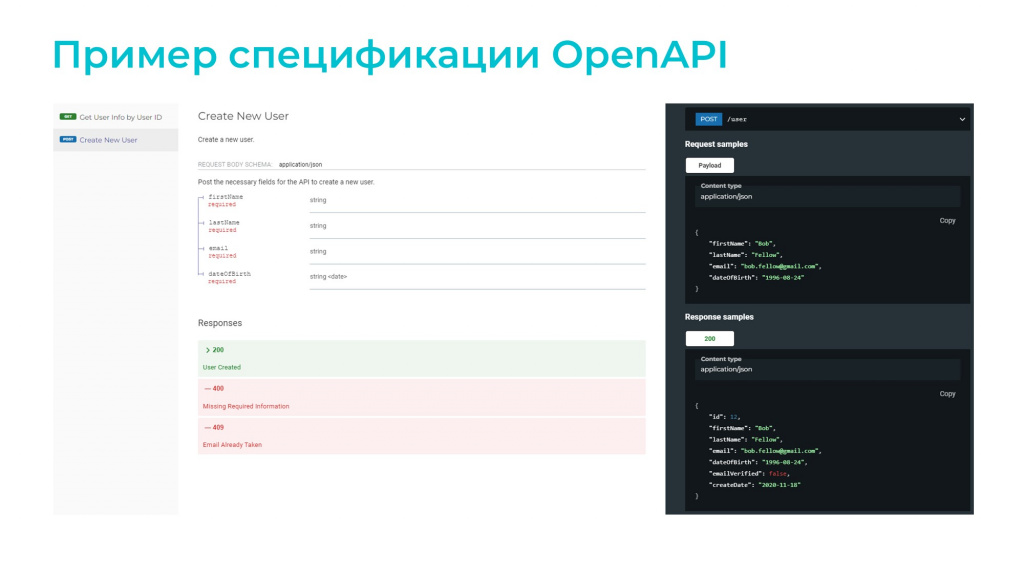
Разберем, как работает Portman на небольшом примере API, которое управляет пользователями. Пример состоит всего из двух конечных точек.
Первая конечная точка – это создание пользователя.
-
На вход принимается POST-запрос с телом в виде JSON с четырьмя полями: имя, фамилия, дата рождения и email. На email дополнительно стоит ограничение, что он не может быть больше 255 символов.
-
Сервер должен вернуть код ответа:
-
200 – в случае, если все успешно;
-
400 и 409 – если что-то пошло не так: 400 – не прошла валидация входящих параметров, 409 – пользователь с таким email уже существует.
-
-
В случае успеха в ответе будет присутствовать идентификатор созданного пользователя и все поля, которые были переданы на вход.

Вторая конечная точка – это получение данных о пользователе. Здесь все просто:
-
код 200 – если все хорошо;
-
код 404 – если пользователь не найден.

Попробуем запустить Portman и указать ему файл спецификации, который мы приводим для примера.
Portman – это консольная утилита, но бояться его не стоит, интерфейс довольно дружелюбный:
-
При запуске он предложит вам пошаговый мастер с вопросами по настройке данного проекта тестирования.
-
Самый важный пункт – это, конечно же, правильно указать путь к спецификации. Причем путь может быть как локальным, так и адресом в сети интернет.
-
И в конце даже любезно напишет, какой командой правильно запустить тесты.
Единственное, что он не сделает – он не включит встраивание тестов в коллекцию, потому что не знает, к каким конечным точкам нужно применять тесты, а к каким не нужно.
Но самое простое, что можно изначально сделать – это включить тесты, которые у нас есть, для всех конечных точек и посмотреть, что будет.

Указать ограничение, к каким конечным точкам применять тесты, можно в параметре openApiOperation конфигурационного файла в формате:
-
метод (GET, POST, PUT либо символ подстановки «*»)
-
два двоеточия «::»
-
и путь к конечной точке.
В данном примере мы включили все тесты.
Некоторые тесты параметризуются:
-
Например, можно ограничить время запроса responseTime, указав определенное количество миллисекунд, в течение которых должен прийти ответ.
-
Также параметризуется schemaValidation, потому что схема представлена в формате JSON, и там есть параметр additionalProperties, разрешающий дополнительные реквизиты. По умолчанию они всегда разрешены, но мы можем форсировать их, выключить, и тогда схема будет проверяться четко один в один.

Запустим тесты и посмотрим, что же за коллекция у нас сгенерировалась.
Мы, конечно, 1С-ники, и скорее всего JavaScript не знаем. Но тесты читаются легко – даже с минимальными знаниями английского языка можно понять, что происходит.
Обратите внимание на последний тест – это тест валидации схемы. Это то, за что я люблю Portman. Писать такую портянку вручную и потом следить за ее актуальностью – это очень сложно. А здесь все генерируется автоматически для каждой конечной точки.

Запустим тесты второй раз и посмотрим на их результаты – мы увидим, что тесты упадут.
Это логично, потому что и в первый, и во второй раз Portman использовал при создании пользователя один и тот же email, а по умолчанию ожидается, что код ответа будет одним из двухсотых.
Причем тот же email отправляется из-за того, что в файле спецификации был указан пример для читаемости. По умолчанию Portman использует параметры из примеров, если они есть, либо генерирует какие-то случайные значения автоматически, если примера нет. В нашем случае пример был.

Чтобы этого избежать, мы можем указать в конфигурационном файле правила заполнения полей запроса.
Причем мы можем указывать значения именно конкретных полей – нам не обязательно писать целиком весь запрос. Некоторые поля нам важны, некоторые нет, и те, которые нам действительно важны, мы можем определить. Остальные пусть каким-то случайным алгоритмом из примера возьмутся, нам это не важно.

Для описания заполнения полей по определенным правилам в конфигурационном файле существует секция owerwrites. Здесь видно, что она применяется к одной конечной точке – POST::/users, и меняет поля имени, фамилии и email.
Для заполнения значений в этой секции удобно использовать динамические переменные Рostman, которые каждый раз будут возвращать случайные данные – это могут быть случайные названия городов, цветов, IP-адреса. Все это встроено в Postman.
В документации Postman перечислены варианты динамических переменных, которые можно прописать в параметрах заполнения Postman. Например, параметр {{$randomExampleEmail}} генерирует не просто случайный email, а email в домене example.net, чтобы при тестировании отправки письма оно не ушло реальному пользователю.
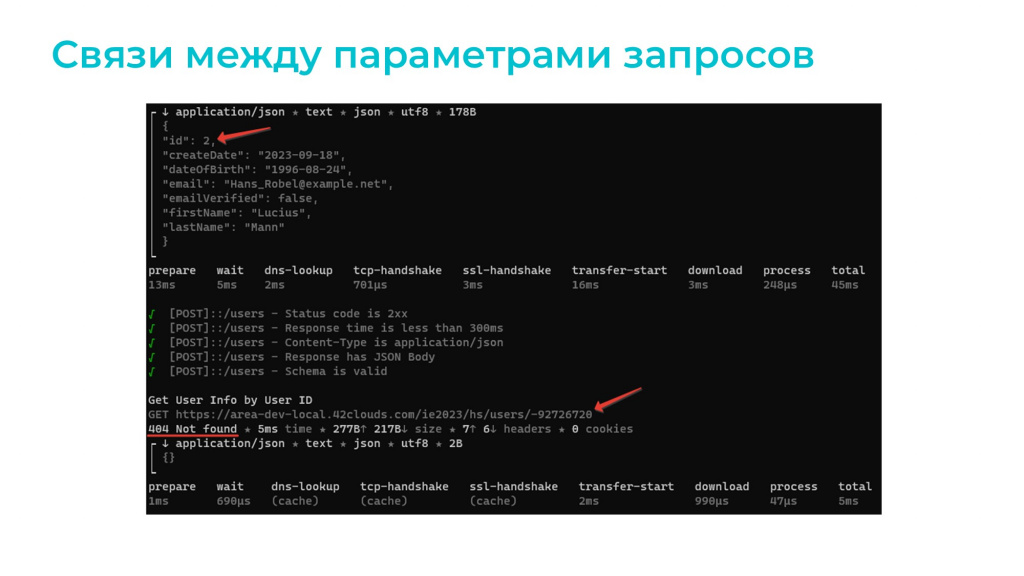
Посмотрим, что же у нас получилось – видно, что сгенерировался случайный адрес электронной почты.
Казалось бы, все хорошо, но при выполнении второго теста GET-запрос отправляется со случайным значением пользователя. И все потому, что Portman не понимает связи между идентификатором пользователя, который был реально создан в результате первого запроса, и параметром userID, прописанным в спецификации GET-запроса.

Чтобы устранить это недоразумение, нужно указать связь между данными параметрами. Связь указывается в два этапа:
-
сначала поле, используемое в запросе, ответе или заголовке, записывается в секции переменных assignVariables;
-
а потом также в секции overwrites указывается, где мы эту переменную будем использовать.
На примере мы в секции assignVariables запишем в качестве переменных два поля ответа:
-
поле id мы запишем в переменную userId,
-
а поле email мы запишем в переменную userEmail.
А дальше в секции overwrites указываем, что будем использовать переменную userId как часть пути при GET-запросе.

Посмотрим, что получилось. Да, наши тесты прошли. Portman нам любезно написал даже в логах, какие переменные он куда присвоил. И все хорошо, за исключением того, что файловая база не успела ответить за 300 миллисекунд. Но, возможно, здесь это и не страшно.

На слайде вы можете увидеть код заполнения переменных.
Обратите внимание, что здесь предусмотрена куча проверок – если на вход пришел не JSON, мы должны вывалиться в исключение, проверки на undefined и прочее.
Генерится очень большое количество кода, которое было бы сложно или вообще лень написать руками. А тут за нас все взяли и написали.
Формат вывода результатов

Чтобы понять, с каким результатом у нас прошли тесты и что упало, нам не обязательно смотреть в консоль. За счет того, что запуск тестов происходит через Newman, мы можем найти в репозитории NPM модуль репортера на наш вкус.
Там более 200 модулей. Самые популярные:
-
различные варианты вывода в JUnit;
-
любимый 1С-никами Allure;
-
можно вывести отчет в отдельный HTML-файл;
-
отправить результаты в какой-то мессенджер;
-
выгрузить в базу;
-
и другие варианты – их очень много.

На слайде – один из необычных репортеров, который показывает, какие коды ответов мы проверили запросами, а какие нет.
Мы видим, что у нас в тестах проверены 200-е коды, но не проверены коды 400 и 404. Как же это сделать?
Вариационные тесты

Для проверки всех кодов ответа, которые заложены в логику конечной точки, существует такое понятие, как вариационные тесты. Это понятие касается чисто Portman.

В вариационных тестах мы указываем, например, что при изменении такого-то поля запроса мы должны ожидать соответствующий код ответа.
В данном случае – если мы передадим адрес электронной почты пользователя, который был уже создан в самом начале, то мы должны получить код ответа 409.
Подобные вариационные тесты мы, по идее, должны написать на каждый ошибочный код и на все вариации, которые нам важны.

Посмотрим на результат выполнения вариационного теста – мы получили код 409, и все проверки прошли успешно.
Фаззинг

По-хорошему, дальше мы должны сделать то же самое и для 400-х кодов ответа. Но тогда придется писать очень большое количество вариационных тестов, потому что 400-й код ответа будет возникать во всех случаях, когда мы не передали в запрос одно из обязательных полей. А поскольку таких обязательных полей у нас в запросе четыре, значит, мы должны написать четыре вариационных теста. Плюс – еще один тест на то, что длина email должна быть меньше или равна 255 символам.
Писать для одного такого простого примера пять дополнительных тестов вручную – нерационально. Поэтому для таких проверок существует метод тестирования фаззинг – когда на вход программного обеспечения передаются случайные или специально подготовленные некорректные данные.

Причем для Portman фаззинг – это более узкое понятие, когда мы передаем все возможные варианты запросов, которые должны привести к ошибкам валидации. Сюда можно отнести:
-
Проверки на отсутствие обязательных полей.
-
Проверки о том, что значения числовых полей должны быть меньше или больше ограничений, указанных в спецификации. Например, если для количества записей в ответе установлено ограничение, что их должно быть меньше 100, то при запросе на большее количество записей должен прийти код ответа с ошибкой.
-
И последнее, что умеет проверять фаззинг-тестирование в Portman – это соответствие ограничениям максимальной и минимальной длин строк, указанных в спецификации. Очень хороший пример – это пароли, для них можно установить ограничение по длине, чтобы они были больше 8, но меньше 20 символов. В нашем случае это будет проверка на ограничение по количеству символов адреса электронной почты. При фаззинг-тестировании Portman попытается все эти ограничения как-то превысить или наоборот, сделать значение меньше, чем нужно.

В отличие от всех остальных тестов, когда мы оперируем с определенными полями, в фаззинге мы можем оперировать только с областями – применять фаззинг к конкретным областям запроса:
-
requestBody – использование фаззинга в теле запроса;
-
requestQueryParams – использование фаззинга в параметрах строки запроса;
-
requestHeaders – использование фаззинга в заголовках.

Существует пять основных тестов, которые я уже назвал:
-
requiredFields – это обязательные поля;
-
minimumNumberFields, maximumNumberFields применяются к числовым полям и пытаются сделать их меньше или больше, чем указано в спецификации;
-
minLengthFields, maxLengthFields применяются к строковым полям и пытаются сделать их длину больше или меньше указанной в спецификации.

В качестве небольшого примера сделаем вариационный тест, потому что фаззинг – это тоже разновидность вариационных тестов. Применим его ко всем конечным точкам и включим все тесты, которые можно для тела запроса.

В итоге будет создано действительно пять тестов. Последние два видны на слайде:
-
Create New User[Fuzzing] [required dateOfBirth] – тест генерирует запрос, в теле которого отсутствует поле dateOfBirth (дата рождения). Сервер вернул 400 код ошибки – все хорошо, тест прошел.
-
Create New User[Fuzzing] [maximum length email] – проверяет превышение длины адреса электронной почты. В тесте был сгенерирован очень длинный адрес электронной почты – там используется дополнение символами. Опять же, сервер вернул 400-й код ошибки, все хорошо.
Остальные тесты на экране не отображаются.
Итоговые результаты (репортер «htmlextra»)

В итоге мы путем редактирования небольшого конфигурационного файла, не написав ни строчки кода, получили тесты, в которых выполняется 8 запросов к серверу и 34 проверки. Да, там часть проверок очень простая, тем не менее мы убедились, что все наши конечные точки работают именно так, как описано в спецификации.
Мне кажется, что это простой инструмент, его стоит немного изучить и можно использовать.
Вопросы и ответы
Вы показывали пример теста для методов создания пользователей и получения данных о пользователях. Как Portman понимает, какой запрос надо выполнить первым, а какой – вторым, как сортируется порядок? Ведь если мы сначала будем запрашивать данные о пользователях, а их еще нет, не сломается ли тест?
Существует несколько путей, как можно это решить.
-
Первый – это в лоб. Есть специальная секция конфигурационного файла, которая позволяет настроить порядок запросов. В ней мы можем расположить тесты именно так, как нам нужно.
-
Второй вариант – это использовать интеграционные тесты. В терминологии Portman это тесты, которые группируют запросы и выполняют их именно в определенном порядке.
-
Либо третий вариант – существует группировка запросов по тегам. В спецификации OpenAPI мы можем каждой конечной точке назначить свой тег, разбить запросы по тегам и тогда внутри одного тега запросы будут группироваться и сортироваться.
Наверное, самый простой вариант – это именно глобально определить тот порядок запросов, который вам нужен. А дальше внутри вариационных тестов вы уже регулируете порядком их описания – они выполняются именно в том порядке, как они расположены в файле.
Кого заставить писать тесты HTTP-сервисов?
У нас тесты пишут разработчики, и я считаю, что это правильно. Потому что API – это именно техническая часть разработки ПО.
В команде отдельной должности тестировщика как человека, который пишет тесты.
Тесты пишут разработчики и, по-моему, все довольны таким подходом.
Вы в начале доклада сказали, что используете тестирование API в условиях CI. Это значит, что тесты, которые генерируются по спецификации, еще раз генерятся в условиях CI? Или вы их где-то отдельно сохраняете для джоба и потом тоже как-то апдейтите? Как это происходит?
У нас в структуре репозитория исходники конфигурации хранятся в одной папке, а в другой папке – конфигурационный файл Portman. И в переменных окружения указано, что данная ветка, например, должна выполняться на таком-то сервере.
И просто есть джоба, которая берет файл спецификации из Git (он у нас хранится в общем макете) и запускает Portman с командой: «Portman, оттуда возьми спецификацию, отсюда конфигурацию, примени вот к тому серверу». И все запускается.
А в какой момент вы апдейтите конфигурацию Portman? По мере доработки тестов, и структуры проекта?
Конфигурация Portman апдейтится вручную – именно в ней мы пишем тесты.
Но там есть часть тестов, которая генерится автоматически при каждом запуске Portman. Мы ее не пишем. Она генерируется, выполняется и мы про нее забываем.
А где происходит связывание переменных?
Связывание происходит тоже в конфигурационном файле, который лежит рядом в репозитории.
Получается, что когда нам нужно поменять структуру тестов, дописать какую-то новую связь, мы его дорабатываем?
Именно так – если у нас появляется новая конечная точка, мы пишем под нее новую фичу.
Здесь возникает интересный момент – Portman генерирует тесты по умолчанию при наших настройках на все конечные точки. И если в спецификации появилась новая конечная точка, но разработчик забыл написать на нее тест, автоматически к этой конечной точке будут применены какие-то случайные параметры, и тест будет запущен. С вероятностью 99% он упадет и разработчику придется писать этот тест – дописывать этот конфигурационный файл. Он его допишет в своей ветке, тесты пройдут, и он может создавать пулл-реквест.
Рассматривали ли вы фреймворк, который называется YAXUnit? Там тесты пишутся на языке 1С. Просто знание Postman и Portman – это отдельные компетенции, которые нужно растить. А в случае, когда пишешь на 1С, любой человек может посмотреть, из-за чего упал тест.
И насколько я знаю, в YAXUnit нет тех специализированных инструментов для тестирования HTTP-сервисов, которые предоставляет Postman. И это одна из причин использовать Postman в данном случае.
Что проверяют тесты, которые генерируются автоматически? Возврат ответов 200, 404 и 500?
В показанном примере производится проверка на коды ответов, на заголовки, которые приходят от сервера, и на тело ответа – на то, что оно соответствует спецификации.
Кроме этого в Portman существует еще один тип тестов – тесты контента. Их можно использовать, если необходимо убедиться, что в данном конкретном поле придет именно цифра «3». Увы, я в докладепро эти тесты рассказать не успел, потому что у меня были ограничения по таймингу. За рамками доклада эти тесты существуют, их тоже стоит изучить.
На автоматические тесты Portman можно смотреть, как на дымовые тесты – особенно на фаззинг, там именно случайные данные отправляются. А тестирование на контент и предметную логику действительно можно переносить в YAXUnit.
У вас один человек отвечает за наполнение и актуализацию тестов, или несколько разработчиков могут одновременно с этим работать? Потому что у нас ситуация следующая. У нас отдельно есть веберы, которые нам пишут контракт данных, и они его постоянно дополняют. Есть разработчики на 1С, их тоже несколько человек, которые под этот контракт пишут бэкенд на 1С. Соответственно, в контракте уже что-то описано, но на бэкенде оно еще не реализовано. У вас один человек пишет тесты под все эти изменения, или каждый дописывает свою часть по мере готовности на бэкенде?
У нас разработка построена таким образом, что спецификация не может выехать без реализации.
Спецификация описывается, помещается в определенную ветку в Git, и для нее накидывается реализация.
А чтобы написать на это тесты, они должны писаться в этой же ветке, иначе мы выехать не сможем – тесты не пройдут.
Получается, что кто пишет реализацию конечной точки, тот и тесты пишет.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART EVENT.
Вступайте в нашу телеграмм-группу Инфостарт